Bab 7 Pengenalan Pola Asosiasi

Gambar 7.1: Sumber: blogs.oracle.com
//TODO: Membahas dasar-dasar pola asosiasi (association rules) pada data dengan algoritma apriori menggunakan R. Association rules sering dikenal dengan istilah Market Basket Analysis atau MBA.
Pada Bab ini kita akan menggunakan package {tidyverse}, {arules}, {arulesViz} dan {visNetwork}. Pastikan package tersebut sudah terinstall. Aktifkan package tersebut dengan perintah berikut ini.
library(tidyverse)
library(arules)
library(arulesViz)
library(igraph)7.1 Data Groceries
Contoh kasus yang pertama adalah kita akan menggunakan data groceries.csv. Data ini berisi catatan transaksi belanja di sebuah perbelanjaan. Setiap baris menunjukkan satu transaksi dan isinya adalah produk apa saja yang dibeli pada transaksi tersebut. Produk yang berbeda dipisahkan dengan tanda koma (,).

Karena struktur data sudah sesuai dengan yang dibutuhkan maka kita dapat gunakan fungsi read.transactions() dari package {arules}.
groceries <- arules::read.transactions("data/groceries.csv", sep = ",")
inspect(groceries[1:3])## items
## [1] {citrus fruit,
## margarine,
## ready soups,
## semi-finished bread}
## [2] {coffee,
## tropical fruit,
## yogurt}
## [3] {whole milk}Kita lihat ringkasan dari data transaksi ini dengan fungsi summary().
Total ada 9.385 transaksi yang dicatat pada data ini dan ada 169 jenis produk yang dibeli. Produk yang paling banyak dibeli adalah whole milk, other vegetables, rolls/buns, soda, yogurt, dan sebagainya. Kemdian dibagian bawah setelah most frequent items adalah banyaknya transaksi berdasarkan jumlah produk pada transaksi tersebut. Transaksi yang berisi hanya satu produk saja ada 2.159 transaksi, 1.643 transaksi yang berisi dua produk, dan sebagainya. Ringkasan statistik yang diberikan menunjukkan bahwa paling sedikit produk yang dibeli dalam sebuah transaksi hanya satu produk dan paling banyak ada 32 barang dalam satu transaksi. Rataan banyaknya produk dalam satu transaksi pada data ini adalah 4.4 produk, sedangkan mediannya adalah 3 produk.
summary(groceries)## transactions as itemMatrix in sparse format with
## 9835 rows (elements/itemsets/transactions) and
## 169 columns (items) and a density of 0.02609146
##
## most frequent items:
## whole milk other vegetables rolls/buns soda
## 2513 1903 1809 1715
## yogurt (Other)
## 1372 34055
##
## element (itemset/transaction) length distribution:
## sizes
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
## 2159 1643 1299 1005 855 645 545 438 350 246 182 117 78 77 55 46
## 17 18 19 20 21 22 23 24 26 27 28 29 32
## 29 14 14 9 11 4 6 1 1 1 1 3 1
##
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.000 2.000 3.000 4.409 6.000 32.000
##
## includes extended item information - examples:
## labels
## 1 abrasive cleaner
## 2 artif. sweetener
## 3 baby cosmeticsKita bisa memperoleh data most frequent items secara terpisah dari fungsi itemFrequency().
freq_item <- itemFrequency(groceries, type = "absolute")
sort(freq_item, decreasing = TRUE)[1:20]## whole milk other vegetables rolls/buns
## 2513 1903 1809
## soda yogurt bottled water
## 1715 1372 1087
## root vegetables tropical fruit shopping bags
## 1072 1032 969
## sausage pastry citrus fruit
## 924 875 814
## bottled beer newspapers canned beer
## 792 785 764
## pip fruit fruit/vegetable juice whipped/sour cream
## 744 711 705
## brown bread domestic eggs
## 638 624untuk mendapatkan pola asosiasi MBA dengan algoritma apriori kita gunakan fungsi apriori() dari package {arules}. Data yang dibutuhkan oleh fungsi ini sangat spesific, yaitu class “transaction”. Karena data groceries sudah dalam format yang sesuai dengan yang dibutuhkan oleh fungsi apriori() dapat langsung kita gunakan. Parameter yang dapat ditambahkan adalah batas support, confidence, minlen, dan sebagainya.
Support pada MBA dihitung berdasarkan peluang beirkut
support(A⇒B)=Banyaknya transaksi yang memuat A dan BBanyaknya seluruh n transaksi
Confidence dihitung dengan cara
confidence(A⇒B)=Banyaknya transaksi yang memuat A dan BBanyaknya transaksi yang memuat A saja
Misalnya kita tentukan asosiasi yang ingin dibentuk memiliki support minimal 3% dan confidence sebesar 20% serta banyaknya produk lebih dari 2.
groceries_rules <- apriori(
data = groceries,
parameter = list(
support = 0.03, # minimum support
confidence = 0.20, # minimum confidence
minlen = 2 # minimum banyaknya produk dalam satu rule
)
)## Apriori
##
## Parameter specification:
## confidence minval smax arem aval originalSupport maxtime support minlen
## 0.2 0.1 1 none FALSE TRUE 5 0.03 2
## maxlen target ext
## 10 rules TRUE
##
## Algorithmic control:
## filter tree heap memopt load sort verbose
## 0.1 TRUE TRUE FALSE TRUE 2 TRUE
##
## Absolute minimum support count: 295
##
## set item appearances ...[0 item(s)] done [0.00s].
## set transactions ...[169 item(s), 9835 transaction(s)] done [0.01s].
## sorting and recoding items ... [44 item(s)] done [0.00s].
## creating transaction tree ... done [0.08s].
## checking subsets of size 1 2 3 done [0.17s].
## writing ... [25 rule(s)] done [0.00s].
## creating S4 object ... done [0.01s].Setelah menjalankan program di atas kita akan memperoleh sebanyak 25 aturan yang memenuhi kriteria tersebut.
Kita lihat 6 aturan pertama yang memiliki confidence paling tinggi.
inspect(head(groceries_rules))## lhs rhs support confidence coverage
## [1] {whipped/sour cream} => {whole milk} 0.03223183 0.4496454 0.07168277
## [2] {pip fruit} => {whole milk} 0.03009659 0.3978495 0.07564820
## [3] {pastry} => {whole milk} 0.03324860 0.3737143 0.08896797
## [4] {citrus fruit} => {whole milk} 0.03050330 0.3685504 0.08276563
## [5] {sausage} => {rolls/buns} 0.03060498 0.3257576 0.09395018
## [6] {bottled water} => {whole milk} 0.03436706 0.3109476 0.11052364
## lift count
## [1] 1.759754 317
## [2] 1.557043 296
## [3] 1.462587 327
## [4] 1.442377 300
## [5] 1.771048 301
## [6] 1.216940 338Selanjutnya kita tampilkan asosiasi darilift yang paling tinggi. Semakin besar nilai lift semakin kuat asosiasi tersebut.
inspect(sort(groceries_rules, by = "lift")[1:3])## lhs rhs support confidence coverage
## [1] {root vegetables} => {other vegetables} 0.04738180 0.4347015 0.10899847
## [2] {other vegetables} => {root vegetables} 0.04738180 0.2448765 0.19349263
## [3] {sausage} => {rolls/buns} 0.03060498 0.3257576 0.09395018
## lift count
## [1] 2.246605 466
## [2] 2.246605 466
## [3] 1.771048 301Kita jg dapat menampilkan asosiasi berdasarkan support dan confidence.
inspect(sort(groceries_rules, by = "support")[1:3])## lhs rhs support confidence coverage
## [1] {other vegetables} => {whole milk} 0.07483477 0.3867578 0.1934926
## [2] {whole milk} => {other vegetables} 0.07483477 0.2928770 0.2555160
## [3] {rolls/buns} => {whole milk} 0.05663447 0.3079049 0.1839349
## lift count
## [1] 1.513634 736
## [2] 1.513634 736
## [3] 1.205032 557inspect(sort(groceries_rules, by = "confidence")[1:3])## lhs rhs support confidence coverage
## [1] {whipped/sour cream} => {whole milk} 0.03223183 0.4496454 0.07168277
## [2] {root vegetables} => {whole milk} 0.04890696 0.4486940 0.10899847
## [3] {root vegetables} => {other vegetables} 0.04738180 0.4347015 0.10899847
## lift count
## [1] 1.759754 317
## [2] 1.756031 481
## [3] 2.246605 466Selanjutnya kita dapat memilih asosiasi berdasarkan nama produk yang dibeli. Misalnya kita ingin mencari semua asosiasi yang ada ketika buah whole milk dibeli.
milk_rules <- subset(groceries_rules, lhs %in% "whole milk")
inspect(milk_rules)## lhs rhs support confidence coverage lift
## [1] {whole milk} => {yogurt} 0.05602440 0.2192598 0.255516 1.571735
## [2] {whole milk} => {rolls/buns} 0.05663447 0.2216474 0.255516 1.205032
## [3] {whole milk} => {other vegetables} 0.07483477 0.2928770 0.255516 1.513634
## count
## [1] 551
## [2] 557
## [3] 736Atau, kita dapat memilih asosiasi berdasarkan beberapa nama produk yang dibeli, misalnya whole milk atau root vegetables.
milk_rules <- subset(groceries_rules, lhs %in% c("whole milk", "root vegetables"))
inspect(milk_rules)## lhs rhs support confidence coverage
## [1] {root vegetables} => {other vegetables} 0.04738180 0.4347015 0.1089985
## [2] {root vegetables} => {whole milk} 0.04890696 0.4486940 0.1089985
## [3] {whole milk} => {yogurt} 0.05602440 0.2192598 0.2555160
## [4] {whole milk} => {rolls/buns} 0.05663447 0.2216474 0.2555160
## [5] {whole milk} => {other vegetables} 0.07483477 0.2928770 0.2555160
## lift count
## [1] 2.246605 466
## [2] 1.756031 481
## [3] 1.571735 551
## [4] 1.205032 557
## [5] 1.513634 736Buat visualisasi
subrules <- head(sort(groceries_rules, by = "confidence"), n = 20L)
ig <- plot(subrules, method = "graph")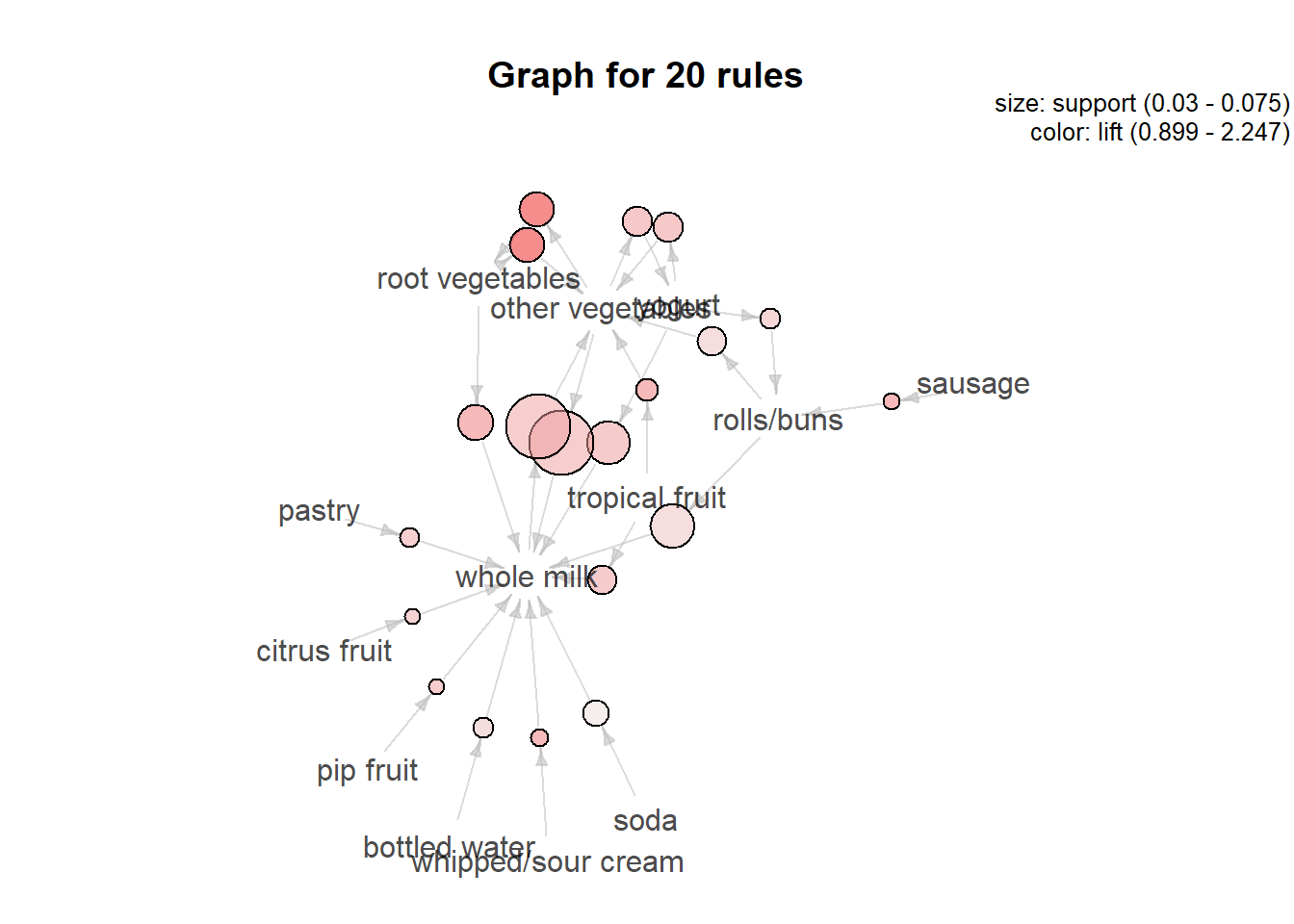
7.2 Data Kontainer dan Dwelling Time
Kita lakukan penyiapan data agar sesuai dengan yang dibutuhkan untuk association rules atau Market Basket Analysis.
Data yang digunakan adalah data dari Flow_Of_Docs terminal JICT selama tahun 2020. Data ini sudah diolah dan disiapkan dalam file “fl_pelatihan.rds”. Oleh karena itu pastikan kita sudah import data tersebut dengan menjalankna perintah berikut ini.
library(readr)
fl_pelatihan <- readr::read_rds("data/fl_pelatihan.rds")Jika data karantina bernilai [NULL] maka diganti menjadi NON KARANTINA. Selain itu kita kategorisasi/diskretisasi nnilai DT pada batas 3 hari. Artinya jika DT < 3 hari maka kita kategorikan sebagai DT Rendah, sedangkan jika DT >= 3 hari maka kita kategorikan DT Tinggi.
fl_mba <- fl_pelatihan %>%
transmute(container_id = container_id,
# Kategorisasi karantina untuk data [NULL]
karantina = case_when(karantina == "[NULL]" ~ "NON KARANTINA",
TRUE ~ karantina),
# Kategorisasi DT
kategori_dt = case_when(dt < 3 ~ "DT Rendah",
TRUE ~ "DT Tinggi"),
# Gabungkan "karakter" masing-masing kontainer
items = paste(mita_non_mita,
jalur,
flag_lartas,
prenon_nonpre,
postborder,
karantina,
kategori_dt,
sep = ","),
# RUbah menjadi list
items = str_split(items, ",")
) %>%
# Buang variabel yang tidak dibutuhkan
select(-karantina, -kategori_dt)view(fl_mba[1:10, ])Data tersebut dijadikan sebagai data transactions.
transaction <- as(fl_mba$items, "transactions")Untuk melihat data per kontainer kita gunakan fungsi inspect().
inspect(transaction[1:3])## items
## [1] {DT Tinggi,
## HIJAU,
## N,
## NON KARANTINA,
## NON MITA,
## NON_PRENO,
## POST-BORDER}
## [2] {DT Tinggi,
## HIJAU,
## N,
## NON KARANTINA,
## NON MITA,
## NON_PRENO,
## POST-BORDER}
## [3] {DT Tinggi,
## HIJAU,
## N,
## NON,
## NON KARANTINA,
## NON MITA,
## NON_PRENO}Kemudian jalankan program berikut ini untuk membuat aturan asosiasi.
mba <- apriori(data = transaction,
parameter = list(
support = 0.25,
confidence = 0.60,
minlen = 3
)
)## Apriori
##
## Parameter specification:
## confidence minval smax arem aval originalSupport maxtime support minlen
## 0.6 0.1 1 none FALSE TRUE 5 0.25 3
## maxlen target ext
## 10 rules TRUE
##
## Algorithmic control:
## filter tree heap memopt load sort verbose
## 0.1 TRUE TRUE FALSE TRUE 2 TRUE
##
## Absolute minimum support count: 17816
##
## set item appearances ...[0 item(s)] done [0.00s].
## set transactions ...[19 item(s), 71265 transaction(s)] done [0.13s].
## sorting and recoding items ... [13 item(s)] done [0.01s].
## creating transaction tree ... done [0.23s].
## checking subsets of size 1 2 3 4 5 done [0.00s].
## writing ... [153 rule(s)] done [0.02s].
## creating S4 object ... done [0.05s].Kita memperoleh 153 aturan. Selanjutnya jika ada aturan yang berulang akan kita buang.
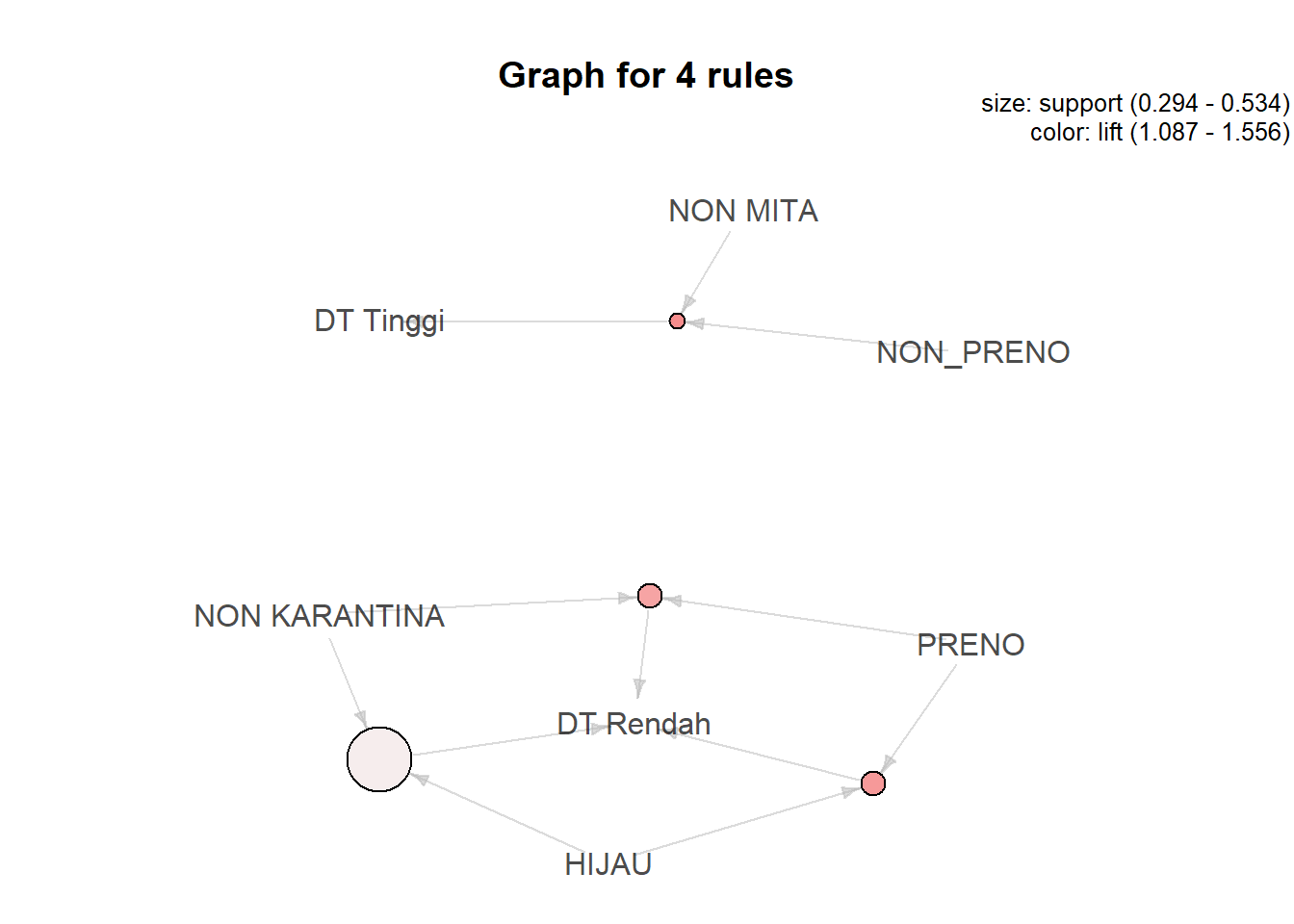
rules <- mba[!is.redundant(mba)]
rules <- subset(rules, rhs %in% c("DT Tinggi", "DT Rendah"))
inspect(rules)## lhs rhs support confidence coverage
## [1] {NON KARANTINA,PRENO} => {DT Rendah} 0.3368273 0.8705618 0.3869080
## [2] {HIJAU,PRENO} => {DT Rendah} 0.3379499 0.8953160 0.3774644
## [3] {NON MITA,NON_PRENO} => {DT Tinggi} 0.2943942 0.6357576 0.4630604
## [4] {HIJAU,NON KARANTINA} => {DT Rendah} 0.5344278 0.6429970 0.8311513
## lift count
## [1] 1.471830 24004
## [2] 1.513681 24084
## [3] 1.556255 20980
## [4] 1.087094 38086rules_dt <- tibble(lhs = labels(lhs(rules)),
rhs = labels(rhs(rules)),
quality(rules)) %>%
arrange(desc(lift))dim(rules_dt)## [1] 4 7head(rules_dt, 10)## # A tibble: 4 x 7
## lhs rhs support confidence coverage lift count
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <int>
## 1 {NON MITA,NON_PRENO} {DT Tinggi} 0.294 0.636 0.463 1.56 20980
## 2 {HIJAU,PRENO} {DT Rendah} 0.338 0.895 0.377 1.51 24084
## 3 {NON KARANTINA,PRENO} {DT Rendah} 0.337 0.871 0.387 1.47 24004
## 4 {HIJAU,NON KARANTINA} {DT Rendah} 0.534 0.643 0.831 1.09 38086subrules <- head(sort(rules, by = "confidence"), n = 20L)
ig <- plot(subrules, method = "graph")