Kapitola 10 Riešenie úloh z cvičení
10.1 Úvod do R
dat <- datasets::mtcarsstr(dat)
## 'data.frame': 32 obs. of 11 variables:
## $ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
## $ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
## $ disp: num 160 160 108 258 360 ...
## $ hp : num 110 110 93 110 175 105 245 62 95 123 ...
## $ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
## $ wt : num 2.62 2.88 2.32 3.21 3.44 ...
## $ qsec: num 16.5 17 18.6 19.4 17 ...
## $ vs : num 0 0 1 1 0 1 0 1 1 1 ...
## $ am : num 1 1 1 0 0 0 0 0 0 0 ...
## $ gear: num 4 4 4 3 3 3 3 4 4 4 ...
## $ carb: num 4 4 1 1 2 1 4 2 2 4 ...
head(dat, 5)
## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2dat$kml <- dat$mpg * 0.425144aut <- dat$am == 0
c(automat = mean(dat$kml[aut]),
manual = mean(dat$kml[!aut])
)
## automat manual
## 7.290101 10.370243subset(dat, subset = gear==5 & wt<3, select = c(cyl, disp, hp))
## cyl disp hp
## Porsche 914-2 4 120.3 91
## Lotus Europa 4 95.1 113
## Ferrari Dino 6 145.0 175convert <- function(x, impunit = c("mile", "gallon", "inch", "pound"), toSI = TRUE) {
p <- toSI*2 - 1
const <- switch(impunit[1],
mile = 1.609,
gallon = 3.785,
inch = 0.254,
pound = 0.453592
)
x * const^p
}
# Súčasťou definície novej funkcie by mal byť aj príklad jej použitia:
convert(4, "inch")
## [1] 1.016
convert(1.016, "inch", toSI = FALSE)
## [1] 4- Pomocou klasického príkazu for:
tmp <- numeric(length = nrow(dat)) # vytvorenie prázdneho vektora
for (i in 1:nrow(dat)) {
tmp[i] <- convert(dat[i,"disp"]^(1/3), "inch")^3
}
rm(i) # for vytvorí pomocnú indexovú premennú i ako globálnu, odporúčam upratať
tmp # výsledok
## [1] 2.621930 2.621930 1.769803 4.227863 5.899343 3.687089 5.899343 2.403982
## [9] 2.307299 2.746472 2.746472 4.519552 4.519552 4.519552 7.734694 7.538049
## [17] 7.210308 1.289662 1.240501 1.165120 1.968086 5.211086 4.981667 5.735472
## [25] 6.554826 1.294578 1.971364 1.558410 5.751859 2.376124 4.932506 1.982835Elegantnejšie a rýchlejšie pomocou sapply:
sapply(dat$wt, convert, impunit = "pound")
## [1] 1.1884110 1.3040770 1.0523334 1.4582983 1.5603565 1.5694283 1.6193234
## [8] 1.4469585 1.4288148 1.5603565 1.5603565 1.8461194 1.6918982 1.7145778
## [15] 2.3813580 2.4602830 2.4244492 0.9979024 0.7325511 0.8323413 1.1181043
## [22] 1.5966438 1.5580885 1.7417933 1.7440612 0.8777005 0.9706869 0.6862847
## [29] 1.4378866 1.2564498 1.6193234 1.2609858# alternatívne:
#+ eval=F
sapply(dat$wt, function(x) convert(x, impunit = "pound"))Ak je funkcia už vektorizovaná, netreba používať funkcie pre cykly. Vektorizovať sa dá napr. pomocou funkcie Vectorize, alebo vhodnou konštrukciou funkcie pomocou už vektorizovaných funkcií. Tak bola vytvorená napr. aj naša funkcia convert, preto nasledujúci príkaz tiež funguje.
convert(dat$wt, impunit = "pound")setwd("/media/tomas/SAM32/documents/math/edu/R_ucebnica")datRT <- read.table("data/mtcars.txt", header = T, skip = 2, dec=",", sep = "",
na.strings = "?")
all.equal(target = datRT, current = dat)
## [1] "Length mismatch: comparison on first 11 components"
## [2] "Component \"vs\": 'is.NA' value mismatch: 0 in current 2 in target"Tým, že sme do dat pridali stĺpec kml, líšia sa šírkou (Length mismatch). V stĺpci vs sú v cieľovom (target) objekte 2 chýbajúce hodnoty (NA).
10.2 Základné nástroje na prieskumnú analýzu
data(Cars93, package = "MASS")? Cars93summary(Cars93)
## Manufacturer Model Type Min.Price Price
## Chevrolet: 8 100 : 1 Compact:16 Min. : 6.70 Min. : 7.40
## Ford : 8 190E : 1 Large :11 1st Qu.:10.80 1st Qu.:12.20
## Dodge : 6 240 : 1 Midsize:22 Median :14.70 Median :17.70
## Mazda : 5 300E : 1 Small :21 Mean :17.13 Mean :19.51
## Pontiac : 5 323 : 1 Sporty :14 3rd Qu.:20.30 3rd Qu.:23.30
## Buick : 4 535i : 1 Van : 9 Max. :45.40 Max. :61.90
## (Other) :57 (Other):87
## Max.Price MPG.city MPG.highway AirBags
## Min. : 7.9 Min. :15.00 Min. :20.00 Driver & Passenger:16
## 1st Qu.:14.7 1st Qu.:18.00 1st Qu.:26.00 Driver only :43
## Median :19.6 Median :21.00 Median :28.00 None :34
## Mean :21.9 Mean :22.37 Mean :29.09
## 3rd Qu.:25.3 3rd Qu.:25.00 3rd Qu.:31.00
## Max. :80.0 Max. :46.00 Max. :50.00
##
## DriveTrain Cylinders EngineSize Horsepower RPM
## 4WD :10 3 : 3 Min. :1.000 Min. : 55.0 Min. :3800
## Front:67 4 :49 1st Qu.:1.800 1st Qu.:103.0 1st Qu.:4800
## Rear :16 5 : 2 Median :2.400 Median :140.0 Median :5200
## 6 :31 Mean :2.668 Mean :143.8 Mean :5281
## 8 : 7 3rd Qu.:3.300 3rd Qu.:170.0 3rd Qu.:5750
## rotary: 1 Max. :5.700 Max. :300.0 Max. :6500
##
## Rev.per.mile Man.trans.avail Fuel.tank.capacity Passengers
## Min. :1320 No :32 Min. : 9.20 Min. :2.000
## 1st Qu.:1985 Yes:61 1st Qu.:14.50 1st Qu.:4.000
## Median :2340 Median :16.40 Median :5.000
## Mean :2332 Mean :16.66 Mean :5.086
## 3rd Qu.:2565 3rd Qu.:18.80 3rd Qu.:6.000
## Max. :3755 Max. :27.00 Max. :8.000
##
## Length Wheelbase Width Turn.circle
## Min. :141.0 Min. : 90.0 Min. :60.00 Min. :32.00
## 1st Qu.:174.0 1st Qu.: 98.0 1st Qu.:67.00 1st Qu.:37.00
## Median :183.0 Median :103.0 Median :69.00 Median :39.00
## Mean :183.2 Mean :103.9 Mean :69.38 Mean :38.96
## 3rd Qu.:192.0 3rd Qu.:110.0 3rd Qu.:72.00 3rd Qu.:41.00
## Max. :219.0 Max. :119.0 Max. :78.00 Max. :45.00
##
## Rear.seat.room Luggage.room Weight Origin Make
## Min. :19.00 Min. : 6.00 Min. :1695 USA :48 Acura Integra: 1
## 1st Qu.:26.00 1st Qu.:12.00 1st Qu.:2620 non-USA:45 Acura Legend : 1
## Median :27.50 Median :14.00 Median :3040 Audi 100 : 1
## Mean :27.83 Mean :13.89 Mean :3073 Audi 90 : 1
## 3rd Qu.:30.00 3rd Qu.:15.00 3rd Qu.:3525 BMW 535i : 1
## Max. :36.00 Max. :22.00 Max. :4105 Buick Century: 1
## NA's :2 NA's :11 (Other) :87Súbor údajov o 93 autách predávaných v USA v roku 1993 obsahuje 93 riadkov a 27 stĺpcov, väčšina premenných (stĺpcov) ako napr. cena Price je kvantitatívnych (numerických), niektoré sú kvalitatívne, napr. výrobca Manufacturer. Podľa toho je zostavený súhrn funkciou summary. Iný súhrn ponúka napr.
priceUSA <- subset(Cars93, subset = Origin=="USA", select = Price, drop=T)
hist(priceUSA)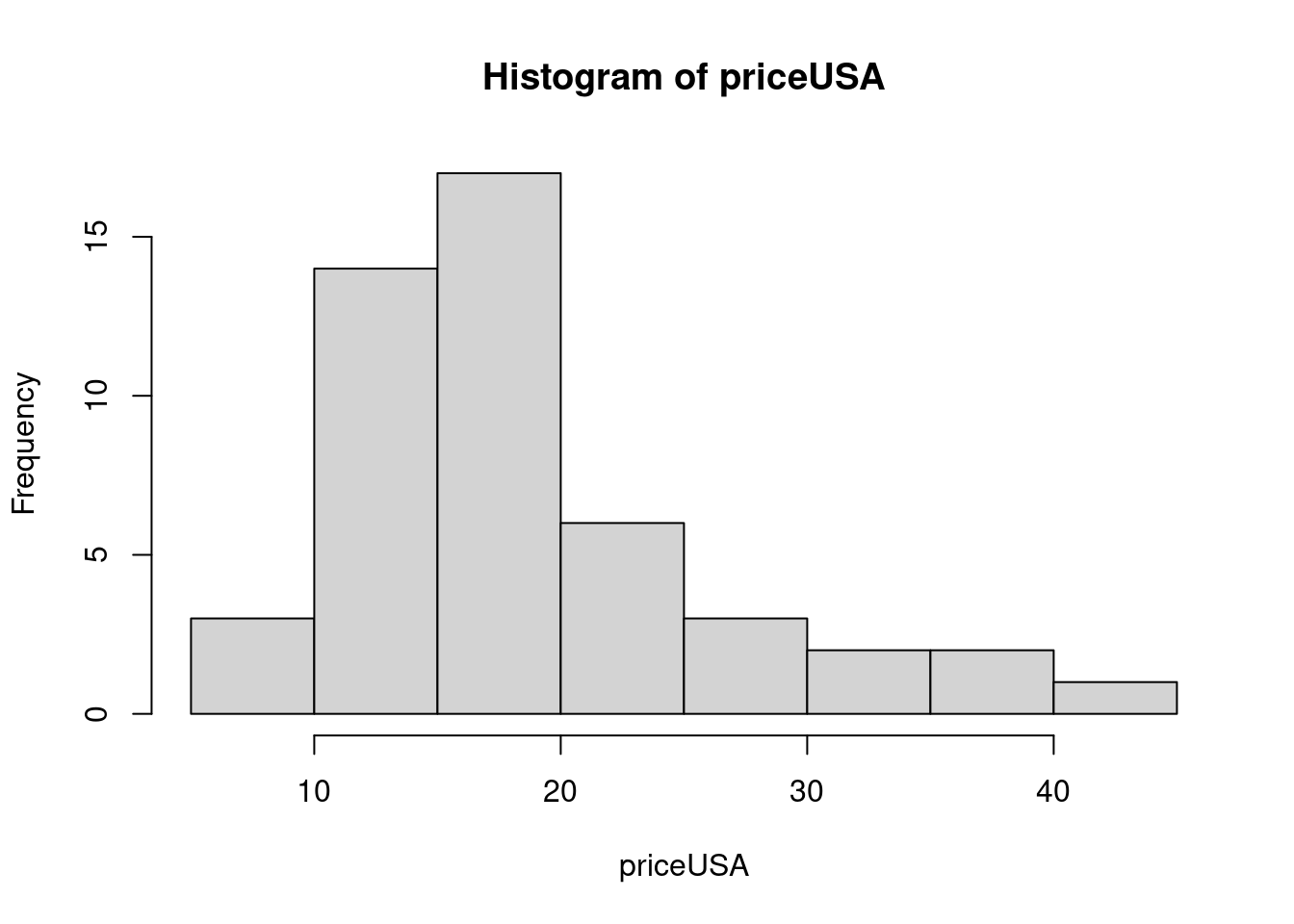
summary(priceUSA)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 7.40 13.47 16.30 18.57 20.73 40.10Rozdelenie je asymetrické, pravdepodobnejšie (častejšie) sú lacnejšie autá. Preto je medián (16 300$) menší ako priemerná hodnota (18 570$)
pocetnostManuf <- sort(table(Cars93$Manufacturer), decreasing=T)
barplot(pocetnostManuf, las=2, cex.names=0.7)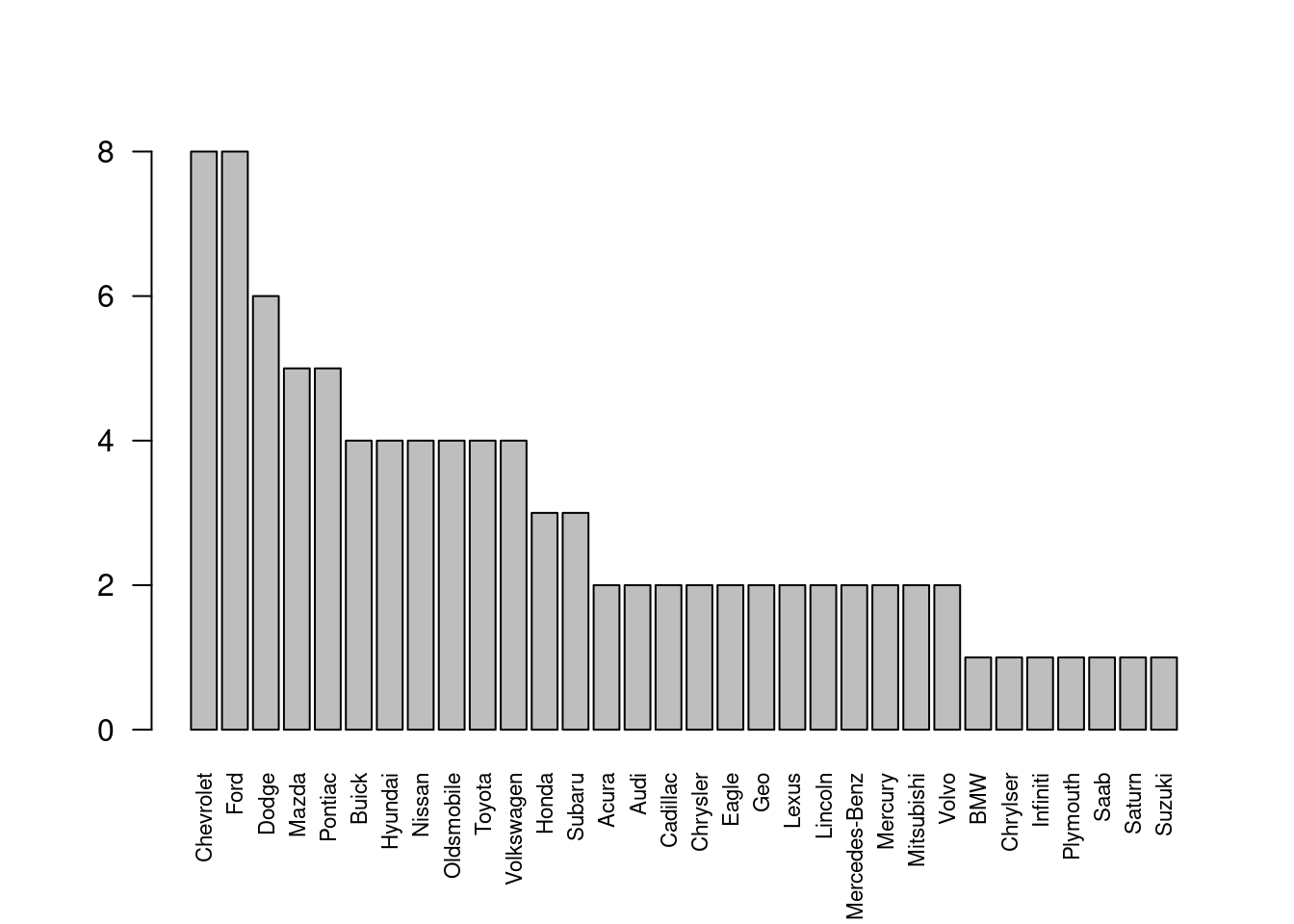
pie(pocetnostManuf,cex=0.7)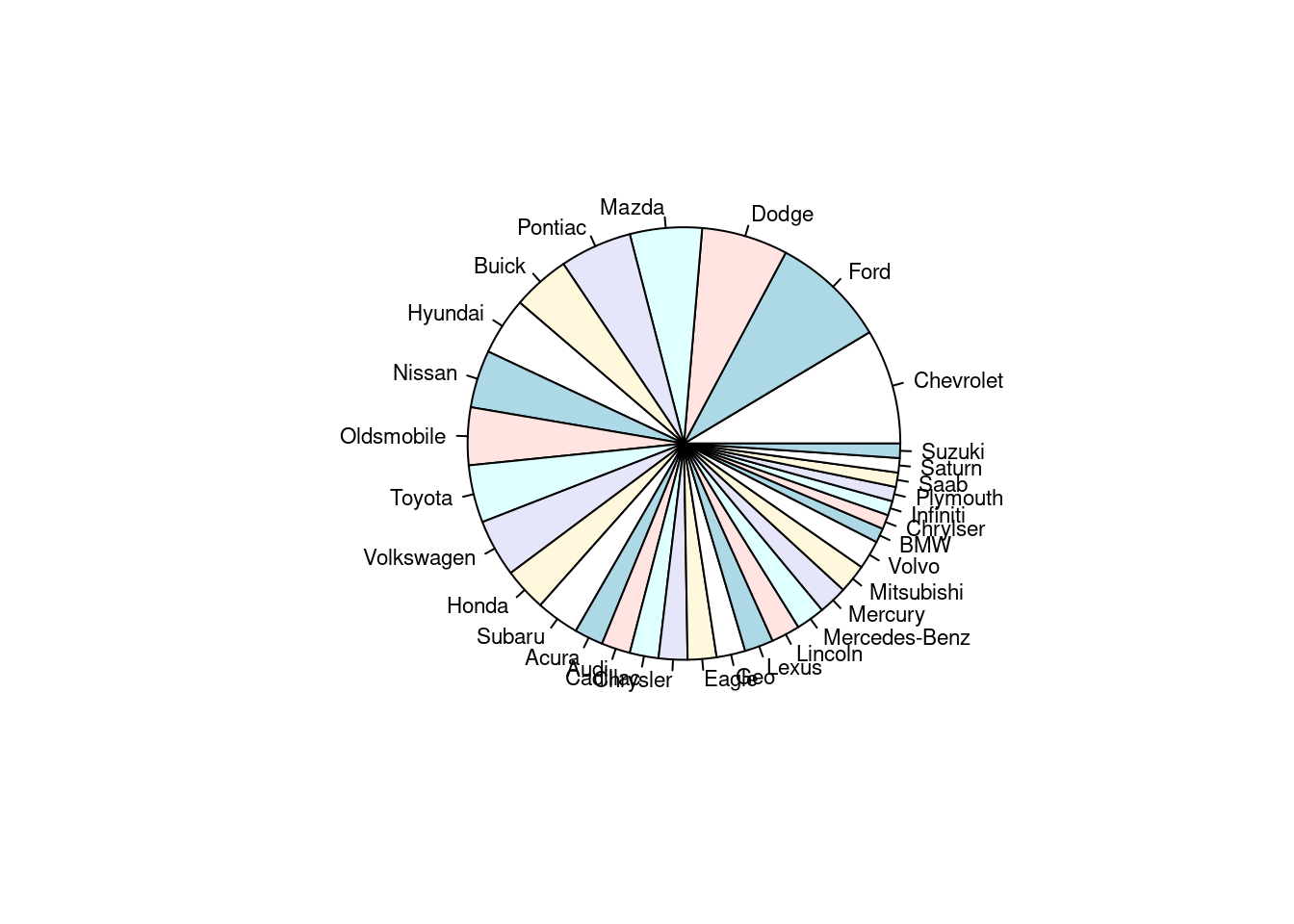
dotchart(pocetnostManuf, cex=0.7)
## Warning in dotchart(pocetnostManuf, cex = 0.7): 'x' is neither a vector nor a
## matrix: using as.numeric(x)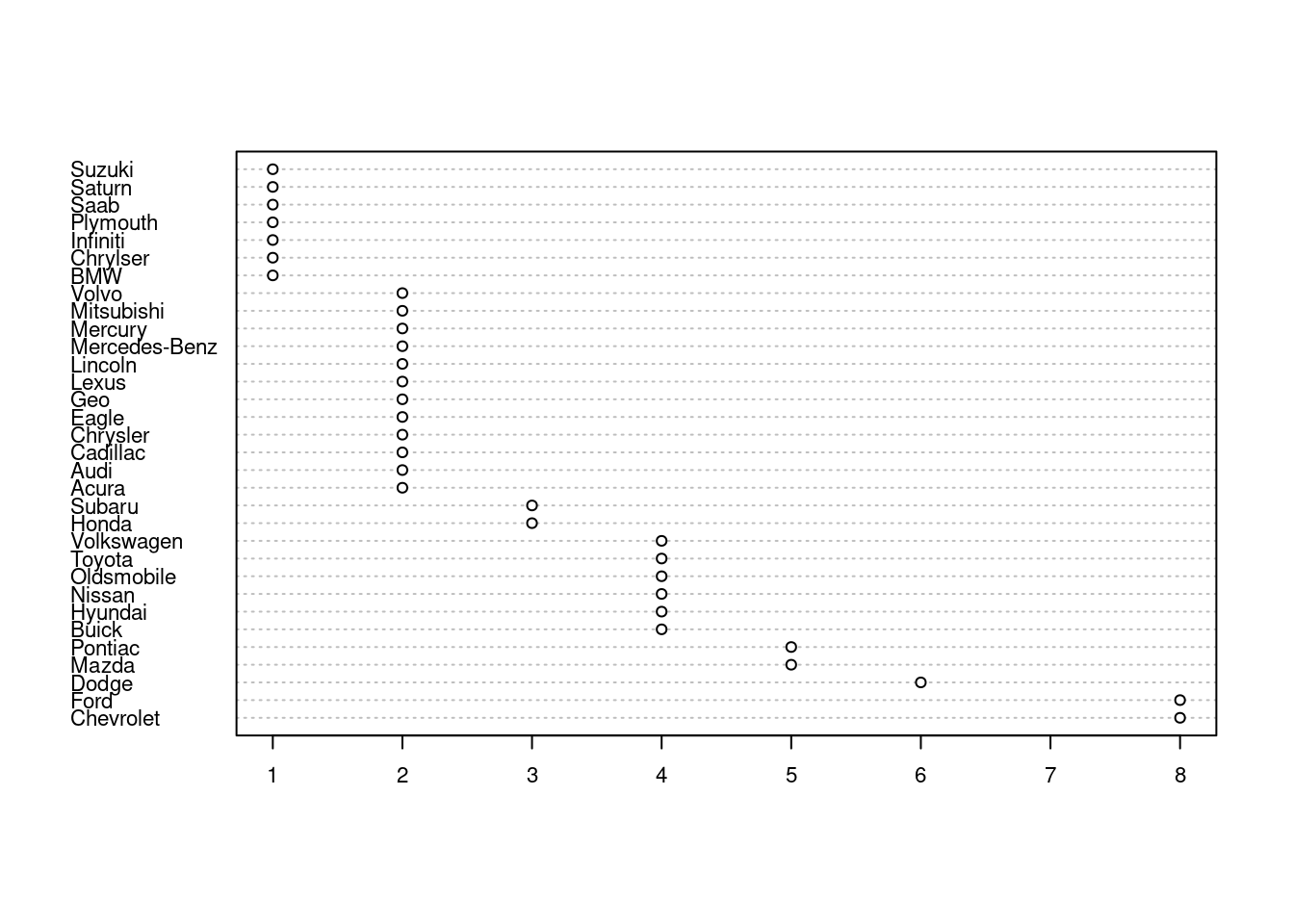
Najprehľadnejší je asi stĺpcový graf, prípadne aj bodový graf. Koláčový graf sa hodí na zobrazenie podielu nanajvýš zopár skupín. (Ľudský mozog nie je veľmi dobrý v rozlišovaní rozdielov v kruhových výsekoch, ľahšie vníma rozdiely obdĺžnikových tvarov.)
plot(Price ~ AirBags, data=Cars93)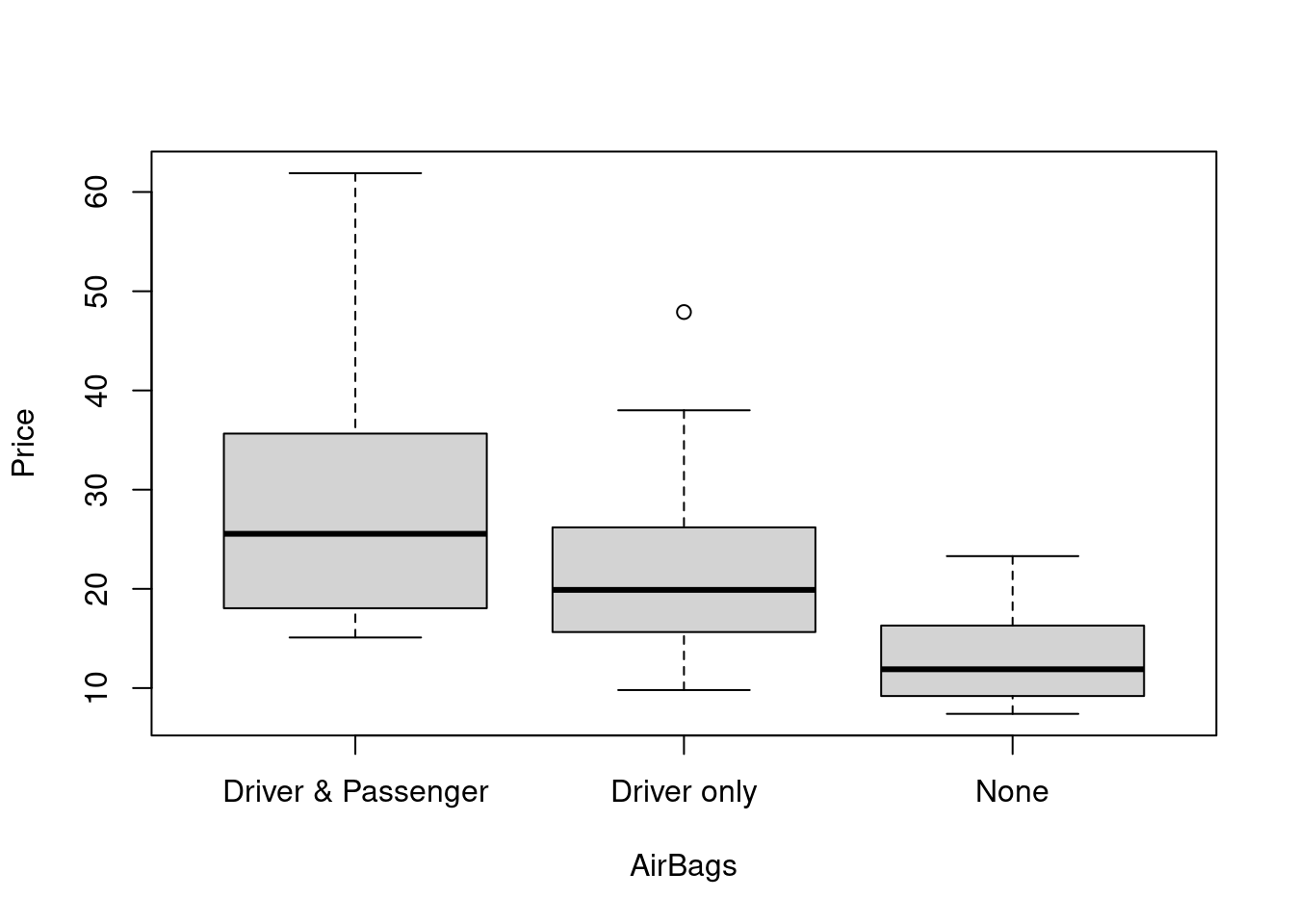
Jednoznačne cena rastie s výbavou.
plot(Horsepower ~ EngineSize, data=Cars93, col = Cars93$Origin, pch=20)
legend("bottomright", legend = levels(Cars93$Origin), col = 1:2, pch = 20)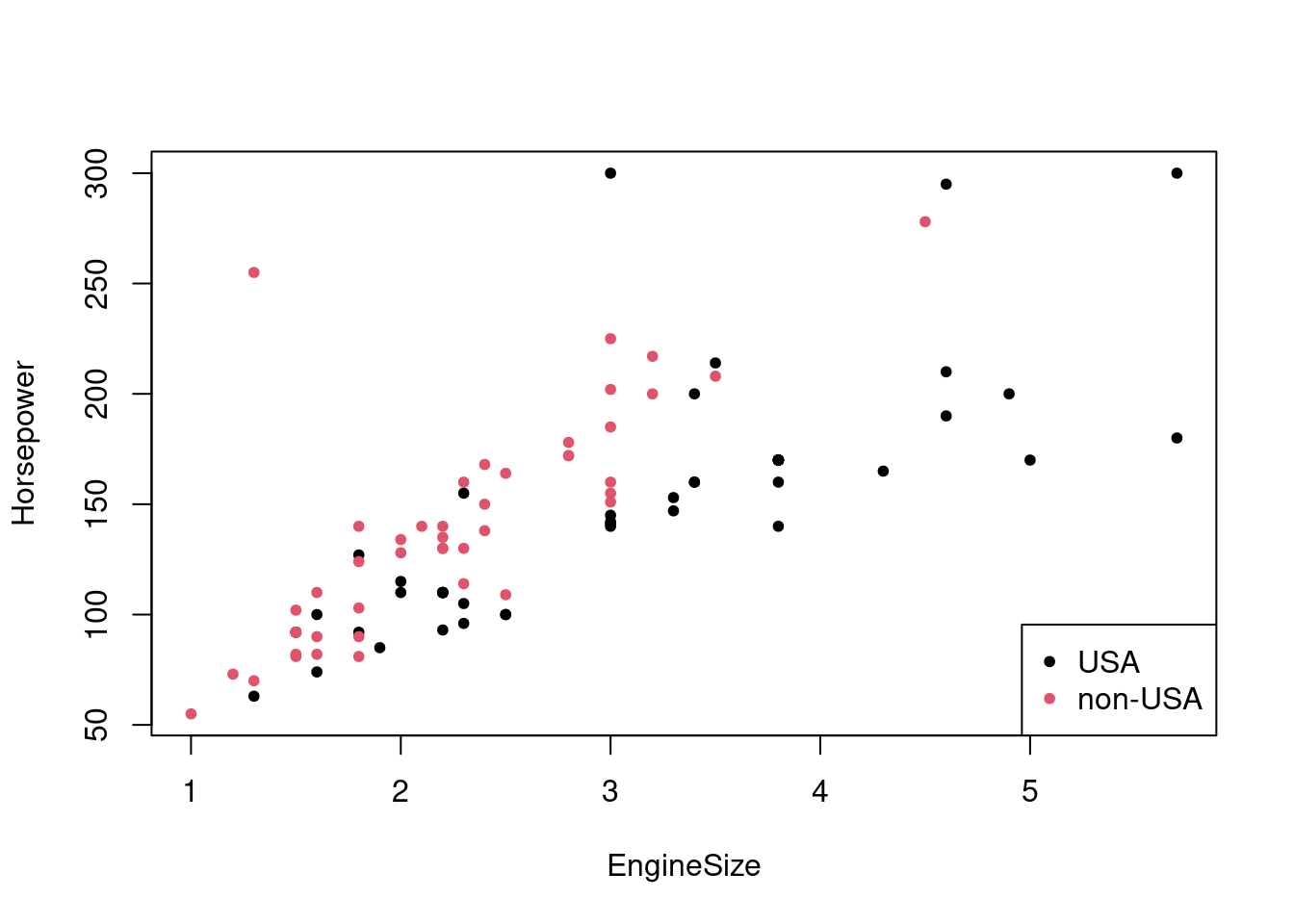
Vyzerá to, že neamerické modely dosahujú pri rovnakom zdvihovom objeme vyšší výkon ako americké a rozdiel sa s objemom zvyšuje.
Cars93$Type <- factor(
x = Cars93$Type,
levels = c("Small", "Sporty", "Compact", "Midsize", "Large", "Van")
)
# automatické zoradenie tried podľa priemernej hmotnosti:
# Cars93$Type <- reorder(Cars93$Type, X = Cars93$Weight, FUN = mean)
mosaicplot(Type ~ Man.trans.avail, data=Cars93)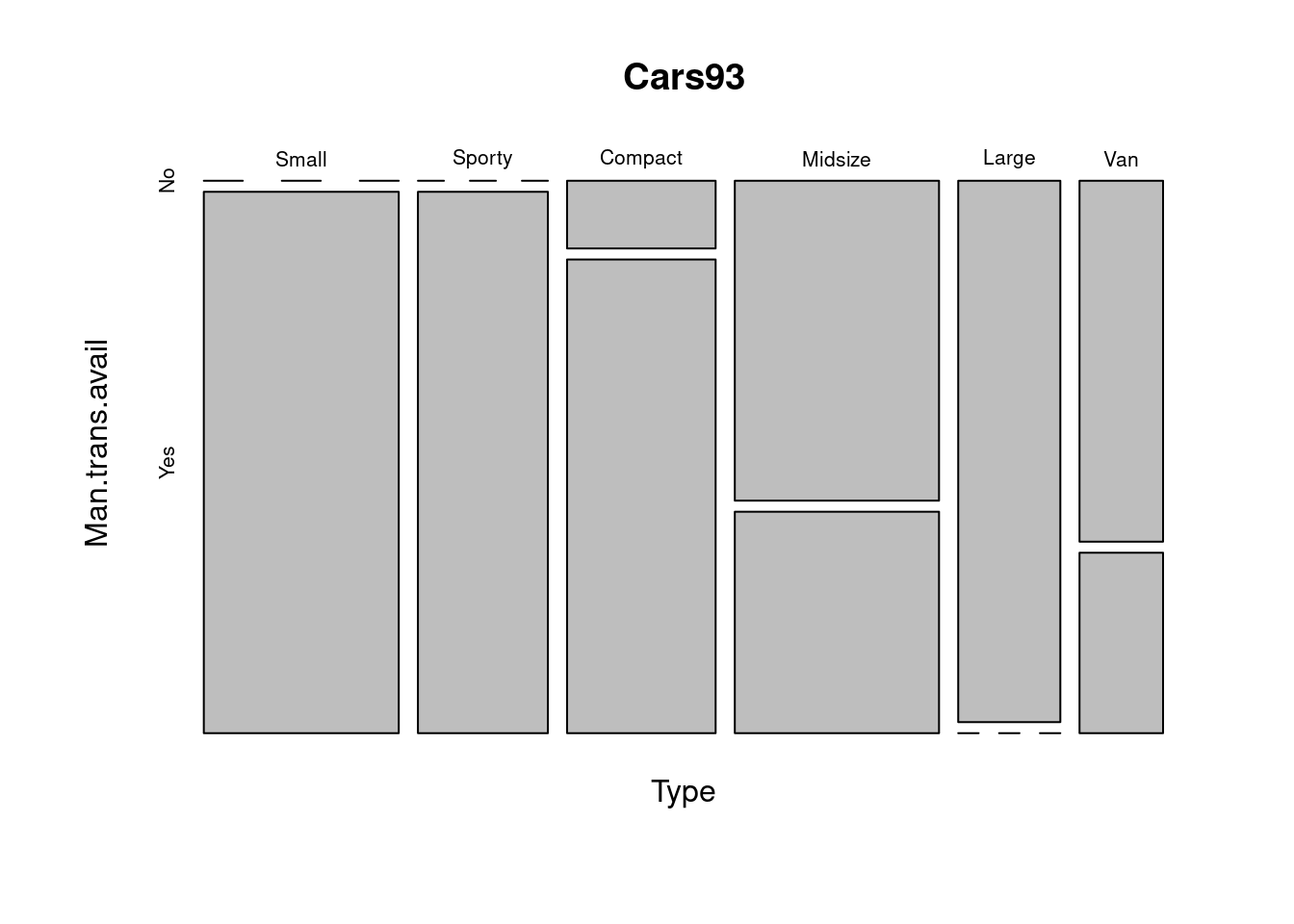
Dostupnosť manuálnej prevodovky je doménou menších, kompaktných áut.
10.3 Transformácia údajov a súhrny pomocou dplyr
data(Cars93, package = "MASS")library(dplyr)
##
## Attaching package: 'dplyr'
## The following objects are masked from 'package:stats':
##
## filter, lag
## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union
auta93 <- select(Cars93, 1:3, contains("Price"), -contains(".Price"), starts_with("MPG"), AirBags:Horsepower, - DriveTrain, Weight, Origin)auta93 %>%
rename(CylindersVolume = EngineSize) %>%
mutate(Weight = Weight * 0.4536) %>%
filter(Weight < 1200 & Origin == "USA") %>%
arrange(Type, Price) %>%
print() %>%
group_by(Type) %>%
summarise(mean = mean(MPG.city), .groups = "drop")
## Manufacturer Model Type Price MPG.city MPG.highway AirBags
## 1 Pontiac Sunbird Compact 11.1 23 31 None
## 2 Chevrolet Cavalier Compact 13.4 25 36 None
## 3 Ford Festiva Small 7.4 31 33 None
## 4 Pontiac LeMans Small 9.0 31 41 None
## 5 Dodge Colt Small 9.2 29 33 None
## 6 Ford Escort Small 10.1 23 30 None
## 7 Saturn SL Small 11.1 28 38 Driver only
## 8 Eagle Summit Small 12.2 29 33 None
## 9 Mercury Capri Sporty 14.1 23 26 Driver only
## 10 Plymouth Laser Sporty 14.4 23 30 None
## Cylinders CylindersVolume Horsepower Weight Origin
## 1 4 2.0 110 1168.020 USA
## 2 4 2.2 110 1129.464 USA
## 3 4 1.3 63 836.892 USA
## 4 4 1.6 74 1065.960 USA
## 5 4 1.5 92 1029.672 USA
## 6 4 1.8 127 1147.608 USA
## 7 4 1.9 85 1131.732 USA
## 8 4 1.5 92 1041.012 USA
## 9 4 1.6 100 1111.320 USA
## 10 4 1.8 92 1197.504 USA
## # A tibble: 3 × 2
## Type mean
## <fct> <dbl>
## 1 Compact 24
## 2 Small 28.5
## 3 Sporty 23
detach("package:dplyr", unload = TRUE)10.4 Vizualizácia pomocou ggplot2
data(Cars93, package = "MASS")`%>%` <- magrittr::`%>%`
library(ggplot2)
Cars93 %>%
dplyr::filter(Origin == "USA") %>%
ggplot(aes(x = Price)) + geom_histogram(bins = 5)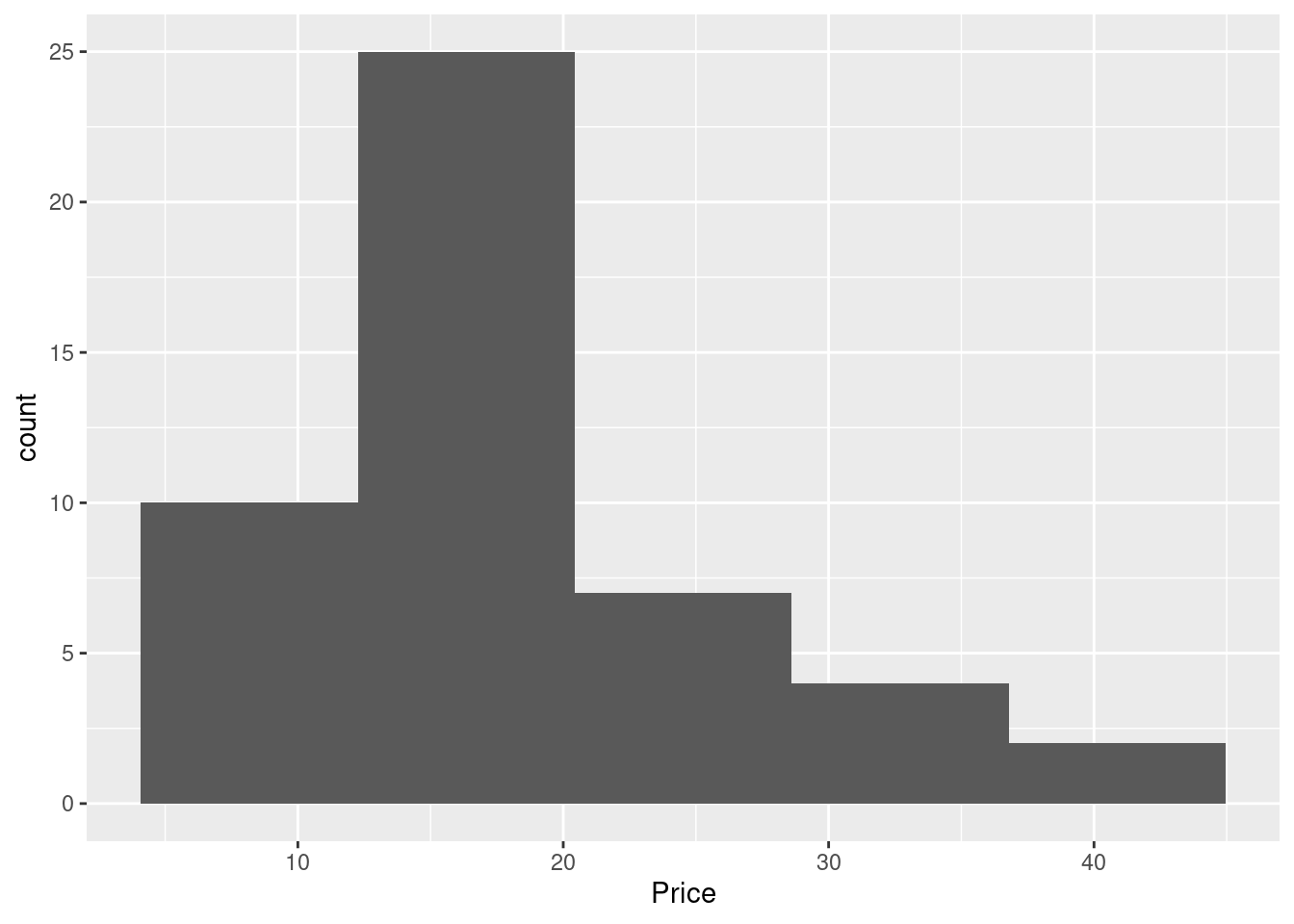 3.
3.
ggplot(Cars93) +
aes(x = EngineSize, y = MPG.city, size = Weight, shape = Type, color = Cylinders) +
geom_point() +
facet_grid(rows = vars(DriveTrain))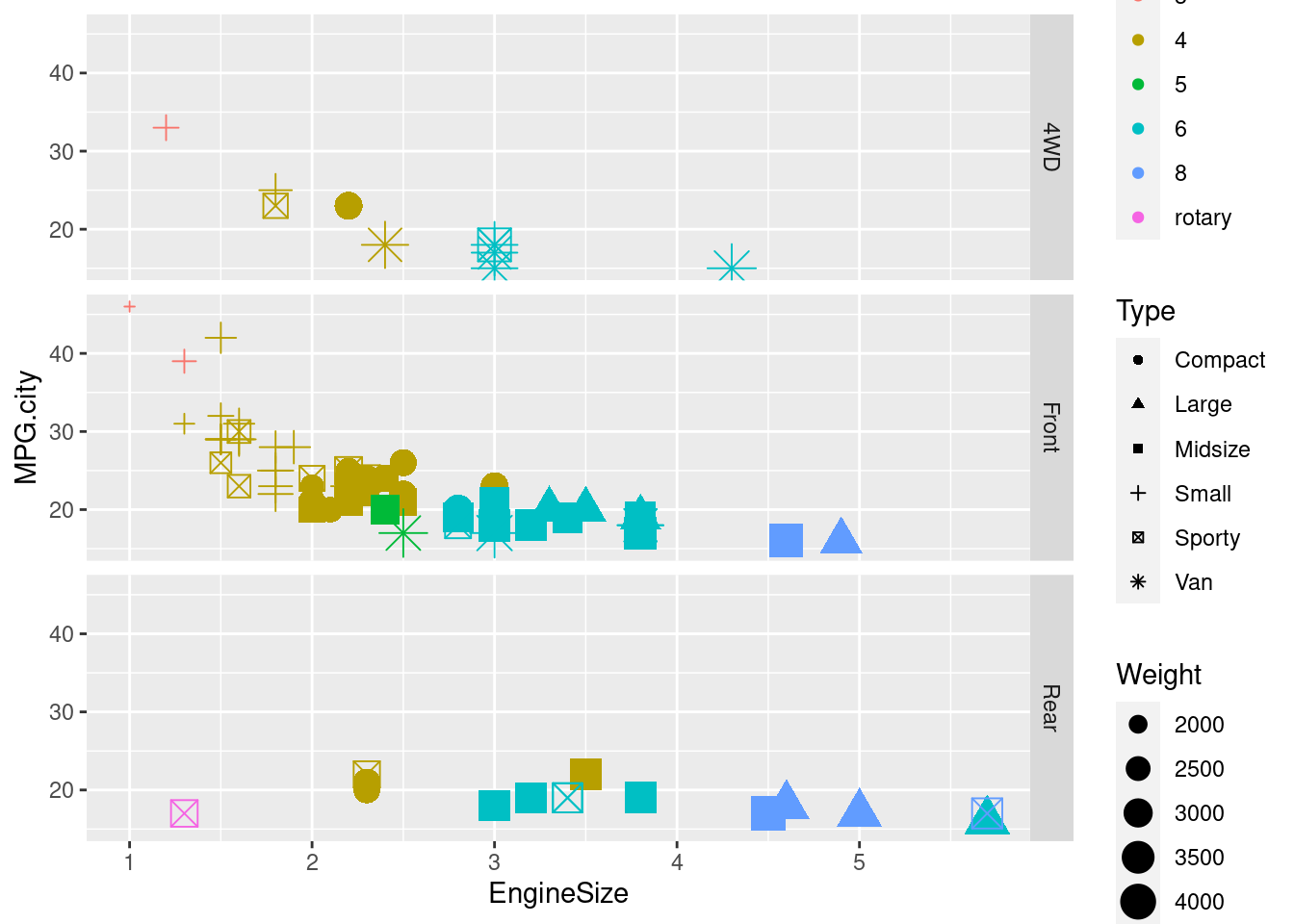 4.
4.
"https://datahub.io/core/covid-19/r/countries-aggregated.csv" %>%
url() %>%
read.csv() %>%
dplyr::mutate(Date = as.Date(Date)) %>%
dplyr::filter(Country %in% c("Czechia", "Hungary", "Poland", "Slovakia"),
Date > "2020-09-01") %>%
ggplot(aes(x = Date, y = Confirmed, group = Country, color = Country)) +
geom_line()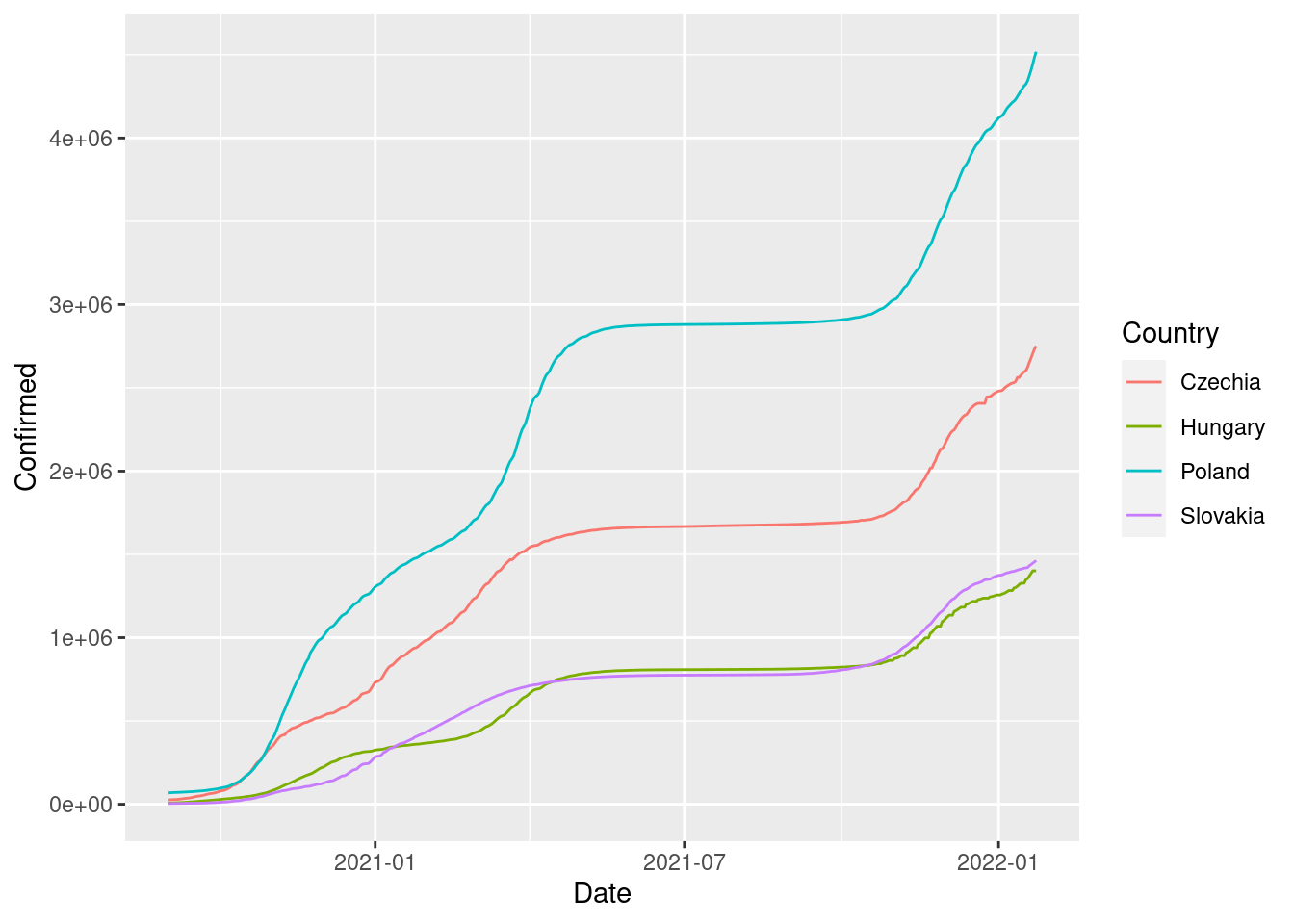
10.5 Čistenie údajov pomocou tidyr
head(USArrests)
## Murder Assault UrbanPop Rape
## Alabama 13.2 236 58 21.2
## Alaska 10.0 263 48 44.5
## Arizona 8.1 294 80 31.0
## Arkansas 8.8 190 50 19.5
## California 9.0 276 91 40.6
## Colorado 7.9 204 78 38.7? USArrestsDruh zločinu predstavujú stĺpce assault (napadnutie), murder (vražda), rape (znásilnenie).
`%>%` <- magrittr::`%>%`
library(ggplot2)
USArrests %>%
dplyr::mutate(state = rownames(.)) %>%
tidyr::pivot_longer(cols = c(Assault,Murder,Rape),
names_to = "crime", values_to = "cases") %>%
ggplot(mapping = aes(x = UrbanPop, y = cases, color = crime)) +
geom_point() + scale_y_log10()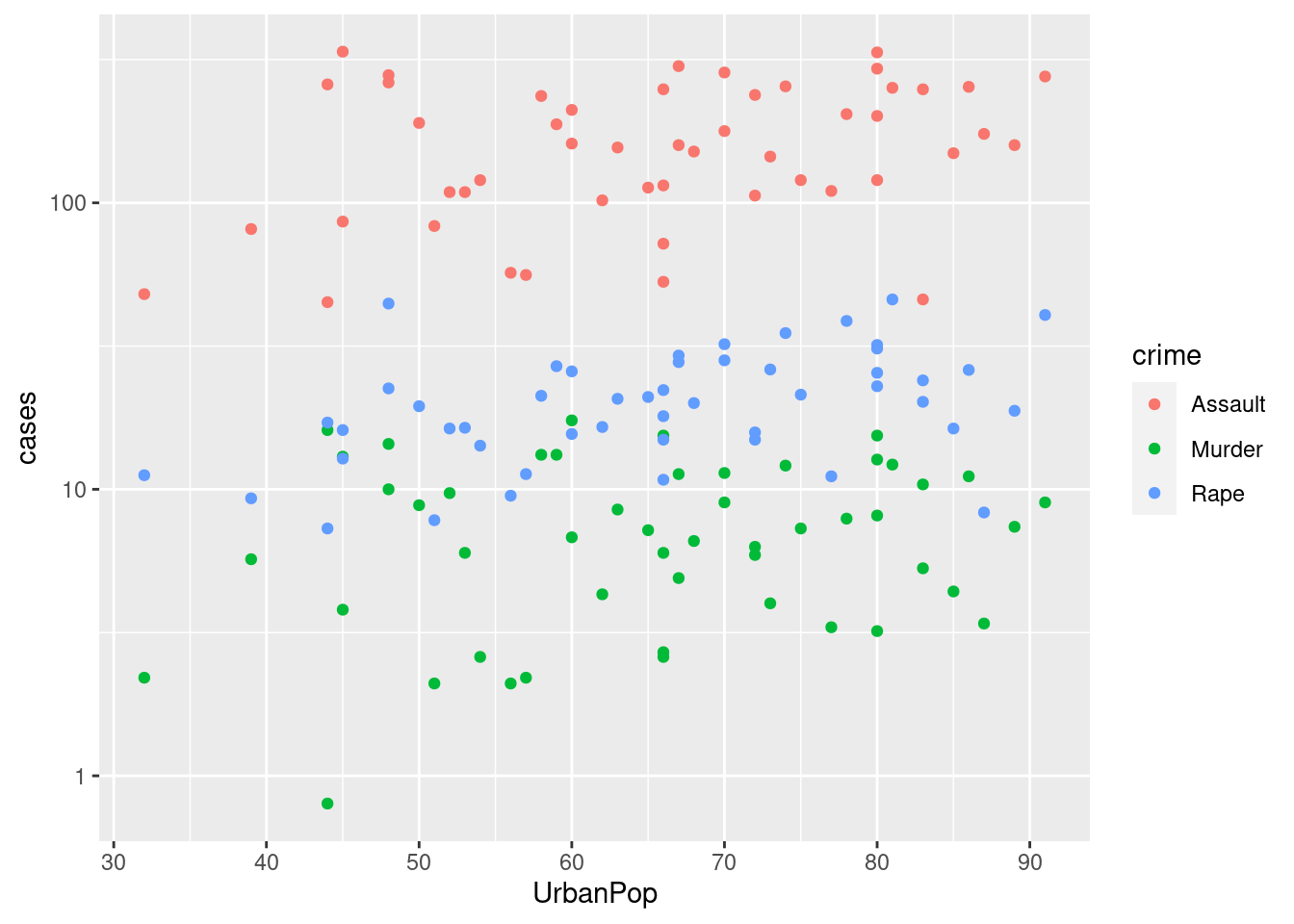
USArrests %>%
dplyr::mutate(state = rownames(.)) %>%
tidyr::pivot_longer(cols = c(Assault, Murder, Rape),
names_to = "crime", values_to = "cases") %>%
ggplot(mapping = aes(x = UrbanPop, y = cases, color = crime)) +
geom_text(mapping = aes(label = state), size = 2, check_overlap = F) +
facet_grid(rows = vars(crime), scales = "free_y")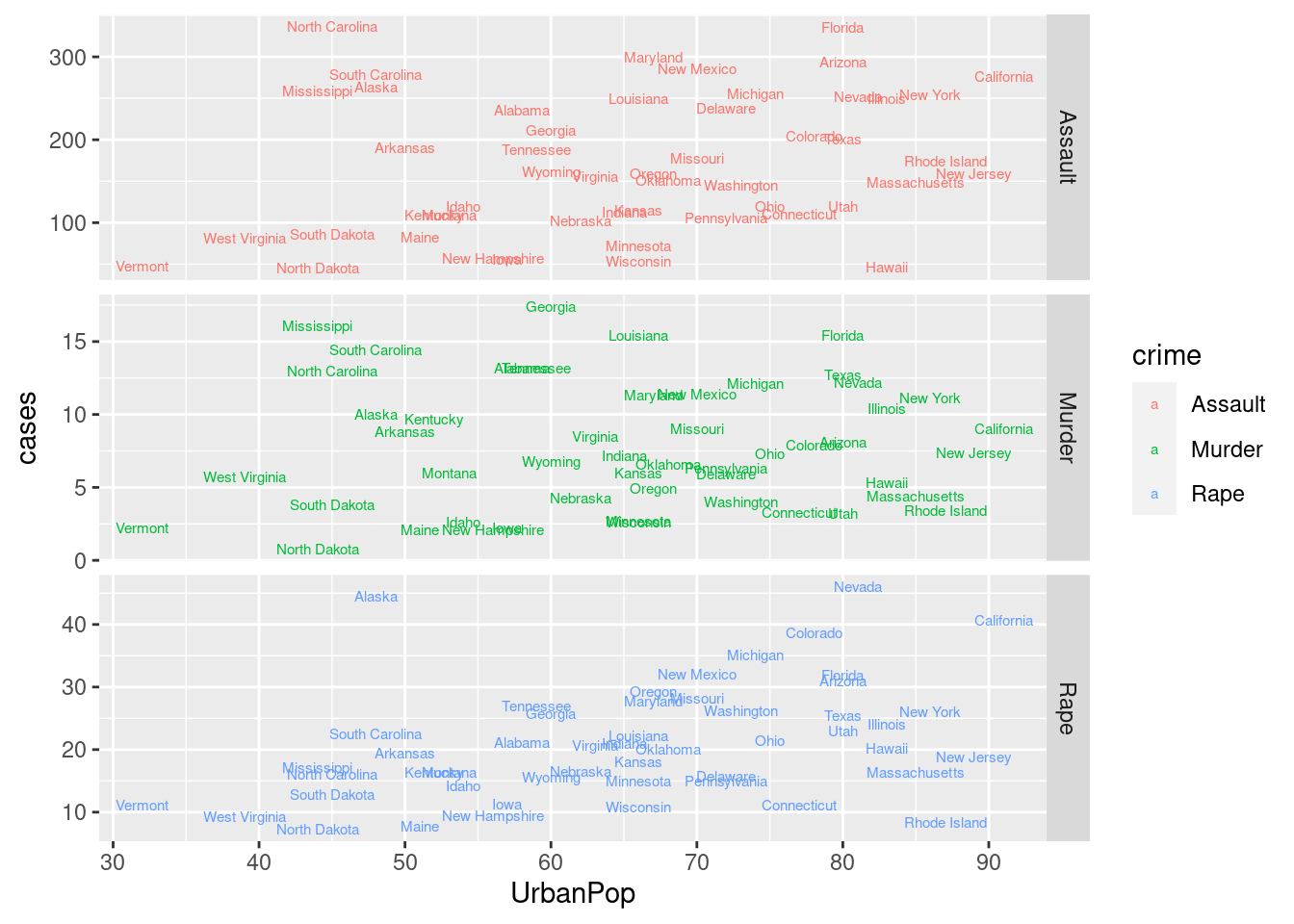
dat <- tidyr::tibble(x = c("8,8,3", "2,4,9", "5,6")) a) dat %>%
tidyr::separate(x, into = c("pred","počas","po"), sep = ",") %>%
dplyr::mutate(meno = c("Adam","Bibiana","Cindy")) %>%
tidyr::pivot_longer(cols = c(pred,počas,po), names_to = "test", values_to = "body") %>%
dplyr::mutate(body = as.numeric(body),
test = factor(test, levels = c("pred","počas","po"))) %>%
ggplot(aes(x = test, y = body, group = meno, color = meno)) +
geom_point() + geom_line() +
labs(y = "počet bodov", title = "Výsledky študentov v kurze")
## Warning: Expected 3 pieces. Missing pieces filled with `NA` in 1 rows [3].
## Warning: Removed 1 rows containing missing values (geom_point).
## Warning: Removed 1 row(s) containing missing values (geom_path).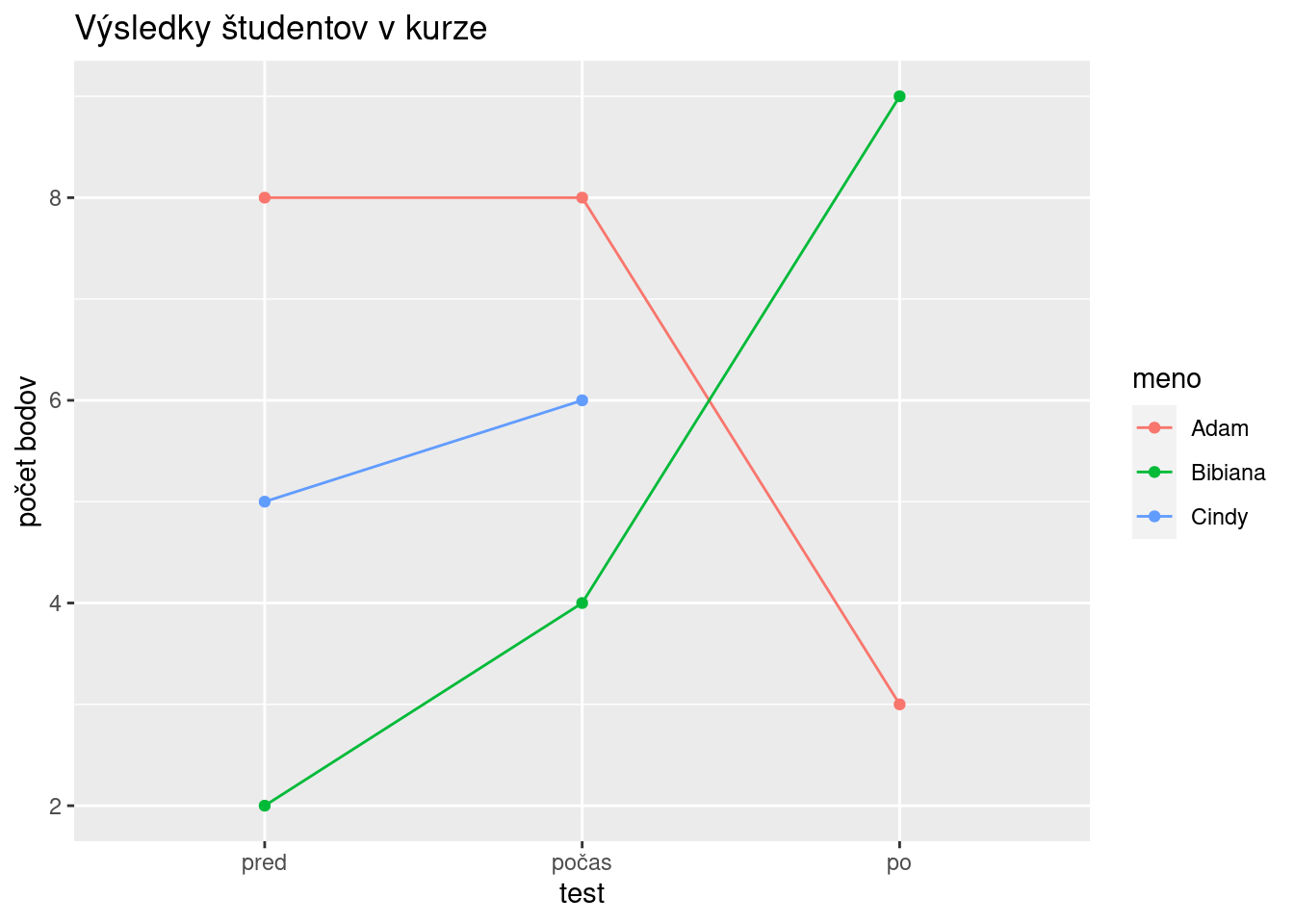
b) Z grafu vidieť, že Adam sa ulieval, na začiatku aj počas kurzu mal 8 bodov, ale po kurze už iba 3. Naopak, Bibi sa snažila, pred kurzom mala iba 2 body a po kurze až 9. O Cindy vieme povedať len to, že sa snažila zo začiatku testu, nepoznáme jej údaj z posledného testu. ```
c) Do funkcie separate by sme doplnili argument fill = "left".
dat %>%
tidyr::separate(x, into = c("pred","počas","po"), sep = ",", fill = "left") %>%
dplyr::mutate(meno = c("Adam","Bibiana","Cindy")) %>%
tidyr::pivot_longer(cols = c(pred,počas,po), names_to = "test", values_to = "body") %>%
dplyr::mutate(body = as.numeric(body),
test = factor(test, levels = c("pred","počas","po"))) %>%
ggplot(aes(x = test, y = body, group = meno, color = meno)) +
geom_point() + geom_line() +
labs(y = "počet bodov", title = "Výsledky študentov v kurze")
## Warning: Removed 1 rows containing missing values (geom_point).
## Warning: Removed 1 row(s) containing missing values (geom_path).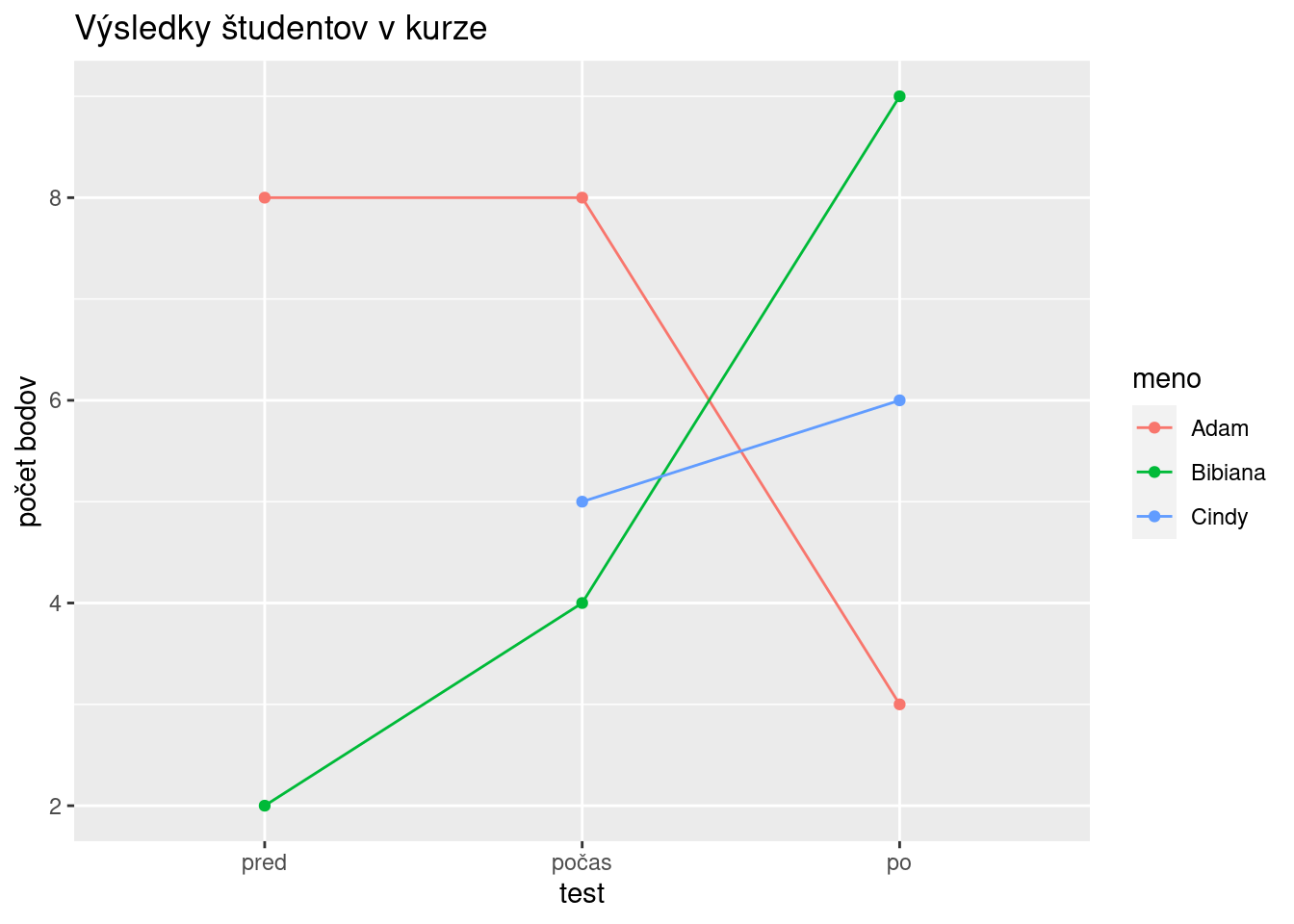
10.6 Interaktívna vizualizácia
`%>%` <- magrittr::`%>%`mtcars %>%
dplyr::mutate(cyl = as.factor(cyl)) %>%
ggvis::ggvis(x = ~disp, y = ~mpg) %>%
ggvis::layer_points(fill = ggvis::input_select(c("cyl", "am"), map=as.name, label = "farba:"))library(ggplot2)library(shiny)
# Užívateľské prostredie:
ui <- fluidPage( # použi fluid Bootstrap layout
# nadpis stránky
titlePanel("Závislosť dojazdu od zdvihového objemu"),
# vytvor riadok s bočným panelom
sidebarLayout(
# definuj bočný panel s jedným vstupom
sidebarPanel(
selectInput("var3", "Faktor:",
choices = c("cyl", "am")
)
),
# vytvor miesto pre graf a tabuľku
mainPanel(
plotOutput("mileagePlot"),
helpText("Priemer v skupine:"),
tableOutput("summaryTable")
)
)
)
# Server:
server <- function(input, output) { # definuj server pre Shiny app
# zaplň miesto vytvorené pre graf a tabuľku
output$mileagePlot <- renderPlot({
mtcars %>%
dplyr::mutate(across(c(cyl,am), factor)) %>%
ggplot(aes(x = disp, y = mpg)) +
geom_point(aes_string(color = input$var3))
})
output$summaryTable <- renderTable({
mtcars %>%
dplyr::group_by(across(input$var3)) %>%
dplyr::summarize(disp = mean(disp), mpg = mean(mpg), .groups = "drop")
})
}
# Skombinovanie frontend-u a backendu-u.
shinyApp(ui, server)
# uvoľnenie nepotrebných knižníc
detach("package:shiny")p <- mtcars %>%
dplyr::mutate(cyl = as.factor(cyl), model = rownames(.)) %>%
ggplot(aes(x = disp, y = mpg, color = cyl, label = model))
plotly::ggplotly(p + geom_point(), tooltip=c("label", "x", "y"))10.7 Efektívne programovanie
multiodhadLM_p <- function(data, N) {
mat <- as.matrix(data)
estimLM <- function(i) {
Ys <- mat[i,]
X <- cbind(1, Ys[,1])
c( solve(t(X) %*% X) %*% t(X) %*% Ys[,2] )
}
n <- nrow(mat)
ind <- replicate(N, sample(n, n, replace=TRUE))
cl <- parallel::makeCluster(3)
parallel::clusterExport(cl, varlist = "mat", envir = environment())
out <- parallel::parApply(cl, X = ind, MARGIN = 2, FUN = estimLM)
parallel::stopCluster(cl)
out
}
system.time(sim <- multiodhadLM_p(mtcars[c("wt","disp")], 5000))["elapsed"]
## elapsed
## 0.277
apply(sim, MARGIN = 1, quantile, probs = c(0.025, 0.975))
## [,1] [,2]
## 2.5% -182.04856 101.3907
## 97.5% -94.40245 129.2023// obsah súboru median.cpp
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
NumericVector sort_C(NumericVector x) {
int n = x.size();
double xi;
for(int i = 0; i <= n-2; ++i) {
for(int j = i+1; j <= n-1; ++j) {
xi = x[i];
if (x[j] < xi) {
x[i] = x[j];
x[j] = xi;
}
}
}
return x;
}
// [[Rcpp::export]]
double median_C(NumericVector x) {
int n = x.size();
NumericVector y = sort_C(x);
int i = floor(n/2);
double out;
if (n % 2 == 0) {
out = (y[i-1]+y[i])/2;
} else {
out = y[i];
}
return out;
}Rcpp::sourceCpp(file = "median.cpp")sort_C(16:11)
## [1] 11 12 13 14 15 16
median_C(16:11)
## [1] 13.5Funkcia sort_C sa dá nahradiť napr. preusporiadaním kópie vstupného vektora pomocou std::sort.
Rcpp::cppFunction(code = "double median_C(NumericVector x) {
int n = x.size();
NumericVector y = clone(x);
std::sort(y.begin(), y.end());
int i = std::floor(n/2);
double out;
if (n % 2 == 0) {
out = (y[i-1]+y[i])/2;
} else {
out = y[i];
}
return out;
}")Úplne najjednoduchšie je osladiť si život pomocnými funkciami, ktoré prostrediu C++ balík Rcpp sprístupňuje z prostredia R.
Rcpp::cppFunction(code = "double median_C(NumericVector x) {
return median(x);
}")Ulož dáta do csv súborov:
write.table(nycflights13::flights, file = "data/nycflights13_flights.csv",
sep = ",", row.names = FALSE)
write.table(nycflights13::planes, file = "data/nycflights13_planes.csv",
sep = ",", row.names = FALSE)Zapíš súbory do databázy. Externým súborom by sa nemuseli vytvoriť tabuľky so správnym formátom polí, napr. by všetky boli textové a bolo by potrebné ich typ manuálne meniť, alebo neskôr pri filtrovaní používať textové hodnoty, napr. day == “1”.
con <- DBI::dbConnect(drv = RSQLite::SQLite(), dbname = "data/nycflights13.db")
DBI::dbWriteTable(conn = con, name = "Flights", value = "data/nycflights13_flights.csv", overwrite=T)
DBI::dbWriteTable(conn = con, name = "Planes", value = "data/nycflights13_planes.csv", overwrite=T)
dplyr::tbl(con, from = "Flights")
DBI::dbDisconnect(con)Vytvor nové spojenie, zlúč tabuľky a vykresli:
nycflights13_con <- DBI::dbConnect(drv = RSQLite::SQLite(), dbname = "data/nycflights13.db")
dplyr::tbl(nycflights13_con, from = "Flights") %>%
dplyr::filter(month == 1, day == 1, dep_time > 500 & dep_time < 800) %>%
dplyr::select(tailnum, origin) %>%
dplyr::left_join(y = dplyr::tbl(nycflights13_con, from = "Planes"),
by = "tailnum") %>%
dbplot::dbplot_histogram(x = seats, bins = 10)
DBI::dbDisconnect(nycflights13_con)Filtrovanie sa dá vykonať aj po zlúčení tabuliek, ale je to menej efektívne.
Aby sa dali použiť pokročilejšie funkcie ggplot2, napr. vykreslenie po skupinách (group, colour), je pravdepodobne potrebné stiahnuť zobrazované údaje lokálne, a použiť ggplot2::ggplot namiesto dbplot.