4 glm
glm即为广义线性模型。在线性回归中使用lm()函数必须满足因变量正态分布。大概就像身高体重直径之类的值,如果是数量,或者存在不存在这样的是否问题就不是正态分布,要用glm。
4.1 泊松分布
如果因变量是非负整数,比如一天卖出多少包子,一块地有多少虫子之类就用泊松分布。数据species中的Species列为因变量,表示发现的植物种数(非负整数泊松分布),Biomass为生物量,是连续变量。pH是分类变量。
species <- read.table("species.txt", header = T)
head(species)## pH Biomass Species
## 1 high 0.4692972 30
## 2 high 1.7308704 39
## 3 high 2.0897785 44
## 4 high 3.9257871 35
## 5 high 4.3667927 25
## 6 high 5.4819747 29用table()命令可以查看pH分为几档,分别出现了几次。这里可以看到分为了high, low, mid 三档,分别出现30 次。
table(species$pH)##
## high low mid
## 30 30 30split()命令可以把Species按照pH的高中低不同分开。生成一个list of 3。同理Biomass也按照pH不同分成三份。spp[1]是list of 1,还是list。spp[[1]]就变成了数值型变量。画图时要使用数值型变量作为横纵坐标,即spp[[1]]这样的形式。
spp <- split(species$Species, species$pH)
bio <- split(species$Biomass, species$pH)
str(spp[1])## List of 1
## $ high: int [1:30] 30 39 44 35 25 29 23 18 19 12 ...str(spp[[1]])## int [1:30] 30 39 44 35 25 29 23 18 19 12 ...plot一个空框(type=“n”),准备添加图像。横轴画Biomass,纵轴画Species。pH不同使用不同的符号(pch)。
plot(species$Biomass, species$Species, type = "n")
points(bio[[1]], spp[[1]], pch = 16)
points(bio[[2]], spp[[2]], pch = 17)
points(bio[[3]], spp[[3]])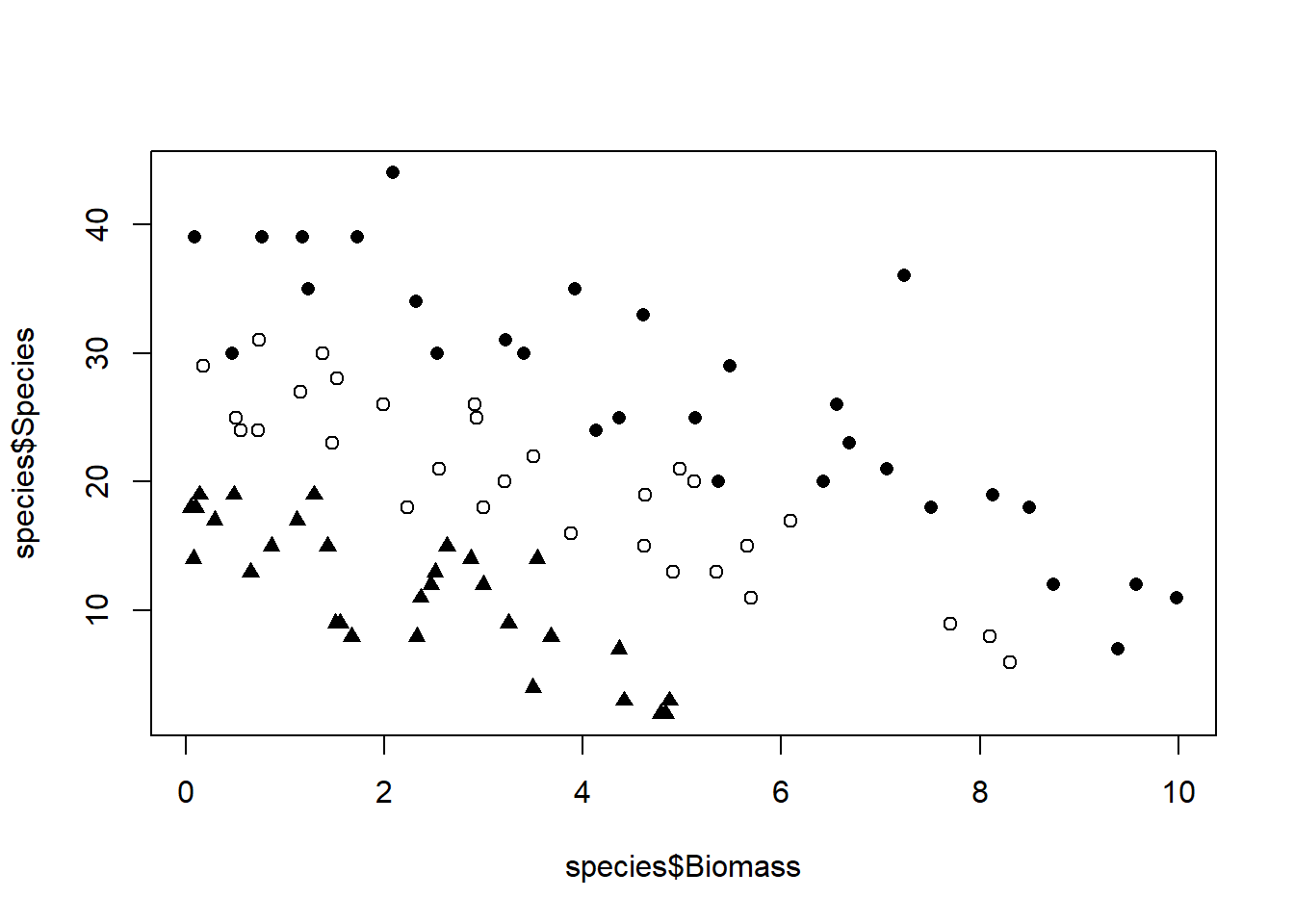
建模。这里poisson也可以写成family = binomial,Biomass*pH相当于Biomass+pH + Biomass:pH,即既分别考虑了Biomass和pH对因变量Species的影响,又考虑了交互项的影响。也就是说,Biomass对Species有影响,pH对Species也有影响。但当Biomass又大,pH又小的时候,Species下降的程度有可能远远小于Biomass和pH单独造成的影响,这种双管齐下时超出的部分就用交互项表示4。
model1 <- glm(Species ~ Biomass * pH, poisson, data = species)林小姝. (2013). (1 封私信 / 8 条消息) 计量经济学中回归模型交叉项是怎么回事?—知乎. https://www.zhihu.com/question/21152574↩︎