8.1 ¿Por qué necesitamos crear nuestrar propias funciones?
Supongamos que tenemos un jefe que nos ha pedido crear un histograma con datos de edad que hemos recogido en una encuesta.
Esto es sencillo de resolver pues contamos con la función hist() que hace exactamente esto. Sólo tenemos que dar un vector numérico como argumento para generar una gráfica (veremos esto con más detalle en el capítulo 12).
Primero, generaremos datos aleatorios sacados de una distribución normal con la función rnorm(). Esta función tiene los siguientes argumentos:
n: Cantidad de números a generar.mean: Media de la distribución de la que sacaremos nuestros números.sd: Desviación estándar de la distribución de la que sacaremos nuestros números.
Además, llamaremos set.seed() para que estos resultados sean replicables. Cada que llamamos rnorm() se generan número aleatorios diferentes, pero si antes llamamos a set.seed(), con un número específico como argumento obtendremos los mismos resultados.
Obtendremos 1500 números con media 15 y desviación estándar .75.
set.seed(173)
edades <- rnorm(n = 1500, mean = 15, sd = .75)Veamos los primero diez números de nuestro objeto.
edades[1:10]## [1] 15.79043 14.68603 16.29119 14.66079 15.25658 14.62890 14.87498
## [8] 16.35364 16.04607 16.35803Ahora, sólo tenemos que ejecutar hist() con el argumento x igual a nuestro vector y obtendremos un histograma.
# Histograma
hist(x = edades)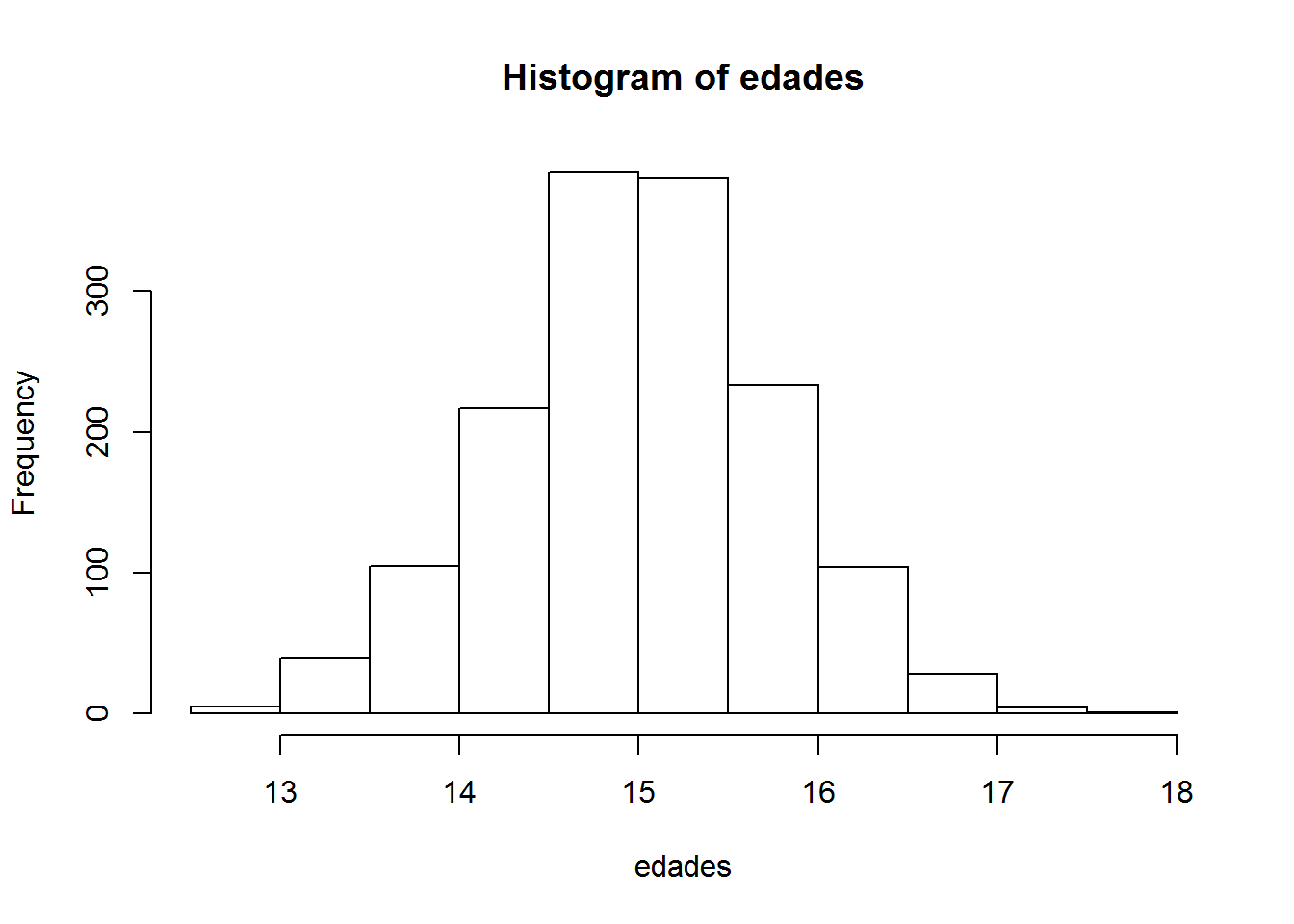
Estupendo. Hemos logrado nuestro objetivo.
Nuestro jefe está satisfecho, pero le gustaría que en el histograma se muestre la media y desviación estándar de los datos, que tenga un título descriptivo y que los ejes estén etiquetados en español, además de que las barras sean de color dorado.
Suena complicado, pero podemos calcular la media de los datos usando la función mean(), la desviación estándar con sd() y podemos agregar los resultados de este cálculo al histograma usando la función abline(). Para agregar título, etiquetas en español y colores al histograma sólo basta agregar los argumentos apropiados a la función hist().
No te preocupes mucho por los detalles de todo esto, lo veremos más adelante.
Calculamos media y desviación estándar de nuestros datos.
media <- mean(edades)
desv_est <- sd(edades)Agregamos líneas con abline(), para la media de rojo y desviación estándar con azúl. También ajustamos los argumentos de hist().
hist(edades, main = "Edades", xlab = "Datos", ylab = "Frecuencia", col = "gold")
abline(v = media, col = "red")
abline(v = media + (desv_est * c(1, -1)), col = "blue")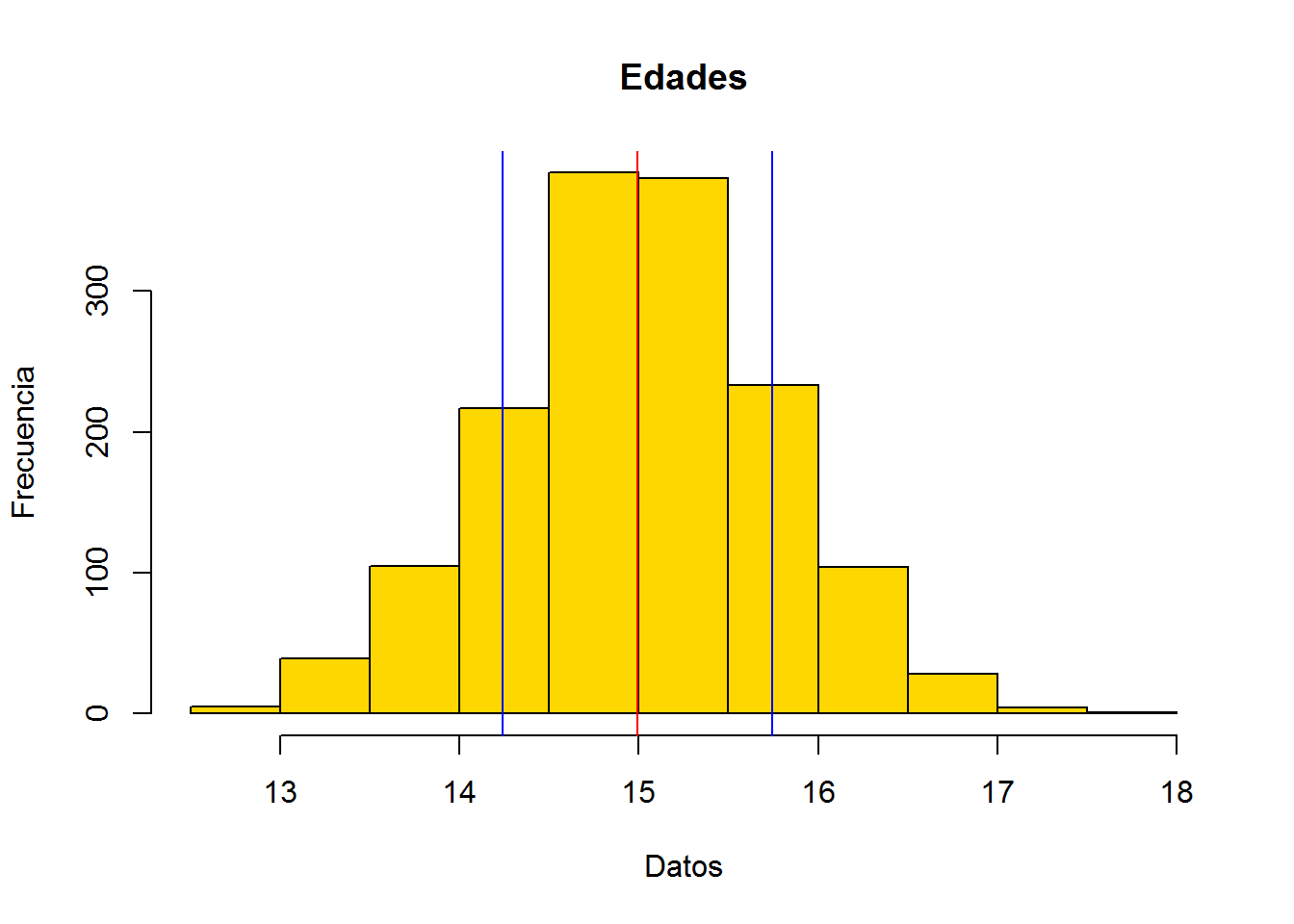
Con esto nuestro jefe ahora sí ha quedado complacido. Tanto, que nos pide que hagamos un histograma igual para todas las variables numéricas de esa encuesta. Que son cincuenta en total.
Para cumplir con esta tarea podríamos usar el código que ya hemos escrito. Simplemente lo copiamos y pegamos cincuenta veces, cambiando los valores para cada una de variables que nos han pedido.
Pero hacer las cosas de este modo propicia errores y es difícil de corregir y actualizar.
Para empezar, si copias el código anterior cincuenta veces, tendrás un script con más de 400 líneas. Si en algún momento te equivocas porque escribiste “Enceusta” en lugar de “Encuesta”, incluso con las herramientas de búsqueda de RStudio, encontrar donde está el error será una tarea larga y tediosa.
Y si tu jefe en esta ejemplo quiere que agregues, quites o modifiques tu histograma, tendrás que hacer el cambio cincuenta veces, una para cada copia del código. De nuevo, con esto se incrementa el riesgo de que ocurran errores.
Es en situaciones como esta en las que se hace evidente la necesidad de crear nuestras propias funciones, capaces de realizar una tarea específica a nuestros problemas, y que pueda usarse de manera repetida. Así reducimos errores, facilitamos hacer correcciones o cambios y nos hacemos la vida más fácil, a nosotros y a quienes usen nuestro código después.