Chapter 2 How can you play FAIR?
2.1 Introduction
If you want to make your A. fumigatus observations more FAIR, it is best to begin the process from the beginning. This ensures that you do not forget to write down any critical details. To start data entry, you have to be aware of the data structure of the ASPAR_KR database (Figure 2.1):
Investigation: Here you should record the purpose of your study and the author and publishing information.
Example: Investigating azole resistance of Aspergillus fumigatus spores in Dutch hospitals.Study: Here you record the sub-investigations of your study.
Example: Resistance occurance in the Rijnstate hostpital.Observation units: Here you indicate what observations were made. Any experimental factors are indicated at this level.
Example: The ward for cancer treatment.Sample: Here you indicate what you sampled. Repeated measures or experimental time point samples can be indicated here.
Example: The culture taken from floor near patient room A2 and its MIC dilution series.Assay: Here you indicate what was measured and when. Assay results cannot be analysed further.
Example: The PCR amplification of CYP51A taken from the culture.

Figure 2.1: Classes availible within the ASPAR KR database. Each class `owns’ lower level classess. For example, a sample has associated assays.
ASPAR_KR has versions of the Sample and Assay class, called packages. These packages are like pre-defined templates for your experiments. They allow ASPAR_KR to check whether anything is missing and whether everything is filled in correctly, leading to a FAIRer dataset. The aforementioned data structures, excel templates and validation programme, are based on the FAIRDS Nijsse, Schaap, and Koehorst (2023).
During their 10:15 coffee break Marie and Peter are discussing the subject of FAIR data. “Now the NWO wants researchers to use FAIR data practices! How am I supposed to do that while I am also busy with data analysis?” “Well”, says Marie, “I’ve recently heard of the ASPAR_KR project, and how it aims for a solution for researchers just like you.” “I’ve already started using it”, she noted as she got out her laptop. When you have verified the basic syntax of your FAIR data template;
2.2 Choosing the right packages for your experiments
To start, go to ASPAR_KR metadata configurator. You will be greeted with a webpage as is shown (Figure 2.2). On this webpage you’ll find two fields to fill in. Project specific metadata and Experimental metadata. When these are filled in, you can click on GENERATE WORKBOOK, to make an excel file where the metadata can be filled in.
Marie Logs on to her computer and goes to
https://aspar-kr.bioinformatics.nl/template, where she fills out the web form together with Peter for his research.
Using the excel sheet generated by this webpage, the FAIRification process can begin.
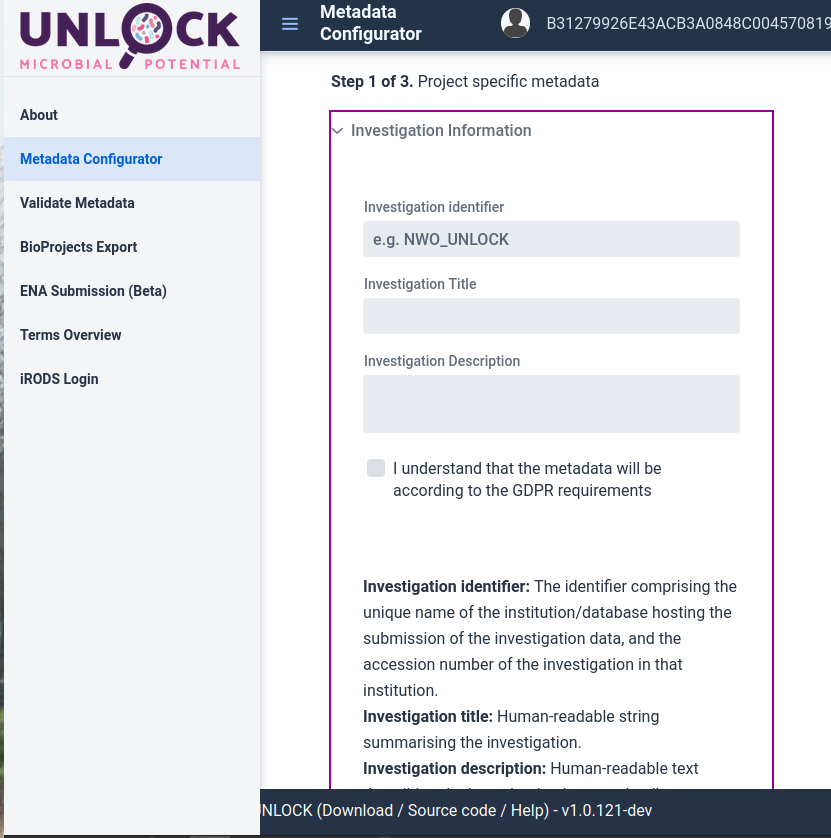
Figure 2.2: Screenshot of the FAIRDS interface for generating a metadata excel file.
2.2.1 Investigation specific meta data
The investigation describes the field of study. If your research is (going to be) published, you can fill in the title and abstract of your study here. Otherwise you should come up with a title and abstract. It is important to write clear description fields, so others can easily use your dataset. In Investigation identifier it is important that the identifier will be unique to the database.
Whenever you feel like ASPAR_KR cannot for fill your needs, you can suggest a package. Besides suggesting it is also possible to extend an existing package
2.2.2 Experiment specific metadata
What you fill in here depends on your research and the results you obtain. There are packages for ObservationUnits, Samples and Assays, they are documented in Chapter 5.1. At minimum, the required fields of a package should be able to describe your research well enough that somebody can understand the dataset without extra context.
Peter completed a differential study of azole resistance in A. fumigatus from compost made from farms vs garden waste.
2.3 Filling in the Excel form.
After creating the form for your investigation, you can start to go to work.
The Excel sheet generated by the template web app makes a spreadsheet for each class shown in Figure 2.2.
It is important to take the time to fill in all of the fields carefully. This makes sure that any future user of the data set can easily understand your experimental design. If you have any questions about the meaning for different column names, check the terms overview on the FAIRDS website.
2.3.1 Study
A Study is a set of observational units of which samples are measured to address a specific question. This question, together with the experimental factors used to address it should be specified in the study description.
2.3.2 Observation unit
In the observation unit, the experimental factors should be indicated in columns of the following format:
id |
fcr_watered |
fct_sun_hours |
|---|---|---|
| 1 | yes | 20 |
| 2 | no | 5 |
This makes it easy for users of the data set to understand what experimental treatments were applied over the experimental units.
2.3.3 Sample
Repeated measures are indicated in the Sample class. Any experimental factor that changes between repeated sampling of the same observation unit is indicated here.
Some packages in of the Sample class ask for latitude and longitude fields. These should be specified in the WGS84 format, which is also used by open street maps (OSM) or Google earth.
2.4 FAIRification using ASPAR_KR.
When the excel sheet is filled in, comes the validation step. Here, the ASPAR_KR programme makes sure that all syntax is as expected and that the numbers, such as coordinates are valid. If everything is determined to be correct, ASPAR_KR offers the button DOWNLOAD RDF. When this button is clicked, the RDF dataset is downloaded.
If there is an issue with the document, ASPAR_KR will detect it, and report it in the text box Description (Figure 2.3). If you have any questions about the error messages given by ASPAR_KR, please reach out to Sibbe Bakker.

Figure 2.3: Log of the validation actions of ASPAR KR. The FAIRified dataset can be obtained by clicking `DOWNLOAD RDF’
2.5 Submission of your worksheet and RDF data.
When you have verified the basic syntax of your FAIR data template using the web-tool. You can submit it, by sending it to sibbe<dot>bakker<at>wur.nl. Then the dataset will be reviewed and if deemed of sufficient quality, will be made part of the next ASPAR_KR release.