Capítulo 8 Métodos basados en Deep Learning
Las redes neuronales artificiales son un modelo computacional vagamente inspirado en el comportamiento observado en su homólogo biológico. Consiste en un conjunto de unidades, llamadas neuronas artificiales, conectadas entre sí para transmitirse señales. La información de entrada atraviesa la red neuronal (dónde se somete a diversas operaciones) produciendo unos valores de salida. Las redes neuronales artificiales pueden utilizarse como métodos de pronóstico de series temporales, como veremos más adelante.
Cada neurona está conectada con otras a través de unos enlaces. En estos enlaces el valor de salida de la neurona anterior es multiplicado por un valor de peso. Estos pesos en los enlaces pueden incrementar o inhibir el estado de activación de las neuronas adyacentes. Del mismo modo, a la salida de la neurona, puede existir una función limitadora o umbral, que modifica el valor resultado o impone un límite que se debe sobrepasar antes de propagarse a otra neurona. Esta función se conoce como función de activación.
Así, tenemos la capa de entrada formada por las entradas a la red, la capa de salida formada por las neuronas que constituyen la salida final de la red, y las capas ocultas formadas por las neuronas que se encuentran entre los nodos de entrada y de salida. Una RNA puede tener varias capas ocultas o no tener ninguna. Las conexiones sinápticas (las flechas que llegan y salen de las neuronas) indican el flujo de la señal a través de la red, y tienen asociadas un peso sináptico correspondiente. Si la salida de una neurona va dirigida hacia dos o más neuronas de la siguiente capa, cada una de estas últimas recibe la salida neta de la neurona anterior. La cantidad de capas de una RNA es la suma de las capas ocultas más la capa de salida.
Un ejemplo sencillo de perceptrón multicapa (RNA con capas ocultas) lo podemos ver en la Figura 8.1:
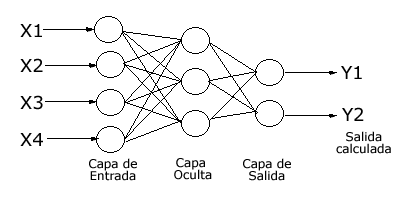
Figura 8.1: Ejemplo de perceptrón multicapa
El problema habitual con este tipo de redes multicapa es el de, dados un conjunto de datos ya clasificados, de los que se conoce la salida deseada, proporcionar los pesos adecuados de la red para que se obtenga una aproximación correcta de las salidas si la red recibe únicamente los datos de entrada.
Estos sistemas aprenden y se forman a sí mismos, en lugar de ser programados de forma explícita, y sobresalen en áreas donde la detección de soluciones o características es difícil de expresar con la programación convencional. Para realizar este aprendizaje automático, normalmente, se intenta minimizar una función de pérdida que evalúa la red en su total. Los valores de los pesos de las neuronas se van actualizando buscando reducir el valor de la función de pérdida. Este proceso se realiza mediante la propagación hacia atrás.
El objetivo de la red neuronal es resolver los problemas de la misma manera que el cerebro humano, aunque las redes neuronales son más abstractas. Las redes neuronales actuales suelen contener desde unos miles a unos pocos millones de unidades neuronales.
Las redes neuronales se han utilizado para resolver una amplia variedad de tareas, como la visión artificial y el reconocimiento de voz, que son difíciles de resolver usando la ordinaria programación basada en reglas. Históricamente, el uso de modelos de redes neuronales marcó un cambio de dirección significativo a finales de los años ochenta. Se pasa de sistemas expertos con conocimiento incorporado en reglas a sistemas caracterizados por el conocimiento incorporado en los parámetros de un modelo cognitivo.
Históricamente, el avance clave en el desarrollo de las redes neuronales fue el algoritmo de propagación hacia atrás que resuelve eficazmente el problema del entrenamiento rápido de redes neuronales de múltiples capas (Werbos 1975). El proceso de propagación hacia atrás utiliza la diferencia entre el resultado producido y el resultado deseado para cambiar los “pesos” de las conexiones entre las neuronas artificiales.
Este algoritmo de entrenamiento de la red por propagación hacia atrás se puede resumir muy brevemente en los siguiente puntos:
- Empezar con unos pesos sinápticos cualesquiera (generalmente elegidos al azar).
- Introducir datos de entrada (en la capa de entrada) elegidos al azar entre el conjunto de datos de entrada que se van a usar para el entrenamiento.
- Dejar que la red genere un vector de datos de salida (propagación hacia delante).
- Comparar la salida generada por al red con la salida deseada.
- La diferencia obtenida entre la salida generada y la deseada (denominada error) se usa para ajustar los pesos sinápticos de las neuronas de la capa de salidas.
- El error se propaga hacia atrás (back-propagation), hacia la capa de neuronas anterior, y se usa para ajustar los pesos sinápticos en esta capa.
- Se continúa propagando el error hacia atrás y ajustando los pesos hasta que se alcance la capa de entradas.
- Este proceso se repetirá con los diferentes datos de entrenamiento.
Sin embargo, para redes de múltiples capas que usan la propagación hacia atrás se presenta el problema del desvanecimiento del gradiente. Un caso particular son las redes neuronales recurrentes (RNNs). Aunque los errores se propagan de una capa a otra, disminuyen exponencialmente con el número de capas, y eso impide el ajuste hacia atrás de los pesos de las neuronas basado en esos errores. Las redes profundas se ven particularmente afectadas. Más adelante veremos cómo resolver este problema mediante el uso de unas redes concretas.
8.1 Estrategias de pronóstico
En los problemas con series temporales es muy común pronosticar más de un valor en el futuro. En particular, esto es la parte central del objetivo de este trabajo. Para este fin, se debe elegir una estrategia de varios pasos adelante.
Esta cuestión suele abordarse de dos formas diferentes, que describimos a continuación, pues utilizar una u otra ha sido del todo relevante en los resultados arrojados por los métodos basados en redes neuronales.
8.1.1 La estrategia de entrada múltiple y salida múltiple
Esta estrategia se caracteriza por el uso de un vector de valores objetivo. La longitud de este vector es igual a la cantidad de períodos a pronosticar. Por ejemplo, pronosticar el flujo de tráfico para las próximas 48 horas a intervalos de 15 minutos conlleva un vector objetivo de \(48*4=192\) valores. La cantidad de valores pasados de la serie que se consideren para pronosticar el vector objetivo es independiente del tamaño del vector objetivo y dependerá en cada caso del algoritmo que se utilice y de la naturaleza del problema.
En esta estrategia, una sóla ejecución del algoritmo, con los datos pasados que necesite, da como resultado el pronóstico con el horizonte necesario.
8.1.2 La estrategia recursiva
La estrategia recursiva o iterativa es el enfoque utilizado, por ejemplo, por ARIMA (método paramétrico, como vimos más arriba) para pronosticar varios períodos. Básicamente, se utiliza un modelo que solo pronostica un paso adelante, de modo que el modelo se aplica de forma iterativa para pronosticar todos los períodos futuros. Cuando las observaciones históricas que se usen como características de la nueva instancia no estén disponibles, se pueden usar predicciones previas en su lugar.
8.2 Redes autorregresivas
Un primer acercamiento al uso de redes neuronales para el problema del pronóstico del flujo de tráfico es utilizar las conocidas como redes neuronales autorregresivas.
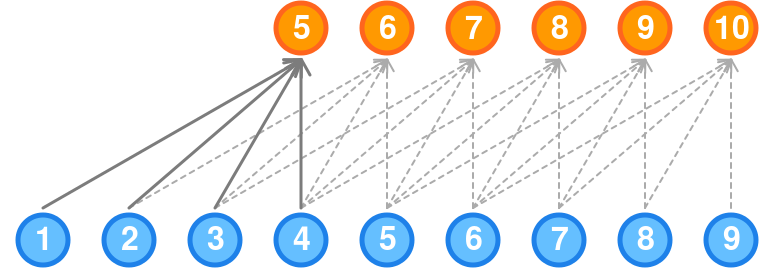
Figura 8.2: Arquitectura NNAR básica
La clave para el uso de este tipo de redes es considerar los datos ordenados de la serie temporal como entradas de la red, del mismo modo que usamos los valores retrasados en un modelo de autorregresión lineal. A estos modelos se les llama redes neuronales de autorregresión o modelos NNAR.
Cuando se trata de pronósticos utilizando este algoritmo, la red se aplica de forma iterativa. Para pronosticar un paso adelante, simplemente utilizamos las entradas históricas disponibles. Para pronosticar dos pasos adelante, usamos el pronóstico de un paso como entrada, junto con los datos históricos. Este proceso continúa hasta que hayamos computado todos los pronósticos requeridos.
En lugar de implementar este tipo de redes desde cero, para los experimentos que se han realizado en este trabajo se ha utilizado la función nnetar del paquete forecast (Hyndman et al. 2018).
Sin embargo, los resultados obtenidos con este algoritmo para la batería de experimentos realizados no han sido buenos. Aparte de lo negativo de los resultados, los tiempos de cálculo son muy superiores a los utilizados por otros algoritmos y métodos tratados. Esto motiva que el presente estudio no haya seguido esta línea y que no se incluyan los resultados en las tablas que se incluyen en los distintos apartados.
8.3 LSTM univariado
Las redes neuronales recurrentes, RNN, son un tipo de redes capaces de reconocer y predecir secuencias de datos a lo largo del tiempo, como textos, genomas, discurso hablado o series numéricas. Este tipo de redes se fundamentan en bucles que permiten que la salida de la red o de una parte de ella en un momento dado sirva como entrada de la propia red en el siguiente momento.
Para entender el funcionamiento de las RNNs, podemos considerar un perceptrón multicapa con una sóla capa oculta de manera que la salida del perceptrón es utilizada como entrada en la siguiente evaluación. Este bucle en la arquitectura de la red es precisamente lo que permite a la red “recordar” información a lo largo del tiempo. En la medida en la que le añadimos capas, su capacidad de modelado irá creciendo de manera que será capaz de reconocer mayores secuencias cada vez con menor error.

Figura 8.3: Arquitectura RNN básica
Véase la Figura 8.3, dónde:
- \(\text{A}\) es una red neuronal
- \(X_t\) es la entrada de la red
- \(h_t\) es la salida de la red
Precisamente es el bucle que conecta la red consigo misma el mecanismo que permite que la red tenga memoria.
Las RNNs pueden verse también como múltiples copias de la misma red, cada una de ellas pasando información a su sucesora. Véase la Figura 8.4. En cada momento del tiempo \(t\), la red recibe como entrada tanto \(X_t\) como su propia salida \(h_{t-1}\) en el instante \(t-1\).
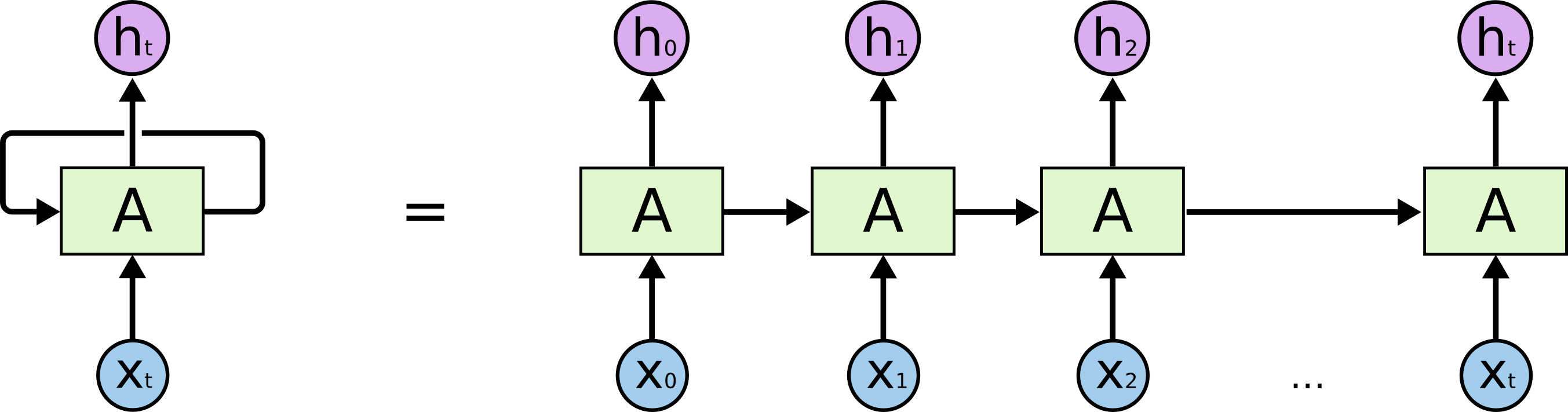
Figura 8.4: Arquitectura RNN expandida
Las RNNs tienen un contratiempo importante conocido como problema del desvanecimiento del gradiente; es decir, tienen dificultades para aprender dependencias de largo alcance. Cuando se realiza la propagación hacia atrás, es decir, nos movemos hacia atrás en la red y calculamos los gradientes de pérdida (error) con respecto a los pesos, los gradientes tienden a ser cada vez más pequeños a medida que nos movemos hacia atrás en la red. Esto significa que las neuronas en las capas anteriores aprenden muy lentamente en comparación con las neuronas en las capas posteriores en la jerarquía. Las capas anteriores de la red son las más lentas de entrenar. Este es un problema en todos los tipos de redes neuronales, pero particularmente es nocivo para redes en dónde lo que se pretende es tener la componente de memoria necesaria para pronóstico de series temporales.
Afortunadamente, este problema fue resuelto por (Hochreiter and Schmidhuber 1997) mediante la creación de las LSTM. Las redes de memoria a corto/largo plazo, LSTM, son un tipo especial de RNN, capaz de aprender dependencias a largo plazo.
Las LSTM están diseñados explícitamente para evitar el problema de dependencia a largo plazo. Recordar información durante largos períodos de tiempo es prácticamente su comportamiento predeterminado. Todas las redes neuronales recurrentes tienen la forma de una cadena de módulos repetitivos de la red neuronal. En las RNN estándar, este módulo de repetición tendrá una estructura muy simple, como una sola capa de activación. Los LSTM también tienen esta estructura tipo cadena, pero el módulo de repetición tiene una estructura diferente. En lugar de tener una sola capa de red neuronal, hay cuatro que interactúan de una manera muy especial (Figura 8.5).
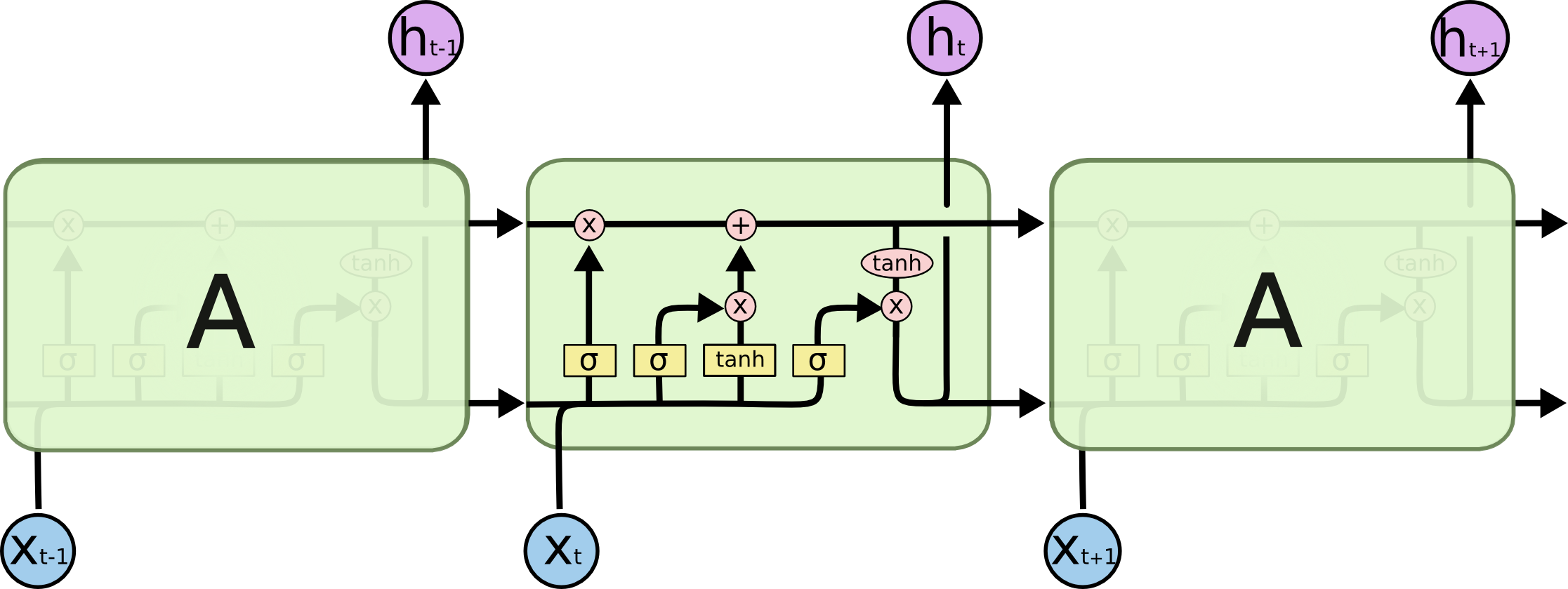
Figura 8.5: Capas de las celdas LSTM
La clave de las redes LSTM es el estado de la célula, la línea horizontal que recorre la parte superior del diagrama. El estado de la célula es algo así como una cinta transportadora. Corre hacia abajo por toda la cadena, con solo algunas interacciones lineales menores. Es muy fácil que la información fluya sin cambios. El LSTM tiene la capacidad de eliminar o agregar información al estado de la célula, cuidadosamente regulado por estructuras llamadas compuertas.
Las puertas son una forma de permitir que la información fluya. Se componen de una capa de red neuronal sigmoidea y una operación de multiplicación puntual. La capa sigmoide produce números entre cero y uno, que describen la cantidad de cada componente que debe dejarse pasar. Un valor de cero significa “no dejar pasar nada”, mientras que un valor de uno significa “dejar pasar todo”. Un LSTM tiene tres de estas compuertas, para proteger y controlar el estado de la celda.
Para ampliar conocimientos sobre el funcionamiento de las redes LSTM se recomienda revisar el fantástico artículo (Olah 2015).
Afortunadamente, para utilizar este tipo de red no es necesario implementarlas desde cero, sino que se pueden utilizar distintos frameworks. Como se explicará más adelante, los experimentos que hemos realizado se han basado en Keras sobre TensorFlow.
8.3.1 Descripción del experimento
Las LSTMs son sensibles a la escala de los datos de entrada, especialmente cuando se utilizan las funciones de activación sigmoide (por defecto) o tanh. Para evitar este problema, hemos reescalado los datos al rango de 0 a 1.
La siguiente parte se relaciona con la estructura como se le presentan las series a la red para que proceda al aprendizaje. Las redes LSTM, al menos en la implementación de Keras, esperan una entrada del tipo [muestras, pasos de tiempo, características]. Para esto, dada una serie de carga, se ha elegido un tamaño de sub-serie de entrenamiento (look back) y un tamaño de sub-serie de pronóstico (look ahead).
Sin embargo, es importante resaltar que en el caso de este algoritmo no se han obtenido buenos resultados considerando la serie en crudo (con los outlayers propios que pueda tener). Se ha comprobado que el algoritmo converge mejor y da mejores resultados si la serie se suaviza a granularidad de 1 hora.
En el contexto del suavizado indicado anteriormente, el valor look ahead utilizado es \(92/4 = 48\). Recordemos que el objetivo de esta investigación son pronósticos a 48 horas vista (96 valores con granularidad de 15 minutos, es decir, 48 con granularidad de una hora).
Respecto a la estrategia de pronóstico seguida, se ha utilizado la múltiple. Se han realizado bastantes pruebas siguiendo la estrategia recursiva no habiéndose llegado a resultados satisfactorios.
Tras muchas pruebas en las que se ha contrastado tanto los resultados arrojados por el algoritmo como los recursos y tiempo necesarios para el entrenamiento, se ha observado que un valor de look back que ofrece un buen rendimiento es tomar el mismo que se utiliza para look ahead (48 valores).
Por otro lado, hay dos formas de definir las redes LSTM en keras: redes con estado (statefull) o redes sin estado (stateless) entre muestras dentro del mismo lote de entrenamiento. Cuando se definen redes que con estado, esto significa que las muestras que componen los diferentes lotes de cada época de entrenamiento deben ser consecutivas en su índice dentro del lote.
En este trabajo se han probado ambos enfoques no llegándose a conseguir que las redes que no se definen con estado converjan.
Para las redes que se definen con estado, efectivamente sí se han conseguido que converjan y los pronósticos, como veremos más adelante, son relativamente satisfactorios. La parte que tiene que ver con diseccionar una serie de carga en distintos lotes, garantizando que los lotes satisfagan las indicaciones dadas más arriba ha sido realmente trabajosa, pero finalmente los resultados han sido redes LSTM’s capaces de pronosticar el flujo.
Se ha prestado especial atención a que las redes no acaben sobre-entrenadas. Esto se gestiona con bastante ergonomía en keras, disponiendo de callbacks que paran el entrenamiento cuando la mejora en la disminución de errores no es significativa tras una o más épocas.
En el capítulo de resultados veremos cómo se comportan estos algoritmos en comparación con los métodos paramétricos que hemos explorado en los apartados anteriores. Pero por ahora, por ejemplo, para el terminal 5575, en la Figura 8.6, podemos ver los pronósticos hechos con LSTM. Obsérvese como los pronósticos con LSTM están bastante suavizados, en coherencia con los comentarios sobre suavizado de datos hechos más arriba.
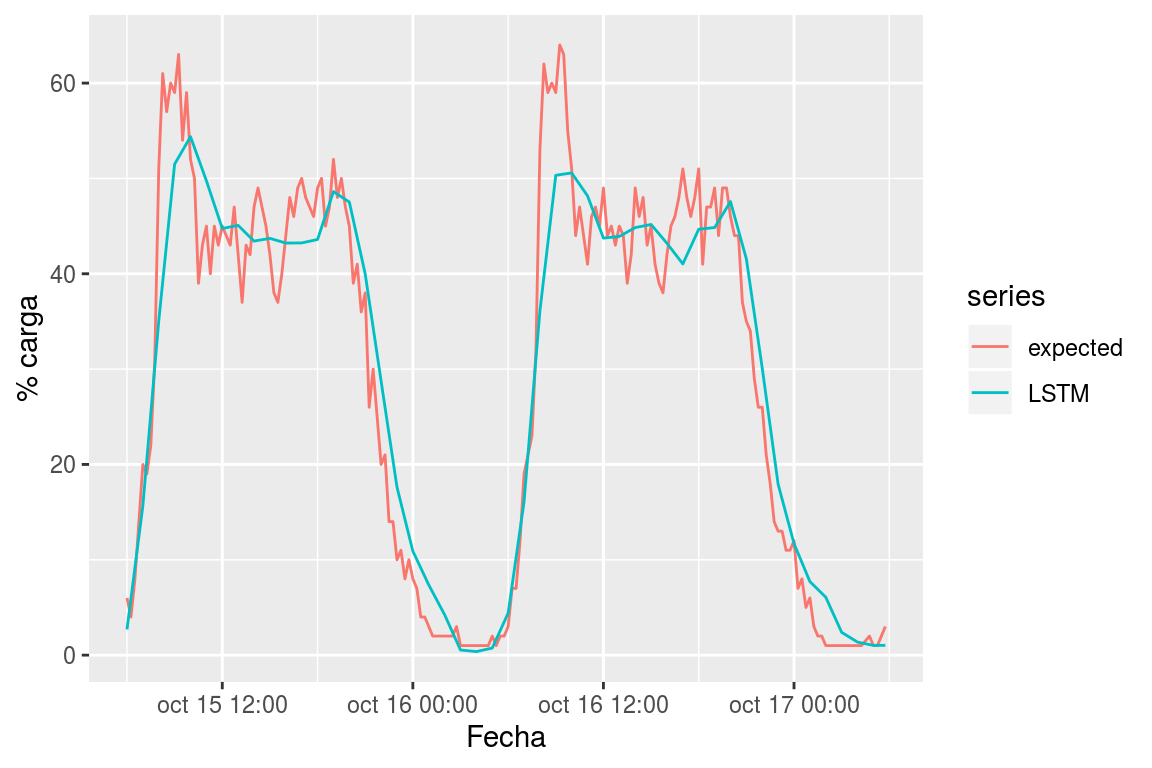
Figura 8.6: Pronóstico del flujo de carga para el terminal 5.575 con LSTM
8.4 LSTM con variables exógenas
En las series del flujo de tráfico existe una componente de comportamiento humano que no debe ser despreciada. En particular, los humanos ajustamos nuestros hábitos según las horas del día y los días de la semana. Esta información viene reportada en los datos que hemos trabajado, pero hasta ahora, en ninguno de los modelos anteriores hemos considerado esta información como una variable de entrada.
Es de esperar que ayudando al modelo ofreciéndole como entrada esta nueva fuente de información ofrezca un rendimiento mejor. En particular, esto puede ser de especial utilidad en los modelos basados en aprendizaje profundo, independientemente de que hay técnicas que permiten seguir este enfoque también con los modelos paramétricos.
Esta técnica se ha seguido para algunos modelos basados en LSTM. Concretamente, los modelos LSTM-Exo DH Raw Scale Mean y LSTM-Exo DH Agg5 Scale Mean han sido construidos de este modo.
Para ambos modelos, se han utilizado además de los datos de carga de la serie, dos nuevas variables exógenas, la hora del día y el día de la semana. En lugar de construir modelos complejos, con varias vías de entrada, se han encapsulado estas variables junto con la carga en una única variable formada por 3 componentes. Como suele ser habitual en el caso de redes neuronales, los datos han sido escalados al intervalo [-1,1].
En ambos casos, los resultados han mejorado bastante, como veremos en detalle en el capítulo de resultados.
Bibliografía
Hochreiter, Sepp, and Jürgen Schmidhuber. 1997. “Long Short-Term Memory.” Neural Computation 9 (8). MIT Press: 1735–80.
Hyndman, Rob, George Athanasopoulos, Christoph Bergmeir, Gabriel Caceres, Leanne Chhay, Mitchell O’Hara-Wild, Fotios Petropoulos, Slava Razbash, Earo Wang, and Farah Yasmeen. 2018. forecast: Forecasting Functions for Time Series and Linear Models. http://pkg.robjhyndman.com/forecast.
Olah, Christopher. 2015. “Understanding Lstm Networks.” http://colah.github.io/posts/2015-08-Understanding-LSTMs. http://colah.github.io/posts/2015-08-Understanding-LSTMs.
Werbos, P.J. 1975. Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences. Harvard University. https://books.google.es/books?id=z81XmgEACAAJ.