Chapter 16 Error Probabilities, Power Function, Most Powerful Tests(Lecture on 02/18/2020)
Usually, hypothesis tests are evaluated and compared through their probabilities of making mistakes.
FIGURE 16.1: Two types of errors in hypothesis testing
Suppose \(R\) denotes the rejection region for a test. Then for \(\theta\in\Theta_0\), the test will make a mistake if \(\mathbf{x}\in R\), so the porbability of a Type I Error is \(P_{\theta}(\mathbf{X}\in R)\). For \(\theta\in\Theta_0^c\), the probability of a Type II Error is \(P_{\theta}(\mathbf{X}\in R^c)=1-P_{\theta}(\mathbf{X}\in R)\). The function of \(\theta\), \(P_{\theta}(\mathbf{X}\in R)\) contains all the information about the test with rejection region \(R\).
Example 16.1 (Binomial Power Function) Let \(X\sim Bin(5,\theta)\). Consider testing \(H_0:\theta\leq\frac{1}{2}\) versus \(H_1:\theta>\frac{1}{2}\). Consider first the test that rejects \(H_0\) if and only if all “successes” are observed. The power function for this test is \[\begin{equation} \beta_1(\theta)=P_{\theta}(\mathbf{X}\in R)=P_{\theta}(\mathbf{X}=5)=\theta^5 \tag{16.1} \end{equation}\]
In examing this power function, we might decide that although the probability of Type I Error is acceptable low (\(\beta_1(\theta)\leq(\frac{1}{2})^5=0.0312\)) for all \(\theta\leq\frac{1}{2}\), the probability of a Type II Error is too high (\(\beta_1(\theta)\) is too small) for most \(\theta>\frac{1}{2}\). The probability of a Type II Error is less than \(\frac{1}{2}\) only if \(\theta>(\frac{1}{2})^{1/5}=0.87\). To achiece samller Type II Error probabilities, we might consider using the test that rejects \(H_0\) if \(X=3,4,5\). The power function is then \[\begin{equation} \beta_1(\theta)={5 \choose 3}\theta^3(1-\theta)^2+{5 \choose 4}\theta^4(1-\theta)+\theta^5 \tag{16.2} \end{equation}\] The second test has achieved a smaller Type II error probability in that \(\beta_2(\theta)\) is larger for \(\theta>\frac{1}{2}\). But the Type I Error probability is larger for the second test as \(\beta_2(\theta)\) is larger for \(\theta\leq\frac{1}{2}\). If a choice is to be made between these two tests, the researcher must decide which error structure, that described by \(\beta_1(\theta)\) or that described by \(\beta_2(\theta)\) is more acceptable. The two power function is shown in Figure 16.2.
FIGURE 16.2: Power functions for Binomial distribution example
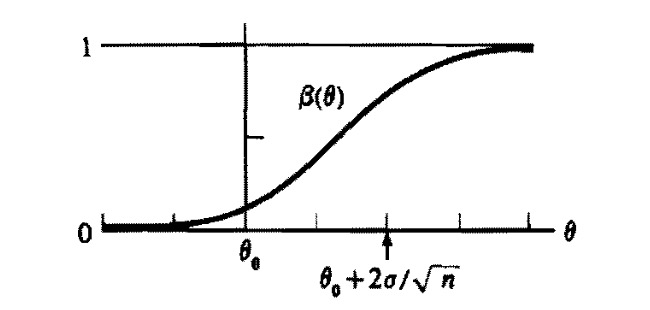
FIGURE 16.3: Shape of power function for normal distribution.
Typically, the power function of a test will depend on the sample size \(n\). If \(n\) can be chosen by the experimenter, consideration of the power function might help determine what sample size is appropriate in an experiment.
Definition 16.3 (Size \(\alpha\) Test) For \(0\leq\alpha\leq 1\), a test with power function \(\beta(\theta)\) is a size \(\alpha\) test if \(\sup_{\theta\in\Theta_0}\beta(\theta)=\alpha\).
The set of level \(\alpha\) tests contains the set of size \(\alpha\) tests. A size \(\alpha\) test is usually more computationally hard to construct than a level \(\alpha\) tests.
- Experimenters commonly specify the level of the test they wish to use, tyoical choices being \(\alpha=0.01,0.05,0.10\). In fixing the level of the test, the experimenter is controlling only the Type I Error probabilities, not the Type II Error. If this approach is taken, the experimenter should specify the null and alternative hypotheses so that it is most important to control the Type I Error probability.
The restriction to size \(\alpha\) tests lead to the choice of one out of the class of tests.
Example 16.4 (Size of LRT) In general, a size \(\alpha\) LRT is constructed by choosing \(c\) such that \(\sup_{\theta\in\Theta_0}P_{\theta}(\lambda(\mathbf{X})\leq c)=\alpha\). In Example 15.1, \(\Theta_0\) consists of the single point \(\theta=\theta_0\) and \(\sqrt{n}(\bar{X}-\theta_0)\sim N(0,1)\) if \(\theta=\theta_0\). So the test reject \(H_0\) if \(|\bar{X}-\theta_0|\geq\frac{z_{\alpha/2}}{\sqrt{n}}\) where \(z_{\alpha/2}\) satisfies \(P(Z\geq z_{\alpha/2})=\alpha/2\) with \(Z\sim N(0,1)\), is the size \(\alpha\) LRT. Specifically, this corresponds to choosing \(c=exp(-z^2_{\alpha/2}/2)\) but it is not necessary to calculate it out.
For the problem in Example 15.2, finding a size \(\alpha\) LRT is done as follows. The LRT rejects \(H_0\) if \(\min_iX_i\geq c\), where \(c\) is chosen so that this is a size \(\alpha\) test. If \(c=-\frac{\log\alpha}{n}+\theta_0\), then \[\begin{equation} P_{\theta_0}(\min_iX_i\geq c)=e^{-n(c-\theta_0)}=\alpha \tag{16.5} \end{equation}\] Since \(\theta\) is a location parameter of \(\min_iX_i\), \[\begin{equation} P_{\theta}(\min_iX_i\geq c)\leq P_{\theta_0}(\min_iX_i\geq c),\quad \forall\theta\leq\theta_0 \tag{16.6} \end{equation}\] Thus \[\begin{equation} \sup_{\theta\in\Theta_0}\beta(\theta)=\sup_{\theta\leq\theta_0}P_{\theta}(\min_iX_i\geq c)=P_{\theta_0}(\min_iX_i\geq c)=\alpha \tag{16.7} \end{equation}\] and this \(c\) yields the size \(\alpha\) LRT.Definition 16.6 (Cutoff Points) We use a series of notations to represent the probability of having probability to the right of it for the corresponding distributions. Such as
\(z_{\alpha}\) satisfies \(P(Z>z_{\alpha})=\alpha\) where \(Z\sim N(0,1)\).
\(t_{n-1,\alpha/2}\) satisfies \(P(T_{n-1}>t_{n-1,\alpha/2})=\alpha/2\) where \(T_{n-1}\sim t_{n-1}\).
\(\chi^2_{p,1-\alpha}\) satisfies \(P(\chi_p^2>\chi^2_{p,1-\alpha})=1-\alpha\) where \(\chi_p^2\sim \chi_p^2\).
\(z_{\alpha}, t_{n-1,\alpha/2}\) and \(\chi^2_{p,1-\alpha}\) are known as cutoff points.
A minimization of the Type II Error probability without some control of the Type I Error probability is not very meaningful. In general, restriction to the class \(\mathcal{C}\) must involve some restriction on the Type I Error probability. We will consider the class \(\mathcal{C}\) be the class of all level \(\alpha\) tests. In such case, the Definition 16.8 is calles a UMP level \(\alpha\) test.
- The requirement of UMP is very strong. UMP may not exist in many problems. In problem that have UMP tests, a UMP test might be considered as the best test in the class.
Theorem 16.1 (Neyman-Pearson Lemma) Consider testing \(H_0:\theta=\theta_0\) versus \(H_1:\theta=\theta_1\), where the p.d.f. or p.m.f. corresponding to \(\theta_i\) is \(f(\mathbf{x}|\theta_i),i=0,1\), using a test with rejection region \(R\) that satisfies \[\begin{equation} \left\{\begin{aligned} & \mathbf{x}\in R &\quad f(\mathbf{x}|\theta_1)>kf(\mathbf{x}|\theta_0)\\ & \mathbf{x}\in R^c &\quad f(\mathbf{x}|\theta_1)<kf(\mathbf{x}|\theta_0) \end{aligned} \right. \tag{16.11} \end{equation}\] for some \(k\geq 0\) and \[\begin{equation} \alpha=P_{\theta_0}(\mathbf{X}\in R) \tag{16.12} \end{equation}\] Then
(Sufficiency) Any test that satisfies (16.11) and (16.12) is a UMP level \(\alpha\) test.
- (Necessity) If there exists a test satisfying (16.11) and (16.12) with \(k>0\), then every UMP level \(\alpha\) test is a size \(\alpha\) test (satisfies (16.12)) and every UMP level \(\alpha\) test satisfies (16.11) except perhaps on a set A satisfying \(P_{\theta_0}(\mathbf{X}\in A)=P_{\theta_1}(\mathbf{X}\in A)=0\).
Proof. The proof is for \(f(\mathbf{x}|\theta_0)\) and \(f(\mathbf{x}|\theta_1)\) being p.d.f. of continuous random variables. For discrete random variables just replacing integrals with sums.
Note first that any test satisfying (16.12) is a size \(\alpha\) and hence a level \(\alpha\) test because \(\sup_{\theta\in\Theta_0}P_{\theta}(\mathbf{X}\in R)=P_{\theta_0}(\mathbf{X}\in R)=\alpha\), since \(\Theta_0\) has ony one point.
To ease notation, we define a test function, a function on the sample space that is 1 if \(\mathbf{x}\in R\) and 0 if \(\mathbf{x}\in R^c\). That is, it is the indicator function of the rejection region. Let \(\phi(\mathbf{x})\) be the test function of a test satisfying (16.11) and (16.12). Let \(\phi^{\prime}(\mathbf{x})\) be the test function of any other level \(\alpha\) test, and let \(\beta(\theta)\) and \(\beta^{\prime}(\theta)\) be the power functions corresponding to the tests \(\phi\) and \(\phi^{\prime}\), respectively. Because \(0\leq\phi^{\prime}(\mathbf{x})\leq 1\), (16.11) implies that \[\begin{equation} (\phi(\mathbf{x})-\phi^{\prime}(\mathbf{x}))(f(\mathbf{x}|\theta_1)-kf(\mathbf{x}|\theta_0))\geq 0,\quad \forall\mathbf{x} \tag{16.13} \end{equation}\] Thus \[\begin{equation} \begin{split} 0&\leq\int_{\mathcal{X}}(\phi(\mathbf{x})-\phi^{\prime}(\mathbf{x}))(f(\mathbf{x}|\theta_1)-kf(\mathbf{x}|\theta_0))d\mathbf{x}\\ &=\beta(\theta_1)-\beta^{\prime}(\theta_1)-k(\beta(\theta_0)-\beta^{\prime}(\theta_0)) \end{split} \tag{16.14} \end{equation}\]
The first statement is proved by noting that, since \(\phi^{\prime}\) is a level \(\alpha\) test and \(\phi\) is a size \(\alpha\) test, \(\beta(\theta_0)-\beta^{\prime}(\theta_0)=\alpha-\beta^{\prime}(\theta_0)\geq 0\). Thus (16.14) implies that
\[\begin{equation}
0\leq\beta(\theta_1)-\beta^{\prime}(\theta_1)-k(\beta(\theta_0)-\beta^{\prime}(\theta_0))\leq\beta(\theta_1)-\beta^{\prime}(\theta_1)
\tag{16.15}
\end{equation}\]
showing that \(\beta(\theta_1)\geq\beta^{\prime}(\theta_1)\) and hence \(\phi\) has greater power than \(\phi^{\prime}\). Since \(\phi^{\prime}\) was an arbitrary level \(\alpha\) test and \(\theta_1\) is the only point in \(\theta_0^c\), \(\phi\) is a UMP level \(\alpha\) test.
To prove the second statement, let \(\phi^{\prime}\) now be the test function for any UMP level \(\alpha\) test. By part (a), \(\phi\), the test satisfying (16.11) and (16.12), is also a UMP level \(\alpha\) test, thus \(\beta(\theta_1)=\beta^{\prime}(\theta_1)\). This fact, (16.13) and \(k>0\) imply \[\begin{equation} \alpha-\beta^{\prime}(\theta_0)=\beta(\theta_0)-\beta^{\prime}(\theta_0)\leq0 \tag{16.16} \end{equation}\]
Now since \(\phi^{\prime}\) is a level \(\alpha\) test, \(\beta^{\prime}(\theta_0)\leq\alpha\). Thus, \(\beta^{\prime}(\theta_0)=\alpha\), that is, \(\phi^{\prime}\) is a size \(\alpha\) test. It also implies that (16.13) is an equality. The nonnegative integrand \((\phi(\mathbf{x})-\phi^{\prime}(\mathbf{x}))(f(\mathbf{x}|\theta_1)-kf(\mathbf{x}|\theta_0))\) will have a zero integral only if \(\phi^{\prime}\) satisfies (16.11), except perhaps on a set A with \(\int_Af(\mathbf{x}|\theta_i)d\mathbf{x}=0\). Therefore, the second statement is true.Proof.
```In terms of the original sample \(\mathbf{X}\), the test based on \(T\) has the rejection region \(R=\{\mathbf{x}:T(\mathbf{x})\in S\}\). By the Factorization Theorem, the p.d.f. or p.m.f. of \(\mathbf{X}\) can be written as \(f(\mathbf{x}|\theta_i)=g(T(\mathbf{x})|\theta_i)h(\mathbf{x})\), \(i=0,1\), for some nonnegative function \(h(\mathbf{x})\). Multiplying the inequalities in (16.17) by this nonnegative function, we see that \(R\) satisfies \[\begin{equation} \left\{\begin{aligned} &\mathbf{x}\in R &\quad f(\mathbf{x}|\theta_1)=g(T(\mathbf{x})|\theta_1)h(\mathbf{x})>kg(T(\mathbf{x})|\theta_0)h(\mathbf{x})=kf(\mathbf{x}|\theta_0)\\ &\mathbf{x}\in R^c &\quad f(\mathbf{x}|\theta_1)=g(T(\mathbf{x})|\theta_1)h(\mathbf{x})<kg(T(\mathbf{x})|\theta_0)h(\mathbf{x})=kf(\mathbf{x}|\theta_0) \end{aligned} \right. \tag{16.19} \end{equation}\] Also by (16.18) \[\begin{equation} P_{\theta_0}(\mathbf{X}\in R)=P_{\theta_0}(T(\mathbf{X})\in S)=\alpha \tag{16.20} \end{equation}\] So, by sufficiency part of Neyman-Pearson Lemma, the test based on \(T\) is a UMP level \(\alpha\) test.