2.9 Memanipulasi Dataset
Pada Chapter 2.9, kita akan belajar bagaimana memanipuasi dataset. Adapun yang menjadi topik bahasan dalam Chapter 2.9, antara lain:
- Melakukan subset dataset,
- Agregasi variabel pada dataset,
- Melakukan drop observasi pada dataset,
- Melakukan drop observasi dengan missing value,
- Mengelompokkan variabel menjadi variabel factor dan nilai,
- Menggabungkan dua dataset, dan,
- Modifikasi lainnya.
2.9.1 Melakukan Subset Dataset
Pada analisis data, kita sering kali tidak membutuhkan seluruh observasi dari data yang kita miliki. Kita akan melakukan filter untuk memperoleh data sesuai dengan keperluan kita. Selain itu, melihat subset data berdasarkan kriteria tertentu membantu kita untuk melakukan analisis ekspolarif terhadap data yang kita miliki.
Untuk melakukan subset data, kita memelukan sebuah ekpresi atau formula yang dapat mengecek satu persatu data yang memenuhi formula subset yang telah dibentuk. Sebagai contoh, kita ingin memperoleh dataset tanpa nilai missing value pada variabel namavariabel. Berikut adalah contoh sintaks formula atau ekspresi yang digunakan:
Untuk membuat formula atau ekspresi tersebut, kita dapat menggunakan kembali operator operasi yang telah dijelaskan pada Chapter 2.1. Langkah-langkah untuk melakukan subset pada dataset adalah sebagai berikut:
- Pada menu
Data, klikData/Active data set/Subset active data set.... - Pada jendela yang muncul spesifikasikan variabel yang akan dipilih pada dataset baru dan formula subset yang digunakan (lihat Tabel 2.17). Klik
OK. - Untuk mengecek dataset, klik toolbar
View data set.
Visualisasi tahapan tersebut ditampilkan pada Gambar 2.20.
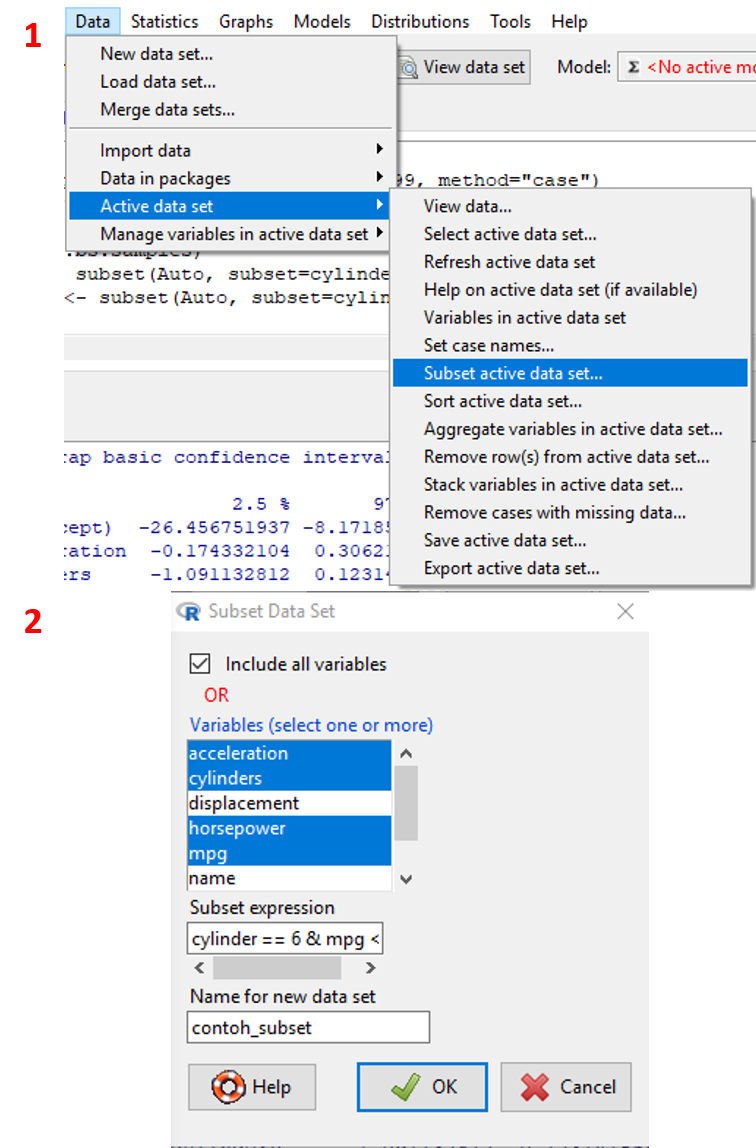
Gambar 2.20: Tampilan tahapan melakukan subset pada dataset.
Secara umum sintaks untuk melakukan proses subset adalah sebagai berikut:
| No. | Item | Jenis Input | Keterangan |
|---|---|---|---|
| 1. | Include all variables |
check box | opsi apakah akan menyertakan seluruh variabel pada hasil subset |
| 2. | Variables |
select box | daftar nama variabel yang dapat dipilih untuk ditampilkan pada hasil subset |
| 3. | Subset expression |
text input | formula atau ekpresi subset yang digunakan |
| 4. | Name for new data set |
text imput | opsi untuk memberikan nama pada dataset baru atau tidak (dataset lama akan dihapus) |
2.9.2 Agregat Variabel pada Dataset
Submenu agregate variables in active dataset memberikan ringkasan nilai satu atau beberapa variabel berdasarkan level variabel factor dan menghasilkan dataset baru dengan satu observasi untuk tiap level factor. Proses agregasi mengaplikasikan beberapa fungsi seperti mean(), sum(), atau fungsi lainnya untuk menghasilkan sebuah nilai untuk setiap observasi pada tiap variabel dan level factor.
Fungsi statistika deskriptif bawaan yang dapat digunakan pada R Commander ditampilkan pada Tabel 2.18.
| Fungsi | Keterangan |
|---|---|
mean |
rata-rata |
median |
median |
sum |
jumlah seluruh observasi dalam sebuah variabel |
quantile |
kuantil data |
min |
nilai observasi minimum |
max |
nilai observasi maksimum |
IQR |
rentang antar kuartil |
mad |
simpangan absolut median |
sd |
simpangan baku |
var |
varians |
Tahapan agregasi variabel dilakukan melalui langkah-langkah berikut:
- Pada menu
Data, klikData/Active data set/Aggregate variables in active data set.... - Spesifikan variabel yang akan dilakukan agregasi, factor level yang digunakan, dan fungsi agregat yang digunakan (lihat Tabel 2.19). Klik
OK. - Untuk mengecek dataset, klik toolbar
View data set.
Visualisasi tahapan tersebut ditampilkan pada Gambar 2.21.
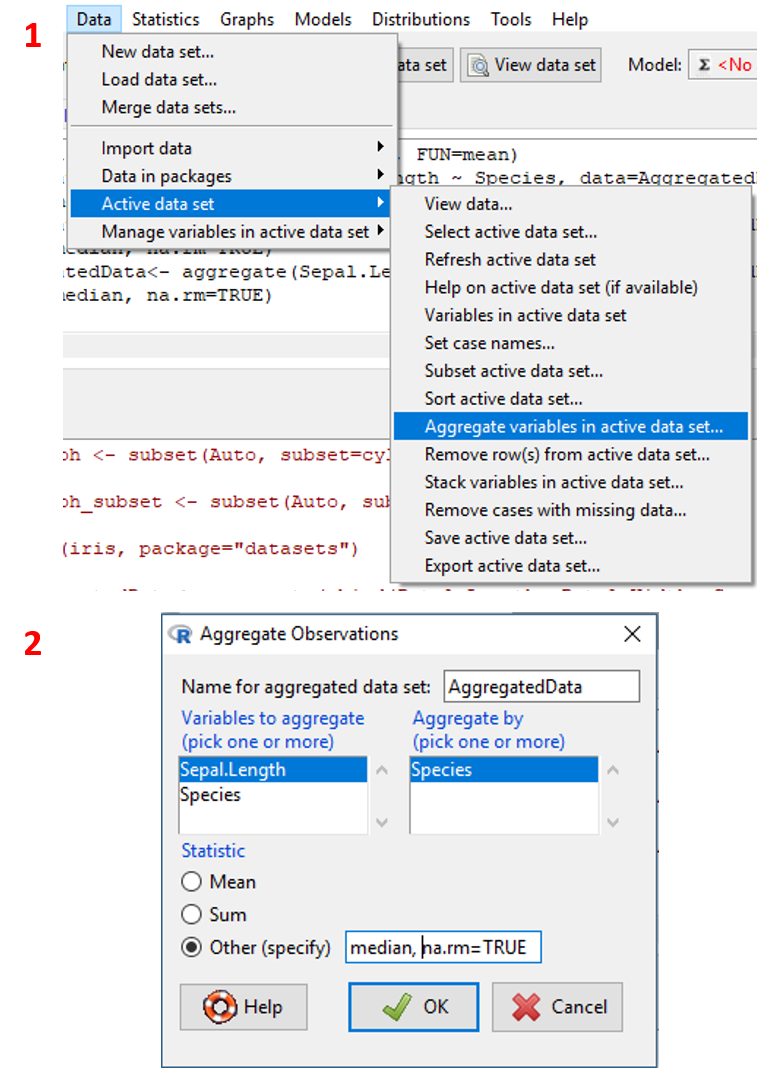
Gambar 2.21: Tampilan tahapan agregasi variabel.
| No. | Item | Jenis Input | Keterangan |
|---|---|---|---|
| 1. | Name for aggregated.. |
text input | input nama dataset baru yang dihasilkan |
| 2. | Variables to aggregate |
select box | daftar nama variabel yang dapat dipilih untuk diagregasi |
| 3. | Aggregated by |
select box | daftar nama variabel factor yang digunakan untuk agregasi |
| 4. | Statistic |
text imput | fungsi statistik yang digunakan untuk agregasi |
Sintaks untuk melakukan proses agragasi secara umu dituliskan sebagai berikut:
Argumen ... pada sintaks tersebut merupakan argumen tambahan pada fungsi statistik yang digunakan. Secara umum argumen tambahan yang digunakan fungsi yang ditampilkan pada Tabel 2.18 adalah na.rm=TRUE, yaitu: jika data mengandung missing value, maka observasi yang mengandung missing value tersebut akan di drop. Selain argumen tersebut, fungsi quantile memerlukan argumen spesifikasi prob atau spesifikasi kuantil yang akan ditampilkan (misal:prob=0.5 untuk kuantil ke-50 atau median). Untuk menambahkan argumen tersebut, pembaca dapat menspesifikasikannya pada bagian Statistic pada jendela aggregate observations yaitu pada pilihan Other (specify) seperti yang ditunjukkan pada Gambar 2.21.
2.9.3 Melakukan Drop Observasi pada Dataset
Kita dapat melakukan drop terhadap sejumlah baris observasi berdasarkan indeks (nomor baris observasinya) atau nama baris observasinya. Seleksi baris yang akan didrop dilakukan menggunakan metode yang ditampilkan pada Tabel 2.12, yaitu: baris individual (contoh: 1), set baris (contoh: 1,2,3..,k), atau rentang baris (contoh: 1:5) untuk seleksi menggunakan indeks. Langkah-langkah untuk melakukan seleksi baris yang akan didrop adalah sebagai berikut:
- Pada menu
Data, klikData/Active data set/Remove row(s) from active data set.... - Spesifikan index baris yang akan di drop dan nama output dataset baru (lihat Tabel 2.20). Klik
OK. - Untuk mengecek dataset, klik toolbar
View data set.
Visualisasi tahapan tersebut ditampilkan pada Gambar 2.22.
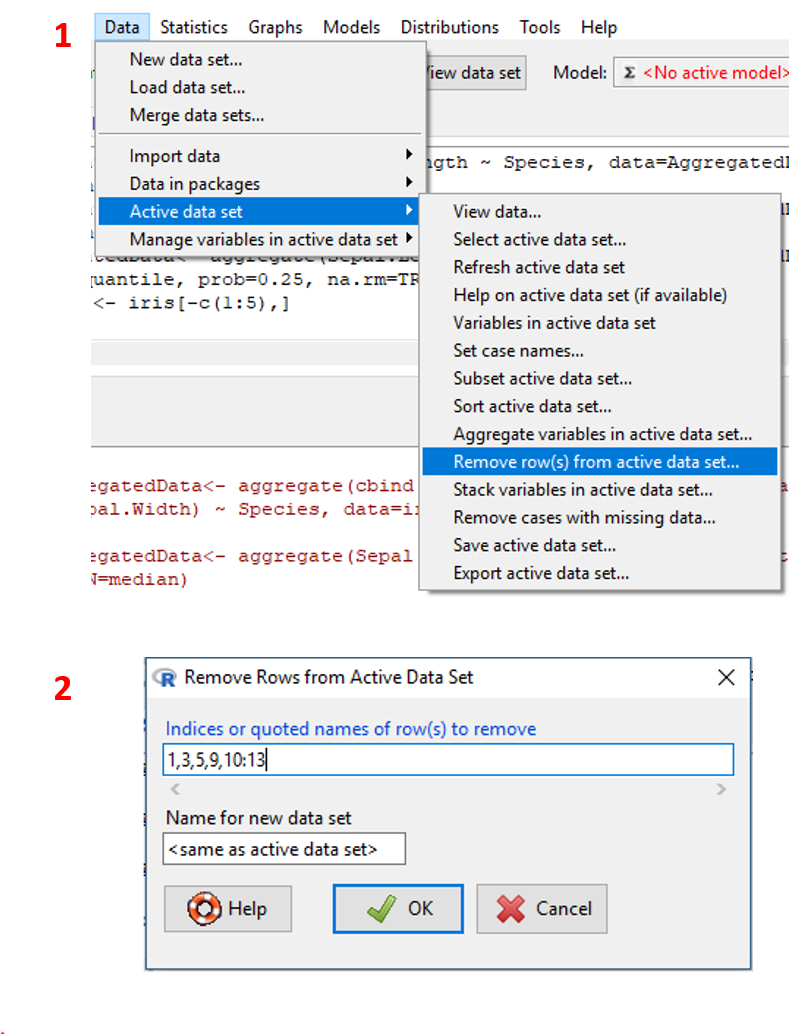
Gambar 2.22: Tampilan tahapan melakukan drop observasi.
Sintaks yang digunakan untuk melakukan drop baris observasi secara umu adalah sebagai berikut:
| No. | Item | Jenis Input | Keterangan |
|---|---|---|---|
| 1. | Indices or quoted... |
text input | indeks atau nama baris yang akan di drop atau di hapus |
| 2. | Name for new data set |
text input | input nama dataset baru yang dihasilkan |
2.9.4 Melakukan Drop Observasi dengan Missing Value
Selain menggunakan submenu subset active data set, drop missing value dapat pula dilakukan dengan menggunakan submenu remove cases with missing data. Perbedaan antara metode pertama dan kedua adalah pada metode kedua drop missing value dilakukan pada seluruh variabel dalam dataset. Tahapan untuk melakukannya adalah sebagai berikut:
- Pada menu
Data, klikData/Active data set/Remove cases with missing data.... - Spesifikan variabel yang akan dipilih untuk dataset baru dan nama output dataset (lihat Tabel 2.21). Klik
OK. - Untuk mengecek dataset, klik toolbar
View data set.
Visualisasi tahapan tersebut ditampilkan pada Gambar 2.23.
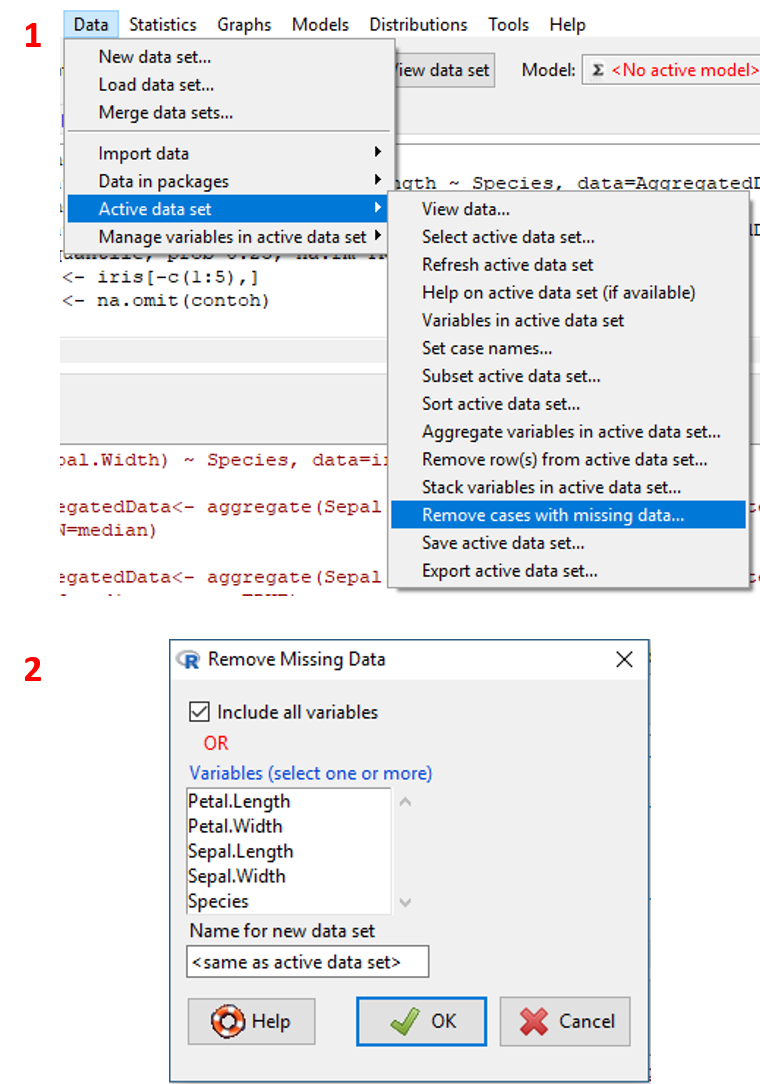
Gambar 2.23: Tampilan tahapan melakukan drop observasi dengan missing value.
Sintaks untuk melakukan drop missing value pada seluruh variabel dalam dataset secara umum adalah sebagai berikut:
| No. | Item | Jenis Input | Keterangan |
|---|---|---|---|
| 1. | Include all variables |
check box | pilihan apakah akan menyertakan seluruh variabel pada dataset baru atau tidak |
| 2. | Variables |
select box | daftar variabel yang dapat dipilih untuk disertakan dalam dataset baru |
| 3. | Name for new data set |
text input | input nama dataset baru |
2.9.5 Mengelompokkan Variabel Menjadi Variabel Factor dan Nilai
Submenu stack variables in active data set membuat sebuah dataset baru dimana dua atau lebih variabel ditumpuk menjadi variabel satu variabel dengan nilai variabel sebelumnya ditampilkan pada variabel nilai. Jika terdapat \(n\) observasi dalam dataset dan \(k\) variabel, maka dataset baru akan terdiri dari 2 variabel (factor dan numeric) dan \(n\times k\) observasi. Tahapan untuk melakukannya adalah sebagai berikut:
- Pada menu
Data, klikData/Active data set/Stack variables in active data set.... - Spesifikan variabel yang akan dipilih untuk dataset baru dan nama output dataset (lihat Tabel 2.22). Klik
OK. - Untuk mengecek dataset, klik toolbar
View data set.
Visualisasi tahapan tersebut ditampilkan pada Gambar 2.24.
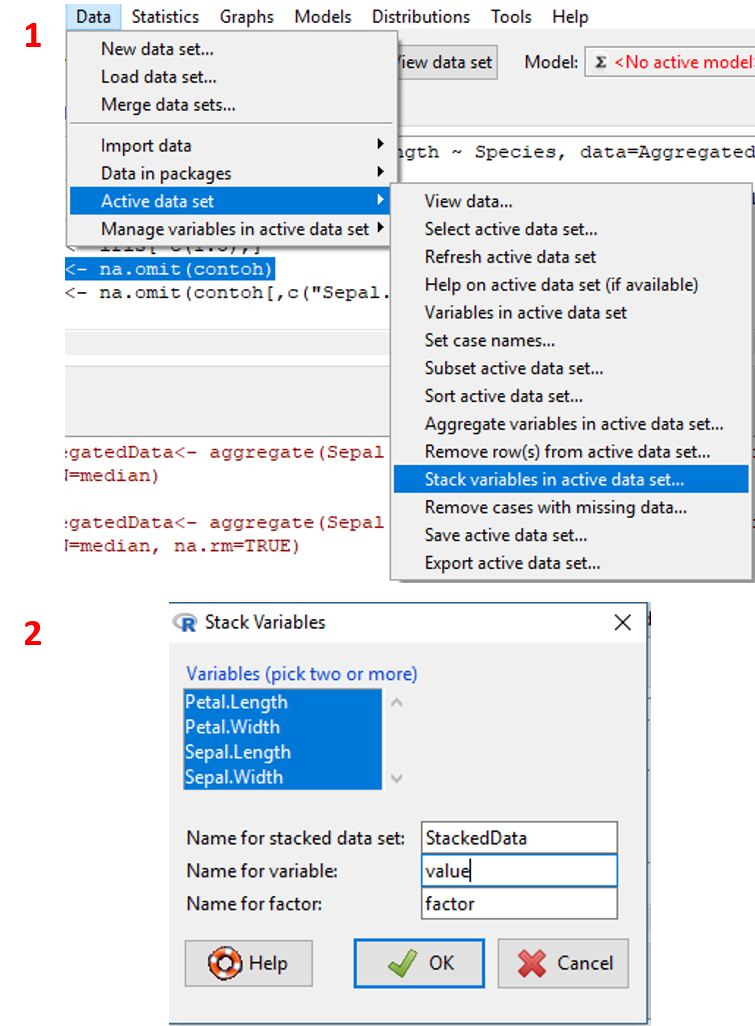
Gambar 2.24: Tampilan tahapan mengelompokkan variabel menjadi variabel factor dan nilai.
Terdapat dua buah sintaks dalam melakukan proses pengelompokan data. Sintaks pertama melakukan pengelompokan data, sedangkan sintaks kedua merubah nama kolom dataset baru. Kedua sintaks tersebut adalah sebagai berikut:
datasetbaru <- stack(dataset[, c("variabel1","variabel2",..)])
names(datasetbaru) <- c("value", "factor")| No. | Item | Jenis Input | Keterangan |
|---|---|---|---|
| 1. | Variables |
select box | daftar variabel yang dapat dipilih untuk dikelompokkan |
| 2. | Name for staked data.. |
text input | nama dataset baru hasil pengelompokan |
| 3. | Name for variable |
text input | nama variabel nilai hasil pengelompokkan |
| 4. | Name for factor |
text input | nama variabel factor hasil pengelompokan nama variabel pada dataset sebelumnya |
2.9.6 Menggabungkan Dua Dataset
Untuk menggabungkan dua buah dataset, kedua dataset perlu memiliki elemen kunci yang sama. Secara default R Commander mengambil rownames sebagai elemen kunci, sehingga elemen kunci yang dimiliki oleh masing-masing dataframe haruslah konsisten satu sama lain. Penggabungan dataset dapat dilakukan melalui penggabungan kolom dan baris. Penggabungan juga dapat dilakukan melalui elemen unik dari baris maupun kolom. Maksudnya adalah R Commander hanya menggabungkan dataset yang memiliki elemen kunci sama (rownames sama) pada kedua dataset. Jika terdapat observasi pada dataset 1 dan tidak memiliki rownames atau elemen kunci sama pada dataset 2, maka observasi tersebut akan dihapus dari proses penggabungan data. Tahapan penggabungan dua buah dataset adalah sebagai berikut:
- Pada menu
Data, klikData/Merge data set.... - Pada jendela yang muncul, klik dataset yang akan digabungkan dan cara penggabungannya (lihat Tabel 2.23). Klik
OK. - Untuk mengecek dataset, klik toolbar
View data set.
Visualisasi tahapan tersebut ditampilkan pada Gambar 2.25.
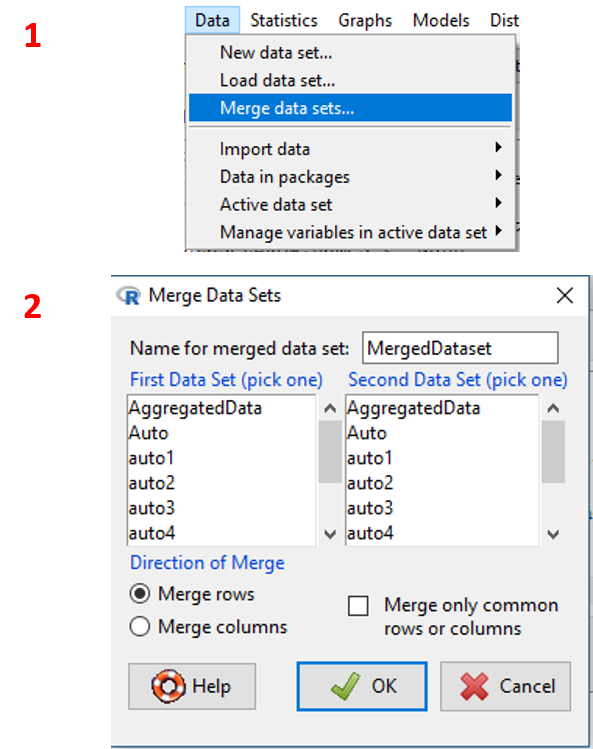
Gambar 2.25: Tampilan tahapan menggabungkan dua buah dataset.
Sintaks yang digunakan untuk menggabungkan dua buah dataset secara umum adalah sebagai berikut:
# penggabungan baris tanpa mempertimbangkan
# elemen unik
datasetbaru <- mergeRows(data1, data2, common.only=FALSE)
# pengagbungan kolom dengan mempertimbangkan
# elemen unik
datasetbaru <- merge(data1, data2, all=FALSE, by="row.names")
rownames(datasetbaru) <- datasetbaru$Row.names
datasetbaru$Row.names <- NULL| No. | Item | Jenis Input | Keterangan |
|---|---|---|---|
| 1. | Name for merge data set |
text input | input nama dataset baru |
| 2. | First Data set |
select box | daftar dataset pertama yang akan digabung |
| 3. | Second Data set |
select box | daftar dataset kedua yang akan digabung |
| 4. | Direction or Merge |
radio button | pilihan cara penggabungan |
| 5. | Merge only common... |
check box | opsi apakah hanya observasi dengan elemen unik yang ada pada dua buah dataset yang akan digabungkan |
2.9.7 Modifikasi Lainnya
Daftar submenu yang digunakan untuk melakukan modifikasi dataset lainnya pada R Commander, antara lain:
Select active data set: submenu ini memiliki fungsi sama dengan toolbarData set, yaitu: memilih dataset yang diaktifkan. Jika pada jendela yang muncul terdapat beberapa dataset yang dapat diaktifkan, pembaca dapat memilih satu dataset dari daftar tersebut untuk diaktifkan.Refresh active data set: submenu yang berfungsi untuk melakukan reset informasi yang dipertahankan terkait dataset yang aktif, seperti: nama vraiabel pada dataset, jenis data pada dataset tersebut, dll. Pembaca mungkinperlu melakukan refresh terhadap dataset yang aktif jika pembaca melakukan sebuah perubahan pada dataset tersebut diluar menuR Commander.Help on active data set: menampilkan dokumentasi terkait dataset yang aktif (biasanya dataset yang ada dalam sebuah paket).Variables in active data set: menampilkan daftar variabel yang ada dalam data set.Set case name: memilih sebuah variabel pada dataset aktif dan selanjutnya menjadikan variabel tersebut sebagai rownames observasi dalam dataset tersebut.