Part 7 Random Forests
In the previous chapter, I talked a little bit about decision trees, what they look like, the CART algorithm for generating a classification decision tree, and also a little bit about variable importance.
Unfortunately, decision trees are prone to overfitting: a phenomena whereby the decision tree fits perfectly on a set of training data, but performs poorly on testing data.
Hence, enter random forests: an algorithm that combines the results of multiple decision trees to make conclusions about any given data point. Random forests are great because:
- The data need not be normalized prior to actually performing the algorithm (though the same can also be said for decision trees).
- Predictions are more accurate in a sense - this is because the final, predicted outcome of the data is the average of multiple decision trees.
However, note that random forests are generally slow - this is because many decision trees have to be made. Furthermore, random forest models are also prone to overfitting in some cases and are also not as interpretable as decision trees are.
7.1 How Does a Random Forest Model Work?
I think this graphic I pulled off from here does a pretty good job summarizing how classification in the random forest algorithim works:
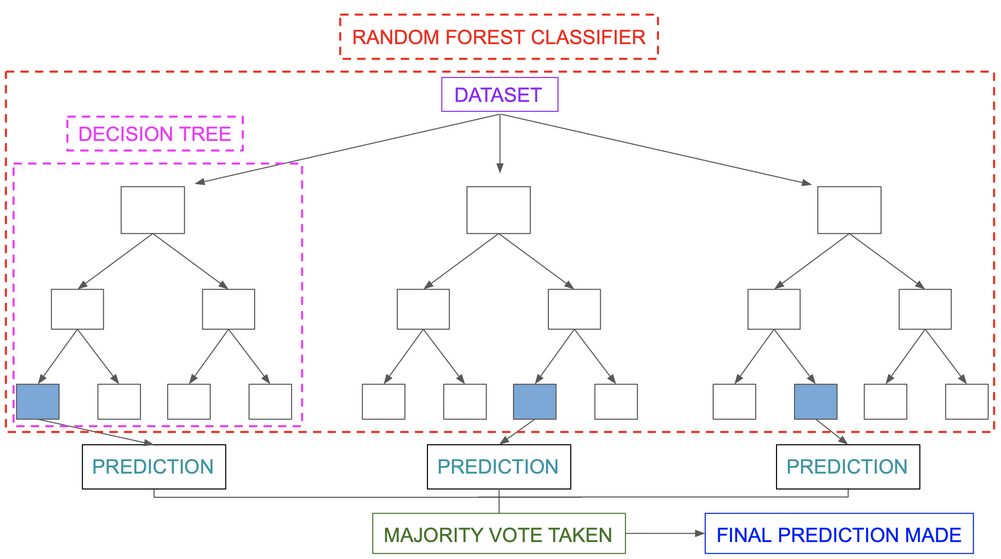
Figure 7.1: Classification in Random Forests
But, here’s how the algorithm works in a nutshell:
- We select \(K\) data points from the training set of data.
- We then build multiple decision trees with the selected data points (i.e., we build multiple decision trees with subsets of the training set).
- We then decide how many trees to build - I believe that training a random forest model with the
randomForestpackage in R will build 500 trees by default. - We repeat steps 1 - 2 until we’ve considered all possible subsets of training data to train our decision trees on.
- For each data point, we find the predictions of each decision tree and assign the data points to the category that is predicted the most.
7.2 Ranger Random Forest
As it turns out, the “Ranger” is an acronym for Random forest generator. After some digging around on Google Scholar, I found a paper written by the authors of the ranger package (i.e., the package that I used to build a random forest classifier).
It seems like ranger’s version of the above random forest algorithm is fast because it is written in C++ and sourced back into R via Rcpp. Other than that, the main idea behind the random forest is still the same.
The paper does delve quite a bit into other R implementations of the random forest algorithm (i.e., randomForest), a handful of examples, and also evaluates the performance (e.g., speed, gini coefficients, etc.) of ranger against other similar packages.