Capítulo 3 Instalando e conhecendo pacotes do R
3.1 O que é um pacote?
Até aqui utilizamos o que chamamos de Base R, ou seja, sintaxe e funções básicas do R usando apenas os pacotes padrões e pré-carregados. Ao digitar ?sum()no console, por exemplo, podemos ver que se trata de uma função do pacote {base}.
No entanto, um dos motivos que tem tornado o R bastante popular nos últimos anos foi o crescimento da sua comunidade de desenvolvedores e, consequentemente, de pacotes disponíveis para utilização. Atualmente o CRAN Comprehensive R Archive Network possui mais de 19 mil pacotes disponíveis, para as mais diversas aplicações. A utilização de alguns desses pacotes aumenta de forma acentuada a experiência com o R. Poderemos constatar que muitas das tarefas que vimos até então podem ser realizadas de forma mais simples, ágil e intuitiva utilizando funções específicas trazidas por determinados pacotes. Você inclusive pode fazer o seu próprio pacote!
Além do CRAN, podemos utilizar milhares de pacotes disponibilizados através do GitHub e outros repositórios como o (Bioconductor)[https://www.bioconductor.org].
Os pacotes são as unidades fundamentais do código R reproduzível. Eles incluem funções R reutilizáveis, a documentação que descreve como usá-las e dados de exemplo. (Hadley Wickham 2015)
Um pacote é um conjunto relacionado de funções, arquivos de ajuda e arquivos de dados que foram empacotados juntos. Pacotes em R são similares a módulos em Pearl, bibliotecas em C/C++ e classes em Java. (Adler 2012)
Para ver os pacotes carregados por padrão no R, use o comando seguinte:
getOption("defaultPackages")## [1] "datasets" "utils" "grDevices" "graphics" "stats" "methods"Se você deseja ver todos os pacotes disponíveis em sua biblioteca, utilize o comando library(). Para visualizar os pacotes carregados, use (.packages()). No RStudio, é possível visualizar os pacotes carregados através da aba Packages e carregá-los clicando na caixa de seleção ao lado do nome do pacote.
Uma outra função interessante do RStudio é o autocompletar para funções. Além de apresentar as funções com nomenclatura similar, ele também indica o respectivo nome pacote ao qual a função pertence entre chaves. No exemplo a seguir, temos a função substr() selecionada e podemos constatar que se trata de uma função do pacote base. Por sua vez, a função substituteDirect() faz parte do pacote methods.
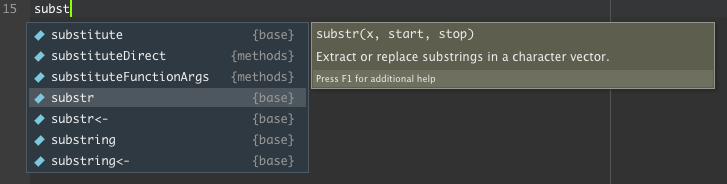
Figura 3.1: Auto-completar no RStudio para seleção de funções
3.2 Instalando pacotes no R
Uma vez que o repositório de pacotes está disponível na internet, o primeiro requisito para instalar pacotes no R é possuir uma conexão com a mesma. Se você está usando o RStudio, instalar um pacote é bem simples, uma vez que já existe um repositório padrão. O segundo passo é saber o nome do pacote que deseja instalar.
Há vários métodos de descobrir pacotes para realizar a tarefa que desejamos, como:
- Livros, manuais e artigos;
- Fóruns e plataformas colaborativas de desenvolvedores como o Stackoverflow;
- Mídias sociais;
- Blogs, lista de e-mails, GitHub.
Um bom começo é consultar termos que deseja no site RDocumentation.
Vamos começar instalando um dos pacotes mais famosos do R, o dplyr. Para instalar o citado pacote, basta utilizarmos a função install.packages() e passar o nome do pacote como carácter.
install.packages("dplyr")Uma vez instalado, sempre que desejarmos utilizar uma função de um determinado pacote, devemos carregar o mesmo. Podemos fazer isso usando a função library(). Vamos carregar o pacote dplyr.
library(dplyr)3.3 Conhecendo as funções de um pacote
Uma vez instalado um pacote, chega a hora de descobrirmos suas funções. Os pacotes do CRAN possuem um manual3 de referência detalhando cada uma das funções disponíveis.
Uma outra forma de aprendermos sobre para que cada função serve é através das vignettes (vinhetas). Você pode explorar as vinhetas de um pacote através da função browseVignettes().
Uma vinheta é um guia de formato longo para o seu pacote. A documentação da função é ótima se você souber o nome da função que você precisa, mas é inútil de outra forma. Uma vinheta é como um capítulo de livro ou um trabalho acadêmico: pode descrever o problema que seu pacote foi projetado para resolver e, em seguida, mostrar ao leitor como resolvê-lo. Uma vinheta deve dividir funções em categorias úteis e demonstrar como coordenar várias funções para resolver problemas. As vinhetas também são úteis se você quiser explicar os detalhes do seu pacote. Por exemplo, se você implementou um algoritmo estatístico complexo, talvez queira descrever todos os detalhes em uma vinheta para que os usuários do seu pacote possam entender o que está acontecendo nos bastidores e ter certeza de que você implementou o algoritmo corretamente. (Tradução livre) (Hadley Wickham 2015)
Podemos também ver exemplos através de sites específicos dos pacotes. O pacote dplyr, por exemplo, possui seu endereço na web no qual podemos acessar e descobrir diversos exemplos da utilização das funções.
Nota: Para listar todas as funções de um pacote, execute o comando
ls("package:dplyr")
Outro ponto também importante mencionarmos é que os pacotes, como já vimos, também possuem dados. Geralmente os pacotes trazem consigo conjuntos de dados para que possamos reproduzir os exemplos de forma fácil. O Base R também possui diversos exemplos de dados e que normalmente são utilizados recorrentemente nas vignettes. É o caso do data frame mtcars.
head(mtcars)## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1No caso do pacote dplyr, podemos citar o objeto starwars que traz dados dos personagens dos filmes Star Wars.
## # A tibble: 87 × 14
## name height mass hair_color skin_color eye_color birth_year sex gender homeworld species films vehicles starships
## <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <list> <list> <list>
## 1 Luke Skywalker 172 77 blond fair blue 19 male masculine Tatooine Human <chr [5]> <chr [2]> <chr [2]>
## 2 C-3PO 167 75 <NA> gold yellow 112 none masculine Tatooine Droid <chr [6]> <chr [0]> <chr [0]>
## 3 R2-D2 96 32 <NA> white, blue red 33 none masculine Naboo Droid <chr [7]> <chr [0]> <chr [0]>
## 4 Darth Vader 202 136 none white yellow 41.9 male masculine Tatooine Human <chr [4]> <chr [0]> <chr [1]>
## 5 Leia Organa 150 49 brown light brown 19 female feminine Alderaan Human <chr [5]> <chr [1]> <chr [0]>
## 6 Owen Lars 178 120 brown, grey light blue 52 male masculine Tatooine Human <chr [3]> <chr [0]> <chr [0]>
## 7 Beru Whitesun lars 165 75 brown light blue 47 female feminine Tatooine Human <chr [3]> <chr [0]> <chr [0]>
## 8 R5-D4 97 32 <NA> white, red red NA none masculine Tatooine Droid <chr [1]> <chr [0]> <chr [0]>
## 9 Biggs Darklighter 183 84 black light brown 24 male masculine Tatooine Human <chr [1]> <chr [0]> <chr [1]>
## 10 Obi-Wan Kenobi 182 77 auburn, white fair blue-gray 57 male masculine Stewjon Human <chr [6]> <chr [1]> <chr [5]>
## # … with 77 more rows3.4 A coletânia de pacotes Tidyverse
O Tidyverse (Hadley Wickham et al. 2019a) é uma coletânea de pacotes poderosos para a importação, manipulação e visualização de dados. Na verdade é mais do que isso, o Tidyverse é uma filosofia, uma ideia de como tratar os dados de uma forma eficiente e reproduzível.
The tidyverse encompasses the repeated tasks at the heart of every data science project: data import, tidying, manipulation, visualisation, and programming. We expect that almost every project will use multiple domain-specific packages outside of the tidyverse: our goal is to provide tooling for the most common challenges; not to solve every possible problem. Notably, the tidyverse doesn’t include tools for statistical modelling or communication. These toolkits are critical for data science, but are so large that they merit separate treatment. The tidyverse package allows users to install all tidyverse packages with a single command. (Hadley Wickham et al. 2019b)
Quando carregamos o pacote tidyverse estamos carregando os seguintes pacotes: dplyr, ggplot2, tidyr, readr, purrr, tibble, stringr, forcats.
Figura 3.2: Pacotes do Tidyverse
Além dos pacotes já mencionados, estão incluídos os pacotes hms, lubridate, feather, haven, httr, jsonlite, readxl, rvest, xml2, modelr e broom. Ao longo do nosso curso abordaremos vários desses, de acordo com nossa necessidade. O tidyverse é capitaneado pelo time da RStudio.