Chapter 7 Results
7.1 Summary statistics
Summary statistics were produced to review the pattern of responses of individuals included in the data set. Please note, that all comments that refer to respondents reflect only the respondents included in the 2011 Census Teaching File, and not descriptive statistics for the Census Population as a whole. Summary statistics produced using the data set show that:
- The majority of respondents resided in the South East and London. A relatively small proportion reside in North East and Wales.
- Almost all respondents resided in a non-communal establishment
- The majority of respondents were living in a family that was composed of a married or same-sex civil partnership couple
- Almost all respondents were usual residents at the collection address during time of collection
- There were a similar number of male and female respondents in the data set
- The majority of respondents were aged 0 to 15
- The majority of respondents were single and had never married or registered for a same-sex civil partnership
- The majority of respondents were not school children nor were they in full time study
- The majority of respondents were born in the United Kingdom
- The majority of respondents reported as being in very good health at time of collection
- With respect to Ethnicity, the majority of respondents identified as White
- With respect to religion, the majority of respondents identified as Christian. The second largest group were those that stated they had no religion.
- The two most prevalent categories for economic activity were employee and retired
- Of those that were eligible to answer the Occupation item, the majority were either in a Professional or Elementary occupation
- Of those that were eligible to answer the Industry item, the majority were employed in the Wholesale and retail trade industry
- Of those that were eligible to answer the hours worked item, the majority worked between 31 and 38 hours per week
- Of those eligible to answer the Social Grade item, the majority would be classed into the Supervisory, Clerical, and Junior Managerial social group
# Study the data: 1) How many units, 2) How many attributes? and
# 3) How many missing units?
str(Census)
summary(Census)
sapply(apply(Census[, c(-1, -19)], 2, table), function(x) x / sum(x))
missing_values <- sapply(Census, function(y) sum(length(which(is.na(y)))))
missing_values <- data.frame(missing_values)
# Look for relationship between variables
ggcorr(Census[, -1],
nbreaks = 8, palette = "RdGy",
label = TRUE, label_size = 3, label_color = "white"
)
ggsave("images/cor_all.png")Bar charts were used to review the distribution of responses for each categorical variable in the complete, training and test data sets (see Figures 2 to 4). As expected, there was a similar response pattern for a each variable between the complete, training and test data sets.
# Compare the test and training datasets
str(Census.train.label)
str(Census.test.label)
summary(Census.train.label)
summary(Census.test.label)
sapply(apply(Census.train.label[, c(-1, -19)], 2, table), function(x) x / sum(x))
sapply(apply(Census.test.label[, c(-1, -19)], 2, table), function(x) x / sum(x))
# Plot distribution of variables
Census.graph <- subset(Census, select=-hours.cont)
melt.Census <- melt(Census.graph)
melt.Census <- melt.Census[!melt.Census$value==-9,]
head(melt.Census)
ggplot(data = melt.Census, aes(x = value)) +
geom_bar() +
facet_wrap(~variable, scales = "free")
ggsave("images/dist_all.png")
# Plot distribution of variables
Census.train.graph <- subset(Census.train.label, select=-hours.cont)
melt.Census.train.graph <- melt(Census.train.graph)
melt.Census.train.graph <- melt.Census.train.graph[!melt.Census.train.graph$value==-9,]
head(melt.Census.train.graph)
ggplot(data = melt.Census.train.graph, aes(x = value)) +
geom_bar() +
facet_wrap(~variable, scales = "free")
ggsave("images/dist_train.png")
Census.test.graph <- subset(Census.test.label, select=-hours.cont)
melt.Census.test.graph <- melt(Census.test.graph)
melt.Census.test.graph <- melt.Census.test.graph[!melt.Census.test.graph$value==-9,]
head(melt.Census.test.graph)
ggplot(data = melt.Census.test.graph, aes(x = value)) +
geom_bar() +
facet_wrap(~variable, scales = "free")
ggsave("images/dist_test.png")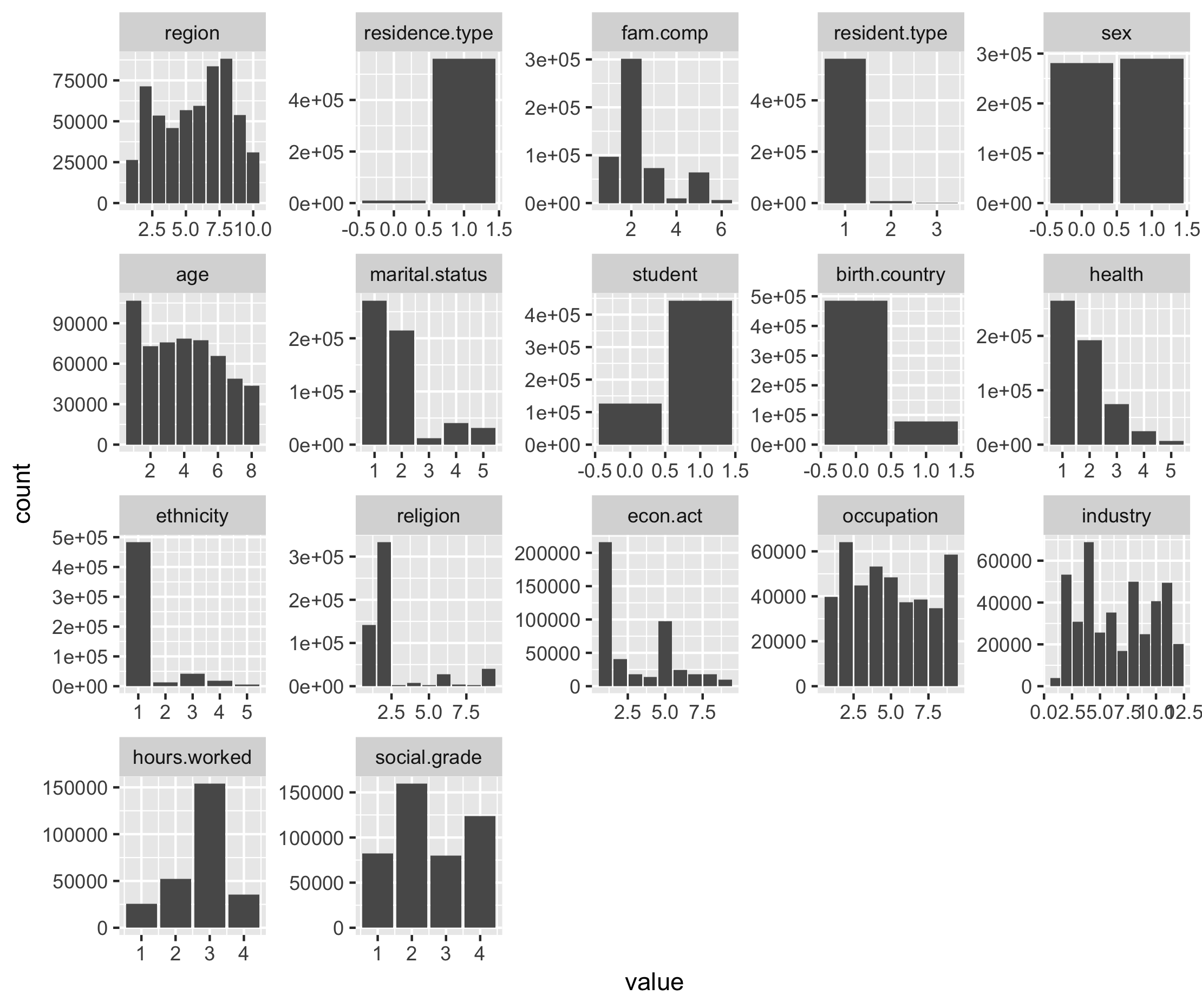
Figure 6.1. Distribution of responses for variables in complete Census Teaching File
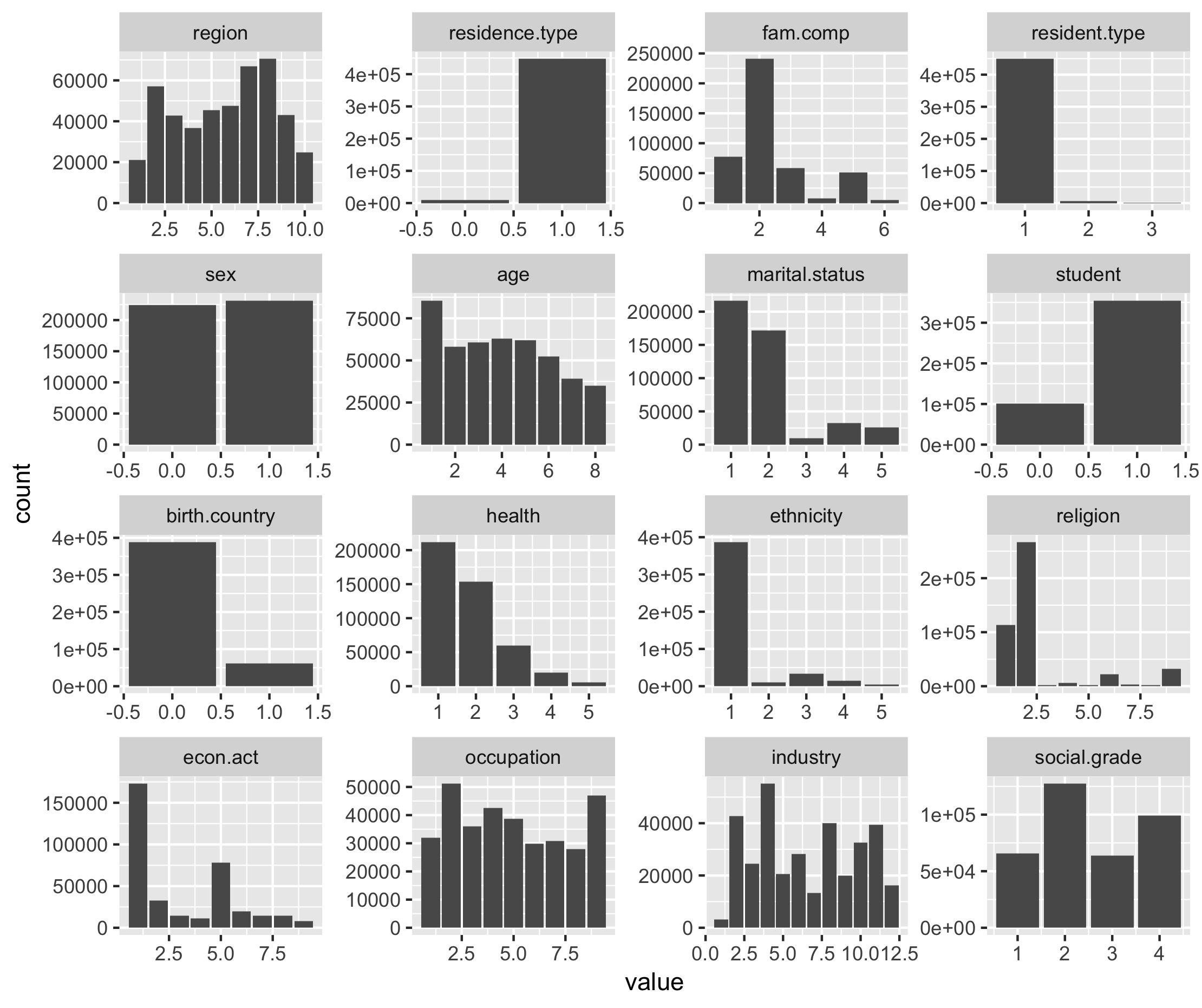
Figure 6.2. Distribution of responses for variables in training dataset
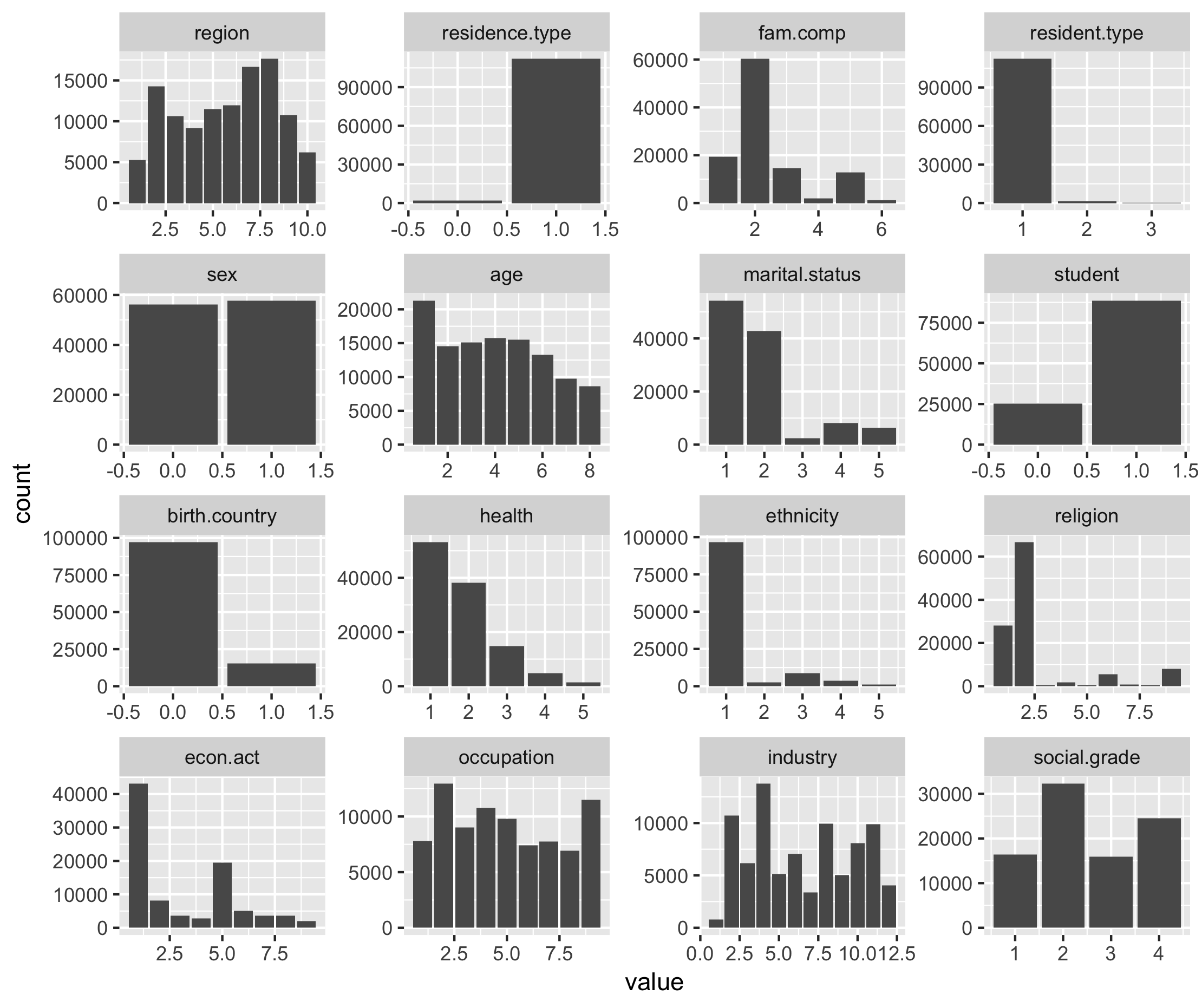
Figure 6.3. Distribution of responses for variables in test dataset
7.2 Comparison of imputation methods
The results for the different imputation methods are presented for each imputable variable. Performance measures were selected based on the type of imputable variable used (i.e. categorical or continuous). Please refer to the links below for guidance on interpreting the performance measures:
- Root mean squared error and mean absolute error (for continuous variables)
- Confusion matrix (for categorical variables)
For the categorical imputable variables, plots of the Observed vs Predicted are provided to give an indication of which categories each method predicted relatively well.
7.2.1 Economic Activity
The results shows that:
- XGBoost predicted economic activity with greater accuracy relative to donor and mode imputation
- Compared to donor based methods, the XGBoost model appeared to have greater sensitivity for the different classes of economic activity. That is, for any given class of economic activity, the model based approach was more likely to predict the correct response relative to donor based methods.
- The Mixed Methods model was the least accurate imputation method for the multi-class variable, economic activity.
| XGBoost | CANCEIS | MixedMethods | Mode | |
|---|---|---|---|---|
| Accuracy | 0.78 | 0.44 | 0.26 | 0.47 |
| Kappa | 0.61 | 0.14 | 0.06 | NA |
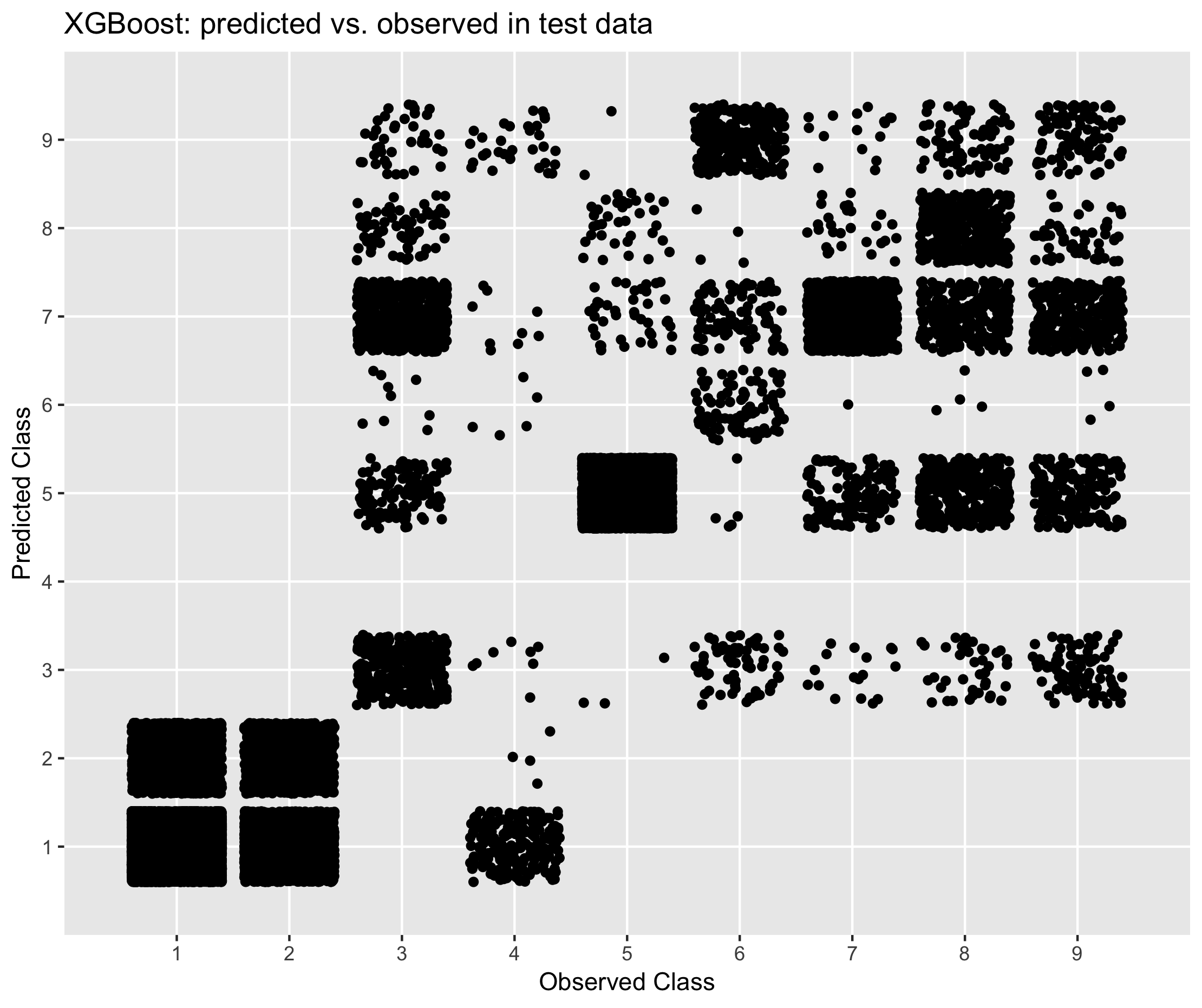
Figure 6.4. Performance of XGBoost in predicting economic activity
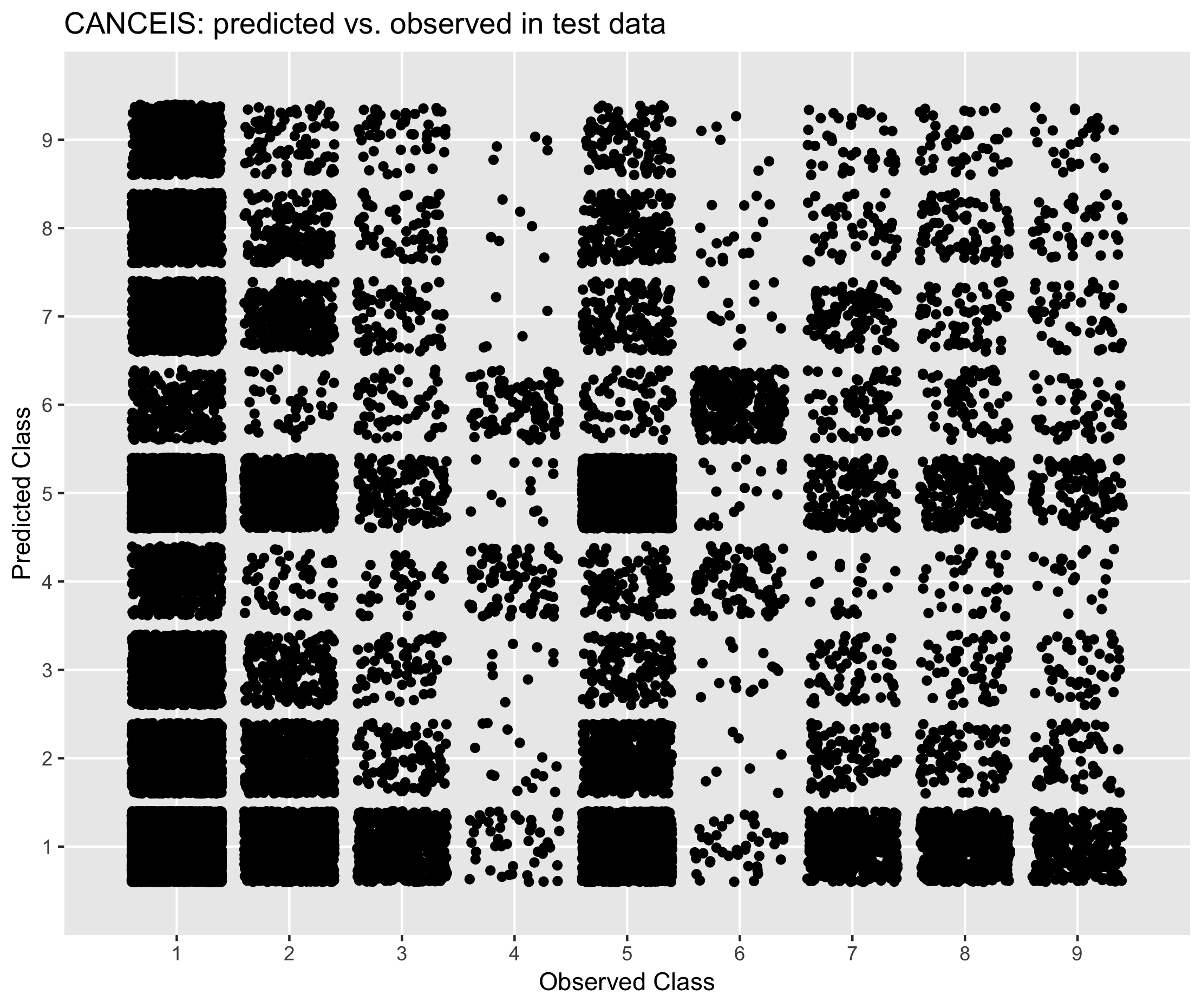
Figure 6.5. Performance of CANCEIS in predicting economic activity
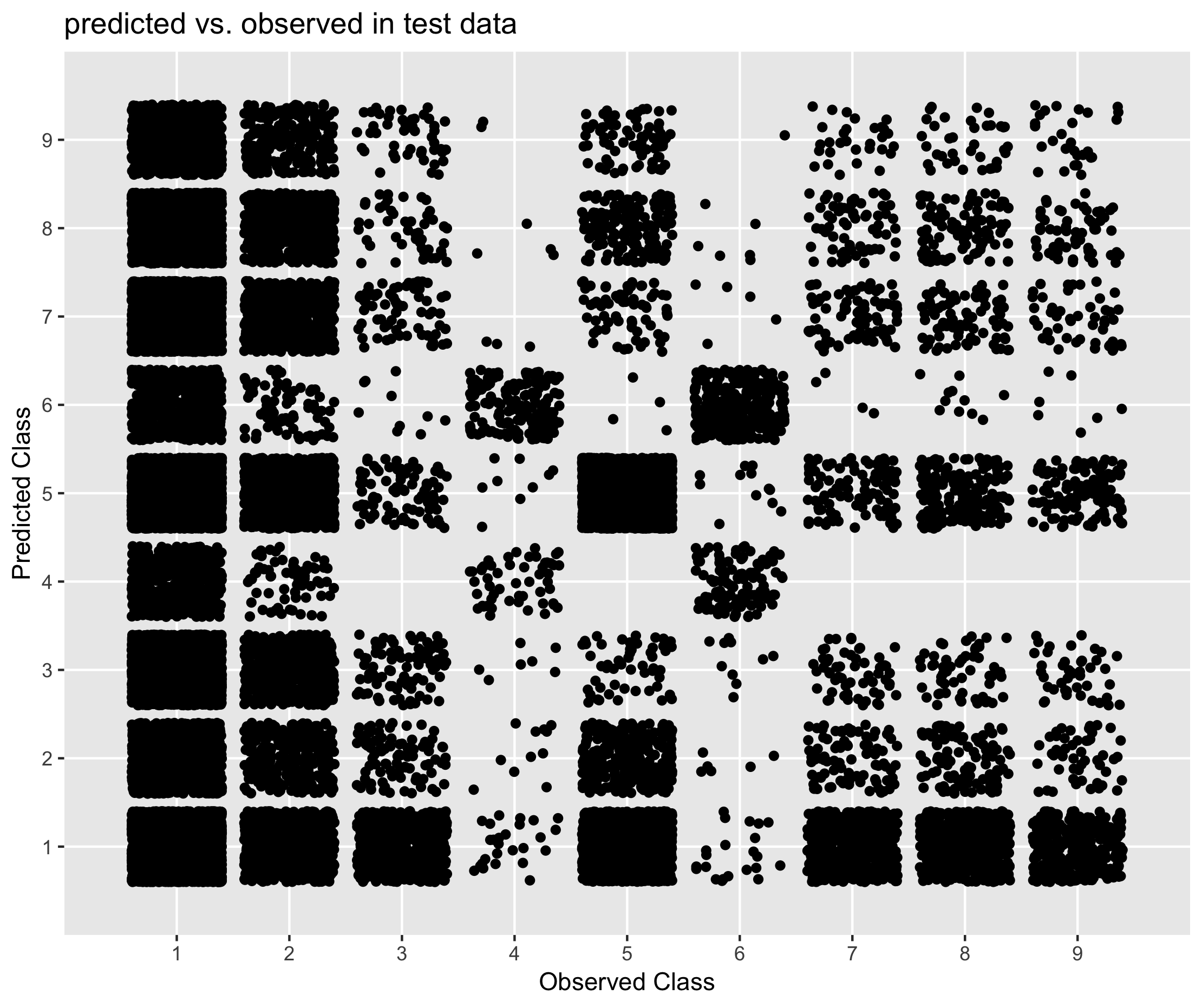
Figure 6.6. Performance of Mixed Methods approach in predicting economic activity
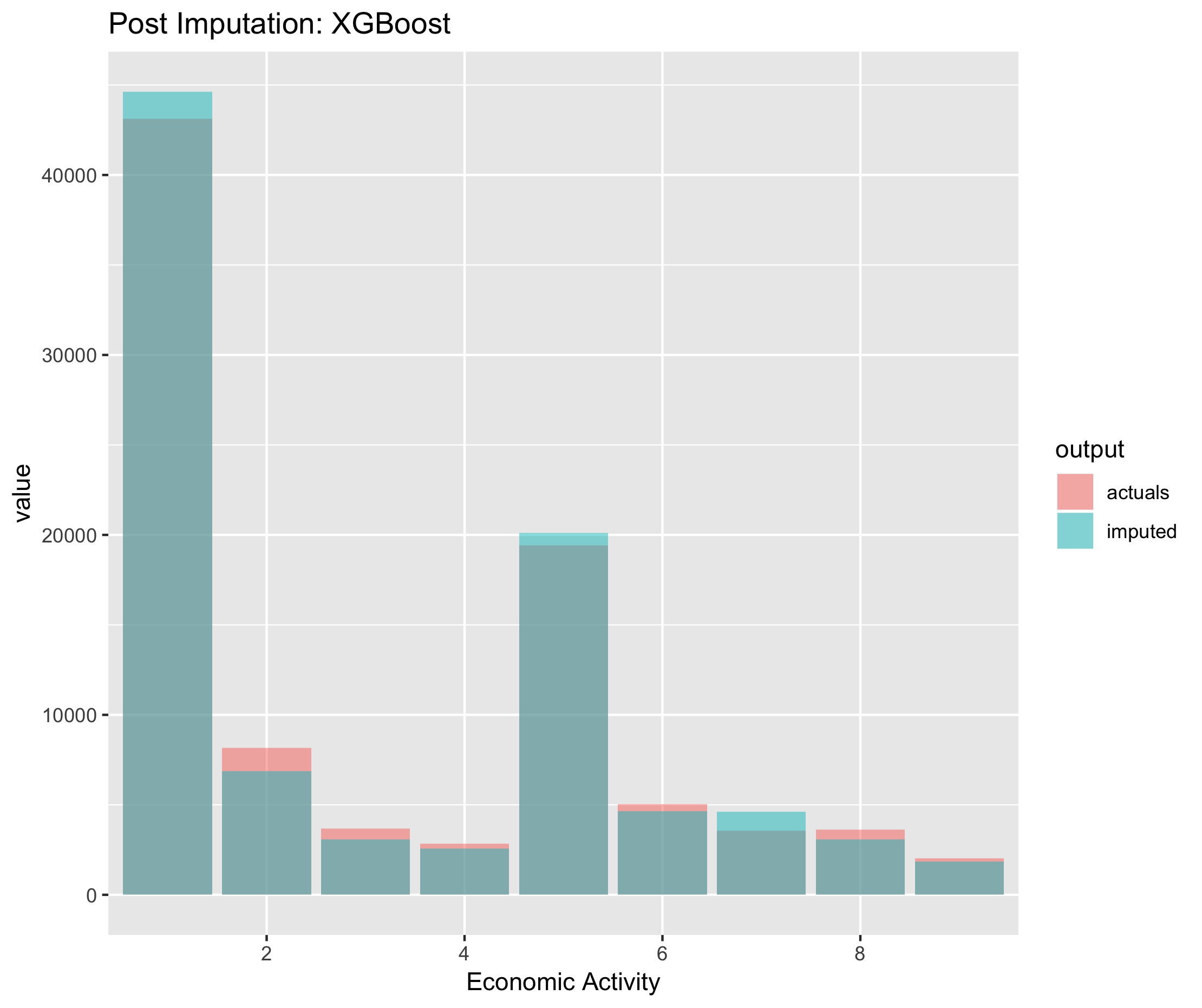
Figure 6.7. Post imputation distribution of economic activity using XGBoost imputation
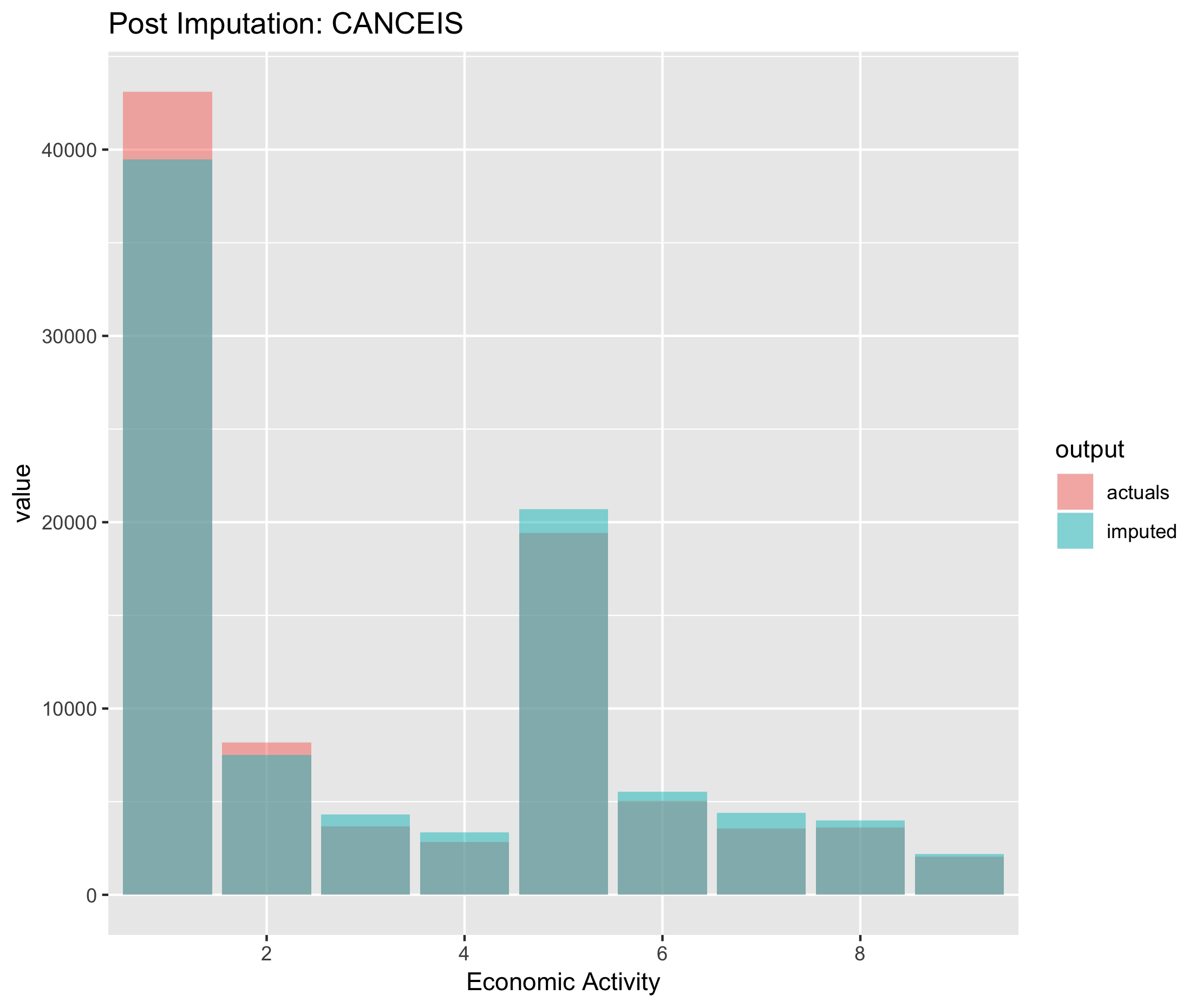
Figure 6.8. Post imputation distribution of economic activity using CANCEIS imputation
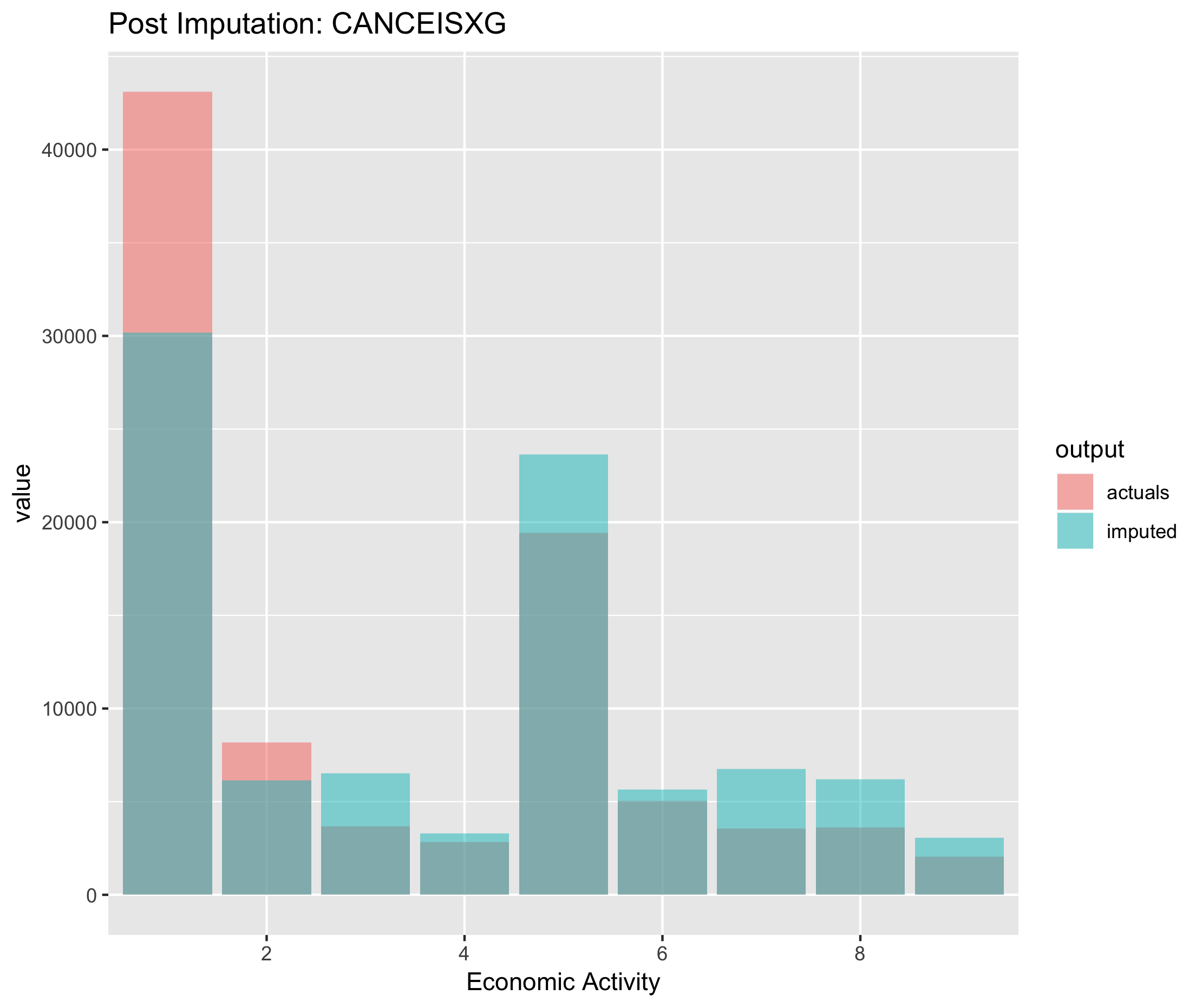
Figure 6.9. Post imputation distribution of economic activity using CANCEIS imputation
7.2.2 Hours worked
The results shows that:
- XGBoost predicted hours worked with greater accuracy relative to donor and mode imputation
- Median imputation and the Mixed Methods approach had a similar level of accuracy
- Donor based imputation had the lowest level of accuracy
| XGBoost | CANCEIS | MixedMethods | Median | |
|---|---|---|---|---|
| MAE | 9.71 | 13.54 | 13.85 | 10.51 |
| RMSE | 12.31 | 17.27 | 17.64 | 13.5 |
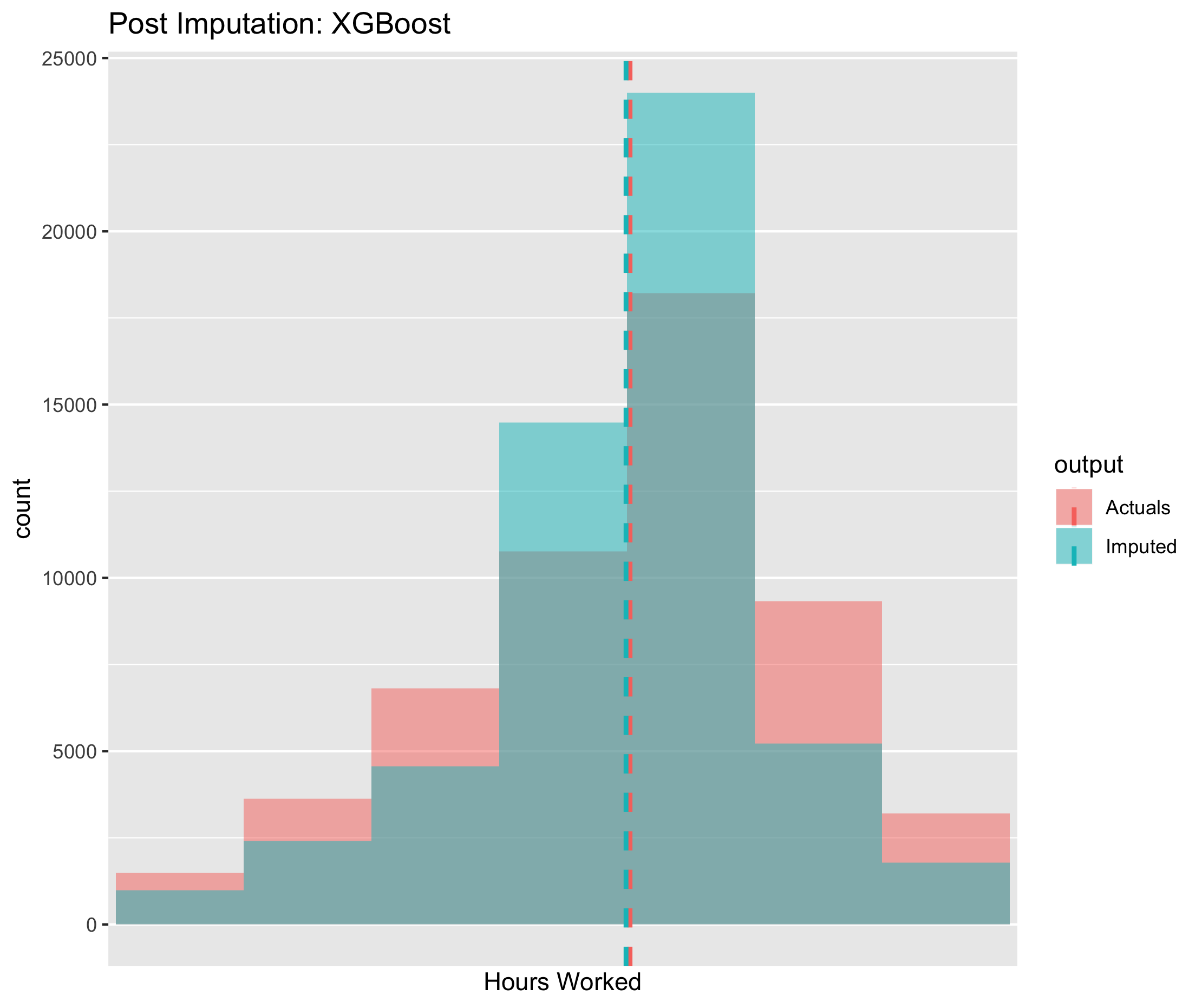
Figure 6.10. Post imputation distribution of economic activity using CANCEIS imputation
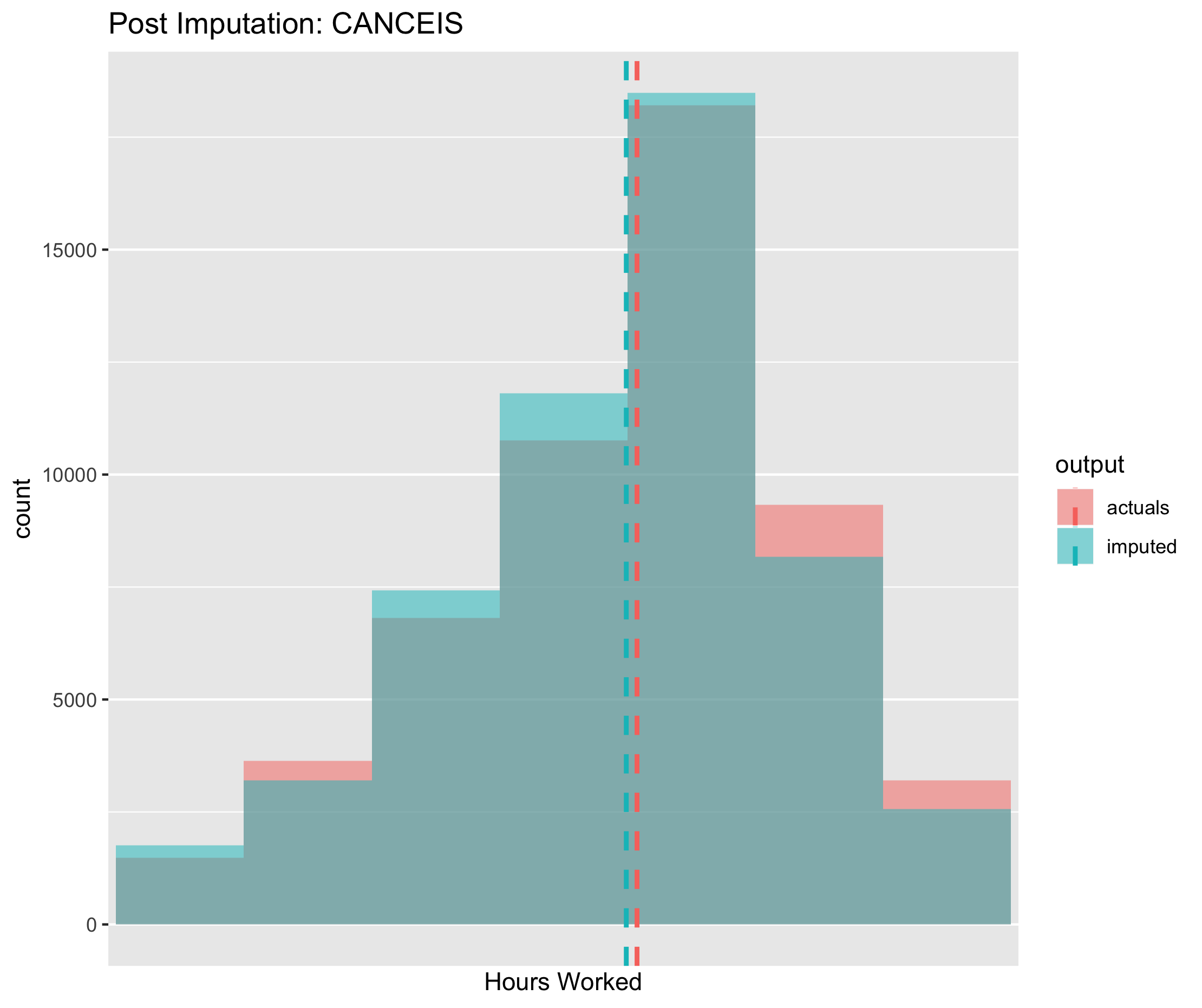
Figure 6.11. Post imputation distribution of economic activity using CANCEIS imputation
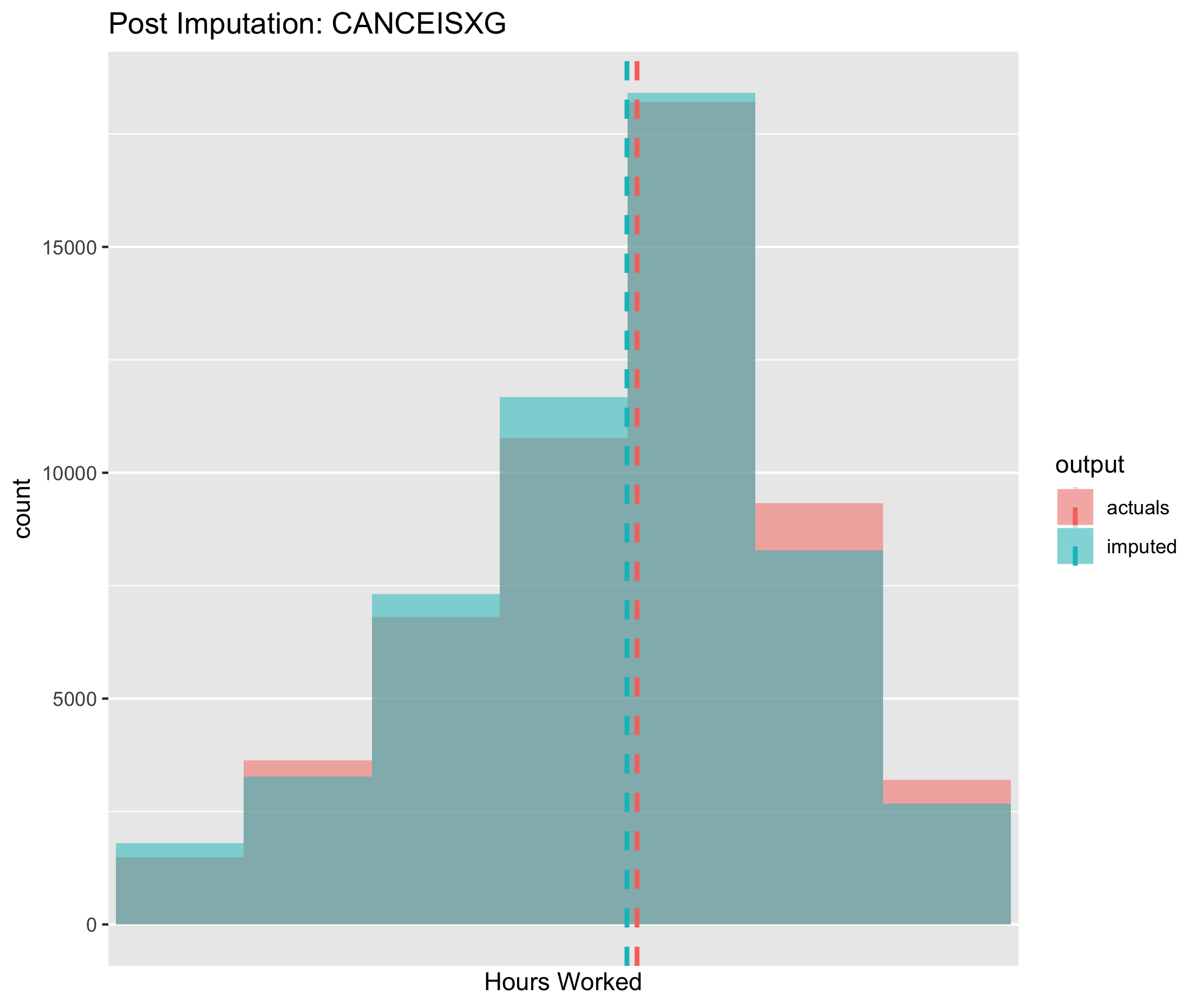
Figure 6.12. Post imputation distribution of economic activity using CANCEIS imputation
7.2.4 Student
The results shows that:
- All three approaches performed with similar degree of accuracy, whilst out-performing mode imputation
- Compared to donor based methods, the XGBoost model appeared to have greater sensitivity for the different classes of student status. That is, for both students and non-students, the model based approach was more likely to predict the correct response relative to donor based methods.
| XGBoost | CANCEIS | MixedMethods | Mode | |
|---|---|---|---|---|
| Accuracy | 0.97 | 0.88 | 0.91 | 0.78 |
| Kappa | 0.92 | 0.55 | 0.69 | NA |
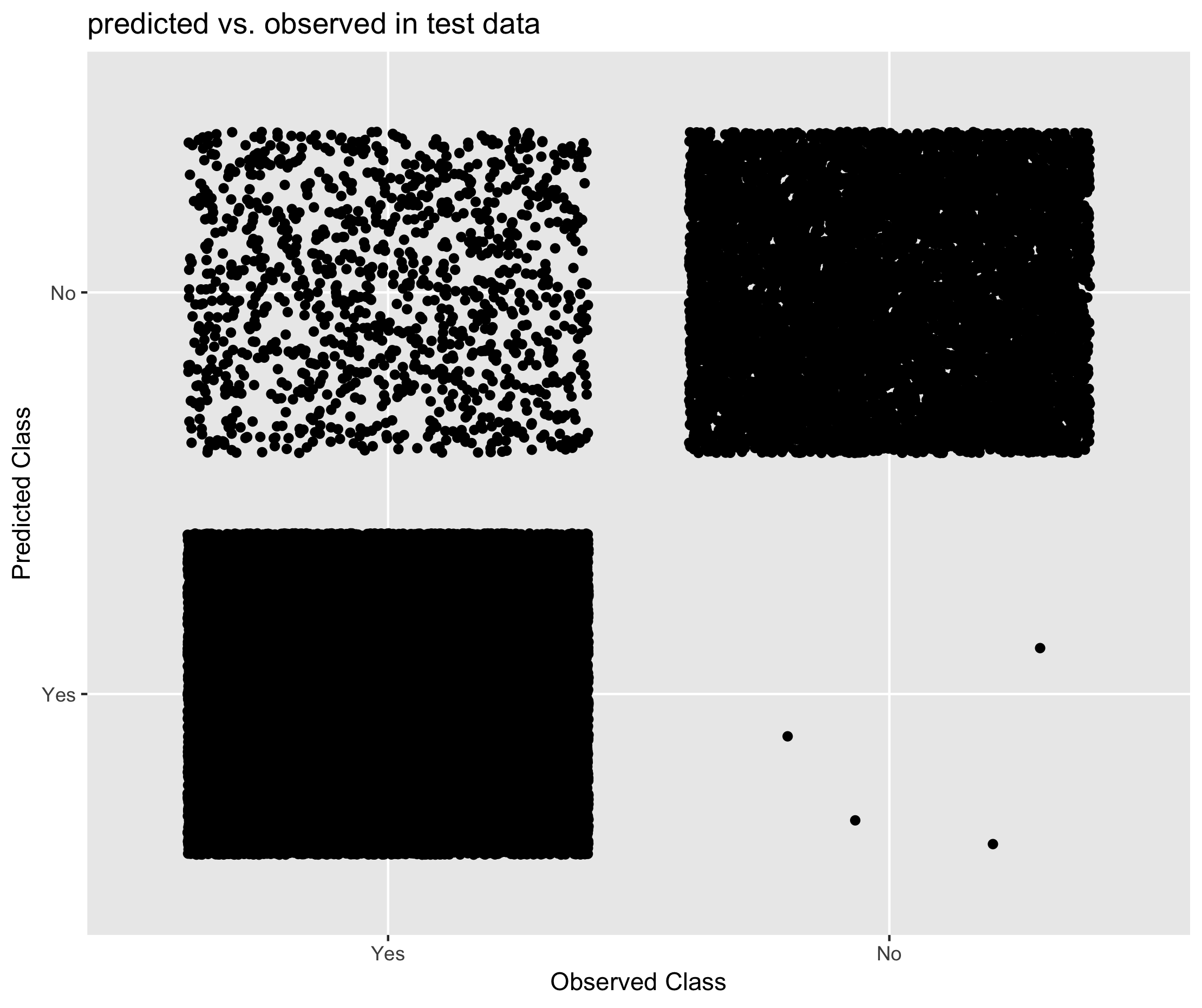
Figure 6.19. Performance of XGBoost in predicting student status
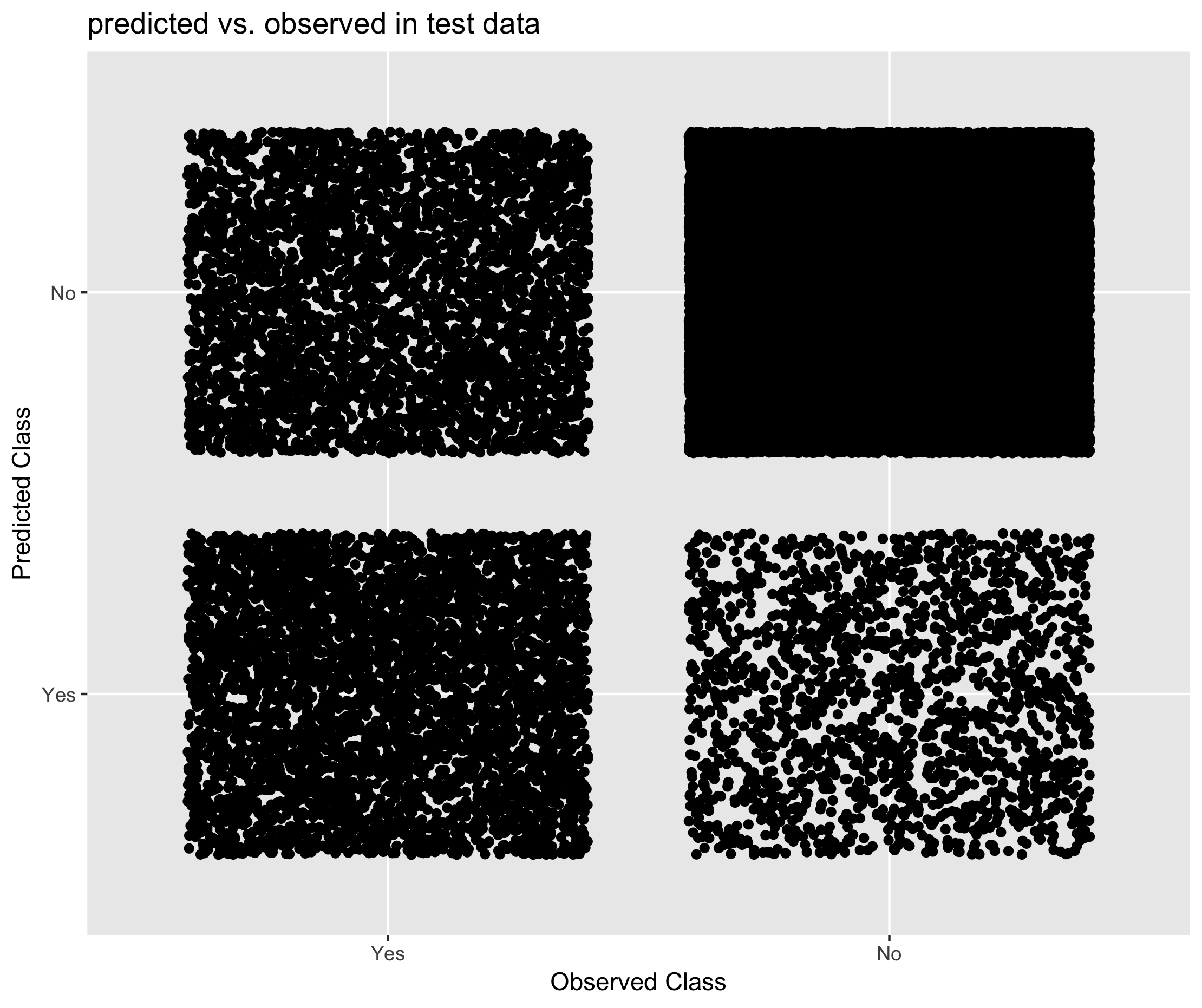
Figure 6.20. Performance of CANCEIS in predicting student status
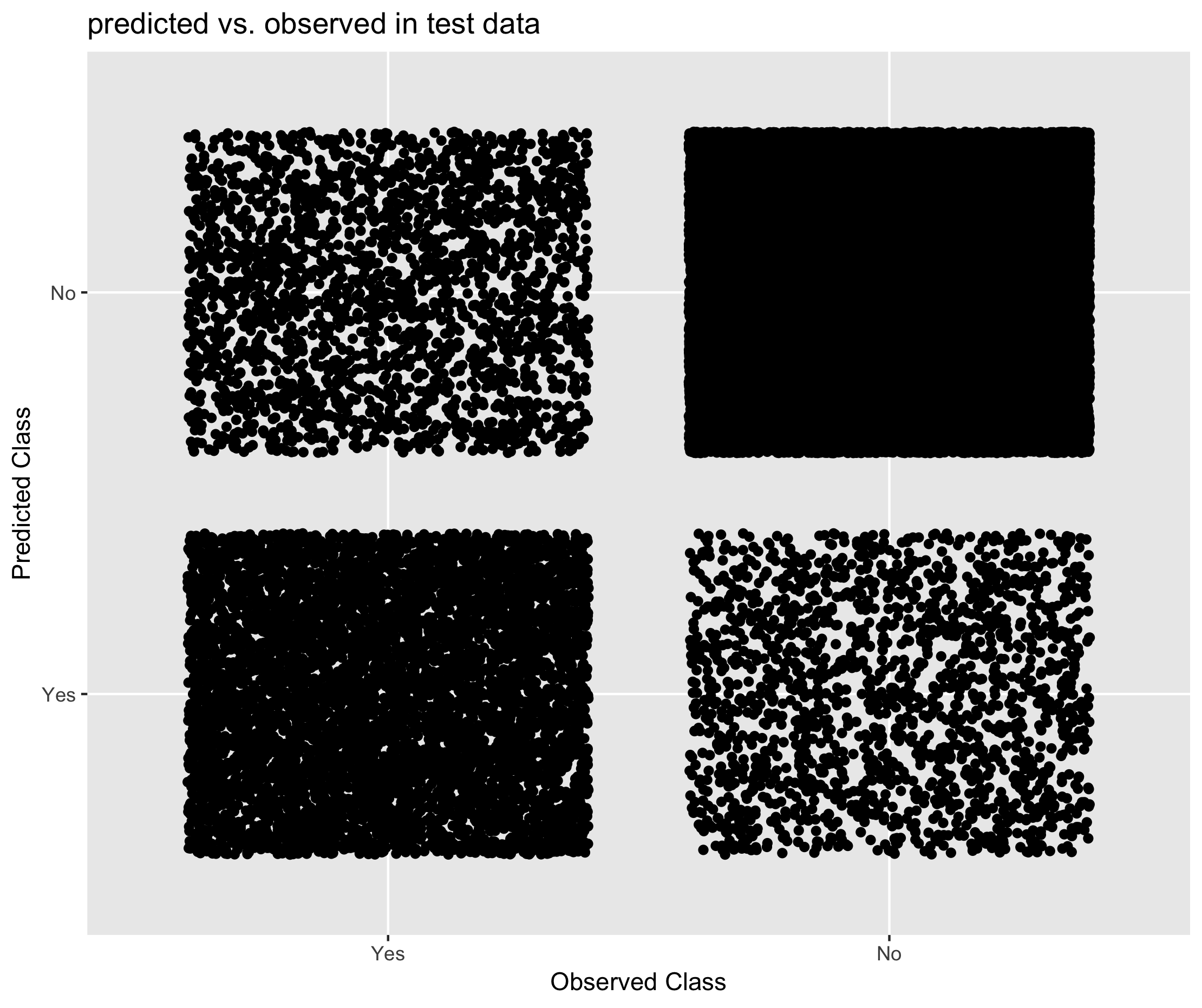
Figure 6.21. Performance of Mixed Methods approach in predicting student status
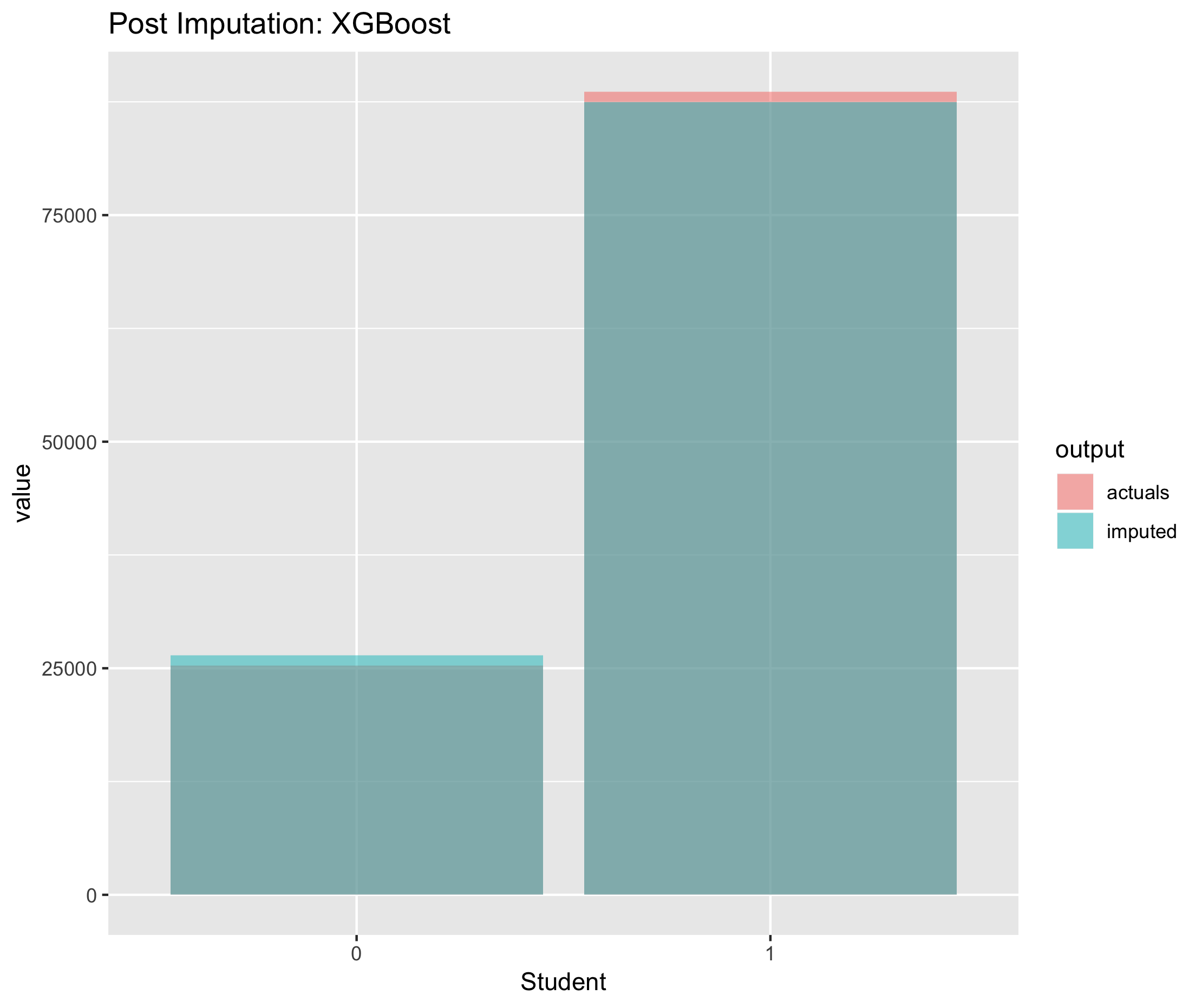
Figure 6.22. Post imputation distribution of economic activity using CANCEIS imputation
Figure 6.23. Post imputation distribution of economic activity using CANCEIS imputation
Figure 6.24. Post imputation distribution of economic activity using CANCEIS imputation
7.2.3 Social Grade
The results shows that:
Figure 6.13. Performance of XGBoost in predicting social grade
Figure 6.14. Performance of CANCEIS in predicting social grade
Figure 6.15. Performance of Mixed Methods approach in predicting social grade
Figure 6.16. Post imputation distribution of economic activity using CANCEIS imputation
Figure 6.17. Post imputation distribution of economic activity using CANCEIS imputation
Figure 6.18. Post imputation distribution of economic activity using CANCEIS imputation