6 Efficient data carpentry
There are many words for data processing. You can clean, hack, manipulate, munge, refine and tidy your dataset, ready for the next stage, typically modelling and visualisation. Each word says something about perceptions towards the process: data processing is often seen as dirty work, an unpleasant necessity that must be endured before the real, fun and important work begins. This perception is wrong. Getting your data ‘ship shape’ is a respectable and in some cases vital skill. For this reason we use the more admirable term data carpentry.
This metaphor is not accidental. Carpentry is the process of taking rough pieces of wood and working with care, diligence and precision to create a finished product. A carpenter does not hack at the wood at random. He or she will inspect the raw material and select the right tool for the job. In the same way data carpentry is the process of taking rough, raw and to some extent randomly arranged input data and creating neatly organised and tidy data. Learning the skill of data carpentry early will yield benefits for years to come. “Give me six hours to chop down a tree and I will spend the first four sharpening the axe” as the saying goes.
Data processing is a critical stage in any project involving any datasets from external sources, i.e. most real world applications. In the same way that technical debt, discussed in Chapter 5, can cripple your workflow, working with messy data can lead to project management hell.
Fortunately, done efficiently, at the outset of your project (rather than half way through, when it may be too late), and using appropriate tools, this data processing stage can be highly rewarding. More importantly from an efficiency perspective, working with clean data will be beneficial for every subsequent stage of your R project. So, for data intensive applications, this could be the most important chapter of book. In it we cover the following topics:
- Tidying data with tidyr
- Processing data with dplyr
- Working with databases
- Data processing with data.table
Prerequisites
This chapter relies on a number of packages for data cleaning and processing - test they are installed on your computer and load them with:
library("tibble")
library("tidyr")
library("stringr")
library("readr")
library("dplyr")
library("data.table")RSQLite and ggmap are also used in a couple of examples, although they are not central to the chapter’s content.
6.1 Top 5 tips for efficient data carpentry
- Time spent preparing your data at the beginning can save hours of frustration in the long run.
- ‘Tidy data’ provides a concept for organising data and the package tidyr provides some functions for this work.
- The
data_frameclass defined by the tibble package makes datasets efficient to print and easy to work with. - dplyr provides fast and intuitive data processing functions; data.table has unmatched speed for some data processing application.
- The
%>%‘pipe’ operator can help clarify complex data processing workflows.
6.2 Efficient data frames with tibble
tibble is a package that defines a new data frame class for R, the tbl_df. These ‘tibble diffs’ (as their inventor suggests they should be pronounced) are like the base class data.frame, but with more user friendly printing, subsetting, and factor handling.
A tibble data frame is an S3 object with three classes, tbl_df, tbl, and data.frame. Since the object has the data.frame tag, this means that if a tbl_df or tbl method isn’t available, the object will be passed on to the appropriate data.frame function.
To create a tibble data frame, we use tibble function
library("tibble")
tibble(x = 1:3, y = c("A", "B", "C"))
#> # A tibble: 3 × 2
#> x y
#> <int> <chr>
#> 1 1 A
#> 2 2 B
#> 3 3 CThe example above illustrates the main differences between the tibble and base R approach to data frames:
- When printed, the tibble diff reports the class of each variable.
data.frameobjects do not. - Character vectors are not coerced into factors when they are incorporated into a
tbl_df, as can be seen by the<chr>heading between the variable name and the second column. By contrast,data.frame()coerces characters into factors which can cause problems further down the line. - When printing a tibble diff to screen, only the first ten rows are displayed. The number columns printed depends on the window size.
Other differences can be found in the associated help page - help("tibble").
You can create a tibble data frame row-by-row using the tribble function.
Exercise
Create the following data frame
df_base = data.frame(colA = "A")Try and guess the output of the following commands
print(df_base)
df_base$colA
df_base$col
df_base$colBNow create a tibble data frame and repeat the above commands.
6.3 Tidying data with tidyr and regular expressions
A key skill in data analysis is understanding the structure of datasets and being able to ‘reshape’ them. This is important from a workflow efficiency perspective: more than half of a data analyst’s time can be spent re-formatting datasets (H. Wickham 2014b), so getting it into a suitable form early could save hours in the future. Converting data into a ‘tidy’ form is also advantageous from a computational efficiency perspective: it is usually faster to run analysis and plotting commands on tidy data.
Data tidying includes data cleaning and data reshaping. Data cleaning is the process of re-formatting and labelling messy data. Packages including stringi and stringr can help update messy character strings using regular expressions; assertive and assertr packages can perform diagnostic checks for data integrity at the outset of a data analysis project. A common data cleaning task is the conversion of non-standard text strings into date formats as described in the lubridate vignette (see vignette("lubridate")). Tidying is a broader concept, however, and also includes re-shaping data so that it is in a form more conducive to data analysis and modelling. The process of reshaping is illustrated by Tables 6.1 and 6.2, provided by H. Wickham (2014b) and loaded using the code below:
library("efficient")
data(pew) # see ?pew - dataset from the efficient package
pew[1:3, 1:4] # take a look at the data
#> # A tibble: 3 × 4
#> religion `<$10k` `$10--20k` `$20--30k`
#> <chr> <int> <int> <int>
#> 1 Agnostic 27 34 60
#> 2 Atheist 12 27 37
#> 3 Buddhist 27 21 30Tables 6.1 and 6.2 show a subset of the ‘wide’ pew and ‘long’ (tidy) pewt datasets, respectively. They have different dimensions, but they contain precisely the same information. Column names in the ‘wide’ form in Table 6.1 became a new variable in the ‘long’ form in Table 6.2. According to the concept of ‘tidy data’, the long form is correct. Note that ‘correct’ here is used in the context of data analysis and graphical visualisation. Because R is a vector-based language, tidy data also has efficiency advantaged: it’s often faster to operate on few long columns than many short ones. Furthermore the powerful and efficient packages dplyr and ggplot2 were designed around tidy data. Wide data is common, however, can be space efficient and is common for presentation in summary tables, so it’s useful to be able to transfer between wide (or otherwise ‘untidy’) and tidy formats.
Tidy data has the following characteristics (H. Wickham 2014b):
- Each variable forms a column.
- Each observation forms a row.
- Each type of observational unit forms a table.
Because there is only one observational unit in the example (religions), it can be described in a single table. Large and complex datasets are usually represented by multiple tables, with unique identifiers or ‘keys’ to join them together (Codd 1979).
Two common operations facilitated by tidyr are gathering and splitting columns.
6.3.1 Make wide tables long with gather()
Gathering means making ‘wide’ tables ‘long’, by converting column names to a new variable. This is done with the function gather() (the inverse of which is spread()). The process is illustrated in Tables 6.1 and 6.2 respectively. The code that performs this operation is provided in the code block below. This converts a table with 18 rows and 10 columns into a tidy dataset with 162 rows and 3 columns (compare the output with the output of pew, shown above):
dim(pew)
#> [1] 18 10
pewt = gather(data = pew, key = Income, value = Count, -religion)
dim(pewt)
#> [1] 162 3
pewt[c(1:3, 50),]
#> # A tibble: 4 × 3
#> religion Income Count
#> <chr> <chr> <int>
#> 1 Agnostic <$10k 27
#> 2 Atheist <$10k 12
#> 3 Buddhist <$10k 27
#> 4 Orthodox $20--30k 23The above code demonstrates the three arguments that gather() requires:
data, a data frame in which column names will become row values.key, the name of the categorical variable into which the column names in the original datasets are converted .value, the name of cell value columns.
As with other functions in the ‘tidyverse’, all arguments are given using bare names, rather than character strings. Arguments 2 and 3 can be specified by the user, and have no relation to the existing data. Furthermore an additional argument, set as -religion, was used to remove the religion variable from the gathering, ensuring that the values in this columns are the first column in the output. If no -religion argument were specified, all column names are used in the key, meaning the results simply report all 180 column/value pairs resulting from the input dataset with 10 columns by 18 rows:
gather(pew)
#> # A tibble: 180 × 2
#> key value
#> <chr> <chr>
#> 1 religion Agnostic
#> 2 religion Atheist
#> 3 religion Buddhist
#> 4 religion Catholic
#> # ... with 176 more rows| religion | <$10k | $10–20k | $20–30k |
|---|---|---|---|
| Agnostic | 27 | 34 | 60 |
| Atheist | 12 | 27 | 37 |
| Buddhist | 27 | 21 | 30 |
| religion | Income | Count |
|---|---|---|
| Agnostic | <$10k | 27 |
| Atheist | <$10k | 12 |
| Buddhist | <$10k | 27 |
| Agnostic | $10–20k | 34 |
| Atheist | $10–20k | 27 |
| Buddhist | $10–20k | 21 |
| Agnostic | $20–30k | 60 |
| Atheist | $20–30k | 37 |
| Buddhist | $20–30k | 30 |
6.3.2 Split joint variables with separate()
Splitting means taking a variable that is really two variables combined and creating two separate columns from it. A classic example is age-sex variables (e.g. m0-10 and f0-15 to represent males and females in the 0 to 10 age band). Splitting such variables can be done with the separate() function, as illustrated in the Tables 6.3 and 6.4 and in the code chunk below. See ?separate for more information on this function.
agesex = c("m0-10", "f0-10") # create compound variable
n = c(3, 5) # create a value for each observation
agesex_df = tibble(agesex, n) # create a data frame
separate(agesex_df, col = agesex, into = c("age", "sex"))
#> # A tibble: 2 × 3
#> age sex n
#> * <chr> <chr> <dbl>
#> 1 m0 10 3
#> 2 f0 10 5| agesex | n |
|---|---|
| m0-10 | 3 |
| f0-10 | 5 |
| sex | age | n |
|---|---|---|
| m | 0-10 | 3 |
| f | 0-10 | 5 |
6.3.3 Other tidyr functions
There are other tidying operations that tidyr can perform, as described in the package’s vignette (vignette("tidy-data")). The wider issue of manipulation is a large topic with major potential implications for efficiency (Spector 2008) and this section only covers some of the key operations. More important is understanding the principles behind converting messy data into standard output forms.
These same principles can also be applied to the representation of model results. The broom package provides a standard output format for model results, easing interpretation (see the broom vignette). The function broom::tidy() can be applied to a wide range of model objects and return the model’s output in a standardized data frame output.
Usually it is more efficient to use the non-standard evaluation version of variable names, as these can be auto completed by RStudio. In some cases you may want to use standard evaluation and refer to variable names using quote marks. To do this, affix _ can be added to dplyr and tidyr function names to allow the use of standard evaluation. Thus the standard evaluation version of separate(agesex_df, agesex, c("sex", "age"), 1) is separate_(agesex_df, "agesex", c("sex", "age"), 1).
6.3.4 Regular expressions
Regular expressions (commonly known as regex) is a language for describing and manipulating text strings. There are books on the subject, and several good tutorials on regex in R (e.g. Sanchez 2013), so we’ll just scratch the surface of the topic, and provide a taster of what is possible. Regex is a deep topic. However, knowing the basics can save a huge amount of time from a data tidying perspective, by automating the cleaning of messy strings.
In this section we teach both stringr and base R ways of doing pattern matching. The former provides easy to remember function names and consistency. The latter is useful to know as you’ll find lots of base R regex code in other people code as stringr is relatively new and not installed by default. The foundational regex operation is to detect whether or not a particular text string exists in an element or not which is done with grepl() and str_detect() in base R and stringr respectively:
library("stringr")
x = c("Hi I'm Robin.", "DoB 1985")
grepl(pattern = "9", x = x)
#> [1] FALSE TRUE
str_detect(string = x, pattern = "9")
#> [1] FALSE TRUE
Note: stringr does not include a direct replacement for grep(). You can use which(str_detect()) instead.
Notice that str_detect() begins with str_. This is a common feature of stringr functions: they all do. This can be efficient because if you want to do some regex work, you just need to type str_ and then hit Tab to see a list of all the options. The various base R regex function names, by contrast, are to remember, including regmatches(), strsplit() and gsub(). The stringr equivalents have more intuitive names that relate to the intention of the functions: str_match_all(), str_split() and str_replace_all(), respectively.
There is much else to say on the topic but rather than repeat what has been said elsewhere, we feel it is more efficient to direct the interested reader towards existing excellent resources for learning regex in R. We recommend reading, in order:
- The Strings chapter of Grolemund and Wickham (2016).
- The stringr vignette (
vignette("stringr")). - A detailed tutorial on regex in base R (Sanchez 2013).
- For more advanced topics, reading the documentation of and online articles about the stringi package, on which stringr depends.
Exercises
What are the three criteria of tidy data?
Load and look at subsets of these datasets. The first is the
pewdatasets we’ve been using already. The second reports the points that define, roughly, the geographical boundaries of different London boroughs. What is ‘untidy’ about each?
head(pew, 10)
#> # A tibble: 10 × 10
#> religion `<$10k` `$10--20k` `$20--30k` `$30--40k` `$40--50k` `$50--75k`
#> <chr> <int> <int> <int> <int> <int> <int>
#> 1 Agnostic 27 34 60 81 76 137
#> 2 Atheist 12 27 37 52 35 70
#> 3 Buddhist 27 21 30 34 33 58
#> 4 Catholic 418 617 732 670 638 1116
#> # ... with 6 more rows, and 3 more variables: `$75--100k` <int>,
#> # `$100--150k` <int>, `>150k` <int>
data(lnd_geo_df)
head(lnd_geo_df, 10)
#> name_date population x y
#> 1 Bromley-2001 295535 544362 172379
#> 2 Bromley-2001 295535 549546 169911
#> 3 Bromley-2001 295535 539596 160796
#> 4 Bromley-2001 295535 533693 170730
#> 5 Bromley-2001 295535 533718 170814
#> 6 Bromley-2001 295535 534004 171442
#> 7 Bromley-2001 295535 541105 173356
#> 8 Bromley-2001 295535 544362 172379
#> 9 Richmond upon Thames-2001 172330 523605 176321
#> 10 Richmond upon Thames-2001 172330 521455 172362Convert each of the above datasets into tidy form.
Consider the following string of phone numbers and fruits from (Wickham 2010):
strings = c(" 219 733 8965", "329-293-8753 ", "banana", "595 794 7569",
"387 287 6718", "apple", "233.398.9187 ", "482 952 3315", "239 923 8115",
"842 566 4692", "Work: 579-499-7527", "$1000", "Home: 543.355.3679")Write functions in stringr and base R that return:
- A logical vector reporting whether or not each string contains a number.
- Complete words only, without extraneous non-letter characters.
str_detect(string = strings, pattern = "[0-9]")
#> [1] TRUE TRUE FALSE TRUE TRUE FALSE TRUE TRUE TRUE TRUE TRUE
#> [12] TRUE TRUE
str_extract(strings, pattern = "[A-z]+")
#> [1] NA NA "banana" NA NA "apple" NA
#> [8] NA NA NA "Work" NA "Home"6.4 Efficient data processing with dplyr
After tidying your data, the next stage is generally data processing. This includes the creation of new data, for example a new column that is some function of existing columns, or data analysis, the process of asking directed questions of the data and exporting the results in a user-readable form.
Following the advice in Section 4.4, we have carefully selected an appropriate package for these tasks: dplyr, which roughly means ‘data frame pliers’. dplyr has a number of advantages over base R and data.table approaches to data processing:
- dplyr is fast to run (due to its C++ backend) and intuitive to type
- dplyr works well with tidy data, as described above
- dplyr works well with databases, providing efficiency gains on large datasets
Furthermore, dplyr is efficient to learn (see Chapter 10). It has small number of intuitively named functions, or ‘verbs’. These were partly inspired by SQL, one of the longest established languages for data analysis, which combines multiple simple functions (such as SELECT and WHERE, roughly analogous to dplyr::select() and dplyr::filter()) to create powerful analysis workflows. Likewise, dplyr functions were designed to be used together to solve a wide range of data processing challenges (see Table 6.5).
| dplyr function(s) | Description | Base R functions |
|---|---|---|
| filter(), slice() | Subset rows by attribute (filter) or position (slice) | subset(), [ |
| arrange() | Return data ordered by variable(s) | order() |
| select() | Subset columns | subset(), [, [[ |
| rename() | Rename columns | colnames() |
| distinct() | Return unique rows | !duplicated() |
| mutate() | Create new variables (transmute drops existing variables) | transform(), [[ |
| summarise() | Collapse data into a single row | aggregate(), tapply() |
| sample_n() | Return a sample of the data | sample() |
Unlike the base R analogues, dplyr‘s data processing functions work in a consistent way. Each function takes a data frame object as its first argument and results in another data frame. Variables can be called directly without using the $ operator. dplyr was designed to be used with the ’pipe’ operator %>% provided by the magrittr package, allowing each data processing stage to be represented as a new line. This is illustrated in the code chunk below, which loads a tidy country level dataset of greenhouse gas emissions from the efficient package, and then identifies the countries with the greatest absolute growth in emissions from 1971 to 2012:
library("dplyr")
data("ghg_ems", package = "efficient")
top_table =
ghg_ems %>%
filter(!grepl("World|Europe", Country)) %>%
group_by(Country) %>%
summarise(Mean = mean(Transportation),
Growth = diff(range(Transportation))) %>%
top_n(3, Growth) %>%
arrange(desc(Growth))The results, illustrated in table 6.6, show that the USA has the highest growth and average emissions from the transport sector, followed closely by China. The aim of this code chunk is not for you to somehow read it and understand it: it is to provide a taster of dplyr’s unique syntax, which is described in more detail throughout the duration of this section.
| Country | Mean | Growth |
|---|---|---|
| United States | 1462 | 709 |
| China | 214 | 656 |
| India | 85 | 170 |
Building on the ‘learning by doing’ ethic, the remainder of this section works through these functions to process and begin to analyse a dataset on economic equality provided by the World Bank. The input dataset can be loaded as follows:
# Load global inequality data
data(wb_ineq)dplyr is a large package and can be seen as a language in its own right. Following the ‘walk before you run’ principle, we’ll start simple, by filtering and aggregating rows.
6.4.1 Renaming columns
Renaming data columns is a common task that can make writing code faster by using short, intuitive names. The dplyr function rename() makes this easy.
Note in this code block the variable name is surrounded by back-quotes (`). This allows R to refer to column names that are non-standard. Note also the syntax: rename takes the data frame as the first object and then creates new variables by specifying new_variable_name = original_name.
library("dplyr")
wb_ineq = rename(wb_ineq, code = `Country Code`)To rename multiple columns the variable names are simply separated by commas. The base R and dplyr way of doing this is illustrated on an older version of the dataset (not run) to illustrate how long, clunky and inefficient names can be converted into short and lean ones.
# The dplyr way (rename two variables)
wb_ineq = rename(wb_ineq,
top10 = `Income share held by highest 10% [SI.DST.10TH.10]`,
bot10 = `Income share held by lowest 10% [SI.DST.FRST.10]`)
# The base R way (rename five variables)
names(wb_ineq)[5:9] = c("top10", "bot10", "gini", "b40_cons", "gdp_percap")6.4.2 Changing column classes
The class of R objects is critical to performance. If a class is incorrectly specified (e.g. if numbers are treated as factors or characters) this will lead to incorrect results. The class of all columns in a data frame can be queried using the function str() (short for display the structure of an object), as illustrated below, with the inequality data loaded previously.15
vapply(wb_ineq, class, character(1))
#> Country code Year Year Code top10 bot10
#> "character" "character" "integer" "character" "numeric" "numeric"
#> gini b40_cons gdp_percap
#> "numeric" "numeric" "numeric"This shows that although we loaded the data correctly all columns are seen by R as characters. This means we cannot perform numerical calculations on the dataset: mean(wb_ineq$gini) fails.
Visual inspection of the data (e.g. via View(wb_ineq)) clearly shows that all columns except for 1 to 4 (Country, Country Code, Year and Year Code) should be numeric. We can re-assign the classes of the numeric variables one-by one:
wb_ineq$gini = as.numeric(wb_ineq$gini)
mean(wb_ineq$gini, na.rm = TRUE) # now the mean is calculated
#> [1] 40.5However the purpose of programming languages is to automate tasks and reduce typing. The following code chunk re-classifies all of the numeric variables using data.matrix(), which converts the data frame to a numeric matrix:
cols_to_change= 5:9 # column ids to change
wb_ineq[cols_to_change] = data.matrix(wb_ineq[cols_to_change])
vapply(wb_ineq, class, character(1))
#> Country code Year Year Code top10 bot10
#> "character" "character" "integer" "character" "numeric" "numeric"
#> gini b40_cons gdp_percap
#> "numeric" "numeric" "numeric"As is so often the case with R, there are many ways to solve the problem. Below is a one-liner using unlist() which converts list objects into vectors:
wb_ineq[cols_to_change] = as.numeric(unlist(wb_ineq[cols_to_change]))Another one-liner to achieve the same result uses dplyr’s mutate_each function:
wb_ineq = mutate_each(wb_ineq, "as.numeric", cols_to_change)As with other operations there are other ways of achieving the same result in R, including the use of loops via apply() and for(). These are shown in the chapter’s source code.
6.4.3 Filtering rows
dplyr offers an alternative way of filtering data, using filter().
# Base R: wb_ineq[wb_ineq$Country == "Australia",]
aus2 = filter(wb_ineq, Country == "Australia")filter() is slightly more flexible than [: filter(wb_ineq, code == "AUS", Year == 1974) works as well as filter(wb_ineq, code == "AUS" & Year == 1974), and takes any number of conditions (see ?filter). filter() is slightly faster than base R.16 By avoiding the $ symbol, dplyr makes subsetting code concise and consistent with other dplyr functions. The first argument is a data frame and subsequent raw variable names can be treated as vector objects: a defining feature of dplyr. In the next section we’ll learn how this syntax can be used alongside the %>% ‘pipe’ command to write clear data manipulation commands.
There are dplyr equivalents of many base R functions but these usually work slightly differently. The dplyr equivalent of aggregate, for example is to use the grouping function group_by in combination with the general purpose function summarise (not to be confused with summary in base R), as we shall see in Section 6.4.5.
6.4.4 Chaining operations
Another interesting feature of dplyr is its ability to chain operations together. This overcomes one of the aesthetic issues with R code: you can end-up with very long commands with many functions nested inside each other to answer relatively simple questions. Combined with the group_by() function, pipes can help condense thousands of lines of data into something human readable. Here’s how you could use the chains to summarize average Gini indexes per decade, for example:
wb_ineq %>%
select(Year, gini) %>%
mutate(decade = floor(Year / 10) * 10) %>%
group_by(decade) %>%
summarise(mean(gini, na.rm = TRUE))
#> # A tibble: 6 × 2
#> decade `mean(gini, na.rm = TRUE)`
#> <dbl> <dbl>
#> 1 1970 40.1
#> 2 1980 37.8
#> 3 1990 42.0
#> 4 2000 40.5
#> # ... with 2 more rowsOften the best way to learn is to try and break something, so try running the above commands with different dplyr verbs. By way of explanation, this is what happened:
- Only the columns
Yearandginiwere selected, usingselect(). - A new variable,
decadewas created, only the decade figures (e.g. 1989 becomes 1980). - This new variable was used to group rows in the data frame with the same decade.
- The mean value per decade was calculated, illustrating how average income inequality was greatest in 1992 but has since decreased slightly.
Let’s ask another question to see how dplyr chaining workflow can be used to answer questions interactively: What the 5 most unequal years for countries containing the letter g? Here’s how chains can help organise the analysis needed to answer this question step-by-step:
wb_ineq %>%
filter(grepl("g", Country)) %>%
group_by(Year) %>%
summarise(gini = mean(gini, na.rm = TRUE)) %>%
arrange(desc(gini)) %>%
top_n(n = 5)
#> Selecting by gini
#> # A tibble: 5 × 2
#> Year gini
#> <int> <dbl>
#> 1 1980 46.9
#> 2 1993 46.0
#> 3 2013 44.5
#> 4 1981 43.6
#> # ... with 1 more rowsThe above function consists of 6 stages, each of which corresponds to a new line and dplyr function:
- Filter-out the countries we’re interested in (any selection criteria could be used in place of
grepl("g", Country)). - Group the output by year.
- Summarise, for each year, the mean Gini index.
- Arrange the results by average Gini index
- Select only the top 5 most unequal years.
To see why this method is preferable to the nested function approach, take a look at the latter. Even after indenting properly it looks terrible and is almost impossible to understand!
top_n(
arrange(
summarise(
group_by(
filter(wb_ineq, grepl("g", Country)),
Year),
gini = mean(gini, na.rm = TRUE)),
desc(gini)),
n = 5)This section has provided only a taster of what is possible dplyr and why it makes sense from code writing and computational efficiency perspectives. For a more detailed account of data processing with R using this approach we recommend R for Data Science (Grolemund and Wickham 2016).
Exercises
- Try running each of the chaining examples above line-by-line, so the first two entries for the first example would look like this:
wb_ineq
#> # A tibble: 6,925 × 9
#> Country code Year `Year Code` top10 bot10 gini b40_cons
#> <chr> <chr> <int> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 Afghanistan AFG 1974 YR1974 NA NA NA NA
#> 2 Afghanistan AFG 1975 YR1975 NA NA NA NA
#> 3 Afghanistan AFG 1976 YR1976 NA NA NA NA
#> 4 Afghanistan AFG 1977 YR1977 NA NA NA NA
#> # ... with 6,921 more rows, and 1 more variables: gdp_percap <dbl>followed by:
wb_ineq %>%
select(Year, gini)
#> # A tibble: 6,925 × 2
#> Year gini
#> <int> <dbl>
#> 1 1974 NA
#> 2 1975 NA
#> 3 1976 NA
#> 4 1977 NA
#> # ... with 6,921 more rowsExplain in your own words what changes each time.
- Use chained dplyr functions to answer the following question: In which year did countries without and ‘a’ in their name have the lowest level of inequality?
6.4.5 Data aggregation
Data aggregation involves creating summaries of data based on a grouping variable, in a process that has been referred to as ‘split-apply-combine’. The end result usually has the same number of rows as there are groups. Because aggregation is a way of condensing datasets it can be a very useful technique for making sense of large datasets. The following code finds the number of unique countries (country being the grouping variable) from the ghg_ems dataset stored in the efficient package.
# data available online, from github.com/csgillespie/efficient_pkg
data(ghg_ems, package = "efficient")
names(ghg_ems)
#> [1] "Country" "Year" "Electricity" "Manufacturing"
#> [5] "Transportation" "Other" "Fugitive"
nrow(ghg_ems)
#> [1] 7896
length(unique(ghg_ems$Country))
#> [1] 188Note that while there are almost \(8000\) rows, there are fewer than 200 countries: factors would have been a more space efficient way of storing the countries data.
To aggregate the dataset using dplyr package, you divide the task in two: to group the dataset first and then to summarise, as illustrated below.17
library("dplyr")
group_by(ghg_ems, Country) %>%
summarise(mean_eco2 = mean(Electricity, na.rm = TRUE))
#> # A tibble: 188 × 2
#> Country mean_eco2
#> <chr> <dbl>
#> 1 Afghanistan NaN
#> 2 Albania 0.641
#> 3 Algeria 23.015
#> 4 Angola 0.791
#> # ... with 184 more rows
The example above relates to a wider programming: how much work should one function do? The work could have been done with a single aggregate() call. However, the Unix philosophy states that programs should “do one thing well”, which is how dplyr’s functions were designed. Shorter functions are easier to understand and debug. But having too many functions can also make your call stack confusing.
To reinforce the point, this operation is also performed below on the wb_ineq dataset:
data(wb_ineq, package="efficient")
countries = group_by(wb_ineq, Country)
summarise(countries, gini = mean(gini, na.rm = TRUE))
#> # A tibble: 176 × 2
#> Country gini
#> <chr> <dbl>
#> 1 Afghanistan NaN
#> 2 Albania 30.4
#> 3 Algeria 37.8
#> 4 Angola 50.6
#> # ... with 172 more rowsNote that summarise is highly versatile, and can be used to return a customised range of summary statistics:
summarise(countries,
# number of rows per country
obs = n(),
med_t10 = median(top10, na.rm = TRUE),
# standard deviation
sdev = sd(gini, na.rm = TRUE),
# number with gini > 30
n30 = sum(gini > 30, na.rm = TRUE),
sdn30 = sd(gini[ gini > 30 ], na.rm = TRUE),
# range
dif = max(gini, na.rm = TRUE) - min(gini, na.rm = TRUE)
)
#> # A tibble: 176 × 7
#> Country obs med_t10 sdev n30 sdn30 dif
#> <chr> <int> <dbl> <dbl> <int> <dbl> <dbl>
#> 1 Afghanistan 40 NA NaN 0 NA NA
#> 2 Albania 40 24.4 1.25 3 0.364 2.78
#> 3 Algeria 40 29.8 3.44 2 3.437 4.86
#> 4 Angola 40 38.6 11.30 2 11.300 15.98
#> # ... with 172 more rowsTo showcase the power of summarise used on a grouped_df, the above code reports a wide range of customised summary statistics per country:
- the number of rows in each country group
- standard deviation of Gini indices
- median proportion of income earned by the top 10%
- the number of years in which the Gini index was greater than 30
- the standard deviation of Gini index values over 30
- the range of Gini index values reported for each country.
Exercises
Refer back to the greenhouse gas emissions example at the outset of section 6.4, in which we found the top 3 countries in terms of emissions growth in the transport sector. a) Explain in words what is going on in each line. b) Try to find the top 3 countries in terms of emissions in 2012 - how is the list different?
Explore dplyr’s documentation, starting with the introductory vignette, accessed by entering
vignette("introduction").Test additional dplyr ‘verbs’ on the
wb_ineqdataset. (More vignette names can be discovered by typingvignette(package = "dplyr").)
6.4.6 Non standard evaluation
The final thing to say about dplyr does not relate to the data but the syntax of the functions. Note that many of the arguments in the code examples in this section are provided as raw names: they are raw variable names, not surrounded by quote marks (e.g. Country rather than "Country"). This is called non-standard evaluation (NSE) (see vignette("nse")). NSE was used deliberately, with the aim of making the functions more efficient for interactive use. NSE reduces typing and allows autocompletion in RStudio.
This is fine when using R interactively. But when you’d like to use R non-interactively, code is generally more robust using standard evaluation: it minimises the chance of creating obscure scope-related bugs. Using standing evaluation also avoids having to declare global variables if you include the code in a package. For this reason most functions in tidyr and dplyr have two versions: one that uses NSE (the default) and another that uses standard evaluation requires the variable names to be provided in quote marks. The standard evaluation versions of functions are denoted with the affix _. This is illustrated below with the gather() function, used above:
# 1: Default NSE function
group_by(cars, cut(speed, c(0, 10, 100))) %>% summarise(mean(dist))
#> # A tibble: 2 × 2
#> `cut(speed, c(0, 10, 100))` `mean(dist)`
#> <fctr> <dbl>
#> 1 (0,10] 15.8
#> 2 (10,100] 49.0
# 2: Standard evaluation using quote marks
group_by_(cars, "cut(speed, c(0, 10, 100))") %>% summarise_("mean(dist)")
#> # A tibble: 2 × 2
#> `cut(speed, c(0, 10, 100))` `mean(dist)`
#> <fctr> <dbl>
#> 1 (0,10] 15.8
#> 2 (10,100] 49.0
# 3: Standard evaluation using formula, tilde notation (recommended standard evaluation method)
group_by_(cars, ~cut(speed, c(0, 10, 100))) %>% summarise_(~mean(dist))
#> # A tibble: 2 × 2
#> `cut(speed, c(0, 10, 100))` `mean(dist)`
#> <fctr> <dbl>
#> 1 (0,10] 15.8
#> 2 (10,100] 49.06.5 Combining datasets
The usefulness of a dataset can sometimes be greatly enhanced by combining it with other data. If we could merge the global ghg_ems dataset with geographic data, for example, we could visualise the spatial distribution of climate pollution. For the purposes of this section we join ghg_ems to the world data provided by ggmap to illustrate the concepts and methods of data joining (also referred to as merging).
library("ggmap")
world = map_data("world")
names(world)
#> [1] "long" "lat" "group" "order" "region" "subregion"Visually compare this new dataset of the world with ghg_ems (e.g. via View(world); View(ghg_ems)). It is clear that the column region in the former contains the same information as Country in the latter. This will be the joining variable; renaming it in world will make the join more efficient.
world = rename(world, Country = region)
ghg_ems$All = rowSums(ghg_ems[3:7])
Ensure that both joining variables have the same class (combining character and factor columns can cause havoc).
How large is the overlap between ghg_ems$Country and world$Country? We can find out using the %in% operator, which finds out how many elements in one vector match those in another vector. Specifically, we will find out how many unique country names from ghg_ems are present in the world dataset:
unique_countries_ghg_ems = unique(ghg_ems$Country)
unique_countries_world = unique(world$Country)
matched = unique_countries_ghg_ems %in% unique_countries_world
table(matched)
#> matched
#> FALSE TRUE
#> 20 168This comparison exercise has been fruitful: most of the countries in the co2 dataset exist in the world dataset. But what about the 20 country names that do not match? We can identify these as follows:
(unmatched_countries_ghg_ems = unique_countries_ghg_ems[!matched])
#> [1] "Antigua & Barbuda" "Bahamas, The"
#> [3] "Bosnia & Herzegovina" "Congo, Dem. Rep."
#> [5] "Congo, Rep." "Cote d'Ivoire"
#> [7] "European Union (15)" "European Union (28)"
#> [9] "Gambia, The" "Korea, Dem. Rep. (North)"
#> [11] "Korea, Rep. (South)" "Macedonia, FYR"
#> [13] "Russian Federation" "Saint Kitts & Nevis"
#> [15] "Saint Vincent & Grenadines" "Sao Tome & Principe"
#> [17] "Trinidad & Tobago" "United Kingdom"
#> [19] "United States" "World"It is clear from the output that some of the non-matches (e.g. the European Union) are not countries at all. However, others, such as ‘Gambia, The’ and the United States clearly should have matches. Fuzzy matching can help find which countries do match, as illustrated the first non-matching country below:
(unmatched_country = unmatched_countries_ghg_ems[1])
#> [1] "Antigua & Barbuda"
unmatched_world_selection = agrep(pattern = unmatched_country, unique_countries_world, max.distance = 10)
unmatched_world_countries = unique_countries_world[unmatched_world_selection]What just happened? We verified that first unmatching country in the ghg_ems dataset was not in the world country names. So we used the more powerful agrep to search for fuzzy matches (with the max.distance argument set to 10. The results show that the country Antigua & Barbuda from the ghg_ems data matches two countries in the world dataset. We can update the names in the dataset we are joining to accordingly:
world$Country[world$Country %in% unmatched_world_countries] =
unmatched_countries_ghg_ems[1]The above code reduces the number of country names in the world dataset by replacing both “Antigua” and “Barbuda” to “Antigua & Barbuda”. This would not work other way around: how would one know whether to change “Antigua & Barbuda” to “Antigua” or to “Barbuda”.
Thus fuzzy matching is still a laborious process that must be complemented by human judgement. It takes a human to know for sure that United States is represented as USA in the world dataset, without risking false matches via agrep.
6.6 Working with databases
Instead of loading all the data into RAM, as R does, databases query data from the hard-disk. This can allow a subset of a very large dataset to be defined and read into R quickly, without having to load it first. R can connect to databases in a number of ways, which are briefly touched on below. Databases is a large subject area undergoing rapid evolution. Rather than aiming at comprehensive coverage, we will provide pointers to developments that enable efficient access to a wide range of database types. An up-to-date history of R’s interfaces to databases can be found in README of the DBI package, which provides a common interface and set of classes for driver packages (such as RSQLite).
RODBC is a veteran package for querying external databases from within R, using the Open Database Connectivity (ODBC) API. The functionality of RODBC is described in the package’s vignette (see vignette("RODBC")) and nowadays its main use is to provide an R interface to SQL Server databases which lacks a DBI interface.
The DBI package is a unified framework for accessing databases allowing for other drivers to be added as modular packages. Thus new packages that build on DBI can be seen partly as a replacement of RODBC (RMySQL, RPostgreSQL, and RSQLite) (see vignette("backend") for more on how DBI drivers work). Because the DBI syntax applies to a wide range of database types we use it here with a worked example.
Imagine you have access to a database that contains the ghg_ems data set.
# Connect to a database driver
library("RSQLite")
con = dbConnect(SQLite(), dbname = ghg_db) # Also username & password arguments
dbListTables(con)
rs = dbSendQuery(con, "SELECT * FROM `ghg_ems` WHERE (`Country` != 'World')")
df_head = dbFetch(rs, n = 6) # extract first 6 rowThe above code chunk shows how the function dbConnect connects to an external database, in this case a MySQL database. The username and password arguments are used to establish the connection. Next we query which tables are available with dbListTables, query the database (without yet extracting the results to R) with dbSendQuery and, finally, load the results into R with dbFetch.
Be sure never to release your password by entering it directly into the command. Instead, we recommend saving sensitive information such as database passwords and API keys in .Renviron, described in Chapter 2. Assuming you had saved your password as the environment variable PSWRD, you could enter pwd = Sys.getenv(“PSWRD”) to minimise the risk of exposing your password through accidentally releasing the code or your session history.
Recently there has been a shift to the ‘noSQL’ approach for storing large datasets. This is illustrated by the emergence and uptake of software such as MongoDB and Apache Cassandra, which have R interfaces via packages mongolite and RJDBC, which can connect to Apache Cassandra data stores and any source compliant with the Java Database Connectivity (JDBC) API.
MonetDB is a recent alternative to relational and noSQL approaches which offers substantial efficiency advantages for handling large datasets (Kersten et al. 2011). A tutorial on the MonetDB website provides an excellent introduction to handling databases from within R.
There are many wider considerations in relation to databases that we will not cover here: who will manage and maintain the database? How will it be backed up locally (local copies should be stored to reduce reliance on the network)? What is the appropriate database for your project. These issues can have major efficiency, especially on large, data intensive projects. However, we will not cover them here because it is a fast-moving field. Instead, we direct the interested reader towards further resources on the subject, including:
- The website for sparklyr, a recent package for efficiently interfacing with the Apache Spark stack.
- db-engines.com/en/: a website comparing the relative merits of different databases.
- The
databasesvignette from the dplyr package. - Getting started with MongoDB in R, an introductory vignette on non-relational databases and map reduce from the mongolite package.
6.6.1 Databases and dplyr
To access a database in R via dplyr, one must use one of the src_ functions to create a source. Continuing with the SQLite example above, one would create a tbl object, that can be queried by dplyr as follows:
library("dplyr")
ghg_db = src_sqlite(ghg_db)
ghg_tbl = tbl(ghg_db, "ghg_ems")The ghg_tbl object can then be queried in a similar way as a standard data frame. For example, suppose we wished to filter by Country. Then we use the filter function as before:
rm_world = ghg_tbl %>%
filter(Country != "World")In the above code, dplyr has actually generated the necessary SQL command, which can be examined using explain(rm_world). When working with databases, dplyr uses lazy evaluation: the data is only fetched at the last moment when it’s needed. The SQL command associated with rm_world hasn’t yet been executed, this is why tail(rm_world) doesn’t work. By using lazy evaluation, dplyr is more efficient at handling large data structures since it avoids unnecessary copying. When you want your SQL command to be executed, use collect(rm_world).
The final stage when working with databases in R is to disconnect, e.g.:
dbDisconnect(conn = con)Exercises
Follow the worked example below to create and query a database on land prices in the UK using dplyr as a front end to an SQLite database. The first stage is to read-in the data:
# See help("land_df", package="efficient") for details
data(land_df, package="efficient")The next stage is to create an SQLite database to hold the data:
# install.packages("RSQLite") # Requires RSQLite package
my_db = src_sqlite("land.sqlite3", create = TRUE)
land_sqlite = copy_to(my_db, land_df, indexes = list("postcode", "price")) What class is the new object land_sqlite?
Why did we use the indexes argument?
From the above code we can see that we have created a tbl. This can be accessed using dplyr in the same way as any data frame can. Now we can query the data. You can use SQL code to query the database directly or use standard dplyr verbs on the table.
# Method 1: using sql
tbl(my_db, sql('SELECT "price", "postcode", "old/new" FROM land_df'))
#> Source: query [?? x 3]
#> Database: sqlite 3.8.6 [land.sqlite3]
#>
#> price postcode `old/new`
#> <int> <chr> <chr>
#> 1 84000 CW9 5EU N
#> 2 123500 TR13 8JH N
#> 3 217950 PL33 9DL N
#> 4 147000 EX39 5XT N
#> # ... with more rowsHow would you erform the same query using select()? Try it to see if you get the same result (hint: use backticks for the old/new variable name).
6.7 Data processing with data.table
data.table is a mature package for fast data processing that presents an alternative to dplyr. There is some controversy about which is more appropriate for different tasks.18 Which is more efficient to some extent depends on personal preferences and what you are used to. Both are powerful and efficient packages that take time to learn, so it is best to learn one and stick with it, rather than have the duality of using two for similar purposes. There are situations in which one works better than another: dplyr provides a more consistent and flexible interface (e.g. with its interface to databases, demonstrated in the previous section) so for most purposes we recommend learning dplyr first if you are new to both packages. dplyr can also be used to work with the data.table class used by the data.table package so you can get the best of both worlds.
data.table is faster than dplyr for some operations and offers some functionality unavailable in other packages, moreover it has a mature and advanced user community. data.table supports rolling joins (which allow rows in one table to be selected based on proximity between shared variables (typically time) and non-equi joins (where join criteria can be inequalities rather than equal to).
This section provides a few examples to illustrate how data.table differs and (at the risk of inflaming the debate further) some benchmarks to explore which is more efficient. As emphasised throughout the book, efficient code writing is often more important than efficient execution on many everyday tasks so to some extent it’s a matter of preference.
The foundational object class of data.table is the data.table. Like dplyr’s tbl_df, data.table’s data.table objects behave in the same was as the base data.frame class. However the data.table paradigm has some unique features that make it highly computationally efficient for many common tasks in data analysis. Building on subsetting methods using [ and filter(), mentioned previously, we’ll see data.tables’s unique approach to subsetting. Like base R data.table uses square brackets but (unlike base R but like dplyr) uses non-standard evaluation so you need not refer to the object name inside the brackets:
library("data.table")
data(wb_ineq_renamed) # from the efficient package
wb_ineq_dt = data.table(wb_ineq_renamed) # convert to data.table class
aus3a = wb_ineq_dt[Country == "Australia"]
Note that the square brackets do not need a comma to refer to rows with data.table objects: in base R you would write wb_ineq_renamed[wb_ineq_renamed$Country == “Australia”,].
To boost performance, one can set ‘keys’, analogous to ‘primary keys in databases’. These are ‘supercharged rownames’ which order the table based on one or more variables. This allows a binary search algorithm to subset the rows of interest, which is much, much faster than the vector scan approach used in base R (see vignette("datatable-keys-fast-subset")). data.table uses the key values for subsetting by default so the variable does not need to be mentioned again. Instead, using keys, the search criteria is provided as a list (invoked below with the concise .() syntax below, which is synonymous with list()).
setkey(wb_ineq_dt, Country)
aus3b = wb_ineq_dt[.("Australia")]The result is the same, so why add the extra stage of setting the key? The reason is that this one-off sorting operation can lead to substantial performance gains in situations where repeatedly subsetting rows on large datasets consumes a large proportion of computational time in your workflow. This is illustrated in Figure 6.1, which compares 4 methods of subsetting incrementally larger versions of the wb_ineq dataset.
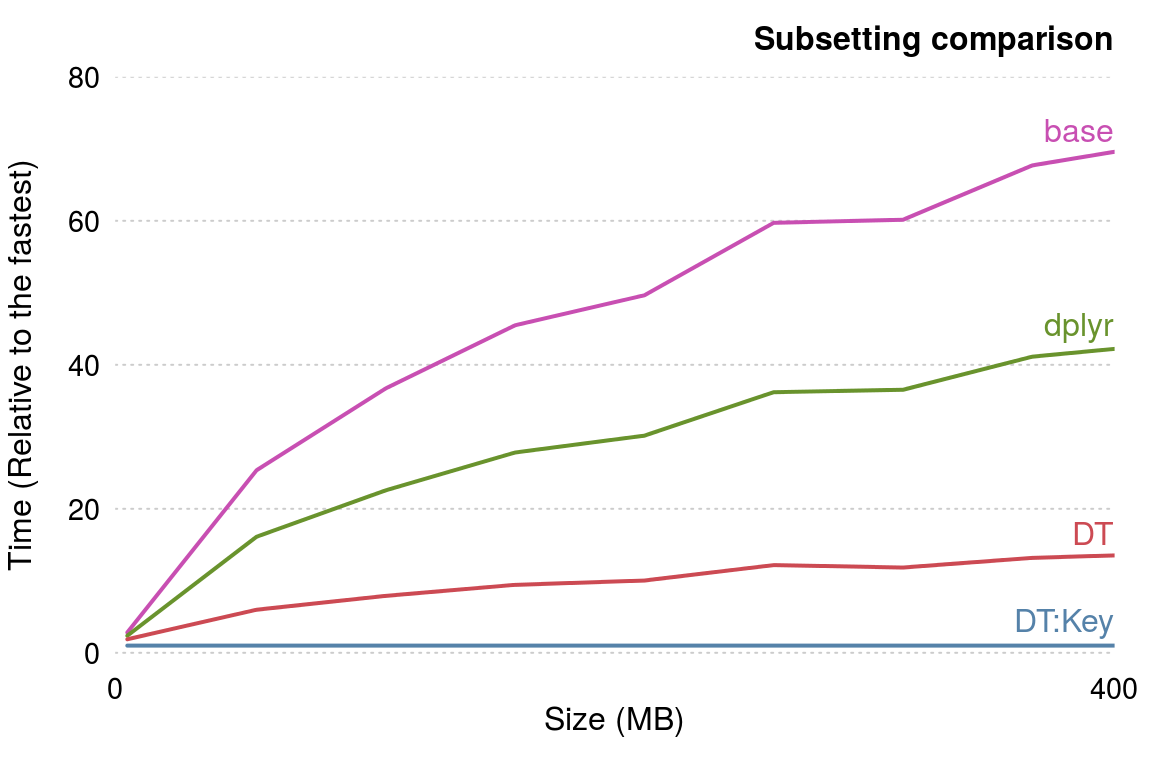
Figure 6.1: Benchmark illustrating the performance gains to be expected for different dataset sizes.
Figure 6.1 demonstrates that data.table is much faster than base R and dplyr at subsetting. As with using external packages to read in data (see Section 5.3), the relative benefits of data.table improve with dataset size, approaching a ~70 fold improvement on base R and a ~50 fold improvement on dplyr as the dataset size reaches half a Gigabyte. Interestingly, even the ‘non key’ implementation of data.table subset method is faster than the alternatives: this is because data.table creates a key internally by default before subsetting. The process of creating the key accounts for the ~10 fold speed-up in cases where the key has been pre-generated.
This section has introduced data.table as a complimentary approach to base and dplyr methods for data processing. It offers performance gains due to its implementation in C and use of keys for subsetting tables. data.table offers much more, however, including: highly efficient data reshaping; dataset merging (also known as joining, as with left_join in dplyr); and grouping. For further information on data.table, we recommend reading the package’s datatable-intro, datatable-reshape and datatable-reference-semantics vignettes.
References
Wickham, Hadley. 2014b. “Tidy Data.” The Journal of Statistical Software 14 (5).
Codd, E. F. 1979. “Extending the database relational model to capture more meaning.” ACM Transactions on Database Systems 4 (4): 397–434. doi:10.1145/320107.320109.
Spector, Phil. 2008. Data Manipulation with R. Springer Science & Business Media.
Sanchez, Gaston. 2013. “Handling and Processing Strings in R.” Trowchez Editions. http://www.academia.edu/download/36290733/Handling_and_Processing_Strings_in_R.pdf.
Grolemund, G., and H. Wickham. 2016. R for Data Science. O’Reilly Media.
Wickham, Hadley. 2010. “Stringr: Modern, Consistent String Processing.” The R Journal 2 (2): 38–40.
Kersten, Martin L, Stratos Idreos, Stefan Manegold, Erietta Liarou, and others. 2011. “The Researcher’s Guide to the Data Deluge: Querying a Scientific Database in Just a Few Seconds.” PVLDB Challenges and Visions 3.
str(wb_ineq)is another way to see the contents of an object, but produces more verbose output.↩Note that
filteris also the name of a function used in the base stats library. Usually packages avoid using names already taken in base R but this is an exception.↩The equivalent code in base R is:
e_ems = aggregate(ghg_ems$Electricity, list(ghg_ems$Country), mean, na.rm = TRUE, data = ghg_ems) nrow(e_ems).↩One question on the stackoverflow website titled ‘data.table vs dplyr’ illustrates this controversy and delves into the philosophy underlying each approach.↩