Kapitola 9 Efektívne programovanie
R je i napriek občasným frustrujúcim zážitkom elegantný jazyk, dobre stavaný na analýzu údajov a štatistiku. Jeho efektivita vo veľkej miere závisí od spôsobu, akým je používaný: architektúra kódu (zrozumiteľnosť a škálovateľnosť), využívanie pokročilých nástrojov a HW vybavenia, prepojenie s inými jazykmi (ktoré sú na danú úlohu optimálne). Práve na tieto výzvy sa snažia reagovať nasledujúce podkapitoly.
Komplexnejšie túto problematiku rozoberá napr. kniha (Gillespie a Lovelace 2016).
9.1 Kvalita kódu
Dobrý kód je nielen funkčný a rýchly, ale aj čitateľný. Buď si vytvoríme vlastný štýl písania kódu – a môže to dopadnúť všelijako (https://xkcd.com/1513/) – alebo sa inšpirujeme skúsenosťami iných ľudí (napr. https://style.tidyverse.org/).
Podpora formátovania v štýle tidyverse je v prostredí RStudio zakomponovaná prostredníctvom balíkov styler alebo lintr. Štýlom sa rozumejú zásady ako napr.:
- názvy súborov by mali byť zmysluplné, končiť príponou
.R(alebo.Rmd) nie.r, ďalej by mali obsahovať len alfanumerické znaky, pomlčku-a podčiarkovník_, - názvy objektov (podstatné mená) a funkcií (slovesá) obsahujú malé písmená, čísla a znak
_, nekopírujú názvy, ktoré už sú bežne používané v systéme R, - medzera po čiarke aj okolo operátorov
<-,+,-,==, - globálne objekty sú definované mimo tela funkcie (obmedziť účel funkcie iba na tok vstup-výstup),
- zátvorky ohraničujúce bloky umiestniť:
{na koniec riadku, a}na začiatok riadku, - identifikácia argumentov plnými menami,
- vyhnúť sa implicitnej konverzii dátového typu (ako napr.
TRUE + 1 = 2), - dlhšie volanie funkcie rozdeliť na viac riadkov, argumenty zoskupiť podľa dĺžky alebo logického súvisu,
- preferovať
"pred'pri tvorbe reťazcov, plné názvy logických hodnôt (TRUE,FALSE) pred skratkami (T,F), - komentáre by mali začínať mriežkou a medzerou, a ak je komentárov viac ako kódu, vhodnejší než R script bude formát RMarkdown,
- komentáre v kóde by mali vysvetľovať „prečo”, a nie „čo” alebo „ako”. Mali by začínať veľkým písmenom, tak ako veta – v prípade viacerých viet končiť bodkou.
- Použiť
return()iba ak treba funkciu ukončiť predčasne, - vyhnúť sa reťazeniu príkazov pomocou „potrubia” (
%>%), ak treba manipulovať naraz viac ako s jedným objektom alebo pomenovať medzivýsledky, - pred pipe operátor by mala byť medzera a za ním zalomenie riadku,
- vyhnúť sa reťazeniu funkcií bez naznačených zátvoriek, použitiu operátora
%<>%alebo priradeniu premennej na konci potrubia. - Podobné zásady ako pre potrubie platí aj pre spájanie vrstiev ggplot.
9.2 Zapojenie celého procesoru – paralelizácia
Veľa výpočtov v R sa dá zrýchliť paralelizáciou. Paralelný výpočet je súbežné vykonávanie odlišných častí rozsiahleho výpočtu na viacerých procesorových jednotkách (vlákna, jadrá, procesory). Teoreticky, ak jedna paralelizovateľná úloha zaberie na jednom procesore \(x\) sekúnd, potom na \(n\) procesoroch by mala trvať \(x/n\) sekúnd. Prakticky sa to dosiahnuť nedá, pretože určitý čas zaberie rozdeľovanie čiastkových úloh, prenos údajov či čakanie na pomalšie súčasti, no aj priblíženie k tomu času stojí za námahu pri návrhu kódu. Obzvlášť v modernej dobe, keď sú už aj bežné osobné počítače osadené mnohojadrovými procesormi.
Trochu teórie a hlavne praktické príklady použitia štandardného balíku parallel nájdeme v lekcii (Erricson 2020), či v knihe (R. D. Peng 2016, kap. 22 Parallel Computation).
Sú dve metódy paralelizácie:
- Socket spustí novú reláciu R osobitne na každom jadre (ako po sieti). Výhodou metódy je, že funguje na ľubovoľnom operačnom systéme, nevýhodou zas nutnosť načítať všetky potrebné balíky, funkcie, nastavenia a objekty.
- Forking skopíruje aktuálnu reláciu R na každé jadro. Výhodou je implementačná jednoduchosť a vyššia rýchlosť, nevýhodou naopak to, že funguje len na tzv. POSIX systémoch (BSD, Linux, Mac, Unix) a nie na OS Windows.
Najlepšie sa paralelizujú cykly, ktorých slučky sú navzájom nezávislé, teda funkcie ako apply a lapply. Ich argumentom je jednak matica, data.frame alebo list, a jednak funkcia, ktorá sa aplikuje na každý riadok, stĺpec, alebo element. Ilustrujme to na jednoduchom príklade, v ktorom treba zoradiť prvky stĺpcov matice podľa veľkosti. Najprv vytvoríme jednoduchú funkciu pre zoradenie prvkov jedného vektora pomocou vnorených for-cyklov a podmienky, a overíme jeho funkčnosť:
sort_for <- function(x) {
n <-length(x)
for(i in 1:(n-1)) {
for(j in (i+1):n) {
xi <- x[i]
if(x[j] < xi) {
x[i] <- x[j]
x[j] <- xi
}
}
}
x
}
sort_for(c(3,2,4,2))
## [1] 2 2 3 4Na ilustráciu poslúži matica náhodných čísel z normálneho rozdelenia rozmeru \(1000\times12\).
n <- 12e+3
mat <- matrix(rnorm(n), n/12, 12)
str(mat)
## num [1:1000, 1:12] 0.8512 0.6578 0.0926 -0.763 0.1029 ...Rýchlosť zoradenia jedného stĺpca
system.time( sort_for(mat[,1]) )
## user system elapsed
## 0.043 0.004 0.046je približne 1/12 času potrebného na zoradenie všetkých stĺpcov sériovo (jedného po druhom):
system.time( apply(mat, 2, sort_for) )
## user system elapsed
## 0.583 0.000 0.583(Tzv. user time je čas, ktorý procesoru zabral beh systému R, naopak system time pre danú úlohu venoval operačný systém a nakoniec elapsed time je čas, ktorý uplynul od spustenia po ukončenie úlohy. Ak je elapsed nižší ako súčet ostatných dvoch dokopy, pravdepodobne sa k slovu dostala implicitná paralelizácia. Na druhú stranu, ak je väčší, bežia v systéme aj iné, nesúvisiace ale časovo náročné úlohy.)
Ak procesor podporuje prácu vo viacerých vláknach, je možné štandardné sériové riešenie paralelizovať, a to napr. pomocou predinštalovaného balíka parallel.
library(parallel)Najprv zistíme počet logických jadier (vlákien). Z nich je bezpečné ponechať jedno vlákno pre beh operačného systému.
detectCores()
## [1] 16Postup aplikovaný pri paralelizácii je zhrnutý v nasledujúcich bodoch:
- Rozdelenie údajov na jednotlivé vlákna.
- Skopírovanie funkcie na každé z vlákien.
- Súbežné vykonanie funkcie na podmnožine údajov.
- Zhromaždenie výsledkov zo všetkých vlákien.
Pri každej súbežnej slučke cyklu sa čaká na dokončenie výpočtov zo všetkých vlákien a až potom začne nová, preto je vhodné navrhnúť podmnožiny údajov vyvážene. Náš prípad je z tohto pohľadu triviálny, pretože podmnožiny súboru údajov (stĺpce matice) sú rovnako veľké.
V systéme Linux najprv skúsime metódu forking. Keďže však balík parallel nemá analógiu funkcie apply pre túto metódu, treba stĺpce najprv oddeliť, až potom použiť mclapply.
mat_list <- split(mat, col(mat))
cas <- system.time(
mclapply(mat_list, sort_for, mc.cores = 3)
)
cas
## user system elapsed
## 0.390 0.015 0.209Čas sa paralelizáciou zredukoval približne na polovicu, z toho drvivú väčšinu tvorí čas „child” procesov vyvedených z rodičovského ako hroty vidličky (fork).
c(cas)
## user.self sys.self elapsed user.child sys.child
## 0.000 0.007 0.209 0.390 0.008Druhá metóda, socket, vyžaduje najprv vytvorenie strapca (cluster) R sedení, do ktorých musíme exportovať našu funkciu. Klaster môže bežať na jadrách jedného osobného počítača, procesoroch jedného servera ale pokojne aj na počítačoch jednej počítačovej siete.
cl <- makeCluster(3)
clusterExport(cl, varlist = c("sort_for"))
system.time(
parApply(cl, X = mat, MARGIN = 2, FUN = sort_for)
)
## user system elapsed
## 0.003 0.000 0.242
stopCluster(cl)Tento prístup neumožňuje priame zistenie času spotrebovaného v „klastri”.
Na záver treba ešte raz upozorniť, že uvedený príklad je iba ilustračný, systém R má zabudovaný oveľa efektívnejší nástroj na zoradenie prvkov vektora.
system.time( apply(mat, MARGIN = 2, sort) )
## user system elapsed
## 0.001 0.000 0.001Funkcia sort, tak ako väčšina ostatných v systéme R, je implementovaná v niektorom z kompilovaných programovacích jazykov. V nasledujúcej kapitole si ukážeme ako prepojiť všestrannosť intepretovaného jazyka R s rýchlosťou kompilovaného jazyka C.
9.3 Zrýchlenie výpočtov pomocou C(++)
Niekedy rýchlosť intepretovaného kódu R nestačí. Môže byť dobre odladený, môžu byť efektívne využité natívne knižnice alebo zapojené všetky dostupné procesorové vlákna, ale i tak na zvolenú úlohu nestačí. Sú to najmä nasledujúce príklady, kedy prichádza čas využiť výhody kompilovaného kódu jazyka C:
- cykly, ktoré sa nedajú ľahko vektorizovať pre závislosť po sebe nasledujúcich iterácií,
- rekurzívne úlohy, pri ktorých sa niektoré funkcie volajú mnoho miliónov-krát,
- úlohy vyžadujúce dátové štruktúry a algoritmy, ktorými Rko nedisponuje (napr. ordered maps, double-ended queues).
Balík Rcpp výrazne zjednodušuje prepojenie C++ a R, a to obojsmerne, čiže umožňuje využiť rýchlosť jedného v druhom a bohatstvo knižníc druhého v prvom. Na začiatok odporúčame prehľadový článok (Eddelbuettel a Balamuta 2018), neskôr základnú príručku (Wickham 2019, kapitola High performance functions with Rcpp v prvej verzii a kapitola 25 Rewriting R code in C++ v druhej verzii knihy) a nakoniec podrobný manuál (Tsuda 2020).
9.3.1 Jednoduchý príklad
Pre jednoduchú ilustráciu prepíšme funkciu na zoradenie prvkov vektora z predošlej časti do jazyka C
library(Rcpp)
cppFunction('NumericVector sort_C(NumericVector x) {
int n = x.size();
double xi;
for(int i = 0; i <= n-2; ++i) {
for(int j = i+1; j <= n-1; ++j) {
xi = x[i];
if (x[j] < xi) {
x[i] = x[j];
x[j] = xi;
}
}
}
return x;
}')
sort_C(c(3,2,4,2))
## [1] 2 2 3 4a porovnajme čas potrebný na vykonanie oboch funkcií, ak vstupný vektor má 5000 prvkov.
vec <- rnorm(5e3)
system.time( sort_for(vec) )
## user system elapsed
## 1.186 0.000 1.188
system.time( sort_C(vec) )
## user system elapsed
## 0.014 0.000 0.015Kompilovaný kód je v tomto prípade asi 100-násobne rýchlejší oproti interpretovanému.
Samozrejme vstavaná funkcia sort je ešte oveľa rýchlejšia, pretože jej implementácia v jazyku C je optimalizovaná.
system.time( sort(vec) )
## user system elapsed
## 0 0 09.3.2 Maticové výpočty
Štýl tvorenia kódu C++ (nielen v prostredí Rcpp) závisí od použitých knižníc, napr. manipuláciu s poliami (najmä vektory a matice) veľmi uľahčuje knižnica Armadillo (a s Rcpp jej implementácia RcppArmadillo). Nástroje každej knižnice (či je to Rcpp, Armadillo alebo štandardná knižnica std) však zväčša vyžadujú vlastné dátové štruktúry (napr. Rcpp::NumericVector oproti arma::vec), medzi ktorými je treba robiť konverziu, aby sa tieto nástroje dali využiť. Nasleduje zoznam užitočných zdrojov týkajúcich sa práce s poliami a najmä s knižnicou Armadillo:
- http://arma.sourceforge.net/docs.html
- https://github.com/petewerner/misc/wiki/RcppArmadillo-cheatsheet
- https://thecoatlessprofessor.com/programming/cpp/common-operations-with-rcpparmadillo/
- https://scholar.princeton.edu/sites/default/files/q-aps/files/slides_day4_am.pdf
- https://zenglix.github.io/Rcpp_basic/
Použitie knižnice Rcpparmadillo ilustruje nasledujúci príklad, v ktorom pomocou metódy bootstrap vypočítame intervalový odhad parametrov lineárneho štatistického modelu. Téma modelovania pozorovaných údajov presahuje záber tejto učebnice, žiadna kapitola sa jej doteraz nevenovala, preto je na tomto mieste potrebný krátky úvod do problému. Majme dve náhodné premenné \(X\) (hmotnosť automobilu) a \(Y\) (zdvihový objem valcov) a predpokladajme lineárnu závislosť medzi nimi, \(Y = a + b X + \varepsilon\), kde okrem deterministickej časti s parametrami \(a\) (absolútny člen, tzv. intercept) a \(b\) (sklon, slope) vystupuje aj náhodný člen \(\varepsilon\) (šum, noise). Parametre sú väčšinou neznáme, no dajú sa na základe konkrétnych pozorovaní premenných \(X\) a \(Y\) odhadnúť. Keďže sa dá model prepísať na \(Y = (a,b)(1,X) + \varepsilon\), dosadením \(n\) pozorovaní \(x_i\) a \(y_i\) dostaneme sústavu \(n\) rovníc \(y_i = (a,b)(1,x_i)+\varepsilon\), \(i=1,\ldots,n\), o dvoch neznámych, v maticovom tvare \[ \mathbf{y}=\mathbf{X}\cdot\beta + \boldsymbol{\varepsilon},\qquad \text{kde }\quad \mathbf{y}=\begin{pmatrix} y_1 \\ \vdots \\ y_n\end{pmatrix},\quad \mathbf{X}= \begin{pmatrix} 1 & x_1 \\ \vdots & \vdots \\ 1 & x_n\end{pmatrix},\quad \boldsymbol{\varepsilon} = \begin{pmatrix} \varepsilon_1 \\ \vdots \\ \varepsilon_n\end{pmatrix}, \] a neznáme sú prvky vektora \(\beta=(a,b)^T\). Sústava je pre \(n>2\) zjavne preurčená, a tak našim cieľom je dostať čo najlepší odhad \(\beta\). Najčastejšie používaná metóda – metóda maximálnej vierohodnosti – je v prípade normálne rozdeleného šumu \(\varepsilon_i\sim N(0,\sigma)\), \(\forall i\), totožná s metódou najmenších štvorcov, ktorá minimalizuje súčet druhých mocnín prvkov vektora rezíduí \(\boldsymbol{\varepsilon}\). Prakticky je odhad vypočítaný pomocou vzťahu \[ \hat\beta=\left(\mathbf{X}^T\cdot\mathbf{X}\right)^{-1}\cdot \mathbf{X}^T\cdot\mathbf{y}. \] V prípade hmotnosti a zdvihového objemu
dat <- mtcars[c("wt", "disp")]
X <- cbind(1, dat$wt)
y <- dat$disp
beta <- solve(t(X) %*% X) %*% t(X) %*% y
c( beta )
## [1] -131.1484 112.4781dostávame odhad regresnej priamky v tvare \(Y = -131.1 + 112.48 X\), ktorá aj podľa obrázku dobre korešponduje s pozorovaniami.
plot(disp ~ wt, dat)
abline(coef = beta, lwd=2, col=4)
legend("bottomright", legend=c("data", "model"), pch=c(1,NA), lty=c(0,1), col=c(1,4))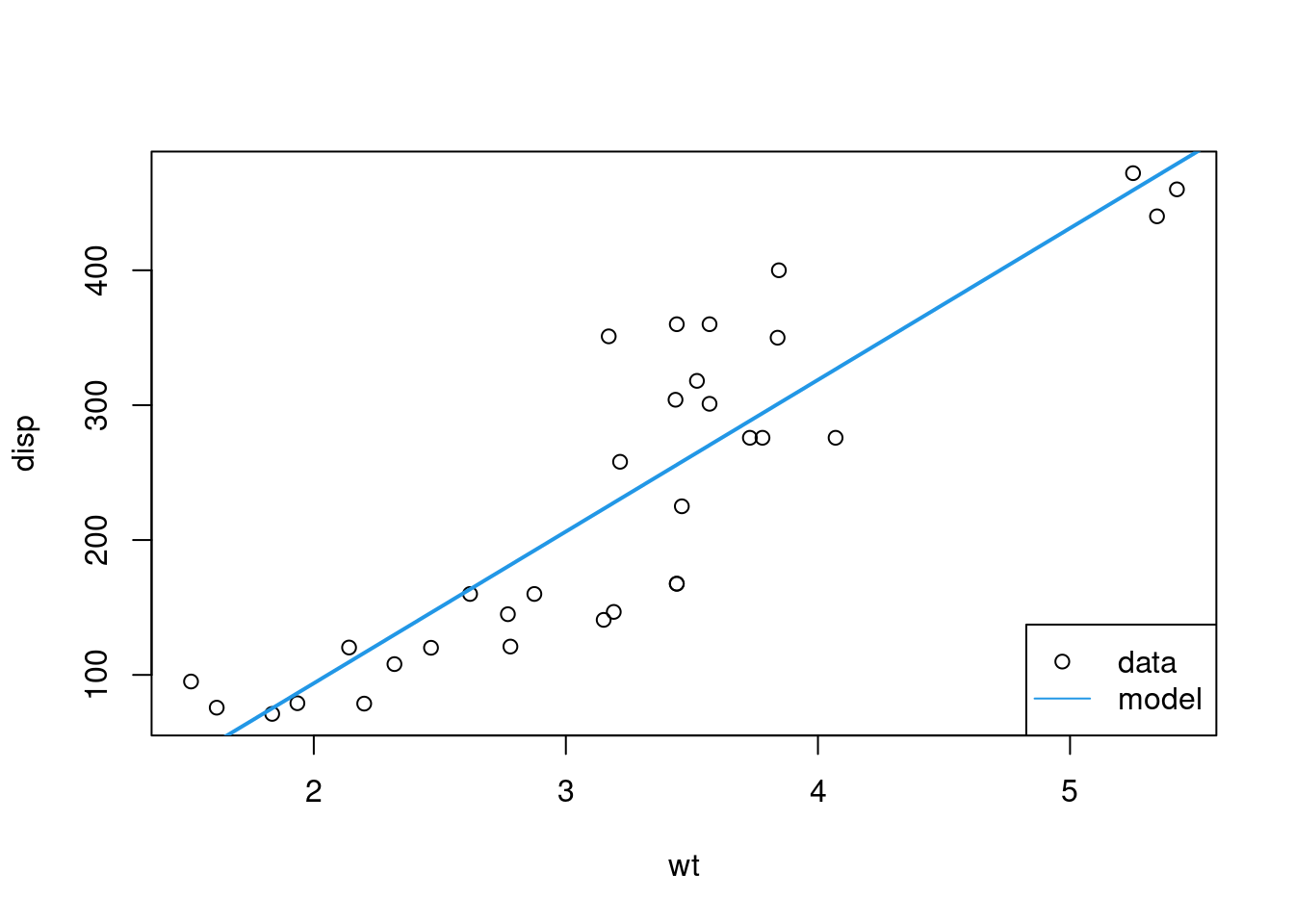
Pozorovania však predstavujú náhodný výber (zo základného súboru). Za iných podmienok (iná vzorka modelov áut) by pozorované hmotnosti a objemy mali iné hodnoty a odhad parametrov regresnej priamky by sa zmenil tiež. Keďže v štatistike ide o matematický popis predovšetkým základného súboru, určuje sa okrem bodového odhadu aj ten intervalový. To je interval, v ktorom sa s určitou pravdepodobnosťou (najčastejšie 0,95) nachádza skutočná hodnota parametra (získateľná iba z celého základného súboru). Interval spoľahlivosti sa dá odhadnúť niekoľkými spôsobmi. Ak je splnený predpoklad normality rezíduí \(\varepsilon_i\), konštruuje sa symetricky okolo bodového odhadu pomocou t-rozdelenia. Iný prístup predstavuje metóda bootstrap – nie je viazaná normalitou, no je náročnejšia na výkon počítača. Postup je nasledovný:
- zo súboru všetkých pozorovaní dĺžky \(n\) sa náhodne vyberie \(N\) vzoriek dĺžky \(n\) (s opakovaním),
- pre každú vzorku sa odhadnú parametre regresnej priamky, takže vo výsledku bude \(N\) dvojíc odhadov (priesečník a sklon priamky),
- z \(N\) realizácií parametra sa vyberie jeho 2,5 %-ný a 97,5 %-ný kvantil, ktoré tvoria hranice 95 %-ného intervalu spoľahlivosti.
Počet opakovaní \(N\) sa bežne volí v tisícoch, preto neoptimalizovaný výpočet môže v prípade zložitejších modelov trvať minúty až hodiny. Keďže odhad parametrov je jednoduchým problémom lineárnej algebry, ale v simulácii opakovaný veľmi veľa krát, je metóda bootstrap ideálna na implementáciu v kompilovanom jazyku.
Začneme definíciou funkcie. Opäť by sa dala použiť funkcia cppFunction, tentokrát aj s argumentom depends = "RcppArmadillo". Komplikovanejší kód je však výhodnejšie písať do oddeleného súboru s príponou .cpp a potom načítať pomocou funkcie sourceCpp. Jednak sa tým využije schopnosť editoru zvýrazniť syntax, jednak sa ľahšie identifikuje chyba podľa čísla riadku. V našej ukážke bude obsah súboru reprezentovať reťazec v argumente code:
Rcpp::sourceCpp(code = "
#include <RcppArmadillo.h>
// [[Rcpp::depends(RcppArmadillo)]]
using namespace Rcpp;
// [[Rcpp::export]]
arma::mat multiodhadLM_C(NumericMatrix dat, int N) {
int n = dat.nrow();
arma::mat paraM(2,N);
arma::colvec unit = arma::ones(n,1);
arma::mat Y = as<arma::mat>(dat);
arma::mat X;
arma::uvec i;
arma::uvec j01 = {0, 1};
for (int k = 0; k < N; k++) {
i = as<arma::uvec>(sample(n, n, true)) - 1;
arma::mat Ys = Y.submat(i,j01);
X = arma::join_horiz(unit, Ys.col(0));
paraM.col(k) = arma::solve(X.t() * X, X.t() * Ys.col(1));
}
return paraM;
}
")Prvý riadok kódu jazyka C sprístupňuje triedy a funkcie definované v knižnici RcppArmadillo. Druhý riadok indikuje kompilátoru závislosť na balíku RcppArmadillo (žiaľ oba riadky sú potrebné). Ak by chýbal príkaz v treťom riadku, názvy všetkých použitých objektov z balíku Rcpp by museli obsahovať predponu (prefix) svojej príslušnosti, napríklad Rcpp::NumericMatrix. To sa nevzťahuje na príkazy za reťazcom //, ktorý kompilátoru jazyka C indikuje, že v riadku nasleduje komentár. Preto príkaz na export funkcie do prostredia R, // [[Rcpp::export]], musí obsahovať predponu.
Samotná funkcia čaká na vstupe maticové pole dátového typu z Rcpp (pozorované údaje) a prirodzené číslo (počet simulácií), naopak vráti maticové pole typu Armadillo. Konverzia medzi R a C++ je ošetrená automaticky, v C++ však s ich rozdielnosťou treba počítať. Keďže z knižnice Armadillo potrebujeme užitočné funkcie join_horiz (analógia rbind v R), ones (pole vyplní jednotkami) či solve, a metódy .nrow (počet riadkov), .submat (časť matice), .col (stĺpec matice), .t (transponovanie), je nutné konvertovať maticu triedy Rcpp do triedy knižnice Armadillo (arma) pomocou funkcie as
V jazyku R by funkcia multiodhadLM_C bola jednoduchšia (netreba deklarovať typ premenných),
multiodhadLM_R <- function(dat, N) {
n <- nrow(dat)
paraM <- matrix(nrow = 2, ncol = N)
for(k in 1:N) {
i <- sample(n, n, replace=TRUE)
Ys <- dat[i,]
X <- cbind(1, Ys[,1])
paraM[,k] <- solve(t(X) %*% X) %*% t(X) %*% Ys[,2]
}
}ale aj približne 15-krát pomalšia (použitie for cyklu namiesto sapply má iba minimálny vplyv).
system.time(
sim <- multiodhadLM_C(as.matrix(dat), 5000)
)
system.time(
multiodhadLM_R(as.matrix(dat), 5000)
)
sim[,1:5] # prvých 5 dvojíc
## user system elapsed
## 0.009 0.000 0.010
## user system elapsed
## 0.160 0.000 0.161
## [,1] [,2] [,3] [,4] [,5]
## [1,] -129.3814 -153.6921 -153.0908 -154.7458 -145.8308
## [2,] 112.6642 124.0603 115.0109 126.0249 116.3214Z výslednej matice sim rozmeru \(2\times N\) už stačí len vypočítať požadovaný súhrn.
suhrn <- apply(sim, 1, function(x)
c(mean = mean(x), median = median(x), quantile(x, c(0.025, 0.975)))
)
suhrn
## [,1] [,2]
## mean -133.97528 113.3539
## median -132.57435 112.6663
## 2.5% -181.76654 101.7658
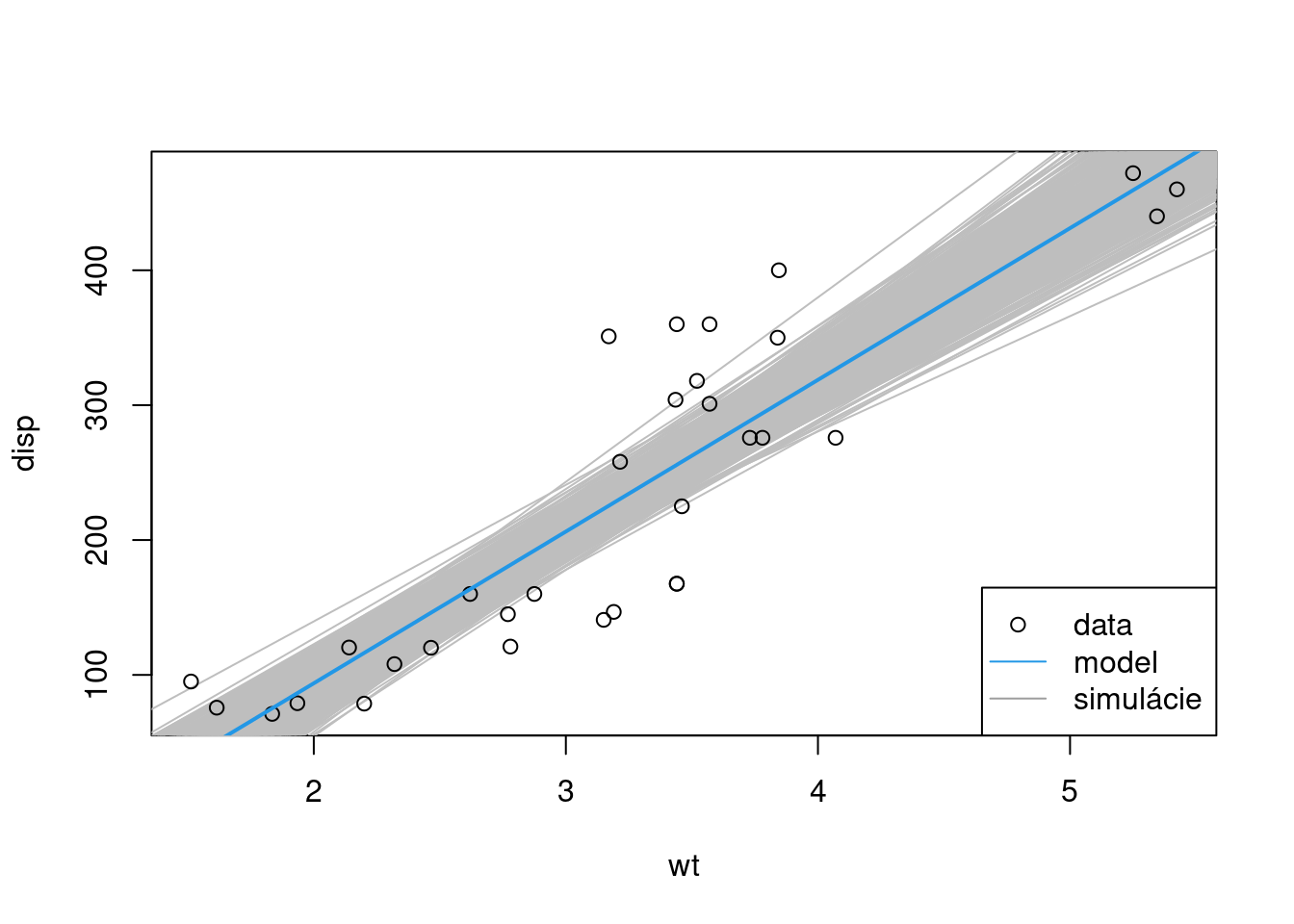
## 97.5% -94.96105 128.8691Prirodzene, stredná hodnota i medián sú blízke odhadom z pôvodného výberu dat, skutočná hodnota parametrov základného súboru však s vysokou pravdepodobnosťou (95 %) môže ležať kdekoľvek v rozsahu \(a\in(-181.77,-94.96)\), \(b\in(101.77,128.87)\). Najlepšie to ilustruje graf, ktorý okrem pôvodného odhadu regresnej priamky zobrazuje aj jej bootstrap simulácie.
plot(disp ~ wt, dat, type="n") # prázdny graf
for(i in 1:1000) abline(coef = sim[,i], col = "grey") # stačí zobraziť len 1000
points(disp ~ wt, dat) # zobrazenie až po simuláciách kvôli prekrytu
abline(coef = beta, lwd = 2, col = 4)
legend("bottomright", legend=c("data", "model", "simulácie"),
pch=c(1,NA, NA), lty=c(0,1,1), col=c(1,4,8)
)
9.4 Práca s veľkými tabuľkami – databázy
Pri transformácii údajov sme si ukázali, aký efektívny nástroj má systém R v balíku dplyr. Až do tejto chvíle sme vždy pracovali s dátovými súbormi, ktoré sa bez problémov zmestili do pamäte bežného osobného počítača. Celkom pochopiteľne je R-ko ako analytický nástroj schopný pracovať aj s oveľa väčším objemom údajov, tie sú však už uložené v relačných databázach. Relačná databáza je súhrn údajov uchovávaný v navzájom prepojených tabuľkách. Získavať údaje z databáz je možné pomocou dopytovacieho jazyka (napr. SQL), počítačový program na ich správu a tvorbu dopytov sa nazýva systém riadenia bázy údajov (napr. SQLite, PostgreSQL, MySQL, MariaDB, Oracle, Microsoft Access). Databázovým systémom sa zvykne súhrnne označovať dvojica – databáza a systém jej riadenia.
V tejto podkapitole si krátko priblížime jazyk SQL a na ilustračnej databáze ukážeme prístup k záznamom z prostredia R (Finley, Doser, a Vince 2020, kap. 13 Databases and R).
9.4.1 SQL
Každá tabuľka relačnej databázy pozostáva zo stĺpcov (polia) a riadkov (záznamy) – podobne ako data frame v R, kde stĺpce nazývame premennými a riadky pozorovaniami. Tabuľky sú spravidla tematicky zamerané, majú však spoločné kľúčové pole, pomocou ktorého je možné prepojiť záznamy v jednotlivých tabuľkách, napr. v databáze študentov by jedna tabuľka obsahovala kontaktné údaje (nazvime ju „kontakty”), druhá študijné výsledky z jednotlivých predmetov („známky”) a kľúčovým poľom v každej z nich by bolo identifikačné číslo študenta. Vďaka prepojeniu (vzťahu, relácii) tabuliek môžeme napr. konkrétnemu študentovi zaslať jeho známky.
Syntax jazyka SQL (Structured Query Language) je podobná ako syntax prirodzeného jazyka, typický príkaz má tvar súvetia: hlavná, rozkazovacia veta začína prísudkom, pokračuje predmetom a ďalšie členy, resp. vedľajšie vety vyjadrujú sériu podmienok. Napr. požiadavka
SELECT email FROM kontakty WHERE id = '007'vyberie všetky záznamy z pola email v tabuľke kontakty, ktoré spĺňajú podmienku identifikačného čísla rovného hodnote 007. Zložitejšie požiadavky obsahujú logickú spojku AND, prepojovací príkaz JOIN alebo zoskupovanie podľa hodnôt konkrétneho poľa GROUP BY. Okrem toho možno prvky z databázy nielen vyberať ale aj vkladať, modifikovať či odstraňovať (INSERT, UPDATE, DELETE) a mnoho ďalšieho (https://www.sqltutorial.org).
9.4.2 Prístup z R
Práca s veľkými súbormi údajov v R prináša množstvo ťažkostí, úzke premostenie medzi prostredím a databázovým systémom bráni narábať s dátami rovnako rýchlo ako s lokálnymi objektami typu data frame. Historicky sa to riešilo dvoma spôsobmi: jedným sa dáta do lokálnej pamäte sťahovali po menších častiach, druhým sa sťahoval celý súbor naraz. Ani jedno riešenie nie je ideálne, pretože poskytujú iba čiastkový obraz o dátach, alebo spomaľujú analýzu, nehovoriac o potrebe sťahovať dáta pri každej aktualizácii databázy a zahlteniu pamäte počítača. Hlavný problém oboch prístupov je, že sa snažia manipuláciu s databázou vykonať lokálne. Efektívnejším riešením by však bolo prinútiť systém R zaslať SQL požiadavku databázovému systému, ktorý vráti data frame vhodný pre ďalšiu analýzu – ideálne bez toho, aby sme sa museli jazyk SQL sami učiť. Jedným takým nástrojom je už dobre známy balík dplyr, ktorý umožňuje manipulovať so vzdialenými databázami rovnako pohodlne ako s dátovým rámcom.
Ukážeme si to na príklade a použijeme pri tom jednoduchý a voľne šíriteľný databázový systém SQLite. Ten je vhodný aj pre domáce použitie, pretože nevyžaduje samostatný beh servera, databáza je uložená v jedinom súbore a prístup ku nemu zabezpečuje malý program21. Napriek svojej jednoduchosti dokáže SQLite zabezpečiť manipuláciu s mnohými gigabajtami údajov, funguje na ňom väčšina webových stránok, avšak na väčšie projekty nestačí, neumožňuje napr. prácu so skupinami (to čo v dplyr poznáme ako group_by). Na serióznejšie úlohy sa odporúča napr. (rovnako voľne šíriteľný) PostgreSQL, ktorý však už musí bežať na serveri (hoci aj lokálne na PC) a teda vyžaduje jeho konfiguráciu. Aby Rko dokázalo komunikovať s databázovými systémami, je potrebný balík DBI, ovládač ku konkrétnemu systému SQLite zabezpečuje balík RSQLite a mozaiku medzičlánkov ku nástrojom dplyr dopĺňa balík dbplyr. Podrobnejšie informácie o integrácii databáz v R aj v RStudio sú na stránke https://db.rstudio.com.
V príklade použijeme voľne dostupnú ilustračnú databázu chinook, ktorú stačí stiahnuť zo stránky https://www.sqlitetutorial.net/sqlite-sample-database/ do pracovného adresára. Prvým krokom je vytvorenie spojenia s databázovým systémom (systém riadenia + databáza) a zobrazenie zoznamu tabuliek.
chinook <- DBI::dbConnect(drv = RSQLite::SQLite(), dbname = "data/chinook.db")
DBI::dbListTables(chinook)
## [1] "Album" "Artist" "Customer" "Employee"
## [5] "Genre" "Invoice" "InvoiceLine" "MediaType"
## [9] "Playlist" "PlaylistTrack" "Track"Chinook22 je databáza fiktívneho digitálneho obchodu s hudbou obsahujúca informácie o umelcoch, albumoch, piesňach, zamestnancoch obchodu, zákazníkoch a faktúrach za obdobie 4 rokov. Vezmime si napríklad tabuľku o zamestnancoch.
employees <- dplyr::tbl(src = chinook, from = "Employee")
employees
## # Source: table<Employee> [?? x 15]
## # Database: sqlite 3.38.3
## # [/media/tomas/SAM32/documents/math/edu/R_ucebnica/data/chinook.db]
## EmployeeId LastName FirstName Title ReportsTo BirthDate HireDate Address City
## <int> <chr> <chr> <chr> <int> <chr> <chr> <chr> <chr>
## 1 1 Adams Andrew Gene… NA 1962-02-… 2002-08… 11120 … Edmo…
## 2 2 Edwards Nancy Sale… 1 1958-12-… 2002-05… 825 8 … Calg…
## 3 3 Peacock Jane Sale… 2 1973-08-… 2002-04… 1111 6… Calg…
## 4 4 Park Margaret Sale… 2 1947-09-… 2003-05… 683 10… Calg…
## 5 5 Johnson Steve Sale… 2 1965-03-… 2003-10… 7727B … Calg…
## 6 6 Mitchell Michael IT M… 1 1973-07-… 2003-10… 5827 B… Calg…
## 7 7 King Robert IT S… 6 1970-05-… 2004-01… 590 Co… Leth…
## 8 8 Callahan Laura IT S… 6 1968-01-… 2004-03… 923 7 … Leth…
## # … with 6 more variables: State <chr>, Country <chr>, PostalCode <chr>,
## # Phone <chr>, Fax <chr>, Email <chr>Vyzerá takmer ako tabuľka formátu tibble, iba navyše obsahuje meta-informácie o databáze. Podobne pohodlne sa s ňou pomocou dplyr aj robí.
salesSupportAgents <- employees %>%
dplyr::filter(Title == "Sales Support Agent") %>%
dplyr::select(LastName, FirstName, Phone, Email) %>%
dplyr::arrange(LastName)
salesSupportAgents
## # Source: lazy query [?? x 4]
## # Database: sqlite 3.38.3
## # [/media/tomas/SAM32/documents/math/edu/R_ucebnica/data/chinook.db]
## # Ordered by: LastName
## LastName FirstName Phone Email
## <chr> <chr> <chr> <chr>
## 1 Johnson Steve 1 (780) 836-9987 steve@chinookcorp.com
## 2 Park Margaret +1 (403) 263-4423 margaret@chinookcorp.com
## 3 Peacock Jane +1 (403) 262-3443 jane@chinookcorp.comPožiadavku SQL, ktorá bola pri tom na pozadí zaslaná databázovému systému, si môžme zobraziť
dplyr::show_query(salesSupportAgents)
## <SQL>
## SELECT `LastName`, `FirstName`, `Phone`, `Email`
## FROM `Employee`
## WHERE (`Title` = 'Sales Support Agent')
## ORDER BY `LastName`ale kľudne akúkoľvek SQL požiadavku aj poslať priamo.
DBI::dbGetQuery(chinook, '
SELECT "LastName", "FirstName", "Phone", "Email"
FROM "Employee"
WHERE "Title" = "Sales Support Agent"
ORDER BY "LastName"
')Objekty chinook, employees a salesSupportAgents sú stále iba spojenia, i keď sa vďaka výpisu tvária ako dátové objekty. Presvedčíme sa o tom napr. požiadavkou na zistenie počtu riadkov.
salesSupportAgents %>% nrow()
## [1] NAVýber z databázy sa však do lokálneho dátového objektu dá uložiť, len si treba vopred overiť, či objem sťahovaných dát zodpovedá našej predstave, rýchlosti pripojenia a hardvéru lokálneho počítača.
salesSupportAgents %>% dplyr::summarise(n())
## Warning: ORDER BY is ignored in subqueries without LIMIT
## ℹ Do you need to move arrange() later in the pipeline or use window_order() instead?
## # Source: lazy query [?? x 1]
## # Database: sqlite 3.38.3
## # [/media/tomas/SAM32/documents/math/edu/R_ucebnica/data/chinook.db]
## `n()`
## <int>
## 1 3
salesSupportAgents %>% dplyr::collect()
## # A tibble: 3 × 4
## LastName FirstName Phone Email
## <chr> <chr> <chr> <chr>
## 1 Johnson Steve 1 (780) 836-9987 steve@chinookcorp.com
## 2 Park Margaret +1 (403) 263-4423 margaret@chinookcorp.com
## 3 Peacock Jane +1 (403) 262-3443 jane@chinookcorp.comPrvým príkazom bola do databázy zaslaná SQL požiadavka na počet riadkov. V tomto prípade teda ide iba o malú tabuľku, ktorá sa druhým príkazom stiahla okamžite.
Podobne ako pri zisťovaní počtu riadkov, ani zobrazenie údajov v databáze pomocou ggplot2 nejde vykonať priamo, dá sa však použiť balík dbplot ktorý potrebné výpočty urobí na strane databázového systému a výsledok vykreslí lokálne.
employees %>%
dbplot::dbplot_bar(x = Title) +
ggplot2::labs(title = "Pozície zamestnancov") +
ggplot2::ylab("Počet") +
ggplot2::theme_classic()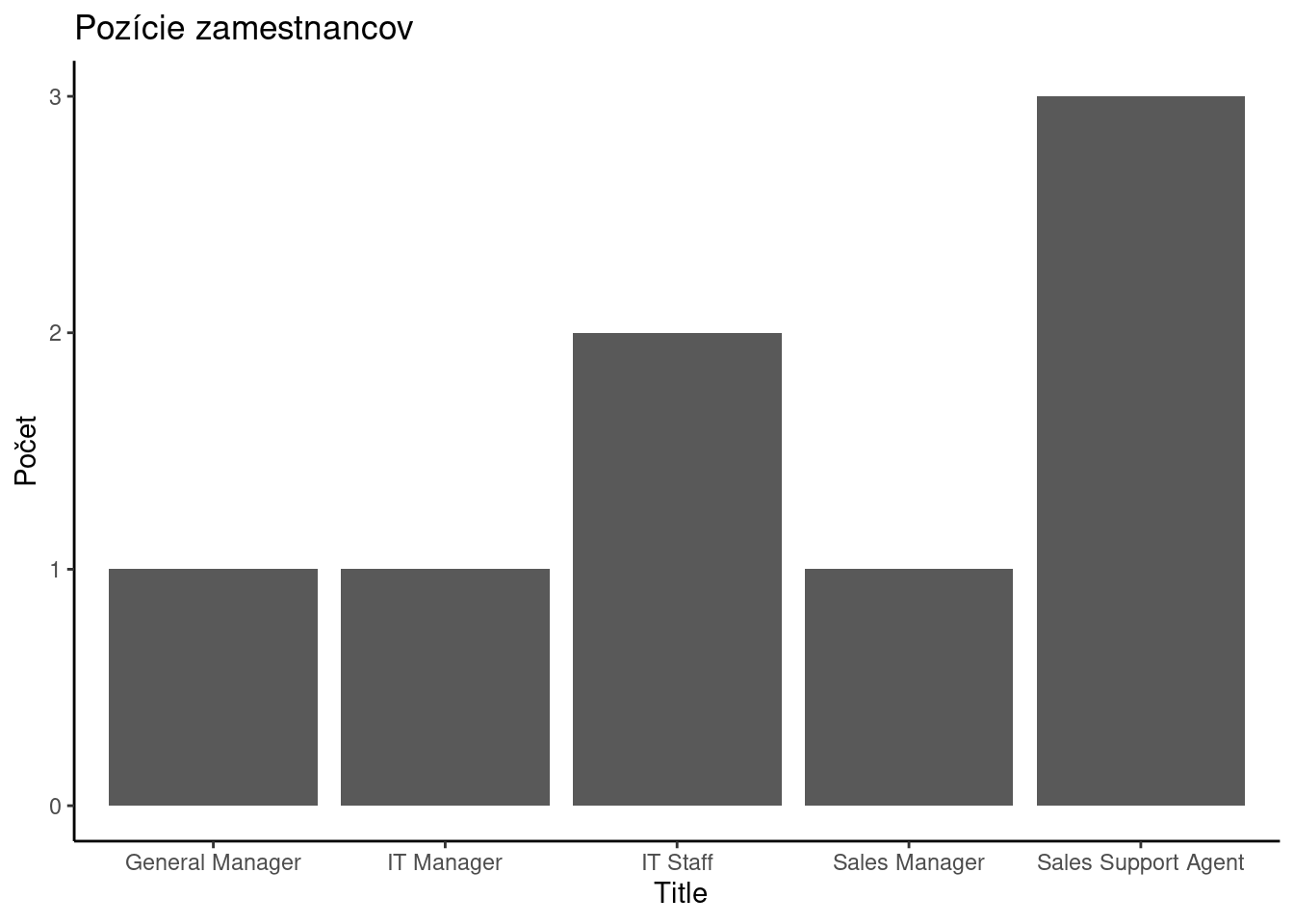
Chinook je relačná databáza, tabuľky navzájom súvisia, napríklad tabuľka „Album” v každom zázname obsahuje aj ID umelca „ArtistId”, toto pole je pochopiteľne prítomné aj v tabuľke „Artist” a prepája obe tabuľky, preto sa nazýva kľúčové. Využijeme ho na vypísanie všetkých ponúkaných albumov skupiny „R.E.M.”. Na to je potrebné obe tabuľky najprv zlúčiť. V balíku dplyr na zlučovanie tabuliek slúži niekoľko funkcií s príponou *_join* a predponami inner, left, right a full, ktoré sa líšia tým, ako riešia prítomnosť implicitne chýbajúcich hodnôt v kľúčovom poli prvej (ľavej) a druhej (pravej) tabuľky – teda tých záznamov, ktoré sa nachádzajú iba v jednej tabuľke. Detailne o tom píše (Wickham a Grolemund 2016, kap. 13 Relational data).
dplyr::tbl(src = chinook, from = "Artist") %>%
dplyr::filter(Name == "R.E.M.") %>%
dplyr::inner_join(y = dplyr::tbl(src = chinook, from = "Album"), # alebo left_join
by = "ArtistId")
## # Source: lazy query [?? x 4]
## # Database: sqlite 3.38.3
## # [/media/tomas/SAM32/documents/math/edu/R_ucebnica/data/chinook.db]
## ArtistId Name AlbumId Title
## <int> <chr> <int> <chr>
## 1 124 R.E.M. 188 Green
## 2 124 R.E.M. 189 New Adventures In Hi-Fi
## 3 124 R.E.M. 190 The Best Of R.E.M.: The IRS YearsPo skončení práce s databázovým systémom je potrebné databázu odpojiť:
DBI::dbDisconnect(chinook)9.4.3 Vytvorenie databázy
Videli sme, že balík dplyr je dobrý nástroj na získanie údajov z databázy, veľmi sa však nehodí na jej modifikáciu, teda vkladanie a odstraňovanie záznamov z databázy. Zapisovanie tabuliek do databázy (novej či existujúcej) je možné iba z existujúceho objektu v prostredí R.
con <- DBI::dbConnect(drv = RSQLite::SQLite(), dbname = "data/mtcars.db")dplyr::copy_to(dest = con, df = mtcars, name = "mtcars", temporary = FALSE, overwrite = T)
dplyr::tbl(src = con, from = "mtcars") %>% head()
## # Source: lazy query [?? x 11]
## # Database: sqlite 3.38.3
## # [/media/tomas/SAM32/documents/math/edu/R_ucebnicadata/mtcars.db]
## mpg cyl disp hp drat wt qsec vs am gear carb
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 21 6 160 110 3.9 2.62 16.5 0 1 4 4
## 2 21 6 160 110 3.9 2.88 17.0 0 1 4 4
## 3 22.8 4 108 93 3.85 2.32 18.6 1 1 4 1
## 4 21.4 6 258 110 3.08 3.22 19.4 1 0 3 1
## 5 18.7 8 360 175 3.15 3.44 17.0 0 0 3 2
## 6 18.1 6 225 105 2.76 3.46 20.2 1 0 3 1Databázové systémy však majú zmysel práve vtedy, keď náš súbor údajov je priveľký na to, aby sa zmestil do voľnej pamäte RAM (alebo je práca s ním pomalá), teda keď zaberá miesto rádovo v jednotkách, desiatkach či stovkách GB. Taký súbor je potom potrebné dostať do databázy buď po častiach, alebo priamo z textového CSV súboru uloženom na pevnom disku. Ukážeme si druhý spôsob, treba však súbor pripraviť/upraviť tak, aby desatinné miesta v numerických hodnotách oddeľoval znak . (bodka, nie čiarka), a počet prvkov v hlavičkovom riadku zodpovedal počtom prvkov v ostatných riadkoch. Funkcia DBI::dbWriteTable automaticky určí správny formát jednotlivých polí, no umožňuje ho zadať aj manuálne.
# príprava ilustračného súboru
mtcars %>%
tibble::rownames_to_column(var = "model") %>%
write.table(file = "data/mtcars.csv", sep = ",", row.names = FALSE)
# zápis súboru do tabuľky databázy
DBI::dbWriteTable(conn = con, name = "mtcars", value = "data/mtcars.csv",
overwrite = TRUE, skip = 0, sep = ",")
#odpojenie databázy
DBI::dbDisconnect(con)Najviac možností importu dávajú pochopiteľne priamo nástroje systému SQLite, pre bežného používateľa je najjednoduchšie použiť niektorý z grafických prostredí ako napr. SQLite Browser alebo SQLite Studio.
9.5 Cvičenie
- Paralelizujte odhad intervalu spoľahlivosti parametrov regresnej priamky z tretej podkapitoly.
- Funkciu sort_C z tretej kapitoly umiestnite do súboru s príponou .cpp, použite ju v ďalšej funkcii na výpočet mediánu a obe nastavte tak, aby boli viditeľné po načítaní funkciou sourceCpp. Ich funkčnosť vyskúšajte v R. Ako by ste si výpočet mediánu uľahčili s pomocou hotových funkcií v štandardnej knižnici std alebo pomocou tzv. sugar funkcií z Rcpp?
- Z balíku nycflights13 uložte všetky dátové rámce, ktoré sú potrebné na dokončenie tejto úlohy, do textových súborov vo formáte .csv a tieto importujte do SQLite databázy uloženej v súbore nycflights13.db do zodpovedajúcich tabuliek (import si vyskúšajte aj v externom programe – čím sa bude líšiť ďalší postup?). Vytvorte nové spojenie, a pomocou príkazov nad touto databázou (dáta sa nesmú nachádzať v objekte prostredia R) v histograme zobrazte prehľad kapacity lietadiel, ktoré 1.1.2013 vzlietli v ranných hodinách z New Yorku.
- Ako by ste charakterizovali svoj štýl programovania, v čom sa líši od odporúčaní komunity napr. okolo ekosystému tidyverse?
Literatúra
Nástroje SQLite sú v operačnom systém MacOS predinštalované, OS Linux ich má v repozitároch jednotlivých distribúcií, jedine pre OS Windows ich je potrebné stiahnuť. Na stránke https://www.sqlitetutorial.net/download-install-sqlite/ sa nachádza jednoduchý návod aj s odkazom na grafické používateľské prostredia.↩︎
Databáza je alternatívou ku staršej ilustračnej databáze Northwind, názov chinook odkazuje na vetry vo vnútrozemí západu Severnej Ameriky.↩︎