Capítulo 1 Tidy Data y manipulación de datos
1.1 Paquetes necesarios para este capítulo
Para este capitulo necesitas tener instalado el paquete tidyverse
En este capítulo se explicará qué es una base de datos tidy (Wickham and others 2014) y se aprenderá a usar funciones del paquete dplyr (Wickham et al. 2019) para manipular datos.
Dado que este libro es un apoyo para el curso BIO4022, esta clase del curso puede también ser seguida en este link. El video de la clase se encuentra disponible en este link.
1.2 Tidy data
Una base de datos tidy es una base de datos en la cuál (modificado de (Leek 2015)):
- Cada vararible que se medida debe estar en una columna.
- Cada observación distinta de esa variable debe estar en una fila diferente.
En general, la forma en que representaríamos una base de datos tidy en R es usando un data frame.
1.3 dplyr
El paquete dplyr es definido por sus autores como una gramática para la manipulación de datos. De este modo sus funciones son conocidas como verbos. Un resumen útil de muchas de estas funciones se encuentra en este link.
Este paquete tiene un gran número de verbos y sería difícil ver todos en una clase, en este capítulo nos enfocaremos en sus funciones más utilizadas, las cuales son:
- %>% (pipeline)
- group_by (agrupa datos)
- summarize (resume datos agrupados)
- mutate (genera variables nuevas)
- filter (encuentra filas con ciertas condiciones)
- select junto a starts_with, ends_with o contains
en el siguiente video puedes aprender sobre el pipeline (%>%), group_by y summarize
1.3.1 Pipeline (%>%)
El pipeline es un simbolo operatorio %>% que sirve para realizar varias operaciones de forma secuencial sin recurrir a parentesis anidados o a sobrescribir muúltiples bases de datos.
Para ver como funciona esto como un vector, supongamos que se tiene una variable a la cual se quiere primero obtener su logaritmo, luego su raíz cuadrada y finalmente su promedio con dos cifras significativas. Para realizar esto se debe seguir lo siguiente:
Si se utiliza pipeline, el código sería mucho más ordenado. En ese caso, se partiría por el objeto a procesar y luego cada una de las funciones con sus argumentos si es necesario:
## [1] 0.99El código con pipeline es mucho más fácil de interpretar a primera vista ya que se lee de izquierda a derecha y no de adentro hacia afuera.
1.3.2 summarize
La función summarize toma los datos de un data frame y los resume. Para usar esta función, el primer argumento que tomaríamos sería un data frame, se continúa del nombre que queremos darle a una variable resumen, seguida del signo = y luego la fórmula a aplicar a una o mas columnas. COmo un ejemplo se utilizará la base de datos iris (Anderson 1935) que viene en R y de las cual podemos ver parte de sus datos en la tabla 1.1
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species |
|---|---|---|---|---|
| 5.8 | 4.0 | 1.2 | 0.2 | setosa |
| 4.7 | 3.2 | 1.6 | 0.2 | setosa |
| 5.1 | 3.8 | 1.9 | 0.4 | setosa |
| 5.2 | 2.7 | 3.9 | 1.4 | versicolor |
| 6.4 | 2.9 | 4.3 | 1.3 | versicolor |
| 5.5 | 2.5 | 4.0 | 1.3 | versicolor |
| 6.5 | 3.0 | 5.8 | 2.2 | virginica |
| 6.0 | 2.2 | 5.0 | 1.5 | virginica |
| 6.1 | 2.6 | 5.6 | 1.4 | virginica |
| 5.9 | 3.0 | 5.1 | 1.8 | virginica |
Si quisieramos resumir esa tabla y generar un par de variables que fueran la media y la desviación estándar del largo del pétalo, lo haríamos con el siguiente código:
library(tidyverse)
Summary.Petal <- summarize(iris, Mean.Petal.Length = mean(Petal.Length),
SD.Petal.Length = sd(Petal.Length))El resultado se puedde ver en la tabla 1.2, en el cuál se obtienen los promedios y desviaciones estándar de los largos de los pétalos. Es importante notar que al usar summarize, todas las otras variables desapareceran de la tabla.
| Mean.Petal.Length | SD.Petal.Length |
|---|---|
| 3.758 | 1.765298 |
1.3.3 group_by
La función group_by por si sola no genera cambios visibles en las bases de datos. Sin embargo, al ser utilizada en conjunto con summarize permite resumir una variable agrupada (usualmente) basada en una o más variables categóricas.
Se puede ver que para el ejemplo con el caso de las plantas del género Iris, el resumen que se obtiene en el caso de la tabla 1.2 no es tan útil considerando que tenemos tres especies presentes. Si se quiere ver el promedio del largo del pétalo por especie, se debe ocupar la función group_by de la siguiente forma:
BySpecies <- group_by(iris, Species)
Summary.Byspecies <- summarize(BySpecies, Mean.Petal.Length = mean(Petal.Length),
SD.Petal.Length = sd(Petal.Length))Esto dá como resultado la tabla 1.3, con la cuál se puede ver que Iris setosa tiene pétalos mucho más cortos que las otras dos especies del mismo género.
| Species | Mean.Petal.Length | SD.Petal.Length |
|---|---|---|
| setosa | 1.462 | 0.1736640 |
| versicolor | 4.260 | 0.4699110 |
| virginica | 5.552 | 0.5518947 |
1.3.3.1 group_by en más de una variable
Se puede usar la función group_by en más de una variable, y esto generaría un resumen anidado. Como ejemplo se usará la base de datos mtcars presente en R (Henderson and Velleman 1981). Esta base de datos presenta una variable llamada mpg (miles per gallon) y una medida de eficiencia de combustible. Se resumirá la información en base a la variable am (que se refiere al tipo de transmisión, donde 0 es automático y 1 es manual) y al número de cilindros del motor. Para eso se utilizará el siguiente código:
Como puede verse en la tabla 1.4, en todos los casos los autos con cambios manuales tienen mejor eficiencia de combustible. Se podría probar el cambiar el orden de las variables con las cuales agrupar y observar los distintos resultados que se pueden obtener.
| cyl | am | Eficiencia |
|---|---|---|
| 4 | 0 | 22.90000 |
| 4 | 1 | 28.07500 |
| 6 | 0 | 19.12500 |
| 6 | 1 | 20.56667 |
| 8 | 0 | 15.05000 |
| 8 | 1 | 15.40000 |
1.3.4 mutate
Esta función tiene como objetivo crear variables nuevas basadas en otras variables. Es muy facil de usar, como argumento se usa el nombre de la variable nueva que se quiere crear y se realiza una operación con variables que ya estan ahí. Por ejemplo, si se continúa el trabajo con la base de datos Iris, al crear una nueva variable que sea la razón entre el largo del pétalo y el del sépalo, resulta lo siguiente:
El resultado de esta operación es la tabla 1.5. Siempre la variable que se acaba de crear aparecerá al final del data frame.
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species | Petal.Sepal.Ratio |
|---|---|---|---|---|---|
| 5.8 | 4.0 | 1.2 | 0.2 | setosa | 0.21 |
| 4.7 | 3.2 | 1.6 | 0.2 | setosa | 0.34 |
| 5.1 | 3.8 | 1.9 | 0.4 | setosa | 0.37 |
| 5.2 | 2.7 | 3.9 | 1.4 | versicolor | 0.75 |
| 6.4 | 2.9 | 4.3 | 1.3 | versicolor | 0.67 |
| 5.5 | 2.5 | 4.0 | 1.3 | versicolor | 0.73 |
| 6.5 | 3.0 | 5.8 | 2.2 | virginica | 0.89 |
| 6.0 | 2.2 | 5.0 | 1.5 | virginica | 0.83 |
| 6.1 | 2.6 | 5.6 | 1.4 | virginica | 0.92 |
| 5.9 | 3.0 | 5.1 | 1.8 | virginica | 0.86 |
1.3.4.1 El pipeline en data frames
POr ejemplo se quiere resumir la variable recien creada de la razón entre el sépalo y el petalo. Para hacer esto, si se partiera desde la base de datos original, tomaría varias líneas de código y la creación de múltiples bases de datos intermedias
DF <- mutate(iris, Petal.Sepal.Ratio = Petal.Length/Sepal.Length)
BySpecies <- group_by(DF, Species)
Summary.Byspecies <- summarize(BySpecies, MEAN = mean(Petal.Sepal.Ratio),
SD = sd(Petal.Sepal.Ratio))Otra opción es usar paréntesis anidados, lo que se traduce en el siguiente código:
Summary.Byspecies <- summarize(group_by(mutate(iris, Petal.Sepal.Ratio = Petal.Length/Sepal.Length),
Species), MEAN = mean(Petal.Sepal.Ratio), SD = sd(Petal.Sepal.Ratio))Esto se simplifica mucho más al usar el pipeline, lo cual permite partir en un Data Frame y luego usar el pipeline. Esto permite obtener el mismo resultado que en las operaciones anteriores con el siguiente código:
Summary.Byspecies <- iris %>% mutate(Petal.Sepal.Ratio = Petal.Length/Sepal.Length) %>%
group_by(Species) %>% summarize(MEAN = mean(Petal.Sepal.Ratio),
SD = sd(Petal.Sepal.Ratio))Estos tres códigos son correctos (tabla 1.6), pero definitivamente el uso del pipeline da el código más conciso y fácil de interpretar sin pasos intermedios.
| Species | MEAN | SD |
|---|---|---|
| setosa | 0.2927557 | 0.0347958 |
| versicolor | 0.7177285 | 0.0536255 |
| virginica | 0.8437495 | 0.0438064 |
1.3.5 filter
Esta función permite seleccionar filas que cumplen con ciertas condiciones, como tener un valor mayor a un umbral o pertenecer a cierta clase Los símbolos más típicos a usar en este caso son los que se ven en la tabla 1.7.
| simbolo | significado | simbolo_cont | significado_cont |
|---|---|---|---|
| > | Mayor que | != | distinto a |
| < | Menor que | %in% | dentro del grupo |
| == | Igual a | is.na | es NA |
| >= | mayor o igual a | !is.na | no es NA |
| <= | menor o igual a | | & | o, y |
Por ejemplo si se quiere estudiar las características florales de las plantas del género Iris, pero no tomar en cuenta a la especie Iris versicolor se deberá usar el siguiente código:
data("iris")
DF <- iris %>% filter(Species != "versicolor") %>% group_by(Species) %>%
summarise_all(mean)De esta forma se obtiene como resultado la tabla 1.8. En este caso se introduce la función summarize_all de summarize, la cual aplica la función que se le da como argumento a todas las variables de la base de datos.
| Species | Sepal.Length | Sepal.Width | Petal.Length | Petal.Width |
|---|---|---|---|---|
| setosa | 5.006 | 3.428 | 1.462 | 0.246 |
| virginica | 6.588 | 2.974 | 5.552 | 2.026 |
Por otro lado si se quiere estudiar cuántas plantas de cada especie tienen un largo de pétalo mayor a 4 y un largo de sépalo mayor a 5 se deberá usar el siguiente código:
DF <- iris %>% filter(Petal.Length >= 4 & Sepal.Length >= 5) %>%
group_by(Species) %>% summarise(N = n())En la tabla tabla 1.9 se ve que con este filtro desaparecen de la base de datos todas las plantas de Iris setosa y que todas menos una planta de Iris virginica tienen ambas características.
| Species | N |
|---|---|
| versicolor | 39 |
| virginica | 49 |
1.3.6 select
Esta función permite seleccionar las variables a utilizar dado que en muchos casos nos encontraremos con bases de datos con demasiadas variables y por lo tanto, se querrá reducirlas para solo trabajar en una tabla con las variables necesarias.
Con select hay varias formas de trabajar, por un lado se puede escribir las variables que se utilizarán, o restar las que no. En ese sentido estos cuatro códigos dan exactamente el mismo resultado. Esto se puede ver en la tabla 1.10
| Species | Petal.Length | Petal.Width |
|---|---|---|
| setosa | 1.462 | 0.246 |
| versicolor | 4.260 | 1.326 |
| virginica | 5.552 | 2.026 |
1.3.7 Joins
Los ejemplos a continuación se basan en el código generado por Garrick Aden-Buie en su repositorio de animaciones de verbos del tidyverse (Aden-Buie 2018).
El paquete dplyr, tiene una serie de funciones de apellido join: anti_join, full_join, inner_join, left_join, right_join y semi_join, en general no son tan fáciles de entender a primera vista, por lo que se trabajará con dos tablas muy simples (Tabla 1.11), las cuales tienen dos columnas cada una
## Warning: `data_frame()` is deprecated, use `tibble()`.
## This warning is displayed once per session.
|
|
1.4 left join
Como vemos en la figura 1.1
##
Frame 1 (1%)
Frame 2 (2%)
Frame 3 (3%)
Frame 4 (4%)
Frame 5 (5%)
Frame 6 (6%)
Frame 7 (7%)
Frame 8 (8%)
Frame 9 (9%)
Frame 10 (10%)
Frame 11 (11%)
Frame 12 (12%)
Frame 13 (13%)
Frame 14 (14%)
Frame 15 (15%)
Frame 16 (16%)
Frame 17 (17%)
Frame 18 (18%)
Frame 19 (19%)
Frame 20 (20%)
Frame 21 (21%)
Frame 22 (22%)
Frame 23 (23%)
Frame 24 (24%)
Frame 25 (25%)
Frame 26 (26%)
Frame 27 (27%)
Frame 28 (28%)
Frame 29 (29%)
Frame 30 (30%)
Frame 31 (31%)
Frame 32 (32%)
Frame 33 (33%)
Frame 34 (34%)
Frame 35 (35%)
Frame 36 (36%)
Frame 37 (37%)
Frame 38 (38%)
Frame 39 (39%)
Frame 40 (40%)
Frame 41 (41%)
Frame 42 (42%)
Frame 43 (43%)
Frame 44 (44%)
Frame 45 (45%)
Frame 46 (46%)
Frame 47 (47%)
Frame 48 (48%)
Frame 49 (49%)
Frame 50 (50%)
Frame 51 (51%)
Frame 52 (52%)
Frame 53 (53%)
Frame 54 (54%)
Frame 55 (55%)
Frame 56 (56%)
Frame 57 (57%)
Frame 58 (58%)
Frame 59 (59%)
Frame 60 (60%)
Frame 61 (61%)
Frame 62 (62%)
Frame 63 (63%)
Frame 64 (64%)
Frame 65 (65%)
Frame 66 (66%)
Frame 67 (67%)
Frame 68 (68%)
Frame 69 (69%)
Frame 70 (70%)
Frame 71 (71%)
Frame 72 (72%)
Frame 73 (73%)
Frame 74 (74%)
Frame 75 (75%)
Frame 76 (76%)
Frame 77 (77%)
Frame 78 (78%)
Frame 79 (79%)
Frame 80 (80%)
Frame 81 (81%)
Frame 82 (82%)
Frame 83 (83%)
Frame 84 (84%)
Frame 85 (85%)
Frame 86 (86%)
Frame 87 (87%)
Frame 88 (88%)
Frame 89 (89%)
Frame 90 (90%)
Frame 91 (91%)
Frame 92 (92%)
Frame 93 (93%)
Frame 94 (94%)
Frame 95 (95%)
Frame 96 (96%)
Frame 97 (97%)
Frame 98 (98%)
Frame 99 (99%)
Frame 100 (100%)
## Finalizing encoding... done!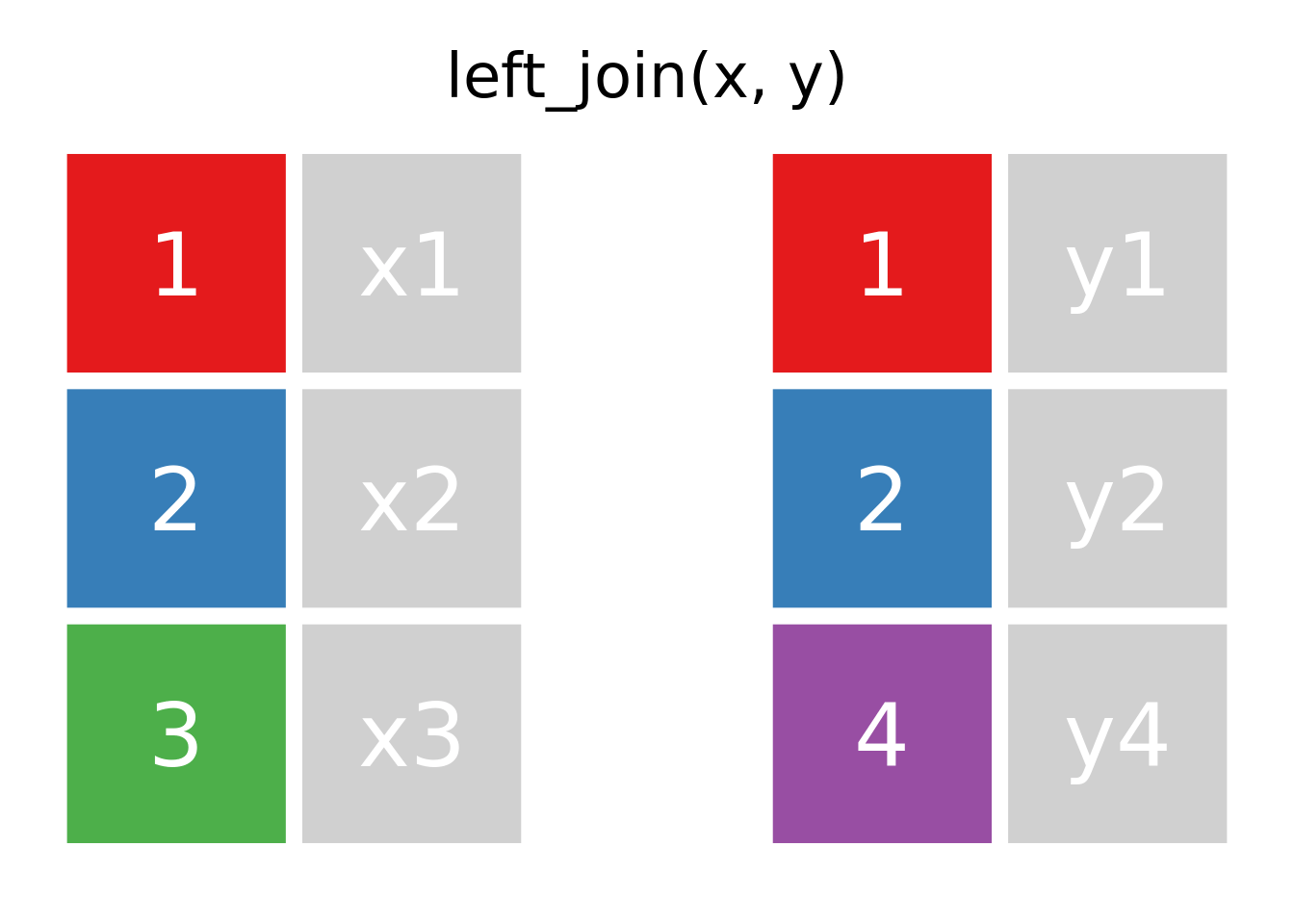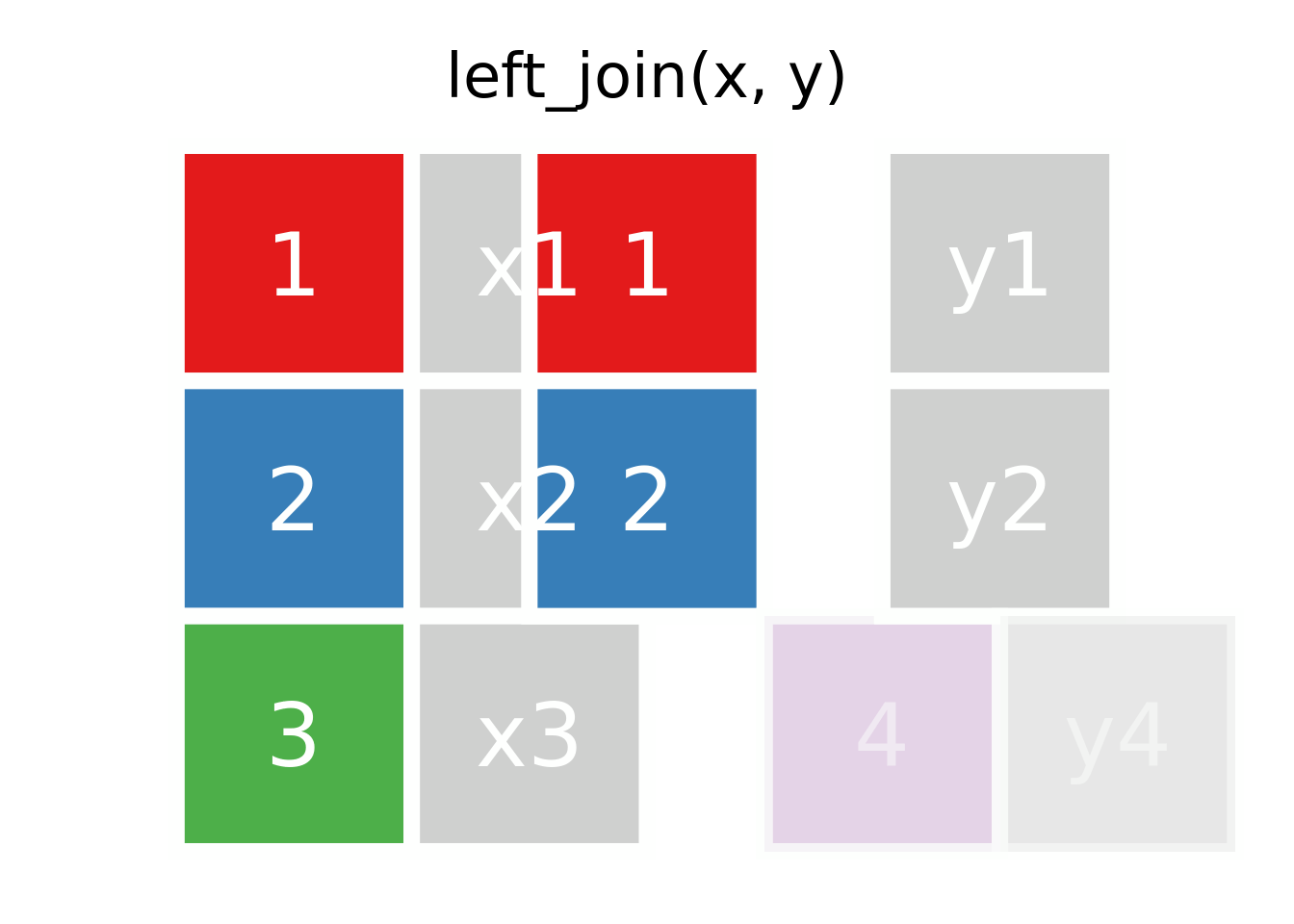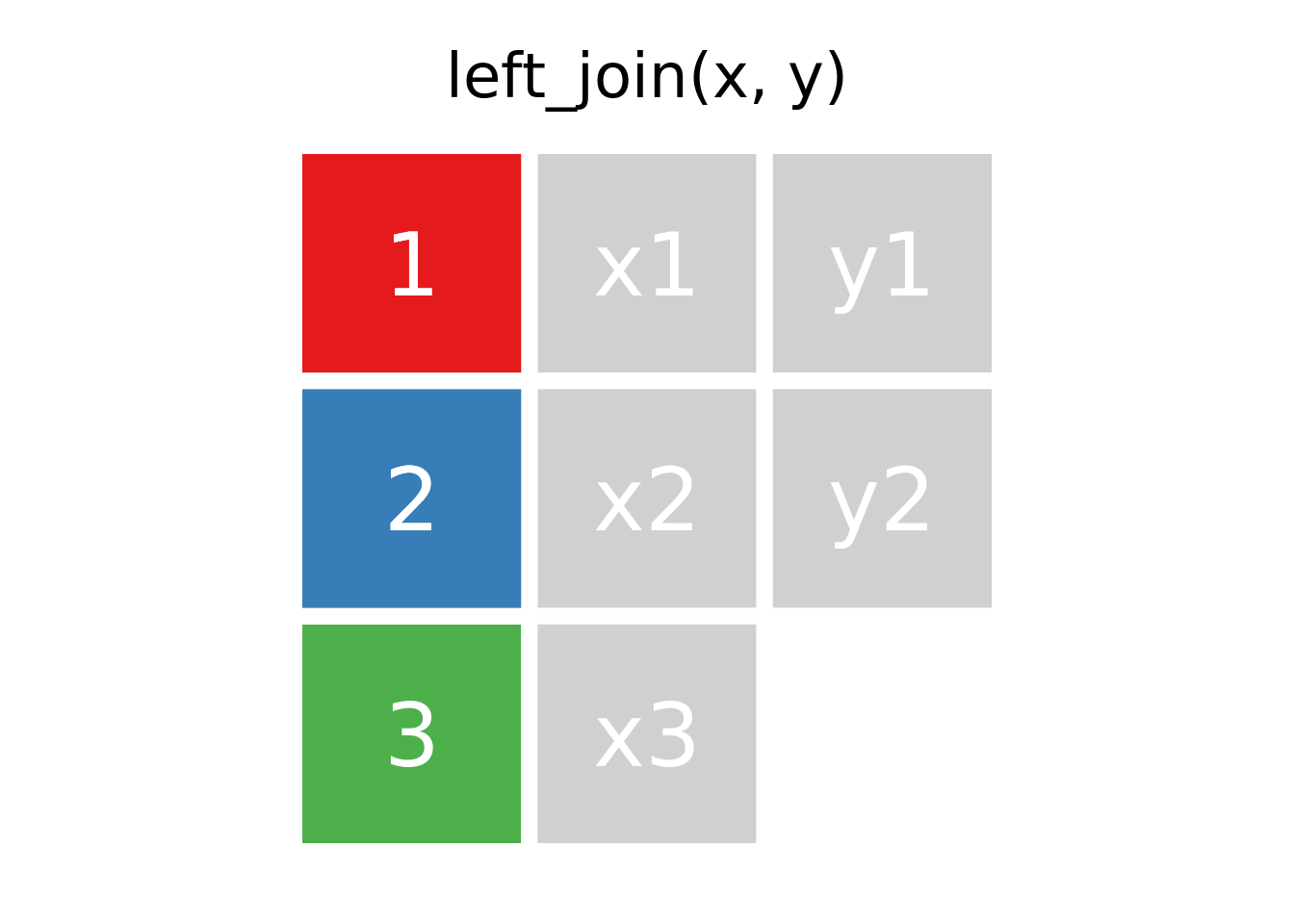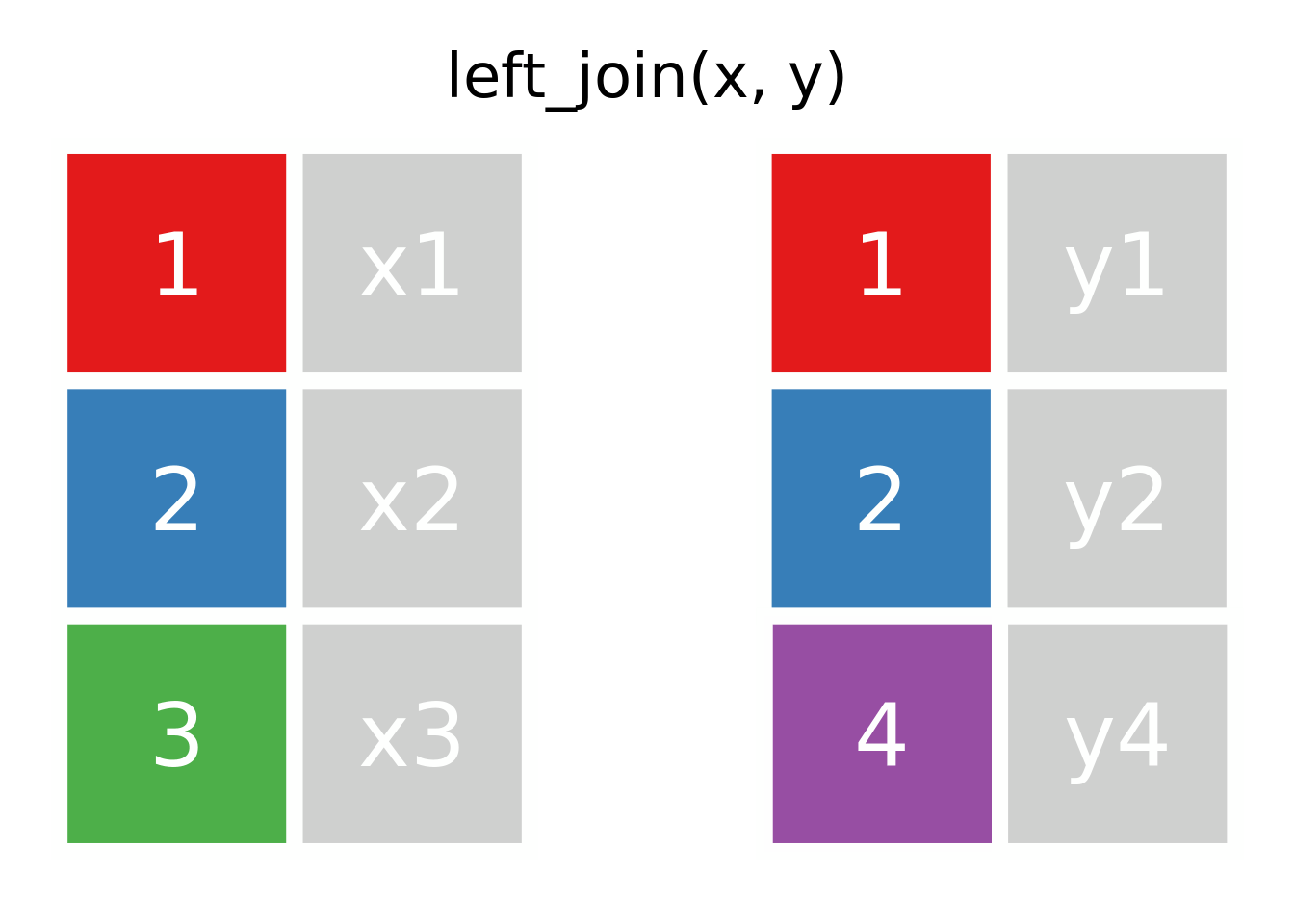
Figura 1.1: animación de left join entre las tablas x e y, cache = TRUE
Entonces
1.4.1 Ejercicios
1.4.1.1 Ejercicio 1
Usando la base de datos storms del paquete dplyr, calcular la velocidad promedio y diámetro promedio (hu_diameter) de las tormentas que han sido declaradas huracanes para cada año.
1.4.1.2 Ejercicio 2
La base de datos mpg del paquete ggplot2 tiene datos de eficiencia vehicular en millas por galón en ciudad (cty) en varios vehículos. Obtener los datos de vehículos del año 2004 en adelante que sean compactos y transformar la eficiencia Km/litro (1 milla = 1.609 km; 1 galón = 3.78541 litros)
Las soluciones a estos ejercicios se encuentran en el capítulo 8
Referencias
Aden-Buie, Garrick. 2018. “Animations of Tidyverse Verbs Using R, the Tidyverse, and Gganimate.” GitHub Repository. https://github.com/gadenbuie/tidy-animated-verbs; GitHub.
Anderson, Edgar. 1935. “The Irises of the Gaspe Peninsula.” Bulletin of the American Iris Society 59: 2–5.
Henderson, Harold V, and Paul F Velleman. 1981. “Building Multiple Regression Models Interactively.” Biometrics. JSTOR, 391–411.
Leek, Jeff. 2015. “The Elements of Data Analytic Style.” J. Leek.—Amazon Digital Services, Inc.
Wickham, Hadley, Romain François, Lionel Henry, and Kirill Müller. 2019. Dplyr: A Grammar of Data Manipulation. https://CRAN.R-project.org/package=dplyr.
Wickham, Hadley, and others. 2014. “Tidy Data.” Journal of Statistical Software 59 (10). Foundation for Open Access Statistics: 1–23.