Capítulo 9 Resultados
Uno de los objetivos fundamentales del presente trabajo es poner a prueba distintos métodos y algoritmos de pronóstico de series temporales para predecir el flujo de tráfico con los datos reportados por los dispositivos de medida de la ciudad de Madrid.
Como hemos visto en los capítulos anteriores, se han utilizado métodos paramétricos, basados en el modelado de series temporales descomponiéndolas en componentes de tendencia y estacionalidad, métodos basados en autorregresión y media móviles, y métodos basados en aprendizaje profundo (deep learning).
Concretamente, se han puesto a prueba los métodos que pueden verse en la siguiente lista. Para cada uno podemos ver una pequeña descripción de su implementación. Para los detalles exactos del método, se recomienda acudir al repositorio (Mañas 2019). Podemos ver que cada experimento viene etiquetado con la familia de métodos a la que pertenece. Esto nos permitirá más adelante seleccionar el mejor de cada familia y expresar los resultados de una forma más clara o resumida atendiendo sólo al método que mejor rinde por familia. Los métodos son:
- Familia ARIMA:
- AUTO ARIMA. Método ARIMA ajustado automáticamente en cada serie.
- SARIMA. Método ARIMA estacional.
- Familia LSTM:
- LSTM Agg4 Diff. LSTM entrenado con los datos de las 8 semanas más recientes, transformando la serie a granularidad de una hora y diferenciando.
- LSTM Agg4 Diff Scale Mean. LSTM entrenado con los datos de las 8 semanas más recientes, transformando la serie a granularidad de una hora, diferenciando y escalando con centro y escala la media.
- LSTM Agg4 Scale Mean. LSTM entrenado con los datos de las 8 semanas más recientes, transformando la serie a granularidad de una hora y escalando con centro y escala la media.
- LSTM LSTM Agg4 Scale SD. LSTM entrenado con los datos de las 8 semanas más recientes, transformando la serie a granularidad de una hora y escalando con centro la media y escala la desviación típica de la serie.
- Familia LSTM Exógeno:
- LSTM-Exo DH Agg5 Scale Mean. LSTM entrenado con los datos de las 8 semanas más recientes, incorporando la hora del día y el día de la semana como variables exógenas, transformando la serie a granularidad de 75 minutos y escalando con centro y escala la media.
- LSTM-Exo DH Raw Scale Mean. LSTM entrenado con los datos de las 8 semanas más recientes, incorporando la hora del día y el día de la semana como variables exógenas y escalando con centro y escala la media.
- Familia MIXTO STL LSTM:
- STL+LSTM Agg5 Scale Mean. Ajuste STL a 6 meses de datos más recientes de la serie considerando estacionalidad semanal. Posteriormente, los residuos de STL se modelan con LSTM transformando la serie a granularidad de 75 minutos.
- STL+LSTM Raw Scale Mean. Ajuste STL a 6 meses de datos más recientes de la serie considerando estacionalidad semanal. Posteriormente, los residuos de STL se modelan con LSTM transformando la serie a granularidad de 1 hora y escalando con centro y escala la media.
- Familia STL:
- STL D. STL con estacionalidad diaria ajustado en toda la serie.
- STL D Reciente. STL con estacionalidad diaria ajustado en los 6 meses de datos previos al punto de pronóstico.
- STL M. STL con estacionalidad mensual ajustado en toda la serie.
- STL M Reciente. STL con estacionalidad mensual ajustado en los 6 meses de datos previos al punto de pronóstico.
- STL W. STL con estacionalidad semanal ajustado en toda la serie.
- STL W Reciente. STL con estacionalidad semanal ajustado en los 6 meses de datos previos al punto de pronóstico.
- STL Y. STL con estacionalidad anual ajustado en toda la serie.
- Familia STLM:
- STLM DW. STLM con estacionalidades diaria y semanal ajustado en toda la serie.
- STLM DWM. STLM con estacionalidades diaria, semanal y mensual ajustado en toda la serie.
- STLM DWM Reciente. STLM con estacionalidades diaria, semanal y mensual ajustado en los 6 meses de datos previos al punto de pronóstico.
- STLM DWY. STLM con estacionalidades diaria, semanal y anual ajustado en toda la serie.
La forma de realizar el experimento de contraste ha sido aplicar los distintos algoritmos puestos a prueba a todas las series de tiempo y comparar los resultados pronosticados por cada algoritmo contra la serie conocida real. En número de dispositivos de los que se tienen datos suficientes como para practicar estos experimentos es 3.976. Esto nos permite confiar en que los promedios de error de cada algoritmo realmente serán significativos de su capacidad de modelado y pronóstico.
Igualmente, el punto de prueba para cada serie se ha elegido aleatoriamente en el intervalo de los últimos 12 meses de datos de la serie, lo que nos libera de posibles sesgos que se pudieran producir por seleccionar siempre puntos en un mismo día del año o de la semana o a una misma hora del día. Recordemos, que como explicábamos más arriba, todos los métodos aplicados a una serie se han aplicado sobre el mismo instante aleatorio en los 12 meses más recientes. Pero este instante no tiene por qué ser el mismo (y no lo es) para todas las series.
Cada algoritmo de los probados ofrece pronósticos a 48 horas vista con una granularidad de 15 minutos. Esto nos permite someterlos a contraste según diferentes horizontes de pronóstico. En el Cuadro 9.1 podemos ver el número de experimentos válidos realizados por cada método de los que citábamos en la lista de anterior.
| Familia | Nombre | Experimentos realizados |
|---|---|---|
| ARIMA | AUTO ARIMA | 3975 |
| ARIMA | SARIMA | 3970 |
| LSTM | LSTM Agg4 Diff | 3719 |
| LSTM | LSTM Agg4 Diff Scale Mean | 3724 |
| LSTM | LSTM Agg4 Scale Mean | 3727 |
| LSTM | LSTM Agg4 Scale SD | 3725 |
| LSTM Exógeno | LSTM-Exo DH Agg5 Scale Mean | 3972 |
| LSTM Exógeno | LSTM-Exo DH Raw Scale Mean | 3972 |
| MIXTO STL LSTM | STL+LSTM Agg5 Scale Mean | 2502 |
| MIXTO STL LSTM | STL+LSTM Raw Scale Mean | 2508 |
| STL | STL D | 3975 |
| STL | STL D Reciente | 3975 |
| STL | STL M | 3973 |
| STL | STL M Reciente | 3974 |
| STL | STL W | 3975 |
| STL | STL W Reciente | 3976 |
| STL | STL Y | 3704 |
| STLM | STLM DW | 3976 |
| STLM | STLM DWM | 3976 |
| STLM | STLM DWM Reciente | 3976 |
| STLM | STLM DWY | 3976 |
En los próximos apartados, siempre que hablemos del error cometido por cualquier método para un horizonte \(h\), nos referimos al agregado de errores cometidos entre en el intervalo de predicciones que van desde el primer valor pronosticado hasta el \(h\)-ésimo valor pronosticado. Es importante tener esto muy presente para la interpretación de los resultados que veremos a continuación.
9.1 Métricas de error
Un mismo pronóstico puede compararse con el valor real esperado atendiendo a diferentes medidas de error.
Un “error” de pronóstico es la diferencia entre un valor observado y su pronóstico. Es decir, “error” no significa un mal funcionamiento, significa la parte impredecible de una observación. Se puede escribir como:
\[e_T = y_T - \hat{y}_T\]
dónde \(\{ y_1, \dots, y_t \}, t \in T\), se refieren a los datos observados y \(\{ \hat{y}_1, \dots, \hat{y}_t \}, t \in T\), son los datos pronosticados.
A priori, no tiene por qué haber una medida del error que sea mejor que otra; para cada caso, dependiendo de la naturaleza del fenómeno que se pronostica, puede convenir utilizar unas u otras métricas, teniendo siempre claro como interpretar la información arrojada por cada una.
Sin embargo, si conviene aclarar la diferencia que hay entre métricas dependientes de la escala y métricas agnósticas de escala. Acudimos nuevamente a (Rob J Hyndman 2018).
Las medidas de error dependientes de la escala son aquellas en las que las mediciones de los errores de pronóstico están en la misma escala que los datos que se pronostican. El principal inconveniente de este tipo de medida es que no se pueden usar para hacer comparaciones entre series que involucran diferentes unidades o series que utilizando la misma unidad tienen unos datos muy diferentes. Por ejemplo, si en una vía la media de carga es del 50% con una varianza del 50% y en otra es sólo del 2% con una varianza del 5%, si un método de pronóstico tuviera un error \(\epsilon\) en ambas series, parece que podríamos pensar que el método modela mejor la vía con mayor carga puesto que la magnitud y variabilidad de los datos es mayor.
Las dos medidas dependientes de la escala más utilizadas se basan en los errores absolutos (MAE) o los errores cuadrados (RMSE). Cuando se comparan los métodos de pronóstico aplicados a una sola serie de tiempo, o a varias series de tiempo con las mismas unidades, el MAE es popular porque es fácil de entender y calcular. Un método de pronóstico que minimiza el MAE conduce a pronósticos de la mediana, mientras que minimizar el RMSE conduce a pronósticos de la media. En consecuencia, el RMSE también se usa ampliamente, a pesar de ser más difícil de interpretar. Más adelante veremos como se definen formalmente.
Las medidas de error agnósticas de escala típicamente se expresan como porcentajes. Los errores de porcentaje tienen la ventaja de estar libres de unidades, por lo que se usan con frecuencia para comparar los rendimientos de pronóstico entre diferentes conjuntos de datos. En el caso de nuestra investigación, esto es bastante importante al ser bastante heterogéneo la distribución que adopta la carga según el dispositivo (véanse las observaciones hechas más arriba sobre medidas dependientes de la escala).
El porcentaje de error típicamente viene dado por:
\[p_t = 100 \frac{e_t}{y_t}, t \in T\]
siendo \(e_t\) el error cometido en el pronóstico en el instante \(t\), \(y_{t}\) el valor real conocido.
La medida más utilizada es el MAPE, que definimos más adelante.
Las medidas basadas en errores de porcentaje tienen la desventaja de ser infinitas o indefinidas si \(y_{t}=0\) para algún \(t\) en el período de interés, y tener valores extremos si algún \(y_{t}\) está próximo a 0.
También tienen la desventaja de que imponen una mayor penalización a los errores negativos que a los positivos. Esta observación condujo al uso del llamado MAPE “simétrico” (sMAPE) propuesto por (Armstrong 1985), que no obstante, no utilizamos en nuestro reporte.
Hechas las aclaraciones anteriores, que nos permitirán interpretar mejor los resultados, describimos ahora cada una de las métricas utilizadas (Hyndman and Koehler 2006):
- ME (error medio) es la media de los errores cometidos en el conjunto de pronósticos.
\[ ME = mean(e_t), t\in T \]
- MAE (error absoluto medio) es la media de los errores absolutos cometidos en el conjunto de pronósticos.
\[ MAE = mean(|e_t|), t\in T \]
- RMSE (raiz del error cuadrático medio) es la raíz cuadrada de la media de los errores cuadráticos cometidos en el conjunto de pronósticos.
\[ RMSE = \sqrt{\text{mean}(e_t^2)}, t\in T \]
- MPE (error porcentual medio) es la media de los errores porcentuales cometidos en el conjunto de pronósticos.
\[ MPE = mean(p_t), t\in T \]
- MAPE (error porcentual absoluto medio) es la media de los errores porcentuales absolutos cometidos en el conjunto de pronósticos.
\[ MAPE = mean(|p_t|), t\in T \]
9.2 Mejores métodos por familia
Tal como comentábamos en el apartado anterior, para una mejor exposición de los resultados, sobre todo pensando en las gráficas, conviene en primer lugar seleccionar el experimento que mejor rendimiento ha ofrecido en el grupo o la familia a la que pertenece.
En ocasiones ocurre que dados dos métodos de los probados, aunque el número de series en el que se han puesto a prueba es muy elevado (cercano a la totalidad de las series que se estudian en este trabajo), es posible que para una o varias series concretas sólo uno de los métodos haya sido probado. Por eso, para la comparación de rendimientos y selección del mejor método, siempre se considera el rendimiento en aquellas series en las que todos los métodos han sido experimentados.
Conviene aclarar que, aunque se han registrado los 192 (2 días cada 15 minutos) pronósticos de cada método, para la presentación en cuadros de los resultados sólo se utilizarán los pronósticos para horizontes de 1 hora vista, 4 horas vista, 12 horas vista, 24 horas vista y 48 horas vista.
Veamos primero el método que mejor rendimiento ofrece en la familia ARIMA. En el Cuadro 9.2 vemos claramente que el mejor rendimiento lo ofrece el método SARIMA (ARIMA estacional).
En el Cuadro 9.3 revisamos los rendimientos para la familia de métodos basada en la descomposición STL. Vemos claramente que el mejor rendimiento lo ofrece el método STL W Reciente (STL con estacionalidad semanal ajustado en los 6 meses de datos previos al punto de pronóstico).
En el Cuadro 9.4 revisamos los rendimientos para la familia de métodos basada en la descomposición STLM (STL considerando la multiestacionalidad de las series). Vemos que el mejor rendimiento lo ofrece el método STLM DWM Reciente (STLM con estacionalidades diaria, semanal y mensual ajustado en los 6 meses de datos previos al punto de pronóstico).
En el Cuadro 9.5 revisamos los rendimientos para la familia de métodos basada en redes neuronales de tipo LSTM. Vemos que el mejor rendimiento lo ofrece el método LSTM Agg4 Scale SD (LSTM entrenado con los datos de las 8 semanas más recientes, transformando la serie a granularidad de una hora y escalando con centro la media y escala la desviación típica de la serie).
En el Cuadro 9.6 revisamos los rendimientos para la familia de métodos MIXTO STL LSTM basada en redes neuronales de tipo LSTM aplicadas a los residuos de utilizar STL. Vemos que los rendimientos son muy similares aunque es sutilmente mejor el método STL+LSTM Agg5 Scale Mean (Método mixto. Ajuste STL a 6 meses de datos más recientes de la serie considerando estacionalidad semanal. Posteriormente, los residuos de STL se modelan con LSTM transformando la serie a granularidad de 75 minutos).
Y por último comprobamos los distintos experimentos realizados con redes neuronales utilizando además variables exógenas. En el Cuadro 9.7 podemos ver que la diferencia no es muy grande pero el mejor método es LSTM-Exo DH Raw Scale Mean (LSTM entrenado con los datos de las 8 semanas más recientes, incorporando la hora del día y el día de la semana como variables exógenas y escalando con centro y escala la media).
| Nombre | 1 horas | 4 horas | 12 horas | 24 horas | 48 horas | 1 horas | 4 horas | 12 horas | 24 horas | 48 horas |
|---|---|---|---|---|---|---|---|---|---|---|
| SARIMA | 3.97 | 5.64 | 7.04 | 7.67 | 8.17 | 32.1 | 39.27 | 44.89 | 49.64 | 49.69 |
| AUTO ARIMA | 4.65 | 8.50 | 12.47 | 13.39 | 14.00 | 35.2 | 65.59 | 116.91 | 147.79 | 154.37 |
| Nombre | 1 horas | 4 horas | 12 horas | 24 horas | 48 horas | 1 horas | 4 horas | 12 horas | 24 horas | 48 horas |
|---|---|---|---|---|---|---|---|---|---|---|
| STL W Reciente | 3.65 | 5.04 | 6.53 | 6.87 | 7.18 | 27.44 | 33.76 | 45.87 | 52.11 | 52.43 |
| STL W | 3.74 | 5.35 | 7.14 | 7.48 | 7.79 | 28.14 | 36.67 | 54.19 | 61.46 | 62.15 |
| STL D Reciente | 4.10 | 6.55 | 9.15 | 9.73 | 10.30 | 29.58 | 44.75 | 69.88 | 81.21 | 82.65 |
| STL D | 4.15 | 6.73 | 9.54 | 10.15 | 10.69 | 29.87 | 46.05 | 73.99 | 86.43 | 87.50 |
| STL M | 4.82 | 9.37 | 16.43 | 17.68 | 18.15 | 32.92 | 62.12 | 142.87 | 174.87 | 177.34 |
| STL M Reciente | 5.53 | 10.35 | 17.81 | 19.23 | 19.64 | 48.18 | 78.52 | 163.75 | 199.73 | 200.74 |
| STL Y | 6.74 | 11.00 | 18.89 | 20.30 | 20.75 | 66.74 | 89.49 | 171.95 | 212.51 | 213.49 |
| Nombre | 1 horas | 4 horas | 12 horas | 24 horas | 48 horas | 1 horas | 4 horas | 12 horas | 24 horas | 48 horas |
|---|---|---|---|---|---|---|---|---|---|---|
| STLM DWM Reciente | 3.83 | 5.34 | 6.95 | 7.32 | 7.63 | 30.50 | 37.29 | 50.92 | 58.25 | 58.66 |
| STLM DW | 3.73 | 5.32 | 7.10 | 7.45 | 7.76 | 28.07 | 36.36 | 53.44 | 60.68 | 61.30 |
| STLM DWM | 3.81 | 5.42 | 7.18 | 7.54 | 7.85 | 29.65 | 37.82 | 54.25 | 61.91 | 62.70 |
| STLM DWY | 4.69 | 6.33 | 8.14 | 8.46 | 8.74 | 41.22 | 48.77 | 63.27 | 71.69 | 71.56 |
| Nombre | 1 horas | 4 horas | 12 horas | 24 horas | 48 horas | 1 horas | 4 horas | 12 horas | 24 horas | 48 horas |
|---|---|---|---|---|---|---|---|---|---|---|
| LSTM Agg4 Scale SD | 5.77 | 6.34 | 7.18 | 7.81 | 8.45 | 43.52 | 42.30 | 45.57 | 48.92 | 50.28 |
| LSTM Agg4 Scale Mean | 5.78 | 6.37 | 7.21 | 7.85 | 8.48 | 44.54 | 42.95 | 45.33 | 49.19 | 51.34 |
| LSTM Agg4 Diff Scale Mean | 4.50 | 7.12 | 9.59 | 10.75 | 12.48 | 29.90 | 44.29 | 64.77 | 79.61 | 90.12 |
| LSTM Agg4 Diff | 4.60 | 7.52 | 10.74 | 12.01 | 14.12 | 29.76 | 45.29 | 69.19 | 86.81 | 99.52 |
| Nombre | 1 horas | 4 horas | 12 horas | 24 horas | 48 horas | 1 horas | 4 horas | 12 horas | 24 horas | 48 horas |
|---|---|---|---|---|---|---|---|---|---|---|
| STL+LSTM Agg5 Scale Mean | 4.37 | 5.32 | 6.31 | 6.57 | 6.92 | 34.91 | 36.83 | 45.53 | 49.12 | 48.75 |
| STL+LSTM Raw Scale Mean | 3.72 | 4.89 | 6.39 | 6.68 | 7.02 | 26.45 | 31.57 | 45.65 | 50.00 | 49.69 |
| Nombre | 1 horas | 4 horas | 12 horas | 24 horas | 48 horas | 1 horas | 4 horas | 12 horas | 24 horas | 48 horas |
|---|---|---|---|---|---|---|---|---|---|---|
| LSTM-Exo DH Raw Scale Mean | 5.15 | 5.56 | 6.08 | 6.35 | 6.85 | 36.91 | 34.21 | 34.47 | 35.04 | 35.80 |
| LSTM-Exo DH Agg5 Scale Mean | 5.73 | 5.96 | 6.43 | 6.73 | 7.12 | 45.83 | 39.41 | 38.11 | 39.51 | 39.76 |
Por lo tanto, podemos recopilar las tablas de resultados anteriores enumerando los mejores métodos por familias. Estos métodos serán los que comparemos entre sí en los siguientes apartados. Son los que se enumeran en el Cuadro 9.8.
| Familia | Método |
|---|---|
| ARIMA | SARIMA |
| LSTM | LSTM Agg4 Scale SD |
| LSTM Exógeno | LSTM-Exo DH Raw Scale Mean |
| MIXTO STL LSTM | STL+LSTM Agg5 Scale Mean |
| STL | STL W Reciente |
| STLM | STLM DWM Reciente |
9.3 Comparación de resultados del mejor método por familia
En el apartado anterior hemos visto cuál es el método que mejor rinde por cada familia. En este apartado vamos a comparar los rendimiento de esos mejores métodos y ver como se comparan unos con otros.
En primer estudiaremos los errores cometidos por los mejores métodos teniendo en cuenta todas las series en las que han sido probados. Recordemos que indicábamos más arriba que las series que se utilizan para comparar el rendimiento de un conjunto de métodos son sólo aquellas en las que todos los métodos del conjunto han sido probadas; de este modo evitamos la influencia de cualquier tipo de sesgo que pudiera ocurrir de que un método hubiera sido probado en series más convenientes que otro.
En el Cuadro 9.9 podemos ver los errores cuadráticos y absoluto medios cometidos por cada método de los seleccionados en el punto anterior.
Podemos observar que en general, el método STL entrenado únicamente con la cola reciente de los datos ofrece los mejores resultados para horizontes pequeños (inferiores a 12 horas vista).
Sin embargo, para horizontes más grandes, vemos como el algoritmo LSTM alimentado con variables exógenas mejora en los resultados. Esto se aprecia principalmente en la métrica porcentual, en dónde no sólo se tiene en cuenta el error que se comete sino como de grande es en relación con el tamaño de la magnitud que se predice.
Por otro lado, en la Figura 9.1 se muestran los distintos errores promedio cometidos por cada algoritmo, en este caso calculados para todos los horizontes (desde 15 minutos hasta 48 horas).
| Nombre | 1 horas | 4 horas | 12 horas | 24 horas | 48 horas | 1 horas | 4 horas | 12 horas | 24 horas | 48 horas |
|---|---|---|---|---|---|---|---|---|---|---|
| LSTM-Exo DH Raw Scale Mean | 5.06 | 5.47 | 5.98 | 6.20 | 6.66 | 36.70 | 33.17 | 34.46 | 34.82 | 35.13 |
| STL W Reciente | 3.63 | 4.86 | 6.20 | 6.57 | 6.88 | 28.18 | 33.23 | 43.29 | 49.60 | 49.54 |
| STL+LSTM Agg5 Scale Mean | 4.34 | 5.29 | 6.27 | 6.54 | 6.90 | 34.96 | 36.89 | 45.66 | 49.18 | 48.87 |
| STLM DWM Reciente | 3.79 | 5.12 | 6.58 | 6.97 | 7.29 | 31.01 | 37.34 | 50.09 | 57.07 | 57.21 |
| SARIMA | 3.96 | 5.57 | 6.87 | 7.47 | 7.90 | 32.07 | 39.27 | 45.71 | 50.80 | 50.52 |
| LSTM Agg4 Scale SD | 5.51 | 6.09 | 6.95 | 7.56 | 8.16 | 40.21 | 39.50 | 45.07 | 48.24 | 49.14 |
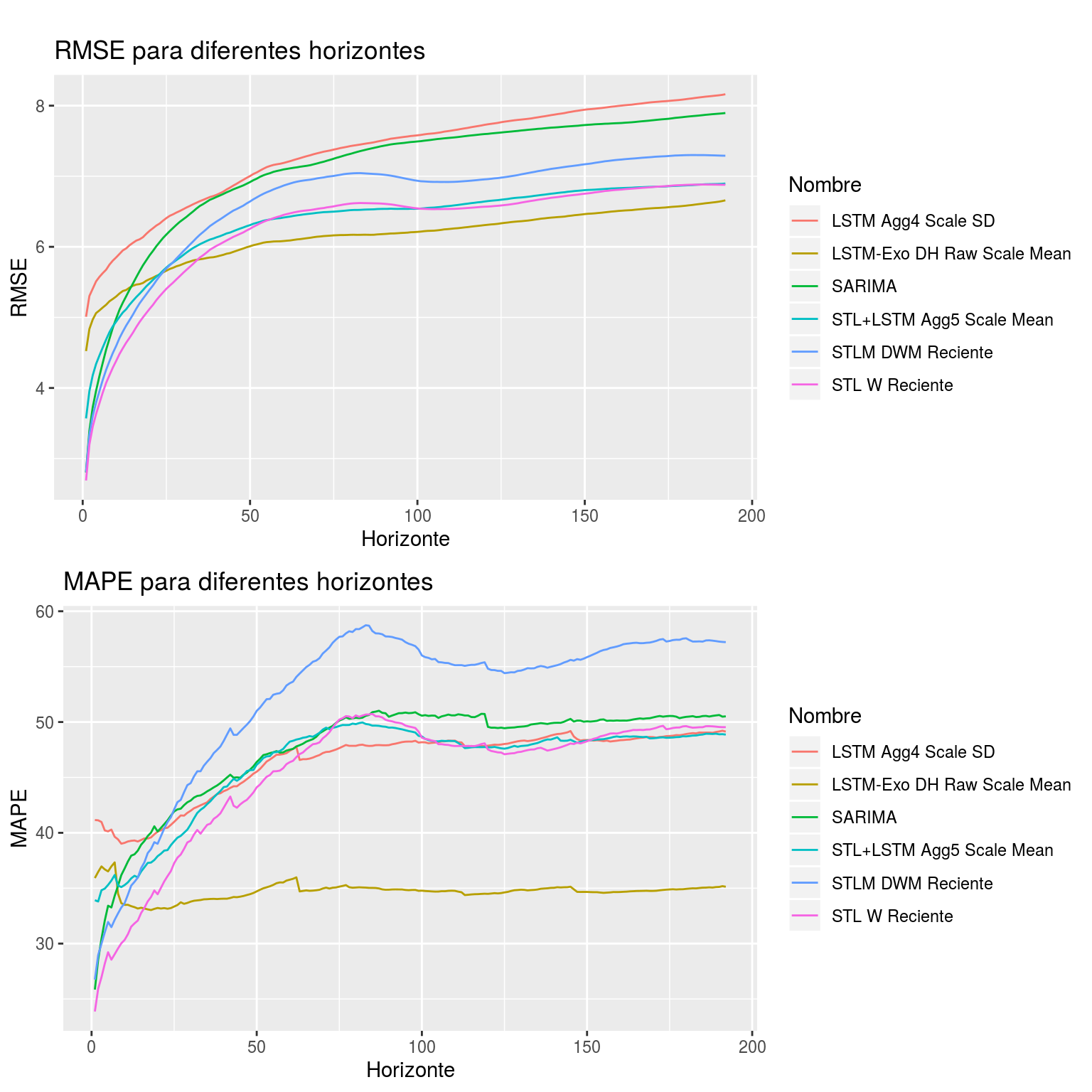
Figura 9.1: Gráfica de errores cometidos por los mejores métodos por familia para todos los horizontes
Podemos observar que el método basado en LSTM utilizando como variables exógenas la hora del día y el día de la semana, además de los datos crudos de la serie escalados y centrados, es el que mejor rendimiento ofrece en términos generales. Sin embargo, en pronósticos a muy corto plazo (inferiores a unas 6 horas) es el algoritmo “STL W Reciente” el que mejor aproxima el pronóstico.
9.4 Resultados segmentando por porcentaje de fallas en los datos
Sin embargo, como vimos en el apartado de relativo a los datos, los dispositivos no siempre reportan correctamente los datos. Es decir, hay fallas en el reporte a lo largo del tiempo, que en algunos casos son bastante significativas.
Para el correcto funcionamiento de los algoritmos es imperativo que la serie no tenga fallas en los datos. Para sobreponerse a este problema, en la mayoría de los casos se ha acudido a técnicas de interpolación para reparar los datos faltantes. Es fácil comprender que este tipo de técnicas pueden comprometer los resultados en la medida en la que el modelo en cuestión se educa con datos “ficticios” que pueden introducir sesgos.
Por eso, en el contraste de resultados, consideramos importante distinguir la capacidad de pronóstico segmentando también por la calidad de los datos reportados por los dispositivos.
Para proceder de este modo, filtramos las métricas obtenidas en los puntos anteriores quedándonos sólo con aquellos experimentos que se ha realizado sobre series que no superan ciertos umbrales de fallas y sobre esto calculamos agregados de errores.
Podemos ver los resultados para series con porcentaje de fallas inferior a 5% en el Cuadro 9.10 y en la Figura 9.2.
| Nombre | 1 horas | 4 horas | 12 horas | 24 horas | 48 horas | 1 horas | 4 horas | 12 horas | 24 horas | 48 horas |
|---|---|---|---|---|---|---|---|---|---|---|
| STL+LSTM Agg5 Scale Mean | 4.39 | 5.21 | 6.22 | 6.53 | 6.86 | 29.91 | 30.11 | 41.67 | 42.92 | 42.77 |
| LSTM-Exo DH Raw Scale Mean | 5.23 | 5.69 | 6.28 | 6.49 | 6.97 | 30.25 | 28.13 | 30.17 | 30.56 | 31.73 |
| STL W Reciente | 3.52 | 4.76 | 6.18 | 6.64 | 7.00 | 20.24 | 27.43 | 38.71 | 46.55 | 46.86 |
| STLM DWM Reciente | 3.63 | 4.91 | 6.27 | 6.73 | 7.12 | 22.99 | 30.15 | 40.23 | 49.21 | 49.78 |
| LSTM Agg4 Scale SD | 5.99 | 6.28 | 7.33 | 8.09 | 8.86 | 37.25 | 33.41 | 41.26 | 45.92 | 49.66 |
| SARIMA | 3.91 | 5.99 | 7.71 | 8.66 | 9.13 | 23.42 | 37.98 | 47.17 | 56.47 | 52.84 |
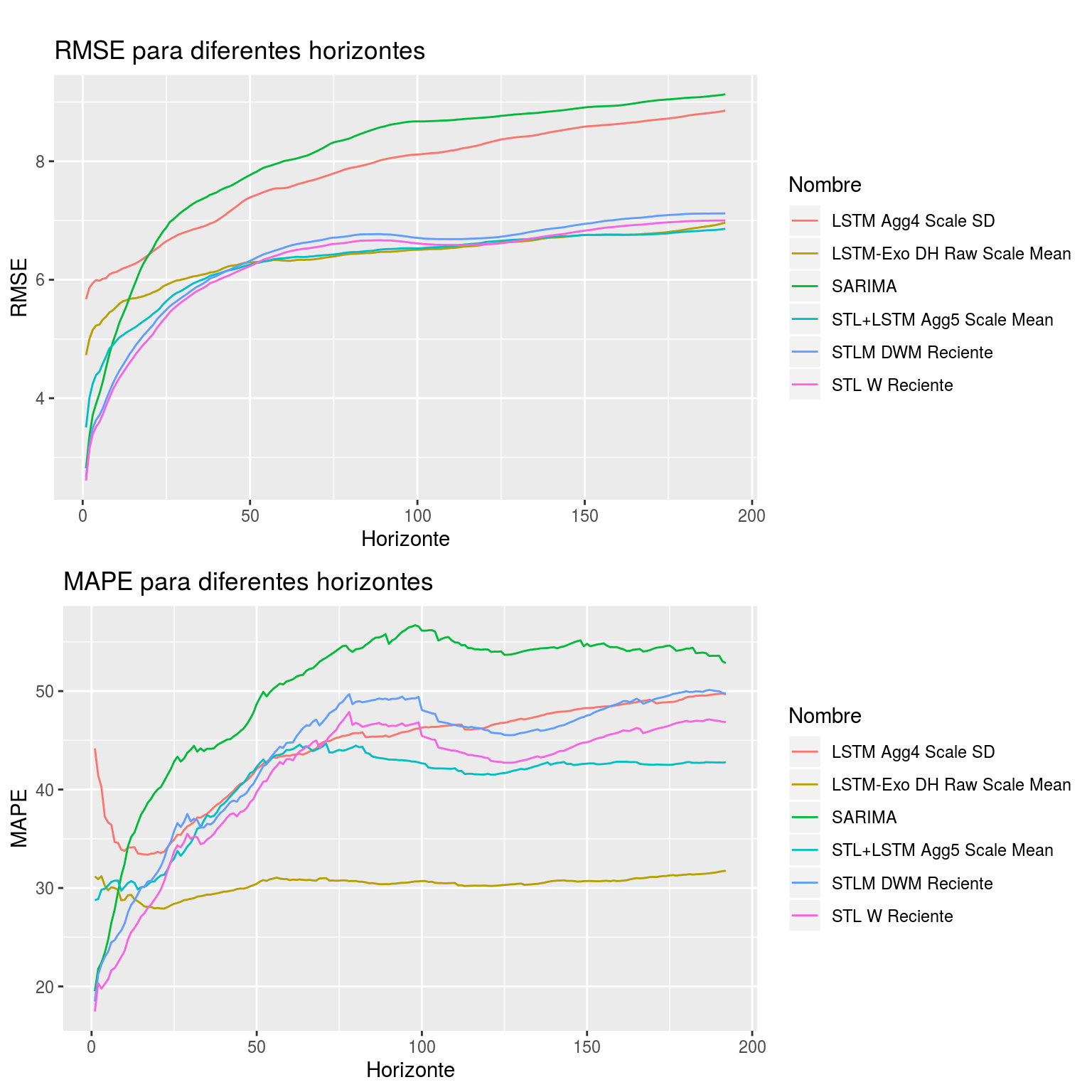
Figura 9.2: Gráfica de errores cometidos por los mejores métodos por familia evaluados en series con porcentaje de fallas inferior al 5%
Podemos observar que nuevamente los resultados del algoritmo STL considerando solo la subserie reciente son los mejores para pronósticos cercanos en el tiempo. Siendo el método LSTM Exógeno el que brinda mejores resultados para pronósticos más lejanos en el tiempo.
En la Figura 9.3 podemos ver la forma como se distribuyen los errores cometidos por los mejores métodos por familia a 48 horas vista. Observamos como las distribuciones que presentan los distintos métodos son bastante similares entre sí. Así mismo, al ser distribuciones unimodales, no parece que haya ningún método que difiera en comportamiento en diferentes conjuntos de series, más allá de la calidad de los datos.
En relación a la calidad de los datos, vemos como los métodos diferentes de SARIMA y LSTM Agg4 Scale SD, en sus predicciones a 48 horas vista, se ven perjudicados cuando sólo se tienen en cuenta aquellas series con escaso porcentaje de fallas. O visto de otro modo, el resto de métodos distintos de estos dos parecen comportarse peor ante series con datos deficientes.
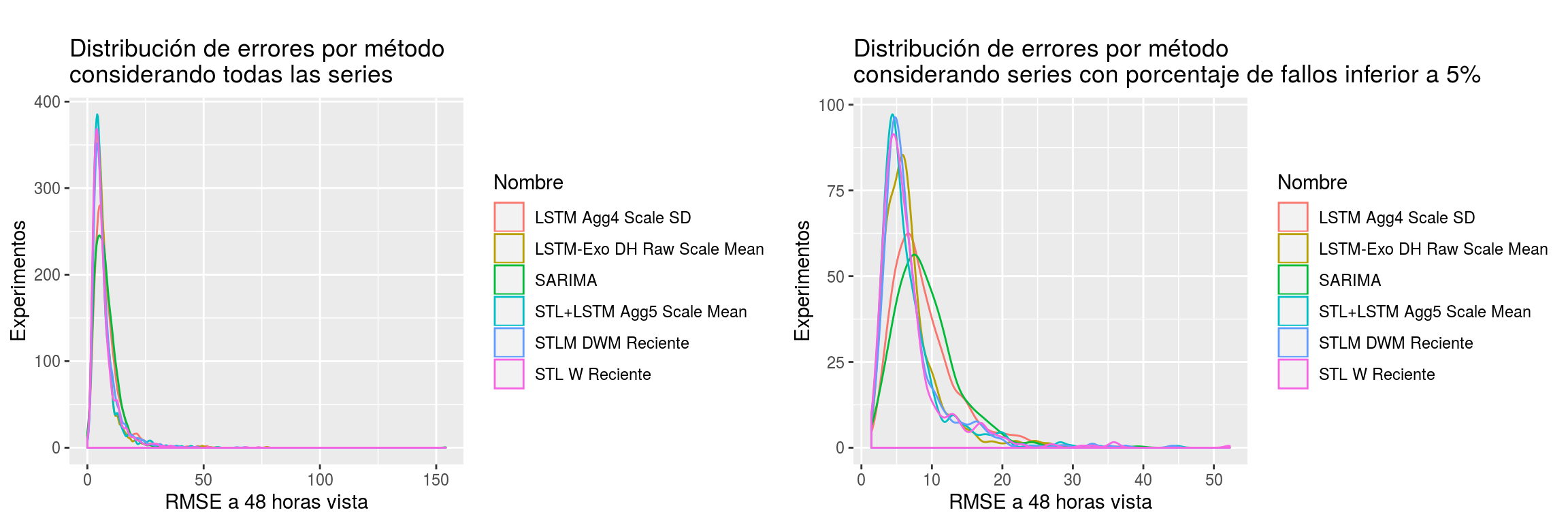
Figura 9.3: Distribución de los errores cometidos por método en pronósticos a 48 horas vista
9.5 Reproductibilidad
Este trabajo y todos los experimentos en él descritos han sido realizados de una u otra manera con el lenguaje de programación R y con los distintos frameworks para creación de textos científicos que ofrece. En particular, ha sido de gran utilidad la librería bookdown (Xie 2018). Todos los experimentos pueden reproducirse ejecutando el código que se expone de manera pública en Github (Mañas 2019).
Los datos descargados y procesados se han guardado en una base de datos MySQL alojada en AWS utilizando el servicio de base de datos en la nube RDS. Se ha guardado además el detalle de todos los experimentos realizados, con las medidas de error asociadas a cada experimento y la subserie pronosticada y esperada. Está prevista la exposición de manera pública de los archivos que permitan recrear la base de datos, facilitando así la continuidad de esta investigación por quien estuviera interesado. Los ficheros se alojarán en el servicio de almacenamiento masivo S3 de Amazon y la url pública de acceso a los mismos se expondrá en el repositorio Github que mencionábamos más arriba.
Finalmente, para la elaboración de este documento nos hemos servido de tres proyectos con RStudio:
Uno con las funciones de utilidad e implementaciones de los experimentos realizados.
Otro, a modo de espacio de trabajo para pruebas de concepto, dónde se han ido elaborando uno a uno los distintos apartados de este documento, a modo de Notebook de R con Rmarkdown (Allaire et al. 2018).
Y por último, un tercer proyecto en dónde se han ido consolidando los distintos apartados utilizando el framework bookdown (Xie 2018).
Como decimos más arriba, todo este material quedará expuesto de manera pública en (Mañas 2019). Durante el desarrollo del trabajo, para dotarnos de privacidad, se han hospedado los repositorios de código y documentos en Bitbucket, también basado en el sistema de control de versiones git.
De suma importancia ha sido también la máquina ndowe que la UNED pone a disposición de sus alumnos como ayuda para el desarrollo de este tipo de trabajos. La cantidad de computación que se ha necesitado para estos experimentos hubiera supuesto un gasto prohibitivo en cualquier proveedor de servicio en la nube y unos tiempos de ejecución enormes en una máquina doméstica.
A modo de resumen:
Se han utilizado más de 40 librerías del lenguaje R.
Se han realizado más de 280 commits de git (consolidaciones de código).
Se han generado más de 2.079 líneas de código para funciones de utilidad y ayuda.
Se ha necesitado de más de 2.000 horas de computación para la realización de los experimentos.
Bibliografía
Allaire, JJ, Yihui Xie, Jonathan McPherson, Javier Luraschi, Kevin Ushey, Aron Atkins, Hadley Wickham, Joe Cheng, and Winston Chang. 2018. Rmarkdown: Dynamic Documents for R. https://CRAN.R-project.org/package=rmarkdown.
Armstrong, Jon Scott. 1985. Long-Range Forecasting. Wiley New York ETC.
Hyndman, Rob J, and Anne B Koehler. 2006. “Another Look at Measures of Forecast Accuracy.” International Journal of Forecasting 22 (4). Elsevier: 679–88.
Mañas, Andrés Mañas. 2019. “Github Home Amanas.” https://github.com/amanas. https://github.com/amanas.
Rob J Hyndman, George Athanasopoulos. 2018. “Forecasting: Principles and Practice.” https://otexts.com/fpp2/. https://otexts.com/fpp2/.
Xie, Yihui. 2018. Bookdown: Authoring Books and Technical Documents with R Markdown. https://CRAN.R-project.org/package=bookdown.