ModernDive
An Introduction to Statistical and Data Sciences via R
Chester Ismay and Albert Y. Kim STARRING FRANK MCGRADE
August 02, 2017
1 Introduction

![]()
Help! I’m new to R and RStudio and I need to learn about them! However, I’m completely new to coding! What do I do? If you’re asking yourself this question, then you’ve come to the right place! Start with our Introduction for Students.
- Are you an instructor hoping to use this book in your courses? Then click here for more information on how to teach with this book.
- Are you looking to connect with and contribute to ModernDive? Then click here for information on how.
- Are you curious about the publishing of this book? Then click here for more information on the open-source technology, in particular R Markdown and the bookdown package.
This is version 0.2.0 of ModernDive published on August 02, 2017. For previous versions of ModernDive, see Section 1.4.
1.1 Introduction for students
This book assumes no prerequisites: no algebra, no calculus, and no prior programming/coding experience. This is intended to be a gentle introduction to the practice of analyzing data and answering questions using data the way data scientists, statisticians, data journalists, and other researchers would.
1.1.1 What you will learn from this book
We hope that by the end of this book, you’ll have learned
- How to use R to explore data.
- How to answer statistical questions using tools like confidence intervals and hypothesis tests.
- How to effectively create “data stories” using these tools.
What do we mean by data stories? We mean any analysis involving data that engages the reader in answering questions with careful visuals and thoughtful discussion, such as How strong is the relationship between per capita income and crime in Chicago neighborhoods? and How many f**ks does Quentin Tarantino give (as measured by the amount of swearing in his films)?. Further discussions on data stories can be found in this Think With Google article.
For other examples of data stories constructed by students like yourselves, look at the final projects for two courses that have previously used ModernDive:
- Middlebury College MATH 116 Introduction to Statistical and Data Sciences using student collected data.
- Pacific University SOC 301 Social Statistics using data from the fivethirtyeight R package.
This book will help you develop your “data science toolbox”, including tools such as data visualization, data formatting, data wrangling, and data modeling using regression. With these tools, you’ll be able to perform the entirety of the “data/science pipeline” while building data communication skills (see Chapter 1.1.2 for more details).
In particular, this book will lean heavily on data visualization. In today’s world, we are bombarded with graphics that attempt to convey ideas. We will explore what makes a good graphic and what the standard ways are to convey relationships with data. You’ll also see the use of visualization to introduce concepts like mean, median, standard deviation, distributions, etc. In general, we’ll use visualization as a way of building almost all of the ideas in this book.
To impart the statistical lessons in this book, we have intentionally minimized the number of mathematical formulas used and instead have focused on developing a conceptual understanding via data visualization, statistical computing, and simulations. We hope this is a more intuitive experience than the way statistics has traditionally been taught in the past and how it is commonly perceived.
Finally, you’ll learn the importance of literate programming. By this we mean you’ll learn how to write code that is useful not just for a computer to execute but also for readers to understand exactly what your analysis is doing and how you did it. This is part of a greater effort to encourage reproducible research (see Chapter 1.1.3 for more details). Hal Abelson coined the phrase that we will follow throughout this book:
“Programs must be written for people to read, and only incidentally for machines to execute.”
We understand that there may be challenging moments as you learn to program. Both of us continue to struggle and find ourselves often using web searches to find answers and reach out to colleagues for help. In the long run though, we all can solve problems faster and more elegantly via programming. We wrote this book as our way to help you get started and you should know that there is a huge community of R users that are always happy to help everyone along as well. This community exists in particular on the internet on various forums and websites such as stackoverflow.com.
1.1.2 Data/science pipeline
You may think of statistics as just being a bunch of numbers. We commonly hear the phrase “statistician” when listening to broadcasts of sporting events. Statistics (in particular, data analysis), in addition to describing numbers like with baseball batting averages, plays a vital role in all of the sciences. You’ll commonly hear the phrase “statistically significant” thrown around in the media. You’ll see articles that say “Science now shows that chocolate is good for you.” Underpinning these claims is data analysis. By the end of this book, you’ll be able to better understand whether these claims should be trusted or whether we should be wary. Inside data analysis are many sub-fields that we will discuss throughout this book (though not necessarily in this order):
- data collection
- data wrangling
- data visualization
- data modeling
- inference
- correlation and regression
- interpretation of results
- data communication/storytelling
These sub-fields are summarized in what Grolemund and Wickham term the “data/science pipeline” in Figure 1.1.
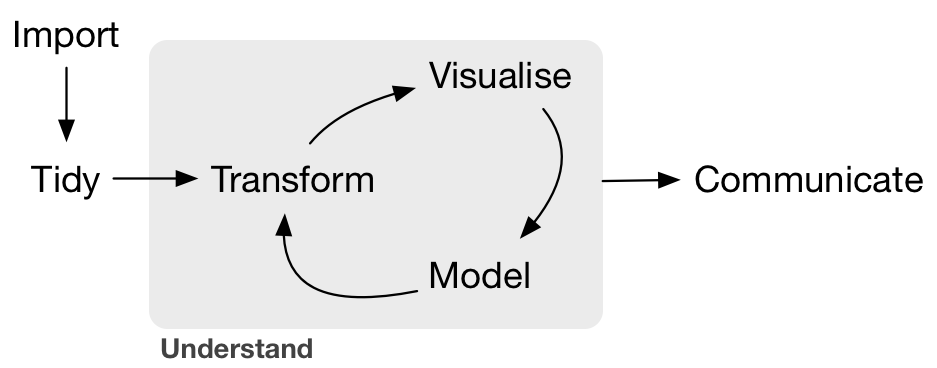
Figure 1.1: Data/Science Pipeline
We will begin by digging into the gray Understand portion of the cycle with data visualization, then with a discussion on what is meant by tidy data and data wrangling, and then conclude by talking about interpreting and discussing the results of our models via Communication. These steps are vital to any statistical analysis. But why should you care about statistics? “Why did they make me take this class?”
There’s a reason so many fields require a statistics course. Scientific knowledge grows through an understanding of statistical significance and data analysis. You needn’t be intimidated by statistics. It’s not the beast that it used to be and, paired with computation, you’ll see how reproducible research in the sciences particularly increases scientific knowledge.
1.1.3 Reproducible research
“The most important tool is the mindset, when starting, that the end product will be reproducible.” – Keith Baggerly
Another goal of this book is to help readers understand the importance of reproducible analyses. The hope is to get readers into the habit of making their analyses reproducible from the very beginning. This means we’ll be trying to help you build new habits. This will take practice and be difficult at times. You’ll see just why it is so important for you to keep track of your code and well-document it to help yourself later and any potential collaborators as well.
Copying and pasting results from one program into a word processor is not the way that efficient and effective scientific research is conducted. It’s much more important for time to be spent on data collection and data analysis and not on copying and pasting plots back and forth across a variety of programs.
In a traditional analyses if an error was made with the original data, we’d need to step through the entire process again: recreate the plots and copy and paste all of the new plots and our statistical analysis into your document. This is error prone and a frustrating use of time. We’ll see how to use R Markdown to get away from this tedious activity so that we can spend more time doing science.
“We are talking about computational reproducibility.” - Yihui Xie
Reproducibility means a lot of things in terms of different scientific fields. Are experiments conducted in a way that another researcher could follow the steps and get similar results? In this book, we will focus on what is known as computational reproducibility. This refers to being able to pass all of one’s data analysis, data-sets, and conclusions to someone else and have them get exactly the same results on their machine. This allows for time to be spent interpreting results and considering assumptions instead of the more error prone way of starting from scratch or following a list of steps that may be different from machine to machine.
1.1.4 Final note for students
At this point, if you are interested in instructor perspectives on this book, ways to contribute and collaborate, or the technical details of this book’s construction and publishing, then continue with the rest of the chapter below. Otherwise, let’s get started with R and RStudio in Chapter 2!
1.2 Introduction for instructors
This book is inspired by three books:
- “Mathematical Statistics with Resampling and R” (Chihara and Hesterberg 2011),
- “OpenIntro: Intro Stat with Randomization and Simulation” (Diez, Barr, and Çetinkaya-Rundel 2014), and
- “R for Data Science” (Grolemund and Wickham 2016).
The first book, while designed for upper-level undergraduates and graduate students, provides an excellent resource on how to use resampling to impart statistical concepts like sampling distributions using computation instead of large-sample approximations and other mathematical formulas. The last two books are free options to learning introductory statistics and data science, providing an alternative to the many traditionally expensive introductory statistics textbooks.
When looking over the large number of introductory statistics textbooks that currently exist, we found that there wasn’t one that incorporated many newly developed R packages directly into the text, in particular the many packages included in the tidyverse collection of packages, such as ggplot2, dplyr, tidyr, and broom. Additionally, there wasn’t an open-source and easily reproducible textbook available that exposed new learners all of three of the learning goals listed at the outset of Chapter 1.1.1.
1.2.1 Who is this book for?
This book is intended for instructors of traditional introductory statistics classes using RStudio, either the desktop or server version, who would like to inject more data science topics into their syllabus. We assume that students taking the class will have no prior algebra, calculus, nor programming/coding experience.
Here are some principles and beliefs we kept in mind while writing this text. If you agree with them, this might be the book for you.
- Blur the lines between lecture and lab
- With increased availability and accessibility of laptops and open-source non-proprietary statistical software, the strict dichotomy between lab and lecture can be loosened.
- It’s much harder for students to understand the importance of using software if they only use it once a week or less. They forget the syntax in much the same way someone learning a foreign language forgets the rules. Frequent reinforcement is key.
- Focus on the entire data/science research pipeline
- We believe that the entirety of Grolemund and Wickham’s data/science pipeline should be taught.
- We believe in “minimizing prerequisites to research”: students should be answering questions with data as soon as possible.
- It’s all about the data
- We leverage R packages for rich, real, and realistic data-sets that at the same time are easy-to-load into R, such as the
nycflights13andfivethirtyeightpackages. - We believe that data visualization is a gateway drug for statistics and that the Grammar of Graphics as implemented in the
ggplot2package is the best way to impart such lessons. However, we often hear: “You can’t teachggplot2for data visualization in intro stats!” We, like David Robinson, are much more optimistic. dplyrhas made data wrangling much more accessible to novices, and hence much more interesting data-sets can be explored.
- We leverage R packages for rich, real, and realistic data-sets that at the same time are easy-to-load into R, such as the
- Use simulation/resampling to introduce statistical inference, not probability/mathematical formulas
- Instead of using formulas, large-sample approximations, and probability tables, we teach statistical concepts using resampling-based inference.
- This allows for a de-emphasis of traditional probability topics, freeing up room in the syllabus for other topics.
- Don’t fence off students from the computation pool, throw them in!
- Computing skills are essential to working with data in the 21st century. Given this fact, we feel that to shield students from computing is to ultimately do them a disservice.
- We are not teaching a course on coding/programming per se, but rather just enough of the computational and algorithmic thinking necessary for data analysis.
- Complete reproducibility and customizability
- We are frustrated when textbooks give examples, but not the source code and the data itself. We give you the source code for all examples as well as the whole book!
- Ultimately the best textbook is one you’ve written yourself. You know best your audience, their background, and their priorities. You know best your own style and the types of examples and problems you like best. Customization is the ultimate end. For more about how to make this book your own, see About this Book.
1.3 Connect and contribute
If you would like to connect with ModernDive, check out the following links:
- If you would like to receive periodic updates about ModernDive (roughly every 3 months), please sign up for our mailing list.
- Contact Albert at albert@moderndive.com and Chester chester@moderndive.com
- We’re on Twitter at ModernDive.
If you would like to contribute to ModernDive, there are many ways! Let’s all work together to make this book as great as possible for as many students and instructors as possible!
- Please let us know if you find any errors, typos, or areas from improvement on our GitHub issues page.
- If you are familiar with GitHub and would like to contribute more, please see Section 1.4 below.
The authors would like to thank Nina Sonneborn, Kristin Bott, and the participants of our USCOTS 2017 workshop for their feedback and suggestions. A special thanks goes to Prof. Yana Weinstein, cognitive psychological scientist and co-founder of The Learning Scientists for her extensive contributions.
1.4 About this book
This book was written using RStudio’s bookdown package by Yihui Xie (Xie 2017). This package simplifies the publishing of books by having all content written in R Markdown. The bookdown/R Markdown source code for all versions of ModernDive is available on GitHub:
- Latest published version The most up-to-date release:
- Version 0.2.0 released on August 02, 2017 (source code).
- Available at ModernDive.com
- Development version The working copy of the next version which is currently being edited:
- Preview of book available at https://ismayc.github.io/moderndiver-book/
- Source code: Available on ModernDive’s GitHub repository page
- Previous versions Older versions that may be out of date:
- Version 0.1.3 released on February 09, 2017 (source code)
- Version 0.1.2 released on January 22, 2017 (source code)
Could this be a new paradigm for textbooks? Instead of the traditional model of textbook companies publishing updated editions of the textbook every few years, we apply a software design influenced model of publishing more easily updated versions. We can then leverage open-source communities of instructors and developers for ideas, tools, resources, and feedback. As such, we welcome your pull requests.
Finally, feel free to modify the book as you wish for your own needs, but please list the authors at the top of index.Rmd as “Chester Ismay, Albert Y. Kim, and YOU!”
1.4.1 Colophon
- ModernDive is written using the CC0 1.0 Universal License; more information on this license is available here.
- ModernDive uses the following versions of R packages (and their dependent packages):
| package | * | version | date | source |
|---|---|---|---|---|
| assertthat | 0.2.0 | 2017-04-11 | CRAN (R 3.3.2) | |
| backports | 1.1.0 | 2017-05-22 | CRAN (R 3.3.2) | |
| base64enc | 0.1-3 | 2015-07-28 | CRAN (R 3.3.0) | |
| BH | 1.62.0-1 | 2016-11-19 | CRAN (R 3.3.2) | |
| bindr | 0.1 | 2016-11-13 | CRAN (R 3.3.2) | |
| bindrcpp | * | 0.2 | 2017-06-17 | CRAN (R 3.3.2) |
| bitops | 1.0-6 | 2013-08-17 | CRAN (R 3.3.0) | |
| caTools | 1.17.1 | 2014-09-10 | CRAN (R 3.3.0) | |
| colorspace | 1.3-2 | 2016-12-14 | CRAN (R 3.3.2) | |
| dichromat | 2.0-0 | 2013-01-24 | CRAN (R 3.3.0) | |
| digest | 0.6.12 | 2017-01-27 | CRAN (R 3.3.2) | |
| dplyr | * | 0.7.2 | 2017-07-20 | CRAN (R 3.3.2) |
| dygraphs | * | 1.1.1.4 | 2017-01-04 | CRAN (R 3.3.2) |
| evaluate | 0.10.1 | 2017-06-24 | CRAN (R 3.3.2) | |
| fivethirtyeight | 0.3.0 | 2017-08-08 | CRAN (R 3.3.2) | |
| gapminder | * | 0.2.0 | 2015-12-31 | CRAN (R 3.3.0) |
| ggdendro | 0.1-20 | 2016-04-27 | CRAN (R 3.3.0) | |
| ggformula | * | 0.5 | 2017-07-24 | CRAN (R 3.3.2) |
| ggplot2 | * | 2.2.1 | 2016-12-30 | CRAN (R 3.3.2) |
| ggplot2movies | * | 0.0.1 | 2015-08-25 | CRAN (R 3.3.0) |
| glue | 1.1.1 | 2017-06-21 | CRAN (R 3.3.2) | |
| graphics | * | 3.3.1 | 2016-06-24 | local |
| grDevices | * | 3.3.1 | 2016-06-24 | local |
| grid | 3.3.1 | 2016-06-24 | local | |
| gridExtra | 2.2.1 | 2016-02-29 | CRAN (R 3.3.0) | |
| gtable | 0.2.0 | 2016-02-26 | CRAN (R 3.3.0) | |
| highr | 0.6 | 2016-05-09 | CRAN (R 3.3.0) | |
| hms | 0.3 | 2016-11-22 | CRAN (R 3.3.2) | |
| htmltools | 0.3.6 | 2017-04-28 | CRAN (R 3.3.2) | |
| htmlwidgets | 0.9 | 2017-07-10 | CRAN (R 3.3.2) | |
| jsonlite | 1.5 | 2017-06-01 | CRAN (R 3.3.2) | |
| knitr | * | 1.17 | 2017-08-10 | CRAN (R 3.3.2) |
| labeling | 0.3 | 2014-08-23 | CRAN (R 3.3.0) | |
| lattice | * | 0.20-35 | 2017-03-25 | CRAN (R 3.3.2) |
| latticeExtra | 0.6-28 | 2016-02-09 | CRAN (R 3.3.0) | |
| lazyeval | 0.2.0 | 2016-06-12 | CRAN (R 3.3.0) | |
| magrittr | 1.5 | 2014-11-22 | CRAN (R 3.3.0) | |
| markdown | 0.8 | 2017-04-20 | CRAN (R 3.3.2) | |
| MASS | 7.3-47 | 2017-04-21 | CRAN (R 3.3.2) | |
| Matrix | 1.2-11 | 2017-08-16 | CRAN (R 3.3.2) | |
| methods | * | 3.3.1 | 2016-06-24 | local |
| mime | 0.5 | 2016-07-07 | CRAN (R 3.3.0) | |
| mosaic | * | 1.0.0 | 2017-07-26 | CRAN (R 3.3.2) |
| mosaicCore | 0.2.0 | 2017-07-24 | CRAN (R 3.3.2) | |
| mosaicData | * | 0.14.0 | 2016-06-17 | CRAN (R 3.3.0) |
| munsell | 0.4.3 | 2016-02-13 | CRAN (R 3.3.0) | |
| nycflights13 | * | 0.2.2 | 2017-01-27 | CRAN (R 3.3.2) |
| okcupiddata | * | 0.1.0 | 2016-08-19 | CRAN (R 3.3.0) |
| pkgconfig | 2.0.1 | 2017-03-21 | CRAN (R 3.3.2) | |
| plogr | 0.1-1 | 2016-09-24 | CRAN (R 3.3.0) | |
| plyr | 1.8.4 | 2016-06-08 | CRAN (R 3.3.0) | |
| purrr | 0.2.3 | 2017-08-02 | CRAN (R 3.3.2) | |
| R6 | 2.2.2 | 2017-06-17 | CRAN (R 3.3.2) | |
| RColorBrewer | 1.1-2 | 2014-12-07 | CRAN (R 3.3.0) | |
| Rcpp | 0.12.12 | 2017-07-15 | CRAN (R 3.3.2) | |
| readr | * | 1.1.1 | 2017-05-16 | CRAN (R 3.3.2) |
| reshape2 | 1.4.2 | 2016-10-22 | CRAN (R 3.3.0) | |
| rlang | 0.1.2 | 2017-08-09 | CRAN (R 3.3.2) | |
| rmarkdown | 1.6 | 2017-06-15 | CRAN (R 3.3.2) | |
| rprojroot | 1.2 | 2017-01-16 | CRAN (R 3.3.2) | |
| scales | 0.4.1 | 2016-11-09 | CRAN (R 3.3.2) | |
| splines | 3.3.1 | 2016-06-24 | local | |
| stats | * | 3.3.1 | 2016-06-24 | local |
| stringi | 1.1.5 | 2017-04-07 | CRAN (R 3.3.2) | |
| stringr | 1.2.0 | 2017-02-18 | CRAN (R 3.3.2) | |
| tibble | 1.3.4 | 2017-08-22 | CRAN (R 3.3.1) | |
| tidyr | * | 0.7.0 | 2017-08-16 | CRAN (R 3.3.2) |
| tidyselect | 0.1.1 | 2017-07-24 | CRAN (R 3.3.2) | |
| tools | 3.3.1 | 2016-06-24 | local | |
| utils | * | 3.3.1 | 2016-06-24 | local |
| xts | 0.10-0 | 2017-07-07 | CRAN (R 3.3.2) | |
| yaml | 2.1.14 | 2016-11-12 | CRAN (R 3.3.2) | |
| zoo | 1.8-0 | 2017-04-12 | CRAN (R 3.3.2) |