Chapter 1 Introduction to R (Week 1)
1.1 Welcome to the Course!
Hi everyone, welcome to the course. This is the introduction to R course at Ewha Womans University.
R is a great programming language for statistical analysis and data science. I hope you enjoy R in this course and find many useful applications for your own field.
This course is designed for students who don’t have any programming background in social science.
In this lecture note,
this fontrepresents R commands, variable names, and package names, and this font(www.ewha.ac.kr) represents hyperlink you can click.In order to maximize your learning in this semester, you should read the weekly reading assignment in our textbook, R for Data Science.
In this lecture notes, I will include interactive code chunks provided by DataCamp that will allow you to actually run and practice R codes within this lecture notes. Please type
3+4and clickRunbutton to ask R to calculate the expression.
- Ok, let’s get started. Today, I will just gently introduce R, RStudio, and some basic terminologies
1.2 Send you questions to intro.r.ewha@gmail.com
- If you have any question on this lecture (e.g., errors in running R, questions about quiz), please send your questions to intro.r.ewha@gmail.com. Then, TA(Teaching Assistant) will answer your questions.
1.3 Why R?
- R is a language specifically designed for statistical analysis.
- If you visit the R project website(https://www.r-project.org/), then you will find that the first line of the website says “R is a free software environment for statistical computing and graphics.” R is a language specifically designed for statistical analysis. Many researchers first implement their experimental methods in statistics and machine learning using R. So you can use many cutting-edge algorithms in R by downloading many packages in R.
- R provides wonderful tools for publication-quality data visualization.
- Data visualization help you to understand your data and present your findings to others. In this lecture, you will learn
ggplot2package for data visualization.
- Data visualization help you to understand your data and present your findings to others. In this lecture, you will learn
- R provides wonderful tools for data wrangling.
- The ultimate goal of using R is to understand your data using data visualization and modeling. Often, however, you need to spend lots of time to make your raw data into the appropriate form for data visualization and modeling. This process is often called data wrangling, which includes data transformation and data tidying. In R, the
dplyrpackage was developed for data transformation, and thetidyrpackage was developed for data tidying. We will cover bothdplyrand ‘tidyr’ packages in this lecture.
- Data wrangling is an important skill in these days to effectively handle data from diverse sources (e.g., facebook, twitter, fMRI, eyetracker, EEG). For example, many servers store user data in the JSON format for data exchange, and so you need to handle JSON files if you want to use user data for your analysis.
- The ultimate goal of using R is to understand your data using data visualization and modeling. Often, however, you need to spend lots of time to make your raw data into the appropriate form for data visualization and modeling. This process is often called data wrangling, which includes data transformation and data tidying. In R, the
- R has active and supportive communities.
- You can find many useful resources from R communities. For example, the
bookdownis an R package for writing books, and bookdown.org provides useful R books written with thebookdownpackage for free. In the bookdown.org, you will find our textbook for this class, which is R for Data Science.
- You can find many useful resources from R communities. For example, the
- R is a free open source software.
1.4 R vs Python
Python is another great programming language. You can find many interesting debates over R vs Python on the internet. Here is an example.
In short, Python is a general-purpose programming language used for a wide variety of applications (e.g., data science, web development, database), whereas R is a programming language focusing on data science.
One of the goals of this course is to give you an opportunity for exploring R so that you can make a decision about which language is best for your purpose. You may need both languages.
“Generally, there are a lot of people who talk about R versus Python like it’s a war that either R or Python is going to win. I think that is not helpful because it is not actually a battle. These things exist independently and are both awesome in different ways.”
— Hadley Wickham
1.5 R vs RStudio
- What is R? R is a programming language. What is a programming language? A programming language is a formal language consisting of a set of instructions (or commands) that allow us to make computers work for us. For example, if you just click the
Runbutton below, then the set of R commands will create a plot for you. For now, you don’t need to worry about what each of those commands means. You will learn theggplot2package for data visualization later.
# Just click the 'Run' button below to run the following R commands to create a plot
library("ggplot2")
ggplot(mtcars, aes(x = disp, y = mpg)) + geom_point() + geom_smooth(method = "lm")## `geom_smooth()` using formula 'y ~ x'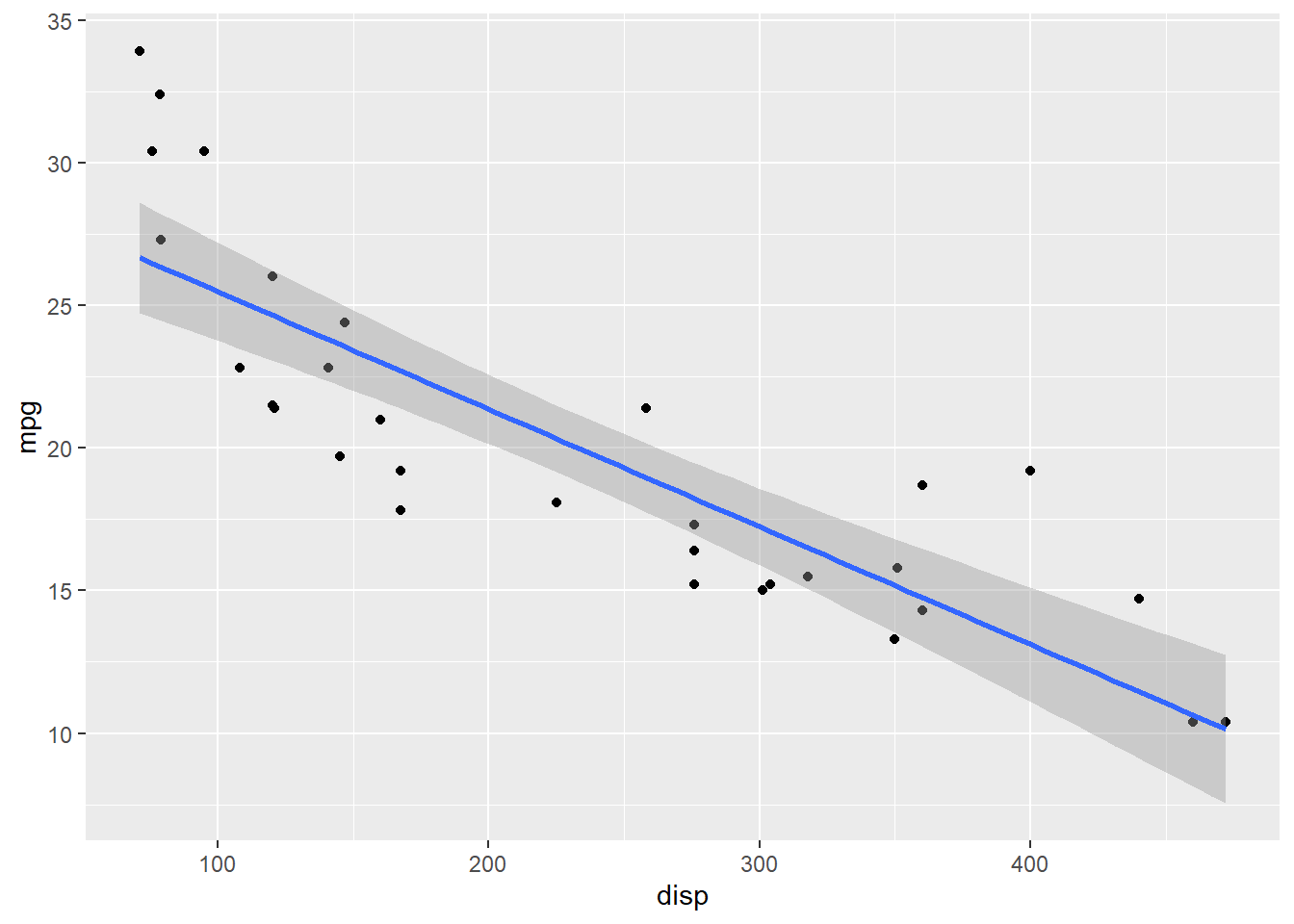
So, the above example clearly indicates that there should be something that can understand the set of instructions (or commands) and then do the job for us. That’s R. So we need to install R to learn R programming language.
Then, what is a RStudio? As the first line of the R project website(https://www.r-project.org/) says, “R is a free software environment for statistical computing and graphics.”, meaning that the R provides some features (e.g., source editor for editing our R codes) that can help R programming. But it’s not that convenient :(
RStudio is an convenient interface between R and users. It is an integrated development environment (IDE) for R.
So, the best practice of using R is to install both R and RStudio, and then use RStudio for your programming. Note that R is still a workhorse and RStudio is an interface for R.
1.6 Let’s install R to your local computer
Please install R for your own operating system from https://www.r-project.org/
- Click the
download Rlink
 2. Click any mirror server you like (e.g.,
2. Click any mirror server you like (e.g., 0-Cloud)

Mirrors
- Click the operating system in your computer

- Click the
basebutton

- Click the
Download Rbutton

- Click the downloaded file to start your installing process
(You will find lots of videos demonstrating installing process on YouTube)
1.7 Let’s install RStudio to your local computer
- Please install FREE version of RStudio Desktop for your own operating system from https://rstudio.com/products/rstudio/download/.
1.8 Let’s install R to your local computer (Korean Windows Users)
This is the special instruction only for students who are using Korean version of Windows. Those students who are using English version of Windows can ignore this instructions.
- 한글 윈도우쓰시는 한국 학생들은 RStudio 설치시 다음과 같은 경우에 RStudio가 설치가 안돼거나 설치되어도 작동이 안할 수 있습니다.
- 사용자명이 한글로 되어 있는경우
- 컴퓨터 이름이 한글로 되어 있는경우
- 설치 폴더 경로중에 한글이 포함된 경우
- 한글 윈도우를 쓰시는 학생들은 사용자명, 컴퓨터 이름, 설치 폴더 경로가 모두 영어가 되어 있는지를 확인하고 다음 링크의 지시를 따라서 설치를 진행해 주시기 바랍니다: https://chancoding.tistory.com/16
- 구글이나 네이버가 가셔서 “RStudio 한글 설치” 이런정도의 키워드로 검색을 해보시면 RStudio설치시 한글과의 충돌로 인한 문제점에 대한 많은 문서들을 발견할 수 있습니다. 문제가 생기면 우선 구글이나 네이버 검색을 통해서 해결해 보시기 바랍니다. 수강인원이 200명이 넘는 대형강의이기 때문에 조교 선생님들이나 제가 최선을 다해서 도와드리겠지만, 하나하나 수강생들의 특수한 경우에 모두 해결책을 제시해 드리기 힘든점 양해 부탁드립니다.
1.9 Let’s launch the RStudio
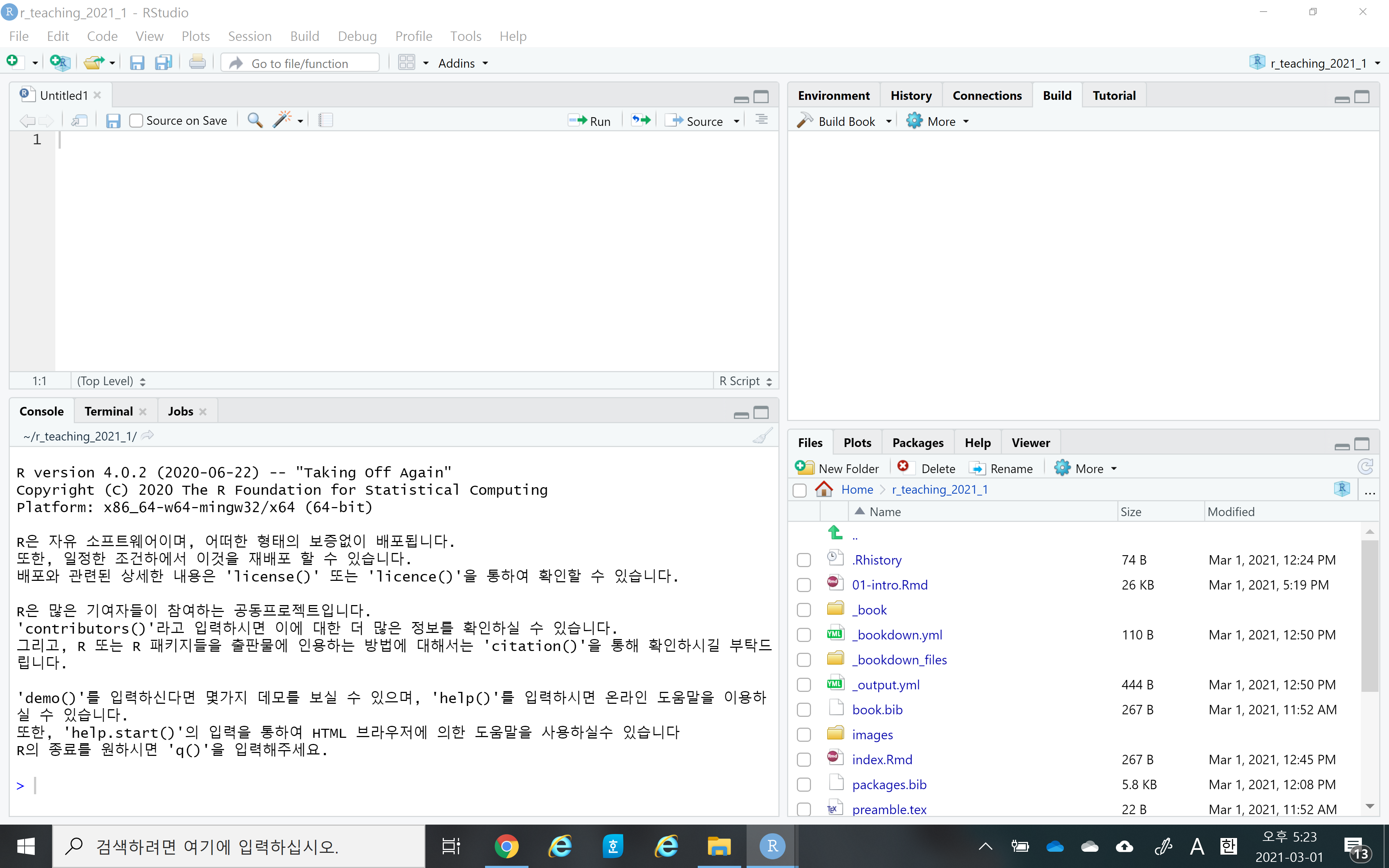
- Once you successfully install R and RStudio, please launch your RStudio. You should see something like the following. Again, the RStudio is a convenient interface (or IDE) for R, and so you only need to launch the RStudio, not R.
Let’s watch a short introductory video for RStudio here
Notice that RStudio consists of four panels (or panes)
- Source editor pane
- This is where you can edit your code in R script or R markdown files
- Console pane
- This is where you can execute your code instantly
- Environment pane
- This is where you can see the objects (or variables)
- File/Plots/Packages/Helps pane
- This is where you can see files, plots, packages, and help documents.
- Source editor pane
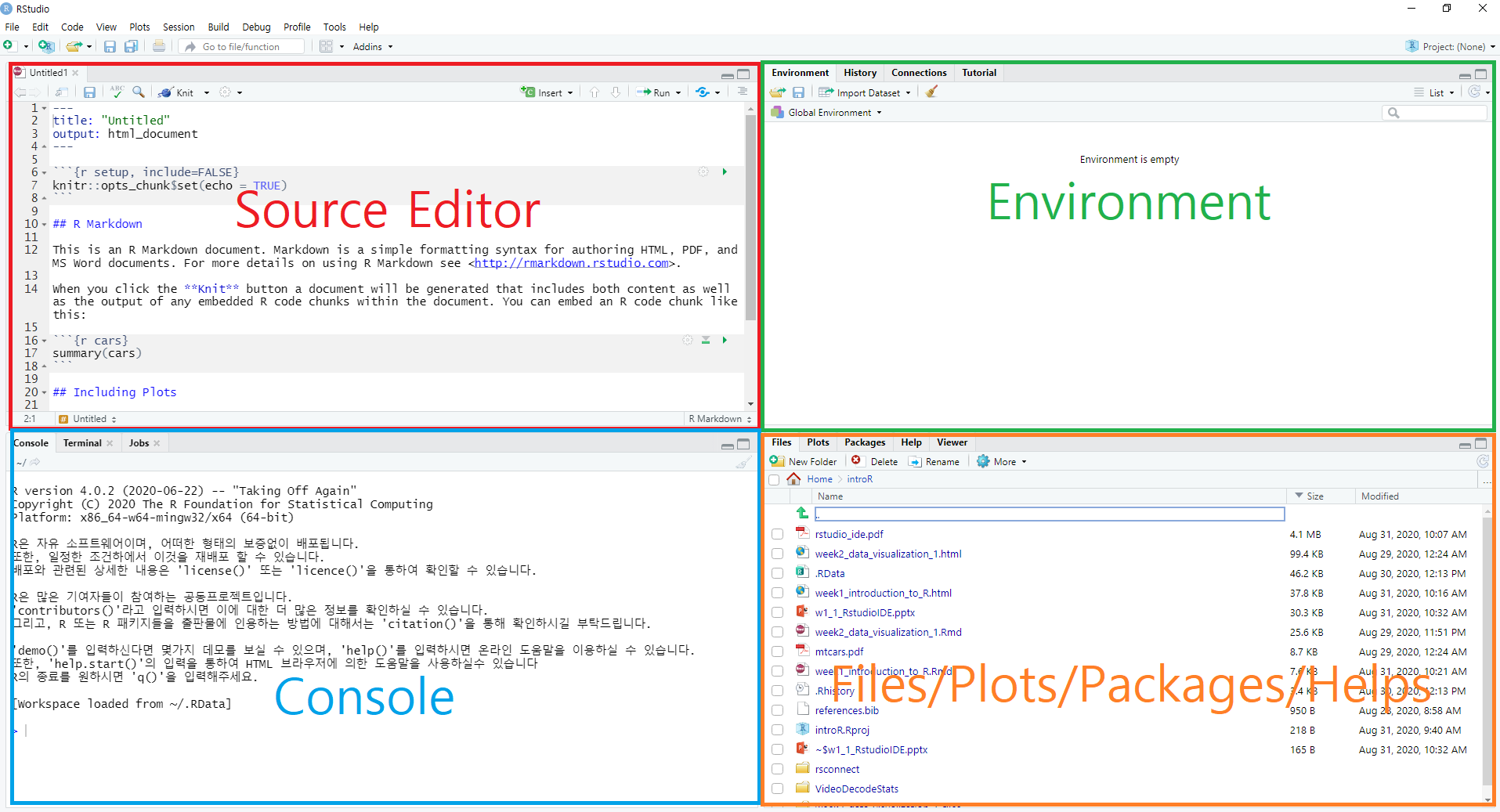
Four main panes in RStudio IDE
- You can find more RStudio features here.
1.10 R Packages
An R package is the collections of functions and data sets developed for a specific purpose. For example, the
carat(short for Classification And REgression Training) package is a package that contains many useful functions for machine learning. We will use thiscaratpackage for our machine learning part in this class.The package system in R is the core part of the R project, and allows any contributor (including you) around the world can contribute to the R project by developing packages.
Currently, the Comprehensive R Archive Network(CRAN) repository contains more than 17,000 packages. A list of R packages are available here.
Installing vs Loading
- Installing means you download the package files from the CRAN repository to your local computer. You may not want to download all the files for the 17,000 packages from the beginning. You may want to download some packages you need into your local computer. You only need to install a package once. An R function named
install.packages()is used to install packages. - Loading means you load functions and data in the package onto your computer memory. Loading functions and data of all packages to memory is inefficient in terms of computers’ memory management. So you only load a package onto memory when you need it. In other word, whenever you want to use functions in a package, you need to load the package that contains the functions. An R function named
library()is used to load packages. - In the above example, we load the
ggplot2package withlibrary("ggplot2")before using theggplot2functions inggplot(mtcars, aes(x = disp, y = mpg)) + geom_point() + geom_smooth(method = "lm")
- Installing means you download the package files from the CRAN repository to your local computer. You may not want to download all the files for the 17,000 packages from the beginning. You may want to download some packages you need into your local computer. You only need to install a package once. An R function named
1.11 Base R vs Tidyverse
- Base R
- Base R refers to the collection of functions and packages that come with a clean install of R.
- Many packages extend Base R.
- Tidyverse
- The
tidyversepackage(https://www.tidyverse.org) is a collection of packages for more efficient data science in R. - In the
tidyversepackage, thedplyr,tidyr,ggplot2, andpurrrpackages provide many useful functions for efficient data transformation, data tidying, data visualization, and iteration, respectively. - Our textbook R for Data Science (Hadley Wickham) is all about the
tidyversepackage. - The goal of the PART I of this course is to learn the
tidyversepackage. (The goal of the PART II is to learning the basics of machine learning)
- The
1.12 Console vs R script file vs R markdown file
For R programming, you need to let computers know what you want them to do for you. Simply, you need to type your R commands. Console, R script file, and R markdown file are three different ways in which you can interact with R.
In the console, you just type the R command at the prompt (i.e.,
>) and press the<Enter>key, then R will execute your commands and show the result. The console allows us to quickly run our commands but the commands will be gone when you quit your R.

The R Console
- The R script is just a text file having the
.Rfile extension. Using the R script, you can store your R commands for later use. Notice that the R script cannot store your results.
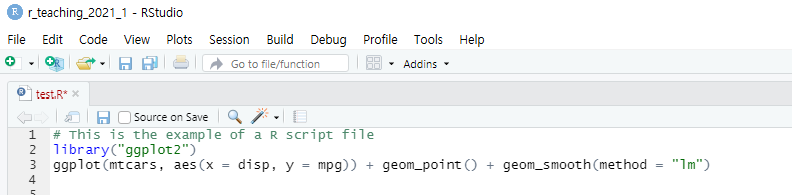
The R script
- The R markdown is also a text file having the
.Rmdfile extension. Using the R markdown, you can store your R commands (gray area), your results, and your texts (white area).
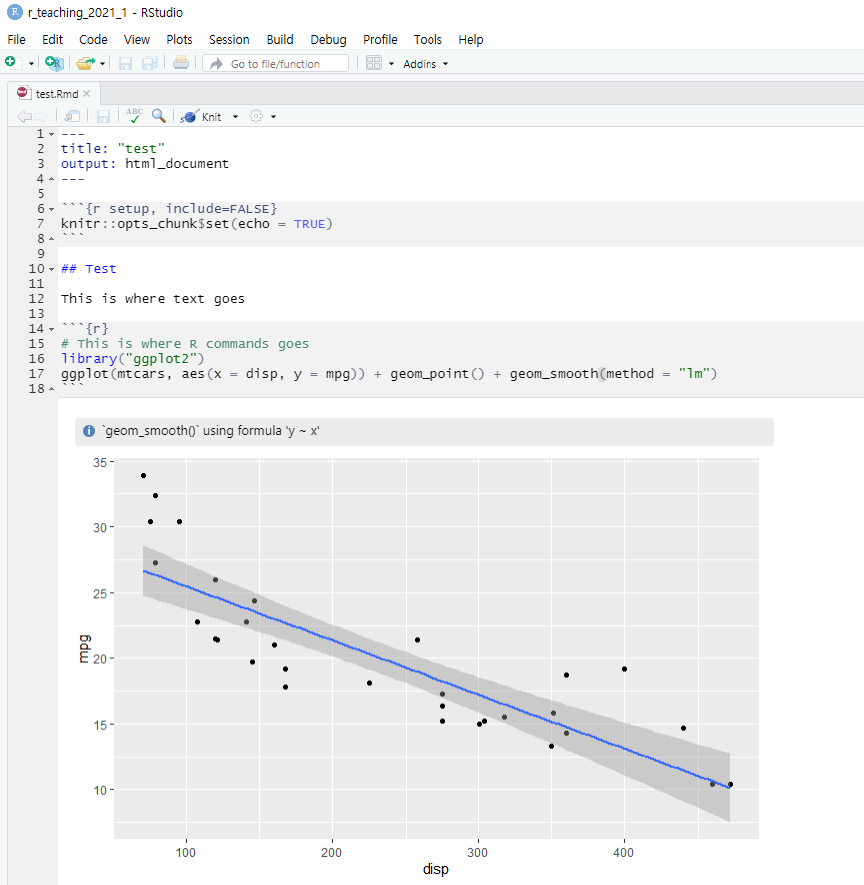
The R markdown
1.13 More about the R makrdown
In this course, we will mainly use the R markdown so that you can learn the advantage of the R markdown. Simply, people use the R markdown because it’s a great tool for communication. In data science, once you analyze your data then you usually want to communicate your findings with others. The R markdown allows you to create documents that include your R codes, results, and texts in a variety of formats such as HTML, PDF, Microsoft Word, and other dynamic documents. It’s a nice example of one-source multi-use.
These days, how you present your work is just as important as what you present. If you learn R markdown, you can present your contents in many different wonderful formats.
This lecture notes was created using the R markdown and then was converted into the html for web lecture notes. More precisely, I used the
bookdownpackage to create this lecture notes. I will introduce thebookdownpackage later in this course so that you can also publish your own lecture notes like this one on the web.Let’s watch a short introductory video for R markdown.
You will be amazed how many nice documents can be created from a simple R markdown text file. Please check nice documents from R markdown here.
If you are serious in R markdown, please read R Markdown: The Definitive Guide(Yihui Xie, J. J. Allaire, Garrett Grolemund).
In this class, we will cover the basic of R markdown.
Let’s explore R markdown a little bit more. You can open a new R markdown template by going
File > New File > R Markdown...
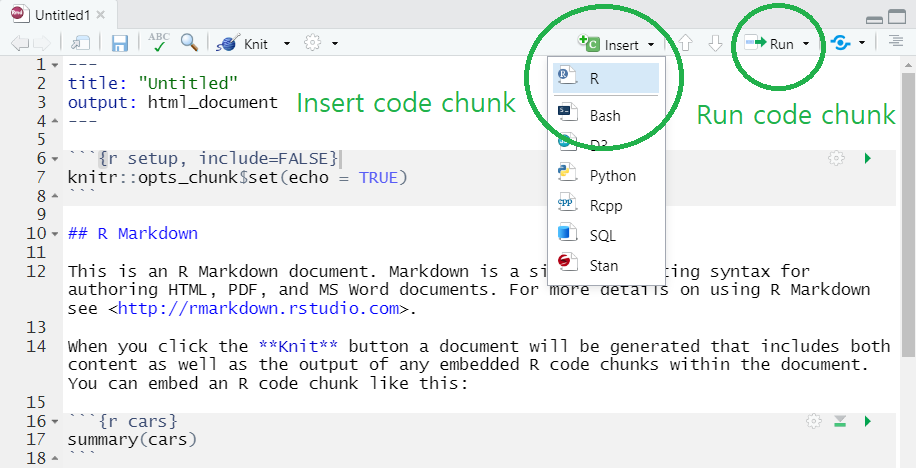
R Markdown template in RStudio
- Notice that R markdown contains white and gray areas. The white area is where your text goes, whereas the gray area is where your R code goes.
- You can create a code chunk by
- clicking
insertand chooseRon the menu (check the green circle on the above image) or - typing a short cut key or
- Windows:
Ctrl + Alt + I - Mac:
Cmd + Option + I
- Windows:
- clicking
- You can run the code in a code chunk by
- clicking
Runon the menu (check the green circle on the above image) or - typing
Ctrl + Enterwhen you place your cursor at the line of the code you want to run
- clicking
- You can find more information on code chunks here
- You can create a code chunk by
- Again, the biggest benefit of using R markdown is that you can create multiple output formats (e.g.s, HTML, PDF, MS Word, Beamer slide, shiny applications, websites).
- For example, you can easily create HTML, PDF, MS Word from your R markdown document by simply clicking
knitbutton and choose the format you want (check the green circle on the below image). - To knit to PDF, you need a Tex typesetting system.
- For example, you can easily create HTML, PDF, MS Word from your R markdown document by simply clicking
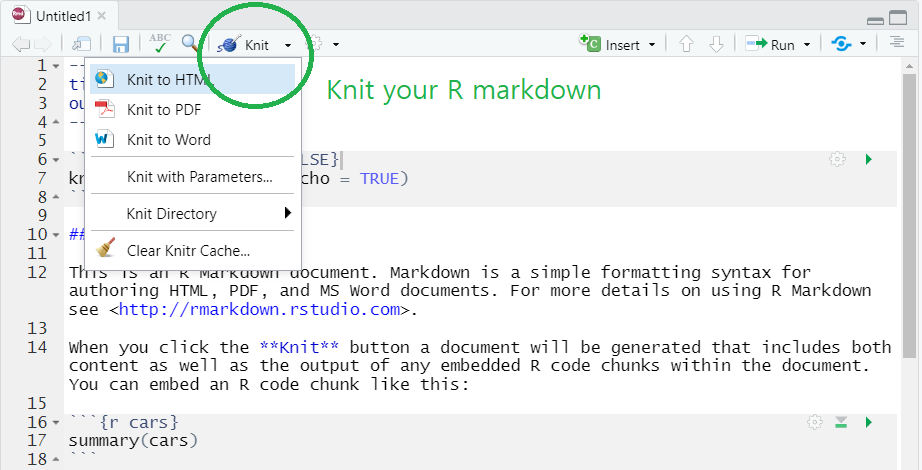
Knit the R markdown to HTML, PDF, and Word
1.14 Useful R resources
You can find many useful resources (many of them are FREE) for learning R on the internet.
Free ebooks
bookdown is an R package that helps you to write and publish books using RStudio. Please check wonderful books on the site. You can freely read those books online.
In this site, you can find our textbook, R for Data Science (Hadley Wickham).
If you are interested in writing and publishing books on the internet like the ones on the bookdown website, please read bookdown: Authoring Books and Technical Documents with R Markdown (Yihui Xie). (This class will not cover this topic)
As you may already know, many researchers around the world create R packages and share with others through R package systems. If you are interested in creating your own R package, please read R Packages (Hadley Wickham). (This class will not cover this topic)
If you think you want to learn more advanced R at the end of this course, please read Advanced R (Hadley Wickham). (This class will not cover this topic)
If you prefer to read those books in Korean, try to translate books using the Chrome web browser: open the ebooks using Chrome web browser, click right mouse button, and choose “translate in Korean.”
You may already notice that the name “Hadley Wickham” appears here and there. Hadley Wickham contributes a lot to R community as a chief scientist at RStudio, creator of
tidyversepackage (ggplot2,dplyr,tidyr,stringr, etc.), and authors of many books. You can find more about Hadley in Hadley’s website.
RStudio Cheatsheets
One of the strengths of R is its package system. There are more than 17,000 packages that extend the functionality of base R. However, it’s difficult to remember all the details of such large number of packages.
RStudio provides RStudio Cheatsheets which summarize features of some important R packages in one or two pages. The cheatsheets will be nice references when you actually work with R for your own project.
1.15 The goal of the R part (PART I) of this course.
- The goal is very simple(?). At the end of the R part of this course, students are expected to have the ability to analyze their own data based on the following process suggested in our textbook:
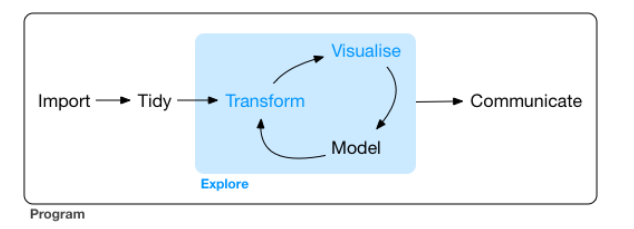
The process in typical data science project
In Ch1 of R for Data Science, the author illustrates the process in typical data science project as follows
- import: read data into R from files (e.g., .csv, .xlsx)
- tidy, transform: get the original data into our desired form
- visualize: create plots to understand data or to present findings
- model: detect patterns from data
- communicate: tell your findings to others
Let’s go over this process with a simple example using a built-in
irisdata.- For now, it’s perfectly ok for you not to understand the specific functions used in the code. Please just focus on the workflow.
Import
- To simplify our example, let’s just use the built-in dataset in R, instead of actually importing the data from a file.
- We will use the Iris data, a quite famous data in data science. The Iris data contains the length and the width of the sepals and petals in centimeters for 150 samples from three species (i.e., setosa, virginica, versicolor) of the Iris flower. For this example, let’s just pretend we actually imported the Iris data from a file.
# Code chunk 1 for HW1
# head() is a function in base-R that display only the first 6 observations
head(iris)## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa- Tidy
- You should be able to see five variables in the Iris dataset:
Sepal.Length,Sepal.Width,Petal.Length,Petal.Width, andSpecies. - Now, I will reshape the structure of the Iris dataset using the following code. You should be able to see the four new variables:
Species,Part,Measure, andValue. - The reshaped dataset is called a tidy dataset.
- Why do we want to have a tidy data? What would be the benefits of having a tidy data?
- You should be able to see five variables in the Iris dataset:
# Code chunk 2 for HW1
# tidying the raw data into the tidy data using `pivot_longer()` and `separate()` functions in the tidyr package
library(tidyverse)
iris %>%
pivot_longer(cols = -Species, names_to = "Part", values_to = "Value") %>%
separate(col = "Part", into = c("Part", "Measure"))## # A tibble: 600 x 4
## Species Part Measure Value
## <fct> <chr> <chr> <dbl>
## 1 setosa Sepal Length 5.1
## 2 setosa Sepal Width 3.5
## 3 setosa Petal Length 1.4
## 4 setosa Petal Width 0.2
## 5 setosa Sepal Length 4.9
## 6 setosa Sepal Width 3
## 7 setosa Petal Length 1.4
## 8 setosa Petal Width 0.2
## 9 setosa Sepal Length 4.7
## 10 setosa Sepal Width 3.2
## # ... with 590 more rows- transform & visualize
- The benefits of the tidy data become clear(?) when you need to transform and visualize the tidy data. With tidy datasets, you can easily transform and visualize your data.
# Code chunk 3 for HW1
# transforming our data using `group_by()` and `summarize()` functions in the dplyr package
# Because we created the `Part` variable in our tidy data,
# we can easily calculate the mean of the `Value` by `Species` and `Part`
iris %>%
pivot_longer(cols = -Species, names_to = "Part", values_to = "Value") %>%
separate(col = "Part", into = c("Part", "Measure")) %>%
group_by(Species, Part) %>%
summarize(m = mean(Value))## `summarise()` regrouping output by 'Species' (override with `.groups` argument)## # A tibble: 6 x 3
## # Groups: Species [3]
## Species Part m
## <fct> <chr> <dbl>
## 1 setosa Petal 0.854
## 2 setosa Sepal 4.22
## 3 versicolor Petal 2.79
## 4 versicolor Sepal 4.35
## 5 virginica Petal 3.79
## 6 virginica Sepal 4.78# Code chunk 4 for HW1
# visualizing our data using `ggplot()` function in the `ggplot2` package
iris %>%
pivot_longer(cols = -Species, names_to = "Part", values_to = "Value") %>%
separate(col = "Part", into = c("Part", "Measure")) %>%
ggplot(aes(x = Value, color = Part)) + geom_boxplot()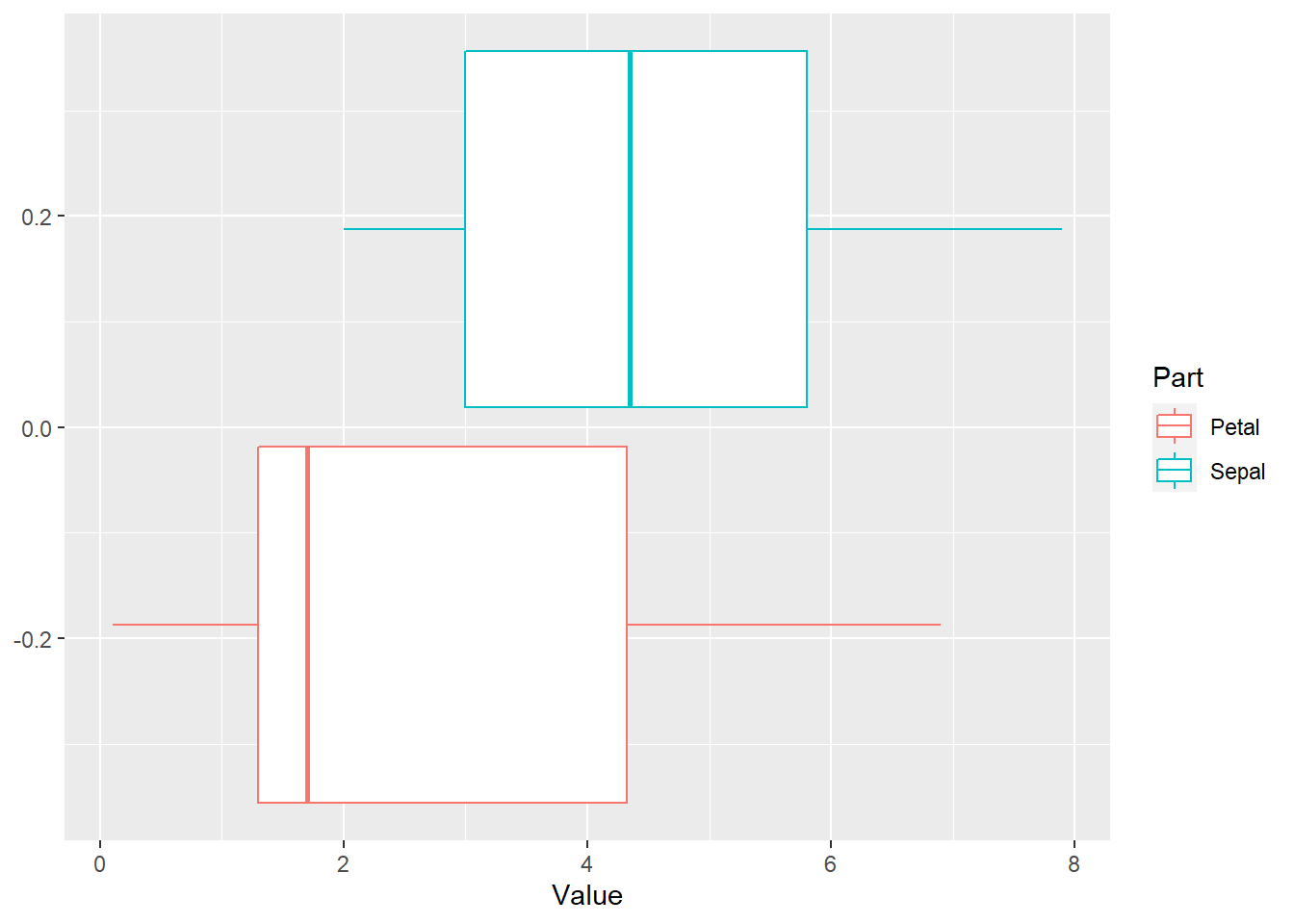
1.16 Homework 1
The goal of this HW1 is just to make sure you successfully install R and RStudio, and you are ready to use R. So if you just submit the html file to the Turnitin for week1, you will get the full credit for HW1.
For HW1, do the following:
- create an R markdown template by going
File > New File > R Markdown...and - replicate the Code chunk 1, 2, 3, and 4 for HW1 above by creating code chunks in the R markdown file created in the step 1
- add your own name, department, and student ID number in white space
- create an HTML by kniting the R markdown
- submit the HTML file to TurnItIn in the week 1 session in the cyber campus.
- create an R markdown template by going