Capítulo 7 Visualización de datos
7.1 Resumen
En este capítulo, aprendemos a crear varios tipos de gráficas usando la librería ggplot2, parte del tidyverse.
- Principales conceptos: histograma, gráfica de dispersión, gráfica de barras.
- Principales funciones:
ggplot(),aes(),geom_histogram(),geom_bar(),geom_col(),geom_point(),labs(),ggsave().
7.1.1 Descargas
Vamos a utilizar las siguientes librerías:
library(tidyverse)## Warning: package 'tidyverse' was built under R version 4.0.3## -- Attaching packages --------------------------------------- tidyverse 1.3.0 --## v ggplot2 3.3.2 v purrr 0.3.4
## v tibble 3.0.4 v dplyr 1.0.2
## v tidyr 1.1.2 v stringr 1.4.0
## v readr 1.3.1 v forcats 0.5.0## Warning: package 'tibble' was built under R version 4.0.3## -- Conflicts ------------------------------------------ tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(gapminder) # datos
library(knitr) # tablas## Warning: package 'knitr' was built under R version 4.0.37.2 Visualización de datos
Visualizamos datos por muchas razones: análisis exploratorio, evaluación de modelos y comunicación de resultados son algunas de las principales. El problema que buscamos resolver en este instructivo es “simple”: cómo hacer para transmitir información visualmente de forma efectiva. El objetivo: producir gráficos como estos:
## `geom_smooth()` using formula 'y ~ x'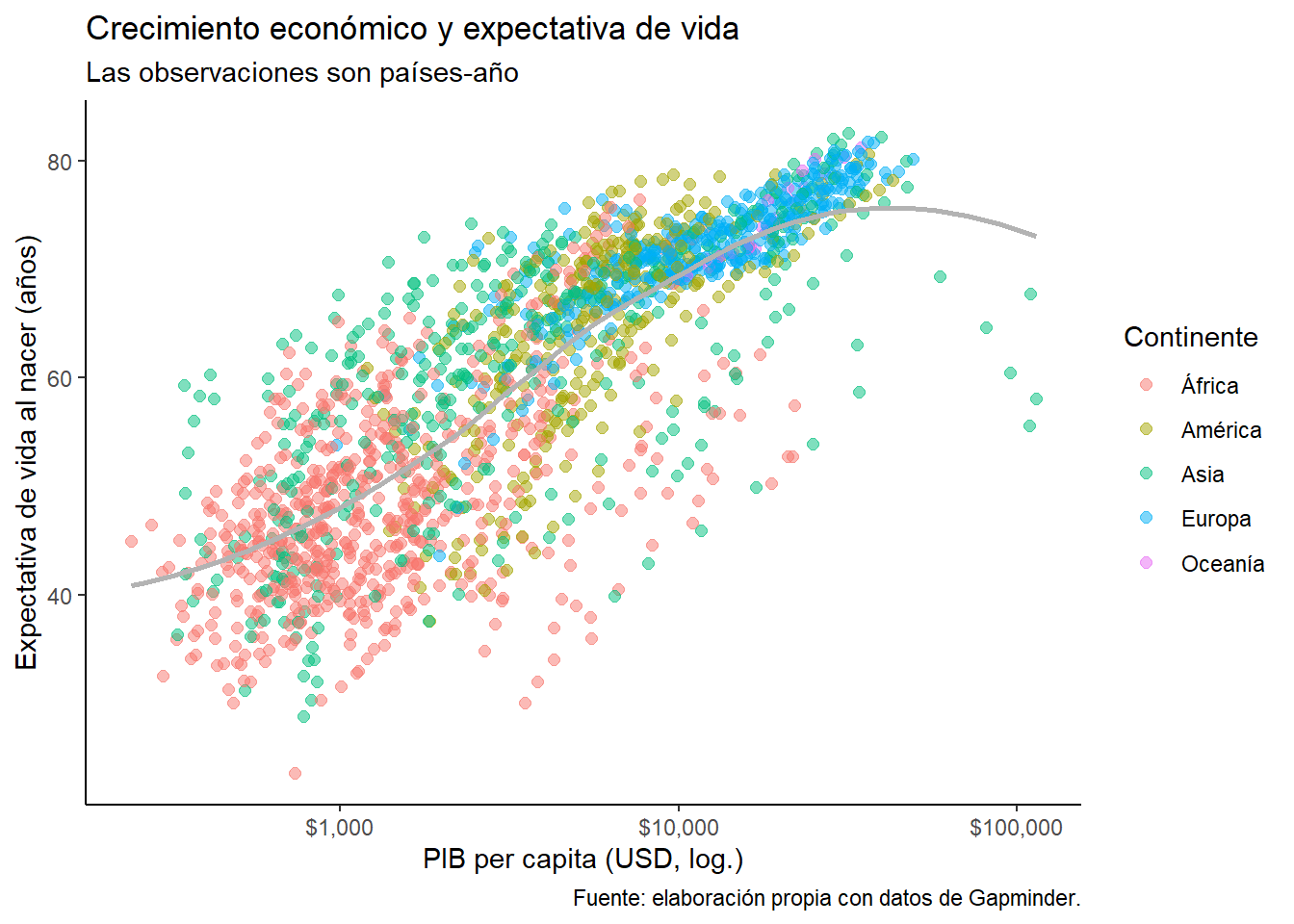
7.2.1 ggplot2: la gramática de los gráficos
La librería ggplot2 disfruta de una inmensa popularidad entre científicos de datos, politólogos, economistas, comunicadores, periodistas de datos y más. La lógica de ggplot2 está basado en la “gramática de los gráficos”: la idea básica es construir gráficas capa por capa, asignando propiedades a variables.
Nuevamente, en ggplot2, los gráficos se construyen por capas siguiendo una estructura:
1. Seleccionamos datos y “mapeamos” (o asignamos) propiedades estéticas a variables usando la función base ggplot() y aes(): asignamos variables a ejes, colores, rellenos, tamaños, etc.
2. Agregamos capas de geometrías o formas usando geom_: así creamos puntos para una gráfica de dispersión, líneas para series de tiempo, barras para un histograma, líneas de tendencia, etc.
3. Cambiamos escalas, ejes, leyendas, coordenadas, fondos, etc.
Así, el formato más básico de una gráfica construida en ggplot2() es:
datos %>%
ggplot(aes(x = variable_x, y = variable_y)) +
geom_()En la práctica:
mpg %>%
ggplot(aes(displ, cty)) +
geom_point()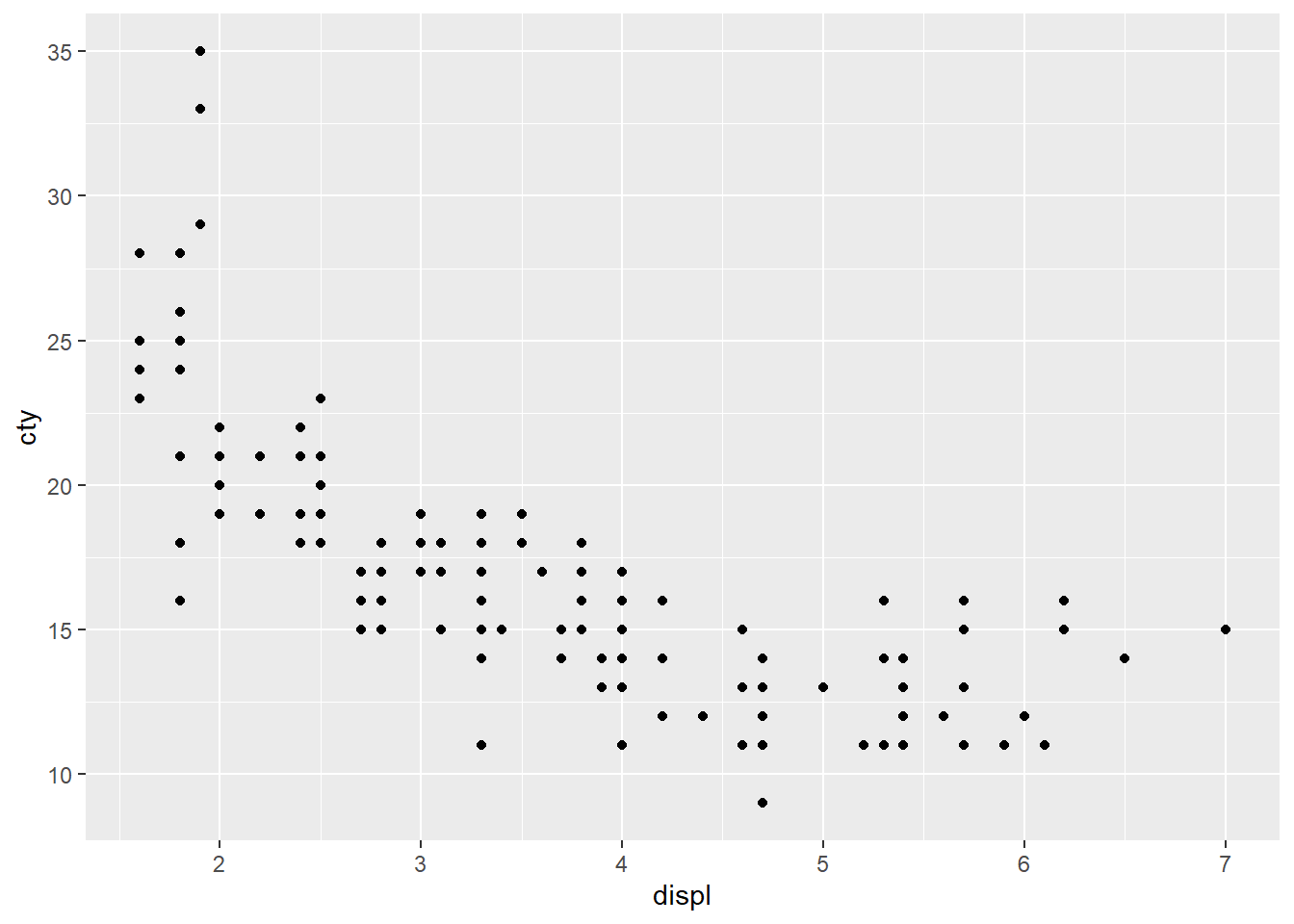
Y agregando más capas:
mpg %>%
ggplot(aes(displ, cty)) +
geom_point() +
labs(x = "Desplazamiento (en L)", y = "Millas por galín (ciudad)")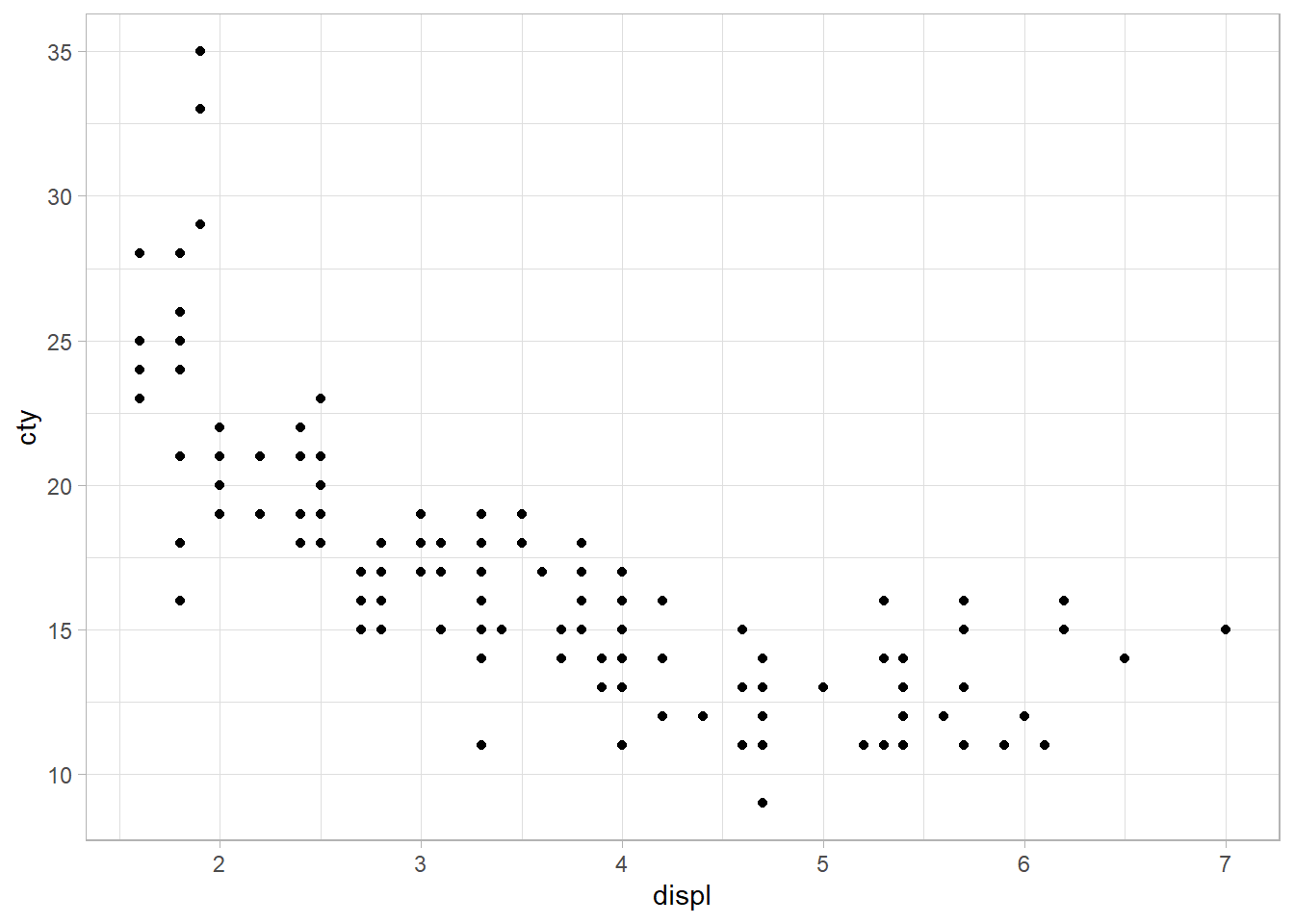
7.2.1.1 Librerías y datos
Como vamos a trabajar extensamente con ggplot2() así como las librerías dplyr() y tidyr(), cargamos estas librerías, incluidas en tidyverse.Además, vamos a usar los datos de gapminder para aprender a usar ggplot2. Luego introduciremos otras librerías opcionales.
Para prepararnos, vamos a realizar algunas transformaciones y adiciones a esta base de datos:
# Crear variable categorica para nivel de ingreso
# Alto: por encima de la media del año + desv. est.
# Medio: por encima de la media del año, pero debajo de media + desv. est
# Bajo: por debajo de la media del año
# Renombrar y reordenar niveles de variables categóricas
gapminder <- gapminder %>%
group_by(year) %>%
mutate(gdpPercap_factor = case_when(
gdpPercap > mean(gdpPercap, na.rm = TRUE) + sd(gdpPercap, na.rm = TRUE) ~ "Alto",
gdpPercap <= mean(gdpPercap, na.rm = TRUE) + sd(gdpPercap, na.rm = TRUE) &
gdpPercap > mean(gdpPercap, na.rm = TRUE) ~ "Medio",
gdpPercap < mean(gdpPercap, na.rm = TRUE) ~ "Bajo"
)
) %>%
ungroup() %>%
mutate(
continent = fct_recode(continent, "Africa" = "África", "Americas" = "América",
"Europe" = "Europa", "Oceania" = "Oceanía"),
gdpPercap_factor = fct_relevel(gdpPercap_factor, "Bajo", after = Inf)
)## Warning: Problem with `mutate()` input `continent`.
## i Unknown levels in `f`: África, América, Europa, Oceanía
## i Input `continent` is `fct_recode(...)`.## Warning: Unknown levels in `f`: África, América, Europa, Oceanía–>
–>
–> –> –> –> –> –> –> –> –> –> –> –>
–>
–> –> –>
7.2.1.2 Temas
Podemos cambiar elementos individuales del tema de una gráfica dentro de la función theme(). Por ejemplo, la posición de la leyenda o el tamaño de la letra de los títulos:
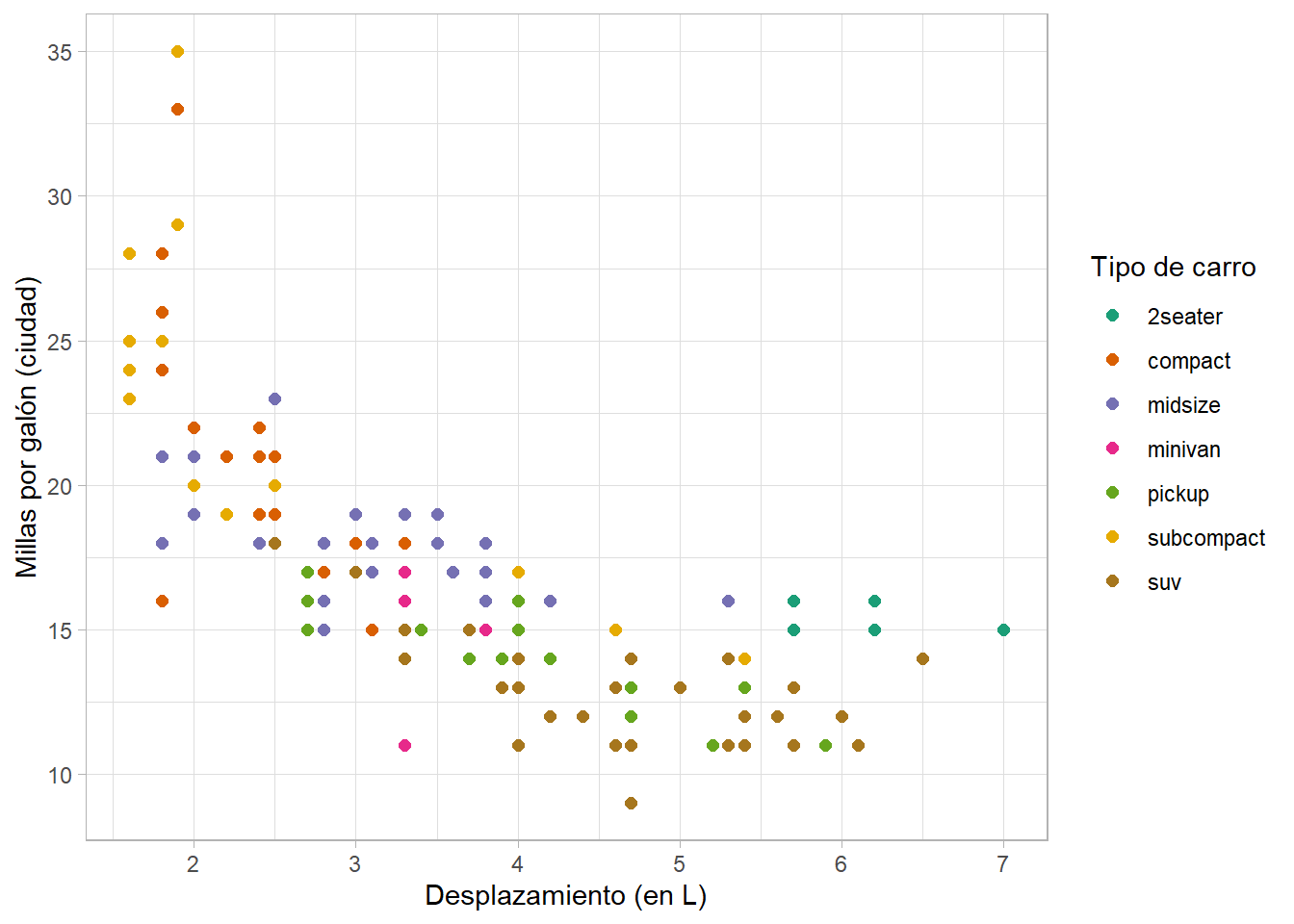
mpg %>%
ggplot(aes(displ, cty, color = factor(cyl))) +
geom_point(size = 2) +
theme(
legend.position = "bottom", ## mover la leyenda
title = element_text(size = 20) ## aumentar el tamaño de la letra de todos los títulos
)
Hay temas que modifican muchos de los elementos de diseño de una gráfica, especialmente el fondo. Podemos cambiar el tema para una sola gráfica:
mpg %>%
ggplot(aes(displ, cty, color = factor(cyl))) +
geom_point(size = 2) +
theme_dark()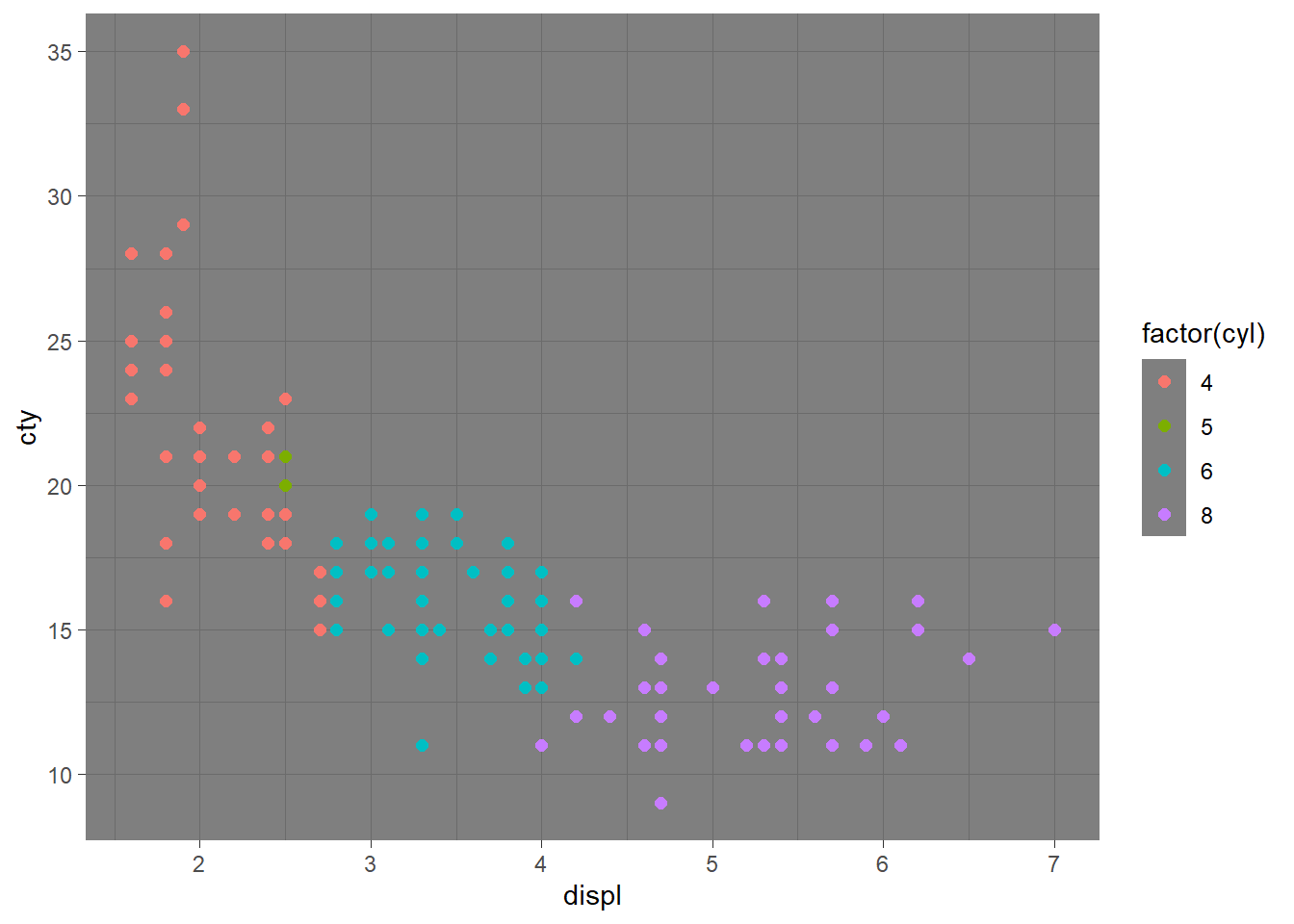
O por ejemplo:
mpg %>%
ggplot(aes(displ, cty, color = factor(cyl))) +
geom_point(size = 2) +
theme_minimal()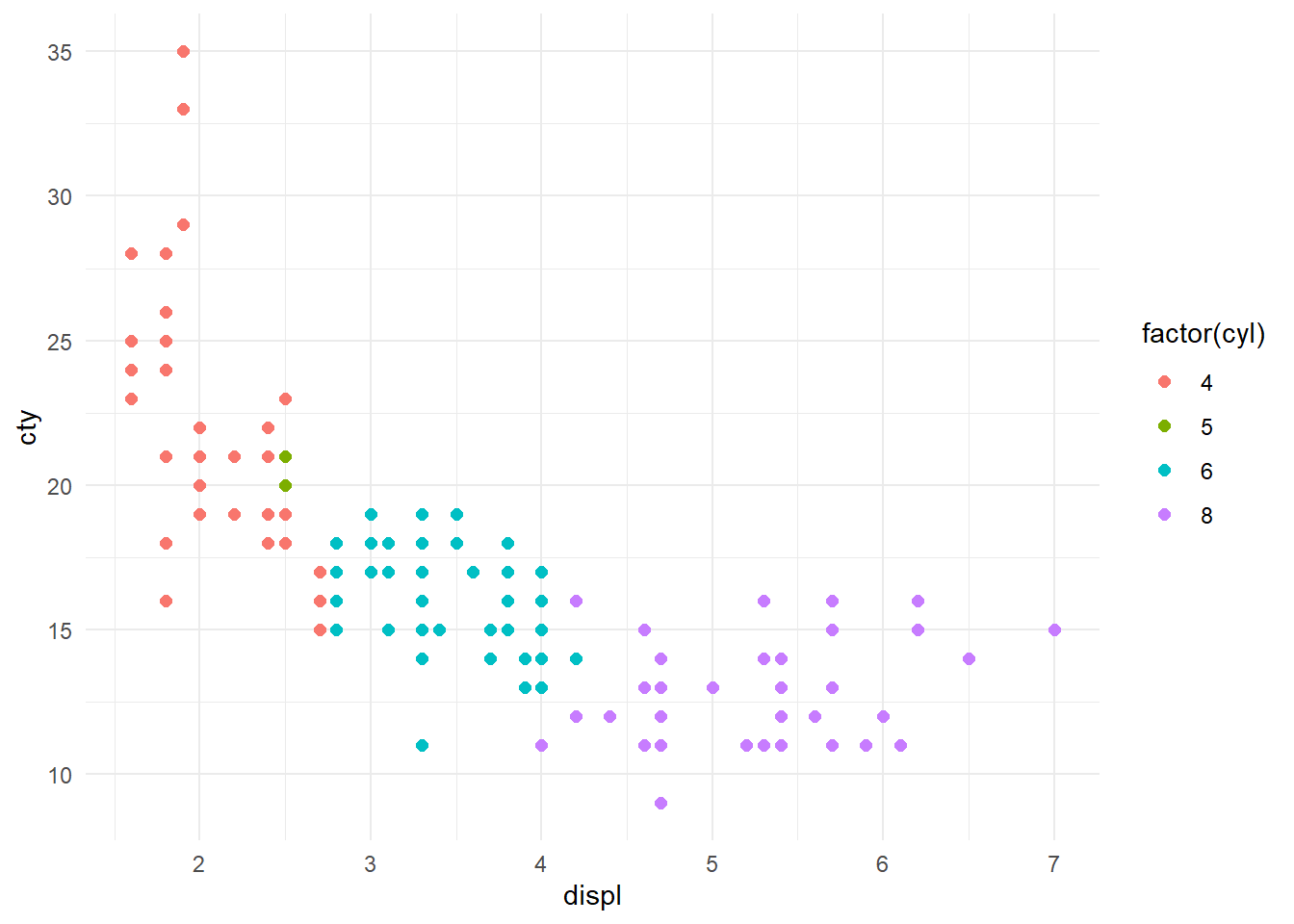
Si vamos a realizar muchas gráficas y queremos que todas tengan el mismo estilo, podemos utilizar la función set_theme() al inicio de un script o RMarkdown - todas las gráficas creadas después, usaran estos elementos de diseño:
theme_set(
theme_classic(
base_size = 12, ## cambiar tamaño de letra base
) +
theme(legend.position = "bottom") ## agregar otros elementos
)Todas las gráficas en adelante usarán ese tema, sin tener que declararlo, a menos que especifiquemos lo contrario:
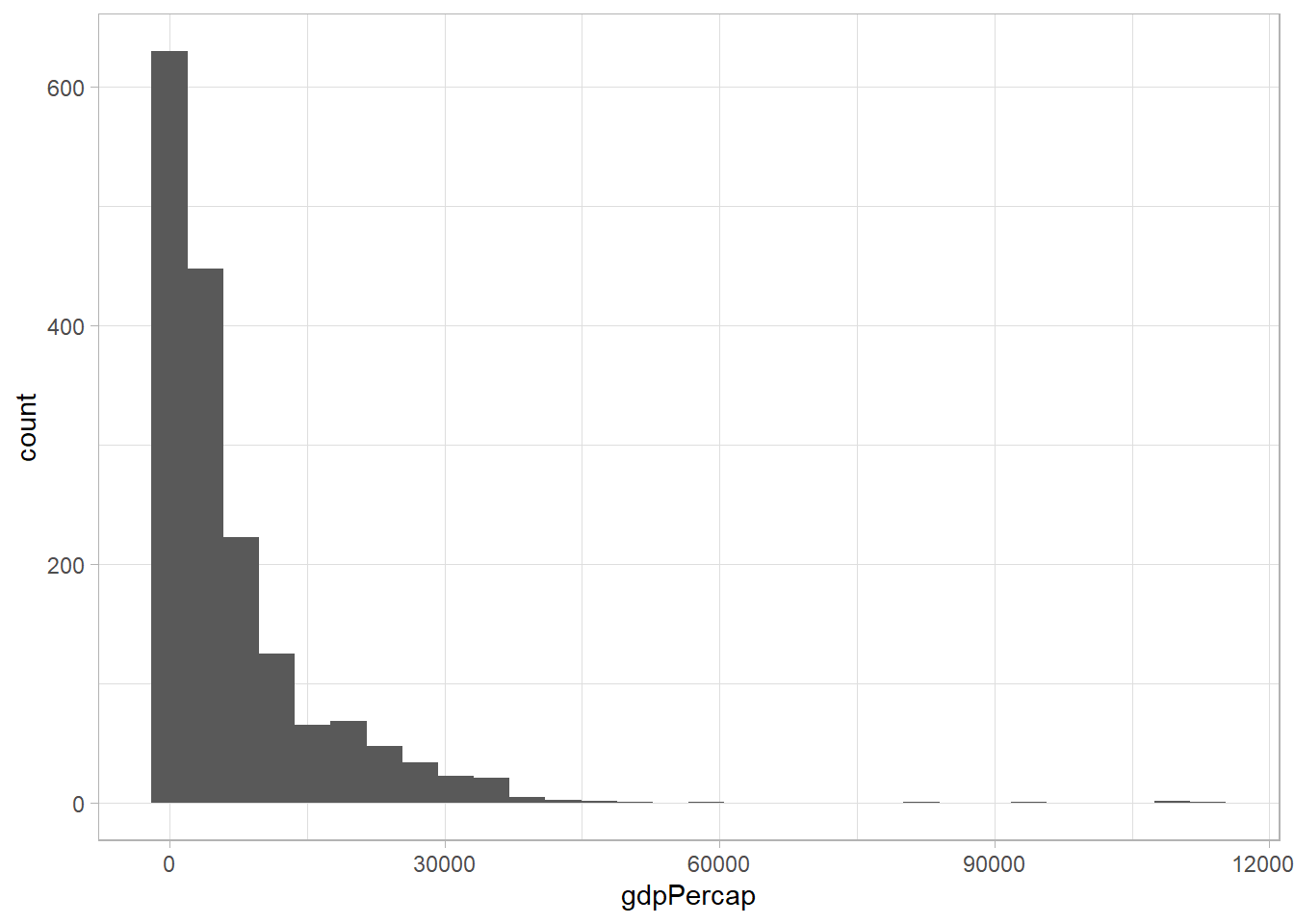
mpg %>%
ggplot(aes(displ, cty, color = factor(cyl))) +
geom_point(size = 2) +
labs(
x = "Desplazamiento del motor (en L)", y = "Millas por galón (ciudad)",
color = "Cilindros", title = "Para ahorrar, busque un motor pequeño",
subtitle = "Desplazamiento, eficiencia y cilindros de 234 autos", caption = "Fuente: EPA."
)
7.3 Tipos de gráficas: la versión rápida
En lo que queda de este instructivo, usamos la librería ggplot2 para realizar gráficas básicas en R. La idea es poder identificar rápidamente el tipo de gráfica para el tipo de información que queremos visualizar y hacerlo de manera sencilla.
7.3.1 Visualización de datos con ggplot2:
Visualizamos datos por muchas razones: análisis exploratorio, evaluación de modelos y comunicación de resultados son algunas de las principales.
La librería ggplot2 disfruta de una inmensa popularidad entre científicos de datos, politólogos, economistas, comunicadores, periodistas de datos y más. La lógica de ggplot2 está basado en la “gramática de los gráficos”: la idea básica es construir gráficas capa por capa, asignando propiedades a variables.
Así, el formato básico de una gráfica construida en ggplot2() es:
datos %>%
ggplot(aes(x = variable_x, y = variable_y)) +
geom_*(opciones...) +
scale_*(opciones...) +
labs(x = "Etiqueta", y = "Otra etiqueta")7.3.2 Principales tipos de gráficas
Existe un gráfico apropiado para el tipo de información que tenemos y que queremos visualizar. Aquí, distinguimos los tipos de gráficas según el número de variables que queremos incluir y su tipo (continua, ordinal, categórica). Por ejemplo, si queremos ver la relación entre dos variables continuas, la opción más evidente es utilizar una gráfica de dispersión. Mientras, si queremos ver la relación entre una continua y una categórica, un diagrama de barras es mejor.
7.3.3 Gráficos de una variable: distribuciones
Visualizamos una variable cuando queremos mostrar la distribución de esta. En estos casos, no hay una segunda variable; el eje vertical es una el número de observaciones (o proporción/porcentaje) que tienen cada valor de la variable que vemos en el eje horizontal. En ggplot2, usamos geom_histogram(), geom_density() (continua) o geom_bar() (discreta).
7.3.3.1 Una variable continua: histograma
Frecuentemente, lo primero que queremos ver es la distribución de una variable continua. En este caso, usamos geom_histogram() para crear un histograma. Aquí, además, modificamos las etiquetas del eje horizontal para que estén en dólares):
gapminder %>%
ggplot(aes(x = gdpPercap)) +
geom_histogram() +
scale_x_continuous(labels = scales::dollar) +
labs(x = "PIB per cápita", y = "Número de observaciones") ## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.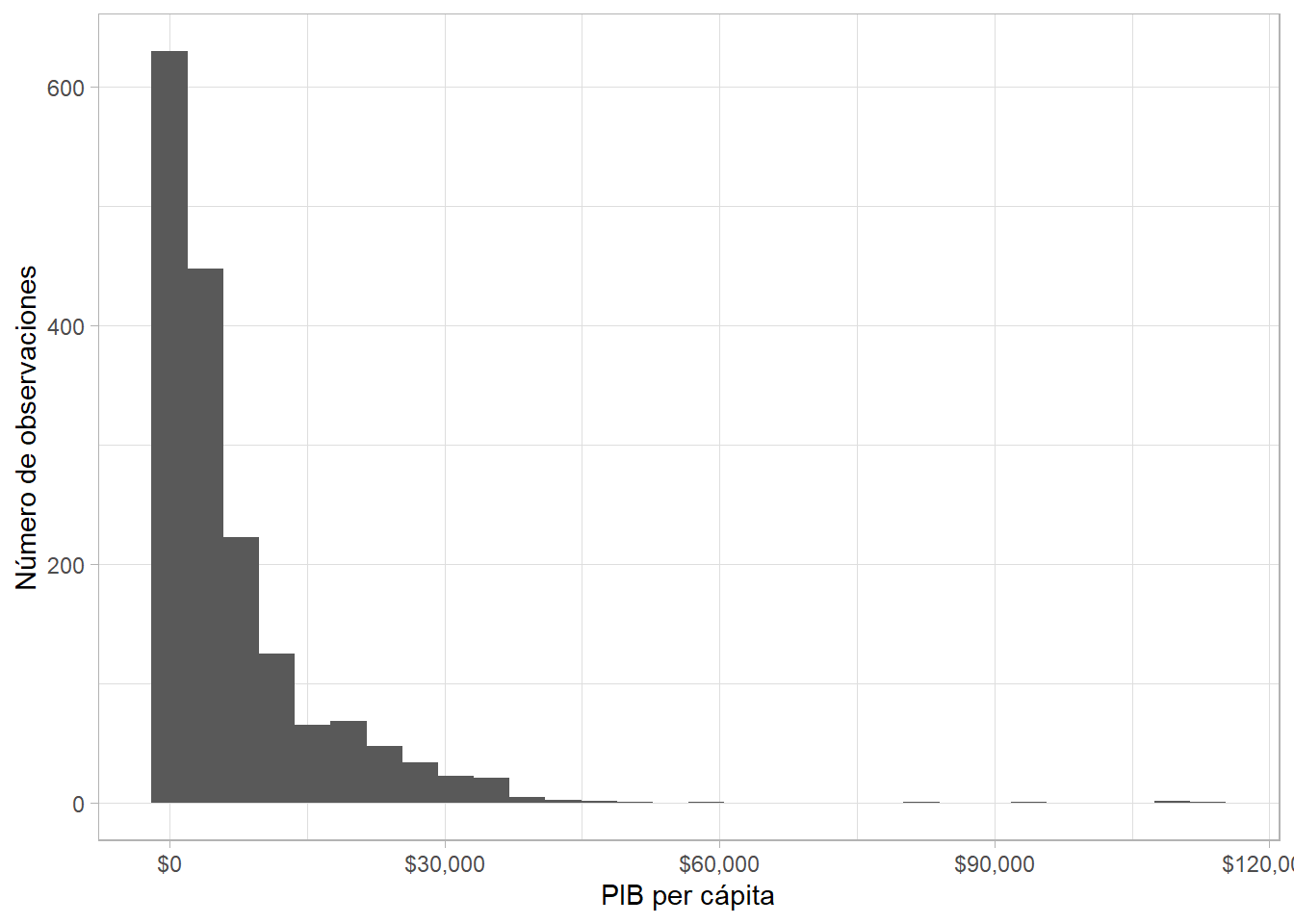
Variables como el PIB per cápita y la población de países con frecuencia presentan distribuciones sesgadas hacia la derecha (right-skewed). Podemos “normalizar” estas variables (mover la distribución un poco) calculando el logaritmo de las mismas. scale_x_log10() nos permite transformar una variable continua en el eje x -en este caso, aplicando un logaritmo base 10- sin tocar el dato subyacente. El resultado es visualmente distinto, pero comparen las etiquetas del eje horizontal:
gapminder %>%
ggplot(aes(x = gdpPercap)) +
geom_histogram() +
scale_x_log10(labels = scales::dollar) +
labs(x = "PIB per cápita", y = "Número de observaciones") ## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.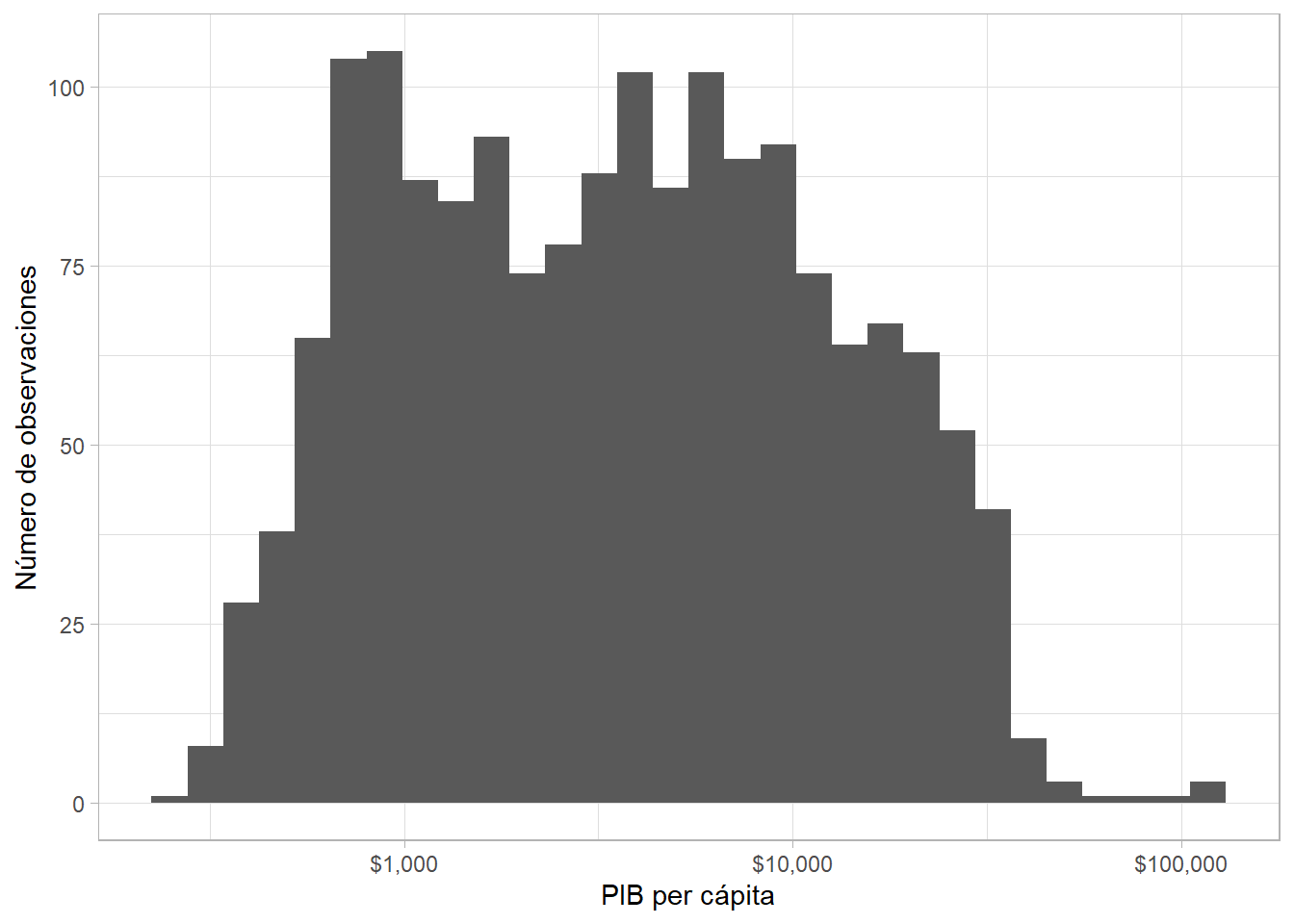
7.3.3.2 Una variable continua: densidad
Otra forma de visualizar la distribución de una variable continua mirando su densidad con geom_density():
gapminder %>%
ggplot(aes(x = gdpPercap)) +
geom_density(alpha = 0.5) +
scale_x_log10(labels = scales::dollar) +
labs(x = "PIB per cápita", y = "Densidad") 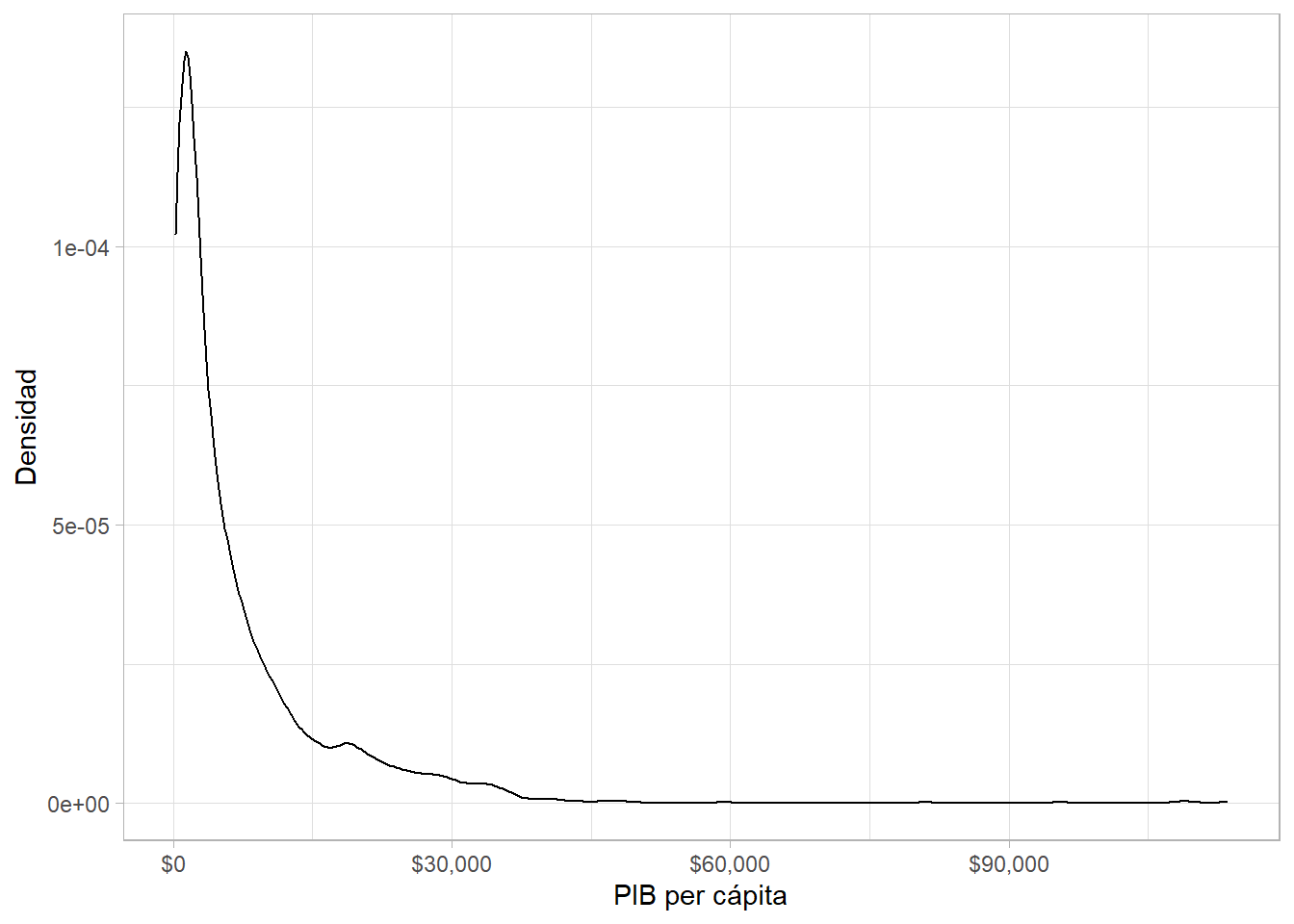
7.3.3.3 Una variable ordinal: barras
En cambio, si tenemos una variable ordinal (categorías ordenadas o números enteros con un rango reducido), podemos ver la distribución con un gráfico de barras creado con geom_col(). Este tipo de gráfica nos dice cuántas observaciones hay en cada grupo o categoría:
gapminder %>%
ggplot(aes(x = gdpPercap_factor)) +
geom_bar() +
labs(x = "Nivel de ingreso", y = "Número de observaciones") 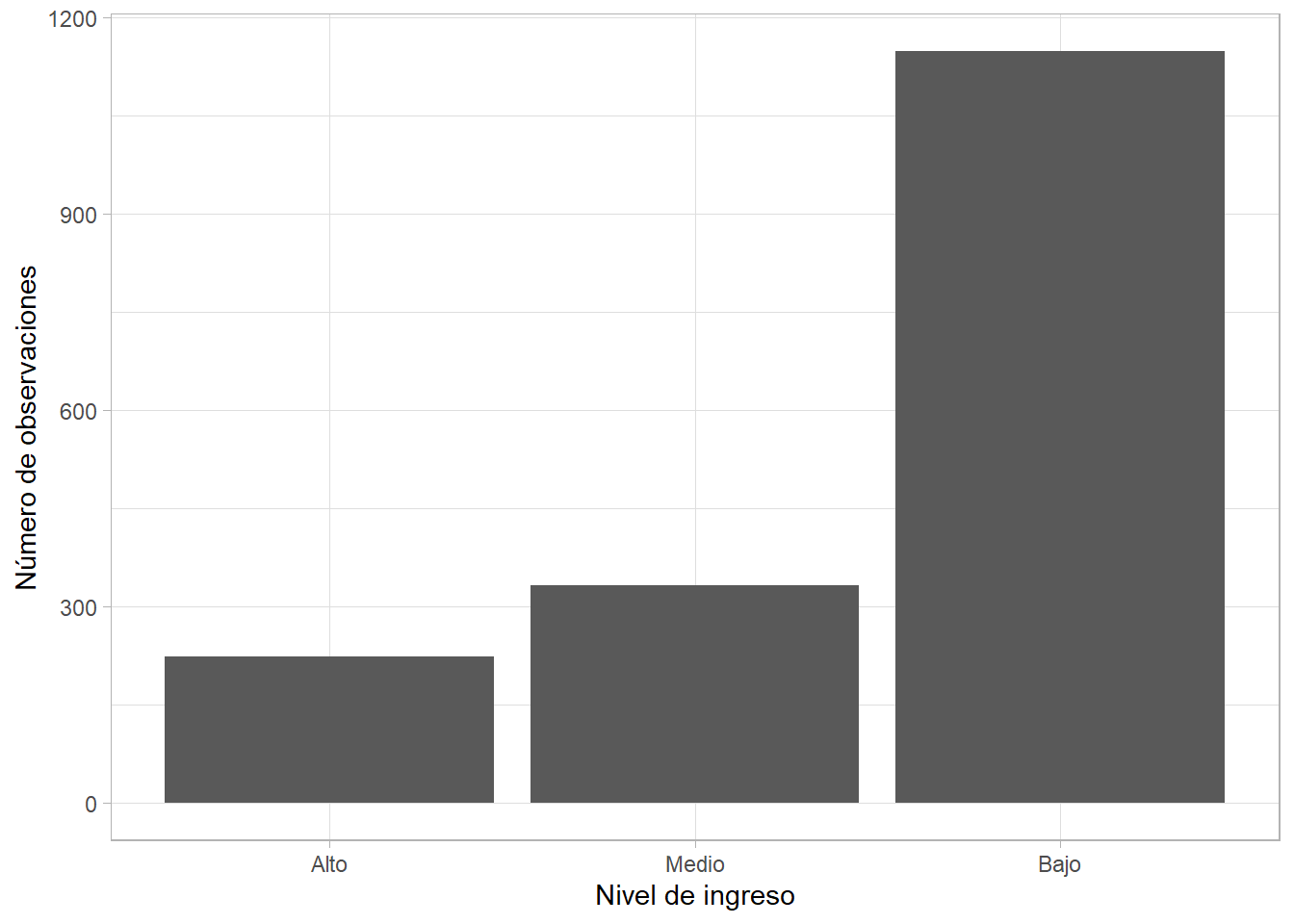
7.3.3.4 Una variable categórica: barras
Si no hay orden en las categorías, igual usamos geom_bar(). Si creemos que el nombre de la variable que estamos visualizando es obvio, podemos eliminar la etiqueta del eje en labs():
gapminder %>%
ggplot(aes(x = continent)) +
geom_bar() +
labs(x = NULL, y = "Número de observaciones") 
Podemos darle orden según el número de observaciones en cada categoría (o sea, según su frecuencia en los datos) con fct_infreq(). Si, además, las etiquetas del eje horizontal son muy largas, podemos girar los ejes con coord_flip():
gapminder %>%
ggplot(aes(x = fct_infreq(continent))) +
geom_bar() +
coord_flip() +
labs(x = NULL, y = "Número de observaciones") 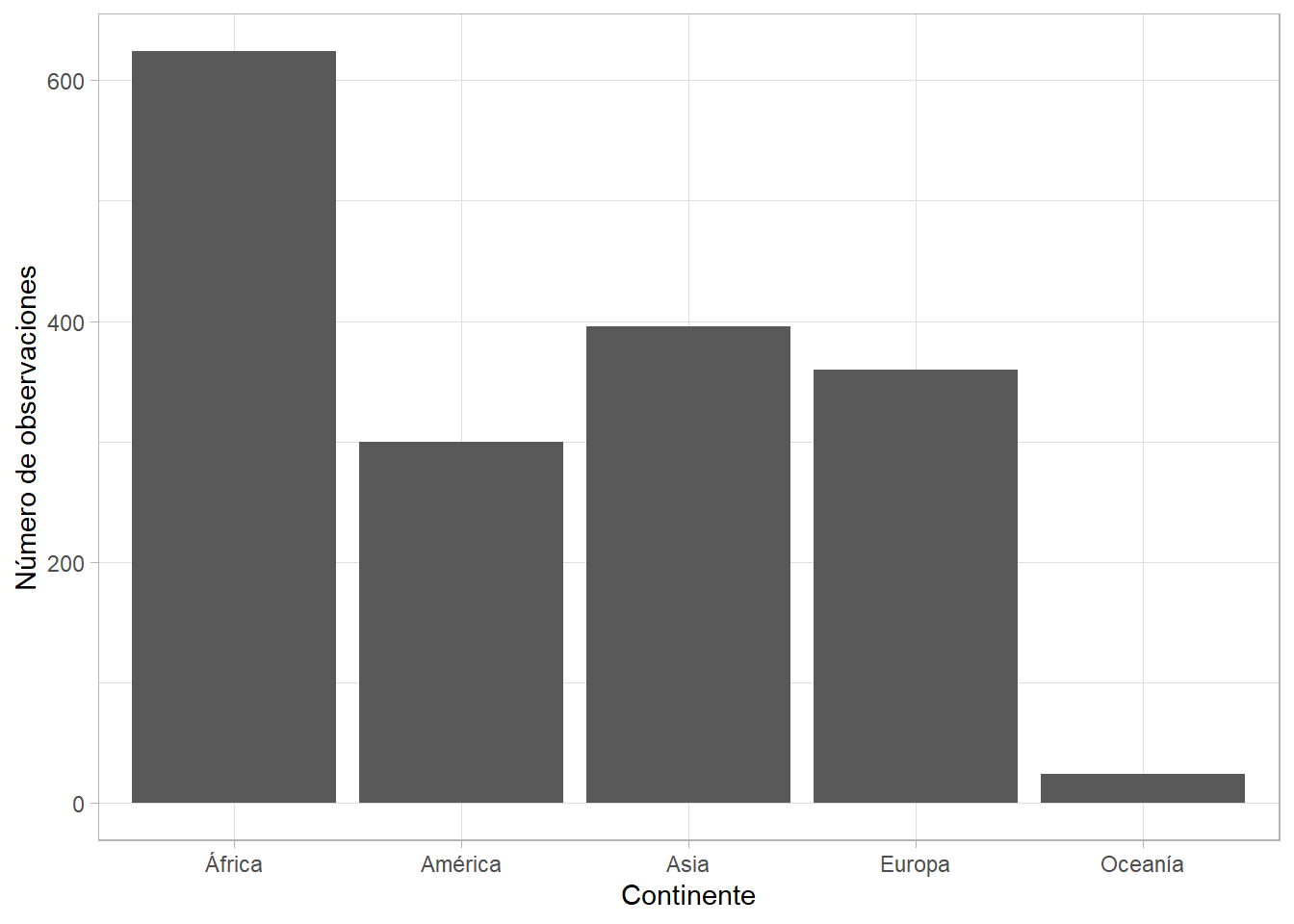
7.3.3.5 Una variable categórica: barras (prop.)
Puede que busquemos lo mismo, pero con proporciones (con base al total), añadiendo algunas propiedas a geom_bar(). También podemos cambiar las etiquetas a porcentajes:
gapminder %>%
ggplot(aes(x = continent)) +
geom_bar(aes(y = ..prop.., group = 1)) +
scale_y_continuous(labels = scales::percent) +
labs(x = NULL, y = "Porcentaje de observaciones")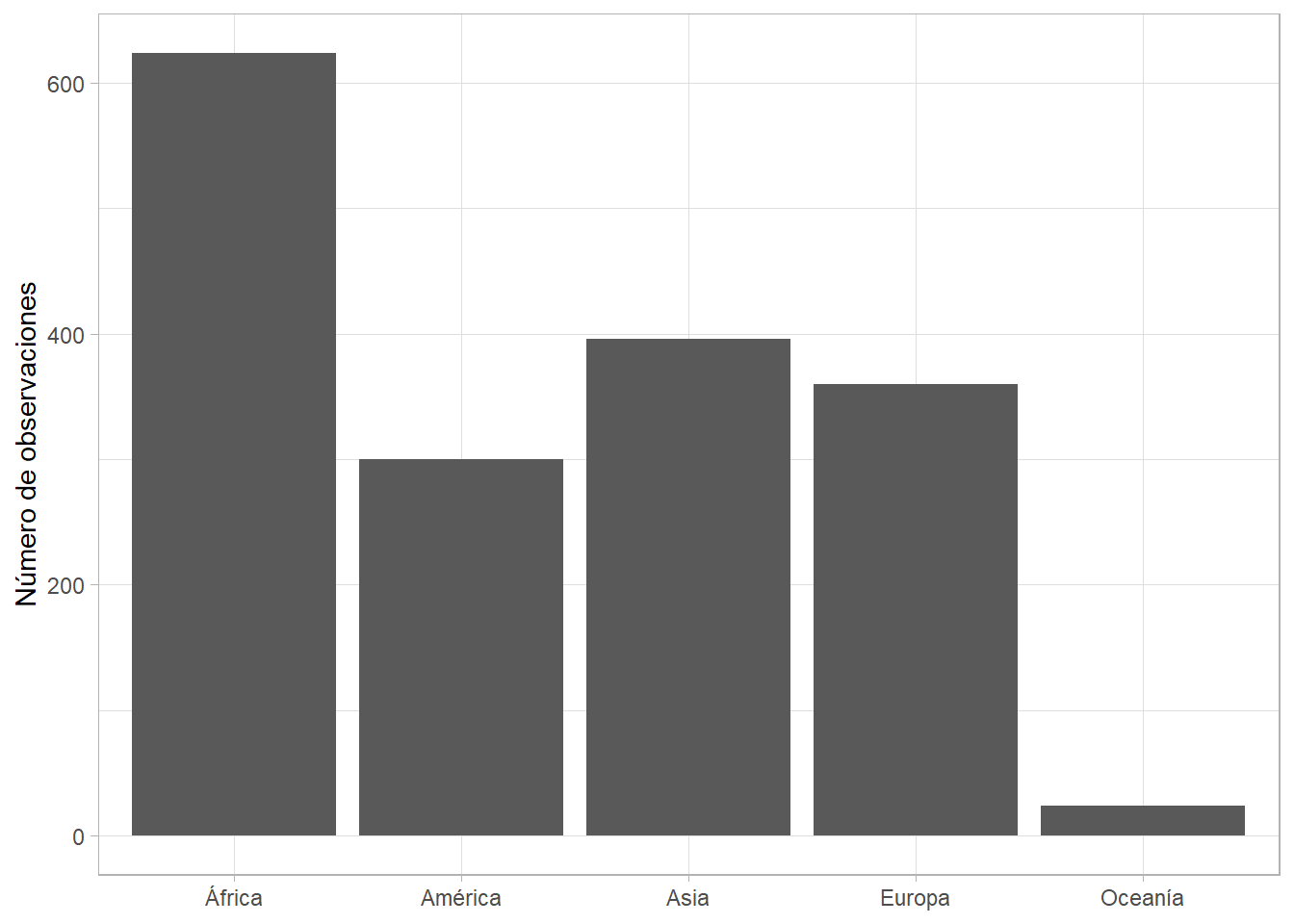
7.3.4 Gráficos de dos variables: relaciones y comparaciones
Graficamos dos variables para explorar la relación entre ellas. Esto nos permite entrever si hay correlaciones o si existen diferencias importantes entre grupos. En ggplot2, usamos geom_point() (continua-continua), geom_col() (continua-categórica) y, a veces, geom_boxplot() y geom_line() (continua-categórica).
7.3.4.1 Dos variables continuas: dispersión
Junto a las gráficas de barras, los gráficos de dispersión para ver relaciones entre variables continuas son los más comúnes tanto para análisis exploratorio de datos, como en la comunicación de información y el periodismo de datos. Los construimos con geom_point(), especificando variables en ambos ejes. Por convención, la variable explicativa (independiente) va en el horizontal.
gapminder %>%
ggplot(aes(x = gdpPercap, y = lifeExp)) +
geom_point() +
scale_x_continuous(labels = scales::dollar) +
labs(x = "PIB per cápita", y = "Expectativa de vida al nacer")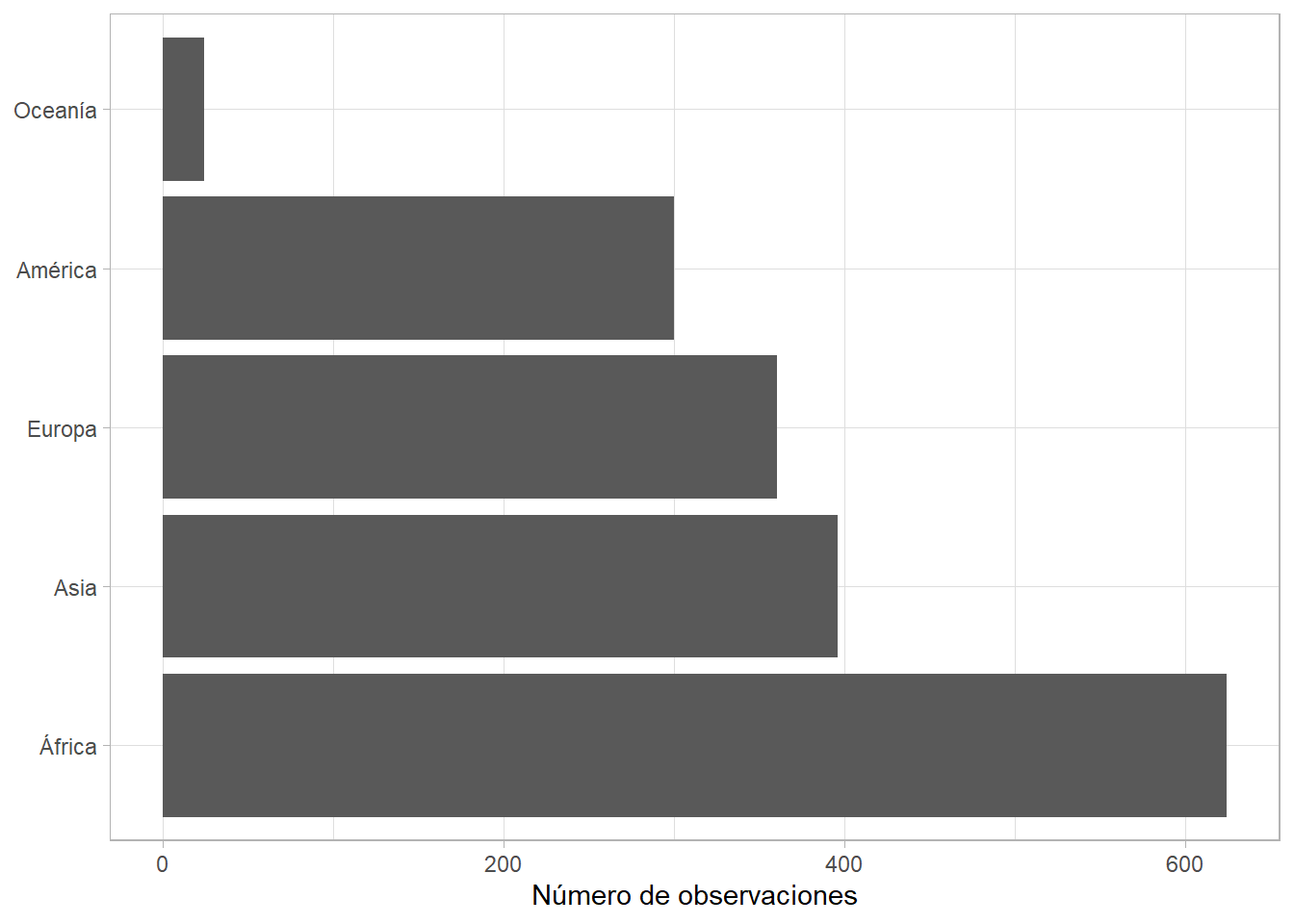
Como la relación parece no es estrictamente lineal, cambiamos el eje a una escala logarítmica. Si hay muchos puntos que se traslapan, modificamos la transparencia de los mismos con el argumento alpha =. Agregamos una línea de tendencia con geom_smooth() (aquí, una regresión lineal simple cuando especificamos method = "lm"):
gapminder %>%
ggplot(aes(x = gdpPercap, y = lifeExp)) +
geom_point(alpha = 0.5) +
geom_smooth(method = "lm", color = "grey50") +
scale_x_log10(labels = scales::dollar) +
labs(x = "PIB per cápita", y = "Expectativa de vida al nacer")## `geom_smooth()` using formula 'y ~ x'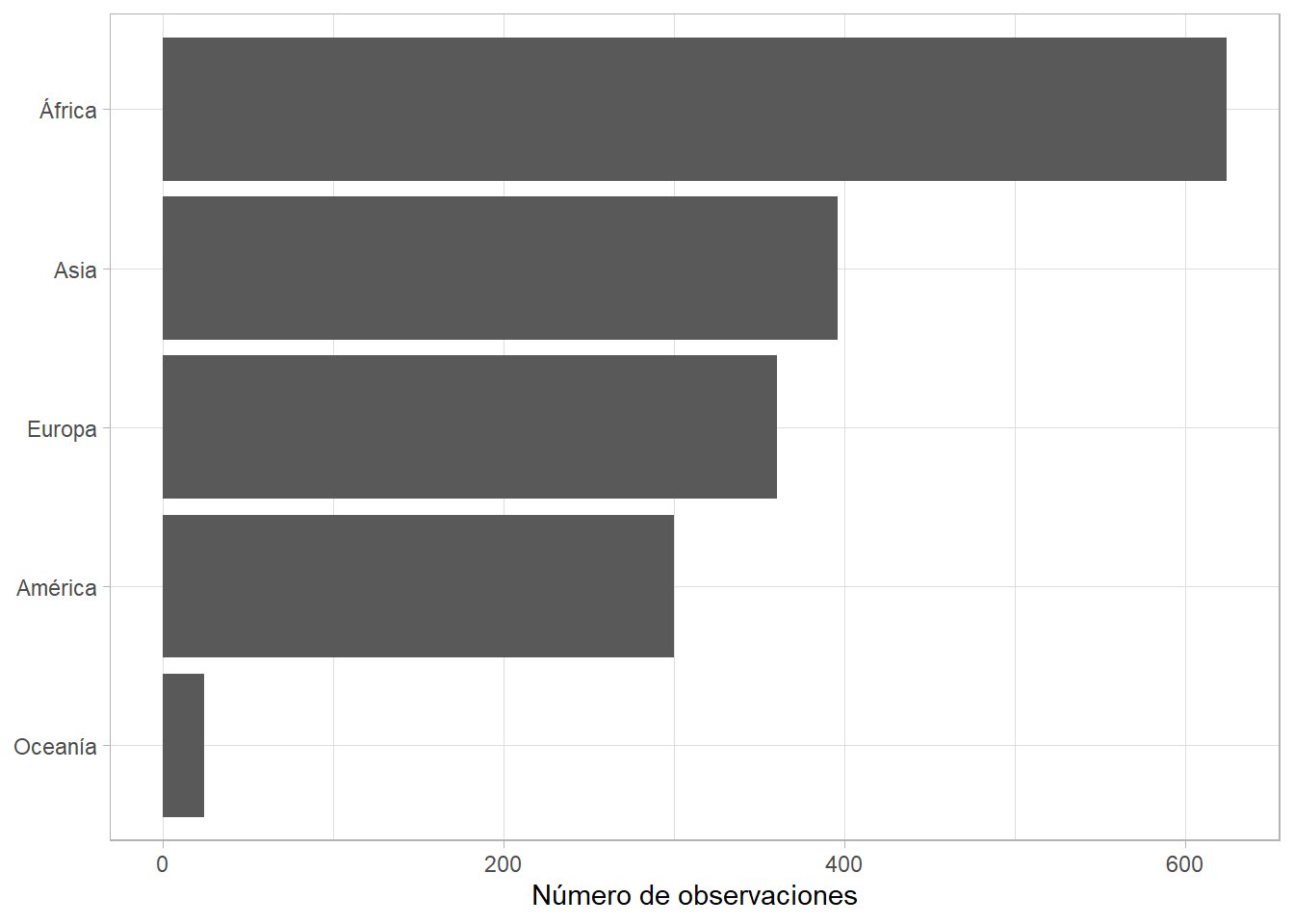
7.3.4.2 Dos variables categóricas: barras y cuentas
¿Qué tal si queremos visualizar la relación entre dos variables categóricas con una gráfica? La primera opción es hacer un diagrama de barras apiladas que nos permite ver las frecuencias de los grupos:
gapminder %>%
ggplot(aes(x = continent, fill = gdpPercap_factor)) +
geom_bar() +
labs(x = "Continente", fill = "Nivel de ingreso") 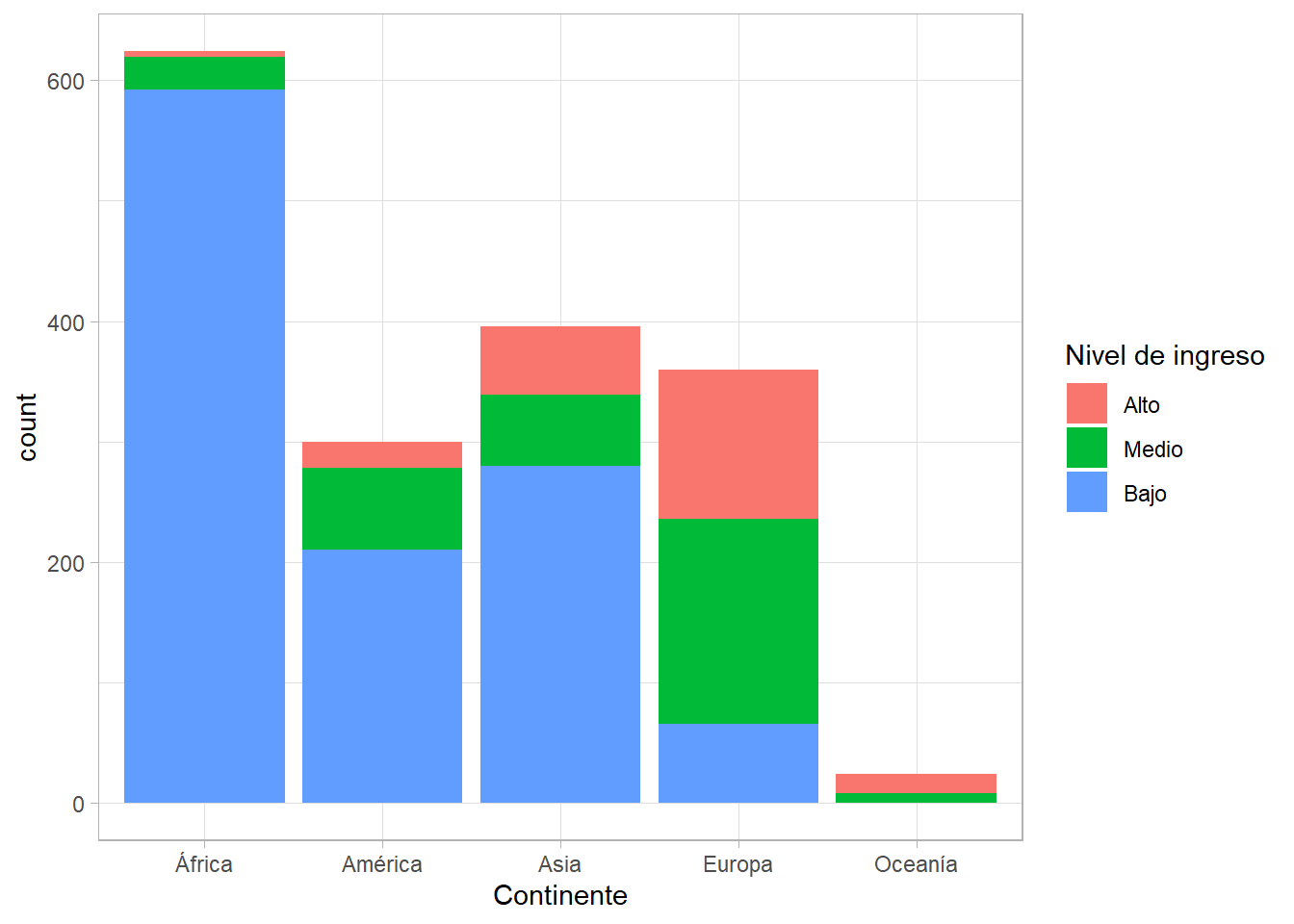
Es difícil comparar entre barras. Una gráfica de barras apiladas, pero con porcentajes en vez de frecuencias, puede ayudar. Especificamos el argumento position = "fill" y ahora las categorías dentro de cada barra suman \(100\%\):
gapminder %>%
ggplot(aes(x = continent, fill = gdpPercap_factor)) +
geom_bar(position = "fill") +
scale_y_continuous(labels = scales::percent) +
labs(x = "Continente", fill = "Nivel de ingreso") 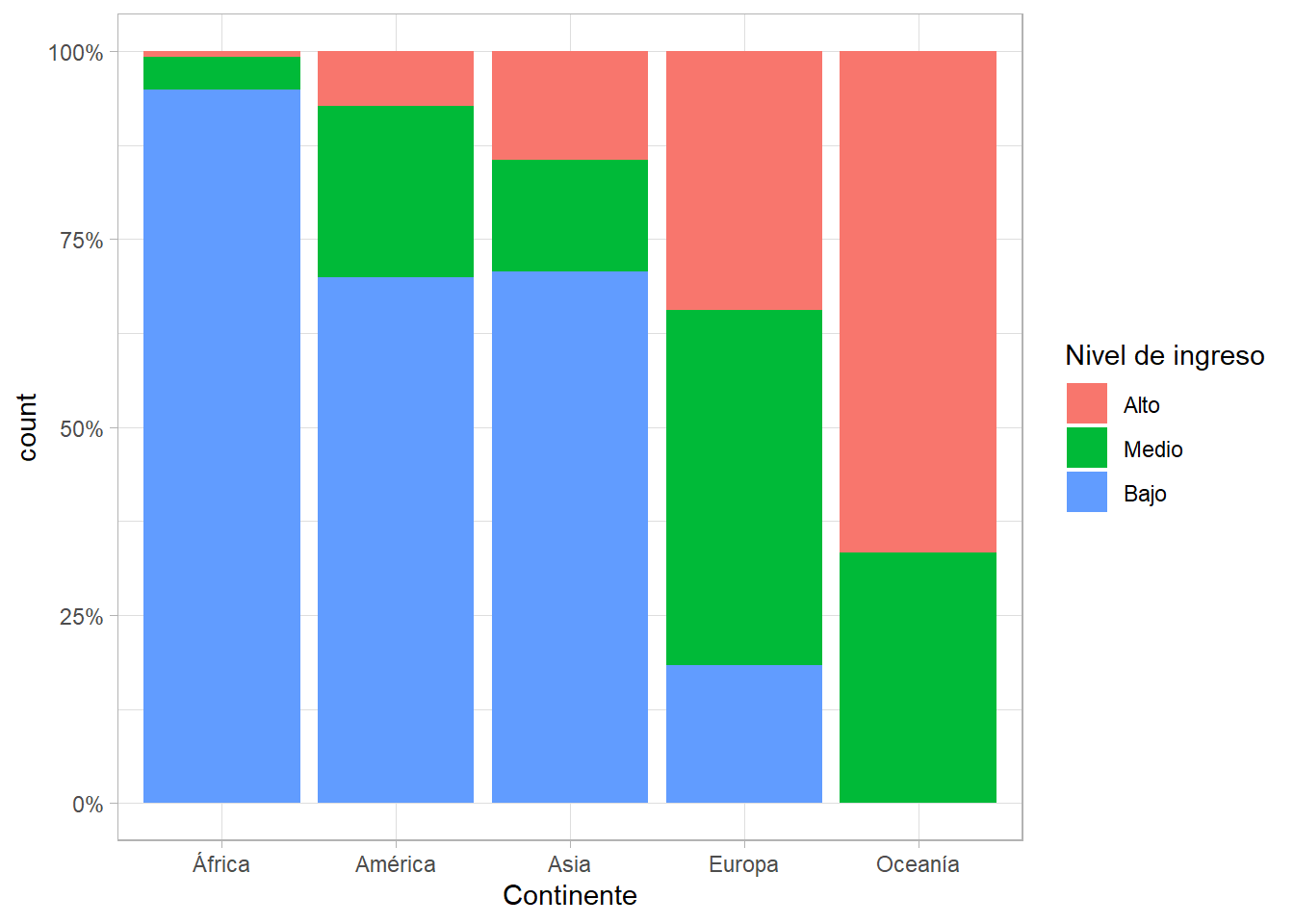
En cambio, si queremos barras agrupadas y no apiladas, especificamos el argumento position = "dodge":
gapminder %>%
ggplot(aes(x = continent, fill = gdpPercap_factor)) +
geom_bar(position = "dodge") +
labs(x = "Continente", fill = "Nivel de ingreso") 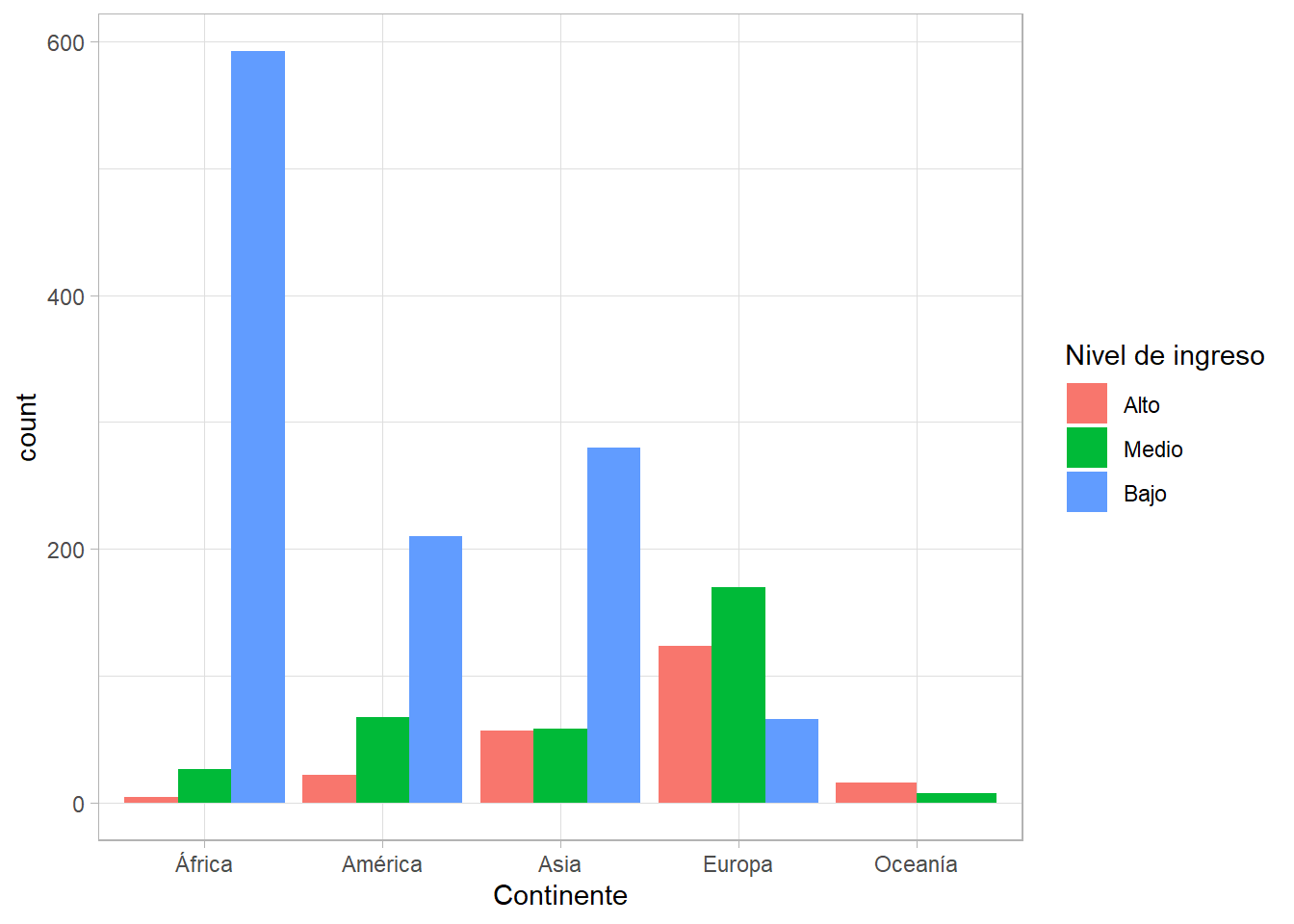
Otra alternativa para ver relaciones entre variables categóricas es usar geom_count(). Es posible, pero los resultados no son los mejores:
gapminder %>%
ggplot(aes(x = continent, y = gdpPercap_factor)) +
geom_count() +
scale_size_continuous(name = "Número de observaciones") +
labs(x = "Continente", y = "Nivel de ingreso") 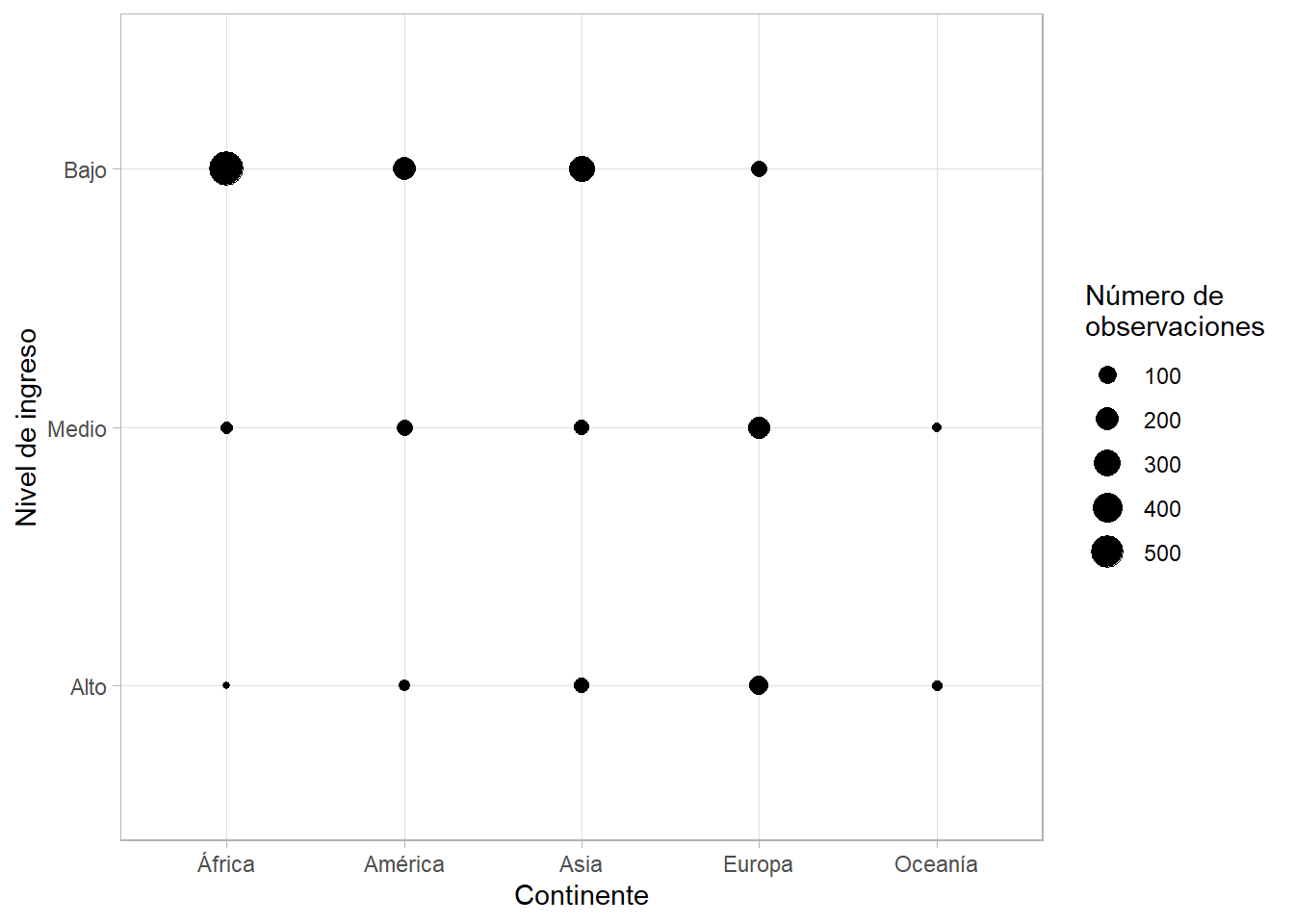
Sin embargo, puede ser preferible hacer tablas cruzadas para este tipo de información. Si queremos imprimirla, podemos usar kable() de knitr junto a un poco de magia de tidyr:
library(knitr)
gapminder %>%
group_by(continent, gdpPercap_factor)%>%
summarise(casos = n()) %>%
pivot_wider(names_from = "continent", values_from = "casos") %>%
kable(
caption = "Tabulación cruzada de continentes y nivel de ingreso",
col.names = c("Nivel de ingreso", "África", "América", "Asia", "Europa", "Oceanía")
)## `summarise()` regrouping output by 'continent' (override with `.groups` argument)| Nivel de ingreso | África | América | Asia | Europa | Oceanía |
|---|---|---|---|---|---|
| Alto | 5 | 22 | 57 | 124 | 16 |
| Medio | 27 | 68 | 59 | 170 | 8 |
| Bajo | 592 | 210 | 280 | 66 | NA |
7.3.4.3 Dos variables: una continua, una categórica
Para comparar distribuciones o estadísticas resumen de una variable continua en dos o más grupos.
7.3.4.3.1 Una cont., una cat.: histogramas por grupo
Comparamos la distribución de una variable continua en dos o más grupos (definidos por una variable categórica u ordinal). Agregamos group = a la función aes(), junto con facet_wrap():
gapminder %>%
ggplot(aes(x = gdpPercap, group = continent)) +
geom_histogram() +
facet_wrap(~ continent) +
scale_x_log10(labels = scales::dollar) +
labs(x = "PIB per cápita", y = "Número de observaciones") ## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.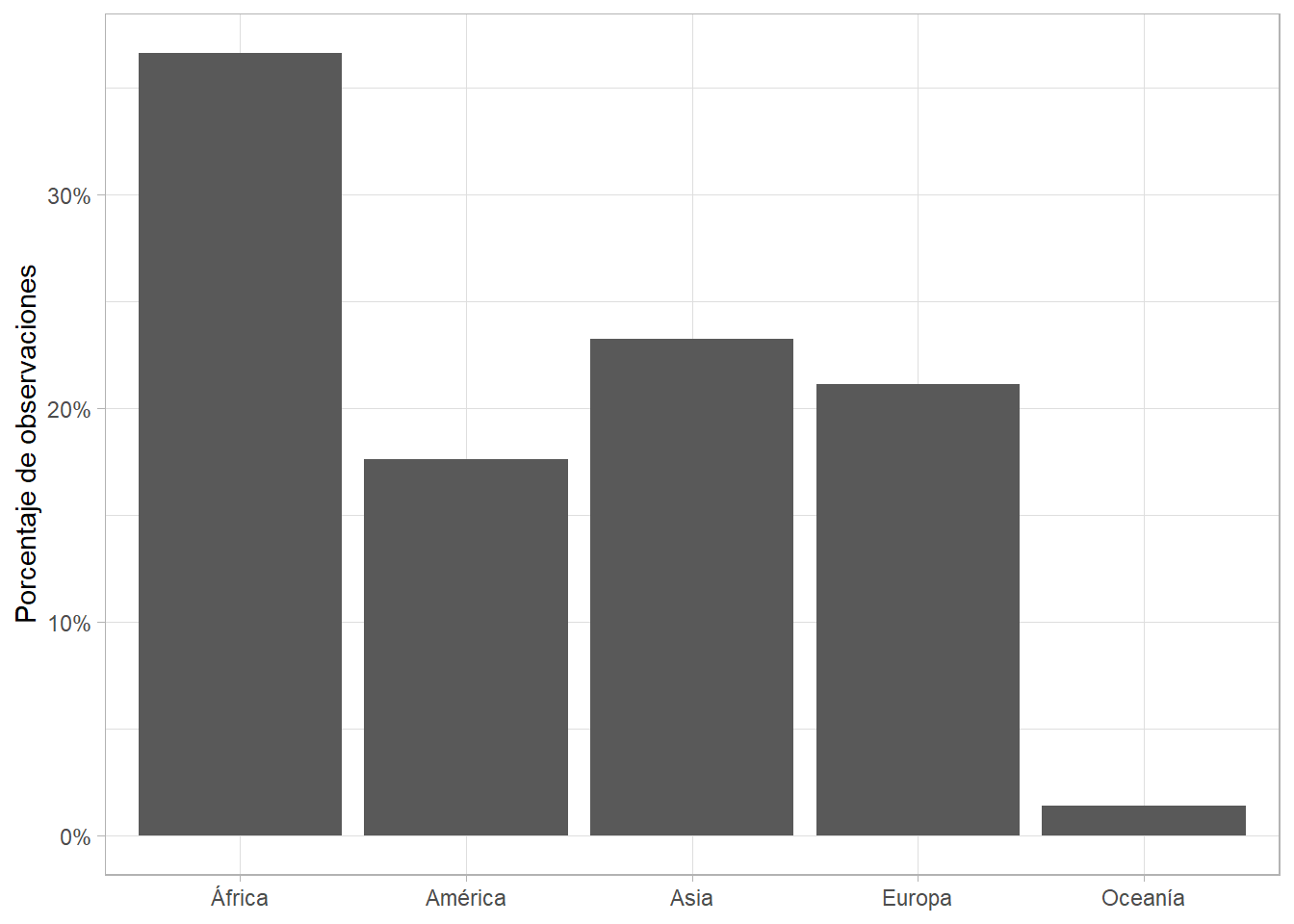
7.3.4.3.2 Una cont., una cat.: barras
En contraste, quizás queremos ver una estadística de una variable para cada grupo con el fin de realizar una comparación. Por ejemplo, la media de una variable numérica, no en general para toda la muestra, sino por grupos definidos por una variable categórica. Comparar medias de grupos es uno de los elementos centrales aen la estadística aplicada en ciencias sociales.
Hacemos uso de group_by() y summarize() primero para encontrar la media de cada grupo y luego usamos geom_col():
gapminder %>%
group_by(continent) %>%
summarize(gdpPercap = mean(gdpPercap, na.rm = TRUE)) %>%
ggplot(aes(x = continent, y = gdpPercap)) +
geom_col() +
scale_y_continuous(labels = scales::dollar) +
labs(x = NULL, y = "PIB per cápita") ## `summarise()` ungrouping output (override with `.groups` argument)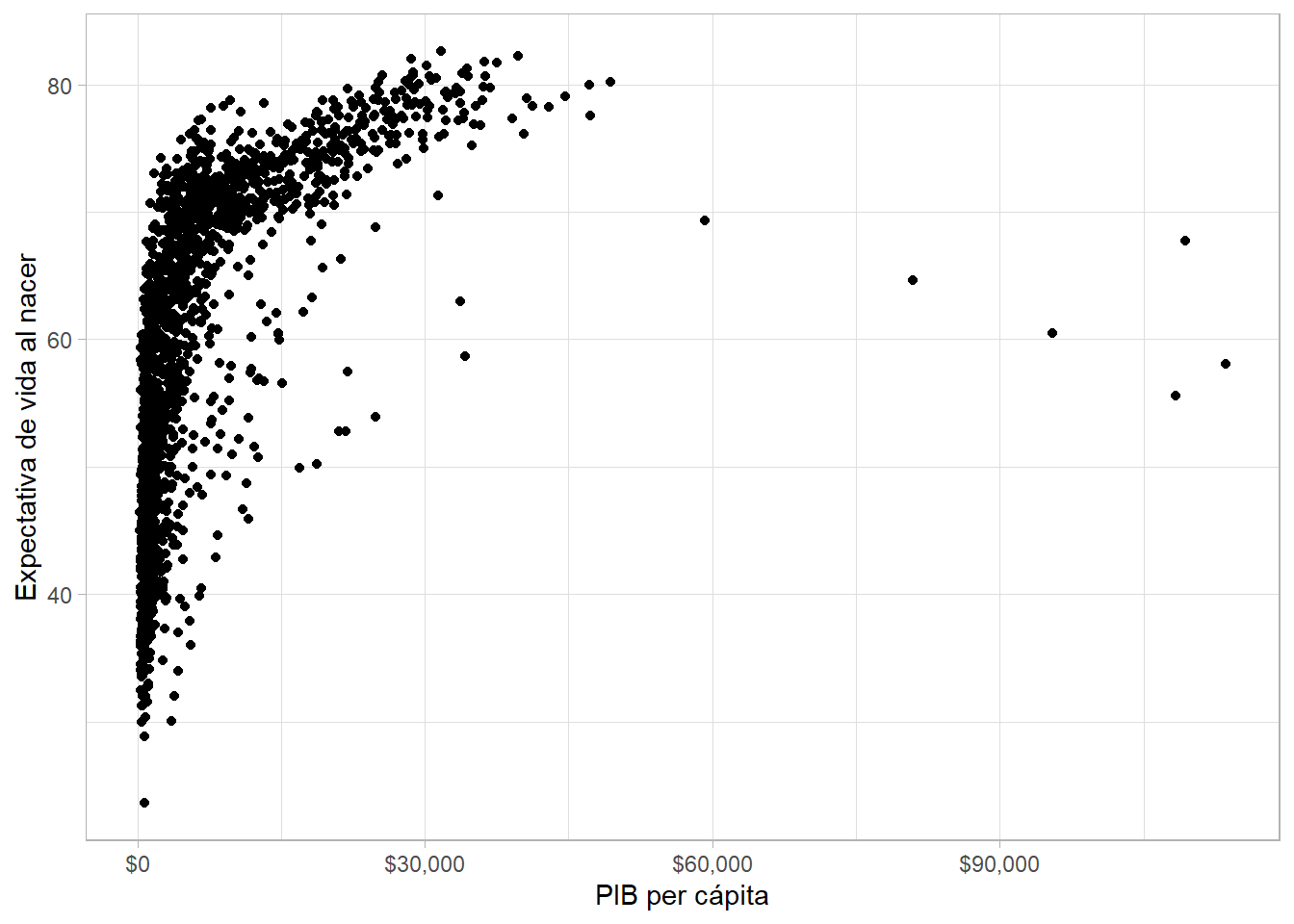
Las funciones fct_reorder() para organizar las categorías según la media de la variable numérica y coord_flip() para girar el eje nos permiten organizar mejor la gráfica:
gapminder %>%
group_by(continent) %>%
summarize(gdpPercap = mean(gdpPercap, na.rm = TRUE)) %>%
ggplot(aes(x = fct_reorder(continent, gdpPercap), y = gdpPercap)) +
geom_col() +
scale_y_continuous(labels = scales::dollar) +
coord_flip() +
labs(x = NULL, y = "PIB per cápita") ## `summarise()` ungrouping output (override with `.groups` argument)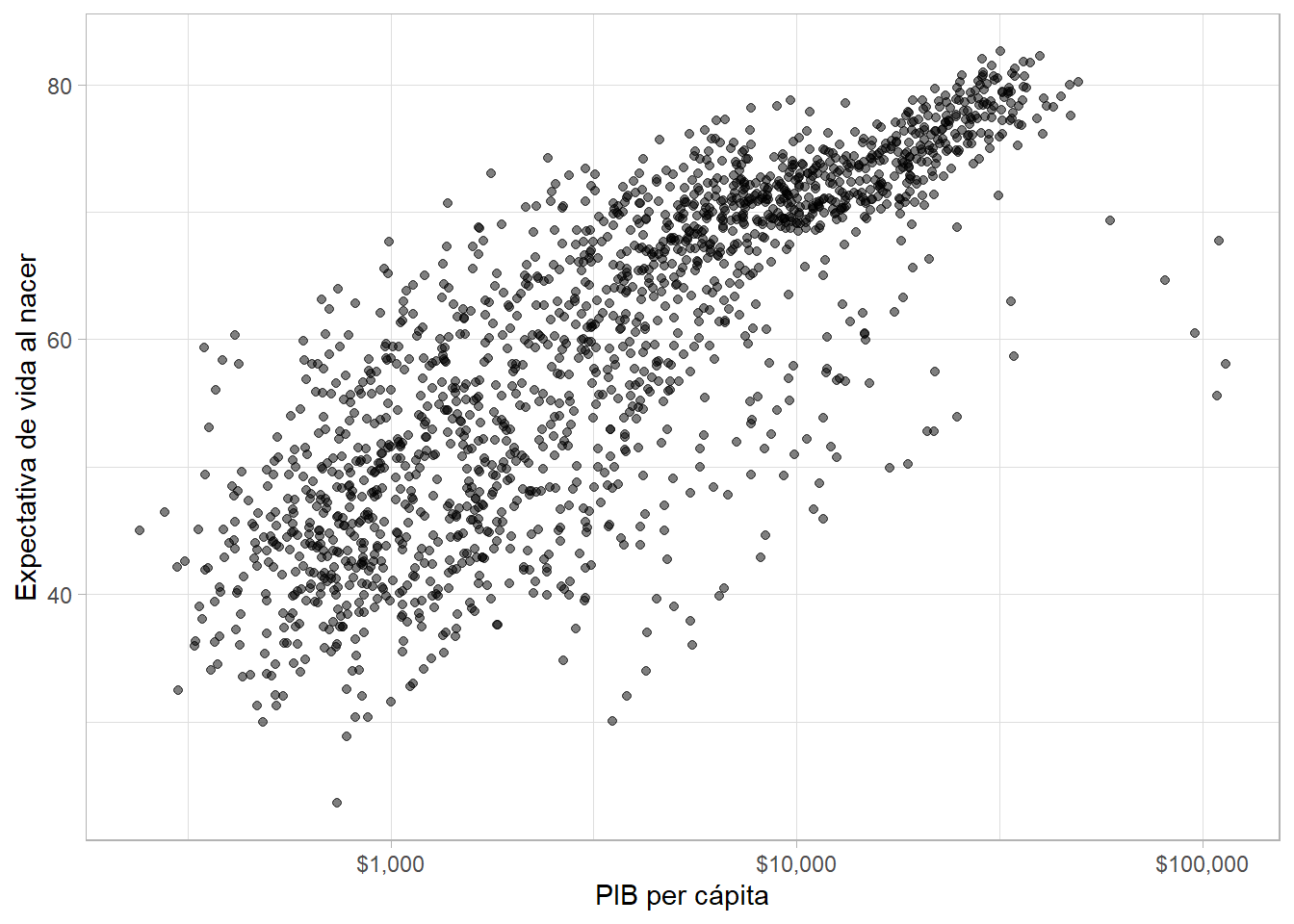
Por otro lado, si queremos ver un solo valor (no un resumen, como la media), geom_col() nos permite hacerlo.
gapminder %>%
filter(year == 2007) %>% # solo un año
top_n(20, gdpPercap) %>% # solo las 20 observaciones con mayor PIB per capita
ggplot(aes(x = fct_reorder(country, gdpPercap), y = gdpPercap)) +
geom_col() +
scale_y_continuous(labels = scales::dollar) +
labs(x = NULL, y = "PIB per cápita") +
coord_flip()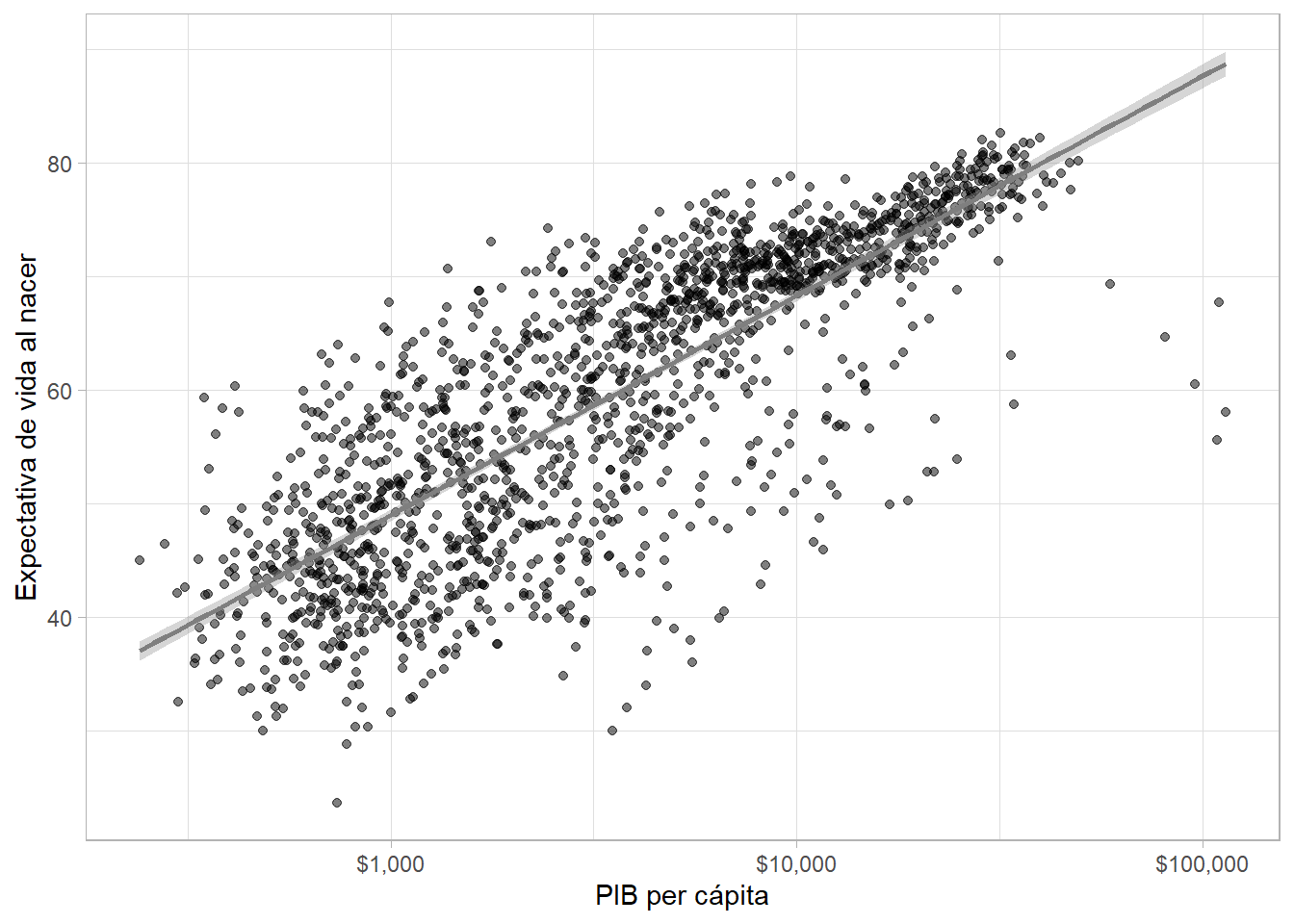
7.3.4.3.3 Una cont., una cat.: cajas
Los diagramas de cajas y bigotes (geom_boxplot()) nos permiten ver la media, el rango intercuartil y los outliers para cada grupo:
gapminder %>%
ggplot(aes(x = continent, y = gdpPercap)) +
geom_boxplot() +
scale_y_log10(labels = scales::dollar) +
coord_flip() +
labs(x = NULL, y = "PIB per cápita") 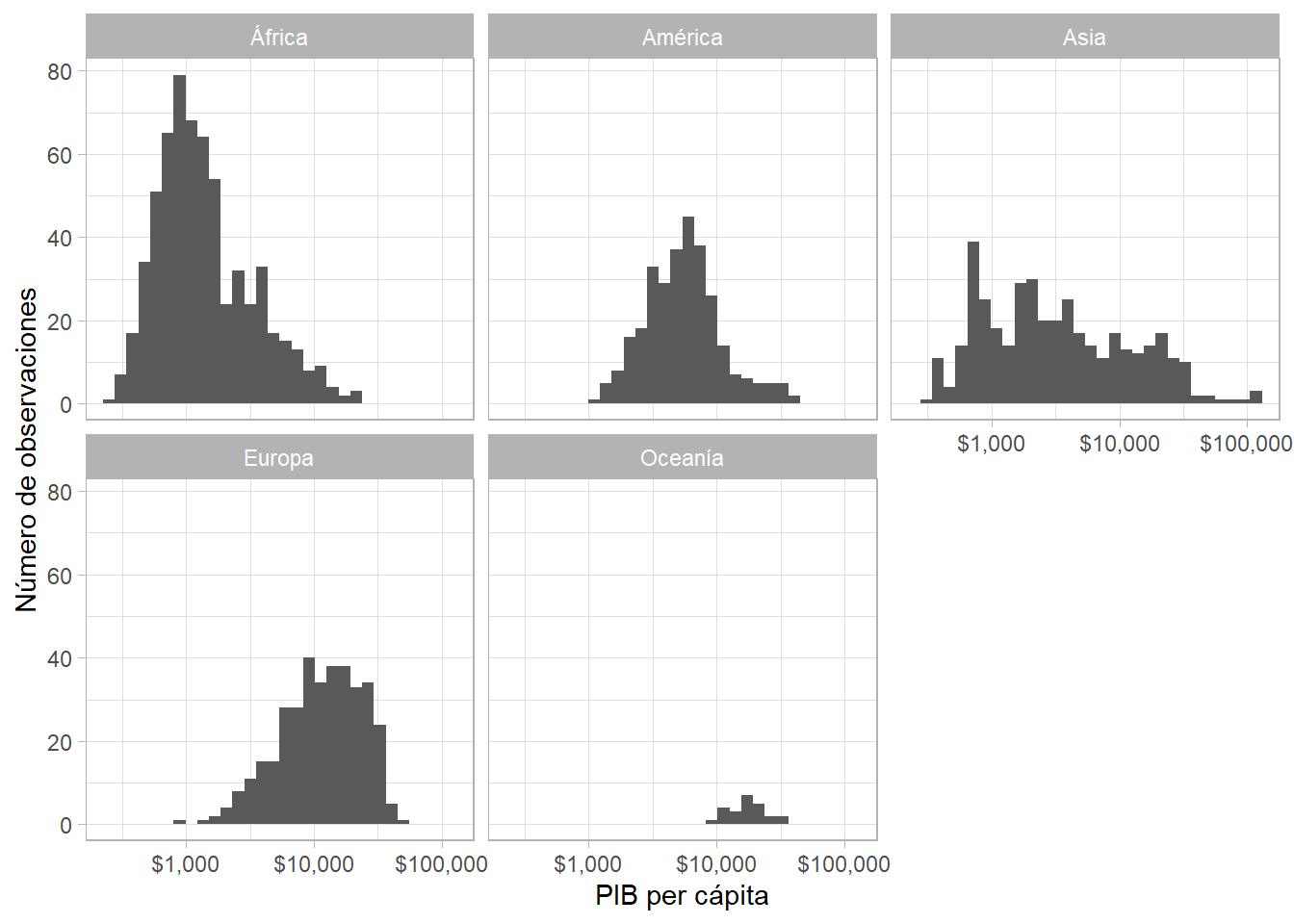
Como alternativa, pueden crear diagramas de violín con geom_violin():
gapminder %>%
ggplot(aes(x = continent, y = gdpPercap, fill = continent)) +
geom_violin() +
scale_y_log10(labels = scales::dollar) +
labs(x = NULL, y = "PIB per cápita") 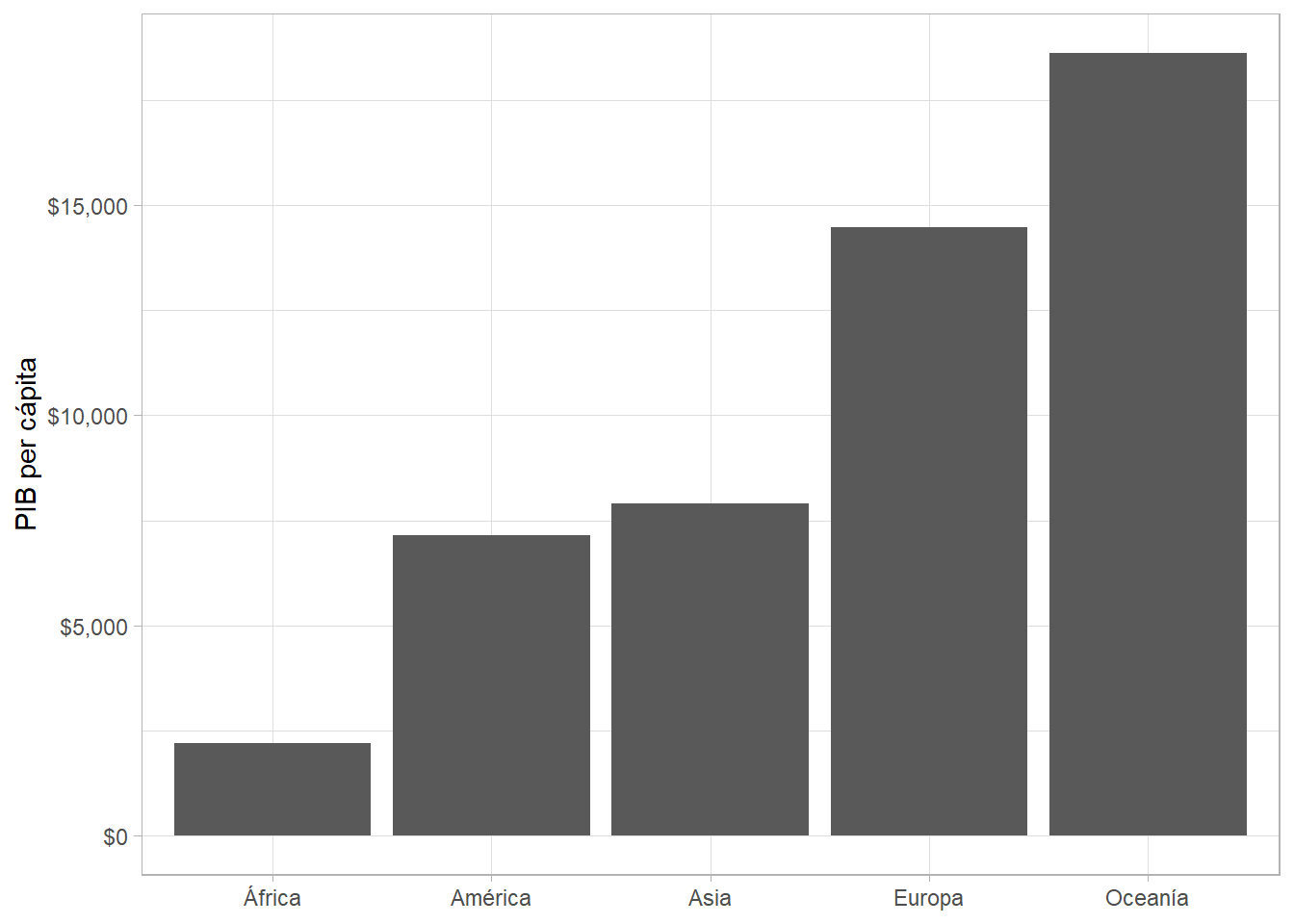
7.3.4.3.4 Una cont., una ord.: series de tiempo
Si tenemos una dimensión temporal, pasamos a geom_line():
gapminder %>%
filter(country == "Colombia") %>%
ggplot(aes(x = year, y = gdpPercap)) +
geom_line() +
scale_y_continuous(labels = scales::dollar) +
labs(x = "Año", y = "PIB per cápita")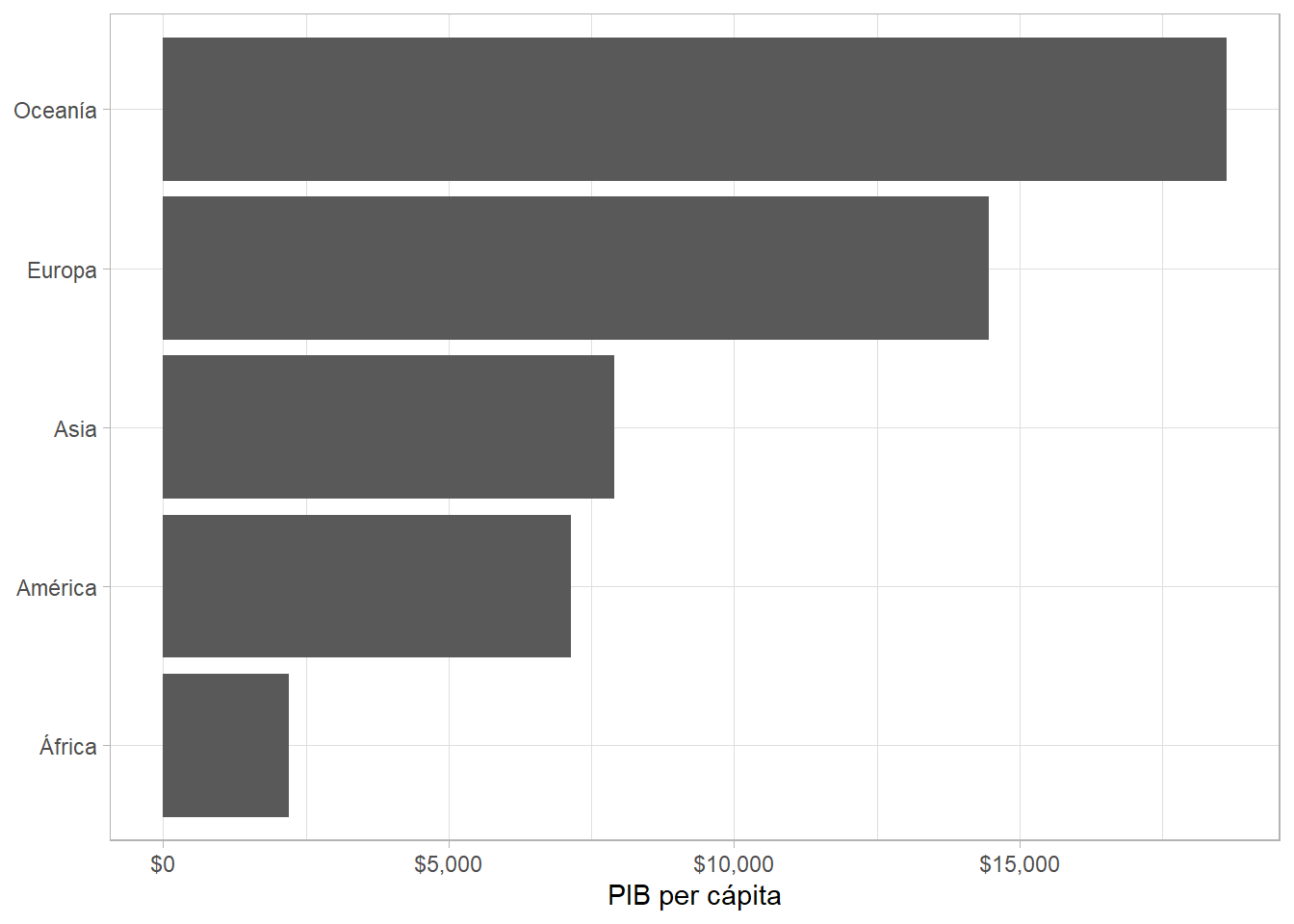
Usar group_by() y summarize() para agregar muchas observaciones en un mismo año. Además, usamos scale_x_continuous() y el argumento breaks = para modificar las etiquetas del eje horizontal:
gapminder %>%
group_by(year) %>%
summarize(gdpPercap = mean(gdpPercap, na.rm = TRUE)) %>%
ggplot(aes(x = year, y = gdpPercap)) +
geom_line() +
scale_y_continuous(labels = scales::dollar) +
scale_x_continuous(breaks = seq(1952, 2007, by = 5)) +
labs(x = "Año", y = "PIB per cápita promedio")## `summarise()` ungrouping output (override with `.groups` argument)
7.3.5 Gráficos de tres variables: interacciones o moderación
Construimos gráficas con tres variables para mostrar la interacción entre dos variables en relación con una tercera o mostrar cómo una modera la relación entre las otras. Está en el límite de lo que es fácil de comunicar visualmente. En ggplot2, usamos geom_point(), geom_col() y, a veces, geom_line().
7.3.5.1 Tres continuas
Usando el argumento color = en la función aes(), construimos una gráfica de dispersión, con colores para una tercera variable continua:
gapminder %>%
mutate(log_pop = log(pop)) %>%
ggplot(aes(x = gdpPercap, y = lifeExp, color = log_pop)) +
geom_point() +
scale_x_log10(labels = scales::dollar) +
labs(x = "PIB per cápita", y = "Expectativa de vida al nacer", color = "Población (log.)")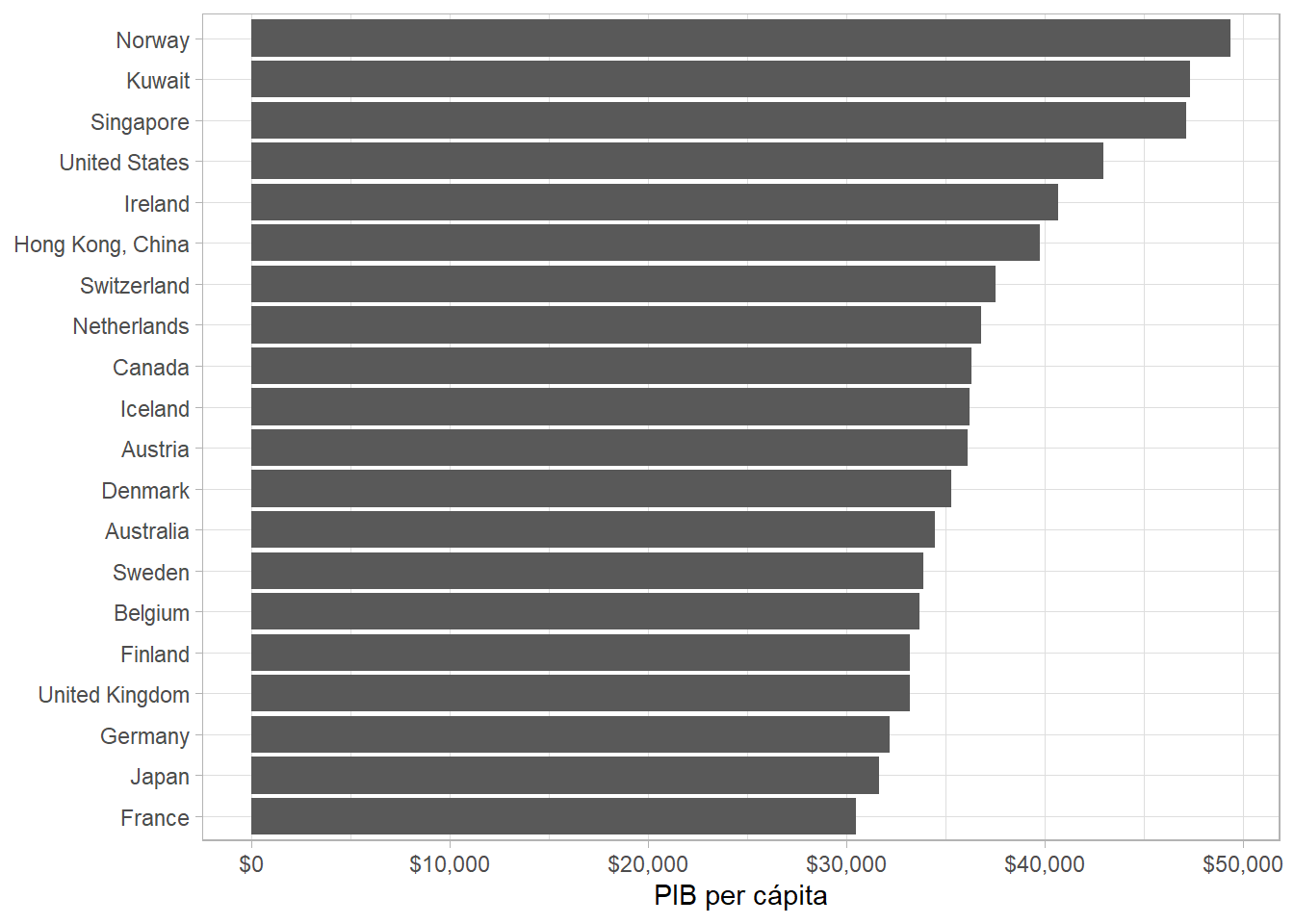
7.3.5.2 Dos cont., una cat.
Gráfica de dispersión, pero queremos que una variable categórica esté representada por el color de cada punto:
gapminder %>%
ggplot(aes(x = gdpPercap, y = lifeExp, color = continent)) +
geom_point(alpha = 0.35) +
scale_x_log10(labels = scales::dollar) +
labs(x = "PIB per cápita", y = "Expectativa de vida al nacer", color = "Continente") 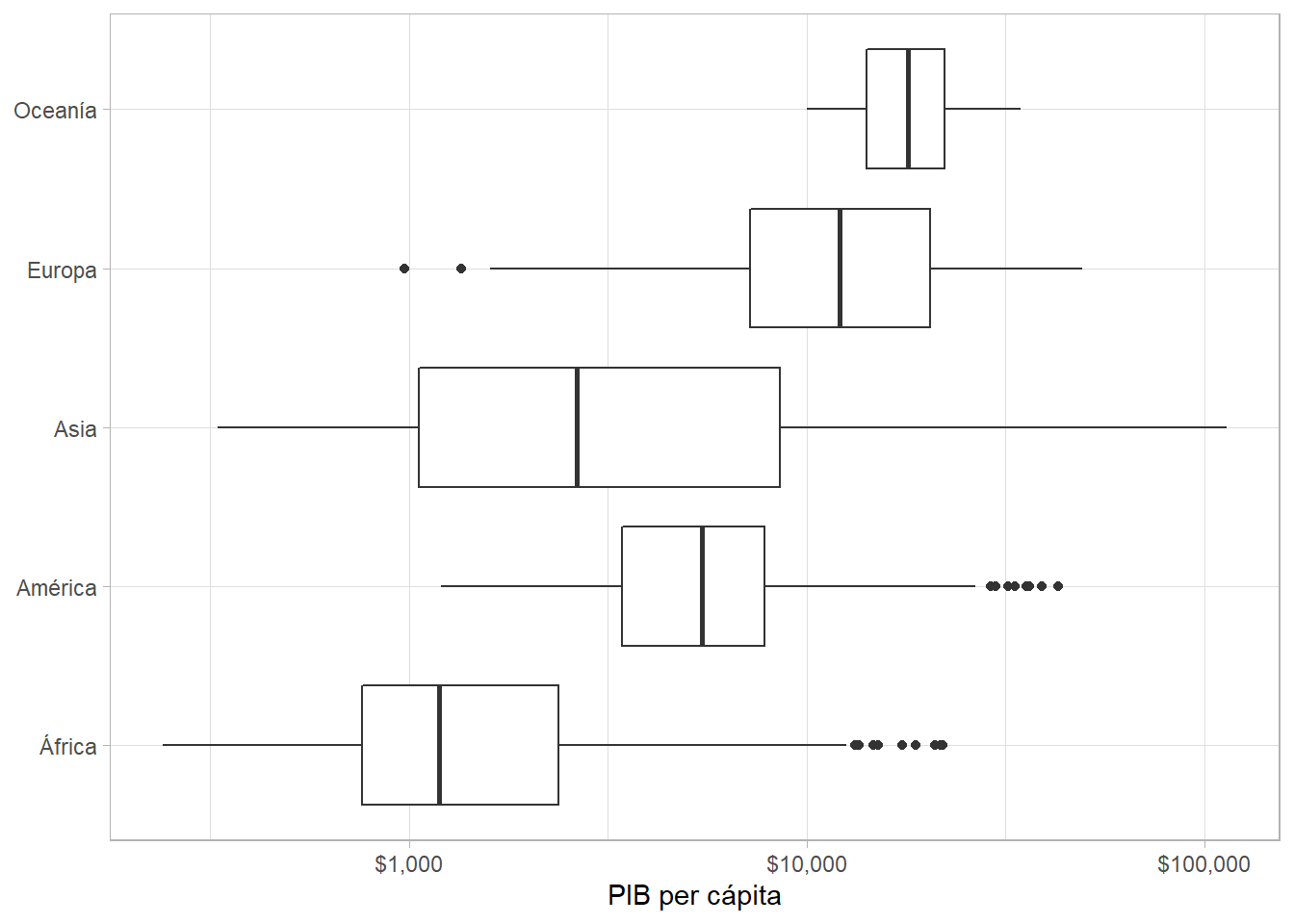
7.3.5.3 Una cont., dos cat.: barras agrupadas
En otras ocasiones, tenemos dos variables categóricas y queremos comparar cómo varía o se comporta una tercera variable numérica en los grupos dados por la combinación de las dos categóricas. Usar geom_col() con el argumento position = "dodge" nos permite poner las barras una al lado de la otra para facilitar la comparación y hacer un diagrama de barras agrupadas:
gapminder %>%
group_by(continent, gdpPercap_factor) %>%
summarize(lifeExp = mean(lifeExp, na.rm = TRUE)) %>%
ggplot(aes(x = continent, y = lifeExp, fill = gdpPercap_factor)) +
geom_col(position = "dodge") +
labs(x = "", y = "Expectativa de vida al nacer", fill = "Nivel de ingreso") ## `summarise()` regrouping output by 'continent' (override with `.groups` argument)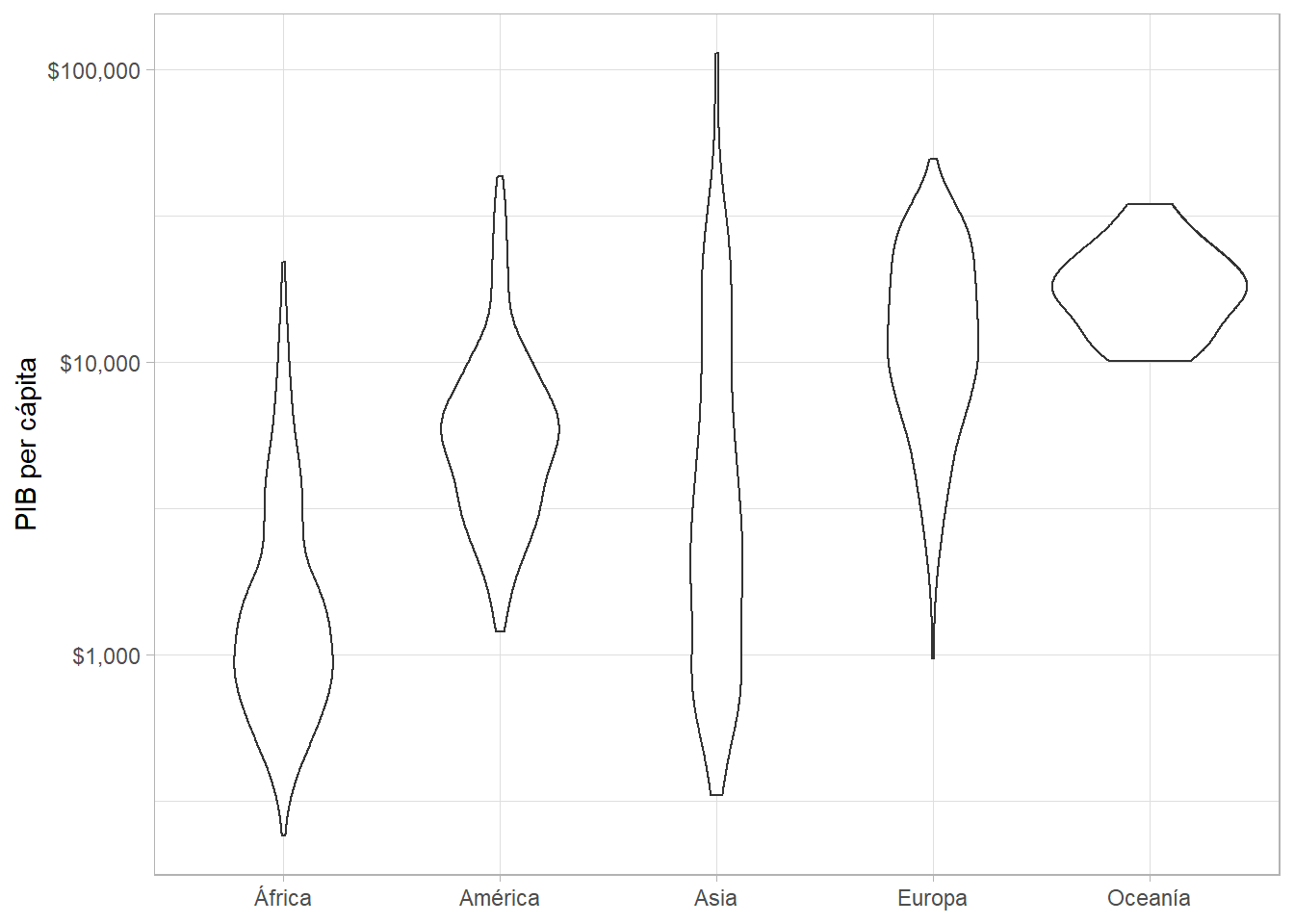
7.3.5.4 Una cont., una ord., una cat.: serie de tiempo
Queremos ver una serie de tiempo, pero con una línea para cada grupo (definido por una variable categórica).
gapminder %>%
filter(country %in% c("Colombia", "Brazil", "Mexico", "Argentina", "Venezuela")) %>%
group_by(year, country) %>%
summarize(gddPercap = mean(gdpPercap, na.rm = TRUE)) %>%
ggplot(aes(x = year, y = gddPercap, color = country)) +
geom_line() +
scale_y_continuous(labels = scales::dollar) +
scale_x_continuous(breaks = seq(1952, 2007, by = 5)) +
labs(x = "Año", y = "PIB per cápita", color = "País")## `summarise()` regrouping output by 'year' (override with `.groups` argument)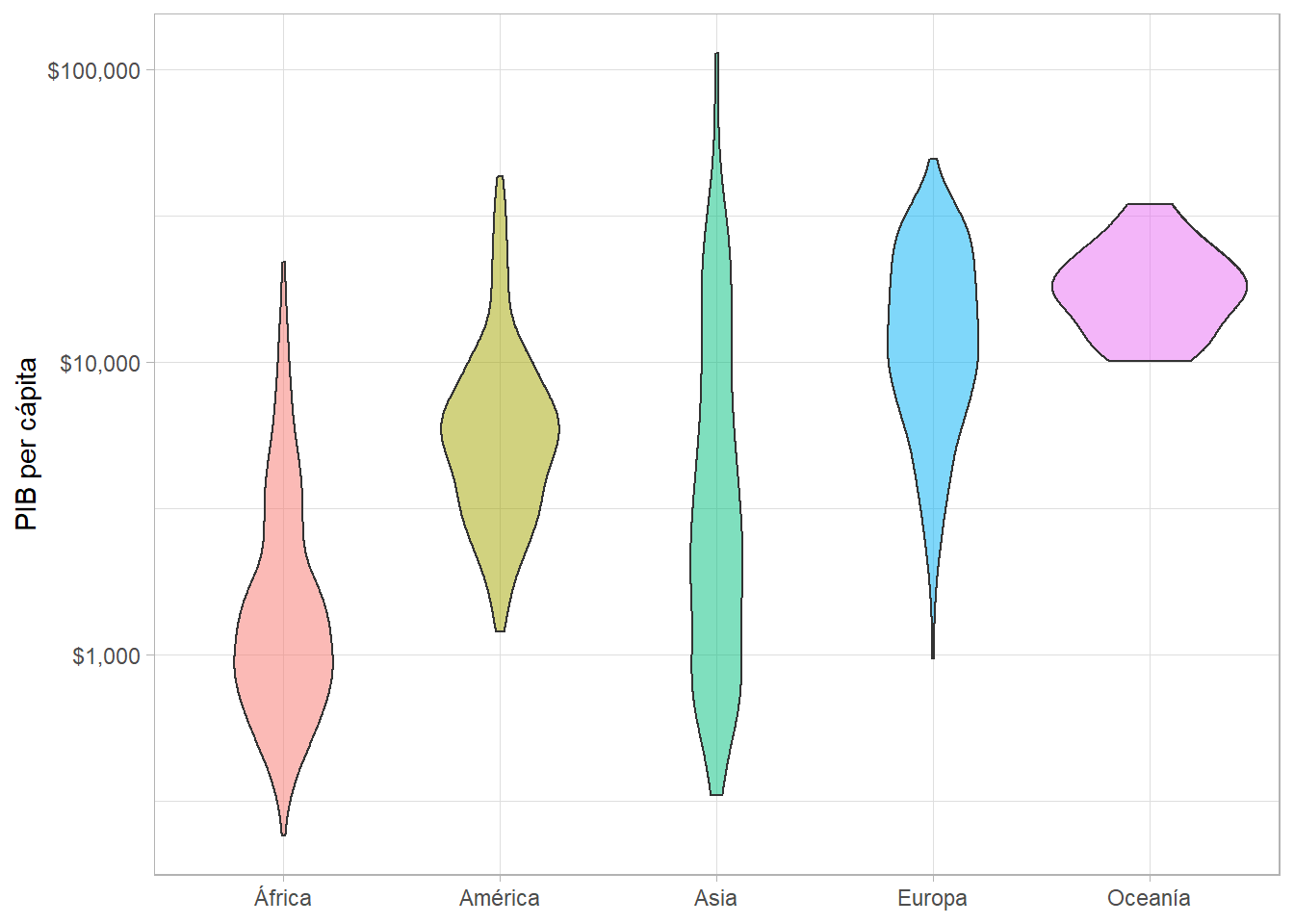
O usamos facet_wrap():
gapminder %>%
ggplot(aes(x = year, y = gdpPercap)) +
geom_line(aes(group = country), alpha = 0.5) +
scale_y_log10(labels = scales::dollar) +
facet_wrap(~ continent, ncol = 3) +
labs(x = "Año", y = "PIB per cápita") 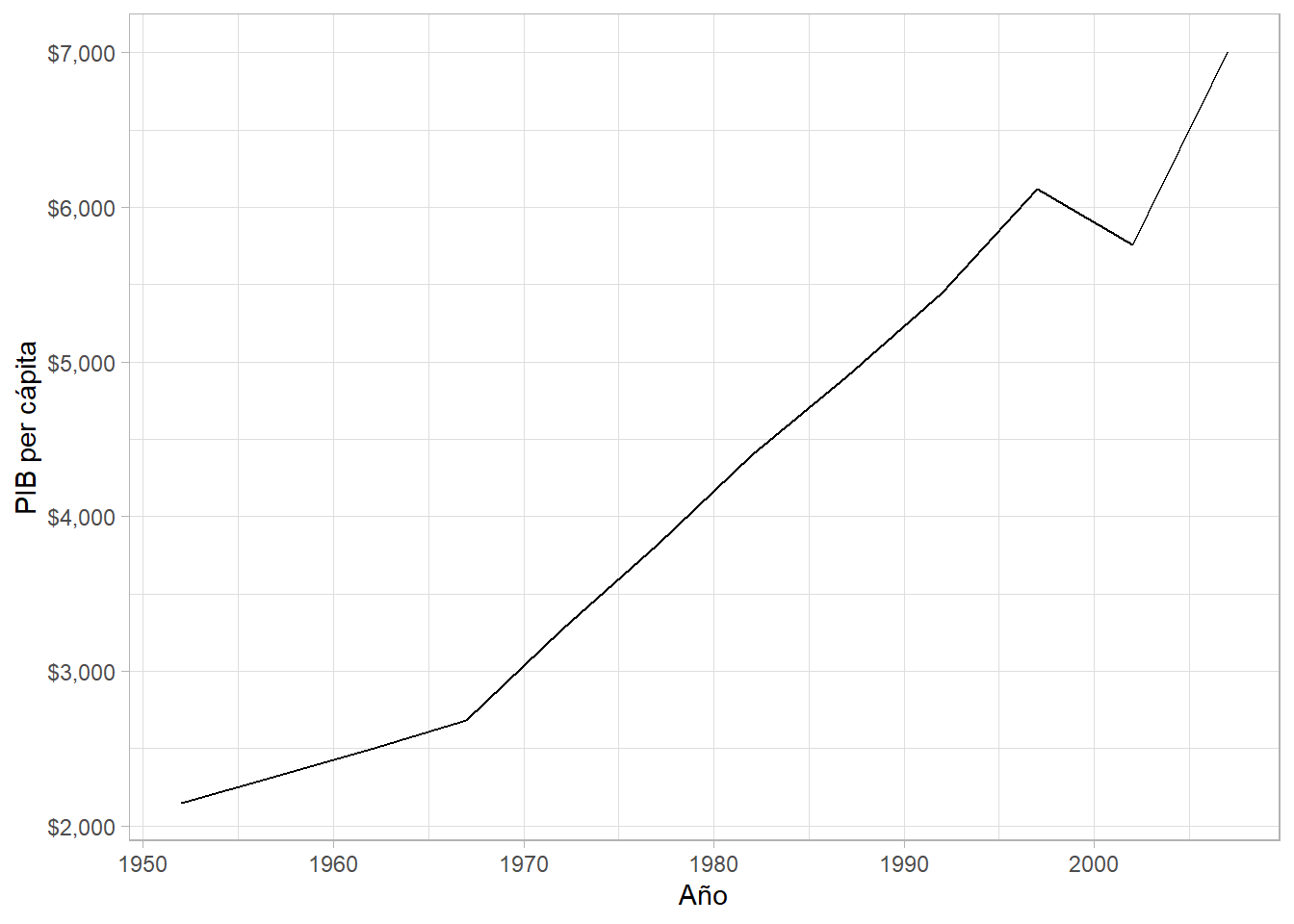
7.3.6 Guardar objetos gráficos
Para guardar una gráfica como archivo (puede ser con extensión .png, .pdf u otras):
gapminder %>%
ggplot(aes(x = gdpPercap, y = lifeExp)) +
geom_point() +
scale_x_log10() +
ggsave("output/graf_disp.png")7.4 Buenas prácticas
Unos últimos comentarios sobre buenas prácticas a la hora de visualizar datos:
- La pregunta y la teoría mandan: ¿cómo me ayuda la gráfica a evaluar o dar soporte a un argumento?
- Variable dependiente: eje vertical; variable independiente: eje horizontal
- Excepciones: histogramas (¡solo hay una variable!) o cuando las etiquetas quedan mejor en el eje vertical (texto, como nombres de países o ciudades).
- Menos es más: ¿de verdad necesito usar colores para cada barra si ya hay etiquetas en los ejes (redundancia)? ¿Estoy seguro que quiero mostrar 6 variables (x, y, z, color, tamaño y forma de los puntos) en una sola gráfica? Probablemente no…
- Siempre hay que incluir títulos o etiquetas para los ejes y las leyendas (a menos que sea absolutamente evidente qué información transmiten).
- Título y pie de gráfica pueden ir en la gráfica o en el texto.
- A veces es mejor usar tablas, en particular cuando queremos ver frecuencias.
Hay muchas más formas de personalizar las gráficas:
- Utilizar
annotate()ygeom_text()para anotar gráficas. - Cambiar temas/fondos al agregar
theme_classic()(u otras funcionestheme_()) al final de una gráfica o cambiando el tema para todas las gráficas contheme_set(). - Usar otras paletas de colores:
scale_color_brewer()yscale_fill_brewer()ofrecen varias alternativas para cmbiar los colores y rellenos.
7.5 Taller: visualización de datos
Encontrar una base de datos relevante para el proyecto de investigación. Limpiar y ordenar los datos. El código de esta entrega no debe incluir todo el procedimiento para cargar la base de datos original y el proceso de limpieza y organización de la misma; solo el resultado final de este proceso.
7.5.1 Distribuciones
Crear una gráfica de frecuencias (para variables categóricas) o un histograma (para variables continuas) que muestre la distribución de la variable dependiente del proyecto.
La gráfica debe tener ejes claramente titulados, contar con un título descriptivo y debe especificar la fuente de los datos (1.0 punto).
- Bono: Si la variable dependiente es continua y no está distribuida aproximadamente normal, transformar de forma tal que lo sea y graficar también la distribución de esta nueva variable.
7.5.2 Comparar distribuciones
Crear una gráfica de barras (para variables categóricas) o un histograma (para variables continuas) que compare la distribución de la variable dependiente del proyecto a través de dos o más grupos (o sea, otra variable categórica u ordinal). La variable graficada y los grupos deben ser de interés teórico y empírico en el marco de la pregunta de investigación. Solo deben comparar a través de países, municipios, regiones u otras unidades territoriales si hay una justificación teórica. No es tremendamente interesante comparar continentes o países si nuestra teoría es sobre diferencias políticas, institucionales o económicas. En cambio, es mucho más interesante comparar entre casos con o sin guerra; entre democracias, semidemocracias y autocracias; o entre casos con distintos modelos de desarrollo.
La gráfica debe tener ejes claramente titulados, contar con un título descriptivo y debe especificar la fuente de los datos (1.0 punto).
7.5.3 Relaciones entre variables
Crear una gráfica de dispersión en el cual se presente la relación entre dos variables continuas/numéricas de interés teórico. Solamente deben incluir una tercera variable –colores, tamaños de los puntos, etc.– si tiene sentido teóricamente, esto es, si su teoría sugiere que la tercera variable interactúa con otra o modera su efecto.
Aplican los mismos criterios y recomendaciones de los puntos anteriores (1.0 punto).
7.5.4 Medias de grupos
Crear una gráfica en la cual se compare la media de una variable numérica a través de dos o más grupos (o sea, una variable categórica u ordinal) de interés teórico. Varios tipos de gráficas pueden cumplir con este objetivo.
Aplican los mismos criterios y recomendaciones de los puntos anteriores (1.0 punto).
7.5.5 Interpretación
Ofrecer una interpretación corta de las gráficas (máximo 2-3 oraciones por gráfica) en términos de la pregunta de investigación y cómo estas visualizaciones ayudan a evaluar hipótesis o explorar aspectos interesantes de los datos (1.0 punto).
- Bono: en caso de tener datos en panel o serie de tiempo (o sea, múltiples observaciones de uno o más casos en periodos \(t_1, t_2, t_3, ..., t_n\)), visualizar dicha serie de tiempo para una variable numérica, con una línea por grupo (si hay distintos grupos relevantes). Aplican los mismos criterios y recomendaciones de los puntos anteriores.