Capítulo 2 Almacenando y manipulando datos.
2.1 Objetos. Datos.
Como vimos en el capítulo 1, tras ejecutar un sencillo script (o al escribir instrucciones directamente desde la consola), R es interactivo: responde a las entradas que recibe. Las entradas o expresiones pueden ser, básicamente:
Expresiones aritméticas.
Expresiones lógicas.
Llamadas a funciones.
Asignaciones.
Las expresiones realizan acciones sobre objetos de R. Los objetos en R son entes que tienen ciertas características, metadatos, llamados atributos. No todos los objetos tienen los mismos atributos y, ni tan siquiera, todos los objetos tienen atributos que los caractericen.
Los objetos más importantes en R son ciertas estructuras o contenedores diseñados para almacenar elementos:
Vectores.
Matrices.
Listas.
Data frames.
Factores.
Los elementos almacenados en los objetos se dividen en clases. Entre las diferentes clases, destacan las clases referidas a datos, que pueden ser de diferentes modos: logical (verdadero/falso), numeric (números) o character (cadena de texto). El modo numeric puede ser, a la vez, de tipo integer (número entero) o double (número real). En el caso de logical y carácter, modo y tipo coinciden.
Vamos a profundizar un poco en algunas de estos contenedores de datos. Vamos a suponer que trabajamos en el proyecto que creamos en el capítulo anterior (proyecto “explora”), y que vamos a editar el script que también creamos en tal capítulo (script “explorando.R”, que se encontrará ubicado en la carpeta del proyecto “explora”).
2.1.1 Vectores.
Los vectores, son conjuntos de elementos de la misma clase. Vamos a definir por ejemplo el vector x = (1,3,5,8). Para ello, vamos a escribir en nuestro script:
Ejecutamos la línea (situando el cursor en algún lugar de ella, dentro del script; y pulsando a la vez las teclas Control + Enter o pinchando con el ratón en el botón Run del editor). Ya tenemos nuestro primer objeto de tipo vector en memoria. Por cierto, lo que hemos hecho es una asignación, que se escribe con una flecha creada mediante los signos “<” y “-”. Hemos asignado a un vector llamado “x” los elementos 1, 3, 5 y 8.
Para ver el vector simplemente escribimos en la consola (o en el script) el nombre del vector, “x”. El resultado será:
## [1] 1 3 5 8Además, si miramos en la ventana superior-derecha de R-Studio, veremos que en el Global Environment se muestra nuestro vector y que, además, se nos informa de que tiene modo numérico. El Global Environment nos informa de los objetos que R tiene en memoria:
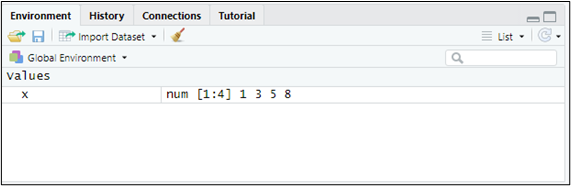
Si queremos obtener un vector de números consecutivos del 2 al 6, basta con ejecutar en la “consola” (o escribir y ejecutar en el script):
Al escribir el nombre del vector “y” en la “consola” obtendremos:
## [1] 2 3 4 5 6Si queremos saber la longitud de un vector, usaremos la función length(). Por ejemplo, length(y) nos devolverá el valor 5. Escribamos en el script y ejecutemos:
## [1] 5Un vector puede incluir, además de números, caracteres o grupos de caracteres alfanuméricos; siempre entrecomillados (lo fundamental es que sean elementos de la misma clase). Por ejemplo, el vector “genero” (¡no pongamos tildes o podemos tener problemas!). Así, si ejecutamos estas dos líneas de código:
Se habrá creado el vector “genero”:
## [1] "Mujer" "Hombre"Podemos obtener la clase de los elementos almacenados en nuestro vector con la función class():
## [1] "character"Si falta un dato en un vector, habrá que escribir “NA” (not available). Por ejemplo, si falta el tercer dato de este vector “z”, este vector se escribirá como:
Para seleccionar un elemento concreto de un vector, indicaremos entre corchetes la posición en la que se encuentra. Por ejemplo, refiriéndonos al vector “x”, para obtener el valor de su tercer elemento, haremos:
## [1] 5Si queremos que se nos muestre los elementos del vector x del 2º al 4º:
## [1] 3 5 8Por último, si queremos sacar en pantalla los elementos 1º y 4º, tendremos que incluir una “c” seguida de un paréntesis que recoja el orden de los elementos que queremos seleccionar:
## [1] 1 82.1.2 Matrices.
Las matrices, internamente en R, son vectores; pero con dos atributos adicionales: número de filas y número de columnas. Se definen mediante la función matrix(). Por ejemplo, para definir la matriz “a”:
\[ \begin{pmatrix} 1 & 4 & 7 \\ 2 & 5 & 8 \\ 3 & 6 & 9 \end{pmatrix} \] Tendremos que escribir:
## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9El número de filas de la matriz (y por tanto, el número de columnas) se fija con el argumento nrow = . También podríamos fijar el número de columnas, con ncol = .
Como vemos, por defecto, R va “cortando” el vector por columnas (si lo preferimos, lo puede hacer también por filas, añadiendo a la función matrix() el argumento by row = true; pero, en nuestro ejemplo, obtendríamos la matriz traspuesta a la que queremos almacenar).
Las dimensiones (número de filas y de columnas) de la matriz pueden obtenerse mediante la función dim():
## [1] 3 33 filas y 3 columnas.
Si queremos seleccionar elementos concretos de una matriz, lo haremos utilizando corchetes para indicar filas y columnas. Hemos de tener en cuenta que, trabajando con matrices, siempre tenemos \[rango de filas, rango de columnas\] Si se deja en blanco el espacio entre el corchete inicial y la coma, esto querrá decir que consideramos todas las filas. Y si no insertamos nada entre la coma y el corchete de cierre, esto significará que consideramos todas las columnas. A continuación tenemos varios ejemplos de código, con el resultado obtenido en la consola:
## [1] 8## [,1] [,2]
## [1,] 4 7
## [2,] 5 8## [,1] [,2]
## [1,] 1 7
## [2,] 2 8
## [3,] 3 9## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 3 6 9Tanto para vectores como para matrices, funcionan las operaciones suma y diferencia sin más complicaciones. En el caso del producto, sin embargo, hay que tener en cuenta que, por ejemplo, a*a devuelve la multiplicación elemento a elemento, es decir:
Devuelve la multiplicación elemento a elemento (en este caso, el cuadrado de cada número, al multiplicar la matriz a por sí misma):
## [,1] [,2] [,3]
## [1,] 1 16 49
## [2,] 4 25 64
## [3,] 9 36 81Para hacer el verdadero producto matricial deberá introducirse:
## [,1] [,2] [,3]
## [1,] 30 66 102
## [2,] 36 81 126
## [3,] 42 96 1502.1.3 Data frames.
Un data frame es un objeto que almacena datos organizados mediante la clase data.frame. Esta organización consiste en que, por filas, se disponen los diferentes casos o sujetos; mientras que por columnas se posicionan las variables. Así:
Es similar a una matriz en el sentido de que tiene dos dimensiones. Podemos acceder a sus elementos con corchetes, tenemos nombres de filas y columnas, y podemos operar con ellas.
Cada columna tiene un nombre, de manera que podemos acceder a una columna concreta con el símbolo
$. Todas las columnas (variables) son vectores con la misma longitud.Cada columna puede ser un vector numérico, factor, de tipo carácter o lógico.
Por ejemplo, vamos a crear el data frame “datos”, con tres variables: “peso”, “altura”, y “color de ojos”, llamadas “Peso”, “Altura” y “Cl.ojos”, respectivamente; para 3 individuos o casos. Una opción es crear primero las tres variables como vectores, y luego crear el data frame mediante la función dataframe():
Peso<-c(68,75,88)
Altura<-c(1.6,1.8,1.9)
Cl.ojos<-c("azules","marrones","marrones")
datos<-data.frame(Peso,Altura,Cl.ojos)Si ahora ejecutamos una línea con el nombre de nuestro data frame, lo obtendremos como resultado en la consola:
## Peso Altura Cl.ojos
## 1 68 1.6 azules
## 2 75 1.8 marrones
## 3 88 1.9 marronesPara obtener los nombres de las variables (es decir, el nombre de cada columna) teclearemos la función:
Obteniéndose:
## [1] "Peso" "Altura" "Cl.ojos"Para obtener solo los datos de la columna (variable) color de ojos teclearemos datos$Cl.ojos:
## [1] "azules" "marrones" "marrones"Y para obtener los datos de peso: datos$Peso:
## [1] 68 75 88Para saber el número de filas y de columnas de una hoja de datos utilizaremos las funciones nrow() y ncol():
## [1] 3## [1] 3Para seleccionar elementos de un data frame, se pueden seguir las mismas reglas que para la selección de elementos de una matriz (con el número de cada fila, que es cada individuo; y el número de cada columna, que es cada variable. Para elegir una variable, no obstante, ya hemos visto que es posible usar su nombre; aunque precedido del nombre del data frame y el signo $. Por ejemplo, si ejecutamos:
## [1] 1.6 1.8 1.9## [1] 1.6 1.8 1.9Obtenemos el mismo resultado.
2.2 Importando datos.
Lo más frecuente es que no tecleemos los datos, como hemos hecho hasta ahora; sino que los importemos a R desde algún contenedor externo (archivo de texto, hoja de cálculo, base de datos…). Nosotros vamos a importar nuestros datos desde Microsoft® Excel®. Vamos a cerrar el script que hemos estado construyendo en los apartados anteriores (para conservarlo hay que guardarlo antes), aunque vamos a seguir trabajando en el mismo proyecto (que habíamos llamado “explora”). Iremos a la carpeta del proyecto y guardaremos en ella los dos archivos de esta práctica (obtén el enlace a los archivos en la sección final del capítulo):
Un archivo de Microsoft® Excel® llamado “eolica_20.xlsx”
Un script con las instrucciones que vamos a mostrar a continuación, y que se llama “explora_eolica.R”
Si abrimos el archivo de Microsoft® Excel® comprobaremos que se compone de tres hojas. La primera muestra el criterio de búsqueda de casos en la un aviso sobre el uso exclusivo que se debe dar a los datos incorporados; la segunda recoge la descripción de las variables consideradas; y la tercera (hoja “Top 20”) guarda los datos que debemos importar desde R-Studio. Estos datos se corresponden con diferentes variables económico-financieras de 20 empresas productoras de electricidad mediante generación eólica. Luego vamos a cerrar el archivo de Microsoft® Excel® y volveremos a R-Studio. Vamos a abrir nuestro script “explora_eolica.R” con File → Open File… Este script contiene el programa que vamos a ir ejecutando en la práctica. La primera línea / instrucción en los scripts suele ser:
La instrucción tiene como objeto limpiar el Environment (memoria) de objetos de anteriores sesiones de trabajo. Para importar los datos localizados en el archivo de Excel “eolica_20.xlsx” el código es:
¡Atención! Si nunca se ha utilizado el paquete {readxl} (que contiene el código necesario para importar datos de un archivo de Microsoft® Excel®), cuando la intentemos activar con la función library() nos dará un error o nos dirá que previamente hay que importarla. En ese caso, iremos a la ventana inferior-derecha y pulsaremos la pestaña Packages, pulsaremos en Install, y emergerá una ventana donde dejaremos el “repositorio” que viene por defecto y, en el campo “Packages”, escribiremos el nombre del “paquete” que contiene la librería que nos hace falta (normalmente coincide con el nombre de la propia librería, en nuestro caso {readxl}. Una vez descargado el “paquete”, podremos ejecutar el código anterior sin problemas.
Otra cuestión importante a tener en cuenta es que, en la hoja de cálculo del ejemplo, los “valores perdidos” o missing values (celdas en las que no hay datos), venían en blanco. Pero, en ocasiones, pueden contener algún tipo de anotación, como por ejemplo, “n.d.” (no disponible). En tal caso, deberá incluirse un argumento más que informe de estas celdas que, sin estar en blanco, no tienen dato:
Volviendo a nuestro ejemplo, podemos observar cómo en el Environment ya aparece un objeto. Este objeto es una estructura de datos tipo data frame, se llama “eolica_20” y contiene 11 columnas, una por cada una de las variables almacenadas en el archivo de Microsoft® Excel®. De estas variables, tres son de tipo cualitativo, formadas por cadenas de caracteres: el nombre de la empresa, “NOMBRE”; y el nombre del grupo empresarial matriz al que pertenece, “MATRIZ”. Puede explorarse el contenido del data frame y los principales estadísticos con la función summary():
## NOMBRE RES ACTIVO FPIOS
## Length:20 Min. : -5662 Min. : 109024 Min. : -77533
## Class :character 1st Qu.: 2865 1st Qu.: 187240 1st Qu.: 27615
## Mode :character Median : 7388 Median : 271636 Median : 77740
## Mean : 50754 Mean : 1183599 Mean : 563678
## 3rd Qu.: 21206 3rd Qu.: 813816 3rd Qu.: 219345
## Max. :727548 Max. :13492812 Max. :6904824
## NA's :1
##
## RENECO RENFIN LIQUIDEZ MARGEN
## Min. :-2.8130 Min. :-359.773 Min. :0.0780 Min. :-302.03
## 1st Qu.: 0.8765 1st Qu.: 1.664 1st Qu.:0.7342 1st Qu.: 12.39
## Median : 3.6150 Median : 10.812 Median :1.2345 Median : 21.42
## Mean : 2.9399 Mean : -3.450 Mean :1.4200 Mean : 16.40
## 3rd Qu.: 4.7735 3rd Qu.: 25.312 3rd Qu.:1.5615 3rd Qu.: 38.56
## Max. : 8.5860 Max. : 52.261 Max. :5.3300 Max. : 208.36
## NA's :1
##
## SOLVENCIA APALANCA MATRIZ
## Min. :-40.74 Min. :-6265.50 Length:20
## 1st Qu.: 11.26 1st Qu.: 16.13 Class :character
## Median : 23.68 Median : 145.93 Mode :character
## Mean : 32.68 Mean : -17.17
## 3rd Qu.: 52.62 3rd Qu.: 504.74
## Max. : 99.08 Max. : 1019.62Veremos cómo aparecen 11 variables con algunos estadísticos básicos.
R ha considerado la primera columna como una variable de tipo cualitativo (atributo). En realidad no es una variable, sino el nombre de los individuos o casos. Para evitar que R tome los nombres de los casos como una variable, podemos redefinir nuestro data frame diciéndole que considere esa primera columna como los nombres de los individuos o filas:
En la línea anterior hemos asignado al data frame “eolica_20” los propios datos de “eolica_20”; pero indicando que la primera columna de datos no es una variable; sino el nombre de los casos. Si hacemos ahora el summary():
## RES ACTIVO FPIOS RENECO
## Min. : -5662 Min. : 109024 Min. : -77533 Min. :-2.8130
## 1st Qu.: 2865 1st Qu.: 187240 1st Qu.: 27615 1st Qu.: 0.8765
## Median : 7388 Median : 271636 Median : 77740 Median : 3.6150
## Mean : 50754 Mean : 1183599 Mean : 563678 Mean : 2.9399
## 3rd Qu.: 21206 3rd Qu.: 813816 3rd Qu.: 219345 3rd Qu.: 4.7735
## Max. :727548 Max. :13492812 Max. :6904824 Max. : 8.5860
## NA's :1 NA's :1
##
## RENFIN LIQUIDEZ MARGEN SOLVENCIA
## Min. :-359.773 Min. :0.0780 Min. :-302.03 Min. :-40.74
## 1st Qu.: 1.664 1st Qu.:0.7342 1st Qu.: 12.39 1st Qu.: 11.26
## Median : 10.812 Median :1.2345 Median : 21.42 Median : 23.68
## Mean : -3.450 Mean :1.4200 Mean : 16.40 Mean : 32.68
## 3rd Qu.: 25.312 3rd Qu.:1.5615 3rd Qu.: 38.56 3rd Qu.: 52.62
## Max. : 52.261 Max. :5.3300 Max. : 208.36 Max. : 99.08
##
## APALANCA MATRIZ
## Min. :-6265.50 Length:20
## 1st Qu.: 16.13 Class :character
## Median : 145.93 Mode :character
## Mean : -17.17
## 3rd Qu.: 504.74
## Max. : 1019.62Vemos que ya no aparece “NOMBRE” como variable, y en el Environment ya aparece el data frame “eolica_20” con 20 observaciones (casos), pero con 10 variables (una menos).
Antes de seguir con la manipulación de nuestros datos, es preciso decir que existen otros muchos formatos de datos que pueden ser importados. Por ejemplo, con el paquete {readr} se pueden importar datos de archivos de texto de tipo tabular (por ejemplo, archivos *.csv). Con el paquete {haven} se pueden capturar los datos almacenados en archivos de SPSS® (.sav), Stata® (.dta), SAS® (.sas7bdat), etc. Finamente, se pueden capturar datos almacenados en páginas web (archivos en formato JSON o XML, o en tablas HTML)) o en bases de datos gestionadas mediante diversos sistemas (SQLite, MySQL, MariaDB, PostgreSQL, Oracle®).
2.3 {dplyr}.
2.3.1 El Tidyverse. Cargando {dplyr}.
El Tidyverse es un conjunto de paquetes / librerías con una filosofía común, como es el uso de ciertas estructuras gramaticales, que facilitan muchas de las tareas y análisis que podrían hacerse con el lenguaje R estándar. Una buena obra para profundizar en el Tidyverse es Wickham and Grolemund (2017).
Uno de esos paquetes es {dplyr}, que proporciona una gramática más sencilla que la del lenguaje R convencional para manipular los objetos de estructuras de datos conocidos como data frames.
Los data frames, como ya sabemos, son estructuras en las que se almacenan datos de modo que, por columnas, se disponen las variables del análisis; y por filas los casos que conforman la muestra / población.
Vamos a suponer que trabajamos dentro del proyecto que hemos creado previamente, de nombre “explora” (ver capítulo 1). Dentro de la carpeta del proyecto guardaremos el script llamado “explora_dplyr.R” y el archivo de Microsoft® Excel® llamado “eolica_20.xlsx”. Si abrimos este último archivo, comprobaremos que se compone de tres hojas. La hoja “Top 20” contiene los datos a importar desde R-Studio. Estos datos se corresponden con diferentes variables económico-financieras de 20 empresas productoras de electricidad mediante generación eólica.
Luego cerraremos el archivo de Microsoft® Excel®, “eolica_20.xlsx”, y volveremos a R-Studio. Después, abriremos nuestro script “explora_dplyr.R” con File → Open File… Este script contiene el programa que vamos a ir ejecutando en la práctica.
La primera línea / instrucción en los scripts suele ser:
La instrucción tiene como objeto limpiar el Environment (memoria) de objetos de anteriores sesiones de trabajo.
Para importar los datos que hay en la hoja “Top 20” del archivo de Microsoft® Excel® llamado “eolica_20.xlsx”, ejecutaremos el código:
Podemos observar como en el Environment ya aparece un objeto. Este objeto es una estructura de datos tipo data frame, se llama “eolica_20” y contiene 11 columnas. R ha considerado la primera columna como una variable de tipo cualitativo. En realidad, la primera columna no es una variable, sino que está formada por el nombre (identificador) de los diferentes casos u observaciones. Para evitar que R tome los nombres de los casos como una variable más, podemos redefinir nuestro data frame diciéndole que tome esa primera columna como los nombres de los individuos:
En la línea anterior hemos asignado al data frame “eolica_20” los propios datos de “eolica_20”; pero indicando que la primera columna de datos no es una variable; sino el nombre de los casos.
A continuación, cargaremos el paquete {dplyr}. Si nunca antes se ha utilizado este paquete, cuando lo intentemos activar con la función library() nos dará un error o nos dirá que previamente hay que importarlo. En ese caso, iremos a la ventana inferior-derecha y pulsaremos la pestaña “Packages”, pulsaremos en Install, y emergerá una ventana donde dejaremos el “repositorio” que viene por defecto y, en el campo Packages, escribiremos el nombre del “paquete” (en nuestro caso {dplyr}). Una vez descargado el “paquete”, podremos ejecutar el código sin problemas:
Para entender mejor la sintaxis que siguen las funciones o instrucciones a las que da acceso {dplyr}, hay que tener en cuenta lo siguiente:
El primer argumento que tiene una función de
{dplyr}es el data frame con el que se va a trabajar.Los otros argumentos describen qué hay que hacer con el data frame especificado en el primer argumento. Es posible referirse a las columnas (variables) del data frame con su nombre, sin utilizar el operador $.
El valor de retorno es un nuevo data frame.
En los siguientes subapartados practicaremos con algunas de las principales funciones que aporta {dplyr}.
2.3.2 Seleccionando columnas de un data frame.
La función clave de {dplyr} para seleccionar una o varias columnas (variables) de un data frame es la función select().
Así, vamos a imaginar por ejemplo que queremos eliminar de nuestro data frame la variable (de tipo “carácter”) MATRIZ. Podremos ejecutar la asignación:
## RES ACTIVO FPIOS
## Min. : -5662 Min. : 109024 Min. : -77533
## 1st Qu.: 2865 1st Qu.: 187240 1st Qu.: 27615
## Median : 7388 Median : 271636 Median : 77740
## Mean : 50754 Mean : 1183599 Mean : 563678
## 3rd Qu.: 21206 3rd Qu.: 813816 3rd Qu.: 219345
## Max. :727548 Max. :13492812 Max. :6904824
## NA's :1
##
## RENECO RENFIN LIQUIDEZ
## Min. :-2.8130 Min. :-359.773 Min. :0.0780
## 1st Qu.: 0.8765 1st Qu.: 1.664 1st Qu.:0.7342
## Median : 3.6150 Median : 10.812 Median :1.2345
## Mean : 2.9399 Mean : -3.450 Mean :1.4200
## 3rd Qu.: 4.7735 3rd Qu.: 25.312 3rd Qu.:1.5615
## Max. : 8.5860 Max. : 52.261 Max. :5.3300
## NA's :1
##
## MARGEN SOLVENCIA APALANCA
## Min. :-302.03 Min. :-40.74 Min. :-6265.50
## 1st Qu.: 12.39 1st Qu.: 11.26 1st Qu.: 16.13
## Median : 21.42 Median : 23.68 Median : 145.93
## Mean : 16.40 Mean : 32.68 Mean : -17.17
## 3rd Qu.: 38.56 3rd Qu.: 52.62 3rd Qu.: 504.74
## Max. : 208.36 Max. : 99.08 Max. : 1019.62Podemos verificar que, en el Environment, el data frame ha pasado a tener una variable menos (9), ya que hemos eliminado la variable MATRIZ. Es decir, con el guión “-” se pueden eliminar directamente variables de un data frame.
Ahora, suponemos que queremos visualizar las variables del data frame “eolica_20”: ACTIVO, FPIOS, LIQUIDEZ, MARGEN, SOLVENCIA y APALANCA (es decir, todas las variables menos RES, RENECO, RENFIN). Para ello, ejecutaremos el código:
## ACTIVO FPIOS LIQUIDEZ MARGEN
## Holding De Negocios De GAS SL. 13492812.0 6904824.000 1.020 91.152
## Global Power Generation SA. 2002458.0 1740487.000 2.006 22.403
## Naturgy Renovables SLU 1956869.0 318475.000 1.263 20.442
## EDP Renovables España SLU 1275939.0 726783.000 1.596 47.193
## Corporacion Acciona Eolica SL 864606.0 136064.000 0.788 20.091
## Saeta Yield SA. 796886.4 665319.556 2.687 16.258
## Elawan Energy SL. 443467.0 186302.006 0.595 208.357
## Olivento SL 381207.0 58340.998 0.771 16.629
## Parque Eolico La Boga SL. 303904.4 29316.797 1.407 1.001
## Naturgy Wind, S.L. 273542.0 28418.000 1.364 39.575
## Viesgo Renovables SL. 269730.0 177707.000 0.272 11.818
## Al-Andalus Wind Power SL 249853.8 21466.121 1.550 12.582
## Innogy Spain SA. 230338.5 85447.212 1.416 -18.025
## Guzman Energia SL 190287.0 -77532.698 0.078 -19.193
## Acciona Eolica Del Levante SL 188354.0 21769.000 2.855 27.520
## Biovent Energia SA 183899.0 70033.000 1.206 22.792
## Esquilvent SL 157630.6 48769.130 5.330 39.476
## Eolica La Janda SL 153429.4 25206.748 1.184 38.256
## Parque Eolico Santa Catalina SL 147742.5 -1664.755 0.388 31.780
## WPD Wind Investment SL. 109023.8 108023.826 0.624 -302.027
##
## SOLVENCIA APALANCA
## Holding De Negocios De GAS SL. 51.174 91.964
## Global Power Generation SA. 86.917 1.044
## Naturgy Renovables SLU 16.274 494.729
## EDP Renovables España SLU 56.960 67.028
## Corporacion Acciona Eolica SL 15.737 422.263
## Saeta Yield SA. 83.489 17.067
## Elawan Energy SL. 42.010 123.771
## Olivento SL 15.304 534.761
## Parque Eolico La Boga SL. 9.646 921.591
## Naturgy Wind, S.L. 10.388 824.537
## Viesgo Renovables SL. 65.883 13.330
## Al-Andalus Wind Power SL 8.591 1019.616
## Innogy Spain SA. 37.096 150.688
## Guzman Energia SL -40.745 -343.542
## Acciona Eolica Del Levante SL 11.557 743.754
## Biovent Energia SA 38.082 141.163
## Esquilvent SL 30.938 218.275
## Eolica La Janda SL 16.428 480.122
## Parque Eolico Santa Catalina SL -1.126 -6265.496
## WPD Wind Investment SL. 99.082 0.000Como no hemos asignado el resultado de la función a ningún “nombre”, R simplemente saca el resultado en pantalla; pero no guarda ningún objeto en el Environment. Si asignamos un select() a un “nombre”, se creará un data frame con ese nombre, y las variables seleccionadas:
eolica_20A <-select(eolica_20, ACTIVO, FPIOS, LIQUIDEZ, MARGEN, SOLVENCIA, APALANCA)
summary (eolica_20A)## RES ACTIVO FPIOS
## Min. : -5662 Min. : 109024 Min. : -77533
## 1st Qu.: 2865 1st Qu.: 187240 1st Qu.: 27615
## Median : 7388 Median : 271636 Median : 77740
## Mean : 50754 Mean : 1183599 Mean : 563678
## 3rd Qu.: 21206 3rd Qu.: 813816 3rd Qu.: 219345
## Max. :727548 Max. :13492812 Max. :6904824
## NA's :1
##
## RENECO RENFIN LIQUIDEZ
## Min. :-2.8130 Min. :-359.773 Min. :0.0780
## 1st Qu.: 0.8765 1st Qu.: 1.664 1st Qu.:0.7342
## Median : 3.6150 Median : 10.812 Median :1.2345
## Mean : 2.9399 Mean : -3.450 Mean :1.4200
## 3rd Qu.: 4.7735 3rd Qu.: 25.312 3rd Qu.:1.5615
## Max. : 8.5860 Max. : 52.261 Max. :5.3300
## NA's :1
##
## MARGEN SOLVENCIA APALANCA
## Min. :-302.03 Min. :-40.74 Min. :-6265.50
## 1st Qu.: 12.39 1st Qu.: 11.26 1st Qu.: 16.13
## Median : 21.42 Median : 23.68 Median : 145.93
## Mean : 16.40 Mean : 32.68 Mean : -17.17
## 3rd Qu.: 38.56 3rd Qu.: 52.62 3rd Qu.: 504.74
## Max. : 208.36 Max. : 99.08 Max. : 1019.62Podemos comprobar en el Environment cómo hay otro objeto data frame llamado “eolica_20A”, con 6 variables (y los mismos 20 casos). Este data frame lo podríamos haber creado, también, eliminando del data frame original (“eolica_20”), las variables que nos sobran:
Más aún, si nos fijamos bien, los nombres de todas las variables que hemos excluido empiezan por “RE”, a diferencia de las incluidas. Podríamos haber hecho también:
Y de nuevo obtendríamos el mismo resultado. El argumento starts_with() permite seleccionar variables cuyos nombres comienzan por cierta cadena de caracteres. También se puede hacer mismo con los caracteres finales (ends_with()) o contenidos en alguna posición del nombre (contains()).
Otra posibilidad que tenemos es hacer una copia de un data frame rápidamente con el argumento everything(). Por ejemplo:
Se ha creado el date frame “eolica_20_replica” que es una copia exacta de “eolica_20”.
2.3.3 Seleccionando casos de un data frame.
Además de seleccionar variables, con {dplyr} también se pueden seleccionar casos que cumplan ciertas condiciones. La función para realizar este cometido es filter(). Por ejemplo, si queremos seleccionar las empresas eólicas con un resultado (variable RES) mayor o igual a 50.000 y presentarlas en pantalla, la instrucción será:
## RES ACTIVO FPIOS RENECO RENFIN
## Holding De Negocios De GAS SL. 727548 13492812 6904824 5.264 10.287
## EDP Renovables España SLU 67033 1275939 726783 6.458 11.338
##
## LIQUIDEZ MARGEN SOLVENCIA APALANCA
## Holding De Negocios De GAS SL. 1.020 91.152 51.174 91.964
## EDP Renovables España SLU 1.596 47.193 56.960 67.028Se pueden incluir varias condiciones en un mismo filtro. Por ejemplo, vamos a construir un nuevo data frame llamado “eolica_20B” con las empresas que posean un resultado mayor o igual a 50000 y una rentabilidad económica (variable RENECO) inferior al 6%:
## RES ACTIVO FPIOS
## Holding De Negocios De GAS SL. 727548 13492812 6904824
##
## RENECO RENFIN LIQUIDEZ
## Holding De Negocios De GAS SL. 5.264 10.287 1.02
##
## MARGEN SOLVENCIA APALANCA
## Holding De Negocios De GAS SL. 91.152 51.174 91.964En el Environment aparecerá el data frame “eolica_9B” con solo un caso: la empresa que cumple con ambas condiciones, introducidas mediante el operador lógico relacional “&”, que es el equivalente a la conjunción “y” o, dicho de otro modo, la intersección. Otro operador lógico relacional muy utilizado es la barra vertical “|”, que es el equivalente a la conjunción “o”, es decir, la unión.
Los filtros más usuales son >, <, >=, <=, == (igual, ojo, con dos símbolos de igualdad seguidos) y != (no igual).
2.3.4 Ordenando casos de un data frame.
Además de seleccionar determinados casos u observaciones (filas) de un data frame, con las funciones de {dplyr} también se pueden ordenar estos casos a partir de los valores de ciertas variables (columnas). La función a utilizar es arrange(). Esta función, por defecto, ordena los casos de modo ascendente. Por ejemplo:
## RES ACTIVO FPIOS
## Guzman Energia SL -5661.463 190287.0 -77532.698
## Innogy Spain SA. -5268.573 230338.5 85447.212
## WPD Wind Investment SL. -850.068 109023.8 108023.826
## Parque Eolico La Boga SL. 11.940 303904.4 29316.797
## Saeta Yield SA. 2084.476 796886.4 665319.556
## Global Power Generation SA. 39995.000 2002458.0 1740487.000
## Naturgy Renovables SLU 42737.000 1956869.0 318475.000
## Al-Andalus Wind Power SL 4403.214 249853.8 21466.121
## Olivento SL 7388.175 381207.0 58340.998
## Elawan Energy SL. 12818.975 443467.0 186302.006
## Naturgy Wind, S.L. 8500.000 273542.0 28418.000
## Parque Eolico Santa Catalina SL 3645.278 147742.5 -1664.755
## Biovent Energia SA NA 183899.0 70033.000
## Corporacion Acciona Eolica SL 29592.000 864606.0 136064.000
## Acciona Eolica Del Levante SL 6853.000 188354.0 21769.000
## Holding De Negocios De GAS SL. 727548.000 13492812.0 6904824.000
## EDP Renovables España SLU 67033.000 1275939.0 726783.000
## Esquilvent SL 9010.214 157630.6 48769.130
## Eolica La Janda SL 9880.091 153429.4 25206.748
## Viesgo Renovables SL. 4609.000 269730.0 177707.000
##
## RENECO RENFIN LIQUIDEZ
## Guzman Energia SL -2.813 6.904 0.078
## Innogy Spain SA. -2.708 -7.302 1.416
## WPD Wind Investment SL. -1.040 -1.049 0.624
## Parque Eolico La Boga SL. 0.162 1.684 1.407
## Saeta Yield SA. 0.360 0.432 2.687
## Global Power Generation SA. 1.393 1.603 2.006
## Naturgy Renovables SLU 1.959 12.043 1.263
## Al-Andalus Wind Power SL 2.349 27.350 1.550
## Olivento SL 2.553 16.684 0.771
## Elawan Energy SL. 3.615 8.605 0.595
## Naturgy Wind, S.L. 3.949 38.018 1.364
## Parque Eolico Santa Catalina SL 4.053 -359.773 0.388
## Biovent Energia SA 4.551 11.952 1.206
## Corporacion Acciona Eolica SL 4.562 28.990 0.788
## Acciona Eolica Del Levante SL 4.985 43.139 2.855
## Holding De Negocios De GAS SL. 5.264 10.287 1.020
## EDP Renovables España SLU 6.458 11.338 1.596
## Esquilvent SL 7.621 24.633 5.330
## Eolica La Janda SL 8.586 52.261 1.184
## Viesgo Renovables SL. NA 3.200 0.272
##
## MARGEN SOLVENCIA APALANCA
## Guzman Energia SL -19.193 -40.745 -343.542
## Innogy Spain SA. -18.025 37.096 150.688
## WPD Wind Investment SL. -302.027 99.082 0.000
## Parque Eolico La Boga SL. 1.001 9.646 921.591
## Saeta Yield SA. 16.258 83.489 17.067
## Global Power Generation SA. 22.403 86.917 1.044
## Naturgy Renovables SLU 20.442 16.274 494.729
## Al-Andalus Wind Power SL 12.582 8.591 1019.616
## Olivento SL 16.629 15.304 534.761
## Elawan Energy SL. 208.357 42.010 123.771
## Naturgy Wind, S.L. 39.575 10.388 824.537
## Parque Eolico Santa Catalina SL 31.780 -1.126 -6265.496
## Biovent Energia SA 22.792 38.082 141.163
## Corporacion Acciona Eolica SL 20.091 15.737 422.263
## Acciona Eolica Del Levante SL 27.520 11.557 743.754
## Holding De Negocios De GAS SL. 91.152 51.174 91.964
## EDP Renovables España SLU 47.193 56.960 67.028
## Esquilvent SL 39.476 30.938 218.275
## Eolica La Janda SL 38.256 16.428 480.122
## Viesgo Renovables SL. 11.818 65.883 13.330En cambio, para ordenar de modo descendente, hay que utilizar el argumento desc():
## RES ACTIVO FPIOS
## Eolica La Janda SL 9880.091 153429.4 25206.748
## Esquilvent SL 9010.214 157630.6 48769.130
## EDP Renovables España SLU 67033.000 1275939.0 726783.000
## Holding De Negocios De GAS SL. 727548.000 13492812.0 6904824.000
## Acciona Eolica Del Levante SL 6853.000 188354.0 21769.000
## Corporacion Acciona Eolica SL 29592.000 864606.0 136064.000
## Biovent Energia SA NA 183899.0 70033.000
## Parque Eolico Santa Catalina SL 3645.278 147742.5 -1664.755
## Naturgy Wind, S.L. 8500.000 273542.0 28418.000
## Elawan Energy SL. 12818.975 443467.0 186302.006
## Olivento SL 7388.175 381207.0 58340.998
## Al-Andalus Wind Power SL 4403.214 249853.8 21466.121
## Naturgy Renovables SLU 42737.000 1956869.0 318475.000
## Global Power Generation SA. 39995.000 2002458.0 1740487.000
## Saeta Yield SA. 2084.476 796886.4 665319.556
## Parque Eolico La Boga SL. 11.940 303904.4 29316.797
## WPD Wind Investment SL. -850.068 109023.8 108023.826
## Innogy Spain SA. -5268.573 230338.5 85447.212
## Guzman Energia SL -5661.463 190287.0 -77532.698
## Viesgo Renovables SL. 4609.000 269730.0 177707.000
##
## RENECO RENFIN LIQUIDEZ
## Eolica La Janda SL 8.586 52.261 1.184
## Esquilvent SL 7.621 24.633 5.330
## EDP Renovables España SLU 6.458 11.338 1.596
## Holding De Negocios De GAS SL. 5.264 10.287 1.020
## Acciona Eolica Del Levante SL 4.985 43.139 2.855
## Corporacion Acciona Eolica SL 4.562 28.990 0.788
## Biovent Energia SA 4.551 11.952 1.206
## Parque Eolico Santa Catalina SL 4.053 -359.773 0.388
## Naturgy Wind, S.L. 3.949 38.018 1.364
## Elawan Energy SL. 3.615 8.605 0.595
## Olivento SL 2.553 16.684 0.771
## Al-Andalus Wind Power SL 2.349 27.350 1.550
## Naturgy Renovables SLU 1.959 12.043 1.263
## Global Power Generation SA. 1.393 1.603 2.006
## Saeta Yield SA. 0.360 0.432 2.687
## Parque Eolico La Boga SL. 0.162 1.684 1.407
## WPD Wind Investment SL. -1.040 -1.049 0.624
## Innogy Spain SA. -2.708 -7.302 1.416
## Guzman Energia SL -2.813 6.904 0.078
## Viesgo Renovables SL. NA 3.200 0.272
##
## MARGEN SOLVENCIA APALANCA
## Eolica La Janda SL 38.256 16.428 480.122
## Esquilvent SL 39.476 30.938 218.275
## EDP Renovables España SLU 47.193 56.960 67.028
## Holding De Negocios De GAS SL. 91.152 51.174 91.964
## Acciona Eolica Del Levante SL 27.520 11.557 743.754
## Corporacion Acciona Eolica SL 20.091 15.737 422.263
## Biovent Energia SA 22.792 38.082 141.163
## Parque Eolico Santa Catalina SL 31.780 -1.126 -6265.496
## Naturgy Wind, S.L. 39.575 10.388 824.537
## Elawan Energy SL. 208.357 42.010 123.771
## Olivento SL 16.629 15.304 534.761
## Al-Andalus Wind Power SL 12.582 8.591 1019.616
## Naturgy Renovables SLU 20.442 16.274 494.729
## Global Power Generation SA. 22.403 86.917 1.044
## Saeta Yield SA. 16.258 83.489 17.067
## Parque Eolico La Boga SL. 1.001 9.646 921.591
## WPD Wind Investment SL. -302.027 99.082 0.000
## Innogy Spain SA. -18.025 37.096 150.688
## Guzman Energia SL -19.193 -40.745 -343.542
## Viesgo Renovables SL. 11.818 65.883 13.330En el supuesto de que, por ejemplo, hubiera varias empresas con la misma rentabilidad económica (RENECO), podría añadirse otro criterio de ordenación con otra variable, que afectaría a tales empresas para deshacer el “empate” en rentabilidad económica. Por ejemplo, para ordenar de modo ascendente por rentabilidad y, en caso de que haya rentabilidades iguales, por liquidez (variable LIQUIDEZ), se ejecutaría:
## RES ACTIVO FPIOS
## Guzman Energia SL -5661.463 190287.0 -77532.698
## Innogy Spain SA. -5268.573 230338.5 85447.212
## WPD Wind Investment SL. -850.068 109023.8 108023.826
## Parque Eolico La Boga SL. 11.940 303904.4 29316.797
## Saeta Yield SA. 2084.476 796886.4 665319.556
## Global Power Generation SA. 39995.000 2002458.0 1740487.000
## Naturgy Renovables SLU 42737.000 1956869.0 318475.000
## Al-Andalus Wind Power SL 4403.214 249853.8 21466.121
## Olivento SL 7388.175 381207.0 58340.998
## Elawan Energy SL. 12818.975 443467.0 186302.006
## Naturgy Wind, S.L. 8500.000 273542.0 28418.000
## Parque Eolico Santa Catalina SL 3645.278 147742.5 -1664.755
## Biovent Energia SA NA 183899.0 70033.000
## Corporacion Acciona Eolica SL 29592.000 864606.0 136064.000
## Acciona Eolica Del Levante SL 6853.000 188354.0 21769.000
## Holding De Negocios De GAS SL. 727548.000 13492812.0 6904824.000
## EDP Renovables España SLU 67033.000 1275939.0 726783.000
## Esquilvent SL 9010.214 157630.6 48769.130
## Eolica La Janda SL 9880.091 153429.4 25206.748
## Viesgo Renovables SL. 4609.000 269730.0 177707.000
##
## RENECO RENFIN LIQUIDEZ
## Guzman Energia SL -2.813 6.904 0.078
## Innogy Spain SA. -2.708 -7.302 1.416
## WPD Wind Investment SL. -1.040 -1.049 0.624
## Parque Eolico La Boga SL. 0.162 1.684 1.407
## Saeta Yield SA. 0.360 0.432 2.687
## Global Power Generation SA. 1.393 1.603 2.006
## Naturgy Renovables SLU 1.959 12.043 1.263
## Al-Andalus Wind Power SL 2.349 27.350 1.550
## Olivento SL 2.553 16.684 0.771
## Elawan Energy SL. 3.615 8.605 0.595
## Naturgy Wind, S.L. 3.949 38.018 1.364
## Parque Eolico Santa Catalina SL 4.053 -359.773 0.388
## Biovent Energia SA 4.551 11.952 1.206
## Corporacion Acciona Eolica SL 4.562 28.990 0.788
## Acciona Eolica Del Levante SL 4.985 43.139 2.855
## Holding De Negocios De GAS SL. 5.264 10.287 1.020
## EDP Renovables España SLU 6.458 11.338 1.596
## Esquilvent SL 7.621 24.633 5.330
## Eolica La Janda SL 8.586 52.261 1.184
## Viesgo Renovables SL. NA 3.200 0.272
##
## MARGEN SOLVENCIA APALANCA
## Guzman Energia SL -19.193 -40.745 -343.542
## Innogy Spain SA. -18.025 37.096 150.688
## WPD Wind Investment SL. -302.027 99.082 0.000
## Parque Eolico La Boga SL. 1.001 9.646 921.591
## Saeta Yield SA. 16.258 83.489 17.067
## Global Power Generation SA. 22.403 86.917 1.044
## Naturgy Renovables SLU 20.442 16.274 494.729
## Al-Andalus Wind Power SL 12.582 8.591 1019.616
## Olivento SL 16.629 15.304 534.761
## Elawan Energy SL. 208.357 42.010 123.771
## Naturgy Wind, S.L. 39.575 10.388 824.537
## Parque Eolico Santa Catalina SL 31.780 -1.126 -6265.496
## Biovent Energia SA 22.792 38.082 141.163
## Corporacion Acciona Eolica SL 20.091 15.737 422.263
## Acciona Eolica Del Levante SL 27.520 11.557 743.754
## Holding De Negocios De GAS SL. 91.152 51.174 91.964
## EDP Renovables España SLU 47.193 56.960 67.028
## Esquilvent SL 39.476 30.938 218.275
## Eolica La Janda SL 38.256 16.428 480.122
## Viesgo Renovables SL. 11.818 65.883 13.330Obviamente, en este ejemplo concreto el resultado es el mismo que se obtuvo con arrange(eolica_20, RENECO), puesto que no hay rentabilidades iguales entre las 20 empresas de la muestra.
2.3.5 Cambiando el nombre de las variables de un data frame.
{dplyr} cuenta con una función que cambia fácilmente el nombre de una variable o columna de un data frame: la función rename(). Por ejemplo, si queremos cambiar el nombre de la variable SOLVENCIA por SOLVE, simplemente ejecutaremos:
Podemos comprobar en el Environment, despegando el objeto “eolica_20”, cómo ya no aparece la variable SOLVENCIA; pero sí SOLVE en su lugar (obviamente, con los mismos datos). Es necesario tener en cuenta que en el lado izquierdo de la igualdad hay que poner el nuevo nombre, y en la derecha el antiguo. Además, en el mismo rename() se pueden cambiar los nombres de varias variables, separando las igualdades correspondientes con comas.
2.3.6 Añadiendo variables como transformación de otras variables en un data frame.
El paquete {dplyr} también permite añadir a un data frame variables que son el resultado de someter a otras variables a diversas transformaciones. La función para realizar este cometido es mutate().
Así, por ejemplo, imaginemos que necesitamos calcular una variable como el cociente entre los resultados obtenidos y el activo. A esta nueva variable la denominaremos RATIO. El código será:
# Añadiendo variables como transformacion de otras variables
eolica_20 <- mutate (eolica_20, RATIO = RES / ACTIVO)
summary(eolica_20)## RES ACTIVO FPIOS RENECO
## Min. : -5662 Min. : 109024 Min. : -77533 Min. :-2.8130
## 1st Qu.: 2865 1st Qu.: 187240 1st Qu.: 27615 1st Qu.: 0.8765
## Median : 7388 Median : 271636 Median : 77740 Median : 3.6150
## Mean : 50754 Mean : 1183599 Mean : 563678 Mean : 2.9399
## 3rd Qu.: 21206 3rd Qu.: 813816 3rd Qu.: 219345 3rd Qu.: 4.7735
## Max. :727548 Max. :13492812 Max. :6904824 Max. : 8.5860
## NA's :1 NA's :1
##
## RENFIN LIQUIDEZ MARGEN SOLVE
## Min. :-359.773 Min. :0.0780 Min. :-302.03 Min. :-40.74
## 1st Qu.: 1.664 1st Qu.:0.7342 1st Qu.: 12.39 1st Qu.: 11.26
## Median : 10.812 Median :1.2345 Median : 21.42 Median : 23.68
## Mean : -3.450 Mean :1.4200 Mean : 16.40 Mean : 32.68
## 3rd Qu.: 25.312 3rd Qu.:1.5615 3rd Qu.: 38.56 3rd Qu.: 52.62
## Max. : 52.261 Max. :5.3300 Max. : 208.36 Max. : 99.08
##
## APALANCA RATIO
## Min. :-6265.50 Min. :-0.029752
## 1st Qu.: 16.13 1st Qu.: 0.009852
## Median : 145.93 Median : 0.021840
## Mean : -17.17 Mean : 0.022180
## 3rd Qu.: 504.74 3rd Qu.: 0.035305
## Max. : 1019.62 Max. : 0.064395
## NA's :1En la transformación de variables mediante la función mutate(), se pueden utilizar funciones integradas en otros paquetes de R. Por ejemplo, si queremos calcular la variable ACTIVOS_ACUM como la variable que recoge los activos acumulados de las empresas, comenzando por la empresa con menor activo, podríamos utilizar la función cumsum() del paquete {base}, y hacer:
eolica_20 <- arrange(eolica_20, ACTIVO)
eolica_20 <- mutate (eolica_20, ACTIVOS_ACUM = cumsum(ACTIVO))
select(eolica_20, ACTIVO, ACTIVOS_ACUM)## ACTIVO ACTIVOS_ACUM
## WPD Wind Investment SL. 109023.8 109023.8
## Parque Eolico Santa Catalina SL 147742.5 256766.3
## Eolica La Janda SL 153429.4 410195.8
## Esquilvent SL 157630.6 567826.4
## Biovent Energia SA 183899.0 751725.4
## Acciona Eolica Del Levante SL 188354.0 940079.4
## Guzman Energia SL 190287.0 1130366.4
## Innogy Spain SA. 230338.5 1360704.9
## Al-Andalus Wind Power SL 249853.8 1610558.7
## Viesgo Renovables SL. 269730.0 1880288.7
## Naturgy Wind, S.L. 273542.0 2153830.7
## Parque Eolico La Boga SL. 303904.4 2457735.1
## Olivento SL 381207.0 2838942.0
## Elawan Energy SL. 443467.0 3282409.0
## Saeta Yield SA. 796886.4 4079295.4
## Corporacion Acciona Eolica SL 864606.0 4943901.4
## EDP Renovables España SLU 1275939.0 6219840.4
## Naturgy Renovables SLU 1956869.0 8176709.4
## Global Power Generation SA. 2002458.0 10179167.4
## Holding De Negocios De GAS SL. 13492812.0 23671979.4Podemos verificar cómo se ha integrado en el data frame la variable ACTIVOS_ACUM.
Un último ejemplo de adición de una variable que es transformación de otras. En este caso, crearemos la variable TAM (tamaño), que es categórica (los datos son conjuntos de carcteres). Esta variable toma valor “G” para las empresas con un valor de la variable ACTIVO mayor que 1.000.000, y “P” para las que tengan un valor en la variable ACTIVO menor o igual a 1.000.000. Para calcular automáticamente esta nueva variable categórica, utilizaremos la función de {base} cut(). De este modo, haremos:
eolica_20 <- mutate(eolica_20, TAM = cut(ACTIVO,
breaks = c(-Inf, 1000000, Inf), labels = c("P", "G")))
select(eolica_20, ACTIVO, TAM)## ACTIVO TAM
## WPD Wind Investment SL. 109023.8 P
## Parque Eolico Santa Catalina SL 147742.5 P
## Eolica La Janda SL 153429.4 P
## Esquilvent SL 157630.6 P
## Biovent Energia SA 183899.0 P
## Acciona Eolica Del Levante SL 188354.0 P
## Guzman Energia SL 190287.0 P
## Innogy Spain SA. 230338.5 P
## Al-Andalus Wind Power SL 249853.8 P
## Viesgo Renovables SL. 269730.0 P
## Naturgy Wind, S.L. 273542.0 P
## Parque Eolico La Boga SL. 303904.4 P
## Olivento SL 381207.0 P
## Elawan Energy SL. 443467.0 P
## Saeta Yield SA. 796886.4 P
## Corporacion Acciona Eolica SL 864606.0 P
## EDP Renovables España SLU 1275939.0 G
## Naturgy Renovables SLU 1956869.0 G
## Global Power Generation SA. 2002458.0 G
## Holding De Negocios De GAS SL. 13492812.0 GPodemos advertir cómo la función cut(), que incluimos dentro de nuestra función de {dplyr} mutate(), tiene, a su vez, varios argumentos: la variable numérica de referencia (ACTIVO); el argumento “breaks”, en el que decimos los intervalos en que quedarán divididos los casos (uno, de menos infinito a 1.000.000; y otro de 1.000.000 a más infinito), y “labels”, que es el valor que tomará la variable creada (TAM) según el intervalo en el que se sitúe cada caso de la muestra.
Cabe destacar que podíamos haber escrito el código para crear la variable TAM de un modo más elegante y cómodo, utilizando el operador “pipe” (%>%). Este operador permite concatenar una serie de instrucciones:
eolica_20 <- eolica_20 %>% mutate(TAM = cut(ACTIVO,
breaks = c(-Inf, 1000000, Inf), labels = c("P", "G")))
select(eolica_20, ACTIVO, TAM)## ACTIVO TAM
## WPD Wind Investment SL. 109023.8 P
## Parque Eolico Santa Catalina SL 147742.5 P
## Eolica La Janda SL 153429.4 P
## Esquilvent SL 157630.6 P
## Biovent Energia SA 183899.0 P
## Acciona Eolica Del Levante SL 188354.0 P
## Guzman Energia SL 190287.0 P
## Innogy Spain SA. 230338.5 P
## Al-Andalus Wind Power SL 249853.8 P
## Viesgo Renovables SL. 269730.0 P
## Naturgy Wind, S.L. 273542.0 P
## Parque Eolico La Boga SL. 303904.4 P
## Olivento SL 381207.0 P
## Elawan Energy SL. 443467.0 P
## Saeta Yield SA. 796886.4 P
## Corporacion Acciona Eolica SL 864606.0 P
## EDP Renovables España SLU 1275939.0 G
## Naturgy Renovables SLU 1956869.0 G
## Global Power Generation SA. 2002458.0 G
## Holding De Negocios De GAS SL. 13492812.0 GPodríamos interpretar la línea de código así: “asigna al data frame”eolica_20” sus propios datos, después (%>%) crea la variable TAM con la función cut() y añádela a “eolica_20”.
2.3.7 Extrayendo y sintetizando información de las variables de un data frame.
Otra posibilidad que permite {dplyr} es extraer y sintetizar la información de las variables contenidas en un data frame. Para ello, nos ayudaremos de la función summarise(). Como ejemplo, calculemos la rentabilidad financiera media de las 20 empresas:
#Extrayendo información de las variables de un data frame
summarise(eolica_20, RENFIN_media = mean(RENFIN)) ## RENFIN_media
## 1 -3.45005A veces, es de gran utilidad combinar summarise() con group_by(), que extrae la información por grupos definidos por una de las variables. Para ilustrarlo, vamos a utilizar la variable recién creada TAM, para hacer dos grupos de empresas: las de menor (“P”) y las de mayor (“G”) volumen de activo; tras lo cual calcularemos la media de las rentabilidades para cada grupo:
## # A tibble: 2 × 2
## TAM RENFIN_media
## <fct> <dbl>
## 1 P -6.52
## 2 G 8.82Hemos utilizado el operador pipe (%>%) para concatenar diferentes instrucciones de {dplyr}: primero agrupar casos, y luego calcular las medias de cada grupo. Es decir, en este caso se podría “traducir” la línea de código como: “Toma el data frame”eolica_9”, divide los casos en grupos según el valor de la variable TAM, y para cada grupo calcula la media de la variable RENFIN”.
2.4 Exportando datos.
Antes de concluir el capítulo, vamos a tratar brevemente el aspecto de la exportación de datos.
R cuenta con un formato propio de datos, que se traduce en archivos de extensión “RData”, y que puede incluir cualquier objeto de R. Como ejemplo, en el siguiente script, llamado “explora_exporta.R” (obtener aquí), vamos a importar los datos del archivo de Microsoft (R) Excel (R) “eolica_20.xlsx”, y el data frame donde almacenemos los datos vamos a exportarlo como el archivo de datos de R “eolica_20.RData”. Posteriormente, borraremos el data frame del Environment y recuperaremos los datos cargando ese archivo “eolica_20.RData”. Por supuesto, seguimos trabajando, como en todo el capítulo, en el proyecto “explora”.
Tras abrir el script “explora_exporta.R”, las primeras líneas de código que veremos serán las que ya hemos estudiado para borrar el contenido del Environment, importar los datos de la hoja “Top 20” del archivo “eolica_20.xlsx” (situado en nuestra carpeta de proyecto), y tratar la variable “NOMBRE” para transformarla en el conjunto de nombres de las filas:
# Exportando datos de empresas eolicas (disculpad la falta de tildes)
rm(list = ls())
# DATOS
library(readxl)
eolica_20 <- read_excel("eolica_20.xlsx", sheet = "Top 20")
eolica_20 <- data.frame(eolica_20, row.names = 1)
summary(eolica_20)## RES ACTIVO FPIOS RENECO
## Min. : -5662 Min. : 109024 Min. : -77533 Min. :-2.8130
## 1st Qu.: 2865 1st Qu.: 187240 1st Qu.: 27615 1st Qu.: 0.8765
## Median : 7388 Median : 271636 Median : 77740 Median : 3.6150
## Mean : 50754 Mean : 1183599 Mean : 563678 Mean : 2.9399
## 3rd Qu.: 21206 3rd Qu.: 813816 3rd Qu.: 219345 3rd Qu.: 4.7735
## Max. :727548 Max. :13492812 Max. :6904824 Max. : 8.5860
## NA's :1 NA's :1
##
## RENFIN LIQUIDEZ MARGEN SOLVENCIA
## Min. :-359.773 Min. :0.0780 Min. :-302.03 Min. :-40.74
## 1st Qu.: 1.664 1st Qu.:0.7342 1st Qu.: 12.39 1st Qu.: 11.26
## Median : 10.812 Median :1.2345 Median : 21.42 Median : 23.68
## Mean : -3.450 Mean :1.4200 Mean : 16.40 Mean : 32.68
## 3rd Qu.: 25.312 3rd Qu.:1.5615 3rd Qu.: 38.56 3rd Qu.: 52.62
## Max. : 52.261 Max. :5.3300 Max. : 208.36 Max. : 99.08
##
## APALANCA MATRIZ
## Min. :-6265.50 Length:20
## 1st Qu.: 16.13 Class :character
## Median : 145.93 Mode :character
## Mean : -17.17
## 3rd Qu.: 504.74
## Max. : 1019.62Posteriormente, se exportará el data frame “eolica_20” al archivo de formato R, “eolica_20.RData”, mediante la función save:
Puede comprobarse cómo se ha generado el archivo correspondiente en la carpeta de proyecto. Para comprobar que la exportación es correcta, vamos a borrar del Environment el data frame “eolica_20”. Después, cargaremos el archivo “eolica_20.RData”. Como resultado, podremos comprobar que tenemos un nuevo data frame “eolica_20” que es exactamente igual al que teníamos al principio:
# Borrando el data frame eolica_20
rm(eolica_20)
# Importando el archivo .RData con los mismos datos
load("eolica_20.RData")
summary (eolica_20)## RES ACTIVO FPIOS RENECO
## Min. : -5662 Min. : 109024 Min. : -77533 Min. :-2.8130
## 1st Qu.: 2865 1st Qu.: 187240 1st Qu.: 27615 1st Qu.: 0.8765
## Median : 7388 Median : 271636 Median : 77740 Median : 3.6150
## Mean : 50754 Mean : 1183599 Mean : 563678 Mean : 2.9399
## 3rd Qu.: 21206 3rd Qu.: 813816 3rd Qu.: 219345 3rd Qu.: 4.7735
## Max. :727548 Max. :13492812 Max. :6904824 Max. : 8.5860
## NA's :1 NA's :1
##
## RENFIN LIQUIDEZ MARGEN SOLVENCIA
## Min. :-359.773 Min. :0.0780 Min. :-302.03 Min. :-40.74
## 1st Qu.: 1.664 1st Qu.:0.7342 1st Qu.: 12.39 1st Qu.: 11.26
## Median : 10.812 Median :1.2345 Median : 21.42 Median : 23.68
## Mean : -3.450 Mean :1.4200 Mean : 16.40 Mean : 32.68
## 3rd Qu.: 25.312 3rd Qu.:1.5615 3rd Qu.: 38.56 3rd Qu.: 52.62
## Max. : 52.261 Max. :5.3300 Max. : 208.36 Max. : 99.08
##
## APALANCA MATRIZ
## Min. :-6265.50 Length:20
## 1st Qu.: 16.13 Class :character
## Median : 145.93 Mode :character
## Mean : -17.17
## 3rd Qu.: 504.74
## Max. : 1019.62Por supuesto, hay más formatos en los que se pueden exportar datos desde R. Por ejemplo, a un archivo de Microsoft (R) Excel (R). Un modo de hacerlo es haciendo uso de la función write_xlsx() del paquete {writexl}. Para que en la hoja de cálculo resultante se incluyan los nombres de las filas (empresas eólicas), hemos tenido previamente que crear un vector con el nombre de estas (vector “NOMBRE”), mediante la función row.names(), y unir ese vector al data frame “eolica_20”, a modo de primera columna, creando un nuevo finalmente un data frame llamado “eolica_20n”, para lo que se ha utilizado la función cbind(), que permite pegar columnas de datos que tengan un mismo número de filas.
Como resultado de todo el código, se ha obtenido el archivo de Microsoft (R) Excel (R) “eolica_20_new.xlsx”:
2.5 Materiales para realizar las prácticas del capítulo.
En esta sección se muestran los links de acceso a los diferentes materiales (scripts, datos…) necesarios para llevar a cabo los contenidos prácticos del capítulo.
Datos (en formato Microsoft (R) Excel (R)):
- eolica_20.xlsx (obtener aquí)
Scripts:
explora_eolica.R (obtener aquí)
explora_dplyr.R (obtener aquí)
explora_exporta.R (obtener aquí)