Capítulo 5 Visualização
Além de trabalhar com os números - o que é relevante para compreensão do contexto da informação - é necessário apresentar aos leitores visualizações que estejam em acordo com análise realizada.
Regras para uma boa visualização (Kristin Fontichiaro 2017):
Construa gráficos com clareza e simplicidade em mente: Deixe que os dados se apresentem. Gráfico muitos complexos, além da dificuldade natural de interpretação, podem provocar desconfiança e desconforto. Se o gráfico está ficando muito complexo, considere dividi-lo em várias partes.
Faça com que a Interpretação do gráfico seja intuitiva: Comece escolhendo um título bastante direto para o gráfico. Inclua legendas, labels, símbolos, cores, tudo que for necessário para tirar toda redundância e dúvidas sobre a informação. Deixe claro quais as unidades de medida está usando e dê destaque aos elementos mais importantes.
Respeite os princípios matemáticos: Quando estiver usando formas para representar proporções, garanta que o tamanho relativo represente de forma fidedigna a comparação. Como boa prática, mantenha as visualizações usando gráficos de duas dimensões.
Figura 5.1: Exemplo de como não se representar proporção em um gráfico
Realize vários testes de visualização antes de escolher a versão final: É importante tentar apresentar a informação com diferentes gráficos e elementos visuais, para tentar compreender qual a combinação que favorece melhor a divulgação da informação.
Deixe claro quais são as fontes de informação: O ideal, no contexto de relatórios reproduzíveis, é que as fontes sejam citadas e estejam seguindo os conceitos envolvidos com dados abertos (ver capítulo 2)
5.1 Ferramentas
Graças ao conjunto de visualizações contidas no pacote ggplot2, R provê as ferramentas necessárias para fazer várias visualizações de dados em um amplo espectro de possibilidades. Além disso, os modernos frameworks de visualização baseados em javascript que surgiram após o lançamento da biblioteca D3.js, em sua maior parte, já estão integrados ao ambiente R através de pacotes que simplificam a vida do analista de negócio. São exemplos de frameworks de visualização já integrados com R:
Para ver quais pacotes R utilizar para utilizar essas e outras opções de frameworks de visualização de dados, consulte o website HTML Widgets for R.
5.2 A Gramática da Visualização
Para os exemplos a seguir, vamos usar, na maioria das vezes, um data.frame conhecido como mpg, já disponível na biblioteca ggplot2:
## # A tibble: 234 x 11
## manufacturer model displ year cyl trans drv cty hwy fl class
## <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
## 1 audi a4 1.8 1999 4 auto… f 18 29 p comp…
## 2 audi a4 1.8 1999 4 manu… f 21 29 p comp…
## 3 audi a4 2 2008 4 manu… f 20 31 p comp…
## 4 audi a4 2 2008 4 auto… f 21 30 p comp…
## 5 audi a4 2.8 1999 6 auto… f 16 26 p comp…
## 6 audi a4 2.8 1999 6 manu… f 18 26 p comp…
## 7 audi a4 3.1 2008 6 auto… f 18 27 p comp…
## 8 audi a4 q… 1.8 1999 4 manu… 4 18 26 p comp…
## 9 audi a4 q… 1.8 1999 4 auto… 4 16 25 p comp…
## 10 audi a4 q… 2 2008 4 manu… 4 20 28 p comp…
## # … with 224 more rows5.2.1 Construindo a Visualização
Para construir a visualização utilizando ggplot2, o seguinte template deve ser observado (Garret Grolemund 2016):
ggplot(data = <DATA>) +
<GEOM_FUNCTION>(mapping = aes(<MAPPINGS>)),
stat=<STAT>, position=<POSITION>) +
<COORDINATE_FUNCTION> +
<FACET_FUNCTION> +
<SCALE_FUNCTION> +
<THEME_FUNCTION>Considerando então as estruturas contidas no template:
- DATA: Passar como parâmetro data.frame específico para contendo os dados que serão utilizados na visualização, seguindo a filosofia tidy data (ver capítulo 3).
- GEOM_FUNCTION: Use essa função para representar como gostaria que os dados fossem apresentados na visualização. Por exemplo, GEOM_POINT para representação na forma de pontos.
- POSITION: Função para ajuste de posição no gráfico.
- MAPPINGS: Mapeamento das variáveis no gráfico. Por exemplo em se tratando de duas variáveis apresentadas em um eixo cartesiano, passar a informação de valores para os eixos X e Y.
- COORDINATE_FUNCTION: Quando necessário, indicar qual o formato do plano onde será apresentado a informação. Por exemplo, para sair do plano cartesiano para o polar, utilizar método coord_polar.
- FACET_FUNCTION: Forma uma matriz de painéis para apresentação dos gráficos. Necessário quando deseja apresentar mais de um gráfico em uma mesma estrutura visual.
- SCALE_FUNCTION: Apresenta a escala de cores que será utilizada no gráfico.
- THEME_FUNCTION: Função que define padrões de cores sob a forma de temas para tornar a visualização mais agradável e adaptada ao contexto visual da análise.
5.2.2 Exemplos
Os exemplos abaixos foram tirados do livro R for Data Science (Garret Grolemund 2016).
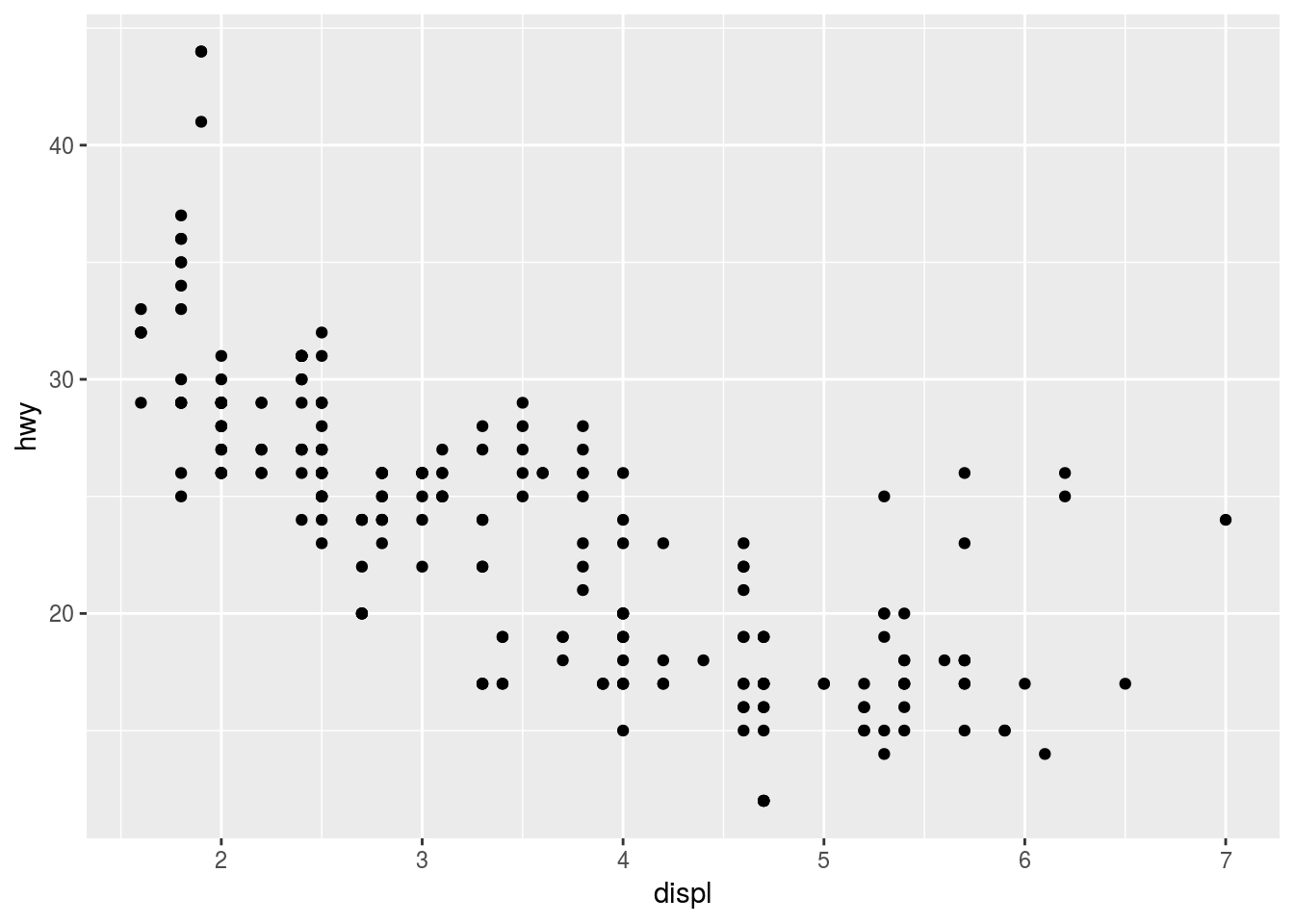
O primeiro exemplo, apresentado na figura a seguir, gera um gráfico com pontos representando a variável displ (eixo x) e hwy (eixo y). Por padrão, gera as informações em um plano cartesiano. Dimensiona as medidas na mesma ordem de grandeza do conjunto de valores para cada variável.
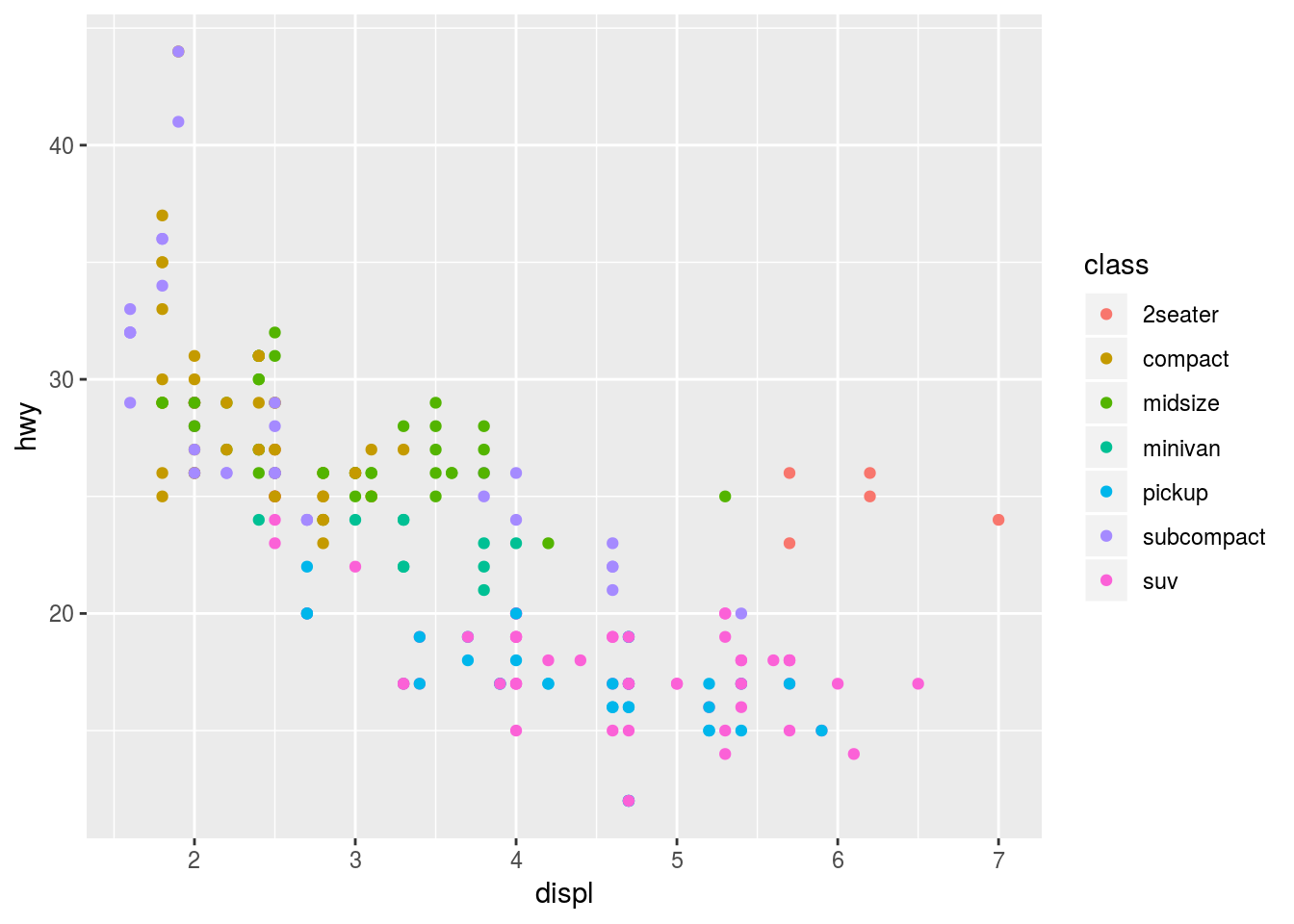
Aqui, uma pequena adaptação na geração do gráfico: a inclusão da variável color como parâmetro para apresentar, no gráfico, a classe dos carros, através do uso das cores. Com isso, colocamos mais uma informação no gráfico.
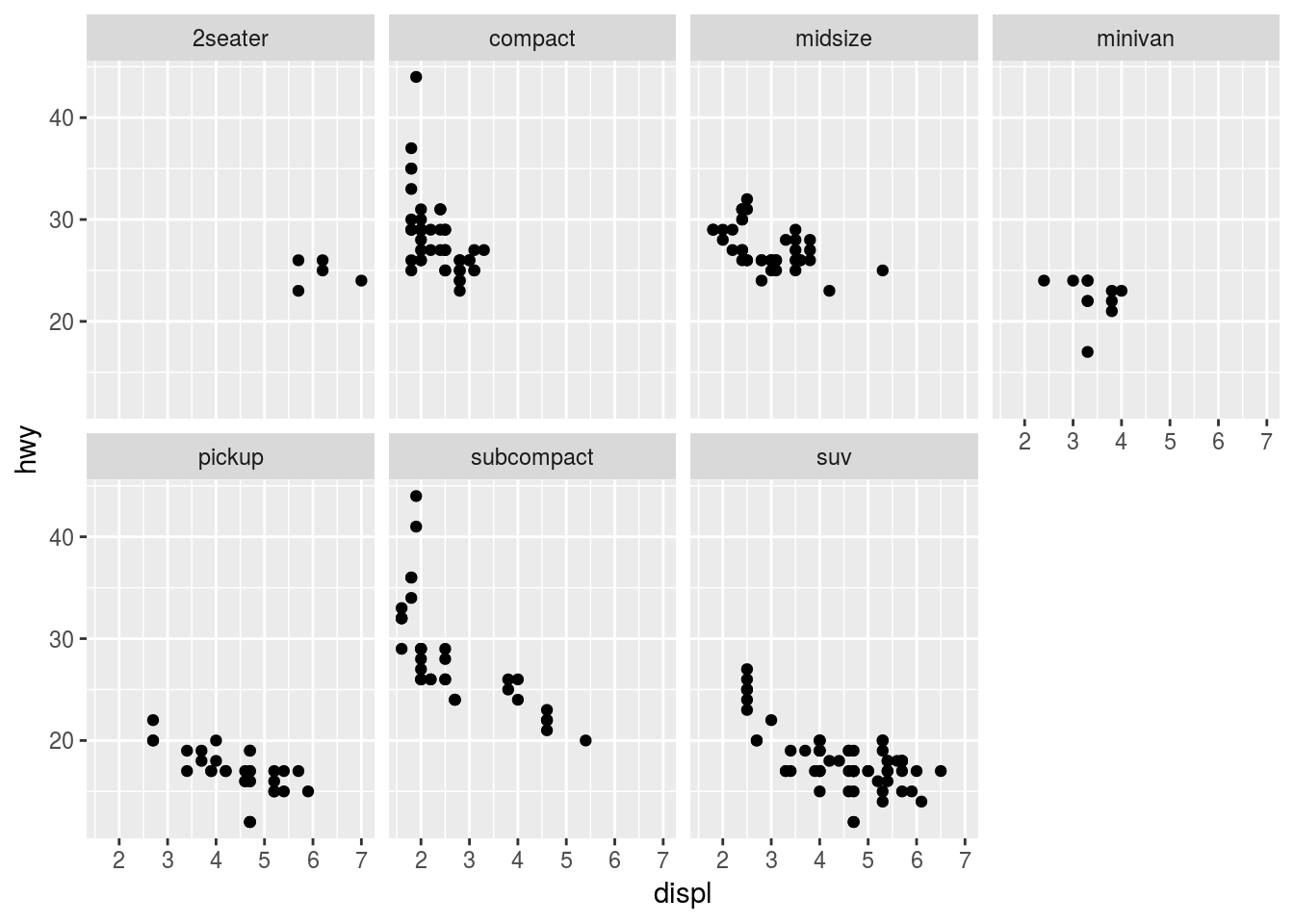
Colocando o método face_wrap é possível apresentar a visualização das variáveis de forma discriminada em função da variável class. A variável nrow é utilizada para indicar o número de linhas que devem ser utilizadas para renderizar os gráficos.
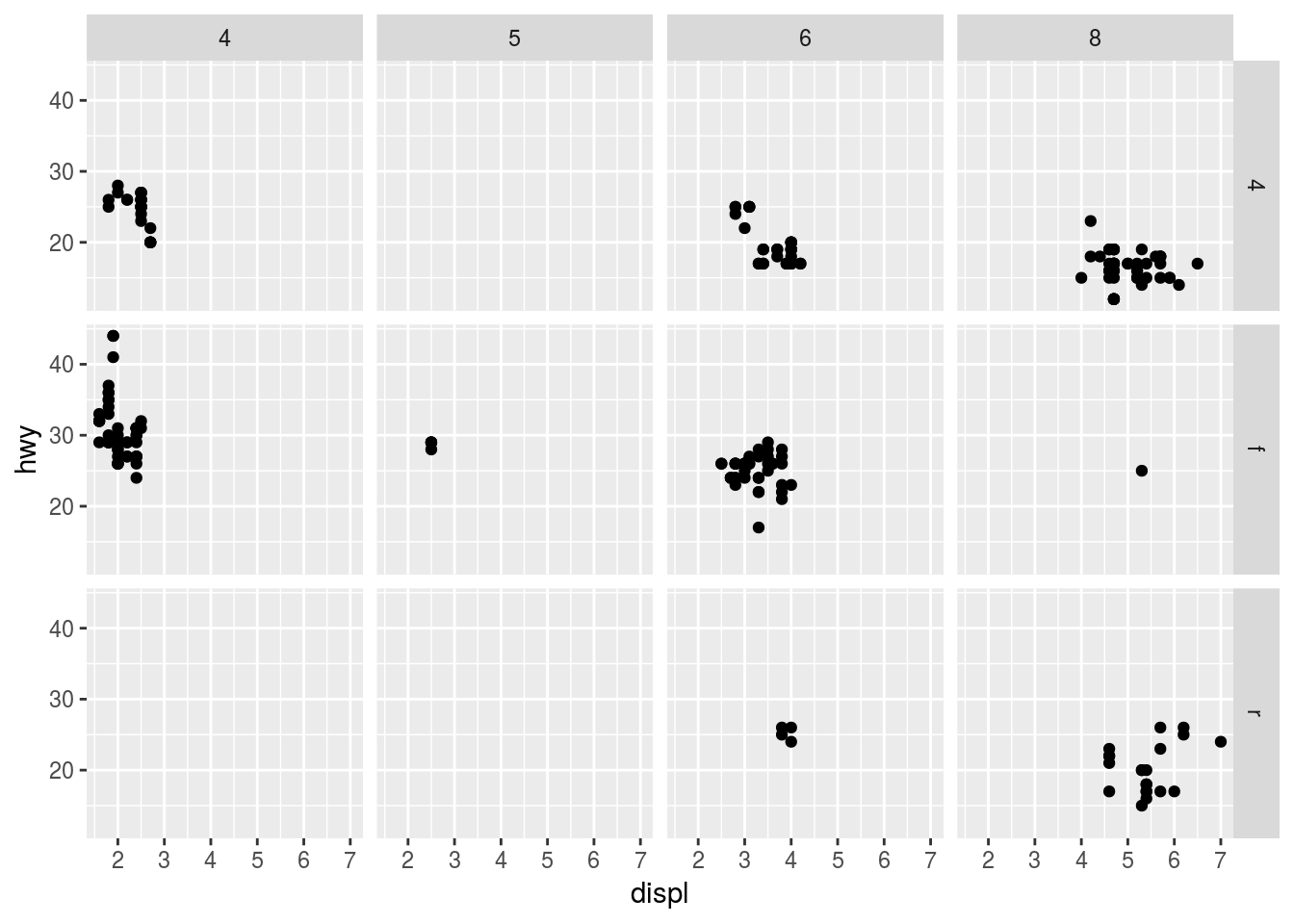
Aqui, um caso onde o gráfico é gerado colocando na dimensão facet as informações de mais duas variáveis: drv e cyl. É possível constatar que a adição de vários eixos da informação deixa o gráfico muito confuso, não sendo considerada uma boa prática essa decisão.
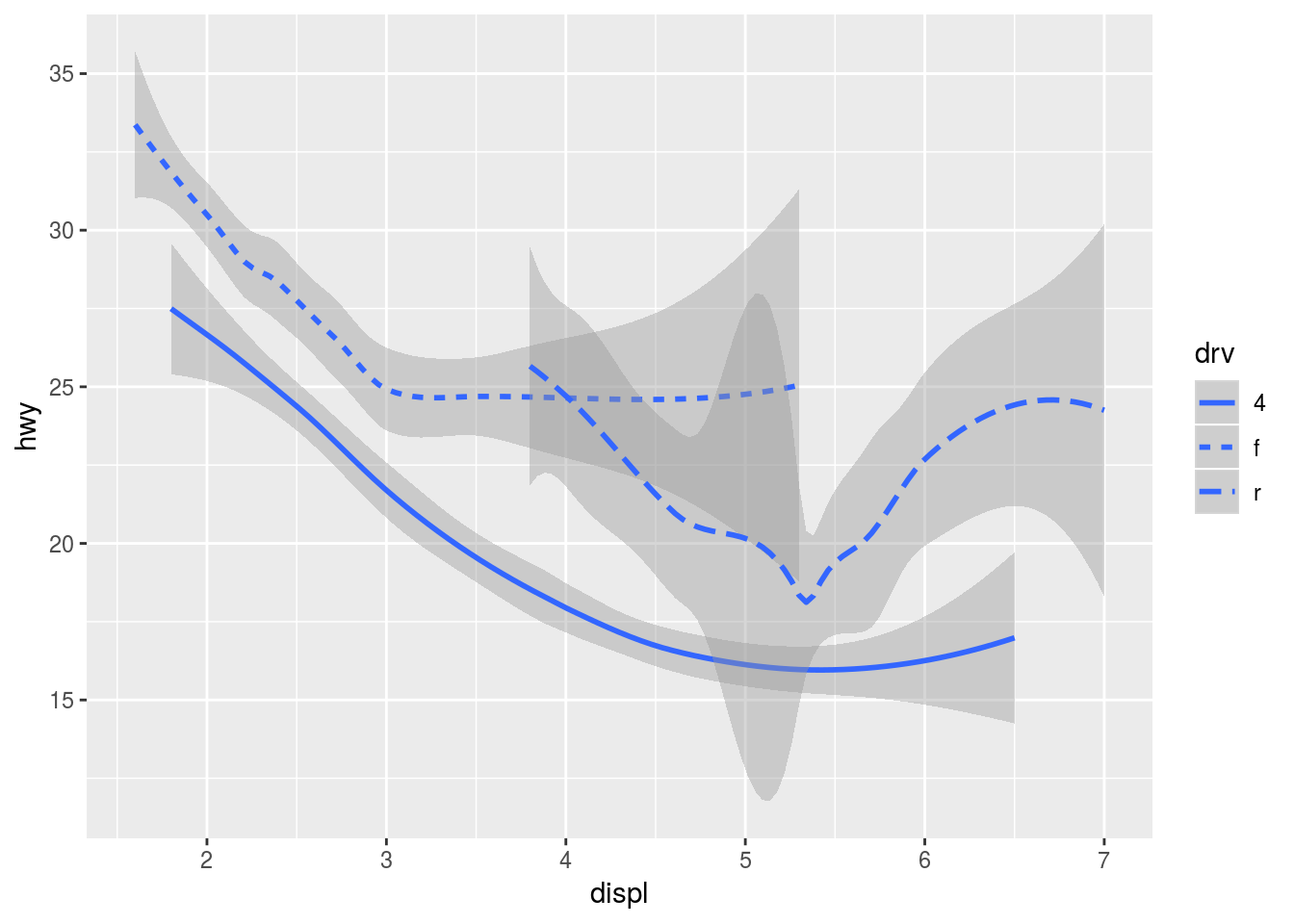
Mudando a GEOM_FUNCTION (selecionando geom_smooth) para renderizar o mesmo gráfico é possível substituir a visualização através de pontos por uma ou mais curvas refletindo a variação estatística da curva.
Dica: para saber mais informações sobre o método geom_smooth, digite ?geom_smooth no console do RStudio.
É possível combinar diferentes funções para incrementar o gráfico de visualização. No caso abaixo, incluímos uma combinação de pontos e curvas (através dos métodos geom_point e geom_smooth) para uma visualização mais completa. A variável class é representada através de cores com a inclusão do parâmetro color dentro do método aes passado para a construção dos pontos.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, color = class)) +
geom_smooth(mapping = aes(x = displ, y = hwy))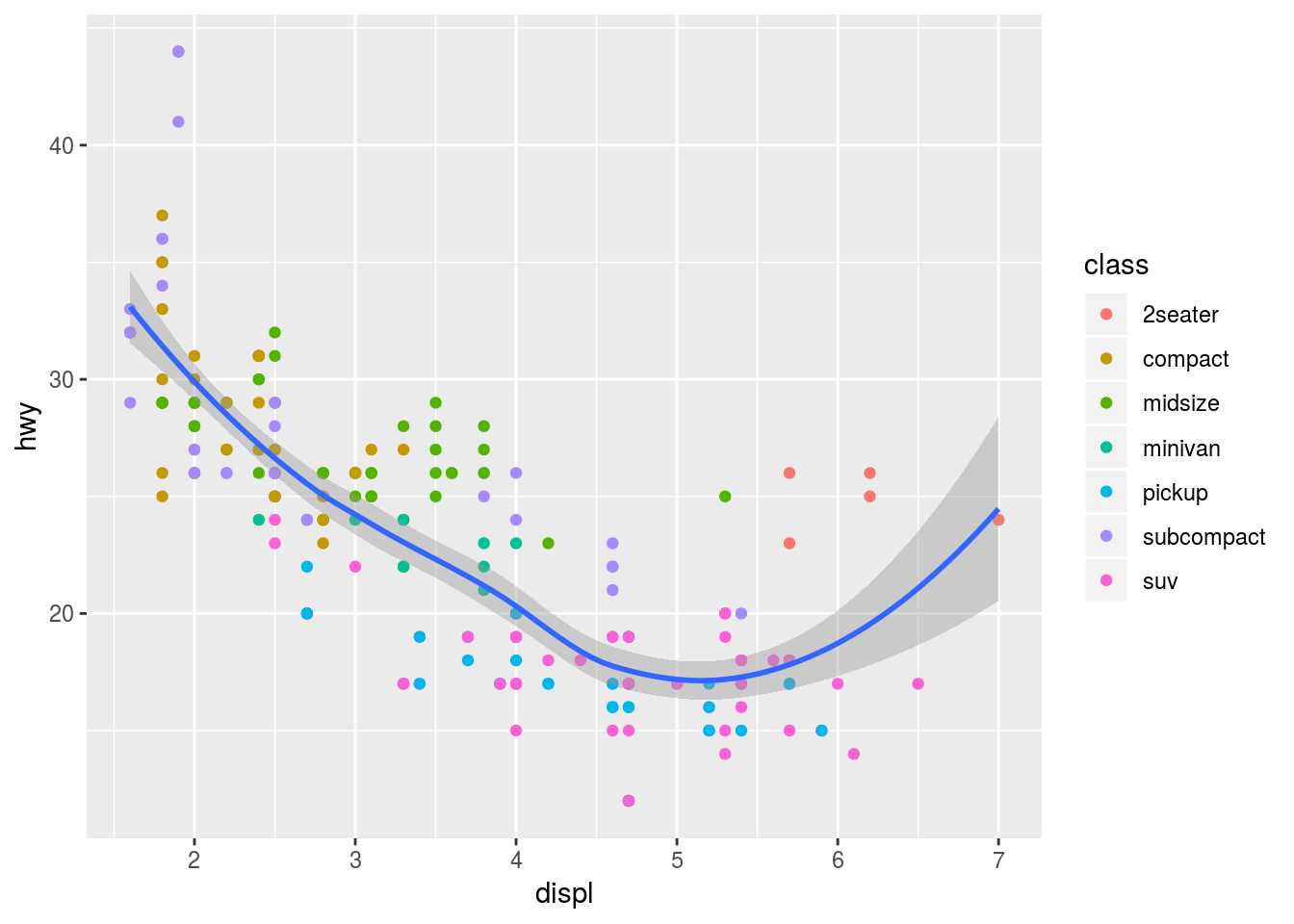
A seguir apresentamos um exemplo de visualização onde a cuava renderizada é limitada a uma classe específica. Para isso, aplicamos um filtro (através do método filter) para preenchimento do parâmetro data. . O parâmetro se é preenchido para informar se deve ou não ser apresentado visualmente o intervalo de confiança ao redor da curva (parte levemente hachurada que acompanha a curva no gráfico).
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_point(mapping = aes(color = class)) +
geom_smooth(data = filter(mpg, class == "subcompact"), se = TRUE)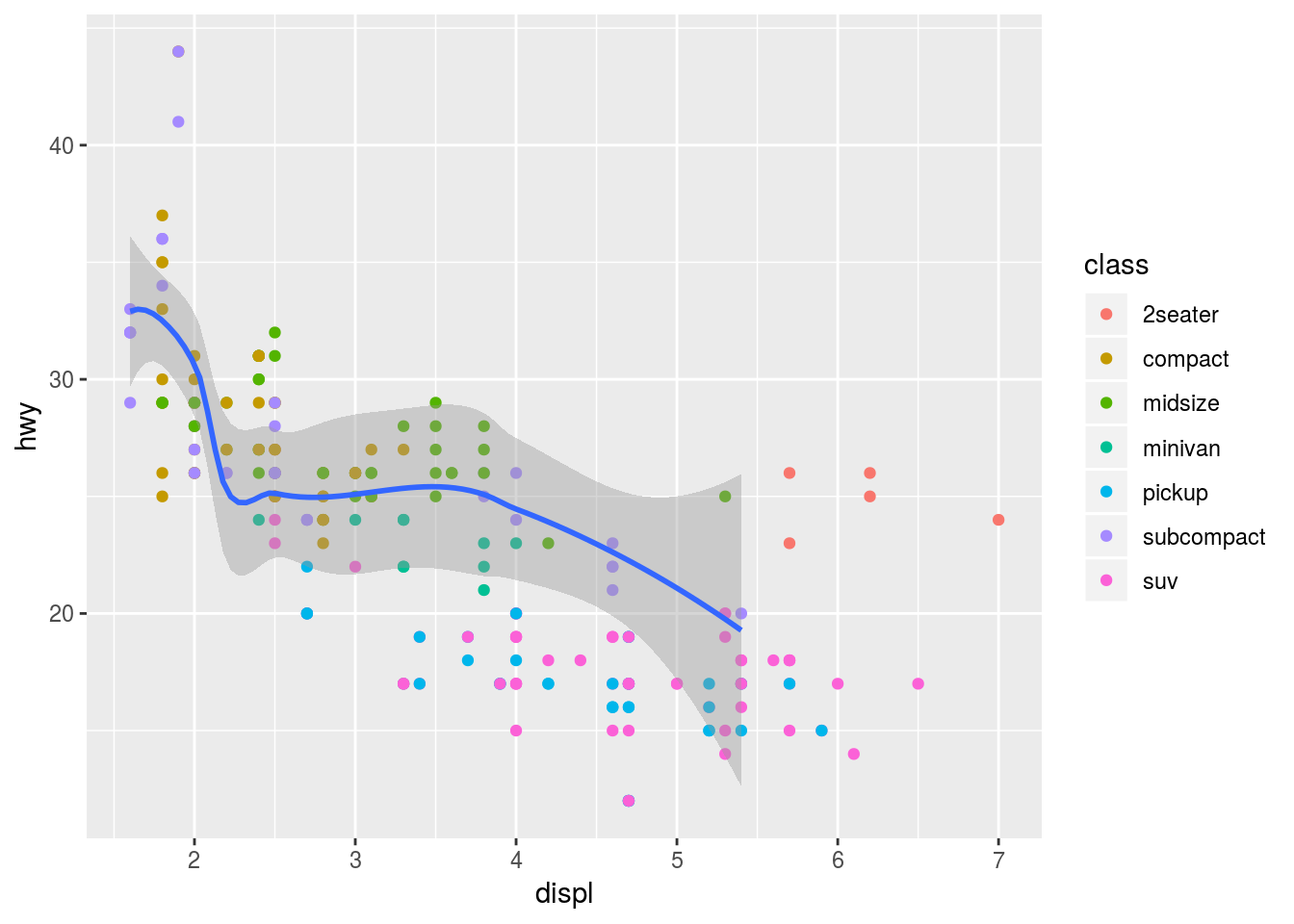
5.3 Decidindo a Visualização
Nesse tópico discutiremos boas práticas de visualização, com exemplos do uso da biblioteca ggplot2 para construir tais visualizações.
5.3.1 Parte do Todo
Exemplos de Visualização onde você deseja visualizar uma parte de um todo.
5.3.1.1 Gráfico de Pizza
Trata-se de um círculo (comumente construído em duas dimensões) dividido em partes que representam (proporcionalmente) uma parte do todo.
O Problema
O ser humano possui dificuldade em comparar ângulos. No exemplo a seguir, é necessário um maior cuidado na observação para compreender qual “fatia” possui o maior ângulo. Diferenciar entre tamanho de “fatias” entre os gráficos é muito difícil.
df1 <- data.frame(
group = c("A", "B", "C", "D", "E"),
value = c(10,35,55,75,93)
)
df2 <- data.frame(
group = c("A", "B", "C", "D", "E"),
value = c(10,35,53,75,93)
)
df3 <- data.frame(
group = c("A", "B", "C", "D", "E"),
value = c(10,29,50,75,93)
)
# Barplot
pie1 <- ggplot(df1, aes(x="", y=value, fill=group)) +
geom_bar(width = 1, stat = "identity") +
coord_polar("y", start=0) +
scale_fill_brewer(palette="Blues")+
theme_minimal()
pie2 <- ggplot(df2, aes(x="", y=value, fill=group)) +
geom_bar(width = 1, stat = "identity") +
coord_polar("y", start=0) +
scale_fill_brewer(palette="Blues")+
theme_minimal()
pie3 <- ggplot(df3, aes(x="", y=value, fill=group)) +
geom_bar(width = 1, stat = "identity") +
coord_polar("y", start=0) +
scale_fill_brewer(palette="Blues")+
theme_minimal()
plot(pie1)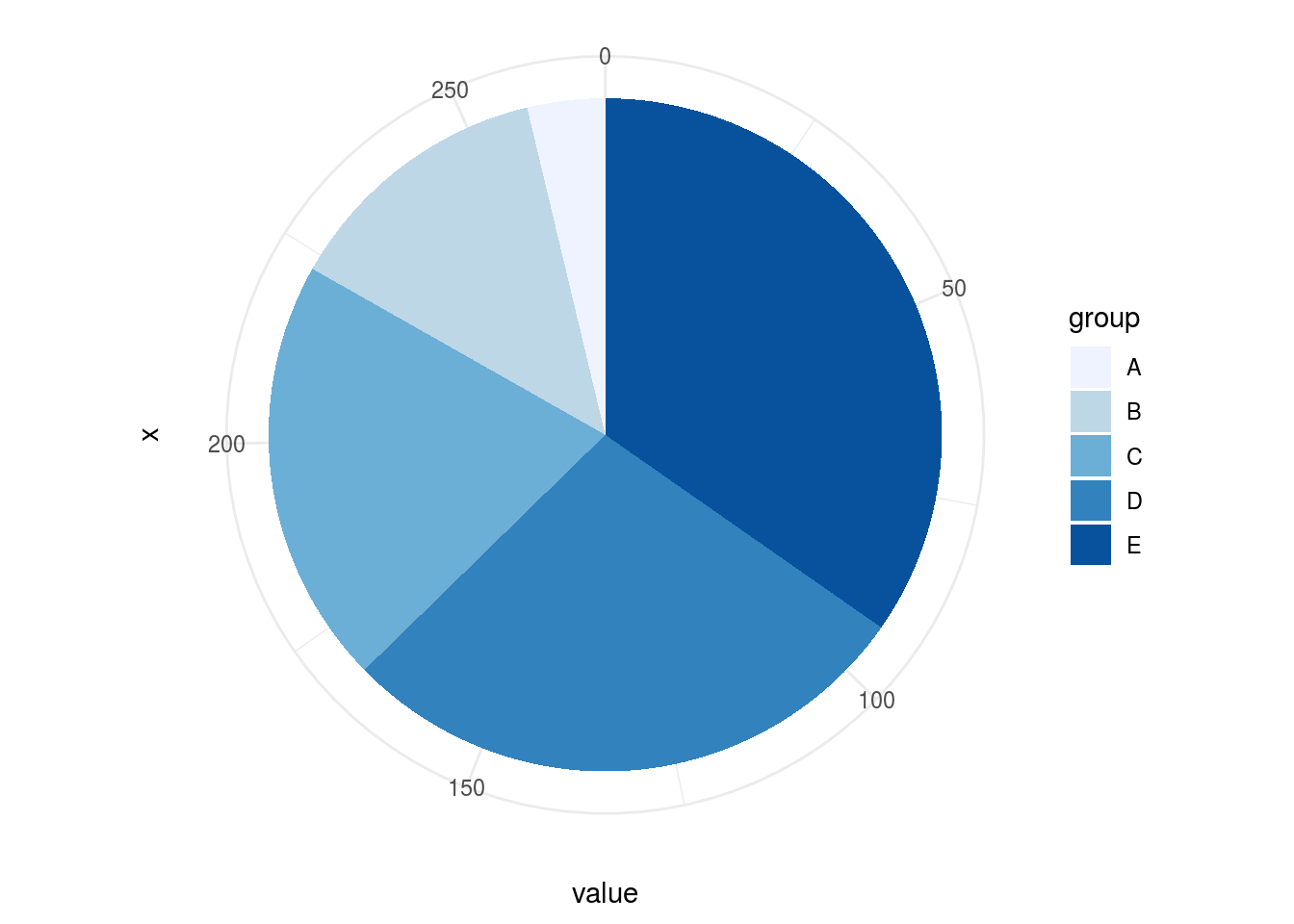
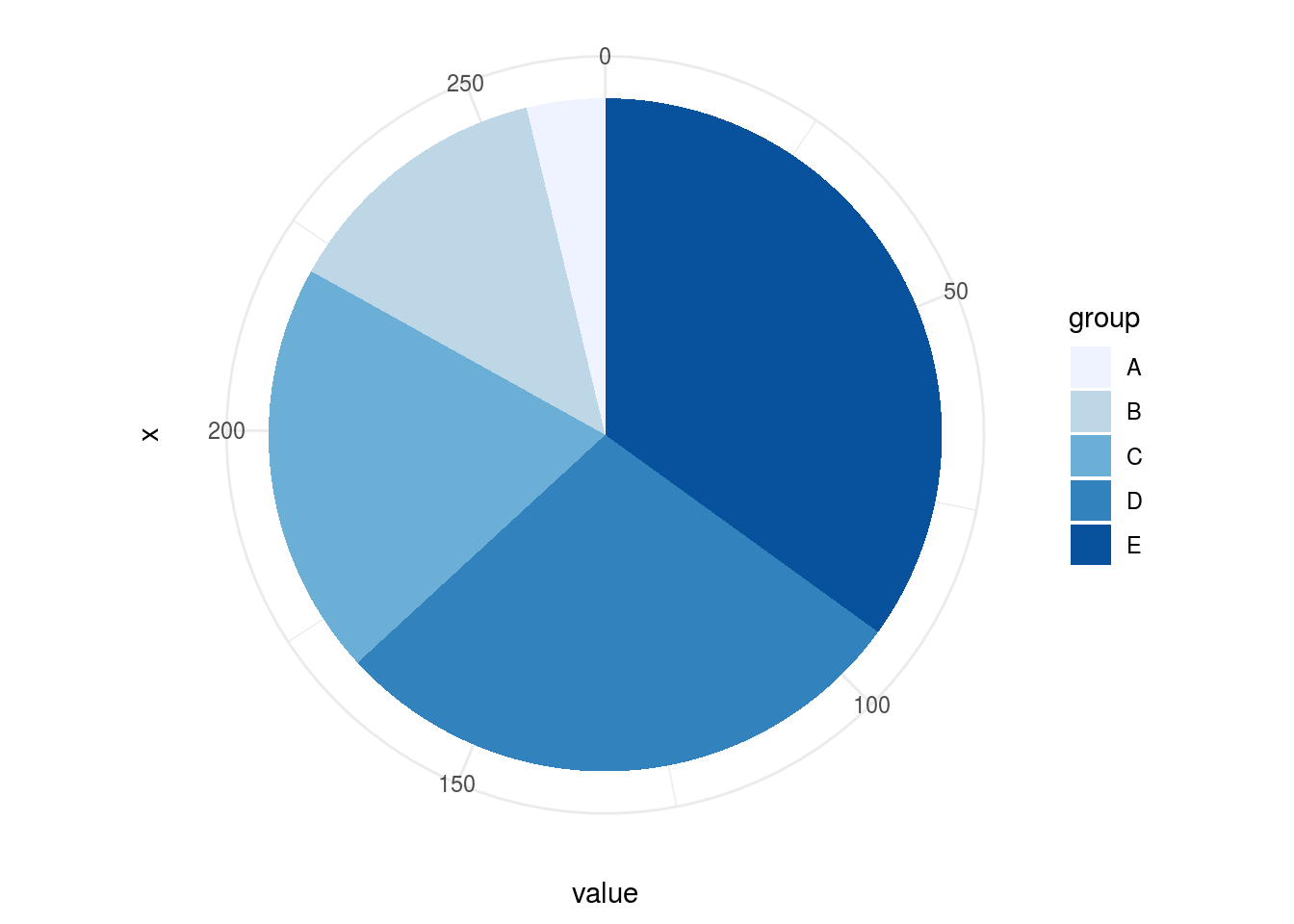
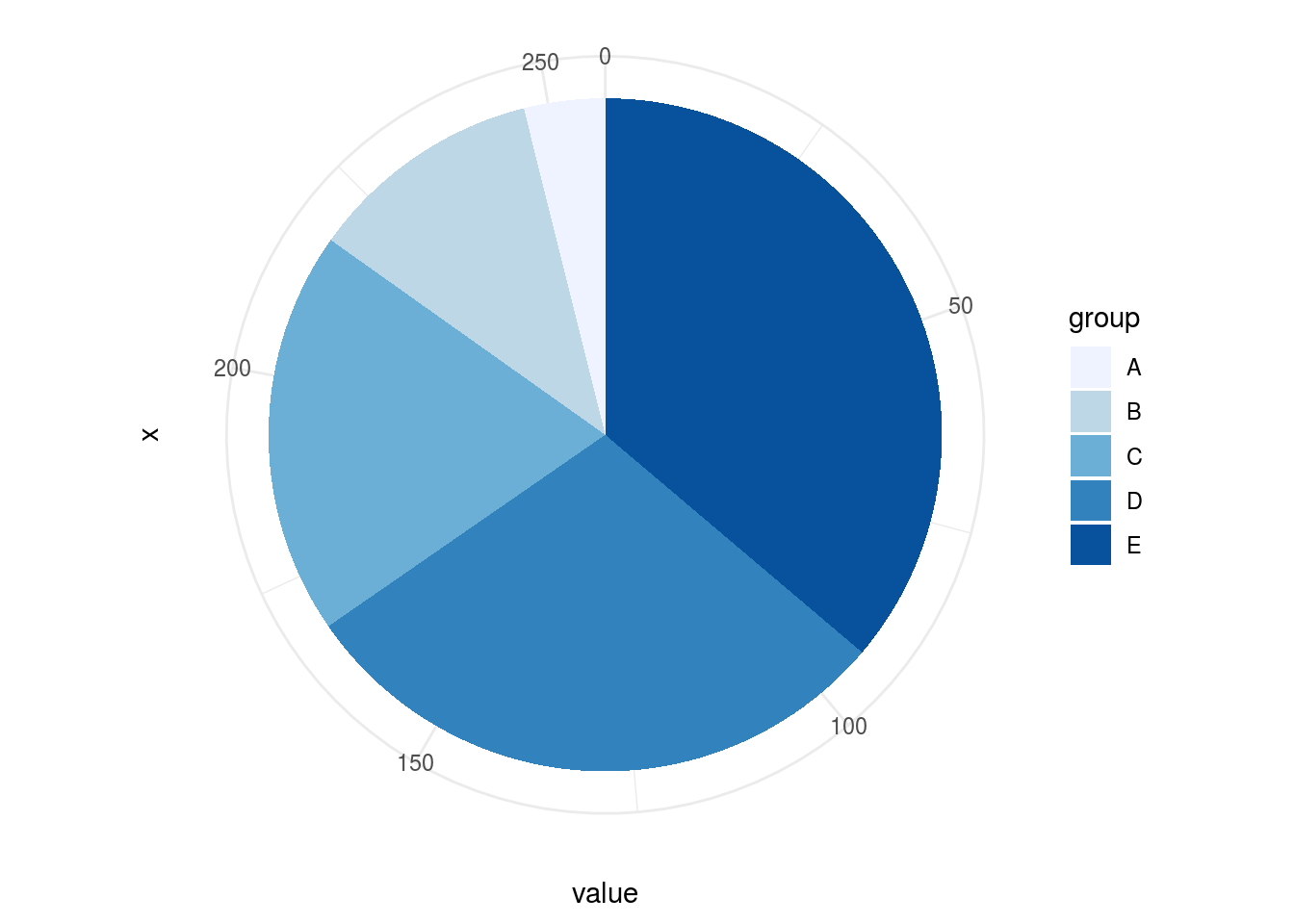
5.3.1.2 Gráfico de Barras
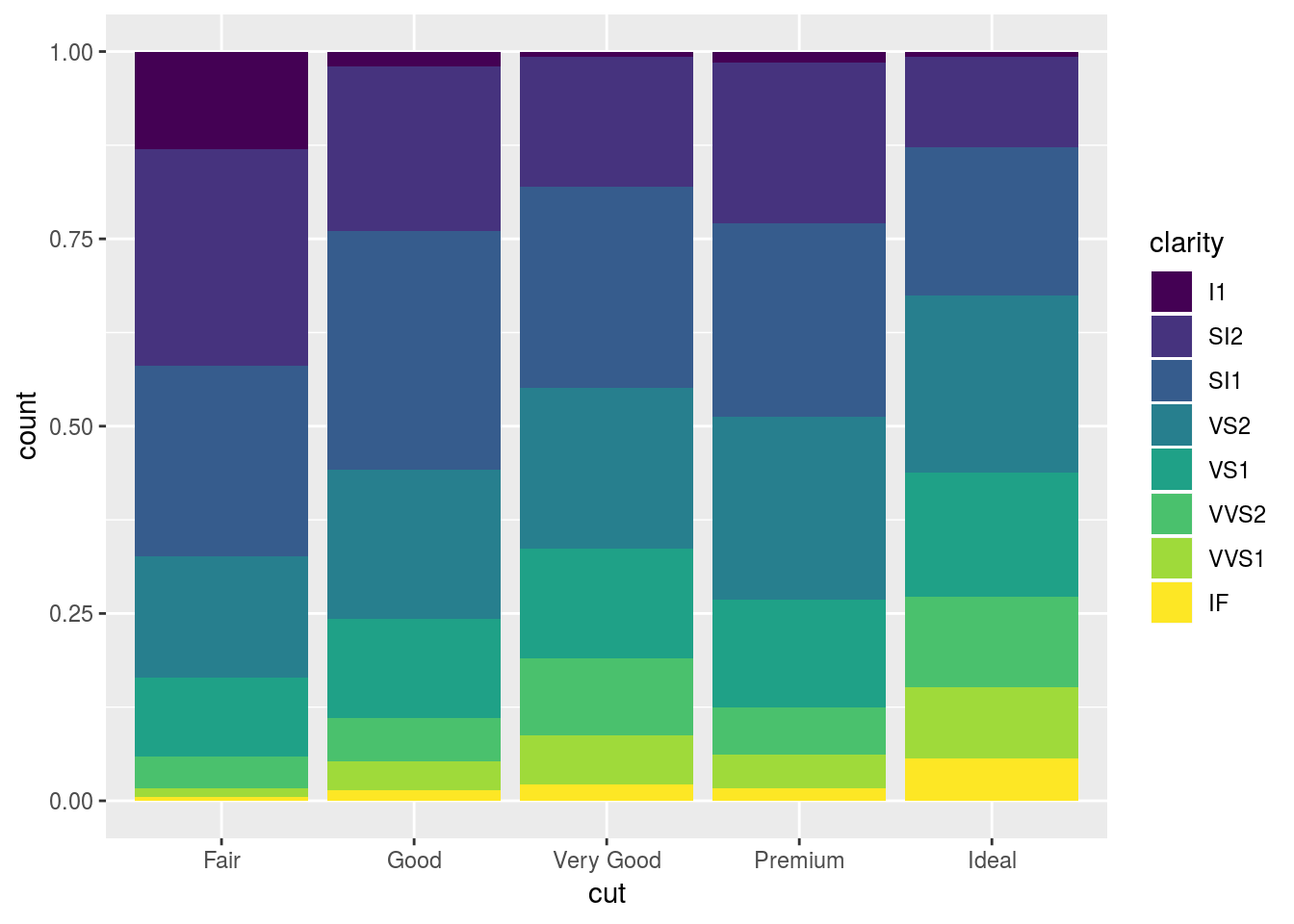
Uma alternativa ao gráfico de pizza e o radar, O BarPlot é um gráfico quantitativo que ajuda a rankear e a ordenar as categorias de visualização de forma bastante intuitiva e familiar.
Para visualizar com uso de gráfico de barras, é necessário usar a função geom_bar. Como parâmetro é necessário preencher o parâmetro position informando o tipo de apresentação do gráfico de barras.
Exemplo 1: Gráfico de Barras com Distribuição Horizontal
Exemplo 2: Gráfico de Barras com Distribuição Vertifical
Exemplo 3: Gráfico de Barras no formato de Pirulito
No gráfico a seguir, apresenta visualmente a variação (mínimo e máximo) através de um gráfico de barra no formato horizontal.
Para essa visualização é necessário executar a seguinte linha de código: install.packages(“viridis”,“patchwork”,“hrbrthemes”,“fmsb”,“colormap”)
library(tidyverse)
library(viridis)
library(patchwork)
library(hrbrthemes)
library(fmsb)
library(colormap)
# Create data: note in High school for Jonathan:
set.seed(1)
data <-as.data.frame(matrix( sample( 2:20 , 20 , replace=T) , ncol=10))
colnames(data) <- c("math" , "english" , "biology" , "music" , "R-coding", "data-viz" , "french" , "physic", "statistic", "sport" )
data <-rbind(rep(20,10) , rep(0,10) , data)
# Barplot
data %>% slice(c(3,4)) %>% t() %>% as.data.frame() %>% add_rownames() %>% arrange(V1) %>% mutate(rowname=factor(rowname, rowname)) %>%
ggplot( aes(x=rowname, y=V1)) +
geom_segment( aes(x=rowname ,xend=rowname, y=V2, yend=V1), color="grey") +
geom_point(size=5, color="#69b3a2") +
geom_point(aes(y=V2), size=5, color="#69b3a2", alpha=0.1) +
coord_flip() +
theme_ipsum() +
theme(
panel.grid.minor.y = element_blank(),
panel.grid.major.y = element_blank(),
axis.text = element_text( size=48 )
) +
ylim(0,20) +
ylab("mark") +
xlab("")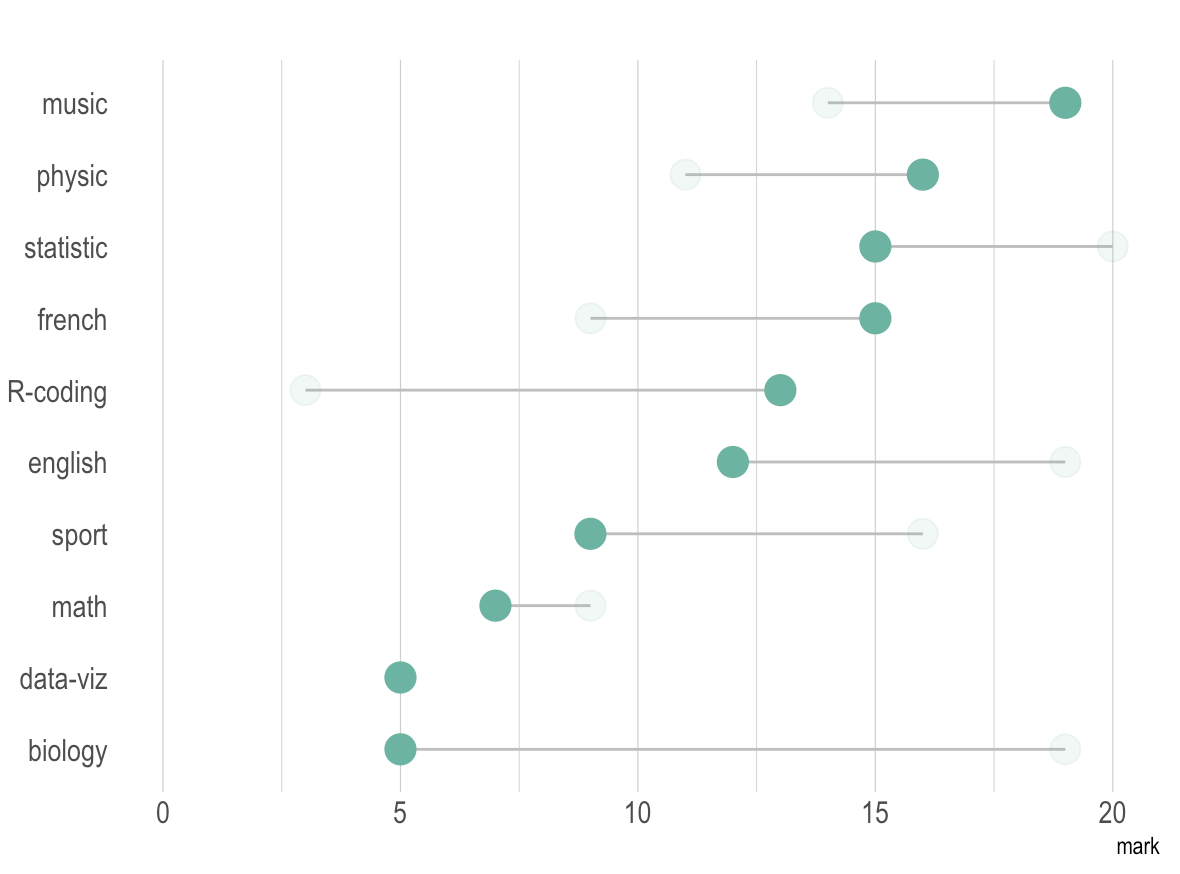
Figura 5.2: Exemplo de Gráfico Pirulito
O gráfico de barras visa responder questões como:
- Quais categorias possuem os maiores e menores valores?
- Como uma variável se comporta em diferentes categorias?
- Como múltiplas categorias se comportam, quando comparadas diretamente?
5.3.1.3 Gráfico de Radar (ou teia)
Esse gráfico representa, sob uma forma de bi-dimensional uma ou mais séries de valores quantitativos. Cada variável tem seu próprio vértice. Todos os vértices se encontram em um ponto central da visualização. Veja o exemplo (retirado do site r-graph-gallery.com):
Para essa visualização é necessário executar a seguinte linha de código: install.packages(“viridis”,“patchwork”,“hrbrthemes”,“fmsb”,“colormap”)
# Libraries
library(tidyverse)
library(viridis)
library(patchwork)
library(hrbrthemes)
library(fmsb)
library(colormap)
# Create data
set.seed(1)
data <- as.data.frame(matrix( sample( 2:20 , 10 , replace=T) , ncol=10))
colnames(data) <- c("math" , "english" , "biology" , "music" , "R-coding", "data-viz" , "french" , "physic", "statistic", "sport" )
# To use the fmsb package, I have to add 2 lines to the dataframe: the max and min of each topic to show on the plot!
data <- rbind(rep(20,10) , rep(0,10) , data)
# Custom the radarChart !
par(mar=c(0,0,0,0))
radarchart( data, axistype=1,
#custom polygon
pcol=rgb(0.2,0.5,0.5,0.9) , pfcol=rgb(0.2,0.5,0.5,0.5) , plwd=4 ,
#custom the grid
cglcol="grey", cglty=1, axislabcol="grey", caxislabels=seq(0,20,5), cglwd=0.8,
#custom labels
vlcex=0.8
)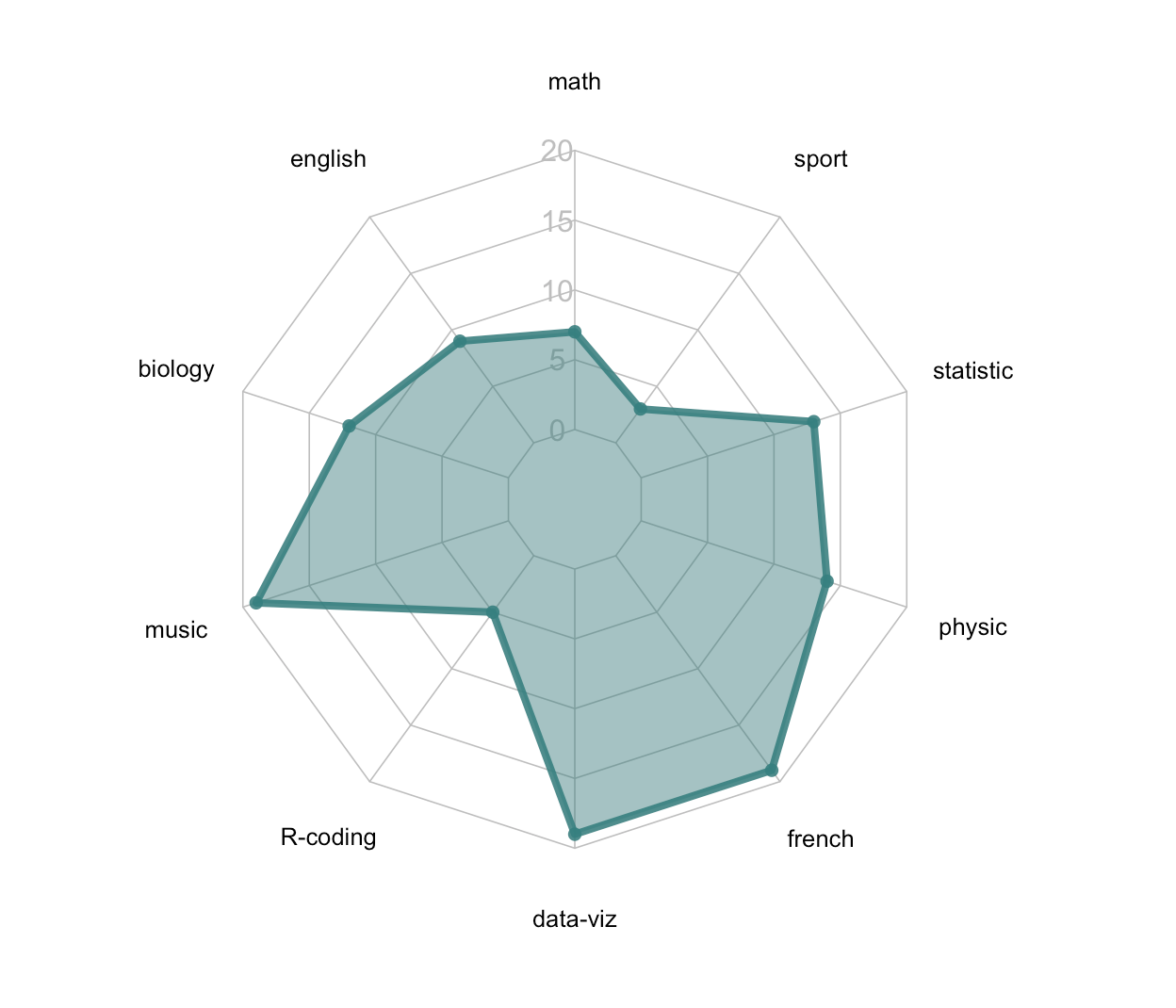
Figura 5.3: Exemplo de Gráfico Radar
Parte dos autores recomenda muita cautela no uso de gráfico Radar nas visualizações. Isso se deve ao fato de, uma pequena mudança na escala apresentada no gráfico provocar diferentes conclusões. Veja o exemplo da figura a seguir:
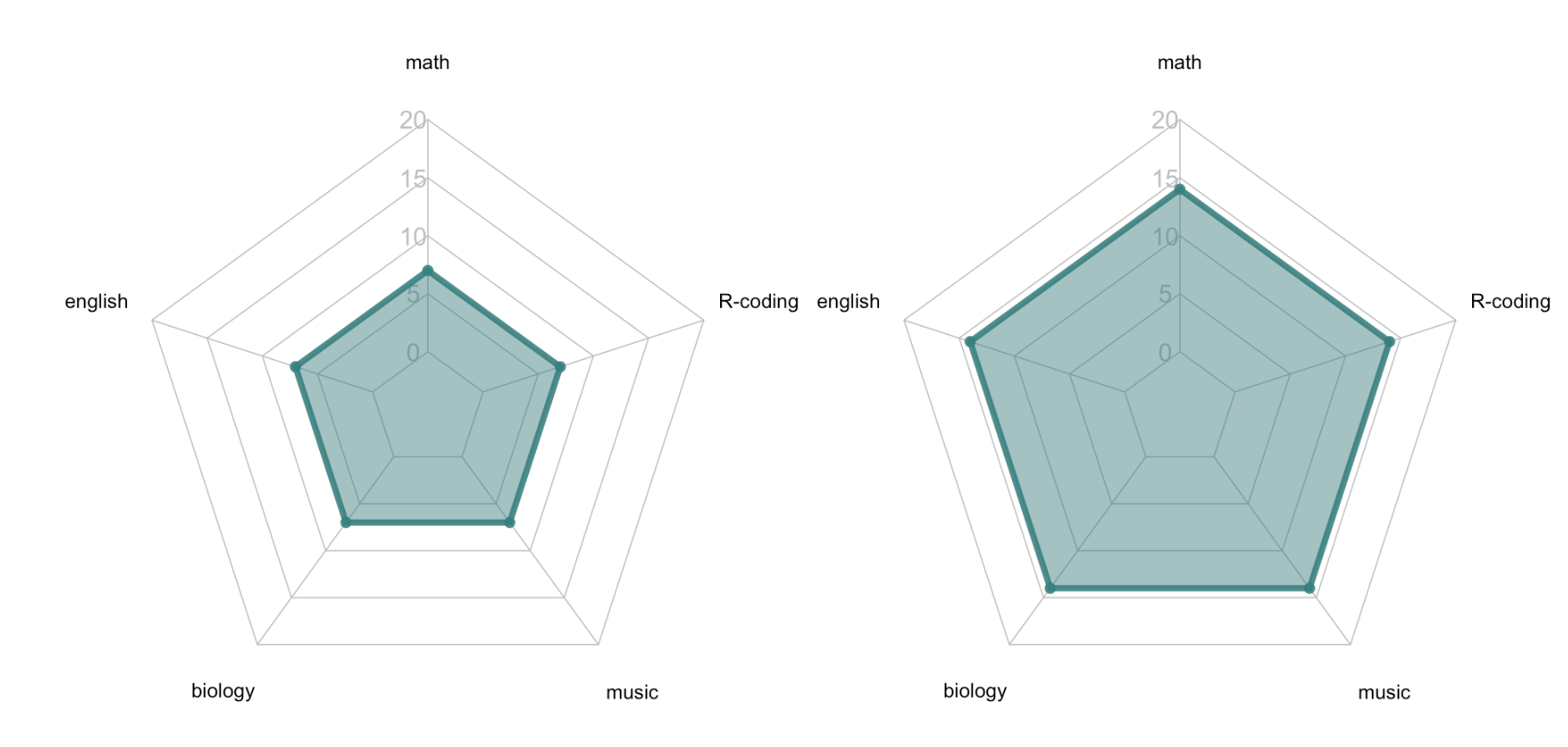
Figura 5.4: Comparativo de Gráfico de Radar com Mudança de Escala
Além disso, os seguintes fatores podem contribuir para uma má construção de um gráfico radar:
- Valores quantitativos são mais facilmente representados através de barras horizontais ou verticais. Incluir muitos valores em um círculo pode provocar confusão na dimensão (ver exemplo do gráfico de pizza acima) ou vários valores sobrepostos, o que dificulta a legibilidade;
- É mais difícil rankear as informações em um gráfico em formato circular.
- A ordem que a informação é apresentada pode levar a diferentes conclusões. A figura a seguir, retirada do site r-graph-gallery.com, mostra as mesmas categorias sendo apresentadas em diferentes ordens.
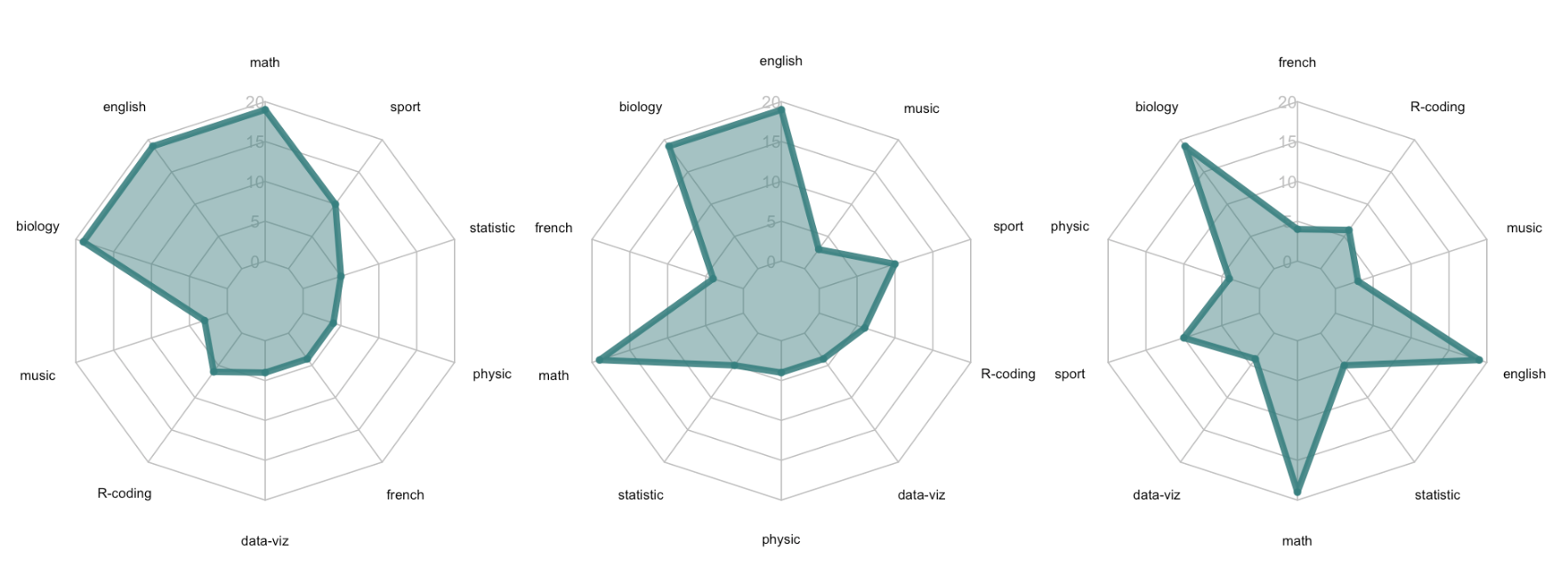
Figura 5.5: Comparativo de Radar mudando ordem de apresentação das categorias
5.3.2 Distribuição
A seguir, apresentamos algumas visualizações úteis quando queremos representar visualmente algumas distribuições.
5.3.2.1 Histograma
Um Histograma é a representação da distribuição de uma variável numérica. Através da função geom_histogram() é possível facilmente construir um. Vamos ao exemplo:
library(ggplot2)
# dataset:
data=data.frame(value=rnorm(100))
# basic histogram
p <- ggplot(data, aes(x=value)) +
geom_histogram()
plot(p)## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.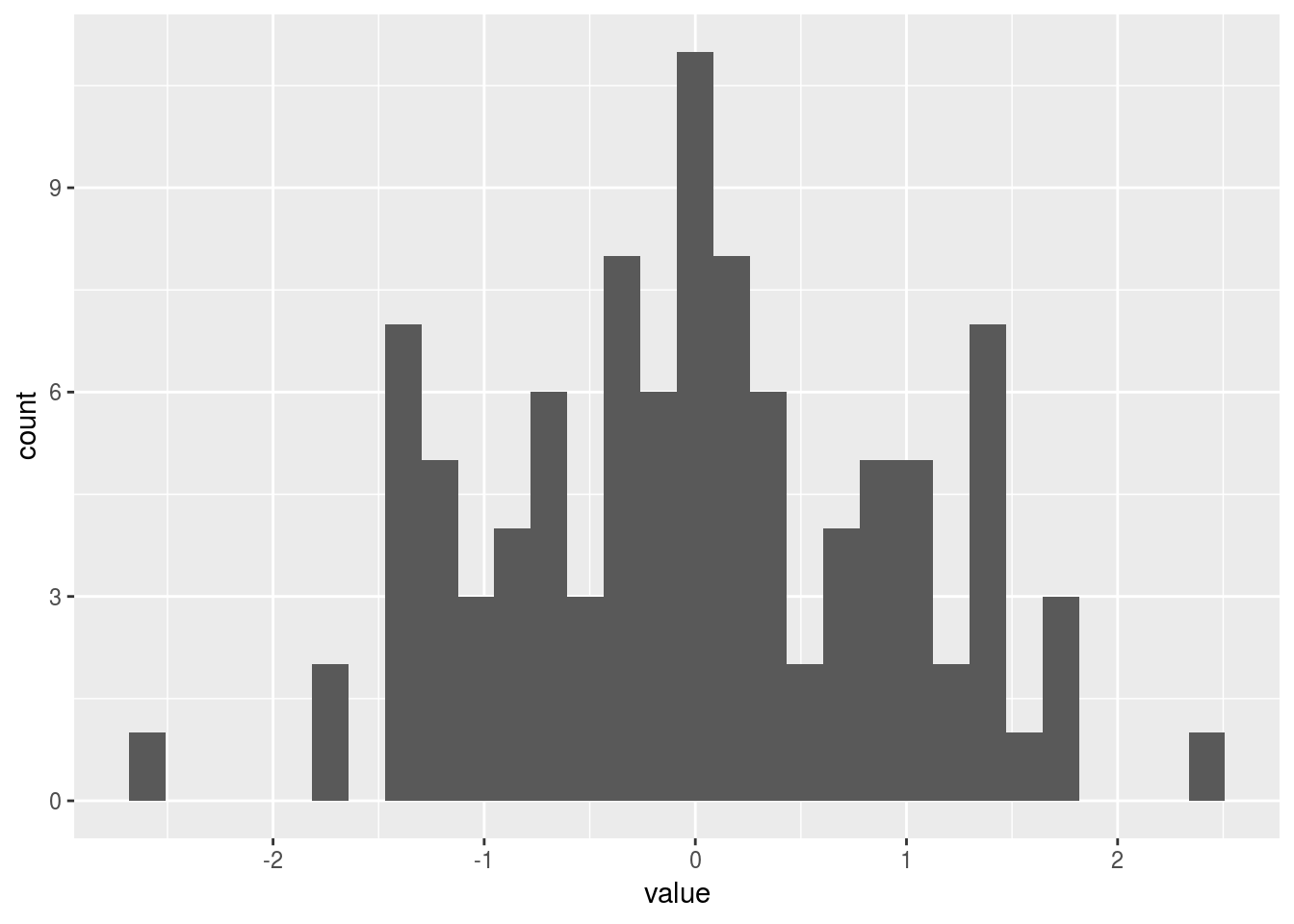
Na construção do Histograma é importante definir a largura com que as variáveis numéricas serão categorizadas. Essa medida é definida através da variável binwidth, um dos parâmetros da função geom_histogram:
library(ggplot2)
# dataset:
data=data.frame(value=rnorm(100))
# basic histogram
p <- ggplot(data, aes(x=value)) +
geom_histogram(binwidth = 2)
plot(p)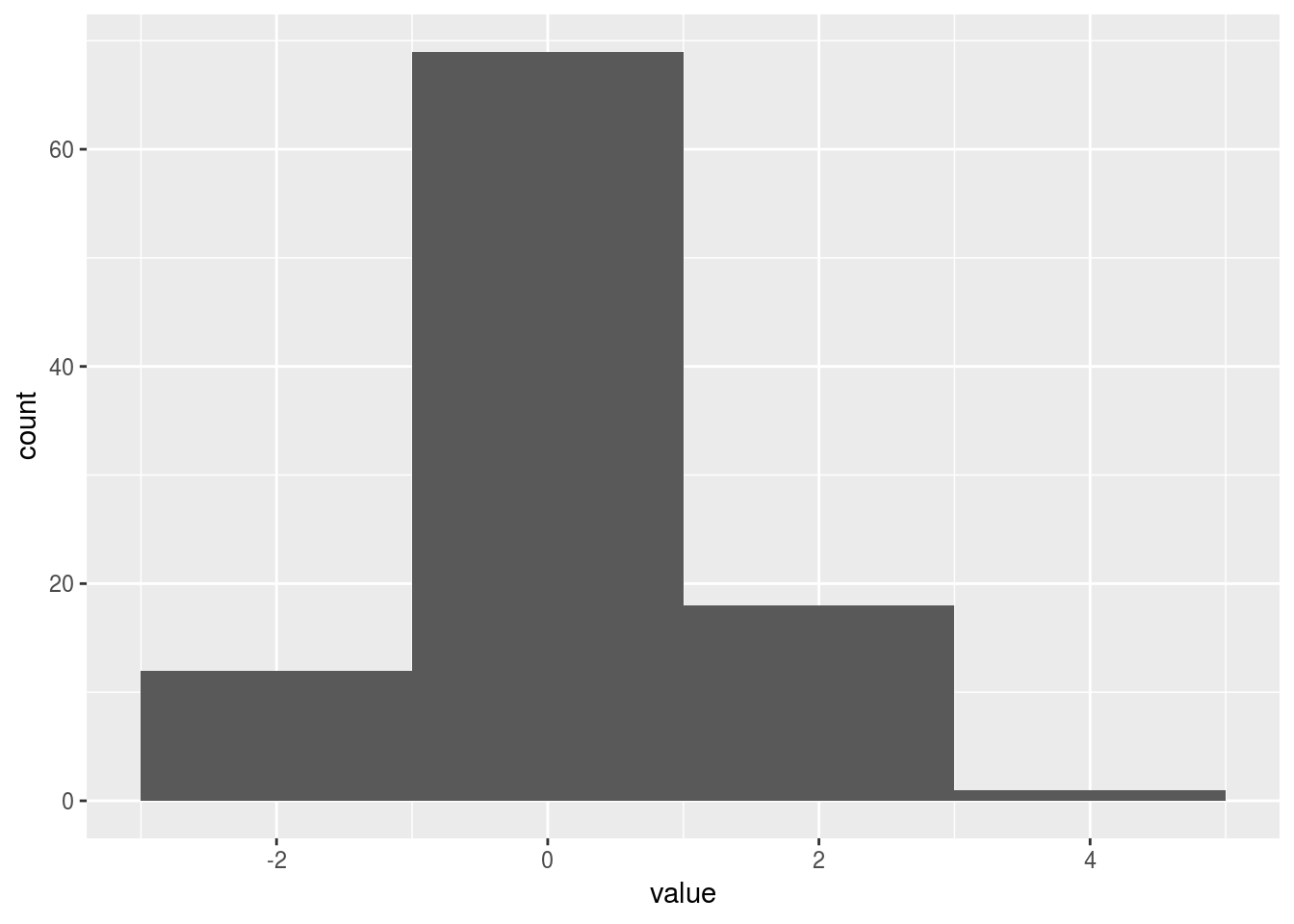
5.3.2.2 Boxplot
Boxplot é uma visualização capaz de apresentar uma distribuição visualmente através do indicativo de qual o menor valor, o percentil 25, a mediana, o percentil 75, o valor máximo e potenciais outliers.
A figura abaixo (retirada do site leansigmacorporation) descreve como ler o box plot. A parte do meio representa os quartis inferior e superior (25/75). A linha próxima ao meio da caixa representa a mediana. As retas conectadas à caixa (em ambos os lados) representa o máximo e o mínimo da distribuição. Eventuais pontos plotados ao redor do box plot representa outliers (ou “pontos fora da curva”).
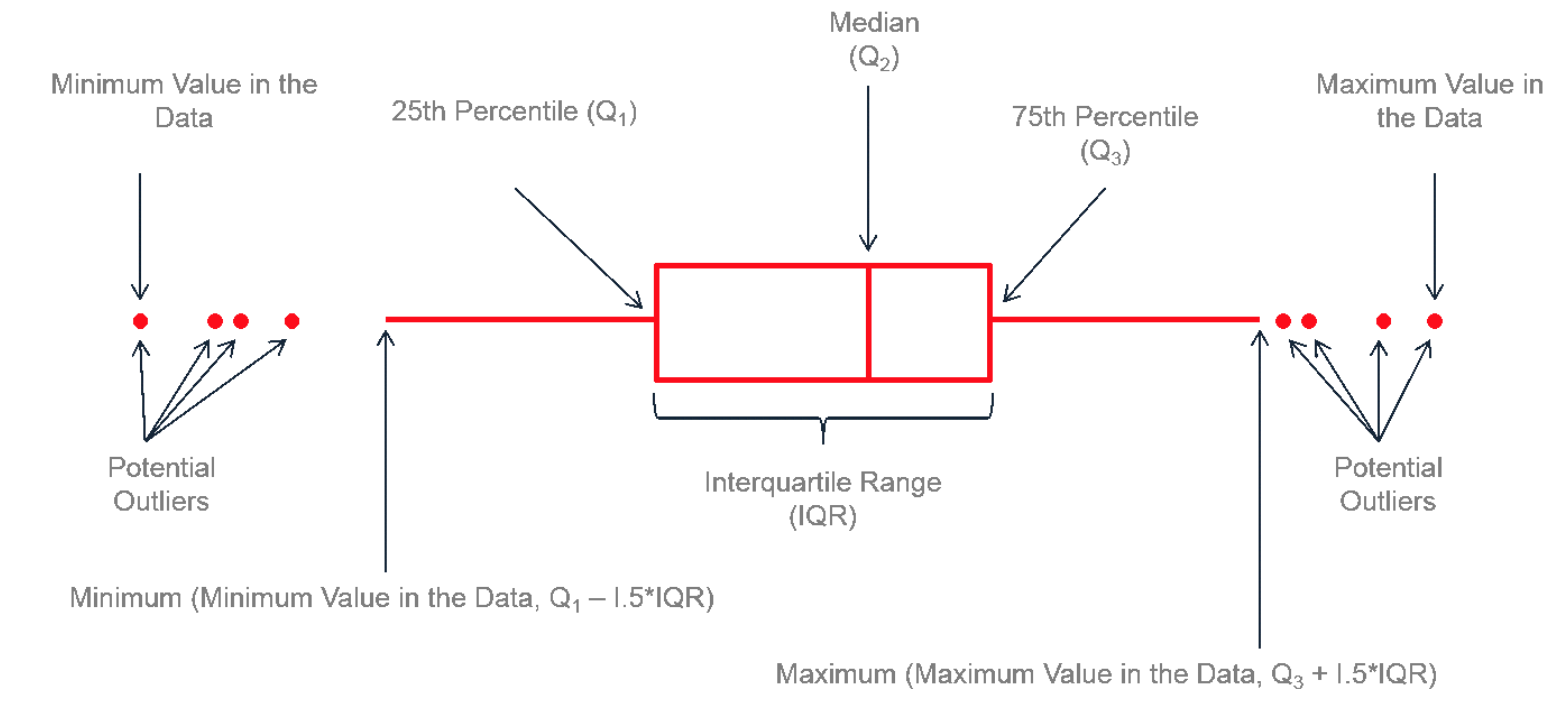
Figura 5.6: A anatomia do Boxplot
A seguir, um exemplo de construção da visualização de um gráfico boxplot com 4 variáveis com o uso da função geom_jitter , que inclui uma pequena “ruído” aleatório na posição de cada ponto plotável, evitando que haja sobreposição entre os pontos.
# Libraries
library(tidyverse)
library(hrbrthemes)
library(viridis)
# create a dataset
data <- data.frame(
name=c( rep("A",500), rep("B",500), rep("B",500), rep("C",20), rep('D', 100) ),
value=c( rnorm(500, 10, 5), rnorm(500, 13, 1), rnorm(500, 18, 1), rnorm(20, 25, 4), rnorm(100, 12, 1) )
)
# Plot
data %>%
ggplot( aes(x=name, y=value, fill=name)) +
geom_boxplot() +
scale_fill_viridis(discrete = TRUE, alpha=0.6) +
geom_jitter(color="black", size=0.4, alpha=0.9) +
theme_ipsum() +
theme(
legend.position="none",
plot.title = element_text(size=11)
) +
ggtitle("A boxplot com jitter") +
xlab("")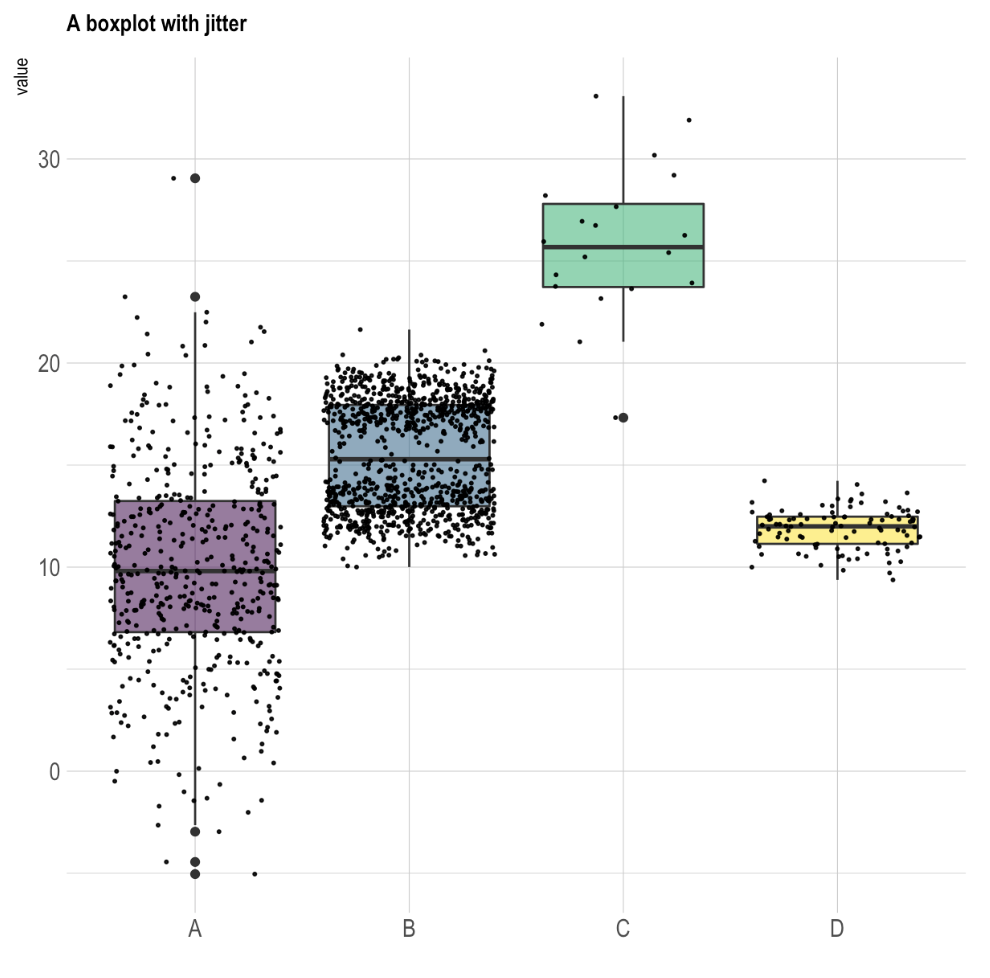
Figura 5.7: Exemplo de Boxplot
5.3.2.3 Gráfico de Densidade
O gráfico de densidade apresenta a distribuição de uma variável numérica.
# Libraries
library(ggplot2)
library(dplyr)
# Load dataset from github
data <- read.table("https://raw.githubusercontent.com/holtzy/data_to_viz/master/Example_dataset/1_OneNum.csv", header=TRUE)
# Make the histogram
data %>%
filter( price<300 ) %>%
ggplot( aes(x=price)) +
geom_density(fill="#69b3a2", color="#e9ecef", alpha=0.8)Um conteúdo consolidando todo o material de visualização com ggplot2 pode ser obtido diretamente através do seguinte link.
Referências
Garret Grolemund, Hadley Wickham &. 2016. R for Data Science. 1st ed. Sebastapol, CA: O’REILLY. https://r4ds.had.co.nz/.
Kristin Fontichiaro, Jo Angela Oehrli et al. 2017. “Create Data Literate Students.” -: Michigan Publishing. https://www.amazon.com/Creating-Literate-Students-Kristin-Fontichiaro/dp/1607854244.