9 Desambiguação de dados de usuários.
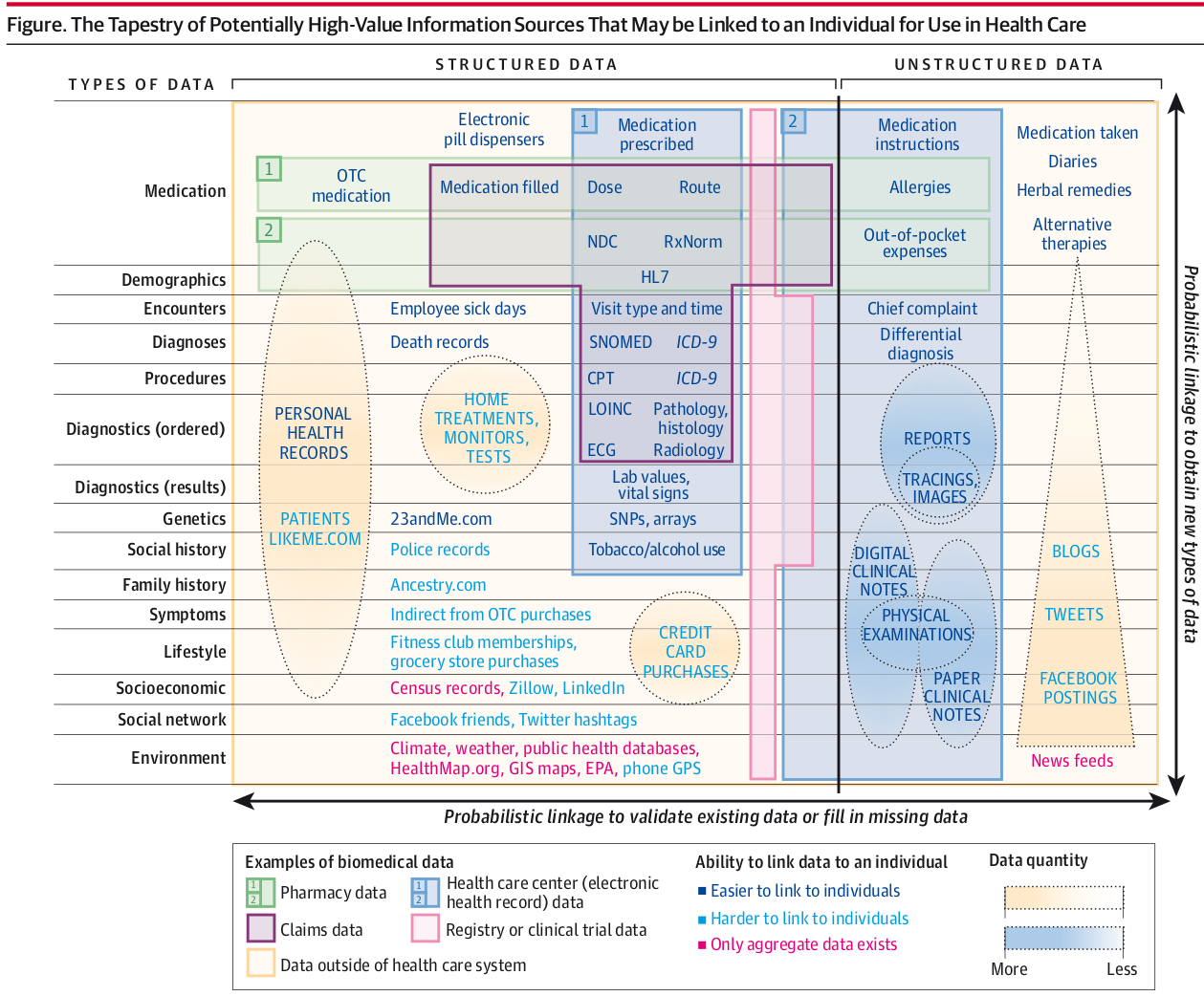
Caption for the picture.
9.1 Pareamento probabilístico onde não há integridade referencial
Na integridade referencial há univocidade do dado.
- Elementos para Deduplicação / Pareamento
- Verificação dos dados, avaliação da semântica
- Deduplicação / Pareamento determinístico
- Deduplicação / Pareamento probabilístico
- Caracterização e escolha de campos de cruzamento
- Determinação da pontuação e escolha do ponto de corte
- Geração de identificador único
9.1.1 To linkage or not to linkage?
Relacionamento de registros (record linkage) é uma técnica que permite identificar registros distintos pertencentes a uma mesma entidade.
9.1.2 Deduplicação x Pareamento
A deduplicação ocorre quando faz-se o pareamento a mesma base de dados.
Exemplo: SIA com SIA, SIH com SIH. Aqui, define-se quais autorizações pertencem ao mesmo indivíduo.
| autorizacao_sia | usuariosus |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 1 |
| 4 | 2 |
| 5 | 3 |
| 6 | 1 |
| 7 | 4 |
Diz-se pareamento, quando o processo é realizado em bases diferentes.
Exemplo: SIH com SINAM, SIA com SIH. Aqui, define-se grupos de autorizações de sistemas distintos para o mesmo indivíduo.
| autorizacao_sih | usuariosus |
|---|---|
| 1 | 3 |
| 2 | 4 |
| 3 | 5 |
| 4 | 6 |
| 5 | 7 |
| 6 | 8 |
| autorizacao_sia | usuariosus |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 1 |
| 4 | 2 |
| 5 | 3 |
| 6 | 1 |
| 7 | 4 |
9.1.3 Determinístico x Probabilístico
O relacionamento determinístico considera como pertencentes à mesma entidade os registros cuja chave é unívoca, a qual pode ser composta de um ou mais identificadores.
O relacionamento probabilítico compara os registros em pares e os classifica em prováveis, improváveis ou duvidosos.
9.1.4 Tarefas do relacionamento de registros
- Padronização de registros
- Grande quantidade de registros
- Variações de campos entre as bases
9.1.5 Padronização de registros
Eleva a probabilidade de campos equivalentes serem identificados como tais pelo relacionamento.
- Etapas:
- Limpeza
- Padronização
- Divisão dos identificadores em termos (parsing)
9.1.5.1 Limpeza
- Etapa mais trabalhosa e crítica.
- Busca por inconsistências dificultam o relacionamento:
- erros de preenchimento
- dados incompletos ou ausentes
Exemplo: - em campos de nomes - remover eventuais caracteres especiais - remover " DE “,” DA “,” DO “,” DOS “,” DAS “,” E " - datas - remover datas superiores a atual - remover datas muito anteriores a atual (por exemplo, do século XIX) - verificar se a data é válida (30/02/2015)
Alternativa: separar nome e sobrenome, data em dia, mês e ano.
A freqüência de campos incompletos modifica diretamente a probabilidade de obtenção de pares, especialmente no caso de bases de dados dependente de poucos identificadores para o seu pareamento.
9.1.5.2 Padronização
Codificar os campos em formato comum para sua comparação, de forma que esta codificação seja consistente.
Exemplo: Converter “São José do Vale do Rio Preto” em “3305158” conforme IBGE.
Eliminação de entradas fora de escopo e a verificação da integridade das bases.
Exemplo: “S. José do Vale do Rio Preto”
- Divisão dos identificadores em termos (parsing)
A divisão em termos consiste na subdivisão das variáveis, de forma a serem mais facilmente comparadas por um procedimento automático, implementado em computador.
Exemplo: Subdivisão de endereços em logradouro, número e complemento, subdivisão de nomes em nome e sobrenome
9.1.6 Custo computacional
Em um tempo de execução \(n^2\), quando \(n\) dobra, o tempo de execução aumenta 4 vezes;
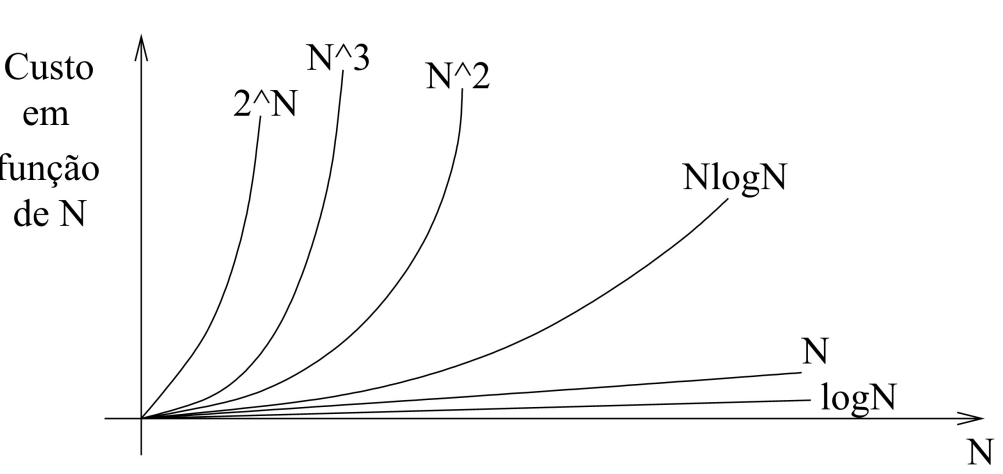
Caption for the picture.
9.1.7 Indexação
A indexação, sem dúvida, é a maior vantagem oferecida pelos bancos de dados.
Sem a indexação, uma busca é linear.
Com a indexação, o SGBD recupera mais rapidamente o registro.
Cenário: Deduplicação SIA, 2000 a 2007
4.258.570 de apacs 3.418.795 de apacs de medicamentos
Resultou em 547.278 pacientes. 2.488.195 de apacs aproveitadas (72,7%)
Combinação de 3.418.795 registros dois a dois:
\[C^n_k=\binom{n}{k}=\frac{n!}{k!(n-k)}=\frac{3.418.795!}{2\times1\times(3.418.795-2)}=\]
\[\frac{3.418.795\times3.418.794\times3.418.793!}{2\times3.418.793!}=\frac{3.418.795\times3.418.794}{2}=5.844.077.916.615\]
4.258.570 de apacs 3.418.795 de apacs de medicamentos
Resultou em 547.278 pacientes. 2.488.195 de apacs aproveitadas (72,7%)
9.1.8 Blocagem
Reduz o número de comparações comparando, em geral, pares com maior probabilidade de equivalência.
- concordassem em primeiro nome, sobrenome e município de residência;
- concordassem em primeiro nome, sobrenome e data de nascimento;
- concordassem em CPF;
- concordassem em data de nascimento, município de residência e sexo.
Pares que atendessem a mais de um critério foram comparados somente uma vez.
A utilização de quatro critérios diferentes objetivou reduzir a probabilidade de um par verdadeiro não ser encontrado devido a um erro de preenchimento das variáveis de blocagem.

Caption for the picture.
Soundex
CONCEIAO e CONCEICAO
tem uma concordância de 0,98, considerando-se equivalentes.
Consulta para identificar o valor do soundex:
SELECT SOUNDEX(campo) FROM tabela;Consulta para armazenar o valor.
UPDATE `tabela` SET `campo_soundex`=SOUNDEX(campo);9.2 Exercício
Vamos realizar uma deduplicação de registros usando consultas SQL.
Use o arquivo “nomes_deduplicacao.csv”.
| autorizacao | NOME_COMPLETO | estado | nascimento_dia | nascimento_mes | nascimento_ano |
|---|---|---|---|---|---|
| 1 | ABNER PEREIRA DA SILVA | MG | 8 | 3 | 2088 |
| 2 | ACYR SALGARELLO | MG | 18 | 8 | 1941 |
| 3 | ADALBERTO MORAIS NETTO | MG | 8 | 11 | 2095 |
| 4 | ADALGISA CORREIA LACERDA | MG | 7 | 2 | 1983 |
| 5 | ADAUTO DE MOURA PAIVA | MG | 6 | 6 | 1910 |
| 6 | ADILMA BRITO PEREIRA DE SANTANA | NA | NA | NA | |
| 7 | ADILSON CARLOS LUIZ | SP | 8 | 2 | 1983 |
| 8 | ADILSON FERREIRA DE SOUZA | MG | 23 | 9 | 1936 |
| 9 | ADIRLAINE SUYENE DA TERRA CALDEIRA VAZ | MG | 29 | 8 | 2058 |
- Crie uma coluna para o primeiro nome.
- Crie uma coluna para o último nome.
- Crie uma coluna para o soundex do primeiro nome.
- Crie uma coluna para o soundex do último nome.
- Se tiver dificuldades use o arquivo “nomes_deduplicacao.sql”. O arquivo contempla as etapas 1 a 4.
-- adiciona coluna
ALTER TABLE `nomes_deduplicacao`
ADD `primeiro_nome` VARCHAR(50) NULL AFTER `nascimento_ano`;
-- atualiza com o primeiro nome
UPDATE `nomes_deduplicacao`
SET `primeiro_nome`=substring_index(`NOME_COMPLETO`, " ", 1);
-- atualiza com o ultimo nome
UPDATE `nomes_deduplicacao`
SET `ultimo_nome`=substring_index(`NOME_COMPLETO`, ' ', -1);
-- exemplo de soundex
UPDATE `nomes_deduplicacao`
set `primeiro_nome_soundex`=soundex(`primeiro_nome`),
`ultimo_nome_soudex`=soundex(`ultimo_nome`);
-- exemplo de limpeza
UPDATE `nomes_deduplicacao`
SET NOME_COMPLETO = REPLACE(NOME_COMPLETO, " DE ", " ")
FROM `nomes_deduplicacao`
- Faça um pareamento com todos os pares possíveis usando o estado na blocagem. Crie a tabela com CREATE TABLE.
- Insira campos para atribuir pontuação de correspondência, por exemplo, 10 pontos quando o primeiro nome for equivalente e 5 pontos quando o soudex for equivalente.
- Insira um campo para armazenar a soma dos pontos e consulte do maior para o menor usando ORDER BY.
- Defina um valor de corte.
-- cria tabela com todos os pares possíveis
DROP table IF EXISTS pareamento;
create table pareamento as
SELECT A.autorizacao as autorizacaoA,
B.autorizacao as autorizacaoB,
A.NOME_COMPLETO as NOME_COMPLETO_A,
B.NOME_COMPLETO as NOME_COMPLETO_B
FROM `nomes_deduplicacao` A,
nomes_deduplicacao B
WHERE A.autorizacao < B.autorizacao
AND A.estado = B.estado;
-- adiciona campos para fazer a pontuacao
ALTER TABLE `pareamento`
ADD `primeiro_nome` INT NOT NULL DEFAULT '0' AFTER `autorizacaoB`,
ADD `ultimo_nome` INT NOT NULL DEFAULT '0' AFTER `primeiro_nome`,
ADD `primeiro_nome_soundex` INT NOT NULL DEFAULT '0' AFTER `ultimo_nome`,
ADD `ultimo_nome_soundex` INT NOT NULL DEFAULT '0' AFTER `primeiro_nome_soundex`,
ADD `ano_nascimento` INT NOT NULL DEFAULT '0' AFTER `ultimo_nome_soudex`;
-- atualiza a pontuacao
UPDATE
pareamento A,
nomes_deduplicacao B,
nomes_deduplicacao C
SET
A.primeiro_nome=10
where A.autorizacaoA=B.autorizacao
and A.autorizacaoB=C.autorizacao
and C.primeiro_nome=B.primeiro_nome
UPDATE
pareamento A,
nomes_deduplicacao B,
nomes_deduplicacao C
SET
A.ultimo_nome=10
where A.autorizacaoA=B.autorizacao
and A.autorizacaoB=C.autorizacao
and C.ultimo_nome=B.ultimo_nome;
UPDATE
pareamento A,
nomes_deduplicacao B,
nomes_deduplicacao C
SET
A.primeiro_nome_soundex=10
where A.autorizacaoA=B.autorizacao
and A.autorizacaoB=C.autorizacao
and C.primeiro_nome_soundex=B.primeiro_nome_soundex;
UPDATE
pareamento A,
nomes_deduplicacao B,
nomes_deduplicacao C
SET
A.ultimo_nome_soundex=10
where A.autorizacaoA=B.autorizacao
and A.autorizacaoB=C.autorizacao
and C.ultimo_nome_soundex=B.ultimo_nome_soundex;
SELECT `autorizacaoA`, `autorizacaoB`,
(`primeiro_nome` + `ultimo_nome` + `primeiro_nome_soundex` + `ultimo_nome_soundex`) x
ORDER BY 3 DESC;