# librerias necesarias
library(readr)
library(ggplot2)3 Visualización de datos
3.1 Visualización de datos univariados
El primer paso en cualquier análisis de datos integral es explorar cada variable de importación por separado. Los gráficos univariados trazan la distribución de datos de una sola variable. La variable puede ser cualitatativa (género, tipo de trabajo) o cuantitativa (edad, peso, ingresos).
Se usará Stroke Prediction Dataset extraido de “kaggle.com/datasets/fedesoriano/stroke-prediction-dataset” y subido al github.
# cargamos el dataset a explorar
url <- "https://raw.githubusercontent.com/JulioArapa/mypackage/main/healthcare-dataset-stroke-data.csv"
heart <- read.csv(url)3.1.1 Cualitativas
El género, estado de tabaquismo o el tipo de residencia de los pacientes son variables cualitativas. La distribución de una sola variable cualitativa generalmente se traza con un gráfico de barras, un gráfico circular, entre otros.
3.1.1.1 Gráfico de barras
Se usará el gráfico de barras para mostrar la distribución de los pacientes por su estado de tabaquismo.
# trazo de la distribución por estado de tabaquismo
ggplot(heart, aes(x = smoking_status)) +
geom_bar()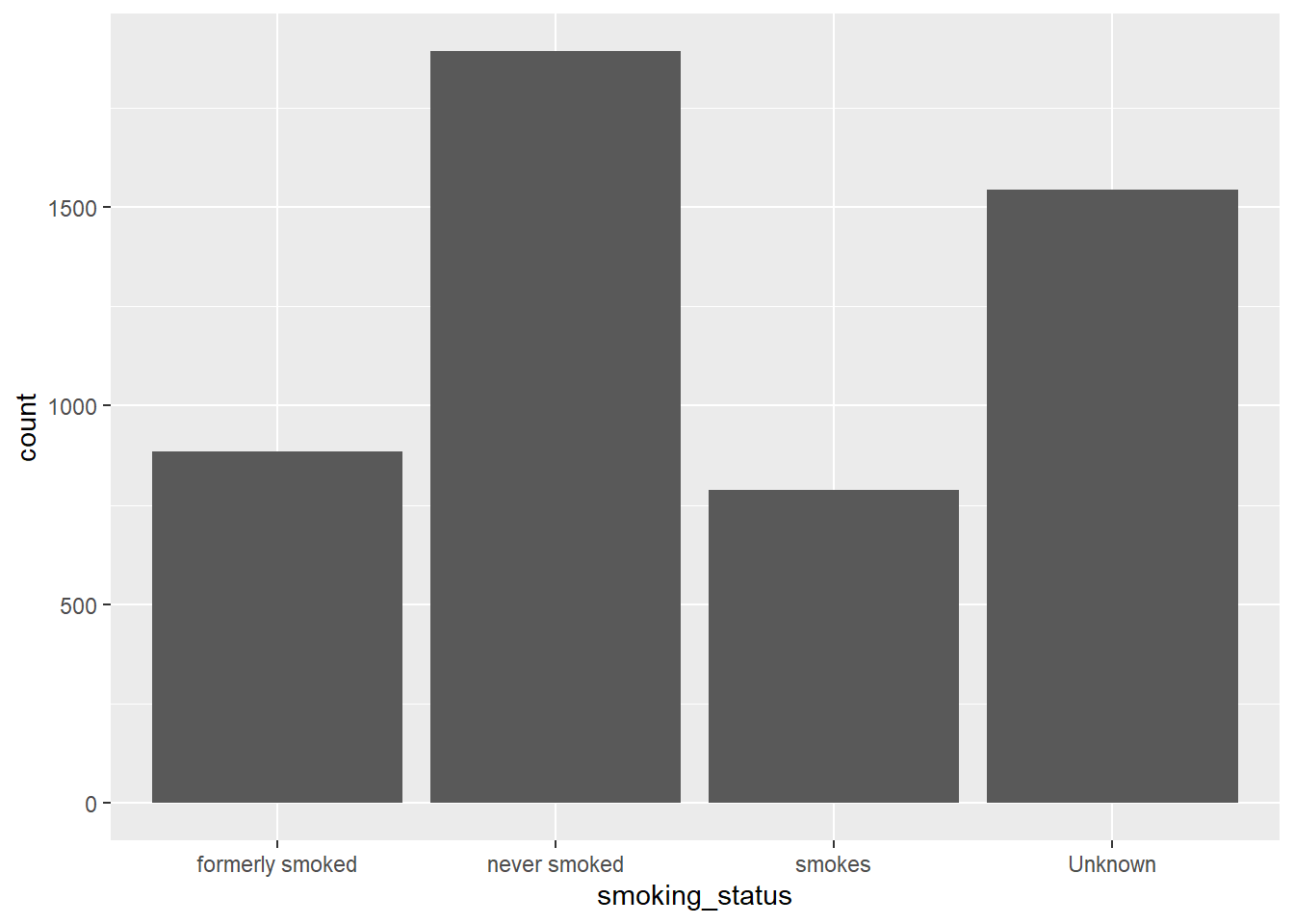
Podemos notar que la mayor cantidad de pacientes nunca ha fumado seguido por los que se desconoce su estado.
Se puede modificar los colores de relleno y borde de la barra, las etiquetas de trazado y el título agregando opciones a la función geom_bar. En ggplot2, el parámetro de relleno se usa para especificar el color de áreas como barras, rectángulos y polígonos.
# Trazo de la distribución del estado de tabaquismo con colores y etiquetas
ggplot(heart, aes(x=smoking_status)) +
geom_bar(fill = "cornflowerblue",
color="black") +
labs(x = "Estado de tabaquismo",
y = "Frecuencia",
title = "Pacientes por estado de tabaquismo")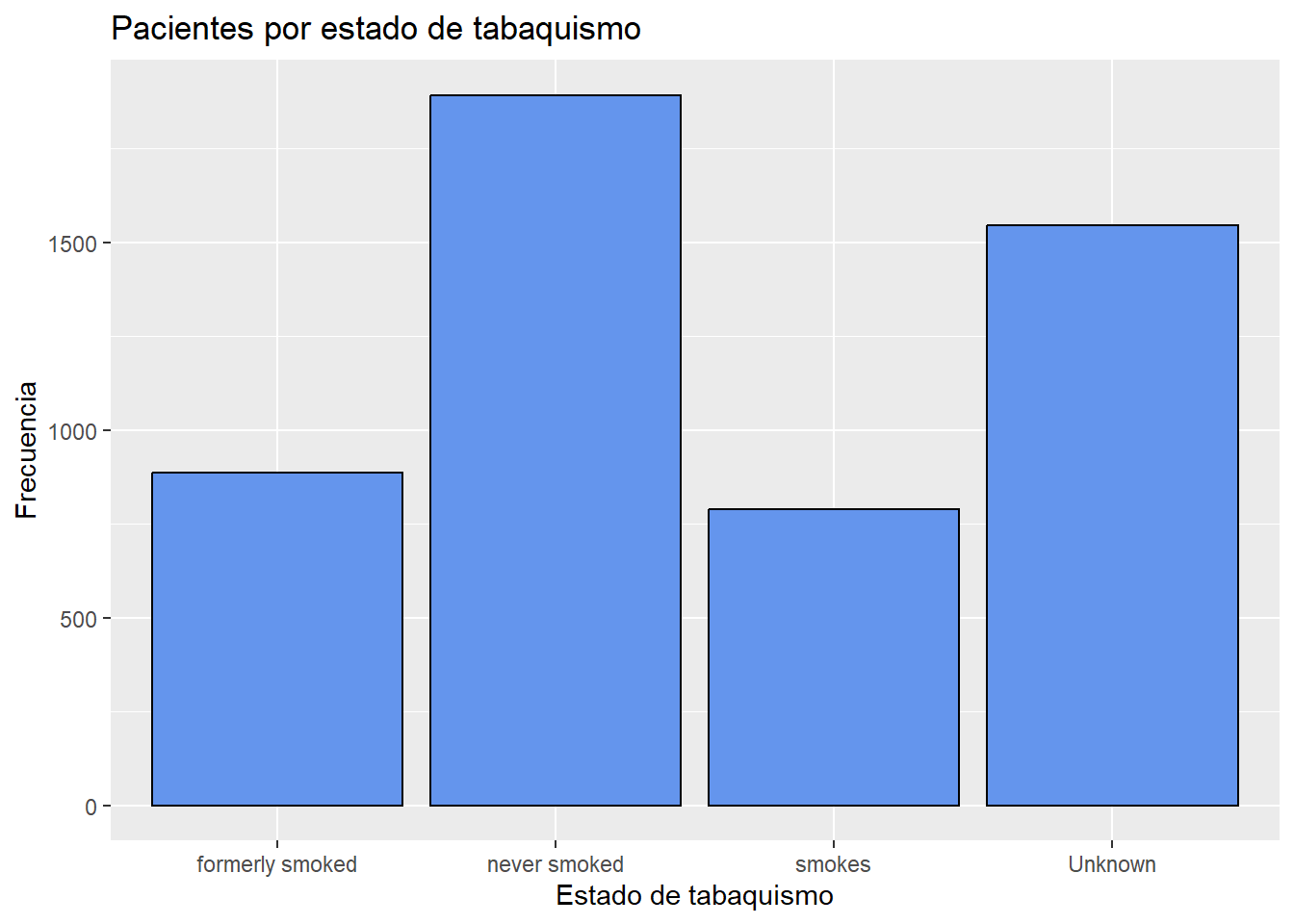
Porcentajes
Las barras pueden representar porcentajes en lugar de recuentos. Para los gráficos de barras, el código aes(x=race) es en realidad un atajo para aes(x = race, y = after_stat(count)), donde count es una variable especial que representa la frecuencia dentro de cada categoría. Puede utilizar esto para calcular porcentajes especificando y variable explícitamente.
# Trazo de la distribución como porcentaje
ggplot(heart,
aes(x = smoking_status, y = after_stat(count/sum(count)))) +
geom_bar(fill = "cornflowerblue",
color="black") +
labs(x = "Estado de tabaquismo",
y = "Porcentaje",
title = "Pacientes por estado de tabaquismo") +
scale_y_continuous(labels = scales::percent)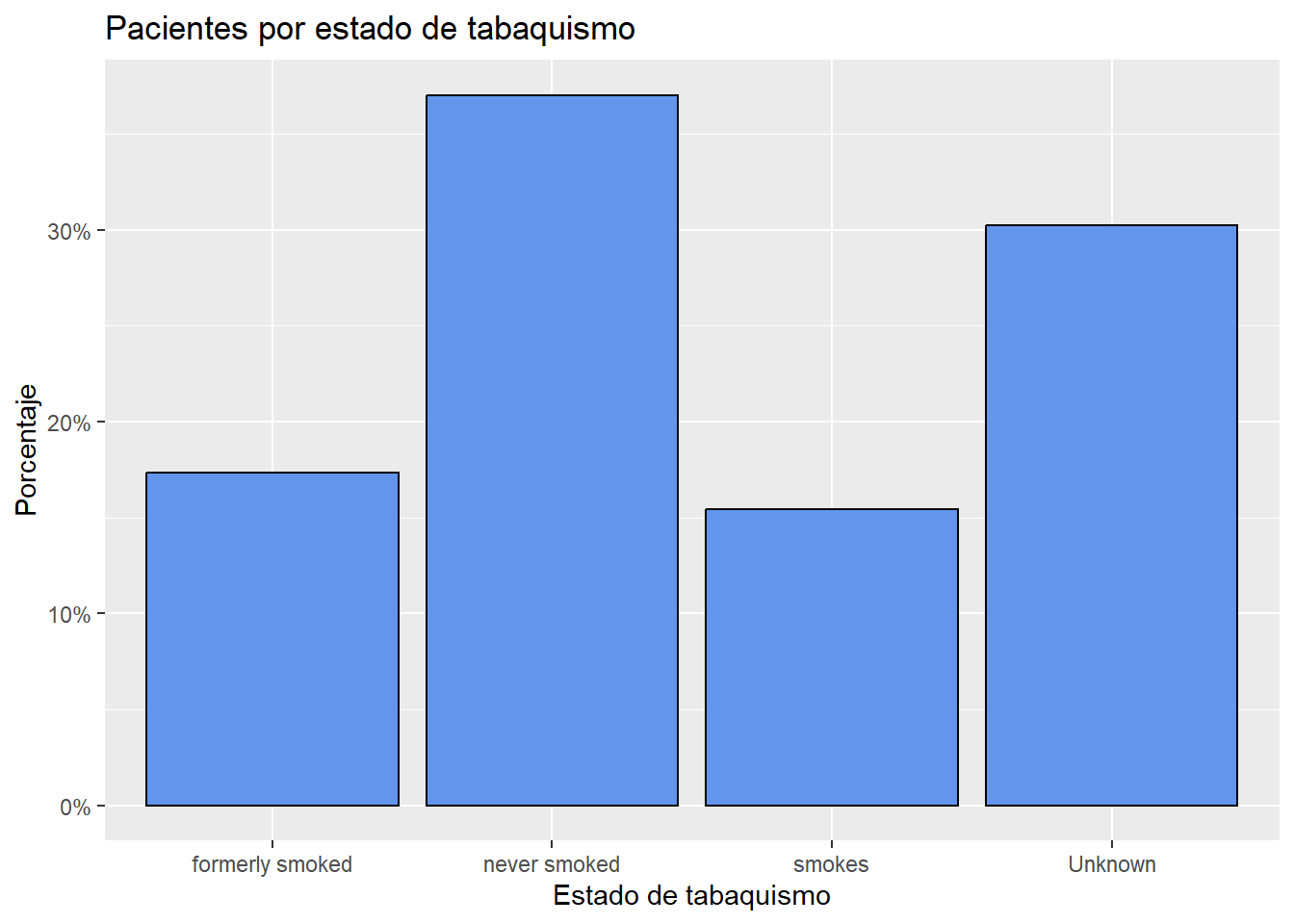
En el código anterior, el paquete scales se utiliza para agregar símbolos % a las etiquetas del eje y .
Clasificar categorias
A menudo resulta útil ordenar las barras por frecuencia. En el código siguiente, las frecuencias se calculan explícitamente. Luego, la función reorder se utiliza para ordenar las categorías por frecuencia. La opción stat="identity" le dice a la función de trazado que no calcule los recuentos, porque se suministran directamente.
# Se calcula el número de participantes en cada categoria de la variables estado de tabaquismo
suppressPackageStartupMessages(library(dplyr))
library(dplyr)
plotdata <- heart %>%
count(smoking_status)
plotdata smoking_status n
1 Unknown 1544
2 formerly smoked 885
3 never smoked 1892
4 smokes 789Este nuevo conjunto de datos se utiliza luego para crear el gráfico.
# Gráfico de barras en orden ascendente
ggplot(plotdata,
aes(x = reorder(smoking_status, n), y = n)) +
geom_bar(stat="identity",fill = "cornflowerblue",
color="black") +
labs(x = "Estado de tabaquismo",
y = "Frecuencia",
title = "Pacientes por su estado de tabaquismo")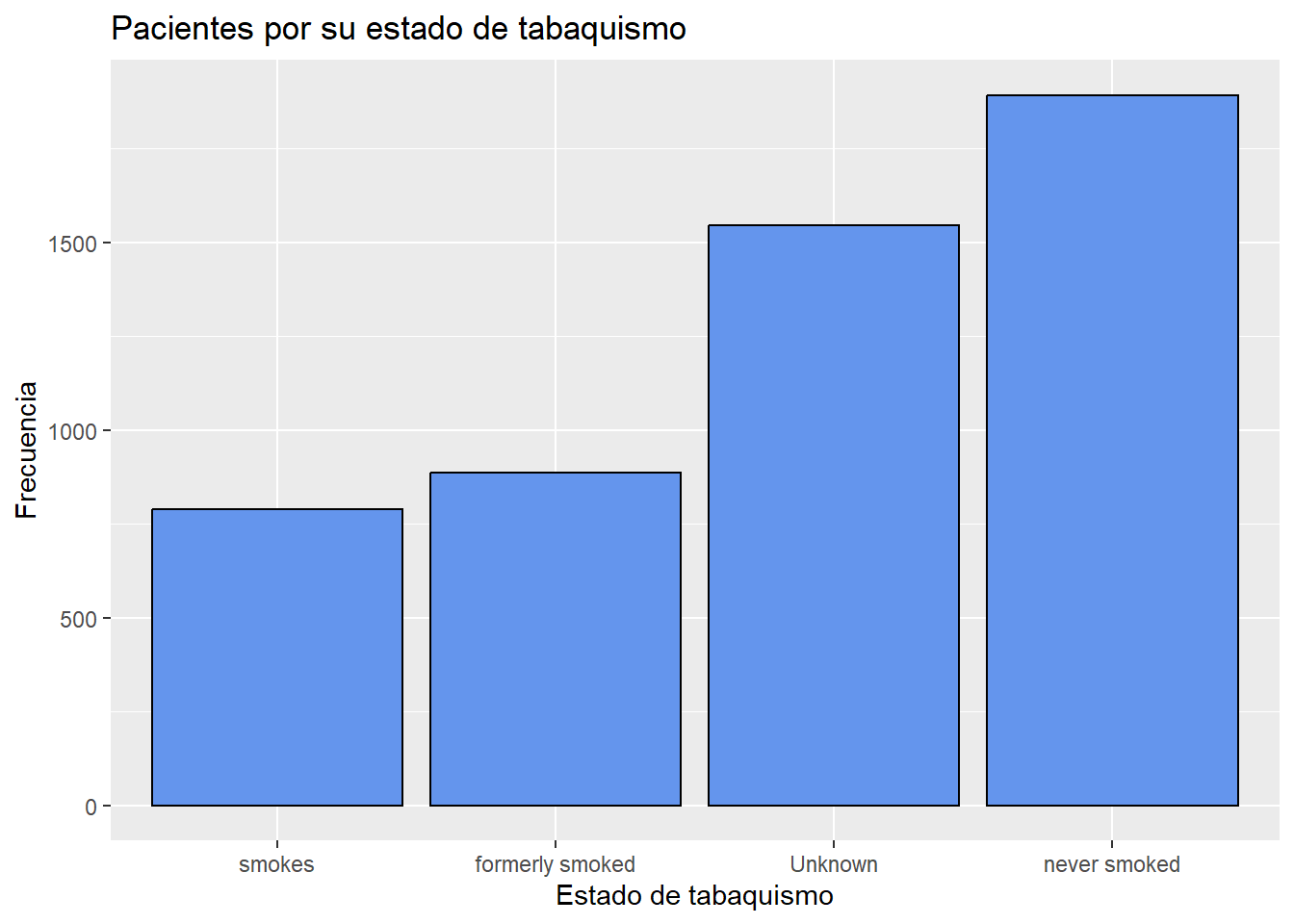
Las barras del gráfico están ordenadas de forma ascendente. Se usa reorder(race, -n) para ordenar en orden descendente.
Barra de etiquetado
Si deseamos etiquetar cada barra con su valor numérico
# Trazo de barras ordenado y con etiqueta numérica
ggplot(plotdata,
aes(x = reorder(smoking_status, n), y = n)) +
geom_bar(stat="identity",fill = "cornflowerblue",
color="black") +
geom_text(aes(label = n), vjust=-0.5) +
labs(x = "Estado de taquismo",
y = "Frecuencia",
title = "Pacientes por su estado de tabaquismo")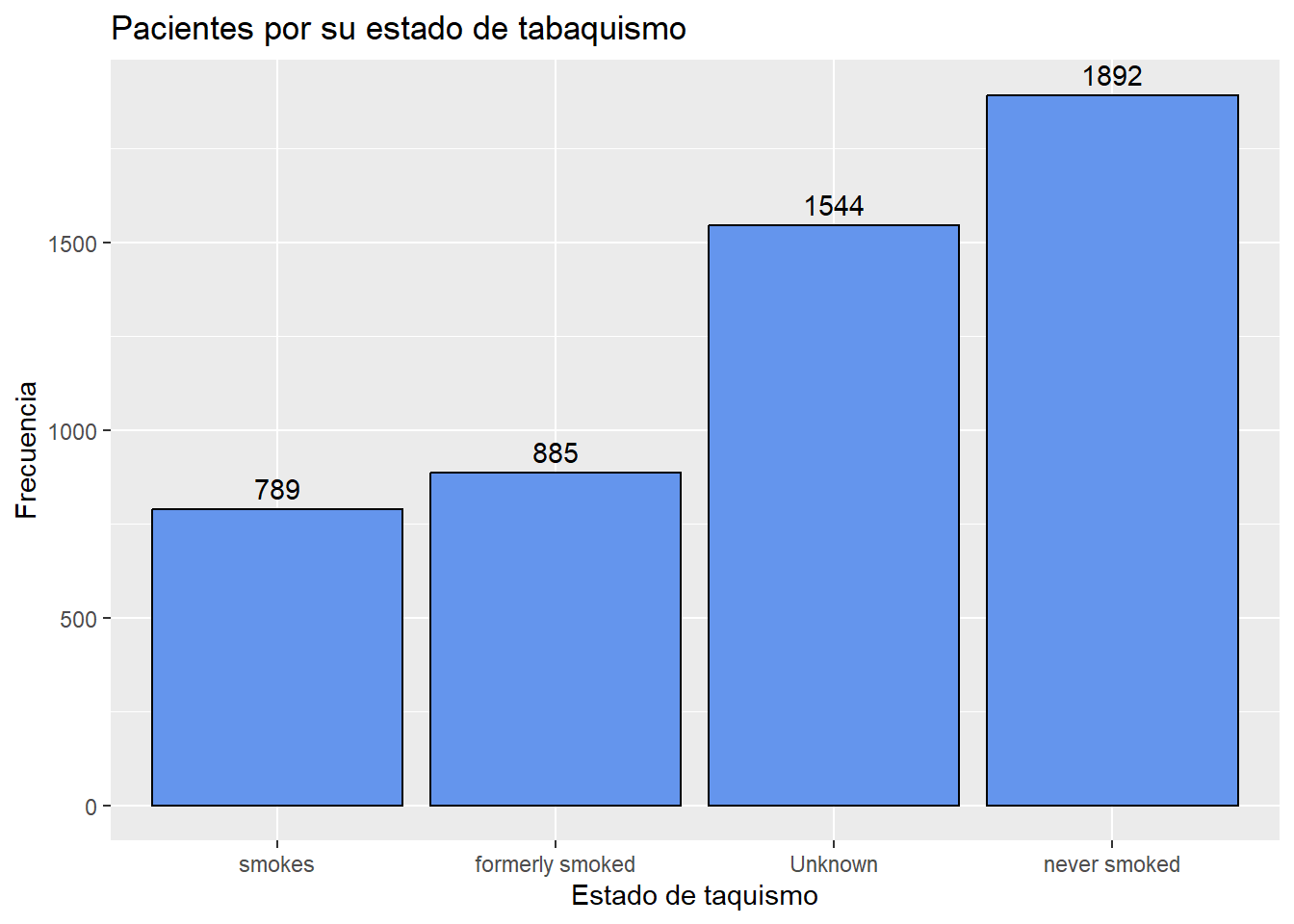
Aquí geom_text agrega las etiquetas y vjust controla la justificación vertical.
Ahora el signo menos en reorder(race, -pct) se utiliza para ordenar las barras en orden descendente.
library(dplyr)
suppressPackageStartupMessages(library(scales))
library(scales)
plotdatas <- heart %>%
count(smoking_status) %>%
mutate(pct = n / sum(n),
pctlabel = paste0(round(pct*100), "%"))
# Trazo de barras como porcentaje,
# en orden descendente con etiquetas
ggplot(plotdatas,
aes(x = reorder(smoking_status, -pct), y = pct)) +
geom_bar(stat="identity", fill="indianred3", color="black") +
geom_text(aes(label = pctlabel), vjust=-0.25) +
scale_y_continuous(labels = percent) +
labs(x = "Estado de tabaquismo",
y = "Porcentaje",
title = "Pacientes por su estado de tabaquismo")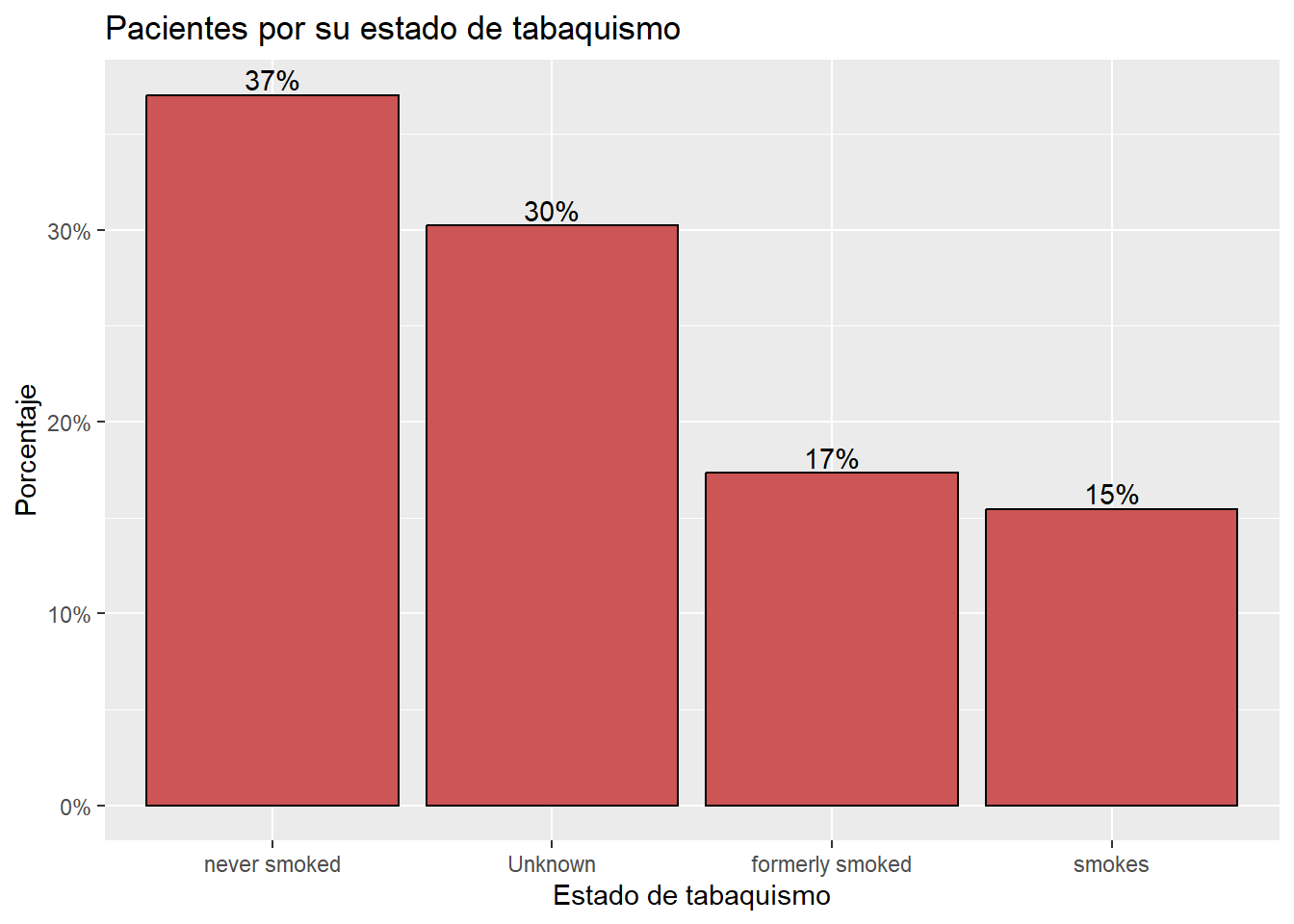
Etiquetas superpuestas
Las etiquetas de valores cualitativos pueden superponerse si hay muchas categorías o las etiquetas son largas.
En este caso, puedes invertir los ejes x e y con la función coord_flip.
# horizontal bar chart
ggplot(heart, aes(x = work_type)) +
geom_bar(fill = "cornflowerblue",
color="black") +
labs(x = "",
y = "Frecuencia",
title = "Participantes por su tipo de trabajo") +
coord_flip()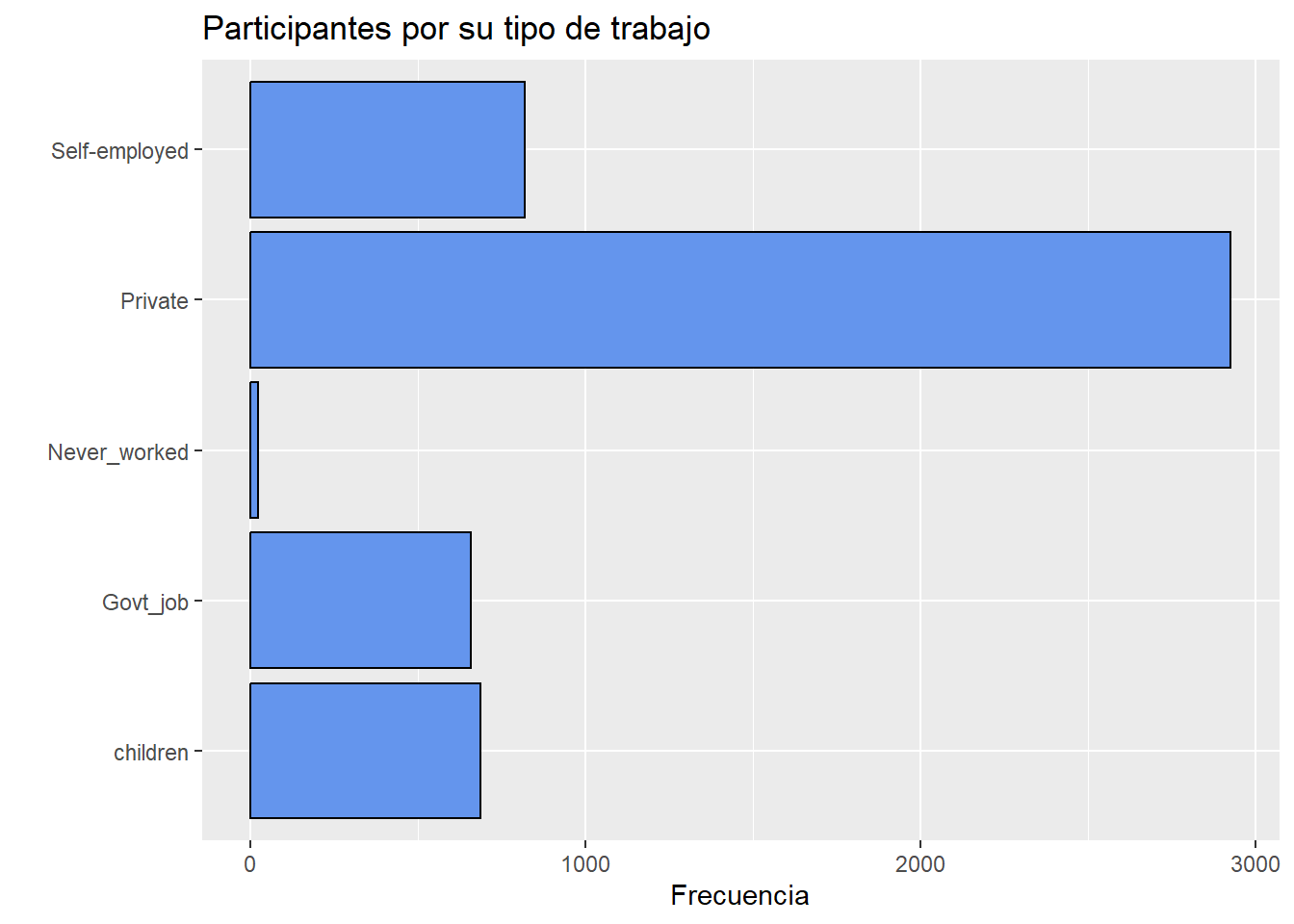
O alternativamente se pueden rotar las etiquetas de los ejes.
# Gráfico de barras con etiquetas rotadas
ggplot(heart, aes(x=work_type)) +
geom_bar(fill="cornflowerblue", color="black") +
labs(x = "",
y = "Frecuencia",
title = "Pacientes por su tipo de trabajo") +
theme(axis.text.x = element_text(angle = 45,
hjust = 1))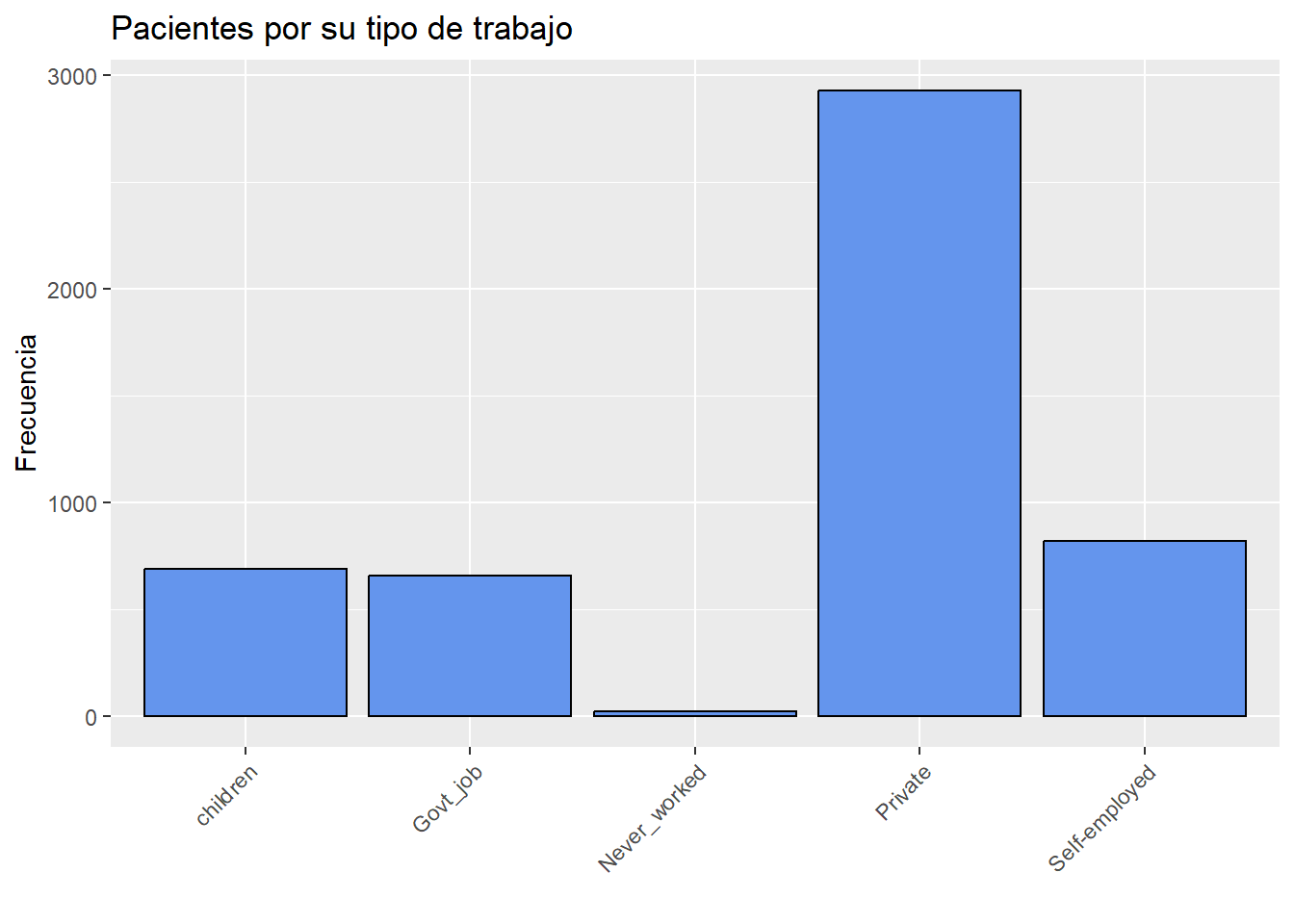
3.1.1.2 Gráfico circular
Se usa para comparar cada categoría con el conjunto (por ejemplo, qué proporción de participantes son hispanos en comparación con todos los participantes) y el número de categorías es pequeño, entonces los gráficos circulares son los adecuados
Se utiliza el paquete tidyverse para calcular el porcentaje de cada tipo de trabajo del dataset que le pusimos “heart”. El código agrupa los datos según la columna “work_type”, cuenta las ocurrencias de cada tipo, quita la agrupación de los datos y luego calcula el porcentaje para cada tipo de trabajo.
suppressPackageStartupMessages(library(tidyverse))
library(tidyverse)
porcentaje_work_type <- heart %>%
group_by(work_type) %>%
count() %>%
ungroup() %>%
mutate(porcentaje = n/sum(n)*100)Se utiliza ggplot2 para crear un gráfico circular. Toma los datos de “porcentaje_work_type” y mapea el porcentaje en el eje y, utilizando el tipo de trabajo para diferenciar las barras. Además, agrega etiquetas de porcentaje en cada barra.
La función geom_bar(stat = "identity") crea las barras y geom_text añade las etiquetas de porcentaje. coord_polar(theta = "y") transforma el gráfico de barras en un gráfico circular.
theme_void() elimina elementos como ejes y leyendas, dejando solo las barras circulares. scale_fill_brewer(palette = "Blues") establece la paleta de colores.
# Gráfico de pastel para "porcentaje_work_type"
ggplot(data=porcentaje_work_type,
aes(x=1,y=porcentaje, fill=work_type))+
geom_bar(stat="identity")+
geom_text(aes(label=paste0(round(porcentaje,1),"%")),
position=position_stack(vjust=0.5))+
coord_polar(theta = "y")+
theme_void()+
scale_fill_brewer(palette="Blues")+
labs(title = "Porcentaje de la muestra")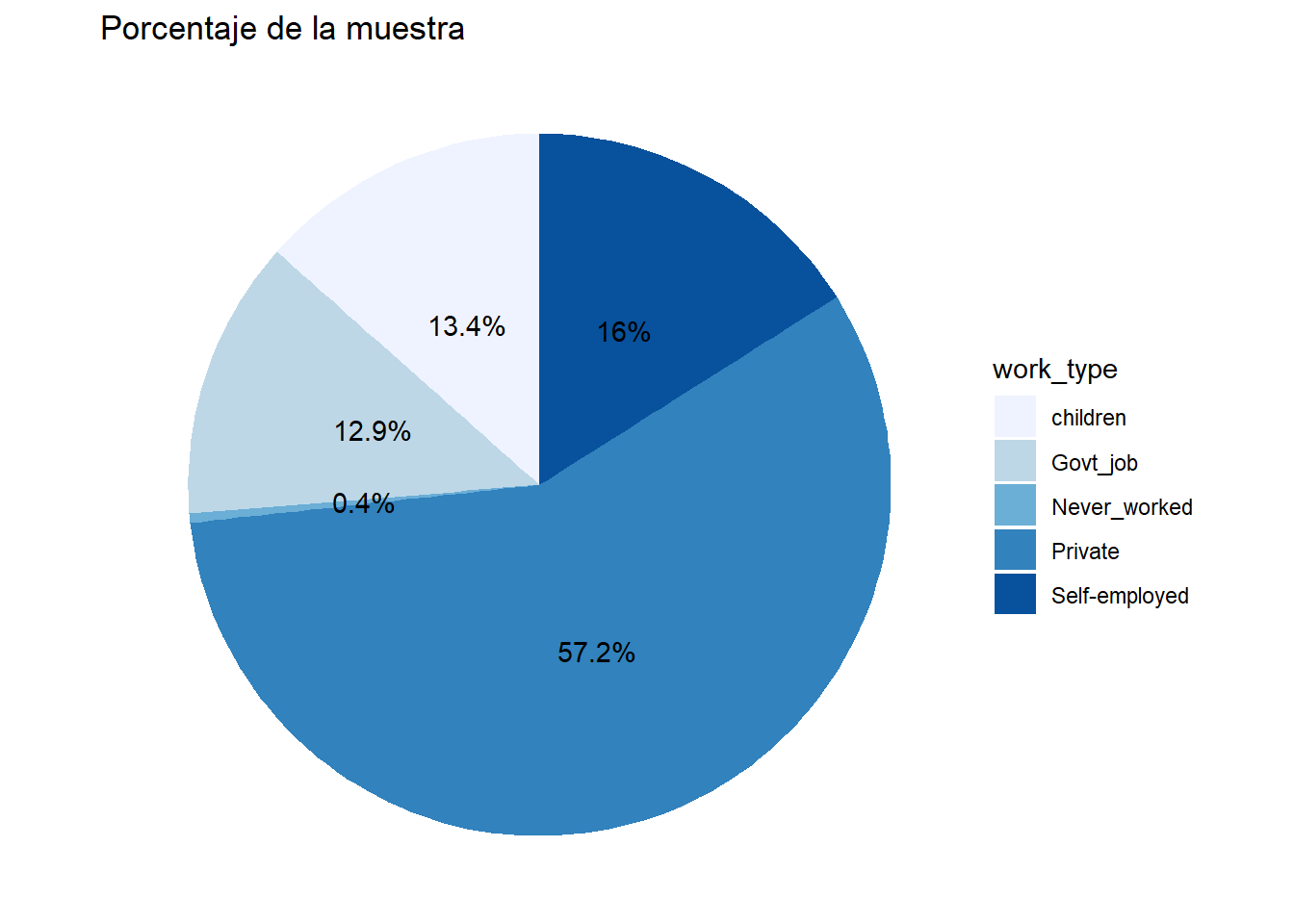
3.1.2 Cuantitativas
La distribución de una única variable cuantitativa generalmente se traza con un histograma, un diagrama de densidad o un diagrama de puntos.
3.1.2.1 Histograma
En un histograma, los valores de una variable generalmente se dividen en rangos adyacentes de igual ancho (llamados bins), y el número de observaciones en cada contenedor se traza con una barra vertical.
# Distribución de la edad usando un histograma
ggplot(heart, aes(x = age)) +
geom_histogram(fill = "cornflowerblue",
color = "white",
bins = 10) +
labs(title="Pacientes por edad",
x = "Edad")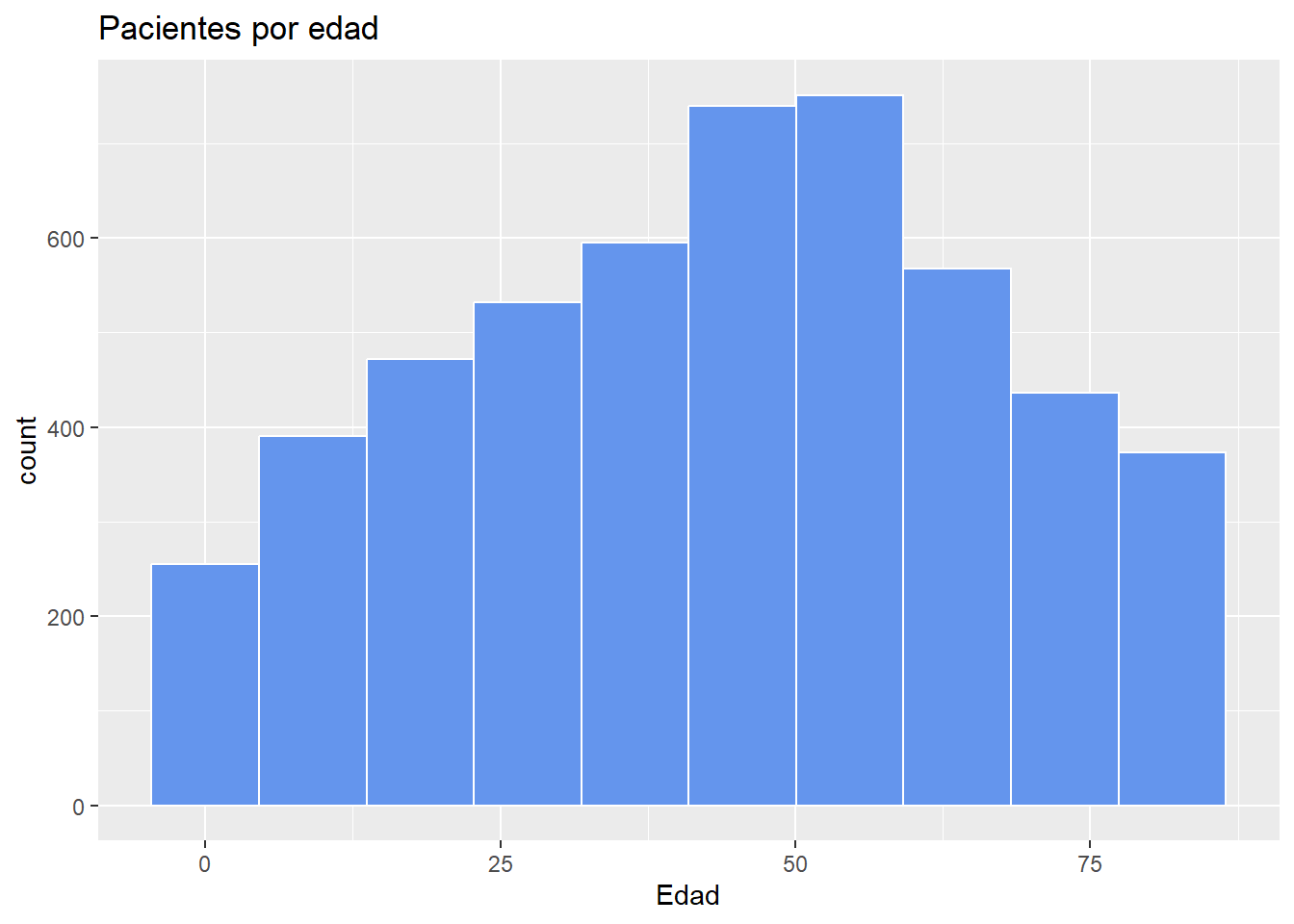
Al igual que con los gráficos de barras, el eje y puede representar recuentos o porcentajes del total.
# Trazo del histograma con porcentajes en el eje y
library(scales)
ggplot(heart,
aes(x = age, y= after_stat(count/sum(count)))) +
geom_histogram(fill = "indianred3",
color = "white",
bins = 10) +
labs(title="Pacientes por edad",
y = "Porcentaje",
x = "Edad") +
scale_y_continuous(labels = percent)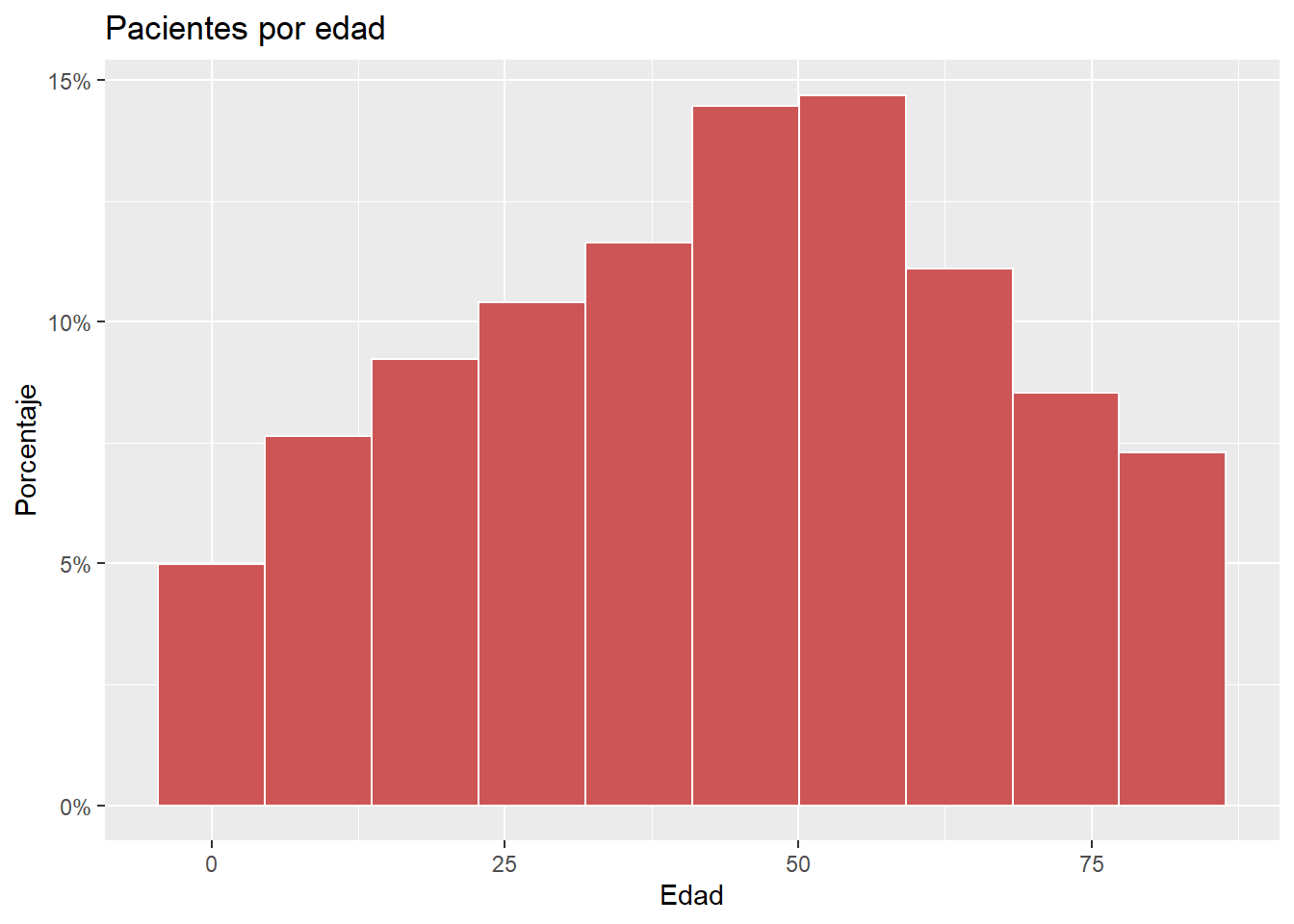
3.1.2.2 Gráfico de densidad
La estimación de la gráfico de densidad es un método no paramétrico para estimar la función de densidad de probabilidad de una variable aleatoria continua. Básicamente, estamos intentando dibujar un histograma suavizado, donde el área bajo la curva sea igual a uno.
Usamos la función geom_density() del paquete ggplot2
# Gráfico de densidad con relación a la edad
ggplot(heart, aes(x = age)) +
geom_density(color="cornflowerblue",
size=1.2) +
labs(title = "Pacientes por edad")Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.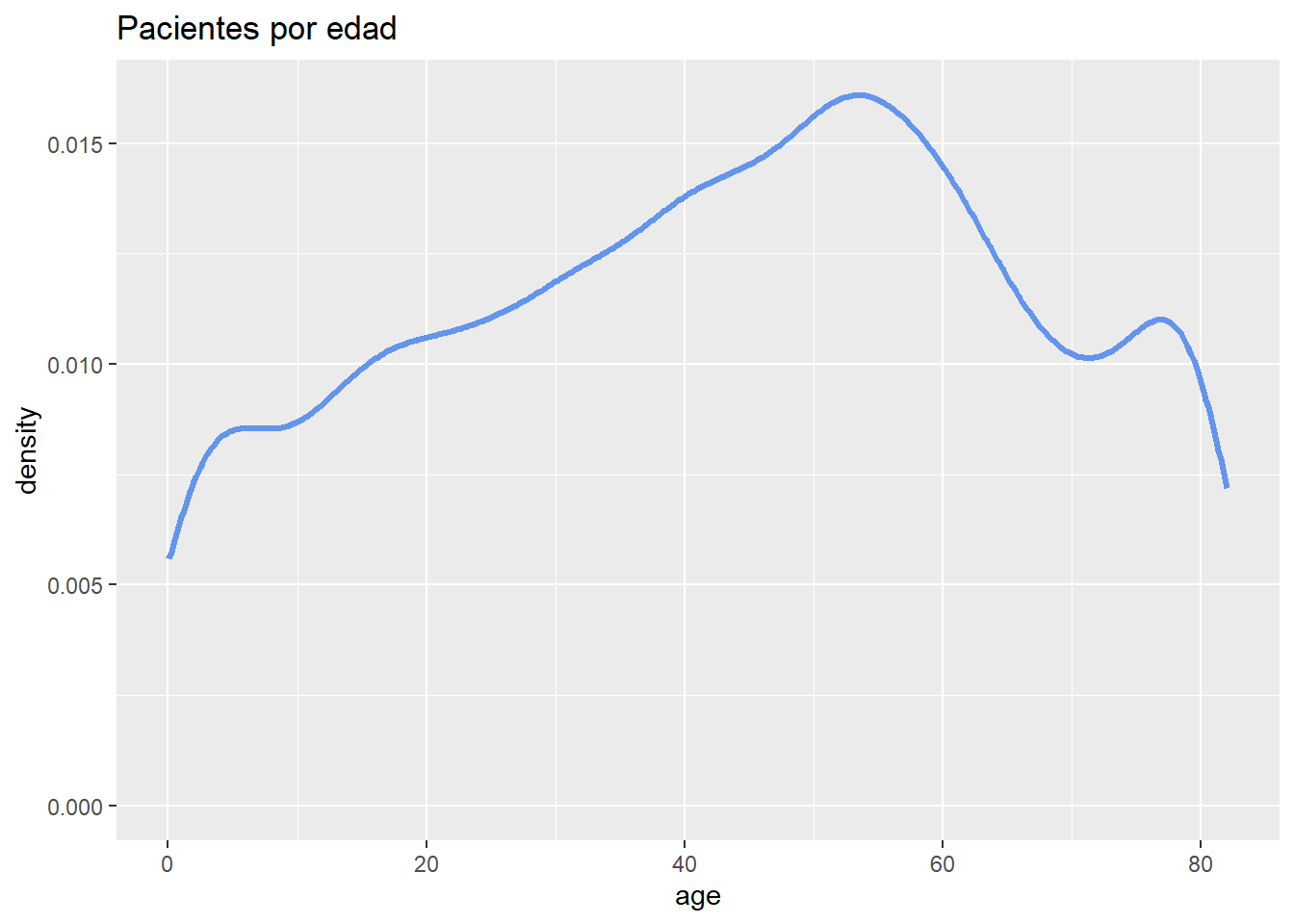
A continuación se genera un histograma respecto a la edad junto con su respectivo gráfico de densidad utilizando ggplot2.
geom_histogram crea el histograma, configurando el número de contenedores (bins = 10) y ajustando el color, la transparencia y el relleno de las barras.
geom_density traza la curva de densidad sobre el histograma, configurando el color, transparencia y tamaño de la línea.
# Histograma y gráfico de densidad respecto a la edad
ggplot(heart, aes(x = age)) +
geom_histogram(aes(y = after_stat(density)),
bins = 10,
color = "white",
alpha = 2,
fill = "cornflowerblue") +
geom_density(alpha = 0.5,
color = "indianred3",
linewidth = 1.2) +
labs(title = "Histograma y gráfico de densidad",
x = "Edad",
y = "Frecuencia / Densidad")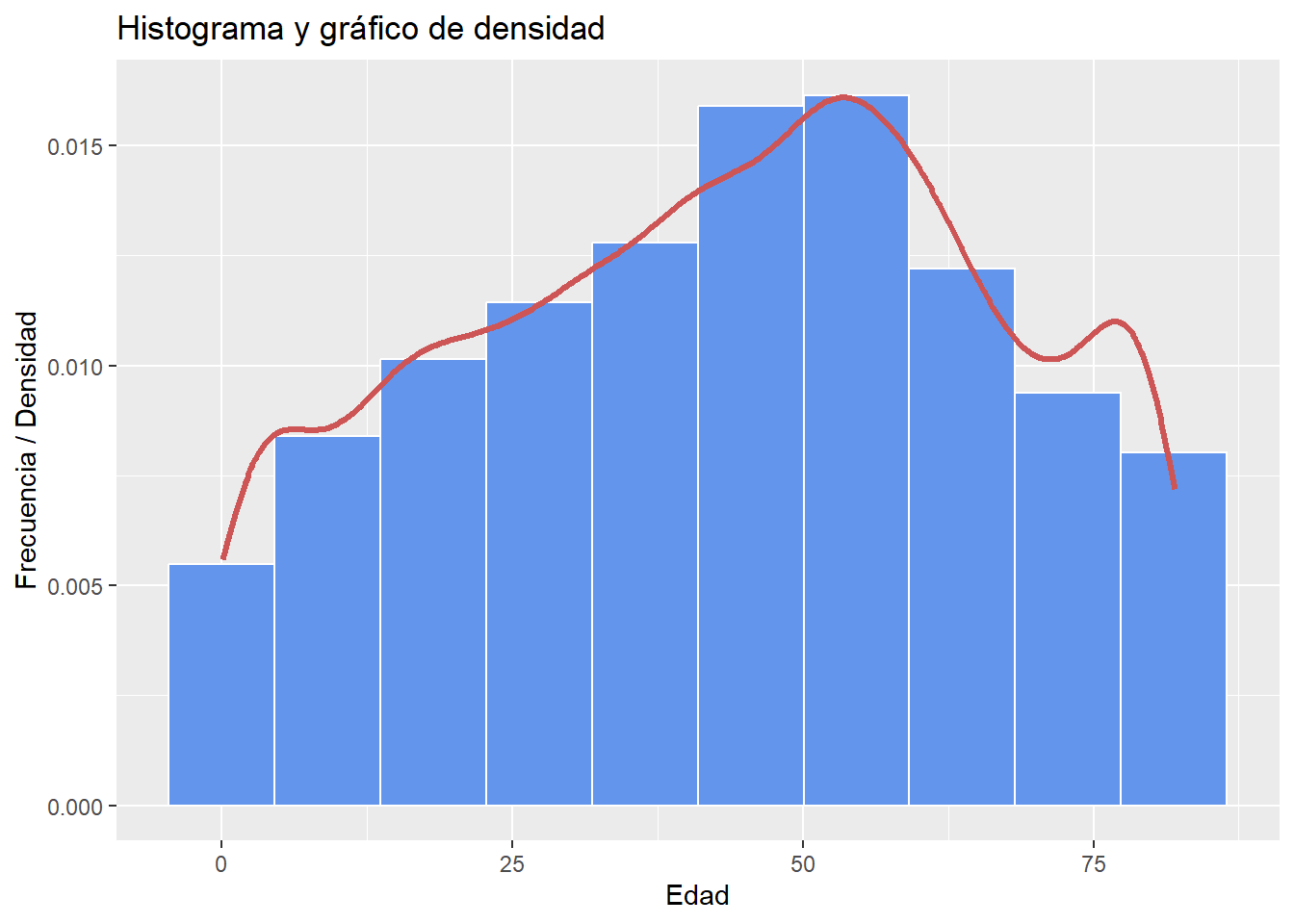
3.1.2.3 Gráfico de puntos
Otra alternativa al histograma es el gráfico de puntos. Nuevamente, la variable cuantitativa se divide en bins, pero en lugar de barras de resumen, cada observación está representada por un punto.
# Muestre de 50 pacientes ya que la data es muy grande
library(dplyr)
sampled_data2 <- heart %>%
sample_n(50, replace = FALSE)
# Distribución de las edades con gráfico de puntos
ggplot(sampled_data2, aes(x = age)) +
geom_dotplot(fill = "gold",
color="black") +
labs(title = "Pacientes por edad",
y = "Proporción",
x = "Edad")Bin width defaults to 1/30 of the range of the data. Pick better value with
`binwidth`.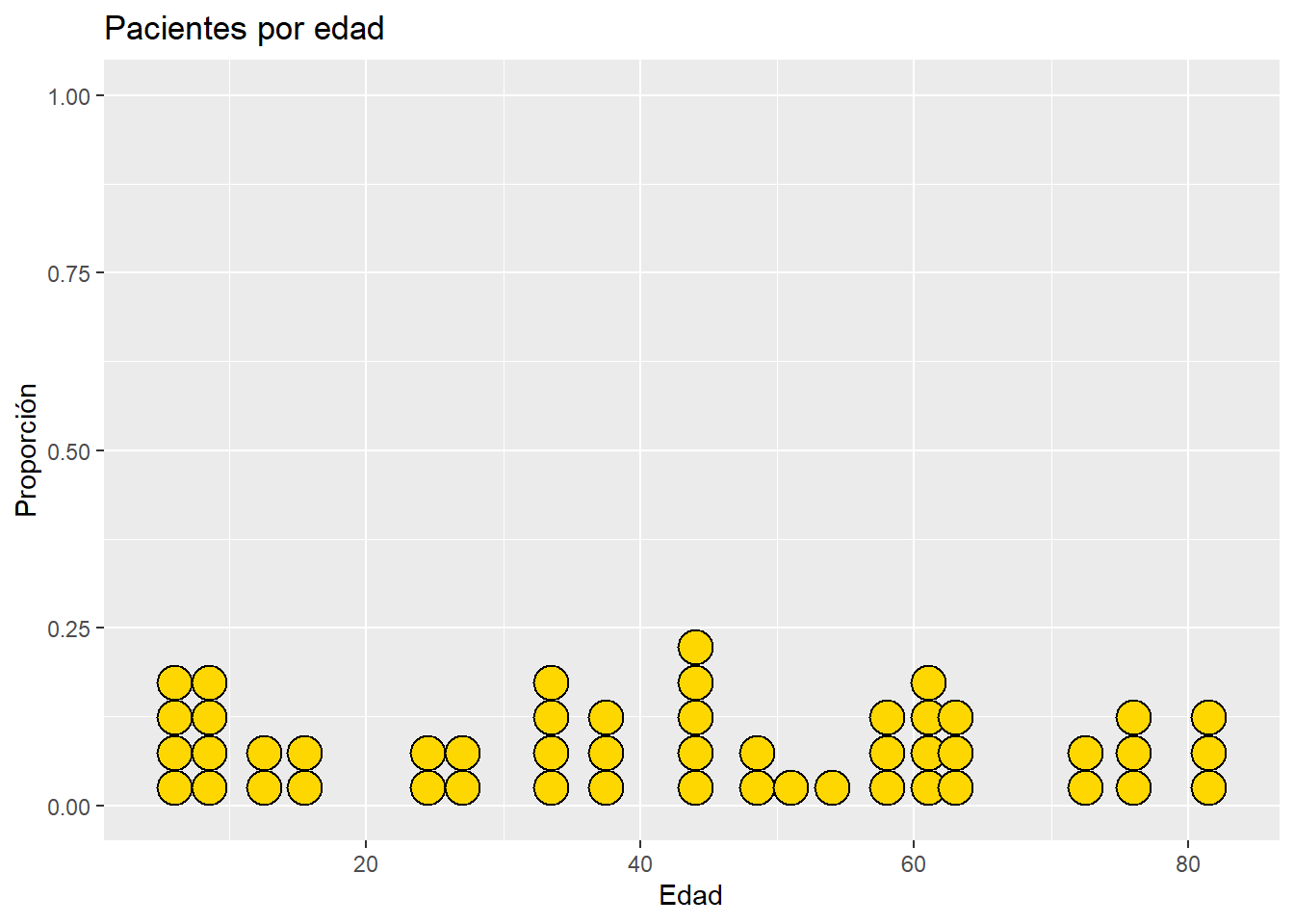
3.2 Visualización de datos bivariados
Una de las preguntas más fundamentales en la investigación es “¿Cuál es la relación entre A y B?”. Los gráficos bivariados muestran la relación entre dos variables. El tipo de gráfico dependerá del nivel de medición de cada variable (cualitativa o cuantitativa).
3.2.1 Variable cualitativa vs cualitativa
Al trazar la relación entre dos variables cualitativas, normalmente se utilizan gráficos de barras apiladas, agrupadas o segmentadas.
3.2.1.1 Gráfico de barras apiladas
Examinemos la relación entre estado de tabaquismo y género de los pacientes del dataset heart.
# Gráfico de barras apiladas
ggplot(heart, aes(x = smoking_status, fill = gender)) +
geom_bar(position = "stack")+
labs(title = "Estado de tabaquismo por el género del paciente",
x = "Estado de tabaquismo",
y = "Frecuencia")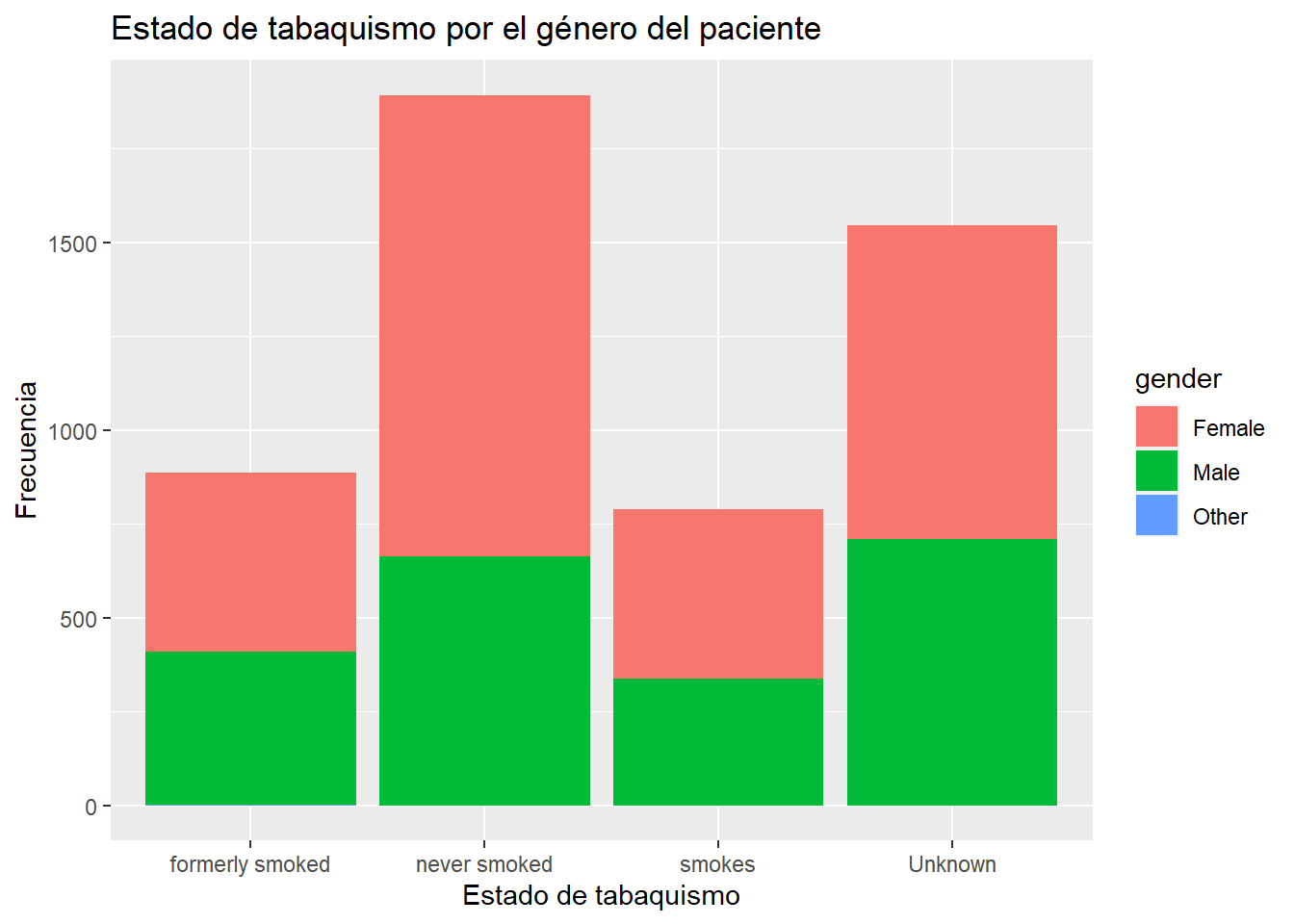
Del gráfico notamos que la mayor frecuencia se da en aquellos que nunca fumaron de los cuales más del 50% son de género femenino.
3.2.1.2 Gráfico de barras agrupadas
Los gráficos de barras agrupados colocan barras para la segunda variable categórica una al lado de la otra. Para crear un gráfico de barras agrupadas, se usa la opción position = "dodge".
# Gráfico de barras agrupadas
ggplot(heart, aes(x = smoking_status, fill = gender)) +
geom_bar(position = "dodge")+
labs(title = "Estado de tabaquismo vs género de pacientes",
x = "Estado de tabaquismo",
y = "Frecuencia")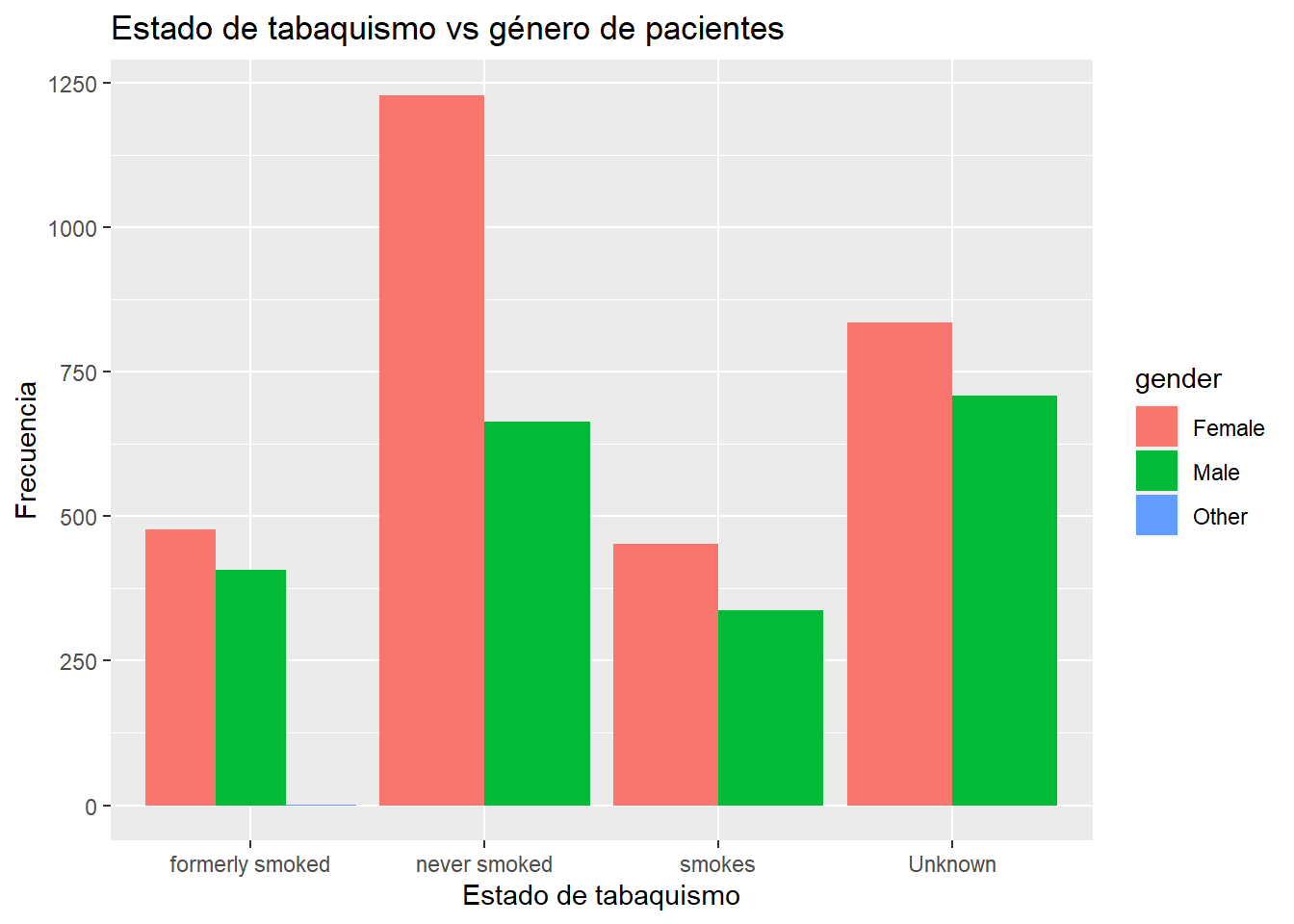
3.2.1.3 Gráfico de barras segmentadas
Un gráfico de barras segmentadas es un gráfico de barras apiladas donde cada barra representa el 100 por ciento. Puede crear un gráfico de barras segmentado utilizando la opción position = "filled".
factor modifica el orden de las categorías para la variable de clase y tanto el orden como las etiquetas para la variable de unidad.
scale_y_continuous modifica las etiquetas de las marcas de graduación del eje y
labs proporciona un título y cambio las etiquetas para los ejes x e y, y la leyenda
scale_fill_brewer cambia el esquema de color de relleno
theme_minimal elimina el fondo gris y cambia el color de la cuadrícula
# Diagrama de barras, donde cada barra representa el 100%
library(scales)
ggplot(heart,
aes(x = factor(work_type,
levels = c("children", "Govt_job",
"Never_worked", "Private",
"Self-employed")),
fill = factor(smoking_status,
labels = c("formely smoked",
"never smoked",
"smokes",
"unknown")))) +
geom_bar(position = "fill") +
scale_y_continuous(breaks = seq(0, 1, .2),
label = percent) +
scale_fill_brewer(palette = "Set2") +
labs(y = "Porcentaje",
fill="Drive Train",
x = "Tipo de trabajo",
title = "Tipo de trabajo por estado de tabaquismo") +
theme_minimal()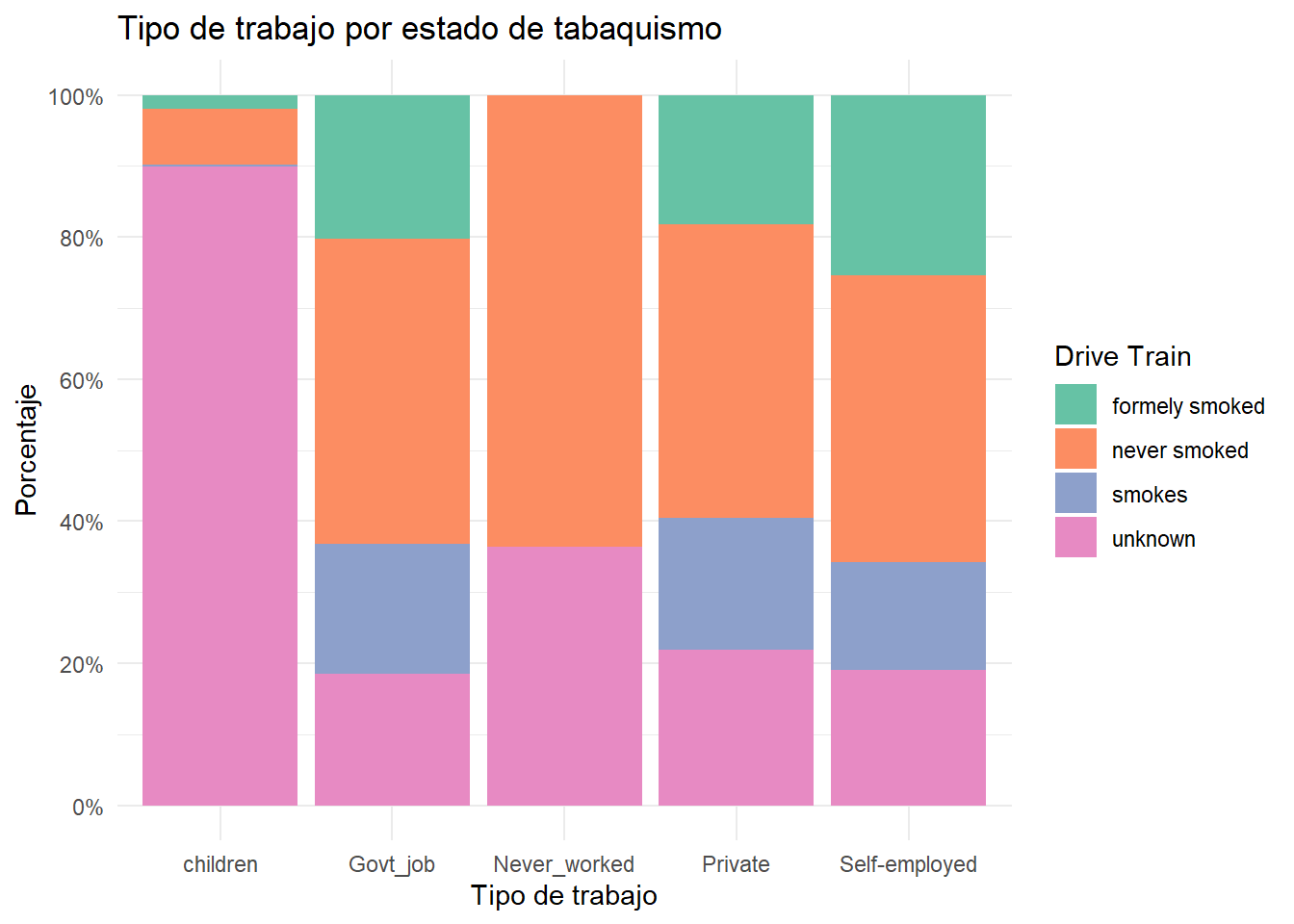
3.2.2 Variable cuantitativa vs cuantitativa
La relación entre dos variables cuantitativas normalmente se muestra mediante diagramas de dispersión y gráficos de líneas.
3.2.2.1 Diagrama de dispersión
La visualización más simple de dos variables cuantitativas es un diagrama de dispersión, en el que cada variable está representada en un eje. Aquí usaremos una muestra de 500 pacientes del dataset heart.
library(dplyr) # Cargar librería dplyr para realizar muestreo
# Muestreo aleatorio de 500 puntos de tus datos
sampled_data <- heart %>%
sample_n(500, replace = FALSE) # Puedes ajustar el número de puntos a mostrar
ggplot(sampled_data, aes(x = age, y = avg_glucose_level)) +
geom_point(color = "cornflowerblue") +
labs(title = "Gráfico de dispersión de una muestra de 500 pacientes",
x = "Edad",
y = "Nivel de glucosa")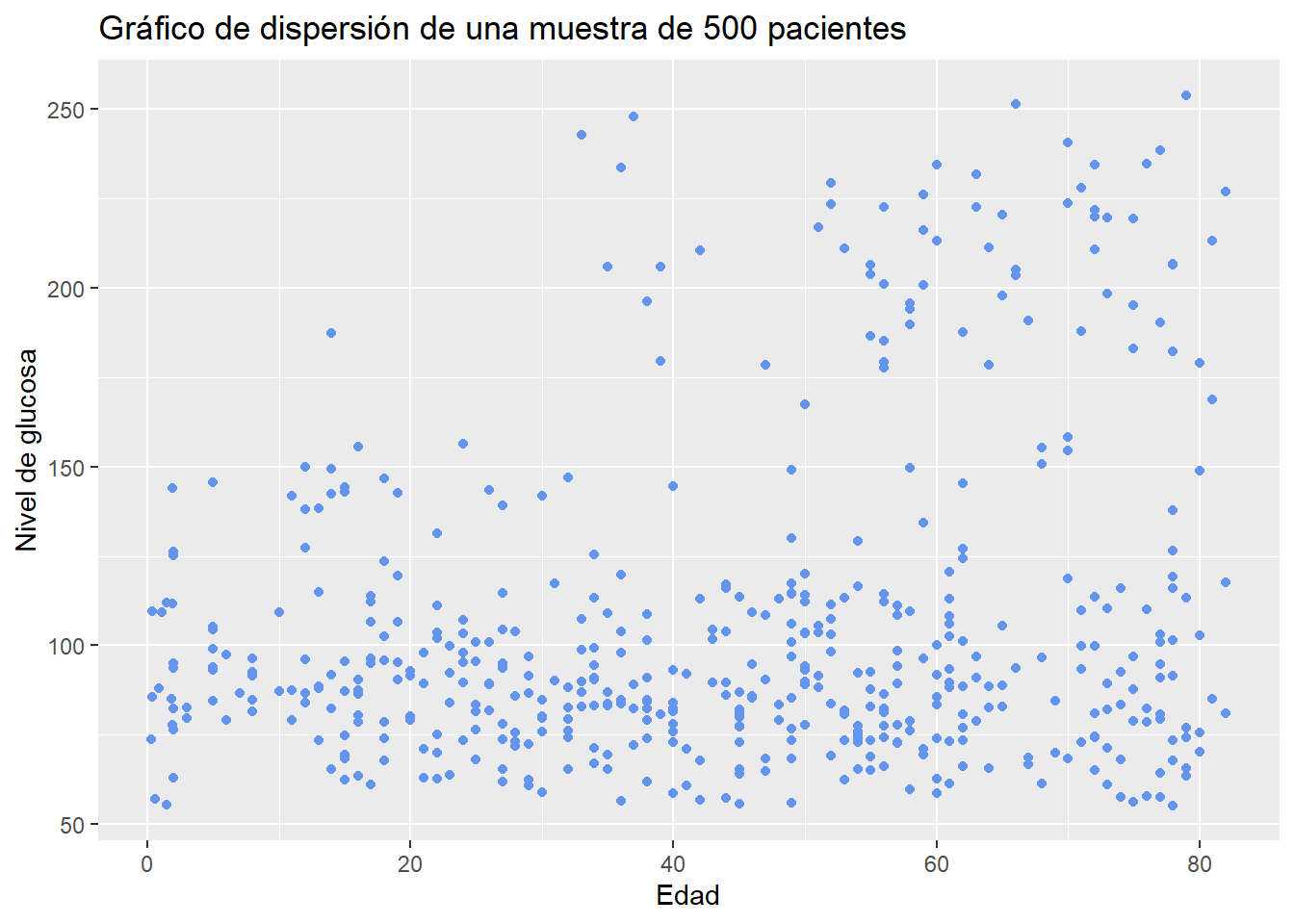
Claramente, el nivel de glucosa aumenta con la edad de los pacientes.
Normalmente se utiliza una línea cuadrática (una curva) o cúbica (dos curvas). Rara vez es necesario utilizar polinomios de orden superior (>3). Agregar una línea de ajuste cuadrático al conjunto de datos salariales produce el siguiente resultado.
# Diagrama de dispersión con línea cuadrática de mejor ajuste
ggplot(sampled_data, aes(x = age, y = avg_glucose_level)) +
geom_point(color= "cornflowerblue") +
geom_smooth(method = "lm",
formula = y ~ poly(x, 2),
color = "indianred3")+
labs(x = "Edad",
y = "Nivel de glucosa (mg/dL)",
title = "Edad vs Nivel de glucosa de una muestra de 500")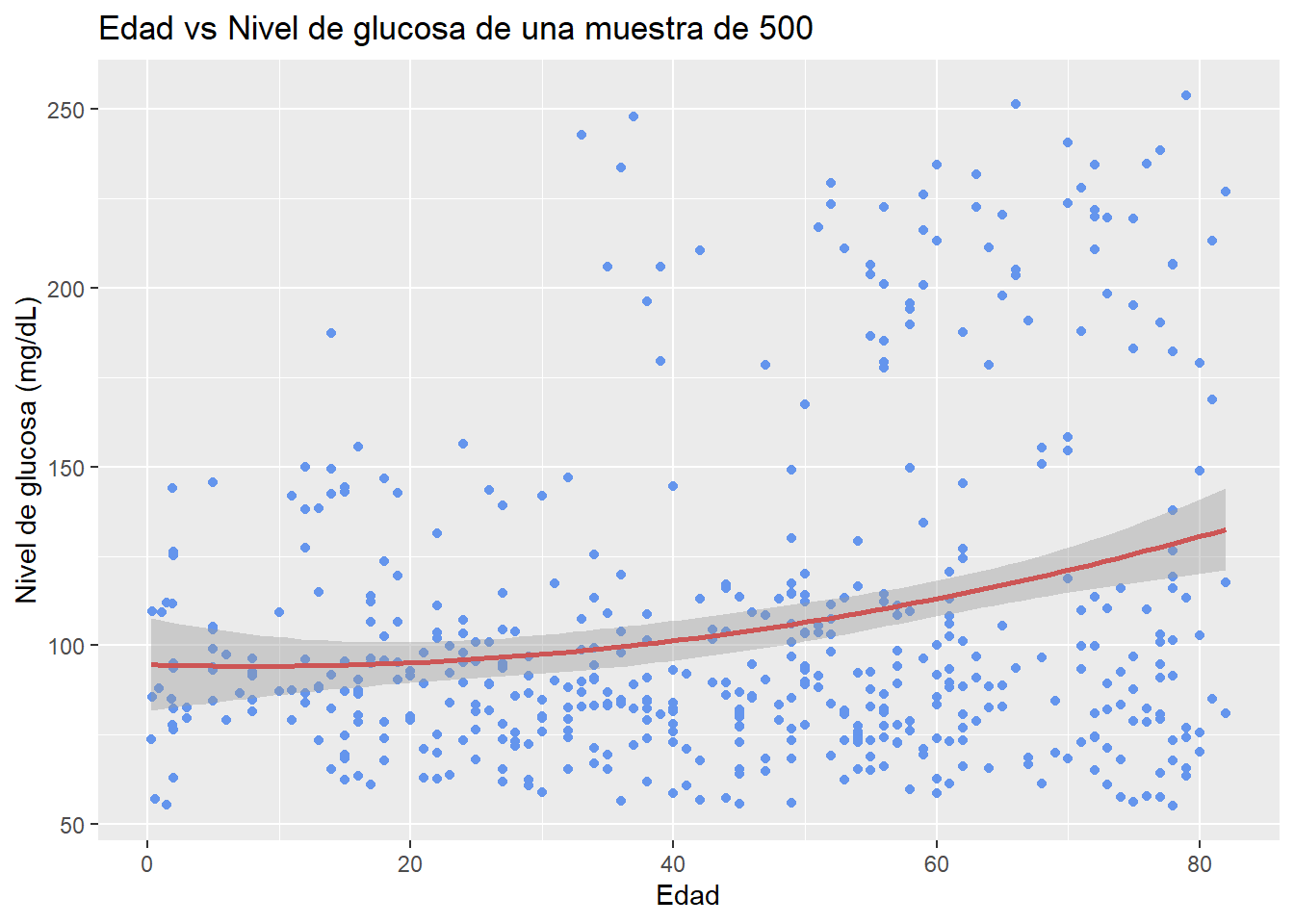
3.2.3 Variable cualitativa vs cuantitativa
Al trazar la relación entre una variable cualitativa y una variable cuantitativa, hay disponibles una gran cantidad de tipos de gráficos. Estos incluyen gráficos de barras que utilizan estadísticas resumidas, diagramas de densidad agrupados, diagramas de caja uno al lado del otro, diagramas de violín uno al lado del otro, diagramas de cresta, entre otros.
3.2.3.1 Gráfico de barras
También puede utilizar gráficos de barras para mostrar otras estadísticas resumidas (por ejemplo, medias o medianas) en una variable cuantitativa para cada nivel de una variable cualitativa.
Por ejemplo , el siguiente gráfico muestra la media del nivel de glucosa por su estado de tabaquismo.
# Gráfico del promedio de glucosa vs estado de tabaquismo
library(dplyr)
plotdata3 <- heart %>%
group_by(smoking_status) %>%
summarize(mean_avgglu = mean(avg_glucose_level))
library(scales)
ggplot(plotdata3, aes(x = smoking_status, y = mean_avgglu)) +
geom_bar(stat = "identity", fill = "cornflowerblue") +
geom_text(aes(label = round(mean_avgglu, 2)), vjust = -0.5) +
scale_y_continuous(breaks = seq(0, 300, 50)) +
labs(title = "Nivel promedio de glucosa por estado de tabaquismo",
x = "Estado de tabaquismo",
y = "Nivel promedio de glucosa")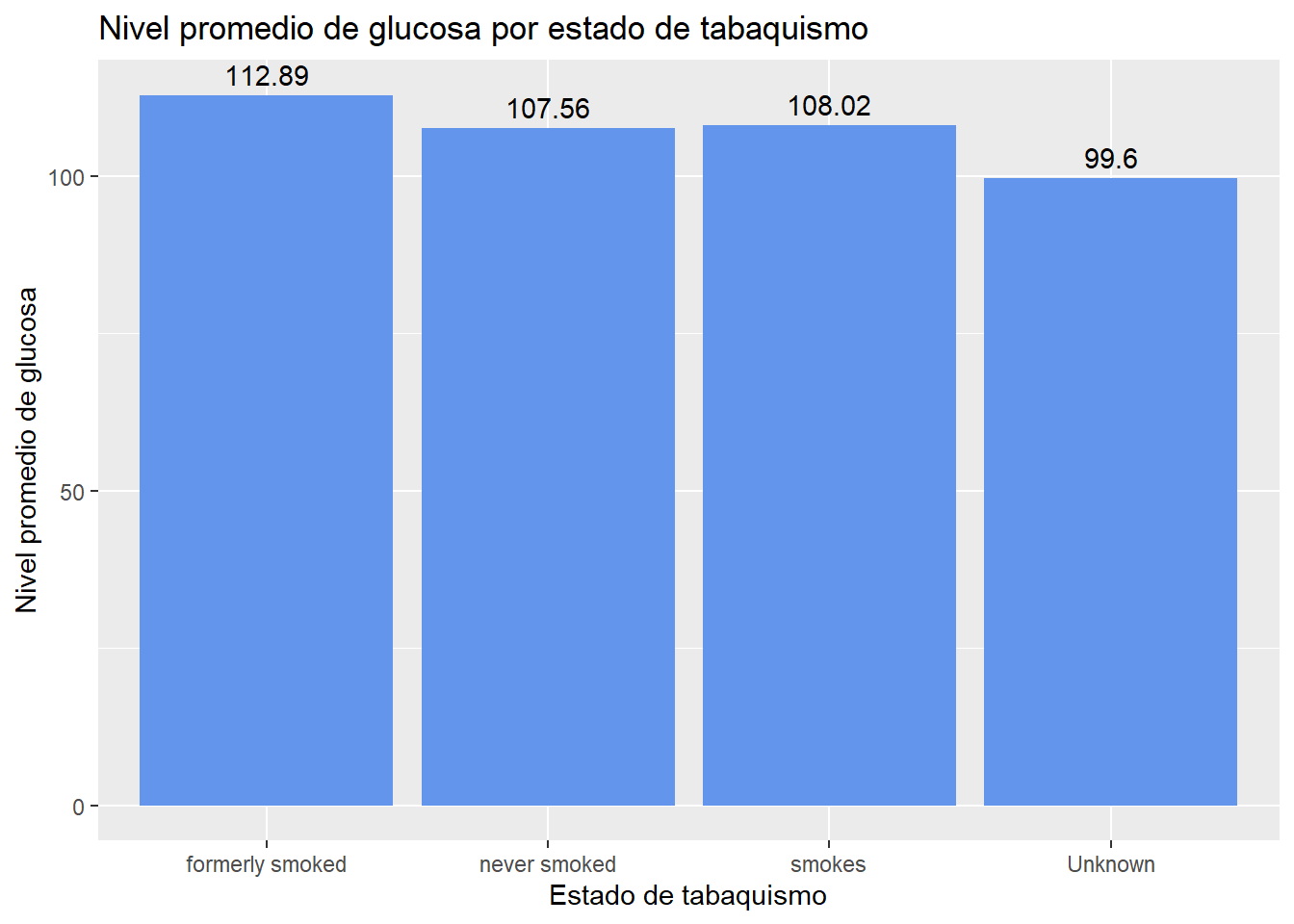
3.2.3.2 Diagramas de densidad agrupados
A continuación se genera un gráfico de densidad que muestra la distribución del nivel de glucosa, diferenciando por el estado de tabaquismo en el conjunto de datos “heart”.
ggplot(heart, aes(x = avg_glucose_level, fill = smoking_status)) +
geom_density(alpha = 0.4) +
labs(title = "Nivel de glucosa por estado de tabaquismo",
x="Nivel de glucosa",
y="Densidad")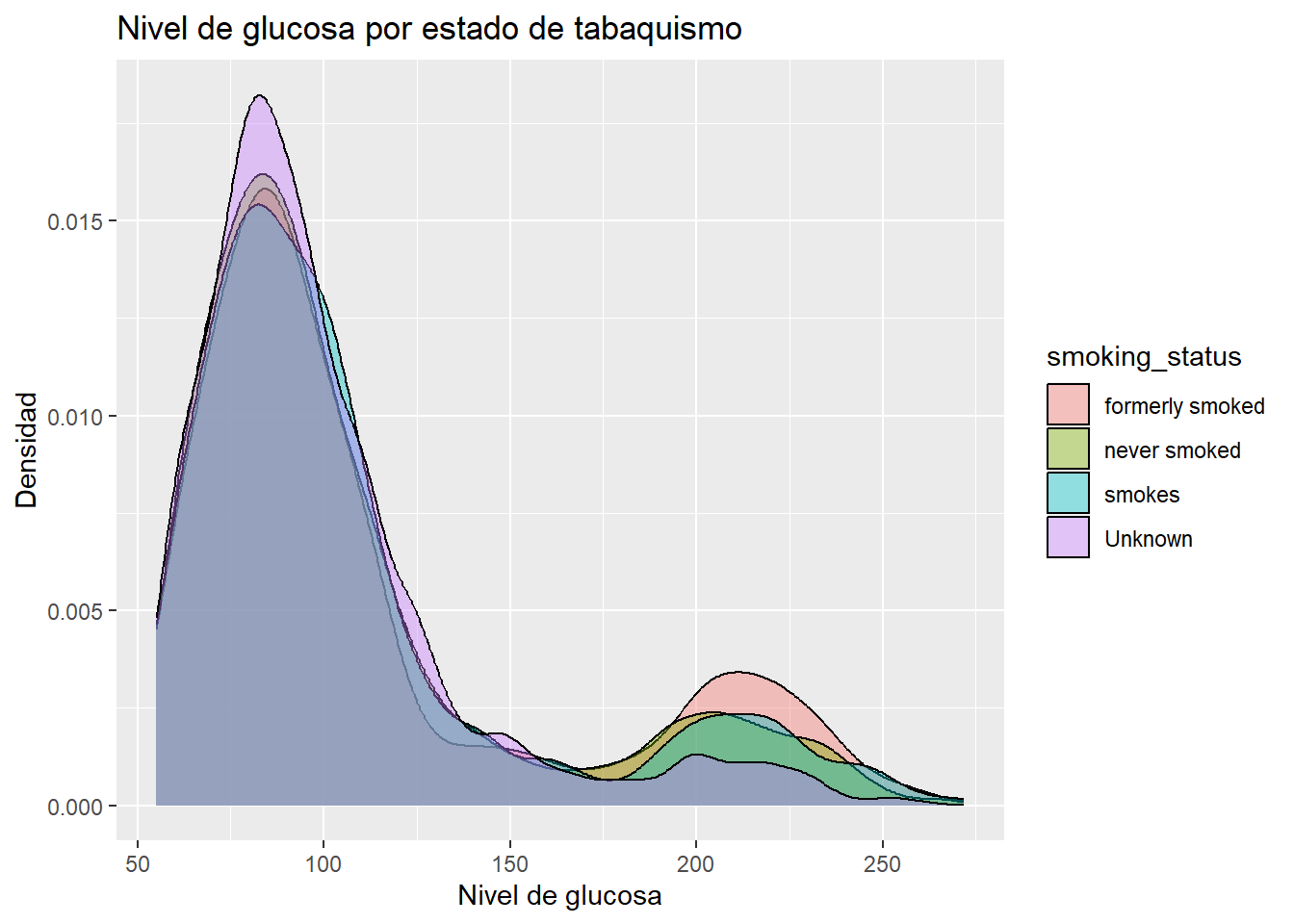
3.2.3.3 Diagrama de caja
A continucación se genera un gráfico de caja (“boxplot”) para mostrar la distribución del nivel de glucosa según el estado de tabaquismo en el conjunto de datos “heart”.
# Boxplot de nivel de glucosa por estado de tabaquismo
ggplot(heart, aes(x = smoking_status, y = avg_glucose_level)) +
geom_boxplot() +
labs(title = "Nivel de glucosa por estado de tabaquismo",
x="Estado de tabaquismo",
y="Nivel de glucosa")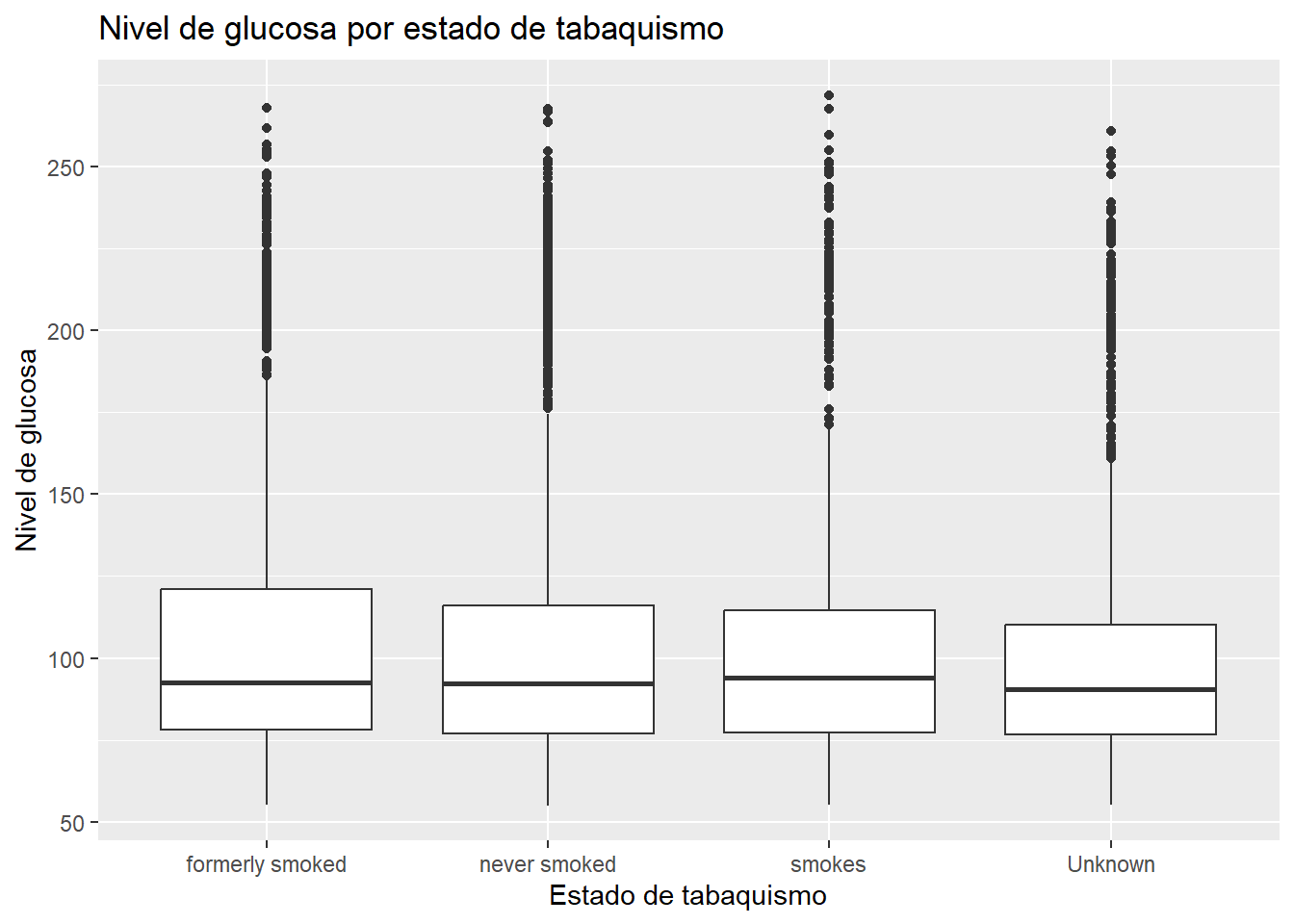
3.2.3.4 Gráfico de violín
El gráfico de violin es útil para ver tanto la distribución de los datos como sus estadísticas resumidas en un solo gráfico.
# Gráfico de violin del nivel de glucosa por estado de tabaquismo
ggplot(heart, aes(x = smoking_status, y = avg_glucose_level)) +
geom_violin(fill = "cornflowerblue") +
geom_boxplot(width = .15,
fill = "orange",
outlier.color = "orange",
outlier.size = 2) +
labs(title = "Distribución nivel de glucosa por estado de tabaquismo",
x="Estado de tabaquismo",
y="Nivel de glucosa")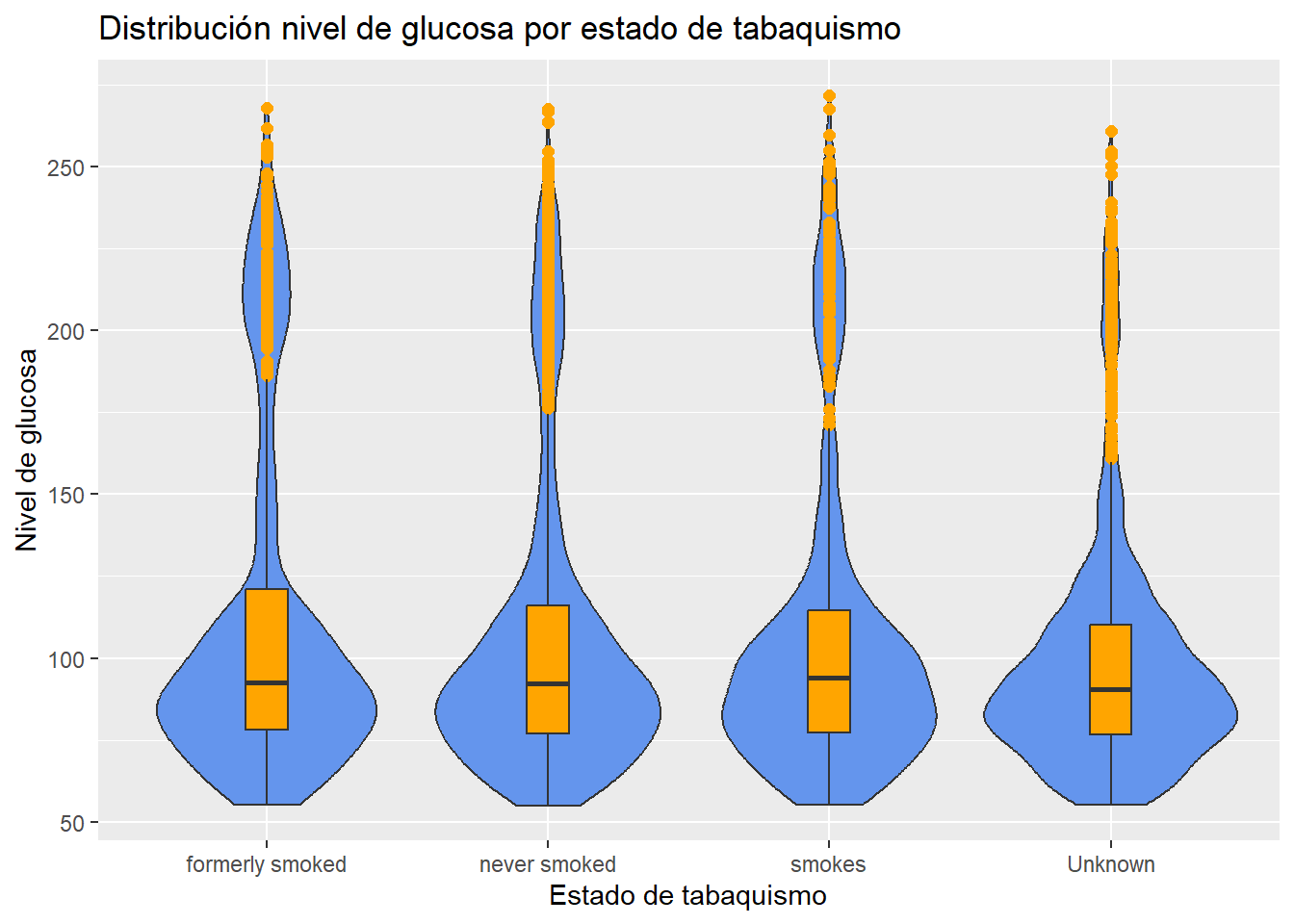
3.2.3.5 Gráfico de crestas
Muestra la distribución de una variable cuantitativa para varios grupos. Son similares a los gráficos de densidad con faceting verticales, pero ocupan menos espacio. Los gráficos de crestas se crean con el paquete ggridges.
library(ggplot2)
library(ggridges)
ggplot(heart,
aes(x = avg_glucose_level, y = smoking_status, fill = smoking_status)) +
geom_density_ridges() +
theme_ridges() +
labs(title="Nivel de glucosa por estado de tabaquismo",
x="Nivel de glucosa",
y="Estado de tabaquismo") +
theme(legend.position = "none")Picking joint bandwidth of 6.24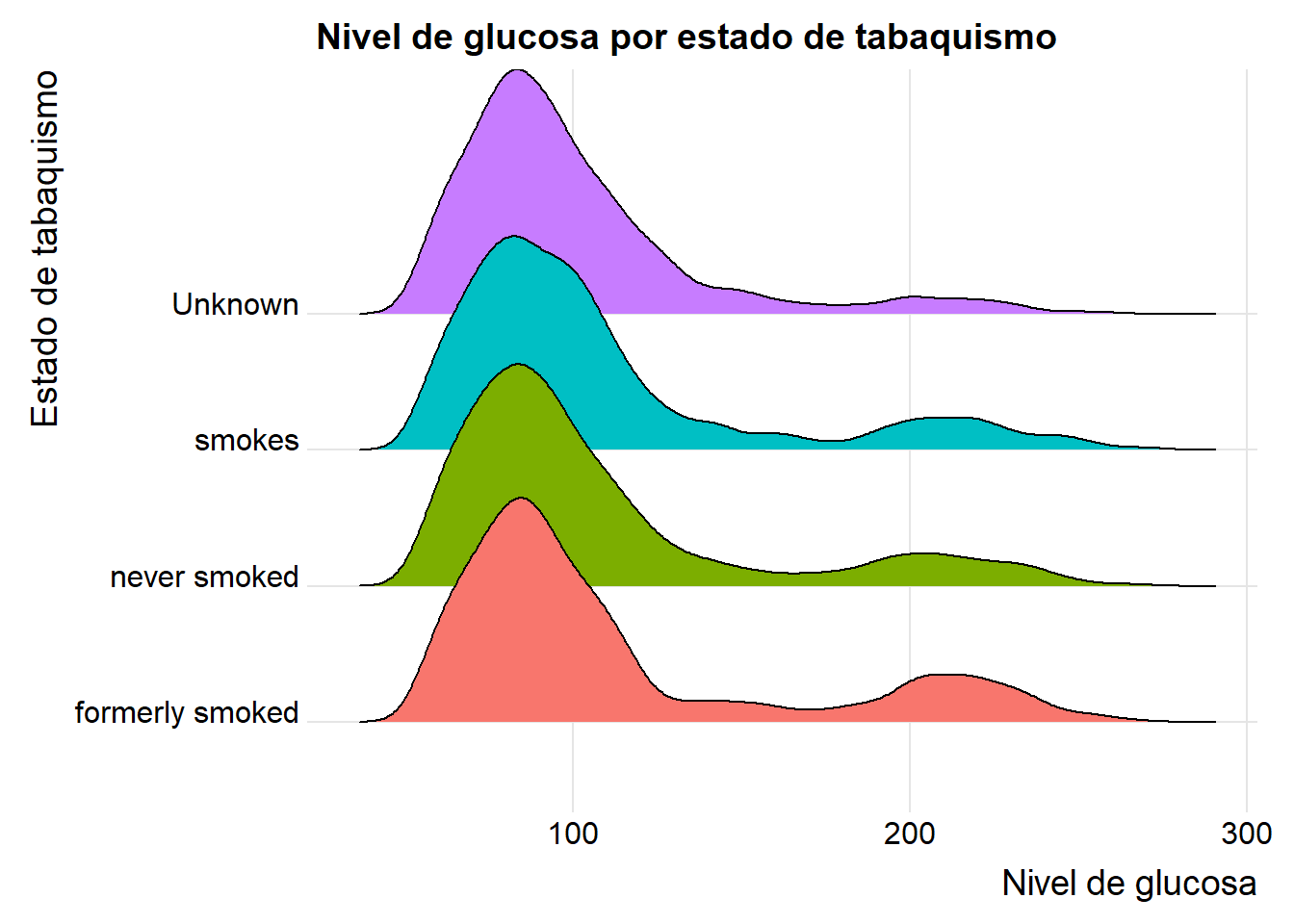
Notamos que quienes fumaron y fuman actualmente presentan un nivel elevado de glucosa.
3.3 Visualización de datos bivariados multivariados
Los gráficos multivariados muestran las relaciones entre tres o más variables. Hay dos métodos comunes para acomodar múltiples variables: agrupar y facetar.
3.3.1 Grouping
En grouping, los valores de las dos primeras variables se asignan a los ejes x e y. Luego, se asignan variables adicionales a otras características visuales como color, forma, tamaño, tipo de línea y transparencia. La agrupación le permite trazar los datos de varios grupos en un solo gráfico.
Usando la muestra sampled_data del dataset heart, mostremos la relación entre edad y nivel de glucosa.
# Gráfico edad vs nivel de glucosa, color por tipo de residencia
ggplot(sampled_data, aes(x = age,
y = avg_glucose_level,
color=Residence_type)) +
geom_point() +
labs(title = "Nivel de glucosa por tipo de residencia y edad")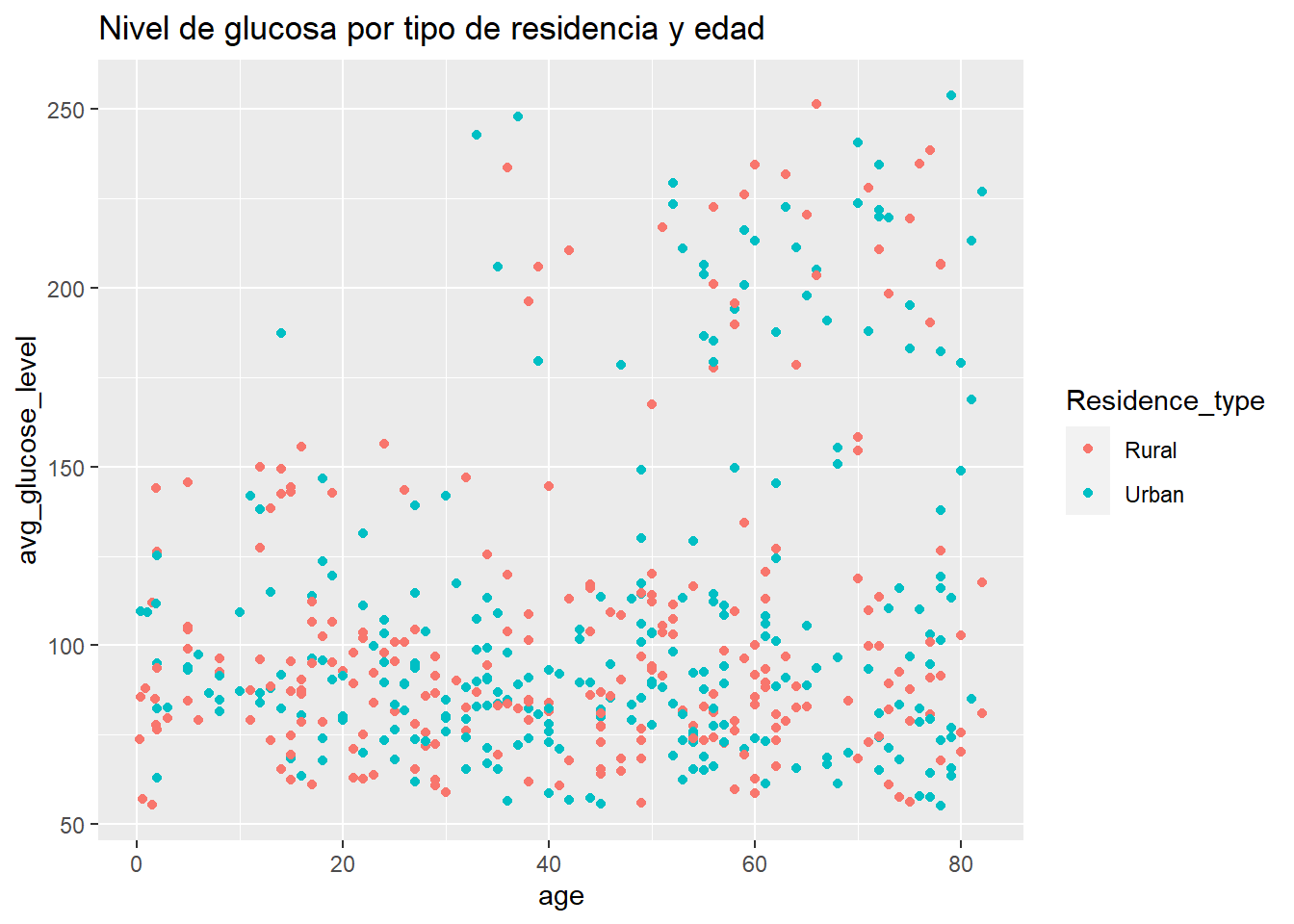
También podemos agregar el género de los pacientes usando la forma de los puntos para indicar el sexo. Aumentaremos el tamaño de los puntos y la transparencia para que los puntos individuales sean más claros.
ggplot(sampled_data, aes(x = age,
y = avg_glucose_level,
color = Residence_type,
shape = gender)) +
geom_point(size = 3, alpha = .6) +
labs(title = "Nivel de glucosa por tipo de residencia, género y edad")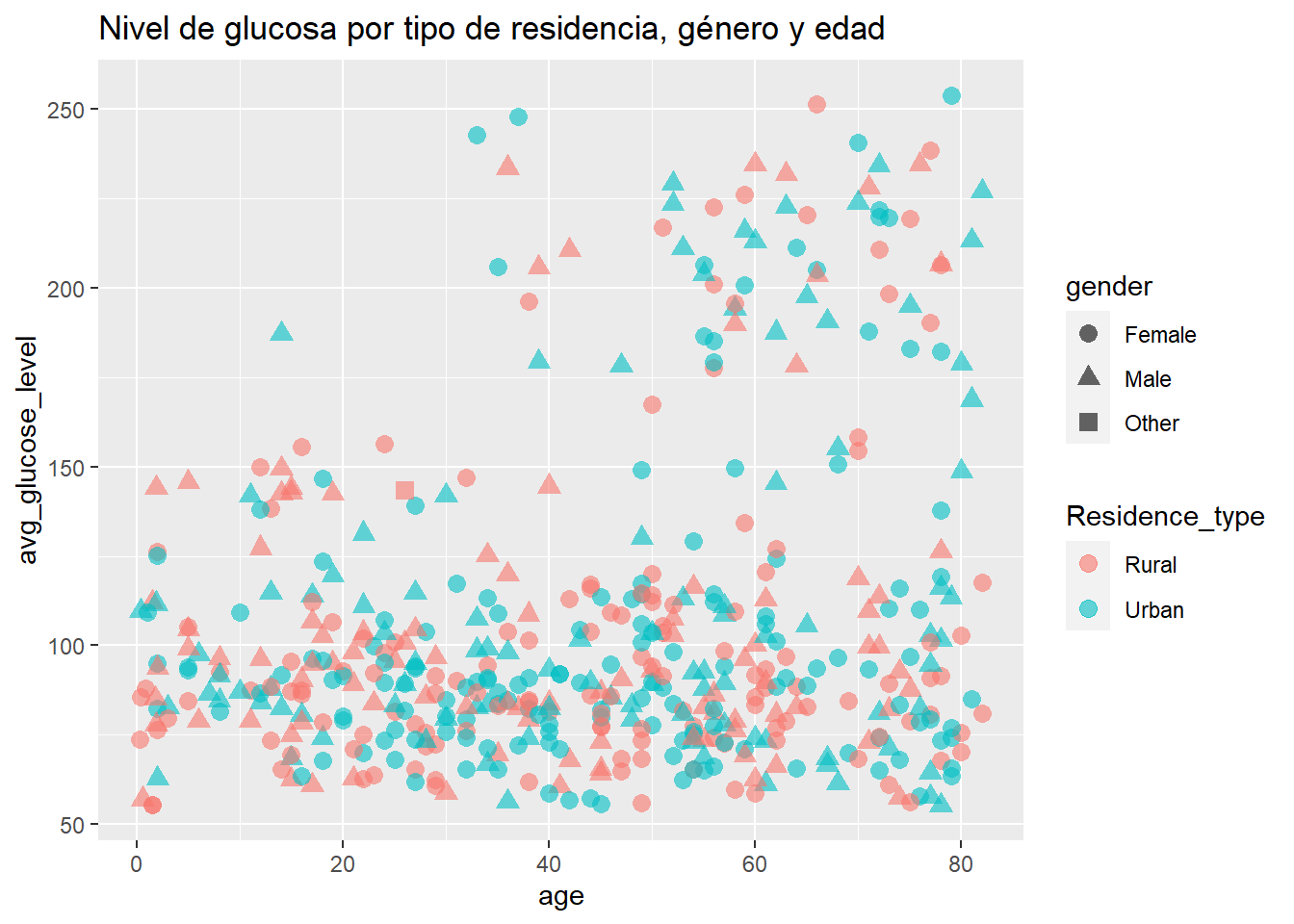
3.3.2 Faceting
En faceting, un gráfico consta de varios gráficos separados o pequeños múltiplos, uno para cada nivel de una tercera variable o combinación de dos variables.
A continuación se crea un conjunto de histogramas separados por estado de tabaquismo para mostrar la distribución de la edad en función del estado de tabaquismo en la muestra “sampled_data”
# Gráfico de histogramas de edad por estado de tabaquismo
ggplot(sampled_data, aes(x = age)) +
geom_histogram(fill = "cornflowerblue",
color = "white",
bins=10) +
facet_wrap(~smoking_status, ncol = 1) +
labs(title = "Edad por estado de tabaquismo",
x="Edad",
y="Frecuencia")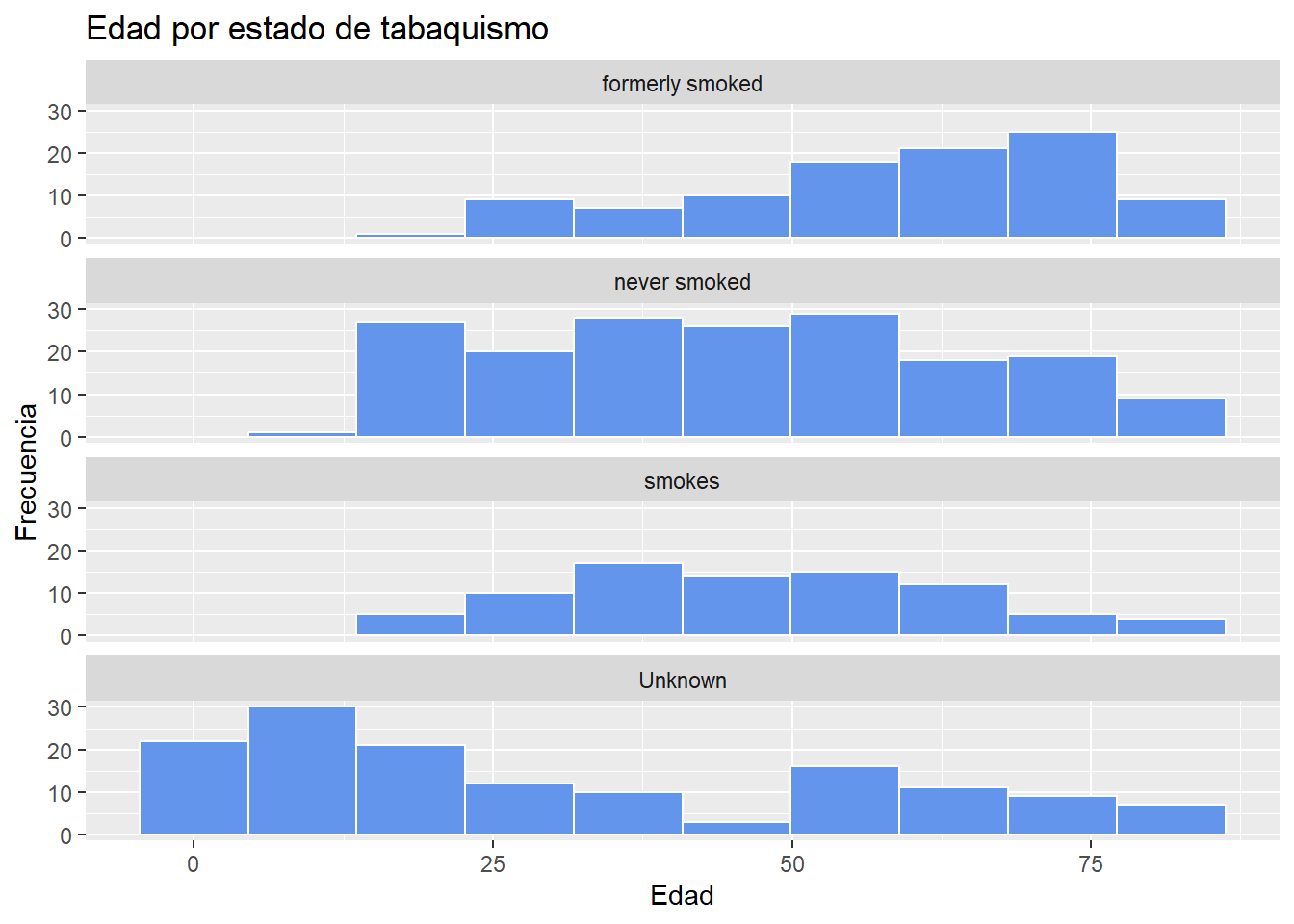
También podemos generar un gráfico que explora la relación entre la edad, el nivel de glucosa y el género, diferenciando por tipo de residencia (rural o urbano) en la muestra de datos “sampled_data”.
# Gráfico del nivel de glucosa por edad, género y tipo de residencia
ggplot(sampled_data, aes(x= age,
y = avg_glucose_level,
color=gender)) +
geom_point(size = 2,
alpha=.5) +
geom_smooth(method="lm",
se=FALSE,
linewidth = 1.5) +
facet_wrap(~factor(Residence_type,
labels = c("Rural", "Urbano")),
ncol = 1) +
scale_y_continuous() +
theme_minimal() +
scale_color_brewer(palette="Set1") +
labs(title = paste0("Relación entre nivel de glucosa, edad, ",
"género y el tipo de residencia"),
color = "Género",
x = "Edad",
y = "Nivel de glucosa")`geom_smooth()` using formula = 'y ~ x'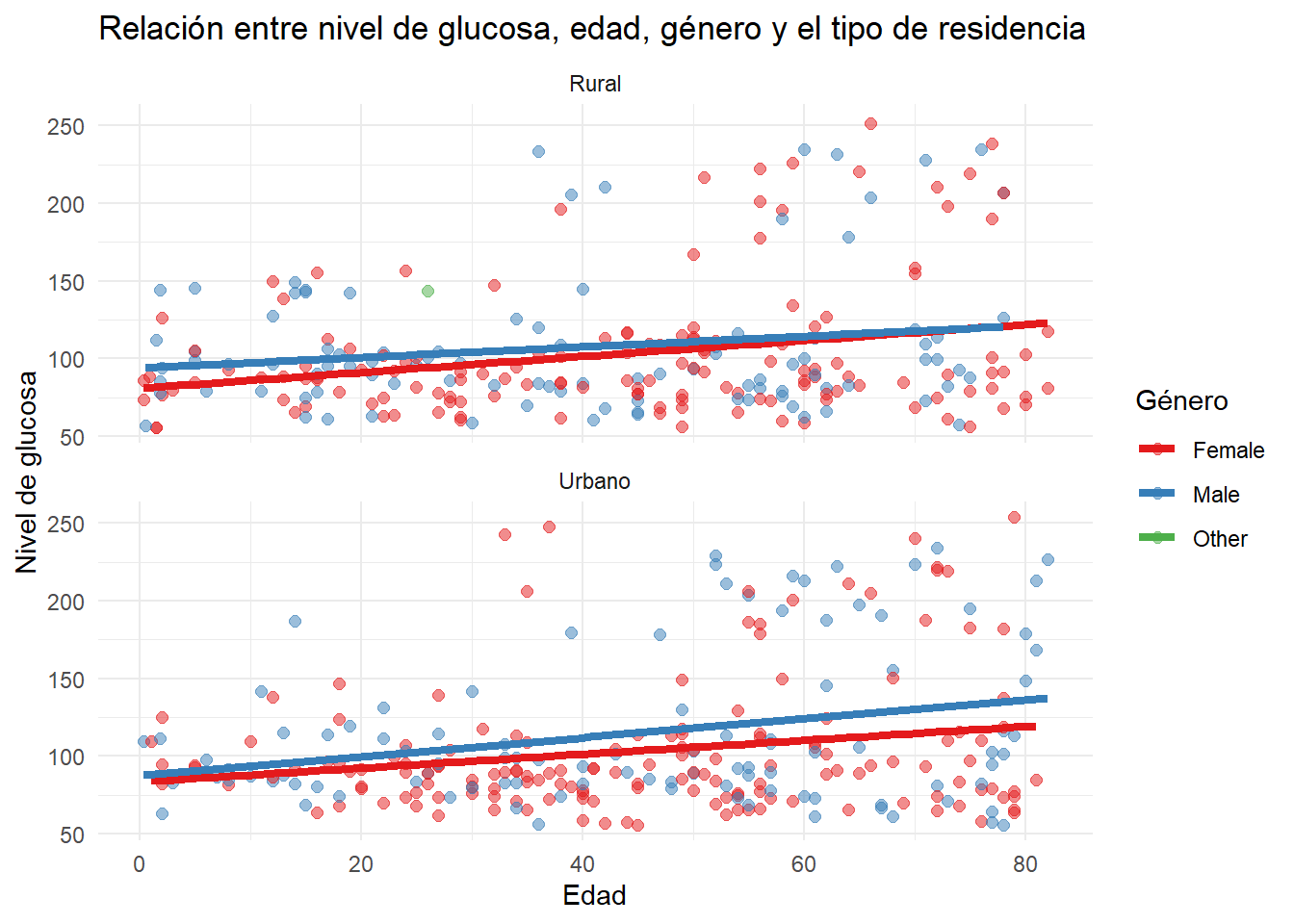
3.4 Visualización de datos avanzados
3.4.1 Gráfico en 3D
Se utilizan las librerías plotly y scatterplot3d en R para generar un gráfico tridimensional (scatter3d) con una muestra aleatoria de datos del dataset “heart” llamado “sampled_data2”.
suppressPackageStartupMessages(library(plotly))
library(plotly)
library(scatterplot3d)
sampled_data2 <- heart %>%
sample_n(50, replace = FALSE) # muestra aleatoria de 50 filas
# Gráfico 3D usando plot_ly
plot_ly(data=sampled_data2,x=sampled_data2$age,
y=sampled_data2$id, z=sampled_data2$avg_glucose_level,
type="scatter3d",color=~sampled_data2$Residence_type) %>%
layout(scene = list(xaxis = list(title = "Edad"),
yaxis = list(title = "Id"),
zaxis = list(title = "Nivel de glucosa"))) # etiquetasNo scatter3d mode specifed:
Setting the mode to markers
Read more about this attribute -> https://plotly.com/r/reference/#scatter-modeWarning in RColorBrewer::brewer.pal(N, "Set2"): minimal value for n is 3, returning requested palette with 3 different levels
Warning in RColorBrewer::brewer.pal(N, "Set2"): minimal value for n is 3, returning requested palette with 3 different levelsEste tipo de gráfico tridimensional es útil para visualizar relaciones entre tres variables diferentes, en este caso, la edad, el ID y el nivel de glucosa, además de usar el color para indicar el tipo de residencia.
3.4.2 Gráficos animados
Los gráficos animados son una forma excelente de visualizar cambios en datos a lo largo del tiempo o de mostrar una secuencia de eventos. Si bien el paquete gganimate es una opción popular para crear gráficos animados en R, también hay otros métodos para generar animaciones, como el uso del paquete magick, que permite trabajar con imágenes y secuencias de fotogramas para crear animaciones.
A continucación se creará un conjunto de gráficos usando el paquete gapminder y ggplot2, y luego se convertiran en una animación utilizando el paquete magick.
library(magick)Linking to ImageMagick 6.9.12.96
Enabled features: cairo, freetype, fftw, ghostscript, heic, lcms, pango, raw, rsvg, webp
Disabled features: fontconfig, x11library(gapminder)
library(ggplot2)
img <- image_graph(600, 340, res = 96)
datalist <- split(gapminder, gapminder$year)
out <- lapply(datalist, function(data){
p <- ggplot(data, aes(gdpPercap, lifeExp, size = pop, color = continent)) +
scale_size("population", limits = range(gapminder$pop)) + geom_point() + ylim(20, 90) +
scale_x_log10(limits = range(gapminder$gdpPercap)) + ggtitle(data$year) + theme_classic()
print(p)
})
dev.off()png
2 animation <- image_animate(img, fps = 2, optimize = TRUE)
print(animation)# A tibble: 12 × 7
format width height colorspace matte filesize density
<chr> <int> <int> <chr> <lgl> <int> <chr>
1 gif 600 340 sRGB TRUE 0 96x96
2 gif 385 243 sRGB TRUE 0 96x96
3 gif 395 237 sRGB TRUE 0 96x96
4 gif 374 232 sRGB TRUE 0 96x96
5 gif 393 225 sRGB TRUE 0 96x96
6 gif 373 234 sRGB TRUE 0 96x96
7 gif 354 234 sRGB TRUE 0 96x96
8 gif 308 210 sRGB TRUE 0 96x96
9 gif 320 260 sRGB TRUE 0 96x96
10 gif 331 218 sRGB TRUE 0 96x96
11 gif 356 208 sRGB TRUE 0 96x96
12 gif 347 208 sRGB TRUE 0 96x96 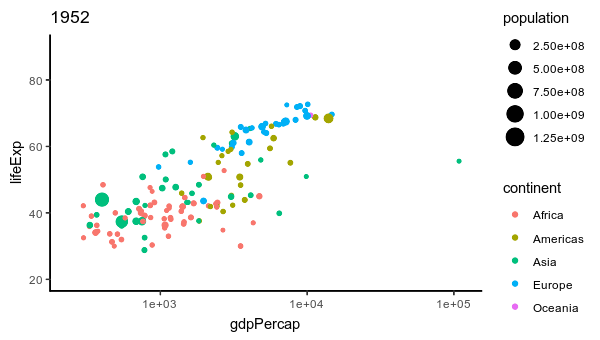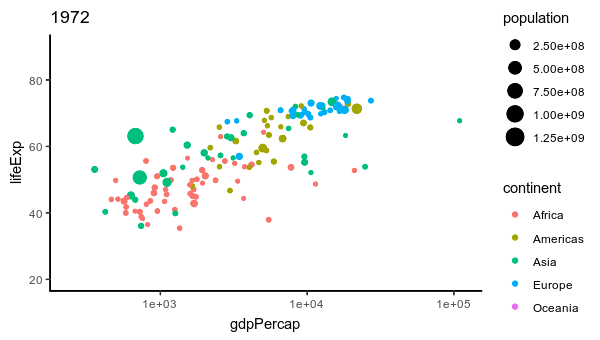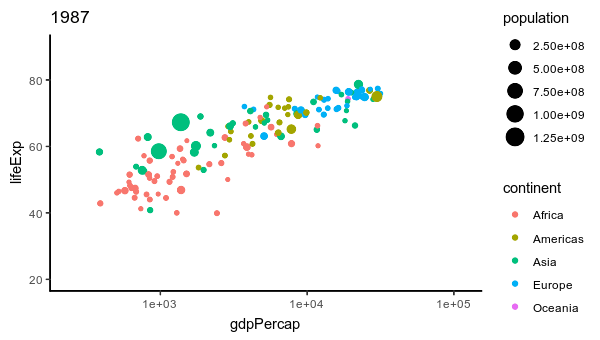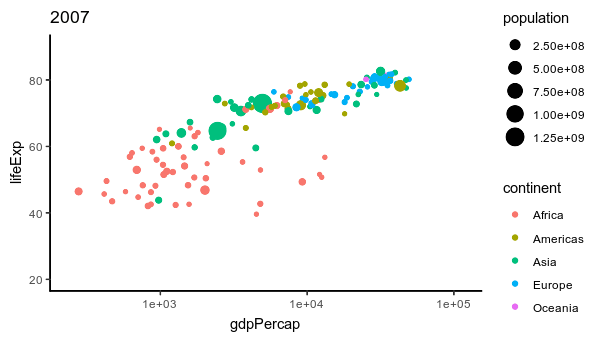
Lo que se hizo es:
Crea un lienzo gráfico (img) usando image_graph. Dividir los datos de gapminder por años. Iterar sobre cada conjunto de datos de año en gapminder, crear un gráfico con ggplot2 utilizando la información de cada año e imprimir. Cerrar el lienzo gráfico con dev.off(). Finalmente convertir los gráficos generados en una animación con image_animate.
Esencialmente, este código crea una serie de gráficos de dispersión utilizando datos de gapminder para cada año, con la esperanza de que al final se genere una animación que muestre cómo cambian la expectativa de vida, el PIB per cápita y la población a lo largo del tiempo en diferentes continentes.