Bab 5 Pembandingan
//TODO: Membahas pembandingan nilai kelompok menggunakan R.
Pada Bab ini kita akan menggunakan package {tidyverse} dan {scales}. Pastikan package tersebut sudah terinstall.
library(tidyverse)
library(scales)Data yang digunakan adalah data dari Flow_Of_Docs terminal JICT selama tahun 2020. Data ini sudah diolah dan disiapkan dalam file “fl_pelatihan.rds”. Oleh karena itu pastikan kita sudah import data tersebut dengan menjalankna perintah berikut ini.
library(readr)
fl_pelatihan <- readr::read_rds("data/fl_pelatihan.rds")Kita dapat mengetahui perbedaan nilai statistik berdasarkan kelompok dari kategori dengan menggunakan cara berikut ini. Karena variable banyaknya kamar tidur dan kamar mandi adalah diskret, maka untuk contoh kali ini kita anggap sebagai kategorik. Misalnya kita ingin tahu perbedaan rataan Dwelling Time (DT) terminal JICT selama tahun 2020 berdasarkan jalur.
fl_pelatihan %>%
group_by(jalur) %>%
summarise(avg_dt = mean(dt))## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 3 x 2
## jalur avg_dt
## <chr> <dbl>
## 1 HIJAU 3.17
## 2 KUNING 6.93
## 3 MERAH 10.8fl_pelatihan %>%
filter(dt <= 25) %>%
ggplot(mapping = aes(x = jalur, y = dt, fill = jalur)) +
geom_boxplot(alpha = 0.7) +
scale_fill_manual(values = c("MERAH" = "red",
"KUNING" = "yellow",
"HIJAU" = "green")) +
labs(title = "Perbedaan Sebaran Dwelling Time Berdasarkan Jalur",
subtitle = "Subset DT <= 25 Hari",
x = "Jalur",
y = "Dwelling Time (Hari)") +
coord_flip() +
theme_minimal() +
theme(legend.position = "none", text = element_text(size = 16))
fl_pelatihan %>%
filter(dt <= 25) %>%
ggplot(mapping = aes(x = dt, fill = jalur, color = jalur)) +
geom_density(alpha = 0.7) +
scale_fill_manual(values = c("MERAH" = "red",
"KUNING" = "yellow",
"HIJAU" = "green")) +
scale_color_manual(values = c("MERAH" = "red",
"KUNING" = "yellow",
"HIJAU" = "green")) +
labs(title = "Density Plot Dwelling Time JICT 2020",
subtitle = "Subset DT <= 25 Hari",
x = "Dwelling Time (Hari)",
y = "Density") +
theme_minimal() +
theme(legend.position = "none", text = element_text(size = 16))
Seperti yang sudah dijelaskan di bab sebelumnya, hasil di atas sesuai dengan yang diharapkan yaitu rataan DT pada jalur Hijau lebih tinggi. Sekarang bagaimana jika dilihat berdasarkan ketgori pada variabel mita_non_mita.
fl_pelatihan %>%
group_by(mita_non_mita) %>%
summarise(avg_dt = mean(dt))## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 2 x 2
## mita_non_mita avg_dt
## <chr> <dbl>
## 1 MITA 2.34
## 2 NON MITA 4.05Rataan DT selama tahun 2020 di terminal JICT untuk Mitra Utama (MITA) lebih kecil dibandingkan dengan NON MITA.
Bagaimana jika dilihat berdasarkan negara asal?
fl_pelatihan %>%
group_by(prenon_nonpre) %>%
summarise(avg_dt = mean(dt)) %>%
arrange(avg_dt)## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 2 x 2
## prenon_nonpre avg_dt
## <chr> <dbl>
## 1 PRENO 1.62
## 2 NON_PRENO 4.83Rataan DT untuk kontainer PRENO yang masuk ke terminal JICT selama tahun 2020 lebih cepat dibandingkan dengan NON_PRE.
Bagaimana jika melihat rataan DT berdasarkan lebih dari satu variable kategorik sekaligus?
fl_pelatihan %>%
group_by(jalur, mita_non_mita) %>%
summarise(avg_dt = mean(dt))## `summarise()` regrouping output by 'jalur' (override with `.groups` argument)## # A tibble: 4 x 3
## # Groups: jalur [3]
## jalur mita_non_mita avg_dt
## <chr> <chr> <dbl>
## 1 HIJAU MITA 2.34
## 2 HIJAU NON MITA 3.53
## 3 KUNING NON MITA 6.93
## 4 MERAH NON MITA 10.8Tampilan akan lebih mudah dilihat jika dibuat tabulasi silang seperti berikut. Kita dapat lakukan pivoting data sehingga isi dari variable mita_non_mita menjadi nama variable. Perhatikan hasil berikut ini.
fl_pelatihan %>%
group_by(jalur, mita_non_mita) %>%
summarise(avg_dt = round(mean(dt), 2)) %>%
pivot_wider(id_cols = jalur,
names_from = mita_non_mita,
values_from = avg_dt,
values_fill = 0)## `summarise()` regrouping output by 'jalur' (override with `.groups` argument)## # A tibble: 3 x 3
## # Groups: jalur [3]
## jalur MITA `NON MITA`
## <chr> <dbl> <dbl>
## 1 HIJAU 2.34 3.53
## 2 KUNING 0 6.93
## 3 MERAH 0 10.8Hasilnya diurutkan berdasarkan nama negara secara alfabet.
Dengan membuat visualisasi yang baik dan benar umunya akan diperoleh informasi yang lebih lengkap.
fl_pelatihan %>%
group_by(jalur, mita_non_mita) %>%
summarise(avg_dt = round(mean(dt), 2)) %>%
ggplot(mapping = aes(x = mita_non_mita, y = avg_dt, fill = jalur)) +
geom_col(alpha = 0.7, position = position_dodge()) +
geom_text(aes(label = avg_dt), position = position_dodge(0.9), vjust = -0.25) +
scale_fill_manual(values = c("MERAH" = "red",
"KUNING" = "yellow",
"HIJAU" = "green")) +
labs(x = "Mitra Utama",
y = "Rataan DT (Hari)",
fill = "Jalur") +
theme_minimal()## `summarise()` regrouping output by 'jalur' (override with `.groups` argument)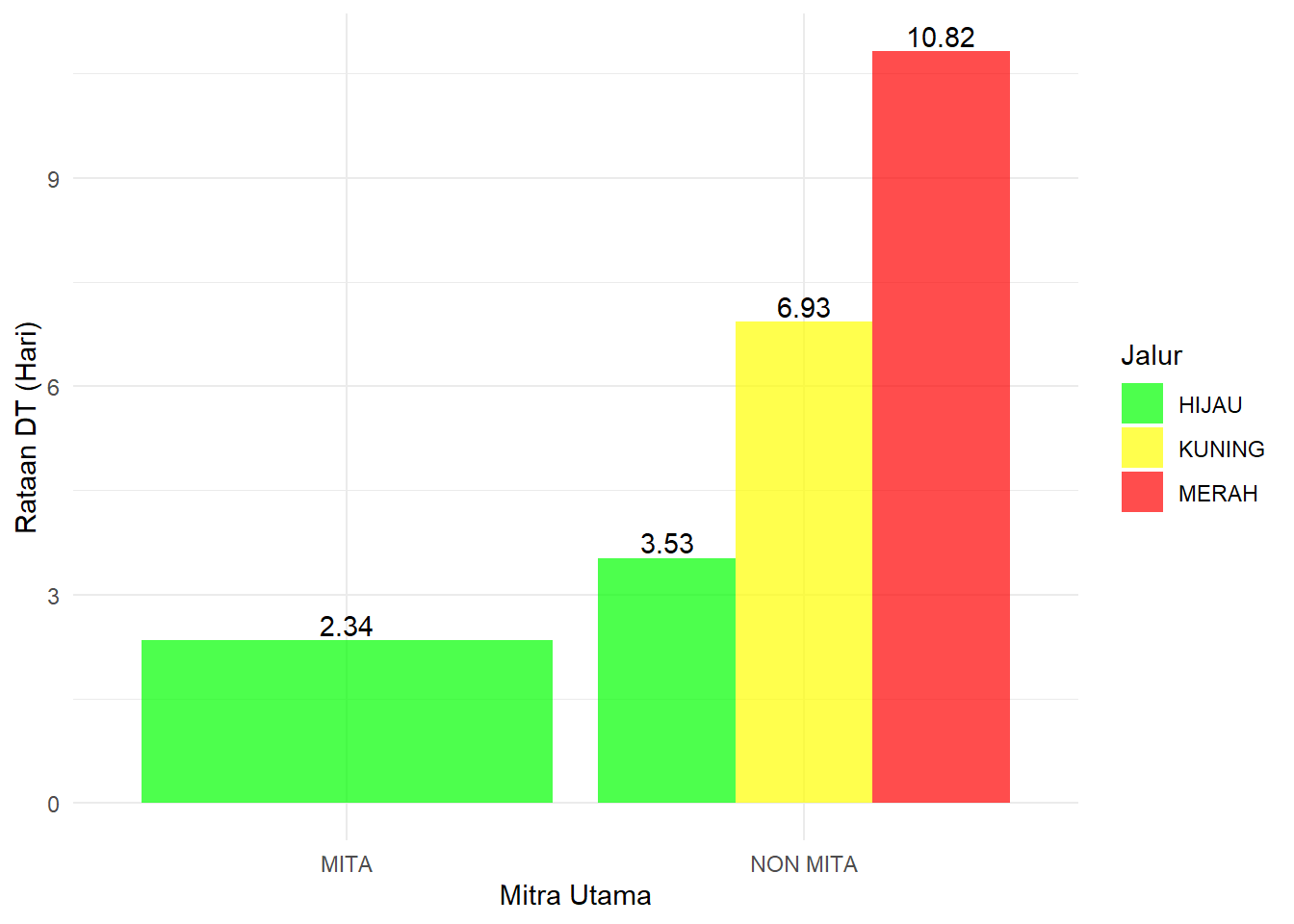
Kontainer dari Mitra Utama hanya melalui jalur Hijau dengan rataan DT sekitar 2,34 hari. Non Mita terbagi menjadi tiga jalur, yaitu Hijau, Kuning dan Merah dengan rataan DT masing-masing sebesar 3,53, 6,93, dan 10,82 hari.