9 以 tibble 處理 Tibbles
本章為 Wickham and Grolemund (2016) 第 7 章內容。
本部分(第 9、10、11、12、13、14、15 章)要談的是資料整理(data wrangling)。
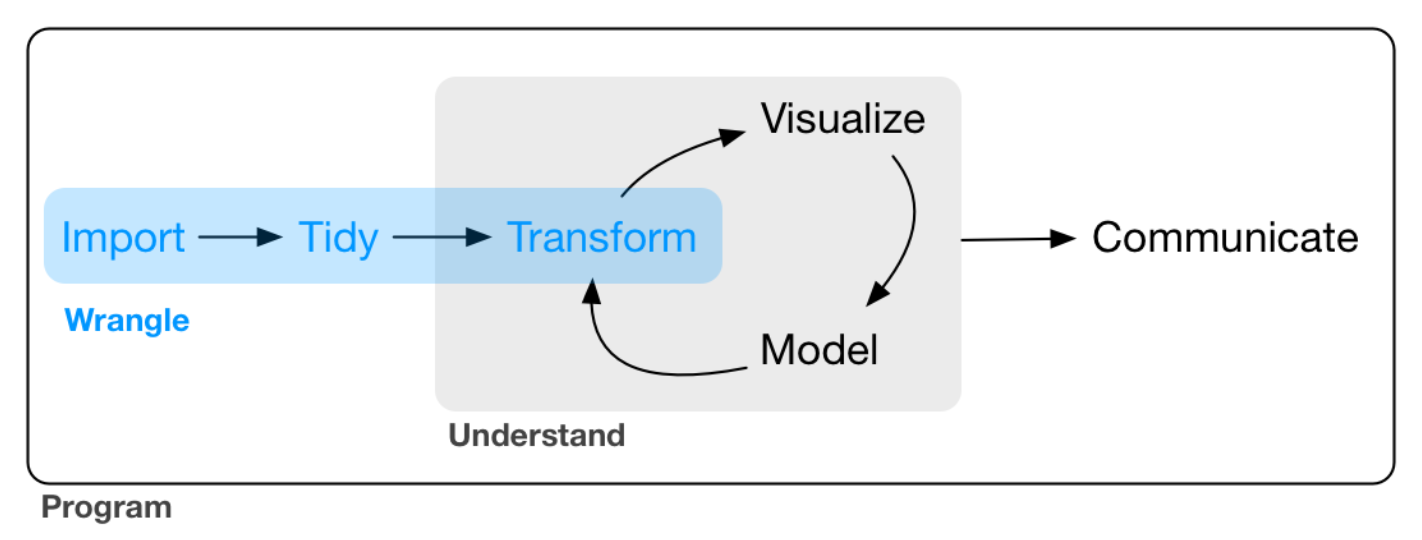
Figure 9.1: Data wrangling.
9.1 創建 Tibbles
9.1.1 把 Data Frames 轉換 Tibbles
Tibbles 也是一種 data frames。要把 data frames 轉換成 tibbles 很簡單,只要使用 as_tibble() 函數即可,如:
as_tibble(iris)## # A tibble: 150 × 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <fct>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # … with 140 more rows9.1.2 透過向量創建 Tibbles
我們也可以透過向量來創建 tibbles,如:
tibble(
x = 1 : 5,
y = 1,
z = x ^ 2 + y
)## # A tibble: 5 × 3
## x y z
## <int> <dbl> <dbl>
## 1 1 1 2
## 2 2 1 5
## 3 3 1 10
## 4 4 1 17
## 5 5 1 26Tibbles 的 column 還可以取名為本來在 base R 的語法中不合法的變數名稱,即 nonsynaptic names,例如非字母開頭或者有特殊字元或空格,只要用兩個 \ 包圍即可,而要使用這些變數的話同樣要以 \ 來包圍,如:
tibble(
` ` = 1 : 3,
`:)` = 1,
`2049` = ` ` ^ 2 + `:)`
)## # A tibble: 3 × 3
## ` ` `:)` `2049`
## <int> <dbl> <dbl>
## 1 1 1 2
## 2 2 1 5
## 3 3 1 109.1.3 以 Transposed Tibble tribble() 創建 Tibbles
我們也可以 tribble(),即 transposed tribble 來創建 tibbles。使用 tribble() 的方式如下:
tribble(
~x, ~y, ~z,
#--/--/----
"a", 2, 3.4,
"s", 4, NA
)## # A tibble: 2 × 3
## x y z
## <chr> <dbl> <dbl>
## 1 a 2 3.4
## 2 s 4 NA事實上,#--/--/---- 並非必須的(也只是一個註解),但便於我們辨識變數與變數值。
9.2 Tibbles 與 Data Frames 的比較
9.2.1 Printing
tibble(
a = lubridate::now() + runif(1e3) * 86400,
b = lubridate::today() + runif(1e3) * 30,
c = 1:1e3,
d = runif(1e3),
e = sample(letters, 1e3, replace = TRUE)
)## # A tibble: 1,000 × 5
## a b c d e
## <dttm> <date> <int> <dbl> <chr>
## 1 2021-09-01 21:13:57 2021-09-18 1 0.312 u
## 2 2021-09-02 05:19:48 2021-09-08 2 0.390 g
## 3 2021-09-01 13:35:51 2021-09-04 3 0.517 f
## 4 2021-09-02 06:55:39 2021-09-04 4 0.149 h
## 5 2021-09-02 05:41:01 2021-09-16 5 0.406 r
## 6 2021-09-02 00:11:25 2021-09-06 6 0.000758 c
## 7 2021-09-02 05:28:45 2021-09-21 7 0.347 e
## 8 2021-09-01 23:12:44 2021-09-26 8 0.485 l
## 9 2021-09-02 04:06:47 2021-09-18 9 0.232 t
## 10 2021-09-01 12:36:58 2021-09-06 10 0.314 i
## # … with 990 more rows印出 tibbles 時,預設只會印出前 10 個 rows,而每個 column 之下都會印出其型態。
那如果我們想要同時看到更多觀察值怎麼辦?有以下幾種做法:
- 使用
print(),決定要印出多少 rows 與 columns;其中,n = 2代表印出 2 個 rows,而width = Inf代表印出所有 columns,如:
nycflights13::flights %>%
print(n = 2, width = Inf)## # A tibble: 336,776 × 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 1 1 517 515 2 830 819
## 2 2013 1 1 533 529 4 850 830
## arr_delay carrier flight tailnum origin dest air_time distance hour minute
## <dbl> <chr> <int> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 11 UA 1545 N14228 EWR IAH 227 1400 5 15
## 2 20 UA 1714 N24211 LGA IAH 227 1416 5 29
## time_hour
## <dttm>
## 1 2013-01-01 05:00:00
## 2 2013-01-01 05:00:00
## # … with 336,774 more rows或者使用
options(tibble.print_max = n, tibble.print_min = m):如果有超過m個 rows,則只印出n個 rows。所以如果tibble.print_min設置為Inf則會印出所有的 rows;而options(tibble.width = Inf)會印出所有的 columns。使用
View(),最容易閱讀的方式。
9.2.2 Subsetting
如果我們要取出 tibble 的某個變數,我們需要使用 $ 與 [[,前者可以使我們取出指定的變數名稱的變數;後者除了可以使我們取出指定的變數名稱的變數以外,還能取出指定位置的變數,如新增一個 tibble:
df <- tibble(
x = runif(5), # x 為均勻分配的 5 個數字
y = rnorm(5) # y 為常態分配的 5 個數字
)# Extract by name
df$x # [1] 0.1552525 0.2570212 0.2929349 0.7355940 0.3282747
df[["x"]] # [1] 0.1552525 0.2570212 0.2929349 0.7355940 0.3282747
# Extract by position
df[[1]] # [1] 0.1552525 0.2570212 0.2929349 0.7355940 0.3282747想要在此時使用 pipe 的話要記得加上 .,如:
df %>% .$x # [1] 0.1552525 0.2570212 0.2929349 0.7355940 0.3282747
df %>% .[["x"]] # [1] 0.1552525 0.2570212 0.2929349 0.7355940 0.32827479.3 古老的程式碼
有些古老的函數無法使用 tibble,這時候我們需要使用 as.data.frame() 將 tibble 轉換回 data frame。如果 tibble 不相容於某古老的函數,那很有可能是因為 [(即 subsetting)的函數。在 tidyverse 中,多半可以不用 [,而透過 dplyr::filter() 與 dplyr::select() 來達到類似的結果。此外,在 base R 中,使用 [ 有時候會回傳一個 data frame,而有時會回傳一個向量;不過在 tibbles 中,使用 [ 都會回傳 tibble。