第6章 データの操作
人生という庭は,哲学者らが便宜的に説く姿からはほど遠い。
もう少し耕した方が良さそうだ。
— ロジャー・ゼラズニー40
本章は,私の基準からしてもちょっと変わった内容を含んでいます。本章の目的は,データを扱う際の実際的な問題について説明することです。これについては,本書の他の場所ではあまり触れられていません。実際のデータセットを扱う際の問題点は,それらがとても乱雑であるということです。分析に適した形で変数が格納されていないということもよくありますし,データセットに多数の欠損値が含まれているようなこともあります。データの一部のみを分析したいということもあるでしょう。他にもさまざまなことがあります。つまり,データセットの変数を分析に適した形にするためには,さまざまなデータ操作を行わなくてはならないのです。本章は,こうした実際上の問題に関する基本的な部分を説明することを目的としています。実際のデータを扱う際にさまざまな実際的問題が生じることからこの章を書くに至ったわけですが,本書の他の章と同様,ここでも小規模な練習用データセットを用いて説明していきます。本章の内容は基本的にはいろいろなテクニックの紹介であり,全体としてまとまったストーリーがあるわけではありません。そこで,まず最初に扱う項目をリストアップしておこうと思います。
このように,本章では非常に広く,そしてたくさんの内容を扱います。この章は,本書の中でもとくに長くて難しい部分かもしれませんが,それでも多数ある重要なトピックのほんの一部を表面的に説明したものに過ぎません。これは私からのアドバイスですが,この章を一度読み通したうえで,できる限りいろいろと試してみるようにしてください。一度にすべてを理解する必要はありませんし,とくに後半部分は理解できないからといって心配しすぎる必要はありません。本書のこの後の部分でもこの章の内容が必要になることはわずかですし,基本的なことだけ理解できていれば十分だからです。ただし,本書の後の方になって,私がここで説明する概念のいくつかを理解するために,この章に戻ってくることになるでしょう。
6.1 データの集計とクロス集計
データ分析において非常に一般的な作業の1つに,度数分布表またはクロス集計表の作成があります。その作業はjamoviでできますので,その方法をこのセクションで説明します。
6.1.1 1つの変数で表を作成する
まずは簡単な例から始めましょう。私には小さな子供がいますので,『In the Night Garden41』のようなテレビ番組をよく見ます。そしてnightgarden.csvファイルには,その番組での会話を私が書き留めたデータが含まれています。このファイルにある,speaker(話し手)とutterance(発話)という2つの変数がここでの対象です。このデータセットをjamoviで開き,スプレッドシートでどのようなデータか見てみましょう。データは次のようになっているはずです。
「speaker(話し手)」 変数:
upsy-daisy upsy-daisy upsy-daisy upsy-daisy tombliboo tombliboo makka-pakka
makka-pakka makka-pakka makka-pakka
「utterance(発話)」変数:
pip pip onk onk ee oo pip pip onk onk
これを見ると,私の頭がどうかしているということがよくわかるはずです。このデータで,たとえば番組の各キャラクターが話した回数を数える必要があったとします。jamoviの「Descriptives(記述統計)」画面には「Frequency tables(度数分布表)」というチェックボックスがあり,それを使えば図6.1のような結果が得られます。
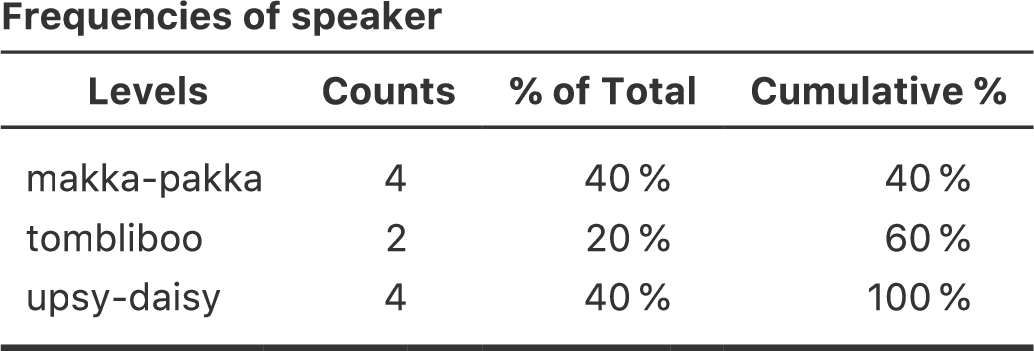
図6.1: speaker変数の度数分布表
この表の最初の行には,speaker変数の何を示しているのかが説明されています。「Levels」の列は,データに含まれている話し手(speaker)の一覧で,「Counts」の列はその話し手のがデータの中に何個含まれているかを示しています。要するにこれは度数分布表です。
jamoviの「Frequency tables(度数分布表)」チェックボックスは,1つの変数に対して1つの表しか作成してくれません。speaker(話し手)とutterance(発話)の2つの変数を組み合わせ,それぞれの話し手がそれぞれの発話を何回行ったかを知りたいような場合には,クロス集計表,すなわち分割表を作成する必要があります。jamoviでは,「Frequencies(頻度)」>「Contingency Tables(分割表)」>「Independent Samples(対応なしのサンプル)」で,speaker(話し手)変数を「Rows(行)」に,utterances(発話)変数を「Columns(列)」に設定します。このように設定すると,図6.2のような分割表が得られます。
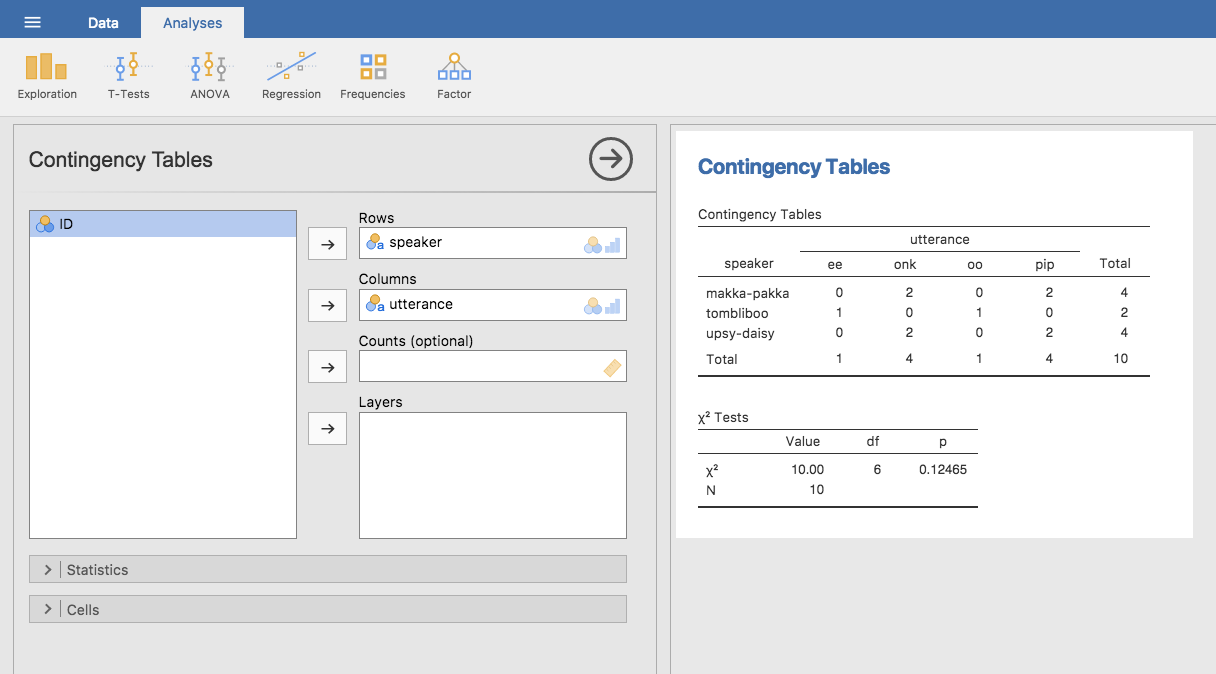
図6.2: speaker(話し手)変数とutterance(発話)変数の分割表。
ここでは「\(\chi^2\) Tests」の表については忘れてください。これについては第10章で説明します。この分割表を解釈する際は,ここに示されているのがデータの度数だという点に注意してください。つまり,1行2列目の2という数字は,Makka-Pakka(1行目)による「onk」(2列目)という発話がこのデータセットには2個含まれていたという意味です。
6.1.2 分割表へのパーセンテージの追加
図6.2には度数そのものが示されています。つまり,指定した変数の各水準の組み合わせでその観測値がいくつあったかという数が示されているわけです。しかし,個数だけでなくパーセントも示したいという場合があるでしょう。「Contingency Tables(分割表)」画面の「Cells(セル)」オプションにはさまざまなパーセントのためのチェックボックスがあります。まず,「Row(行)」のチェックボックスをオンにすると,結果画面の「Contingency Table」(分割表)は図6.3のようになります。
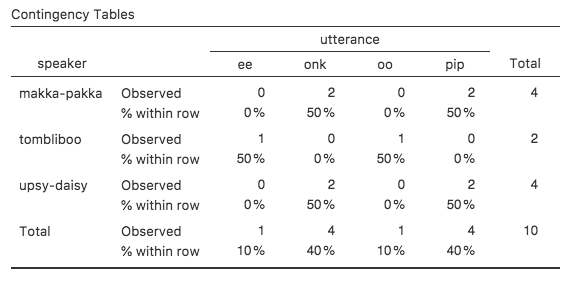
図6.3: speaker(話し手)変数とutterance(発話)変数の分割表に行ごとのパーセントを示したもの。
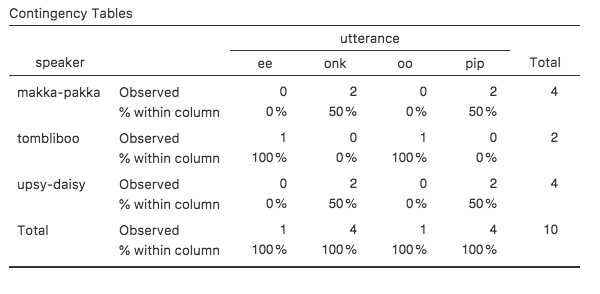
図6.4: speaker(話し手)変数とutterance(発話)変数の分割表に列ごとのパーセントを示したもの。
ここに表示されているのは,キャラクターごとの各発話のパーセントです。つまり,Makka-Pakkaの発話は「pip」が50%で,残りの50%は「onk」ということです。この結果と列ごとのパーセンテージを示した場合とを比較してみましょう(「Cells(セル)」画面の「Row(行)」のチェックを外して「Column(列)」にチェックを入れてください)。その結果が図6.4です。この表には,各発話ごとのキャラクターのパーセントが示されています。たとえば,「ee」という発話が会った場合に,(このデータセットの中では)その話し手がTomblibooである割合が100%ということです。
6.2 jamoviの論理式
jamoviにおけるデータ変換の多くでは,論理値という考え方がとても重要です。論理値とは,ある値が真であるか偽であるかを表したものです。jamoviでは,論理値は非常にわかりやすい形で使用されます。論理値としてはtrue(真)とfalse(偽)という2種類の値があります。このようにとてもシンプルにも関わらず,論理値は非常に便利なものなのです。それではこの値について見ていくことにしましょう。
6.2.1 数学的真実の評価
ジョージ・オーウェルの古典,『1984年』には,全体主義の党が掲げる「2足す2は5である」というスローガンが登場します。これは,人間の自由を政治的に支配できれば,こうした基本的な真理すら破壊できるという考え方です。これは恐ろしい考えです。そしてなんと,主人公のウィンストン・スミスは,最終的に拷問に屈し,この主張に同意してしまうのです。そしてこの小説では「人間には無限の可塑性がある」と語られます。私は人類にとってこの主張が真でないと強く確信していますし42,もちろん,jamoviにとっても真ではありません。jamoviには完全な可塑性というものはありませんし,少なくとも基本的な計算に関しては,何が真で何がそうでないのかということに関しては確たる意見を持っているのです。
2+2を計算させれば必ず毎回同じ答えを返してくれますし,その答えが5であることはありません43。もちろん,これはjamoviが単に計算をしているだけです。\(2+2 = 4\)が正しいかどうかについて尋ねたわけではありません。こうした判断を明示的にjamoviにさせたい場合には,2+2==4という命令文を使います。
一体何をしたのかというと,これは,等価演算子と呼ばれる==記号を用いて,jamoviに「真か偽か」の判断をさせているのです44。では,jamoviが党のスローガンをどう判断するか見てみましょう。次の式を「数式(formula)」ボックスに入力して新しい変数を計算させます。
さて結果はどうなったでしょうか。スプレッドシートに表示された新しい計算変数の列には「false」(偽)がずらりと表示されるはずです。やったね! 自由万歳! とまあそんな感じです。では,もしjamoviに2足す2が5であるということを2+2=5といった文を使って信じ込ませようとしたらどうなるでしょうか。これをRのような他のプログラムで実行するとエラーメッセージが表示されます。ところが,これをjamoviで実行すると,「false」(偽)の値がずらりと表示されるのです。どうなっているのでしょうか。どうやらjamoviは非常に賢くて,正しい等価演算子(==)を使おうが等号(=)を使おうが,あなたが2+2=5が真であるか同かをテストしているのだということをきちんと認識してくれているようです。
6.2.2 論理演算
ここまで,論理演算について見てきました。ただし,お見せしたのはもっとも単純な例です。こう聞いても驚かないでしょうが,論理演算は普通の計算を組み合わせたり,関数と組み合わせたりして複雑な形で使用することができます。たとえば次のようにです。
または
それだけではありません。表6.1に見られるように,論理演算子にはいくつかの基本的な数学概念を表す複数のものが用意されているのです。これらは見ればわかるのではないかと思います。たとえば,未満(より小)演算子(<)は,左側の数値が右側の数値よりも小さいかどうかをチェックします。左側の方が値が小さければtrue(真)を返し,2つの値が同じか,右側の値の方が小さければfalse(偽)という答えを返します。
これに対し,以下演算子(<=)の場合は,その名前が示すとおりの振る舞いをします。つまり,左側の値が右側よりも小さい場合,または2つの値が同じ場合にtrue(真)を返すのです。となれば,超過(より大)演算子(>)と以上演算子(>=)がどのような振る舞いをするかはもうおわかりでしょう。
論理演算子リストのその次にあるのは不等価演算子(!=)で,これも他と同じように見たとおりの働きをします。これは,この記号の左右で値が等しくない場合にtrue(真)を返します。つまり,\(2+2\)は\(5\)ではありませんので,これを計算させると新しい計算変数にはtrueの値が入力されます。やってみましょう。
| 演算 | 演算子 | 入力例 | 結果 |
|---|---|---|---|
| 未満(より小) | < | 2 < 3 | true |
| 以下 | <= | 2 <= 2 | true |
| 超過(より大) | > | 2 > 3 | false |
| 以上 | >= | 2 >= 2 | true |
| 等価(等しい) | == | 2 == 3 | false |
| 不等価(等しくない) | != | 2 != 3 | true |
これで終わりではありません。あと3つ,知っておくとよい論理演算子があります(表6.2)。それは否定演算子(NOT),かつ(論理積)演算子(and)そしてまたは(論理和)演算子(or)です。
| 演算 | 演算子 | 入力例 | 結果 |
|---|---|---|---|
| 否定 | NOT | NOT(1==1) | false |
| または | or | (1==1) or (2==3) | true |
| かつ | and | (1==1) and (2==3) | false |
他の論理演算子同様に,その振る舞いは大体その名前からわかるのではないでしょうか。たとえば,「\(2+2 = 4\) または \(2+2 = 5\)である」という評価を行えば,その答えはイエス(true)になります。これは「いずれか」が正しいことを評価する文ですので,2つのうちどちらか一方でも真であれば,真ということになるのです。これがor演算子の働きです45。
一方で,「\(2+2 = 4\) かつ \(2+2 = 5\)」では,その答えはノー(false)になります。「かつ」では,その両方が真でなくてはならないからです。これがand演算子の働きです。
最後に,否定演算子です。これも単純ですが,言葉で説明のはちょっとやっかいです。もし「\(2+2 = 5\)ではない」という文の評価を行えば,この文は正しい(true)ということになるでしょう。それは,「\(2+2 = 5\)は間違い(false)」だからです。そして実際その通りです。jamoviで計算させるには次のように書きます。
つまり,2+2 == 5はfalse (偽)の文なので,NOT(2+2==5)の答えはtrue(真)ということになるわけです。結局,「偽でない」ということは「真」であるというのと同じことだからです。もちろん,現実世界においてはそう言い切れない場合もあります。ただ,jamoviの世界は私たちの世界よりずっと白と黒がはっきりしています。jamoviにとっては,すべては真か偽のどちらかなのです。グレーというのは許されません。
もちろん,この\(2+2 = 5\)の例では,「否定」演算子(NOT)と「等価」演算子(==)の2つを使用する必要はありません。次のように「不等価」演算子(!=)で表すこともできます。
6.2.3 文字に対する論理演算
こうした論理演算子は,論理データと同様に文字に対しても使用できますが,これについて少し説明しておこうと思います。jamoviがそれぞれの演算をどのように解釈するかについてはすこし注意しておく必要があるからです。このセクションでは,等価演算子(==)が文字に対してどのように適用されるのかを説明します。とくに重要なのはこの部分です。もちろん,不等価演算子(!=)は==とは正反対の答えを返しますので,これについても説明していることにはなるのですが,!=の使用については特別に例を示したりはしません。
さて,それでは見ていきましょう。ある意味,これはとても簡単です。たとえば,jamoviに“cat”と“dog”が同じかどうかを聞きたければ次のように書きます。
とてもわかりやすいですね。そしてjamoviがこうした判断もできるということをしっておくと役立ちます。同様に,jamoviは“cat”と“cat”が同じであることも判断できます。
これも期待通りの答えが返ってきます。ただし,jamoviは文法や空白に対してあまり寛容でないという点には注意しておく必要があります。もし2つの文字列にそうした違いがある場合には,jamoviは2つが同じではないという判断をします。たとえば次のような場合です。
“cat” == “CAT”
“cat” == “c a t”
文字に対して論理演算子を使用することもできます。たとえば,jamoviは文字列に対して「<」や「>」という演算子を使用することもできるのです。この場合,アルファベット順に見た場合に2つの文字列のどちらが先に来るかという判断になります。大抵は。じつはこれはちょっとややこしいのですが,まずは簡単な例から見てみましょう。
jamoviでは,この例の評価結果はtrue(真)になります。それは,“cat”がアルファベット順では“dog”より前に来るからです。そのためjamoviではこの文は真であると判断されます。そして,もし“cat”が“anteater”より前に来るかどうかを答えさせれば,その結果はfalse(偽)になります。ここまではいいですね。ただし,文字データの扱いは,辞書の場合より少し複雑です。たとえば,“cat”と“CAT”を比較するとどうなるでしょうか。先に来るのは? では試してみましょう。
その結果はtrue(真)になります。つまり,jamoviでは大文字は小文字よりも先にくると判断されるのです。まあいいでしょう。これに関しては驚く人はいないはずです。ところが,驚くことに,jamoviではすべて大文字で書かれた単語がすべて小文字で書かれたものよりも先に来ると判断されてしまうのです。つまり,“anteater” < “zebra”は真であり,“ANTEATER” < “ZEBRA”も真なのですが,“anteater” < “ZEBRA”は真ではないのです。試してみてください。
この結果はfalse(偽)になります。なんとも変な感じですね。以上の点を踏まえ,jamoviがさまざまな文字の順序をどのように判断しているのかを知るには表6.3が参考になるでしょう。
| ! " # $ % & ’ ( ) * + , - . / , 0 1 2 3 4 5 6 7 8 9 : ; < = > ? @ |
| A B C D E F G H I J K L M N O P Q R S T U V W X Y Z [ ] , ^ _ ` |
| a b c d e f g h i j k l m n o p q r s t u v w x y z } | { |
6.3 変数の変換と記録
実際のデータ分析場面では,あなたのデータに含まれている変数が必要な形になっていないということも珍しいことではありません。たとえば,連続値の変数(年齢など)を少数のカテゴリ(若者・中年・高齢者など)に区分した方が便利な場合もあります。また,数値変数を別の数値変数に変換したい場合というのもあるかもしれません(元の数値の絶対値を分析したい場合など)。このセクションでは,jamoviでこうした操作を行うための基本的な方法について説明します。
6.3.1 変換変数の作成
まずは変数の変換からです。文字通りにとれば,これは変数に対して何らかの変換を行うということになりますが,実際には元の変数値に対して比較的単純な数学関数を適用して新しい変数を作成することを言います。そうした新しい変数を作るのは,関心のある対象をよりうまく表現した形にするためであったり,実施したい統計検定の前提を満たすためであったりします。統計的検定やその前提についてはまだ話していませんので,ここでは1つめの例について説明することにします。
10人にある1つの質問をしたという,単純な研究の例で考えてみましょう。質問は次の通りです。
「恐竜はかっこいい」という文について,あなたはどの程度その通りだと思いますか。「1(まったくその通りでない)」から「7(まったくその通りである)」でお答えください。
では,そのデータを読み込んでみてみましょう。likert.omvというデータファイルでは,10人の人々のリカート尺度での反応得点が1つの変数に収められています。ただ,このままでは反応データとしてあまりいい形でないかもしれません。反応尺度は左右対称になっていますので,中間点を0(どちらでもない)として,左右の両端をそれぞれ\(-3\)(まったくその通りでない)と\(+3\)(まったくその通りである)とした方がわかりやすそうです。そのような形でデータを記録しておけば,それがどのような意味を持っているのかをよりうまく反映した形になります。このような変換はとても簡単です。元の値からそれぞれ4を引けばいいのです。jamoviでは,こうした変換は新しい変数を計算させることで可能です。「Data(データ)」>「Compute(計算)」と進むと,新しい変数がスプレッドシートに追加されるのがわかります。この変数の名前はlikert.centredとしましょう(この通り名前を入力してください)そして,図6.5にあるように数式ボックスに「likert.raw - 4」と式を入力してください。
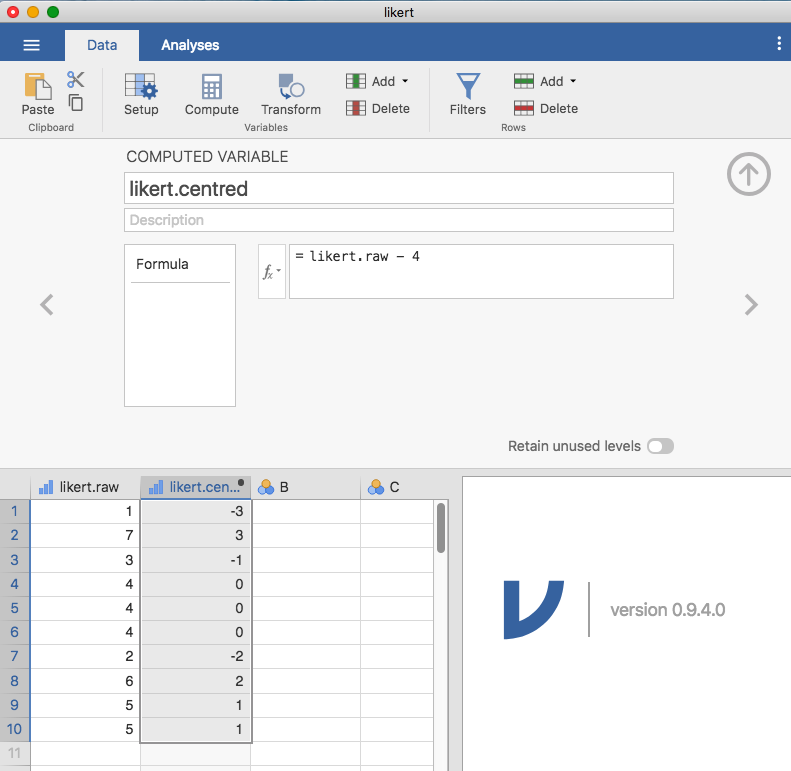
図6.5: jamoviで新しい変数を計算させている様子。
データをこのような形に変換しておくと便利なのは,意見の向きと意見の強さを別々に分析したいという場面もよくあるからです。その場合,向きと強さを分けるために,likert.centred変数に大して2種類の変換を行います。まず,opinion.strength変数には中心化された値の絶対値を入力します(「ABS」関数を使用します)46 。「Compute(計算)」ボタンを使用して新しい変数をjamoviに追加してください。この変数にopinion.strengthと名前をつけ,今度は数式ボックスの横にあるfxボタンをクリックします。これをクリックすると,さまざまな「Functions(関数)」とその関数で使用できる「Variables(変数)」が表示されるので,「ABS」をダブルクリックして,その後に 「likert.centred」をダブルクリックします。すると,「Formula(関数)」ボックスの中身は「ABS(likert.centred)となり,図6.6にあるようにスプレッドシートの新しい変数にその値が入力されます。
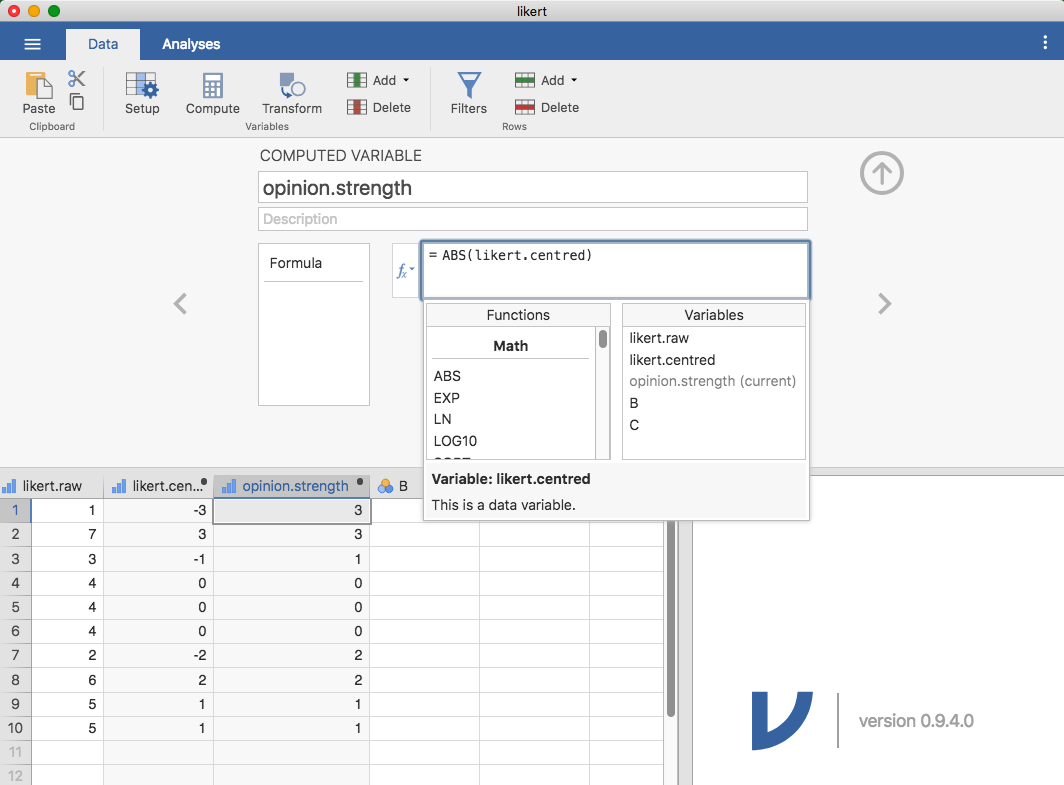
図6.6: fxボタンと関数の使用。
次に,意見の強さは考えず,意見の向きだけを含んだ変数を計算します。つまり,変数の符号だけを見るわけです。jamoviでは,IF関数を使えばこれができます。「Compute(計算)」ボタンで新しい変数を作り,名前をopinion.signとしたら,数式ボックスに「IF(likert.centred == 0, 0, likert.centred / opinion.strength)」と入力します。
こうすると,likert.centred変数の負の値は\(-1\)に,正の値は\(1\)に変換され,ゼロは\(0\)のままになるのがわかります。
この「IF」コマンドが何をしているのか詳しく見てみましょう。jamoviでは,「IF」文は’IF(expression, value, else)’のように3つの部分で構成されています。最初の部分である「expression(式)」は,論理式または数式です。この例では,「likert.centred == 0」が入力されています。この式の答えは,likert.centredの値がゼロの場合に「真」になります。2つめの部分は「value(値)」で,これは先ほどの式が「真」であった場合に新しい変数に入力される値です。先ほどの例では,likert.centredが0の場合には新しい変数の値を0にしなさいと指示しているわけです。3つめの「else(それ以外)」には,式の結果が「偽」の場合,つまりlikert.centredがゼロでない場合に使用される論理値や数式を入力します。先ほどの例では,likert.centredをopinion.strengthで割って,likert.centredの元の値の符号によって,-1または+1になるようにしているのです47。
これでおしまいです。手元には3つの新しい変数ができました。これらの変数はどれも元のlikert.raw変数に対する有用な変換です。
6.3.2 少数カテゴリへの区分
変数値を少数の水準を含む離散変数に変換したいということは非常に多くの場面で生じます。たとえば,社交的な場に参加する人々の年齢分布に関心があるとします。
いくつかの状況では,こうしたデータを少数のカテゴリーにグループ化した方が便利です。たとえば,このデータを若者(0-20),成人(21-40),年長者(41-60)の3つに大まかに分類するとします。これはかなり大まかな分類であり,この分類はこのデータセットでしか意味をなさないものです(たとえば,一般的には40代を「年長者」とするのは変でしょう)。jamoviで変数を分割するのにはすでに取りあげたIF関数を使用します。ただし,今度はIFを入れ子にして使う必要があります。どういうことかというと,IF文を複数設定して,最初のIFの式が「真」の場合には1つめの値を設定し,2つめのIFの式が「真」の場合は2つめの値,3つめのIFが「真」の場合は3つめの値を設定するのです。これは次のように書くことができます。
IF(Age >= 21 and Age <= 40, 2,
IF(Age >= 41 and Age <= 60, 3 )))
このとき,左かっこが全部で3つありますので,最後に右かっこが3つ必要になるという点に注意してください。そうでないとエラーになります。jamoviでのこのデータ変換は図6.7のようになります。ここでは,度数分布も表示されています。
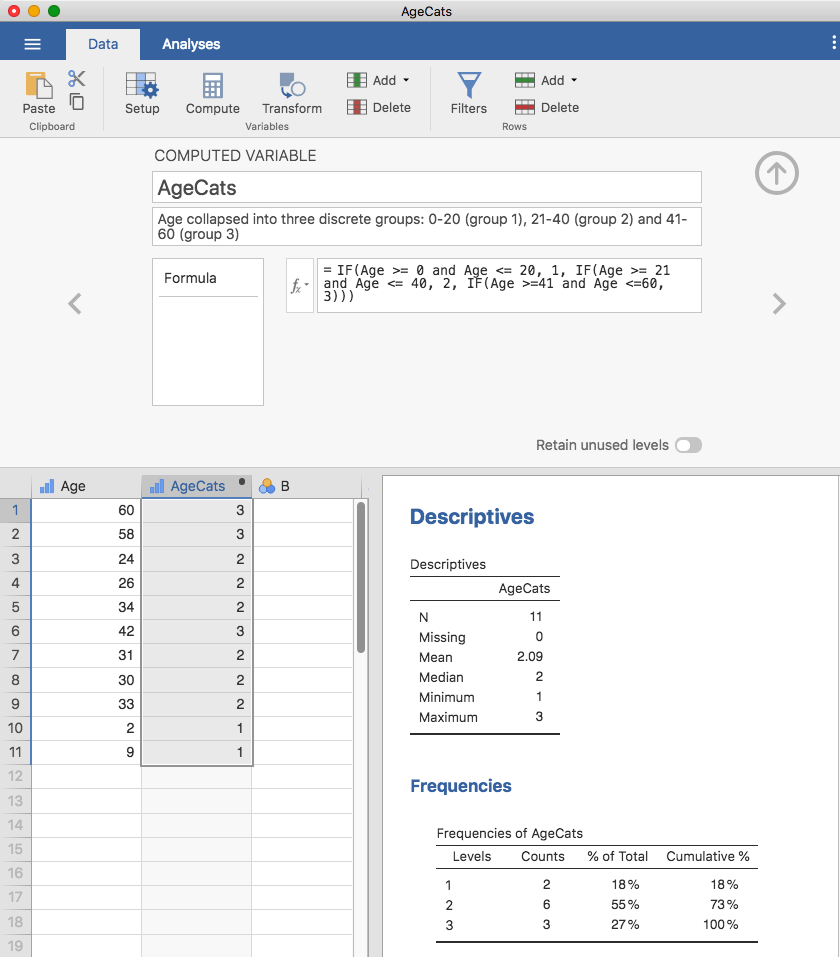
図6.7: IF関数で変数値を少数のカテゴリーに分割した様子。
結果として出力されるカテゴリーが,その研究プロジェクトの視点から見て意味のあるものであるかどうかをしっかり考えるようにしてください。もしそのカテゴリーに意味があるように思えなければ,このカテゴリーを用いたデータ分析は無意味なものになってしまう可能性が高いでしょう。もっと一般的なことをいうと,多くの人は自分の(連続的でごちゃごちゃした)データを少数の(離散的でシンプルな)カテゴリーに分類し直し,元のデータではなくその分類結果を分析することを好むようです48。根本的にダメだとまではいいませんが,時に重大な問題を引き起こすことになりますので,こうした分割を行う場合には十分注意しておくようにしてください。
6.3.3 複数の変数に変換を適用する
場合によっては,1つ以上の変数に対して同じ変数変換を行いたいということがあります。たとえば,複数の質問紙項目について同じ方法で再計算や記録を行ったりする場合です。jamoviの嬉しい機能の1つに,「Data(データ)」>「Transform(変換)」を用いて変数の変換を行えるという点があります。これは保存したり複数の変数に適用したりできるのです。最初のリカート尺度の例に戻りましょう。10人の回答値が1つの変数に収められているlikert.omvファイルを使用します。保存したり複数の変数に適用したりできる変換を作成するには(これと同じような変数が複数あるという仮定します),まずスプレッドシートビューで最初に変換を作成する変数を選択(クリック)します。この例では,likert.raw変数です。次に,「Data(データ)」の「Transform(変換)」ボタンをクリックします。すると,図6.8のような画面が表示されるはずです。
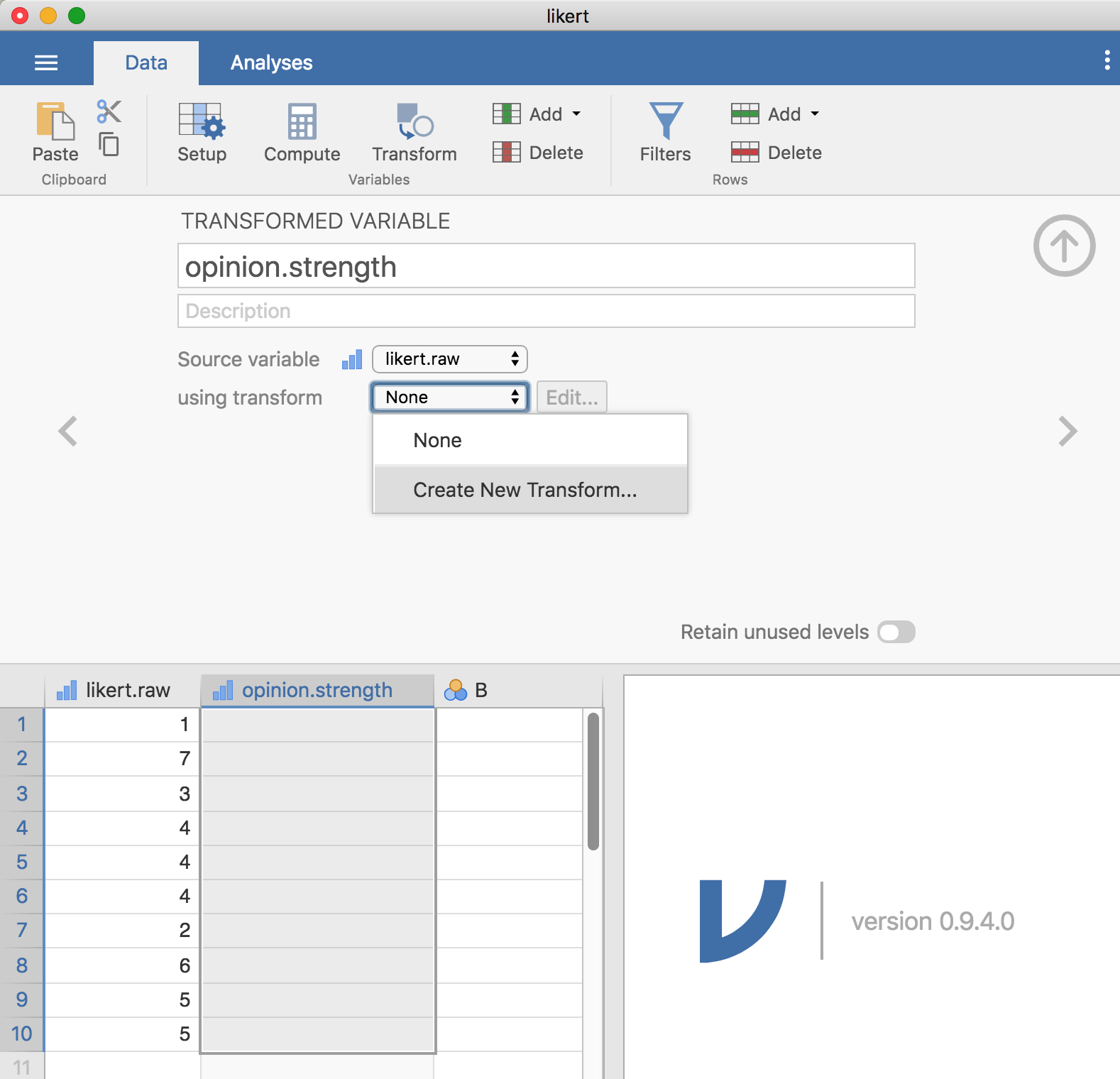
図6.8: 「Transform(変換)」コマンドによる変数変換。
新しい変数に名前をつけます。ここではopinion.strengthとしておきましょう。そして,「using transform(変換を使用)」のプルダウンメニューから「Create New Transform…(新規に変換を作成)」を選択します。ここで新しい変換を作成し,名前をつけると,それを好きなだけ他の変数に再適用することができます。変換には,自動的に「Transform 1」という名前がつけられます(なんとも独創的な名前ですよね。でも変更したければ変更できますよ。) そして図6.9のように数式ボックスに「ABS($source - 4)」という式を入力し,キーボードのEnterキー(Returnキー)を押します。するとほら,あっという間に新たな変換が作成され,それがlikert.rawに適用されました。いい感じ,でしょ? ここで,式の中で変数名の代わりに「$source」という表現を用いてる点に注意してください。これは,複数の変数に対して同じ変換を適用できるようにするための書き方です。その際に変換元になる変数の部分は,「$source」という書き方をしておく必要があるのです。作成した変換は保存していつでも使うことができます(データセットを.omvファイルとして保存した場合です。そうでないと変換は保存されません)。
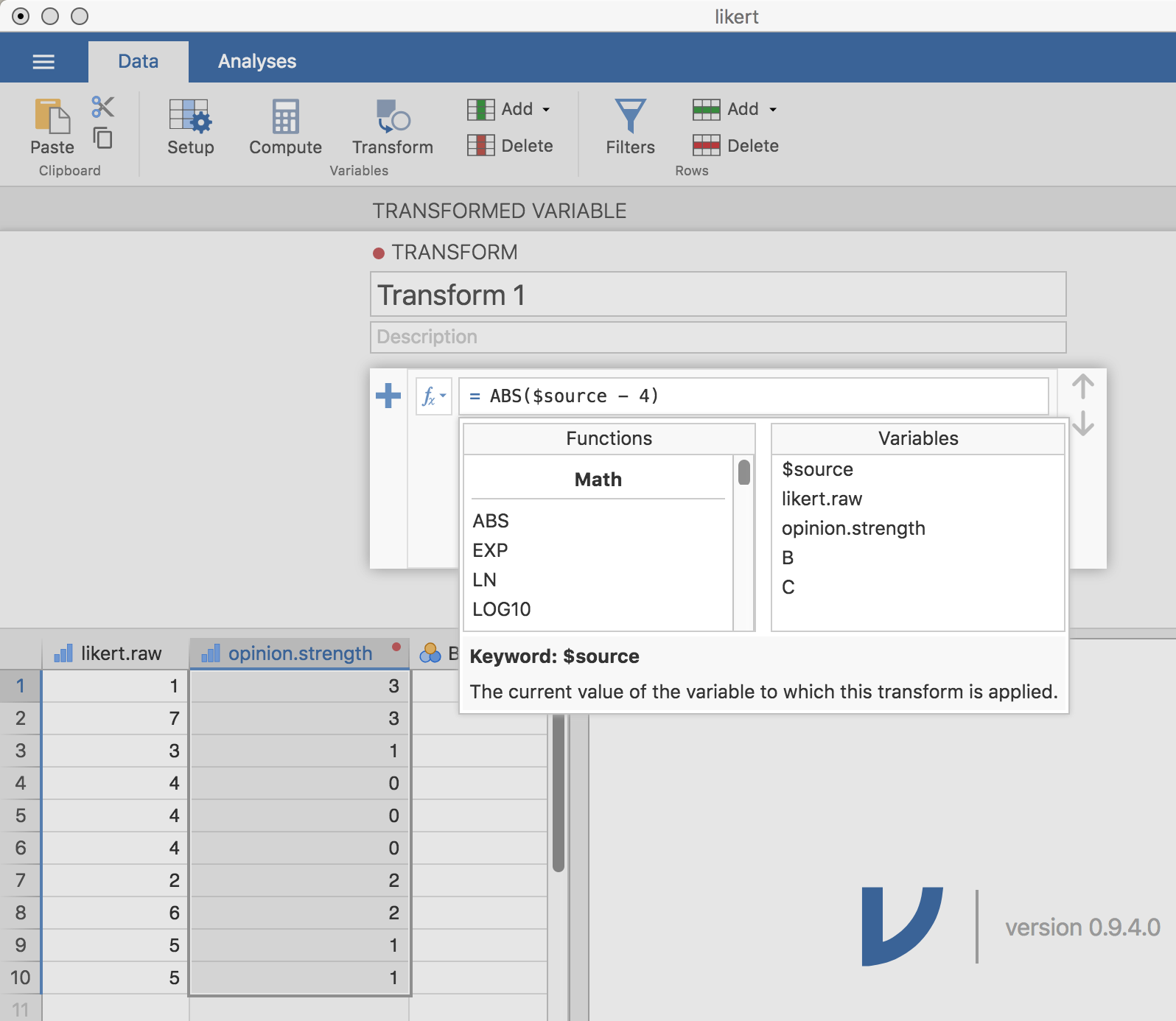
図6.9: jamoviでの変換の指定。独創的な「Transform 1」という名前で作成される。
2つめの,社交的な場に参加した人々の年齢を区分する例についても変換を作成することができます。もちろんそうしたいですよね。この場合には,変数を「若者」,「成人」,「年長者」の3グループに区分しました。これと同じことを,今度は「Transform(変換)」>「Add condition(条件の追加)」からやってみましょう。このデータセット(先ほどのデータセットを開いてください。もし保存していなければ,もう一度作成してください)で,新しい変数変換の設定を行います。変換変数の名前はAgeCatsとし,作成する変換の名前はAgegroupingsとしましょう。そして数式ボックスの隣にある大きな「+」マークをクリックします。これは「Add condition(条件の追加)」ボタンで,図6.10には大きな赤い矢印をつけておいたので,どこにあるかは一目瞭然です。図6.10の通り変換を再設定したら,新しい値がスプレッドシートに表示されます。このAgegroupingsという変換を保存しておけば,いつでも何度でも好きなときに再利用することができるのです。まあ「年齢」の変数が複数あるということはそうそうないでしょう。ですがjamoviで変換を設定する方法がこれでわかったわけですから,他の変数に対してもこの手順で変換をすればいいわけです。そうした操作が必要になる典型的な場面として,たとえば20項目の質問紙データがあって,元の値は1から6で記録されているのだけれども,何らかの理由でそれを1から3にコード化し直したいというようなケースが考えられます。この場合,jamoviで変換を作成すれば,再コード化したい変数それぞれにその変換を簡単に適用することができます。
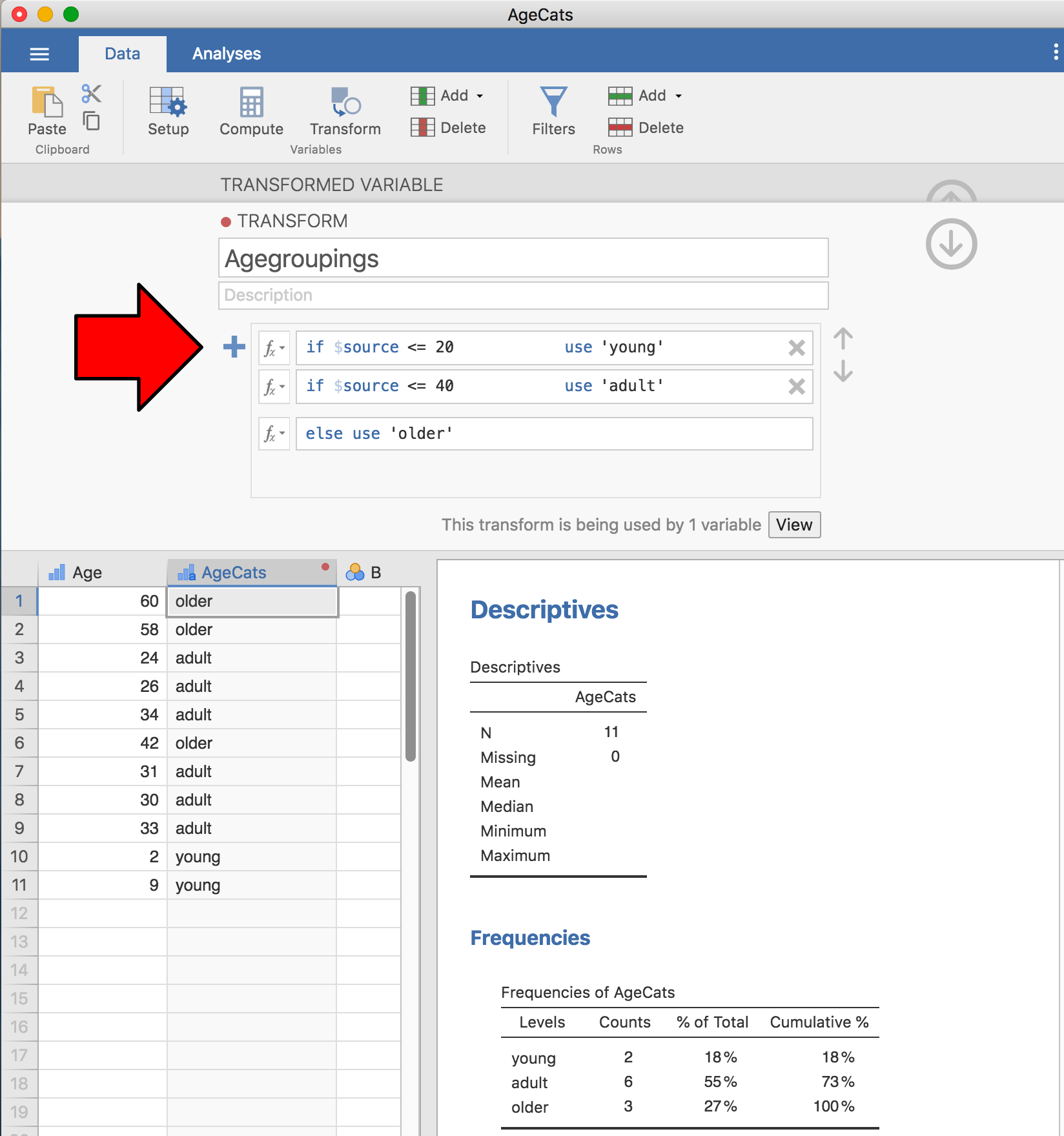
図6.10: 「Add condition(条件の追加)」で3つのカテゴリに分類し直した様子。
6.4 その他の数学関数および演算子
セクション6.3では,変数変換の基本的な考え方に触れ,そうした変数変換のほとんどは簡単な数学関数や演算子で構成されていることを説明しました。このセクションでは,現実場面でのデータ分析にとって非常に役立つその他の数学的関数や算術演算子について説明しておこうと思います。表6.4は,ここで取りあげるさまざまな数学関数の要約です49。これらはさまざまな関数のうちのごく一部でしかありませんが,これらはデータ分析では日常的に使用されることの多いものであり,どれもjamoviで使用できるものです。
| 関数 | 入力例 | 結果 | |
|---|---|---|---|
| 平方根 | SQRT(x) | SQRT(25) | 5 |
| 絶対値 | ABS(x) | ABS(-23) | 23 |
| 常用対数(10を底とする) | LOG10(x) | LOG10(1000) | 3 |
| 自然対数(\(e\)を底とする) | LN(x) | LN(1000) | 6.908 |
| 指数関数 | EXP(x) | EXP(6.908) | 1000.245 |
| ボックス・コックス変換 | BOXCOX(x, lamda) | BOXCOX(6.908, 3) | 109.551 |
6.4.1 対数と指数
先ほど述べたように,jamoviには便利な数学関数がたくさん内蔵されていますが,それらすべてについてここで説明する必要はないでしょう。ここまでは,本書の中で必要になる機能だけに絞って説明してきました。ただし,対数と指数に関してはその例外にしたいと思います。これらを本書で使用することはありませんが,一般的な統計の世界ではこれらはありふれたものです。それだけでなく,変数の対数値(つまり変数値を対数変換した値)を分析するのが便利な場面というのはたくさんあります。本書の読者の多く(おそらくほとんど)が,これまでに対数や指数を学んできたことでしょう。ですが,過去の経験からいって,社会科学の統計クラスを受講する学生の大部分は高校以来対数はご無沙汰という人たちですので,ここで簡単に復習をしておこうと思います。
対数と指数を理解する最も簡単な方法は,それらを実際に計算してみて,それらが他の単純な計算とどういう関係にあるかを見ることです。対数と指数の関数として,jamoviにはLN(),LOG10(),EXP()があります。まず,LOG10()について見てみましょう。これは常用対数と呼ばれるものです。対数は,基本的には\(x\)乗の「逆」と考えてください。常用対数の場合,10の\(x\)乗と深く関連しています。たとえば,10の3乗は1000です。数学的には次のように書きます。
\[ 10^3 = 1000 \]
対数を理解するコツは,「10の3乗は1000」であるという文と「1000の(常用)対数は3である」という文が同じ意味だということを認識することです。数学的には,後半の文は次のように記述します。
\[ \log_{10}( 1000 ) = 3 \]
さて,LOG10()関数が10の\(x\)乗に関係したものであるということは,他の数字の\(x\)乗に関係した対数(底が10以外の対数)もあるのではないかと思った人もいるでしょう。そう,その通りです。10という数字自体に,数学的に特別な意味はありません。10進数が支配的な世界に暮らす私たちにとってはこれは便利な数字ですが,数学という悪魔的な世界では,私たちが使用する10進数は嘲笑の的です。悲しいことに,私たちがどのような数のシステムを使用していようと,宇宙の法則はそれにはお構いなしなのです。とにかく,こうした宇宙の無関心さの結果,10を底にして対数を計算するということに特別な根拠はありません。たとえば,2を底として対数を計算することもできるのです。統計においては,10や2を底とする対数ではなく,自然対数と呼ばれる対数をよく見ることになります。これは,\(e\)を底とする対数です。いつの日かこの対数に出くわすこともあるでしょうから,\(e\)が何かをここで説明しておきましょう。ネイピア数として知られる\(e\)という数値は,小数点以下の数値が無限に続くあの忌々しい「無理数」の一種で,数学ではとくに重要な数の1つとして考えられています。\(e\)を最初の数桁だけ記載すると次のような値になります。
\[ e = 2.718282 \]
本書では扱いませんが,統計では\(e\)の\(x\)乗を計算する必要がある場面にたびたび遭遇します。\(e\)を\(x\)乗することを\(x\)の指数関数といい,これは\(e^x\)や\(\exp(x)\)のように書かれます。jamoviには指数関数を計算するEXP()という関数がありますが,これは当然のことでしょう。この\(e\)という数が統計にはしょっちゅう出てくるので,自然対数(つまり\(e\)を底とする対数)もたびたび登場します。数学者はこれを,\(\log_e(x)\)や\(\ln(x)\)のように書きます。事実,jamoviでもこれと同じ方式を用いています。LN()関数は,自然対数を求めるための関数です。
さて,これで本書における指数や対数の話はおしまいです。
6.5 サブセットの抽出
データ処理の中でもとくに重要なものの1つに,データの中から特定の一部(サブセット)だけを取り出すということがあります。たとえば,特定の実験条件のデータだけを分析対象としたい場合や50歳以上の人のデータだけをじっくり見てみたい場合などです。そのためには,まず関心のある観測値だけを含むサブセットを抽出するフィルタを設定する必要があります。
このセクションでは,以前に使用したnightgarden.csvデータセットを使います。この章を一気に読んでいれば,すでに手元のjamoviウィンドウの中にこのデータセットがあるはずです。このセクションでは,speakerとutteranceという2つの変数に注目しましょう(これらの変数がどんなものであったかを忘れてしまった人はセクション6.1を参照してください)。ここでは,Makka-Pakkaの発話だけを取り出したいとします。そのためには,jamoviでフィルタを設定しなくてはなりません。まず「Data(データ)」タブの「Filters(フィルタ)」をクリックしてフィルタウィンドウを開いてください。それから,「Filter 1」の入力欄に次のように入力します。
これが終わったら,スプレッドシートに「Filter 1」という名前の新しい列が追加されているはずです(図6.11参照)。
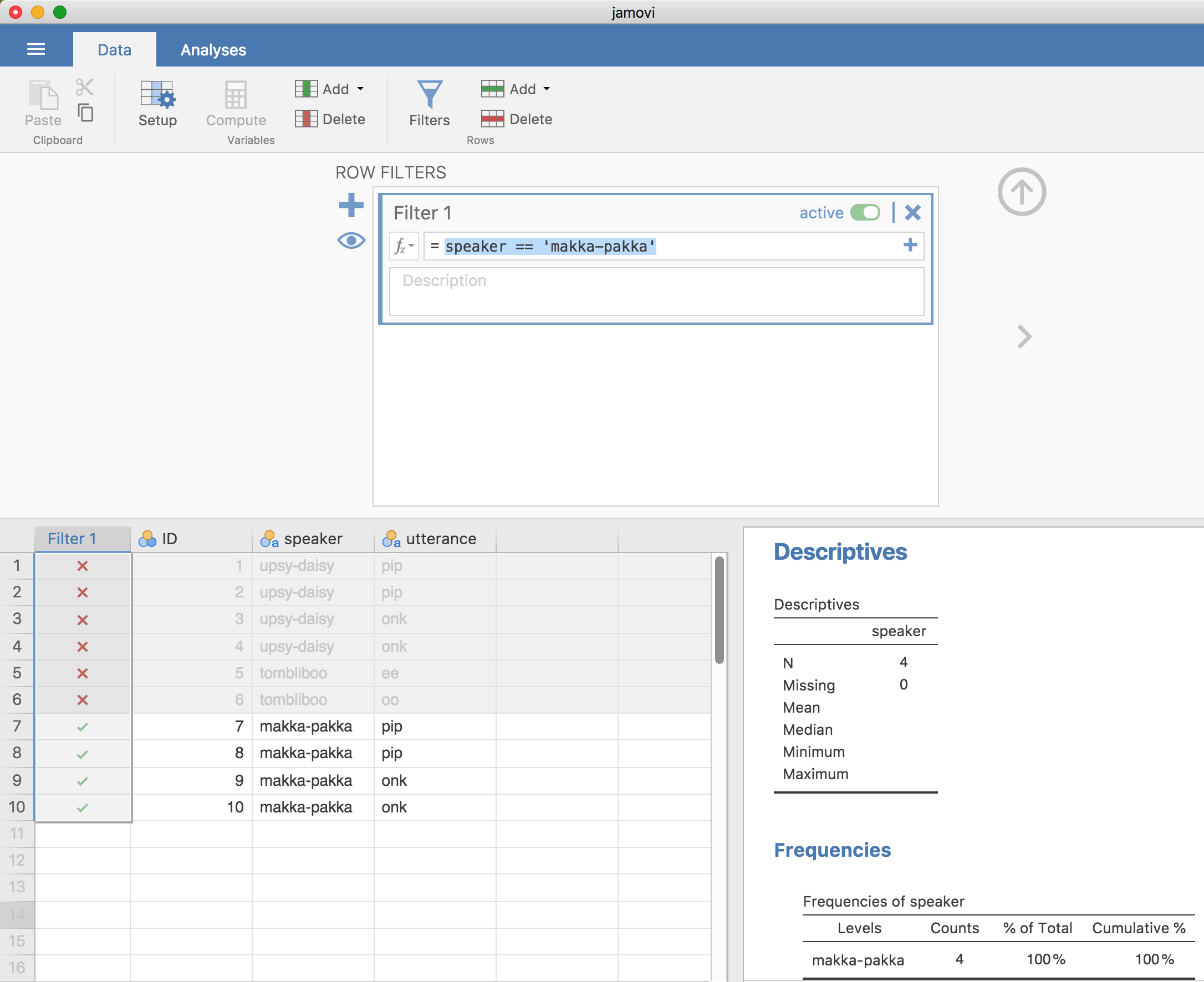
図6.11: nightgarden.csvデータのサブセットの作成。
この列では,speaker(話し手)が「makka-pakka」でない行はグレーになっていて,speaker(話し手)が「makka-pakka」である行には緑のチェックマークが示され,選択された状態になっています。これをテストするには,speaker(話し手)変数に対して「Exploration(探索)」>「Descriptives(記述統計)」>「Frequency tables(度数分布表)」を実行し,どのような結果になるかを見てみてください。さあ,やってみましょう。
このようなシンプルな例だけでなく,論理式を使ってもっと複雑なフィルタを作成することもできます。たとえば,発話が「pip」または「oo」の行だけを抽出したいとします。その場合,「Filter 1」の入力欄に次のように入力します。
『ハングマンの帰還(Home is the Hangman)』(1975年)より引用。↩
訳注:イギリスの子供向け番組。↩
中二病的に「かっこよく」なろうとしたことがありますが,できないことも多々ありました。↩
これは「Compute(計算)」の新規変数画面で可能です。すべてのセルで新規変数として2+2を計算しても役には立ちませんが。↩
これは等号(=)とはまったく違う演算子である点に注意してください。jamoviで論理式を作成する際によくある打ち間違いは,==のつもりで=と入力してしまうことです(他の統計プログラムでも,=と==の区別は重要です。)。これにはとくに注意してください。私は10代の頃からいろいろなプログラミング言語を使ってきましたが,いまだによく間違えます。私がイケてない10代だったのはきっとそのせいでしょうね。そしていまだにイケてないのもそのせいでしょう。↩
ここはjamoviのヘンテコな部分です。たとえば2+2 == 5のような単純な論理式を入力した場合には,jamoviはスプレッドシートの対応する列にfalse(またはtrue’)と表示してくれます。じつはその背後では,jamoviはfalseを0として,そしてtrueを1として扱っているのです。そして(2+2==4) or (2+2==5)のような少し複雑な論理式を入力した場合,jamoviはその式の結果が「偽」か「真」かに応じて単に0か1を表示するだけなのです。↩
数値の絶対値というのは,その数値が正か負かに関わらず,ゼロからの距離を意味するものと考えることができます。↩
likert.centredの値の符号を確かめる際に,単にlikert.centred/opinion.strengthとするのでなくIFを使って0を0のままにしておく手順が必要な理由は,数値を0で割ることが数学的に不可能だからです。0で割ったらどうなるか試してみてください。↩
本書をもう少し先まで読み進めた後でもう一度このセクションを読み直したとすると,これの典型的な例の1つとしてAgeを予測変数とする回帰分析を行う代わりにAgeCatsをグループ変数として分散分析を行う場合があげられます。このような分析方法が有効な場面もあるのです。たとえば,Ageと結果変数が非線形の関係にあり,非線形回帰をやりたくない場合がそうです。ただし,そうすることに本当に合理的な理由がない限り,あまり良い方法とは言えません。他のさまざまな問題(データが正規性の仮定に違反するなど)が生じる可能性が高くなり,統計力も大きく損なわれるからです。↩