18 网络数据分析
网络数据分析又是另一个大话题,微信、微博、论坛、知乎、豆瓣、美团等等应用都或多或少自带了社交属性。人不能脱离社会存在,社交是人的一种本能,身处洪流之中,即是复杂社会网络中的一个节点。网络分析的内容有很多,比如社区探测、节点影响力分析等。网络图是表示节点之间关系的图,核心在于关系的刻画。用来表达网络关系的是稀疏矩阵,以及为处理这种矩阵而专门优化的矩阵计算库,如 Matrix 包、rsparse 包和 RcppEigen 包(Bates 和 Eddelbuettel 2013)等。图关系挖掘和计算的应用场景非常广泛,如社交推荐(社交 App)、风险控制(银行征信、企业查)、深度学习(图神经网络)、知识图谱(商户、商家、客户的实体关系网络)、区块链、物联网(IoT)、反洗钱(金融监管)、数据治理(数据血缘图谱)等。
本文将分析 R 语言社区开发者之间的协作关系网络。首先基于 CRAN (The Comprehensive R Archive Network)上发布的 R 包元数据信息,了解 R 语言社区 R 包及其维护者的规模,以及根据元数据中的信息发掘社区中的组织,最后,分析开发者在协作网络中的影响力,并将结果可视化。本文主要用到的工具有 igraph 包,操作图数据和图计算的 tidygraph 包,以及可视化图数据的 ggraph 包。
18.1 R 语言社区的规模
从 CRAN 上的 R 包及其开发者数量来看目前 R 语言社区规模。
截止 2022 年 12 月 31 日, CRAN 上发布的 R 包有 18976 个,CRAN 进入年末维护期 2022-12-22 至 2023-01-05。
距离上次更新的时间分布,有的包是一周内更新的,也有的是 10 多年未更新的。
根据发布日期 Published 构造新的一列 — 发布年份。
然后按年统计更新的 R 包数量,如 图 18.1 所示,以 2020 年为例,总数 18976 个 R 包当中有 2470 个 R 包的更新日期停留在 2020 年,占比 2470 / 18976 = 13.02%。过去 1 年内更新的 R 包有 8112 个(包含新出现的 R 包),占总数 8112 / 18976 = 42.75%,过去 2 年内更新的 R 包有 11553 个,占总数 11553 / 18976 = 60.88%,这个占比越高说明社区开发者越活跃。
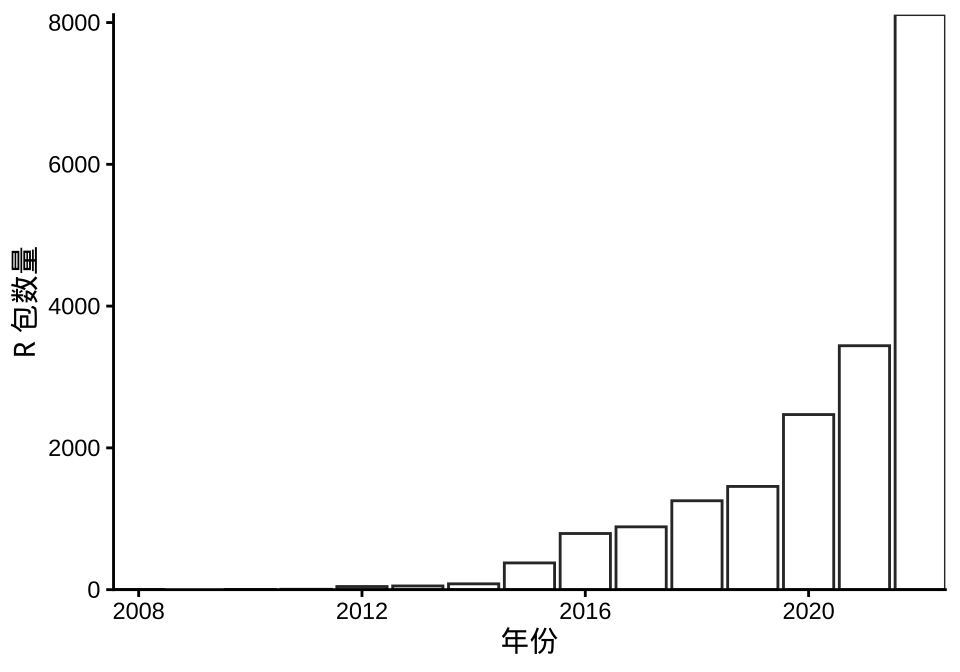
截止 2022-12-31,CRAN 上 R 包的维护者有 10067 人,其中有多少人在 2022 年更新了自己的 R 包呢?有 4820 个维护者,占比 47.96%,也就是说 2022 年,有 4820 个开发者更新了 8112 个 R 包,人均更新 1.68 个 R 包,下 图 18.2 按 R 包发布年份统计开发者数量。
#> [1] 10067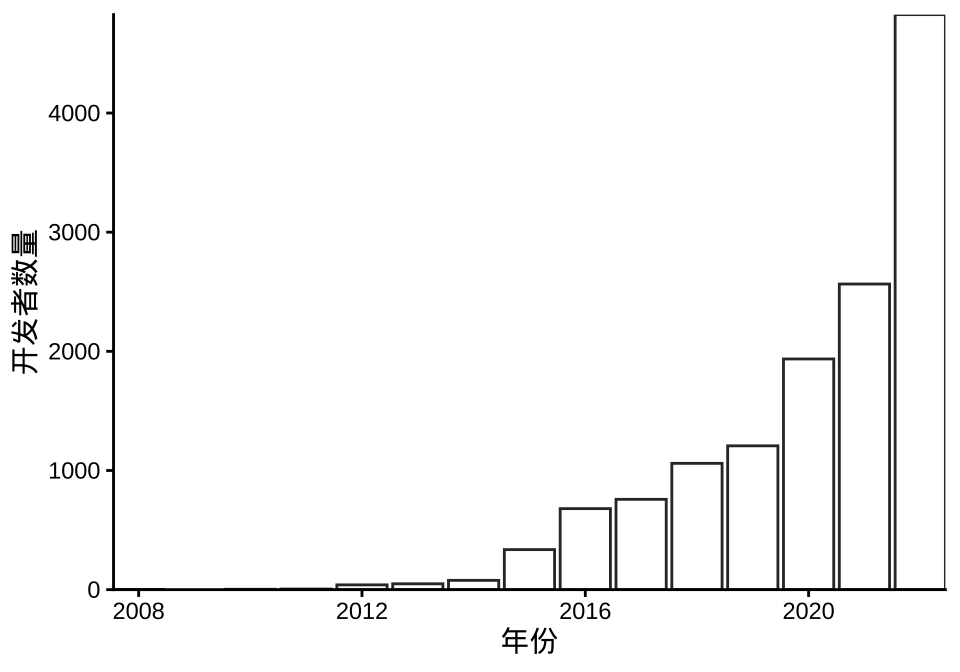
18.2 R 语言社区的组织
除了 RStudio 公司出品的 tidyverse (Wickham 等 2019) 和 tidymodels (Kuhn 和 Wickham 2020),还有一些数据分析、建模的工具箱,如 mlr3verse (Lang 和 Schratz 2023)、easystats (Lüdecke 等 2022)、strengejacke (Lüdecke 2019) 和 DrWhy (Biecek 2023)。也有的组织基本停止了开发,如 Omegahat。还有的被商业公司收购后,不再活跃了,如 Revolution Analytics。它们作为解决方案大都属于一些组织,还有深藏功与名,有待笔者挖掘的。因不存在明显的规律,下面从开发者的邮箱出发,隶属企业、组织往往有统一的邮箱后缀。
str_extract <- function(text, pattern, ...) regmatches(text, regexpr(pattern, text, ...))
# 移除 ORPHANED
pdb <- subset(pdb, subset = Maintainer != "ORPHANED")
# 抽取邮件后缀
extract_email_suffix <- function(x) {
x <- str_extract(text = x, pattern = "<.*?>")
sub(x = x, pattern = ".*?@(.*?)>", replacement = "\\1")
}
pdb$Email_suffix <- extract_email_suffix(pdb$Maintainer)按组织统计扩展包的数量(总的 R 包数量约 2 万),即各个组织开发的 R 包。
#> Email_suffix Package
#> 876 gmail.com 6968
#> 2044 rstudio.com 208
#> 979 hotmail.com 185
#> 1825 outlook.com 152
#> 1971 R-project.org 106
#> 2 163.com 94
#> 210 berkeley.edu 91
#> 2559 umich.edu 91
#> 2819 uw.edu 74
#> 1927 protonmail.com 73
#> 2564 umn.edu 69
#> 581 debian.org 68
#> 2951 yahoo.com 68
#> 1828 outlook.fr 63
#> 2212 stanford.edu 58
#> 155 auckland.ac.nz 57
#> 887 gmx.de 55
#> 2911 wisc.edu 55
#> 895 googlemail.com 50
#> 1970 r-project.org 50不难看出,至少有如下几类:
- 邮件服务提供商。6968 个 R 包使用 gmail 邮箱作为联系维护者的方式,googlemail.com 也是谷歌提供的服务。hotmail.com 和 outlook.com 都是微软提供的邮箱服务,outlook.fr (法国)也是,除此之外,比较大的邮件服务提供商就是 163.com(网易)、 protonmail.com 和 yahoo.com (雅虎)等。
- 商业组织。208 个 R 包来自 RStudio 公司的员工,这些维护者使用 RStudio 公司提供的邮箱。
- 开源组织。R-project.org 和 r-project.org 都是 R 语言组织的联系方式,自不必多说,R 语言核心团队成员不仅维护 R 软件源码,还维护了很多 R 包。debian.org 是 Debian 组织的联系方式,都是开源组织(Open Source Org)。
- 教育机构。berkeley.edu 、umich.edu 等以 edu 结尾的北美(国)的大学,gmx.de、 posteo.de 等以 de 结尾的德国大学,ucl.ac.uk 等以 uk 结尾的英国的大学,auckland.ac.nz 等以 nz 结尾的新西兰的大学,uwaterloo.ca 等以 ca 结尾的加拿大的大学。
按组织统计开发者的数量(总的开发者数量约 1 万),即各个组织的 R 包开发者。
#> Email_suffix Maintainer2
#> 876 gmail.com 3800
#> 979 hotmail.com 110
#> 1825 outlook.com 87
#> 2 163.com 57
#> 2559 umich.edu 54
#> 2951 yahoo.com 51
#> 2564 umn.edu 47
#> 1927 protonmail.com 46
#> 2819 uw.edu 46
#> 887 gmx.de 34
#> 210 berkeley.edu 33
#> 2044 rstudio.com 30
#> 895 googlemail.com 28
#> 2212 stanford.edu 27
#> 468 columbia.edu 26
#> 1114 inrae.fr 26
#> 2451 ucl.ac.uk 25
#> 2964 yale.edu 25
#> 635 duke.edu 23
#> 1906 posteo.de 23可见,大部分开发者采用邮件服务提供商的邮件地址。3800 个开发者使用来自谷歌的 gmail.com、197 个开发者使用来自微软的 hotmail.com 或 outlook.com,57 个开发者使用来自网易的 163.com,51 个开发者使用来自雅虎的 yahoo.com,46 个开发者使用来自 Proton 的 protonmail.com。
无论从开发者数量还是 R 包数量的角度看,都有两个显著特点。其一马太效应,往头部集中,其二,长尾分布,尾部占比接近甚至超过 50%。
18.2.1 美国、英国和加拿大
1666 个开发者来自以 edu 为后缀的邮箱。各个组织(主要是大学)及其 R 包开发者数据如下:
#> [1] 1666#> Email_suffix Maintainer2
#> 2559 umich.edu 54
#> 2564 umn.edu 47
#> 2819 uw.edu 46
#> 210 berkeley.edu 33
#> 2212 stanford.edu 27
#> 468 columbia.edu 26
#> 2964 yale.edu 25
#> 635 duke.edu 23
#> 2911 wisc.edu 23
#> 482 cornell.edu 22
#> 2444 ucdavis.edu 21
#> 1929 psu.edu 19
#> 2449 uchicago.edu 19
#> 2830 vanderbilt.edu 19
#> 1660 ncsu.edu 18
#> 1663 nd.edu 18
#> 1008 iastate.edu 17
#> 1919 princeton.edu 17
#> 1815 osu.edu 16
#> 2523 uiowa.edu 16好吧,几乎全是美国各个 NB 大学的,比如华盛顿大学( uw.edu)、密歇根大学(umich.edu)、加州伯克利大学(berkeley.edu)等等。顺便一说,美国各个大学的网站,特别是统计院系很厉害的,已经帮大家收集得差不多了,有留学打算的读者自取,邮箱后缀就是学校/院官网。
有些邮箱后缀带有院系,但是并没有向上合并到学校这一级,比如 stanford.edu 、stat.stanford.edu 和 alumni.stanford.edu 等没有合并统计。实际上,使用 edu 邮箱的教育机构大部份位于美国。有的邮箱来自教育机构,但是不以 edu 结尾,比如新西兰奥克兰大学 auckland.ac.nz 、瑞士苏黎世联邦理工学院 stat.math.ethz.ch 等美国以外的教育机构。下面分别查看英国和加拿大的情况。
350 个开发者来自以 uk 为后缀的邮箱。各个组织(主要是大学)及其 R 包开发者数据如下:
#> [1] 350#> Email_suffix Maintainer2
#> 2451 ucl.ac.uk 25
#> 329 cam.ac.uk 17
#> 295 bristol.ac.uk 15
#> 1088 imperial.ac.uk 14
#> 658 ed.ac.uk 13
#> 1286 lancaster.ac.uk 11
#> 1363 lse.ac.uk 9
#> 1605 mrc-bsu.cam.ac.uk 9
#> 2878 warwick.ac.uk 9
#> 870 glasgow.ac.uk 8
#> 1364 lshtm.ac.uk 8
#> 1424 manchester.ac.uk 8
#> 636 durham.ac.uk 7
#> 744 exeter.ac.uk 7
#> 2260 statslab.cam.ac.uk 7
#> 2188 soton.ac.uk 6
#> 2972 york.ac.uk 6
#> 978 hotmail.co.uk 5
#> 1948 qmul.ac.uk 5
#> 248 bioss.ac.uk 4258 个开发者来自以 ca 为后缀的邮箱。各个组织(主要是大学)及其 R 包开发者数据如下:
#> [1] 258#> Email_suffix Maintainer2
#> 2822 uwaterloo.ca 19
#> 1397 mail.mcgill.ca 14
#> 2123 sfu.ca 12
#> 2801 utoronto.ca 12
#> 2426 ualberta.ca 11
#> 2239 stat.ubc.ca 9
#> 2434 ubc.ca 9
#> 2813 uvic.ca 8
#> 952 hec.ca 7
#> 1416 mail.utoronto.ca 718.2.2 CRAN 和 RStudio
下面根据邮箱后缀匹配抽取 CRAN 团队及开发的 R 包,规则也许不能覆盖所有的情况,比如署名 CRAN Team 的维护者代表的是 CRAN 团队,XML 和 RCurl 包就由他们维护。再比如,Brian Ripley 的邮箱 ripley@stats.ox.ac.uk 就不是 CRAN 官网域名。读者若有补充,欢迎 PR 给我。
代码
cran_dev <- subset(pdb,
subset = grepl(
x = Maintainer,
pattern = paste0(c(
"(@[Rr]-project\\.org)", # 官方邮箱
"(ripley@stats.ox.ac.uk)", # Brian Ripley
"(p.murrell@auckland.ac.nz)", # Paul Murrell
"(paul@stat.auckland.ac.nz)", # Paul Murrell
"(maechler@stat.math.ethz.ch)", # Martin Maechler
"(mmaechler+Matrix@gmail.com)", # Martin Maechler
"(bates@stat.wisc.edu)", # Douglas Bates
"(pd.mes@cbs.dk)", # Peter Dalgaard
"(ligges@statistik.tu-dortmund.de)", # Uwe Ligges
"(tlumley@u.washington.edu)", # Thomas Lumley
"(t.lumley@auckland.ac.nz)", # Thomas Lumley
"(martyn.plummer@gmail.com)", # Martyn Plummer
"(luke-tierney@uiowa.edu)", # Luke Tierney
"(stefano.iacus@unimi.it)", # Stefano M. Iacus
"(murdoch.duncan@gmail.com)", # Duncan Murdoch
"(michafla@gene.com)" # Michael Lawrence
), collapse = "|")
),
select = c("Package", "Maintainer")
) |>
transform(Maintainer = gsub(
x = Maintainer, pattern = '(<([^<>]*)>)|(")', replacement = ""
)) |>
transform(Maintainer = gsub(
x = Maintainer, pattern = "(R-core)|(R Core Team)", replacement = "CRAN Team"
)) |>
transform(Maintainer = gsub(
x = Maintainer,
pattern = "(S. M. Iacus)|(Stefano M.Iacus)|(Stefano Maria Iacus)",
replacement = "Stefano M. Iacus"
)) |>
transform(Maintainer = gsub(
x = Maintainer, pattern = "(Toby Hocking)",
replacement = "Toby Dylan Hocking"
)) |>
transform(Maintainer = gsub(
x = Maintainer, pattern = "(John M Chambers)", replacement = "John Chambers"
))
cran_dev <- aggregate(data = cran_dev, Package ~ Maintainer, FUN = function(x) length(unique(x)))
cran_dev <- cran_dev[order(cran_dev$Package, decreasing = TRUE), ]
knitr::kable(head(cran_dev, ceiling(nrow(cran_dev) / 2)),
col.names = c("团队成员", "R 包数量"), row.names = FALSE
)
knitr::kable(tail(cran_dev, floor(nrow(cran_dev) / 2)),
col.names = c("团队成员", "R 包数量"), row.names = FALSE
)| 团队成员 | R 包数量 |
|---|---|
| Kurt Hornik | 28 |
| Simon Urbanek | 26 |
| Achim Zeileis | 25 |
| Martin Maechler | 25 |
| Torsten Hothorn | 25 |
| Paul Murrell | 19 |
| Toby Dylan Hocking | 17 |
| Brian Ripley | 12 |
| Thomas Lumley | 12 |
| Uwe Ligges | 9 |
| Duncan Murdoch | 7 |
| David Meyer | 6 |
| CRAN Team | 5 |
| 团队成员 | R 包数量 |
|---|---|
| Friedrich Leisch | 5 |
| Luke Tierney | 5 |
| Michael Lawrence | 5 |
| Stefan Theussl | 5 |
| Bettina Grün | 3 |
| John Chambers | 3 |
| Simon Wood | 3 |
| Bettina Gruen | 2 |
| Deepayan Sarkar | 2 |
| Douglas Bates | 2 |
| Martyn Plummer | 2 |
| Peter Dalgaard | 1 |
Kurt Hornik、Simon Urbanek、Achim Zeileis 等真是高产呐!除了维护 R 语言核心代码,还开发维护了那么多 R 包。以 Brian Ripley 为例,看看他都具体维护了哪些 R 包。
代码
| Package | Title |
|---|---|
| boot | Bootstrap Functions (Originally by Angelo Canty for S) |
| class | Functions for Classification |
| fastICA | FastICA Algorithms to Perform ICA and Projection Pursuit |
| gee | Generalized Estimation Equation Solver |
| KernSmooth | Functions for Kernel Smoothing Supporting Wand & Jones (1995) |
| MASS | Support Functions and Datasets for Venables and Ripley’s MASS |
| mix | Estimation/Multiple Imputation for Mixed Categorical and Continuous Data |
| nnet | Feed-Forward Neural Networks and Multinomial Log-Linear Models |
| pspline | Penalized Smoothing Splines |
| RODBC | ODBC Database Access |
| spatial | Functions for Kriging and Point Pattern Analysis |
| tree | Classification and Regression Trees |
震惊!有一半收录在 R 软件中,所以已经持续维护 20 多年了。下面继续根据邮箱后缀将 RStudio 团队的情况统计出来,结果见下表。
代码
rstudio_dev <- subset(pdb,
subset = grepl(x = Maintainer, pattern = "(posit.co)|(rstudio.com)|(yihui.name)"),
select = c("Package", "Maintainer")
) |>
transform(Maintainer = extract_maintainer(Maintainer))
rstudio_dev <- aggregate(data = rstudio_dev, Package ~ Maintainer, FUN = function(x) length(unique(x)))
rstudio_dev <- rstudio_dev[order(rstudio_dev$Package, decreasing = TRUE), ]
knitr::kable(head(rstudio_dev, ceiling(nrow(rstudio_dev) / 2)),
col.names = c("团队成员", "R 包数量"), row.names = FALSE
)
knitr::kable(tail(rstudio_dev, floor(nrow(rstudio_dev) / 2)),
col.names = c("团队成员", "R 包数量"), row.names = FALSE
)| 团队成员 | R 包数量 |
|---|---|
| Hadley Wickham | 48 |
| Yihui Xie | 22 |
| Max Kuhn | 18 |
| Lionel Henry | 15 |
| Winston Chang | 15 |
| Daniel Falbel | 13 |
| Jennifer Bryan | 13 |
| Davis Vaughan | 11 |
| Carson Sievert | 10 |
| Tomasz Kalinowski | 8 |
| Barret Schloerke | 6 |
| Thomas Lin Pedersen | 6 |
| Hannah Frick | 5 |
| Christophe Dervieux | 4 |
| Joe Cheng | 4 |
| Julia Silge | 4 |
| 团队成员 | R 包数量 |
|---|---|
| Cole Arendt | 3 |
| Edgar Ruiz | 3 |
| JJ Allaire | 3 |
| Kevin Kuo | 3 |
| Kevin Ushey | 3 |
| Richard Iannone | 3 |
| Aron Atkins | 2 |
| Romain François | 2 |
| Yitao Li | 2 |
| Brian Smith | 1 |
| Emil Hvitfeldt | 1 |
| Garrick Aden-Buie | 1 |
| James Blair | 1 |
| Nathan Stephens | 1 |
| Nick Strayer | 1 |
CRAN 和 RStudio 团队是 R 语言社区最为熟悉的,其它团队需借助一些网络分析算法挖掘了。
18.3 R 语言社区的开发者
18.3.1 最高产的开发者
继续基于数据集 pdb ,将维护 R 包数量比较多的开发者统计出来。
代码
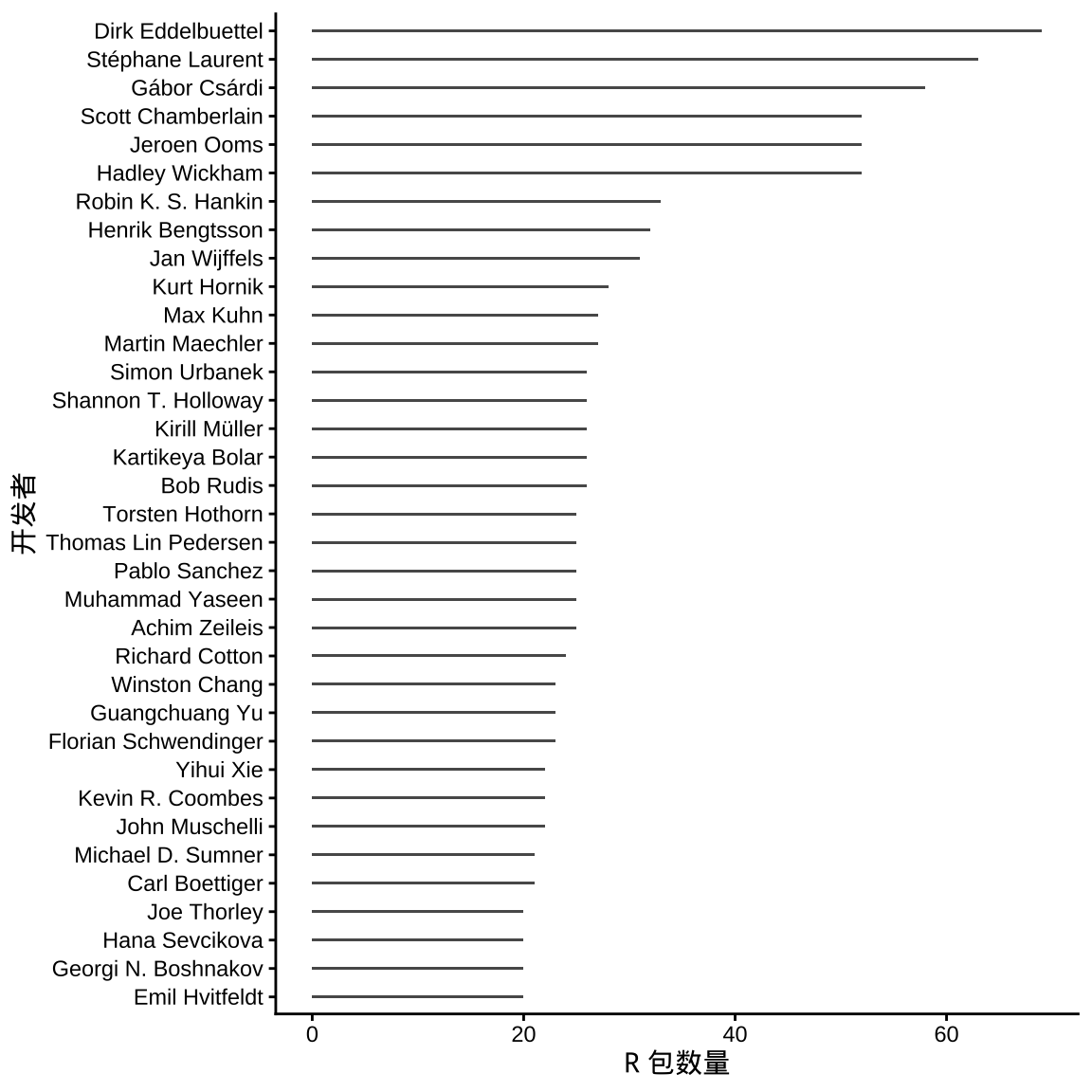
这些开发者的主页和主要的 R 社区贡献如下:
- Dirk Eddelbuettel 维护了 Rcpp、RcppEigen 等流行的 R 包,通过 Rcpp 包将很多优秀的 C++ 库引入 R 语言社区。
- Stéphane Laurent 维护了很多与 shiny、htmlwidgets 相关的 R 包,比如 rAmCharts4 包。
- Gábor Csárdi 维护了 igraph 包以及大量帮助 R 包开发的基础设施,RStudio 雇员。
- Hadley Wickham 维护了 ggplot2、dplyr、devtools 等流行的 R 包,RStudio 雇员。
- Jeroen Ooms 维护了 magick、curl 以及大量帮助 R 包开发的基础设施。
- Scott Chamberlain 维护了很多与 HTTP/Web 相关的 R 包,rOpenSci 联合创始人。
- Robin K. S. Hankin 维护了很多与贝叶斯、多元统计相关的 R 包。
- Henrik Bengtsson 维护了 future 和 parallelly 等流行的 R 包,在并行计算方面有很多贡献。
- Jan Wijffels 维护了很多与自然语言处理、图像识别相关的 R 包,比如 udpipe 、BTM 和 word2vec 等包,Bnosac 团队成员。
- Kurt Hornik 参与维护 R 软件代码并许多与自然语言处理相关的 R 包,R 核心团队成员。
- Martin Maechler 维护了 Matrix 包,R 核心团队成员。
- Max Kuhn 维护了 tidymodels 等包,RStudio 雇员。
- Bob Rudis 维护了一些与 ggplot2 相关的 R 包,如 ggalt、hrbrthemes 和 statebins 等。
- Kartikeya Bolar 维护了很多统计与 shiny 结合的 R 包,比如方差分析、逻辑回归、列联表、聚类分析等。
- Kirill Müller 维护了 DBI 等大量与数据库连接的 R 包。
- Shannon T. Holloway 维护了许多与生存分析相关的 R 包。
- Simon Urbanek 维护了 rJava、Rserve 等流行的 R 包,R 核心团队成员,负责维护 R 软件中与 MacOS 平台相关的部分。
- Achim Zeileis 维护了 colorspace 等流行的 R 包,R 核心团队成员。
- Muhammad Yaseen 维护了多个与 Multiple Indicator Cluster Survey 相关的 R 包。
- Pablo Sanchez 维护了多个与市场营销平台连接的 R 语言接口,Windsor.ai 组织成员。
- Thomas Lin Pedersen 维护了 patchwork、 gganimate 和 ggraph 等流行的 R 包,RStudio 雇员。
- Torsten Hothorn 在统计检验方面贡献了不少内容,比如 coin 和 multcomp 等包,R 核心团队成员。
- Richard Cotton 维护了 assertive 和 rebus 系列 R 包,代码可读性检查。
- Florian Schwendinger 维护了大量运筹优化方面的 R 包,扩展了 ROI 包的能力。
- Guangchuang Yu 维护了 ggtree 和 ggimage 等 R 包,在生物信息和可视化领域有不少贡献。
- Winston Chang 维护了 shiny 等流行的 R 包,RStudio 雇员。
- John Muschelli 维护了多个关于神经图像的 R 包。
- Kevin R. Coombes 维护了多个关于生物信息的 R 包,如 oompaBase 和 oompaData 等。
- Yihui Xie 维护了 knitr 、rmarkdown 等流行的 R 包,RStudio 雇员。
- Carl Boettiger 维护了多个接口包,比如 rfishbase 等,rOpenSci 团队成员。
- Michael D. Sumner 维护了多个空间统计相关的 R 包。
- Emil Hvitfeldt 维护了多个统计学习相关的 R 包,如 fastTextR 包等,RStudio 雇员。
- Georgi N. Boshnakov 维护了多个金融时间序列相关的 R 包,如 fGarch、timeDate 和 timeSeries 等包。
- Hana Sevcikova 维护了多个与贝叶斯人口统计相关的 R 包。
- Joe Thorley 维护了多个与贝叶斯 MCMC 相关的 R 包,Poisson Consulting 雇员。
统计开发者数量随维护 R 包数量的分布,发现,开发 1 个 R 包的开发者有 6732 人,开发 2 个 R 包的开发者有 1685 人,第二名是第一名的五分之一,递减规律非常符合指数分布。
#>
#> 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
#> 6732 1685 725 328 177 82 80 52 37 37 29 15 18 8 11 7
#> 17 18 19 20 21 22 23 24 25 26 27 28 31 32 33 52
#> 1 3 4 4 2 3 3 1 5 5 2 1 1 1 1 3
#> 58 63 69
#> 1 1 1过滤掉非常高产的开发者,可以发现变化规律服从幂律分布。
ggplot(data = pdb_ctb, aes(x = Package)) +
geom_histogram(binwidth = 1) +
theme_classic() +
labs(x = "R 包数量", y = "开发者")
ggplot(data = pdb_ctb[pdb_ctb$Package <= 20, ], aes(x = Package)) +
geom_histogram(binwidth = 1, fill = NA, color = "gray20") +
scale_y_log10() +
theme_classic() +
labs(x = "R 包数量", y = "开发者")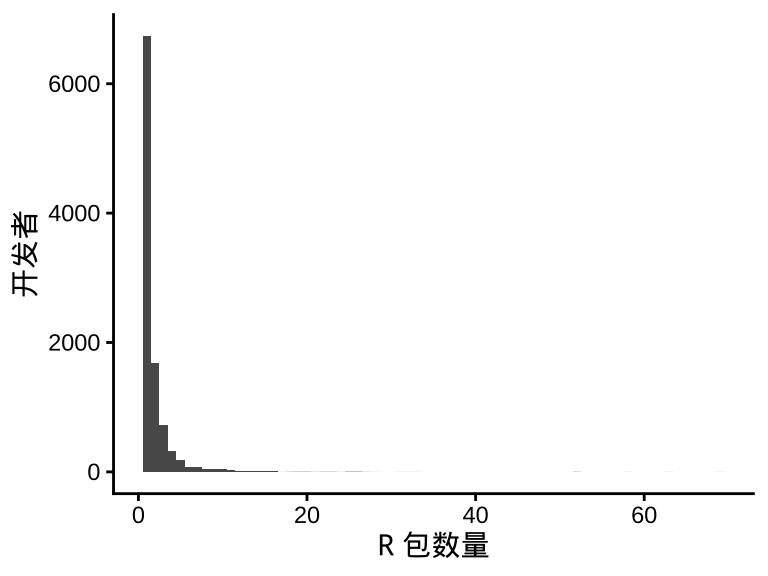
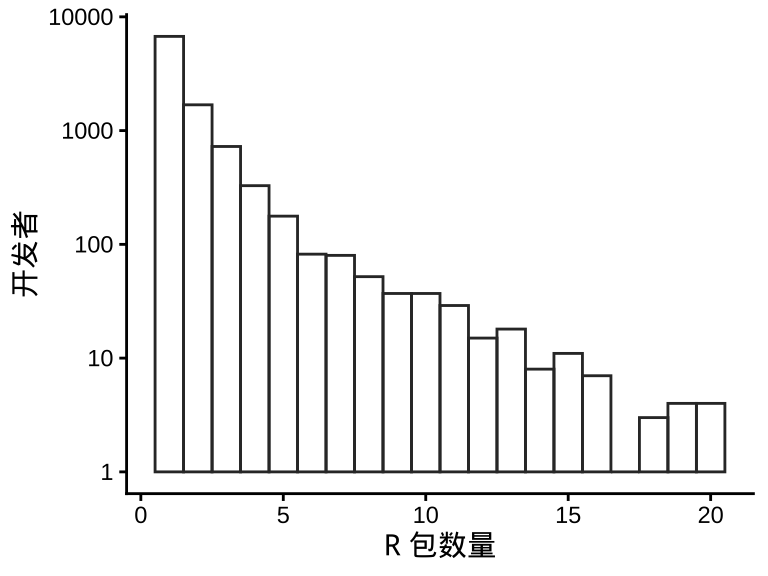
最高产 Top 1% 的开发者 131 人(开发 R 包超过 10 个的开发者)贡献了 2329 / 18976 = 12.3% 的扩展包 ,高产的是商业公司、开源组织、大学机构。
#> [1] 131 2#> [1] 2329最低产 Bottom 的开发者 6732 人(仅开发一个 R 包的开发者)占总开发者的比例 6732 / 10067 = 66.87%, 贡献了 6732 / 18976 = 35.5 % 的扩展包 ,低产的人是主体。
18.3.3 节点出入度分布
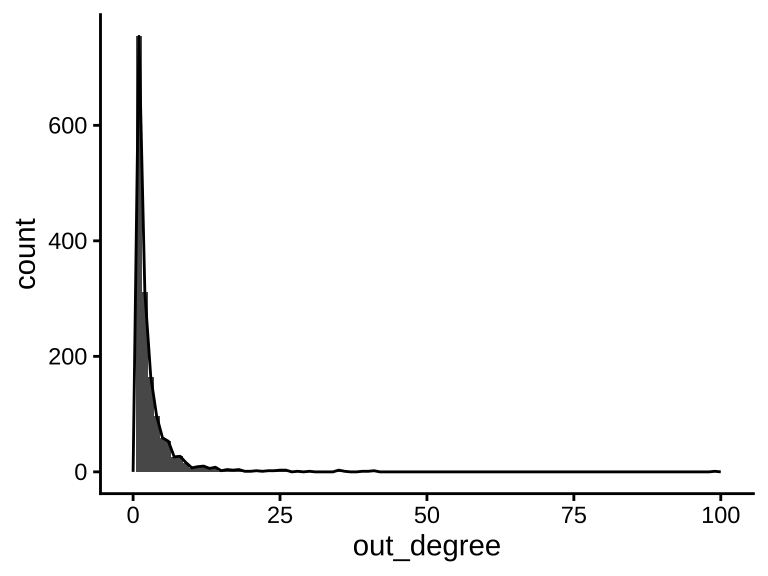
下面简化这个网络,仅考虑贡献者也是维护者的情况,就是说网络中所有节点既是维护者也是贡献者,这会过滤掉组织机构、大量没有在 CRAN 发过 R 包的贡献者、从没给其它维护者做贡献的维护者。简化后,网络节点的出度、入度的分布图如下。
# Maintainer 的入度
pdb_authors_net_indegree <- pdb_authors_dt[Authors %in% Maintainer,
][, .(in_degree = length(Authors)), by = "Maintainer"]
# Authors 的出度
pdb_authors_net_outdegree <- pdb_authors_dt[Authors %in% Maintainer,
][, .(out_degree = length(Maintainer)), by = "Authors"]
ggplot(pdb_authors_net_indegree, aes(x = in_degree)) +
geom_histogram(binwidth = 1) +
geom_freqpoly(binwidth = 1) +
theme_classic()
ggplot(pdb_authors_net_outdegree, aes(x = out_degree)) +
geom_histogram(binwidth = 1) +
geom_freqpoly(binwidth = 1) +
theme_classic()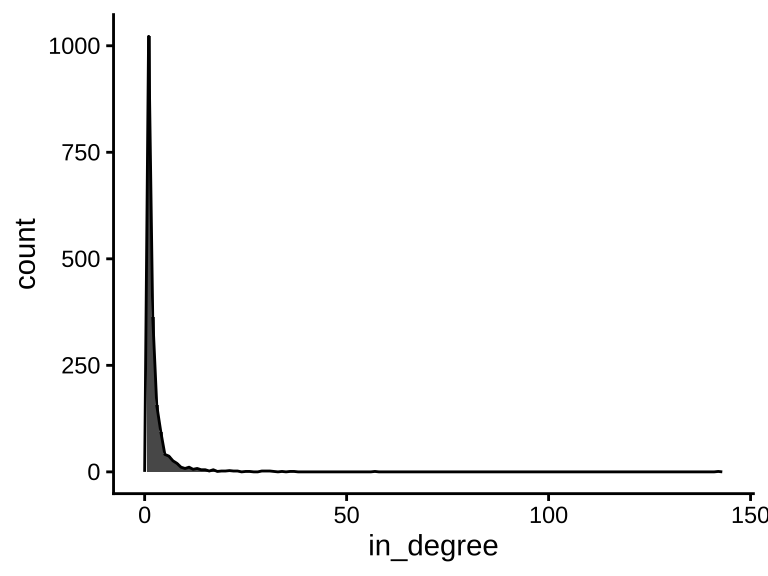
18.3.4 可视化协作网络
节点的大小以维护者维护的 R 包数量来表示,边的大小以维护者之间协作次数来表示。为了美观起见,更为了突出重点,仅保留协作次数大于 1 的边。
#> Authors Maintainer edge_cnt
#> <char> <char> <int>
#> 1: Jim Hester Gábor Csárdi 10
#> 2: Hadley Wickham Lionel Henry 10
#> 3: Joe Cheng Carson Sievert 9
#> 4: Hadley Wickham Jennifer Bryan 8
#> 5: Steven Andrew Culpepper James Joseph Balamuta 8
#> ---
#> 528: Aaron Wolen Scott Chamberlain 2
#> 529: Bob Rudis Simon Garnier 2
#> 530: Marco Sciaini Simon Garnier 2
#> 531: Carlos Morales Martin Chan 2
#> 532: Md Yeasin Ranjit Kumar Paul 2#> Maintainer vertex_cnt
#> <char> <int>
#> 1: Hadley Wickham 43
#> 2: Gábor Csárdi 33
#> 3: Jeroen Ooms 28
#> 4: Scott Chamberlain 28
#> 5: Yihui Xie 21
#> ---
#> 579: Katriona Goldmann 1
#> 580: Carlo Pacioni 1
#> 581: Michael Scholz 1
#> 582: Javier Roca-Pardinas 1
#> 583: Xianying Tan 1这是一个有向图,其各个字段含义如下。
- Maintainer 维护者(代表流 to)
- Authors 贡献者(代表源 from)
-
edge_cnt边的大小表示维护者 Maintainer 和贡献者 Authors 的协作次数 -
vertex_cnt顶点大小表示维护者 Maintainer 维护的 R 包数量
下面先考虑用 igraph 包可视化这个复杂的有向带权网络。pdb_authors_net_edge 和 pdb_authors_net_vertex 都是数据框,首先调用 igraph 包的函数 graph_from_data_frame() 将其转化为网络类型 igraph ,然后使用函数 plot() 绘制网络图。
代码
# 构造图
library(igraph)
pdb_authors_graph <- graph_from_data_frame(d = pdb_authors_net_edge, vertices = pdb_authors_net_vertex, directed = TRUE)
# 可视化
op <- par(mar = rep(0, 4))
plot(pdb_authors_graph,
edge.width = (E(pdb_authors_graph)$edge_cnt) / 2,
edge.arrow.size = .01,
edge.curved = .1,
layout = layout.kamada.kawai,
vertex.size = (V(pdb_authors_graph)$vertex_cnt) / 8,
vertex.label.cex = sqrt(V(pdb_authors_graph)$vertex_cnt) / 8
)
on.exit(par(op), add = TRUE)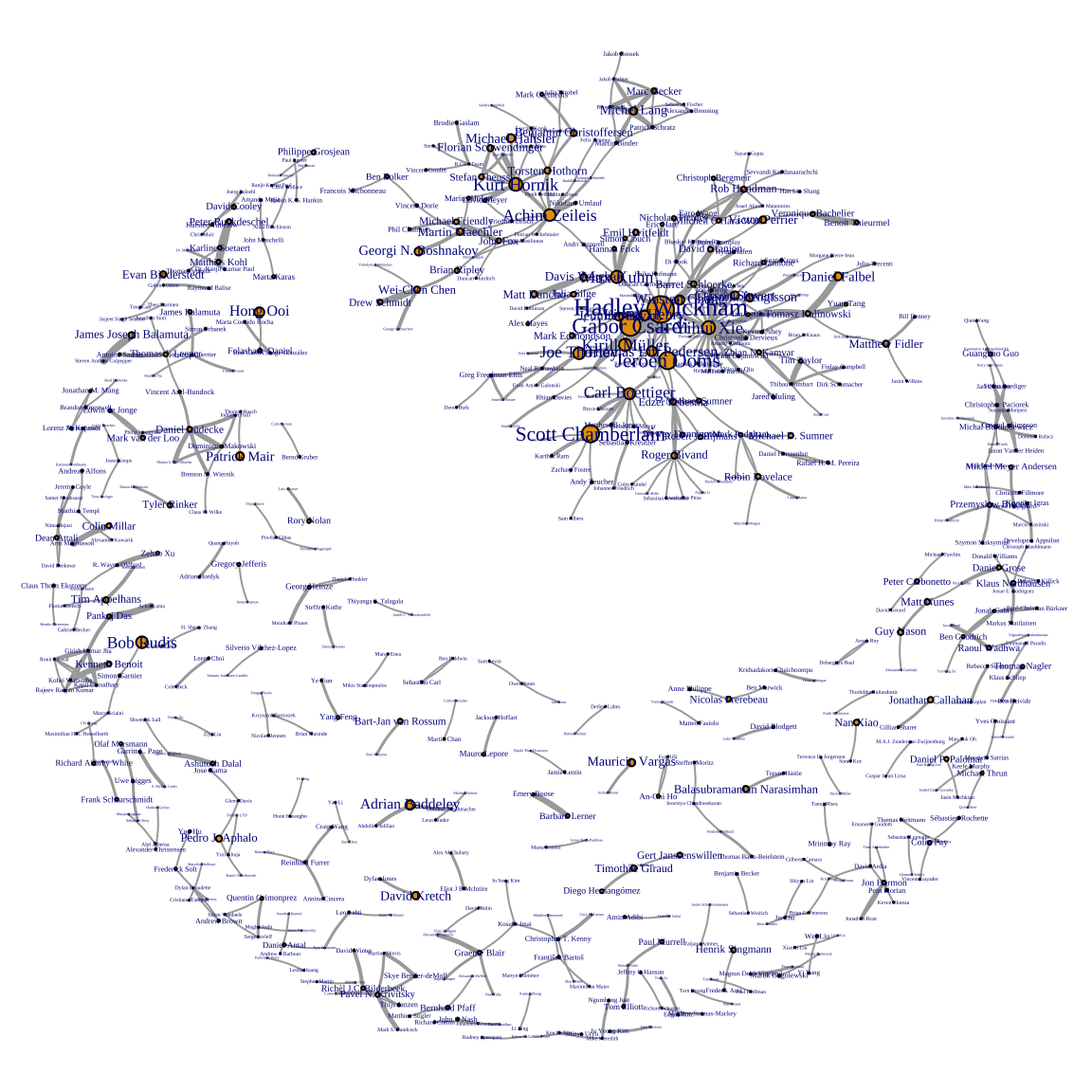
协作关系弱的开发者占大部分,构成一个「月亮」的造型,其中,不乏维护多个 R 包的开发者,这些人要么单干,要么在专业小领域、小组织内协作。与之相对应的是协作关系较强的开发者,人数虽少,影响力却大,构成一个「太阳」的造型。协作得多往往意味着维护的 R 包也不少,甚至同属于一个组织,因此,高产的开发者、影响力大的组织聚集在一起,如 R Core Team、RStudio、rOpenSci 等。
#> IGRAPH clustering edge betweenness, groups: 181, mod: 0.88
#> + groups:
#> $`1`
#> [1] "Matt Nunes" "Daniel Grose" "Guy Nason"
#> [4] "Rebecca Killick" "Idris Eckley" "Alessandro Cardinali"
#>
#> $`2`
#> [1] "Jin Zhu" "Shiyun Lin"
#>
#> $`3`
#> [1] "Julio Trecenti" "Henrik Bengtsson" "Morgane Pierre-Jean"
#> [4] "Zhian N. Kamvar" "Pierre Neuvial" "Michal Bojanowski"
#> + ... omitted several groups/verticesigraph 包提供多种社区探测的算法,上面简单使用函数 cluster_edge_betweenness() 来探测,结果显示有 181 个社区。社区 1 包含的成员如下:
#> [1] "Matt Nunes" "Daniel Grose" "Guy Nason"
#> [4] "Rebecca Killick" "Idris Eckley" "Alessandro Cardinali"社区 3、14、21、34、46、52、75 的成员是比较多的。其中,社区 3 是以 RStudio 为核心的大社区,社区 14 是以 CRAN 为核心的大社区。
#> [1] "Julio Trecenti" "Henrik Bengtsson" "Morgane Pierre-Jean"
#> [4] "Zhian N. Kamvar" "Pierre Neuvial" "Michal Bojanowski"
#> [7] "Ian Lyttle" "Thomas Lin Pedersen" "Yihui Xie"
#> [10] "Dirk Schumacher" "Jeroen Ooms" "Gábor Csárdi"
#> [13] "Sean Kross" "Carl Boettiger" "Neal Richardson"
#> [16] "Ryan Hafen" "Matthew Fidler" "Hadley Wickham"
#> [19] "Mark Edmondson" "Kirill Müller" "Richard Iannone"
#> [22] "Carson Sievert" "Winston Chang" "Lionel Henry"
#> [25] "Jennifer Bryan" "Michael Sumner" "Scott Chamberlain"
#> [28] "Garrick Aden-Buie" "Daniel Falbel" "Matthew B. Jones"
#> [31] "Hiroaki Yutani" "Taiyun Wei" "Jim Hester"
#> [34] "Romain François" "Greg Freedman Ellis" "Rhian Davies"
#> [37] "Bryce Mecum" "Steph Locke" "Christophe Dervieux"
#> [40] "Jonathan Keane" "Thibaut Jombart" "Dewey Dunnington"
#> [43] "Anne Cori" "Bill Denney" "Jared Huling"
#> [46] "Wush Wu" "Atsushi Yasumoto" "Barret Schloerke"
#> [49] "Yuan Tang" "Duncan Garmonsway" "Edzer Pebesma"
#> [52] "Sebastian Meyer" "Derek Burk" "Tim Taylor"
#> [55] "Alicia Schep" "Tomasz Kalinowski" "Michael Rustler"
#> [58] "Joe Cheng" "Bhaskar Karambelkar" "Sebastian Kreutzer"
#> [61] "JJ Allaire" "JooYoung Seo" "Zachary Foster"
#> [64] "Malcolm Barrett" "Aaron Wolen" "Bruno Tremblay"
#> [67] "Justin Wilkins" "Yixuan Qiu" "Johannes Friedrich"
#> [70] "Kevin Ushey" "Steven M. Mortimer" "Karthik Ram"
#> [73] "Jorrit Poelen" "Maëlle Salmon" "Aron Atkins"
#> [76] "Ramnath Vaidyanathan" "Thomas Leeper" "Dirk Eddelbuettel"
#> [79] "Xianying Tan"#> [1] "Achim Zeileis" "Michael Hahsler" "Michel Lang"
#> [4] "Nikolaus Umlauf" "Vincent Dorie" "Bettina Gruen"
#> [7] "Bernd Bischl" "Ben Bolker" "Marc Becker"
#> [10] "Friedrich Leisch" "Brian Ripley" "Michael Friendly"
#> [13] "John Fox" "Kurt Hornik" "Patrick Schratz"
#> [16] "Volodymyr Melnykov" "Martin Maechler" "George Ostrouchov"
#> [19] "Drew Schmidt" "Georgi N. Boshnakov" "Wei-Chen Chen"
#> [22] "Stefan Theussl" "David Meyer" "Jakob Bossek"
#> [25] "Francois Michonneau" "Marius Hofert" "Florian Schwendinger"
#> [28] "Felix Zimmer" "Martin Binder" "Phil Chalmers"
#> [31] "Lukas Sablica" "Sebastian Fischer" "Lennart Schneider"
#> [34] "Jakob Richter" "Florian Wickelmaier" "Rudolf Debelak"
#> [37] "Duncan Murdoch" "Alexander Brenning" "Ingo Feinerer"同时,在 RStudio 这个大社区下,有一些与之紧密相关的小社区,比如 Rob Hyndman 等人的时间序列社区、Roger Bivand 等人的空间统计社区。
#> [1] "Asael Alonzo Matamoros" "Nicholas Tierney"
#> [3] "Sevvandi Kandanaarachchi" "Rob Hyndman"
#> [5] "Di Cook" "Mitchell O'Hara-Wild"
#> [7] "Han Lin Shang" "Sayani Gupta"
#> [9] "Earo Wang" "Christoph Bergmeir"#> [1] "Sebastian Jeworutzki" "Roger Bivand" "Colin Rundel"
#> [4] "Angela Li" "Gianfranco Piras" "Patrick Giraudoux"
#> [7] "Giovanni Millo"结合前面的 图 18.6 ,知道有很多小圈圈,这些放一边,重点关注那些大的圈圈,见下图。
代码
op <- par(mar = rep(0, 4))
plot(eb, pdb_authors_graph,
edge.width = (E(pdb_authors_graph)$edge_cnt) / 4,
edge.arrow.size = .01,
edge.curved = .1,
layout = layout.kamada.kawai,
vertex.size = (V(pdb_authors_graph)$vertex_cnt) / 8,
vertex.label.cex = sqrt(V(pdb_authors_graph)$vertex_cnt) / 8
)
on.exit(par(op), add = TRUE)
下面使用 tidygraph 包构造图数据、计算节点中心度,dplyr 包操作数据。中心度代表节点(开发者)的影响力(或者重要性)。最后,借助 ggraph 包绘制维护者之间的贡献网络,节点的大小代表维护者影响力的强弱。
代码
pdb_authors_g <- tidygraph::as_tbl_graph(pdb_authors_net_edge, directed = T) |>
dplyr::mutate(Popularity = tidygraph::centrality_degree(mode = 'in'))
library(ggraph)
ggraph(pdb_authors_g, layout = "kk") +
geom_edge_fan(aes(alpha = after_stat(index)), show.legend = FALSE) +
geom_node_point(aes(size = Popularity), alpha = 0.5) +
theme_graph(base_family = "sans")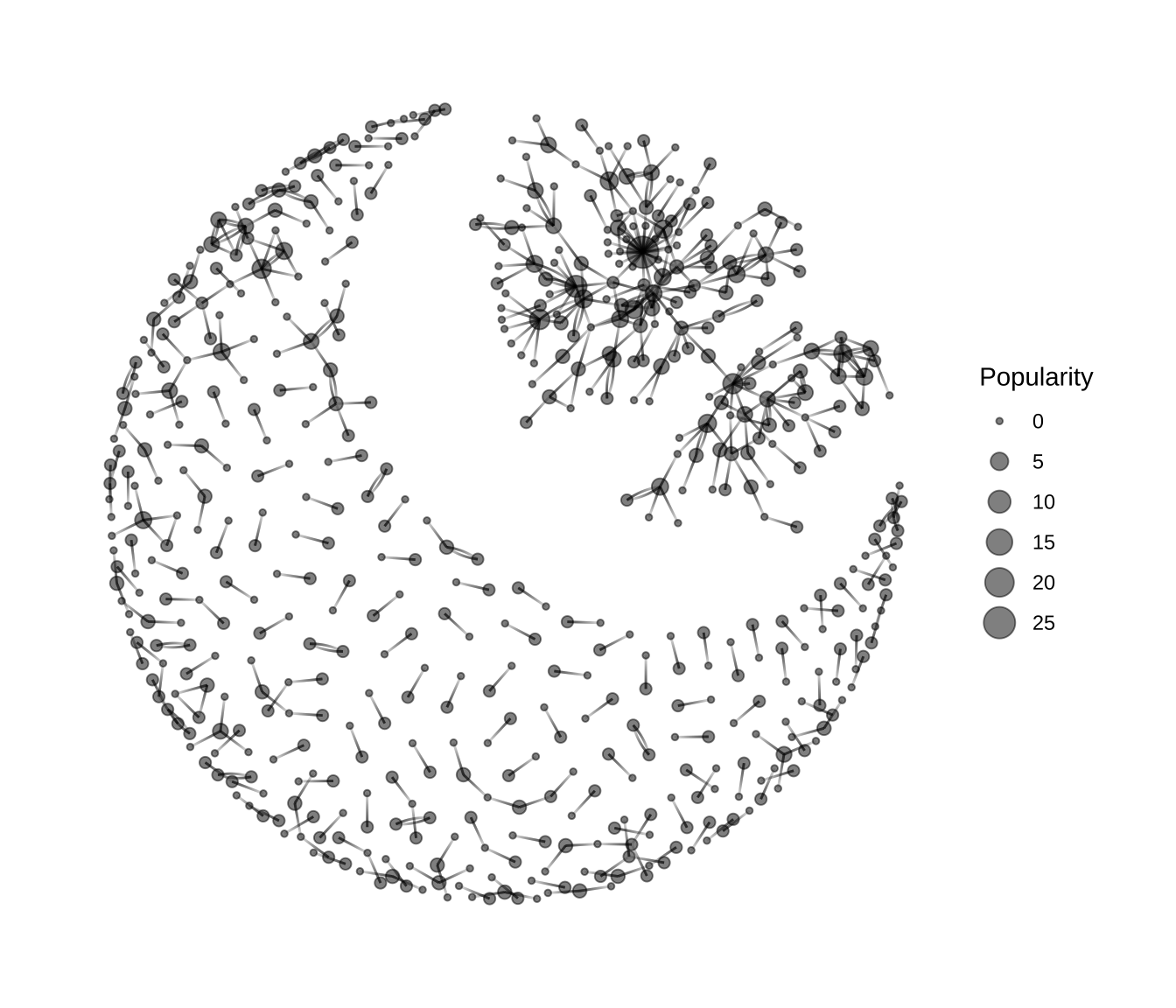
前面两个网络图基于同一份数据、同样的网络布局算法,得到非常类似的结果。静态图上的标签相互重叠,影响细节的观察和探索,比如连接 CRAN 和 RStudio 两大阵营的通道。下面使用 visNetwork 包制作交互式网络图形,它是 JS 库 vis-network 的 R 语言接口, 使用 visNetwork 包绘制交互式网络图后,可以在图上使用鼠标放大、拖拽。可以发现在 CRAN 社区的 Achim Zeileis 和 RStudio 社区的 Max Kuhn 之间是由 Andri Signorell 牵线搭桥。此外,读者若有兴趣,可以使用 Richard Iannone 开发的 DiagrammeR 包制作静态的矢量网页图形。
代码
library(visNetwork)
# 将 igraph 对象转为 visNetwork 包可用的数据
dat <- toVisNetworkData(pdb_authors_graph)
nodes_df <- dat$nodes
nodes_df$value <- nodes_df$vertex_cnt
edges_df <- dat$edges
edges_df$value <- edges_df$edge_cnt
# 输入节点和边的数据
visNetwork(nodes = nodes_df, edges = edges_df, height = "600px") |>
visIgraphLayout(randomSeed = 20232023, layout = "layout.kamada.kawai")18.4 扩展阅读
R 语言网络分析方面的著作有 Erick Kolaczyk 的书籍《Statistical Analysis of Network Data with R》(Kolaczyk 和 Csárdi 2020),网络可视化方面,推荐 Hadley Wickham 的著作《ggplot2: Elegant Graphics for Data Analysis》(Wickham, Navarro, 和 Pedersen 2024) 的第七章,Sam Tyner 等人的文章《Network Visualization with ggplot2》(Tyner, Briatte, 和 Hofmann 2017) 也值得一看。
在网络数据分析方面, igraph 是非常流行的分析框架 ,它是由 C 语言写成的,非常高效。同时,它提供多种语言的接口,其 R 语言接口 igraph 包在 R 语言社区也是网络数据分析的事实标准,被很多其它做网络分析的 R 包所引用。开源的 Gephi 软件适合处理中等规模的网络分析和可视化。大规模图计算可以用 Apache Spark 的 GraphX。R 语言这层,主要还是对应数据分析和数据产品,用在内部咨询和商业分析上。
企业级的图存储和计算框架,比较有名的是 Neo4j ,它有开源版本和商业版本。Nebula Graph 开源分布式图数据库,具有高扩展性和高可用性,支持千亿节点、万亿条边、毫秒级查询,有中文文档,有企业应用案例(美团图数据库平台建设及业务实践)。阿里研发的 GraphScope 提供一站式大规模图计算系统,支持图神经网络计算。
18.5 习题
- 类似开发者协作关系的分析,可以统计 R 包被多少 R 包依赖,依赖数量的分布。统计 R 包被依赖的深度(若 R 包 A 被 R 包 B 依赖,R 包 B 被 R 包 C 依赖,以此类推)。进而,构建、分析、可视化依赖关系网络,分析 R 包的影响力。
- 本文基于 2022 年 12 月 31 日的 R 包元数据进行分析,请与 2023 年 12 月 31 日的数据比较。