Capítulo 1 Introducción.
1.1 Llámalo Estadística.
Todo el mundo habla de las estadísticas. Constantemente se hace referencia a estas en los medios de comunicación, todo está medido y estructurado por estos entes que convierten la realidad en una amalgama de números. Y más aún en el campo del comportamiento humano, es decir, lo que conocemos como Ciencias Sociales. A diario nos llegan las estadísticas sobre la intención de voto cuando hay unas elecciones, del crecimiento de la economía en términos del PIB, del comportamiento de los precios medido mediante el concepto de inflación…
El secreto de la relevancia que les damos a las estadísticas subyace en que, de partida, suponen una forma sintética y objetiva de representar la realidad que nos rodea, de manera que podemos abarcar el conocimiento de tal realidad de un modo más o menos plausible. Y esta representación de la realidad es a priori objetiva porque las estadísticas se elaboran siguiendo unas metodologías que se apoyan en un lenguaje universal: las matemáticas.
Sí. El lenguaje matemático es un lenguaje que pueden entender todas las personas, tengan la procedencia que tengan, y sean de la condición que sean. Si necesitas comunicarte con casi cualquier persona del mundo, habla en inglés. Si necesitas comunicarte con cualquier persona del mundo, hazlo mediante las matemáticas, aunque sean matemáticas más o menos elementales.
Por ello, las estadísticas se expresan en lenguaje matemático.
Pero lo que comúnmente entendemos como estadísticas no son más que unos resultados, unos outputs de la Estadística. La Estadística en realidad es algo mucho más complejo. Es una Ciencia. Las estadísticas son construidas usando el método estadístico; pero la Estadística se utiliza para muchas más cosas que para publicar estadísticas.
1.1.1 Concepto de Estadística.
El término “Estadística” proviene de la palabra latina status, “el Estado”, y fue acuñado por Achenwall a mediados del siglo XVIII con el significado de “recogida, procesamiento y utilización de datos por parte del Estado”.
Sin embargo, tal y como se entiende hoy en día, es decir, en el sentido de Ciencia Estadística, surgió como resultado de la integración de dos disciplinas: la Aritmética Política, en ese sentido de la cuantificación del Estado; y del Cálculo de Probabilidades, que nace en el siglo XVII como Teoría Matemática de los juegos de azar y que podríamos asociar al sentido de Estadística Matemática.
Ciñéndonos pues a este último sentido, a lo largo de la Historia se han dado múltiples definiciones de Estadística. Fisher propone una definición quizá demasiado generalista al decir que la Ciencia Estadística es esencialmente una rama de las matemáticas aplicada a los datos observados. Una reflexión que puede ayudar a delimitar la definición de la Ciencia Estadística es la que realiza (Peña 1983) cuando realiza la siguiente reflexión:
“La Estadística como disciplina científica ocupa un lugar muy singular en el conjunto de las ciencias. La Física, la Medicina o la Sociología tienen un área sustantiva de conocimiento y cuando utilizan modelos matemáticos, los subordinan al objeto principal de hacer avanzar el conocimiento en su parcela de estudio de la realidad. El objetivo de la Matemática, en contraposición, es ampliar la concepción y generalidad de sus propias herramientas analíticas, con absoluta independencia de la posible relación entre los entes matemáticos abstractos y los fenómenos reales. La Estadística participa de esos dos objetivos, aunque con rasgos muy peculiares. Su campo de estudio son los fenómenos aleatorios que están presentes, en mayor o menor medida, en toda actividad humana de adquisición de conocimiento empírico.”
En este mismo sentido, (Martín-Pliego 2004) apunta:
“La Estadística, por tanto, se configura como la tecnología del método científico que proporciona instrumentos para la toma de decisiones cuando éstas se adoptan en ambiente de incertidumbre, siempre que esa incertidumbre pueda ser medida en términos de probabilidad. Por ello, la Estadística se preocupa de los métodos de recogida y descripción de datos, así como de generar técnicas para el análisis de esta información.”
En definitiva, la Estadística reúne tanto la concepción derivada de la Aritmética Política, entendida como recopilación sistemática de datos cara a la descripción de la realidad (“hacer” estadísticas); como la concepción probabilística, entendida como la modelización de dicha realidad cuando está inscrita en un ambiente de incertidumbre, con el objeto de acotar dicha incertidumbre y servir de ayuda en la toma decisiones (representar matemáticamente el comportamiento de fenómenos sujetos a incertidumbre, cuando contamos con datos que caracterizan a esos fenómenos).
1.1.2 El método estadístico.
En cuanto al método seguido por la Ciencia Estadística, prima el razonamiento inductivo: las hipótesis que se plantean en la investigación implican propiedades observables en un conjunto de casos, cuyo análisis lleva a formular hipótesis más generales, aplicables ya a un conjunto mayor de casos. El método estadístico consiste, en definitiva, en sistematizar y organizar este procedimiento de aprendizaje que parte de lo particular para llegar a lo general.
En la aplicación del método estadístico podemos diferenciar una serie de etapas básicas que se exponen a continuación:
a) Planteamiento del problema. Consiste en definir el objeto de la investigación, (¿qué quiero obtener? ¿a dónde quiero llegar?), para lo cual debemos precisar la población de referencia y determinar las características que debemos observar y cómo serán recogidas. El resultado de esta fase es un sistema de características de interés observadas en un subconjunto de la población representativo de esta, al que llamamos muestra. Estas características se llamarán variables si están en escala métrica; o atributos, variables cualitativas o factores si están en escala no-métrica (nominal u ordinal). Las variables toman valores para cada elemento o caso de la muestra. Los atributos adoptan una categoría o nivel para cada uno de los casos que integran la muestra. Según los objetivos planteados en la investigación, el tamaño de la muestra, tipo de características, etc., se podrá hacer una primera selección de los posibles tipos de técnicas y modelos estadíticos a aplicar.
b) Recogida y preparación de la información muestral. Los datos, que son los valores (en caso de trabajar con variables) o categorías o niveles (en el caso de trabajar con atributos o factores) que adoptan los distintos casos que constituyen la muestra en relación con las características de interés de la población; han de ser obtenidos de las fuentes disponibles. Estas fuentes pueden ser primarias, cuando somos los propios investigadores los que generamos los datos (a través de la observación o la realización de encuestas), o secundarias, cuando estos datos ya han sido generados y/o recopilados por otros investigadores o instituciones. En cualquier caso, la muestra debe ser lo suficientemente amplia como para extraer conclusiones válidas para toda la población, y los datos deben ser de calidad, pues son la materia prima con la que trabajamos. Para ello, un requisito importante es que las fuentes de datos sean fiables.
c) Depuración de los datos. Antes de utilizar los datos muestrales conviene aplicar un análisis descriptivo que permitirá detectar posibles inconsistencias en los datos identificando los valores anómalos, posibles errores, etc. En esta fase es clave tanto identificar las carencias de datos existentes (datos faltantes o missing data), como identificar aquellos elementos de la muestra que no representan bien a la población, puesto que presentan comportamientos extraños en alguna o algunas de las variables o atributos en estudio (casos atípicos u outliers).
d) Aplicación de técnicas o modelos estadísticos para obtener resultados generalizables al conjunto de la población. Una vez se tienen claros los objetivos de la investigación y las características de la información muestral de la que se dispone (datos), y se han depurado convenientemente los datos, será el momento de plantear qué técnica o modelo estadístico aplicar. Aquí podemos distinguir, a su vez, distintas subetapas.
Por un lado, la aplicación correcta de ciertas técnicas o modelos de naturaleza inferencial, requiere del cumplimiento por parte de los datos de ciertos patrones de comportamiento (por ejemplo, el cumplimiento por parte de las variables de un comportamiento acorde con una Ley Normal). Así, deberán aplicarse una serie de pruebas para comprobar hasta qué punto los datos de partida cumplen con estos patrones.
Tras superar el punto anterior, podrá aplicarse la técnica o modelo a los datos para obtener los resultados que contribuyan a cubrir los objetivos de la investigación (usualmente, esta etapa se corresponde con la de estimación del modelo estadístico aplicado).
Por último, los resultados deben ser sometidos a una subetapa de validación y contraste, en la que se valora hasta qué punto los resultados representan el comportamiento real de los casos estudiados (estudio de la bondad del modelo), y el grado de aptitud técnica del modelo, en el sentido de si el modelo estimado cumple con los requisitos que garantizan la calidad de los resultados (por ejemplo, si se cumplen ciertas hipótesis básicas que garanticen que los coeficientes estimados del modelo gozan de las mejores propiedades estadísticas, como insesgadez, eficiencia y consistencia).
En esta etapa, además, se intentará simplificar el modelo, es decir, conseguir un modelo tan sencillo como sea posible, sin más parámetros de los necesariosy, que represente la realidad sin mucha pérdida de calidad con respecto a otro modelo más complejo, o sea, ciñéndose al principio de parsimonia de la modelización.
e) Crítica y diagnosis del modelo. Si una vez culminada la fase anterior se considera que el modelo es válido y técnicamente correcto, podrá ser adoptado para ayudar a la toma de decisiones, mediante análisis estructural, realización de previsiones o planteamiento de simulaciones. En caso contrario, si el modelo no se considera válido y/o correcto, deberemos reformular dicho modelo repitiendo las etapas anteriores hasta obtener un modelo que represente la realidad en estudio más adecuado.
En definitiva, el método estadístico sigue el método científico en cuanto a que tiene unas etapas bien delimitadas en las que se trata el conocimiento a priori (teoría) para obtener un conocimiento a posteriori, lo que pasa a engrosar el cuerpo de la Ciencia.
Es relevante destacar cómo, a su vez, el método científico, al ser aplicado al resto de ciencias, y a la propia Ciencia Estadística, recurre al método estadístico en su ejecución. Así, por ejemplo, en la etapa de recogida de evidencias observables (datos), a fin de verificar las consecuencias o hipótesis que se desprenden de una teoría previa, la Estadística interviene tanto a partir de la Teoría de Muestras como del Diseño de Experimentos para garantizar la validez y coherencia de los datos. En una fase posterior del método científico, se pasaría a verificar la nueva teoría que se desprende de las hipótesis articuladas a partir de la teoría preexistente. Nuevamente aquí interviene la Estadística como herramienta auxiliar, mediante la modelización inferencial. Además, en todo el proceso, que abarca tanto la observación de la realidad como a la generalización de los resultados como modo de confirmar una nueva teoría, aparece la incertidumbre en mediciones y resultados, por lo que el papel de la Estadística como procedimiento para la medición de dicha incertidumbre es indispensable.
De lo dicho se desprende una característica que hace de la Estadística una ciencia singular: su carácter de ciencia instrumental que auxilia al resto de ciencias en el desarrollo de sus cuerpos de conocimiento. De ahí que la Estadística es aplicada en la totalidad de las ciencias, bien sean naturales, jurídicas o sociales, y en todos los campos del saber, desde las áreas más técnicas hasta en las propias humanidades. Es decir, la Estadística es una herramienta fundamental en todo el proceso de adquisición de conocimientos a través de datos empíricos y, desde este punto de vista, podemos referirnos a la afirmación de (Mood 1963):
“La Estadística es la tecnología del método científico”.
Esta extensión de la Ciencia Estadística como ciencia auxiliar de otras ciencias, junto con su crecimiento y madurez metodológica, ha permitido el nacimiento de áreas con un cuerpo de conocimiento específico que pueden ser consideradas, a su vez, como entidades con la categoría de ciencia, como pueden ser la Psicometría, la Estadística Económica y la Econometría[1]. Así, a continuación, nos centraremos en la Estadística Económica, rama que ha ocupado un papel primordial en el desarrollo de la propia Ciencia Estadística desde el principio de sus orígenes.
[1] En nuestra opinión, no existe una delimitación clara entre Estadística Económica y Econometría, siendo la diferencia en todo caso un matiz dependiente de las técnicas y el enfoque empleado al enfrentarse a un determinado estudio. Quizá ambas disciplinas pudieran englobarse en otra disciplina más general que podría ser llamada ‘Economía Cuantitativa’. Véase en relación con este respecto (Hernández-Alonso 2000).
1.1.3 Economía y Estadística.
La aplicación del método estadístico a la Economía puede entenderse como el proceso de representación de los sistemas económicos, constituidos por los distintos agentes que operan en las economías, y las relaciones que los ligan. La Economía suele especificar dichas relaciones dándoles forma de teorías económicas. No obstante, las teorías económicas con frecuencia son demasiado imprecisas a la hora de plantear modelos económicos verificables. Como Paul Samuelson apunta ((Samuelson 2006)):
“Solo en una muy pequeña parte de las obras de Economía teóricas o aplicadas se ha tratado la derivación de los teoremas significativos operacionalmente. En parte, por lo menos, tal situación se debe a los malos preconceptos metodológicos, según los cuales, las leyes económicas deducidas de los supuestos a priori poseen rigor y validez, independientemente de cualquier conducta humana real… De hecho, las obras de economía rebosan de malas generalizaciones.”
La aplicación de los instrumentos estadísticos, y en concreto del Método Estadístico, permite dotar a la Teoría Económica del grado de concreción necesario para verificar en los sistemas reales el cumplimiento y la validez de dichas teorías. Este proceso de representación de sistemas reales puede llegar a tal grado de especificación que se puedan cuantificar las consecuencias en los cambios provocados en los elementos y relaciones del sistema ((Intriligator 1996), capítulo II). Sin embargo, por muy alto que sea el nivel de especificación del modelo que representa la realidad económica, este deberá llevar implícito cierta carga de abstracción de la realidad a la que representa, para poder ser abarcable. La realidad económica, el sistema económico, supera necesariamente en complejidad a cualquier modelo propuesto por la Teoría Económica, ya que el sistema económico depende, en última instancia, de fenómenos inmersos en cierto grado de incertidumbre; lo que es atribuible, a su vez, a su vinculación con el comportamiento humano. De este hecho se deduce la necesidad de incluir en la modelización de la realidad económica elementos estocásticos, lo que origina una visión no determinista, sino probabilista de la realidad económica.
Como señala (Martín-Pliego 2004), parte del conjunto de técnicas estadísticas aplicadas a la investigación económica es común a otras ciencias, mientras que otra parte es específica de este tipo de investigación, fruto de una evolución de la aplicación de la disciplina en el tratamiento de los temas económicos. Entre estas metodologías específicas se encuentran el estudio de las series temporales económicas, de la distribución de la renta, la construcción y análisis de números índices, la modelización regional, el análisis input-output e intersectorial, las técnicas demográficas e incluso, en nuestra opinión, la propia Econometría.
1.2 ¿Qué es R y cómo nos ayuda a analizar datos desde el punto de vista estadístico?
En los apartados anteriores hemos partido del concepto de Estadística como ciencia instrumental hasta llegar a la Estadística Económica, como aquel cuerpo de la Ciencia Económica que se sirve de las herramientas que ofrece la Estadística para profundizar en el conocimiento de la realidad económica.
Pero claro, lo interesante de esto es llevarlo a la práctica. Se necesita un soporte de hardware y software para poder aplicar las técnicas estadísticas a los datos económicos, con el objetivo de crear conocimiento a partir de dichos datos. Este conocimeinto se traducirá en una reducción de la incertidumbre que inevitablemente viene aparejada a los fenómenos económicos, lo que redundará en una mejor toma de decisiones.
En los últimos tiempos se ha producido una evolución de hardware sin precedentes, lo que ha dado soporte al desarrollo de un potente software dedicado al análisis de datos (todo tipo de datos, no solamente económicos). Este software permite a cualquier investigador aplicar las últimas técnicas de análisis estadístico a cualquier masa de datos, lo que ha supuesto una verdadera revolución. A su vez, esta realidad se ha retroalimentado, de modo que se ha producido un constante avance en el desarrollo de técnicas y tecnologías de análisis de datos cada vez más complejas. Así, podemos hablar de técnicas de aprendizaje automático o machine learning (supervisado, no-supervisado o reforzado) o, más recientemente, de modelos de análisis basados en la inteligencia artificial.
En este caldo de cultivo, en el que se dispone de grandes masas de datos, de hardware capaz de procesarlas, y de técnicas capaces de extraer información de las mismas, se ha desarrollado un software cada vez más potente que une todos estos elementos para modelizar la realidad. Este software se concreta en aplicaciones y plataformas diversas: SPSS, Stata, SAS… Y también lenguajes de programación orientados al análisis estadístico y matemático, como pueden ser Python, Matlab, Julia o… R.
Sí. R no es solo una aplicación al uso. Es todo un lenguaje de programación, orientado principalmente a la analítica de datos, sobre todo desde una perspectiva estadística. R es un proyecto de GNU, por lo que los usuarios son libres de modificarlo y extenderlo. R se distribuye como software libre bajo la licencia GNU y es multiplataforma, lo que ha facilitado su difusión y la existencia de una comunidad muy activa de ususarios y desarrolladores.
1.3 Instalación de R y R-Studio.
Como ya se ha mencionado, R es un software o lenguaje de uso y difusión gratuitos, bajo licencia GNU. El modo de instalar R es sencillo: basta con ir a la web CRAN (Comprehensive R Archive Network) y descargar la última versión disponible en el sistema operativo del que se sea usuario (en este manual, Microsoft® Windows®). Se ejecutará el archivo descargado, y se completará la instalación.
Una limitación de R es la interfaz o IDE (entorno de desarrollo integrado) que incorpora. Es decir, el “software” con el que se interactúa con el lenguaje R. Esta IDE es muy poco amigable. Para superar esta limitación, existen IDEs alternativas, entre las que destaca RStudio, desarrollada por Posit® Software. Esta IDE es gratuita. De nuevo, simplemente tendremos que ir a la web deRStudio y descargar e instalar la versión gratuita.
1.4 R y RStudio. Comienzo: Proyectos.
Tras instalar R y su IDE RStudio, podremos comenzar a trabajar. Para ello, abriremos RStudio pulsando en el icono correspondiente. Aparecerá la siguiente ventana:
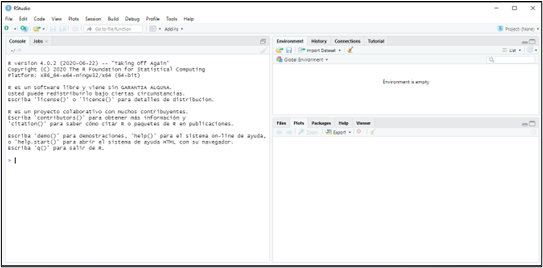
La parte izquierda de la ventana es la consola. La consola es la sección de RStudio donde podemos manejar R mediante la introducción de código. Por ejemplo, podemos escribir 2+2 después del cursor (signo “>”), y pulsar Enter. La propia consola nos devolverá el valor 4:
## [1] 4De todos modos, la forma más eficiente de trabajar es mediante “proyectos” y “scripts”.
Un proyecto básicamente viene asociado a la carpeta donde R trabajará, buscando los datos que sean sus “inputs”, y, en su caso, enviando sus resultados u “outputs”. Dicho de otro modo, es una carpeta más de nuestro sistema de carpetas o directorios; pero a la que dotamos de una característica especial: ser un proyecto de R. Si abrimos desde RStudio el proyecto, estaremos diciendo a R que, por defecto, preferentemente busque todos los archivos e inputs (datos, etc.) que necesite en esa carpeta de proyecto; y que, en su caso, guarde en tal carpeta los outputs que genere.
Para crear un nuevo proyecto, seguiremos la instrucción File → New Project, luego se nos preguntará si se crea el proyecto en una nueva carpeta o en una ya existente. Vamos a crearlo, por ejemplo, en el disco extraíble D, carpeta R, subcarpeta “explora”, que ya está creada. Nos saldrá una ventana para buscar la carpeta y, cuando la encontremos, pulsaremos Open y Create Project. Ya tendremos creado nuestro proyecto. Si nos vamos al explorador de Windows®, y buscamos la carpeta “explora”, encontraremos que en tal carpeta aparece un archivo de nombre “explora”, con un icono de un cubo con una “R”. Ese archivo lo que está haciendo es actuar como un “faro” que le dice a R que, cuando trabajemos en el proyecto “explora”, todos los archivos de datos necesarios estarán en esa carpeta (también llamada “explora”, porque el proyecto adopta el nombre de la carpeta donde lo localizamos). Y que, si nuestro trabajo aporta algún fichero de “output”, también se depositará en esa carpeta del proyecto.
En futuras sesiones, si queremos trabajar en el mismo proyecto, en lugar de seguir la ruta File → New Project, tendremos que hacer File → Open Project.
1.5 Scripts.
En cuanto a los scripts, son programas o rutinas donde varias instrucciones se ejecutan secuencialmente. Para crear un script, se seguirá la ruta File → New File → R Script. Y si el script lo guardamos, ¿dónde lo hará? Pues en la carpeta “explora”, que es la del proyecto en el que estamos trabajando.
Informáticamente, un script es simplemente un archivo de texto plano. Se puede modificar con cualquier editor de texto. Afortunadamente, para no estar entrando y saliendo de R-Studio, esta interfaz incorpora un editor de scripts, lo cual es muy cómodo.
Vemos cómo ahora, a la izquierda de RStudio, ha aparecido, en la parte superior, una nueva ventana, pasando la consola a ocupar la parte inferior. Es la ventana del “editor”:
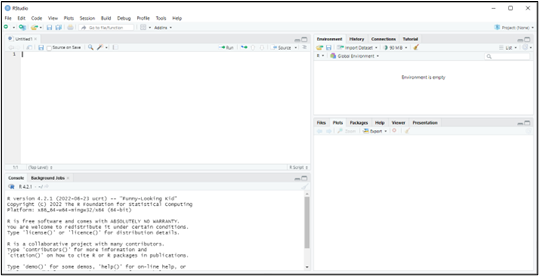
Igual que con los proyectos, podemos crear desde RStudio un script nuevo, o abrir uno preexistente; y modificarlo, ejecutarlo, o volverlo a guardar.
Vamos a comenzar a escribir nuestro script. Si queremos hacer un comentario que no ejecute ninguna instrucción, éste irá precedido del símbolo almohadilla o hashtag “#”. Luego, vamos a ordenar a R que haga la operación de suma: 2+2. Escribimos, por tanto, en el editor:
Si pulsamos Control + Mayúsculas + ENTER o al desplegable de Source → Source with Echo, se ejecutará el script (para ejecutar solo la línea donde está el cursor, pulsaremos Control + ENTER o el botón de Run; y para ejecutar varias líneas, hemos de sombrearlas y pulsar Control + ENTER o el botón de Run). En la consola aparecerá:
## [1] 4Podemos guardar el script con File → Save As… ¿Dónde se guardará por defecto? Pues en la carpeta “explora”, que es la de nuestro proyecto. Una vez nuestro script ya tiene nombre, podemos ir guardándolo de vez en cuando pulsando simplemente en el botón del “disquete” del editor. Vamos a llamarlo, por ejemplo, “explorando”. Si vamos, en el explorador de Windows®, a nuestra carpeta de proyecto, veremos que hay un archivo de texto llamado “explorando” con extensión “.R” (explorando.R). Este script lo podremos ejecutar cuantas veces queramos sin tener que escribir nada, o reescribirlo si vemos que no funciona o que necesitamos hacer modificaciones. Esa es la ventaja de trabajar con scripts.
Para recuperar un script en una nueva sesión de trabajo simplemente tenemos que seguir las instrucciones File → Open File… y seleccionarlo.
1.6 Funciones.
R trabaja con datos y funciones, principalmente. Pero, ¿qué es una función?
Una función es un conjunto o sistema de instrucciones que convierten unos datos de entrada o inputs en otros datos de salida, resultados, u outputs. Una función puede ser muy sencilla o ser verdaderamente compleja. Por otro lado, no todas las funciones están integradas en “paquetes”; sino que el usuario puede crear sus propias funciones (por ejemplo, escribiéndolas en un script) y ejecutarlas.
Las partes básicas de una función son:
Entradas, inputs o argumentos: son las diversas informaciones necesarias para realizar el procedimiento de la función. Los argumentos pueden ser introducidos por el usuario, o pueden venir dados por defecto, lo que quiere decir que, si el usuario no dota de valor a un argumento, este tomará automáticamente un valor prestablecido.
Cuerpo: está formado por un conjunto de instrucciones que transforman los inputs o entradas en los outputs o salidas. Si el cuerpo de la función está formado por varias instrucciones, éstas deben escribirse entre llaves
{ }.Salidas: son los resultados u output de la función. Si una función ofrece como salida varios tipos de objetos, estos objetos suelen ser almacenados en una estructura de almacenaje de lista.
Como ejemplo, vamos a integrar en nuestro script una función, llamada “suma”. Esta función requerirá de dos entradas o argumentos (dos números cualesquiera), y ofrecerá, como resultado, salida u output; la suma de tales entradas. El código es:
Ahora, una vez ejecutado el código anterior; si queremos sumar, por ejemplo, los números 12 y 16, solo tendremos que teclear en la consola, o escribir en el script y hacer run, a la línea:
## [1] 281.7 Paquetes (packages).
R es un lenguaje de programación en torno al cual se ha desarrollado una cantidad casi inimaginable de recursos: funciones, bases de datos, utilidades… Tal es la cantidad de recursos, que no sería operativo abrir R (directamente, o a través de una IDE, como RStudio) y tener inmediatamente todos esos recursos activos y preparados para ser utilizados. Además, R debería ser actualizado de un modo casi constante.
Por todo ello, todos los recursos disponibles están organizados mediante “paquetes” (“packages” en inglés). Un paquete es una colección de funciones y/o un conjunto de datos desarrollados por la comunidad de R. Estos incrementan el potencial de R ampliando sus capacidades básicas, o añadiendo otras nuevas.
De hecho, cuando abrimos R, algunos de estos paquetes, que se han instalado junto al propio lenguaje, se activan. Pero solo algunos. Un ejemplo es el paquete {base} o el paquete {stats} (R Core Team 2024).
La mayor parte de los paquetes disponibles no forman parte, por “defecto”, en la misma instalación de R. Se encuentran en diversos servidores llamados repositorios. El más importante, es CRAN, que es el “repositorio oficial” y que alberga más de 10.000 paquetes. Pero existen otros repositorios, a destacar, por ejemplo, GitHub.
Para instalar un paquete en nuestra máquina que esté albergado en CRAN, un modo sencillo es, dentro de R-Studio, pulsar en la ventana inferior / izquierda sobre la pestaña “Packages”, y sobre el botón “Install”. Emergerá entonces una ventana donde hay un campo para escribir el nombre del paquete (al comenzar a escribirlo, el propio R-Studio te sugerirá los paquetes disponibles). Esto equivale a usar (bien directamente en la consola, o bien como línea de código insertada en un script) la instrucción install.packages(), con el nombre del paquete entre comillas (si son varios, pues irán separados por comas.
Una vez se tiene instalado el paquete, ya no habrá que volver a instalarlo para utilizarlo; sino activarlo. De hecho, todos los paquetes que no se encuentran por defecto en la propia instalación de R, deben ser activados para poder usar sus funcionalidades y/o datos. Para hacerlo, se debe utilizar la instrucción library(), y el nombre del paquete dentro del paréntesis.
Del nombre de esta instrucción surge la confusión común de tomar como sinónimos las palabras “paquete” y “librería” en el entorno de R. Si nos referimos a estas colecciones de funcionalidades y/o datos; lo correcto es “paquete”, ya que “librería” tiene más que ver con la organización informática de un software.
1.8 Help! (sistema de ayuda).
A veces podemos albergar dudas sobre la correcta utilización de las funcionalidades y herramientas que nos proporciona un paquete. Hay varias fuentes de ayuda para intentar encontrar respuesta a las cuestiones que se nos plantean.
Una opción, para obtener información general sobre un paquete, es utilizar la función help(), con el argumento “package”. Por ejemplo:
Observaremos como en la ventana inferior / izquierda de R-Studio nos saldrá la información correspondiente. De hecho, en tal ventana existe una pestaña “Help” para obtener la ayuda sin teclear código.
Además, cada función puede ser consultada individualmente mediante help("nombre de la función") o help(function, package = "package") si el paquete no ha sido cargado. Estas instrucciones nos mostrarán la descripción de la función y sus argumentos acompañados de ejemplos de utilización. Por ejemplo:
La instrucción anterior nos aporta la documentación sobre la función rm() del paquete {base} de R (nota: este paquete se activa por defecto al abrir R o R-Studio; por lo que el segundo argumento, con el nombre del paquete que contiene la instrucción no es necesario).
Otra opción para mostrar información de ayuda es la exploración de las “viñetas” (vignettes). Las viñetas son documentos que muestran de un modo más detallado las funcionalidades de un paquete. La información de las viñetas de un paquete están disponibles en el archivo “documentation”. Puede obtenerse una lista de las viñetas de nuestros paquetes instalados con la función browseVignettes(). Si solo queremos consultar las viñetas de un paquete concreto pasaremos como argumento a la función el nombre del mismo: browseVignettes(package = "packagename"). En ambos casos, una ventana del navegador se abrirá para que podamos fácilmente explorar el documento.
Si optamos por permanecer en la consola, la instrucción vignette() nos mostrará una lista de viñetas, vignette(package = "packagename") las viñetas incluidas en el paquete, y una vez identificada la viñeta de interés podremos consultarla mediante vignette("vignettename").