Bab 4 Statistik Ringkasan
//TODO: Membahas tentang statistik ringkasan, cara mendapatkan dan menampilkannya menggunakan R.
Pada Bab ini kita akan menggunakan package {tidyverse}, {scales} dan {e1071}. Pastikan package tersebut sudah terinstall.
library(tidyverse)
library(scales)
library(e1071)Data yang digunakan adalah data dari Flow_Of_Docs terminal JICT selama tahun 2020. Data ini sudah diolah dan disiapkan dalam file “fl_pelatihan.rds”. Oleh karena itu pastikan kita sudah import data tersebut dengan menjalankna perintah berikut ini.
library(readr)
fl_pelatihan <- readr::read_rds("data/fl_pelatihan.rds")Untuk mengetahui banyaknya data/baris/observasi dan kolom/variabel, kita dapat gunakan fungsi dim().
dim(fl_pelatihan)## [1] 71265 23Ada sebanyak 71265 observasi dan 23 variabel pada data ini.
Untuk melihat beberapa baris data, gunakan fungsi head().
head(fl_pelatihan)## # A tibble: 6 x 23
## tanggal container_id berth_time hari_berth waktu_berth iso_code
## <date> <chr> <dttm> <fct> <chr> <chr>
## 1 2019-12-21 APHU6242420 2019-12-20 09:30:20 Jumat 03:00-10:00 45G1
## 2 2019-12-21 APHU6242420 2019-12-20 09:30:20 Jumat 03:00-10:00 45G1
## 3 2019-12-20 APHU6247083 2019-12-20 09:30:20 Jumat 03:00-10:00 4500
## 4 2019-12-31 APHU6363910 2019-12-31 09:25:31 Selasa 03:00-10:00 4500
## 5 2019-12-31 APHU6364578 2019-12-31 09:25:31 Selasa 03:00-10:00 45G1
## 6 2019-12-31 APHU6364578 2019-12-31 09:25:31 Selasa 03:00-10:00 45G1
## # ... with 17 more variables: container_status <chr>, exim <chr>,
## # carrier <chr>, pol <chr>, pod <chr>, nama_negara_asal <chr>,
## # discharge_time <dttm>, stacking_time <dttm>, hari_stacking <fct>,
## # waktu_stacking <chr>, mita_non_mita <chr>, jalur <chr>, flag_lartas <chr>,
## # prenon_nonpre <chr>, postborder <chr>, karantina <chr>, dt <dbl>head(fl_pelatihan, 10)## # A tibble: 10 x 23
## tanggal container_id berth_time hari_berth waktu_berth iso_code
## <date> <chr> <dttm> <fct> <chr> <chr>
## 1 2019-12-21 APHU6242420 2019-12-20 09:30:20 Jumat 03:00-10:00 45G1
## 2 2019-12-21 APHU6242420 2019-12-20 09:30:20 Jumat 03:00-10:00 45G1
## 3 2019-12-20 APHU6247083 2019-12-20 09:30:20 Jumat 03:00-10:00 4500
## 4 2019-12-31 APHU6363910 2019-12-31 09:25:31 Selasa 03:00-10:00 4500
## 5 2019-12-31 APHU6364578 2019-12-31 09:25:31 Selasa 03:00-10:00 45G1
## 6 2019-12-31 APHU6364578 2019-12-31 09:25:31 Selasa 03:00-10:00 45G1
## 7 2019-12-31 APHU6437822 2019-12-31 09:25:31 Selasa 03:00-10:00 45G1
## 8 2019-12-29 APHU6524402 2019-12-29 12:30:29 Minggu 10:00-18:00 4500
## 9 2019-12-25 APHU6584016 2019-12-25 14:15:25 Rabu 10:00-18:00 45G1
## 10 2019-12-20 APHU6601052 2019-12-20 09:30:20 Jumat 03:00-10:00 45G1
## # ... with 17 more variables: container_status <chr>, exim <chr>,
## # carrier <chr>, pol <chr>, pod <chr>, nama_negara_asal <chr>,
## # discharge_time <dttm>, stacking_time <dttm>, hari_stacking <fct>,
## # waktu_stacking <chr>, mita_non_mita <chr>, jalur <chr>, flag_lartas <chr>,
## # prenon_nonpre <chr>, postborder <chr>, karantina <chr>, dt <dbl>4.1 Histogram
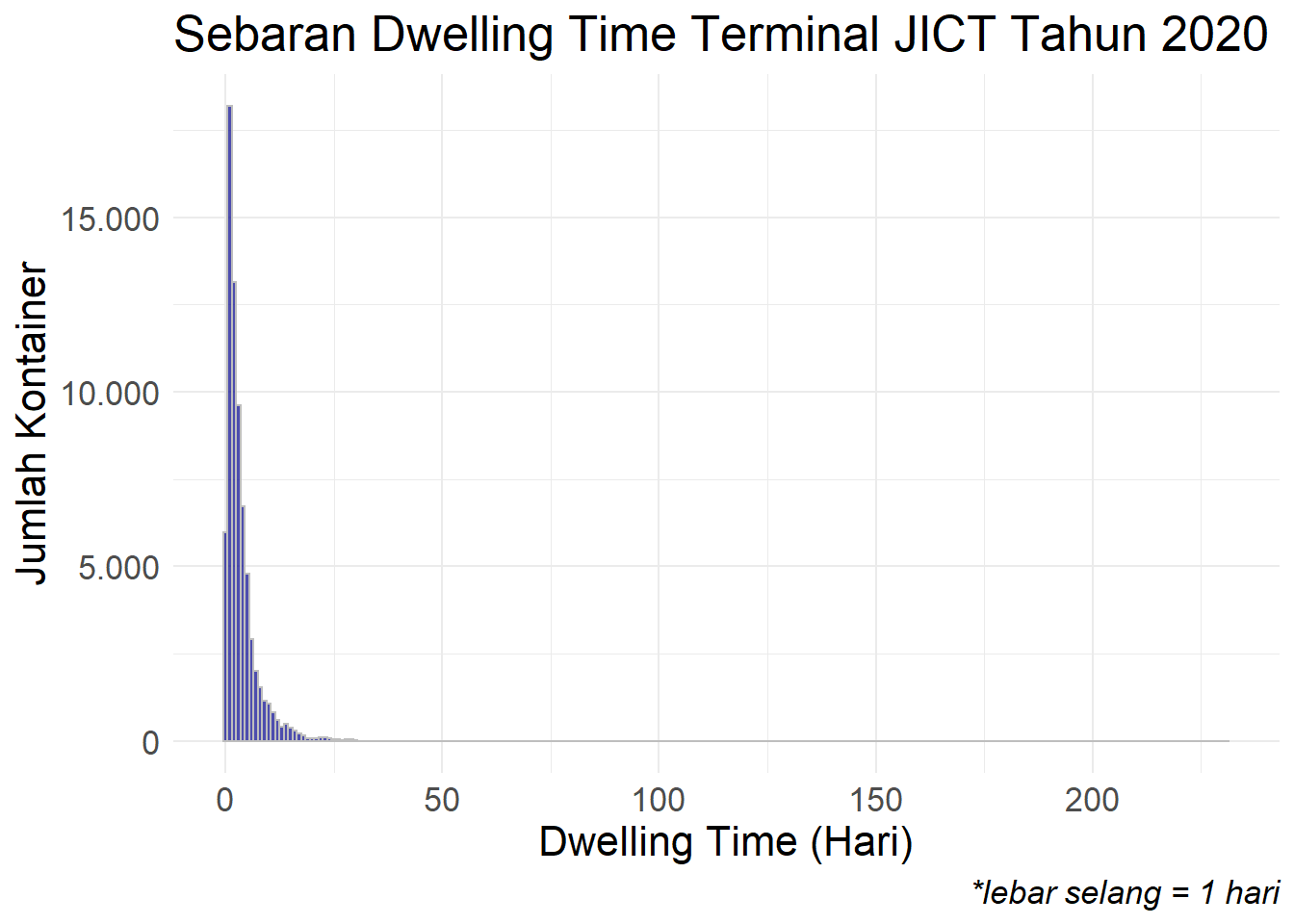
Kita lihat sebaran dari Dwelling Time (DT) terminal JICT selama tahun 2020.
fl_pelatihan %>%
ggplot(mapping = aes(x = dt)) +
geom_histogram(binwidth = 1, fill = "darkblue", color = "grey", alpha = 0.7) +
scale_y_continuous(labels = comma_format(big.mark = ".", decimal.mark = ",")) +
theme_minimal() +
labs(title = "Sebaran Dwelling Time Terminal JICT Tahun 2020",
caption = "*lebar selang = 1 hari",
x = "Dwelling Time (Hari)",
y = "Jumlah Kontainer") +
theme(text = element_text(size = 16),
plot.caption = element_text(face = "italic")
)
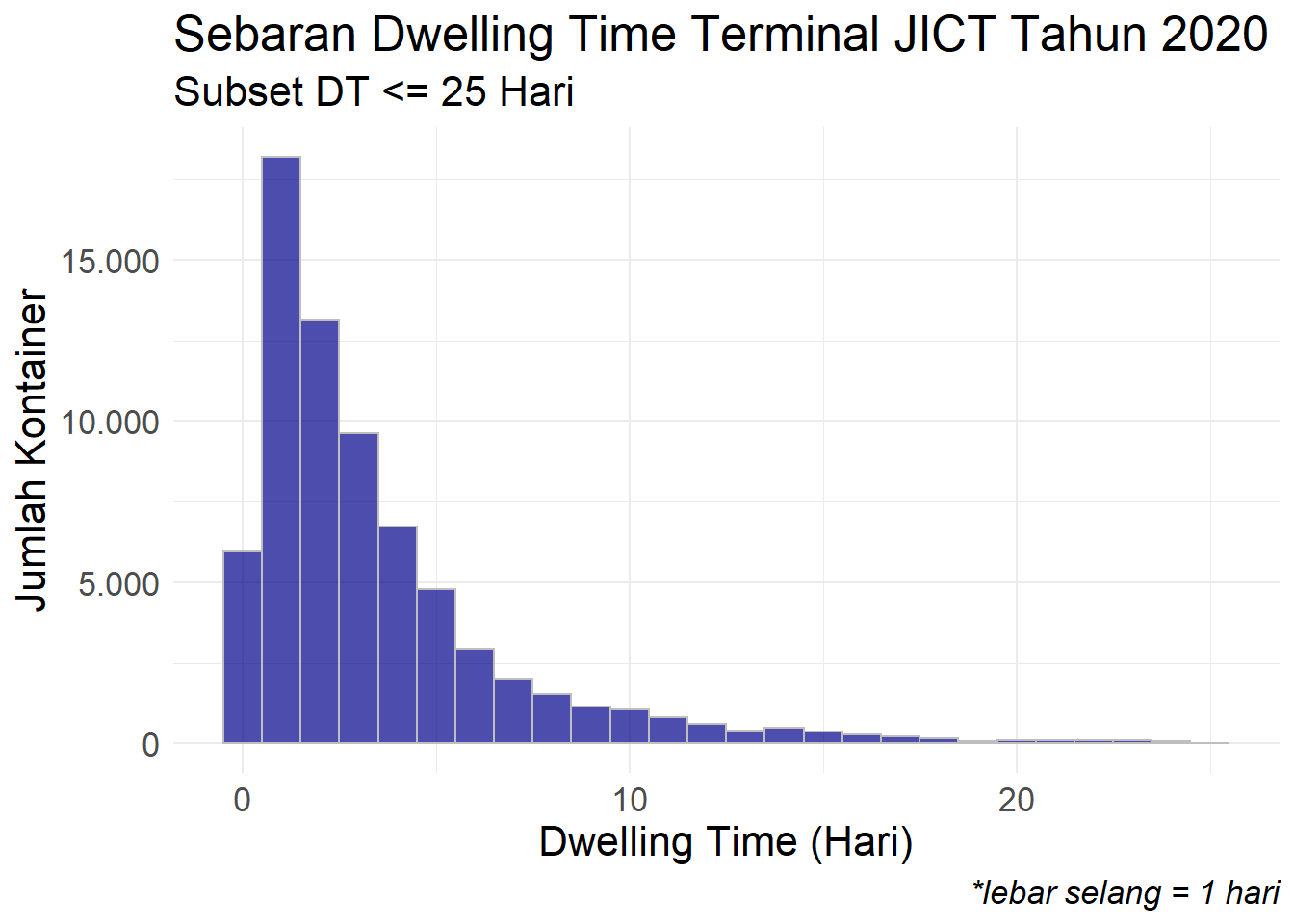
Kita ambil data dengan DT kurang dari atau sama dengan 25 hari kemudian kita lihat histogramnya.
fl_pelatihan %>%
filter(dt <= 25) %>%
ggplot(mapping = aes(x = dt)) +
geom_histogram(binwidth = 1, fill = "darkblue", color = "grey", alpha = 0.7) +
scale_y_continuous(labels = comma_format(big.mark = ".", decimal.mark = ",")) +
theme_minimal() +
labs(title = "Sebaran Dwelling Time Terminal JICT Tahun 2020",
subtitle = "Subset DT <= 25 Hari",
caption = "*lebar selang = 1 hari",
x = "Dwelling Time (Hari)",
y = "Jumlah Kontainer") +
theme(text = element_text(size = 16),
plot.caption = element_text(face = "italic")
)
Berikutnya kita subset lagi untuk data dengan DT kurang dari 5 hari dan lihat sebarannya.
fl_pelatihan %>%
filter(dt < 5) %>%
ggplot(mapping = aes(x = dt)) +
geom_histogram(binwidth = 0.1, fill = "darkblue", color = "grey", alpha = 0.7) +
scale_y_continuous(labels = comma_format(big.mark = ".", decimal.mark = ",")) +
theme_minimal() +
labs(title = "Sebaran Dwelling Time Terminal JICT Tahun 2020",
subtitle = "Subset DT < 5 Hari",
caption = "*lebar selang = 0.1 hari",
x = "Dwelling Time (Hari)",
y = "Jumlah Kontainer") +
theme(text = element_text(size = 16),
plot.caption = element_text(face = "italic")
)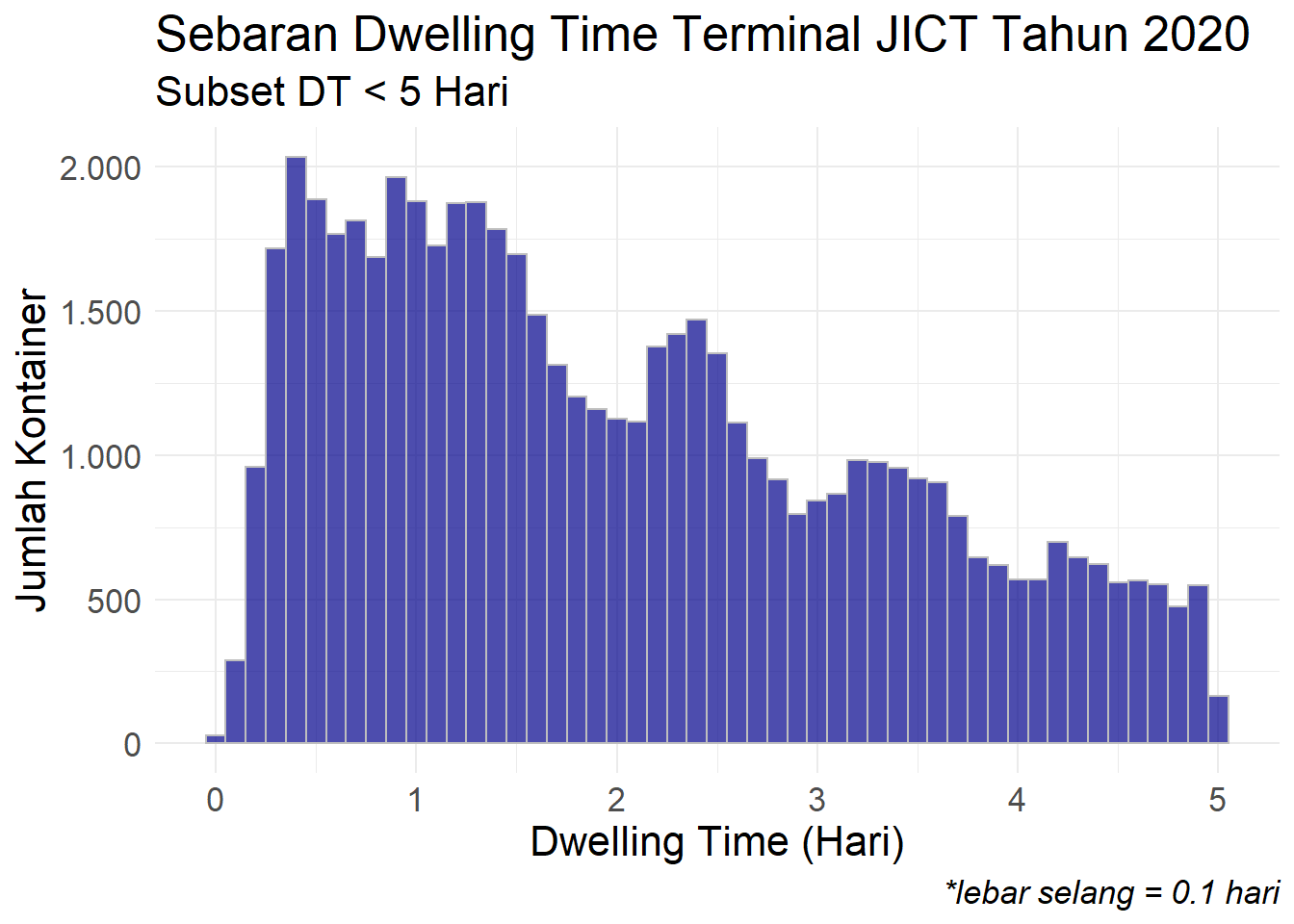 Untuk membuat histogram dari kurva normal kita gunakan perintah berikut ini. Fungsi
Untuk membuat histogram dari kurva normal kita gunakan perintah berikut ini. Fungsi rnorm(100000) adalah untuk membangkitkan bilangan acak dari sebaran Normal sebanyak 100.000 bilangan.
set.seed(1001)
xnorm <- rnorm(100000)
ggplot(data = data.frame(x = xnorm), mapping = aes(x)) +
geom_histogram(fill = "darkblue", color = "grey", alpha = 0.7) +
labs(x = NULL,
y = "frekuensi") +
theme_minimal() ## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
4.2 Data Numerik
Yang pertama kita akan membahas statistik ringkasan untuk data numerik.
4.2.1 Ukuran Pemusatan
4.2.1.1 Rataan
Rataan atau rata-rata (mean), dinotasikan dengan ˉx, dapat diperoleh dengan cara berikut ini.
ˉx=x1+x2+x3+x4+⋯+xnn=1nn∑i=1xi dengan n adalah banyaknya data.
Misalkan sebuah vector x berisi nilai x = {1, 3, 5, 2, 4, 6, 9}. Maka rataan dari x adalah
ˉx=1+3+5+2+4+6+97=307=4.285714
Gunakan fungsi mean() untuk memperoleh rataan.
x <- c(1, 3, 5, 2, 4, 6, 9)
sum(x)/length(x)## [1] 4.285714mean(x)## [1] 4.285714Sekarang giliran Anda mencoba, berapakah nilai rataan dari Dwelling Time (DT) terminal JICT selama tahun 2020?
mean(fl_pelatihan$dt)## [1] 3.5746394.2.1.2 Median
Median (Me) adalah nilai yang berada pada posisi tengah-tengah setelah data diurutkan. Jika banyaknya data adalah ganjil maka posisinya ada di tengah, sedangkan jika banyaknya data adalah genap maka hitung nilai rataan dari dua data yang berada di tengah.
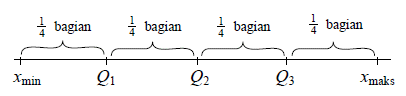
Misal x berisi data {1, 3, 5, 2, 4, 6, 9} maka median dari x adalah
x' = {1, 2, 3, 4, 5, 6, 9}
Me = 4
Di R Anda dapat gunakan fungsi median() untuk mendapatkan nilai tersebut dengan mudah.
x <- c(1, 3, 5, 2, 4, 6, 9)
median(x)## [1] 4Untuk x adalah data dengan banyaknya data adalah genap {1, 3, 5, 2, 4, 6} maka median dari x adalah
x' = {1, 2, 3, 4, 5, 6}
Me = (3 + 4)/2 = 3.5
x <- c(1, 3, 5, 2, 4, 6)
median(x)## [1] 3.5Berapakah nilai median dari DT terminal JICT selama tahun 2020?
median(fl_pelatihan$dt)## [1] 2.39Jadi 50% amatan/kontainer yang masuk ke terminal JICT selama tahun 2020 memiliki DT di bawah 2.39 hari dan 50% amatan/kontainer lainnya memiliki DT di atas 2.39 hari.
4.2.1.3 Modus
Modus adalah nilai yang paling banyak muncul di dalam gugus data. R tidak tersedia fungsi untuk mendapatkan modus, sehingga kita perlu membuat fungsi sendiri. Berikut ini fungsi yang dapat digunakan untuk mengetahui nilai modus dari gugus data.
modus <- function(x, return_multiple = FALSE, na.rm = FALSE) {
if(na.rm){
x <- na.omit(x)
}
ux <- unique(x)
freq <- tabulate(match(x, ux))
mode_loc <- if(return_multiple) which(freq == max(freq)) else which.max(freq)
return(ux[mode_loc])
}set.seed(1001)
x <- sample(1:10, 500, replace = TRUE)
table(x)## x
## 1 2 3 4 5 6 7 8 9 10
## 40 45 58 47 56 58 55 46 54 41Dengan fungsi modus() diperoleh nilai modus
modus(x)## [1] 3Untuk tetap mendapatkan semua nilai modus jika ada lebih dari satu modus maka gunakan argumen return_multiple = TRUE.
modus(x, return_multiple = TRUE)## [1] 3 6Berpakah modus dari DT terminal JICT selama tahun 2020?
modus(fl_pelatihan$dt)## [1] 0.42modus(fl_pelatihan$dt, return_multiple = TRUE)## [1] 0.42 0.354.2.2 Ukuran Penyebaran
4.2.2.1 Range
Range adalah selisih nilai terbesar dan terkecil pada suatu gugus data.
Range=Xmax−Xmin
Pada program R, fungsi range() menghasilkan dua nilai, yaitu Xmin dan Xmax.
range(x)## [1] 1 10Jika ingin mendapatkan nilai range yang berupa selisih antara dua nilai tersebut kita dapat gunakan fungsi diff()
diff(range(x))## [1] 9Berapa range dari DT terminal JICT selama tahun 2020?
range(fl_pelatihan$dt)## [1] 0.00 230.71diff(range(fl_pelatihan$dt))## [1] 230.714.2.2.2 Inter-Quartile Range
Inter-Quartile Range atau Jangkauan Antar Kuartil diperoleh dengan cara
IQR=Q3−Q1
Dengan program R kita gunakan fungsi quantile() untuk mendapatkan nilai Q1 dan Q3. Karena Q1 adalah data ke 25% dan Q3 adalah data ke 75%, maka kita tuliskan pada argumen probs.
set.seed(1001)
x <- sample(1:10, 500, replace = TRUE)
IQR <- quantile(x, probs = c(0.25, 0.75))
IQR## 25% 75%
## 3 8diff(IQR)## 75%
## 5Untuk mendapatkan nilai-nilai tersebut dapat menggunakan fungsi summary().
summary(x)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.000 3.000 6.000 5.538 8.000 10.000Mari kita lihat summary dari DT terminal JICT selama tahun 2020.
summary(fl_pelatihan$dt)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.000 1.160 2.390 3.575 4.470 230.7104.2.2.3 Ragam dan Simpangan Baku
Ragam dari data contoh dapat dihitung dengan
s2=1n−1n∑i=1(xi−ˉx)2
Dengan program R dapat diperoleh dengan fungsi var().
var(x)## [1] 7.535627Karena simpangan baku contoh adalah akar kuadrat dari ragam maka diperoleh dengan
s=√s2
sedangkan dengan R dapat diperoleh menggunakan fungsi sqrt() dari hasil var() atau langsung dengan fungsi sd().
sqrt(var(x))## [1] 2.74511sd(x)## [1] 2.74511Berapakah ragam dan simpangan baku dari DT terminal JICT selama tahun 2020?
var(fl_pelatihan$dt)## [1] 15.6407sd(fl_pelatihan$dt)## [1] 3.9548334.2.3 Ukuran Bentuk Sebaran
4.2.3.1 Skewness
Formula untuk mendapatkan nilai skewness adalah
skewness=∑ni=1(xi−ˉx)3n×s3
Untuk memperoleh nilai skewness kita perlu fungsi dari package {e1071}, yaitu fungsi skewness().
x <- rexp(1000)library(e1071)
skewness(x)## [1] 1.907461Untuk skewness dengan koefisien Fisher-Pearson
skewness=√n(n−1)n−2×∑ni=1(xi−ˉx)3n×s3
skewness(x, type = 2)## [1] 1.913197Karena skewness bernilai positif artinya bentuk sebaran data lebih menjulur ke kanan. Untuk melihatnya kita dapat memmbuat histogram dari data tersebut.
data.frame(x = x) %>%
ggplot(mapping = aes(x)) +
geom_histogram(bins = 6, fill = "grey", color = "white") +
theme_minimal()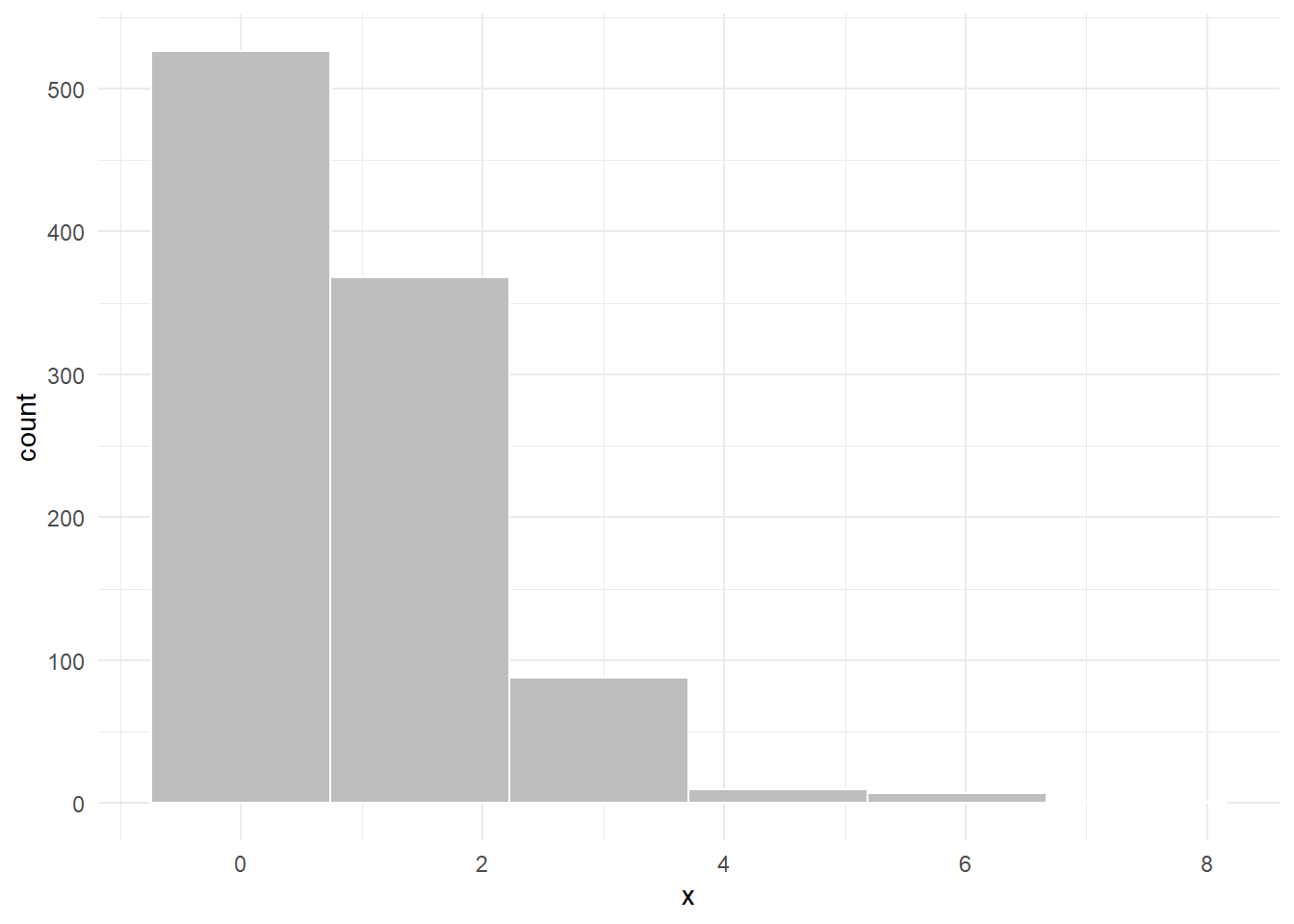
Pada data yang menulur ke sebelah kiri
data.frame(x = -x) %>%
ggplot(mapping = aes(x)) +
geom_histogram(bins = 6, fill = "grey", color = "white") +
theme_minimal()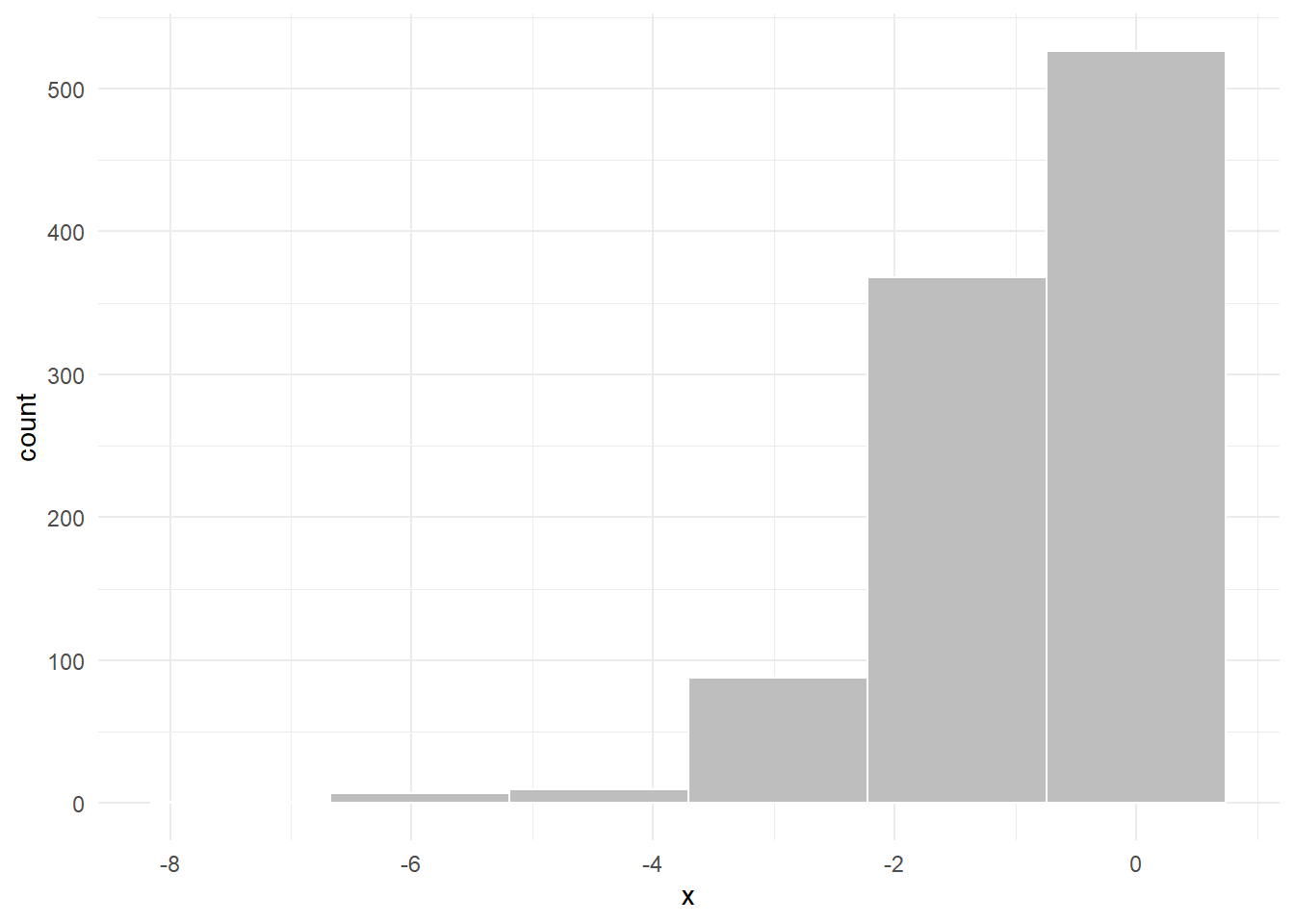
skewness(-x)## [1] -1.907461Berapa nilai skewness dari DT terminal JICT selama tahun 2020?
skewness(fl_pelatihan$dt)## [1] 5.2736194.2.3.2 Kurtosis
Formula kurtosis yang digunakan secara default pada fungsi kurtosis() dari package {e1071} adalah
kurtosis=∑ni=1(xi−ˉx)4n×s4−3
set.seed(1001)
x <- rnorm(100000)
data.frame(x = x) %>%
ggplot(mapping = aes(x = x)) +
geom_histogram(bins = 30, fill = "darkblue", color = "grey", alpha = 0.7) +
theme_minimal()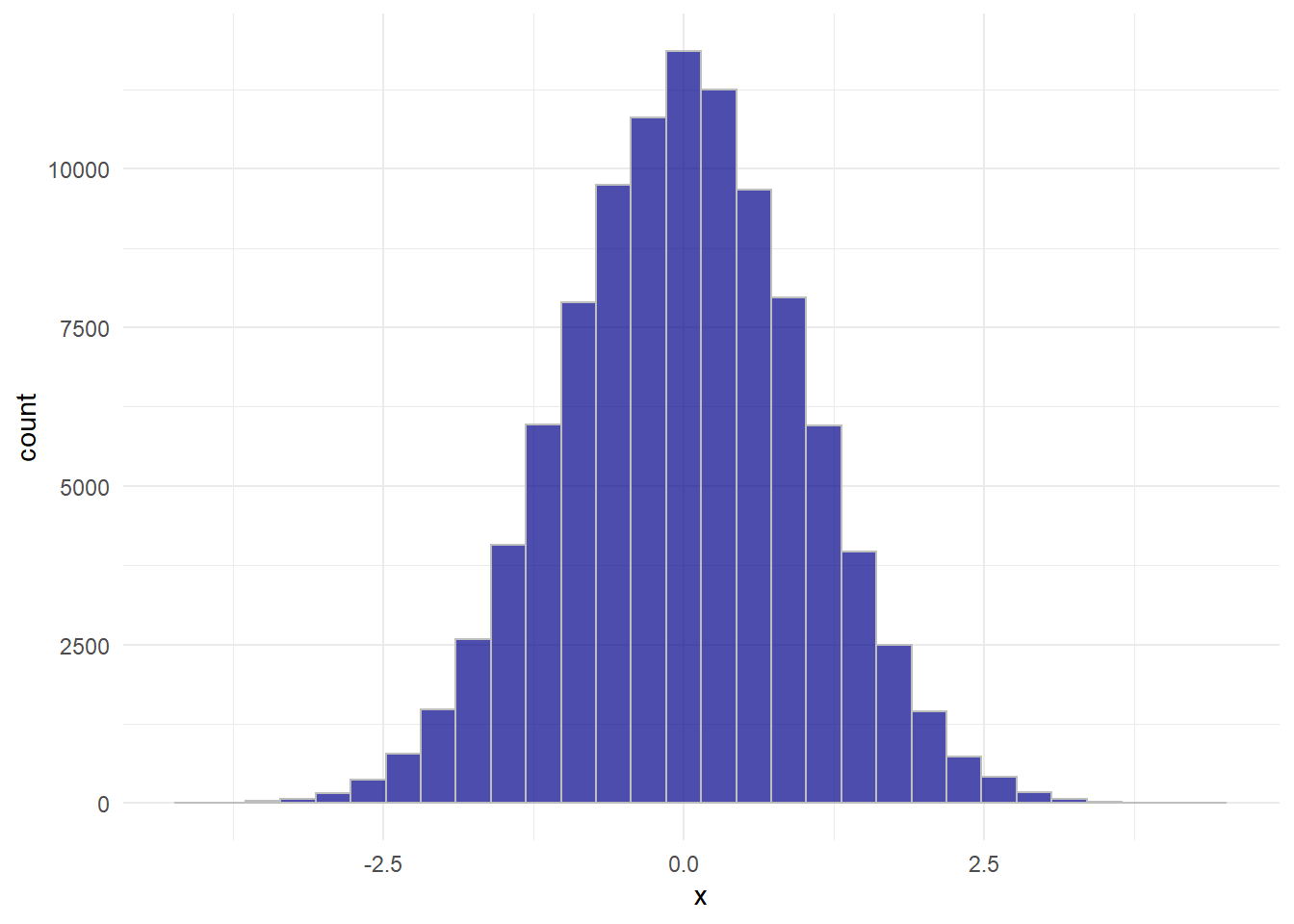
kurtosis(x)## [1] 0.002579773Berapa nilai kurtosis dari DT terminal JICT selama tahun 2020 dan apa artinya?
kurtosis(fl_pelatihan$dt)## [1] 163.1807Kurtosis bernilai positif dan nilainya pun cukup tinggi, artinya ekor sebaran data sangat kurus dibandingkan sebaran normal.
4.3 Data Kategorik
Statistik ringkasan pada data kategorik pertama dan paling sering digunakan adalah menghitung banyaknya kategori atau kelas pada sebuah gugus data. Misalnya pada data fl_pelatihan ada variable kategorik, diantaranya yaitu jalur. Untuk mendapatkan banyaknya amatan pada masing-masing jalur, kita dapat gunakan perintah berikut ini.
fl_pelatihan %>%
count(jalur)## # A tibble: 3 x 2
## jalur n
## <chr> <int>
## 1 HIJAU 67255
## 2 KUNING 546
## 3 MERAH 3464Hasil seperti di atas juga sering disebut sebagai tabel frekuensi. Untuk mengetahui proporsi atau persentase dai masing-masing kategori terhadap total data gunakan perintah berikut ini.
fl_pelatihan %>%
count(jalur) %>%
mutate(persentase = n/sum(n))## # A tibble: 3 x 3
## jalur n persentase
## <chr> <int> <dbl>
## 1 HIJAU 67255 0.944
## 2 KUNING 546 0.00766
## 3 MERAH 3464 0.0486Kita dapat visualisasikan dalam bentuk diagram batang atau bar chart.
fl_pelatihan %>%
count(jalur) %>%
mutate(pct = round(n/sum(n)*100, 2)) %>%
ggplot(mapping = aes(x = reorder(jalur, -n), y = n, fill = jalur, color = jalur)) +
geom_bar(stat = "identity") +
geom_text(aes(label = paste0(pct, "%")), color = "black", vjust = -0.25, size = 8) +
scale_y_continuous(labels = scales::comma_format(big.mark = ".", decimal.mark = ","),
limits = c(0, 70000)) +
scale_fill_manual(values = c("MERAH" = "red",
"KUNING" = "yellow",
"HIJAU" = "green")) +
scale_color_manual(values = c("MERAH" = "red",
"KUNING" = "yellow",
"HIJAU" = "green")) +
labs(x = "Jalur",
y = "Jumlah Kontainer") +
theme_minimal() +
theme(legend.position = "none",
text = element_text(size = 16),
panel.grid.minor = element_blank())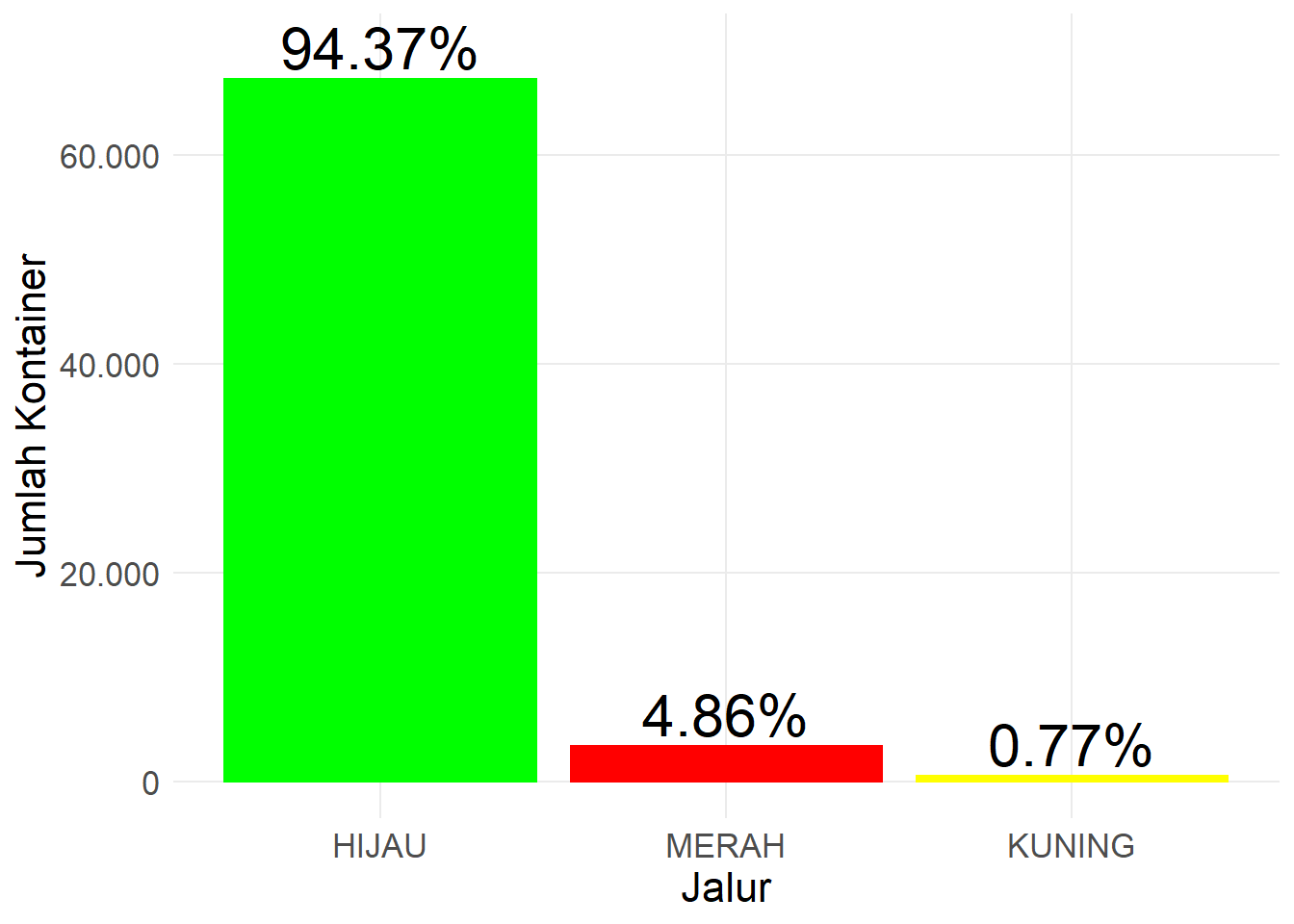
Kita dapat menghitung rataan harga rumah yang terjual berdasarkan banyaknya kamar tidur.
fl_pelatihan %>%
group_by(jalur) %>%
summarise(avg_dt = mean(dt)) %>%
ungroup()## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 3 x 2
## jalur avg_dt
## <chr> <dbl>
## 1 HIJAU 3.17
## 2 KUNING 6.93
## 3 MERAH 10.8Tentunya seperti yang sudah diketahui bahwa rataan DT untuk kontainer yang melalui jalur Hijau lebih kecil (lebih cepat) dibandingkan dengan jalur yang lain. Kita bisa juga menampilkannya menggunakan barplot.
fl_pelatihan %>%
group_by(jalur) %>%
summarise(avg_dt = mean(dt)) %>%
ungroup() %>%
ggplot(mapping = aes(x = jalur, y = avg_dt, fill = jalur, color = jalur)) +
geom_col(alpha = 0.7) +
scale_fill_manual(values = c("MERAH" = "red",
"KUNING" = "yellow",
"HIJAU" = "green")) +
scale_color_manual(values = c("MERAH" = "red",
"KUNING" = "yellow",
"HIJAU" = "green")) +
labs(x = "Jalur",
y = "Rataan DT (Hari)") +
theme_minimal() +
theme(legend.position = "none",
text = element_text(size = 16),
panel.grid.minor = element_blank())## `summarise()` ungrouping output (override with `.groups` argument)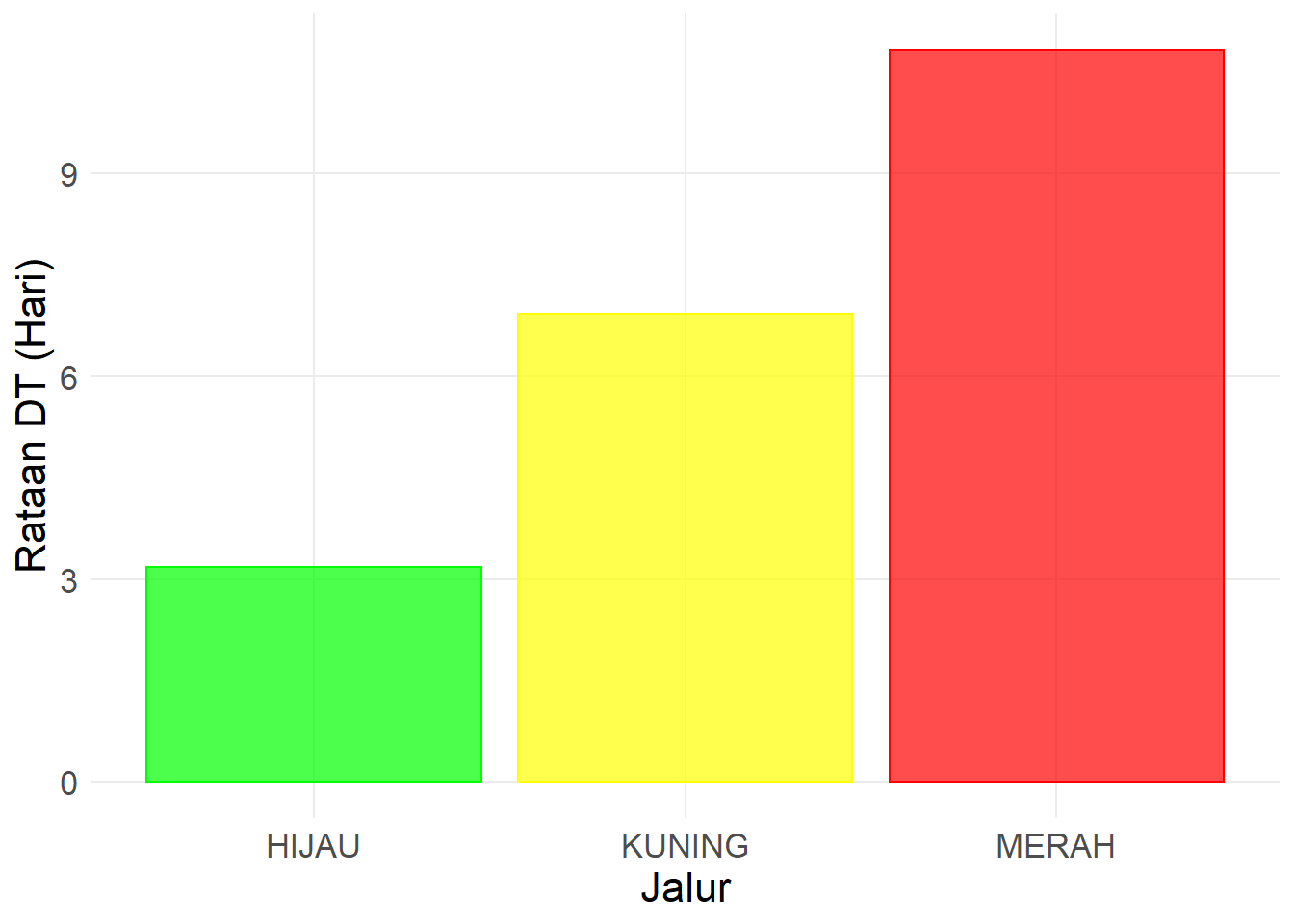
Misalnya kita juga ingin mengetahui frekuensi banyaknya kontainer berdasarkan jalur dan lartas.
fl_pelatihan %>%
group_by(jalur, flag_lartas) %>%
summarise(n = n()) %>%
ungroup()## `summarise()` regrouping output by 'jalur' (override with `.groups` argument)## # A tibble: 6 x 3
## jalur flag_lartas n
## <chr> <chr> <int>
## 1 HIJAU N 42548
## 2 HIJAU Y 24707
## 3 KUNING N 456
## 4 KUNING Y 90
## 5 MERAH N 2718
## 6 MERAH Y 746Tampilannya akan lebih mudah dibaca jika kita buat menjadi tabulasi silang.
fl_pelatihan %>%
group_by(jalur, flag_lartas) %>%
summarise(n = n()) %>%
pivot_wider(id_cols = jalur,
names_from = flag_lartas,
names_prefix = "lartas ",
values_from = n,
values_fill = 0)## `summarise()` regrouping output by 'jalur' (override with `.groups` argument)## # A tibble: 3 x 3
## # Groups: jalur [3]
## jalur `lartas N` `lartas Y`
## <chr> <int> <int>
## 1 HIJAU 42548 24707
## 2 KUNING 456 90
## 3 MERAH 2718 746Atau kita lihat dalam nilai proporsinya.
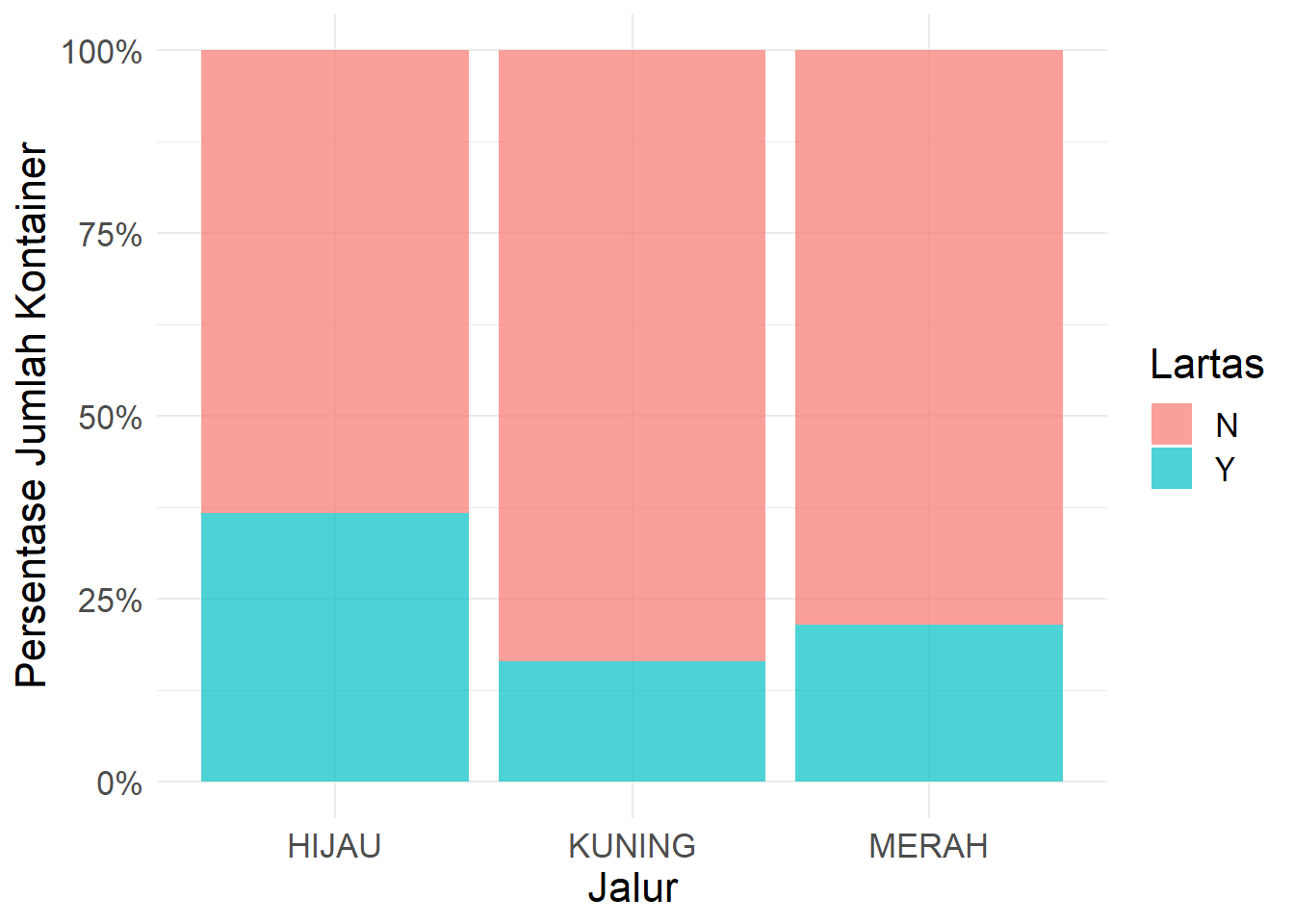
fl_pelatihan %>%
group_by(jalur, flag_lartas) %>%
summarise(n = n()) %>%
mutate(persentase = n/sum(n))## `summarise()` regrouping output by 'jalur' (override with `.groups` argument)## # A tibble: 6 x 4
## # Groups: jalur [3]
## jalur flag_lartas n persentase
## <chr> <chr> <int> <dbl>
## 1 HIJAU N 42548 0.633
## 2 HIJAU Y 24707 0.367
## 3 KUNING N 456 0.835
## 4 KUNING Y 90 0.165
## 5 MERAH N 2718 0.785
## 6 MERAH Y 746 0.215fl_pelatihan %>%
group_by(jalur, flag_lartas) %>%
summarise(n = n()) %>%
mutate(persentase = n/sum(n)) %>%
pivot_wider(id_cols = jalur,
names_from = flag_lartas,
names_prefix = "lartas ",
values_from = persentase,
values_fill = 0)## `summarise()` regrouping output by 'jalur' (override with `.groups` argument)## # A tibble: 3 x 3
## # Groups: jalur [3]
## jalur `lartas N` `lartas Y`
## <chr> <dbl> <dbl>
## 1 HIJAU 0.633 0.367
## 2 KUNING 0.835 0.165
## 3 MERAH 0.785 0.215Agar hasilnya lebih enak dilihat, kita tampilkan hanya dua angka dibelakang desimal dengan fungsi round().
fl_pelatihan %>%
group_by(jalur, flag_lartas) %>%
summarise(n = n()) %>%
mutate(persentase = round(n/sum(n)*100, 2)) %>%
pivot_wider(id_cols = jalur,
names_from = flag_lartas,
names_prefix = "lartas ",
values_from = persentase,
values_fill = 0)## `summarise()` regrouping output by 'jalur' (override with `.groups` argument)## # A tibble: 3 x 3
## # Groups: jalur [3]
## jalur `lartas N` `lartas Y`
## <chr> <dbl> <dbl>
## 1 HIJAU 63.3 36.7
## 2 KUNING 83.5 16.5
## 3 MERAH 78.5 21.5Visualisasi berupa stacked barplot.
fl_pelatihan %>%
group_by(jalur, flag_lartas) %>%
summarise(n = n()) %>%
mutate(persentase = round(n/sum(n), 4)) %>%
ggplot(mapping = aes(x = jalur, y = persentase, fill = flag_lartas)) +
geom_col(alpha = 0.7) +
scale_y_continuous(labels = scales::percent_format()) +
labs(x = "Jalur",
y = "Persentase Jumlah Kontainer",
fill = "Lartas") +
theme_minimal() +
theme(text = element_text(size = 16))## `summarise()` regrouping output by 'jalur' (override with `.groups` argument)