Bab 8 Pemodelan Berbasis Classification Tree dan Machine Learning
Pada subbab ini kita akan membahas beberapa cara membuat model regresi menggunakan R. Kita aktifkan terlebih dahulu package yang dibutuhkan.
library(readr)
library(rpart)
library(rpart.plot)
library(ranger)
library(tidyverse)
library(tidymodels)8.1 Import Data
Data yang digunakan adalah data dari Flow_Of_Docs terminal JICT selama tahun 2020. Data ini sudah diolah dan disiapkan dalam file “fl_pelatihan.rds”. Oleh karena itu pastikan kita sudah import data tersebut dengan menjalankna perintah berikut ini.
jict <- readr::read_rds("data/fl_pelatihan.rds")
jict <- jict %>%
# Pilih data kontainer dengan DT lebih dari nol (0)
filter(dt > 0) %>%
transmute(hari_berth,
waktu_berth,
hari_stacking,
waktu_stacking,
iso_code,
container_status,
exim,
nama_negara_asal,
mita_non_mita,
jalur,
flag_lartas,
prenon_nonpre,
postborder,
# Mengganti nilai [NULL] pada variabel karantina menjadi "NON KARANTINA"
karantina = case_when(karantina == "[NULL]" ~ "NON KARANTINA",
TRUE ~ karantina),
dt
) %>%
# Buang observasi jika minimal ada salah satu nilai yang NA (missing)
drop_na()
# Banyaknya observasi (baris) dan variable (kolom)
dim(jict)## [1] 71261 15Kita lihat struktur datanya menggunakan fungsi glimpse() dari package {dplyr}.
dplyr::glimpse(jict)## Rows: 71,261
## Columns: 15
## $ hari_berth <fct> Jumat, Jumat, Jumat, Selasa, Selasa, Selasa, Selas...
## $ waktu_berth <chr> "03:00-10:00", "03:00-10:00", "03:00-10:00", "03:0...
## $ hari_stacking <fct> Sabtu, Sabtu, Jumat, Selasa, Selasa, Selasa, Selas...
## $ waktu_stacking <chr> "03:00-10:00", "03:00-10:00", "10:00-18:00", "10:0...
## $ iso_code <chr> "45G1", "45G1", "4500", "4500", "45G1", "45G1", "4...
## $ container_status <chr> "F", "F", "F", "F", "F", "F", "F", "F", "F", "F", ...
## $ exim <chr> "I", "I", "I", "I", "I", "I", "I", "I", "I", "I", ...
## $ nama_negara_asal <chr> "China", "China", "China", "China", "China", "Chin...
## $ mita_non_mita <chr> "NON MITA", "NON MITA", "NON MITA", "NON MITA", "N...
## $ jalur <chr> "HIJAU", "HIJAU", "HIJAU", "HIJAU", "HIJAU", "HIJA...
## $ flag_lartas <chr> "N", "N", "N", "N", "Y", "Y", "Y", "Y", "N", "N", ...
## $ prenon_nonpre <chr> "NON_PRENO", "NON_PRENO", "NON_PRENO", "NON_PRENO"...
## $ postborder <chr> "POST-BORDER", "POST-BORDER", "NON", "NON", "BORDE...
## $ karantina <chr> "NON KARANTINA", "NON KARANTINA", "NON KARANTINA",...
## $ dt <dbl> 14.13, 14.13, 14.53, 3.52, 3.33, 3.33, 2.53, 4.54,...8.2 Split Data: train dan test
Kita bagi dua data tersebut secara acak menjadi train dan test dengan proporsi sekitar 70% untuk data train dan sekitar 30% sisanya ke dalam data test.
# Pilih kontainer dengan DT <= 4
jict <- jict %>%
filter(dt <= 4)
set.seed(1001)
jict_split <- rsample::initial_split(data = jict,
prop = 0.7)
# ambil data bagian training
jict_train <- jict_split %>%
rsample::training()
dplyr::glimpse(jict_train)## Rows: 35,411
## Columns: 15
## $ hari_berth <fct> Selasa, Selasa, Selasa, Selasa, Selasa, Jumat, Rab...
## $ waktu_berth <chr> "03:00-10:00", "03:00-10:00", "03:00-10:00", "03:0...
## $ hari_stacking <fct> Selasa, Selasa, Selasa, Selasa, Selasa, Jumat, Rab...
## $ waktu_stacking <chr> "10:00-18:00", "10:00-18:00", "10:00-18:00", "10:0...
## $ iso_code <chr> "4500", "45G1", "45G1", "45G1", "45G1", "2200", "2...
## $ container_status <chr> "F", "F", "F", "F", "F", "F", "F", "F", "F", "F", ...
## $ exim <chr> "I", "I", "I", "I", "I", "I", "I", "I", "I", "I", ...
## $ nama_negara_asal <chr> "China", "China", "China", "China", "China", "Chin...
## $ mita_non_mita <chr> "NON MITA", "NON MITA", "NON MITA", "NON MITA", "N...
## $ jalur <chr> "HIJAU", "HIJAU", "HIJAU", "HIJAU", "HIJAU", "HIJA...
## $ flag_lartas <chr> "N", "Y", "Y", "N", "N", "N", "Y", "N", "Y", "N", ...
## $ prenon_nonpre <chr> "NON_PRENO", "PRENO", "NON_PRENO", "NON_PRENO", "N...
## $ postborder <chr> "NON", "BORDER", "BORDER", "NON", "NON", "POST-BOR...
## $ karantina <chr> "NON KARANTINA", "NON KARANTINA", "KARANTINA TUMBU...
## $ dt <dbl> 3.52, 3.33, 2.53, 3.86, 3.72, 0.69, 1.26, 1.03, 2....# ambil data bagian testing
jict_test <- jict_split %>%
rsample::testing()
dplyr::glimpse(jict_test)## Rows: 15,175
## Columns: 15
## $ hari_berth <fct> Selasa, Rabu, Rabu, Rabu, Rabu, Jumat, Jumat, Sela...
## $ waktu_berth <chr> "03:00-10:00", "03:00-10:00", "03:00-10:00", "03:0...
## $ hari_stacking <fct> Selasa, Rabu, Rabu, Rabu, Rabu, Jumat, Jumat, Sela...
## $ waktu_stacking <chr> "10:00-18:00", "10:00-18:00", "10:00-18:00", "10:0...
## $ iso_code <chr> "45G1", "22G1", "2210", "2210", "2210", "4500", "4...
## $ container_status <chr> "F", "F", "F", "F", "F", "F", "F", "F", "F", "F", ...
## $ exim <chr> "I", "I", "I", "I", "I", "I", "I", "I", "I", "I", ...
## $ nama_negara_asal <chr> "China", "Malaysia", "Singapore", "Singapore", "Ma...
## $ mita_non_mita <chr> "NON MITA", "NON MITA", "MITA", "MITA", "NON MITA"...
## $ jalur <chr> "HIJAU", "HIJAU", "HIJAU", "HIJAU", "HIJAU", "HIJA...
## $ flag_lartas <chr> "Y", "Y", "Y", "Y", "Y", "N", "N", "N", "N", "N", ...
## $ prenon_nonpre <chr> "PRENO", "NON_PRENO", "NON_PRENO", "NON_PRENO", "N...
## $ postborder <chr> "BORDER", "BORDER", "BORDER", "BORDER", "BORDER", ...
## $ karantina <chr> "NON KARANTINA", "KARANTINA TUMBUHAN", "KARANTINA ...
## $ dt <dbl> 3.33, 1.31, 2.49, 3.00, 1.95, 0.79, 0.79, 3.49, 1....8.3 Menggunakan Framework Tidymodels
Karena di R untuk melakukan sebuah pekerjaan dapat menggunakan beberapa package, maka framework package {tidymodels} menyediakan fungsi yang dapat digunakan dengan cara yang sama meskipun kita ingin menggunakan package yang berbeda.
Yang perlu diingat, ketika kita melakukan penyiapan data pada data training sebelum membuat model, maka kita juga harus menyiapkan data yang ingin diprediksi dengan tahapan yang sama. Package {tidymodels} menyiapkan hal tersebut dan menyebutnya dengan istilah recipe (resep, seperti membuat olahan makanan).
jict_recipe <- jict %>%
recipes::recipe(dt ~ .) %>%
recipes::prep()
jict_recipe## Data Recipe
##
## Inputs:
##
## role #variables
## outcome 1
## predictor 14
##
## Training data contained 50586 data points and no missing data.jict_training <- jict_recipe %>%
recipes::bake(rsample::training(jict_split))
dplyr::glimpse(jict_training)## Rows: 35,411
## Columns: 15
## $ hari_berth <fct> Selasa, Selasa, Selasa, Selasa, Selasa, Jumat, Rab...
## $ waktu_berth <fct> 03:00-10:00, 03:00-10:00, 03:00-10:00, 03:00-10:00...
## $ hari_stacking <fct> Selasa, Selasa, Selasa, Selasa, Selasa, Jumat, Rab...
## $ waktu_stacking <fct> 10:00-18:00, 10:00-18:00, 10:00-18:00, 10:00-18:00...
## $ iso_code <fct> 4500, 45G1, 45G1, 45G1, 45G1, 2200, 2210, 2200, 22...
## $ container_status <fct> F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F,...
## $ exim <fct> I, I, I, I, I, I, I, I, I, I, I, I, I, I, I, I, I,...
## $ nama_negara_asal <fct> China, China, China, China, China, China, Malaysia...
## $ mita_non_mita <fct> NON MITA, NON MITA, NON MITA, NON MITA, NON MITA, ...
## $ jalur <fct> HIJAU, HIJAU, HIJAU, HIJAU, HIJAU, HIJAU, HIJAU, H...
## $ flag_lartas <fct> N, Y, Y, N, N, N, Y, N, Y, N, N, Y, Y, Y, Y, N, Y,...
## $ prenon_nonpre <fct> NON_PRENO, PRENO, NON_PRENO, NON_PRENO, NON_PRENO,...
## $ postborder <fct> NON, BORDER, BORDER, NON, NON, POST-BORDER, BORDER...
## $ karantina <fct> NON KARANTINA, NON KARANTINA, KARANTINA TUMBUHAN, ...
## $ dt <dbl> 3.52, 3.33, 2.53, 3.86, 3.72, 0.69, 1.26, 1.03, 2....jict_testing <- jict_recipe %>%
recipes::bake(rsample::testing(jict_split))
dplyr::glimpse(jict_testing)## Rows: 15,175
## Columns: 15
## $ hari_berth <fct> Selasa, Rabu, Rabu, Rabu, Rabu, Jumat, Jumat, Sela...
## $ waktu_berth <fct> 03:00-10:00, 03:00-10:00, 03:00-10:00, 03:00-10:00...
## $ hari_stacking <fct> Selasa, Rabu, Rabu, Rabu, Rabu, Jumat, Jumat, Sela...
## $ waktu_stacking <fct> 10:00-18:00, 10:00-18:00, 10:00-18:00, 10:00-18:00...
## $ iso_code <fct> 45G1, 22G1, 2210, 2210, 2210, 4500, 4500, 22G1, 45...
## $ container_status <fct> F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F,...
## $ exim <fct> I, I, I, I, I, I, I, I, I, I, I, I, I, I, I, I, I,...
## $ nama_negara_asal <fct> China, Malaysia, Singapore, Singapore, Malaysia, C...
## $ mita_non_mita <fct> NON MITA, NON MITA, MITA, MITA, NON MITA, MITA, MI...
## $ jalur <fct> HIJAU, HIJAU, HIJAU, HIJAU, HIJAU, HIJAU, HIJAU, H...
## $ flag_lartas <fct> Y, Y, Y, Y, Y, N, N, N, N, N, N, N, N, N, N, N, N,...
## $ prenon_nonpre <fct> PRENO, NON_PRENO, NON_PRENO, NON_PRENO, NON_PRENO,...
## $ postborder <fct> BORDER, BORDER, BORDER, BORDER, BORDER, POST-BORDE...
## $ karantina <fct> NON KARANTINA, KARANTINA TUMBUHAN, KARANTINA TUMBU...
## $ dt <dbl> 3.33, 1.31, 2.49, 3.00, 1.95, 0.79, 0.79, 3.49, 1....8.4 Regression Tree
Selanjutnya kita akan membuat model regresi dengan algoritma pohon klasifikasi atau yang sering dikenal dengan istilah regression tree. Kita gunakan decision_tree() untuk dapat menggunakan pohon klasifikasi dengan mode regression. Package yang akan kita gunakan sebagai engine-nya adalah {rpart}.
## inisial model -----
jict_tree <- parsnip::decision_tree(min_n = 100) %>%
parsnip::set_mode("regression") %>%
parsnip::set_engine("rpart")Kita buat model dengan fit inisial model di atas dengan menggunakan data training, yaitu jict_training.
## fit model -----
model_jict_tree <- jict_tree %>%
parsnip::fit(dt ~ ., data = jict_training)Kita lihat informasi lebih lengkap dari model tersebut.
## informasi detil model -----
model_jict_tree## parsnip model object
##
## Fit time: 2.7s
## n= 35411
##
## node), split, n, deviance, yval
## * denotes terminal node
##
## 1) root 35411 38861.360 1.7612920
## 2) prenon_nonpre=PRENO 18072 13940.260 1.2416070
## 4) postborder=BORDER 5607 3078.075 0.9901462 *
## 5) postborder=BORDER_POST-BORDER,NON,POST-BORDER 12465 10348.160 1.3547190 *
## 3) prenon_nonpre=NON_PRENO 17339 14953.270 2.3029470
## 6) hari_stacking=Senin,Rabu,Kamis 8065 6266.502 2.0355180 *
## 7) hari_stacking=Selasa,Jumat,Sabtu,Minggu 9274 7608.368 2.5355120
## 14) hari_stacking=Selasa,Jumat,Minggu 6713 5871.858 2.4059510 *
## 15) hari_stacking=Sabtu 2561 1328.450 2.8751230 *Kita tampilkan plot dari pohon regresi ini menggunakan fungsi rpart.plot() dari package {rpart.plot}.
## plot tree ------
rpart.plot(model_jict_tree$fit,
fallen.leaves = TRUE,
roundint = FALSE,
cex = 0.8,
box.palette = "RdBu",
nn = TRUE)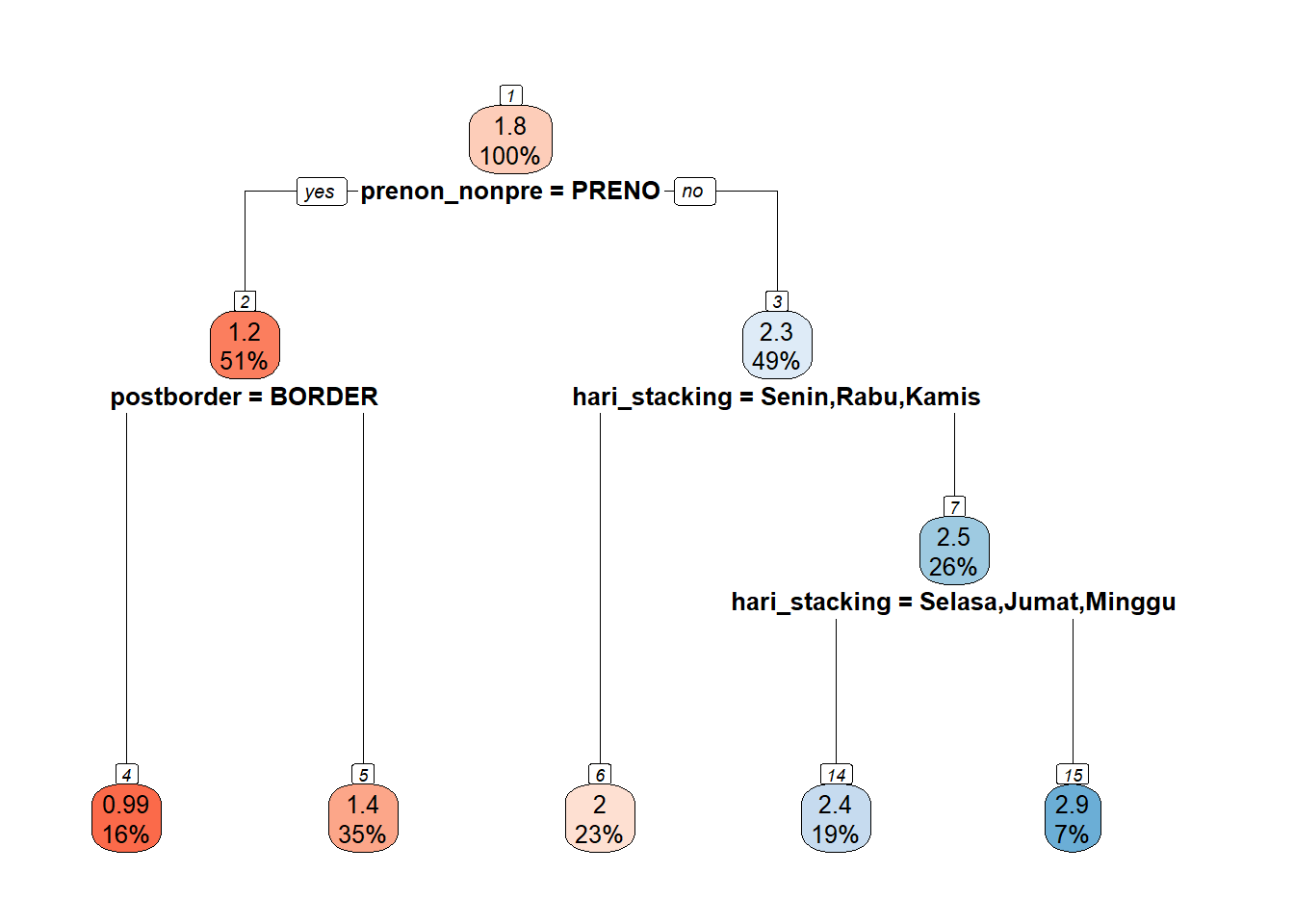
Kita lihat hasil prediksi terhadap data testing.
## prediksi data testing -----
predict(model_jict_tree, jict_testing)## # A tibble: 15,175 x 1
## .pred
## <dbl>
## 1 0.990
## 2 2.04
## 3 2.04
## 4 2.04
## 5 2.04
## 6 1.35
## 7 1.35
## 8 2.41
## 9 1.35
## 10 1.35
## # ... with 15,165 more rows## nilai ukuran kebaikan -> RMSE, R-sq, MAE -----
model_jict_tree %>%
predict(jict_testing) %>%
dplyr::bind_cols(jict_testing %>%
dplyr::select(dt)) %>%
yardstick::metrics(truth = dt, estimate = .pred)## # A tibble: 3 x 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 rmse standard 0.879
## 2 rsq standard 0.302
## 3 mae standard 0.7108.5 Random Forest
Yang terakhir kita akan coba membuat model dengan menggunakan algoritma Random Forest. Package yang digunakan sebagai engine-nya adalah {ranger}.
# Random Forest -----
jict_rf <- rand_forest(
# Banyaknya pohon
trees = 500
) %>%
set_mode("regression") %>%
set_engine("ranger") %>%
set_args(importance = "impurity")Membuat model dari data training.
model_jict_rf <- jict_rf %>%
fit(dt ~ ., data = jict_training)
model_jict_rf## parsnip model object
##
## Fit time: 43s
## Ranger result
##
## Call:
## ranger::ranger(formula = formula, data = data, num.trees = ~500, importance = ~"impurity", num.threads = 1, verbose = FALSE, seed = sample.int(10^5, 1))
##
## Type: Regression
## Number of trees: 500
## Sample size: 35411
## Number of independent variables: 14
## Mtry: 3
## Target node size: 5
## Variable importance mode: impurity
## Splitrule: variance
## OOB prediction error (MSE): 0.5874607
## R squared (OOB): 0.46471298.5.1 Variable Important
Salah satu hal yang bisa kita ketahui dari hasil model random forest adalah tingkat kepentingan variable yang digunakan. Dari grafik di bawah ini terlihat bahwa luas bangunan merupakan variable yang paling berpengaruh terhadap harga rumah dibandingkan variable lain, yaitu usia bangunan dan jumlah kamar mandi.
## Plot variable importance rf -----
imp <- ranger::importance(model_jict_rf$fit)
varimp <- tibble(variable = names(imp), importance = imp)
varimp %>%
ggplot(mapping = aes(x = reorder(variable, importance), y = importance)) +
geom_col() +
labs(x = "variable",
y = "Importance") +
coord_flip() +
theme_minimal()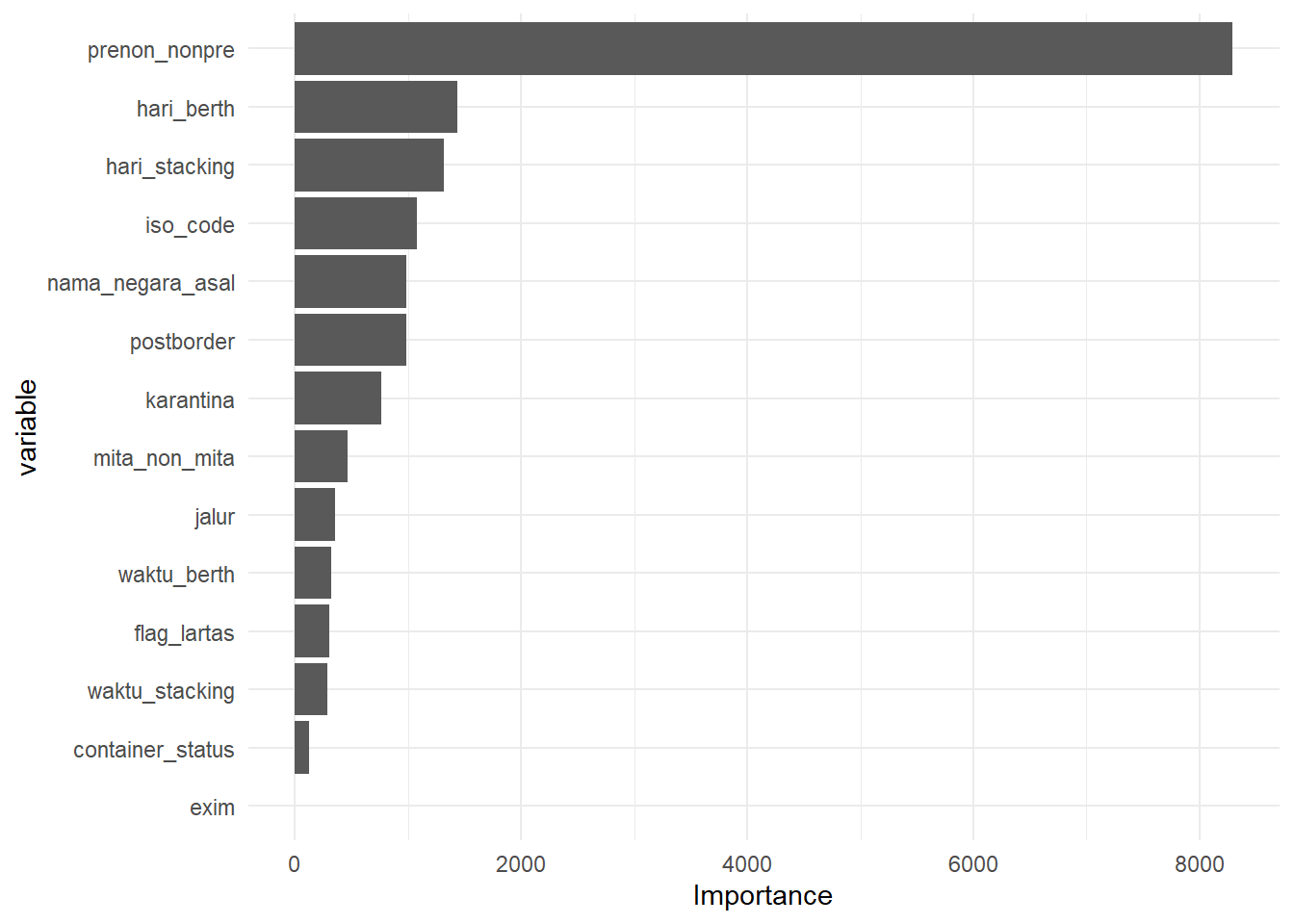
8.5.1.1 Prediksi data testing
## prediksi data testing -----
predict(model_jict_rf, jict_testing)## # A tibble: 15,175 x 1
## .pred
## <dbl>
## 1 1.34
## 2 2.04
## 3 2.03
## 4 2.03
## 5 2.05
## 6 1.08
## 7 1.08
## 8 2.59
## 9 1.08
## 10 1.08
## # ... with 15,165 more rowsMenggabungkan data testing dengan hasil prediksinya dan menghitung ukuran kebaikan model.
## nilai ukuran kebaikan -> RMSE, R-sq, MAE -----
model_jict_rf %>%
predict(jict_testing) %>%
bind_cols(jict_testing %>%
select(dt)) %>%
metrics(truth = dt, estimate = .pred)## # A tibble: 3 x 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 rmse standard 0.771
## 2 rsq standard 0.474
## 3 mae standard 0.614## MAPE -----
model_jict_rf %>%
predict(jict_testing) %>%
bind_cols(jict_testing %>%
select(dt)) %>%
mape(truth = dt, estimate = .pred) %>%
select(-.estimator)## # A tibble: 1 x 2
## .metric .estimate
## <chr> <dbl>
## 1 mape 71.0