Capítulo 8 Regresión lineal
8.1 Resumen
En este instructivo, aprendemos a estimar modelos de regresión lineal en R usando la función básica lm(), interpretar y presentar los resultados y realizar diagnósticos y modificaciones a los modelos que estimamos. El objetivo final es utilizar técnicas estadísticas para evaluar nuestros modelos teóricos.
- Principales conceptos: regresión lineal, tabla de regresión, predicciones (valores esperados), diagnósticos.
- Principales funciones:
lm(),modelsummary(),ggpredict().
Vamos a utilizar las siguientes librerías:
library(tidyverse)## Warning: package 'tidyverse' was built under R version 4.0.3## -- Attaching packages --------------------------------------- tidyverse 1.3.0 --## v ggplot2 3.3.2 v purrr 0.3.4
## v tibble 3.0.4 v dplyr 1.0.2
## v tidyr 1.1.2 v stringr 1.4.0
## v readr 1.3.1 v forcats 0.5.0## Warning: package 'tibble' was built under R version 4.0.3## -- Conflicts ------------------------------------------ tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(lmtest) # diagnosticos modelos## Loading required package: zoo##
## Attaching package: 'zoo'## The following objects are masked from 'package:base':
##
## as.Date, as.Date.numericlibrary(sandwich) # corregir errores estandar
library(ggeffects) # efectos en modelos de regresion
library(modelsummary) # tablas de regresion
theme_set(theme_classic(base_size = 12))8.2 Modelos de regresión lineal en R
Supongamos que tenemos una pregunta sobre la relación (causal) entre el ingreso de un individuo y su nivel educativo. Nuestra hipótesis es que a mayor número de años de educación, mayor ingreso anual en promedio. Buscamos y encontramos datos al respecto (y los guardamos en el archivo riverside_final.csv, disponible aquí) y los cargamos en R:
# cargar datos
riverside <- read_csv("data/riverside_final.csv")## Parsed with column specification:
## cols(
## edu = col_double(),
## income = col_double(),
## senior = col_double(),
## gender = col_double(),
## party = col_double()
## )Reorganizamos un poco los datos -recodificamos unas variables- y miramos las primeras filas:
# recodificar variables categóricas
riverside <- riverside %>%
mutate(
gender = factor(gender, levels = c(0, 1), labels = c("Mujer", "Hombre")),
party = factor(party, levels = c(0, 1, 2), labels = c("Rep.", "Dem.", "Ind."))
)
# imprimir los datos a la consola
head(riverside)## # A tibble: 6 x 5
## edu income senior gender party
## <dbl> <dbl> <dbl> <fct> <fct>
## 1 8 26430 9 Mujer Dem.
## 2 8 37449 7 Hombre Rep.
## 3 10 34182 16 Mujer Dem.
## 4 10 25479 1 Mujer Ind.
## 5 10 47034 14 Hombre Rep.
## 6 12 37656 14 Hombre Rep.Vemos que tenemos información sobre ingreso, nivel educativo, experiencia laboral, género y afiliación partidista para 32 individuos. Podemos empezar a trabajar.
8.3 Análisis exploratorio y visualización
Empezamos haciendo un poco de análisis exploratorio de datos. Primero, veamos un resumen de las variables usando la función summary():
summary(riverside)## edu income senior gender party
## Min. : 8 Min. :25479 Min. : 1.00 Mujer :18 Rep.:10
## 1st Qu.:12 1st Qu.:44513 1st Qu.: 9.75 Hombre:14 Dem.:15
## Median :16 Median :55830 Median :15.00 Ind.: 7
## Mean :16 Mean :53742 Mean :14.81
## 3rd Qu.:20 3rd Qu.:62717 3rd Qu.:20.25
## Max. :24 Max. :82726 Max. :27.00Una implementación moderna de este tipo de resúmenes son las librería gtsummary, vtable y skimr.
Como nuestras variables de interés (ingreso y educación) ambas son numéricas, un gráfico de dispersión es apropiado:
riverside %>%
ggplot(aes(edu, income)) +
geom_point() +
scale_y_continuous(labels = scales::dollar) +
labs(x = "Educación (años)", y = "Ingreso anual (USD)")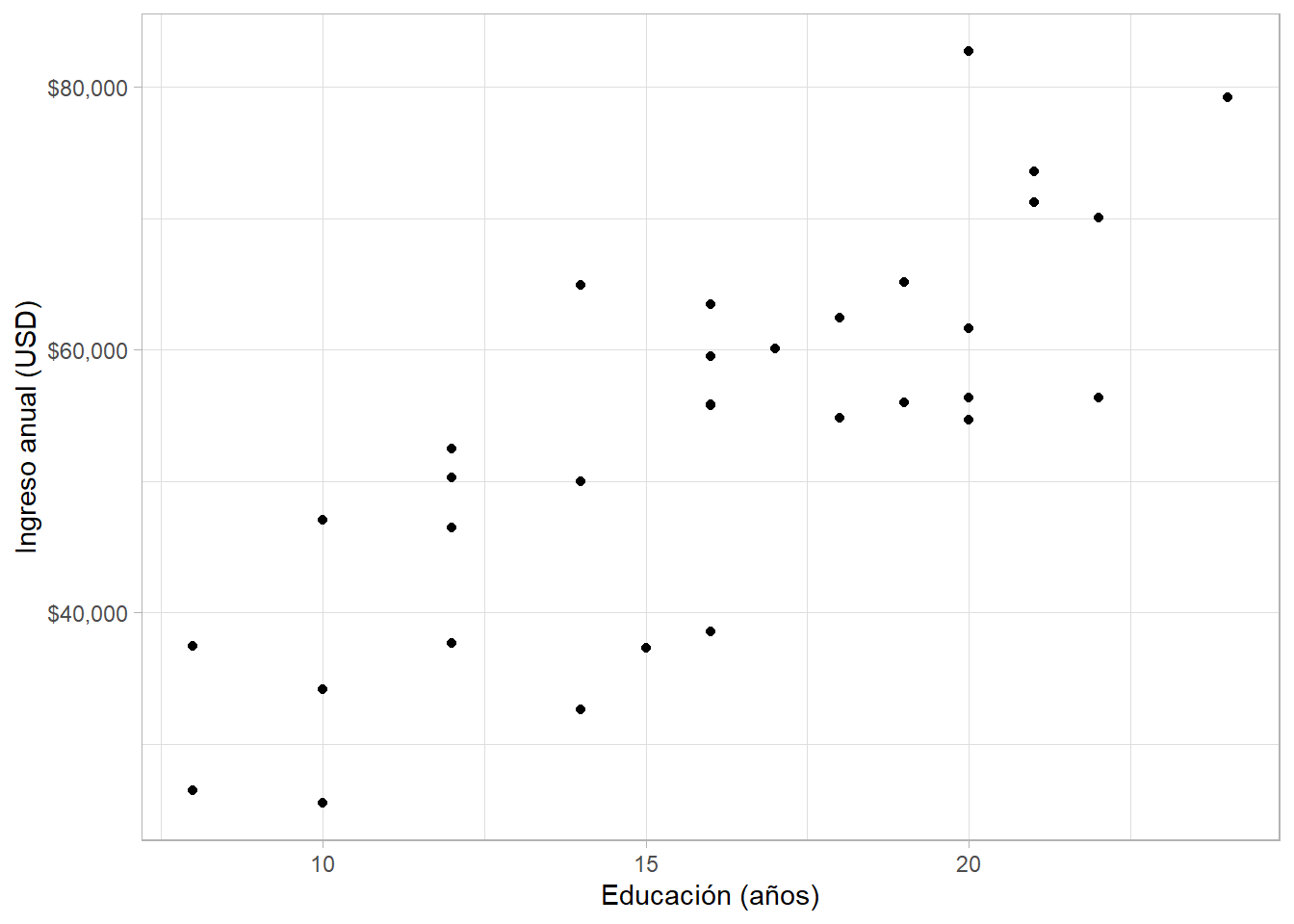
Parece que hay una relación lineal positiva entre ambas variables. Sin embargo, después de revisar la literatura, creemos que la experiencia laboral y el género de un individuo también impactan su ingreso. Así que exploramos la relación entre la experiencia profesional (en años) de cada individuo y su ingreso:
riverside %>%
ggplot(aes(senior, income)) +
geom_point() +
scale_y_continuous(labels = scales::dollar) +
labs(x = "Experiencia laboral (años)", y = "Ingreso anual (USD)")
Vemos un patrón similar. Además, podemos mirar la relación entre género -una variable categórica binaria en nuestros datos- e ingreso:
riverside %>%
ggplot(aes(gender, income)) +
geom_boxplot() + # caja y bigote
scale_y_continuous(labels = scales::dollar) +
labs(x = "Género", y = "Ingreso anual (USD)")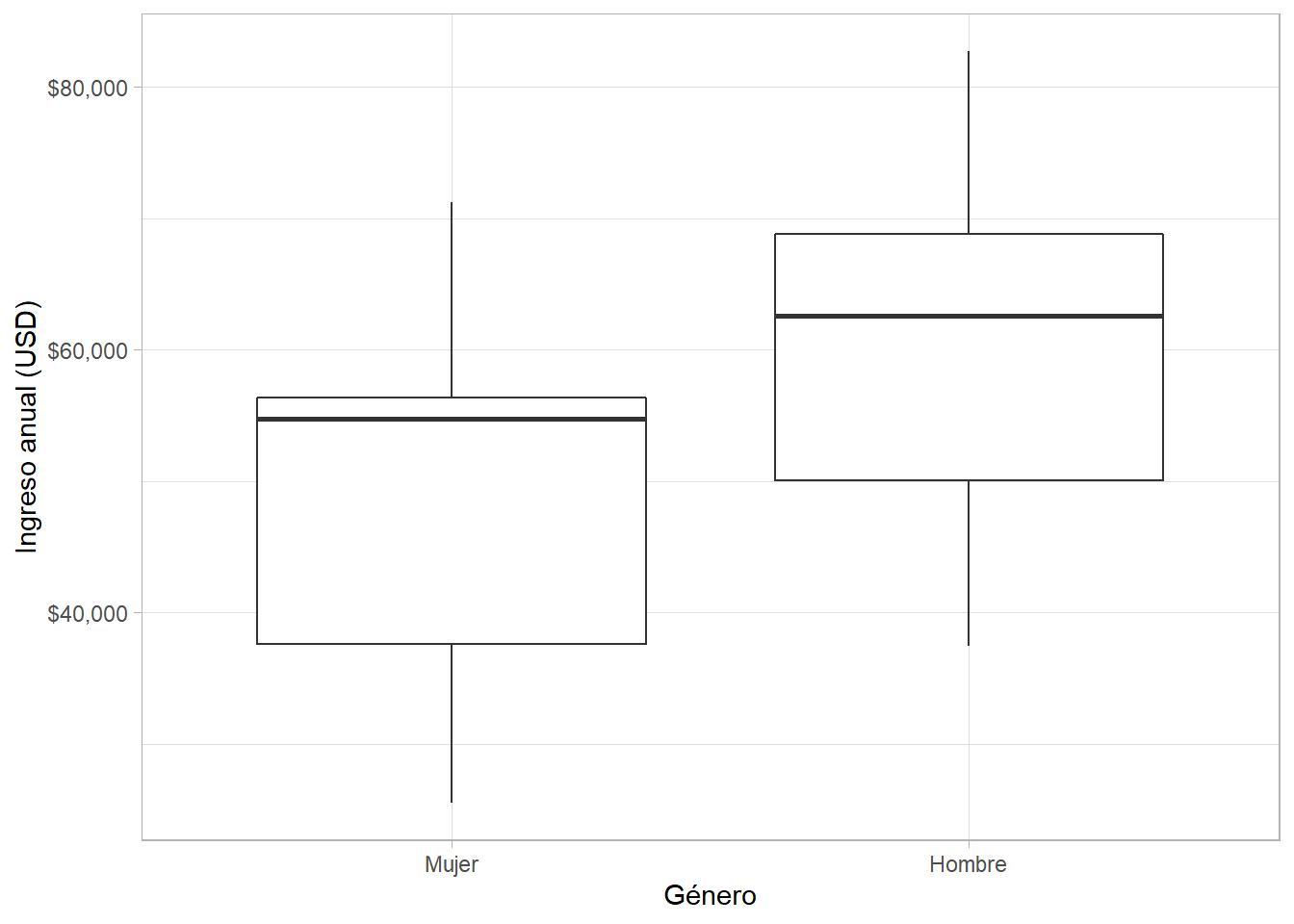
8.4 Análisis de regresión
Basados en nuestra teoría y la literatura, creemos que el ingreso de un individuo \(i\) es una función lineal del nivel de educación, la experiencia laboral y el género de dicho individuo. Entonces, el modelo que vamos a estimar es el siguiente:
\[ \hat{\text{Ingreso}}_i = \hat{\alpha} + \hat{\beta}_1 \text{Educación}_i + \hat{\beta}_2 \text{Experiencia}_i + \hat{\beta}_3 \text{Hombre}_i + \hat{u}_i \]
8.4.1 Estimación
En R, estimamos modelos de regresión lineal usando la función lm(). Esta función toma como principal argumento una fórmula de la forma y ~ x + z, donde y es la variable dependiente y x y z son variables independientes.
Estimemos un modelo simple (\(\text{Ingreso}_i = \alpha + \hat{\beta} \text{Educación}_i\)) y guardémoslo como un nuevo objeto:
modelo_simple <- lm(income ~ edu, data = riverside)Así de sencillo. Si queremos explorar los resultados del modelo, podemos usar la función summary():
summary(modelo_simple)##
## Call:
## lm(formula = income ~ edu, data = riverside)
##
## Residuals:
## Min 1Q Median 3Q Max
## -15808 -5783 2088 5127 18379
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 11321.4 6123.2 1.849 0.0743 .
## edu 2651.3 369.6 7.173 5.56e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 8978 on 30 degrees of freedom
## Multiple R-squared: 0.6317, Adjusted R-squared: 0.6194
## F-statistic: 51.45 on 1 and 30 DF, p-value: 5.562e-08Vemos varios elementos, incluyendo coeficientes (Estimate), errores estándar (Std. Error) y p-values (Pr(>|t|)) de cada variable, más unas estadísticas del ajuste del modelo en general (como el \(R^2\)). Estos elementos se pueden extraer individualmente, por ejemplo:
coef(modelo_simple)## (Intercept) edu
## 11321.379 2651.297Por ahora, nos vamos a enfocar en los coeficientes. Recordemos brevemente la interpretación básica de los coeficientes de un modelo de regresión lineal:
- El intercepto (\(\alpha\)) es el valor esperado de \(Y\) (ingreso, en este caso) cuando todas las variables independientes \(= 0\).
- El coeficiente de regresión de una variable independiente (\(\beta\)) es el incremento en el valor esperado de \(Y\) (ingreso) asociado a un incremento de una unidad en \(X\) (educación).
Podemos tener modelos de regresión con variables independientes categóricas, por ejemplo binarias (también llamadas variables dummy o variables indicador). Usemos la variable gender que toma dos valores en los datos: “Hombre” y “Mujer”. Estimemos el modelo con la misma función, pero cambiando la variable independiente:
modelo_genero <- lm(income ~ gender, data = riverside)
summary(modelo_genero)##
## Call:
## lm(formula = income ~ gender, data = riverside)
##
## Residuals:
## Min 1Q Median 3Q Max
## -23459 -10673 4280 8085 22807
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 48938 3225 15.175 1.29e-15 ***
## genderHombre 10980 4876 2.252 0.0318 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 13680 on 30 degrees of freedom
## Multiple R-squared: 0.1446, Adjusted R-squared: 0.1161
## F-statistic: 5.072 on 1 and 30 DF, p-value: 0.03179Recordemos que cuando se trata de variables independientes binarias, la interpretación de los coeficientes cambia levemente:
- \(\alpha\) es el valor esperado de \(Y\) cuando el valor de \(X\) es la categoría de referencia - en este caso, \(\hat{Y}\) cuando \(X = \text{Mujer}\).
- \(\beta\) es la diferencia en el valor esperado de \(Y\) para la(s) otra(s) categoría(s) de la variable categórica.1 En este caso, cuando \(X = 1\) (hombre), \(\hat{Y} = \hat{\alpha} + \hat{\beta}\). Cuando \(X = 0\) (mujer), entonces \(\hat{Y} = \hat{\alpha}\).
8.4.1.1 Regresión múltiple
Sin embargo, dado nuestro modelo teórico, nos interesa estimar un modelo de regresión múltiple con más de una variable independiente. Para esto, agregamos más variables independientes a la fórmula con el operador +. Estimamos el modelo, lo guardamos como un objeto e imprimimos a la consola un resumen:
modelo_ingreso <- lm(income ~ edu + senior + gender, data = riverside)
summary(modelo_ingreso)##
## Call:
## lm(formula = income ~ edu + senior + gender, data = riverside)
##
## Residuals:
## Min 1Q Median 3Q Max
## -11558 -4899 -1245 3058 11157
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4309.2 4444.3 0.970 0.340541
## edu 2229.8 274.1 8.136 7.4e-09 ***
## senior 669.5 172.9 3.871 0.000593 ***
## genderHombre 8774.6 2246.6 3.906 0.000541 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6261 on 28 degrees of freedom
## Multiple R-squared: 0.8328, Adjusted R-squared: 0.8149
## F-statistic: 46.5 on 3 and 28 DF, p-value: 5.292e-11Esta información es suficiente para interpretar la magnitud, dirección y significancia de los coeficientes. Luego volveremos a este modelo para discutir cómo interpretarlo.
8.4.1.2 Especificación del modelo
Además de añadir términos (variables independientes) a un modelo, podemos también cambiar la forma en que las variables entran al modelo. Dos transformaciones comunes son los logaritmos y los términos multiplicativos.
8.4.1.2.1 Logaritmos
La regresión lineal está diseñada para funcionar mejor con variables dependientes con distribuciones normales (o cercanas a la normal). Cuando encontramos una variable con una distribución sesgada hacia la derecha (muchos casos con valores bajos), aplicarle la función logarítmica permite mover la distribución de forma tal que se acerque más a la normal. Como la función logarítmica aplica una transformación afín, no cambia la estructura subyacente de los datos. Por otro lado,
Podríamos pensar que la asociación entre experiencia laboral e ingreso no es lineal, sino que exhibe rendimientos decrecientes: pasar de 0 a 5 años de experiencia se asociaría con un aumento en el ingreso mayor que pasar de 10 a 15 años de experiencia. Es posible que una transformación logarítmica de la variable senior nos permita capturar intuiciones teóricas como los rendimientos decrecientes. Recordemos la forma de una función logarítmica para hacer la conexión con esta idea teórica:
tibble(
x = 1:100,
log_x = log(x)
) %>%
ggplot(aes(x, log_x)) +
geom_line(color = "red")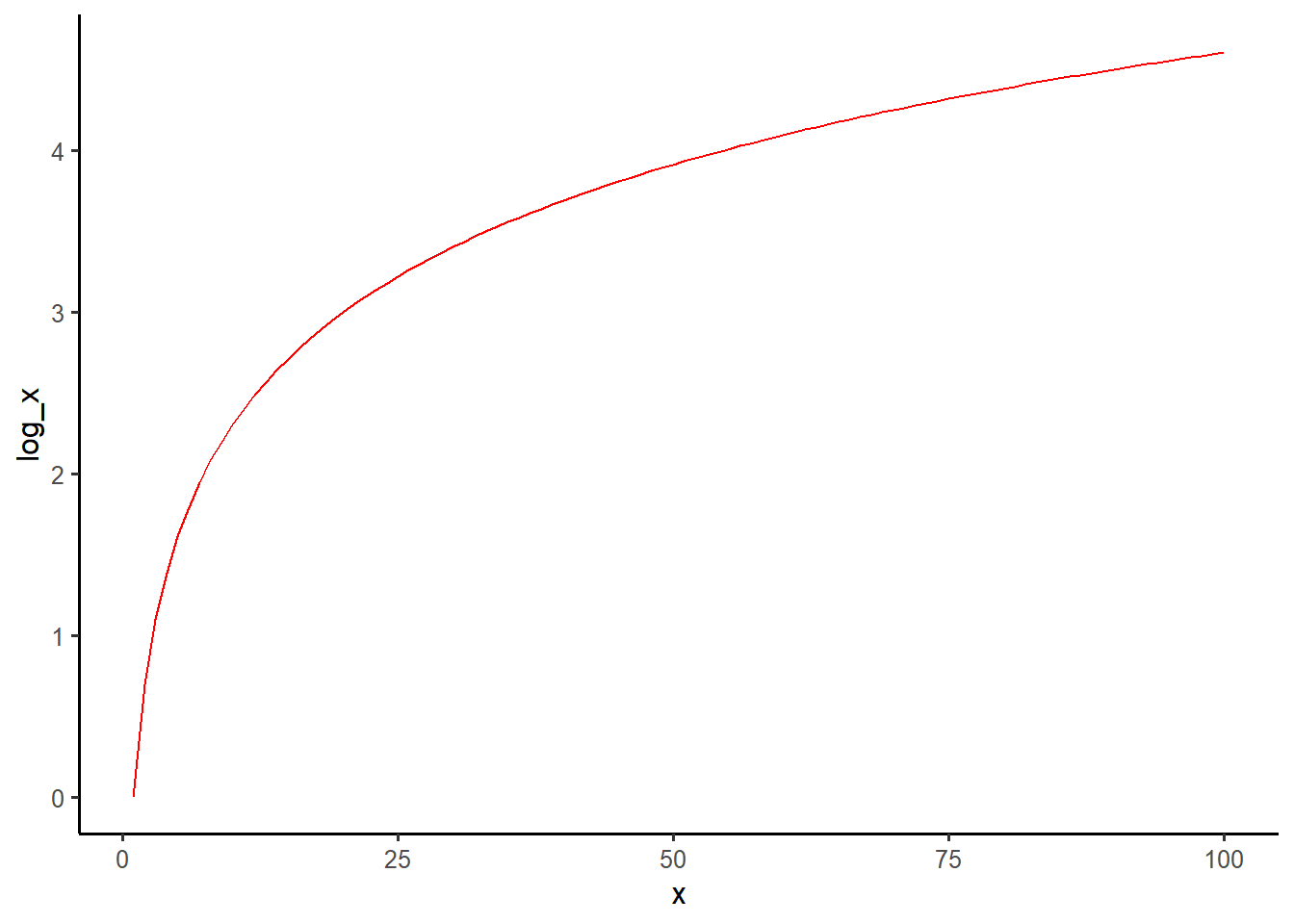
Para valores bajos de \(x\), el aumento correspondiente de \(\log(x)\) es mayor que el aumento cuando los valores de \(x\) son mayores.
Ahora, exploremos la relación entre el logaritmo natural de la experiencia en años y el ingreso:
riverside %>%
ggplot(aes(log(senior), income)) +
geom_point() +
scale_y_continuous(labels = scales::dollar) +
scale_x_continuous(trans = "log") +
labs(x = "Experiencia laboral (años), log.", y = "Ingreso anual (USD)")## Warning: Transformation introduced infinite values in continuous x-axis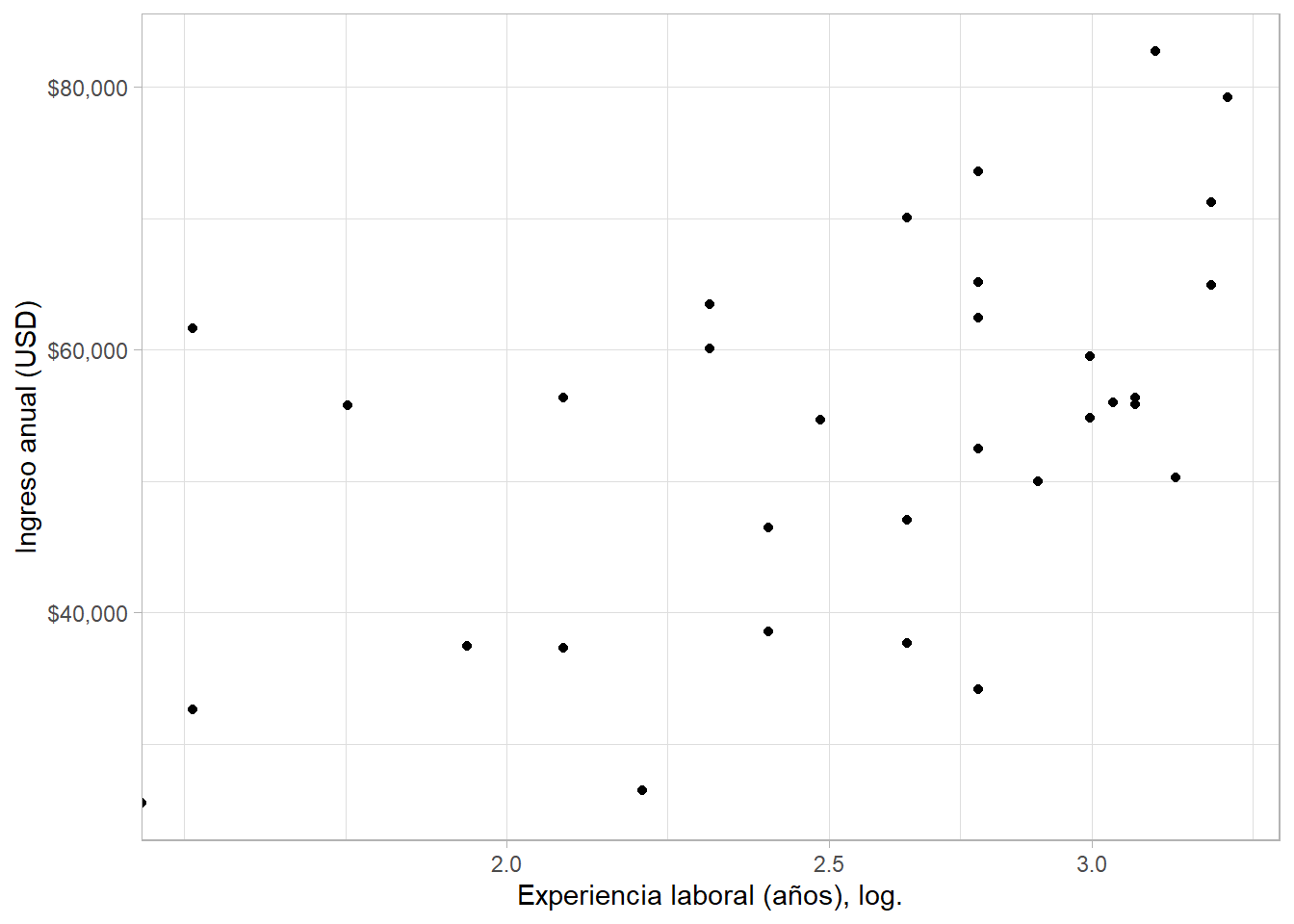
Podemos estimar el logaritmo (natural) y usarlo directamente en un modelo en la fórmula de lm() con la función log():
lm(income ~ edu + log(senior) + gender, data = riverside) %>%
summary()##
## Call:
## lm(formula = income ~ edu + log(senior) + gender, data = riverside)
##
## Residuals:
## Min 1Q Median 3Q Max
## -12643.8 -3946.4 -844.8 5905.2 11116.7
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -2915.9 5400.9 -0.540 0.59354
## edu 2252.9 280.3 8.037 9.44e-09 ***
## log(senior) 6620.1 1841.1 3.596 0.00123 **
## genderHombre 8710.2 2305.6 3.778 0.00076 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6416 on 28 degrees of freedom
## Multiple R-squared: 0.8245, Adjusted R-squared: 0.8056
## F-statistic: 43.83 on 3 and 28 DF, p-value: 1.046e-10Sin embargo, es preferible realizar la transformación antes, para poder tener información (como por ejemplo, estadísticas resumen) de la variable transformada, como lo hicimos arriba - aquí repetimos la operación como demostración:
riverside <- riverside %>%
mutate(senior_log = log(senior))Para estimar el modelo con la variable de experiencia en versión logaritmo, simplemente la agregamos a la fórmula en lm():
modelo_log <- lm(income ~ edu + senior_log + gender, data = riverside)
summary(modelo_log)##
## Call:
## lm(formula = income ~ edu + senior_log + gender, data = riverside)
##
## Residuals:
## Min 1Q Median 3Q Max
## -12643.8 -3946.4 -844.8 5905.2 11116.7
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -2915.9 5400.9 -0.540 0.59354
## edu 2252.9 280.3 8.037 9.44e-09 ***
## senior_log 6620.1 1841.1 3.596 0.00123 **
## genderHombre 8710.2 2305.6 3.778 0.00076 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6416 on 28 degrees of freedom
## Multiple R-squared: 0.8245, Adjusted R-squared: 0.8056
## F-statistic: 43.83 on 3 and 28 DF, p-value: 1.046e-10Recordemos que en este caso, los demás coeficientes y el intercepto se interpretan igual, pero el coeficiente para la variable transformada se interpreta de manera diferente: un aumento de \(1\%\) en \(X\) (ojo, no en \(\log(X)\)) se asocia con un incremento de \(\hat{\beta} \times 0.01\) en \(\hat{Y}\).
Es posible también transformar la variable dependiente de manera logarítmica (un modelo log-normal) o tanto la dependiente como una independiente (un modelo log-log). La interpretación en esos casos también cambia, pero no la discutimos aquí.
8.4.1.2.2 Términos multiplicativos o interacciones
Supongamos que creemos que la asociación entre \(X_1\) y \(Y\) (el coeficiente \(\beta_1\)) depende del valor de \(X_2\).2 En otras palabras, creemos que hay una variable que modera la asociación entre \(X_1\) y \(Y\). En este caso, podemos estimar un modelo lineal con términos multiplicativos o interacciones entre las variables independientes. Las interacciones nos permiten capturar una noción teórica interesante que nos permiten capturar esta idea.
En términos prácticos, una interacción es una multiplicación entre dos variables. Pueden ser dos variables numéricas, dos categóricas (recordemos que para efectos de estimar modelos, las categorías se convierten en enteros) o una numérica y una categórica. La interacción más común es la interacción entre una variable numérica y una categórica. En este caso, podríamos pensar que la relación entre educación (una variable numérica) e ingreso es distinta para hombres y para mujeres (categorías). Incorporamos esta noción teórica al modelo que vamos a estimar:
\[ \hat{\text{Ingreso}}_i = \hat{\alpha} + \hat{\beta}_1 \text{Educación}_i + \hat{\beta}_2 \text{Hombre}_i + \hat{\beta}_3 (\text{Educación}_i \times \text{Hombre}_i) + \hat{u}_i \]
En R, simplemente multiplicamos los dos términos en la fórmula de lm() - esto se puede hacer antes y crear una nueva columna en los datos:
modelo_inter <- lm(income ~ edu*gender, data = riverside)
summary(modelo_inter)##
## Call:
## lm(formula = income ~ edu * gender, data = riverside)
##
## Residuals:
## Min 1Q Median 3Q Max
## -11731.7 -4818.9 -838.7 6594.1 13264.8
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 8330.53 7499.90 1.111 0.276
## edu 2573.72 461.01 5.583 5.66e-06 ***
## genderHombre 9295.21 10625.09 0.875 0.389
## edu:genderHombre 23.21 640.23 0.036 0.971
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 7757 on 28 degrees of freedom
## Multiple R-squared: 0.7434, Adjusted R-squared: 0.7159
## F-statistic: 27.04 on 3 and 28 DF, p-value: 2.028e-08Noten que el modelo incluye tanto el término multiplicativo (edu:genderHombre), como los componentes del mismo; esto es por diseño. La interpretación de los coeficientes de las variables que no hacen parte de una interacción permanece igual, pero la forma en que interpretamos la asociación entre \(X_1\) y \(Y\) y entre \(X_2\) y \(Y\) cambia de manera importante:
- Cuando \(X_2 = 0 = \text{"Mujer"}\), el intercepto es \(\alpha\) y la asociación entre \(X_1\) y \(Y\) es \(\beta_1\).
- Cuando \(X_2 = 1 = \text{"Hombre"}\), el intercepto es \(\alpha + \beta_2\) y la asociación entre \(X_1\) y \(Y\) es \(\beta_1 + \beta_3\).
8.4.2 Diagnósticos
El modelo de regresión lineal por mínimos cuadrados ordinarios (MCO u OLS) es el estimador lineal insesgado de mínima varianza (“OLS is BLUE”) cuando se cumplen una serie de supuestos, entre ellos, supuestos sobre los errores \(u\) y su distribución. R nos permite realizar unos diagnósticos para evaluar si estos supuestos se cumplen.
8.4.2.1 Linealidadad
En OLS, asumimos que \(Y\) es una función lineal de las variables independientes. Evaluamos este supuesto visualmente con una gráfica de los valores esperados del modelo (las predicciones) vs. los residuos del mismo, buscando si hay una relación entre ambos:
plot(modelo_ingreso, which = 1)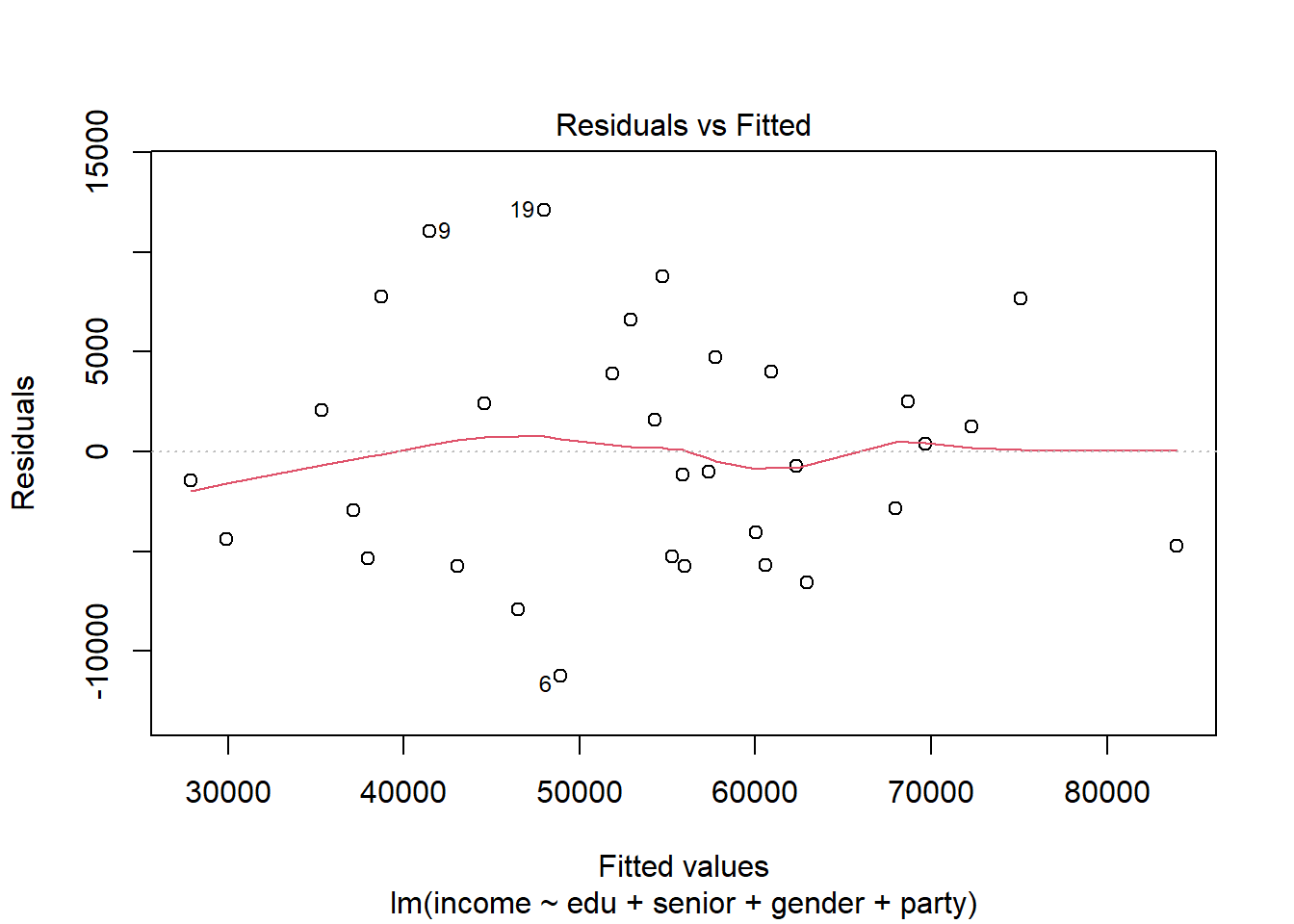
Si vemos una relación clara (¡miren la línea roja!), hay un problema de linealidad. Violar este supuesto es un problema de específicación del modelo, o sea qué variables incluimos y de qué forma entran. En este caso, podríamos transformar nuestras variables independientes con logaritmos o funciones exponenciales.
8.4.2.2 Normalidad
OLS asume que los residuos (errores) del modelo están distribuidos normalmente. Nuevamente, realizamos una evaluación visual del supuesto (una gráfica Q-Q), buscando que los puntos no se desvíen mucho de la línea diagonal, especialmente en los extremos:
plot(modelo_ingreso, which = 2)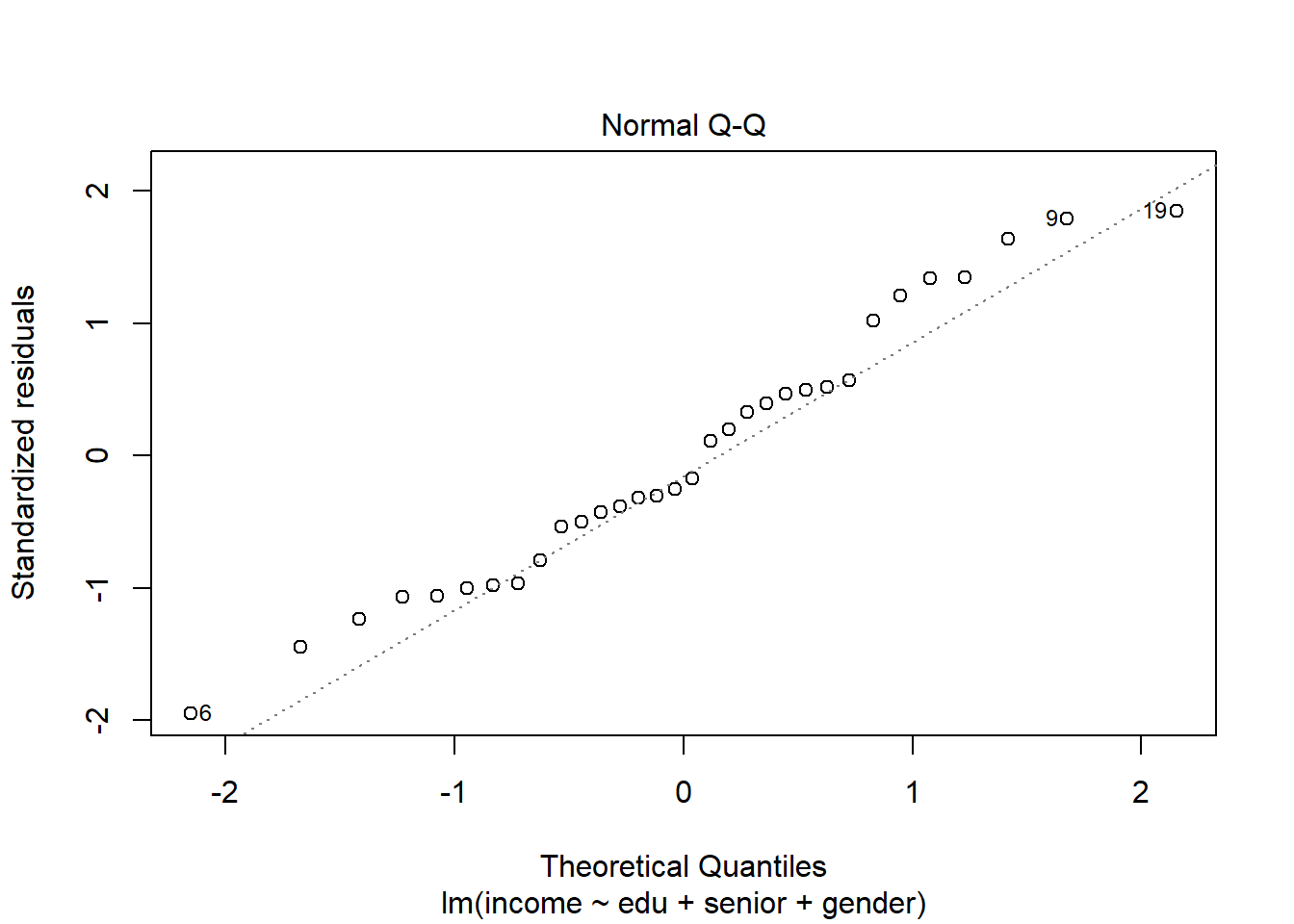
Otra opción es usar un prueba estadística, como el test de Shapiro o el Kolmogorov-Smirnoff, vía las funciones shapiro.test(). Si obtenemos un p-value menor a 0.05, rechazamos la hipótesis nula de normalidad en la distribución de los residuos:
shapiro.test(resid(modelo_ingreso))##
## Shapiro-Wilk normality test
##
## data: resid(modelo_ingreso)
## W = 0.96973, p-value = 0.492Cuando vemos violaciones muy severas de este supuesto, puede que haya un problema con nuestra variable dependiente. Quizás en realidad sea una medida binaria, categórica u ordinal con pocos niveles. En estos casos, podemos buscar medidas alternativas u técnicas distintas a la regresión lineal por OLS.
8.4.2.3 Independencia
Un supuesto muy importante es que las observaciones son sacadas de una muestra de manera independiente; en otras palabras, que no hay patrones de dependencia espacial, temporal o multinivel entre observaciones. Este es un supuesto que podemos evaluar simplemente conociendo nuestros datos y teoría. ¿Mis casos son países que observo año tras año? ¿O quizás espero que lo que sucede en un municipio afecte a los vecinos? Esas son situaciones de autocorrelación temporal y/o espacial. Otra forma de evaluar este supuesto es viendo mapas o series de tiempo de nuestra variable dependiente en búsqueda de tendencias.
Sin embargo, también existen pruebas estadísticas para evaluar el supuesto de independencia. El test de Durbin-Watson, implementado con la función dwtest() de la librería lmtest, es una de estas pruebas:
dwtest(modelo_ingreso)##
## Durbin-Watson test
##
## data: modelo_ingreso
## DW = 1.6656, p-value = 0.1272
## alternative hypothesis: true autocorrelation is greater than 0Un p-value por encima de 0.05 es consistente con la hipótesis nula de no autocorrelación.
Violaciones al supuesto de independencia se solucionan estimando un modelo distinto; en algunas ocasiones, muy distinto. Estos son temas avanzados que no cubrimos aquí, pero más adelante discutimos los estimadores de efectos fijos para analizar datos en panel.
8.4.2.4 Homoesquedasticidad
El supuesto de homoesquedasticidad significa que la varianza de los residuos es constante. Violar este supuesto -los errores están correlacionados entre sí, por ejemplo, y la varianza de los mismos no es constante- implica que los errores estándar estarían mal estimados (más pequeños de lo que deberían ser), dándonos una falsa sensación de confianza.
Para evaluar este supuesto, podemos construir un gráfico de valores esperados de \(Y\) versus los residuos estandarizados (en realidad, la raíz cuadrada de los valores absolutos de estos errores). Cuando se cumple el supuesto, no debemos observar ninguna relación clara entre ambos valores:
plot(modelo_ingreso, which = 3)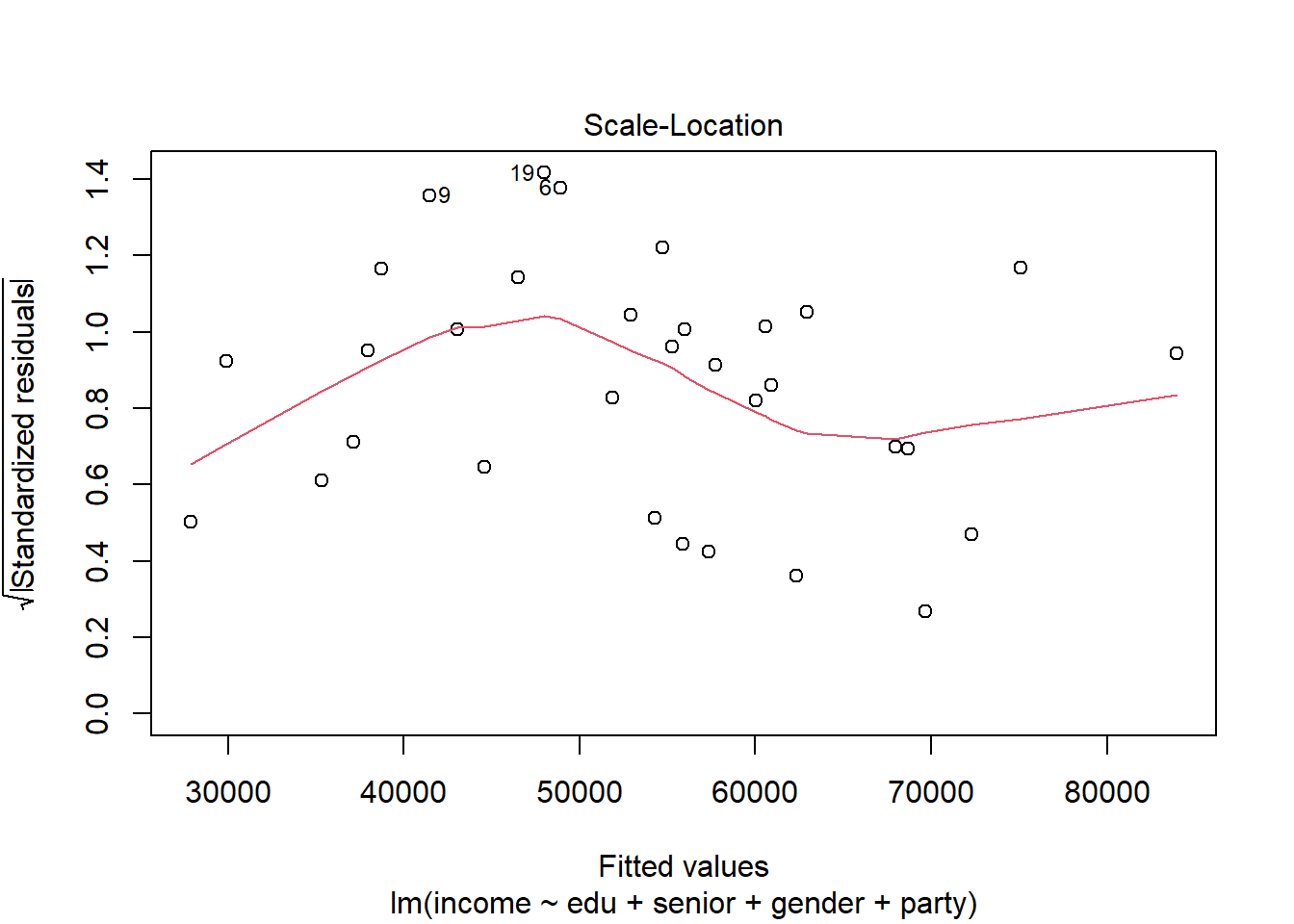
Buscamos que a) la línea roja sea aproximadamente horizontal y b) la dispersión de los puntos no cambie mucho en función de los valores esperados. Aquí parece que tenemos un problema de heteroesquedasticidad.
Un test de Breusch-Pagan nos permitiría ponerle más precisión a este diagnóstico. Usamos la función bptest(), nuevamente de la librería lmtest. Veamos:
bptest(modelo_ingreso)##
## studentized Breusch-Pagan test
##
## data: modelo_ingreso
## BP = 0.64256, df = 3, p-value = 0.8866La hipótesis nula en esta prueba es homoesquedasticidad. Si la rechazamos con un p-value bajo (menor a 0.05), tenemos heteroesquedasticidad.
Una de las razones por las que podemos encontrar heteroesquedasticidad en un modelo es que tenemos observaciones con mucha influencia sobre los resultados; podríamos decir que son atípicas. La \(D\) de Cook es una estadística que nos permite medir la influencia de una observación en un modelo de regresión lineal. Vamos a calcular esta estadística para cada una de las observaciones que utilizamos en nuestro modelo y vamos a colocarlas junto a dichas observaciones en un tibble:
datos_modelo <- bind_cols(
modelo_ingreso$model,
d_cook = cooks.distance(modelo_ingreso)
)
head(datos_modelo)## income edu senior gender d_cook
## 1 26430 8 9 Mujer 0.004363751
## 2 37449 8 7 Hombre 0.006869922
## 3 34182 10 16 Mujer 0.010902332
## 4 25479 10 1 Mujer 0.005936892
## 5 47034 10 14 Hombre 0.006310266
## 6 37656 12 14 Hombre 0.108969950Ahora, podemos buscar y eliminar las observaciones con una \(D\) de Cook alta. Dos reglas informales sugieren que observaciones con valores por encima de 1 o con valores por encima de 3 veces la media pueden tener alta influencia. Vamos a eliminar estas observaciones, reestimar el modelo y volver a evaluar el supuesto de homoesquedasticidad:
datos_modelo %>%
filter(d_cook < 3*mean(d_cook, na.rm = TRUE)) %>%
lm(income ~ edu + senior + gender, data = .) %>%
plot(., which = 3)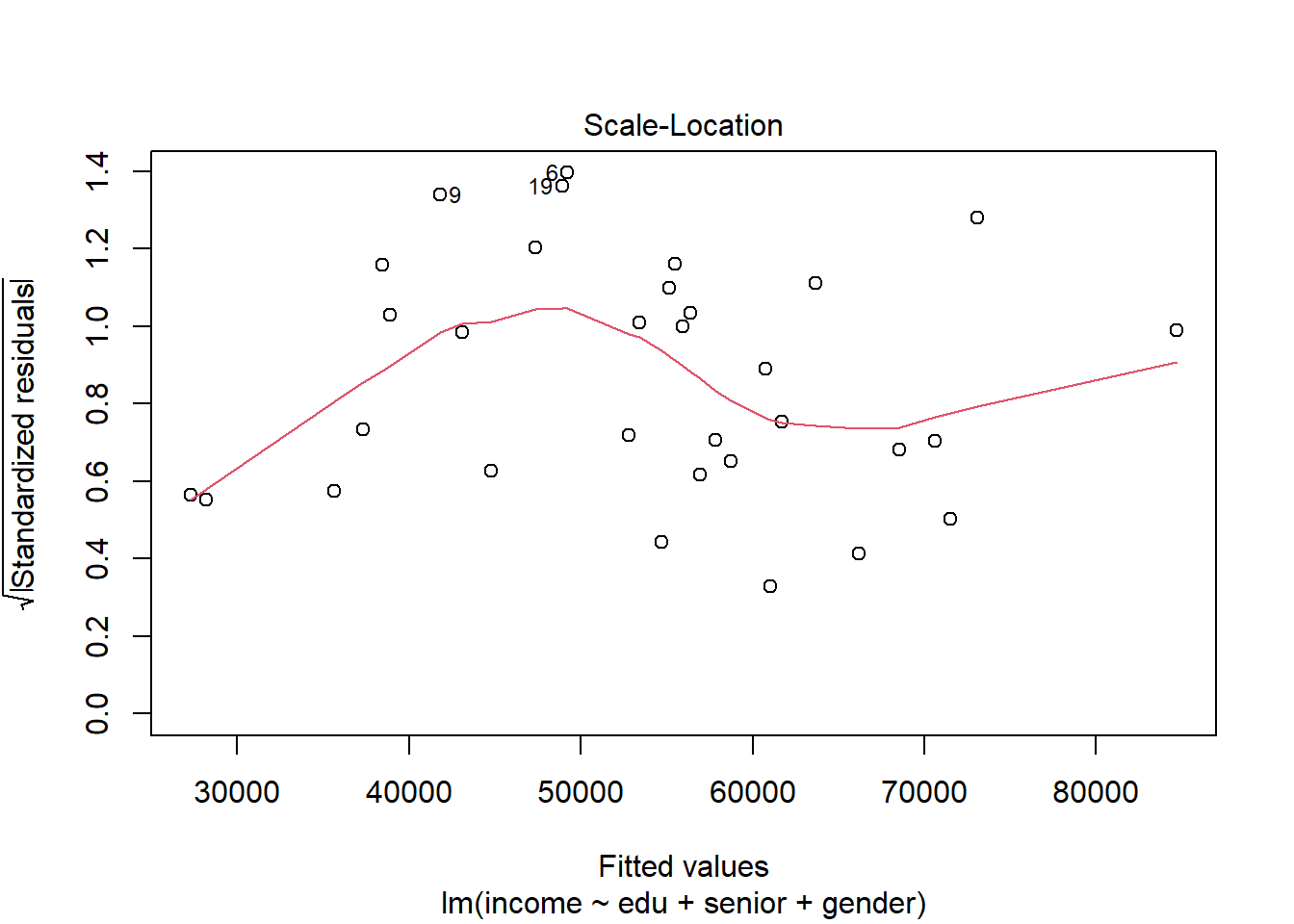
Parece que no mejoró mucho la situación. Otra opción para lidiar con los problemas asociados con la heteroesquedasticidad es corregir los errores estándar después de estimar el modelo y diagnosticarlo. Después de todo, sabemos que ese es el efecto de violar el supuesto. Vamos a utilizar la función coeftest() de la librería sandwich para recalcular los errores estándar. El resultado son lo que llamamos “erorres estándar robustos”:
coeftest(modelo_ingreso, vcov = vcovHC)##
## t test of coefficients:
##
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4309.22 4044.57 1.0654 0.295782
## edu 2229.83 226.58 9.8412 1.369e-10 ***
## senior 669.48 144.95 4.6188 7.861e-05 ***
## genderHombre 8774.57 2278.26 3.8514 0.000625 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Noten que los errores estándar de las variables edu y senior ahora son más grandes. La práctica de estimar errores estándar robustos de distintos tipos es bastante común en en Ciencia Política y Economía.
Hay otras soluciones al problema de heteroesquedasticidad, como aplicar “weighted least squares” (WLS) o usar técnicas como el bootstrap. Por el momento, procedemos con nuestro análisis y reportamos nuestros resultados, pero entendiendo que nuestros errores estándar pueden estar mal estimados.
8.5 Más Interpretación
Hasta ahora, hemos discutido brevemente cómo interpretar los coeficientes de un modelo de regresión múltiple con distintas especificaciones, utilizando la función summary() para ver estos resultados. Pero podemos refinar un poco más la interpretación.
summary(modelo_ingreso)##
## Call:
## lm(formula = income ~ edu + senior + gender, data = riverside)
##
## Residuals:
## Min 1Q Median 3Q Max
## -11558 -4899 -1245 3058 11157
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4309.2 4444.3 0.970 0.340541
## edu 2229.8 274.1 8.136 7.4e-09 ***
## senior 669.5 172.9 3.871 0.000593 ***
## genderHombre 8774.6 2246.6 3.906 0.000541 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6261 on 28 degrees of freedom
## Multiple R-squared: 0.8328, Adjusted R-squared: 0.8149
## F-statistic: 46.5 on 3 and 28 DF, p-value: 5.292e-11Podemos interpretar la dirección, magnitud y significancia de cada uno de los coeficientes utilizando lo que ya sabemos y nuestras discusiones previas:
- Educación (variable continua): ceteris paribus, cada incremento de una unidad en la variable se asocia con un incremento de aproximadamente 2230 unidades en la variable dependiente. En otras palabras, manteniendo las demás variables constantes, un año adicional de educación se asocia en promedio con un incremento de 2230 USD en el ingreso anual.
- Experiencia (continua): ceteris paribus, cada incremento de de una unidad en la variable se asocia con un incremento de aproximadamente 6.69 unidades en la variable dependiente. En otras palabras, manteniendo las demás variables constantes, un año adicional de experiencia laboral se asocia en promedio con un incremento de 6.69 USD en el ingreso anual.
- Género (categórica): ceteris paribus, ser hombre se asocia con un incremento de 8775 unidades en la variable dependiente, comparado con la categoría de base (ser mujer). En otras palabras, manteniendo las demás variables constantes, el ingreso anual de un hombre es en promedio 8775 USD que el de una mujer.
Estos tres coeficientes son estadísticamente significativos (\(p < 0.05\)), lo cual indica que la probabilidad de observar estos valores si la hipótesis nula (\(\beta = 0\)) fuese cierta es menos del 5%. O sea, es tan poco probable observar estos coeficientes, que ya que los observamos, debe ser que la hipótesis nula no representa el mundo real. En el mundo en que la hipótesis nula es cierta, \(\beta = 0\) – el p-value nos dice si el \(\beta\) que observamos/estimamos encaja en un mundo en que \(\beta = 0\).
8.5.1 Predicciones y efectos
Una de las herramientas más potentes que nos da un modelo de regresión lineal es la capacidad de hacer predicciones. Una predicción no es más que el valor esperado de \(Y\) para determinados valores de las variables independientes. Hallamos estos valores esperados o predicciones utilizando los coeficientes estimados y reemplazando los valores de las variables independientes en la ecuación del modelo de regresión lineal.
Calculemos un valor esperado “a mano” usando nuestro modelo. Primero, vamos a extraer los coeficientes del modelo usando coef() y pluck() - están en el orden en que aparecen en el resumen del modelo:
alfa <- coef(modelo_ingreso) %>% pluck(1)
beta_edu <- coef(modelo_ingreso) %>% pluck(2)
beta_exp <- coef(modelo_ingreso) %>% pluck(3)
beta_gen <- coef(modelo_ingreso) %>% pluck(4)Ahora, vamos a seleccionar valores de las variables independientes que nos interesan:
intercepto <- 1 # siempre es 1
edu <- 10 # 10 años de educacion
exp <- max(riverside$senior, na.rm = TRUE) # ejecutiva
gen <- 0 # mujerFinalmente, reemplazamos para hallar el valor esperado de \(Y\):
intercepto + beta_edu*edu + beta_exp+exp + beta_gen*gen## [1] 22995.83Comparemos con nuestra predicción para un hombre:
gen <- 1
intercepto + beta_edu*edu + beta_exp+exp + beta_gen*gen## [1] 31770.39¡La diferencia entre ambos valores esperados es exactamente el coeficiente de la variable género!
Con esta información, podemos hacer inferencias sobre la relación entre las variables de interés. En otras palabras, podemos ver “efectos”, asumiendo que hemos superado los distintos obstáculos a la inferencia causal.
Podemos automatizar, o si se quiere “tercerizar” este proceso. Digamos que estamos interesados en conocer el ingreso esperado de una mujer con educación y experiencia promedio en comparación con un hombre con las mismas cualificaciones. Vamos a usar la librería ggeffects, específicamente la función ggpredict(). Tomamos el modelo, lo pasamos a la función y especificamos las variables y los valores que nos interesan. La función mantiene las variables numéricas no especificadas constantes en sus valores promedio y mantiene las categóricas en su valor de referencia (es importante entonces recodificar bien):
modelo_ingreso %>%
ggpredict(terms = c("gender"))##
## # Predicted values of income
## # x = gender
##
## x | Predicted | SE | 95% CI
## ---------------------------------------------------
## Mujer | 49903.25 | 1480.18 | [47002.15, 52804.35]
## Hombre | 58677.82 | 1679.84 | [55385.39, 61970.25]
##
## Adjusted for:
## * edu = 16.00
## * senior = 14.81O de pronto nos interesa comparar el valor esperado del ingreso de individuos cuando se tiene poca y mucha experiencia:
modelo_ingreso %>%
ggpredict(terms = c("senior[minmax]"))##
## # Predicted values of income
## # x = senior
##
## x | Predicted | SE | 95% CI
## -----------------------------------------------
## 1 | 40656.05 | 2723.10 | [35318.88, 45993.22]
## 27 | 58062.54 | 2656.82 | [52855.27, 63269.82]
##
## Adjusted for:
## * edu = 16.00
## * gender = MujerPodemos incluir más variables:
modelo_ingreso %>%
ggpredict(terms = c("gender","senior[minmax]"))##
## # Predicted values of income
## # x = gender
##
## # senior = 1
##
## x | Predicted | SE | 95% CI
## ---------------------------------------------------
## Mujer | 40656.05 | 2723.10 | [35318.88, 45993.22]
## Hombre | 49430.62 | 3024.51 | [43502.69, 55358.55]
##
## # senior = 27
##
## x | Predicted | SE | 95% CI
## ---------------------------------------------------
## Mujer | 58062.54 | 2656.82 | [52855.27, 63269.82]
## Hombre | 66837.11 | 2591.86 | [61757.17, 71917.06]
##
## Adjusted for:
## * edu = 16.008.6 Presentar resultados
Dos formas principales de presentar los resultados de una regresión: tablas y gráficas. Vamos a utilizar las librerías ggeffects y sjPlot para esto.
8.6.1 Tablas de regresión
Casi todos los artículos que utilizan modelos de regresión presentan los resultados en tablas. En ellas, típicamente vemos los coeficientes, intervalos de confianza o errores estándar, la significancia de los coeficientes (con p-values), el número de observaciones y algunas medidas del ajuste del modelo, como el \(R^2\).
Para hacer tablas, podemos usar las librerías stargazer, texreg, sjPlot o gtsummary, entre otras, dependiendo de nuestras necesidades. Aquí, usamos modelsummary() de modelsummary. Le pasamos nuestro modelo y la función arroja una tabla formateada.
modelsummary(
modelo_ingreso
)| Model 1 | |
|---|---|
| (Intercept) | 4309.217 |
| (4444.267) | |
| edu | 2229.835 |
| (274.070) | |
| senior | 669.480 |
| (172.943) | |
| genderHombre | 8774.568 |
| (2246.648) | |
| Num.Obs. | 32 |
| R2 | 0.833 |
| R2 Adj. | 0.815 |
| AIC | 656.0 |
| BIC | 663.4 |
| Log.Lik. | -323.014 |
| F | 46.504 |
Los argumentos de la función nos permiten cambiar muchos de los elementos de la tabla, en particular traducir algunos de inglés a español o usar intervalos de confianza en vez de errores estándar:
modelsummary(
modelo_ingreso,
coef_map = c(
"(Intercept)" = "(Intercepto)",
"edu" = "Educación",
"senior" = "Experiencia",
"genderHombre" = "Género: hombre"
),
statistic = "conf.int",
output = "html",
title = "Resultados del análisis."
)| Model 1 | |
|---|---|
| (Intercepto) | 4309.217 |
| [-4794.451, 13412.886] | |
| Educación | 2229.835 |
| [1668.428, 2791.242] | |
| Experiencia | 669.480 |
| [315.224, 1023.737] | |
| Género: hombre | 8774.568 |
| [4172.518, 13376.617] | |
| Num.Obs. | 32 |
| R2 | 0.833 |
| R2 Adj. | 0.815 |
| AIC | 656.0 |
| BIC | 663.4 |
| Log.Lik. | -323.014 |
| F | 46.504 |
Una tabla de regresión puede presentar varios modelos lado a lado para efectos de comparación. Si ponemos los modelos en una lista antes, podemos darles nombres en la tabla:
lista_modelos <- list(
"Completo" = modelo_ingreso,
"Logaritmo" = modelo_log,
"Interacción" = modelo_inter
)
modelsummary(
lista_modelos, # varios modelos
coef_map = c(
"(Intercept)" = "(Intercepto)",
"edu" = "Educación",
"senior" = "Experiencia",
"senior_log" = "Experiencia (log.)",
"genderHombre" = "Género: hombre",
"edu:genderHombre" = "Educación × Género: hombre"
)
)| Completo | Logaritmo | Interacción | |
|---|---|---|---|
| (Intercepto) | 4309.217 | -2915.927 | 8330.532 |
| (4444.267) | (5400.909) | (7499.898) | |
| Educación | 2229.835 | 2252.883 | 2573.723 |
| (274.070) | (280.320) | (461.005) | |
| Experiencia | 669.480 | ||
| (172.943) | |||
| Experiencia (log.) | 6620.134 | ||
| (1841.091) | |||
| Género: hombre | 8774.568 | 8710.221 | 9295.210 |
| (2246.648) | (2305.636) | (10625.087) | |
| Educación × Género: hombre | 23.209 | ||
| (640.228) | |||
| Num.Obs. | 32 | 32 | 32 |
| R2 | 0.833 | 0.824 | 0.743 |
| R2 Adj. | 0.815 | 0.806 | 0.716 |
| AIC | 656.0 | 657.6 | 669.7 |
| BIC | 663.4 | 664.9 | 677.1 |
| Log.Lik. | -323.014 | -323.798 | -329.872 |
| F | 46.504 | 43.833 | 27.040 |
Estas tablas las podemos exportar como archivos de tipo HTML, que después podemos incorporar a un documento Word o similar:
modelsummary(
modelo_ingreso,
output = "output/tabla_modelo_ingreso.docx"
)8.6.2 Gráficas
Visualizar los resultados de modelos, especialmente las predicciones y la incertidumbre de estos, puede ayudar mucho a entenderlos mejor y comunicar nuestros resultados. Vamos a usar la función ggpredict de ggeffects. También podríamos usar sjPlot o hacerlo completamente “a mano”.
Como mencionamos arriba, podemos usar ggpredict() para ver los “efectos” de distintas variables, entendidos como el cambio en la variable dependiente para distintos valores de las independientes. Para esto, especificamos las variables independientes que nos interesan con terms =. Esta función mantiene constantes los factores (variables categóricas) en su categoría de referencia y las variables numéricas según su valor promedio.
Le aplicamos la función al modelo y pasamos los resultados a plot(): aquí, vemos el valor esperado (predicción) de la variable dependiente ingreso en todo el rango de la variable educación, controlando por género (categoría de referencia: mujer) y experiencia (constante en la media). Como ggeffects funciona con ggplot2, podemos modificar y agregar utilizando los trucos que ya conocemos:
modelo_ingreso %>%
ggpredict(terms = "edu") %>%
plot() +
scale_y_continuous(labels = scales::dollar) +
labs(title = "Valores esperados de ingreso para distintos valores de educación",
subtitle = "Mujeres, controlando por experiencia laboral",
x = "Educación (años)", y = "Ingreso (USD)")## Scale for 'y' is already present. Adding another scale for 'y', which will
## replace the existing scale.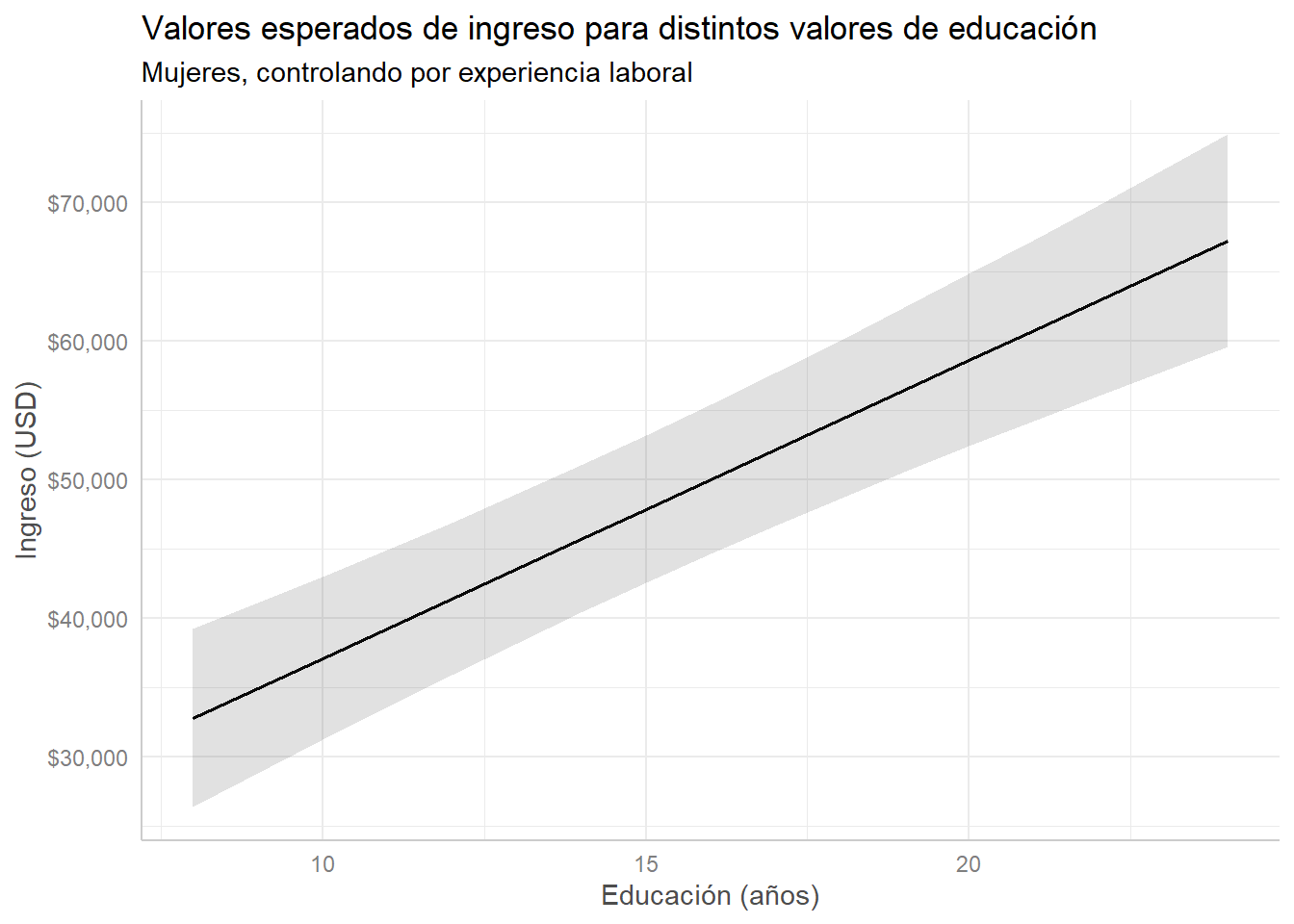
Adicionalmente, podemos especificar dos variables independientes para visualizar aún más variación. Vemos cómo la “línea base” de ingreso (el intercepto) es distinto para hombres y mujeres. Así, visualizamos más claramente la diferencia en ingreso para hombres y mujeres, por ejemplo. Además, esto evidencia que incluir una variable categórica esencialmente crea un intercepto distinto para cada grupo, sin cambiar la pendiente (el coeficiente):
modelo_ingreso %>%
ggpredict(terms = c("edu", "gender")) %>%
plot() +
scale_y_continuous(labels = scales::dollar) +
labs(title = "Valores esperados de ingreso para distintos valores de educación y experiencia",
x = "Educación (años)", y = "Ingreso (USD)", color = "Género")## Scale for 'y' is already present. Adding another scale for 'y', which will
## replace the existing scale.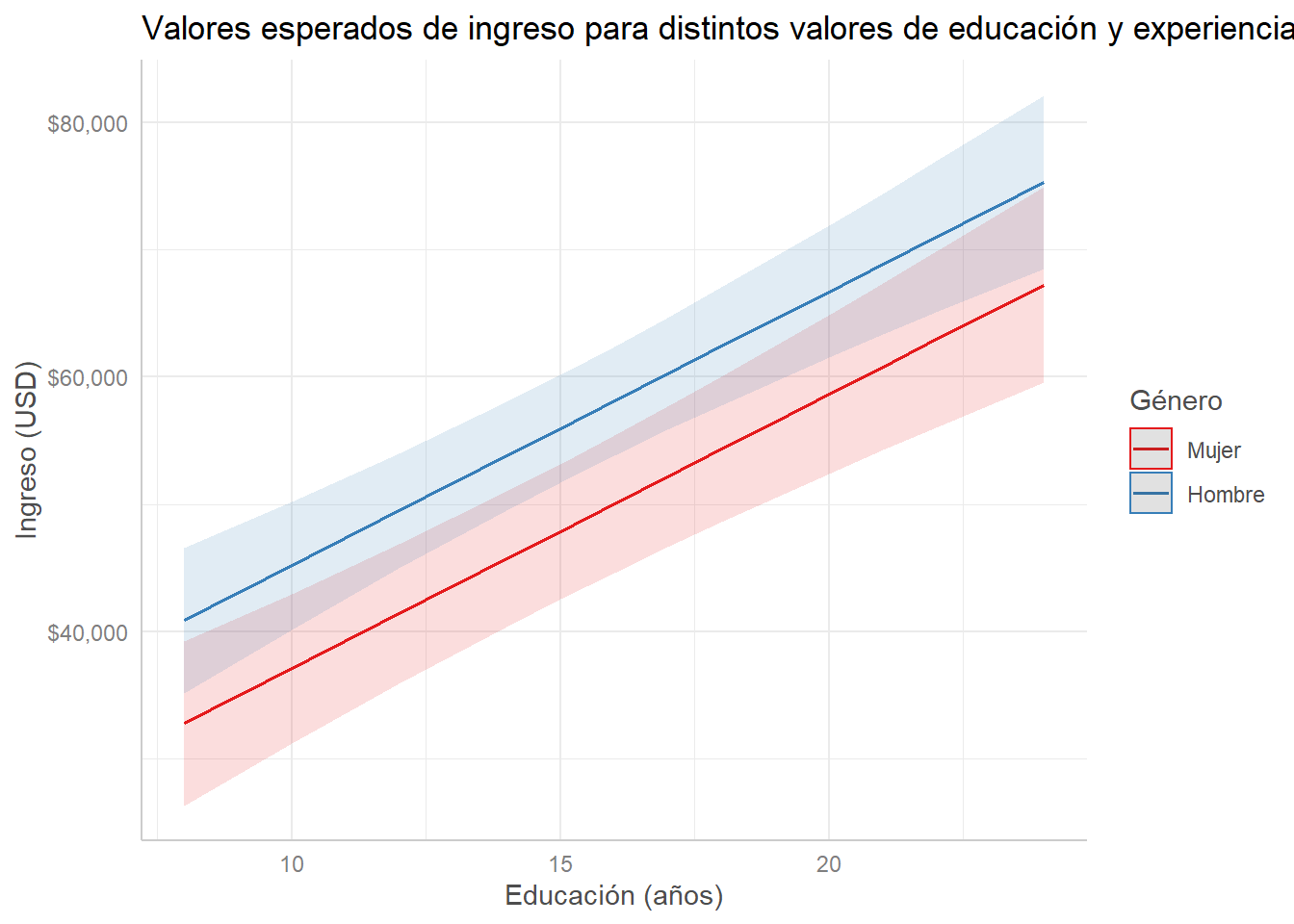
Si las dos variables son numéricas, ggpredict() automáticamente escoge tres valores del rango de la segunda variable que le pasamos (incluyendo la media) y grafica tres líneas:
modelo_ingreso %>%
ggpredict(terms = c("edu", "senior")) %>%
plot() +
scale_y_continuous(labels = scales::dollar) +
labs(title = "Valores esperados de ingreso para distintos valores de educación y experiencia",
x = "Educación (años)", y = "Ingreso (USD)", color = "Experiencia")## Scale for 'y' is already present. Adding another scale for 'y', which will
## replace the existing scale.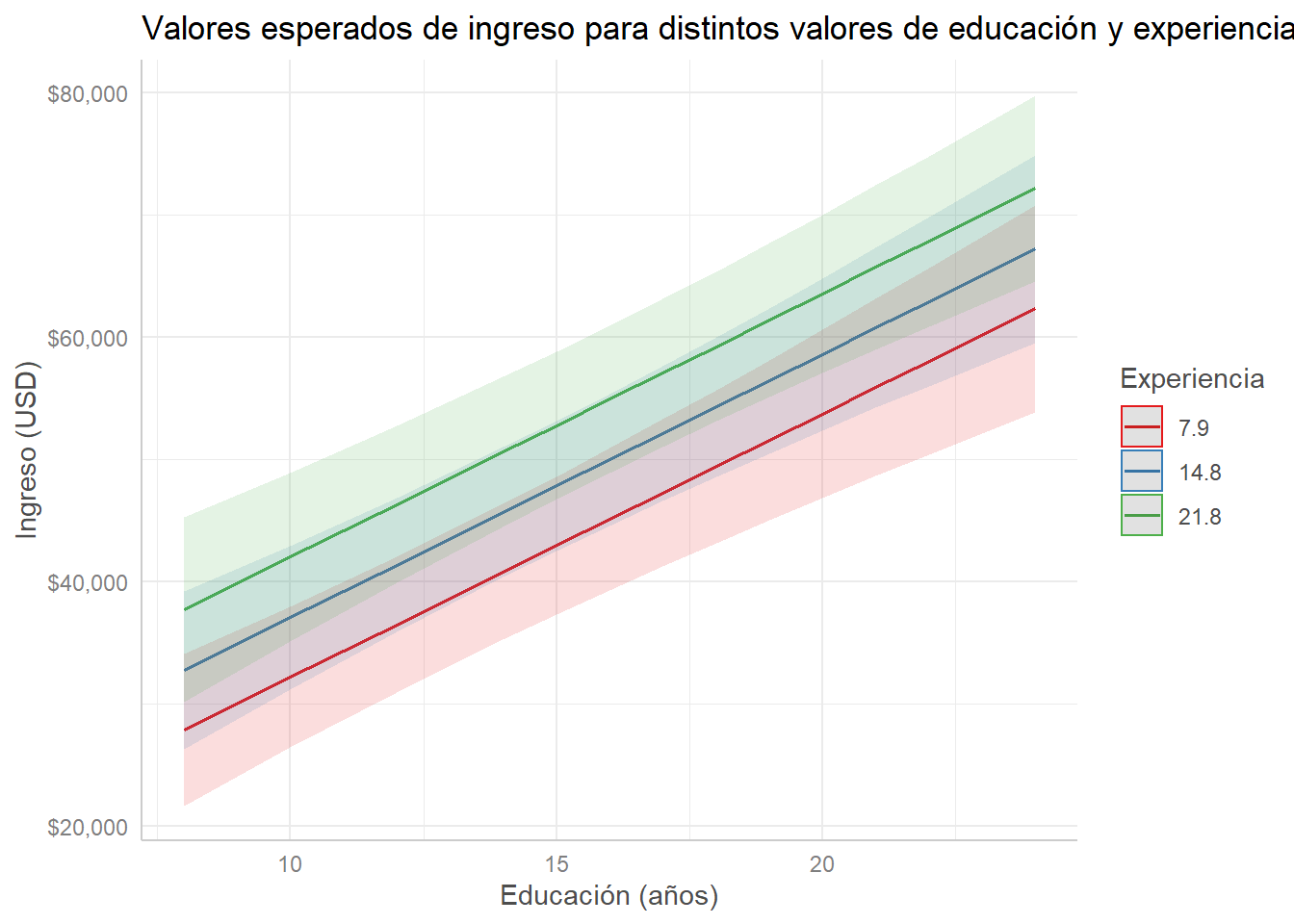
Podemos espeficiar cuántas líneas queremos ver y los valores que debe tomar la segunda variable independiente:
modelo_ingreso %>%
ggpredict(terms = c("edu", "senior [5, 25]")) %>%
plot() +
scale_y_continuous(labels = scales::dollar) +
labs(title = "Valores esperados de ingreso para distintos valores de educación y experiencia",
x = "Educación (años)", y = "Ingreso (USD)", color = "Experiencia")## Scale for 'y' is already present. Adding another scale for 'y', which will
## replace the existing scale.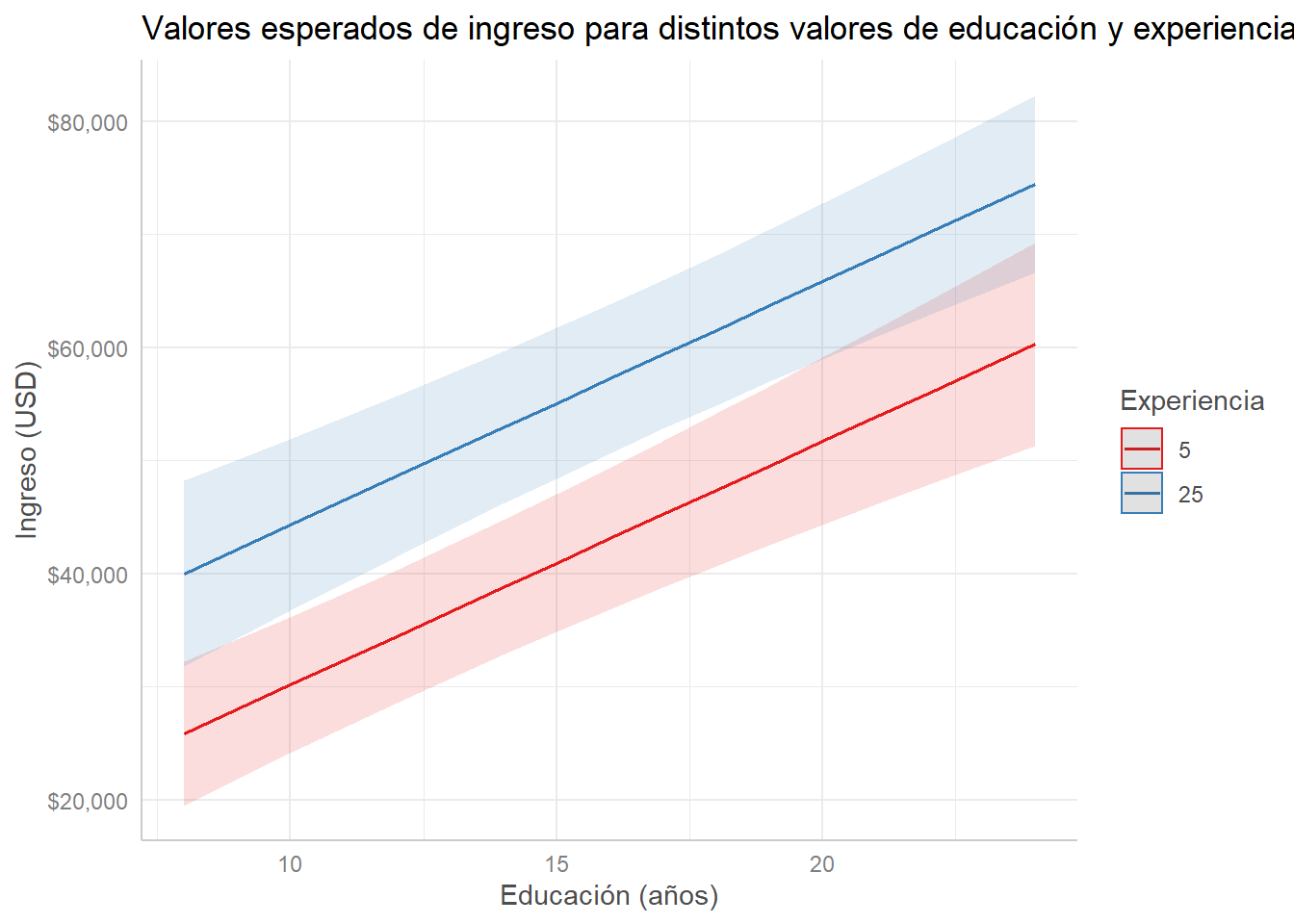
Finalmente, podemos cambiar el orden de las variables en terms = si nos interesa resaltar el efecto de una variable más que la otra:
modelo_ingreso %>%
ggpredict(terms = c("gender", "edu [5, 15, 25]")) %>%
plot() +
scale_y_continuous(labels = scales::dollar) +
labs(title = "Valores esperados de ingreso para distintos valores de género y educación",
x = "Género", y = "Ingreso (USD)", color = "Educación")## Scale for 'y' is already present. Adding another scale for 'y', which will
## replace the existing scale.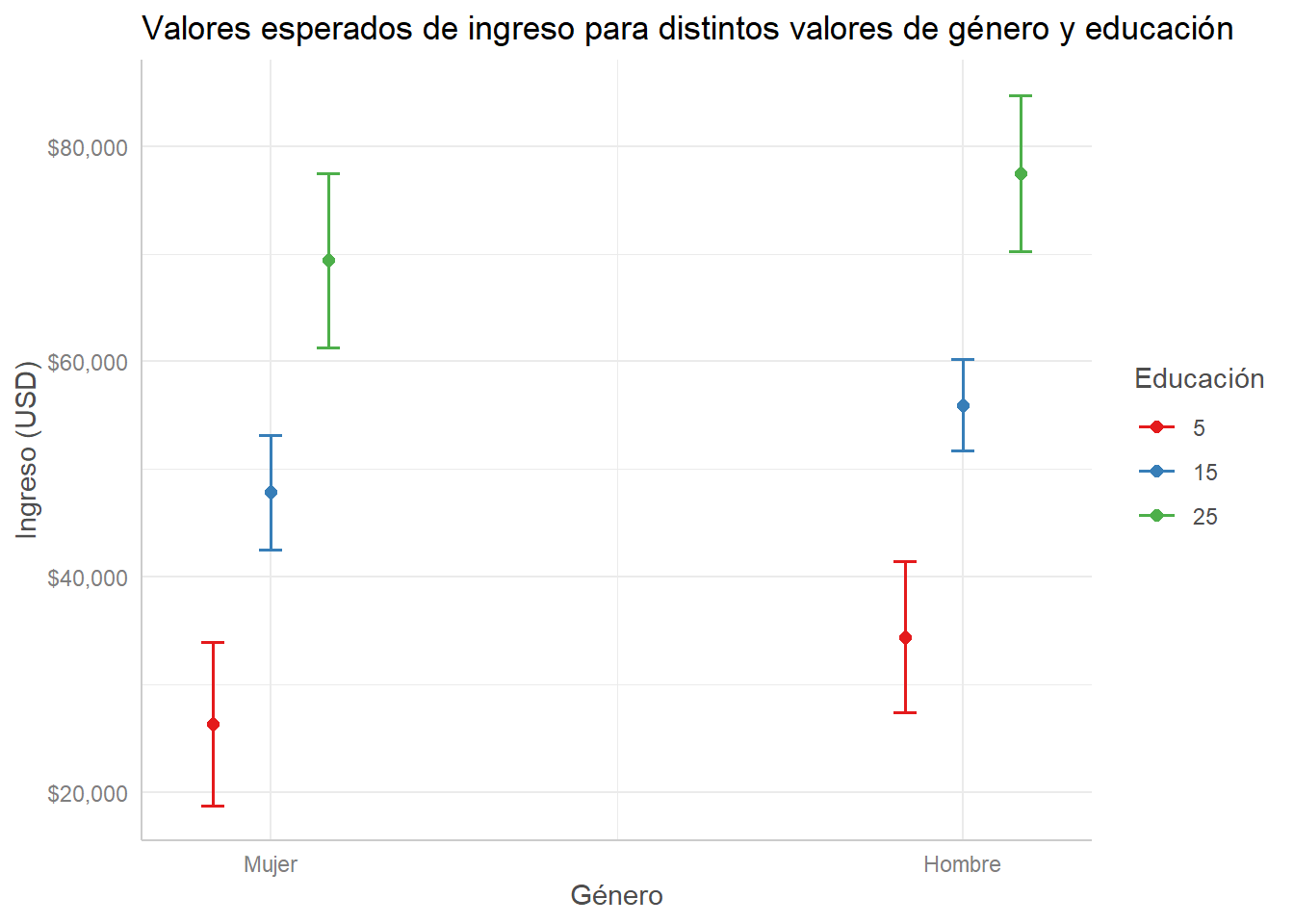
modelo_ingreso %>%
ggpredict(terms = c("senior", "edu [5, 25]")) %>%
plot() +
scale_y_continuous(labels = scales::dollar) +
labs(title = "Valores esperados de ingreso para distintos valores de educación y experiencia",
x = "Experiencia (años, log)", y = "Ingreso (USD)", color = "Educación")## Scale for 'y' is already present. Adding another scale for 'y', which will
## replace the existing scale.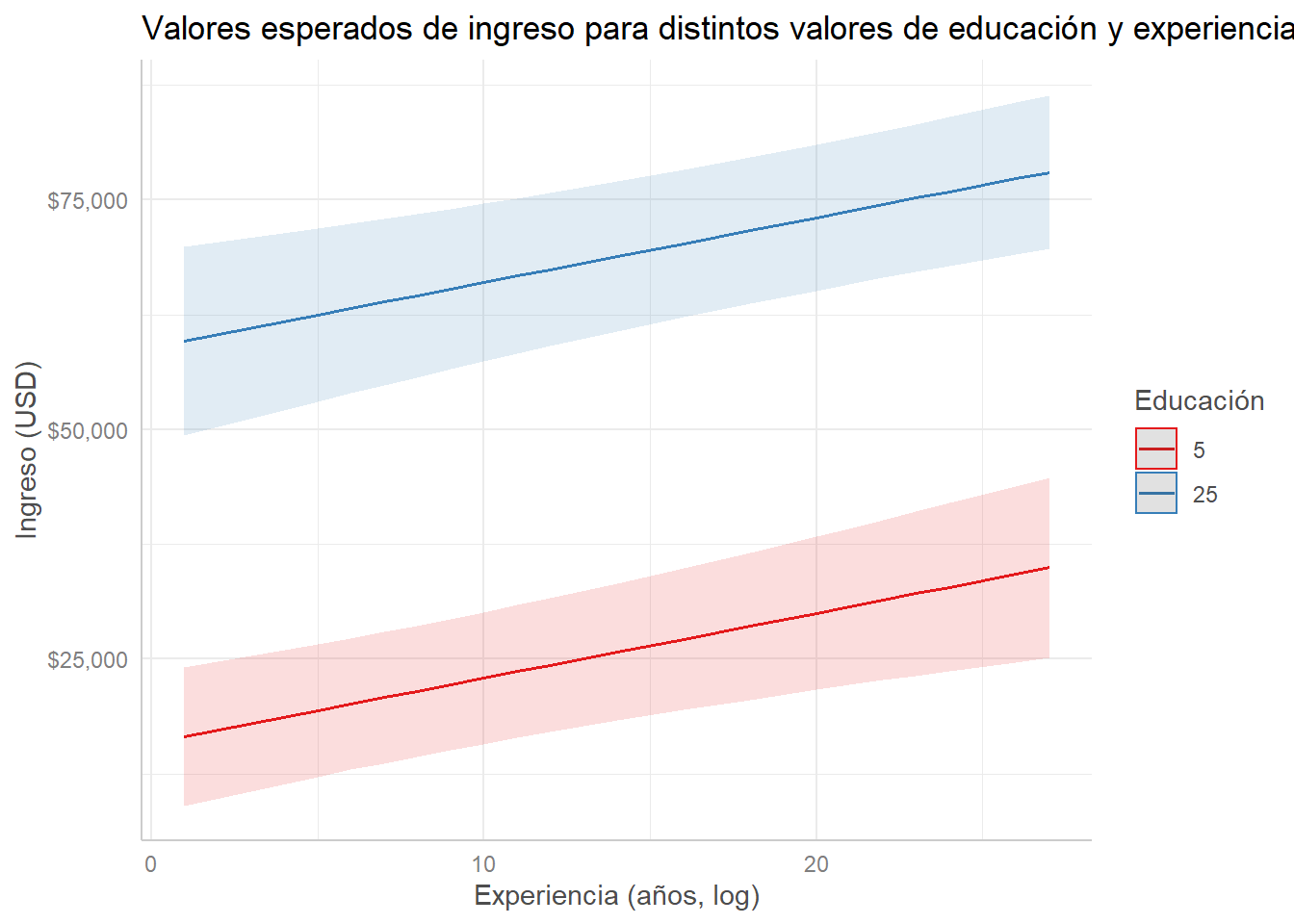
8.7 Conclusiones
Utilidad de los modelos de regresión lineal:
- Predicción: si cumplimos con los supuestos básicos, podemos hacer predicciones puntuales precisas basados en la asociación entre variables.
- Explicación: si cumplimos con más supuestos (evitamos problemas de endogeneidad y de sesgo por variables omitidas), podemos hacer inferencias sobre relaciones de tipo causal.
Otras posibilidades:
- Variables dependientes categóricas: regresión logística y modelos por máxima verosimilitud (MLE o maximum likelihood estimation).
- Experimentos: podemos usar OLS para encontrar la diferencia de medias.
- Data Science: regresión como modelo predictivo que se puede “entrenar”.
Utilizar R para el análisis estadístico:
- Curva de aprendizaje, pero grandes posibilidades.
- Practicar, practicar y practicar.
- Google es nuestro amigo.
8.8 Taller
Encontrar una base de datos relevante para el proyecto de investigación. Limpiar y ordenar los datos. El código de esta entrega no debe incluir todo el procedimiento para cargar la base de datos original y el proceso de limpieza y organización de la misma; solo el resultado final de este proceso.proceso.
8.8.1 Estimación
Estimar dos modelos de regresión lineal múltiple usando la función lm() de R. Los modelos estimados deben cumplir con los siguientes requisitos (1.0 punto):
- La variable dependiente en ambos debe ser la variable dependiente del proyecto de investigación. Idealmente esta debe ser una variable de tipo continuo, pero excepcionalmente puede ser de tipo ordinal (si tiene \(\geq 7\) categorías ordenadas) o binaria/dummy (entendiendo que la regresión lineal no es el mejor modelo para este tipo de variables). En estos dos casos, deben asegurarse que las variables estén codificadas como tipo numérico o
dblen R. - Las variables independientes deben ser a) factores potencialmente explicativos de la variable dependiente y b) variables de control. La selección de variables debe estar basada en su revisión de literatura, teoría e hipótesis.
- Debe haber por lo menos una variable independiente numérica en uno de los dos modelos. Si no tienen una, deben buscar más datos.
- Debe haber por lo menos una variable independiente categórica binaria en uno de los dos modelos. Si no tienen una, deben crearla a partir de otra.
- Dado el punto 5 de este taller, es recomendable que por lo menos uno de los modelos tenga ambos tipos de variables.
- Sugerencia: Si la literatura sugiere un debate entre dos enfoques teóricos, pueden estimar un modelo que represente cada enfoque (por ejemplo, un modelo solo con variables institucionales y otro solo con variables sociológicas), seguido de un modelo con todas las variables.
- O pueden construir el modelo completo de manera progresiva: un modelo con solo variables independientes de interés teórico, seguido de uno que añade variables de control.
8.8.2 Comunicación de resultados
Presentar los resultados de los modelos estimados en una sola tabla de regresión, usando las funciones de las librerías texreg, sjPlot, modelsummary o stargazer para producirla, teniendo en cuenta las siguientes indicaciones (1.0 punto).
- La tabla debe tener título y los coeficientes deben estar nombrados apropiadamente (o sea, con algo distinto al nombre de la variable en la base de datos). Ambas funciones tienen estas opciones.
- Deben guardar la tabla como archivo HTML.
- Nota: Pueden ejecutar
?nombre_de_funen la consola para explorar todas las opciones de estas funciones y cómo utilizarlas.
8.8.3 Diagnóstico
Evaluar si los modelos estimados cumplen el supuesto de homoesquedasticidad (\(\text{Var}(e_i) = \sigma^2\)) y si hay observaciones con un grado alto de influencia. Esta evaluación puede hacerse de manera visual o gráfica o usando tests estadísticos. Deben incluir un breve párrafo en el que consignen sus apreciaciones al respecto (1.0 punto).
8.8.4 Interpretación
Interpretar sustantivamente todos los coeficientes de los modelos incluídos en la tabla y la incertidumbre en torno a estos estimadores (pueden usar p-values o intervalos de confianza). No es necesario interpretar el coeficiente del intercepto. Cuando decimos “sustantivamente” nos referimos a que las interpretaciones deben hacer especial énfasis en la forma en que los resultados de los modelos se conectan con la evaluación de las hipótesis propuestas en el proyecto (1.0 punto).
8.8.5 Interpretación gráfica
Usando uno de los dos modelos de regresión estimados en el primer punto, construir una gráfica con ggpredict donde se presenten valores predecidos o esperados de la variable dependiente (pronósticos) para el rango de valores de una variable numérica y para todas las categorías de una variable categórica binaria (manteniendo constantes las demás variables). La gráfica debe mostrar los valores esperados de la variable dependiente (con intervalos de confianza) para dos o más grupos (definidos por la variable categórica) a lo largo del rango de una variable independiente numérica (1.0 punto).
8.9 Ejercicios adicionales
8.9.1 Votos por Trump
Digamos que nos interesa estudiar los resultados de las elecciones presidenciales de 2016 en Estados Unidos. Para este proyecto, utilizamos una base de datos que incluye información sobre un conjunto de variables sociales y políticas a nivel de condado (municipio). Para esto, vamos a cargar una serie de librerías adicionales:
library(socviz) # datos y herramientas para visualizar datos sociales##
## Attaching package: 'socviz'## The following object is masked _by_ '.GlobalEnv':
##
## edulibrary(gtsummary) # tablas resúmen
library(texreg) # tablas de regresión## Version: 1.36.23
## Date: 2017-03-03
## Author: Philip Leifeld (University of Glasgow)
##
## Please cite the JSS article in your publications -- see citation("texreg").##
## Attaching package: 'texreg'## The following object is masked from 'package:tidyr':
##
## extractVeamos el resumen de algunas de estas variables - la tabla a continuación (construida con tbl_summary()) muestra la media y desviación estándar (variables numéricas) y el número de observaciones por grupo (variables categóricas):
# seleccionamos y transformamos datos
county_data_sub <- county_data %>%
as_tibble() %>%
select(name, state, census_region, black, white, hh_income,
per_dem_2016, per_gop_2016, partywinner12) %>%
mutate(partywinner12 = fct_explicit_na(partywinner12),
black = black/100,
white = white/100,
hh_income = log(hh_income))
# estadisticas resumen
county_data_sub %>%
select(-name, -state) %>%
tbl_summary(
missing = "no",
label = list(black ~ "Prop. afro",
white ~ "Prop. blanco",
hh_income ~ "Ingreso promedio (log.)",
per_dem_2016 ~ "Prop. voto Dem.",
per_gop_2016 ~ "Prop. voto Rep.",
census_region ~ "Región",
partywinner12 ~ "Partido 2012"),
statistic = list(all_continuous() ~ "{mean} ({sd})")
) %>%
bold_labels()| Characteristic | N = 31951 |
|---|---|
| Región | |
| Midwest | 1067 (33%) |
| Northeast | 226 (7.1%) |
| South | 1440 (45%) |
| West | 461 (14%) |
| Prop. afro | 0.09 (0.14) |
| Prop. blanco | 0.85 (0.16) |
| Ingreso promedio (log.) | 10.71 (0.24) |
| Prop. voto Dem. | 0.32 (0.15) |
| Prop. voto Rep. | 0.64 (0.16) |
| Partido 2012 | |
| Democrat | 686 (21%) |
| Republican | 2455 (77%) |
| (Missing) | 54 (1.7%) |
|
1
Statistics presented: n (%); mean (SD)
|
|
Queremos entender la variación en la proporción de votos obtenidos por el candidato Demócrata (Donald Trump) en la elección de 2016 en cada condado. A continuación, vemos la distribución de esta variable:
county_data %>%
ggplot(aes(per_gop_2016)) +
geom_histogram() +
labs(x = "Prop. voto Rep.", y = "Número de condados")## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.## Warning: Removed 54 rows containing non-finite values (stat_bin).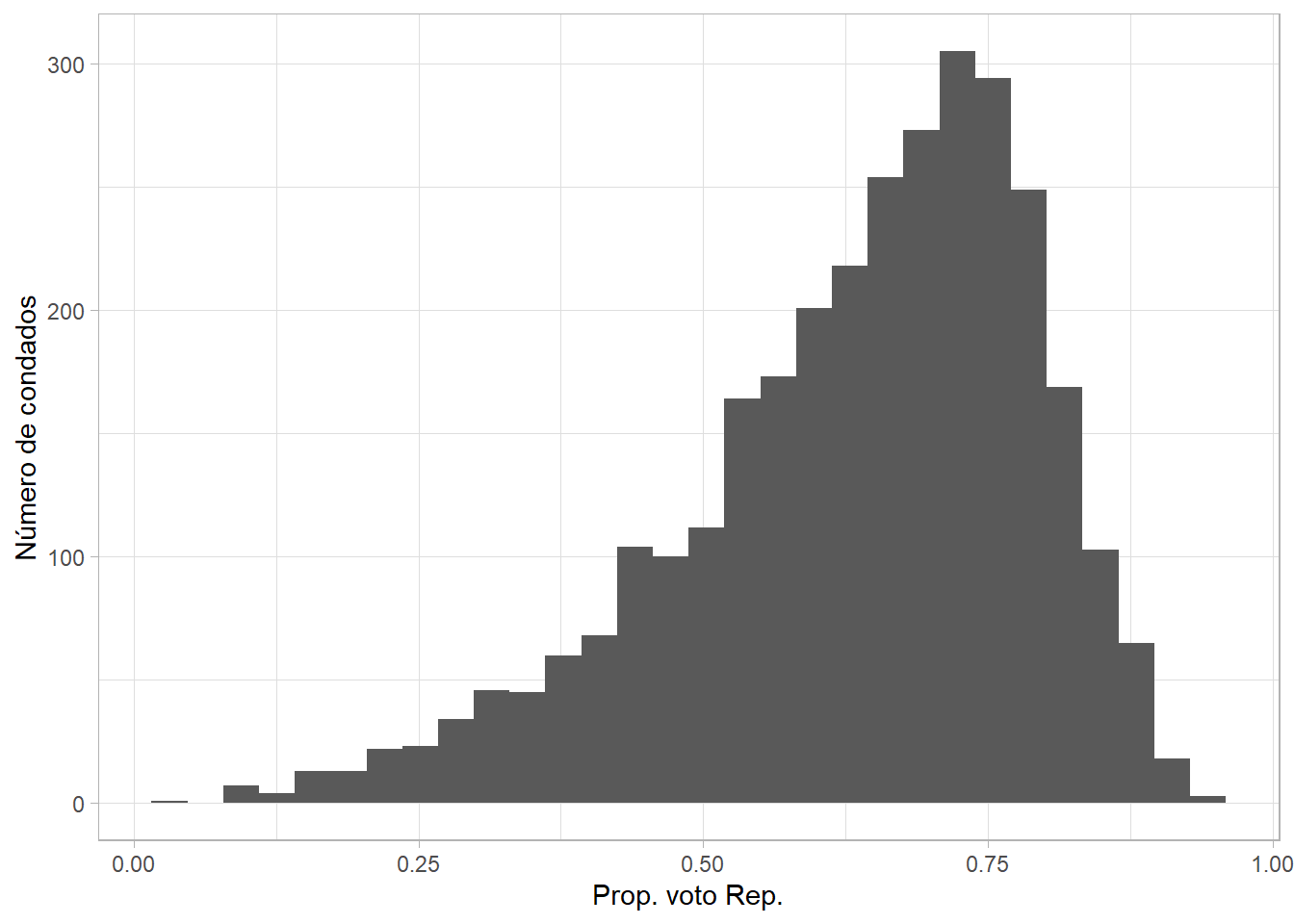
Nuestra teoría sugiere que esperamos ver una mayor proporción de votos por Trump en condados con una mayor proporción de individuos que se identifican como blancos. La siguiente gráfica de dispersión explora esta relación:
county_data %>%
ggplot(aes(white, per_gop_2016)) +
geom_point(alpha = 0.5) +
labs(x = "Prop. blanco", y = "Prop. voto Rep.")## Warning: Removed 54 rows containing missing values (geom_point).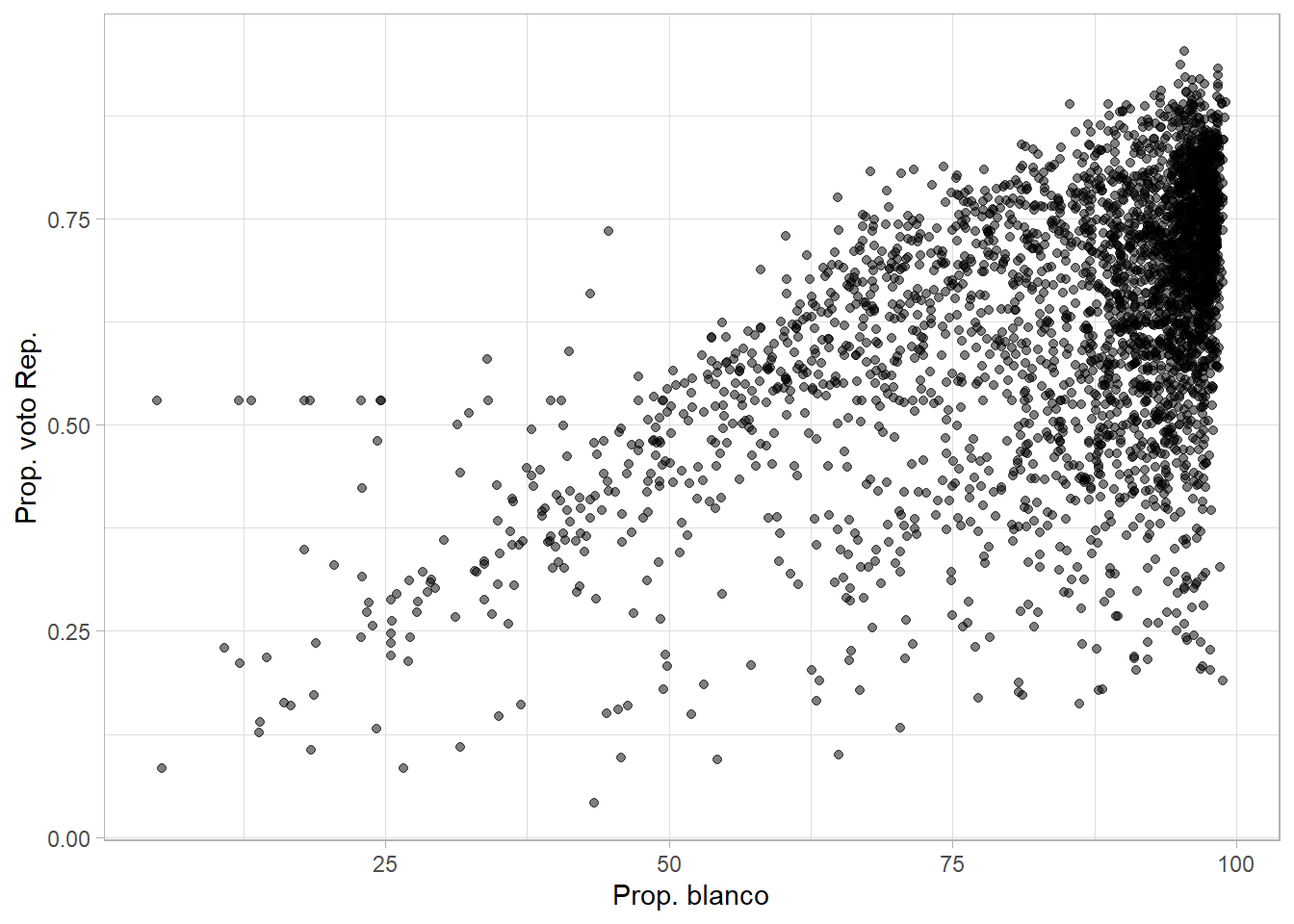
Para evaluar esta hipótesis, estimamos un modelo de regresión lineal múltiple. La variable dependiente es la proporción de votos por el candidato Republicano en cada condado. La variable independiente de interés es la proporción de habitantes blancos en cada condado. Además, incluimos varias variables de control: el logaritmo natural del ingreso promedio (en USD) de los hogares en cada condado, una dummy que indica el partido ganador en 2012 por condado y la región donde se ubica el condado. La ecuación que estimamos es:
\[ \hat{\text{Prop. voto Rep.}} = \alpha + \hat{\beta}_1 \times \text{Prop. blanco}_i + \hat{\beta}_2 \times \text{log(Ingreso)}_i + \hat{\beta}_3 \times \text{Partido 2012}_i + \hat{\beta}_4 \times \text{Región}_i + \hat{u}_i \]
La siguiente tabla muestra los resultados del modelo. Incluye el coeficiente (\(\beta\)) estimado para cada variable y el intercepto, así como intervalos de confianza del 95% entre paréntesis y la significancia estadística de cada coeficiente, además de unas estadísticas resumen del modelo (como el \(\text{R}^2\)).
modelo_rep <- lm(per_gop_2016 ~ white + hh_income + partywinner12 + census_region, data = county_data)
htmlreg(
modelo_rep, star.symbol = "\\*", doctype = FALSE,
digits = 3, caption = "Resultados del modelo de regresión lineal.",
caption.above = TRUE, center = TRUE,
custom.model.names = "OLS",
custom.coef.names = c(
"Intercepto", "Prop. Blanco", "Ingreso prom. (log.)",
"Partido 2012: Rep.", "Región: Nordeste", "Región: Sur",
"Región: Oeste"
)
)8.9.1.1 Interpretación
Para cada coeficiente, interpretar:
- Dirección.
- Magnitud.
- Significancia estadística.
8.9.1.2 Predicciones
Con la ecuación y los resultados, podemos hacer predicciones sobre el valor esperado de \(Y\) (proporción de votos por Trump) para distintos valores de las variables independientes. ¿Cuál es el valor esperado de \(Y\) para los siguientes perfiles de condados?
- 80% blanco, en la región Sur, en un condado en el que los Republicanos ganaron en 2012- las demás variables en sus medias (ver la tabla de estadísticas descriptivas).
- 20% blanco, en el Nordeste, en un condado en el que los Demócratas ganaron en 2012- nuevamente, establecemos las demás variables en sus medias.
8.9.2 Duración de gobiernos democráticos
Algunos politólogos argumentan que la variación en la duración de gobiernos democráticos en el periodo posguerra se explica por características de los gobiernos de turnos: el nivel de apoyo parlamentario de los partidos en el gobierno, el número de partidos en el mismo y la disciplina que las organizaciones partidistas pueden imponer a sus miembros. En otras palabras, tenemos el siguiente modelo teórico de la duración de un gobierno:
\[ \text{Duración gob.} = f(\text{Apoyo parl. gob.} + \text{Núm. partidos gob.} + \text{Disciplina part.} + \text{Comp. estocástico}) \]
8.9.2.1 Datos
Como estudiantes de Ciencia Política, buscamos datos al respecto para evaluar este argumento y nos encontramos con una base de datos recopilada por Rob Franzese hace unos años a partir del Political Data Handbook of OECD Countries con datos para países de la OCDE. La base de datos se encuentra en el archivo OECD_country_data.xls aquí.
- Cargue los datos en R usando las funciones y librerías apropiadas para un archivo
.xls.
Afortunadamente, el archivo también incluye un diccionario de variables (en inglés) en la segunda pestaña del archivo. Pista: read_excel() tiene un argumento sheet =.
- Identifique las variables relevantes para estimar el modelo especificado arriba y asegúrese que estén en el formato adecuado.
8.9.2.2 Regresión
La información contenida en esta base de datos nos permite decir algo sobre el argumento teórico sugerido al inicio.
- Utilizando estos datos, estime un modelo de regresión lineal sencillo (sin utilizar variables transformadas) que evalúe el argumento, presente los resultados en una tabla de regresión e interpretelos de forma sustancial (en términos del argumento).
8.9.2.3 Críticas
Frente a estos resultados, una colega sugiere que lo que está sucediendo es un poco distinto. Ella dice: “la disciplina partidista no tiene un efecto independiente sobre la duración de los gobiernos. Más bien, condiciona el efecto del apoyo legislativo al gobierno y del número de partidos en la coalición sobre la duración”.
- Especifique un modelo que tome en cuenta esta crítica, estímelo via OLS e interprete los efectos de las variables independientes sobre la dependiente:
8.9.2.4 Extra: comparar modelos
¿Cómo adjudicamos entre estos modelos? Otra colega sugiere que una prueba F, realizada por medio de un análisis de varianza (ANOVA) de los dos modelos, podría decirnos algo sobre cuál es mejor.
- Realice una prueba F y concluya cuál modelo prefiere en términos estadísticos y teóricos:
8.9.2.5 Comunicar resultados
Es útil visualizar los resultados de modelos estadísticos como estos. Para el siguiente punto, seleccione el modelo que crea que se ajusta mejor a los datos y representa mejor la teoría.
- Construya una gráfica que muestre el efecto del número de partidos en la coalición de gobierno y del apoyo legislativo al gobierno sobre la duración de los mismos cuando la disciplina partidista es alta y cuando es baja. Incluya intervalos de confianza en la gráfica.
8.9.3 Opinión pública sobre el presidente
Supongamos que queremos entender las percepciones y evaluaciones de individuos sobre los presidentes, particularmente los de USA. Por inspiración de las diosas politológicas, sabemos que el modelo “real” es:
\[ \text{Eval. presid.} = \alpha + \beta_1\text{Afroamericano} + \beta_2\text{ID partidista} + \beta_3\text{Ideología} + \beta_4\text{Eval. idiosincrática} + \beta_5\text{Eval. sociotrópica} + \epsilon \]
Esta es una versión de un modelo clásico en Ciencia Política, el cual considera que las evaluaciones individuales de los políticos son una función de posiciones ideológicos y percepciones de la economía. Queremos evaluar este modelo.
8.9.3.1 Datos
Nuevamente, buscamos datos y encontramos la encuesta del American National Election Study (ANES) para 2004, en la cual le preguntaron a los encuestados por su percepción del entonces presidente George W. Bush. Los datos se encuentran en el archivo nes_2004_data.csv aquí. Las principales variables son:
| Nombre de variable | Definición |
|---|---|
| thermom | Sentimientos por Bush (1:100; 0=mal, 100=bien) |
| race | Raza/etnicidad (10, 12, 13, 14 y 15=afroamericano) |
| partyid | Identificación partidista (0=muy Demócrata, 3=independiente, 6=muy Republicano, 7=otro) |
| libcon | ¿Liberal o conservador? (1=liberal, 3=moderado, 5=conservador, 7=no responde) |
| betteroff | Situación económica familiar el último año (1-5; 1=peor, 3=igual, 5=mejor) |
| economy | Situación económica del país el último año (1-5; 1=peor, 3=igual, 5=mejor) |
| edulevel | Nivel educativo máximo (0-7; 0=sin bachillerato, 7=posgrado) |
- Cargue el archivo de datos y realice los procedimientos necesarios para asegurarse que las variables estén debidamente codificadas.
8.9.3.2 Modelos
Aprovechemos que sabemos que el modelo de arriba es el “real”.
Estime el modelo “real”, interprete los coeficientes y diga algo sobre la interpretación causal de los mismos.
Estime el siguiente modelo -llamémoslo “modelo 2”-, que tiene una variable menos y donde los coeficientes son estimados (\(\hat{\beta}\) en vez de \(\beta\)):
\[ \text{Eval. presid.} = \alpha + \hat{\beta_1}\text{Afroamericano} + \hat{\beta_2}\text{ID partidista} + \hat{\beta_3}\text{Eval. idiosincrática} + \hat{\beta_4}\text{Eval. sociotrópica} + \epsilon \]
- Estime este otro modelo -llamémoslo algo creativo, como “modelo 3”-, que tiene una variable más y donde los coeficientes son estimados (\(\hat{\beta}\) en vez de \(\beta\)):
\[ \text{Eval. presid.} = \alpha + \hat{\beta_1}\text{Afroamericano} + \hat{\beta_2}\text{ID partidista} + \hat{\beta_3}\text{Ideología} + \hat{\beta_4}\text{Eval. idiosincrática} + \hat{\beta_5}\text{Eval. sociotrópica} + \hat{\beta_6}{Educación} + \epsilon \]
8.9.3.3 Extra: presentar resultados
Presente los resultados de los tres modelos en una tabla y saque conclusiones sobre el sesgo de los coeficientes en el modelo 2 y la eficiencia del modelo 3.
Presente gráficamente y discuta los efectos de todas las variables independientes en uno de los modelos.