Lab 10 Logistic regression
10.1 Introduction
In the previous labs we learned about the linear model and how to use it. This is, in fact, an extremely useful tool in quantitative research and potentially for your Research Report. As you saw, this model can be applied to study a dependent numeric variable. However, we do not often have many numeric variables in social science research. Instead, we have preferences, opinions, and statuses, expressed as categorical variables. We can extend our skills using the logistic regression model. This is useful to evaluate a binomial dependent variable, which is a dependent variable with only two possible outcomes.
10.2 Logistic regression
Logistic regression is useful when the dependent variable has only two possible outcomes, this type of variables is called binary, binomial, or dichotomous (sometimes also as dummy which is slightly different). Some examples in social sciences are:
- choices (e.g walk/drive, yes/no),
- results (e.g. pass/fail, win/lose),
- behaviour (e.g. smoker/non-smoker, member/not-member, religious/not-religious) or
- status (e.g. employed/unemployed, married/single).
The logistic model produces a probability as the outcome, which is defined as \(p\). A probability will always go from 0 to 1. Where 0 means that there is no chance that an event will happen, whereas 1 means that it is certain that the event will occur. The logistic model can help us to answer questions such as: What makes people more likely to…?
10.2.1 Extending the linear model
Binary variables can be represented with a 0 when the dependent variable is not present, and 1 when it is. You may then be wondering why we can’t simply use a linear model if the probability is a numeric variable that goes from 0 to 1. Let’s practice with the NILT data set to answer this question.
Before moving on, set your RStudio environment by following the next steps:
- Go to your ‘Quants lab group’ in RStudio Cloud;
- Open your own ‘NILT2’ project from your ‘Quants lab group’;
- Once in the project, create a new R Script file (a simple R Script, NOT an
.Rmdfile). - Save the script document as ‘logit_model.’
Reproduce the code below, by copying, pasting and running it from your new script.
First, install the jtools package. This is useful to print the summary of a model, among other things.
install.packages("jtools")Load the tidyverse and jtools and read the nilt_r_object.rds file which is stored in the ‘data’ folder and contains the NILT survey.
## Load the packages
library(tidyverse)
library(jtools)
# Read the data from the .rds file
nilt <- readRDS("data/nilt_r_object.rds")We will explore the respondent’s opinion on long-term policy for Northern Ireland using the nirelnd2 variable. If you look at the documentation, you will see this is a categorical variable that contains five possible responses. First, we will coerce this variable as factor and print a table with the number of observations for each category in the data set:
nilt$nirelnd2 <- as_factor(nilt$nirelnd2)
table(nilt$nirelnd2)##
## Not answered/refused
## 0
## Dont know
## 0
## To remain part of the United Kingdom, with direct rule
## 151
## To remain part of the United Kingdom, with devolved government
## 608
## To reunify with the rest of Ireland?
## 185
## (Independent state)
## 62
## Other answer (specify)
## 18Let’s imagine that our research question is about Northern Ireland (NI) independence, for example (n.b. this is merely an exercise to learn about the statistical technique, and not about nor make the political statement per se). We can transform the variable above into a new binary variable called ni_ind, which assigns 1 if the respondent chose ‘Independent state,’ or 0 otherwise. We will do this using the ifelse() function (this function evaluates a condition in the first argument, if this is satisfied, assigns the value of the second argument, if not, it takes the value in the third argument).
nilt$ni_ind <- ifelse(nilt$nirelnd2 == '(Independent state)', 1, 0)Now, let’s look at a table of our new variable:
table(nilt$ni_ind)##
## 0 1
## 962 62In total, only 62 respondents thought that the long-term NI policy should be an independent state and 962 chose any of the other options.
We may think that this preference (whether NI should be independent or not) would be correlated with age. We can start by simply checking the mean age for both groups:
nilt %>%
group_by(ni_ind) %>%
summarise(age = mean(rage, na.rm = T))## # A tibble: 3 × 2
## ni_ind age
## <dbl> <dbl>
## 1 0 51.0
## 2 1 40.9
## 3 NA 45.1Respondents who said that the NI long-term policy should be an independent state are more than 10 years younger on average compared to the ones who chose a different option. This may suggest that age is playing a role in this binary opinion.
We will produce a scatter plot, locating the ni_ind variable on the Y axis (as typically for the dependent variables) and age rage on the X axis. We will use the geom_jitter() function to plot the points adding some random noise to their original value (0 or 1) since the dependent variable contains only two levels. Otherwise points will overlap along two lines only, making it difficult to visualize a pattern.
nilt %>%
filter(!is.na(ni_ind)) %>%
ggplot(aes(x =rage , y= ni_ind)) +
geom_jitter(width = 0, height = 0.1) +
labs(title = "Respondent's age vs NI independence",
x = "Respondent's age", y = "NI independence" )
From the plot above we can confirm that the people who chose independent NI are younger, e.g. only 4 data points are more than 70 years old and no-one is older than 80.
Just to illustrate what happens, we will overlay a straight line adjusted by a linear model to describe the points above modelling the probability using the geom_smooth():
nilt %>%
filter(!is.na(ni_ind)) %>%
ggplot(aes(x =rage , y= ni_ind)) +
geom_jitter(width = 0, height = 0.1) +
geom_smooth(method = "lm", se= FALSE, col = "red", linetype = "dashed") +
labs(title = "Respondent's age vs NI independence",
x = "Respondent's age", y = "NI independence")
This linear model represented by the red line is describing the overall pattern where the probability that someone prefers an independent state for NI decreases as age increases. However, there is a major drawback, this model is predicting negative values for people older than 80 years (aprox). You can see this from the red line on the right-hand side of the plot when it crosses the horizontal value of 0. This does not make sense, since a probability will always be between 0 and 1. Therefore, we need a different technique which describes this relationship better.
This time, we will overlap a line using a logit model using the geom_smooth() again, but specifying ‘glm’ as the method and family ‘binomial.’
nilt %>%
filter(!is.na(ni_ind)) %>%
ggplot(aes(x =rage , y= ni_ind)) +
geom_jitter(width = 0, height = 0.1) +
geom_smooth(method = "lm", se= FALSE, col = "red", linetype = "dashed") +
geom_smooth(method = "glm", method.args = list(family = "binomial"), se =FALSE) +
labs(title = "Respondent's age vs NI independence",
x = "Respondent's age", y = "NI independence")
From the plot, we can see that the blue line fitted by a logit model is no longer a straight line. This property helps to overcome the issue identified before. On the right-hand side of the plot we see that the blue line does not touch 0 in the horizontal axis and on the the left-hand side we can see that the probabilities estimated are higher for younger people.
10.2.2 Fitting a logit model
We have seen the probability that someone prefers an independent state for NI decreases as age increases. Therefore, there is a negative relationship between these two variables. But how can we describe this relationship numerically and obtain more information about it?
We can fit a logit model using the glm() function, this takes the formula as the first argument, specifying the dependant variable followed by the independent variable (as in the linear model lm() function). Then, separated by a comma, we have to specify the data. Lastly, we define the family as ‘binomial.’
We will fit a logit model using ni_ind as the dependent variable and rage the independent, as below:
m7 <- glm(ni_ind ~ rage, data = nilt, family = 'binomial')
m7##
## Call: glm(formula = ni_ind ~ rage, family = "binomial", data = nilt)
##
## Coefficients:
## (Intercept) rage
## -1.19628 -0.03411
##
## Degrees of Freedom: 1020 Total (i.e. Null); 1019 Residual
## (183 observations deleted due to missingness)
## Null Deviance: 462
## Residual Deviance: 443 AIC: 447When we print our m7 model, R will return the estimated coefficients for the intercept and the slope for the independent variable and some other basic information, e.g. the number of observations deleted to fit this model.
The interpretation of the coefficients is not as straightforward as in a linear model. In the next section we will discuss how to interpret the output of the logit model.
10.2.3 Formal specification
As we discussed above, we are interested in modelling the probability of an event to occur. However, probabilities are non-linear. This make it a bit tricky to interpret its relationship with the independent variables. Fortunately, the link function helps us to establish a linear relationship between the dependent \(p\) and the independent variable \(\beta\). The logit model can be expressed as follows:
\[ logit(p)=\beta_0 + \beta_1 x + \epsilon \]
where
\[ logit(p) = \text{log} \left( \frac{p}{1-p} \right) \]
The above means that the outcome of the logit model is in the log odds \(\text{log} \left( \frac{p}{1-p} \right)\). Therefore, for every unit change of the independent variable \(x\), we can expect an increase/decrease in the log odds by a factor of the estimated coefficient \(\beta_1\).
10.3 Interpreting logistic regression
As a generic interpretation, we can say that the coefficients estimated increase/decrease the chance of the outcome happens.
The scale of the output, the log odds, is an unusual concept and difficult to communicate and understand. This is why many researchers opt to report their findings as the odds ratio. That means, we want to take away the \(\text{log}\) from the output and leave only the probability that something will happen over the probability that it will not, like this: \(\frac{p}{1-p}\). This form of the result is called the odds ratio (OR) and can be understood as the ratio of success to non-success.
To do so, we need to reverse the output of our model. To reverse a logarithmized number we need to exponentiate it. We can do it ‘manually’ in R or we can use the summ() function from the jtools package, specifying the argument exp = TRUE. Using our example above we have:
jtools::summ(m7, exp = TRUE)| Observations | 1021 (183 missing obs. deleted) |
| Dependent variable | ni_ind |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| 𝛘²(1) | 19.03 |
| Pseudo-R² (Cragg-Uhler) | 0.05 |
| Pseudo-R² (McFadden) | 0.04 |
| AIC | 447.00 |
| BIC | 456.86 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 0.30 | 0.15 | 0.62 | -3.26 | 0.00 |
| rage | 0.97 | 0.95 | 0.98 | -4.13 | 0.00 |
| Standard errors: MLE |
Now our estimate coefficients are in the odd ratio (OR) scale, which makes it easier to interpret (see the first column exp(Est) in the table). In general, we can interpret the coefficients in their OR scale as follow:
- OR = 1, any effect
- OR < 1, decreases the odds
- OR > 1, increases the odds.
By exponentiating the coefficients our results will not change, they will only be expressed in a different scale.
From the example above, the estimate coefficient for age is 0.97. This is slightly smaller than 1, which means that the odds of someone preferring NI as an independent state are expected to decrease for every additional year older a respondent is.
Being more specific, we can interpret these changes as percentage using 1 as the reference. In the example above: 0.97 minus 1 equals -0.03. That is for every year older a respondent is the odds of preferring NI as an independent state decrease by 3%.
The other columns (2.5%, 97.5%, z val., p) tell us how confident we can be about the estimate. A quite often reported result is the p-value (‘p’ in the output table). To be able to say that there is a significant relationship between the dependant and independent variable the cut-off value is generally agreed to be equal or less than 0.05. In our example, this is far smaller than 0.05. This is why the p-value is rounded to 0.00. Therefore, we can say there is a significant relationship between the respondent age and the preference for NI to be independent.
10.4 Multivariete logit model
(You don’t need to reproduce the code of this section in your script).
As we did with the linear model, we can add more than one independent variable to explore the relationship with a dependent variable.
Let’s say that in addition to age rage we are interested in the role that religion religcat can play in the preference of NI being an independent state. The first thing we can do is create a two-way contingency table to see the distribution of the respondents who prefer NI as independent by religion.
t1 <- addmargins(table(nilt$religcat, nilt$ni_ind), 1)
prop.table(t1, 1) * 100##
## 0 1
## Catholic 91.831683 8.168317
## Protestant 97.356828 2.643172
## No religion 90.066225 9.933775
## Sum 94.053518 5.946482Then, we can visualize this relationship. Since both are categorical variables, we will use a stacked bar plot.
nilt %>%
filter(!is.na(ni_ind)) %>%
ggplot(., aes(x = as.factor(ni_ind), fill = religcat)) +
geom_bar(position = 'fill' ) +
labs(title = "Respondent's religion vs NI independence",
x = "NI independence", y = "Composition by religion")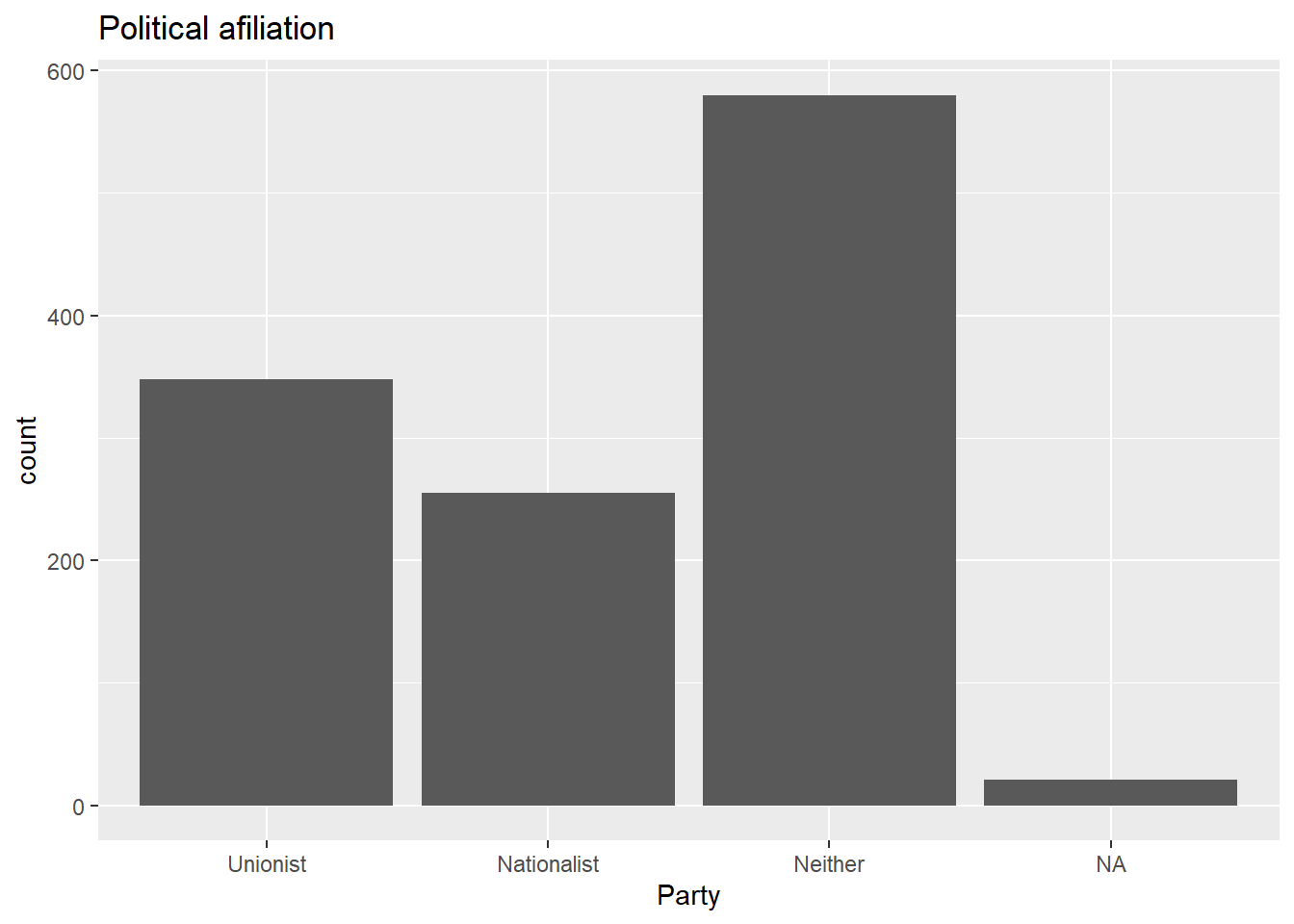
From the table and the plot we see that there is a smaller proportion of protestants who chose the option of NI as an independent state. By contrast the proportion of catholics who prefer being independent is larger. Furthermore, there are more respondents with no religion who prefer being independent in proportional terms.
Now, let’s fit the a logit model with religion as an additional independent variable and print the estimated coefficient in the OR scale using the summ function:
m8 <- glm(ni_ind ~ rage + religcat, data = nilt, family = 'binomial')
jtools::summ(m8, exp = TRUE)| Observations | 1006 (198 missing obs. deleted) |
| Dependent variable | ni_ind |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| 𝛘²(3) | 29.41 |
| Pseudo-R² (Cragg-Uhler) | 0.08 |
| Pseudo-R² (McFadden) | 0.07 |
| AIC | 427.73 |
| BIC | 447.39 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 0.31 | 0.14 | 0.68 | -2.94 | 0.00 |
| rage | 0.97 | 0.96 | 0.99 | -3.36 | 0.00 |
| religcatProtestant | 0.35 | 0.18 | 0.70 | -3.00 | 0.00 |
| religcatNo religion | 1.19 | 0.62 | 2.28 | 0.52 | 0.60 |
| Standard errors: MLE |
There are three general parts of the result summary, the first is the general model info, the second is some general measures to assess how good our model is, and the third is the table including the coefficients.
From the model info it is important to note the number of observations deleted, 198 in this example.
From the model fit, we have two pseudo-R-squared (R²) measures: Cragg-Uhler and McFadden. In the logit model we do not have a proper adjusted r-squared, and the interpretation is not the same as in the linear model. However, these measures give us some idea how our model is performing in relative terms form 0 to 1 (the closer to 1 the better). For instance, the Cragg-Uhler pseudo-R-squared increased from 0.05 to 0.08 by adding religion in m8.
In the third section we have the values for the estimated coefficients. We can see that age rage remains the same as in m7. The the variable religcat appended two of the three categories. Again, the category not shown is the reference, ‘Catholic’ in our example. The interpretation of the categorical variable is in comparative terms. For instance, protestant respondents have a coefficient lower than 1, which means that they are less likely to prefer NI to be an independent state compared to people with catholic faith. Being more specific, the odds of preferring NI as independent are 65% lower among protestants compared to catholics (0.35 - 1). This relationship is significant, since the p-value is lower than 0.05. In contrast, having no religion increases the odds of preferring NI being independent by 19% compared to catholic respondents. However, if we look at the p-value, we see this relationship is not significant. Therefore, the interpretation of the coefficients is not meaningful.
10.5 Some model generalities and assumptions
The logit model is part of a set of models called the Generalized Linear Models (GLM). The criterion to estimate the parameters is the Maximum Likelihood Estimate (MLE), and not the sum of the squared residuals (SSR), as in the linear model.
As the linear model, the logit model also makes many assumptions. In contrast to the linear model, this does not require a linear relationship between the dependent and independent variables. Also, the residuals are not conceptualized the same as in the linear model and they are not assumed to be normally distributed. However, the logit model still requires the observations to be independent, among others things. We will not cover the checks for these assumptions in this course. For now, we would suggest you to be transparent and acknowledge the limitations if you use this technique.
10.6 Lab activities
You will explore the interreligious relations in Northern Ireland measured by the acceptance of a close relative marrying someone of a different religion in the variable smarrrlg. This variable asks Would you mind or not mind if one of your close relatives were to marry someone of a different religion?. The possible answers are three: 1 Would mind a lot / 2 Would mind a little / 3 Would not mind.
Using the nilt object complete the following activities in your logit_model.R R Script:
- Coerce the variable
smarrrlgto factor using theas_factor()function. - Print a simple table of this variable using the
table()function. - From the three possible options, create a new binary variable called
marr_mixusing theifelse()function. Assign ‘1’ if the response is Would mind a lot or 2 Would mind a little and ‘0’ otherwise. You can copy and run the code below.
nilt$marr_mix <- ifelse(nilt$smarrrlg == 'Would mind a lot' | nilt$smarrrlg == 'Would mind a little', 1, 0)- Create a stacked bar plot using
ggplot(), inaes()setmarr_mixin the x axis, andfilltoreligcat. Use thegeom_bar()function, and within this specify thepositionargument to ‘fill.’ Filter out the missing values formarr_mixbefore passing the data to ggplot. - Fit a logit model using the
marr_mixas the dependent variable,persinc2andreligcatas the independent variables. Assign it to and object calledm9. - Use the
jtools::summ()function to print the summary of the results, setting theexpargument toTRUE. - Which of the independent variables is/are significant?
- Do you think personal income is playing a role?
- How do you interpret the coefficient for protestant respondents?