Capítulo 2 Conhecendo os principais objetos do R
2.1 Vetores Atômicos
2.1.1 O que é um vetor?
Até então aprendemos a armazenar dados em variáveis. No entanto, muitas vezes precisamos armazenar uma sequência de dados. Suponhamos que você deseja armazenar as idades de uma turma de 30 alunos. Criar uma variável para cada um dos alunos nos parece um pouco sem sentido. É para isso que o R dispõe de alguns objetos capazes de lidar com grandes quantidades de dados de uma maneira mais inteligente.
O objeto que iremos conhecer agora se chama vetor. Na linguagem R, um vetor atômico é uma sequência de dados de um mesmo tipo. Para criarmos um vetor no R a função utilizada é a c() e o processo é bastante simples. Vejamos um exemplo de criação de um vetor com os componentes {3, 23, 44} atribuído a uma variável y.
vetor1 <- c(3, 23, 44)
vetor1## [1] 3 23 44Como já foi mencionado, os vetores armazenam dados de um mesmo tipo. Isso quer dizer que não podemos armazenar um dado numérico e um dado tipo texto (character) no mesmo vetor. Seguem alguns exemplos.
vetor2 <- c("João", "Paulo", "Pedro", "Francisco")
class(vetor2)## [1] "character"vetor3 <- c(TRUE, FALSE, TRUE, TRUE)
class(vetor3)## [1] "logical"Ao tentarmos criar um vetor atômico com tipos de dados heterogêneos, o R converterá para character. Esse procedimento se chama coerção, e nos ajudará a entender alguns comportamentos em manipulações de dados mais adiante.
NOTA: O R usa sempre a mesma regra de coerção para um mesmo tipo de dado. Se há um carácter presente, todos os demais elementos são transformados em carácter. Doutro lado, lógicos são convertidos em numéricos.
vetor4 <- c(TRUE, 3, "Pedro")
class(vetor4)## [1] "character"Segundo Grolemund (Grolemund 2014):
In some cases, using only a single type of data is a huge advantage. Vectors, matrices, and arrays make it very easy to do math on large sets of numbers because R knows that it can manipulate each value the same way. Operations with vectors, matrices, and arrays also tend to be fast because the objects are so simple to store in memory.
2.1.2 Indexando vetores
Uma vez que aprendemos como criar vetores, chegou o momento de aprendermos a manipulá-los e a realizar algumas operações. Vamos começar criando um vetor com cinco elementos numéricos e depois realizar algumas operações.
vetor5 <- c(20, 12, 35, 19, 60)Uma vez que temos nosso vetor vetor5, podemos recuperar todos os valores de uma só vez ou apenas um ou alguns componentes desejados. A posição inicial de um vetor no R possui valor 1 e segue da esquerda para a direita. Portanto, se quisermos obter o valor contido na posição 2 do vetor5, usamos a seguinte notação: vetor5[2]. Vejamos:
vetor5[2]## [1] 12Uma outra forma de extrairmos os valores desejados de um vetor é através de um outro vetor lógico. Suponhamos que queremos extrair do vetor5 apenas os elementos maiores do que 20. Uma possível solução é a seguinte:
vetor5[vetor5 > 20]## [1] 35 60Como podemos observar, apenas dois valores foram retornados, 35 e 60, ambos maiores do que 20!
2.1.3 Sequências e números aleatórios
Sequências são importantes em várias operações, principalmente por economizar tempo. Uma forma simples de criar uma sequência é utilizando : e estabelecendo o início e o fim. Vejamos um exemplo de como criar uma sequência dos números de 1 a 20.
1:20## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20É possível também que nossa sequência seja formada por um intervalo determinado por nós. Para isso, utilizamos a função seq(). Como exemplo, vamos criar uma sequência de 0 a 50 com um intervalo de 5.
seq(0, 50, 5)## [1] 0 5 10 15 20 25 30 35 40 45 50Outras funções que frequentemente utilizamos no R são as que geram números aleatórias. Tais funções são bastante importantes nos processos de amostragem. As funções mais utilizadas para essa tarefa são: sample() e runif(). Vamos aos exemplos:
#Gerar 20 números inteiros no intervalo de 0 a 100 sem reposição
sample(0:100, 20)
#Gerar 20 valores entre 0 e 1 com reposição
sample(0:1, 20, replace = TRUE)
#Gerar 5 valores decimais entre 0 e 10
runif(5, 0, 10)Podemos gerar também valores aleatórios de variáveis do tipo character. Para isso, podemos utilizar a função sample() e definir um vetor de onde deverá ser selecionada a amostra. Como exemplo, podemos gerar 5 valores aleatórios entre as variáveis categóricas “masculino” e “feminino”. Observe que, como o número de valores gerados supera o conjunto de variáveis, devemos definir a possibilidade de repetição (replace = TRUE).
sample(c("masculino", "feminino"), 5, replace = TRUE)Para gerarmos um determinado texto ou número repetidas vezes, podemos utilizar a função replicate().
replicate(5, "meu texto")## [1] "meu texto" "meu texto" "meu texto" "meu texto" "meu texto"2.1.4 Outras funções importantes para manipular vetores
A tabela seguinte apresenta algumas outras funções importantes para trabalharmos com vetores. É importante que você leia a documentação de cada função para evitar erros.
| Função | Descrição |
|---|---|
paste() |
Concatena vetores e converte para carácter |
order() |
Ordena o vetor |
length() |
Retorna o tamanho do vetor |
names() |
Nomeia os elementos |
cumsum() |
Retorna um vetor que é a soma cumulativa do vetor objeto |
sort() |
Ordena um vetor |
rev() |
Retorna o vetor em ordem decrescente |
is.na() |
Retorna um vetor lógico com TRUE para valor ausente (NA) |
2.2 Data frames
2.2.1 O que é um Data Frame?
Em síntese, data frames são tabelas de dados. Os data frames lembram muito as planilhas Excel e possuem duas dimensões, pois armazenam dados de forma similar. Diferentemente dos vetores, os data frames podem armazenar dados de diferentes tipos, como: carácteres, numéricos, inteiros, e lógicos. No entanto, cada coluna (variável) possui um único tipo de dado com o mesmo número de linhas (observações).
Observe a tabela a seguir. Ela possui dados hipotéticos de seis universitários.
| nome | altura | idade | sexo | peso | fumante | uf | cl_renda | bolsa |
|---|---|---|---|---|---|---|---|---|
| João | 1.80 | 22 | masculino | 78.3 | sim | PB | A | FALSE |
| Pedro | 1.77 | 21 | masculino | 82.1 | não | AL | A | FALSE |
| Amanda | 1.71 | 18 | feminino | 66.5 | sim | PE | B | FALSE |
| Fábio | 1.65 | 20 | masculino | 88.1 | não | PE | C | TRUE |
| Fernanda | 1.66 | 23 | feminino | 58.0 | sim | SP | C | TRUE |
| Gustavo | 1.63 | 19 | masculino | 75.4 | não | CE | NA | FALSE |
O código para criar o data frame exibido acima é o que segue.
df1 <- data.frame(
nome = c("João", "Pedro", "Amanda", "Fábio", "Fernanda", "Gustavo"),
altura = c(1.80, 1.77, 1.71, 1.65, 1.66, 1.63),
idade = c(22, 21, 18, 20, 23, 19),
sexo = c("masculino", "masculino", "feminino", "masculino", "feminino", "masculino"),
peso = c(78.3, 82.1, 66.5, 88.1, 58, 75.4),
fumante = c("sim", "não", "sim", "não", "sim", "não"),
uf = c("PB", "AL", "PE", "PE", "SP", "CE"),
cl_renda = c("A", "A", "B" , "C", "C", NA),
bolsa = c(F, F, F, T, T, F)
)O primeiro ponto a ser observado é que nosso data frame foi criado através de vários vetores. Cada um dos vetores possui um determinado tipo de dado.
Uma das funções básicas mais importantes para começarmos a trabalhar com data frames é a str(). Essa função dá uma visão clara da estrutura do nosso objeto, bem como informa os tipos de dados existentes.
Ao executarmos nossa função com o data frame df1 temos o resultado que segue:
str(df1)## 'data.frame': 6 obs. of 9 variables:
## $ nome : chr "João" "Pedro" "Amanda" "Fábio" ...
## $ altura : num 1.8 1.77 1.71 1.65 1.66 1.63
## $ idade : num 22 21 18 20 23 19
## $ sexo : chr "masculino" "masculino" "feminino" "masculino" ...
## $ peso : num 78.3 82.1 66.5 88.1 58 75.4
## $ fumante : chr "sim" "não" "sim" "não" ...
## $ uf : chr "PB" "AL" "PE" "PE" ...
## $ cl_renda: chr "A" "A" "B" "C" ...
## $ bolsa : logi FALSE FALSE FALSE TRUE TRUE FALSEAnalisando o resultado da função, podemos verificar que nosso data frame possui 6 observações e 8 variáveis. As observações e variáveis nada mais são do que nossas linhas e colunas, respectivamente. Uma outra informação importante é saber o tipo de dado que cada variável (coluna) apresenta. Podemos facilmente constatar que cinco das nossas variáveis são numéricas, três são numéricas e uma é lógica.
O RStudio possui uma maneira mais rápida e intuitiva para apresentar os mesmos dados.
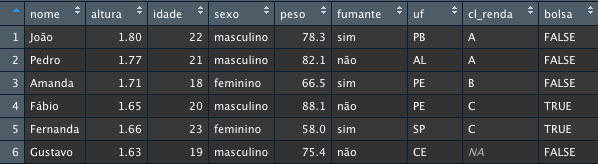
Figura 2.1: Visualização do data frame no RStudio
NOTA: Para visualizarmos o objeto conforme apresentado na Figura 2.1, podemos clicar no objeto apresentado na aba Environment ou executar o comando
View(df1)no console.
2.2.2 Manipulando data frames
Nesse ponto iremos abordar a manipulação de nossos data frames utilizando o Base R, ou seja, com a linguagem padrão do R. Obviamente há inúmeros pacotes que permitem realizar a mesma tarefa de modo até mais intuitivo. No entanto, é prudente nesse ponto apresentarmos a forma básica que também se mostra bastante útil no cotidiano.
Vamos iniciar selecionando uma observação do nosso df1. Para fazermos isso, devemos informar a linha e a coluna da observação que desejamos. O exemplo que segue demonstra a seleção da terceira linha da segunda coluna.
df1[3, 2]## [1] 1.71Agora, vamos selecionar apenas as colunas com dados de nome, sexo e uf.
df1[ ,c("nome", "sexo", "uf")]## nome sexo uf
## 1 João masculino PB
## 2 Pedro masculino AL
## 3 Amanda feminino PE
## 4 Fábio masculino PE
## 5 Fernanda feminino SP
## 6 Gustavo masculino CEPara extrairmos observações, a lógica é a mesma. Segue exemplo de seleção da primeira e da última linha de nosso data frame:
df1[c(1, 6), ]## nome altura idade sexo peso fumante uf cl_renda bolsa
## 1 João 1.80 22 masculino 78.3 sim PB A FALSE
## 6 Gustavo 1.63 19 masculino 75.4 não CE <NA> FALSESelecionar variáveis em um data frame é bastante simples usando a sintaxe: df$x. Onde df é o data frame e x a variável que desejamos selecionar. Para selecionar todos os dados contidos na variável altura, podemos fazer:
df1$altura## [1] 1.80 1.77 1.71 1.65 1.66 1.63Já para selecionar o quarto elemento da variável altura, podemos escrever:
df1$altura[4]## [1] 1.65O RStudio auxilia bastante no trabalho com data frames. Ao digitarmos $ após o nome do nosso objeto, uma lista das variáveis irá aparecer para seleção (Ver Figura 2.2 . Além de economizar tempo, tal função reduz a ocorrência de erros.
Figura 2.2: Auto-completar no RStudio para seleção de variáveis.
2.3 Listas
2.3.1 O que é uma lista?
Em poucas palavras, uma lista no R pode ser entendida como um vetor capaz de armazenar elementos com diferentes tipos de dados, uma vez que agrupam os dados em uma dimensão. Logo, uma mesma lista pode armazenar um vetor, um data frame e uma matriz, por exemplo. Por esse motivo, as listas podem se apresentar de forma bem mais complexa do que os objetos que conhecemos até agora, uma vez que podem conter também outras listas.
Para iniciarmos, vamos criar e exibir uma lista simples, com cinco elementos.
lista1 <- list("João", 1.80, 78.3, F, "PB")
lista1## [[1]]
## [1] "João"
##
## [[2]]
## [1] 1.8
##
## [[3]]
## [1] 78.3
##
## [[4]]
## [1] FALSE
##
## [[5]]
## [1] "PB"É possível perceber que apesar de termos uma aparência similar ao vetor na função que criou a lista1, a exibição se mostra bem diferente. Os colchetes duplos [[]] indicam qual elemento da lista está sendo apresentado, enquanto o simples ([]) nos mostra o subelemento da lista.
Um outro ponto que chama também a nossa atenção é que as listas podem armazenar dados de tamanho e/ou dimensões diversas. Vejamos o exemplo a seguir.
lista2 <- list(c("João","Pedro"), 1.80, 78.3, F, "PB", 1:10)
lista2## [[1]]
## [1] "João" "Pedro"
##
## [[2]]
## [1] 1.8
##
## [[3]]
## [1] 78.3
##
## [[4]]
## [1] FALSE
##
## [[5]]
## [1] "PB"
##
## [[6]]
## [1] 1 2 3 4 5 6 7 8 9 10Para visualizarmos a estrutura da lista, podemos também utilizar a função str(), como segue no exemplo abaixo.
str(lista2)## List of 6
## $ : chr [1:2] "João" "Pedro"
## $ : num 1.8
## $ : num 78.3
## $ : logi FALSE
## $ : chr "PB"
## $ : int [1:10] 1 2 3 4 5 6 7 8 9 102.3.2 Selecionando elementos de uma lista
Para manipularmos listas no R, a sintaxe é similar a que utilizamos com vetores. Para nos referirmos aos elementos da lista pela posição, utilizamos [[ ]]. Veja exemplo a seguir.
lista2[[6]]## [1] 1 2 3 4 5 6 7 8 9 10A segunda forma é a demonstrada a seguir. Ocorre que nessa forma a classe do objeto retornado é uma lista.
lista2[c(1,3)]## [[1]]
## [1] "João" "Pedro"
##
## [[2]]
## [1] 78.3Uma outra forma de selecionarmos os elementos é através do nome dos elementos da lista. Para isso a lista deve possuir nomenclatura para seus elementos. A seguir vamos demonstrar como fazemos tal operação.
lista3 <- list(Turma = "A", Professor = "Luiz", Alunos = df1)Estabelecemos o nome Turma para o primeiro dado da nossa lista lista3, cujo valor é A. Para o segundo elemento, atribuimo o nome de Professor, com valor Luiz. Por sua fez, no elemento chamado Alunos, guardamos nosso data frame df1 (criado na seção 2.2).
Uma vez que temos nossas posições nomeadas, podemos selecionar os dados utilizando o $ ou através dos colchetes duplos, conforme os exemplos que seguem.
lista3$Alunos## nome altura idade sexo peso fumante uf cl_renda bolsa
## 1 João 1.80 22 masculino 78.3 sim PB A FALSE
## 2 Pedro 1.77 21 masculino 82.1 não AL A FALSE
## 3 Amanda 1.71 18 feminino 66.5 sim PE B FALSE
## 4 Fábio 1.65 20 masculino 88.1 não PE C TRUE
## 5 Fernanda 1.66 23 feminino 58.0 sim SP C TRUE
## 6 Gustavo 1.63 19 masculino 75.4 não CE <NA> FALSElista3[["Turma"]]## [1] "A"NOTA: Podemos encontrar uma excelente explicação sobre a seleção de elementos de uma lista no item 4.3 livro Advanced R (Hadley Wickham 2019).
Também podemos selecionar os dados de uma determinada posição de uma lista através das formas que aprendemos até aqui. Suponha que desejamos selecionar as duas primeiras dos dados armazenados no elemento Alunos da nossa lista lista3. Apresentamos a seguir duas formas de fazermos tal operação.
lista3$Alunos[1:2, ]## nome altura idade sexo peso fumante uf cl_renda bolsa
## 1 João 1.80 22 masculino 78.3 sim PB A FALSE
## 2 Pedro 1.77 21 masculino 82.1 não AL A FALSElista3[[3]][1:2, ]## nome altura idade sexo peso fumante uf cl_renda bolsa
## 1 João 1.80 22 masculino 78.3 sim PB A FALSE
## 2 Pedro 1.77 21 masculino 82.1 não AL A FALSENOTA: Devido à sua flexibilidade, encontraremos as listas em argumentos de diversas funções que iremos trabalhar ao longo do curso.
2.3.3 Deletando elementos de uma lista
Remover um elemento de uma lista é uma tarefa simples. Basta atribuirmos NULL ao mesmo.
lista3$Alunos <- NULL
lista3## $Turma
## [1] "A"
##
## $Professor
## [1] "Luiz"