Chương 11 Phân tích gộp mô hình hệ phương trình cấu trúc

I n the last chapter, we showed that meta-analytic models have an inherent multilevel structure. This quality can be used, for example, to extend conventional meta-analysis to three-level models.
A peculiar thing about statistical methods is that they are often put into separate “boxes”. They are treated as unrelated in research and practice, when in fact they are not. For many social science students, for example, it often comes as a surprise to hear that an analysis of variance (ANOVA) and a linear regression with a categorical predictor are doing essentially the same thing55. This often happens because these two methods are traditionally used in different contexts, and taught as separate entities.
In a similar vein, it has been only fairly recently that researchers have started seeing multilevel models as a special form of a structural equation model, or SEM (Mehta and Neale 2005; Bauer 2003). As we learned, every meta-analysis is based on a multilevel model. As consequence, we can also treat meta-analyses as structural equation models in which the pooled effect size is treated as a latent (or unobserved) variable (Cheung 2015, chap. 4.6). In short: meta-analyses are multilevel models; therefore, they can be expressed as structural equation models too.
This does not only mean that we can conceptualize previously covered types of meta-analyses from a structural equation modeling perspective. It also allows us to use SEM to build more complex meta-analysis models. Using meta-analytic SEM, we can test factor analytic models, or perform multivariate meta-analyses which include more than one outcome of interest (to name just a few applications).
Meta-analytic SEM can be helpful when we want to evaluate if certain models in the literature actually hold up once we consider all available evidence. Conversely, it can also be used to check if a theory is not backed by the evidence; or, even more interestingly, if it only applies to a subgroup of individuals or entities.
Application of meta-analytic SEM techniques, of course, presupposes a basic familiarity with structural equation modeling. In the next section, we therefore briefly discuss the general idea behind structural equation modeling, as well as its meta-analytic extension.
11.1 What Is Meta-Analytic Structural Equation Modeling?
Structural equation modeling is a statistical technique used to test hypotheses about the relationship of manifest (observed) and latent variables (Kline 2015, chap. 1). Latent variables are either not observed or observable. Personality, for example, is a construct which can only be measured indirectly, for instance through different items in a questionnaire. In SEM, an assumed relationship between manifest and latent variables (a “structure”) is modeled using the manifest, measured variables, while taking their measurement error into account.
SEM analysis is somewhat different to “conventional” statistical hypothesis tests (such as \(t\)-tests, for example). Usually, statistical tests involve testing against a null hypothesis, such as \(H_0: \mu_1 = \mu_2\) (where \(\mu_1\) and \(\mu_2\) are the means of two groups). In such a test, the researcher “aims” to reject the null hypothesis, since this allows to conclude that the two groups differ. Yet in SEM, a specific structural model is proposed beforehand, and the researcher instead “aims” to accept this model if the goodness of fit is sufficient (Cheung 2015, chap. 2.4.6).
11.1.1 Model Specification
Typically, SEM are specified and represented mathematically through a series of matrices. You can think of a matrix as a simple table containing rows and columns, much like a data.frame object in R (in fact, most data frames can be easily converted to a matrix using the as.matrix function). Visually, SEM can be represented as path diagrams. Such path diagrams are usually very intuitive, and straightforward in their interpretation. Thus, we will start by specifying a SEM visually first, and then move on to the matrix notation.
11.1.1.1 Path Diagrams
Path diagrams represent our SEM graphically. There is no full consensus on how path diagrams should be drawn, yet there are a few conventions. Here are the main components of path diagrams, and what they represent.
| Symbol | Name | Description |
|---|---|---|
| \(\square\) | Rectangle | Manifest/observed variables. |
| \(\circ\) | Circle | Latent/unobserved variables. |
| \(\triangle\) | Triangle | Intercept (fixed vector of 1s). |
| \(\rightarrow\) | Arrow | Prediction. The variable at the start of the arrow predicts the variable at the end of the arrow: Predictor \(\rightarrow\) Target. |
| \(\leftrightarrow\) | Double Arrow | (Co-)Variance. If a double arrow connects two variables (rectangles/circles), it signifies the covariance/ correlation between the two variables. If a double arrow forms a loop on top of one single variable, it signifies the variance of that variable. |
As an illustration, let us create a path diagram for a simple linear (“non-meta-analytic”) regression model, in which we want to predict \(y\) with \(x\). The model formula looks like this:
\[\begin{equation} y_i = \beta_0 + \beta_1x_i + e_i \tag{11.1} \end{equation}\]
Now, let us “deconstruct” this formula. In the model, \(x_i\) and \(y_i\) are the observed variables. There are no unobserved (latent) variables. The true population mean of \(y\) is the regression intercept \(\beta_0\), while \(\mu_x\) denotes the population mean of \(x\). The variance of our observed predictor \(x\) is denoted with \(\sigma^2_x\). Provided that \(x\) is not a perfect predictor of \(y\), there will be some amount of residual error variance \(\sigma^2_{e_y}\) associated with \(y\). There are two regression coefficients: \(\beta_0\), the intercept, and \(\beta_1\), the slope coefficient of \(x\).
Using these components, we can build a path diagram for our linear regression model, as seen below.
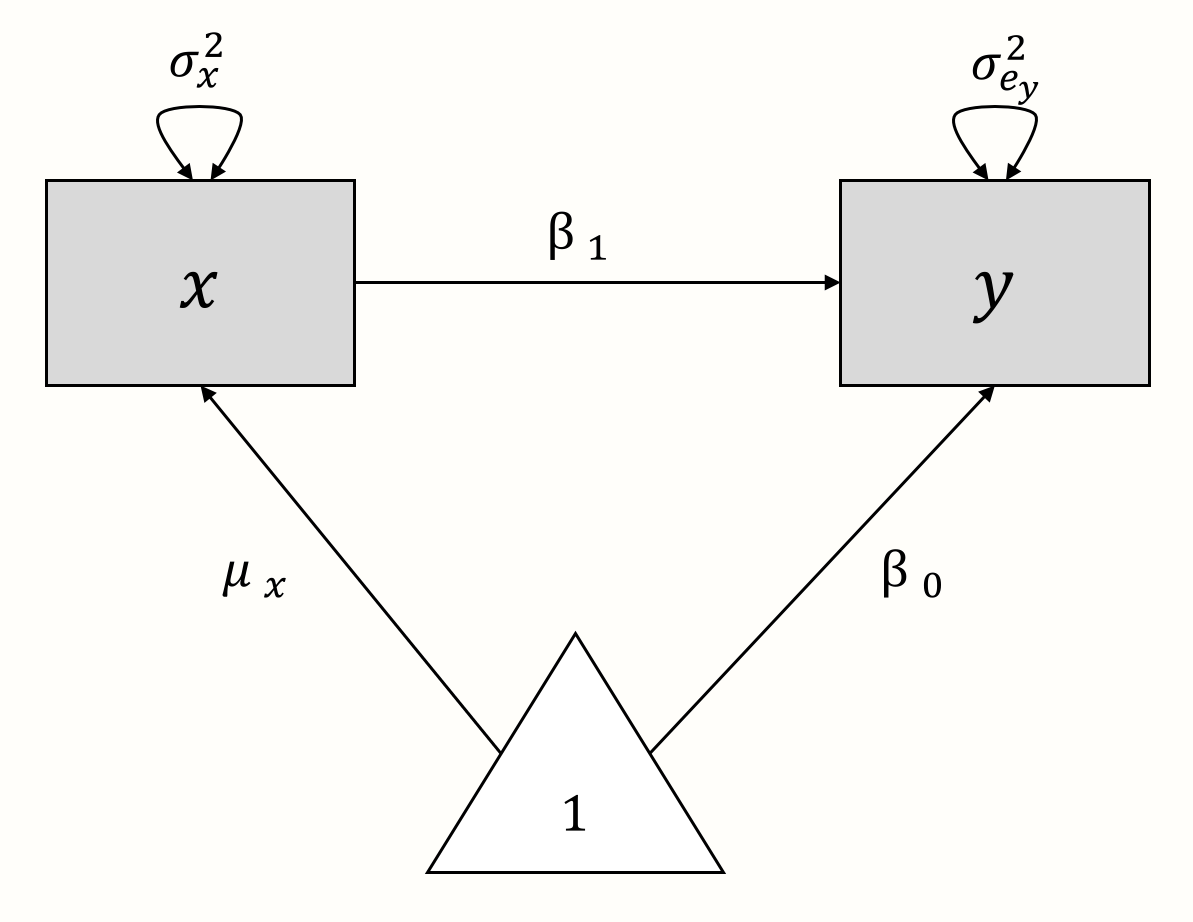
We can also use this graphical model as a starting point to reassemble the regression model equation. From the model, we can infer that \(y\) is influenced by two components: \(x \times \beta_1\) and \(1 \times \beta_0\). If we add these two parts together, we again arrive at the formula for \(y\) from before.
11.1.1.2 Matrix Representation
There are several ways to represent SEM through matrices (Jöreskog and Sörbom 2006; Muthén and Muthén 2012; McArdle and McDonald 1984). Here, we will focus on the Reticular Action Model formulation, or RAM (McArdle and McDonald 1984). We do this because this formulation is used by the {metaSEM} package which we will be introducing later on. RAM uses four matrices: \(\boldsymbol{F}\), \(\boldsymbol{A}\), \(\boldsymbol{S}\), and \(\boldsymbol{M}\). Because the \(\boldsymbol{M}\) matrix is not necessary to fit the meta-analytic SEM we cover, we omit it here (see Cheung 2015 for a more extensive introduction).
We will now specify the remaining \(\boldsymbol{A}\), \(\boldsymbol{F}\) and \(\boldsymbol{S}\) matrices for our linear regression model from before. The three matrices all have the same number of rows and columns, corresponding with the variables we have in our model: \(x\) and \(y\). Therefore, the generic matrix structure of our regression model always looks like this:
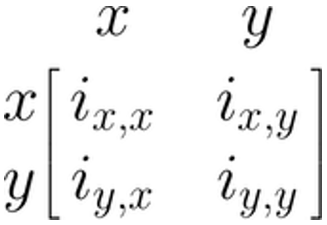
The \(\boldsymbol{A}\) Matrix: Single Arrows
The \(\boldsymbol{A}\) matrix represents the asymmetrical (single) arrows in our path model. We can fill this matrix by searching for the column entry of the variable in which the arrow starts (\(x\)), and then for the matrix row entry of the variable in which the arrow ends (\(y\)). The value of our arrow, \(\beta_1\), is put where the selected column and row intersect in the matrix (\(i_{y,x}\)). Given that there are no other paths between variables in our model, we fill the remaining fields with 0. Thus, the \(\boldsymbol{A}\) matrix for our example looks like this:
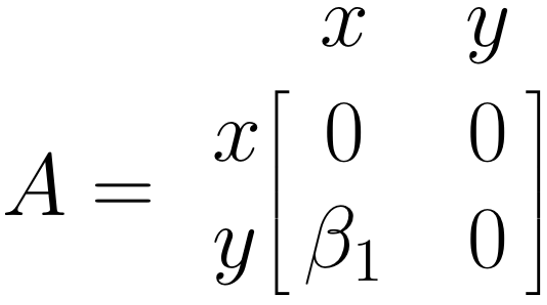
The \(\boldsymbol{S}\) Matrix: Single Arrows
The \(\boldsymbol{S}\) matrix represents the (co-)variances we want to estimate for the included variables. For \(x\), our predictor, we need to estimate the variance \(\sigma^2_x\). For our predicted variable \(y\), we want to know the prediction error variance \(\sigma^2_{e_y}\). Therefore, we specify \(\boldsymbol{S}\) like this:
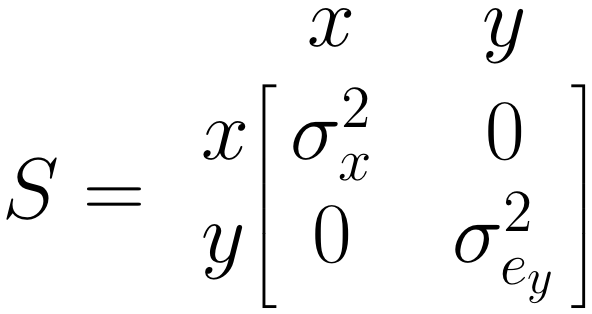
The \(\boldsymbol{F}\) Matrix: Single Arrows
The \(\boldsymbol{F}\) matrix allows us to specify the observed variables in our model. To specify that a variable has been observed, we simply insert 1 in the respective diagonal field of the matrix. Given that both \(x\) and \(y\) are observed in our model, we insert 1 into both diagonal fields:
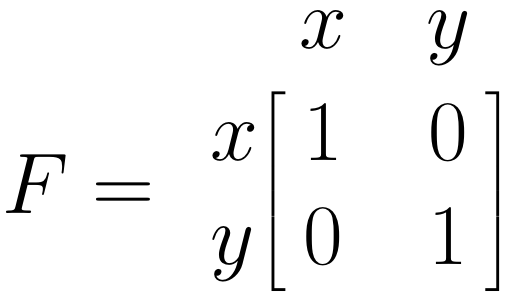
Once these matrices are set, it is possible to estimate the parameters in our SEM, and to evaluate how well the specified model fits the data. This involves some matrix algebra and parameter estimation through maximum likelihood estimation, the mathematical minutiae of which we will omit here. If you are interested in understanding the details behind this step, you can have a look at Cheung (2015), chapter 4.3.
11.1.2 Meta-Analysis From a SEM Perspective
We will now combine our knowledge about meta-analysis models and SEM to formulate meta-analysis as a structural equation model (Cheung 2008).
To begin, let us return to the formula of the random-effects model. Previously, we already described that the meta-analysis model follows a multilevel structure (see Chapter 10.1), which looks like this:
Level 1
\[\begin{equation} \hat\theta_k = \theta_k + \epsilon_k \tag{11.2} \end{equation}\]
Level 2
\[\begin{equation} \theta_k = \mu + \zeta_k \tag{11.3} \end{equation}\]
On the first level, we assume that the effect size \(\hat\theta_k\) reported in study \(k\) is an estimator of the true effect size \(\theta_k\). The observed effect size deviates from the true effect because of sampling error \(\epsilon_k\), represented by the variance \(\widehat{\text{Var}}(\hat\theta_k)=v_k\).
In a random-effects model, we assume that even the true effect size of each study is only drawn from a population of true effect sizes at level 2. The mean of this true effect size population, \(\mu\), is what we want to estimate, since it represents the pooled effect size. To do this, we also need to estimate the variance of the true effect sizes \(\widehat{\text{Var}}(\theta)=\tau^2\) (i.e. the between-study heterogeneity). The fixed-effect model is a special case of the random-effects model in which \(\tau^2\) is assumed to be zero.
It is quite straightforward to represent this model as a SEM graph. We use the parameters on level 1 as latent variables to “explain” how the effect sizes we observe came into being (Cheung 2015, chap. 4.6.2):
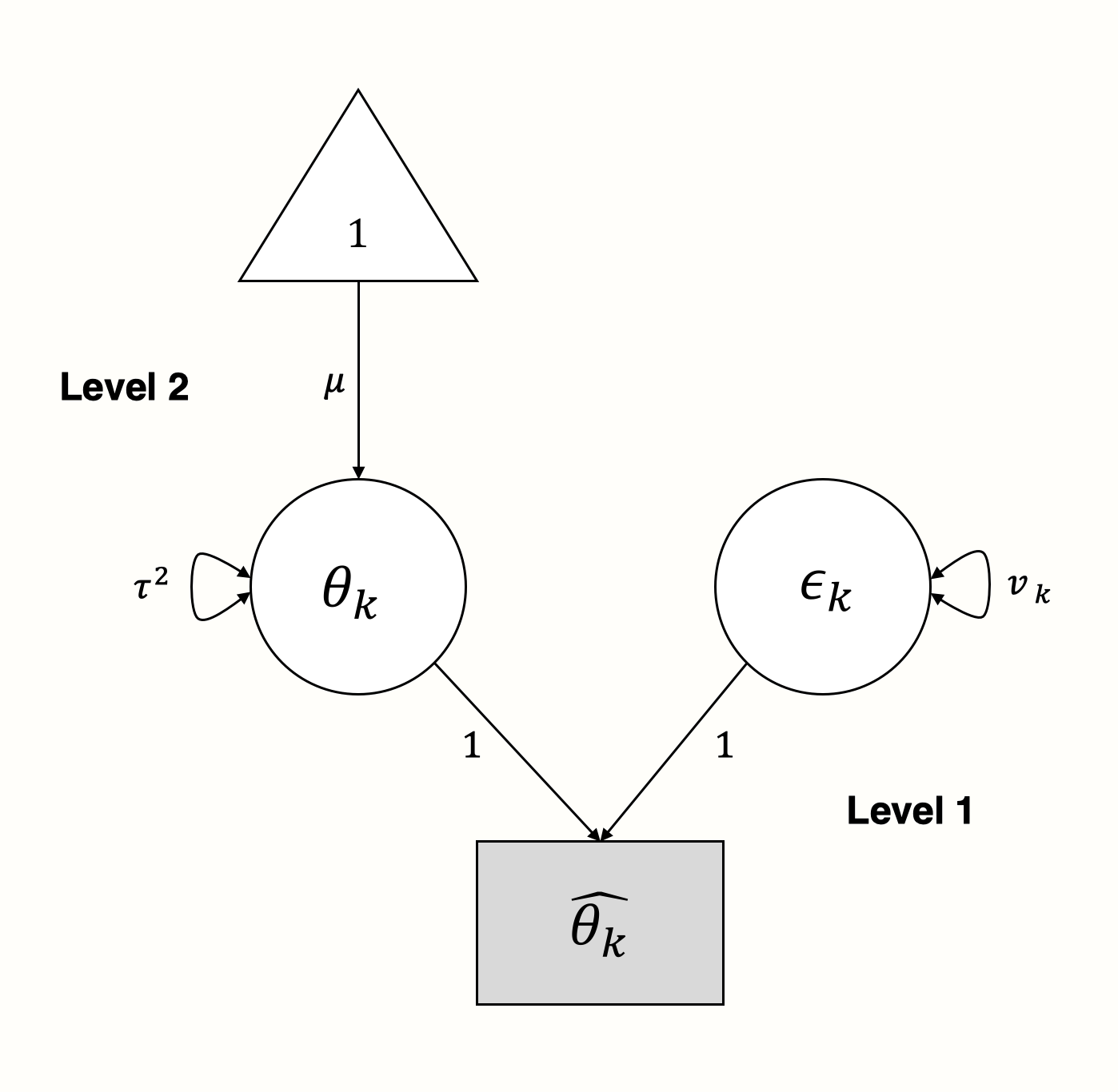
In the graphical model, we see that the observed effect size \(\hat\theta_k\) of some study \(k\) is “influenced” by two arms: the sampling error \(\epsilon_k\) with variance \(v_k\), and the true effect size \(\theta_k\) with variance \(\tau^2\).
11.1.3 The Two-Stage Meta-Analytic SEM Approach
Above, we defined the (random-effects) meta-analysis model from a SEM perspective. Although this is interesting from a theoretical standpoint, the model above is not more or less capable than the meta-analysis techniques we covered before: it describes that effect sizes are pooled assuming a random-effects model.
To really exploit the versatility of meta-analytic SEM, a two-stepped approach is required (Tang and Cheung 2016; Cheung 2015, chap. 7). In Two-Stage Structural Equation Modeling (TSSEM), we first pool the effect sizes of each study. Usually, these effect sizes are correlations between several variables that we want to use for modeling. For each study \(k\), we have a selection of correlations, represented by the vector \(\boldsymbol{r_k} = (r_1, r_2, \dots, r_p)\), where \(p\) is the total number of (unique) correlations. Like in a normal random-effects model, we assume that each observed correlation in study \(k\) deviates from the true average correlation \(\rho\) due to sampling error \(\epsilon_k\) and between-study heterogeneity \(\zeta_k\).
When we take into account that \(\boldsymbol{r_k}\) stands for several correlations contained in one study, we get the following equation for the random-effects model:
\[\begin{align} \boldsymbol{r_k} &= \boldsymbol{\rho} + \boldsymbol{\zeta_k} + \boldsymbol{\epsilon_k} \notag \\ \begin{bmatrix} r_1 \\ r_2 \\ \vdots \\ r_p \end{bmatrix} &= \begin{bmatrix} \rho_1 \\ \rho_2 \\ \vdots \\ \rho_p \end{bmatrix} + \begin{bmatrix} \zeta_1 \\ \zeta_2 \\ \vdots \\ \zeta_p \end{bmatrix} + \begin{bmatrix} \epsilon_1 \\ \epsilon_2 \\ \vdots \\ \epsilon_p \end{bmatrix} \tag{11.4} \end{align}\]
Using this model, we can calculate a vector of pooled correlations, \(\boldsymbol{r}\). This first pooling step allows to evaluate the heterogeneity of effects between studies, and if a random-effects model or subgroup analyses should be used. Thanks to the maximum likelihood-based approach used by the {metaSEM} package, even studies with partially missing data can be included in this step.
In the second step, we then use weighted least squares (see Chapter 8.1.3) to fit the structural equation model we specified. The function for the specified model \(\rho(\hat\theta)\) is (Cheung and Chan 2009; Cheung 2015, chap. 7.4.2):
\[\begin{equation} F_{\text{WLS}}(\hat\theta) = (\boldsymbol{r} - \rho(\hat\theta))^\top \boldsymbol{V}^{-1} ({r} - \rho(\hat\theta)) \tag{11.5} \end{equation}\]
Where \(\boldsymbol{r}\) is the pooled correlation vector. The important part of this formula is \(\boldsymbol{V}^{-1}\), which is an inverted matrix containing the covariances of \(\boldsymbol{r}\). This matrix is used for weighting. Importantly, the formula in this second step is the same no matter if we assume a random or fixed-effect model, because the between study-heterogeneity, if existent, is already taken care of in step 1.
11.2 Multivariate Meta-Analysis
Time to delve into our first worked meta-analytic SEM example. We will begin by using the SEM approach for a multivariate meta-analysis, which is something we have not covered yet. In multivariate meta-analyses, we try to estimate more than just one effect at the same time. Such types of meta-analyses are helpful in cases where we are studying a research topic for which there are several main outcomes, not just one.
Imagine that we are examining the effects of some type of treatment. For this treatment, there could be two types of outcomes which are deemed as important by most experts and are thus assessed in most studies. Multivariate meta-analyses can address this, by estimating the effect sizes for both outcomes jointly in one model. This multivariate approach also allows us to take the correlation between the two outcomes into account. This can be used to determine if studies with a high effect size on one outcome also have higher effect sizes on the other outcome. Alternatively, we might also find out that there is a negative relationship between the two outcomes or no association at all.
It is of note that multivariate meta-analysis can also be performed outside a SEM framework (Schwarzer, Carpenter, and Rücker 2015, chap. 7; Gasparrini, Armstrong, and Kenward 2012). Here, however, we will to show you how to perform them from a SEM perspective. In this and the following examples, we will work with {metaSEM}, a magnificent package for meta-analytic SEM developed by Mike Cheung (2015). As always, we first have to install the {metaSEM} package and load it from your library.
In our example, we will use {dmetar}’s ThirdWave data set again (see Chapter 4.2.1). By default, this data set only contains effects on one outcome, perceived stress. Now, imagine that most studies in this meta-analysis also measured effects on anxiety, which is another important mental health-related outcome. We can therefore use a multivariate meta-analysis to jointly estimate effects on stress and anxiety, and how they relate to each other.
To proceed, we therefore have to create a new data frame first, in which data for both outcomes is included. First, we define a vector containing the effects on anxiety (expressed as Hedges’ \(g\)) as reported in each study, as well as their standard error. We also need to define a vector which contains the covariance between stress and anxiety reported in each study. One study did not assess anxiety outcomes, so we use NA in the three vectors to indicate that the information is missing.
# Define vector with effects on anxiety (Hedges g)
Anxiety <- c(0.224,0.389,0.913,0.255,0.615,-0.021,0.201,
0.665,0.373,1.118,0.158,0.252,0.142,NA,
0.410,1.139,-0.002,1.084)
# Standard error of anxiety effects
Anxiety_SE <- c(0.193,0.194,0.314,0.165,0.270,0.233,0.159,
0.298,0.153,0.388,0.206,0.256,0.256,NA,
0.431,0.242,0.274,0.250)
# Covariance between stress and anxiety outcomes
Covariance <- c(0.023,0.028,0.065,0.008,0.018,0.032,0.026,
0.046,0.020,0.063,0.017,0.043,0.037,NA,
0.079,0.046,0.040,0.041)Then, we use this data along with information from ThirdWave to create a new data frame called ThirdWaveMV. In this data set, we include the effect size variances Stress_var and Anxiety_var, which can be obtained by squaring the standard error.
ThirdWaveMV <- data.frame(Author = ThirdWave$Author,
Stress = ThirdWave$TE,
Stress_var = ThirdWave$seTE^2,
Anxiety = Anxiety,
Anxiety_var = Anxiety_SE^2,
Covariance = Covariance)
format(head(ThirdWaveMV), digits = 2)## Author Stress Stress_var Anxiety Anxiety_var Covariance
## 1 Call et al. 0.71 0.068 0.224 0.037 0.023
## 2 Cavanagh et al. 0.35 0.039 0.389 0.038 0.028
## 3 DanitzOrsillo 1.79 0.119 0.913 0.099 0.065
## 4 de Vibe et al. 0.18 0.014 0.255 0.027 0.008
## 5 Frazier et al. 0.42 0.021 0.615 0.073 0.018
## 6 Frogeli et al. 0.63 0.038 -0.021 0.054 0.032
As we can see, the new data set contains the effect sizes for both stress and anxiety, along with the respective sampling variances. The Covariance column stores the covariance between stress and anxiety as measured in each study.
A common problem in practice is that the covariance (or correlation) between two outcomes is not reported in original studies. If this is the case, we have to estimate the covariance, based on a reasonable assumption concerning the correlation between the outcomes.
Imagine that we do not know the covariance in each study yet. How can we estimate it? A good way is to look for previous literature which assessed the correlation between the two outcomes, optimally in the same kind of context we are dealing with right now. Let us say we found in the literature that stress and anxiety are very highly correlated in post-tests of clinical trials, with \(r_{\text{S,A}} \approx\) 0.6. Based on this assumed correlation, we can approximate the co-variance of some study \(k\) using the following formula (Schwarzer, Carpenter, and Rücker 2015, chap. 7):
\[\begin{equation} \widehat{\text{Cov}}(\theta_{1},\theta_{2}) = SE_{\theta_{1}} \times SE_{\theta_{2}} \times \hat\rho_{1, 2} \tag{11.6} \end{equation}\]
Using our example data and assuming \(r_{\text{S,A}} \approx\) 0.6, this formula can implemented in R like so:
# We use the square root of the variance since SE = sqrt(var)
cov.est <- with(ThirdWaveMV,
sqrt(Stress_var) * sqrt(Anxiety_var) * 0.6)Please note that, when we calculate covariances this way, the choice of the assumed correlation can have a profound impact on the results. Therefore, it is highly advised to (1) always report the assumed correlation coefficient, and (2) conduct sensitivity analyses, where we inspect how results change depending on the correlation we choose.
11.2.1 Specifying the Model
To specify a multivariate meta-analysis model, we do not have to follow the TSSEM procedure (see previous chapter) programmatically, nor do we have to specify any RAM matrices. For such a relatively simple model, we can use the meta function in {metaSEM} to fit a meta-analytic SEM in just one step. To use meta, we only have to specify three essential arguments:
y. The columns of our data set which contain the effect size data. In a multivariate meta-analysis, we have to combine the effect size columns we want to include usingcbind.v. The columns of our data set which contain the effect size variances. In a multivariate meta-analysis, we have to combine the variance columns we want to include usingcbind. We also have to include the column containing the covariance between the effect sizes. The structure of the argument should becbind(variance_1, covariance, variance_2).data. The data set in which the effect sizes and variances are stored.
We save our fitted model under the name m.mv. Importantly, before running meta, please make sure that the {meta} package is not loaded. Some functions in {meta} and {metaSEM} have the same name, and this can lead to errors when running the code in R. It is possible to “unload” packages using the detach function.
Therefore, we first make sure that {meta} is unloaded and then fit the model. The resulting m.mv object can be inspected using summary.
detach(package:meta, unload = TRUE)
m.mv <- meta(y = cbind(Stress, Anxiety),
v = cbind(Stress_var, Covariance, Anxiety_var),
data = ThirdWaveMV)
summary(m.mv)## [...]
## Coefficients:
## Estimate Std.Error lbound ubound z value Pr(>|z|)
## Intercept1 0.570 0.087 0.399 0.740 6.5455 5.9e-13 ***
## Intercept2 0.407 0.083 0.244 0.570 4.9006 9.5e-09 ***
## Tau2_1_1 0.073 0.049 -0.023 0.169 1.4861 0.1372
## Tau2_2_1 0.028 0.035 -0.041 0.099 0.8040 0.4214
## Tau2_2_2 0.057 0.042 -0.025 0.140 1.3643 0.1725
## ---
## Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
## [...]
##
## Heterogeneity indices (based on the estimated Tau2):
## Estimate
## Intercept1: I2 (Q statistic) 0.6203
## Intercept2: I2 (Q statistic) 0.5292
##
## Number of studies (or clusters): 18
## [...]
## OpenMx status1: 0 ("0" or "1": The optimization is considered fine.
## Other values may indicate problems.)11.2.2 Evaluating the Results
Given that the SEM model is fitted using the maximum likelihood algorithm, the first thing we always do is check the OpenMx status right at the end of the output. Maximum likelihood estimation is an optimization procedure, in which parameters are changed iteratively until the optimal solution for the data at hand is found. However, especially with more complex models, it can happen that this optimum is not reached even after many iterations; the maximum likelihood algorithm will then stop and output the parameter values it has approximated so far. Yet, those values for our model components will very likely be incorrect and should not be trusted.
The OpenMx status for our model is 0, which indicates that the maximum likelihood estimation worked fine. If the status would have been anything other than 0 or 1, it would have been necessary to rerun the model, using this code:
rerun(m.mv)In the output, the two pooled effect sizes are shown as Intercept1 and Intercept2. The effect sizes are numbered in the order in which we inserted them into our call to meta. We can see that the pooled effect sizes are \(g_{\text{Stress}}\) = 0.57 and \(g_{\text{Anxiety}}\) = 0.41. Both effect sizes are significant. Under Heterogeneity indices, we can also see the values of \(I^2\), which are \(I^2_{\text{Stress}}\) = 62% and \(I^2_{\text{Anxiety}}\) = 53%, indicating substantial between-study heterogeneity in both outcomes.
The direct estimates of the between-study heterogeneity variance \(\tau^2\) are also provided. We see that there are not only two estimates, but three. To understand what this means, we can extract the “random” values from the m.mv object.
tau.coefs <- coef(m.mv, select = "random")Then, we use the vec2symMat function to create a matrix of the coefficients. We give the matrix rows and columns the names of our variables: Stress and Anxiety.
# Create matrix
tc.mat <- vec2symMat(tau.coefs)
# Label rows and columns
dimnames(tc.mat)[[1]] <- dimnames(tc.mat)[[2]] <- c("Stress",
"Anxiety")
tc.mat## Stress Anxiety
## Stress 0.07331199 0.02894342
## Anxiety 0.02894342 0.05753271We now understand better what the three \(\tau^2\) values mean: they represent the between-study variance (heterogeneity) in the diagonal of the matrix. In the other two fields, the matrix shows the estimated covariance between stress and anxiety. Given that the covariance is just an unstandardized version of a correlation, we can transform these values into correlations using the cov2cor function.
cov2cor(tc.mat)## Stress Anxiety
## Stress 1.0000000 0.4456613
## Anxiety 0.4456613 1.0000000We see that, quite logically, the correlations in the diagonal elements of the matrix are 1. The correlation between effects on stress and anxiety is \(r_{\text{S,A}}\) = 0.45. This is an interesting finding: it shows that there is a positive association between a treatment’s effect on perceived stress and its effect on anxiety. We can say that treatments which have high effects on stress seem to have higher effects on anxiety too.
It is of note that the confidence intervals presented in the summary of m.mv are Wald-type intervals (see Chapter 4.1.2.2). Such Wald-type intervals can sometimes be inaccurate, especially in small samples (DiCiccio and Efron 1996). It may thus be valuable to construct confidence intervals in another way, by using likelihood-based confidence intervals. We can get these CIs by re-running the meta function and additionally specifying intervals.type = "LB".
m.mv <- meta(y = cbind(Stress, Anxiety),
v = cbind(Stress_var, Covariance, Anxiety_var),
data = ThirdWaveMV,
intervals.type = "LB")We have already seen that the output for our m.mv contains non-zero estimates of the between-study heterogeneity \(\tau^2\). We can therefore conclude that the model we just fitted is a random-effects model. The meta function uses a random-effects model automatically. Considering the \(I^2\) values in our output, we can conclude that this is indeed adequate. However, if we want to fit a fixed-effect model anyway, we can do so by re-running the analysis, and adding the parameter RE.constraints = matrix(0, nrow=2, ncol=2). This creates a matrix of 0s which constrains all \(\tau^2\) values to zero:
m.mv <- meta(y = cbind(Stress, Anxiety),
v = cbind(Stress_var, Covariance, Anxiety_var),
data = ThirdWaveMV,
RE.constraints = matrix(0, nrow=2, ncol=2))11.2.3 Visualizing the Results
To plot the multivariate meta-analysis model, we can use the plot function. We also make some additional specifications to change the appearance of the plot. If you want to see all styling options, you can paste ?metaSEM::plot.meta into the console and then hit Enter.
plot(m.mv,
axis.labels = c("Perceived Stress", "Anxiety"),
randeff.ellipse.col = "#014d64",
univariate.arrows.col = "gray40",
univariate.polygon.col = "gray40",
estimate.ellipse.col = "gray40",
estimate.col = "firebrick")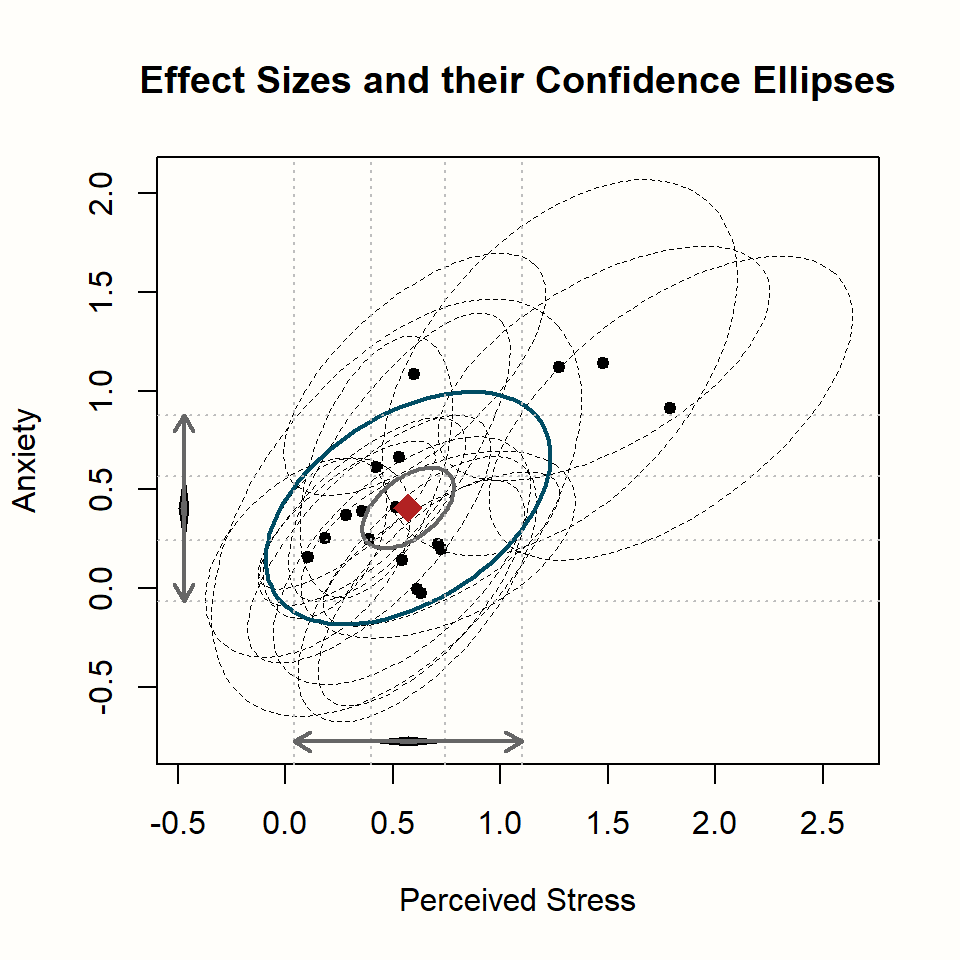
Let us go through what we see. The plot has two axes: an x-axis displaying the effects on stress, and a y-axis, which displays the effects on anxiety. We also see the pooled effect and its 95% confidence interval for both outcomes, symbolized by the black diamond.
In the middle of the plot, the pooled effect of both variables is shown as a red diamond. The smaller blue ellipse represents the 95% confidence interval of our pooled effect; while the larger black ellipse depicts the 95% prediction interval (Chapter 5.2)56.
Lastly, the black dots show the individual studies, where the ellipses with dashed lines represent the 95% confidence intervals.
11.3 Confirmatory Factor Analysis
Confirmatory Factor Analysis (CFA) is a popular SEM method in which one specifies how observed variables relate to assumed latent variables (B. Thompson 2004, chap. 1.1 and 1.2). CFA is often used to evaluate the psychometric properties of questionnaires or other types of assessments. It allows researchers to determine if assessed variables indeed measure the latent variables they are intended to measure, and how several latent variables relate to each other.
For frequently used questionnaires, there are usually many empirical studies which report the correlations between the different questionnaire items. Such data can be used for meta-analytic SEM. This allows us to evaluate which latent factor structure is the most appropriate based on all available evidence.
In this example, we want to confirm the latent factor structure of a (fictitious) questionnaire for sleep problems. The questionnaire is assumed to measure two distinct latent variables characterizing sleep problems: insomnia and lassitude. Koffel and Watson (2009) argue that sleep complaints can indeed be described by these two latent factors.
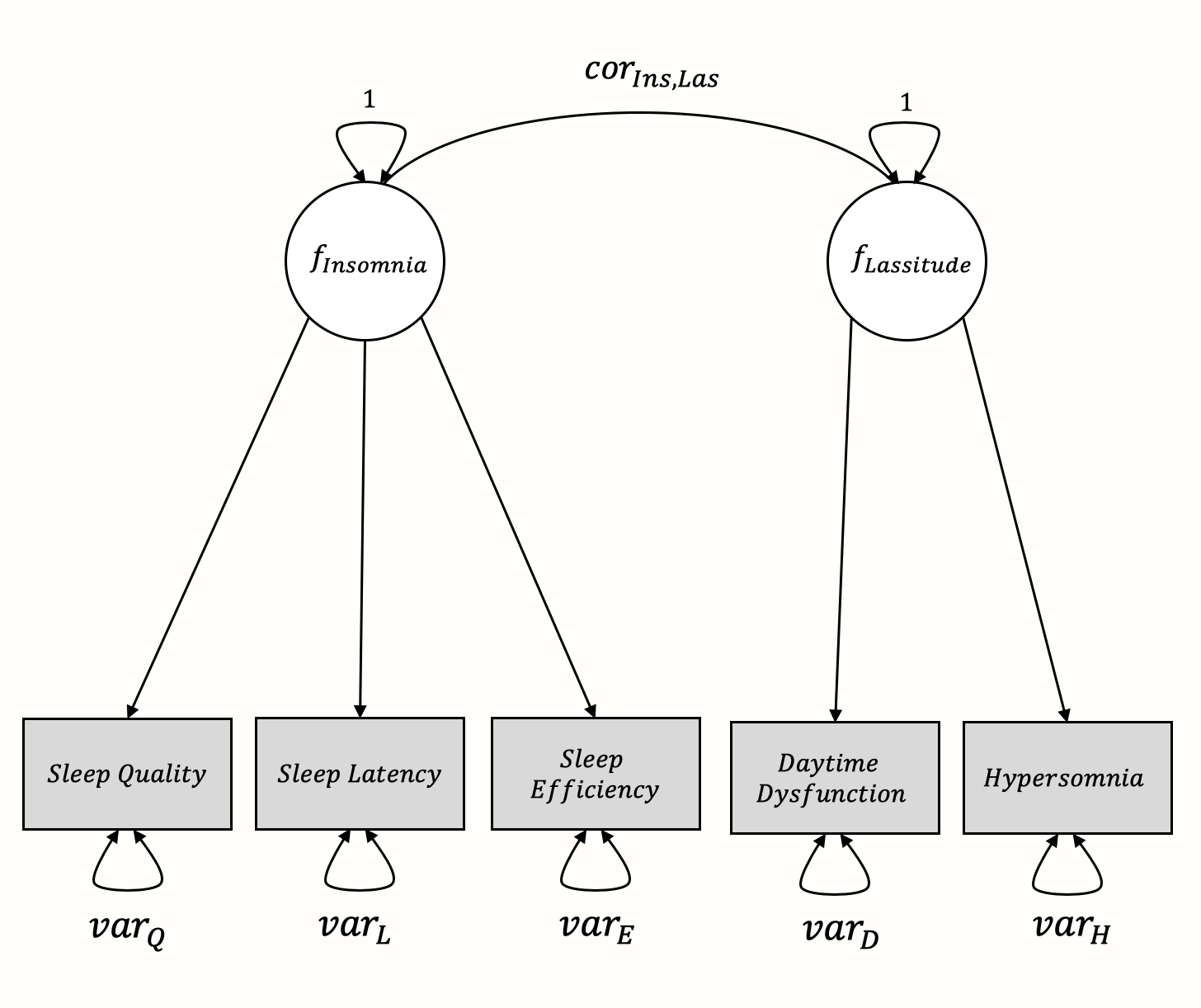
To practice meta-analytic CFA, we simulated results of 11 studies in which our imaginary sleep questionnaire was assessed. We named this data set SleepProblems. Each of these studies contains the inter-correlations between symptoms of sleep complaints as directly measured by our questionnaire. These measured indicators include sleep quality, sleep latency, sleep efficiency, daytime dysfunction, and hypersomnia (i.e. sleeping too much). We assume that the first three symptoms are related because they all measure insomnia as a latent variable, whereas daytime dysfunction and hypersomnia are related because they are symptoms of the lassitude factor.
The proposed structure represented as a graphical model looks like this57:
11.3.1 Data Preparation
Let us first have a look at the SleepProblems data we want to use for our model. This data set has a special structure: it is a list object, containing (1) another list of matrices and (2) a numeric vector. Lists are very versatile R objects and allow to bind together different elements in one big object. Lists can be accessed like data frames using the $ operator. The names function can be used to print the names of objects in the list.
## [1] "data" "n"We see that the list contains two elements, our actual data and n, the sample size of each study. The data object is itself a list, so we can also get the names of its contents using the names function.
names(SleepProblems$data)## [1] "Coleman et al. (2003)" "Salazar et al. (2008)"
## [3] "Newman et al. (2016)" "Delacruz et al. (2009)"
## [5] "Wyatt et al. (2002)" "Pacheco et al. (2016)"
## [...]It is also possible to display specific elements in data using the $ operator.
SleepProblems$data$`Coleman et al. (2003)`## Quality Latency Efficiency DTDysf HypSomnia
## Quality 1.00 0.39 0.53 -0.30 -0.05
## Latency 0.39 1.00 0.59 0.07 0.44
## Efficiency 0.53 0.59 1.00 0.09 0.22
## DTDysf -0.30 0.07 0.09 1.00 0.45
## HypSomnia -0.05 0.44 0.22 0.45 1.00The data list contains 11 elements, one for each of the 11 included studies. A closer look at the Coleman et al. (2003) study reveals that the data are stored as correlation matrices with five variables. Each row and column in the matrix corresponds with one of the sleep complaint symptoms assessed by our questionnaire.
The Coleman et al. (2003) study contains reported correlations for each symptom combination. However, it is also possible to use studies which have missing values (coded as NA) in some of the fields. This is because meta-analytic SEM can handle missing data–at least to some degree.
Before we proceed, let us quickly show how you can construct such a list yourself. Let us assume that we have extracted correlation matrices of two studies, which we imported as data frames into R. Assuming that these data frames are called df1 and df2, we can use the following “recipe” to create a list object that is suitable for further analysis.
# Convert both data.frames to matrices
mat1 <- as.matrix(df1)
mat2 <- as.matrix(df2)
# Define the row labels
dimnames(mat1)[[1]] <- c("Variable 1", "Variable 2", "Variable 3")
dimnames(mat2)[[1]] <- c("Variable 1", "Variable 2", "Variable 3")
# Bind the correlation matrices together in a list
data <- list(mat1, mat2)
names(data) <- c("Study1", "Study2")
# Define sample size of both studies
n <- c(205, # N of study 1
830) # N of study 2
# Bind matrices and sample size together
cfa.data <- list(data, n)11.3.2 Model Specification
To specify our CFA model, we have to use the RAM specification and two-stage meta-analytic SEM procedure we mentioned before. The {metaSEM} package contains separate functions for each of the two stages, tssem1 and tssem2. The first function pools our correlation matrices across all studies, and the second fits the proposed model to the data.
11.3.2.1 Stage 1
At the first stage, we pool our correlation matrices using the tssem1 function. There are four important arguments we have to specify in the function.
Cov. Alistof correlation matrices we want to pool. Note that all correlation matrices in the list need to have an identical structure.n. A numeric vector containing the sample sizes of each study, in the same order as the matrices included inCov.method. Specifies if we want to use a fixed-effect model ("FEM") or random-effects model ("REM").RE.type. When a random-effects model is used, this specifies how the random effects should be estimated. The default is"Symm", which estimates all \(\tau^2\) values, including the covariances between two variables. When set to"Diag", only the diagonal elements of the random-effects matrix are estimated. This means that we assume that the random effects are independent. Although"Diag"results in a strongly simplified model, it is often preferable, because less parameters have to be estimated. This particularly makes sense when the number of variables is high, or the number of studies is low.
In our example, we assume a random-effects model, and use RE.type = "Diag". I will save the model as cfa1, and then call the summary function to retrieve the output.
[...]
Coefficients:
Estimate Std.Error lbound ubound z value Pr(>|z|)
Intercept1 0.444 0.057 0.331 0.557 7.733 < 0.001 ***
Intercept2 0.478 0.042 0.394 0.561 11.249 < 0.001 ***
Intercept3 0.032 0.071 -0.106 0.172 0.459 0.645
Intercept4 0.132 0.048 0.038 0.227 2.756 0.005 **
Intercept5 0.509 0.036 0.438 0.581 13.965 < 0.001 ***
Intercept6 0.120 0.040 0.040 0.201 2.954 0.003 **
Intercept7 0.192 0.060 0.073 0.311 3.170 0.001 **
Intercept8 0.221 0.039 0.143 0.298 5.586 < 0.001 ***
Intercept9 0.189 0.045 0.100 0.279 4.163 < 0.001 ***
Intercept10 0.509 0.023 0.462 0.556 21.231 < 0.001 ***
Tau2_1_1 0.032 0.015 0.002 0.061 2.153 0.031 *
Tau2_2_2 0.016 0.008 0.000 0.032 1.963 0.049 *
Tau2_3_3 0.049 0.023 0.003 0.096 2.091 0.036 *
Tau2_4_4 0.019 0.010 0.000 0.039 1.975 0.048 *
Tau2_5_5 0.010 0.006 -0.001 0.022 1.787 0.073 .
Tau2_6_6 0.012 0.007 -0.002 0.027 1.605 0.108
Tau2_7_7 0.034 0.016 0.001 0.067 2.070 0.038 *
Tau2_8_8 0.012 0.006 -0.000 0.025 1.849 0.064 .
Tau2_9_9 0.017 0.009 -0.001 0.036 1.849 0.064 .
Tau2_10_10 0.003 0.002 -0.001 0.008 1.390 0.164
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
[...]
Heterogeneity indices (based on the estimated Tau2):
Estimate
Intercept1: I2 (Q statistic) 0.9316
Intercept2: I2 (Q statistic) 0.8837
Intercept3: I2 (Q statistic) 0.9336
Intercept4: I2 (Q statistic) 0.8547
Intercept5: I2 (Q statistic) 0.8315
Intercept6: I2 (Q statistic) 0.7800
Intercept7: I2 (Q statistic) 0.9093
Intercept8: I2 (Q statistic) 0.7958
Intercept9: I2 (Q statistic) 0.8366
Intercept10: I2 (Q statistic) 0.6486
[...]
OpenMx status1: 0 ("0" or "1": The optimization is considered fine.
Other values may indicate problems.)A look at the OpenMx status confirms that the model estimates are trustworthy. To make the results more easily digestible, we can extract the fixed effects (our estimated pooled correlations) using the coef function. We then make a symmetrical matrix out of the coefficients using vec2symMat, and add the dimension names for easier interpretation.
# Extract the fixed coefficients (correlations)
fixed.coefs <- coef(cfa1, "fixed")
# Make a symmetric matrix
fc.mat <- vec2symMat(fixed.coefs, diag = FALSE)
# Label rows and columns
dimnames(fc.mat)[[1]] <- c("Quality", "Latency",
"Efficiency", "DTDysf", "HypSomnia")
dimnames(fc.mat)[[2]] <- c("Quality", "Latency",
"Efficiency", "DTDysf", "HypSomnia")
# Print correlation matrix (3 digits)
round(fc.mat, 3)## Quality Latency Efficiency DTDysf HypSomnia
## Quality 1.000 0.444 0.478 0.033 0.133
## Latency 0.444 1.000 0.510 0.121 0.193
## Efficiency 0.478 0.510 1.000 0.221 0.190
## DTDysf 0.033 0.121 0.221 1.000 0.509
## HypSomnia 0.133 0.193 0.190 0.509 1.000We can now see the pooled correlation matrix for our variables. Looking back at the model output, we also see that all correlation coefficients are significant (\(p<\) 0.05), except one: the correlation between sleep quality and daytime dysfunction was not significant. From the perspective of our assumed model, this makes sense, because we expect these variables to load on different factors. We also see that the \(I^2\) values of the different estimates are very large (65-93%).
11.3.2.2 Stage 2
After pooling the correlation matrices, it is now time to determine if our proposed factor model fits the data well. To specify our model, we have to use the RAM formulation this time, and specify the \(\boldsymbol{A}\), \(\boldsymbol{S}\) and \(\boldsymbol{F}\) matrices. To fill the fields in each of these matrices, it is often best to construct an empty matrix first. Structure-wise, all matrices we define do not only contain the observed variables but also the assumed latent variables, f_Insomnia and f_Lassitude. Here is how we can create a zero matrix as a starting point:
# Create vector of column/row names
dims <- c("Quality", "Latency", "Efficiency",
"DTDysf", "HypSomnia", "f_Insomnia", "f_Lassitude")
# Create 7x7 matrix of zeros
mat <- matrix(rep(0, 7*7), nrow = 7, ncol = 7)
# Label the rows and columns
dimnames(mat)[[1]] <- dimnames(mat)[[2]] <- dims
mat## Qlty Ltncy Effcncy DTDysf HypSmn f_Insmn f_Lsstd
## Quality 0 0 0 0 0 0 0
## Latency 0 0 0 0 0 0 0
## Efficiency 0 0 0 0 0 0 0
## DTDysf 0 0 0 0 0 0 0
## HypSomnia 0 0 0 0 0 0 0
## f_Insomnia 0 0 0 0 0 0 0
## f_Lassitude 0 0 0 0 0 0 0\(\boldsymbol{A}\) Matrix
In the \(\boldsymbol{A}\) matrix, we specify the asymmetrical (i.e. single) arrows in our model. Each single arrow starts at the column variable and ends where the column intersects with the entry of the row variable. All other fields which do not represent arrows are filled with 0.
We specify that an arrow has to be “estimated” by adding a character string to the \(\boldsymbol{A}\) matrix. This character string begins with a starting value for the optimization procedure (usually somewhere between 0.1 and 0.3) followed by *. After the * symbol, we specify a label for the value. If two fields in the \(\boldsymbol{A}\) matrix have the same label, this means that we assume that the fields have the same value.
In our example, we use a starting value of 0.3 for all estimated arrows, and label the fields according to the path diagram we presented before.
A <- matrix(c(0, 0, 0, 0, 0, "0.3*Ins_Q", 0 ,
0, 0, 0, 0, 0, "0.3*Ins_L", 0 ,
0, 0, 0, 0, 0, "0.3*Ins_E", 0 ,
0, 0, 0, 0, 0, 0 , "0.3*Las_D",
0, 0, 0, 0, 0, 0 , "0.3*Las_H",
0, 0, 0, 0, 0, 0 , 0 ,
0, 0, 0, 0, 0, 0 , 0
), nrow = 7, ncol = 7, byrow=TRUE)
# Label columns and rows
dimnames(A)[[1]] <- dimnames(A)[[2]] <- dimsThe last step is to plug the \(\boldsymbol{A}\) matrix into the as.mxMatrix function to make it usable for the stage 2 model.
A <- as.mxMatrix(A)\(\boldsymbol{S}\) Matrix
In the \(\boldsymbol{S}\) matrix, we specify the variances we want to estimate. In our example, these are the variances of all observed variables, as well as the correlation between our two latent factors. First, we set the correlation of our latent factors with themselves to 1. Furthermore, we use a starting value of 0.2 for the variances in the observed variables, and 0.3 for the correlations. All of this can be specified using this code:
# Make a diagonal matrix for the variances
Vars <- Diag(c("0.2*var_Q", "0.2*var_L",
"0.2*var_E", "0.2*var_D", "0.2*var_H"))
# Make the matrix for the latent variables
Cors <- matrix(c(1, "0.3*cor_InsLas",
"0.3*cor_InsLas", 1),
nrow=2, ncol=2)
# Combine
S <- bdiagMat(list(Vars, Cors))
# Label columns and rows
dimnames(S)[[1]] <- dimnames(S)[[2]] <- dimsAnd again, we transform the matrix using as.mxMatrix.
S <- as.mxMatrix(S)\(\boldsymbol{F}\) Matrix
The \(\boldsymbol{F}\) matrix, lastly, is easy to specify. In the diagonal elements of observed variables, we fill in 1. Everywhere else, we use 0. Furthermore, we only select the rows of the matrix in which at least on element is not zero (i.e. the last two rows are dropped since they only contain zeros).
# Construct diagonal matrix
F <- Diag(c(1, 1, 1, 1, 1, 0, 0))
# Only select non-null rows
F <- F[1:5,]
# Specify row and column labels
dimnames(F)[[1]] <- dims[1:5]
dimnames(F)[[2]] <- dims
F <- as.mxMatrix(F)11.3.3 Model Fitting
Now, it is time to fit our proposed model to the pooled data. To do this, we use the tssem2 function. We only have to provide the stage 1 model cfa1, the three matrices, and specify diag.constraints=FALSE (because we are not fitting a mediation model). We save the resulting object as cfa2 and then access it using summary.
## [...]
## Coefficients:
## Estimate Std.Error lbound ubound z value Pr(>|z|)
## Las_D 0.688 0.081 0.527 0.848 8.409 < 0.001 ***
## Ins_E 0.789 0.060 0.670 0.908 13.026 < 0.001 ***
## Las_H 0.741 0.088 0.568 0.914 8.384 < 0.001 ***
## Ins_L 0.658 0.053 0.553 0.763 12.275 < 0.001 ***
## Ins_Q 0.613 0.051 0.512 0.714 11.941 < 0.001 ***
## cor_InsLas 0.330 0.045 0.240 0.419 7.241 < 0.001 ***
## ---
## Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
##
## Goodness-of-fit indices:
## Value
## Sample size 3272.0000
## Chi-square of target model 5.2640
## DF of target model 4.0000
## p value of target model 0.2613
## [...]
## RMSEA 0.0098
## RMSEA lower 95% CI 0.0000
## RMSEA upper 95% CI 0.0297
## [...]
## OpenMx status1: 0 ("0" or "1": The optimization is considered fine.
## Other values indicate problems.)We see that the OpenMx status is 0, meaning that the optimization worked fine. In the output, we are provided with estimates for the paths between the two latent factors and the observed symptoms, such as 0.69 for Lassitude \(\rightarrow\) Daytime Dysfunction (Las_D). We also see that, according to the model, there is a significant correlation between the two latent factors: \(r_{\text{Ins,Las}}\) = 0.33.
Most importantly, however, we need to check how well the assumed model fits our data. This can be achieved by having a look at the Goodness-of-fit indices. We see that the goodness of fit test is not significant, with \(\chi^2_4=\) 5.26, \(p=\) 0.26. Contrary to other statistical tests, this outcome is desired, since it means that we accept the null hypothesis that our model fits the data well.
Furthermore, we see that the Root Mean Square Error of Approximation (RMSEA) value is 0.0098. As a rule of thumb, a model can be considered to fit the data well when its RSMEA value is below 0.05, with smaller values indicating a better fit (Browne and Cudeck 1993). Thus, this goodness of fit index also indicates that the model fits our data well.
Alternative Models
A common problem in SEM studies is that researchers often only focus on their own proposed model, and if it fits the data well. If it is found that the assumed model shows a close fit to the data, many researchers often directly conclude that the data prove their theory.
This is problematic because more than one model can fit well to the same data. Therefore, it is necessary to also check for alternative model hypotheses and structures. If the alternative model also fits the data well, it becomes less clear if our proposed structure is really the “correct” one.
11.3.4 Path Diagrams
After the model has been fitted, {metaSEM} makes it quite easy for us to visualize it graphically. However, to draw a path diagram, we first have to install and load the {semPlot} package (Epskamp 2019).
To plot the model, we have to convert it into a format that {semPlot} can use. This can be done using the meta2semPlot function.
cfa.plot <- meta2semPlot(cfa2)We can then use the semPaths function in {semPlot} to generate the graph. This function has many parameters, which can be accessed by typing ?semPaths into the console, and then hitting Enter. Here is our code, and the resulting plot:
# Create Plot labels (left to right, bottom to top)
labels <- c("Sleep\nQuality",
"Sleep\nLatency",
"Sleep\nEfficiency",
"Daytime\nDysfunction",
"Hyper-\nsomnia","Insomnia",
"Lassitude")
# Plot
semPaths(cfa.plot,
whatLabels = "est",
edge.color = "black",
nodeLabels = labels,
sizeMan = 10,
sizeLat = 10,
edge.label.cex = 1)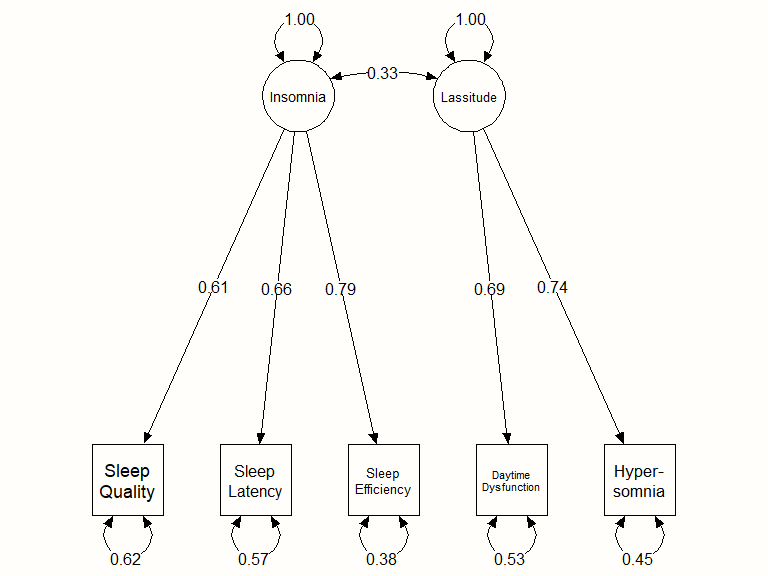
Further Reading
What we covered in this chapter should at best be seen as a rudimentary introduction to meta-analytic SEM. A much more elaborated discussion of this method can be found in Mike Cheung’s definitive book Meta-Analysis: A Structural Equation Modeling Approach (2015). This book also describes various other kinds of meta-analytic structural equation models that we have not covered, and describes how they can be implemented using R.
If you are looking for a shorter (and openly accessible) resource, you can have a look at the {metaSEM} package vignette. The vignette provides a brief discussion of the theory behind meta-analytic SEM and includes several illustrations with R. After {metaSEM} is loaded, the vignette can be downloaded from the Internet by running vignette(“metaSEM”) in the console.
\[\tag*{$\blacksquare$}\]
11.4 Questions & Answers
Test your knowledge!
- What is structural equation modeling, and what is used for?
- What are the two ways through which SEM can be represented?
- Describe a random-effects meta-analysis from a SEM perspective.
- What is a multivariate meta-analysis, and when is it useful?
- When we find that our proposed meta-analytic SEM fits the data well, does this automatically mean that the model is the “correct” one?
Answers to these questions are listed in Appendix A at the end of this book.
11.5 Summary
Structural equation modeling (SEM) is a statistical technique which can be used to test complex relationships between observed (i.e. manifest) and unobserved (i.e. latent) variables.
Meta-analysis is based on a multilevel model, and can therefore also be formulated from a SEM perspective. This can be used to “replicate” random-effects meta-analyses as structural equation models. More importantly, however, this allows us to perform meta-analyses which model more complex relationships between observed effect sizes.
Meta-analytic SEM can be applied, for example, to perform multivariate meta-analyses. In multivariate meta-analyses, two or more outcomes are estimated jointly, while taking the correlation between both outcome measures into account.
Another application of meta-analytic SEM is confirmatory factor analysis. To test the fit of a proposed factor model across all included studies, a two-step procedures must be used. At the first stage, correlation matrices of individual studies are pooled. Then, this pooled correlation matrix is used to fit the assumed SEM.