2 Univariate Statistics – Case Study Socio-Demographic Reporting
2.1 Introduction
The 2020 socio-demographic report on the German state North-Rhine Westphalia continues the state’s social reporting since its beginning in 1992. These reports aim to provide the public with information on the social and demographic conditions and dynamics of North Rhine-Westphalia (NRW).
Social indicators refer to demographic conditions and developments (e.g., population figures, the proportion of people with a migration background), the economy (e.g., unemployment rates, GDP), health, education, housing, public finances, and social inequality.
The report and underlying data we are dealing with in this case study can be accessed online via https://www.sozialberichte.nrw.de.

Analyses based on data from the socio-demographic report are politically relevant. Insights from data analyses may provide politicians and public officials with information on social problems that need to be addressed by political measures. It is thus important that interpretations derived from data analyses are accurate. In the following case study, we take a closer look at the data and use methods from univariate statistics. Please note that the analyses and interpretations below are meant to illustrate data analysis techniques and do not reflect any policy advice.
We will use the following indicators or variables (source https://www.inkar.de):
- Population density
- Proportion of foreigners
- Proportion of unemployed
- Crime rate
- Average age
2.2 Preparing the data
Before we can analyze the data, they must be read in the data analysis program. R uses a lot of so-called “packages” (i.e., software add-ons that facilitate or simplify specific parts of data analysis). For example, the package “readxl” allows us to read data that is stored in an Excel format. As another example, the package “ggplot2” allows us to create print-ready figures. Packages often have a specific syntax to which we refer along the way.
library(readxl) # This command loads the package "readxl". In the markdown document, all required packages are installed in the background using the command "install.packages('packagename')". In the downloadable script files, the installation and activation of the packages is automated.
data_nrw <- read_excel("data/inkar_nrw.xls") # Reads data from Excel format; the directory where the data is to be found can be changed (e.g., "C:/user/documents/folderxyz/inkar_nrw.xls")After reading the file “inkar_nrw.xlsx”, it is stored as an object in R. We can now work with the data. As a first step, we print the first ten rows of the data frame:
kable(head(data_nrw, 10), format = "html", caption = "Selected social indicators NRW") %>%
kable_paper() %>% #Font scheme of the table
scroll_box(width = "100%", height = "100%") #Scrollable box| kkziff | area | aggregat | nonnational | population | flaeche | unemp | avage | crimerate | KN |
|---|---|---|---|---|---|---|---|---|---|
| 05111 | Düsseldorf, Stadt | kreisfreie Stadt | 20.69 | 620523 | 217 | 7.77 | 42.65 | 9998.762 | 5111000 |
| 05112 | Duisburg, Stadt | kreisfreie Stadt | 21.86 | 495885 | 233 | 12.10 | 43.05 | 8640.908 | 5112000 |
| 05113 | Essen, Stadt | kreisfreie Stadt | 16.87 | 582415 | 210 | 11.04 | 43.68 | 7472.201 | 5113000 |
| 05114 | Krefeld, Stadt | kreisfreie Stadt | 17.54 | 226844 | 138 | 11.11 | 44.28 | 8866.532 | 5114000 |
| 05116 | Mönchengladbach, Stadt | kreisfreie Stadt | 17.09 | 259665 | 170 | 10.02 | 43.74 | 8256.396 | 5116000 |
| 05117 | Mülheim an der Ruhr, Stadt | kreisfreie Stadt | 16.12 | 170921 | 91 | 8.31 | 45.23 | 5285.058 | 5117000 |
| 05119 | Oberhausen, Stadt | kreisfreie Stadt | 15.83 | 209566 | 77 | 10.76 | 44.52 | 7378.869 | 5119000 |
| 05120 | Remscheid, Stadt | kreisfreie Stadt | 19.15 | 111516 | 75 | 7.97 | 44.37 | 5635.991 | 5120000 |
| 05122 | Solingen, Klingenstadt | kreisfreie Stadt | 17.13 | 159193 | 90 | 8.15 | 44.11 | 5933.624 | 5122000 |
| 05124 | Wuppertal, Stadt | kreisfreie Stadt | 20.81 | 355004 | 168 | 9.95 | 43.11 | 8059.420 | 5124000 |
The data contains the following variables for all 53 districts and large cities in North-Rhine Westphalia (reference year is 2020):
kkziff = identifier code for the county (Landkreis) or city (kreisfreie Stadt)
area = County / city name
nonnationall = Proportion of foreign-born residents in %
population = Number of inhabitants
flaeche = Land area in square kilometers
unemp = Unemployment rate in %
avage = Average age of the population
crimerate = Crime rate in cases per 100,000 inhabitants
KN = Alternative id code that we need for the map below
2.3 Representation of spatial patterns using maps
One option to represent spatially structured data is in the form of a map.
# Read a so-called shape file for NRW which contains the polygones (e.g., district boundaries) necessary to build maps and merging with structural data
nrw_shp <- st_read("data/dvg2krs_nw.shp")## Reading layer `dvg2krs_nw' from data source
## `C:\Users\ziller\OneDrive - Universitaet Duisburg-Essen\Statistik Bookdown\IntroStats\IS\data\dvg2krs_nw.shp'
## using driver `ESRI Shapefile'
## Simple feature collection with 53 features and 8 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: 280375 ymin: 5577680 xmax: 531791.2 ymax: 5820212
## Projected CRS: ETRS89 / UTM zone 32N
nrw_shp$KN <- as.numeric(as.character(nrw_shp$KN))
nrw_shp <- nrw_shp %>%
right_join(data_nrw, by = c("KN"))
# Building the map using the "ggplot2" package
ggplot() +
geom_sf(data = nrw_shp, aes(fill = unemp), color = 'gray', size = 0.1) +
ggtitle("North-Rhine Westphalia, Germany") +
guides(fill=guide_colorbar(title="Unemployment in %")) +
scale_fill_gradientn(colours=rev(magma(3)),
na.value = "grey100",
) 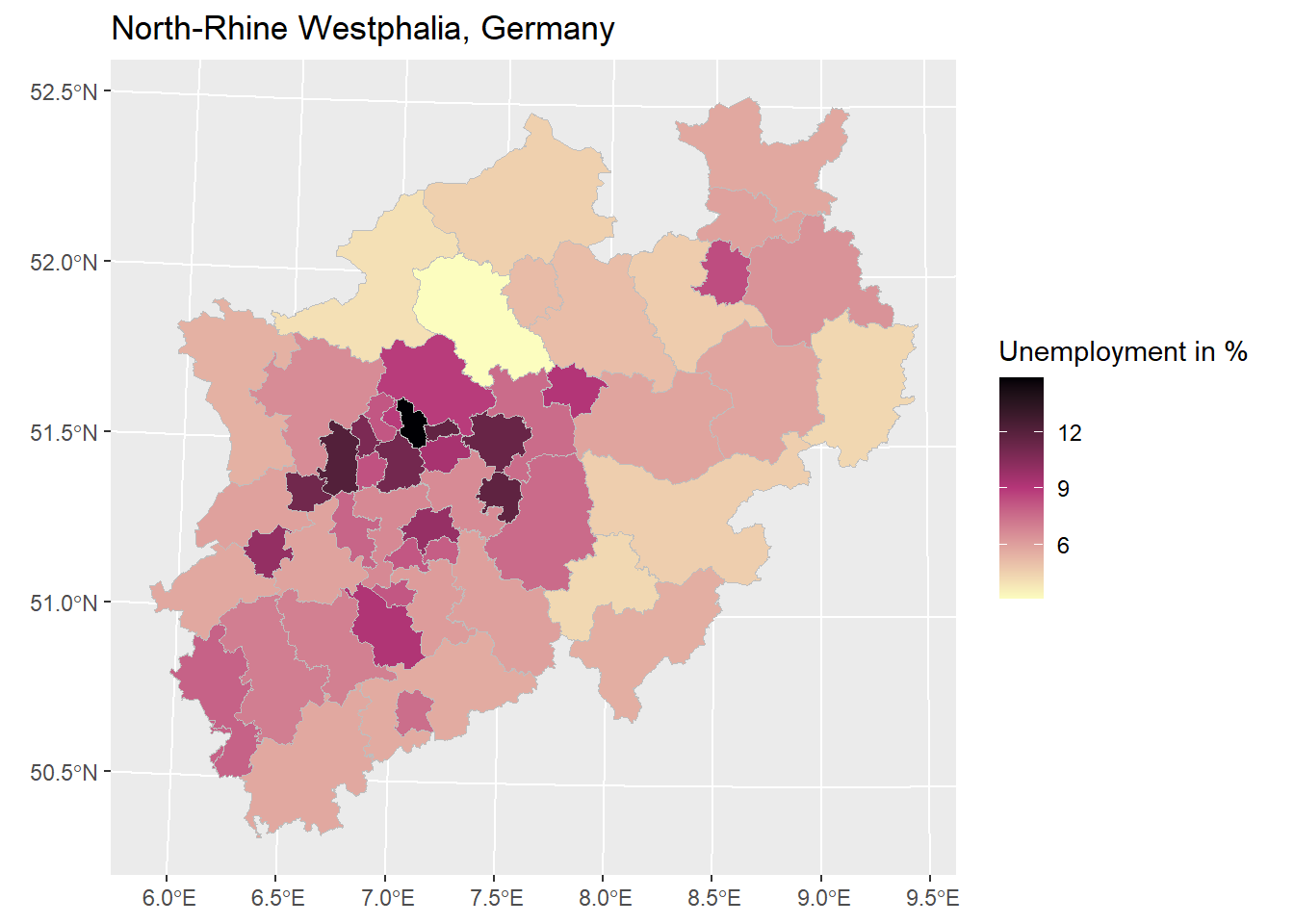
Question: What information is conveyed by the map? What information remains implicit?
Your answer:
Solution:
Maps give a good first impression of the spatial distribution of data.
However, insights depend on further (implicit) information (“What are the specifics of the high-unemployment cities in the middle of the map? Which areas are rural, which are urban?”).
Difficult to make general statements about maps and to compare maps (especially if the breaks that underly the colorization differ).
2.4 Distributions: First insights into the data structure
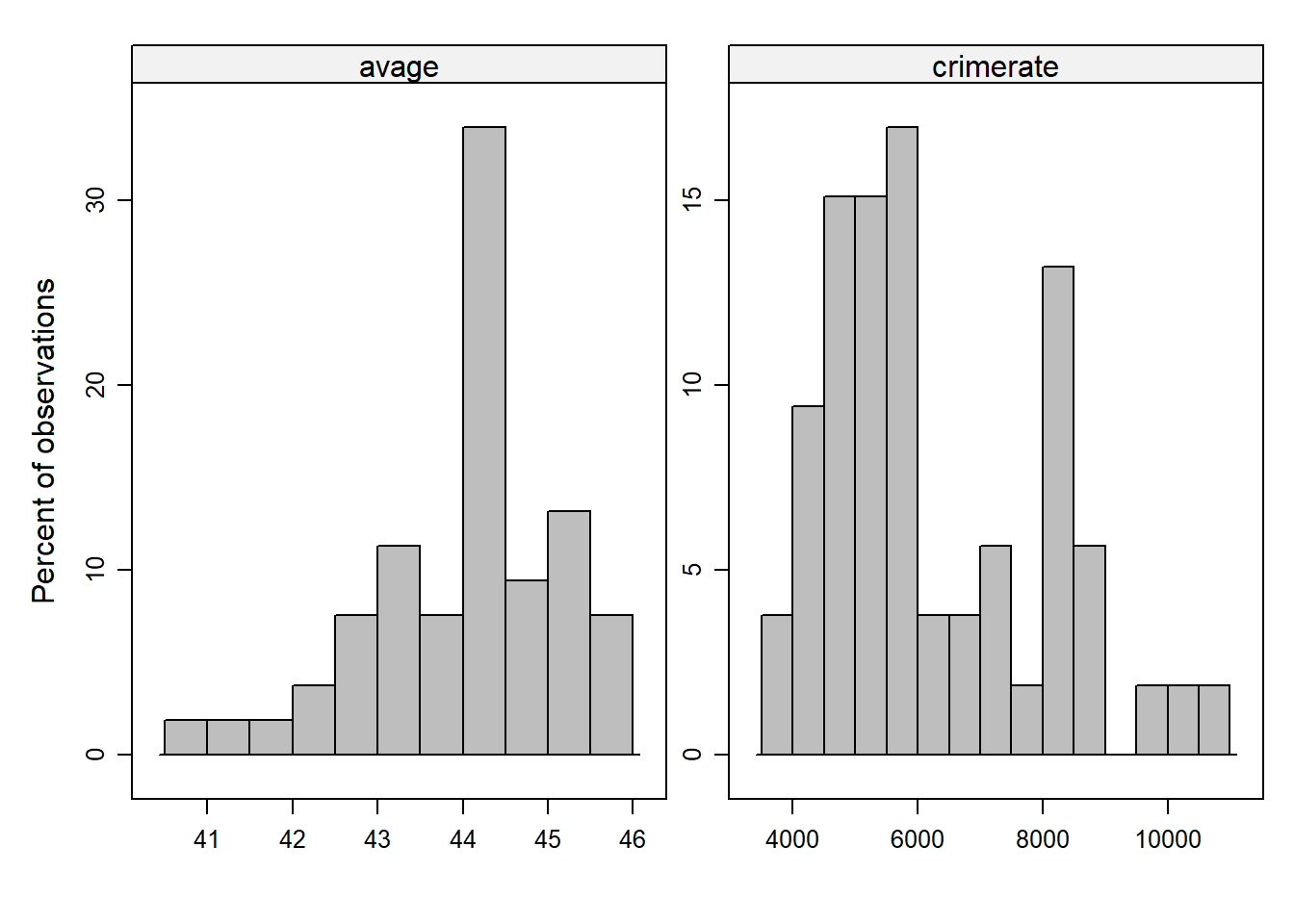
To get an impression about the distribution of the data, histograms can be used (e.g., What are minimum or maximum values? Do observed values are clusterd around the center of the distrubtion or are they widely spread?). Histograms show the frequency of observations across the range of values of a variable. It does not matter how the single observations (i.e., districts in our case) appear in the data set. The histogram ranks observations depending on the values they have on a specific variable. The height of the displayed bars is proportional to the frequency of observations that have corresponding variable values. The width of the bars (also known as bins) represents an interval of values and can be customized (i.e., a few wide bars comprise more observations than many narrow ones).
library(lattice)
data_nrw$popdens <- data_nrw$population/data_nrw$flaeche # This generates the variable for the population density
histogram( ~ popdens + unemp + avage + crimerate,
breaks = 10,
type = "percent",
xlab = "",
ylab = "Percent of observations",
layout = c(2,1),
scales = list(relation="free"),
col = 'grey',
data = data_nrw)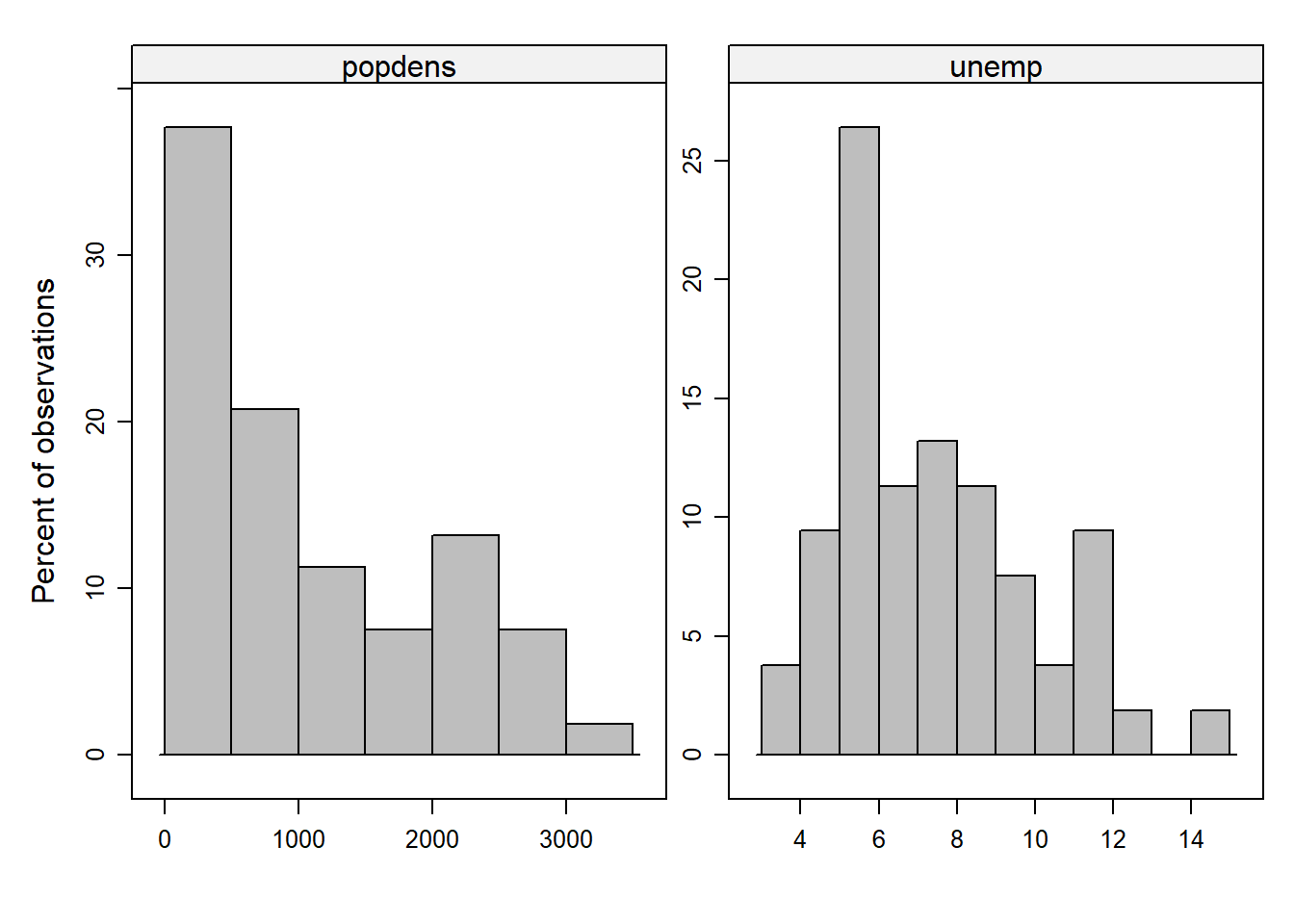
## Alternative approach with the "hist"-function
#hist(data_nrw$unemp)
#hist(data_nrw$avage)
#hist(data_nrw$crimerate)Question: Which characteristics of the data can be identified with histograms? Which aspects remain hidden?
Your answer:
Solution:
What can be seen: The distribution of the data, including the center(s) where most of the observations are located, patterns of skewness, and outliers.
What remains hidden: The specific estimates of the summary statistics (e.g., mean, variance).
2.5 Mean
The mean of a variable is also referred to as a measure of central tendency. It thus represents a good first impression of what is a typical (or expectable) value of a measured characteristic (i.e., a variable). Comparing the mean and the variable value of a specific observation provides information about whether the observation is close to or far from the mean. Besides the arithmetic mean, other measures exist (e.g., the geometric mean), but we do not consider them here.
For the calculation of the mean, all observed values for a variable are added and the sum is then divided by the total number of observations (n).
\(\bar x = \frac{1}{n}\sum_{i=1}^n x_i\) or \(\mu = \frac{1}{N}\sum_{i=1}^N x_i\)
\(\bar x\) and n refer to given data we are working with (e.g., from a sample), \(\mu\) and N refer to the population we want to make statistical statements about. (Note: This distinction becomes relevant in statistical testing, where we use a random sample to draw inferences about an underlying larger population.)
Let’s take a look at the means and other information on the variables in the data set:
summary(data_nrw)## kkziff area aggregat nonnational
## Length:53 Length:53 Length:53 Min. : 6.05
## Class :character Class :character Class :character 1st Qu.: 9.82
## Mode :character Mode :character Mode :character Median :12.19
## Mean :13.45
## 3rd Qu.:16.87
## Max. :21.86
## population flaeche unemp avage
## Min. : 111516 Min. : 51.0 Min. : 3.110 Min. :40.97
## 1st Qu.: 226844 1st Qu.: 170.0 1st Qu.: 5.740 1st Qu.:43.33
## Median : 308335 Median : 543.0 Median : 6.950 Median :44.15
## Mean : 338218 Mean : 643.6 Mean : 7.432 Mean :44.01
## 3rd Qu.: 408662 3rd Qu.:1112.0 3rd Qu.: 8.850 3rd Qu.:44.62
## Max. :1083498 Max. :1960.0 Max. :14.870 Max. :45.81
## crimerate KN popdens
## Min. : 3718 Min. :5111000 Min. : 116.3
## 1st Qu.: 4906 1st Qu.:5166000 1st Qu.: 278.5
## Median : 5636 Median :5512000 Median : 784.7
## Mean : 6244 Mean :5506094 Mean :1072.0
## 3rd Qu.: 7568 3rd Qu.:5770000 3rd Qu.:1768.8
## Max. :10500 Max. :5978000 Max. :3077.3Question: Interpret two means of your choice. Why is no mean displayed for the variable area?
Your answer:
Solution:
The average unemployment rate across the observed districts is 7.4 percent. The mean of the population variable is 338,218, which means that about 338,218 people live in a region, on average.
Means can only be calculated for metric or quasi-metric (typically an ordinal variable with five or more categories) variables. area is a nominal variable.
The displayed tables contain more information than means:
- The median is another measure of centrality (besides the mean and the mode, i.e., the variable value that occurs the most often for a given set of observations):
- The median is the midpoint of a frequency distribution of observed variable values (i.e., it divides ordered observed data into two equal parts).
- Often preferred over the mean for skewed data because the median is not sensitive to outliers (i.e., extreme values).
- Measures of dispersion, such as the range (i.e., maximum value – minimum value) and the standard deviation, both providing information about how the data is distributed.
- Measures of position, such as quartiles and the interquartile range, which are often graphically depicted using boxplots.
2.6 Measures of dispersion: Variance and standard deviation
Imagine for a moment that we not only have the socio-demographic report of NRW available but also a report from another German state. Comparing county characteristics, such as crime rates, across the two states might result in finding that both have the exact same mean. However, the crime rate in State 1 is much more extremely distributed, with particularly high and low values for some counties. In State 2, in contrast, the crime rate is much more evenly distributed around the mean. Determining the degree of dispersion (or scatteredness) of data is an important piece of information that is useful for several further statistical analyses It might also yield practical relevance, as different patterns of dispersion of crime may lead to different policy measures for combating crime. Let us start with calculating the variance.
The variance is the sum of squared deviations.
\(\sigma^2 = \frac{\sum_{i=1}^n (x_i-\mu)^2}{N}\) (Notation for the population) \(s^2 = \frac{\sum_{i=1}^n (x_i-\bar x)^2}{n-1}\) (Notation for the sample; If we apply statistical inference and use a random sample, we need to apply a correction in the denominator “n-1” – referred to as Bessel’s correction)
The standard deviation re-transforms the value back to the scale on which the variable is measured, it is therefore easier to interpret and more commonly used.
\(s = \sqrt{\frac{\sum_{i=1}^n (x_i-\bar x)^2}{n-1}}\)
Here you find a graphical representation of the dispersion of the variables unemp and crimerate. Note that the deviations between observations on the x-axis are purely random to increase the readability of the plot (otherwise, all observations would be lined up like a vertical pearl necklace). The red line is the mean value.
s_unemp <- ggplot(data=data_nrw, aes(y=unemp, x=reorder(area, area), color=area)) +
geom_jitter(height = 0) +
ggtitle("Unemployment rate 2020 in %")
s_unemp + geom_hline(yintercept=7.432, linetype="solid", color = "red", size=0.1) + theme(legend.position="bottom") + theme(legend.text = element_text(size=5)) + theme(axis.title.x=element_blank(), axis.text.x=element_blank(), axis.ticks.x=element_blank())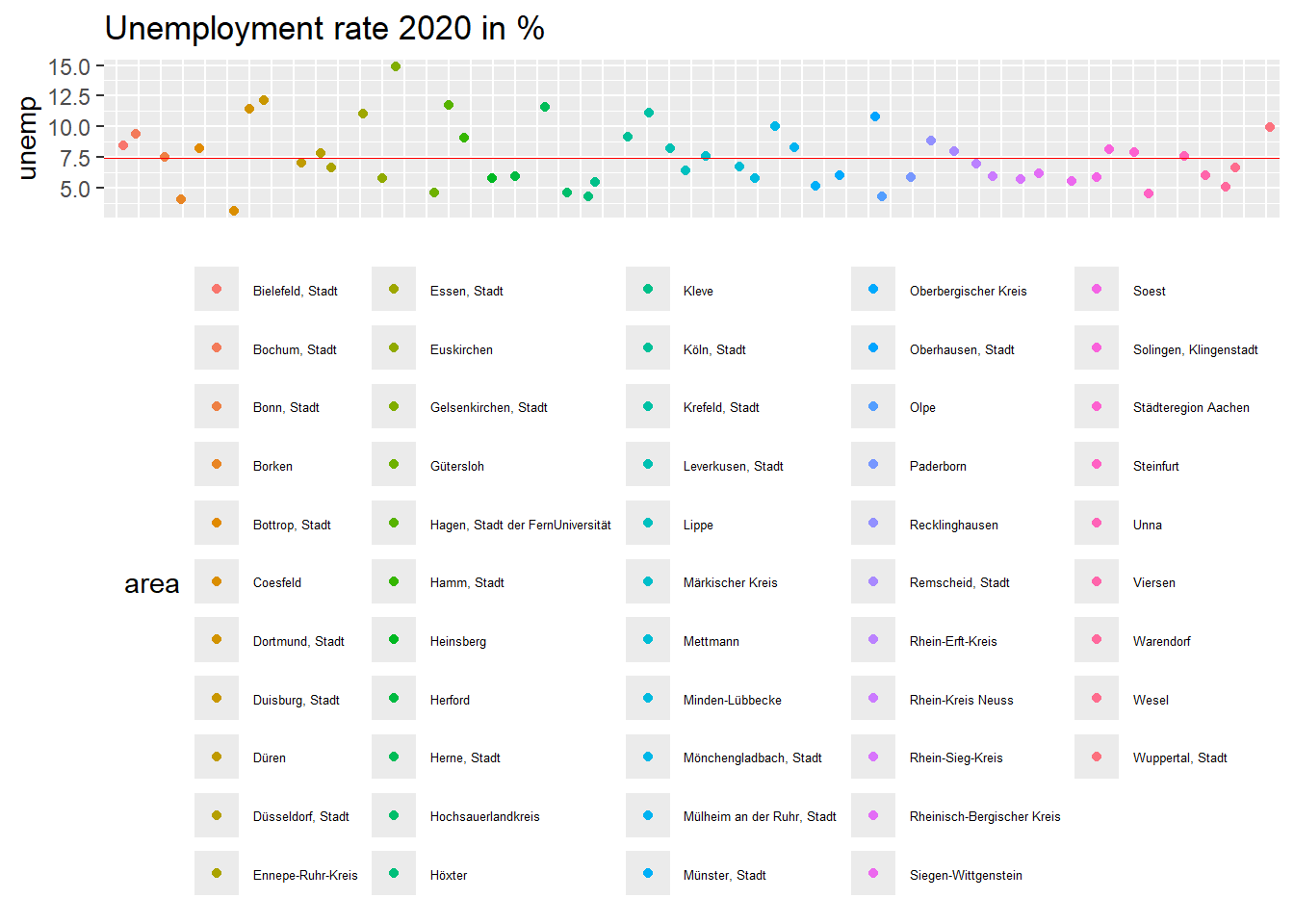
s_crime <- ggplot(data=data_nrw, aes(y=crimerate, x=reorder(area, area), color=area)) +
geom_jitter(height = 0) +
ggtitle("Crime rate 2020")
s_crime + geom_hline(yintercept=6244, linetype="solid", color = "red", size=0.1) + theme(legend.position="bottom") + theme(legend.text = element_text(size=5)) + theme(axis.title.x=element_blank(), axis.text.x=element_blank(), axis.ticks.x=element_blank())
Question: Can you spot which district has the highest unemployment rate? Which county has the lowest crime rate? Can we infer from the graphs which of the two variables is more dispersed?
Your answer:
Solution:
It is quite hard to match the color of the dots with the ones of the legend. Gelsenkirchen has the highest unemployment rate at 14.9%. The district with the lowest crime rate is Lippe.
Because of the different scaling of the variables, it is not possible to infer from this plot which variable is more dispersed. To do so, we would need to calculate the so-called coefficient of variation (see below).
Standard deviation, range, and coefficient of variation calculated with R (unemployment):
sd(data_nrw$unemp)## [1] 2.477591## [1] 11.76
varcoef <- sd(data_nrw$unemp) / mean(data_nrw$unemp) * 100 #how much percent of the mean is the standard deviation?
varcoef## [1] 33.33815Standard deviation, min/max, and coefficient of variation calculated with R (crime rate):
sd(data_nrw$crimerate)## [1] 1775.389## [1] 6782.056## [1] 28.43261To compare the dispersion of variables measured on different scales, we cannot use the variance or standard deviation (as they are measured on the units of the scale) but employ the coefficient of variation (i.e., standard deviation over the mean times 100). Here, higher values imply a higher dispersion of the data.
Interpretation: The variable unemployment is more heterogeneously dispersed (varcoef = 33.3) than the variable crime rate (varcoef = 28.4).
2.7 Position measures: Boxplots and interquartile range
Quartiles divide the ordered data into four parts (Q1 to Q4, where Q4 is the maximum of the observed values), and the median is represented by Q2. Hence, 25% of the observations are below or at Q1, 75% above. Q3-Q1 = interquartile range (IQR), which reflects the range in which the middle 50% of the observations are located.
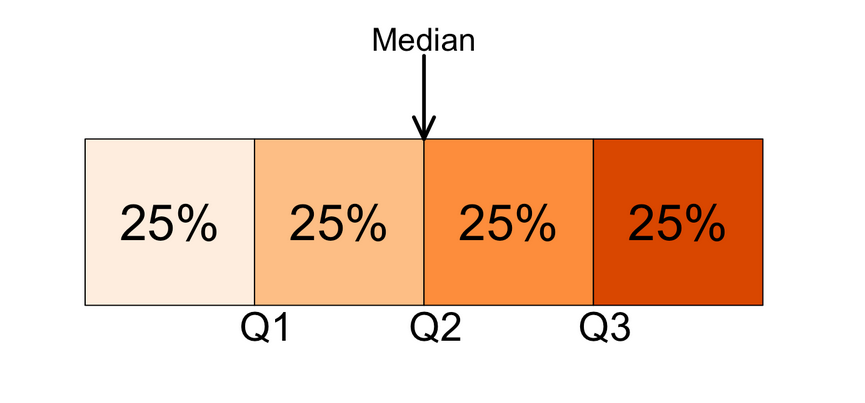
Quartiles and IQR for unemployment rate:
quantile(data_nrw$unemp)## 0% 25% 50% 75% 100%
## 3.11 5.74 6.95 8.85 14.87
unemp.score.quart <- quantile(data_nrw$unemp, names = FALSE)
unemp.score.quart[4] - unemp.score.quart[2]## [1] 3.11Quartiles and IQR for crime rate:
quantile(data_nrw$crimerate)## 0% 25% 50% 75% 100%
## 3718.411 4906.122 5635.991 7568.376 10500.467
crimerate.score.quart <- quantile(data_nrw$crimerate, names = FALSE)
crimerate.score.quart[4] - crimerate.score.quart[2]## [1] 2662.254Boxplots graphically represent the key figures Q1, Q2, Q3. The lower and upper ends of the whiskers are usually the minimum and maximum observed values. To mark observations that are far away from the median (so-called outliers), the maximal width of a whisker is restricted to Q1 - 1.5 x IQR (for the lower whisker) and Q3 + 1.5 x IQR (for the higher upper whisker) respectively. Outliers are represented by points outside of the range of the whisker. The lowest and highest oulier would then mark the minimum/maximum value. For crime rate, the end of the whiskers represent the minimum/maximum value. For unemployment, we find an outlier that represents the maximum of observed values (i.e., Gelsenkirchen with 14.9% unemployment).
Apart from that, the larger the single parts in the boxplot, the greater the dispersion of the data in this area (which can also give an impression of the skewness of the data distribution).
boxplot(data_nrw$unemp,
col = 'blue',
horizontal = FALSE,
ylab = 'in %',
main = 'Unemployment rate')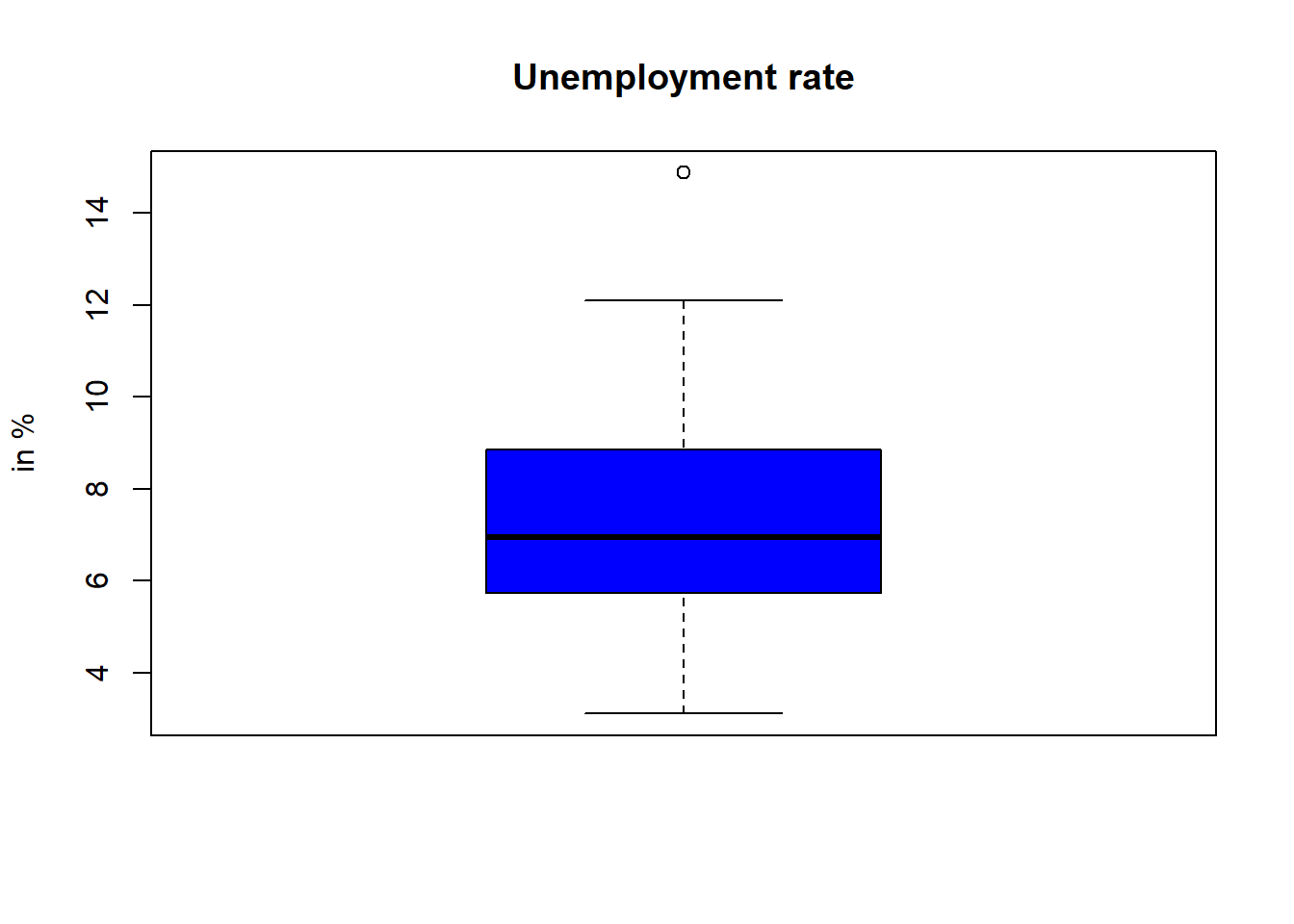
boxplot(data_nrw$crimerate,
col = 'orange',
horizontal = FALSE,
ylab = 'in cases per 100.000 inhab.',
main = 'Crime rate')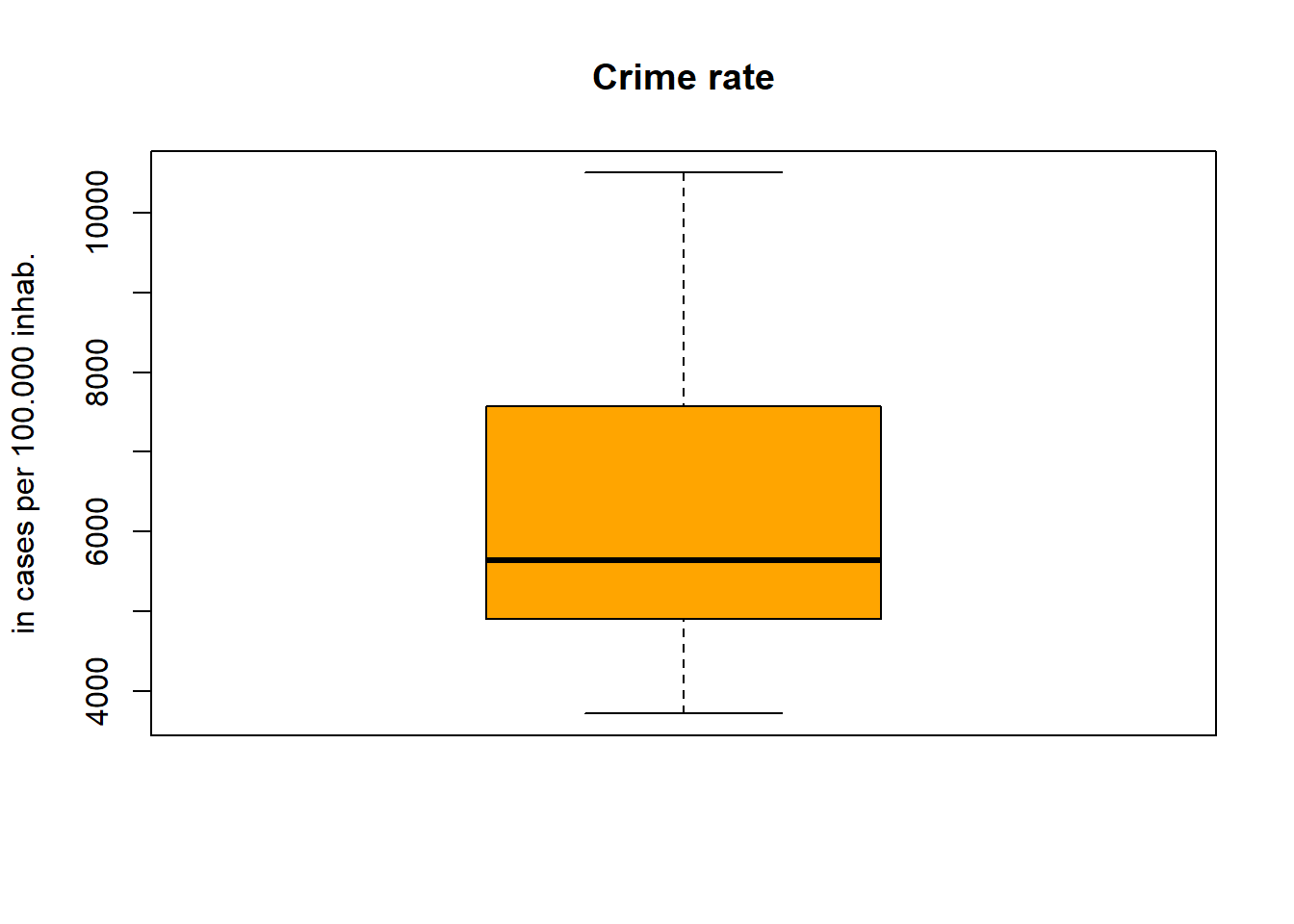
2.8 Conclusion
The provided examples illustrate some basic principles of univariate descriptive statistics. Univariate statistics are important to get an overview of the structure of the data, which may also inform more complex statistical methods. In terms of further steps, we could apply the learned methods and ask: Which counties are most plagued by crime? Which counties have the lowest unemployment, and which have the highest? Where are particularly large numbers of people moving to or from? This may inspire additional questions, like: Why are the observed structures the way they are? These questions concern explanatory analyses. In the following, we take an outlook on this and – by doing so – we refer to further topics that are explained in detail in subsequent chapters.
2.9 Outlook: Does unemployment cause more crime?
To test causal claims like “more unemployment leads to more crime” with observational data (i.e., from surveys or official records) is heroic and rests on various assumptions that need to be fulfilled. The main reason why causal inference with observational (i.e., non-experimental) data is so difficult is that all possible alternative explanations must be eliminated. Otherwise, we cannot be sure whether unemployment is the cause or some other unobserved phenomenon that correlates with unemployment.
For causal inference, the following three conditions must be met:
- X (cause) and Y (effect) must be empirically related to each other (e.g., correlate with each other).
- X must precede Y in time (e.g., can be mapped with panel data).
- Most importantly: All possible alternative explanations must be excluded (e.g., via a randomized experiment or by using control variables in multiple regression).
We will revisit these assumptions in the case study on regression analysis.
2.9.1 Bivariate analysis: Correlation
A good way to get an impression of the direction of a correlation is using a scatter plot.
sc1 <- ggplot(data=data_nrw, aes(x = unemp, y = crimerate)) +
geom_point() +
xlab("Unemployment rate 2020 in %") +
ylab("Crime rate")
sc1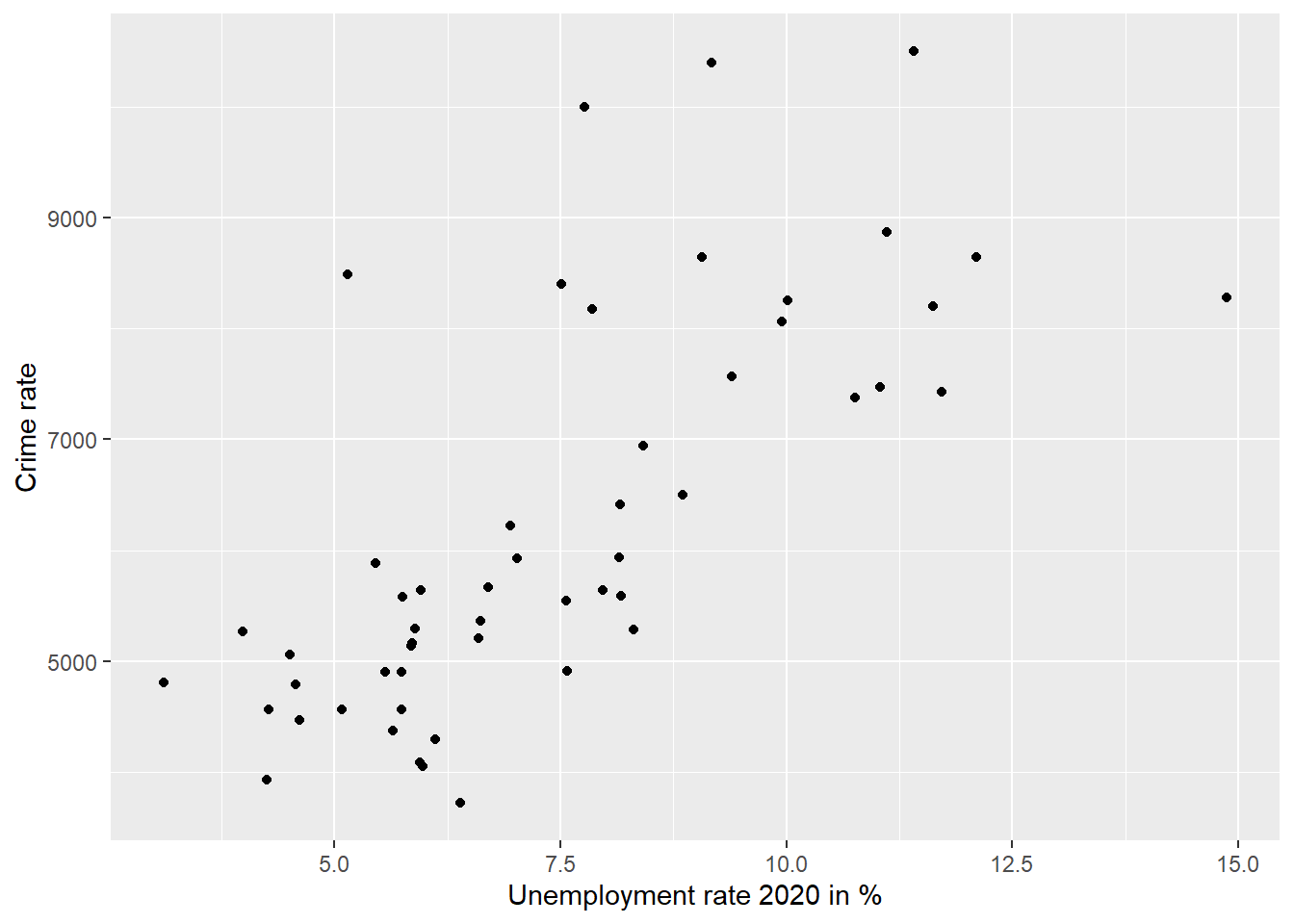
A line that describes the linear relationship between the two variables can be added:
sc1 <- ggplot(data=data_nrw, aes(x = unemp, y = crimerate)) +
geom_point() +
geom_smooth(method = lm, se = FALSE) +
xlab("Unemployment rate in %") +
ylab("Crime rate")
sc1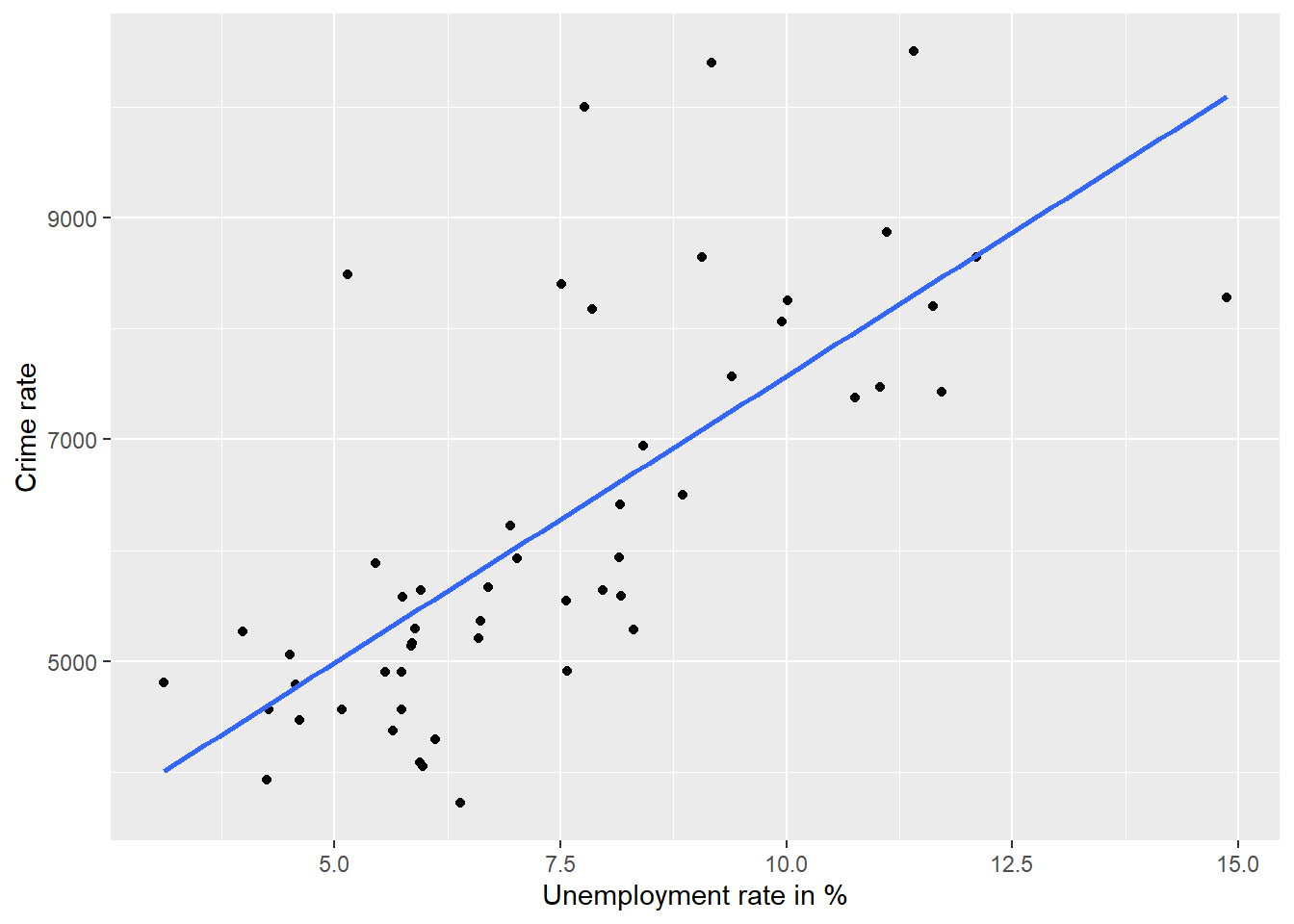
Interpretation: The depicted observations and the fitted line imply a positive correlation. (The higher the unemployment rate, the higher the crime rate.)
Pearson’s correlation coefficient “r” quantifies the correlation: -1 = perfect neg. correlation, 0 = no correlation, +1 = perfect pos. correlation.
## unemp crimerate
## unemp 1.00 0.72
## crimerate 0.72 1.00
##
## n= 53
##
##
## P
## unemp crimerate
## unemp 0
## crimerate 0Interpretation: In this case, the correlation coefficient is r = 0.72 with a p-value of < 0.001. That means that we find a strong positive correlation. The correlation is also statistically significant (we typically speak of a statistically significant result if the p-value is below 0.05), which means that we can be fairly certain that the result is not due to chance but can be interpreted as systematic.
2.9.2 Regression with control variables
The correlation showed that there is a positive (and statistically significant) bivariate relationship between unemployment and crime. But is this relationship causal? One way to assess this is to control for alternative explanations using multiple regression. We use population density as an alternative explanation. After all, it may well be that unemployment and crime occur primarily in an urban context. If that was the case, part of the correlation would not be due to unemployment, but to population density, and unemployment would so to say partly “transport” the effect of population density (if not included in the regression model). Let’s take a look at this.
- Model 1 includes unemployment as an explanatory variable
- Model 2 includes unemployment and population density
model1 <- lm(crimerate ~ 1 + unemp, data = data_nrw)
model2 <- lm(crimerate ~ 1 + unemp + popdens, data = data_nrw)
stargazer(model1, model2, type = "text")##
## =================================================================
## Dependent variable:
## ---------------------------------------------
## crimerate
## (1) (2)
## -----------------------------------------------------------------
## unemp 517.460*** 215.409**
## (69.412) (100.125)
##
## popdens 1.054***
## (0.275)
##
## Constant 2,398.594*** 3,513.062***
## (543.248) (563.493)
##
## -----------------------------------------------------------------
## Observations 53 53
## R2 0.521 0.630
## Adjusted R2 0.512 0.615
## Residual Std. Error 1,240.129 (df = 51) 1,101.398 (df = 50)
## F Statistic 55.575*** (df = 1; 51) 42.557*** (df = 2; 50)
## =================================================================
## Note: *p<0.1; **p<0.05; ***p<0.01Interpretation: If unemployment increases by one percentage point, crime increases by 517 cases per 100,000 inhabitants (Model 1). The relationship is statistically significant. If we now control for population density in Model 2 (and thus hold the influence of population density constant), a one-unit increase in unemployment is associated with an increase of only 215 cases. Population density is also positively associated with crime. Both coefficient estimates are statistically significant at p < 0.01. It thus seems to be a good idea to control for the influence of population density. We might be now much closer to the real effect of unemployment on crime now. However, we do not know this for certain because other alternative explanations are still possible to think of (e.g., the role of age composition or local social policies, as well as alternative explanations at the level of individuals).
Disclaimer: If this outlook has been too complex, no worries. We will go through all the steps in detail in the subsequent case studies.