Chapter 2 向量
{R} 是以物件導向為主的程式語言, 在 {R} 中, 資料或運算指令以具有名稱的 物件 (object), 形式儲存, 資料物件可以是 向量 (vector), 矩陣 (matrix), 陣列 (array), 列表 (Lists), 或 資料框架 (data frames) 等. 在 {R} 中, 資料分析基本上是產生資料物件, 對物件命名, 使用函式對物件運算操作. 透過指令, 很容易地對物件進行統計分析與統計繪圖. {R} 的資料結構與程式寫作相對於目前當紅的其他程式語言較多嚴謹的要求, 本章主要說明 {R} 的基本資料型式與基本運算.
2.1 向量
{R} 的最基本物件是向量, 向量 (vector) 是指包含相同 模式 (mode) 的元素組成. {R} 的基本資料型式稱為 基本模式 (basic mode) 有 numeric, integer, logical, complex, character. 同一向量內的元素不可混合.
單一數值 (scalar), 可視為僅具有單一元素的向量,
標準的向量是
倍精準度 (double) 的
數值向量
(numerical vector).
向量是具有相同基本類型的元素序列,
在 {R} 中, 純量或單一數值
(scalar)
也可看成是長度為 \(1\) 的向量,
向量大體上相當於其他程式語言中的 \(1\)-維度數列,
但在 {R} 中向量並不具有
沒有維度
(no dimension).
例如, 在 {R} 中 x.vec <- c(1, 2, 3),
可以視為 \(1 \times 3\) 的矩陣,
也可以視為 \(3 \times 1\) 的矩陣,
但是, 當向量 x.vec 與其它向量/矩陣進行運算時,
向量 x.vec 會受到與其進行運算的矩陣物件影響,
若任由 {R} 的內在設定,
則常會有意想不到的運算結果.
2.2 向量基本資料類型
{R} 的最基本物件是向量,
向量
是指包含相同
模式
(mode)
的元素組成.
{R} 的基本資料型式稱為
基本模式
(basic mode) 有
numeric, integer, logical, complex, character,
使用函式 class() 可以檢視基本模式.
- numeric, 數值型 (實數型), 含 single 單精準度型與 double 倍精準度型.
# numeric
x1 <- 10.1
x1
## [1] 10.1
class(x1)
## [1] "numeric"
x2 <- 10
x2
## [1] 10
class(x2)
## [1] "numeric"
is.numeric(x2)
## [1] TRUE- integer, 整數向量 (有時需特別指定輸入成 1L, 2L, …).
# integer
y1 <- 1L
y1
## [1] 1
class(y1)
## [1] "integer"
is.integer(y1)
## [1] TRUE
is.numeric(y1)
## [1] TRUE- logical, 邏輯型或布林型 (true or false), 以 TRUE (T) 或 FALSE (F) 呈現, 也可以是 \(1\) 與 \(0\) 整數分別代表 T 與 F.
# logic
yes_id <- TRUE
yes_id
## [1] TRUE
no_id <- FALSE
no_id
## [1] FALSE
class(no_id)
## [1] "logical"
is.logical(no_id)
## [1] TRUE
2 == 3
## [1] FALSE
2 != 3
## [1] TRUE
2 > 3
## [1] FALSE
2 <= 3
## [1] TRUE
4 >= 1
## [1] TRUE
TRUE + 5
## [1] 6
TRUE * 5
## [1] 5
FALSE * 5
## [1] 0
TRUE + FALSE
## [1] 1
TRUE * FALSE
## [1] 0- complex, 複數型.
x = 3+5i
x
## [1] 3+5i
class(x)
## [1] "complex"- character, 文字型或字串型, 通常輸入時在文字兩側加上雙引號 (").
# character
ca <- "yes"
ca
## [1] "yes"
cb <- "this is a book."
cb
## [1] "this is a book."
class(cb)
## [1] "character"
is.character(cb)
## [1] TRUE
"abc" > "abd"
## [1] FALSE
"date" < "dates"
## [1] TRUE資料分析另外常見的日期與類別變數也必須特別處裡.
格式有 Date, POSIXct 與 POSIXt等,
例如, 使用函式 Sys.Date() 可得系統日期.
Sys.Date()
## [1] "2020-10-29"
date1 <- as.Date("2020-09-17")
date1
## [1] "2020-09-17"
class(date1)
## [1] "Date"
as.numeric(date1)
## [1] 18522
date2 <- as.POSIXct("2020-09-17 18:30")
class(date2)
## [1] "POSIXct" "POSIXt"
as.numeric(date2)
## [1] 1600338600詳細的日期與類別變數操作, 以後再詳述.
2.3 向量產生函式 c()
輸入簡單的向量資料, 可以用函式
c()
指令.
c()為 concatenate (連接),
將數值或文字連接成向量.
## c()
## numerical
x.vec <- c(1/1, 1/2, 1/3, 1/4, 1/5)
x.vec
## [1] 1.0000000 0.5000000 0.3333333 0.2500000 0.2000000
## integer
x.vec <- c(1L, 2L, 3L)
x.vec
## [1] 1 2 3
## character
flavors.vec <- c("chocolate", "vanilla", "strawberry") # character
flavors.vec
## [1] "chocolate" "vanilla" "strawberry"
y.vec <- c("Hello", "What's your name?", "Your email?")
y.vec
## [1] "Hello" "What's your name?" "Your email?"
## logical
z.vec <- c(F, T, T, F, F)
z.vec
## [1] FALSE TRUE TRUE FALSE FALSE
## complex
x.complex.vec <- c(8+3i, 9+0i, 2+4i)
x.complex.vec
## [1] 8+3i 9+0i 2+4i
## numerical
x.vec <- c(1/1, 1/2, 1/3, 1/4, 1/5)
y.vec <- c(1, 2, 3, 4, 5)
z.vec <- c(x.vec, 11, 12, y.vec)
z.vec
## [1] 1.0000000 0.5000000 0.3333333 0.2500000 0.2000000 11.0000000 12.0000000 1.0000000 2.0000000
## [10] 3.0000000 4.0000000 5.00000002.4 向量基本運算操作符號
{R} 對物件運算操作有其
基本操作符號
(basic operators), 如同 C 語言,
可以分成算數操作 (arithmetic operator),
相關比較操作 (relation/comparison operator),
邏輯操作 (logical operator).
{R} 也是一種高階程式語言 (programming language),
因此提供了其它程序語言共有的
條件 (if-else),
轉換 (switch),
迴圈 (loop)
與
函式 (function) 等,
程序控制結構語法,
進階資料分析使用高階程式語言與函式寫作進行.
本章先討論基本運算操作.
| 符號 | 定義 |
|---|---|
| - | 減法運算 (Substraction, can be unary or binary) |
| + | 加法運算 (Addition, can be unary or binary) |
| ! | 否定運算 (Unary not) |
| * | 乘法運算 (Multiplication, binary) |
| / | 除法運算 (Division, binary) |
| ^ | 指數乘冪運算 (Exponentiation, binary) |
| %% | 整數除法的餘數 (Modulus, binary) |
| %/% | 整數除法的商數 (Integer divide, binary) |
| %*% | 矩陣內積乘法 (Matrix product, binary) |
| %o% | 矩陣外積乘法 (Outer product, binary) |
| %x% | 矩陣 Kronecker 乘法 (Kronecker product, binary) |
| %in% | 配對運算 (Matching operator, binary, in model formulae: nesting) |
< |
小於 Less than, binary |
> |
大於 Greater than, binary |
== |
相等 Equal to, binary |
!= |
不相等 Not equal to |
>= |
大於或等於 Greater than or equal to, binary |
<= |
小於或等於 Less than or equal to, binary |
& |
邏輯 和, 向量的個別元素使用 (Logical AND, binary, vectorized) |
&& |
邏輯 和, 二元操作 (Logical AND, binary, not vectorized) |
| |
邏輯 或, 向量的個別元素使用 (Logical OR, binary, vectorized) |
|| |
邏輯 或, 二元操作 (Logical OR, binary, not vectorized) |
xor |
邏輯 互斥, 向量個別元素互斥聯集運算, 僅有 1 為 TRUE |
2.5 向量基本算數操作
{R} 向量物件的
算數操作
(arithmetic operator)
符號包含以下符號,
+, -, !, *, /, \^, %%, %/%, %*%, %o%, %x%, %in% 等
算數操作根據最基本的運算次序:
括號, 指數, 乘法, 除法, 加減法, 也就是如同一般手寫計算.
## Arithmetic Operator
1 + 2
## [1] 3
1 + 2 + 3
## [1] 6
3 * 7 * 2
## [1] 42
4/2
## [1] 2
4/3
## [1] 1.333333
2 * 3 + 4
## [1] 10
2 * (3 + 4)
## [1] 14
(3 + 11 * 2)/4
## [1] 6.25
#
x.complex <- (8+3i)+(1+2i)
x.complex
## [1] 9+5i
#
x.vec <- 1:5
y.vec <- c(-1, -2, 0, 2, 4)
z.vec <- c(2, 2, 3, 3, 4)
x.vec + y.vec
## [1] 0 0 3 6 9
x.vec - y.vec
## [1] 2 4 3 2 1
#
x.vec * 2
## [1] 2 4 6 8 10
x.vec * y.vec
## [1] -1 -4 0 8 20
x.vec/2
## [1] 0.5 1.0 1.5 2.0 2.5
x.vec/y.vec
## [1] -1.00 -1.00 Inf 2.00 1.25
#
x.vec^2
## [1] 1 4 9 16 25
x.vec^z.vec
## [1] 1 4 27 64 625
y.vec/2
## [1] -0.5 -1.0 0.0 1.0 2.0
y.vec/x.vec
## [1] -1.0 -1.0 0.0 0.5 0.8
#
y.vec %% 3 # modular arithmetic remainder
## [1] 2 1 0 2 1
y.vec %/% 3 # integer division
## [1] -1 -1 0 0 1
y.vec %/% x.vec
## [1] -1 -1 0 0 02.6 向量關係比較操作
邏輯向量
(logic vector)
的元素值有
TRUE,
FALSE.
可以分別簡寫為
T 和
F.
在 {R} 之內, 向量之間的
關係比較操作
(relation/comparison operator)
可以產生邏輯向量.
關係比較操作符號包含常見的
<,
<=,
>,
>=.
## Relation/Comparison Operator
x.vec <- 1:5
y.vec <- (x.vec > 2)
y.vec
## [1] FALSE FALSE TRUE TRUE TRUE
any(x.vec > 2)
## [1] TRUE
all(x.vec > 2)
## [1] FALSE
#
x.vec <- 1:5
y.vec <- c(0, 2, 4, 6, 8)
#
x.vec < 2
## [1] TRUE FALSE FALSE FALSE FALSE
x.vec <= 2
## [1] TRUE TRUE FALSE FALSE FALSE
x.vec == 2
## [1] FALSE TRUE FALSE FALSE FALSE
x.vec != 2
## [1] TRUE FALSE TRUE TRUE TRUE
#
x.vec < y.vec
## [1] FALSE FALSE TRUE TRUE TRUE
x.vec < (y.vec - 2)
## [1] FALSE FALSE FALSE FALSE TRUE
x.vec <= y.vec
## [1] FALSE TRUE TRUE TRUE TRUE
x.vec <= (y.vec - 2)
## [1] FALSE FALSE FALSE TRUE TRUE
#
x.vec == y.vec
## [1] FALSE TRUE FALSE FALSE FALSE
x.vec == (y.vec - 2)
## [1] FALSE FALSE FALSE TRUE FALSE
x.vec != y.vec
## [1] TRUE FALSE TRUE TRUE TRUE
x.vec != (y.vec - 2)
## [1] TRUE TRUE TRUE FALSE TRUE2.7 向量邏輯操作
在 {R} 之內, 向量之間的
關係比較操作
可以產生邏輯向量.
在 {R} 中可對邏輯向量進行運算操作,
邏輯操作
(logical operator)
符號包含常見的
! (否定),
&, && (AND), | , || (OR),
以及判斷相等的
== 和判斷不等的
!= 等.
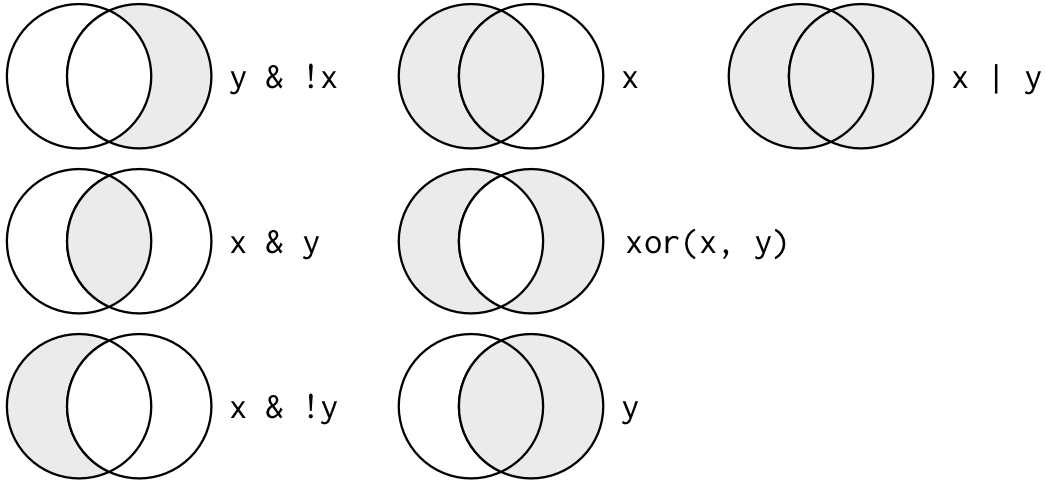
## Logical Operator: AND OR XOR
x.vec <- 1:5
y.vec <- c(0, 2, 4, 6, 8)
(x.vec > 0) & (y.vec > 0) # return vector AND
## [1] FALSE TRUE TRUE TRUE TRUE
(x.vec > 0) && (y.vec > 0) # return scalar AND
## [1] FALSE
#
(x.vec > 0) & ((y.vec - 3) > 0) # return vector AND
## [1] FALSE FALSE TRUE TRUE TRUE
((x.vec-2) > 0) && ((y.vec - 3) > 0) # return scalar AND
## [1] FALSE
#
(x.vec > 0) & ((y.vec + 3) > 0) # return vector AND
## [1] TRUE TRUE TRUE TRUE TRUE
((x.vec-2) > 0) && ((y.vec + 3) > 0) # return scalar AND
## [1] FALSE
#
(x.vec > 0) | (y.vec > 0) # return vector OR
## [1] TRUE TRUE TRUE TRUE TRUE
((x.vec- 2) > 0) | ((y.vec - 3) > 0)
## [1] FALSE FALSE TRUE TRUE TRUE
#
(x.vec > 0) || (y.vec > 0) # return scalar OR
## [1] TRUE
((x.vec-2) > 0) || ((y.vec - 3) > 0)
## [1] FALSE
#
(x.vec > 0) || ((y.vec + 3) > 0) # return scalar OR
## [1] TRUE
((x.vec-2) > 0) || ((y.vec + 3) > 0)
## [1] TRUE
#
xor((x.vec > 0), (y.vec > 0)) # return vector exclusive OR
## [1] TRUE FALSE FALSE FALSE FALSE
xor(((x.vec - 2) > 0), ((y.vec - 3) > 0))
## [1] FALSE FALSE FALSE FALSE FALSE
xor(((x.vec - 2) > 0), ((y.vec + 3) > 0))
## [1] TRUE TRUE FALSE FALSE FALSE
#
xx.vec <- (x.vec <= 3)
yy.vec <- (y.vec >= 4)
xx.vec
## [1] TRUE TRUE TRUE FALSE FALSE
yy.vec
## [1] FALSE FALSE TRUE TRUE TRUE
#
xx.vec && yy.vec
## [1] FALSE
xx.vec & yy.vec
## [1] FALSE FALSE TRUE FALSE FALSE
xx.vec || yy.vec
## [1] TRUE
xx.vec | yy.vec
## [1] TRUE TRUE TRUE TRUE TRUE
xor(xx.vec, yy.vec)
## [1] TRUE TRUE FALSE TRUE TRUE2.8 向量元素命名
向量的每個元素或部分元素都可以命名,
使用者可以在輸入元素時直接給予命名,
或另外使用函式
names()
給予命名.
若要移除命名,
使用函式 unname() 移除命名,
或使用 names(x.vec) <- NULL 移除命名.
## vector names
x.vec <- c(
age = 50,
chol = 220,
dbp = 84,
sbp = 132
) # directly
x.vec
## age chol dbp sbp
## 50 220 84 132
names(x.vec)
## [1] "age" "chol" "dbp" "sbp"
#
x.vec <- c(55, 236, 80, 140)
names(x.vec) <- c("age", "chol", "sbp", "dbp")
#
y.vec.name <- names(x.vec)
y.vec <- c(60, 214, 90, 144)
names(y.vec) <- y.vec.name
y.vec
## age chol sbp dbp
## 60 214 90 1442.9 向量下標與索引 Inxex
一個向量的長度 (length) 是向量元素的數目,
一個向量的個別元素或部分元素可以向量的下標 (index) 取得,
向量的
下標
或
索引
(index)
是在向量名稱後面加 中括號 [i],
並放入下標數目 (或向量) 得到.
原始向量的下標可以採用下列四種方式的任何一種,
正整數, 負整數, 文字或字串與邏輯向量.
## Vector Indexing
## positive integer
x.vec <- 1:50
x.vec[7]
## [1] 7
x.vec[11:15]
## [1] 11 12 13 14 15
y.vec <- x.vec[11:15]
y.vec
## [1] 11 12 13 14 15
## negative integer
z.vec <- 6:10
z.vec[-c(2, 4)]
## [1] 6 8 10
## character string
fruit.vec <- c(5, 10, 1, 20)
fruit.vec
## [1] 5 10 1 20
names(fruit.vec) <- c("orange", "banana", "apple", "peach")
fruit.vec
## orange banana apple peach
## 5 10 1 20
lunch.vec <- fruit.vec[c("apple", "orange")]
lunch.vec
## apple orange
## 1 5
## logical index
x.vec <- c(NA, -2, -1, NA, 1, 2, NA) # NA = missing value
x.vec
## [1] NA -2 -1 NA 1 2 NA
y.vec <- x.vec[!is.na(x.vec)] # !is.na() = check missing value
y.vec
## [1] -2 -1 1 2
z.vec <- x.vec[x.vec > 0 & !is.na(x.vec)]
z.vec
## [1] 1 2
x.vec[x.vec < 0] # Note: NA
## [1] NA -2 -1 NA NA
y.vec[y.vec < 0]
## [1] -2 -1
z.vec[z.vec < 0]
## numeric(0)2.10 遺失值 (缺失值) Missing Values
研究資料,
通常會有
遺失值
或
缺失值
(missing value,
incomplete data**),
在 R 中, 輸入或輸出遺失值,
通常以
NA 表示,
(NA = Not Available),
R 還有另外有
NaN = Not a Number
是指物件運算後產生非數值結果,
以及
NULL
是指物件的長度是 \(0\).
任何對遺失值
(NA) 的算數操作,
會得到遺失值
(NA)
結果.
使用函式
is.na(),
is.nan()
可以查看向量內那些元素是遺失值.
回傳一個邏輯向量.
對遺失值作比較大小運算須非常小心.
要移除遺失值, 可以使用函式
na.omit(),
na.fail(),
na.exclude(),
na.action()
等指令.
且函式 complete.cases() 可以同時移出多個缺失值.
對於不同基本模式的向量元素進行融合,
若不合階層結構,
則 R 回傳缺失值.
## missing value
z.vec <- c(1:2, NA)
is.na(z.vec)
## [1] FALSE FALSE TRUE
log(z.vec)
## [1] 0.0000000 0.6931472 NA
z.vec / 0
## [1] Inf Inf NA
0 / 0
## [1] NaN
Inf - Inf
## [1] NaN
#
is.na(z.vec)
## [1] FALSE FALSE TRUE
is.nan(z.vec)
## [1] FALSE FALSE FALSE
is.nan(0 / 0)
## [1] TRUE
is.na(0 / 0)
## [1] TRUE
#
x.vec <- c(1, 2, NA, 4, NA, 5, 6)
bad <- is.na(x.vec)
x.vec[!bad]
## [1] 1 2 4 5 6
complete.cases(x.vec)
## [1] TRUE TRUE FALSE TRUE FALSE TRUE TRUE
x.vec[complete.cases(x.vec)]
## [1] 1 2 4 5 6
#
x.vec <- c(1, 2, NA, 4, NA, 5, 6)
y.vec <- c("a", "b", NA, "d", NA, "f", "g")
good <- complete.cases(x.vec, y.vec)
good
## [1] TRUE TRUE FALSE TRUE FALSE TRUE TRUE
x.vec[good]
## [1] 1 2 4 5 6
y.vec[good]
## [1] "a" "b" "d" "f" "g"
x.vec <- c(1, 2, 3, NA, NA, 5, 6)
y.vec <- c("a", "b", NA, "d", NA, "f", "g")
good <- complete.cases(x.vec, y.vec)
good
## [1] TRUE TRUE FALSE FALSE FALSE TRUE TRUE
#
data(airquality)
airquality[1:6, ]
## Ozone Solar.R Wind Temp Month Day
## 1 41 190 7.4 67 5 1
## 2 36 118 8.0 72 5 2
## 3 12 149 12.6 74 5 3
## 4 18 313 11.5 62 5 4
## 5 NA NA 14.3 56 5 5
## 6 28 NA 14.9 66 5 6
good <- complete.cases(airquality)
airquality[good,][1:6, ]
## Ozone Solar.R Wind Temp Month Day
## 1 41 190 7.4 67 5 1
## 2 36 118 8.0 72 5 2
## 3 12 149 12.6 74 5 3
## 4 18 313 11.5 62 5 4
## 7 23 299 8.6 65 5 7
## 8 19 99 13.8 59 5 82.11 因子物件與類別變數 Factor
因子物件
(factor)
為處理
類別資料
(categorical data),
提供的一種有效的方法.
類別變數
將變數值分成互斥的類別水準,
在類別變數定義中的特定幾種類別水準是否有大小差距,
又可分類成
名目變數
(nominal variable)
與
有序變數
(ordinal variable),
或稱
名目尺度
與
順序尺度.
其中
名目尺度
是最簡單的測量,
名目尺度將變數值分成互斥的類別水準,
同一變數內的類別水準並無量化大小的差別.
名目尺度用文字或數字表示或標記, 這些數字本身並無任何意義,
例如 左側為 1, 右側為 0;
1 = 拇指, 2 = 食指, 3 = 中指, 4 = 無名指, 5 = 小指.
在名目尺度中,
特別的情形是變數內只有 2 個類別水準,
如存活或死亡, 統計習慣上會分別標記為 0 或 1,
感染或無感染, 這類變數常稱做
二元變數
(dichotomous variable,
binary variable),
二元變數通常有特殊的統計分析方法.
順序尺度
是指同一變數內的類別水準有
輕重, 大小, 強弱, 好壞等級順序之資料.
例如, 疼痛情形有 4 種情境: 無, 輕度, 中度, 重度,
癌症分期為 I, II, III, IV 等 4 期.
雖然順序尺度用數字 \(1, 2, 3, 4, \ldots\) 表示或標記,
但是數字本身通常不能用來做運算, 只能比較相對大小或高低次序,
順序之間的實際差異並無法從標記的數字差異得知.
統計中的類別資料,
有各種不同表示方法,
在電腦的資料儲存時常常是以文字為變數值,
但使用上文字較占空間且無法精準傳達
類別變數的概念.
因此在 {R} 中特別使用
因子
(factor)
來表示.
因子是一種特殊的文字向量,
文字向量中的每一個元素, 取一個離散值,
因子物件 有一個特殊屬性, 稱為
層次,
水平,
水準
或
類別水準
(levels),
表示這組所有可能的離散值.
因子常常是用文字或字串輸入,
有時會使用數值或整數代表,
一但變數設定為因素或因子向量,
{R} 在列印或輸出時,
並不會加上雙引號 ",
且數值或有大小順序的文字,
{R} 在統計分析上都必須特別處理.
在 {R} 中若要設定因子,
可以簡單地用函式
factor()
產生無序因子物件.
factor(x = character(), levels, labels = levels,
exclude = NA, ordered = is.ordered(x), nmax = NA) 其中引數為
x為原始向量, 通常為文字向量, 若是數值向量, {R} 先轉換成文字向量.levels設定類別水準.labels類別水準的標記文字.exclude = NA排除缺失值或某一特定值為一類別水準.ordered = is.ordered(x)設定因子物件類別水準的順序, 仍是無序因子物件.nmax = NA是否類別水準的最大數目.
## factor()
sex <- c("male", "female", "male", "male", "female")
sex
## [1] "male" "female" "male" "male" "female"
class(sex)
## [1] "character"
sex <- factor(sex)
sex
## [1] male female male male female
## Levels: female male
class(sex)
## [1] "factor"
## factor() + levels
sex <- c("male", "female", "male", "male", "female")
sex <- factor(sex, levels = c("female", "male"))
sex
## [1] male female male male female
## Levels: female male
## factor() + levels + labels
x.chr = c("male", "male", "female", "female")
factor(x.chr, levels = c("male", "female", "bisex"))
## [1] male male female female
## Levels: male female bisex
factor(x.chr, levels = c("male", "female", "bisex"),
labels = c("m", "f", "b"))
## [1] m m f f
## Levels: m f b
## factor() + exclude
## factor() + exclude
pain <- c("none", "mild", "moderate", "severe", NA)
factor(pain) # NA is NOT a level.
## [1] none mild moderate severe <NA>
## Levels: mild moderate none severe
factor(pain, exclude = NA) # NA is NOT a level.
## [1] none mild moderate severe <NA>
## Levels: mild moderate none severe
factor(pain, exclude = c(NA)) # NA is NOT a level.
## [1] none mild moderate severe <NA>
## Levels: mild moderate none severe
factor(pain, exclude = NULL) # NA is a level.
## [1] none mild moderate severe <NA>
## Levels: mild moderate none severe <NA>
factor(pain, exclude = "mild") # NA is a level.
## [1] none <NA> moderate severe <NA>
## Levels: moderate none severe <NA>
pain <- factor(pain, exclude = c("mild", NA))
pain # mild and NA are NOT levels.
## [1] none <NA> moderate severe <NA>
## Levels: moderate none severe{R} 中的 factor() 為
無序因子
(unordered factor),
類似於統計分析中的
名目變數
(nominal variable),
無序因子
中的類別水準 (level),
其離散值無大小順序的關係, 如性別的男與女.
{R} 列印無序因子物件時,
類別水準
內建型式依照文字字母順序,
可以使用函式
levels()
查看無序因子物件的類別水準;
也可以使用函式
levels()
設定列印無序因子物件 類別水準 的顯示次序,
{R} 內建顯示次序是依照文字字母或數字排次序,
可以使用函式
levels() 指令,
改變顯示因子物件的次序或方向.
在統計模型中常使用 類別變數 作為解釋變數,
常常必須令 無序因子物件 或 類別變數
的某一個類別水準為
參照水準
(reference level),
以便建構類別型解釋變數內不同類別水準的
對照比較
(contrast comparison).
使用函式
relevel(),
可以改變無序因子類別水準的參考水準.
## unorder
## level()
gender <- c("M", "F", "M", "M", "F")
gender <- factor(gender)
gender
## [1] M F M M F
## Levels: F M
levels(gender)
## [1] "F" "M"
levels(gender) <- c("Female", "Male")
gender
## [1] Male Female Male Male Female
## Levels: Female Male
hypertension <- c("Lo", "Mod", "Hi", "Mod", "Lo", "Hi", "Lo")
hypertension <- factor(hypertension)
hypertension
## [1] Lo Mod Hi Mod Lo Hi Lo
## Levels: Hi Lo Mod
# relevel()
relevel(hypertension, ref = "Lo") # reset a reference level
## [1] Lo Mod Hi Mod Lo Hi Lo
## Levels: Lo Hi Mod
## correct
hypertension <- c("Lo", "Mod", "Hi",
"Mod", "Lo", "Hi", "Lo")
hypertension <- factor(hypertension,
levels = c("Lo", "Mod", "Hi"))
hypertension
## [1] Lo Mod Hi Mod Lo Hi Lo
## Levels: Lo Mod Hi
## error, we will see the correct method later
hypertension <- c("Lo", "Mod", "Hi",
"Mod", "Lo", "Hi", "Lo")
hypertension <- factor(hypertension)
levels(hypertension) <- c("Lo", "Mod", "Hi")
hypertension
## [1] Mod Hi Lo Hi Mod Lo Mod
## Levels: Lo Mod Hi使用 as.integer()
可將類別變數轉換成數值整數,
此數值整數從 1 到 類別水準的整數,
且依照原有的類別水準依序給整數,
使用上必須注意此差異.
## convert to numerical values
hypertension <- c("Lo", "Mod", "Hi", "Mod", "Lo", "Hi", "Lo")
hypertension <- factor(hypertension)
levels(hypertension)
## [1] "Hi" "Lo" "Mod"
hypertension
## [1] Lo Mod Hi Mod Lo Hi Lo
## Levels: Hi Lo Mod
as.integer(hypertension)
## [1] 2 3 1 3 2 1 2
#
levels(hypertension) <- list("Low" = "Lo",
"Moderate" = "Mod",
"High" = "Hi")
hypertension
## [1] Low Moderate High Moderate Low High Low
## Levels: Low Moderate High
as.integer(hypertension)
## [1] 1 2 3 2 1 3 1
#
## convert to numerical values
pain <- c(7, 8, 6, 6, 8, 7)
pain <- factor(pain)
pain
## [1] 7 8 6 6 8 7
## Levels: 6 7 8
as.integer(pain)
## [1] 2 3 1 1 3 2
pain.chr = as.character(pain)
pain.chr
## [1] "7" "8" "6" "6" "8" "7"
pain.num = as.integer(pain.chr)
pain.num
## [1] 7 8 6 6 8 7We describe our methods in this chapter.