12 Bayesian Approaches to Testing a Point (“Null”) Hypothesis
Suppose that you have collected some data, and now you want to answer the question, Is there a non-zero effect or not? Is the coin fair or not? Is there better-than-chance accuracy or not? Is there a difference between groups or not? In the previous chapter, [Kruschke] argued that answering this type of question via null hypothesis significance testing (NHST) has deep problems. This chapter describes Bayesian approaches to the question. (p. 335)
12.1 The estimation approach
Throughout this book, we have used Bayesian inference to derive a posterior distribution over a parameter of interest, such as the bias \(\theta\) of a coin. We can then use the posterior distribution to discern the credible values of the parameter. If the null value is far from the credible values, then we reject the null value as not credible. But if all the credible values are virtually equivalent to the null value, then we can accept the null value. (p. 336)
12.1.1 Region of practical equivalence.
Kruschke began: “A region of practical equivalence (ROPE) indicates a small range of parameter values that are considered to be practically equivalent to the null value for purposes of the particular application” (p. 336, emphasis in the original)
Here’s a plot of Kruschke’s initial coin flip ROPE.
library(tidyverse)
tibble(xmin = .45,
xmax = .55) %>%
ggplot() +
geom_rect(aes(xmin = xmin, xmax = xmax,
ymin = -Inf, ymax = Inf),
color = "transparent", fill = "white") +
annotate("text", x = .5, y = .5, label = "ROPE",
color = "grey67") +
scale_y_continuous(NULL, breaks = NULL) +
labs(title = "Kruschke's coin flip ROPE",
x = expression(theta)) +
coord_cartesian(0:1) +
theme(panel.grid.minor = element_blank())
In the first example (p. 336), we have \(z = 325\) heads out of \(N = 500\) coin flips. To visualize the analysis, we’ll need the Bernoulli likelihood.
bernoulli_likelihood <- function(theta, data) {
n <- length(data)
z <- sum(data)
return(theta^z * (1 - theta)^(n - sum(data)))
}Now we’ll follow the typical steps to combine the prior, which is flat in this case, and the likelihood to get the posterior.
# the data summaries
n <- 500
z <- 325
trial_data <- c(rep(0, times = n - z), rep(1, times = z)) # (i.e., data)
d <-
tibble(theta = seq(from = 0, to = 1, length.out = 1e3)) %>% # (i.e., theta)
# recall Beta(1, 1) is flat
mutate(prior = dbeta(theta, shape1 = 1, shape2 = 1)) %>% # (i.e., p(theta))
mutate(likelihood = bernoulli_likelihood(theta = theta, # (i.e., p(D | theta))
data = trial_data)) %>%
mutate(evidence = sum(prior * likelihood)) %>% # (i.e., p(D))
mutate(posterior = likelihood * prior / evidence) # (i.e., p(theta | D))
glimpse(d)## Observations: 1,000
## Variables: 5
## $ theta <dbl> 0.000000000, 0.001001001, 0.002002002, 0.003003003, 0.004004004, 0.005005005, …
## $ prior <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
## $ likelihood <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
## $ evidence <dbl> 1.367061e-139, 1.367061e-139, 1.367061e-139, 1.367061e-139, 1.367061e-139, 1.3…
## $ posterior <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …Now we can plot the results.
ggplot(data = d) +
geom_rect(xmin = .45, xmax = .55,
ymin = -Inf, ymax = Inf,
color = "transparent", fill = "white") +
geom_ribbon(aes(x = theta, ymin = 0, ymax = posterior),
fill = "grey67") +
annotate("text", x = .5, y = .01, label = "ROPE",
color = "grey67") +
scale_y_continuous(NULL, breaks = NULL) +
labs(title = "Nope, that density ain't in that ROPE.",
x = expression(theta)) +
theme(panel.grid = element_blank())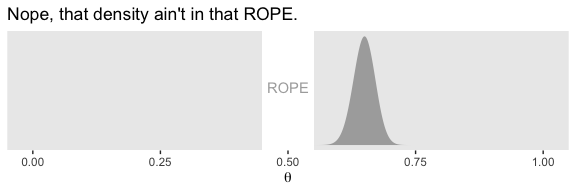
With the formula by \(\operatorname{Beta} (\theta | z + \alpha, N - z + \beta)\), we can analytically compute the Beta parameters for the posterior.
## [1] 326## [1] 176With the hdi_of_icdf() function, we’ll compute the HDIs.
hdi_of_icdf <- function(name, width = .95, tol = 1e-8, ... ) {
incredible_mass <- 1.0 - width
interval_width <- function(low_tail_prob, name, width, ...) {
name(width + low_tail_prob, ...) - name(low_tail_prob, ...)
}
opt_info <- optimize(interval_width, c(0, incredible_mass),
name = name, width = width,
tol = tol, ...)
hdi_lower_tail_prob <- opt_info$minimum
return(c(name(hdi_lower_tail_prob, ...),
name(width + hdi_lower_tail_prob, ...)))
}Compute those HDIs and save them as h.
## [1] 0.6075644 0.6909070Now let’s remake the plot from above, this time with the analytically-derived HDI values.
tibble(theta = seq(from = 0, to = 1, length.out = 1e3)) %>%
ggplot() +
geom_rect(xmin = .45, xmax = .55,
ymin = -Inf, ymax = Inf,
color = "transparent", fill = "white") +
geom_ribbon(aes(x = theta,
ymin = 0, ymax = dbeta(theta, shape1 = alpha, shape2 = beta)),
fill = "grey67", size = 0) +
geom_segment(x = h[1], xend = h[2],
y = 0, yend = 0,
size = 3/4) +
annotate("text", x = .5, y = 17.5, label = "ROPE",
color = "grey67") +
annotate("text", x = .65, y = 4, label = "95%\nHDI") +
scale_y_continuous(NULL, breaks = NULL) +
labs(title = "That `hdi_of_icdf()` function really came through, for us.",
x = expression(theta)) +
theme(panel.grid = element_blank())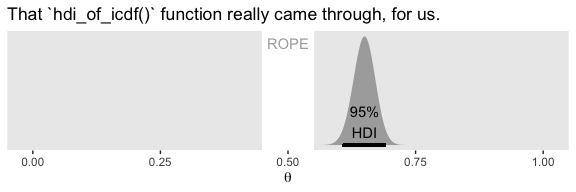
In his second example (p. 337), Kruschke considered \(z = 490\) heads out of \(N = 1000\) flips.
# we need these to compute the likelihood
n <- 1000
z <- 490
trial_data <- c(rep(0, times = n - z), rep(1, times = z))
tibble(theta = seq(from = 0, to = 1, length.out = 1e3)) %>% # (i.e., theta)
mutate(prior = dbeta(theta, shape1 = 1, shape2 = 1)) %>% # (i.e., p(theta))
mutate(likelihood = bernoulli_likelihood(theta = theta, # (i.e., p(D | theta))
data = trial_data)) %>%
mutate(posterior = (likelihood * prior) / sum(likelihood * prior)) %>% # (i.e., p(theta | D))
ggplot() +
geom_rect(xmin = .45, xmax = .55,
ymin = -Inf, ymax = Inf,
color = "transparent", fill = "white") +
geom_ribbon(aes(x = theta, ymin = 0, ymax = posterior),
fill = "grey67") +
scale_y_continuous(NULL, breaks = NULL) +
labs(title = "This posterior sits right within the ROPE.",
x = expression(theta)) +
theme(panel.grid = element_blank())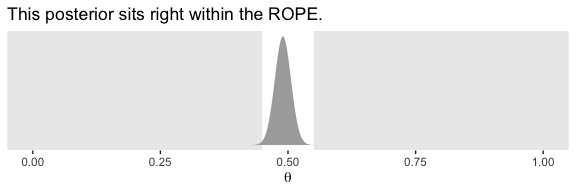
Here are the new HDIs.
## [1] 0.4590949 0.5209562Further down the section, Kruschke offered some perspective on the ROPE approach.
The ROPE limits, by definition, cannot be uniquely “correct,” but instead are established by practical aims, bearing in mind that wider ROPEs yield more decisions to accept the ROPEd value and fewer decision to reject the ROPEd value. In many situations, the exact limit of the ROPE can be left indeterminate or tacit, so that the audience of the analysis can use whatever ROPE is appropriate at the time, as competing theories and measuring devices evolve. When the HDI is far from the ROPEd value, the exact ROPE is inconsequential because the ROPEd value would be rejected for any reasonable ROPE. When the HDI is very narrow and overlaps the target value, the HDI might again fall within any reasonable ROPE, again rendering the exact ROPE inconsequential. When, however, the HDI is only moderately narrow and near the target value, the analysis can report how much of the posterior falls within a ROPE as a function of different ROPE widths…
It is important to be clear that any discrete decision about rejecting or accepting a null value does not exhaustively capture our knowledge about the parameter value. Our knowledge about the parameter value is described by the full posterior distribution. When making a binary decision, we have merely compressed all that rich detail into a single bit of information. The broader goal of Bayesian analysis is conveying an informative summary of the posterior, and where the value of interest falls within that posterior. Reporting the limits of an HDI region is more informative than reporting the declaration of a reject/accept decision. By reporting the HDI and other summary information about the posterior, different readers can apply different ROPEs to decide for themselves whether a parameter is practically equivalent to a null value. The decision procedure is separate from the Bayesian inference. The Bayesian part of the analysis is deriving the posterior distribution. The decision procedure uses the posterior distribution, but does not itself use Bayes’ rule. (pp. 338–339, emphasis in the original)
Full disclosure: I’m not a fan of the ROPE method. Though we’re following along with the text and covering it, here, I will deemphasize it in later sections.
Kruschke then went on to compare the ROPE with frequentist equivalence tests. This is a part of the literature I have not waded into, yet. It appears psychologist Daniël Lakens and colleagues gave written a bit in the topic, recently. Interested readers might start here, here, or here.
12.1.2 Some examples.
Kruschke referenced an analysis from way back in Chapter 9. We’ll need to re-fit the model. First we import data.
## Observations: 948
## Variables: 6
## $ Player <chr> "Fernando Abad", "Bobby Abreu", "Tony Abreu", "Dustin Ackley", "Matt Adams",…
## $ PriPos <chr> "Pitcher", "Left Field", "2nd Base", "2nd Base", "1st Base", "Pitcher", "Pit…
## $ Hits <dbl> 1, 53, 18, 137, 21, 0, 0, 2, 150, 167, 0, 128, 66, 3, 1, 81, 180, 36, 150, 0…
## $ AtBats <dbl> 7, 219, 70, 607, 86, 1, 1, 20, 549, 576, 1, 525, 275, 12, 8, 384, 629, 158, …
## $ PlayerNumber <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 2…
## $ PriPosNumber <dbl> 1, 7, 4, 4, 3, 1, 1, 3, 3, 4, 1, 5, 4, 2, 7, 4, 6, 8, 9, 1, 2, 5, 1, 1, 7, 2…Let’s load brms and, while we’re at it, tidybayes.
Fit the model.
fit1 <-
brm(data = my_data,
family = binomial(link = logit),
Hits | trials(AtBats) ~ 1 + (1 | PriPos) + (1 | PriPos:Player),
prior = c(prior(normal(0, 1.5), class = Intercept),
prior(normal(0, 1), class = sd)),
iter = 3500, warmup = 500, chains = 3, cores = 3,
control = list(adapt_delta = .9),
seed = 12)Let’s use coef() to pull the relevant posterior draws.
## Classes 'tbl_df', 'tbl' and 'data.frame': 9000 obs. of 9 variables:
## $ 1st Base.Intercept : num -1.12 -1.03 -1.01 -1.04 -1.09 ...
## $ 2nd Base.Intercept : num -1.059 -1.072 -1.067 -0.997 -1.169 ...
## $ 3rd Base.Intercept : num -1.01 -1.05 -1.04 -1.06 -1.07 ...
## $ Catcher.Intercept : num -1.17 -1.09 -1.14 -1.14 -1.15 ...
## $ Center Field.Intercept: num -1.05 -1.07 -1.06 -1.06 -1.03 ...
## $ Left Field.Intercept : num -1.08 -1.11 -1.06 -1.06 -1.12 ...
## $ Pitcher.Intercept : num -1.86 -1.87 -1.97 -1.94 -1.88 ...
## $ Right Field.Intercept : num -1.03 -1.05 -1.08 -1.09 -1.01 ...
## $ Shortstop.Intercept : num -1.16 -1.1 -1.14 -1.1 -1.12 ...As we pointed out in Chapter 9, keep in mind that coef() returns the values in the logit scale when used for logistic regression models. So we’ll have to use brms::inv_logit_scaled() to convert the estimates to the probability metric. We can make the difference distributions after we’ve converted the estimates.
c_small <-
c %>%
mutate_all(inv_logit_scaled) %>%
transmute(`Pitcher - Catcher` = Pitcher.Intercept - Catcher.Intercept,
`Catcher - 1st Base` = Catcher.Intercept - `1st Base.Intercept`)
head(c_small)## # A tibble: 6 x 2
## `Pitcher - Catcher` `Catcher - 1st Base`
## <dbl> <dbl>
## 1 -0.102 -0.00921
## 2 -0.117 -0.0131
## 3 -0.120 -0.0256
## 4 -0.116 -0.0201
## 5 -0.109 -0.0110
## 6 -0.106 -0.0161After a little wrangling, we’ll be ready to re-plot the relevant parts of Figure 9.14.
c_small %>%
gather() %>%
mutate(key = factor(key, levels = c("Pitcher - Catcher", "Catcher - 1st Base"))) %>%
ggplot(aes(x = value)) +
geom_rect(xmin = -0.05, xmax = 0.05,
ymin = -Inf, ymax = Inf,
color = "transparent", fill = "white") +
geom_histogram(fill = "grey67", color = "grey92",
size = .2, binwidth = .003) +
stat_pointintervalh(aes(y = 0),
point_interval = mode_hdi, .width = .95) +
scale_y_continuous(NULL, breaks = NULL) +
labs(title = "The ROPE ranges from −0.05 to +0.05",
x = expression(theta)) +
coord_cartesian(c(-.125, .125)) +
theme(panel.grid = element_blank(),
legend.position = "none") +
facet_wrap(~key, scales = "free")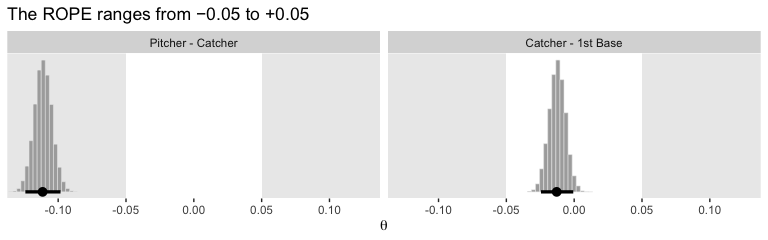
In order to re-plot part of Figure 9.15, we’ll need to employ fitted() to snatch the player-specific posteriors.
# this will make life easier. just go with it
name_list <- c("ShinSoo Choo", "Ichiro Suzuki")
# we'll define the data we'd like to feed into `fitted()`, here
nd <-
my_data %>%
filter(Player %in% c(name_list)) %>%
# these last two lines aren't typically necessary, but they allow us to
# arrange the rows in the same order we find the names in Figures 9.15 and 9/16
mutate(Player = factor(Player, levels = c(name_list))) %>%
arrange(Player)
f <-
fitted(fit1,
newdata = nd,
scale = "linear",
summary = F) %>%
as_tibble() %>%
mutate_all(inv_logit_scaled) %>%
set_names(name_list) %>%
# in this last section, we make our difference distributions
mutate(`ShinSoo Choo - Ichiro Suzuki` = `ShinSoo Choo` - `Ichiro Suzuki`)
glimpse(f)## Observations: 9,000
## Variables: 3
## $ `ShinSoo Choo` <dbl> 0.2836534, 0.3041822, 0.2661348, 0.2970897, 0.2443223, 0.2…
## $ `Ichiro Suzuki` <dbl> 0.2631869, 0.2891847, 0.2999139, 0.2617316, 0.2958017, 0.2…
## $ `ShinSoo Choo - Ichiro Suzuki` <dbl> 0.020466515, 0.014997563, -0.033779074, 0.035358090, -0.05…Now we’re ready to go.
f %>%
ggplot() +
geom_rect(xmin = -0.05, xmax = 0.05,
ymin = -Inf, ymax = Inf,
color = "transparent", fill = "white") +
geom_histogram(aes(x = `ShinSoo Choo - Ichiro Suzuki`),
fill = "grey67", color = "grey92",
size = .2, binwidth = .003) +
stat_pointintervalh(aes(x = `ShinSoo Choo - Ichiro Suzuki`, y = 0),
point_interval = mode_hdi, .width = .95) +
scale_y_continuous(NULL, breaks = NULL) +
labs(title = "ShinSoo Choo - Ichiro Suzuki",
x = expression(theta)) +
coord_cartesian(c(-.125, .125)) +
theme(panel.grid = element_blank())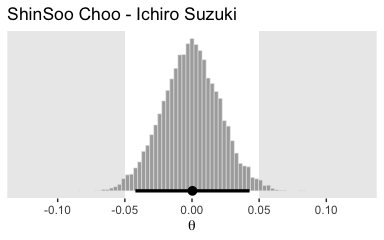
12.1.3 Differences of correlated parameters.
Krushke didn’t explicate where he got the data for Figure 12.1. If we’re willing to presume a multivariate normal distribution, we can get close using the MASS::mvrnorm() function. You can get the basic steps from Sven Hohenstein’s answer to this stats.stacheschange question.
# first we'll make a correlation matrix
# a correlation of .9 seems about right
correlation_matrix <-
matrix(c(1, .9,
.9, 1),
nrow = 2, ncol = 2)
# next we'll specify the means and standard deviations
mu <- c(.58, .42)
sd <- c(.1, .1)
# now we'll use the correlation matrix and standard deviations to make a covariance matrix
covariance_matrix <-
sd %*% t(sd) * correlation_matrix
# after setting our seed, we're ready to simulate
set.seed(12)
d <-
MASS::mvrnorm(n = 1000,
mu = mu,
Sigma = covariance_matrix) %>%
as_tibble() %>%
set_names(str_c("theta[", 1:2, "]"))Now it only takes some light wrangling to prepare the data to make the three histograms in the left panel of Figure 12.1.
d %>%
mutate(`theta[1]-theta[2]` = `theta[1]` - `theta[2]`) %>%
gather() %>%
ggplot(aes(x = value)) +
geom_histogram(fill = "grey67", color = "grey92",
size = .2, bins = 30) +
stat_pointintervalh(aes(y = 0),
point_interval = mode_hdi, .width = .95) +
scale_y_continuous(NULL, breaks = NULL) +
xlab(expression(theta)) +
theme(panel.grid = element_blank()) +
facet_wrap(~key, scales = "free_y", labeller = label_parsed)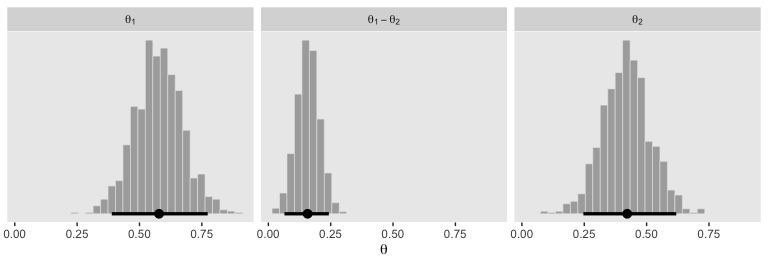
Here’s the scatter plot, showing the correlation. I think we got pretty close!
d %>%
ggplot(aes(x = `theta[1]`, y = `theta[2]`)) +
geom_abline(color = "white") +
geom_point(size = 1/2,
color = "grey50",
alpha = 1/4) +
coord_equal(xlim = 0:1,
ylim = 0:1) +
labs(x = expression(theta[1]),
y = expression(theta[2])) +
theme(panel.grid = element_blank())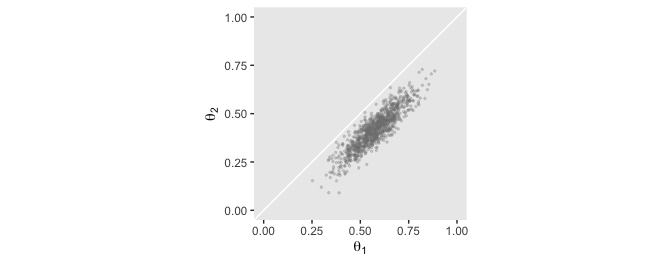
To make the plots in the right panel of Figure 12.1, we just need to convert the correlation from .9 to -.9.
# this time we'll make the correlations -.9
correlation_matrix <-
matrix(c(1, -.9,
-.9, 1),
nrow = 2, ncol = 2)
# we'll have to redo the covariance matrix
covariance_matrix <-
sd %*% t(sd) * correlation_matrix
# here's the updated data
set.seed(1)
d <- MASS::mvrnorm(n = 1000, mu = mu, Sigma = covariance_matrix) %>%
as_tibble() %>%
set_names(str_c("theta[", 1:2, "]"))Here are our right-panel Figure 12.1 histograms.
d %>%
mutate(`theta[1]-theta[2]` = `theta[1]` - `theta[2]`) %>%
gather() %>%
ggplot(aes(x = value)) +
geom_histogram(fill = "grey67", color = "grey92",
size = .2, bins = 30) +
stat_pointintervalh(aes(y = 0),
point_interval = mode_hdi, .width = .95) +
scale_y_continuous(NULL, breaks = NULL) +
xlab(expression(theta)) +
theme(panel.grid = element_blank()) +
facet_wrap(~key, scales = "free_y", labeller = label_parsed)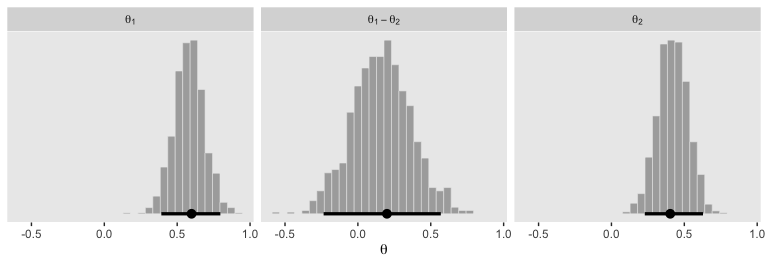
Behold the second scatter plot.
d %>%
ggplot(aes(x = `theta[1]`, y = `theta[2]`)) +
geom_abline(color = "white") +
geom_point(size = 1/2,
color = "grey50",
alpha = 1/4) +
coord_equal(xlim = 0:1,
ylim = 0:1) +
labs(x = expression(theta[1]),
y = expression(theta[2])) +
theme(panel.grid = element_blank())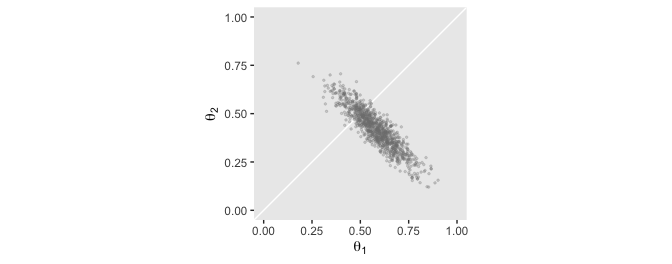
In summary, the marginal distributions of two parameters do not indicate the relationship between the parameter values. The joint distribution of the two parameters might have positive or negative correlation (or even a non-linear dependency), and therefore the difference of the parameter values should be explicitly examined. (pp. 341–342)
12.1.4 Why HDI and not equal-tailed interval?
Though Kruschke told us Figure 12.2 was of a gamma distribution, he didn’t tell us the parameters for that particular gamma. After playing around for a bit, it appeared dgamma(x, 2, .2) worked pretty well.
tibble(x = seq(from = 0, to = 40, by = .1)) %>%
ggplot(aes(x = x)) +
geom_ribbon(aes(ymin = 0,
ymax = dgamma(x, 2, .2)),
fill = "grey67") +
coord_cartesian(xlim = 0:35) +
theme(panel.grid = element_blank())
If you want to get the quantile-based intervals (i.e., the ETIs), you can plug in the desired quantiles into the qgamma() function.
## [1] 1.211046 27.858217To analytically derive the gamma HDIs, we just use the good old hdi_of_icdf() function.
## [1] 0.2118165 23.8258411Next you need to determine how high up to go on the y-axis. For the quantile-based intervals, the ETIs, you can use dgamma(). The trick is pump the output of qgamma() into dgamma().
## [1] 0.038021620 0.004239155We follow the same basic principle to get the y-axis values for the HDIs.
## [1] 0.008121227 0.008121233Now we’ve computed all those values, we can collect them into a tibble with the necessary coordinates to make the ETI and HDI lines in our plot.
(
lines <-
tibble(interval = rep(c("eti", "hdi"), each = 4),
x = c(ex, hx) %>% rep(., each = 2),
y = c(ey[1], 0, 0, ey[2], 0, hy, 0))
)## # A tibble: 8 x 3
## interval x y
## <chr> <dbl> <dbl>
## 1 eti 1.21 0.0380
## 2 eti 1.21 0
## 3 eti 27.9 0
## 4 eti 27.9 0.00424
## 5 hdi 0.212 0
## 6 hdi 0.212 0.00812
## 7 hdi 23.8 0.00812
## 8 hdi 23.8 0We’re finally ready to plot a more complete version of Figure 12.2.
tibble(x = seq(from = 0, to = 40, by = .1)) %>%
ggplot(aes(x = x)) +
geom_ribbon(aes(ymin = 0, ymax = dgamma(x, 2, .2)),
fill = "grey67") +
geom_path(data = lines,
aes(y = y, color = interval),
size = 1) +
geom_text(data = tibble(
x = c(15, 12),
y = c(.004, .012),
label = c("95% ETI", "95% HDI"),
interval = c("eti", "hdi")
),
aes(y = y, color = interval, label = label)) +
scale_color_manual(values = c("black", "white")) +
scale_y_continuous(NULL, breaks = NULL) +
coord_cartesian(xlim = 0:35) +
xlab("Density Value") +
theme(panel.grid = element_blank(),
legend.position = "none")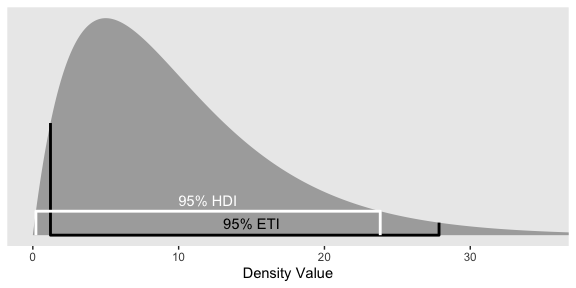
To repeat, ETIs are the only types of intervals available directly by the brms package. When using the default print() or summary() output for a brm() model, the 95% ETIs are displayed in the ‘l-95% CI’ and ‘u-95% CI’ columns.
## Family: binomial
## Links: mu = logit
## Formula: Hits | trials(AtBats) ~ 1 + (1 | PriPos) + (1 | PriPos:Player)
## Data: my_data (Number of observations: 948)
## Samples: 3 chains, each with iter = 3500; warmup = 500; thin = 1;
## total post-warmup samples = 9000
##
## Group-Level Effects:
## ~PriPos (Number of levels: 9)
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## sd(Intercept) 0.32 0.10 0.19 0.59 1.00 2660 4283
##
## ~PriPos:Player (Number of levels: 948)
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## sd(Intercept) 0.14 0.01 0.12 0.15 1.00 3695 5911
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## Intercept -1.17 0.11 -1.40 -0.94 1.00 1507 2262
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).In the output of most other brms functions, the 95% ETIs appear in the Q2.5 and Q97.5 columns. Take fitted(), for example.
## Estimate Est.Error Q2.5 Q97.5
## [1,] -0.9712888 0.07647876 -1.123799 -0.8193551
## [2,] -0.9676824 0.07618627 -1.118517 -0.8174031But as we just did, above, you can always use the convenience functions from the tidybayes package (e.g., mean_hdi()) to get HDIs from a brms fit.
fitted(fit1,
newdata = nd,
scale = "linear",
summary = F) %>%
as_tibble() %>%
gather() %>%
group_by(key) %>%
mean_hdi(value)## # A tibble: 2 x 7
## key value .lower .upper .width .point .interval
## <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
## 1 V1 -0.971 -1.13 -0.830 0.95 mean hdi
## 2 V2 -0.968 -1.11 -0.813 0.95 mean hdiAs you may have gathered, Kruschke clearly prefers using HDIs over ETIs. His preference isn’t without controversy. If you’d like to explore the topic further in the form of saucy twitter banter, the inimitable Dan Simpson has just the thread for you. Here’s the link to the corresponding thread in the Stan discourse forum.
12.2 The model-comparison approach
Recall that the motivating issue for this chapter is the question, Is the null value of a parameter credible? The previous section answered the question in terms of parameter estimation. In that approach, we started with a possibly informed prior distribution and examined the posterior distribution.
In this section we take a different approach. Some researchers prefer instead to pose the question in terms of model comparison. In this framing of the question, the focus is not on estimating the magnitude of the parameter. Instead, the focus is on deciding which of two hypothetical prior distributions is least incredible. One prior expresses the hypothesis that the parameter value is exactly the null value. The alternative prior expresses the hypothesis that the parameter could be any value, according to some form of broad distribution. (p. 344)
12.2.1 Is a coin fair or not?
Some (e.g., Lee & Webb, 2005; Zhu & Lu, 2004) have argued the Haldane prior is superior to the uniform \(\operatorname{Beta} (1, 1)\) when choosing an uninformative prior for \(\theta\). The Haldane, recall, is \(\operatorname{Beta} (\epsilon, \epsilon)\), where \(\epsilon\) is some small value approaching zero (e.g., 0.01). We’ll use our typical steps with the grid aproximation to compute the data for the left column of Figure 12.3 (i.e., the column based on the Haldane prior).
# we need these to compute the likelihood
n <- 24
z <- 7
epsilon <- .01
trial_data <- c(rep(0, times = n - z), rep(1, times = z))
d <-
tibble(theta = seq(from = 0, to = 1, length.out = 1000)) %>%
mutate(prior = dbeta(x = theta, shape1 = epsilon, shape2 = epsilon)) %>%
mutate(likelihood = bernoulli_likelihood(theta = theta,
data = trial_data)) %>%
# we have to slice off the first and last values because they go to infinity on the prior,
# which creats problems when computing the denominator `sum(likelihood * prior)` (i.e., p(D))
slice(2:999) %>%
mutate(posterior = likelihood * prior / sum(likelihood * prior))
head(d)## # A tibble: 6 x 4
## theta prior likelihood posterior
## <dbl> <dbl> <dbl> <dbl>
## 1 0.00100 4.67 9.90e-22 1.61e-15
## 2 0.00200 2.35 1.25e-19 1.02e-13
## 3 0.00300 1.58 2.09e-18 1.15e-12
## 4 0.00400 1.19 1.54e-17 6.39e-12
## 5 0.00501 0.952 7.22e-17 2.40e-11
## 6 0.00601 0.796 2.54e-16 7.07e-11Here’s the left column of Figure 12.3.
p1 <-
d %>%
ggplot(aes(x = theta)) +
geom_ribbon(aes(ymin = 0, ymax = prior),
fill = "grey50") +
annotate(geom = "text", x = .1, y = 4, size = 3.5, label = expression(epsilon == 0.01)) +
scale_y_continuous(breaks = NULL) +
labs(title = "Prior (beta)",
x = expression(theta),
y = expression(paste("Beta(", theta, "|", epsilon, ", ", epsilon, ")"))) +
theme(panel.grid = element_blank())
p2 <-
d %>%
ggplot(aes(x = theta)) +
geom_ribbon(aes(ymin = 0, ymax = likelihood),
fill = "grey50") +
scale_y_continuous(breaks = NULL) +
labs(title = "Likelihood (Bernoulli)",
x = expression(theta),
y = expression(paste("p(D|", theta, ")"))) +
theme(panel.grid = element_blank(),
axis.text.y = element_text())
p3 <-
d %>%
ggplot(aes(x = theta)) +
geom_ribbon(aes(ymin = 0, ymax = posterior),
fill = "grey50") +
scale_y_continuous(breaks = NULL) +
labs(title = "Posterior (beta)",
x = expression(theta),
y = expression(paste("Beta(", theta, "|7.01, 17.01)"))) +
theme(panel.grid = element_blank())
library(patchwork)
p1 / p2 / p3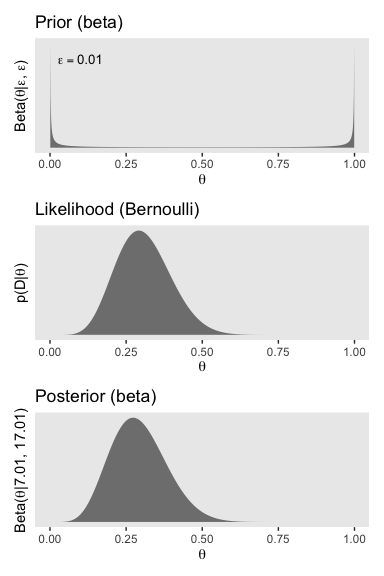
We can calculate the Beta parameters for the posterior using the formula \(\operatorname{Beta} (\theta | z + \alpha, N - z + \beta)\).
## [1] 7.01## [1] 17.01We need updated data for the right column, based on the \(\operatorname{Beta} (2, 4)\) prior.
alpha <- 2
beta <- 4
d <-
tibble(theta = seq(from = 0, to = 1, length.out = 1000)) %>%
mutate(prior = dbeta(x = theta, shape1 = alpha, shape2 = beta)) %>%
mutate(likelihood = bernoulli_likelihood(theta = theta,
data = trial_data)) %>%
# no need to `slice(2:999)` this time
mutate(posterior = likelihood * prior / sum(likelihood * prior))
head(d)## # A tibble: 6 x 4
## theta prior likelihood posterior
## <dbl> <dbl> <dbl> <dbl>
## 1 0 0 0. 0.
## 2 0.00100 0.0200 9.90e-22 8.91e-20
## 3 0.00200 0.0398 1.25e-19 2.24e-17
## 4 0.00300 0.0595 2.09e-18 5.62e-16
## 5 0.00400 0.0791 1.54e-17 5.50e-15
## 6 0.00501 0.0986 7.22e-17 3.21e-14Now here’s the right column of Figure 12.3.
p1 <-
d %>%
ggplot(aes(x = theta)) +
geom_ribbon(aes(ymin = 0, ymax = prior),
fill = "grey50") +
scale_y_continuous(breaks = NULL) +
labs(title = "Prior (beta)",
x = expression(theta),
y = expression(paste("Beta(", theta, "|2, 4)"))) +
theme(panel.grid = element_blank())
p2 <-
d %>%
ggplot(aes(x = theta)) +
geom_ribbon(aes(ymin = 0, ymax = likelihood),
fill = "grey50") +
scale_y_continuous(breaks = NULL) +
labs(title = "Likelihood (Bernoulli)",
x = expression(theta),
y = expression(paste("p(D|", theta, ")"))) +
theme(panel.grid = element_blank(),
axis.text.y = element_text())
p3 <-
d %>%
ggplot(aes(x = theta)) +
geom_ribbon(aes(ymin = 0, ymax = posterior),
fill = "grey50") +
scale_y_continuous(breaks = NULL) +
labs(title = "Posterior (beta)",
x = expression(theta),
y = expression(paste("Beta(", theta, "|9, 21)"))) +
theme(panel.grid = element_blank())
p1 / p2 / p3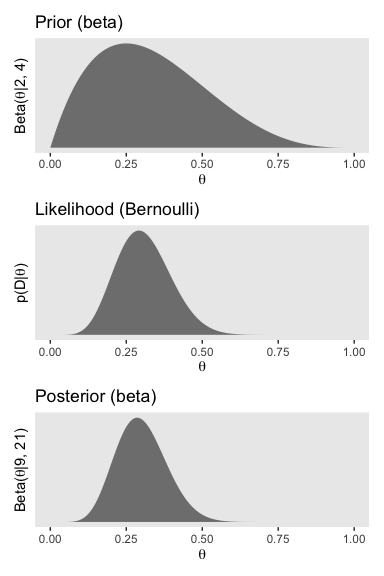
Here are those Beta parameters for that posterior.
## [1] 9## [1] 21Following the formula for the null hypothesis,
\[p(z, N|M_\text{null}) = \theta_\text{null}^z(1 - \theta_\text{null})^{(N - z)},\]
we can compute the probability of the data given the null hypothesis.
## [1] 5.960464e-08The formula for the marginal likelihood for the alternative hypothesis \(M_\text{alt}\) is
\[p(z, N| M_\text{alt}) = \frac{\operatorname{Beta} (z + \alpha_\text{alt}, N - z + \beta_\text{alt})}{\operatorname{Beta} (\alpha_\text{alt}, \beta_\text{alt})}.\]
We can make our own p_d() function to compute the probability of the data given alternative hypotheses. Here we’ll simplify the function a bit to extract z and n out of the environment.
With p_d_null and our p_d() function in hand, we can reproduce and extend the results in Kruschke’s Equation 12.4.
options(scipen = 999)
tibble(shape1 = c(2, 1, .1, .01, .001, .0001, .00001),
shape2 = c(4, 1, .1, .01, .001, .0001, .00001)) %>%
mutate(p_d = p_d(a = shape1, b = shape2)) %>%
mutate(p_d_null = p_d_null) %>%
mutate(bf = p_d / p_d_null) %>%
# this just reduces the amount of significant digits in the output
mutate_all(round, digits = 6)## # A tibble: 7 x 5
## shape1 shape2 p_d p_d_null bf
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2 4 0 0 3.72
## 2 1 1 0 0 1.94
## 3 0.1 0.1 0 0 0.421
## 4 0.01 0.01 0 0 0.0481
## 5 0.001 0.001 0 0 0.00488
## 6 0.0001 0.0001 0 0 0.000489
## 7 0.00001 0.00001 0 0 0.000049Did you notice our use of options(scipen)? With the first line, we turned off scientific notation in the print output. We turned scientific notation back on with the second line. But back to the text,
for now, notice that when the alternative prior is uniform, with \(a_\text{alt} = b_\text{alt} = 1.000\), the Bayes’ factor shows a (small) preference for the alternative hypothesis, but when the alternative prior approximates the Haldane, the Bayes’ factor shows a strong preference for the null hypothesis. As the alternative prior gets closer to the Haldane limit, the Bayes’ factor changes by orders of magnitude. Thus, as we have seen before (e.g. Section 10.6, p. 292), the Bayes’ factor is very sensitive to the choice of prior distribution. (p. 345, emphasis added)
On page 346, Kruschke showed some of the 95% HDIs for the marginal distributions of the various \(M_\text{alt}\)s. We could compute those one at a time with hdi_of_icdf(). But why not work in bulk? Like we did in Chapter 10, let’s make a custom variant hdi_of_qbeta(), which will be more useful within the context of map2().
hdi_of_qbeta <- function(shape1, shape2) {
hdi_of_icdf(name = qbeta,
shape1 = shape1,
shape2 = shape2) %>%
data.frame() %>%
mutate(level = c("ll", "ul")) %>%
spread(key = level, value = ".")
}Compute the HDIs.
tibble(shape1 = z + c(2, 1, .1, .01, .001, .0001, .00001),
shape2 = n - z + c(4, 1, .1, .01, .001, .0001, .00001)) %>%
mutate(h = map2(shape1, shape2, hdi_of_qbeta)) %>%
unnest(h) %>%
mutate_at(vars(ends_with("l")), .funs = ~round(., digits = 4))## # A tibble: 7 x 4
## shape1 shape2 ll ul
## <dbl> <dbl> <dbl> <dbl>
## 1 9 21 0.145 0.462
## 2 8 18 0.141 0.483
## 3 7.1 17.1 0.124 0.472
## 4 7.01 17.0 0.122 0.471
## 5 7.00 17.0 0.122 0.471
## 6 7.00 17.0 0.122 0.471
## 7 7.00 17.0 0.122 0.471As Kruschke mused,
if we consider the posterior distribution instead of the Bayes’ factor, we see that the posterior distribution on \(\theta\) within the alternative model is only slightly affected by the prior… In all cases, the 95% HDI excludes the null value, although a wide ROPE might overlap the HDI. Thus, the explicit estimation of the bias parameter robustly indicates that the null value should be rejected, but perhaps only marginally. This contrasts with the Bayes’ factor, model-comparison approach, which rejected the null or accepted the null depending on the alternative prior.
Further,
of the Bayes’ factors in Equation 12.4, which is most appropriate? If your analysis is driven by the urge for a default, uninformed alternative prior, then the prior that best approximates the Haldane is most appropriate. Following from that, we should strongly prefer the null hypothesis to the Haldane alternative. While this is mathematically correct, it is meaningless for an applied setting because the Haldane alternative represents nothing remotely resembling a credible alternative hypothesis. The Haldane prior sets prior probabilities of virtually zero at all values of \(\theta\) except \(\theta = 0\) and \(\theta = 1\). There are very few applied settings where such a U-shaped prior represents a genuinely meaningful theory. (p. 346).
12.2.2 Bayes’ factor can accept null with poor precision.
Here are the steps to make the left column of Figure 12.4 (i.e., the column based on very weak data and the Haldane prior).
# we need these to compute the likelihood
n <- 2
z <- 1
trial_data <- c(rep(0, times = n - z), rep(1, times = z))
d <-
tibble(theta = seq(from = 0, to = 1, length.out = 1000)) %>%
mutate(prior = dbeta(x = theta, shape1 = epsilon, shape2 = epsilon)) %>%
mutate(likelihood = bernoulli_likelihood(theta = theta,
data = trial_data)) %>%
# like before, we have to slice off the first and last values because they go to infinity on the
# prior, which creats problems when computing the denominator `sum(likelihood * prior)` (i.e., p(D))
slice(2:999) %>%
mutate(posterior = likelihood * prior / sum(likelihood * prior))
p1 <-
d %>%
ggplot(aes(x = theta)) +
geom_ribbon(aes(ymin = 0, ymax = prior),
fill = "grey50") +
annotate(geom = "text", x = .1, y = 4, size = 3.5, label = expression(epsilon == 0.01)) +
scale_y_continuous(breaks = NULL) +
labs(title = "Prior (beta)",
x = expression(theta),
y = expression(paste("Beta(", theta, "|", epsilon, ", ", epsilon, ")"))) +
theme(panel.grid = element_blank())
p2 <-
d %>%
ggplot(aes(x = theta)) +
geom_ribbon(aes(ymin = 0, ymax = likelihood),
fill = "grey50") +
scale_y_continuous(breaks = NULL) +
labs(title = "Likelihood (Bernoulli)",
x = expression(theta),
y = expression(paste("p(D|", theta, ")"))) +
theme(panel.grid = element_blank(),
axis.text.y = element_text())
p3 <-
d %>%
ggplot(aes(x = theta)) +
geom_ribbon(aes(ymin = 0, ymax = posterior),
fill = "grey50") +
scale_y_continuous(breaks = NULL) +
labs(title = "Posterior (beta)",
x = expression(theta),
y = expression(paste("Beta(", theta, "|7.01, 17.01)"))) +
theme(panel.grid = element_blank())
p1 / p2 / p3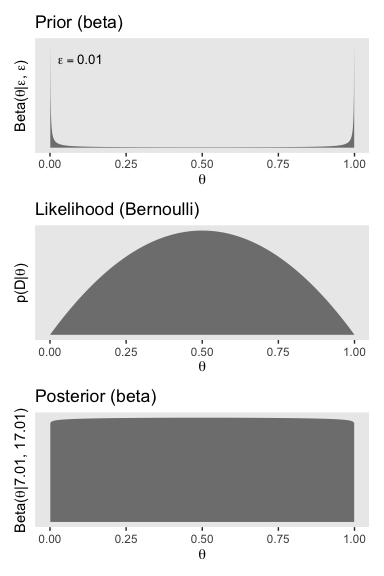
That is one flat posterior! Here are the shape parameters and the HDIs.
## [1] 1.01## [1] 1.01## [1] 0.026 0.974How do we compute the BF?
theta <- .5
a <- epsilon
b <- epsilon
# pD_{null} pD_{alternative}
(theta ^ z * (1 - theta) ^ (n - z)) / (beta(z + a, n - z + b) / beta(a, b))## [1] 51Just like in the text, “the Bayes’ factor is 51.0 in favor of the null hypothesis” (p. 347)!
Here are the steps to make the right column of Figure 12.4, which is based on stronger data and a flat \(\operatorname{Beta} (1, 1)\) prior.
# we need these to compute the likelihood
n <- 14
z <- 7
trial_data <- c(rep(0, times = n - z), rep(1, times = z))
d <-
tibble(theta = seq(from = 0, to = 1, length.out = 1e3)) %>%
mutate(prior = dbeta(x = theta, shape1 = alpha, shape2 = beta)) %>%
mutate(likelihood = bernoulli_likelihood(theta = theta,
data = trial_data)) %>%
# no need to `slice(2:999)` this time
mutate(posterior = likelihood * prior / sum(likelihood * prior))
p1 <-
d %>%
ggplot(aes(x = theta)) +
geom_ribbon(aes(ymin = 0, ymax = prior),
fill = "grey50") +
scale_y_continuous(breaks = NULL) +
labs(title = "Prior (beta)",
x = expression(theta),
y = expression(paste("Beta(", theta, "|1, 1)"))) +
theme(panel.grid = element_blank())
p2 <-
d %>%
ggplot(aes(x = theta)) +
geom_ribbon(aes(ymin = 0, ymax = likelihood),
fill = "grey50") +
scale_y_continuous(breaks = NULL) +
labs(title = "Likelihood (Bernoulli)",
x = expression(theta),
y = expression(paste("p(D|", theta, ")"))) +
theme(panel.grid = element_blank(),
axis.text.y = element_text())
p3 <-
d %>%
ggplot(aes(x = theta)) +
geom_ribbon(aes(ymin = 0, ymax = posterior),
fill = "grey50") +
scale_y_continuous(breaks = NULL) +
labs(title = "Posterior (beta)",
x = expression(theta),
y = expression(paste("Beta(", theta, "|8, 8)"))) +
theme(panel.grid = element_blank())
p1 / p2 / p3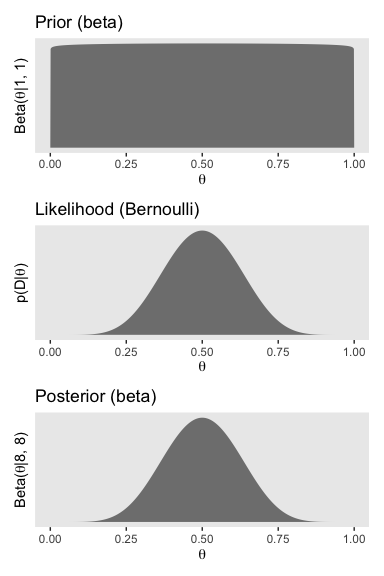
Here are the updated shape parameters and the HDIs.
## [1] 7.01## [1] 7.01## [1] 0.252 0.748Those HDIs are still pretty wide, but much less so than before. Let’s compute the BF.
a <- 1
b <- 1
# pD_{null} pD_{alternative}
(theta ^ z * (1 - theta) ^ (n - z)) / (beta(z + a, n - z + b) / beta(a, b))## [1] 3.14209A BF of 3.14 in favor of the null is lackluster evidence. And happily so given the breadth of the HDIs.
Kruschke discussed how we’d need \(z = 1200\) and \(N = 2400\) before the posterior HDIs would fit within a narrow ROPE like .48 and .52. Here’s what that would look like based on the priors from Figure 12.4.
z <- 1200
n <- 2400
alpha <- z + epsilon
beta <- n - z + epsilon
d <- tibble(theta = seq(from = 0, to = 1, length.out = 1e3))
# the Haldane-based plot
p1 <-
d %>%
ggplot(aes(x = theta)) +
geom_rect(xmin = .48, xmax = .52,
ymin = -Inf, ymax = Inf,
color = "transparent", fill = "white") +
geom_ribbon(aes(ymin = 0, ymax = dbeta(theta, shape1 = alpha, shape2 = beta)),
fill = "grey67", size = 0) +
annotate(geom = "text", x = .01, y = 35, size = 3.5, label = expression(epsilon == 0.01)) +
scale_y_continuous(NULL, breaks = NULL) +
labs(title = "This posterior used the Haldane prior.",
x = expression(theta)) +
theme(panel.grid = element_blank())
# redefine the Beta parameters
alpha <- z + 1
beta <- n - z + 1
# the Beta(1, 1)-based plot
p2 <-
d %>%
ggplot(aes(x = theta)) +
geom_rect(xmin = .48, xmax = .52,
ymin = -Inf, ymax = Inf,
color = "transparent", fill = "white") +
geom_ribbon(aes(ymin = 0, ymax = dbeta(theta, shape1 = alpha, shape2 = beta)),
fill = "grey67", size = 0) +
scale_y_continuous(NULL, breaks = NULL) +
labs(title = "This time we used the flat Beta (1, 1).",
x = expression(theta)) +
theme(panel.grid = element_blank())
p1 / p2 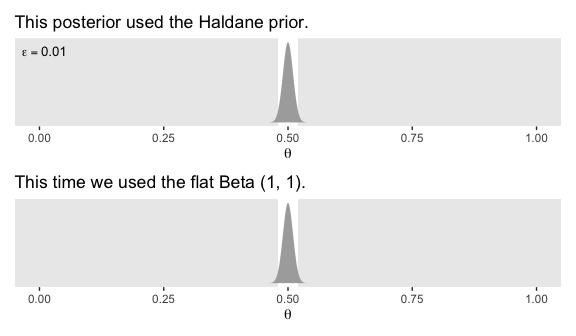
There is no way around this inconvenient statistical reality: high precision demands a large sample size (and a measurement device with minimal possible noise). But when we are trying to accept a specific value of \(\theta\), is seems logically appropriate that we should have a reasonably precise estimate indicating that specific value. (p. 348)
12.2.3 Are different groups equal or not?
Researchers often want to ask the question, Are the groups different or not?
As a concrete example, suppose we conduct an experiment about the effect of background music on the ability to remember. As a simple test of memory, each person tries to memorize the same list of 20 words (such as “chair,” “shark,” “radio,” etc.). They see each word for a specific time, and then, after a brief retention interval, recall as many words as they can. (p. 348)
If you look in Kruschke’s OneOddGroupModelComp2E.R file, you can get his simulation code. Here we’ve dramatically simplified it. This attempt does not exactly reproduce what his script did, but it gets it in spirit.
# For each subject, specify the condition s/he was in,
# the number of trials s/he experienced, and the number correct.
n_g <- 20 # number of subjects per group
n_t <- 20 # number of trials per subject
set.seed(12)
my_data <-
tibble(condition = rep(c("Das Kruschke", "Mozart", "Bach", "Beethoven"), each = 20),
id = 1:80,
n_g = n_g,
n_t = n_t,
group_means = rep(c(.40, .50, .51, .52), each = 20)) %>%
mutate(n_recalled = rbinom(n_g, n_t, group_means))
head(my_data)## # A tibble: 6 x 6
## condition id n_g n_t group_means n_recalled
## <chr> <int> <dbl> <dbl> <dbl> <int>
## 1 Das Kruschke 1 20 20 0.4 5
## 2 Das Kruschke 2 20 20 0.4 10
## 3 Das Kruschke 3 20 20 0.4 11
## 4 Das Kruschke 4 20 20 0.4 7
## 5 Das Kruschke 5 20 20 0.4 6
## 6 Das Kruschke 6 20 20 0.4 4Here are the means for n_recalled, by condition.
## # A tibble: 4 x 2
## condition mean_n_recalled
## <chr> <dbl>
## 1 Bach 10.1
## 2 Beethoven 10.0
## 3 Das Kruschke 7.05
## 4 Mozart 10.212.2.3.1 Model specification in JAGS brms.
Recall that although brms does accommodate models based on the Bernoulli likelihood, it doesn’t do so when the data are aggregated. With our aggregate Bernoulli data, we’ll have to use the conventional binomial likelihood, instead. We’ll compute two models. Our full model will be
\[\begin{align*} \text{n_recalled}_{ij} & \sim \operatorname{Binomial}(n = 20, \theta_{j}), \text{where} \\ \operatorname{logit}(\theta_j) & = \beta_{0_j}. \end{align*}\]
In our equation, \(\beta_{0_j}\) is the group-specific intercept within the logistic regression model. We’ll use the \(N(0, 1.5)\) prior for the intercept. Though it appears strongly regularizing in the log-odds space, it’s quite flat on the \(\theta\) space. If we wanted to be more conservative in the \(\theta\) space, we might use something more like \(N(0, 1)\).
fit2 <-
brm(data = my_data,
family = binomial,
n_recalled | trials(20) ~ 0 + condition,
prior(normal(0, 1.5), class = b),
iter = 2000, warmup = 500, cores = 4, chains = 4,
seed = 12)Here’s the summary for the full model.
## Family: binomial
## Links: mu = logit
## Formula: n_recalled | trials(20) ~ 0 + condition
## Data: my_data (Number of observations: 80)
## Samples: 4 chains, each with iter = 2000; warmup = 500; thin = 1;
## total post-warmup samples = 6000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## conditionBach 0.02 0.10 -0.18 0.21 1.00 7204 4765
## conditionBeethoven 0.01 0.10 -0.18 0.20 1.00 5452 4360
## conditionDasKruschke -0.61 0.10 -0.82 -0.41 1.00 5981 3557
## conditionMozart 0.05 0.10 -0.14 0.25 1.00 6573 4540
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).Do keep in mind that our results will differ from Kruschke’s because of two factors. First, we simulated slightly different data. In the limit, I suspect our data simulation approaches would converge. But we’re far from the limit. Second, we used a different likelihood to model the data, which resulted in slightly different priors. Yet even with those substantial limitations, our results are pretty close.
To make the top portion of Figure 12.5, we’ll need to extract the condition-specific parameters. For that, we’ll employ fixef() and then wrangle a bit.
post <-
fixef(fit2, summary = F) %>%
as_tibble() %>%
transmute(theta_1 = conditionDasKruschke,
theta_2 = conditionMozart,
theta_3 = conditionBach,
theta_4 = conditionBeethoven) %>%
mutate_all(inv_logit_scaled) %>%
transmute(`theta[1]-theta[2]` = theta_1 - theta_2,
`theta[1]-theta[3]` = theta_1 - theta_3,
`theta[1]-theta[4]` = theta_1 - theta_4,
`theta[2]-theta[3]` = theta_2 - theta_3,
`theta[2]-theta[4]` = theta_2 - theta_4,
`theta[3]-theta[4]` = theta_3 - theta_4)
glimpse(post)## Observations: 6,000
## Variables: 6
## $ `theta[1]-theta[2]` <dbl> -0.16238871, -0.15526376, -0.14950457, -0.19457511, -0.15670728, -0.1…
## $ `theta[1]-theta[3]` <dbl> -0.13276798, -0.13755633, -0.15991185, -0.22713044, -0.09358645, -0.1…
## $ `theta[1]-theta[4]` <dbl> -0.10759498, -0.14192878, -0.12375515, -0.18351134, -0.14406561, -0.1…
## $ `theta[2]-theta[3]` <dbl> 0.029620731, 0.017707439, -0.010407282, -0.032555331, 0.063120830, 0.…
## $ `theta[2]-theta[4]` <dbl> 0.0547937243, 0.0133349807, 0.0257494209, 0.0110637702, 0.0126416747,…
## $ `theta[3]-theta[4]` <dbl> 0.025172993, -0.004372458, 0.036156703, 0.043619101, -0.050479156, -0…Now we have the wrangled data, we’re ready to gather() them and plot the top of Figure 12.5.
post %>%
gather() %>%
ggplot(aes(x = value)) +
geom_vline(xintercept = 0, color = "white") +
geom_histogram(color = "grey92", fill = "grey67",
binwidth = .01, size = .2) +
stat_pointintervalh(aes(y = 0),
point_interval = mode_hdi, .width = .95) +
scale_y_continuous(NULL, breaks = NULL) +
coord_cartesian(xlim = c(-.25, .25)) +
theme(panel.grid = element_blank()) +
facet_wrap(~key, labeller = label_parsed)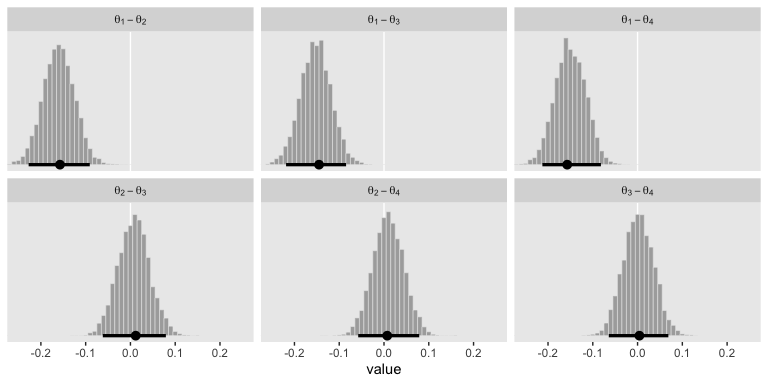
Also, do note we’re working with the \(\theta\) parameters in our aggregated binomial models, rather than \(\omega\)s.
Here’s how you’d get the eact mode and HDI summaries.
## # A tibble: 6 x 7
## key value .lower .upper .width .point .interval
## <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
## 1 theta[1]-theta[2] -0.157 -0.227 -0.091 0.95 mode hdi
## 2 theta[1]-theta[3] -0.145 -0.219 -0.085 0.95 mode hdi
## 3 theta[1]-theta[4] -0.157 -0.213 -0.082 0.95 mode hdi
## 4 theta[2]-theta[3] 0.012 -0.062 0.079 0.95 mode hdi
## 5 theta[2]-theta[4] 0.007 -0.058 0.079 0.95 mode hdi
## 6 theta[3]-theta[4] 0.004 -0.064 0.069 0.95 mode hdiIf we wanted to know what proportion of the difference distributions were greater than 0, we could do something like this.
post %>%
gather() %>%
group_by(key) %>%
summarise(p = mean(value > 0)) %>%
mutate_if(is.double, round, digits = 3)## # A tibble: 6 x 2
## key p
## <chr> <dbl>
## 1 theta[1]-theta[2] 0
## 2 theta[1]-theta[3] 0
## 3 theta[1]-theta[4] 0
## 4 theta[2]-theta[3] 0.585
## 5 theta[2]-theta[4] 0.611
## 6 theta[3]-theta[4] 0.526I got this idea from the great Tristan Mahr, who pointed out that conditional tests like value > 0 compute a vector of TRUE and FALSE values. By nesting that within mean(), you end up with the proportion of those values that are TRUE.
With our Stan/brms method, we don’t have an analogue to the lower portion of Figure 12.5 because we are not fitting the full and restricted models within a single run. Thus, there’s no plot to show the chains traversing from \(M_\text{full}\) to \(M_\text{restricted}\). Rather, our fit2 was just of \(M_\text{full}\). Now we’ll fit \(M_\text{restricted}\), which we’ll save as fit3.
fit3 <-
brm(data = my_data,
family = binomial,
n_recalled | trials(20) ~ 1,
prior(normal(0, 1.5), class = Intercept),
iter = 2000, warmup = 500, cores = 4, chains = 4,
seed = 12)Here we’ll compare the two models with the LOO.
fit2 <- add_criterion(fit2, "loo")
fit3 <- add_criterion(fit3, "loo")
loo_compare(fit2, fit3) %>%
print(simplify = F)## elpd_diff se_diff elpd_loo se_elpd_loo p_loo se_p_loo looic se_looic
## fit2 0.0 0.0 -172.4 4.4 3.3 0.4 344.8 8.8
## fit3 -12.0 5.5 -184.4 6.9 1.2 0.2 368.8 13.8The LOO comparison suggests fit2, the full model with the condition-specific intercepts, is an improvement over the restricted one-intercept-only model. We can also compare the models with their weights via the model_weights() function. Here we’ll use weights = "loo" criterion.
## fit2 fit3
## 9.999937e-01 6.343732e-06Recall that within a given comparison, the weights sum to 1, with better fitting models tending closer to 1 than the other(s). In this case, almost all the weight went to the \(M_\text{full}\), fit2.
12.2.3.2 Bonus: Hypothesis testing in brms.
Disclaimer: I’m not a fan of hypothesis texting within the Bayesian framework. So I generally don’t use these methods. However, it’d seem negligent not to at least mention the convenience function designed for that purpose in brms: the hypothesis() function. From the hypothesis section in the brms reference manual (version 2.10.0) we read:
Among others,
hypothesiscomputes an evidence ratio (Evid.Ratio) for each hypothesis. For a one-sided hypothesis, this is just the posterior probability (Post.Prob) under the hypothesis against its alternative. That is, when the hypothesis is of the forma > b, the evidence ratio is the ratio of the posterior probability ofa > band the posterior probability ofa < b. In this example, values greater than one indicate that the evidence in favor ofa > bis larger than evidence in favor ofa < b. For an two-sided (point) hypothesis, the evidence ratio is a Bayes factor between the hypothesis and its alternative computed via the Savage-Dickey density ratio method. That is the posterior density at the point of interest divided by the prior density at that point. Values greater than one indicate that evidence in favor of the point hypothesis has increased after seeing the data. In order to calculate this Bayes factor, all parameters related to the hypothesis must have proper priors and argumentsample_priorof function brm must be set to"yes". Otherwise Evid.Ratio (and Post.Prob) will beNA. Please note that, for technical reasons, we cannot sample from priors of certain parameters classes. Most notably, these include overall intercept parameters (prior class"Intercept") as well as group-level coefficients. When interpreting Bayes factors, make sure that your priors are reasonable and carefully chosen, as the result will depend heavily on the priors. In particular, avoid using default priors.
Following the a < b format, let’s say we wanted to test the hypothesis \(\theta_\text{Das Kruschke} < \theta_\text{Bach}\), based on fit2. If we convert the relevant parameters from the log-odds metric to the probability scale with inv_logit_scaled(), we can specify that hypothesis as a string and place it into the hypothesis() function.
## Hypothesis Tests for class b:
## Hypothesis Estimate Est.Error CI.Lower CI.Upper Evid.Ratio Post.Prob Star
## 1 (inv_logit_scaled... < 0 -0.15 0.03 -0.21 -0.1 Inf 1 *
## ---
## 'CI': 90%-CI for one-sided and 95%-CI for two-sided hypotheses.
## '*': For one-sided hypotheses, the posterior probability exceeds 95%;
## for two-sided hypotheses, the value tested against lies outside the 95%-CI.
## Posterior probabilities of point hypotheses assume equal prior probabilities.In the Estimate through CI.Upper columns, we got the typical brms summary statistics for model parameters. Those CIs, recall, are ETIs rather than HDIs. To interpret the rest, we read further from the brms reference manual that
the
Evid.Ratiomay sometimes be0orInfimplying very small or large evidence, respectively, in favor of the tested hypothesis. For one-sided hypotheses pairs, this basically means that all posterior samples are on the same side of the value dividing the two hypotheses. In that sense, instead of0orInf, you may rather read it as Evid.Ratio smaller1 / Sor greaterS, respectively, whereSdenotes the number of posterior samples used in the computations.The argument alpha specifies the size of the credible interval (i.e., Bayesian confidence interval). For instance, if we tested a two-sided hypothesis and set
alpha = 0.05(5%) an, the credible interval will contain1 -alpha = 0.95(95%) of the posterior values. Hence,alpha*100% of the posterior values will lie outside of the credible interval. Although this allows testing of hypotheses in a similar manner as in the frequentist null-hypothesis testing framework, we strongly argue against using arbitrary cutoffs (e.g.,p < .05) to determine the ‘existence’ of an effect.
In this case, the entire posterior distribution (i.e., all the iterations of the chains) was below zero and we ended up with an Evid.Ratio = Inf. Our Bayes factor blew up. If we’d like to test a point null hypothesis, we might reformat the equation to \(\theta_\text{Das Kruschke} = \theta_\text{Bach}\).
## Hypothesis Tests for class b:
## Hypothesis Estimate Est.Error CI.Lower CI.Upper Evid.Ratio Post.Prob Star
## 1 (inv_logit_scaled... = 0 -0.15 0.03 -0.22 -0.09 NA NA *
## ---
## 'CI': 90%-CI for one-sided and 95%-CI for two-sided hypotheses.
## '*': For one-sided hypotheses, the posterior probability exceeds 95%;
## for two-sided hypotheses, the value tested against lies outside the 95%-CI.
## Posterior probabilities of point hypotheses assume equal prior probabilities.Here we no longer get summary information in the Evid.Ratio and Post.Prob columns. But we do get that posterior summary information and we also get that little * symbol in the Star column, which was based on the brms default alpha = 0.05.
Let’s see what happens when we test a different kind of directional hypothesis, \(\theta_\text{Motzart} - \theta_\text{Bach} > 0\).
## Hypothesis Tests for class b:
## Hypothesis Estimate Est.Error CI.Lower CI.Upper Evid.Ratio Post.Prob Star
## 1 (inv_logit_scaled... > 0 0.01 0.04 -0.05 0.07 1.41 0.59
## ---
## 'CI': 90%-CI for one-sided and 95%-CI for two-sided hypotheses.
## '*': For one-sided hypotheses, the posterior probability exceeds 95%;
## for two-sided hypotheses, the value tested against lies outside the 95%-CI.
## Posterior probabilities of point hypotheses assume equal prior probabilities.Here we get an underwhelming BF of 1.47. The posterior probability that hypothesis versus its logical alternative is .6. Notice we no longer have a * in the Star column.
12.3 Relations of parameter estimation and model comparison
Back to the text, Kruschke wrapped up this section by explaining
the model comparison focuses on the null value and whether its local probability increases from prior to posterior. The parameter estimation considers the entire posterior distribution, including the uncertainty (i.e., HDI) of the parameter estimate relative to the ROPE.
The derivation of the Bayes’ factor by considering the null value in parameter estimation is known as the Savage-Dickey method. A lucid explanation is provided by Wagenmakers, Lodewyckx, Kuriyal, and Grasman (2010), who also provide some historical references and applications to MCMC analysis of hierarchical models. (pp. 353–354)
Hey, we just read about that Savage-Dickey method when learning about the brms::hypothesis() function!
12.4 Estimation and model comparison?
I’ll leave you to decide. Here’s Kruschke to close us out: “As mentioned above, neither method for null value assessment (parameter estimation or model comparison) is uniquely ‘correct.’ The two approaches merely pose the question of the null value in different ways” (p. 354)
Session info
## R version 3.6.0 (2019-04-26)
## Platform: x86_64-apple-darwin15.6.0 (64-bit)
## Running under: macOS High Sierra 10.13.6
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] patchwork_1.0.0 tidybayes_1.1.0 brms_2.10.3 Rcpp_1.0.2 forcats_0.4.0 stringr_1.4.0
## [7] dplyr_0.8.3 purrr_0.3.3 readr_1.3.1 tidyr_1.0.0 tibble_2.1.3 ggplot2_3.2.1
## [13] tidyverse_1.2.1
##
## loaded via a namespace (and not attached):
## [1] colorspace_1.4-1 ellipsis_0.3.0 ggridges_0.5.1
## [4] rsconnect_0.8.15 ggstance_0.3.2 markdown_1.1
## [7] base64enc_0.1-3 rstudioapi_0.10 rstan_2.19.2
## [10] svUnit_0.7-12 DT_0.9 fansi_0.4.0
## [13] lubridate_1.7.4 xml2_1.2.0 bridgesampling_0.7-2
## [16] knitr_1.23 shinythemes_1.1.2 zeallot_0.1.0
## [19] bayesplot_1.7.0 jsonlite_1.6 broom_0.5.2
## [22] shiny_1.3.2 compiler_3.6.0 httr_1.4.0
## [25] backports_1.1.5 assertthat_0.2.1 Matrix_1.2-17
## [28] lazyeval_0.2.2 cli_1.1.0 later_1.0.0
## [31] htmltools_0.4.0 prettyunits_1.0.2 tools_3.6.0
## [34] igraph_1.2.4.1 coda_0.19-3 gtable_0.3.0
## [37] glue_1.3.1.9000 reshape2_1.4.3 cellranger_1.1.0
## [40] vctrs_0.2.0 nlme_3.1-139 crosstalk_1.0.0
## [43] xfun_0.10 ps_1.3.0 rvest_0.3.4
## [46] mime_0.7 miniUI_0.1.1.1 lifecycle_0.1.0
## [49] gtools_3.8.1 MASS_7.3-51.4 zoo_1.8-6
## [52] scales_1.0.0 colourpicker_1.0 hms_0.4.2
## [55] promises_1.1.0 Brobdingnag_1.2-6 parallel_3.6.0
## [58] inline_0.3.15 shinystan_2.5.0 yaml_2.2.0
## [61] gridExtra_2.3 loo_2.1.0 StanHeaders_2.19.0
## [64] stringi_1.4.3 dygraphs_1.1.1.6 pkgbuild_1.0.5
## [67] rlang_0.4.1 pkgconfig_2.0.3 matrixStats_0.55.0
## [70] HDInterval_0.2.0 evaluate_0.14 lattice_0.20-38
## [73] rstantools_2.0.0 htmlwidgets_1.5 labeling_0.3
## [76] tidyselect_0.2.5 processx_3.4.1 plyr_1.8.4
## [79] magrittr_1.5 R6_2.4.0 generics_0.0.2
## [82] pillar_1.4.2 haven_2.1.0 withr_2.1.2
## [85] xts_0.11-2 abind_1.4-5 modelr_0.1.4
## [88] crayon_1.3.4 arrayhelpers_1.0-20160527 utf8_1.1.4
## [91] rmarkdown_1.13 grid_3.6.0 readxl_1.3.1
## [94] callr_3.3.2 threejs_0.3.1 digest_0.6.21
## [97] xtable_1.8-4 httpuv_1.5.2 stats4_3.6.0
## [100] munsell_0.5.0 shinyjs_1.0