21 RNAseq diferential & exploratory analysis
We going to generate BAM files from the FASTQ files you downloaded, anad then do differential gene expresion analysis in R. There are six yeast RNAseq samples.
Load packages, install if necessary
21.1 Differential Expression Testing
Read the documents: https://bioconductor.org/packages/release/bioc/vignettes/DESeq2/inst/doc/DESeq2.html
In this exercise we are going to walk through the NGS pipeline for rna-seq, starting from FASTQ files and ending with analyzed rna-seq data. While this is running we will try and see if we can recapitulate this in the command line using a shell script. The workflow in this process begins with
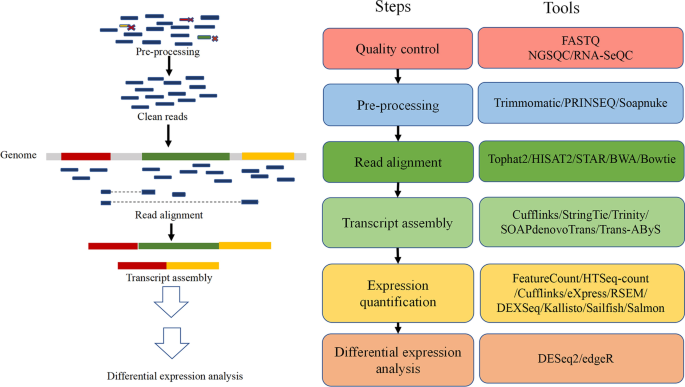
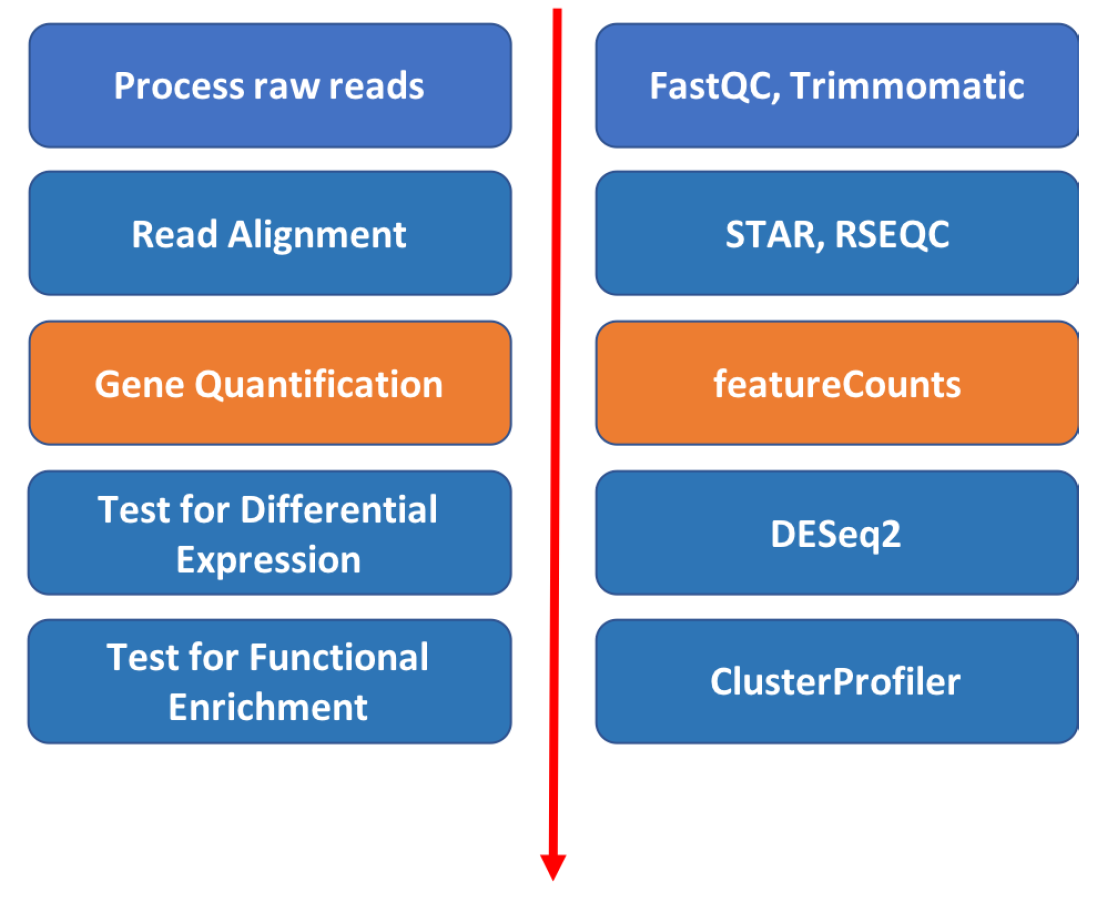
In order to generate a count matrix from FASTQ reads, we need to 1) index the reference file to the genome we are working with, 2) process our raw FASTQ reads, 3) perform quality checks, 4) align the samples to the genome and 4) assemble the alignment to generate the count matrix, as shown in the figure above.
We can do this in R using the Rsubread package, but it is rather slow. So what we are going to do while it is running is to run the same process in the command line using the Conda subread package. The results should be identical, but it will be nice for you to get a feel for both.
Step 1. Indexing the reference genome. Why does it mean to we index a reference file? Indexing a genome can be explained similar to indexing a book. If you want to know on which page a certain word appears or a chapter begins, it is much more efficient/faster to look it up in a pre-built index than going through every page of the book until you found it. Same goes for alignments. Indices allow the aligner to narrow down the potential origin of a query sequence within the genome, saving both time and memory.
To index the reference file we need the reference genome file Saccharomyces_cerevisiae.R64-1-1.dna.toplevel.fa.gz that contains all of the DNA sequences. We also need the gtf file which contains GTF file which contains all of the genomic features, exons, transcripts, genes noncoding regions etc. If we run the alignments and generate the counts in R using this package with the same parameters as we use in subread they should generate identical count matrices. The R version takes about 20’ to run. Make sure you have a copy of Saccharomyces_cerevisiae.R64-1-1.96.gtf.gz and Saccharomyces_cerevisiae.R64-1-1.dna.toplevel.fa.gz in your appropriate directories as listed below.
So we can run this first bit which sets up the names of the files:
setwd("~/Documents/RProjects/genomics/RNA-genomics")
fastq = list.files("FASTQ")
g = grep("fastq.gz",fastq)
fastq = fastq[g]
fastq.files = paste("FASTQ",fastq,sep = "/")
fastq.files = file.path("FASTQ",fastq)
# here we are just generating the names of the bamfiles
# since we want to distinguish these from the bamfiles
# we generated in the terminal, lets put them in a different folder
# let's make that folder
#
bam = gsub("FASTQ/","RBAM/",fastq.files)
bam = gsub(".fastq.gz",".bam",bam)
bam.files = bam
gtf.file = "FASTQ/r64/Saccharomyces_cerevisiae.R64-1-1.96.gtf.gz"
bam.files## [1] "RBAM/ERR458493.bam" "RBAM/ERR458494.bam" "RBAM/ERR458495.bam"
## [4] "RBAM/ERR458500.bam" "RBAM/ERR458501.bam" "RBAM/ERR458502.bam"gtf.file## [1] "FASTQ/r64/Saccharomyces_cerevisiae.R64-1-1.96.gtf.gz"fastq.files## [1] "FASTQ/ERR458493.fastq.gz" "FASTQ/ERR458494.fastq.gz"
## [3] "FASTQ/ERR458495.fastq.gz" "FASTQ/ERR458500.fastq.gz"
## [5] "FASTQ/ERR458501.fastq.gz" "FASTQ/ERR458502.fastq.gz"Here before we start we want to make a folder r64 in the RNA-genomic directory and then set eval = TRUE. Now we’ll run the indexing of the reference:
# first build the index
library(Rsubread)
Rsubread::buildindex(basename="r64/r64.index", memory = 1000,
reference="FASTQ/r64/Saccharomyces_cerevisiae.R64-1-1.dna.toplevel.fa.gz")
Step 2. Align the reads. We will go with the default parameters EXCEPT we will add the argument sortReadsByCoordinates=TRUE which will be convenient for downstream analysis. I also set nthreads to 64, which is the physical core of a CPU to help speed things up – 64 is the maximum for my computer – but the number of threads you use doens’t seem to help the speed much.
OK, let’s start this and go back to our shell script. First I have to set eval = TRUE again.
# report the best mapping location:
Rsubread::align(index = "r64/r64.index", readfile1 = fastq.files,
output_file = bam.files,useAnnotation=TRUE,annot.ext = gtf.file,isGTF = TRUE,nthreads=64,sortReadsByCoordinates=TRUE,
unique=FALSE,nBestLocations = 1)Step 3. Count the reads. Once we have our reads aligned to the genome, the next step is to count how many reads have mapped to each gene as a measure of gene expression. There are many tools that can use BAM files as input and output the number of reads (counts) associated with each feature of interest (genes, exons, transcripts, etc.). Two commonly used counting tools are featureCounts and summarize overlaps.Counting reads is not a straight forward task and there are many factors that bias the final count tally.
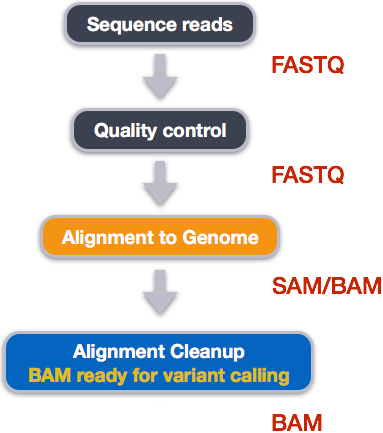
The last panel of this figure should read BAM ready for count calling:
The above tools report the “raw” counts of reads that map to a single location (uniquely mapping) and are best at counting at the gene level. Essentially, total read count associated with a gene (meta-feature) = the sum of reads associated with each of the exons (feature) that “belong” to that gene.
There are other tools that will count multimapping reads (sequences that align to more that one position in the genome), but this is a dangerous thing to do since you will be overcounting the total number of reads which can cause issues with normalization and eventually with accuracy of differential gene expression results – but this is arguable. In RNA-seq, you want to know the total number of transcripts of a particular gene regardless of where it is in the genome and ignoring these genes can lead to missing a lot of genes that may be duplicated in the genome, particularly as these genes are often under the same regulatory control.
Tools for counting require as input multiple BAM files a GTF file which contains all of the genonomic features, exons, transcripts, genes noncoding regions etc.
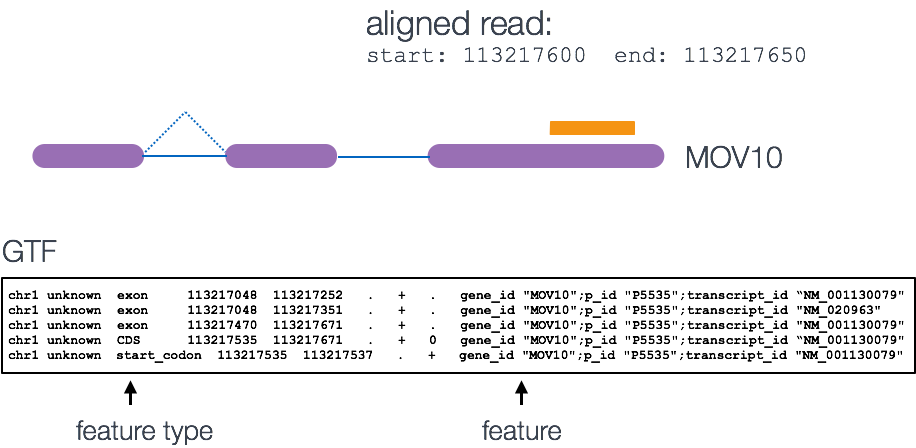
The genomic coordinates of where the BAM reads are mapped are cross-referenced with the genomic coordinates of whichever feature you are interested in counting expression of (GTF), it can be exons, genes or transcripts.
Output of counting = A count matrix, with genes as rows and samples are columns
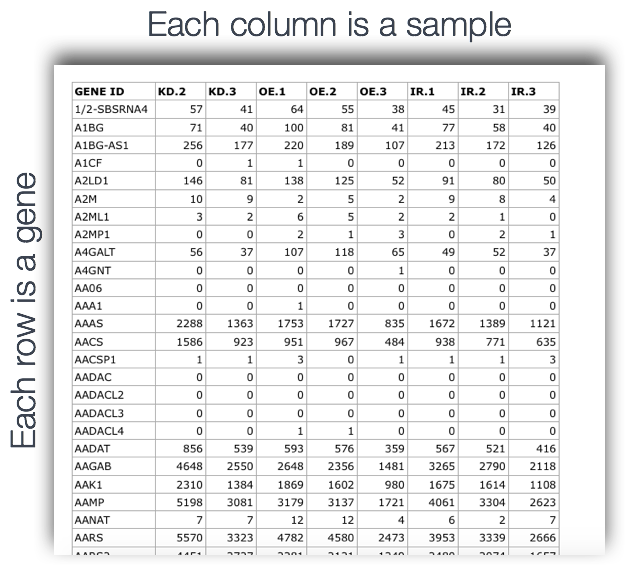 These are the “raw” counts and will be used in statistical programs downstream for differential gene expression.
These are the “raw” counts and will be used in statistical programs downstream for differential gene expression.
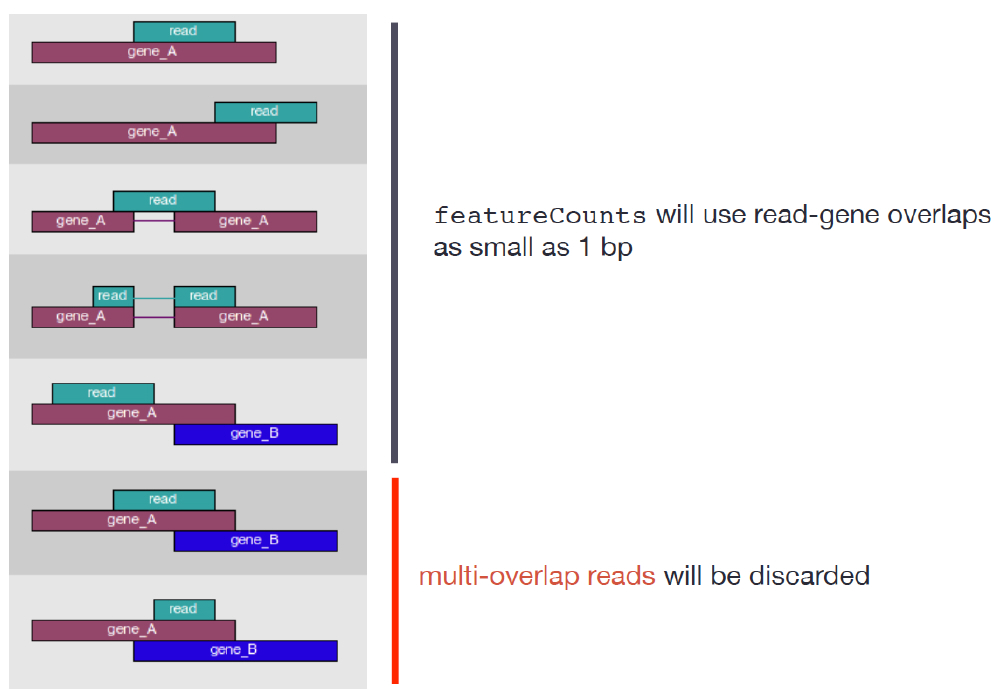
Counting using featureCounts featureCounts is frequently used because it is accurate, fast and is relatively easy to use. It also has a lot of options that other software tools don’t have. featureCounts counts reads that map to a single location (uniquely mapping) and discards reads that are ambiguous, following the scheme in the figure below using the gtf file and BAM files as input.
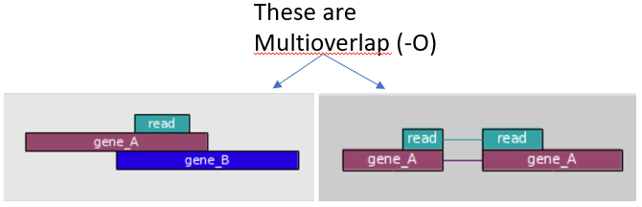
FeatureCounts has an option to count multi-mapping reads, that most other counting software tools don’t have. “Multi-overlapping” reads are reads that overlap with more than one position in the chromosome, but do not overlap more that one feature – not to be confused with “multi-mapping” reads where a read overlaps more than one feature in the genome. For RNA-seq data, a read is called as a multi-mapping read if it has two or more candidate mapping locations that have the same number of mis-matched bases and this number is the smallest in all candidate locations being considered, and not more than 3 mismatches. FeatureCounts is a widely used tool and the consensus is that these multi-mapping reads should not be counted in a RNA-seq experiment because such reads are ambiguous as it is unclear which gene they originated from.
Genomic multireads are primarily due to repetitive sequences or shared domains of paralogous genes. The literature for best practices for RNA seq they explicitly state that these sequences should not be discarded as they normally account for a significant fraction of the mapping output when mapped onto the genome. When the reference is the transcriptome, multi-mapping arises even more often because a read that would have been uniquely mapped on the genome would map equally well to all gene isoforms in the transcriptome that share the exon. In either case — genome or transcriptome mapping — transcript identification and quantification become important challenges for alternatively expressed genes. For this reason we have decided to include these features in our analysis.
featureCounts in RStudio is extensive, and not all the options are set to the same defaults as the ones in the terminal that you can see by typing typing featureCounts -h. So even though the Conda package subread and the R package Rsubread come from the same source, the options are are not the same, and pretty complicated.
library(Rsubread)
fc <- featureCounts(bam.files, annot.ext=gtf.file,
isGTFAnnotationFile=TRUE,
isPaired=FALSE,
###################
allowMultiOverlap = FALSE,countMultiMappingReads = TRUE)##
## ========== _____ _ _ ____ _____ ______ _____
## ===== / ____| | | | _ \| __ \| ____| /\ | __ \
## ===== | (___ | | | | |_) | |__) | |__ / \ | | | |
## ==== \___ \| | | | _ <| _ /| __| / /\ \ | | | |
## ==== ____) | |__| | |_) | | \ \| |____ / ____ \| |__| |
## ========== |_____/ \____/|____/|_| \_\______/_/ \_\_____/
## Rsubread 2.10.5
##
## //========================== featureCounts setting ===========================\\
## || ||
## || Input files : 6 BAM files ||
## || ||
## || ERR458493.bam ||
## || ERR458494.bam ||
## || ERR458495.bam ||
## || ERR458500.bam ||
## || ERR458501.bam ||
## || ERR458502.bam ||
## || ||
## || Paired-end : no ||
## || Count read pairs : no ||
## || Annotation : Saccharomyces_cerevisiae.R64-1-1.96.gtf.gz ( ... ||
## || Dir for temp files : . ||
## || Threads : 1 ||
## || Level : meta-feature level ||
## || Multimapping reads : counted ||
## || Multi-overlapping reads : not counted ||
## || Min overlapping bases : 1 ||
## || ||
## \\============================================================================//
##
## //================================= Running ==================================\\
## || ||
## || Load annotation file Saccharomyces_cerevisiae.R64-1-1.96.gtf.gz ... ||
## || Features : 7416 ||
## || Meta-features : 7036 ||
## || Chromosomes/contigs : 17 ||
## || ||
## || Process BAM file ERR458493.bam... ||
## || Single-end reads are included. ||
## || Total alignments : 1093957 ||
## || Successfully assigned alignments : 934788 (85.5%) ||
## || Running time : 0.01 minutes ||
## || ||
## || Process BAM file ERR458494.bam... ||
## || Single-end reads are included. ||
## || Total alignments : 1078049 ||
## || Successfully assigned alignments : 920443 (85.4%) ||
## || Running time : 0.01 minutes ||
## || ||
## || Process BAM file ERR458495.bam... ||
## || Single-end reads are included. ||
## || Total alignments : 1066501 ||
## || Successfully assigned alignments : 910952 (85.4%) ||
## || Running time : 0.01 minutes ||
## || ||
## || Process BAM file ERR458500.bam... ||
## || Single-end reads are included. ||
## || Total alignments : 1885330 ||
## || Successfully assigned alignments : 1605953 (85.2%) ||
## || Running time : 0.02 minutes ||
## || ||
## || Process BAM file ERR458501.bam... ||
## || Single-end reads are included. ||
## || Total alignments : 1870525 ||
## || Successfully assigned alignments : 1593634 (85.2%) ||
## || Running time : 0.02 minutes ||
## || ||
## || Process BAM file ERR458502.bam... ||
## || Single-end reads are included. ||
## || Total alignments : 1853031 ||
## || Successfully assigned alignments : 1579186 (85.2%) ||
## || Running time : 0.02 minutes ||
## || ||
## || Write the final count table. ||
## || Write the read assignment summary. ||
## || ||
## \\============================================================================//##################Another method of extracting count files from BAM files is by using summarizeOverlaps from the GenomicAlignments package. summarizeOverlaps uses only the exons extracted from the TxDb object (which stores relationships between pre-processed mRNA transcripts, exons, protein coding sequences, and genes construncted from the gtf file.
We specify a number of arguments besides the features and the reads. The mode argument describes what kind of read overlaps will be counted, as in featureCounts (see below). Note that fragments will be counted only once to each gene, even if they overlap multiple exons of a gene which may themselves be overlapping.

library(GenomicFeatures)
txdb <- makeTxDbFromGFF(gtf.file, format="gtf")
exons.by.gene <- exonsBy(txdb, by="gene")
library(Rsamtools)
bam.list <- BamFileList(bam)
library(GenomicAlignments)
# ignore.strand=TRUE -- the prep was not generated by a strand-specific protocol,
# inter.feature=TRUE -- when FALSE, these reads are retained and counted once for each feature they map to
se <- summarizeOverlaps(exons.by.gene, bam.list, mode=Union,
inter.feature=TRUE, singleEnd=TRUE,ignore.strand = TRUE)Now let’s plot the two against each other to see how they compare.
Compare summarizedOverlaps to featureCounts:
m=match(rownames(assay(se) ),rownames(fc$counts))
plot(assay(se[,1]),fc$counts[m,1],ylab = "featureCounts",xlab = "summarizeOverlaps",pch=19)
abline(a=0,b=1)
table(assay(se)==fc$counts[m,])##
## TRUE
## 42216cor.test(assay(se),fc$counts[m,])##
## Pearson's product-moment correlation
##
## data: assay(se) and fc$counts[m, ]
## t = Inf, df = 42214, p-value < 2.2e-16
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 1 1
## sample estimates:
## cor
## 1counts = fc$counts
g = grep("^Y",rownames(counts))
counts = counts[g,]
counts = counts[order(rownames(counts)),]
# Let's give the original names back to the samples
# From the script subreadMapping.sh
cnts = read_tsv("counts.txt",skip = 1)
cts = as.matrix(cnts[,7:12])
rownames(cts)=cnts$Geneid
gg= grep("^Y",cnts$Geneid)
cts = cts[gg,]
cts = cts[order(rownames(cts)),]
colnames(cts)=basename(colnames(cts))
table(counts == cts)##
## FALSE TRUE
## 4286 35218cor.test(counts,cts)##
## Pearson's product-moment correlation
##
## data: counts and cts
## t = 13041, df = 39502, p-value < 2.2e-16
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.9998816 0.9998862
## sample estimates:
## cor
## 0.9998839You can see that the summarizedOverlaps is identical to the featureCounts method of counting reads. And our count matrix generated in the terminal is nearly identical to the one generated in R. The reason it is not identical is because of the parameter nBestLocations. When there are multiMapped reads greater than the number of nBestLocations, the program selects nBestLocations randomly out of those found.
se is a summarized experiment. A word about summarized experiments. The way summarized experiments are set up is that the rownames of the colData or metadata, also sometimes called phenoData, must match the colnames of the assay data – the count data or expression data. Similarly, the rownames of the assay data must match the rowRanges of the featureData. This is all part of Bioconductor’s way of standardizing structures so that they work well with each other across and within packages.
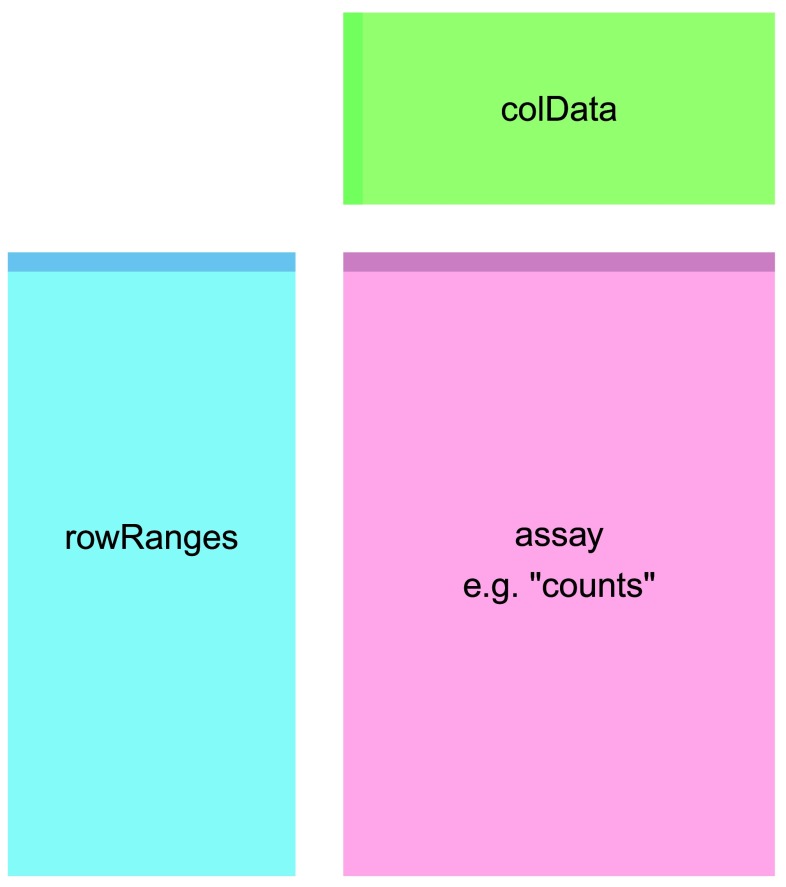
Translating orf names to gene names:
library(org.Sc.sgd.db)
eid = keys(org.Sc.sgd.db)
gene=AnnotationDbi::mapIds(org.Sc.sgd.db, keys = eid, column = "GENENAME", keytype = "ORF")
m=match(rownames(counts),names(gene))
table(is.na(m))##
## FALSE
## 6584wna = which(is.na(gene))
gene[wna]=names(gene)[wna]
length(wna)## [1] 2598genecnts = counts
rownames(genecnts)=gene[m]Let’s rename our colnames of counts from bamfile names back to our original sample names before we start our differential analysis:
library(readr)
library(dplyr)
meta <- read_csv("https://osf.io/cxp2w/download")
meta = meta[,-2]
names(meta)[2] = "genome"
meta$genome = factor(meta$genome)
meta$genome = relevel(meta$genome,ref = "wt")
# make wild-type the reference to which expression in snf2 samples is compared to
meta = meta %>% dplyr::arrange(sample)
meta$sample## [1] "ERR458493" "ERR458494" "ERR458495" "ERR458500" "ERR458501" "ERR458502"meta = data.frame(meta,stringsAsFactors = F)
rownames(meta)=meta$sample
colnames(counts) = gsub(".bam","",colnames(counts))Looks good, this meets the requirement of a summarized experiment:
colnames(counts) == meta$sample## [1] TRUE TRUE TRUE TRUE TRUE TRUE21.2 DESeq2 workflow
To run DESeq2 analysis, you have to check to make sure that all rows labels in meta are columns in data:
all(colnames(counts) == rownames(meta))## [1] TRUECreate the dataset and run the analysis:
dds <- DESeqDataSetFromMatrix(countData = counts, colData = meta, design = ~genome)
dds$genome <- relevel(dds$genome, ref = "wt") # make wild-type the reference to which expression in treatment samples is compared to
dds <- DESeq(dds)- Read in Data
We’ve already read in the metadata for our experiment, let’s view it:
glimpse(meta)## Rows: 6
## Columns: 2
## $ sample <chr> "ERR458493", "ERR458494", "ERR458495", "ERR458500", "ERR458501"…
## $ genome <fct> wt, wt, wt, snf2, snf2, snf2Behind the scenes these steps were run in DESeq2 function:
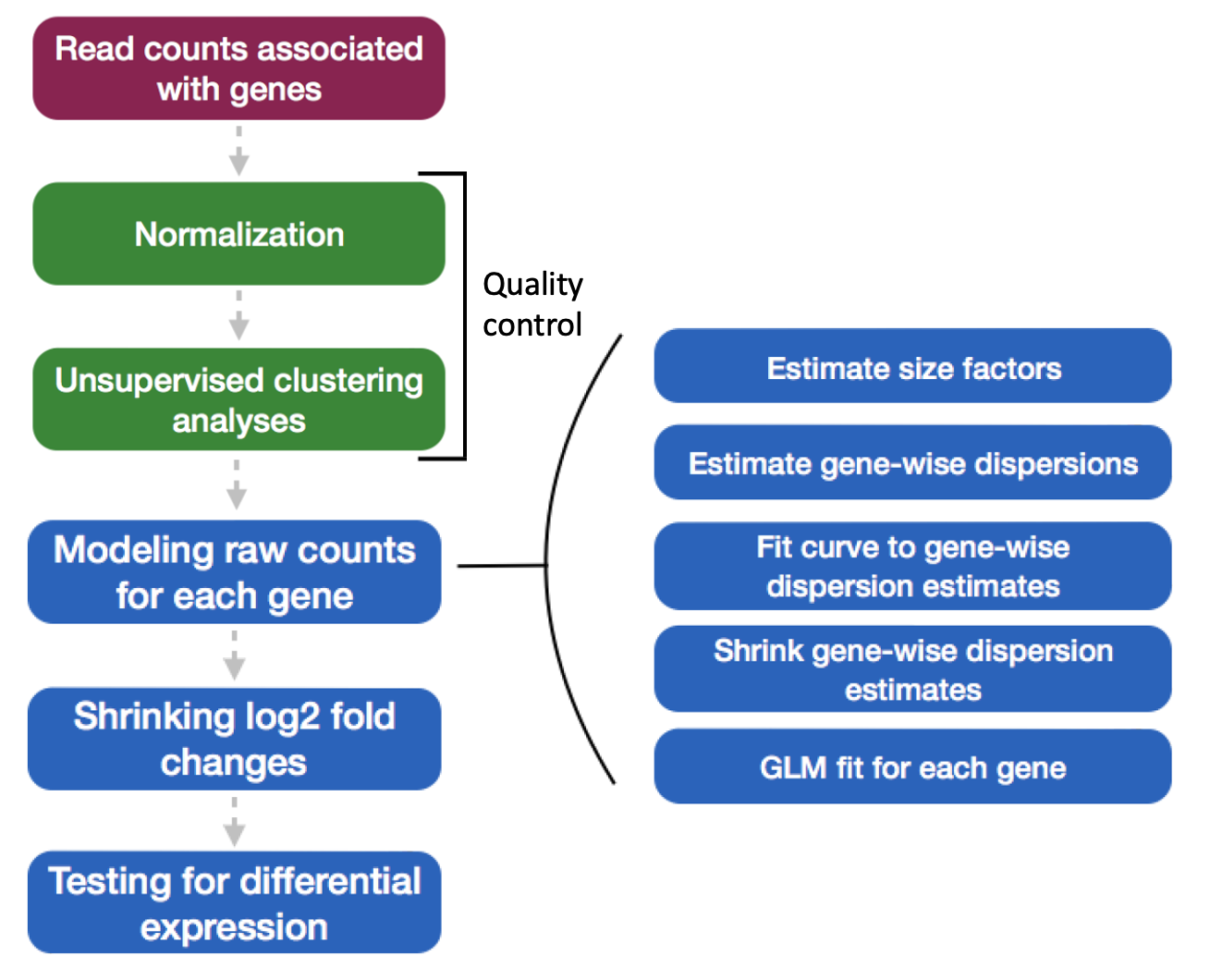
1.estimating size factors 2.gene-wise dispersion estimates 3.mean-dispersion relationship 4.final dispersion estimates 5.fitting model and testing
The design formula design = ~genome tells DESeq2 which factors in the metadata to test, such as control v.s. treatment. Here our condition is wt v.s. snf2 as shown in the meta.
The design can include multiple factors that are columns in the metadata. In this case, the factor that you are testing for comes last, and factors that you want to account for come first. E.g. To test for differences in condition while accounting for sex and age: design = ~ sex + age + condition.

 - Unsupervised Clustering
- Unsupervised Clustering
This step is to asses overall similarity between samples: 1.Which samples are similar to each other, which are different? 2.Does this fit to the expectation from the experiment’s design? 3.What are the major sources of variation in the dataset?
To accomplish this we use Principle component analysis. Principal component analysis (PCA) is a mathematical algorithm that reduces the dimensionality of the data while retaining most of the variation in the data set1. It accomplishes this reduction by identifying directions, called principal components, along which the variation in the data is maximal. By using a few components, each sample can be represented by relatively few numbers instead of by values for thousands of variables. Samples can then be plotted, making it possible to visually assess similarities and differences between samples and determine whether samples can be grouped. PCA can be used to represent samples with a smaller number of variables, visualize samples and genes, and detect dominant patterns of gene expression. PCA is extremely powerful for use in exploring large-scale data sets in which thousands of variables have been measured. It can act as a quick gut check to test whether your data is in aligning with your metadata, for example.
- Principle Components Analysis
Here we use the built in function plotPCA from DESeq2 (built on top of ggplot). The regularized log transform (rlog) improves clustering by log transforming the data.
rld <- rlog(dds, blind=TRUE)
plotPCA(rld, intgroup="genome") + geom_text(aes(label=name))
- Creating contrasts and running a Wald test
The null hypothesis: log fold change = 0 for across conditions. P-values are the probability of rejecting the null hypothesis for a given gene, and adjusted p values take into account that we’ve made many comparisons:
contrast <- c("genome", "wt", "snf2")
res_unshrunken <- DESeq2::results(dds, contrast=contrast)
summary(res_unshrunken)##
## out of 6328 with nonzero total read count
## adjusted p-value < 0.1
## LFC > 0 (up) : 1291, 20%
## LFC < 0 (down) : 895, 14%
## outliers [1] : 0, 0%
## low counts [2] : 245, 3.9%
## (mean count < 1)
## [1] see 'cooksCutoff' argument of ?results
## [2] see 'independentFiltering' argument of ?results# or
res_unshrunken <- DESeq2::results(dds, name = "genome_snf2_vs_wt")Here shows a summary of up- or down-regulated genes:
- Shrinkage of log fold change of genes with very low expression. Genes with very low expression usually have very noisy estimates of log2 fold changes. It is desirable to shrink the fold change of genes with low read counts, but not shrink the fold change of highly expressed genes too much. DEseq2 has implemented several different algorithms for shrinkage. The DESeq2 developers recommend to use apeglm method for shrinkage. Shrinkage is especially important if you plan to use LFC to rank genes for enrichment analysis (e.g., GSEA, to be covered next week).
One more step where information is used across genes to avoid overestimates of differences between genes with high dispersion. This is not done by default, so we run the code:
res <- lfcShrink(dds, coef ="genome_snf2_vs_wt", type="apeglm")
# or
res <- lfcShrink(dds, coef =2, type="apeglm")21.3 Visualizing RNA-seq results
Count Data Transformations:
To improve the distances/clustering for the PCA and heirarchical clustering visualization methods, we need to moderate the variance across the mean by applying the rlog transformation to the normalized counts.
The the rlog transformations of the normalized counts is only necessary for these visualization methods during quality assessment. We will not be using these tranformed counts downstream.
rlog: “transforms the count data to the log2 scale in a way which minimizes differences between samples for rows with small counts, and which normalizes with respect to library size. The transformation is useful for quality control.
rld <- rlog(dds, blind=TRUE)
head(assay(rld), 3)## ERR458493 ERR458494 ERR458495 ERR458500 ERR458501 ERR458502
## YAL001C 6.357508 6.108557 5.919077 6.303782 6.345789 6.282309
## YAL002W 6.034131 6.028975 5.872289 6.097242 6.167179 6.018629
## YAL003W 10.372126 10.341486 10.324758 9.777731 9.767517 9.72334221.4 Components of the PCA analysis - Variance explained
The statistical interpretation of singular values is in the form of variance in the data explained by the various components. The singular values produced by the prcomp (a function in R that produces principal components, along with svd) are in order from largest to smallest and when squared are proportional the amount of variance explained by a given singular vector.
rlog PCA:
data1 <- plotPCA(rld, returnData=TRUE, intgroup = "genome")
#data1$group<-gsub(" : ","_",as.character(data1$group))
percentVar1 <- round(100 * attr(data1, "percentVar"))
PCA<-ggplot(data1, aes(PC1, PC2, color = genome))+ theme_bw()+
geom_point(size=9, alpha = 0.8) + scale_colour_manual(values = c("#44aabb","#bbbbbb"))+
xlab(paste0("PC1: ",percentVar1[1],"% variance")) +
ylab(paste0("PC2: ",percentVar1[2],"% variance")) +
theme(text = element_text(size=20)) + ggtitle("rlog PCA")
PCA
21.5 HeatMaps
rlog HeatMap:
To make heatmaps we need colors. The RColorBrewer package is a nice choice for this. RColorBrewer has several palettes, there are three types: “div”,“seq” and “qual”. You can check them out typing:
library(RColorBrewer)
for (i in 1:5) {
display.brewer.all(n=NULL, type="all", select=NULL, exact.n=TRUE,colorblindFriendly=FALSE)
display.brewer.all(type="div")
display.brewer.all(type="seq")
display.brewer.all(type="qual")
display.brewer.all(colorblindFriendly=TRUE)}
























Each palette has a defined set of colors. To get a list of the palettes type:
brewer.pal.info## maxcolors category colorblind
## BrBG 11 div TRUE
## PiYG 11 div TRUE
## PRGn 11 div TRUE
## PuOr 11 div TRUE
## RdBu 11 div TRUE
## RdGy 11 div FALSE
## RdYlBu 11 div TRUE
## RdYlGn 11 div FALSE
## Spectral 11 div FALSE
## Accent 8 qual FALSE
## Dark2 8 qual TRUE
## Paired 12 qual TRUE
## Pastel1 9 qual FALSE
## Pastel2 8 qual FALSE
## Set1 9 qual FALSE
## Set2 8 qual TRUE
## Set3 12 qual FALSE
## Blues 9 seq TRUE
## BuGn 9 seq TRUE
## BuPu 9 seq TRUE
## GnBu 9 seq TRUE
## Greens 9 seq TRUE
## Greys 9 seq TRUE
## Oranges 9 seq TRUE
## OrRd 9 seq TRUE
## PuBu 9 seq TRUE
## PuBuGn 9 seq TRUE
## PuRd 9 seq TRUE
## Purples 9 seq TRUE
## RdPu 9 seq TRUE
## Reds 9 seq TRUE
## YlGn 9 seq TRUE
## YlGnBu 9 seq TRUE
## YlOrBr 9 seq TRUE
## YlOrRd 9 seq TRUETo use a palette, simply type brewer.pal followed by the number of colors you want and the name of the palette, e.g.:
set1 = brewer.pal(8, "Set1")df <- as.data.frame(colData(rld)[,c("genome", "sample")])
mat_colors1<-list(sample = brewer.pal(12, "Paired")[0:6])
names(mat_colors1$sample)<- df$sample
mat_colors <- list(genome = brewer.pal(12, "Paired")[7:8])
names(mat_colors$genome) <- c("wt", "snf2")
genes <- order(res$padj)[1:50]
pheatmap(assay(rld)[genes, ], cluster_rows=TRUE, show_rownames=FALSE,
cluster_cols=FALSE, annotation_col=df, annotation_colors = c(mat_colors1, mat_colors), fontsize = 12)
Another option for heat maps: plot the difference from the mean normalized count across samples (and optionally change default colors)
With Rlog transformed data:
pal <- brewer.pal(9,"YlOrRd")
mat_colors1<-list(sample = brewer.pal(6 ,"Set2"))
names(mat_colors1$sample)<- df$sample
mat_colors <- list(genome = brewer.pal(2,"Set3")[1:2])
names(mat_colors$genome) <- c("wt", "snf2")
mat <- assay(rld)[genes, ]
mat <- mat - rowMeans(mat)
df <- as.data.frame(colData(rld)[,c("genome", "sample")])
pheatmap(mat, cluster_rows=TRUE, show_rownames=FALSE,
cluster_cols=TRUE, annotation_col=df, annotation_colors = c(mat_colors1, mat_colors), fontsize = 12, color = pal)
Heatmap of sample-to-sample distances
sampleDists <- dist(t(assay(rld)))
sampleDistMatrix <- as.matrix(sampleDists)
rownames(sampleDistMatrix) <- paste(rld$genome, rld$type, sep="-")
colnames(sampleDistMatrix) <- NULL
colors <- colorRampPalette( rev(brewer.pal(9, "Blues")) )(255)
pheatmap(sampleDistMatrix,
clustering_distance_rows=sampleDists,
clustering_distance_cols=sampleDists,
col=colors)
The summary of results after shrinkage can be viewed by typing summary(res) or head(res). If you used head(res) you will be viewing the top few lines of the result containing log2 fold change and p-value. log2FoldChange = log2(snf2count/wtcount)Estimated from the model. padj - Adjusted pvalue for the probability that the log2FoldChange is not zero.
21.6 Saving results
Now you have the table with log2 fold change and you might want to save it for future analysis. A adj value cutoff can be applied here. For example, here p-adj 0.05 is used.
## Filtering to find significant genes
padj.cutoff <- 0.05 # False Discovery Rate cutoff
significant_results <- res[which(res$padj < padj.cutoff),]
## save results using customized file_name
file_name = 'significant_padj_0.05.txt'
# write.table(significant_results, file_name, quote=FALSE)Now you have your analyzed result saved in txt file, which can be imported to Excel.
- Exit R and save the work space
If you want to take a break and exit R, type q(). The workspace will be automatically saved with the extension of .Rproj.
21.7 Review DeSeq2 workflow
These comprise the full workflow:
# Setup DESeq2
dds <- DESeqDataSetFromMatrix(countData = counts, colData = meta, design = ~genome)
# Run size factor estimation, dispersion estimation, dispersion shrinking, testing
dds <- DESeq(dds)
# Tell DESeq2 which conditions you would like to output
contrast <- c("genome", "snf2", "wt")
# Output results to table
res_unshrunken <- results(dds, contrast=contrast)
# Shrink log fold changes for genes with high dispersion
res <- lfcShrink(dds, contrast=contrast, res=res_unshrunken, type = "apeglm")Run DESeq2:
dds <- DESeq(dds)Check out results:
resultsNames(dds)## [1] "Intercept" "genome_snf2_vs_wt"res <- results(dds,name = "genome_snf2_vs_wt")
head(res)## log2 fold change (MLE): genome snf2 vs wt
## Wald test p-value: genome snf2 vs wt
## DataFrame with 6 rows and 6 columns
## baseMean log2FoldChange lfcSE stat pvalue padj
## <numeric> <numeric> <numeric> <numeric> <numeric> <numeric>
## YAL001C 75.2738 0.373054 0.2075316 1.79758 7.22440e-02 1.71245e-01
## YAL002W 65.6960 0.265364 0.2089526 1.26997 2.04094e-01 3.68618e-01
## YAL003W 1117.4769 -1.035731 0.0501449 -20.65476 8.84562e-95 5.32752e-93
## YAL004W 0.0000 NA NA NA NA NA
## YAL005C 1610.8402 -1.300837 0.0418550 -31.07963 4.53974e-212 7.67089e-210
## YAL007C 148.8745 0.230801 0.1392779 1.65713 9.74937e-02 2.13739e-01Summarize results
summary(res, alpha = 0.05) # default significance cut-off is 0.1, changing alpha to 0.05 changes the significance cut-off ##
## out of 6328 with nonzero total read count
## adjusted p-value < 0.05
## LFC > 0 (up) : 697, 11%
## LFC < 0 (down) : 1176, 19%
## outliers [1] : 0, 0%
## low counts [2] : 245, 3.9%
## (mean count < 1)
## [1] see 'cooksCutoff' argument of ?results
## [2] see 'independentFiltering' argument of ?results21.8 Plotting single genes
Now, you can explore individual genes that you might be interested in. A simple plot can be made to compare the expression level of a particular gene. For example, for gene “YOR290C”:
par(pch=19)
plotCounts(dds, gene="YOR290C", intgroup="genome")
IGV
The Integrative Genomics Viewer (IGV) is a high-performance, easy-to-use, interactive tool for the visual exploration of genomic data. It supports flexible integration of all the common types of genomic data and metadata, investigator-generated or publicly available, loaded from local or cloud sources.
Development of IGV has been supported by funding from the National Cancer Institute (NCI) of the National Institutes of Health, the Informatics Technology for Cancer Reserarch (ITCR) of the NCI, and the Starr Cancer Consortium.
https://software.broadinstitute.org/software/igv/download
For this exercise we’ll be making use of IGV that you downloaded. The Saccharomyces cerevisiae genome that we used for the mapping is available here. It can be found under Genome -> S. cerevisiae (sacCer3)
The BAM files can be added tracks. Choose “Tracks -> local file”. Select all the .bam files and the accompanying .bai files.
You should get something like this:
If we want to see our reads we have to zoom in. Unfortunately, the web app doesn’t make it easy to search for genes so we have to do it the hard way.
Question: pick five of your top hits in the DESeq2 analysis and see if they check out.