Kapitola 6 Čistenie údajov pomocou tidyr
Kapitola je spracovaná prevažne s použitím (Wickham a Grolemund 2016, kap. 12), doplnkovo (Ismay a Kim 2019, kap. 4) a stránky projektu Statistical tools for high-throughput data analysis.
6.1 Úvod
Tabuľkové údaje, ktoré majú čistú, usporiadanú (angl. tidy) štruktúru, sa vyznačujú týmito vlastnosťami:
- každá premenná má svoj stĺpec,
- každé pozorovanie je vo svojom riadku a
- každá hodnota má svoju bunku v tabuľke.
Zatiaľ čo čisté dáta sú všetky rovnako čisté, tie neporiadne sú neporiadne svojim vlastným spôsobom. Výhoda čistých údajov spočíva – podobne ako pri iných štandardoch – v dostupnosti väčšieho počtu a ľahšie pochopiteľných nástrojov na prácu s dátami. Príkladom takého subsystému nástrojov v prostredí R je súbor balíkov tidyverse, do ktorého patria tieto známe (i menej známe) balíky:
- tibble – vylepšená koncepcia dátových rámcov a metód manipulácie s nimi,
- readr – rýchly a jednoduchý spôsob importu tabuľkových údajov (prednostne do formátu tibble),
- tidyr – nástroje na vytvorenie čistých dát z tých neporiadnych (Wickham a Henry 2020),
- dplyr – gramatika manipulácie s dátami,
- ggplot2 – vizualizáčný systém založený na gramatike grafiky,
- purrr – konzistentný súbor nástrojov funkcionálneho programovania,
- stringr – súbor nástrojov uľahčujúci prácu so znakovými reťazcami.
Pre ilustráciu, nasledujúca tabuľka8 je čistá:
library(tidyr)
table1
## # A tibble: 6 × 4
## country year cases population
## <chr> <int> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583Vďaka tomu je manipulácia s premennými veľmi jednoduchá. Napríklad jednoducho sa dá vyjadriť podiel pozitívnych prípadov v celej populácii,
table1 %>%
dplyr::mutate(rate = cases / population * 10000)
## # A tibble: 6 × 5
## country year cases population rate
## <chr> <int> <int> <int> <dbl>
## 1 Afghanistan 1999 745 19987071 0.373
## 2 Afghanistan 2000 2666 20595360 1.29
## 3 Brazil 1999 37737 172006362 2.19
## 4 Brazil 2000 80488 174504898 4.61
## 5 China 1999 212258 1272915272 1.67
## 6 China 2000 213766 1280428583 1.67alebo zhrnúť počet prípadov po jednotlivých rokoch,
table1 %>%
dplyr::count(year, wt = cases)
## # A tibble: 2 × 2
## year n
## <int> <int>
## 1 1999 250740
## 2 2000 296920prípadne zobraziť vývoj v jednotlivých krajinách.
library(ggplot2)
ggplot(table1) + aes(year, cases) +
geom_line(aes(group = country), colour = "grey50") +
geom_point(aes(colour = country)) +
scale_x_continuous(n.breaks = 2)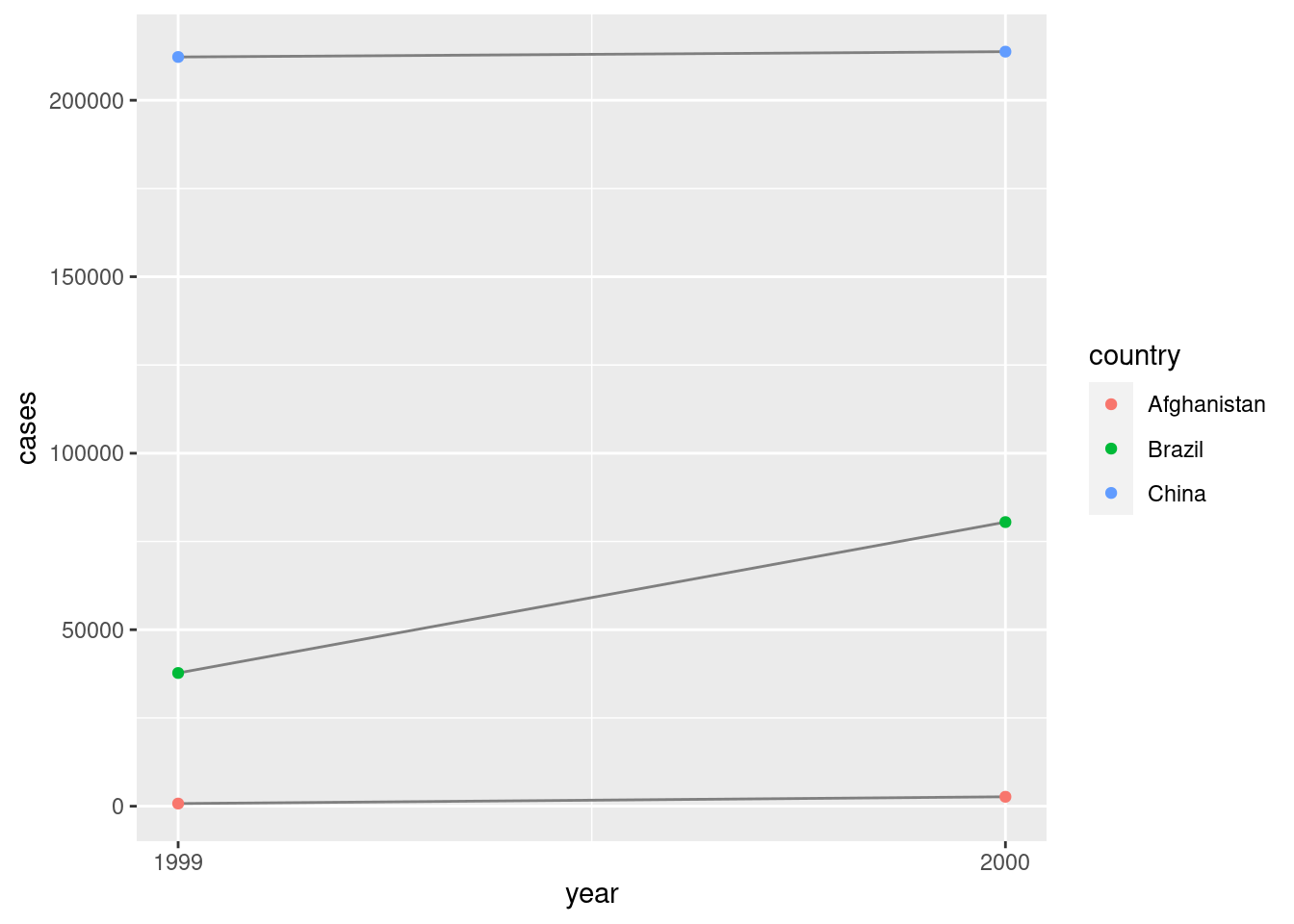
Hoci sa zdá, že princípy poriadku v tabuľkových dátach sú zjavné a príde nám divné, prečo by dáta v praxi mali vyzerať inak, opak je realitou. Väčšia časť zaznamenaných súborov údajov nie je v poriadku, a to najmä preto, že:
- veľa ľudí nie je oboznámených s princípmi čistých údajov, a je ťažké k nim prirodzene dôjsť, kým človek s dátami nestrávi dostatočne veľa času,
- dáta sú často organizované pre úplne iný účel než analýzu.
To znamená, že pre seriózny rozbor údajov bude vo väčšine prípadov potrebné čistenie. Prvým krokom je rozpoznať, čo v tabuľke predstavuje premenné a čo pozorovania. Niekedy je to ľahké, inokedy si to vyžaduje konzultáciu s autormi datasetu. Druhý krok je vyriešiť jeden z dvoch bežných problémov (iba zriedka oboch naraz):
- jedna premenná sa rozprestiera cez viacero stĺpcov,
- jedno pozorovanie je rozstratené po viacerých riadkoch.
Na vyriešenie týchto dvoch problémov budú potrebné dva kľúčové nástroje balíku tidyr: funkcie pivot_longer a pivot_wider. (Slovo pivoting sa dá preložiť ako otáčanie.)
6.2 Zber stĺpcov
V prvom probléme názvy niektorých stĺpcov v skutočnosti nepredstavujú názvy premenných ale hodnoty jednej premennej. Napr. v tabuľke
table4a
## # A tibble: 3 × 3
## country `1999` `2000`
## * <chr> <int> <int>
## 1 Afghanistan 745 2666
## 2 Brazil 37737 80488
## 3 China 212258 213766sú názvy druhého a tretieho stĺpca hodnotami premennej (nazvime ju) year, pričom hodnoty v bunkách týchto stĺpcov sú počty pozitívnych prípadov, čiže premennej cases. Cieľom je vytvoriť stĺpce pre tieto dve premenné, naplniť ich hodnotami (roky a počty prípadov) a staré stĺpce zmazať.
table4a <- table4a %>%
pivot_longer(cols = c(`1999`, `2000`), names_to = "year", values_to = "cases")
table4a
## # A tibble: 6 × 3
## country year cases
## <chr> <chr> <int>
## 1 Afghanistan 1999 745
## 2 Afghanistan 2000 2666
## 3 Brazil 1999 37737
## 4 Brazil 2000 80488
## 5 China 1999 212258
## 6 China 2000 213766S tabuľkou table4a súvisí tabuľka table4b, ktorá namiesto počtu pozitívnych prípadov obsahuje celkový počet v populácii. Najprv si ju zobrazíme, potom „otočíme” na dlhý (a čistý) formát, zobrazíme ju a výsledkom prepíšeme pôvodný objekt 9 10.
table4b <- table4b %>%
print() %>%
pivot_longer(cols = c(`1999`, `2000`), names_to = "year", values_to = "population") %>%
print()
## # A tibble: 3 × 3
## country `1999` `2000`
## * <chr> <int> <int>
## 1 Afghanistan 19987071 20595360
## 2 Brazil 172006362 174504898
## 3 China 1272915272 1280428583
## # A tibble: 6 × 3
## country year population
## <chr> <chr> <int>
## 1 Afghanistan 1999 19987071
## 2 Afghanistan 2000 20595360
## 3 Brazil 1999 172006362
## 4 Brazil 2000 174504898
## 5 China 1999 1272915272
## 6 China 2000 1280428583Prepísané tabuľky table4a a table4b sa teraz prekrývajú v dvoch stĺpcoch, každá však obsahuje aj unikátne stĺpce, je teda prirodzené ich zlúčiť, aby údaje z nich boli dostupné na jednom mieste. To sa dosiahne funkciou left_join z balíka dplyr.
dplyr::left_join(table4a, table4b)
## Joining, by = c("country", "year")
## # A tibble: 6 × 4
## country year cases population
## <chr> <chr> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583Okrem funkcie left_join, ktorá zachováva všetky riadky prvého argumentu, sú v balíku dplyr k dispozícii aj funkcie right_join (zachová riadky druhého argumentu), inner_join (všetky, ktoré sú v oboch zároveň) a full_join (všetky, ktoré sú aspoň v jednom).
6.3 Zber riadkov
V tabuľke table2 nastáva druhý zo spominaných problémov, a síce, že pozorovania sú rozložené do dvoch riadkov:
table2
## # A tibble: 12 × 4
## country year type count
## <chr> <int> <chr> <int>
## 1 Afghanistan 1999 cases 745
## 2 Afghanistan 1999 population 19987071
## 3 Afghanistan 2000 cases 2666
## 4 Afghanistan 2000 population 20595360
## 5 Brazil 1999 cases 37737
## 6 Brazil 1999 population 172006362
## 7 Brazil 2000 cases 80488
## 8 Brazil 2000 population 174504898
## 9 China 1999 cases 212258
## 10 China 1999 population 1272915272
## 11 China 2000 cases 213766
## 12 China 2000 population 1280428583Potrebujeme identifikovať stĺpec, v ktorom sú názvy premenných (type) a stĺpec, v ktorom sú ich hodnoty (count), zvyšok je práca funkcie inverznej ku pivot_longer, čiže pivot_wider:
table2 %>%
pivot_wider(names_from = type, values_from = count)
## # A tibble: 6 × 4
## country year cases population
## <chr> <int> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583Zjednodušene povedané, pivot_longer() tabuľky zoštíhľuje a predlžuje, naopak pivot_wider() robí tabuľky širšie a kratšie.
6.4 Rozdelenie a spojenie stĺpcov
Iný problém nastane, ak stĺpec obsahuje viac než jednu premennú, ako je tomu v nasledujúcej tabuľke,
table3
## # A tibble: 6 × 3
## country year rate
## * <chr> <int> <chr>
## 1 Afghanistan 1999 745/19987071
## 2 Afghanistan 2000 2666/20595360
## 3 Brazil 1999 37737/172006362
## 4 Brazil 2000 80488/174504898
## 5 China 1999 212258/1272915272
## 6 China 2000 213766/1280428583kde sa pod názvom rate nachádza podiel dvoch premenných, cases/population. Riešením je použiť funkciu separate,
table3 %>%
separate(rate, into = c("cases", "population"), sep = "/", convert = TRUE)
## # A tibble: 6 × 4
## country year cases population
## <chr> <int> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583kde argument sep definuje oddeľovací znak (môže byť aj regulárny výraz, prípadne počet znakov od začiatku) a argument convert povolí konverziu reťazca na číslo (alebo logickú hodnotu či NA). Niekedy môže byť užitočné rozdeliť jedno číslo (rok) na viacero (storočie, rok), hoci to dáta robí menej čistými:
table3 %>%
separate(col = year, into = c("century", "year"), sep = 2)
## # A tibble: 6 × 4
## country century year rate
## <chr> <chr> <chr> <chr>
## 1 Afghanistan 19 99 745/19987071
## 2 Afghanistan 20 00 2666/20595360
## 3 Brazil 19 99 37737/172006362
## 4 Brazil 20 00 80488/174504898
## 5 China 19 99 212258/1272915272
## 6 China 20 00 213766/1280428583Inverznú operáciu ku separate zabezpečuje funkcia unite, ktorá môže napraviť rozptýlenie hodnôt jednej premennej v bunkách viacerých stĺpcov (čiže nie v ich názvoch), napr.
table5 %>% print() %>%
unite(col = new, century, year, sep = "")
## # A tibble: 6 × 4
## country century year rate
## * <chr> <chr> <chr> <chr>
## 1 Afghanistan 19 99 745/19987071
## 2 Afghanistan 20 00 2666/20595360
## 3 Brazil 19 99 37737/172006362
## 4 Brazil 20 00 80488/174504898
## 5 China 19 99 212258/1272915272
## 6 China 20 00 213766/1280428583
## # A tibble: 6 × 3
## country new rate
## <chr> <chr> <chr>
## 1 Afghanistan 1999 745/19987071
## 2 Afghanistan 2000 2666/20595360
## 3 Brazil 1999 37737/172006362
## 4 Brazil 2000 80488/174504898
## 5 China 1999 212258/1272915272
## 6 China 2000 213766/12804285836.5 Chýbajúce hodnoty
Problémy pri príprave údajov spôsobuje aj absencia určitého počtu hodnôt. Hodnota môže byť chýbajúca
- explicitne, označená znakom NA,
- implicitne, jednoducho v údajoch chýba.
Trochu nadnesene: explicitne chýbajúca hodnota je prítomnosť absencie; implicitná je zas absencia prítomnosti. Dokážete oba prípady identifikovať v nasledujúcej tabuľke?
stocks <- tibble(
year = c(2015, 2015, 2015, 2015, 2016, 2016, 2016),
qtr = c( 1, 2, 3, 4, 2, 3, 4),
return = c(1.88, 0.59, 0.35, NA, 0.92, 0.17, 2.66)
)V dôsledku toho, ako sú datasety reprezentované, možno z implicitne chýbajúcej hodnoty urobiť explicitnú (NA), napr. konverziou na široký formát a späť
stocks %>%
pivot_wider(names_from = year, values_from = return) %>%
print() %>%
pivot_longer(
cols = c(`2015`, `2016`),
names_to = "year",
values_to = "return",
values_drop_na = FALSE
)
## # A tibble: 4 × 3
## qtr `2015` `2016`
## <dbl> <dbl> <dbl>
## 1 1 1.88 NA
## 2 2 0.59 0.92
## 3 3 0.35 0.17
## 4 4 NA 2.66
## # A tibble: 8 × 3
## qtr year return
## <dbl> <chr> <dbl>
## 1 1 2015 1.88
## 2 1 2016 NA
## 3 2 2015 0.59
## 4 2 2016 0.92
## 5 3 2015 0.35
## 6 3 2016 0.17
## 7 4 2015 NA
## 8 4 2016 2.66Jednoduchšie je však použiť funkciu complete,
stocks %>%
complete(year, qtr)
## # A tibble: 8 × 3
## year qtr return
## <dbl> <dbl> <dbl>
## 1 2015 1 1.88
## 2 2015 2 0.59
## 3 2015 3 0.35
## 4 2015 4 NA
## 5 2016 1 NA
## 6 2016 2 0.92
## 7 2016 3 0.17
## 8 2016 4 2.66ktorá vezme súbor stĺpcov, vytvorí všetky kombinácie a doplní k nim originálne dáta, pričom do ostatných pozícií doplní NA.
Niekedy explicitne chýbajúca hodnota môže znamenať, že zastupuje duplikát predošlej hodnoty (a nikto sa neobťažoval doplniť ju). Vtedy sa na nahradenie NA použije funkcia fill tak, ako v nasledujúcom príklade:
treatment <- tribble(
~ person, ~ treatment, ~response,
"Derrick Whitmore", 1, 7,
NA, 2, 10,
NA, 3, 9,
"Katherine Burke", 1, 4
)
treatment %>%
fill(person)
## # A tibble: 4 × 3
## person treatment response
## <chr> <dbl> <dbl>
## 1 Derrick Whitmore 1 7
## 2 Derrick Whitmore 2 10
## 3 Derrick Whitmore 3 9
## 4 Katherine Burke 1 46.6 Praktický príklad
V poslednej časti predošlej kapitoly o vizualizácii pomocou ggplot2 sme si ukázali tématickú mapu rozšírenia koronavírusu. Hoci dáta boli v čistom tvare, predsa ich bolo v dôsledku rozdielnych štandardov v názvosloví krajín potrebné dočisťovať, aby sa dali zlúčiť dva datasety (hranice krajín a vývoj pandémie).
Siahnime teraz po iných údajoch CSSE Johns Hopkins University. Úlohou bude zobraziť časový rad počtu úmrtí v dôsledku COVID-19 vo vybraných krajinách odo dňa výskytu prvého prípadu (po dátum 2.2.2022). Inšpirácia pochádza z blogu (Kajzar 2020). Pre zmenu, na načítanie dát bude použitý balík readr (a jeho používateľsky jednoduchšia funkcia read_csv):
dat <- readr::read_csv(
"https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv") Ak už odkaz nie je platný, je možné, že v ňom došlo len k drobnej zmene a internetovým vyhľadávačom sa dá nájsť aktuálna poloha súboru. V horšom prípadne je potrebné nájsť úplne nový zdroj údajov v podobnom formáte. Pre väčšie pohodlie prikladáme súbor aj offline.
dat <- readr::read_csv("data/time_series_covid19_deaths_global.csv")
## Rows: 281 Columns: 753
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): Province/State, Country/Region
## dbl (751): Lat, Long, 1/22/20, 1/23/20, 1/24/20, 1/25/20, 1/26/20, 1/27/20, ...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
dat[1:7]
## # A tibble: 281 × 7
## `Province/State` `Country/Region` Lat Long `1/22/20` `1/23/20` `1/24/20`
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 <NA> Afghanistan 33.9 67.7 0 0 0
## 2 <NA> Albania 41.2 20.2 0 0 0
## 3 <NA> Algeria 28.0 1.66 0 0 0
## 4 <NA> Andorra 42.5 1.52 0 0 0
## 5 <NA> Angola -11.2 17.9 0 0 0
## 6 <NA> Antigua and Bar… 17.1 -61.8 0 0 0
## 7 <NA> Argentina -38.4 -63.6 0 0 0
## 8 <NA> Armenia 40.1 45.0 0 0 0
## 9 Australian Capit… Australia -35.5 149. 0 0 0
## 10 New South Wales Australia -33.9 151. 0 0 0
## # … with 271 more rowsÚdaje sú – zjavne – v širokom formáte, pretože dátum sa rozprestiera v záhlaví stĺpcov. Každý riadok zodpovedá jednej krajine (prípadne jej provincii). Po odstránení referenčnej polohy a provincie (naše cieľové krajiny žiadne nemajú) a po transformácii (pivot_longer) bude každý riadok unikátnou kombináciou krajiny a dátumu. Zároveň vidno, že dátum je v tvare mm/dd/yy, je treba ho previesť do formy yyyy-mm-dd, ktorá je v našich končinách čitateľnejšia, a na to sa hodia nástroje z balíku lubridate.
data_to_plot <- dat %>%
dplyr::select(-"Province/State", -Lat, - Long) %>%
dplyr::rename(Country = "Country/Region") %>%
pivot_longer(-Country, names_to = "Date", values_to = "Deaths") %>%
dplyr::mutate(Date = lubridate::mdy(Date)) %>%
dplyr::filter(Country %in% c("Slovakia","Czechia", "Hungary", "Poland", "Ukraine"),
Deaths >= 1,
Date <= "2022-02-02")
data_for_labels <- data_to_plot %>%
dplyr::group_by(Country) %>%
dplyr::slice(which.max(Date))
data_to_plot %>%
ggplot(mapping = aes(x = Date, y = Deaths, group = Country, color = Country)) +
geom_line() +
labs(x = "dátum", y = NULL, title = "Počet úmrtí v okolí Slovenska") +
# umiestnenie popisu radov do grafu (pre efekt)
theme(legend.position = "none") +
geom_text(data = data_for_labels, aes(label = Country), hjust = -0.1, vjust = 0) +
scale_x_date(expand = c(0.15, 1)) # vyhradenie miesta za poslednou hodnotou 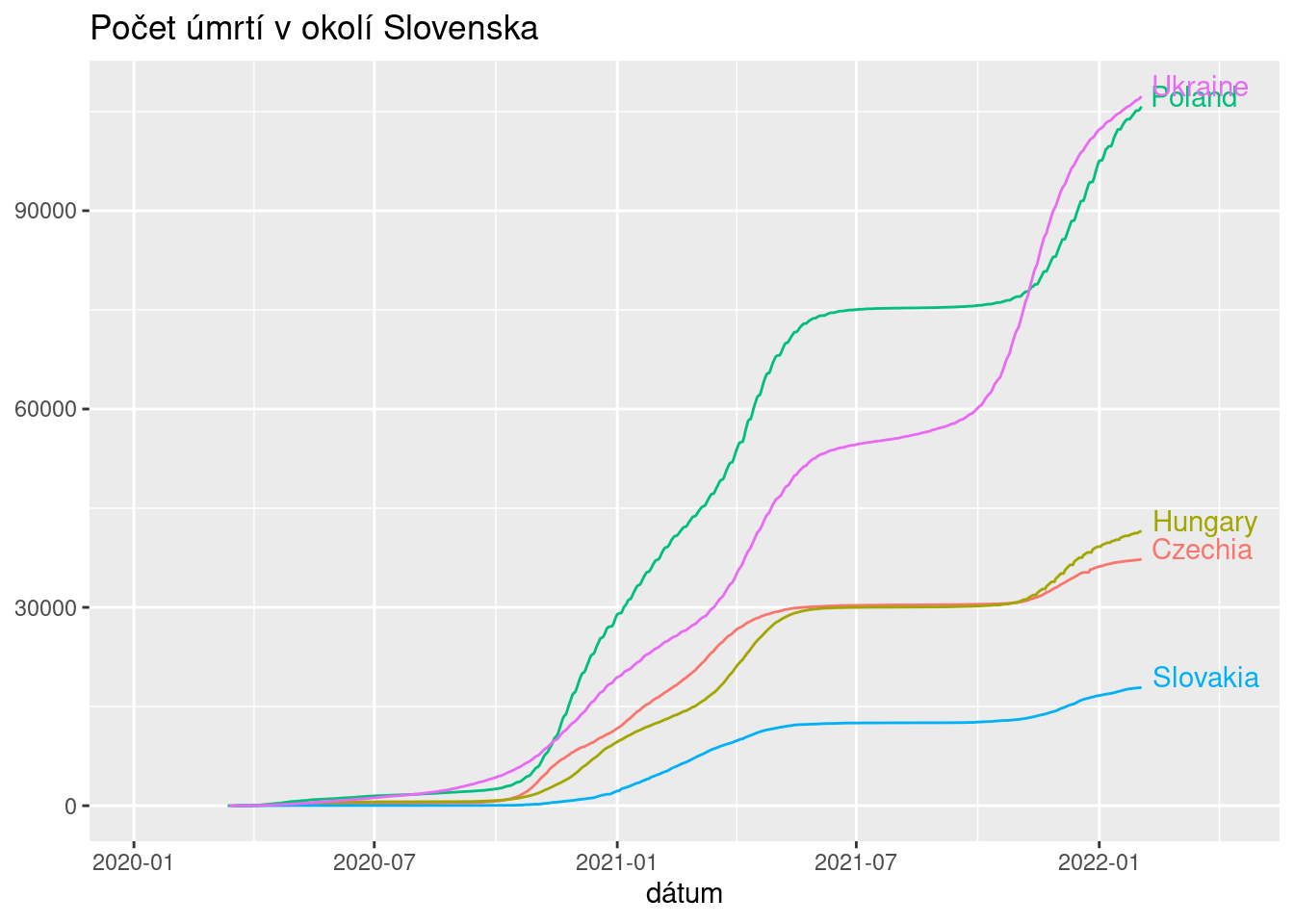
Aby bola zohľadnená aj ľudnatosť krajiny, vyjadrime úmrtnosť na vírus v relatívnej mierke ako podiel počtu prípadov na 1 milión obyvateľov. Na to je potrebný dataset o počte obyvateľov. Načítame najmenší CSV súbor, aký sa dá zbežným hľadaním na internete nájsť.
dat_population <- readr::read_csv(
"https://pkgstore.datahub.io/JohnSnowLabs/population-figures-by-country/population-figures-by-country-csv_csv/data/630580e802a621887384f99527b68f59/population-figures-by-country-csv_csv.csv")## Rows: 263 Columns: 59
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): Country, Country_Code
## dbl (57): Year_1960, Year_1961, Year_1962, Year_1963, Year_1964, Year_1965, ...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.dat_population[1:5]
## # A tibble: 263 × 5
## Country Country_Code Year_1960 Year_1961 Year_1962
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 Aruba ABW 54211 55438 56225
## 2 Afghanistan AFG 8996351 9166764 9345868
## 3 Angola AGO 5643182 5753024 5866061
## 4 Albania ALB 1608800 1659800 1711319
## 5 Andorra AND 13411 14375 15370
## 6 Arab World ARB 92490932 95044497 97682294
## 7 United Arab Emirates ARE 92634 101078 112472
## 8 Argentina ARG 20619075 20953077 21287682
## 9 Armenia ARM 1874120 1941491 2009526
## 10 American Samoa ASM 20013 20486 21117
## # … with 253 more rowsŠtruktúra je podobná ako v predošlom csv súbore, nám bude stačiť posledný rok, názvy niektorých krajín však treba prekódovať (v komplexnejšom prípade pomocou balíku countrycode). Potom už len ponechať predtým vybrané krajiny, spojiť s datasetom úmrtí, vytvoriť relatívnu početnosť a zobraziť. Všimnime si použitie funkcie aes_string vtedy, keď treba na premenné odkázať znakovým reťazcom (napr. ak názov obsahuje medzery):
dat_population %>%
dplyr::transmute(Country = dplyr::recode(Country,
"Slovak Republic" = "Slovakia",
"Czech Republic" = "Czechia"),
Population = Year_2016) %>%
dplyr::filter(Country %in% data_for_labels$Country) %>%
dplyr::right_join(data_to_plot, by = "Country") %>%
dplyr::mutate("Deaths per milion" = Deaths/Population*1e+06) %>%
ggplot(mapping = aes_string(x = "Date", y = as.name("Deaths per milion"),
group = "Country", color = "Country")) +
geom_line()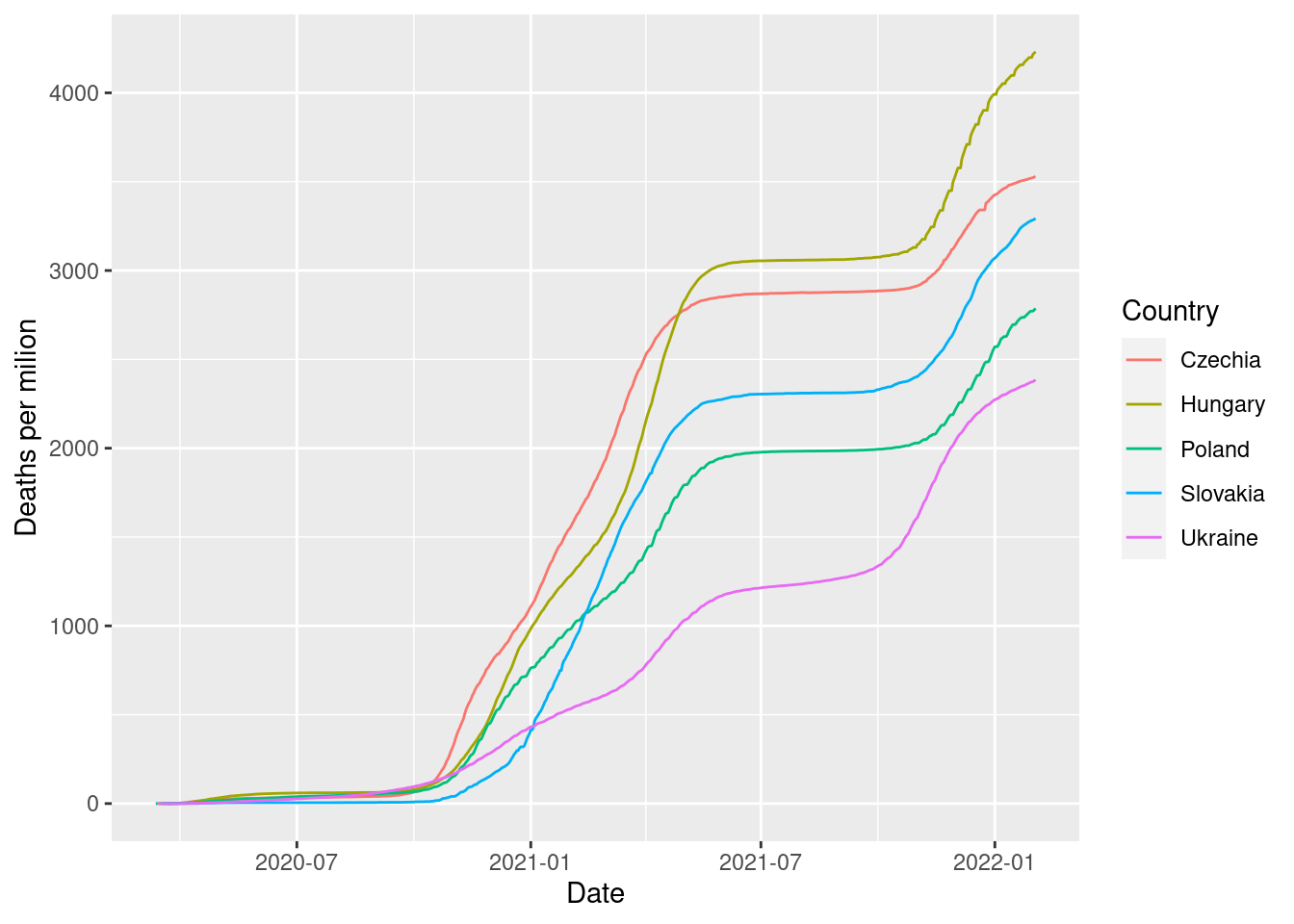
Zdá sa, že Ukrajina je na tom s úmrtnosťou na COVID-19 na začiatku roku 2022 najlepšie spomedzi krajín strednej Európy – nielen z pohľadu relatívneho počtu, ale aj rýchlosti rastu.
Otázky na zamyslenie:
- Vedeli by ste zostaviť takýto graf časových radov (alebo kartogram) z iných datasetov, než boli použité v lekcii? Môžete si ich vyhľadať alebo použiť napr. tie zo stránky https://ourworldindata.org/coronavirus-source-data.
- Aký iný graf by bol podľa vás užitočný v súvislosti s aktuálnou pandémiou? Vedeli by ste ho zrealizovať?
- Je zjavné, že počty potvrdených prípadov nákazy alebo úmrtí iba obmedzene odzrkadľujú skutočné rozšírenie v populácii. To je veľmi závislé od viacerých faktorov, napr. od dostupnosti testov na vírus, rozsahu ich nasadenia v teréne, kapacity zdravotníckych zariadení či ochoty jednotlivých štátov pravdivo zverejňovať svoje štatistiky. Koľko by mohol byť skutočný počet infikovaných ľudí v jednotlivých krajinách? V začiatkoch pandémie bolo zaujímavé čítať napr. blogy https://tomaspueyo.medium.com, neskôr vznikla užitočná stránka https://databezpatosu.sk/ – poznáte iné také, ktoré sa držia faktov a snažia o nadhľad?
6.7 Cvičenie
Načítajte dataset USArrest z balíku datasets, zoznámte sa s významom stĺpcov. Ktoré predstavujú druh zločinu?
Pomocou pipe operátora vytvorte sekvenciu príkazov (v zátvorke je tip, čo pri tom použiť), ktorá
- začne datasetom USArrest,
- pridá premennú state s názvami riadkov, (funkcie mutate alebo cbind,
rownames(.)) - prevedie tabuľku do dlhého formátu, teda zoskupí názvy zločinov do premennej crime a počty zatknutí do premennej cases, (pivot_longer)
- bodovým grafom zobrazí vzťah medzi percentom ľudnatosti v mestských oblastiach (na osi x) a počtom prípadov (v logaritmickej mierke na osi y), pričom farebne sú odlíšené jednotlivé zločiny. (ggplot + scale_y_login10)
V predošlom príklade zmeňte bodový graf na textový (s názvami štátov) a jednotlivé zločiny zobrazte vo svojom vlastnom grafe pod sebou. Zvážte použitie individuálnej mierky na osi y a prispôsobte veľkosť textu. (geom_text + facet_grid, scales, size)
Adam, Bibiana a Cindy sa prihlásili na kurz. Pred ním, počas aj po ňom písali test (hodnotenie 0-10 bodov), výsledky však neboli importované poriadne, niečo sa z nich možno aj stratilo (tabuľka definovaná nižšie, poradie riadkov zodpovedá abecednému radeniu mien študentov). Príkazy sa snažte reťaziť a preferujte funkcie z balíkov ekosystému tidyverse.
Úlohy:- Rozdeľte hodnotenie do stĺpcov podľa času testovania, pripojte mená a pomocou ggplot zobrazte vývoj ich vedomostí do spoločného grafu.
- Kto z nich sa ulieval a kto snažil?
- Čo by ste zmenili vo funkcii separate, ak by ste sa dozvedeli, že Cindy sa prvého testu nemohla zúčastniť?
tibble(x = c("8,8,3", "2,4,9", "5,6"))
## # A tibble: 3 × 1
## x
## <chr>
## 1 8,8,3
## 2 2,4,9
## 3 5,6Literatúra
Zdroj: WHO. Premenné: krajina, rok, počet prípadov TBC a počet obyvateľov.↩︎
Funkcia print() okrem zobrazenia do konzoly vráti to isté, čo dostala na vstupe.↩︎
Takýto sled príkazov si môžme dovoliť iba ak sú jednotlivé príkazy v reťazi odladené, inak dôjde k prepisu vstupného súboru údajov a je treba ho znova načítať.↩︎