Lab 6 Visual exploratory analysis
6.1 Introduction
In this lab, we will extend your skills to explore data by visualizing it…and R is great for this! It is actually a highly-demanded skill in the job market.
Visualizing data is an important process in at least two stages in quantitative research: First, for your as a researcher to get familiar with the data; and second, to communicate your findings. R includes two important tools to achieve this: First, the ggplot2 package (included in tidyverse), a powerful tool to explore and plot data. Second, R Markdown which allows you to create integrated quantitative reports. Combining and mastering the two can create very effective results.
6.2 Data visualization
Visual data exploration withggplot2 (Artwork by @alison_horst).

Figure 6.1: Visual data exploration. Source: Horst (n.d.)
Different plot types serve different types of data. In the last lab, we introduced some functions to summarise your data and to generate summaries for specific types of variable. This will help you to decide what the most suitable plot is for your data or variable. The table below presents a minimal guide to choose the type of plot as a function of the type of data you intend to visualize. In addition, it splits the type of plot by the number of variables included in the visualization, one for univariate, or two for bivariate. Bivariate plots are useful to explore the relationship between variables.
| Univariate | Bivariate | |
|---|---|---|
| Categorical | Bar plot / Pie chart | Bar plot |
| Numeric | Histogram / boxplot | Scatter plot |
| Categorical + Numeric | - | Box plot |
6.2.1 Prepare the Rmd document and data
As we did in the last session, let’s learn by doing. We will continue working in the same project called NILT in RStudio Cloud. Set up your session as follow:
- Go to your ‘Quants lab group’ in RStudio Cloud (log in if necessary);
- Open your own copy of the ‘NILT’ project from the ‘Quants lab group’;
Next, create a new Rmd document following the next steps.
- Create a new Rmd file titled ‘Lab 6. Data visualization’, and write your name in the ‘Author’ space.
- Save the Rmd file clicking on
File>Save as..., usingLab_6in the ‘File name’ box, and click on the ‘Save’ button. - Delete all the contents in the default example with the exception of the first bit which contains the YALM and the first code chunk (that is keeping from line 1 to 10 and deleting everything from line 11).
- In the setup chunk (line 8), change
echofromTRUEtoFALSE(this will hide the code for all chunks in the output).
Once your Rmd document is ready, insert a new R code chunk. To do this, click on the ‘Insert’ button on pane 1, and then click on ‘R’. This will insert an R code chunk as the ones we explored in ‘Test1’.
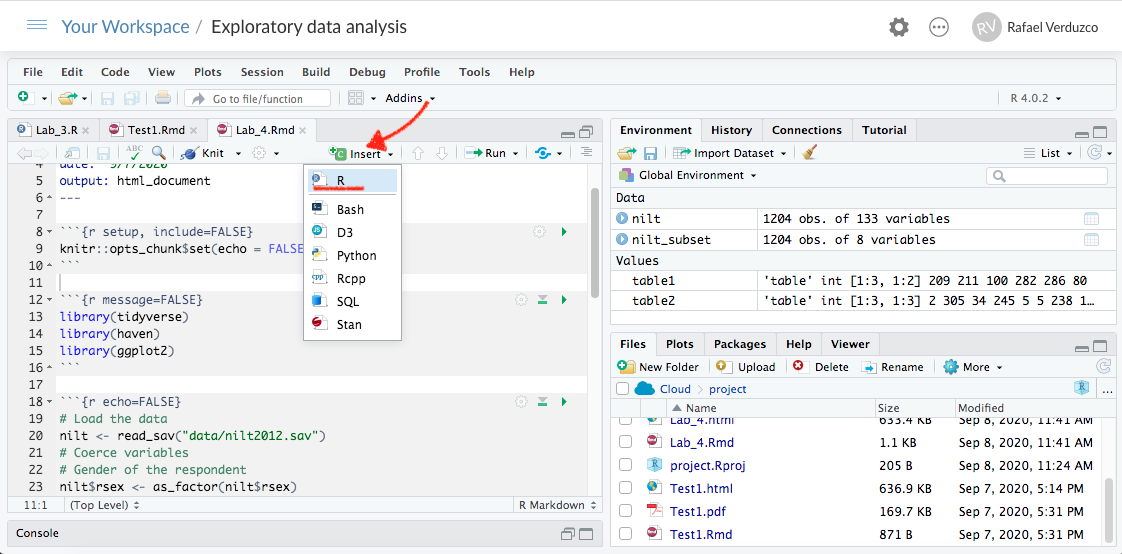
Figure 6.2: Insert a code chunk.
In the body of the first chunk, load the packages that you will need. For now, it will be only tidyverse.
library(tidyverse)After the previous, insert a second chunk. In the body of the code copy and paste the lines below. This is to load the data we downloaded and formatted in the last lab in R format using the readRDS() function (note that we are reading the .rds file and not the original .sav file). Also, we will create a subset called nilt_subset selecting only the variables that we are interested in for now, as we did in the previous lab.
# Load the data from the .rds file we created in the last lab
nilt <- readRDS("data/nilt_r_object.rds")
#Create subset
nilt_subset <- select(nilt, rsex, rage, highqual, religcat, uninatid, ruhappy, rhourswk, persinc2)Run both of the previous chunks individually by clicking on the green arrow located on the top-right of the chunk, as described earlier.
Now that we read the data in, we are ready to start creating our own own plots using the 2012 NILT survey.
You do not need to reproduce each of the examples in the following section, but we suggest you to carefully read the description and try to understand the code syntax.
6.3 Cateogrical variables
Let’s start using the same variables we summarised in our last lab. We started by computing the total number of respondents by gender in a One-Way contingency table. We can easily visualize this using a bar plot with ggplot. This package always takes at least three layers, namely data, aesthetics and geometry. Here, we define the data as the first argument of the ggplot()function with the nilt_subset. The second argument, aesthetics, is separated by a comma and is introduced using the function aes(). In this case we define the X axis x = of the plot by the categories included in the variable rsex. The geometry is specified with the function geom_bar() without arguments for now. Note that we added the geometry using the plus sign + at the end of the previous line code. As an extra, I included the main title and the name of the x axis using the labs() function (you don’t need to copy or run the following code chunks in your .Rmd. This is only for demonstration purposes).
ggplot(nilt_subset, aes(x = rsex)) +
geom_bar() +
labs(title = 'Gender', x = 'Gender of respondent')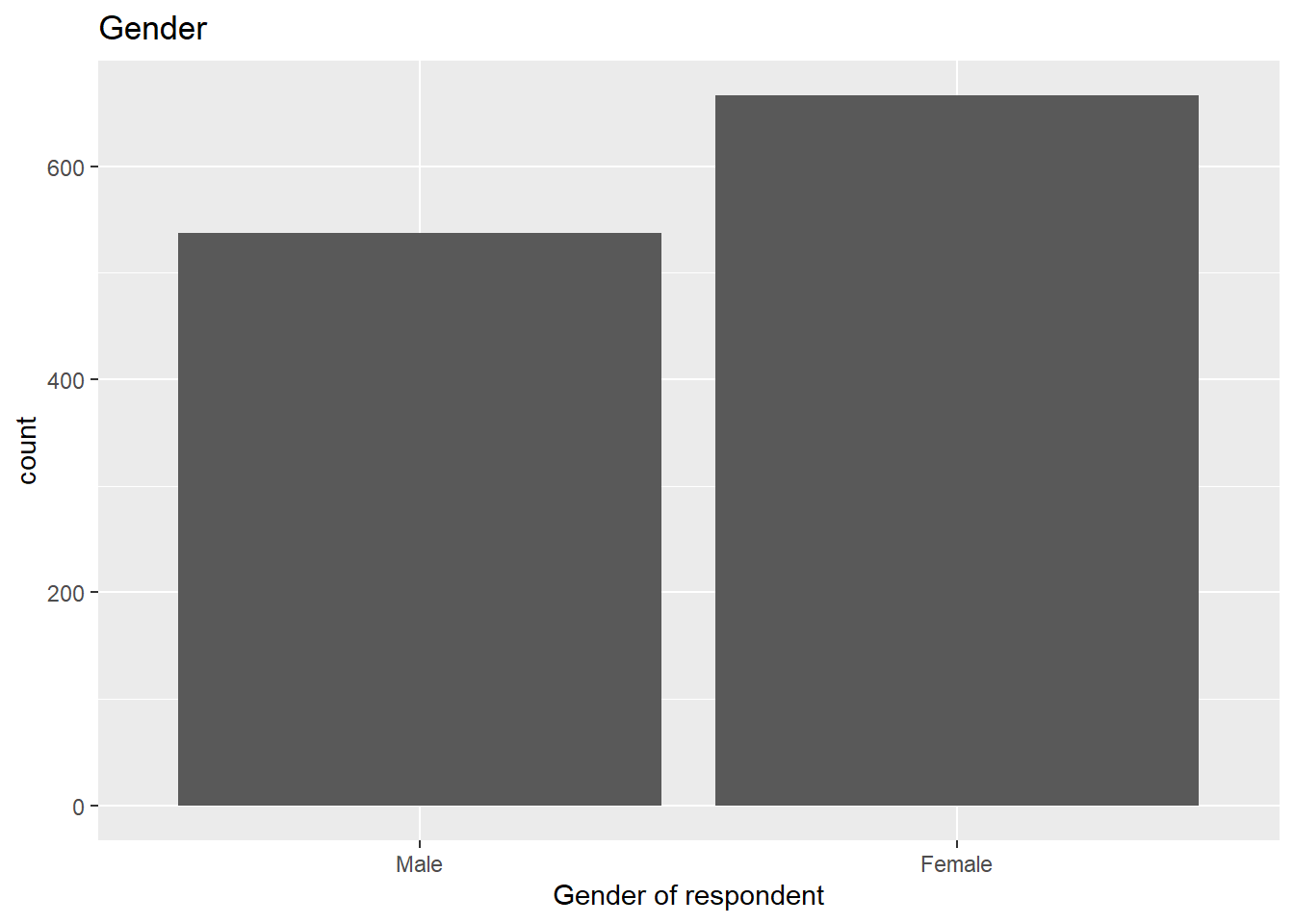
From the plot above, we can graphically see what we found out previously: there are more female respondents than males in our sample. The advantage is that we can have a sense of the magnitude of the difference by visualising it.
6.3.1 Bivariate categorical vs categorical
In Lab 3, we computed a Two-Way contingency table, which included the count of two categorical variables. This summary can be visualized using a stacked bar plot. This is quite similar to the above, with the addition that the area of the vertical plot is coloured by the size of each group.
If we wanted to know how gender is split by religion, we can add the fill argument with a second variable in aesthetics, as shown below.
ggplot(nilt_subset, aes(x = rsex, fill = religcat)) +
geom_bar() +
labs(title = 'Gender by religion', x = 'Gender of respondent')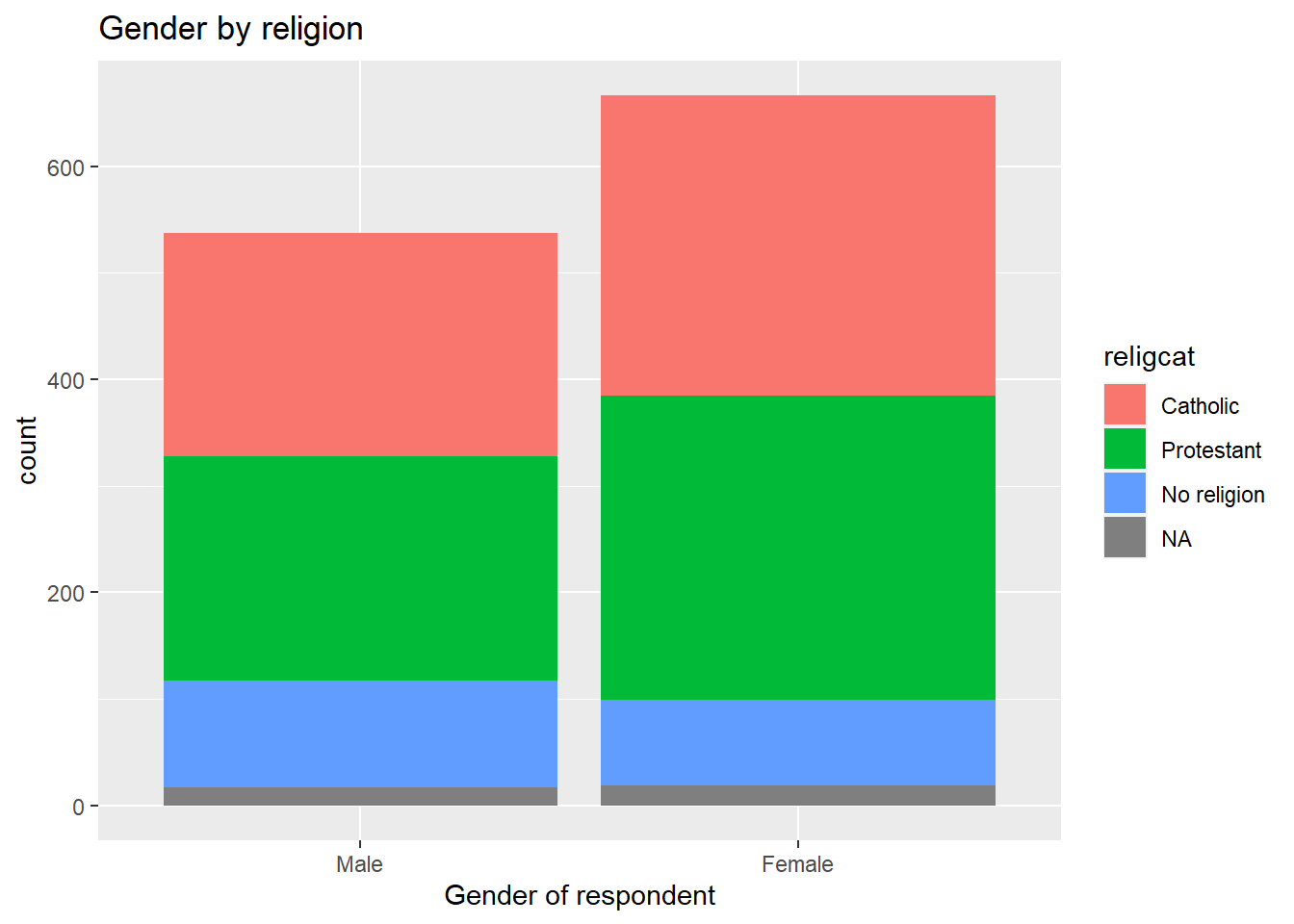
This plot is not very informative, since the total size of female and male respondents is different. The type of visualization will also depend on your specific research question or the topic you are interested in. For example, if I think it is worthwhile visualizing the religion by respondents’ sex. A plot can show us the magnitudes and composition by respondents’ sex for each religion. To do this, we need to change the aesthetics, specifying the religion by category variable religcat on the x axis and fill with gender rsex.
ggplot(nilt_subset, aes(x = religcat, fill = rsex)) +
geom_bar() +
labs(title = 'Religion by gender', x = 'Religion')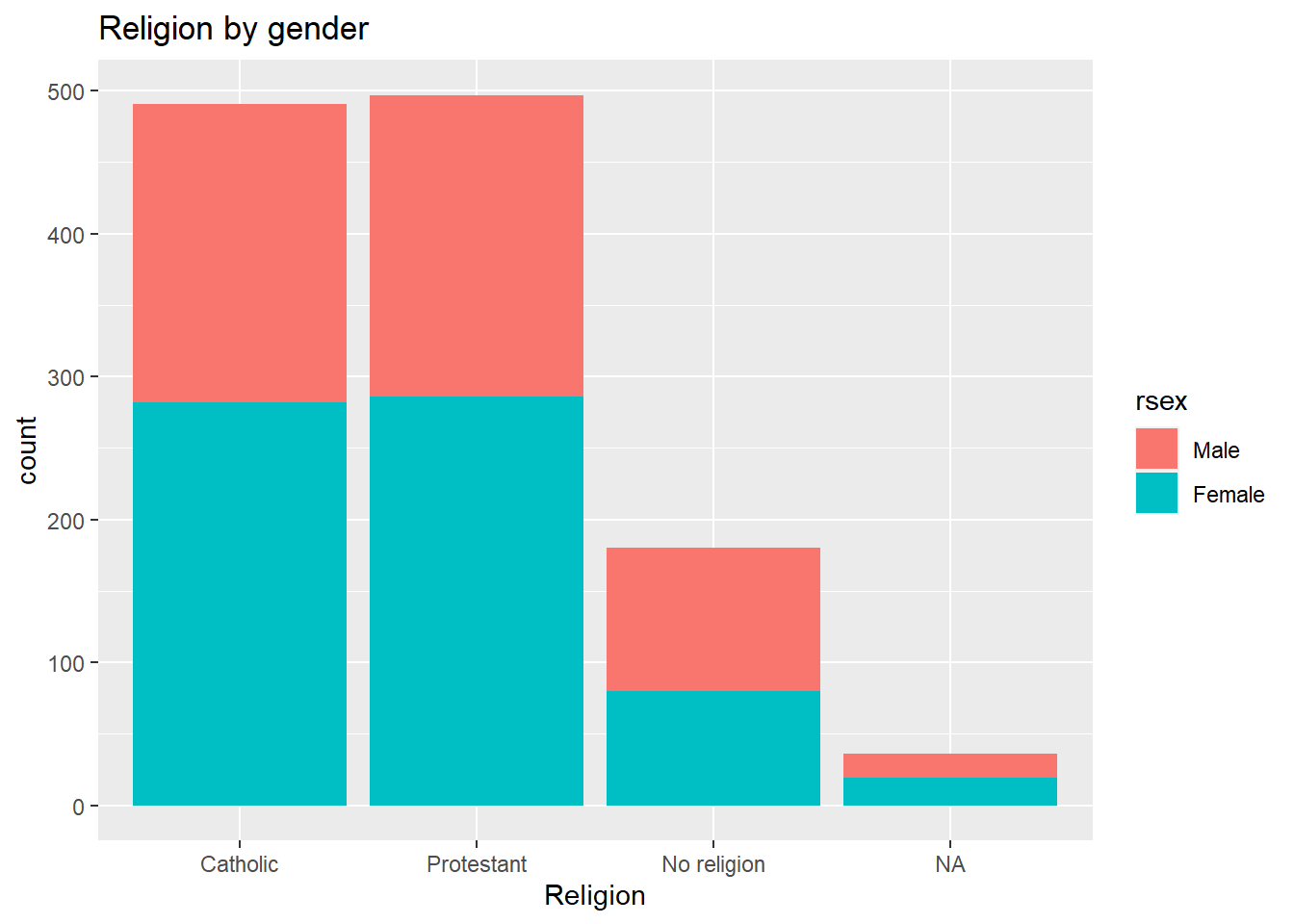
As we can see, catholic and protestant religion are equally popular among the respondents. Also, we can see that these are composed by similar proportions of males and females. One interesting thing is that there are more male respondents with no religion than female participants. Again, we found this out with the descriptive statistics computed in the last lab. However, we have the advantage that we can graphically reprsent and inspect the magnitude of these differences.
6.4 Numeric variables
6.4.1 Univariate numeric
Last time we talked about some measures of centrality and spread for numeric variables. The histogram plot is similar to the bar plot, the difference is that it splits the numeric range in fix “bins” and computes the frequency/count for each bin instead of counting the number of respondents for each numeric value. The syntax is practically the same as the simple bar plot. At this time, we set the the x aesthetic with the numeric variable age rage. Also, the geometry is defined as a histogram, using the geom_histogram() function.
ggplot(nilt_subset, aes(x = rage)) +
geom_histogram() +
labs(title = 'Age distribution')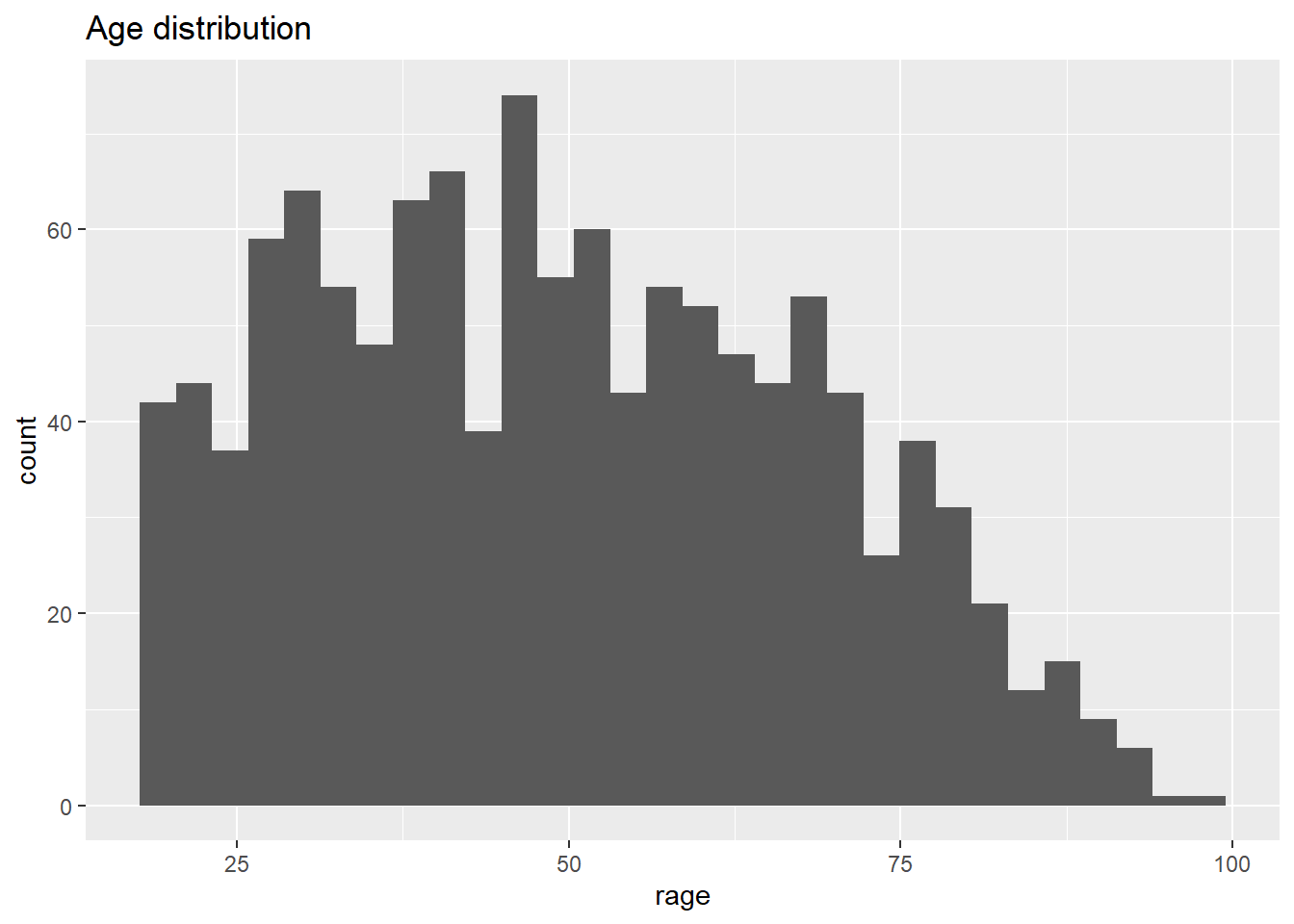
From the histogram, we have age (in bins) on the X axis, and the frequency/count on the y axis. This plot is useful to visualize how respondent’s age is distributed in our sample. For instance, we can quickly see the minimum and maximum value, or the most popular age, or a general trend indicating the largest age group.
A second option to visualize numeric variables is the box plot. Essentially this draws the quartiles of a numeric vector. For this time, rage is defined in the y axis. This is just a personal preference. The geometry is set by the geom_boxplot() function.
ggplot(nilt_subset, aes(y = rage)) +
geom_boxplot() +
labs(title = 'Age boxplot')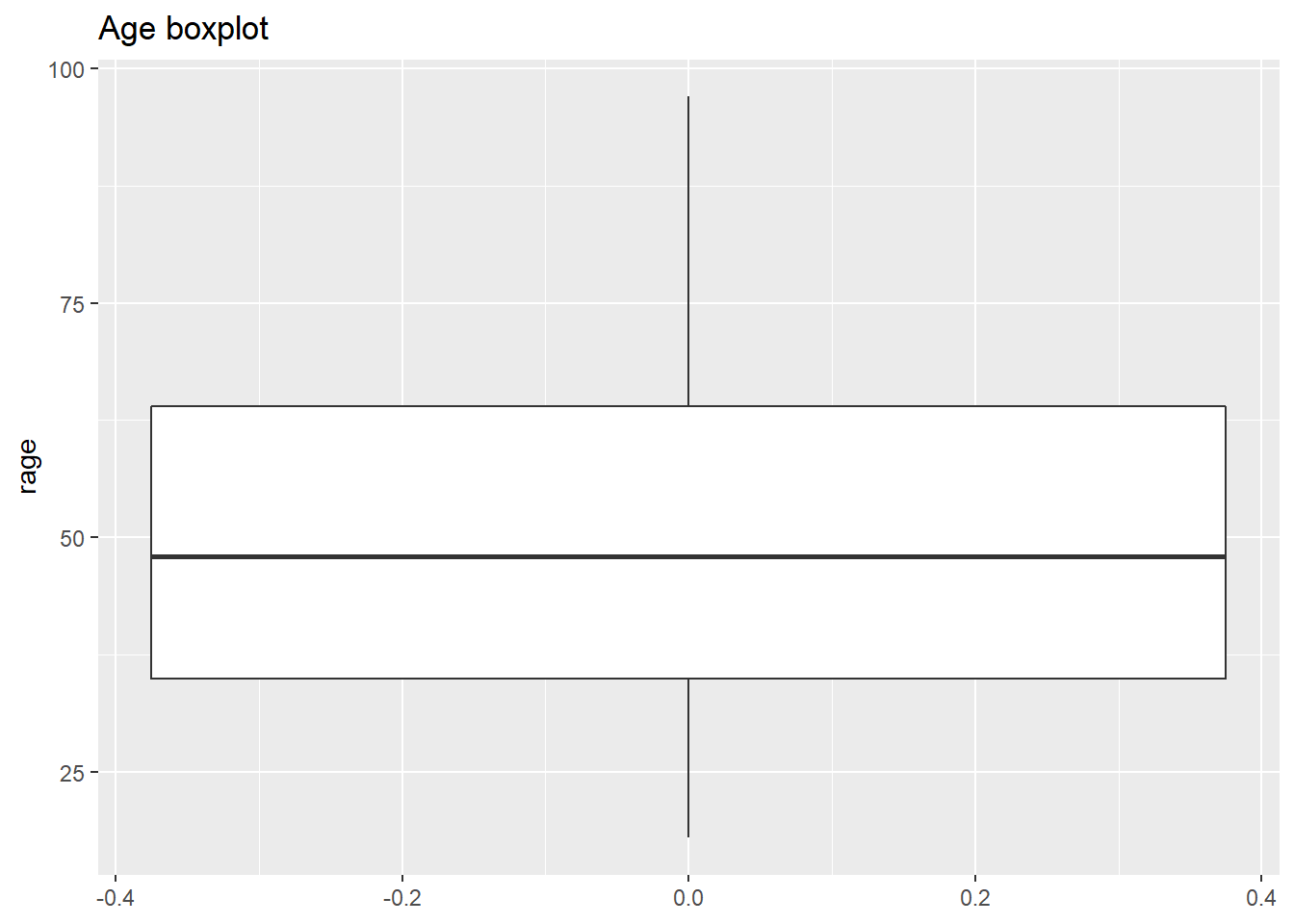
What we see from this plot is the first, second and third quartile. The second quartile (or median) is represented by the black line in the middle of the box. As you can see this is close to 50 years old, as we computed using the quantile() function. The lower edge of the box represents the 2nd quartile, which is somewhere around 35 years old. Similarly the 3rd quartile is represented by the upper edge of the box. We can confirm this by computing the quantiles for this variable.
quantile(nilt_subset$rage, na.rm = T)## 0% 25% 50% 75% 100%
## 18 35 48 64 976.4.2 Bivariate numeric
A useful plot to explore the relationship between two numeric variables is the scatter plot. This plot locates a dot for each observation according to to their respective numeric values. In the example below, we use age rage on the X axis (horizontal), and personal income persinc2 on the Y axis (vertical). This type of plot is useful to explore a relationship between variables.
To generate a scatter plot, we need to define x and y in aesthetics aes(). The geometry is a point, expressed by geom_point(). Note that we are specifying some further optional arguments. First, in aes() alpha regulates the opacity of the dots. This goes from 0.0 (completely translucent) to 1.0 (completely solid fill). Second, in geom_point() we defined position as jitter. This arguments slightly moves the point away from their exact location. These two arguments are desired in this plot because the personal income bands are overlapped. Adding some transparency and noise to their position, can allow to visualize possible patterns easily.
ggplot(nilt_subset, aes(x = rage, y = persinc2, alpha = 0.8)) +
geom_point(position = "jitter") +
labs(title = 'Personal income vs age', x = 'Age', y = 'Personal income (£)')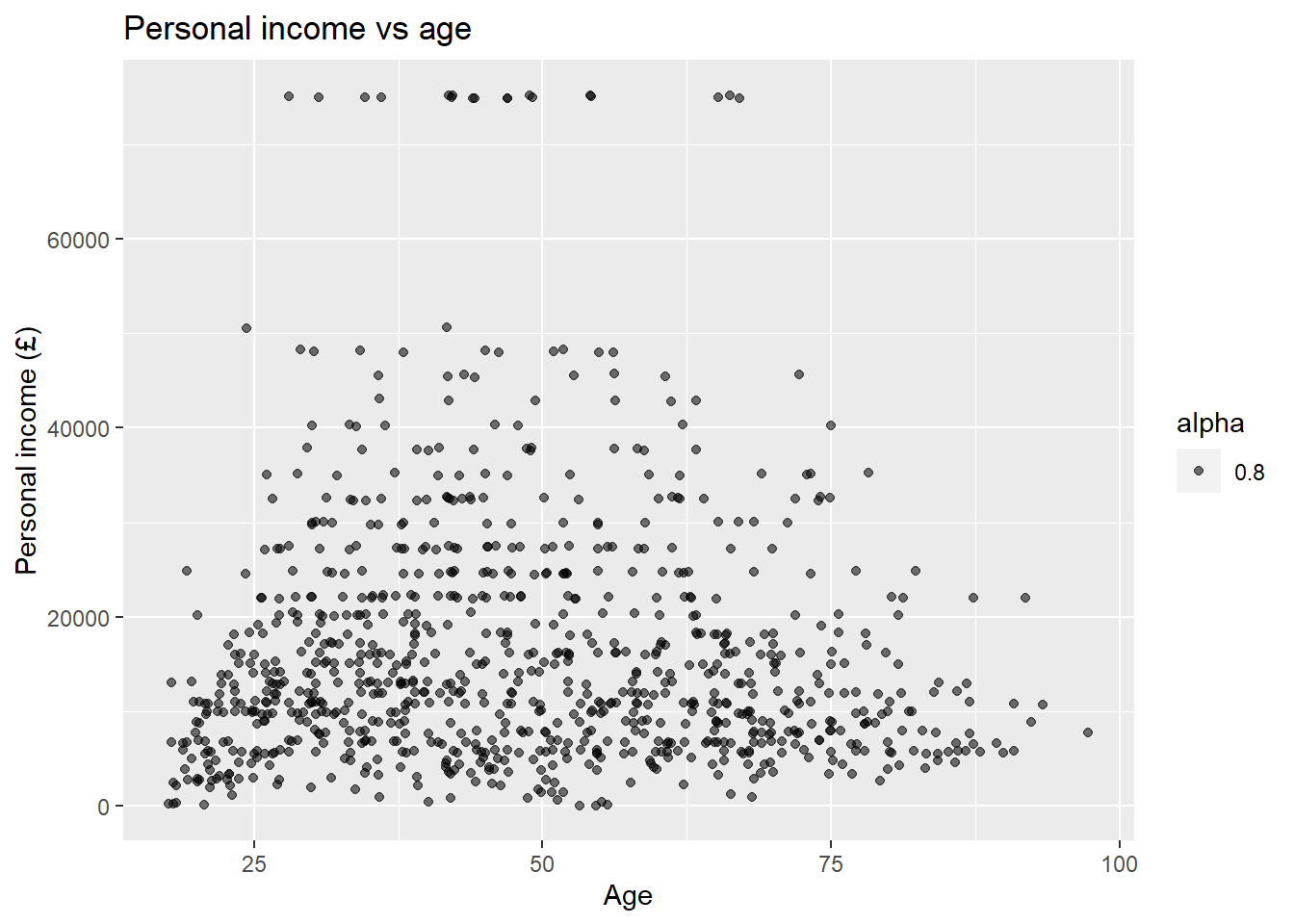
There is not a clear pattern in our previous plot. However, it is interesting to note that most of the people younger than 25 years old earn less than £20K a year. Similarly, most of the people older than 75 earn less than £20K. And only very few earn over £60k a year (looking at the top of the plot).
6.5 Mixed data
Very often we want to summarise central or spread measure by categories or groups. For example, let’s go back to the example of age and respondents’ sex. We can visualize these two variables (which include one numeric and one categorical) using a box plot. To create this, we need to specify the x and y value in aes() and include the geom_boxplot() geometry.
ggplot(nilt_subset, aes(y = rage, x= rsex)) +
geom_boxplot() +
ggtitle('Age by sex')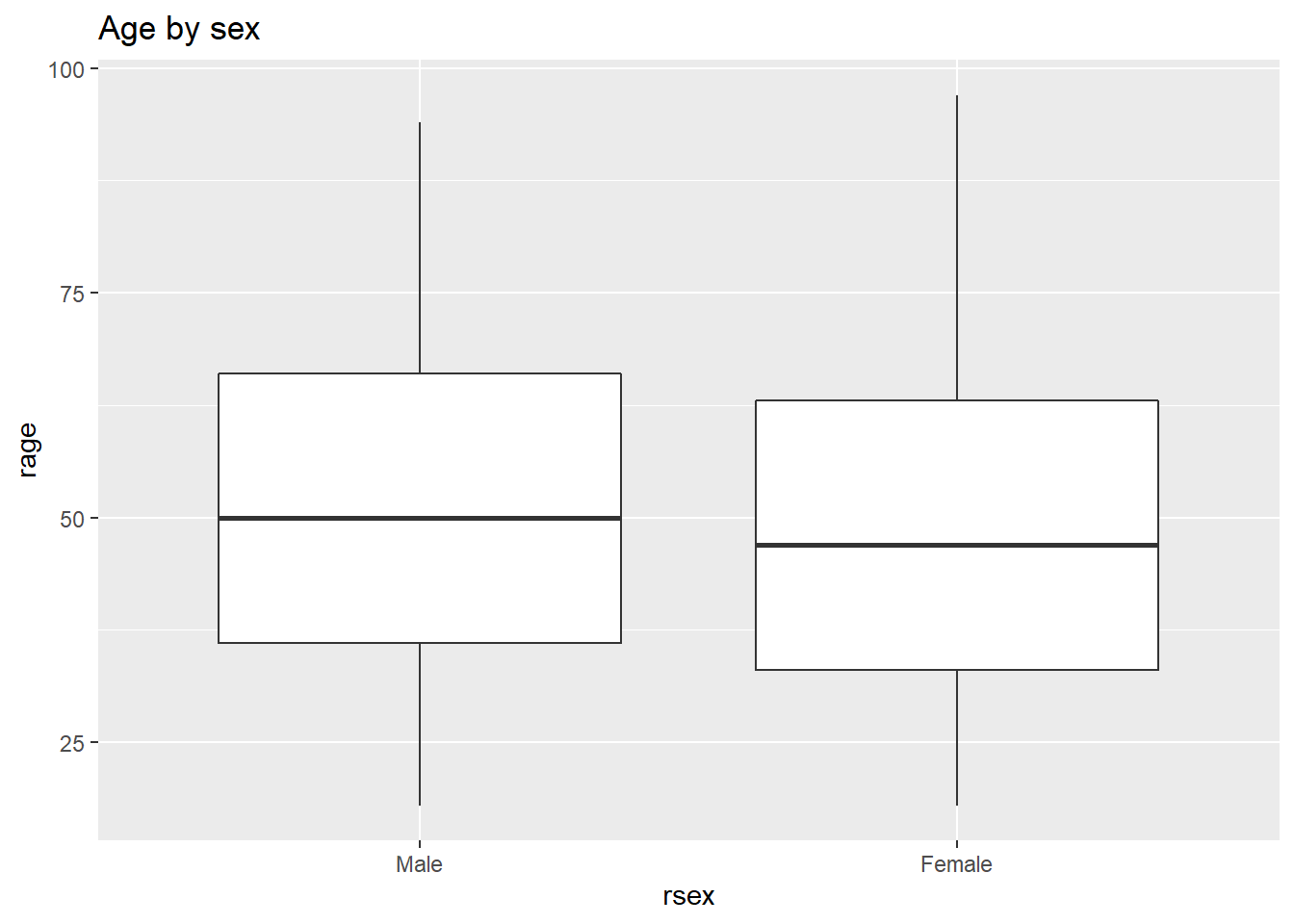
From this, we can visualize that female participants are slightly younger than their male counterparts in the sample.
6.6 Activity
Using the nilt_subset object, complete the tasks below in the Rmd file Lab_6, which you created earlier. Insert a new code chunk for each of these activities and include brief comments as text (outside the chunk) in the Rmd document to introduce or describe the plots. Feel free to copy and adapt the code to create the plots in the examples above.
- Create a first-level header to start a section called “Categorical analysis”;
- Create simple bar plot using the
geom_bar()geometry to visualize the political affiliation reported by the respondents using the variableuninatid; - Based on the plot above, create a ‘stacked bar plot’ to visualize the political affiliation by religion, using the
uninatidandreligcatvariables; - Create a new first-level header to start a section called “Numeric analysis”;
- Create a scatter plot about the relationship between personal income
persinc2on the Y axis and number of hours worked a weekrhourswkon the X axis; - Finally, create a box plot to visualize personal income
persinc2on the Y axis and self-reported level of happinessruhappyon the x axis… Interesting result, Isn’t it? Talk to your lab group-mates and tutors about your results on Zoom (live) or your Lab Group on Teams (online anytime); - Add your own (brief) comments to each of the plots as text in your Rmd file;
- Knit the .Rmd document as HTML or PDF. The knitted file will be saved automatically in your project. You can come back to the Rmd file to make changes if needed and knit it again as many times as you wish.
6.6.1 R Cheatsheets
There are a number of features that you can customize in your plots, including the background, text size, colours, adding more variables. But you don’t have to memorise or remember all this, one thing that is very commonly used by R data scientists are R cheat sheets! They are extremely handy when you try to create a visualisation from scratch, check out the Data Visualization with ggplot2 Cheat Sheet. An extra tip is that you can change the overall look of the plot by adding pre-defined themes. You can read more about it here. Another interesting site is the The R Graph Gallery, which includes a comprehensive showcase of plot types and their respective code.