Capítulo 6 Datos
La presente investigación se fundamenta en el estudio de dos conjuntos de datos que pone a disposición pública el Ayuntamiento de Madrid:
- Histórico de datos del tráfico desde 2013, (CIRCULACION 2018a)
- Ubicación de los puntos de medida del tráfico, (CIRCULACION 2018b)
En los siguientes apartados hacemos una descripción exhaustiva del contenido de ambos conjuntos de datos y de las acciones de preprocesado realizadas para poderlos utilizar.
6.1 Histórico de datos del tráfico desde 2013
Éste primer conjunto de datos, (CIRCULACION 2018a), contiene el histórico de medidas tomadas por los puntos de medida de tráfico de la ciudad de Madrid. Los datos se publican en archivos que contienen los registros de un mes completo y se van incorporando mes a mes.
Los diversos sistemas de control de tráfico de la ciudad de Madrid proporcionan periódicamente y de forma automática datos de todos los detectores de vehículos de los puntos de medida que controlan.
Si el sensor no proporciona información en un periodo, no se contabilizará esa información; no obstante, si el sensor proporciona información pero los parámetros de calidad de la misma no son óptimos la información se integra, pero se reporta como posible error. El error puede deberse a que el sensor detecta parámetros fuera de los rangos establecidos o porque alguno de los sensores que componen el punto de medida no esté operativo (por ejemplo, en un punto de medida de 4 carriles uno de los carriles no está funcionando).
Siguiendo la documentación de (CIRCULACION 2018a), los atributos de los datos históricos del flujo de tráfico tomados por los Puntos de Medida son los que se relacionan en el Cuadro .
| Nombre | Tipo | Descripción |
|---|---|---|
| id | Entero | Identificación única del Punto de Medida en los sistemas de control del tráfico del Ayuntamiento de Madrid. |
| fecha | Fecha | Fecha y hora oficiales de Madrid con formato yyyy-mm-dd hh:mi:ss |
| tipo_elem | Texto | Nombre del Tipo de Punto de Medida: Urbano o M30. |
| intensidad | Entero | Intensidad del Punto de Medida en el periodo
de 15 minutos (vehículos/hora). Un valor negativo implica la ausencia de datos. |
| ocupacion | Entero | Tiempo de Ocupación del Punto de Medida en el
periodo de 15 minutos (%). Un valor negativo implica la ausencia de datos. |
| carga | Entero | Carga de vehículos en el periodo de 15
minutos. Parámetro que tiene en cuenta intensidad, ocupación y capacidad de la vía y establece el grado de uso de la vía de 0 a 100. Un valor negativo implica la ausencia de datos. |
| vmed | Entero | Velocidad media de los vehículos en el periodo
de 15 minutos (Km./h). Sólo para puntos de medida interurbanos M30. Un valor negativo implica la ausencia de datos. |
| error | Texto | Indicación de si ha habido al menos una
muestra errónea o sustituida en el periodo de
15 minutos. N: no ha habido errores ni sustituciones E: los parámetros de calidad de alguna de las muestras integradas no son óptimos S: alguna de las muestras recibidas era totalmente errónea y no se ha integrado |
| periodo_integracion | Entero | Número de muestras recibidas y consideradas para el periodo de integración. |
Podemos observar una muestra de estos datos en el Cuadro 6.1.
| id | fecha | tipo_elem | intensidad | ocupacion | carga | vmed | error | periodo_integracion |
|---|---|---|---|---|---|---|---|---|
| 1001 | 2018-09-01 00:00:00 | M30 | 1140 | 3 | NaN | 62 | N | 5 |
| 1001 | 2018-09-01 00:15:00 | M30 | 1140 | 2 | NaN | 55 | N | 5 |
| 1001 | 2018-09-01 00:30:00 | M30 | 1488 | 4 | NaN | 55 | N | 5 |
| 1001 | 2018-09-01 00:45:00 | M30 | 1068 | 3 | NaN | 55 | N | 5 |
| 1001 | 2018-09-01 01:00:00 | M30 | 1224 | 3 | NaN | 59 | N | 5 |
| 1001 | 2018-09-01 01:15:00 | M30 | 708 | 1 | NaN | 64 | N | 5 |
6.1.1 Tratamiento de los archivos de datos históricos del tráfico
Revisando los datos históricos a lo largo del tiempo, observamos que han cambiado tanto las propiedades de este conjunto de datos como el formato de los archivos csv en dónde se publican, lo que ha conllevado un intenso ejercicio de saneado de la información previo a su explotación.
El carácter de separación de campos en el archivo csv no siempre es el mismo. A veces hay que leer los archivos considerando que es una coma ‘,’ y otras un punto y coma ‘;’.
Respecto a la heterogeneidad con la que se presentan los nombres de las propiedades de las medidas registradas, se ha observado que:
- id e idelem representan la misma propiedad, que unos meses viene informada con un nombre y otros con otro. Adoptamos id como nombre maestro.
- identif es una propiedad que tenemos que descartar, pues no siempre está presente y no tiene relevancia para el resto de nuestra investigación
- los valores de la propiedad tipo_elem viene codificados de forma diferente dependiendo del año y del mes. En particular:
- M30: puede venir codificado como M30, ‘PUNTOS MEDIDA M-30’ o 24. Adoptamos M30 como valor maestro.
- URB: puede venir informado como URB, ‘PUNTOS MEDIDA URBANOS’ o 495. Adoptamos URB como valor maestro.
- el resto de propiedades, en lo relativo al nombre no requieren de corrección
Respecto a la heterogeneidad con la que se presentan los tipos de dato de las propiedades de las medidas registradas, se ha comprobado que:
- la propiedad fecha se guarda como texto, por lo que hay que parsearla apropiadamente a un objeto de tipo timestamp
- las propiedades numéricas (id, intensidad, ocupacion, carga, vmed, periodo_integracion) unas veces vienen expresadas como números y otras como textos (separados por comillas simples o dobles). En todos los casos se procede a su conversión a tipo numérico.
Se han desarrollado funciones que realizan de manera trasparente todas las correcciones descritas en las líneas anteriores, de manera que se pueda trabajar de forma más cómoda y productiva.
6.1.2 Preparación para la explotación
Los datos se publican por meses en ficheros de unos 100 MB, con todas las medidas tomadas a lo largo del mes por todos los puntos de medida.
Cada uno de estos ficheros, descomprimido, ocupa unos 800 MB. Por lo tanto, cada vez que se quisiera revisar los datos de un dispositivo de medida sería necesario descargar el fichero, descomprimirlo, cargarlo en una estructura de datos y luego operarlo. Y eso para cada mes. Es una situación que hace imposible el trabajo.
Para sobreponernos a este inconveniente se ha procedido del siguiente modo:
- hemos creado una tabla en una base de datos con columnas year, month, device y data
- cada una de estas columnas guarda (comprimidos) los datos de las medidas tomadas por el dispositivo device, en el año year y en el mes month correspondientes. Esta información se almacena en la columna data.
- este primer almacenamiento se ha realizado sin transformación/mejora alguna de los datos de medida en bruto; los datos se guardan tal cual se reciben, pero eso sí, troceados en unidades más pequeñas y mucho más manejables.
En particular, en el Cuadro 6.2, podemos ver por año y mes el número de terminales que han estado registrando medidas:
| 2015 | 2016 | 2017 | 2018 | |
|---|---|---|---|---|
| 1 | 3712 | 3797 | 3882 | 3996 |
| 2 | 3735 | 3798 | 3774 | 4001 |
| 3 | 3749 | 3810 | 3902 | 3997 |
| 4 | 3755 | 3780 | 3899 | 4015 |
| 5 | 3755 | 3766 | 3906 | 4023 |
| 6 | 3764 | 3785 | 3904 | 4022 |
| 7 | 3763 | 3802 | 3910 | 4021 |
| 8 | 3748 | 3798 | 3885 | 4014 |
| 9 | 3736 | 3803 | 3912 | 3910 |
| 10 | 3765 | 3807 | 3981 | 3916 |
| 11 | 3777 | 3844 | 3993 | 0 |
| 12 | 3788 | 3900 | 3997 | 0 |
Igualmente, hemos desarrollado un conjunto de funciones convenientes que nos permite descargar las medidas registradas por un terminal concreto en un año y mes concretos. Algunas de las funciones más importantes que se han desarrollado son:
- tff.get.raw.metrics <- function(y = c(), m = c(), d = c()) {…}
- tff.get.parsed.metrics <- function(y = c(), m = c(), d = c()) {…}
- tff.get.parsed.metrics <- function(y = c(), m = c(), d = c()) {…}
- tff.get.parsed.location <- function(y, m, with.ym = F) {…}
- tff.get.all.parsed.locations <- function(with.ym = F) {…}
Un ejemplo de su uso puede verse en el siguiente fragmento de código, que realiza una consulta relativa a las medidas tomadas por el punto de medida 1001 en Septiembre de 2018:
6.1.3 Análisis exploratorio de los datos de flujo
En una primera revisión exploratoria de los datos, Septiembre de 2018, vemos que tenemos informados 10.668.743 registros, recogidos desde 3.910 puntos de medida.
Agrupando por tipo de elemento, Cuadro 6.3, podemos ver los conteos por tipo de registro.
| Freq | % Valid | % Valid Cum. | % Total | % Total Cum. | |
|---|---|---|---|---|---|
| M30 | 1142944 | 10.71 | 10.71 | 10.71 | 10.71 |
| URB | 9525799 | 89.29 | 100.00 | 89.29 | 100.00 |
| <NA> | 0 | NA | NA | 0.00 | 100.00 |
| Total | 10668743 | 100.00 | 100.00 | 100.00 | 100.00 |
Y de particular importancia es observar que no todos los puntos de medida informan la misma cantidad de medidas a lo largo del tiempo.
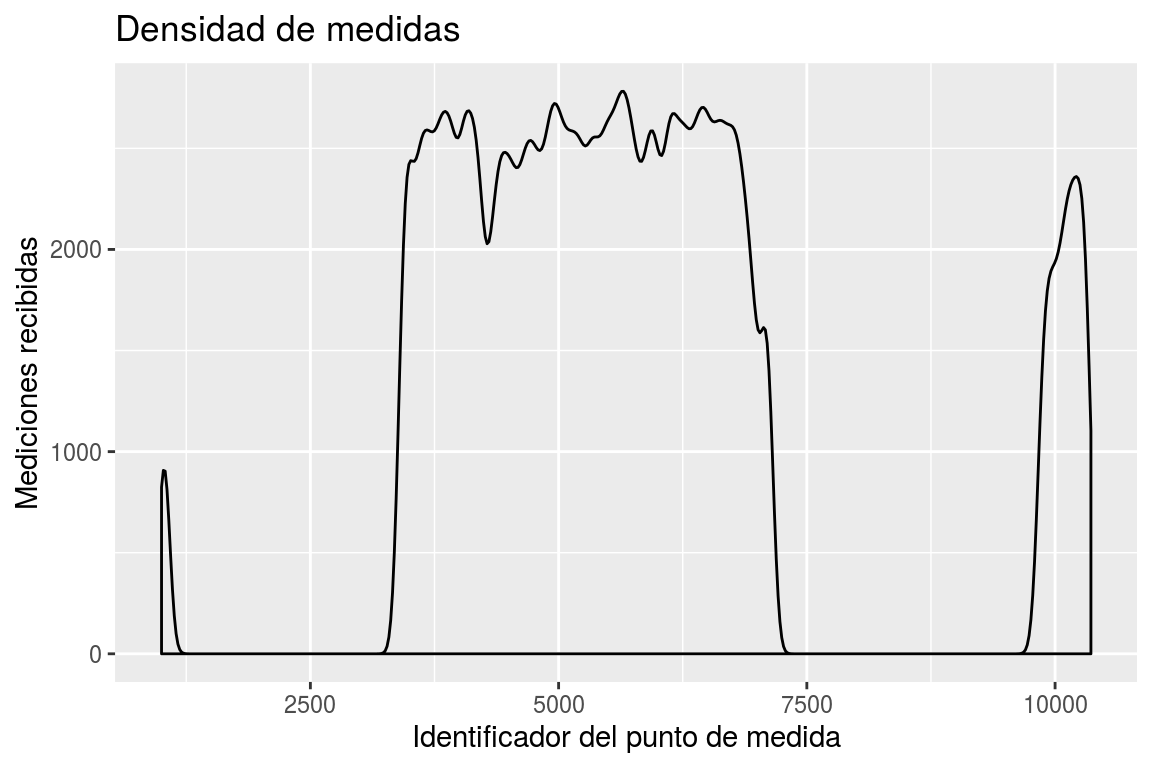
Figura 6.1: Distribución de los identificadores de los puntos de medida
Podemos explorar de forma visual la gráfica de densidad de registros informados por los puntos de medida en Septiembre 2018 (Figura 6.1). Vemos que la cantidad de medidas reportadas cada mes varía según el punto, siendo los detalles de esta variación los que se relacionan en el Cuadro .
| Valor | |
|---|---|
| Media | 2728.58 |
| Des. típica | 421.97 |
| Min | 1.00 |
| Q1 | 2785.00 |
| Mediana | 2864.00 |
| Q3 | 2879.00 |
| Max | 2880.00 |
| MAD | 23.72 |
| IQR | 94.00 |
| CV | 0.15 |
| Skewness | -4.56 |
| SE.Skewness | 0.04 |
| Kurtosis | 22.47 |
| N.Valid | 3910.00 |
| Pct.Valid | 100.00 |
Esto supone que en nuestro trabajo tenemos series con datos faltantes (fallas). Más adelante veremos la técnica seguida para resolver esta problemática.
Por otro lado, podríamos hacer el mismo estudio considerando únicamente aquellos registros que se han etiquetado sin “error”. Sin embargo, para el mes de Septiembre de 2018, ninguno de los registros viene caracterizado como erróneo.
6.2 Ubicación de los puntos de medida del tráfico
Éste segundo conjunto de datos, (CIRCULACION 2018b), contiene el histórico de localizaciones de los puntos de medida del flujo de tráfico. Los datos se publican en archivos que contienen los registros de un mes completo; sin embargo no todos los meses se publican.
La infraestructura de puntos de medida, disponible en la ciudad de Madrid se corresponde con:
- 7.360 detectores de vehículos con las siguientes características:
- 71 incluyen dispositivos de lectura de matrículas
- 158 disponen de sistemas ópticos de visión artificial con control desde el Centro de Gestión de Movilidad
- 1.245 son específicos de vías rápidas y acceso a la ciudad
- y el resto de los 5.886, con sistemas básicos de control de semáforos
- Más de 4.000 puntos de medida:
- 253 con sistemas para el control de velocidad, caracterización de los vehículos y doble lazo de lectura
- 70 de ellos conforman las estaciones de toma de aforos específicas de la ciudad.
Según documenta (CIRCULACION 2018b), los atributos de los datos de ubicación de los puntos de medida son los relacionados en el Cuadro .
| Nombre | Tipo | Descripción |
|---|---|---|
| cod_cent | texto | Código de centralización en los sistemas y que se
corresponde con el campo |
| id | entero | Identificador único y permanente del punto de medida. |
| nombre | texto | Denominación del punto de medida, utilizándose la
siguiente nomenclatura: Para los puntos de medida de tráfico urbano se identifica con la calle y orientación del sentido de la circulación. Para los puntos de vías rápida y accesos a Madrid se identifica con el punto kilométrico, la calzada y si se trata de la vía central, vía de servicio o un enlace. |
| tipo_elem | texto | Descriptor de la tipología del punto de medida según
la siguiente codificación: URB (tráfico URBANO) para dispositivos de control semafórico. M30 (tráfico INTERURBANO) para dispositivos de vías rápidas y accesos a Madrid. |
| x | real | Coordenada X_UTM del centroide de la representación del polígono del punto de medida. |
| y | real | Coordenada Y_UTM del centroide de la representación del polígono del punto de medida. |
6.2.1 Tratamiento de los archivos de datos de localización
Al igual que con los datos de medidas, observamos que a lo largo del tiempo, el conjunto de datos de localización ha cambiado tanto en las propiedades que informa como en el formato de los archivos csv en dónde se publican. Nuevamente esto requiere de un trabajo de saneado previo.
El carácter de separación de campos en el archivo csv no siempre es el mismo. A veces hay que leer los archivos considerando que es una coma ‘,’ y otras un punto y coma ‘;’.
Respecto a la heterogeneidad con la que se presentan los nombres de las propiedades, se ha observado que:
- los valores de la propiedad tipo_elem viene codificados de forma diferente dependiendo del año y del mes. En particular:
- M30: puede venir codificado como M30, ‘PUNTOS MEDIDA M-30’ o M-30. Adoptamos M30 como valor maestro.
- URB: puede venir informado como URBANOS. Adoptamos URB como valor maestro.
- x, st_x y utm_x representan la misma propiedad, que unos meses viene informada con un nombre y otros con otro. Adoptamos x como nombre maestro de la propiedad.
- y, st_y y utm_y representan la misma propiedad, que unos meses viene informada con un nombre y otros con otro. Adoptamos y como nombre maestro de la propiedad.
Respecto a la heterogeneidad con la que se presentan los tipos de dato, se ha comprobado que las coordenadas de localización de los puntos de medida unas veces se guardan utilizando comas ‘,’ como separador de miles y otras puntos ‘.’.
Se han desarrollado funciones que realizan de manera transparente todas las correcciones descritas en las líneas anteriores, de manera que se pueda trabajar de forma más cómoda y productiva.
Al igual que en el caso anterior, los archivos con los datos de localización se han guardado apropiadamente en una tabla de una base de datos. Esto simplifica mucho la tarea de operarlos, pues se evita mantener ficheros.
6.2.2 Muestra de los datos de ubicación de los puntos de medida
Podemos observar una muestra de estos datos en el Cuadro 6.4.
| tipo_elem | id | cod_cent | nombre | x | y |
|---|---|---|---|---|---|
| URB | 3840 | 01001 | Jose Ortega y Gasset E-O - Pº Castellana-Serrano | 441615.3 | 4475768 |
| URB | 3841 | 01002 | Jose Ortega y Gasset O-E - Serrano-Pº Castellana | 441705.9 | 4475770 |
| URB | 3842 | 01003 | Pº Recoletos N-S - Almirante-Prim | 441319.4 | 4474841 |
| URB | 3843 | 01004 | Pº Recoletos S-N - Pl, Cibeles- Recoletos | 441301.6 | 4474764 |
| URB | 3844 | 01005 | (AFOROS) Pº Castellana S-N - Eduardo Dato - Pl,Emilio Castelar | 441605.8 | 4476132 |
| URB | 3845 | 01006 | Pº Recoletos S-N - Villanueva-Jorge Juan | 441383.0 | 4474994 |
Y visualmente, sobre un mapa, podemos observar su distribución geográfica en la Figura 6.2.
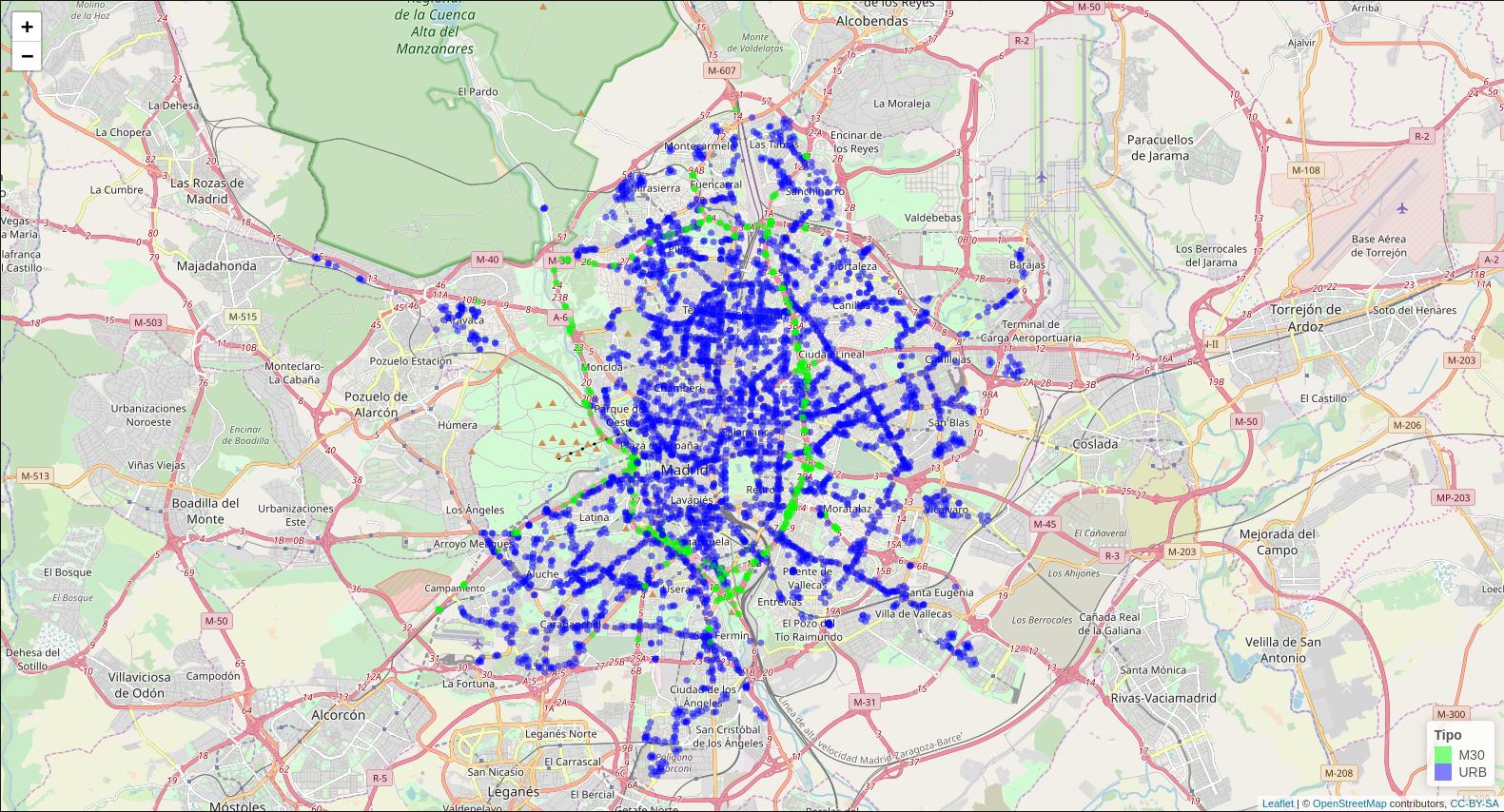
Figura 6.2: Mapa de localización de los Puntos de Medida (Septiembre 2018)
6.2.3 Análisis de corrupción de los datos de localización
Al igual que con los datos de medidas, podemos observar en qué meses se han informado localizaciones de los dispositivos de medida (Cuadro 6.5).
| Año | Mes | Dispositivos |
|---|---|---|
| 2018 | 10 | 4119 |
| 2018 | 9 | 4117 |
| 2018 | 8 | 4102 |
| 2018 | 7 | 4100 |
| 2018 | 6 | 4103 |
| 2018 | 4 | 4101 |
| 2018 | 3 | 4078 |
| 2018 | 2 | 4078 |
| 2018 | 1 | 4072 |
| 2017 | 12 | 4073 |
| 2017 | 11 | 4067 |
| 2017 | 10 | 4058 |
En particular, resulta interesante estudiar cuánto ha variado el valor de localización por dispositivo a lo largo del tiempo.
Hemos comprobado que considerando todo el histórico de localizaciones de terminales, 4.065 de los 4.141 se han visto sometidos a cambios superiores a 1 unidad en sus coordenadas de localización (Cuadro ).
| No | Variable | Estadístico / Valor | Freqs (% Válidos) | Válidos | Perdidos |
|---|---|---|---|---|---|
| 1 | id [entero] |
Media (sd) : 5701.7 (1852.8) min < med < max: 0 < 5450 < 10337 IQR (CV) : 2083 (0.3) |
4065 diferentes | 4065 (100%) |
0 (0%) |
| 2 | x_diff [numerico] |
Media (sd) : 109.3 (4.4) min < med < max: 0.5 < 109.4 < 146.1 IQR (CV) : 0 (0) |
4065 diferentes | 4065 (100%) |
0 (0%) |
| 3 | y_diff [numerico] |
Meadia (sd) : 207.4 (9.5) min < med < max: 1.2 < 207.5 < 426.1 IQR (CV) : 0 (0) |
4064 diferentes 4 ( | 065 100%) |
0 (0%) |
Sin embargo, considerando sólo datos de localización de los terminales desde Noviembre de 2017, vemos que sólo 18 dispositivos tienen cambios significativos en sus coordenadas de localización (Cuadro ).
| No | Variable | Estadístico / Valor | Freqs (% Válidos) | Válidos | Perdidos |
|---|---|---|---|---|---|
| 1 | id [entero] |
Media (sd) : 6726.6 (2118.2) min < med < max: 3714 < 6229 < 10280 IQR (CV) : 1782 (0.3) |
18 diferentes | 18 (100%) |
0 (0%) |
| 2 | x_diff [numerico] |
Media (sd) : 8.4 (8.8) min < med < max: 0.2 < 4.8 < 35.1 IQR (CV) : 8.9 (1) |
18 diferentes | 18 (100%) |
0 (0%) |
| 3 | y_diff [numerico] |
Media (sd) : 5.3 (4.1) min < med < max: 0.9 < 4.5 < 13.4 IQR (CV) : 7.1 (0.8) |
18 diferentes | 18 (100%) |
0 (0%) |
Esto claramente nos indica que los datos de localización históricos están corruptos.
Conclusiones:
- los datos históricos de localización sólo son válidos a partir de Noviembre de 2017
- desde Noviembre de 2017, sólo son fiables los datos de localización del 98,5% de los terminales
- los terminales que caen en el 1,5% cuya localización padece de modificaciones desde Noviembre de 2017 los vamos a descartar en nuestro estudio, por alguna de las siguientes razones:
- porque su localización esté corrupta en el histórico de localizaciones
- porque verdaderamente hayan podido cambiar de localización a lo largo del tiempo, lo cual implicaría una complejidad excesiva en el resto de esta investigación
6.3 Selección de la propiedad objeto de estudio
El objetivo principal de este trabajo es pronosticar el flujo de tráfico en la ciudad de Madrid.
De las propiedades que ofrece el conjunto de datos de medidas tomadas por los dispositivos de medida, las siguientes podrían servir para describir el estado en el que se encuentra el tráfico en un punto dado:
- intensidad: intensidad del punto de medida en el periodo de 15 minutos (vehículos/hora).
- ocupacion: tiempo de ocupación del punto de medida en el periodo de 15 minutos (%).
- carga: carga de vehículos en el periodo de 15 minutos. Parámetro que tiene en cuenta intensidad, ocupación y capacidad de la vía y establece el grado de uso de la vía de 0 a 100.
- vmed: velocidad media de los vehículos en el periodo de 15 minutos (Km./h). Sólo para puntos de medida interurbanos M30.
En primer lugar, descartamos como propiedad objetivo la velocidad media vmed, puesto que este valor solamente se informa para los dispositivos de la M30 y en este estudio se pretende un modelo que pronostique el flujo en cualquier punto de la ciudad (también los urbanos).
De las 3 restantes, realmente sería la carga la propiedad más importante a pronosticar, por tres razones:
- se corresponde con un valor que tiene significado directo sobre la ocupación del punto
- se expresa como un porcentaje, de manera que intuitivamente es fácil de entender (independiente del contexto o peculiaridades del lugar en el que esté el punto de medida)
- es un valor ya cocinado, por lo que una vez pronosticado, no requiere de mayor transformación
Para disponer de información suficiente que permita validar que la propiedad carga es la mejor candidata, se ha revisado que la cantidad relativa de veces que no ha sido informada no sea excesivamente superior a cualquier otra propiedad. En caso contrario, es decir, caso que los datos informados en la propiedad carga realmente fuesen muy precarios, tal vez sería conveniente no seleccionar esta como la propiedad objetivo e intentar adoptar otros enfoques.
Este estudio se ha realizado con los datos de 2018 recogidos por todos los puntos de medida. Para esta labor se ha utilizado el paquete imputeTS (Moritz and Bartz-Beielstein 2017) de R. El resultado, con la cantidad relativa de veces que cada propiedad no ha sido informada de forma correcta se muestra en el Cuadro .
| No | Variable | Estadístico / Valor | Freqs (% Válidos) | Válidos | Perdidos |
|---|---|---|---|---|---|
| 1 | % intensidad NAs [numerico] |
media (sd) : 0.04 (0.09) min < med < max : 0 < 0.02 < 1 IQR (CV) : 0.03 (2.13) |
934 diferentes | 2906 (100%) |
0 (0%) |
| 2 | % ocupacion NAs [numerico] |
media (sd) : 0.08 (0.1) min < med < max : 0 < 0.05 < 1 IQR (CV) : 0.05 (1.25) |
1315 diferentes | 2906 (100%) |
0 (0%) |
| 3 | % carga NAs [numerico] |
media (sd) : 0.05 (0.1) min < med < max : 0 < 0.02 < 1 IQR (CV) : 0.04 (1.86) |
986 diferentes | 2906 (100%) |
0 (0%) |
Vemos que el porcentaje en el que la propiedad carga no está informada correctamente es menor que el homólogo para ocupación. Y no es mucho mayor que el correspondiente valor de la propiedad intensidad.
Por lo tanto, los datos no contravienen el objetivo de pronosticar la propiedad carga, que es la más relevante para este estudio por las razones expuestas más arriba.
Podemos ver la distribución de los porcentajes de datos faltantes en las series de carga reportadas por los dispositivos en todo el histórico de datos en la Figura 6.3.
Nótese que es diferente el análisis de calidad realizado en los párrafos anteriores (medidas recibidas sin valor de carga, intensidad u ocupación), que el análisis al que se refiere la Figura 6.3 (“huecos” en la serie temporal en la que no se han recibido datos, ni de carga ni de ninguna otra propiedad).
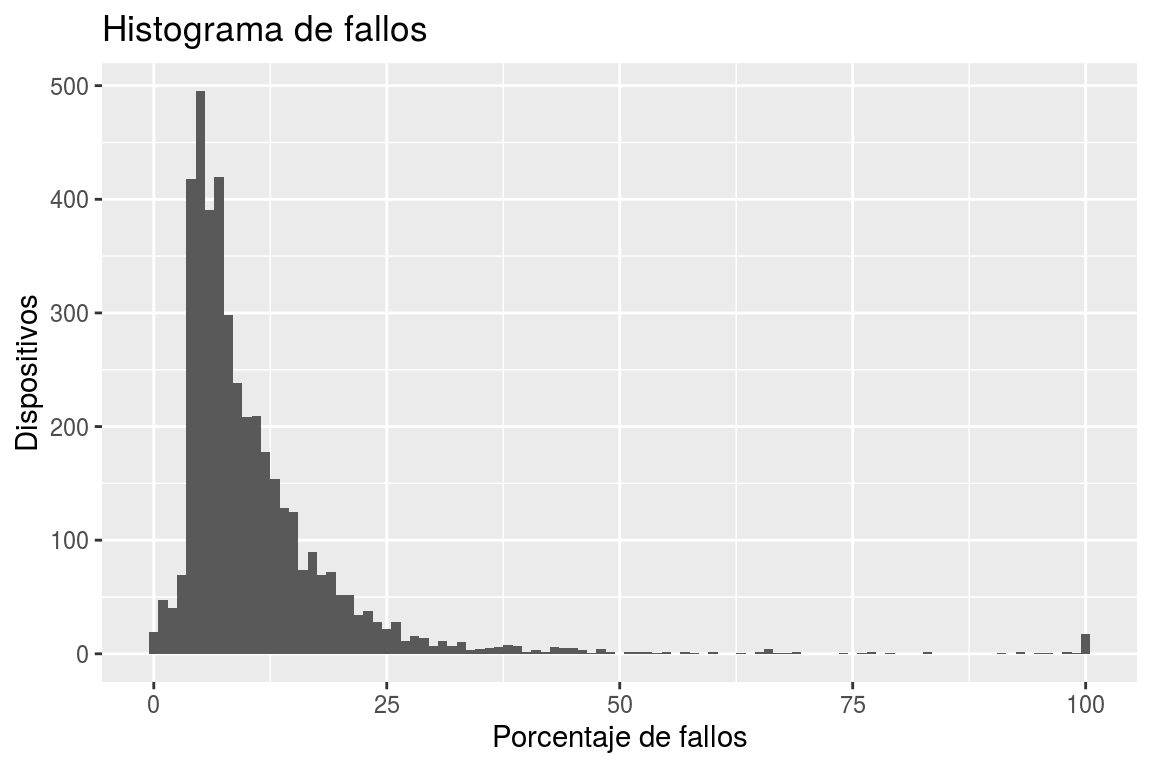
Figura 6.3: Histograma del porcentaje de datos faltantes en los datos reportados por todos los dispositivos
6.4 Análisis exploratorio de la propiedad carga
Es importante determinar de forma heurística el patrón estacional que puedan presentar los datos que vamos a estudiar. De especial ayuda son los gráficos de representación polar para esta tarea.
Con esta finalidad se han explorado las series de carga reportadas por varios dispositivos. En la Figura 6.4 pueden verse las distintas estacionalidades que presenta la propiedad carga para uno de estos dispositivos, sirviendo de generalidad para lo observado en el resto de ellos.
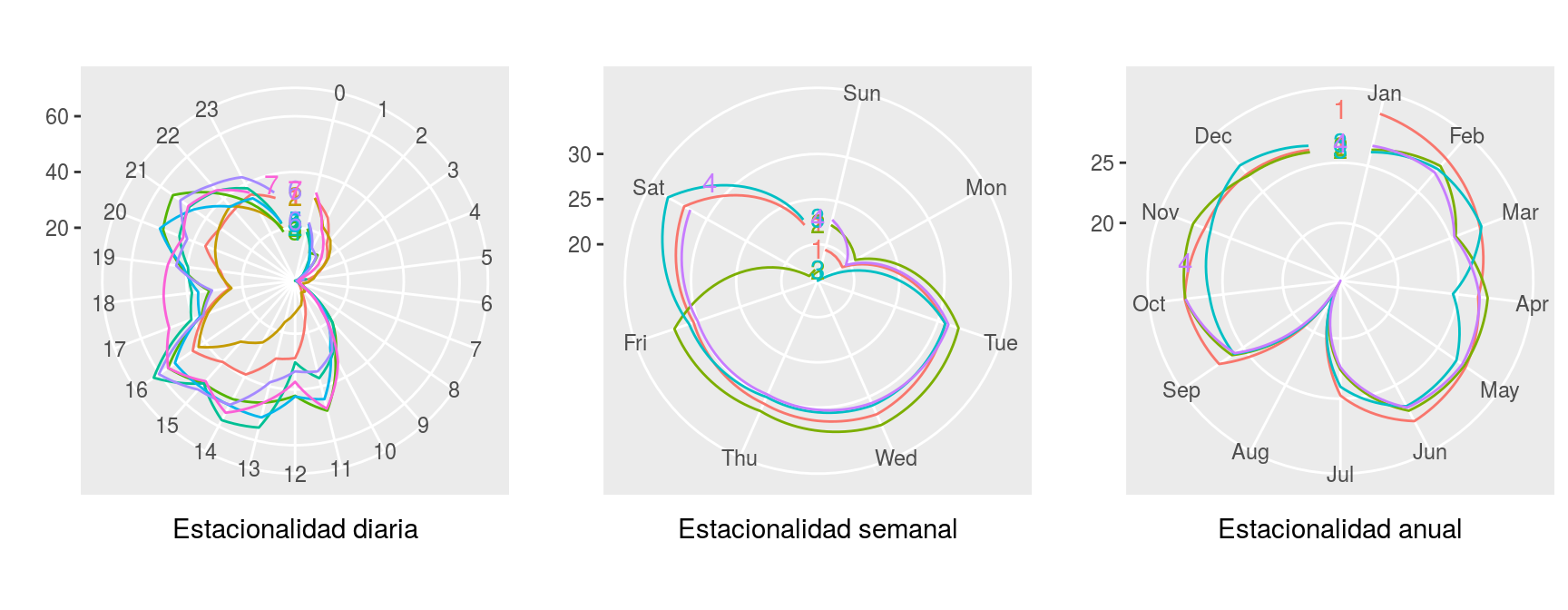
Figura 6.4: Gráfico de diferentes estacionalidades de la carga (dispositivo 4000)
Podemos observar que las series tiene componentes estacionales diarias, semanales y anuales; circunstancia por otro lado bastante natural dada la relación directa entre el flujo de tráfico de una ciudad y el calendario por el que se gobierna la actividad humana.
6.5 Fallas en los datos
La mayoría de los algoritmos de modelado y pronóstico de series temporales requieren de datos que no tengan fallas.
Para tener una idea de lo significativas que pueden llegar a ser estas anomalías en los datos tomados por los dispositivos, podemos observar por ejemplo las medidas tomadas por el dispositivo 10.329 en la primera semana de Julio de 2.018 en la Figura 6.5.
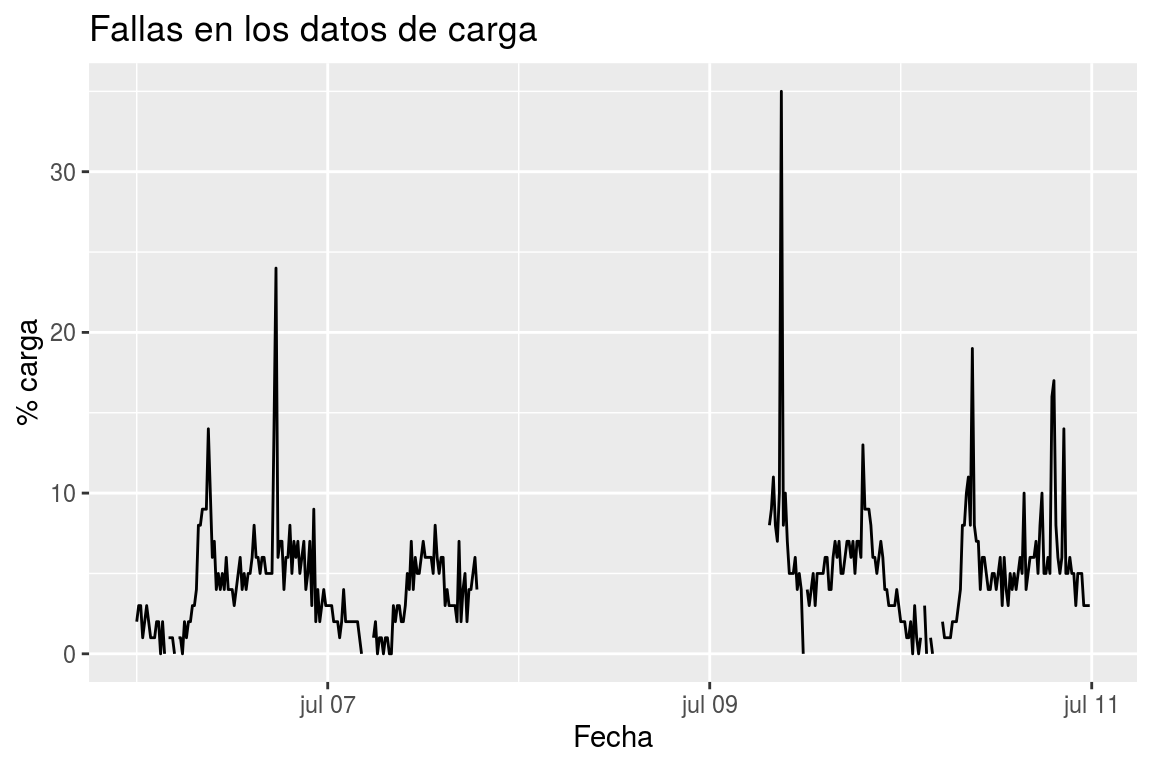
Figura 6.5: Fallas en los datos informados por el dispositivo 10.329 en Julio de 2018
Dependiendo del tipo de algoritmo utilizado en cada caso, se ha seleccionado la técnica más conveniente para la reparación de estas fallas. Por ahora, para el estudio exploratorio de la propiedad carga (principalmente en lo relativo a su estacionalidad) hemos utilizado técnicas muy sencillas, como acarrear el último valor conocido o interpolar con los valores extremos.
Es importante tener en cuenta, que para fallas grandes no será fácil reparar los datos de una manera no nociva. Tarea ésta que por otro lado supone un área de investigación y que excede los límites de este trabajo.
Bibliografía
CIRCULACION, DIRECCIÓN GENERAL DE GESTIÓN Y VIGILANCIA DE LA. 2018a. “Tráfico. Histórico de Datos Del Tráfico Desde 2013.” https://datos.madrid.es/sites/v/index.jsp?vgnextoid=33cb30c367e78410VgnVCM1000000b205a0aRCRD&vgnextchannel=374512b9ace9f310VgnVCM100000171f5a0aRCRD. https://datos.madrid.es/sites/v/index.jsp?vgnextoid=33cb30c367e78410VgnVCM1000000b205a0aRCRD&vgnextchannel=374512b9ace9f310VgnVCM100000171f5a0aRCRD.
CIRCULACION, DIRECCIÓN GENERAL DE GESTIÓN Y VIGILANCIA DE LA. 2018b. “Tráfico. Ubicación de Los Puntos de Medida Del Tráfico.” https://datos.madrid.es/portal/site/egob/menuitem.c05c1f754a33a9fbe4b2e4b284f1a5a0/?vgnextoid=ee941ce6ba6d3410VgnVCM1000000b205a0aRCRD&vgnextchannel=374512b9ace9f310VgnVCM100000171f5a0aRCRD. https://datos.madrid.es/portal/site/egob/menuitem.c05c1f754a33a9fbe4b2e4b284f1a5a0/?vgnextoid=ee941ce6ba6d3410VgnVCM1000000b205a0aRCRD&vgnextchannel=374512b9ace9f310VgnVCM100000171f5a0aRCRD.
Moritz, Steffen, and Thomas Bartz-Beielstein. 2017. “imputeTS: Time Series Missing Value Imputation in R.” The R Journal 9 (1): 207–18. https://journal.r-project.org/archive/2017/RJ-2017-009/index.html.