Capitulo 4 Carga de datos
4.1 Introducción
Ya sabeis que R es un lenguaje de programación orientado al análisis de datos. Lo primero que tenemos que hacer para empezar un análisis con datos en R es, evidentemente, cargar los datos en R.
Vamos a importar y exportar datos en diferentes formatos. Existen muchos tipos de datos, pero nos vamos a centrar en conjuntos de datos que pueden almacenarse en hojas de cálculo, ya que creo que es lo que más vais a usar.
Este diagrama me parece muy bueno para resumir dónde reside el poder de R.
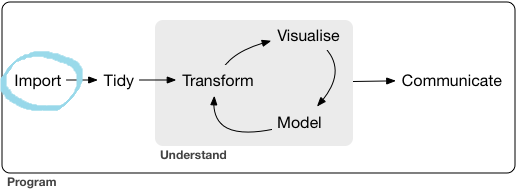
Primer paso: Importar datos (http://r4ds.had.co.nz/)
Cargar datos es una de las primeras frustraciones de alguien que comienza a aprender R. Generalmente piensan: pero si en Excel/SSPSS sólo tengo que pinchar en el fichero!! Como mucho tengo que usar los menús desplegables!!
En R esto también es posible pero lo siento, yo no os voy a mostrar eso. Cuesta un poco más al principio pero una vez lo tienes en tu SCRIPT, es mucho más rápido volver a cargar los datos y hacer todas las operaciones pertinentes para sacar las conclusiones de manera REPRODUCIBLE.
4.1.1 R base vs. nuevos paquetes
R tiene ya unos 20 años. Las funciones de R-base se construyeron pensando en los estadísticos de hace 20 años. Modificar las funciones de R-base haría que código antiguo dejara de funcionar, así que la mayoría de avances y mejoras se producen en los packages.
En el caso de la carga de datos vamos a trabajar con el paquete readr, que es muy parecido a R-base pero en cierto sentido mejora las funciones y las hace más consistentes. Por ejemplo para leer datos CSV la función de R-base es read.csv(); mientas que la función equivalente de readr es read_csv(). Las dos hacen lo mismo, leer datos en formato CSV, pero las nuevas funciones tienen algunas ventajas:
Son más rápidas.
En lugar de generar data.frames, producen tibbles. Las tibbles son en realidad data.frames pero con algunas particularidades.
Las tibbles o “data frames tuneados” tienen unas ciertas ventajas: no convierten por defecto vectores de texto en factores, no usan row names, ni transforman los column names (estas 3 cosas que sí hacen los “data.frames tradicionales” pueden provocar algunas complicaciones, así que mejor tener herramientas que las sorteen).
4.1.2 Obtener información de una función
Si quisíeramos ver todas las funciones que tiene un paquete concreto, por ejemplo ‘readr’, haríamos: ls("package:readr", all = TRUE).
Si queremos ver la documentación de una función concreta; por ejemplo de la función read_csv(), tenemos que utilizar help() o el operador ?. Veámoslo:
#- visualiza la documentación de la función read_csv del package readr.
help(read_csv, package = "readr")
#- si el pkg ya estuviera cargado, funcionaría también así. Si hubiese ambigüedad, RStudio nos avisaría
help(mean)
#- en ese caso tambien funcionaría con el operador ?
?meanAbajo tienes un ejemplo con la función mean().

Como leer las ayudas de R
4.1.3 Datos precargados en R
R-base viene con muchos datos precargados; concretamente en el pkg de R-base llamado ‘datasets’. Además muchos packages contienen también conjuntos de datos. Para ver los datos que tenemos precargados y disponibles en R se usa la función data():
Si queremos ver los datos que hay en un package concreto usaremos data(package = “nombre_pkg”).
4.2 Importar diferentes tipos de bases de datos
Introduciremos funciones para importar/exportar datos de los siguientes formatos:
- Datos en formato texto (o tabulares)
- CSV: .csv (comma separated values o , en castellano, datos separados por comas)
- otros datos en formato texto
- Formatos de otros programas (software propietario)
- SAS
- EXCEL: .xls y .xlsx
Pero se puede cargar datos de todo tipo: SAS, SPSS, netCDF, etc. Existen packages y funciones para cargar (casi) todo tipo de archivos
4.2.1 Datos separados por caracteres
Estamos acostumbrados a visualizar datos en formato tabla. Generalmente las columnas son variables y las filas son observaciones o individuos de esas variables.
Las columnas se separan con un carácter y las filas con un salto de linea. Este carácter puede ser un espacio, un tabulador, una coma, punto y coma etc… El formato más extendido es el CSV, donde las observaciones están separadas por comas.
Estos datos se pueden visualizar en los editores de texto y por eso también se llaman datos en formato texto.
El package ‘readr’ lee datos tabulares con las siguientes funciones:
- si los datos están delimitados por caracteres utiliza:
read_delim(),read_csv(),read_tsv() - si los datos son de anchura fija:
read_fwf()yread_table()
Sólo veremos cómo importar/exportar datos tabulares del primer tipo; es decir, separados por caracteres. Comenzaremos con el formato CSV que es el más utilizado.
4.2.1.1 CSV
CSV significa “comma separated data”. En realidad CSV es un caso particular de “tabular o text data”.
Vamos a comenzar exportando el data.frame ‘iris’, presente en R-Base a formato CSV y luego importarlo.
data("iris")
head(iris)
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosaPara exportar ‘iris’ a un fichero en formato CSV utilizaremos la función write_csv(): solo hay que decirle el objeto que queremos exportar (en este caso un data.frame) y el nombre (junto con la ruta) del archivo donde queremos guardarlo.
Podemos especificar la ruta completa. Yo pongo la mía, pero vosotros tendréis que poner la que os corresponda en cada caso. Por ejemplo:
write_csv(iris, path = "C:/Users/ip30/Dropbox/Terreno/cursos/Formadores IT/Curso intro R/Curso base R/datos/iris.csv")Si estamos usando un proyecto (tal y como vimos en el capítulo 2) o hemos establecido nuestro directorio de trabajo, podemos guardar objetos directamente en ese directorio usando:
Recuerda que para saber cual es tu directorio de trabajo puedes usar la función getwd() y puedes cambiarlo desde los menús de RStudio o con setwd().
Otra forma que uso muchas veces es copiar mi directorio de trabajo en un objeto.
Y cuando quiero guardar uso la función paste() o paste0() para crear el path que me interesa.
## [1] "C:/Users/ip30/Dropbox/Terreno/cursos/Formadores IT/Curso intro R/Curso R base/datos/iris.csv"4.2.1.1.1 Algunas opciones de read_csv() que conviene conocer
A veces los datos tienen ciertos problemas que hay que arreglar; por lo que conviene conocer algunas opciones de read_csv():
col_names:
read_csv()asume que la primera fila contiene los nombres de las variables. Esto puede cambiarse con col_names = FALSE. Puedes proveer nombres a las variables (o columnas) con col_names = c(“X1”, “X2”).read_csv()por defecto importa todas las filas del archivo, pero puedes hacer que comience a importar en la fila que quieras conskip = n.na: En algunos ficheros con datos tabulares los NAs se especifican con algún carácter. Esto podemos tratarlo al leer los datos con el argumentona = "xxx".
Por ejemplo, el chunk que ves abajo utiliza read_csv() para cargar el fichero “iris.csv”. Comienza a importar datos desde la quinta columna, trata los valores 0.2 como NAs y provee un vector con los nombres que queremos para las variables (o columnas).
mi_IRIS <- read_csv(paste0(data.link,"iris.csv"), skip = 5, na = c("0.2"),
col_names = c("X1", "X2", "X3", "X4", "X5"))
## Parsed with column specification:
## cols(
## X1 = col_double(),
## X2 = col_double(),
## X3 = col_double(),
## X4 = col_double(),
## X5 = col_character()
## )
mi_IRIS
## # A tibble: 146 x 5
## X1 X2 X3 X4 X5
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5 3.6 1.4 NA setosa
## 2 5.4 3.9 1.7 0.4 setosa
## 3 4.6 3.4 1.4 0.3 setosa
## 4 5 3.4 1.5 NA setosa
## 5 4.4 2.9 1.4 NA setosa
## 6 4.9 3.1 1.5 0.1 setosa
## 7 5.4 3.7 1.5 NA setosa
## 8 4.8 3.4 1.6 NA setosa
## 9 4.8 3 1.4 0.1 setosa
## 10 4.3 3 1.1 0.1 setosa
## # ... with 136 more rows4.2.1.2 Otros datos tabulares
En realidad, todos los datos tabulares (separados por caracteres) son muy similares. Solo se diferencian en el carácter que hace de separador.
El package ‘readr’ tiene una función específica para cada tipo de datos tabulares. Por ejemplo, si el separador es un punto y coma, la función para importar estos datos es read_csv2(); si el separador es un tabulador, la función es read_tsv(). Pero también tiene una función genérica que sirve para cualquier tipo de separador: read_delim(). Yo recomiendo usar esta última función.
Por ejemplo, podemos cargar el fichero “iris.csv” que hemos exportado anteriormente utilizando la función genérica read_delim(), solo hay que decirle que el separador es una coma. Se lo decimos con la opción delim = ",". Veámoslo:
iris <- read_delim("iris.csv", delim = ",")
## Parsed with column specification:
## cols(
## Sepal.Length = col_double(),
## Sepal.Width = col_double(),
## Petal.Length = col_double(),
## Petal.Width = col_double(),
## Species = col_character()
## )Como el formato tabular más extendido es el CSV; en general, no tendremos necesidad de exportar datos tabulares separados por caracteres distintos a la coma, pero si quisiéramos hacerlo, podríamos hacerlo con write_delim().
Y si quisiéramos importarlos, tendríamos que hacer:
## Parsed with column specification:
## cols(
## Sepal.Length = col_double(),
## Sepal.Width = col_double(),
## Petal.Length = col_double(),
## Petal.Width = col_double(),
## Species = col_character()
## )## # A tibble: 150 x 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # ... with 140 more rows¿PROBAMOS A CARGAR LOS DATOS QUE ME PASASTEIS?
Usemos la funciones str(), head(), summary() para ver lo que tenemos en los datos :).
4.2.2 Importante “,” como decimal
Veremos que algunos datos que deberían de ser numéricos nos los pone como character. Esto suele ser debido a que la hoja de datos ha usado como delimitador decimal la coma (“,”) y no el punto, que es lo que usa R y mayoría de software de programación.
Si nuestra hoja de datos usa un delimitador decimal diferente al punto, tendremos que decirle que delimitador tenemos. Para ello usaremos este argumento: locale=locale(decimal_mark = ","). En este caso estamos diciendo que el delimitador es la coma (“,”)
4.2.3 datos de SAS
El package ‘readr’ tiene una función específica para bases de datos SAS. Las funciones para importar y exportar “datos SAS” se llaman read_sas() y write_sas() :).
Su funcionamiento es igual que read_delim() y write_delim.
4.2.4 Excel
Creo que todos conocemos Excel…
Vamos a usar los package readxl y writexl para exportar e imoprtar ficheros excel, respectivamante.
4.2.4.1 Exportar a excel
Instalemos el paquete writexl y veámoslo:
if (!require("writexl")) install.packages("writexl")
library(writexl)
write_xlsx(iris, paste0(data.link,"iris.xlsx"))La función write_xlsx() permite crear Excel enormes de manera eficiente mediante la especificación use_zip64 = T:
La función write_xlsx() permite añadir datos en varias pestañas a la vez. Para ello:
4.2.4.2 Importar archivos excel
Instalemos el paquete readxl y veámoslo:
if (!require("writexl")) install.packages("writexl")
library(writexl)
iris2 = read_xlsx(paste0(data.link,"iris.xlsx"))
iris2
## # A tibble: 150 x 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # ... with 140 more rowsPor defecto nos ha cargado la primera pestaña, pero si queremos cargar alguna otra, podemos usar la especificación sheet =:
## # A tibble: 146 x 5
## X1 X2 X3 X4 X5
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5 3.6 1.4 NA setosa
## 2 5.4 3.9 1.7 0.4 setosa
## 3 4.6 3.4 1.4 0.3 setosa
## 4 5 3.4 1.5 NA setosa
## 5 4.4 2.9 1.4 NA setosa
## 6 4.9 3.1 1.5 0.1 setosa
## 7 5.4 3.7 1.5 NA setosa
## 8 4.8 3.4 1.6 NA setosa
## 9 4.8 3 1.4 0.1 setosa
## 10 4.3 3 1.1 0.1 setosa
## # ... with 136 more rows## # A tibble: 146 x 5
## X1 X2 X3 X4 X5
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5 3.6 1.4 NA setosa
## 2 5.4 3.9 1.7 0.4 setosa
## 3 4.6 3.4 1.4 0.3 setosa
## 4 5 3.4 1.5 NA setosa
## 5 4.4 2.9 1.4 NA setosa
## 6 4.9 3.1 1.5 0.1 setosa
## 7 5.4 3.7 1.5 NA setosa
## 8 4.8 3.4 1.6 NA setosa
## 9 4.8 3 1.4 0.1 setosa
## 10 4.3 3 1.1 0.1 setosa
## # ... with 136 more rowsTambién podemos ver qué pestañas tiene el archivo de excell mediante la función excel_sheets().
## [1] "Iris1" "Iris2"La función read_xlsx() tiene más posibilidades; como ejemplo, la opción skip = 40 permite empezar a importar los datos a partir de la fila 40.
Si queremos importar todos los libros (o sheets) de un archivo Excel, podemos hacerlo así:
file_path = paste0(data.link,"iris.xlsx")
lista_iris <- lapply(excel_sheets(file_path), read_excel, path = file_path)Hemos guardado los 2 sheets del archivo “iris.xlsx” en un objeto R llamado ‘lista_iris’. Este objeto es una lista con 2 elementos. Cada elemento contiene los datos de cada uno de los 2 sheets. Podemos verlo con str():
## List of 2
## $ : tibble [150 x 5] (S3: tbl_df/tbl/data.frame)
## ..$ Sepal.Length: num [1:150] 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
## ..$ Sepal.Width : num [1:150] 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
## ..$ Petal.Length: num [1:150] 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
## ..$ Petal.Width : num [1:150] 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
## ..$ Species : chr [1:150] "setosa" "setosa" "setosa" "setosa" ...
## $ : tibble [146 x 5] (S3: tbl_df/tbl/data.frame)
## ..$ X1: num [1:146] 5 5.4 4.6 5 4.4 4.9 5.4 4.8 4.8 4.3 ...
## ..$ X2: num [1:146] 3.6 3.9 3.4 3.4 2.9 3.1 3.7 3.4 3 3 ...
## ..$ X3: num [1:146] 1.4 1.7 1.4 1.5 1.4 1.5 1.5 1.6 1.4 1.1 ...
## ..$ X4: num [1:146] NA 0.4 0.3 NA NA 0.1 NA NA 0.1 0.1 ...
## ..$ X5: chr [1:146] "setosa" "setosa" "setosa" "setosa" ...4.2.5 Trabajar con fechas
Las fechas ha sido una de las cosas más arduas de trabajar en R. Cuando cargamos los datos, R no suele reconocer el formato fecha u hora, y carga estos datos como si fueran un character o string. Por lo general, para convertir estos datos en formato fecha y hora podremos usar el paquete y función anytime(), que hace una conversión automática de las fechas. Alguna vez, muy pocas, este paquete puede fallar por lo que conviene que nos familiariceos con una serie de argumentos. La función para hacer estos en tidy.verse es parse_datetime() para fechas y “parse_time()” para horas.
Argumentos clave:
Year: “%Y” (4 dígitos). “%y” (2 dígitos); 00-69 -> 2000-2069, 70-99 -> 1970-1999.
Month: “%m” (2 dígitos), “%b” (nombre abreviado en hora local), “%B” (nombre completo en hora local).
Day: “%d” (2 dígitos), “%e” (opcional dejar espacio), "
Hour: “%H” or “%I”, usar I con AM/PM.
Minutes: “%M”
Seconds: “%S” (segundos), “%OS” (segundos decimales)
Time zone: “%Z” (como nombre, e.g. “America/Chicago”), “%z” (como offset de UTC, e.g. “+0800”)
AM/PM indicator: “%p”.
Abreviaciones: “%D” = “%m/%d/%y”, “%F” = “%Y-%m-%d”, “%R” = “%H:%M”, “%T” = “%H:%M:%S”, “%x” = “%y/%m/%d”.
Ejemplos:
parse_datetime('2016-07-22', format = "%Y-%m-%d")
## [1] "2016-07-22 UTC"
parse_datetime('2016-07-22', format = "%F")
## [1] "2016-07-22 UTC"
parse_time('13:04:47', format = "%H:%M:%S")
## 13:04:47
parse_datetime('2016-07-22 13:04:47', format = "%Y-%m-%d %H:%M:%S")
## [1] "2016-07-22 13:04:47 UTC"
parse_datetime("01Aug2018",format = "%d%b%Y")
## [1] "2018-08-01 UTC"
parse_datetime("01/Aug/2018",format = "%d/%b/%Y")
## [1] "2018-08-01 UTC"
parse_time('01:04:47 PM', format = "%H:%M:%S %p")
## 13:04:47Hagamos unos ejericios. ¿Podemos convertir estos formatos a algo coherente?
Pero por lo general podemos usar el package anytime() y funciones anydate() :).
if(!require(anytime)) {
install.packages("anytime")
library(anytime)}
anytime("01Aug2018")
## [1] "2018-08-01 01:00:00 BST"
anytime("01:08:2018")
## [1] "2018-01-08 01:00:00 GMT"
anytime("2018-08-01")
## [1] "2018-08-01 01:00:00 BST"
anydate("01Aug2018")
## [1] "2018-08-01"
anydate("01:08:2018")
## [1] "2018-01-08"
anydate("2018-08-01")
## [1] "2018-08-01"Y podemos hacer ooperaciones con estas fechas.
a <- anytime("01Aug2018")
b <- anytime("01Aug2019")
b-a
## Time difference of 365 days
b>a
## [1] TRUE
b==a
## [1] FALSEAhora, vamos a cargar la base de datos “Siniestros” y vamos a ver que pasa con las fechas.
Siniestros <- read_delim(paste0(data.link,"Siniestros.txt"),delim=";")
## Parsed with column specification:
## cols(
## CO_SINIESTRO = col_double(),
## IN_RAMO_SINIESTRO = col_double(),
## CO_POLIZA = col_double(),
## FX_FACTURA = col_character(),
## FX_DECLARACION_SINIESTRO = col_character(),
## FX_VENCIMIENTO_SINIESTRO = col_character(),
## CO_DEUDOR = col_character(),
## CO_PAIS_DEUDOR = col_double()
## )mmmmm, nos las ha cargado con ‘character’. Vamos a arreglar esto.
Hay dos maneras de hacer que esto quede de manera correcta:
1- La manera menos elegante: hacer todo a posteriori.
Siniestros$FX_FACTURA2 = anytime(Siniestros$FX_FACTURA)
Siniestros$FX_FACTURA3 = anydate(Siniestros$FX_FACTURA)hemos creado una nueva variable llamada ‘FX_FACTURA2’. La primera vez siempre guardo la variable orginal, en este aso ‘FX_FACTURA’, para comprobar que la conversión ha sido correcta. Vamos a comprobar. Por ejemplo mirando los primeros diez valores.
## [1] "07Dec2017" "31Jan2018" "04Jan2018" "19Dec2017" "28Feb2018" "15Feb2018" "31Jan2018" "31Jan2018" "15Feb2018" "31Jan2018"## [1] "2017-12-07 01:00:00 GMT" "2018-01-31 01:00:00 GMT" "2018-01-04 01:00:00 GMT" "2017-12-19 01:00:00 GMT" "2018-02-28 01:00:00 GMT" "2018-02-15 01:00:00 GMT"
## [7] "2018-01-31 01:00:00 GMT" "2018-01-31 01:00:00 GMT" "2018-02-15 01:00:00 GMT" "2018-01-31 01:00:00 GMT"## [1] "2017-12-07" "2018-01-31" "2018-01-04" "2017-12-19" "2018-02-28" "2018-02-15" "2018-01-31" "2018-01-31" "2018-02-15" "2018-01-31"¿Ha funcionado? Creo que si :). Pues ya podemos, poner “bien” el script y decirle que justo despues de cargar los datos haga la conversión de la variable ‘FX_FACTURA’ pertinente:
Siniestros <- read_delim(paste0(data.link,"Siniestros.txt"),delim=";",
locale=locale(decimal_mark = ",")) ## vuelve a cargar como caracter
Siniestros$FX_FACTURA = anydate(Siniestros$FX_FACTURA)str(Siniestros)
## spec_tbl_df [1,680 x 8] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ CO_SINIESTRO : num [1:1680] 2361644 2361699 2361873 2361874 2361912 ...
## $ IN_RAMO_SINIESTRO : num [1:1680] 1 1 1 1 1 1 1 1 1 1 ...
## $ CO_POLIZA : num [1:1680] 30116947 30141429 30127092 30127092 30138173 ...
## $ FX_FACTURA : Date[1:1680], format: "2017-12-07" "2018-01-31" "2018-01-04" "2017-12-19" ...
## $ FX_DECLARACION_SINIESTRO: chr [1:1680] "01Aug2018" "02Aug2018" "02Aug2018" "02Aug2018" ...
## $ FX_VENCIMIENTO_SINIESTRO: chr [1:1680] "30Jun2018" "31May2018" "19Apr2018" "03Apr2018" ...
## $ CO_DEUDOR : chr [1:1680] "38562212" "36612758" "39201697" "36758941" ...
## $ CO_PAIS_DEUDOR : num [1:1680] 4305 4305 4305 4305 4305 ...
## - attr(*, "spec")=
## .. cols(
## .. CO_SINIESTRO = col_double(),
## .. IN_RAMO_SINIESTRO = col_double(),
## .. CO_POLIZA = col_double(),
## .. FX_FACTURA = col_character(),
## .. FX_DECLARACION_SINIESTRO = col_character(),
## .. FX_VENCIMIENTO_SINIESTRO = col_character(),
## .. CO_DEUDOR = col_character(),
## .. CO_PAIS_DEUDOR = col_double()
## .. )2- La manera más elegante es hacerlo todo desde el mismo momento en el que cargamos los datos.
Siniestros <- read_delim(paste0(data.link,"Siniestros.txt"), delim=";",
locale=locale(decimal_mark = ","),
col_types = cols('FX_FACTURA' = col_datetime("%d%b%Y")))
str(Siniestros)
## spec_tbl_df [1,680 x 8] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ CO_SINIESTRO : num [1:1680] 2361644 2361699 2361873 2361874 2361912 ...
## $ IN_RAMO_SINIESTRO : num [1:1680] 1 1 1 1 1 1 1 1 1 1 ...
## $ CO_POLIZA : num [1:1680] 30116947 30141429 30127092 30127092 30138173 ...
## $ FX_FACTURA : POSIXct[1:1680], format: "2017-12-07" "2018-01-31" "2018-01-04" "2017-12-19" ...
## $ FX_DECLARACION_SINIESTRO: chr [1:1680] "01Aug2018" "02Aug2018" "02Aug2018" "02Aug2018" ...
## $ FX_VENCIMIENTO_SINIESTRO: chr [1:1680] "30Jun2018" "31May2018" "19Apr2018" "03Apr2018" ...
## $ CO_DEUDOR : chr [1:1680] "38562212" "36612758" "39201697" "36758941" ...
## $ CO_PAIS_DEUDOR : num [1:1680] 4305 4305 4305 4305 4305 ...
## - attr(*, "spec")=
## .. cols(
## .. CO_SINIESTRO = col_double(),
## .. IN_RAMO_SINIESTRO = col_double(),
## .. CO_POLIZA = col_double(),
## .. FX_FACTURA = col_datetime(format = "%d%b%Y"),
## .. FX_DECLARACION_SINIESTRO = col_character(),
## .. FX_VENCIMIENTO_SINIESTRO = col_character(),
## .. CO_DEUDOR = col_character(),
## .. CO_PAIS_DEUDOR = col_double()
## .. )4.2.5.1 day,month and year
Si queremos sacar el día, mes o año de la fecha, el paquete lubridate es muy simple de usar.
library(lubridate)
Siniestros$FX_FACTURA[1:5]
## [1] "2017-12-07 UTC" "2018-01-31 UTC" "2018-01-04 UTC" "2017-12-19 UTC" "2018-02-28 UTC"
day(Siniestros$FX_FACTURA)[1:5]
## [1] 7 31 4 19 28
month(Siniestros$FX_FACTURA)[1:5]
## [1] 12 1 1 12 2
year(Siniestros$FX_FACTURA)[1:5]
## [1] 2017 2018 2018 2017 20184.2.6 Añadir X ceros a character
Esto puede ser útil en ciertos casos donde un “ID” o un código requiere tener un número fijo de caracteres.
Para ello, usaremos la función str_pad() del package stringr que a su vez es parte de tidyverse.
el funcionamiento es muy simple:
library(stringr) # o simplemente library(tidyverse) nos carga todos los paquetes de la familia tidyverse
abc=sample(1:100000,100)
str_pad(string = abc, width = 8, side = "left", pad = 0)## [1] "00054230" "00025185" "00062435" "00045015" "00053078" "00004532" "00098029" "00080061" "00033087" "00080960" "00067971" "00040105" "00082727" "00067125"
## [15] "00033880" "00027039" "00003739" "00019110" "00047843" "00041891" "00040210" "00068656" "00067816" "00093792" "00082833" "00053606" "00022656" "00042517"
## [29] "00042726" "00016842" "00052029" "00011561" "00028031" "00012918" "00068340" "00020343" "00071213" "00091879" "00099531" "00046834" "00045108" "00073620"
## [43] "00052385" "00099799" "00006676" "00058672" "00083255" "00067887" "00063372" "00084298" "00048085" "00097204" "00025030" "00062809" "00064519" "00037188"
## [57] "00081961" "00045266" "00010564" "00025104" "00051555" "00080134" "00052598" "00045366" "00060567" "00084052" "00042728" "00082354" "00075973" "00060248"
## [71] "00065231" "00009666" "00035653" "00003830" "00090398" "00032453" "00070842" "00043724" "00063346" "00083270" "00079056" "00034031" "00023970" "00009994"
## [85] "00034611" "00066966" "00070127" "00056451" "00044356" "00000974" "00066230" "00021460" "00040483" "00070555" "00058820" "00081913" "00056942" "00037874"
## [99] "00048641" "00006524"En este caso hemos añadido ceros, a la izquierda hasta que el “string” o código alcanza 8 caracteres.
Probemos a hacerlo con una columna de la base de datos “Siniestros”