Chapter 3 Statistics
Hello! In this tutorial, we’ll be learning how to do some basic statistics in R. For this tutorial, we will also be using the mtcars dataset in the dataset package.
In this tutorial, we will cover the following statistical tests or models.
- Correlations
- ANOVAs
- Linear regressions
In addition to this, we’ll talk briefly about pipes (%>%), which is an essential feature of coding in tidyverse.
library(tidyverse)
library(datasets)Let’s start by using the functions we’re already familar with, str() and summary().
car_data <- mtcars
str(car_data)## 'data.frame': 32 obs. of 11 variables:
## $ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
## $ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
## $ disp: num 160 160 108 258 360 ...
## $ hp : num 110 110 93 110 175 105 245 62 95 123 ...
## $ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
## $ wt : num 2.62 2.88 2.32 3.21 3.44 ...
## $ qsec: num 16.5 17 18.6 19.4 17 ...
## $ vs : num 0 0 1 1 0 1 0 1 1 1 ...
## $ am : num 1 1 1 0 0 0 0 0 0 0 ...
## $ gear: num 4 4 4 3 3 3 3 4 4 4 ...
## $ carb: num 4 4 1 1 2 1 4 2 2 4 ...summary(car_data)## mpg cyl disp hp
## Min. :10.40 Min. :4.000 Min. : 71.1 Min. : 52.0
## 1st Qu.:15.43 1st Qu.:4.000 1st Qu.:120.8 1st Qu.: 96.5
## Median :19.20 Median :6.000 Median :196.3 Median :123.0
## Mean :20.09 Mean :6.188 Mean :230.7 Mean :146.7
## 3rd Qu.:22.80 3rd Qu.:8.000 3rd Qu.:326.0 3rd Qu.:180.0
## Max. :33.90 Max. :8.000 Max. :472.0 Max. :335.0
## drat wt qsec vs
## Min. :2.760 Min. :1.513 Min. :14.50 Min. :0.0000
## 1st Qu.:3.080 1st Qu.:2.581 1st Qu.:16.89 1st Qu.:0.0000
## Median :3.695 Median :3.325 Median :17.71 Median :0.0000
## Mean :3.597 Mean :3.217 Mean :17.85 Mean :0.4375
## 3rd Qu.:3.920 3rd Qu.:3.610 3rd Qu.:18.90 3rd Qu.:1.0000
## Max. :4.930 Max. :5.424 Max. :22.90 Max. :1.0000
## am gear carb
## Min. :0.0000 Min. :3.000 Min. :1.000
## 1st Qu.:0.0000 1st Qu.:3.000 1st Qu.:2.000
## Median :0.0000 Median :4.000 Median :2.000
## Mean :0.4062 Mean :3.688 Mean :2.812
## 3rd Qu.:1.0000 3rd Qu.:4.000 3rd Qu.:4.000
## Max. :1.0000 Max. :5.000 Max. :8.000You can also use individual functions, like mean() and sd() (for standard deviation), to understand the data more.
mean(car_data$mpg, na.rm = TRUE)## [1] 20.09062sd(car_data$mpg, na.rm = TRUE)## [1] 6.026948median(car_data$hp) #horsepower## [1] 123Noticed how we used the na.rm = TRUE argument in the first two functions? If you check out the ?mean help page, you’ll notice that the default for mean() is na.rm = FALSE). In other words, the default is to not strip NA values from the data (this default setting can be useful for avoiding subsequent problems with missing variables).
If you don’t include na.rm = TRUE in this situation, nothing will change. However, it is something to watch out for when you are working with real data.
In ?mean, you’ll also notice that the x argument (as in mean(x)) needs to be a numeric or logical vector (or date/time object). If you use just a numeric, mean() will treat it as a numeric vector of 1 value. If you use a data frame, mean() will return an NA.
mean(4)## [1] 4mean(car_data)## Warning in mean.default(car_data): argument is not numeric or logical: returning
## NA## [1] NA3.1 Correlations
Correlations are a popular way for looking at the relationship between interval or ratio variables. Variables can be positively or negatively correlated.
Let’s look at how closely two variables in mtcars are correlated: hp and mpg. You can check out the relationship between two numeric variables using the plot() function. (Results will show up in the Plots panel)
plot(car_data$hp, car_data$mpg)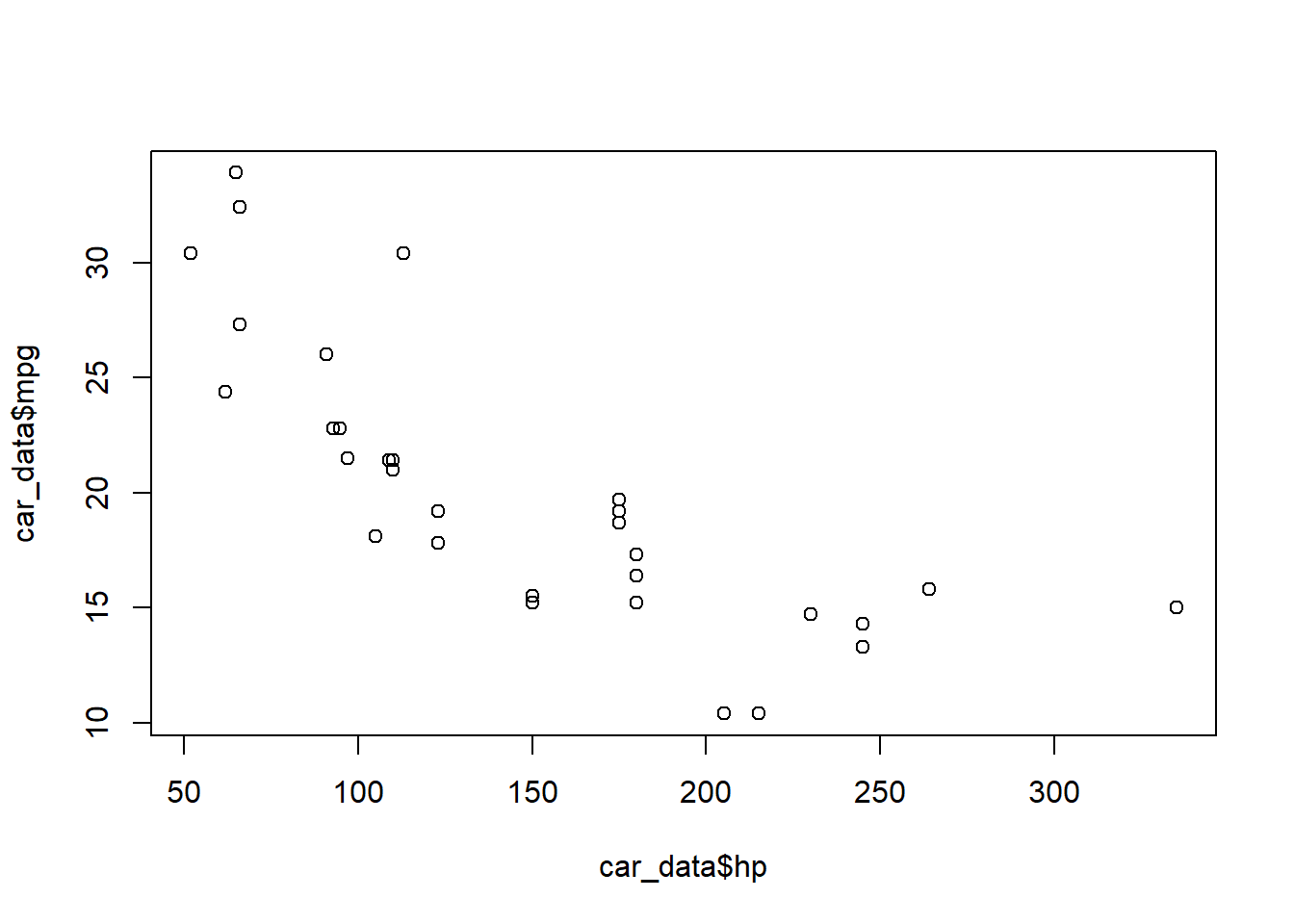 This plot suggests an inverse relationship–horsepower may be negatively related to miles per gallon.
This plot suggests an inverse relationship–horsepower may be negatively related to miles per gallon.
The simplest way to look at the correlation between these variables is to use cor(). The default of cor() is Pearson’s correlations. However, you can also change the method to kendall or spearman.
cor(car_data$hp, car_data$mpg)## [1] -0.7761684cor(car_data$hp, car_data$mpg, method = "spearman")## [1] -0.8946646When you apply cor() to a whole data frame, the function will test the relationship of each variable to one another. However this only works if all of the variables are numerics (if you have a non-numeric variable in the data frame, R will return an error).
cor(car_data)## mpg cyl disp hp drat wt
## mpg 1.0000000 -0.8521620 -0.8475514 -0.7761684 0.68117191 -0.8676594
## cyl -0.8521620 1.0000000 0.9020329 0.8324475 -0.69993811 0.7824958
## disp -0.8475514 0.9020329 1.0000000 0.7909486 -0.71021393 0.8879799
## hp -0.7761684 0.8324475 0.7909486 1.0000000 -0.44875912 0.6587479
## drat 0.6811719 -0.6999381 -0.7102139 -0.4487591 1.00000000 -0.7124406
## wt -0.8676594 0.7824958 0.8879799 0.6587479 -0.71244065 1.0000000
## qsec 0.4186840 -0.5912421 -0.4336979 -0.7082234 0.09120476 -0.1747159
## vs 0.6640389 -0.8108118 -0.7104159 -0.7230967 0.44027846 -0.5549157
## am 0.5998324 -0.5226070 -0.5912270 -0.2432043 0.71271113 -0.6924953
## gear 0.4802848 -0.4926866 -0.5555692 -0.1257043 0.69961013 -0.5832870
## carb -0.5509251 0.5269883 0.3949769 0.7498125 -0.09078980 0.4276059
## qsec vs am gear carb
## mpg 0.41868403 0.6640389 0.59983243 0.4802848 -0.55092507
## cyl -0.59124207 -0.8108118 -0.52260705 -0.4926866 0.52698829
## disp -0.43369788 -0.7104159 -0.59122704 -0.5555692 0.39497686
## hp -0.70822339 -0.7230967 -0.24320426 -0.1257043 0.74981247
## drat 0.09120476 0.4402785 0.71271113 0.6996101 -0.09078980
## wt -0.17471588 -0.5549157 -0.69249526 -0.5832870 0.42760594
## qsec 1.00000000 0.7445354 -0.22986086 -0.2126822 -0.65624923
## vs 0.74453544 1.0000000 0.16834512 0.2060233 -0.56960714
## am -0.22986086 0.1683451 1.00000000 0.7940588 0.05753435
## gear -0.21268223 0.2060233 0.79405876 1.0000000 0.27407284
## carb -0.65624923 -0.5696071 0.05753435 0.2740728 1.00000000Unfortunately, cor() does not provide tests of significance. For that, we have cor.test(), which takes two variables.
cor.test(car_data$hp, car_data$mpg)##
## Pearson's product-moment correlation
##
## data: car_data$hp and car_data$mpg
## t = -6.7424, df = 30, p-value = 1.788e-07
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.8852686 -0.5860994
## sample estimates:
## cor
## -0.7761684These results confirm your cor() function and shows that this correlation is statistically significant.
The way in which we used cor.test() above is called the vector method (because you are provding an x vector and a y vector). Another way to use cor.test() is as a formula (one thing you’ll notice about R is that there are many ways to do the same thing).
A formula in R follows this structure: dependent_variable ~ independent_variable (the formula structure and how the formula is interpreted varies by the function, but if you see ~ in R, you can infer that the line is a formula). For cor.test(), the formula looks like this: ~ x + y, where x and y are two numeric vectors in a data frame. Most functions that take a formula will also have a data argument, where you will state the data.frame with the variables.
cor.test(formula = ~ hp + mpg, #formulas are often written on one line
data = car_data) ##
## Pearson's product-moment correlation
##
## data: hp and mpg
## t = -6.7424, df = 30, p-value = 1.788e-07
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.8852686 -0.5860994
## sample estimates:
## cor
## -0.7761684Notice how the results are the exact same. Regardless of whether you use the vector or the formula strategy, you should get the same results. Importantly, and unlike cor(), cor.test() can only take two variables.
You can read more about cor.test() here.
3.2 Pipes
Before we talk about ANOVAs and Regressions, let’s take a brief pause to talk about pipes. In this section, I will be using the cyl_factor variable from the last tutorial. Let’s create cyl_factor variable using the same process as previously.
car_data$cyl_factor <- as.factor(car_data$cyl)
levels(car_data$cyl_factor) #use this to look at the levels of a factor vector## [1] "4" "6" "8"By this point, you should have a data frame named car_data (or whatever you named it) with 12 variables: the original 11 variables and, cyl_factor, a factor variable with 3 levels.
Alrighty–onto the pipes!
If you see %>% in a code, it is called a pipe. Pipes are common wen writing code with the tidyverse package. In December 2020, R began introducing native pipes (|>) into its development version, but it has yet to be implemented fully. Fun fact: pipes are one of my favorite R features.
Hadley Wickham talks about pipes extensively in R4DS. In short, I think of pipes as the programming equivalent of “and then”. So, for example, if you want to take a data frame and then select a variable and then construct a frequency table, you could write each part out, like below.
new_mtcars_file <- mtcars
new_mtcars_file2 <- select(new_mtcars_file, gear) #select lets you pull out variables of interest
table(new_mtcars_file2$gear) #table is a function you can use to create a frequency or contigency table.##
## 3 4 5
## 15 12 5#try table() on other variables!Or, you can use the pipe operator:
mtcars %>%
select(gear) %>%
table()## gear
## 3 4 5
## 15 12 5Notice how, in this latest chunk of code, I do not save any objects to the enviornment as I had to without pipes. Instead, I called the mtcars dataset, and then used select() to focus on the variable “gear”, and then used table() on the focused data. The order is important: table() cannot take a full data frame, so it was necessary to select(gear) first.
Aesthetically, you’ll often see people start a new line after a pipe. RStudio will also create an indent, so you can tell if the code is “piped.”
Importantly, R tidyverse structues take piping into account substantially. For example, pipes mostly work when the data object is the first argument of a formula (pipes work by assumng that the data object in the first argument is the output of the previous line). As a result, pipes do not always cooperate with base R functions.
3.3 Summarize
Another function() you might find intersting is summarize(), which is from the dplyr package in tidyverse. The goal of summarize() is to summarize variables of an existing data frame (you can also use the British spelling, summarise()). For example, summarize() can be used to identify the mean and standard deviation of multiple variables. The output of summarize() is a data frame with one row and a column for each summary variable. Let’s see how this looks in action.
summarize(car_data, meany = mean(mpg), sd(mpg),
mean(hp), sd(hp),
mean(wt), sd(wt))## meany sd(mpg) mean(hp) sd(hp) mean(wt) sd(wt)
## 1 20.09062 6.026948 146.6875 68.56287 3.21725 0.9784574Notice how the first mean is labeled meany, while the others use the name of the function? This is because I gave the mean(mpg) column a name (meany). You can do this for all the variable, like below:
summarize(car_data, mpg_mean = mean(mpg), sd_mean = sd(mpg),
horsepower_mean = mean(hp), horsepower_sd = sd(hp),
weight_mean = mean(wt), weight_sd = sd(wt))## mpg_mean sd_mean horsepower_mean horsepower_sd weight_mean weight_sd
## 1 20.09062 6.026948 146.6875 68.56287 3.21725 0.9784574(How would you go about making the data frame show the information vertically rather than horizontally? Hint: try piping a t() function to the end of summarize.)
One reason why people like summarize() is that it can be used with another dplyr function, group_by(). group_by() is a function that groups rows in a table based on a variable (column) in the group. Usually, you won’t see this grouping until you actually perform a function. For example, if you group_by() and then use summarize(), the summarize() function will summarize by group. Let’s try this now–we’ll group by the number of cylinders per car, and then summarize the miles per gallon (mpg).
group_by(car_data, cyl_factor) %>%
summarize(mean(mpg), sd(mpg))## # A tibble: 3 x 3
## cyl_factor `mean(mpg)` `sd(mpg)`
## <fct> <dbl> <dbl>
## 1 4 26.7 4.51
## 2 6 19.7 1.45
## 3 8 15.1 2.56Thus far, we have’t saved the results of group_by() %>% summarize(). However, like with most anything in R, you can always assign it to an object, like I do below.
groupedfile <- group_by(car_data, cyl_factor) %>%
summarise(
mean = mean(mpg, na.rm = TRUE),
sd = sd(mpg, na.rm = TRUE)
)
groupedfile## # A tibble: 3 x 3
## cyl_factor mean sd
## <fct> <dbl> <dbl>
## 1 4 26.7 4.51
## 2 6 19.7 1.45
## 3 8 15.1 2.563.4 ANOVA
Now, let’s talk about conducting ANOVAs.
An ANOVA is used to compare means among more than two groups (to compare means between two groups, we would use a t-test). To conduct an ANOVA in R, we would use the aov() function. aov() is a function that takes a formula (like cor.test()). The formula for ANOVAs should look like this: numeric_variable ~ factor_variable (recall that if you see a ~ in the code, you can infer that a formula is being used). In the example below, we will compare mpg for differnt cylinder amounts in cars.
anova_model <- aov(mpg ~ cyl_factor, data = car_data) #this is a formula
anova_model## Call:
## aov(formula = mpg ~ cyl_factor, data = car_data)
##
## Terms:
## cyl_factor Residuals
## Sum of Squares 824.7846 301.2626
## Deg. of Freedom 2 29
##
## Residual standard error: 3.223099
## Estimated effects may be unbalancedSo anova_model, the object you used to store the results of the ANOVA model, reports some basic information, but not everything. If you str() this object, you’ll notice it is a rather complex list with lots of model information.
To present this information in a way that is easier to interpret, we often use summary(). summary() is a function that reports model fit or tests of significance. Use ?summary to learn more about this function.
summary(anova_model)## Df Sum Sq Mean Sq F value Pr(>F)
## cyl_factor 2 824.8 412.4 39.7 4.98e-09 ***
## Residuals 29 301.3 10.4
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Results of this ANOVA test suggest that cars with different cylinders also varies by miles per gallon.
Base R also contains a function for Tukey’s honest significant difference (HSD): TukeyHSD(). Importantly, TukeyHSD()’s first argument is a (usually aov) model.
TukeyHSD(anova_model)## Tukey multiple comparisons of means
## 95% family-wise confidence level
##
## Fit: aov(formula = mpg ~ cyl_factor, data = car_data)
##
## $cyl_factor
## diff lwr upr p adj
## 6-4 -6.920779 -10.769350 -3.0722086 0.0003424
## 8-4 -11.563636 -14.770779 -8.3564942 0.0000000
## 8-6 -4.642857 -8.327583 -0.9581313 0.0112287These results suggest that cars with more cylinders are likely to have a smaller miles per gallon. Applying additional functions is one big reason why people want to store model information in an object. (Alternatively, you can also pipe TukeyHSD(). Try it yourself!)
You can learn more about ANOVAs in R in this sthda tutorial, which also briefly talks about box plots!
3.5 Regression
Finally, we come to linear regressions. In R, linear regression models are constructed using the lm() function. Like ANOVAs (aov()) and correlations (cor.test()), the regression function (lm) takes a formula. The regression formula is y ~ x, which translates into y = a1 + a2*x + e.
regression_model <- lm(mpg ~ cyl_factor, #http://r-statistics.co/Linear-Regression.html
data = car_data)
summary(regression_model)##
## Call:
## lm(formula = mpg ~ cyl_factor, data = car_data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.2636 -1.8357 0.0286 1.3893 7.2364
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 26.6636 0.9718 27.437 < 2e-16 ***
## cyl_factor6 -6.9208 1.5583 -4.441 0.000119 ***
## cyl_factor8 -11.5636 1.2986 -8.905 8.57e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.223 on 29 degrees of freedom
## Multiple R-squared: 0.7325, Adjusted R-squared: 0.714
## F-statistic: 39.7 on 2 and 29 DF, p-value: 4.979e-09One thing you’ll notice when you summary() this model is that cyl_factor is now split into two variables (6 and 8). This process is unique to characters and factors: when lm() (or any formula) interprets a factor variable, it will treat the first level (in this case, “4”) as the default level and will construct dummy variables.
If we use cyl variable, rather than the cyl_factor variable, you’ll notice that dummy variables are not used.
lm(mpg ~ cyl, data = car_data) %>% summary()##
## Call:
## lm(formula = mpg ~ cyl, data = car_data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.9814 -2.1185 0.2217 1.0717 7.5186
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 37.8846 2.0738 18.27 < 2e-16 ***
## cyl -2.8758 0.3224 -8.92 6.11e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.206 on 30 degrees of freedom
## Multiple R-squared: 0.7262, Adjusted R-squared: 0.7171
## F-statistic: 79.56 on 1 and 30 DF, p-value: 6.113e-10Another thing you may want to try is a character variable. For example, construct a cyl_character variable (hint: use as.character()) and put it into an lm() function. The results should look pretty similar to the model with the factor (one reason you would want to use factors, rather than characters, is the ability to rearrange the levels of a factor.)
Learn more about categorical variables in regressions here.
Of course, you can also include more than one dependent variable. Below, we’ll use the following formula: mpg~cyl_factor + wt. The + on the right-hand side signals that more than one variable is being included in the model.
regression_model <- lm(mpg ~ cyl_factor + wt,
data = car_data)
summary(regression_model)##
## Call:
## lm(formula = mpg ~ cyl_factor + wt, data = car_data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.5890 -1.2357 -0.5159 1.3845 5.7915
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 33.9908 1.8878 18.006 < 2e-16 ***
## cyl_factor6 -4.2556 1.3861 -3.070 0.004718 **
## cyl_factor8 -6.0709 1.6523 -3.674 0.000999 ***
## wt -3.2056 0.7539 -4.252 0.000213 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.557 on 28 degrees of freedom
## Multiple R-squared: 0.8374, Adjusted R-squared: 0.82
## F-statistic: 48.08 on 3 and 28 DF, p-value: 3.594e-11There are many, many tutorials for using regressions in R. I’ll list a few below: