Primer Notebook
Primer ejercicio haciendo reportes desde R.
Para las letras en negrita se usa "**"
Para las letras cursivas se usa "*"
Estas son letras en negrita
Esta es letra cursiva
Para configurar un texto como titulo se usa “#”
Para un subtitulo de usa “##”
Para un subtitulo de tercer nivel se usa “###”
Para un subtitulo de cuarto nivel se usa “####”
Agregar imagenes a un documento en R
Para agregar imagenes se usa la sintaxis:
{width=width height=height}
Para lineas horizontales poner 3 asteriscos "***".
Ejecutar scripts de R
La región donde se ejecuta el código de R se denomina “chunck”
# install.packages('devtools')
library(devtools)## Loading required package: usethis# devtools::install_github("XanderHorn/autoEDA")
library(autoEDA)
library(tidyverse)## ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.1 ──## ✔ ggplot2 3.3.5 ✔ purrr 0.3.4
## ✔ tibble 3.1.2 ✔ dplyr 1.0.7
## ✔ tidyr 1.1.3 ✔ stringr 1.4.0
## ✔ readr 1.4.0 ✔ forcats 0.5.1## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()# Analisis univariado (una sola variable)
iris %>% str()## 'data.frame': 150 obs. of 5 variables:
## $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
## $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
## $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
## $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
## $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...overview_1 <- autoEDA(x = iris ) # en lugar de iris escribimos el nombre de nuestra base de datos## Loading required package: RColorBrewer## autoEDA | Setting color theme
## autoEDA | Removing constant features
## autoEDA | 0 constant features removed
## autoEDA | 0 zero spread features removed
## autoEDA | Removing features containing majority missing values
## autoEDA | 0 majority missing features removed
## autoEDA | Cleaning data
## autoEDA | Correcting sparse categorical feature levels
## autoEDA | Performing univariate analysis
## autoEDA | Visualizing data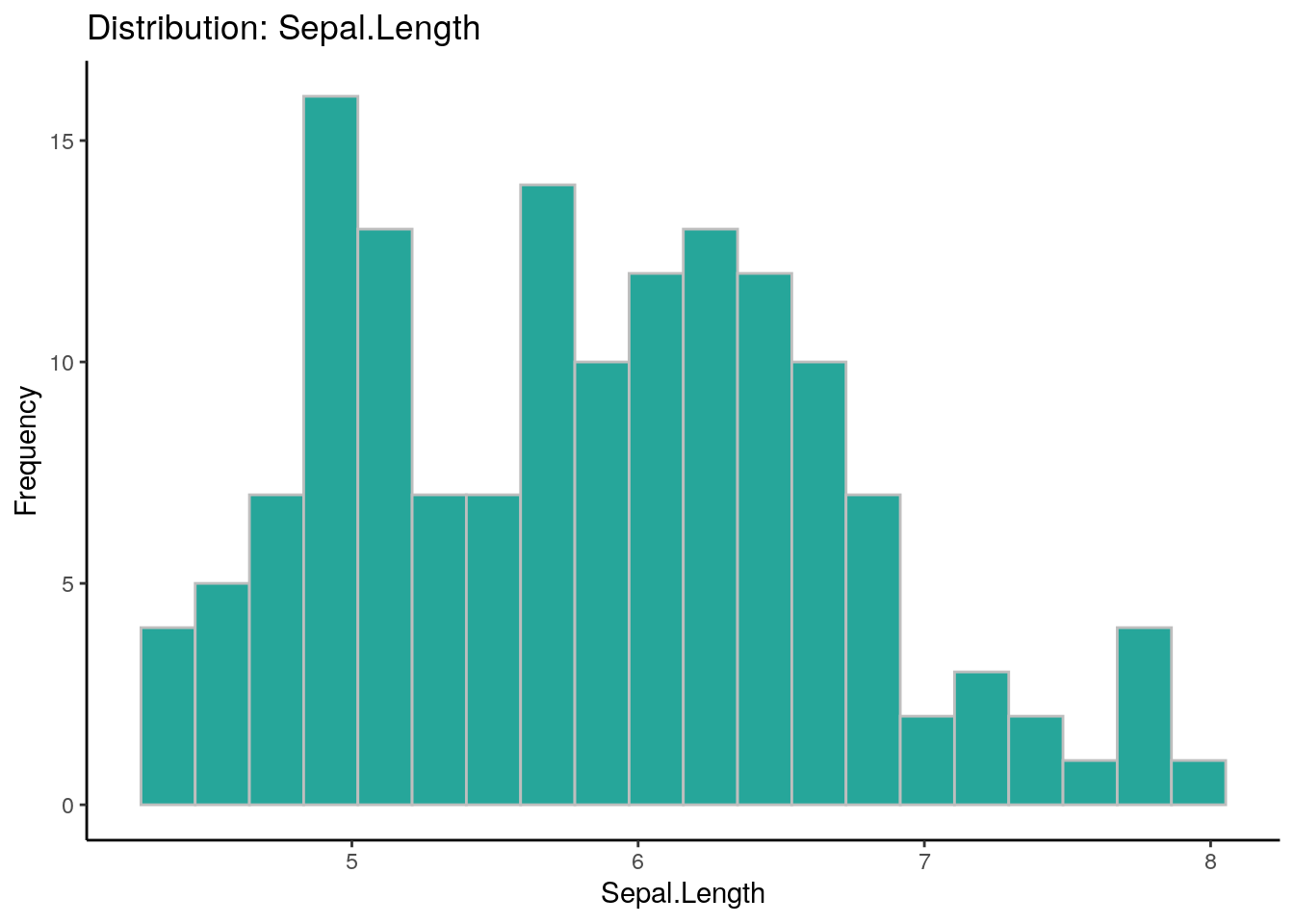
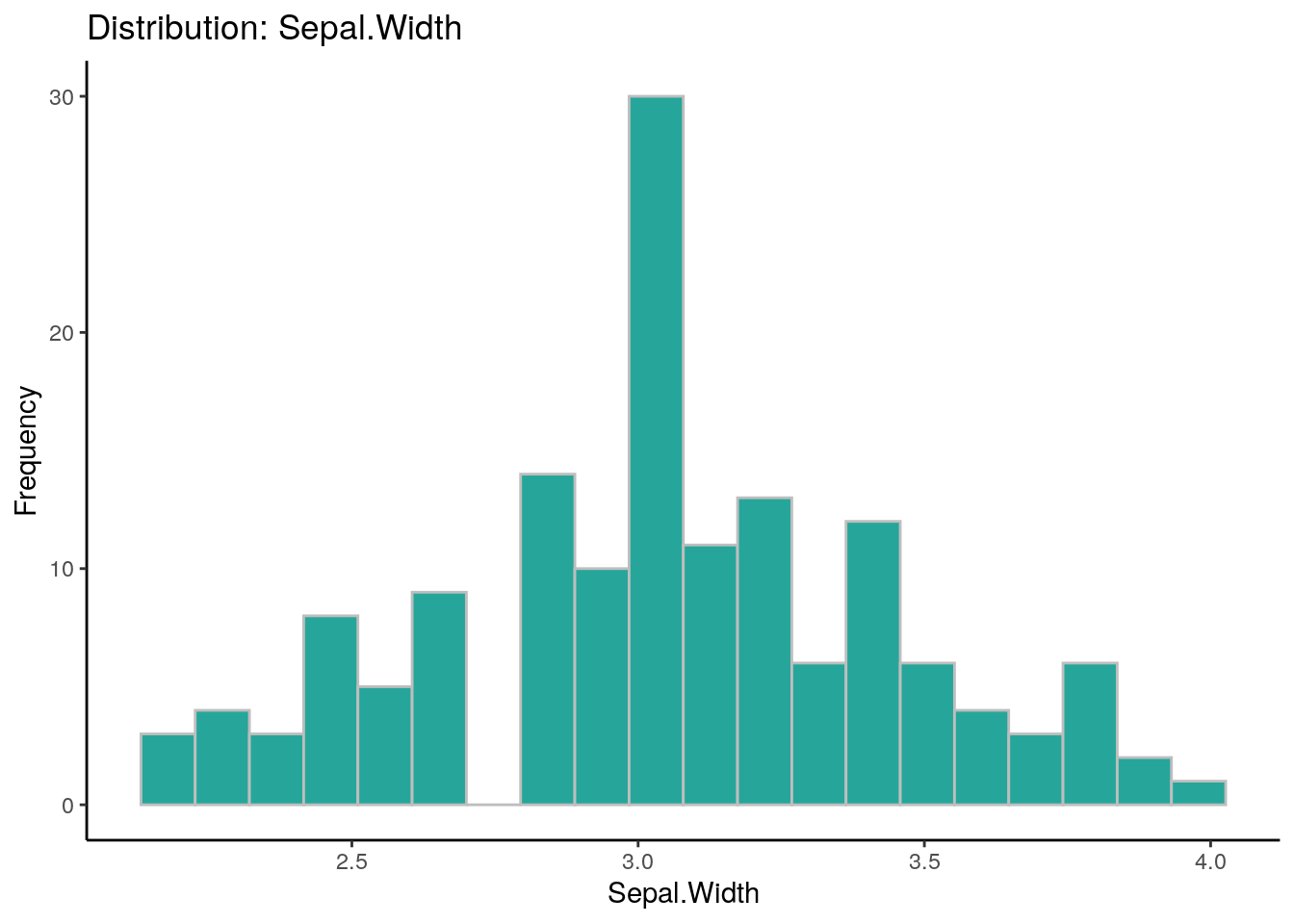
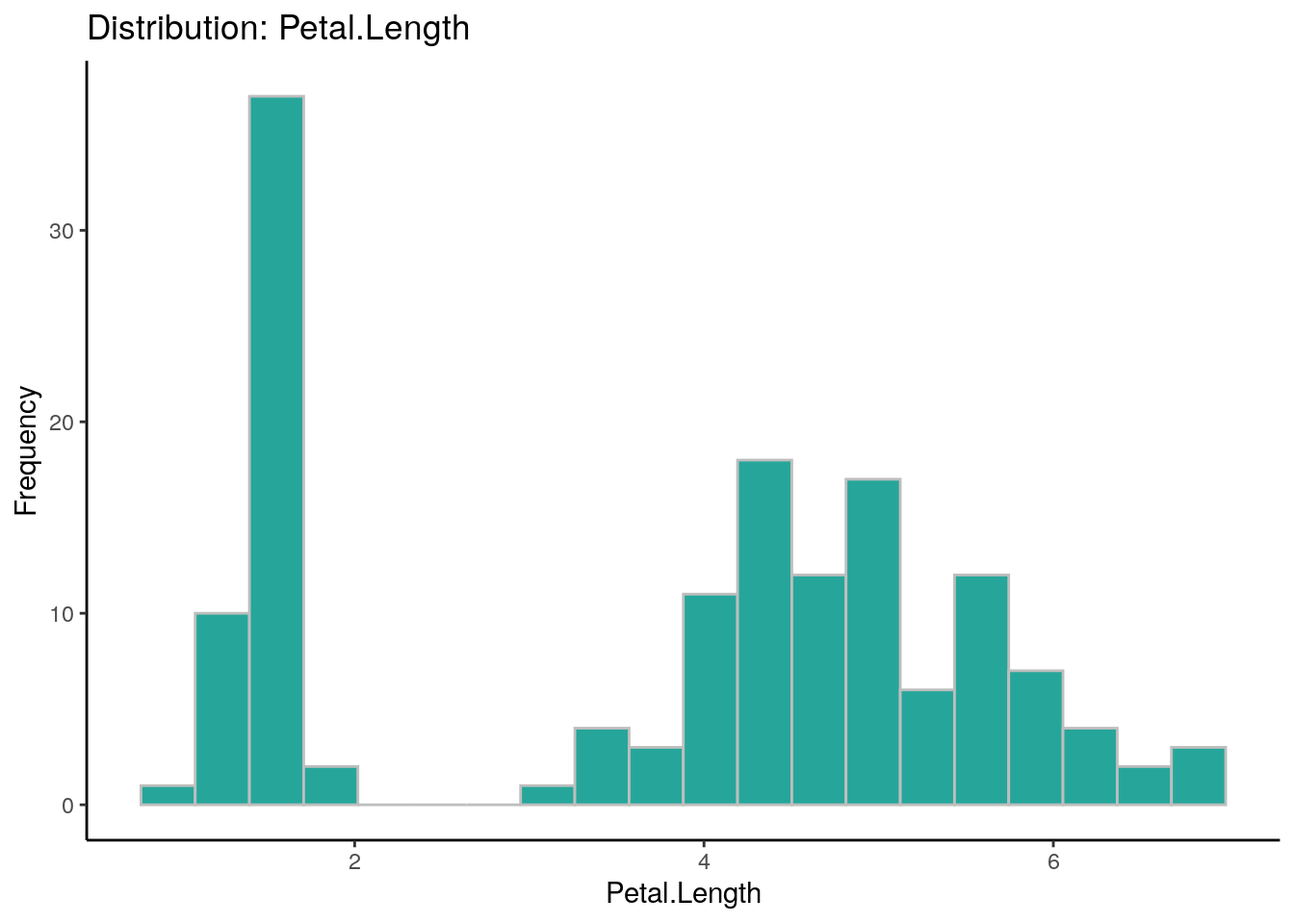
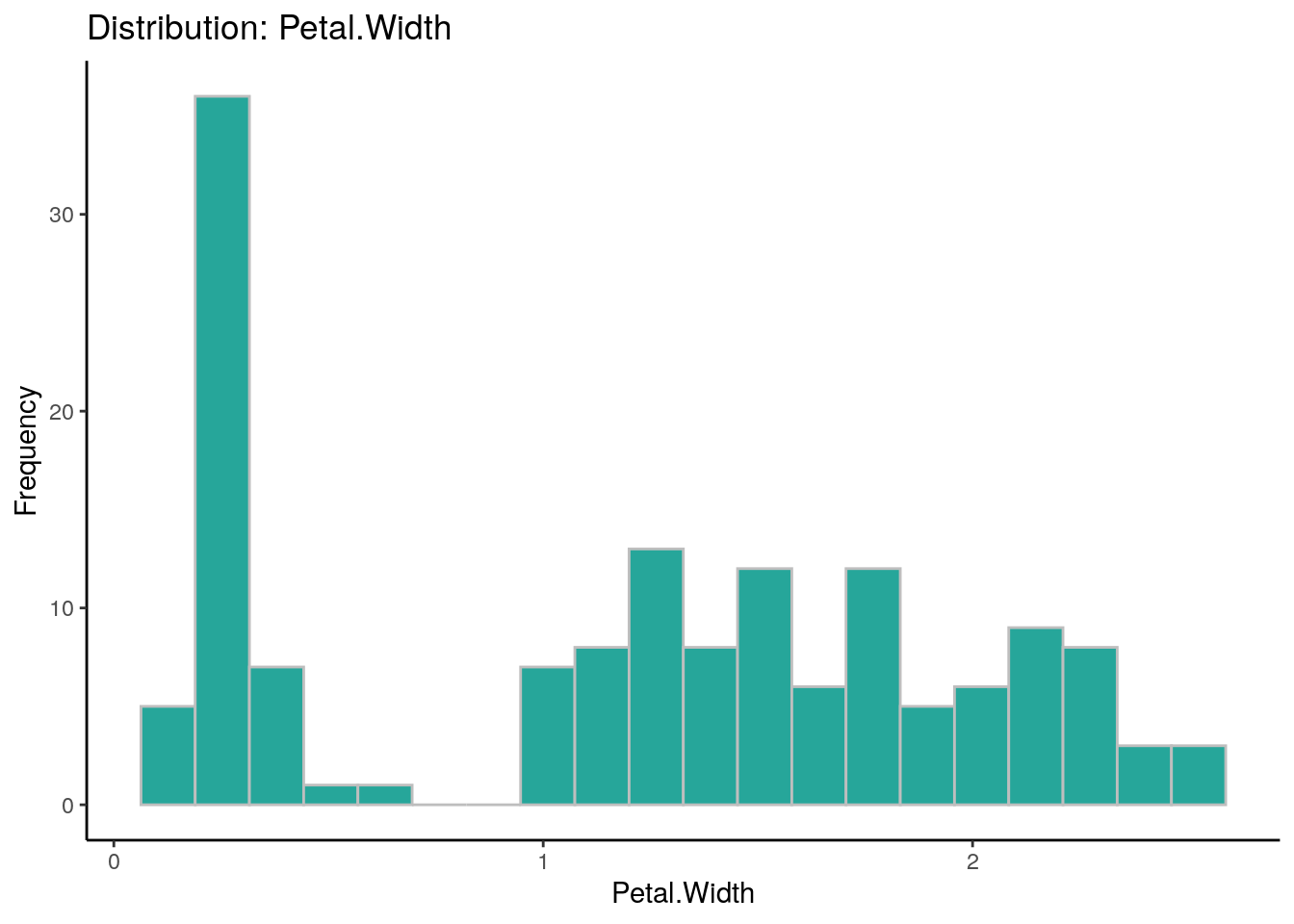
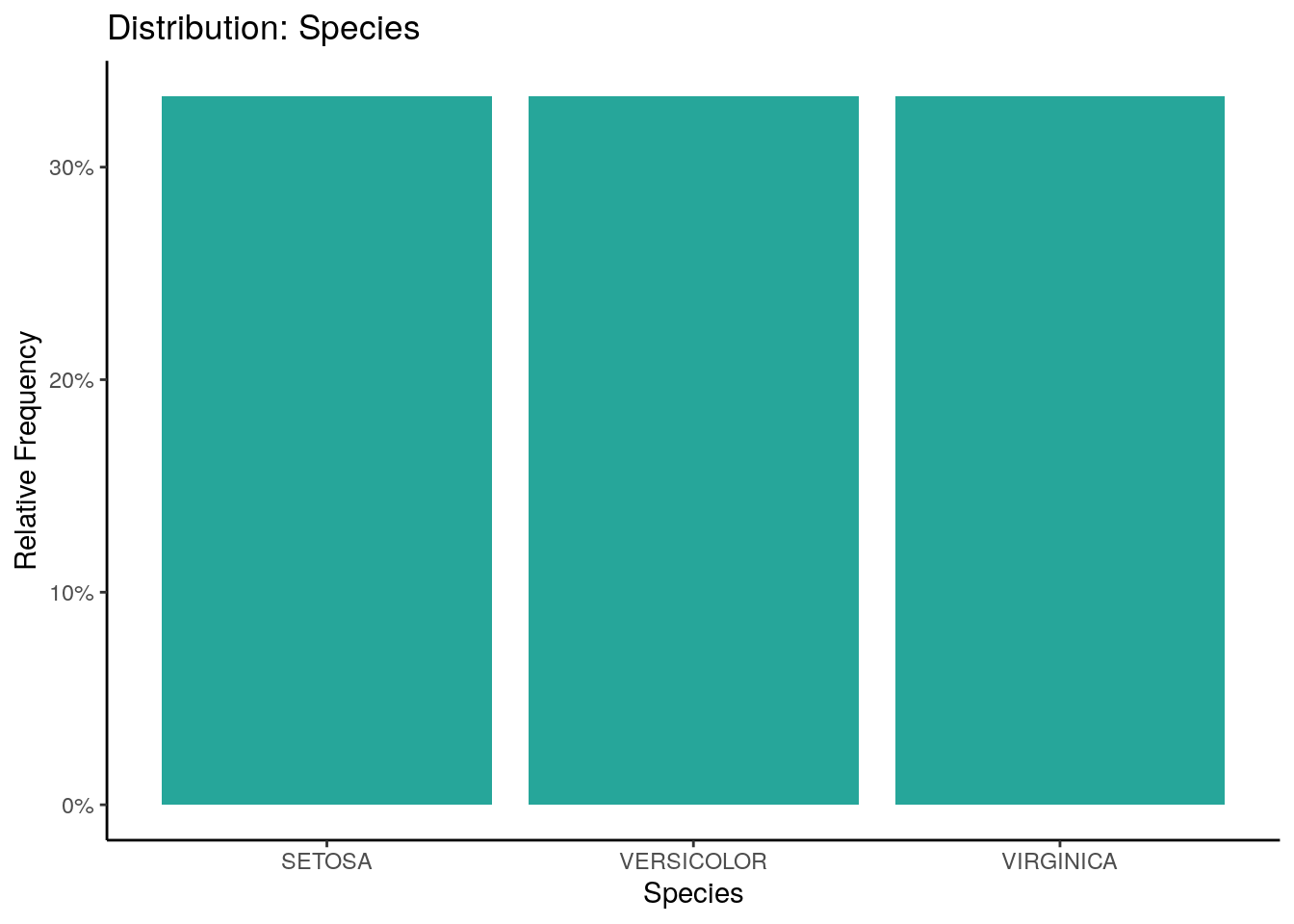
# Cada uno de los parámetro para el EDA automático (Analisis exploratorio de datos) es personalizable
overview_1$Feature## [1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"overview_1$FeatureClass## [1] "numeric" "numeric" "numeric" "numeric" "character"overview_1$FeatureType## [1] "Continuous" "Continuous" "Continuous" "Continuous" "Categorical"overview_1$PercentageMissing## [1] 0 0 0 0 0overview_1$PercentageUnique## [1] 23.33 15.33 28.67 14.67 2.00overview_1$ConstantFeature## [1] "No" "No" "No" "No" "No"overview_1$LowerOutliers## [1] 0 1 0 0 0overview_1$UpperOutliers## [1] 0 3 0 0 0overview_1$ImputationValue## [1] "5.8" "3" "4.35" "1.3" "SETOSA"overview_1$FirstQuartile## [1] 5.1 2.8 1.6 0.3 0.0overview_1$Median## [1] 5.80 3.00 4.35 1.30 0.00overview_1$UpperOutlierValue## [1] 8.35 4.05 10.35 4.05 0.00overview_1$LowerOutlierValue## [1] 3.15 2.05 -3.65 -1.95 0.00overview_1## Feature Observations FeatureClass FeatureType PercentageMissing
## 1 Sepal.Length 150 numeric Continuous 0
## 2 Sepal.Width 150 numeric Continuous 0
## 3 Petal.Length 150 numeric Continuous 0
## 4 Petal.Width 150 numeric Continuous 0
## 5 Species 150 character Categorical 0
## PercentageUnique ConstantFeature ZeroSpreadFeature LowerOutliers
## 1 23.33 No No 0
## 2 15.33 No No 1
## 3 28.67 No No 0
## 4 14.67 No No 0
## 5 2.00 No No 0
## UpperOutliers ImputationValue MinValue FirstQuartile Median Mean Mode
## 1 0 5.8 4.3 5.1 5.80 5.84 5
## 2 3 3 2.0 2.8 3.00 3.06 3
## 3 0 4.35 1.0 1.6 4.35 3.76 1.4
## 4 0 1.3 0.1 0.3 1.30 1.20 0.2
## 5 0 SETOSA 0.0 0.0 0.00 0.00 SETOSA
## ThirdQuartile MaxValue LowerOutlierValue UpperOutlierValue
## 1 6.4 7.9 3.15 8.35
## 2 3.3 4.4 2.05 4.05
## 3 5.1 6.9 -3.65 10.35
## 4 1.8 2.5 -1.95 4.05
## 5 0.0 0.0 0.00 0.00