Chapter 5 data transforms
5.1 준비 사항
데이터 변형을 실습하기 위해 2017년 근로환경조사 자료를 통해 실습할 것입니다.. 자료는 안전보건공단, 근로환경조사 원시자료 사이트 (http://kosha.or.kr/kosha/data/primitiveData.do) 에서 신청할 수 있습니다..
주로 사용하는 자료가 SAS 파일이므로 여기서도 SAS파일을 다운 받아 실습하겠습니다.
# import library ----------------------------------------------------------
if(!require(devtools)) install.packages('devtools')
if(!require(Table1)) install_github("emwozniak/Table1")
if(!require(ggplot2))install.packages('ggplot2')
if(!require(tidyverse)) install.packages('tidyverse')
if(!require(htmlTable)) install.packages('htmlTable')
if(!require(haven)) install.packages('haven')
library(devtools)
library(Table1)
library(ggplot2)
library(tidyverse)
library(htmlTable)다운로드 받은 파일은 경로에 data에 저장하고, 실습을 수행하겠습니다. 보건학데이터과학 수업시간에 나누어준 research_tutor파일을 풀고 project를 싱행하면 자동으로 경로설정이 됩니다.
# import data -------------------------------------------------------------
#SAS file import as a
a=read_sas("data/kwcs5th.sas7bdat") # 근로환경조사 5차
book<- read_csv('data/labes5th.csv')a라는 파일에 근로환경조사를 불러왔고 5행, 5열만 살펴보겠습니다.
## # A tibble: 5 x 5
## ID AS06 HH01 HH02_01 HH02_01_A
## <dbl> <chr> <dbl> <dbl> <dbl>
## 1 24825 서울특별시 3 1 1
## 2 10743 서울특별시 2 1 1
## 3 10744 서울특별시 2 1 2
## 4 24826 서울특별시 1 1 2
## 5 24827 서울특별시 1 1 1코드북도 살펴보죠
## # A tibble: 448 x 4
## codes Labels Storage NAs
## <chr> <chr> <chr> <dbl>
## 1 ID <NA> double 0
## 2 AS06 SQ5. 지역 character 0
## 3 HH01 가구원 수 double 0
## 4 HH02_01 가구원번호 double 0
## 5 HH02_01_A 가주구_성별 double 0
## 6 HH02_01_B 가구주_생년 double 0
## 7 HH02_01_C 가구주 관계 double 0
## 8 HH02_01_D 가구주_경활 double 0
## 9 HH02_01_D_01 무급가구내/외 double 49671
## 10 HH02_01_E 적격대상여부 double 0
## # … with 438 more rows5.2 필터 (filter and select)
가장 많이 사용되고 있는 함수입니다. 행(row)을 고를 때는 filter, 열(column)을 고를 때는 select를 사용합니다..
우선 온콜 여부/빈도, 우울, 연령, 성별, 교육, 근무시간, 종사상지위, 고용형태, 소득 와 관련된 변수를 골라보고, 데이터가 wide 형이므로 select를 사용하면 되겠습니다. 상기 변수를 골라 새로운 데이터 a0를 만들어 보겠습니다.
코드북에서 상기 변수를 갖져오고, 코드북은 long form으로 되어 있으므로 행 (row)를 선정하니, filter를 사용하겠습니다.
## [1] "Q35" "AGE" "TSEX" "TEF1" "Q22_1" "Q05" "Q06"
## [8] "EF11" "EF12" "Q69" "Q62_1_8"## # A tibble: 11 x 4
## codes Labels Storage NAs
## <chr> <chr> <chr> <dbl>
## 1 Q05 Q5. 귀하의 종사상 지위는 다음 중 어디에 해당합니까? double 0
## 2 Q06 Q6. 직장에서 귀하의 종사상 지위는 다음 중 어디에 해당합니까?… double 19905
## 3 Q22_1 Q22. 귀하가 주로 근무하는 직장에서 일주일에 몇 시간을 일하십니까?… double 148
## 4 Q35 Q35. 지난 12개월 동안 [주된 일을 시작한 지가 12개월이 안 된 경우(Q16=?), 주된 … double 0
## 5 Q62_1_8 Q62. 지난 12개월 동안 귀하는 다음과 같은 건강상 문제가 있었습니까? H. 우울감… double 0
## 6 Q69 Q69. 귀하가 주로 하시는 일의 근로 환경을 전반적으로 어떻게 생각하십니까?… double 0
## 7 EF11 EF11. 귀하가 주로 근무하는 직장에서 받는 월평균 소득은 얼마 정도입니까?… double 0
## 8 EF12 EF12. 귀하가 주로 근무하는 직장에서 받는 월평균 소득은 다음 중 어디에 해당합니까?(세금 공… double 45927
## 9 TSEX ▣ 성별 double 0
## 10 TEF1 ▣ 교육수준 double 0
## 11 AGE 조사자연령 double 0좀 보기 불편하니 html 파일로 보겠습니다.
| codes | Labels | Storage | NAs | |
|---|---|---|---|---|
| 1 | Q05 | Q5. 귀하의 종사상 지위는 다음 중 어디에 해당합니까? | double | 0 |
| 2 | Q06 | Q6. 직장에서 귀하의 종사상 지위는 다음 중 어디에 해당합니까? | double | 19905 |
| 3 | Q22_1 | Q22. 귀하가 주로 근무하는 직장에서 일주일에 몇 시간을 일하십니까? | double | 148 |
| 4 | Q35 | Q35. 지난 12개월 동안 [주된 일을 시작한 지가 12개월이 안 된 경우(Q16=?), 주된 직업을 시작한 이후로] 회사로부터 단시간 내에(돌발적으로) 업무에 복귀하라고 얼마나 자주 요청을 받았습니까? | double | 0 |
| 5 | Q62_1_8 | Q62. 지난 12개월 동안 귀하는 다음과 같은 건강상 문제가 있었습니까? H. 우울감 | double | 0 |
| 6 | Q69 | Q69. 귀하가 주로 하시는 일의 근로 환경을 전반적으로 어떻게 생각하십니까? | double | 0 |
| 7 | EF11 | EF11. 귀하가 주로 근무하는 직장에서 받는 월평균 소득은 얼마 정도입니까? | double | 0 |
| 8 | EF12 | EF12. 귀하가 주로 근무하는 직장에서 받는 월평균 소득은 다음 중 어디에 해당합니까?(세금 공제 후 소득) | double | 45927 |
| 9 | TSEX | ▣ 성별 | double | 0 |
| 10 | TEF1 | ▣ 교육수준 | double | 0 |
| 11 | AGE | 조사자연령 | double | 0 |
온콜에 대한 영향이므로, 연령이 65세 미만인 경우만 연구하는 것은 어떨까요? 우선 65세 미만인경우가 몇명인지 살펴 보겠습니다.
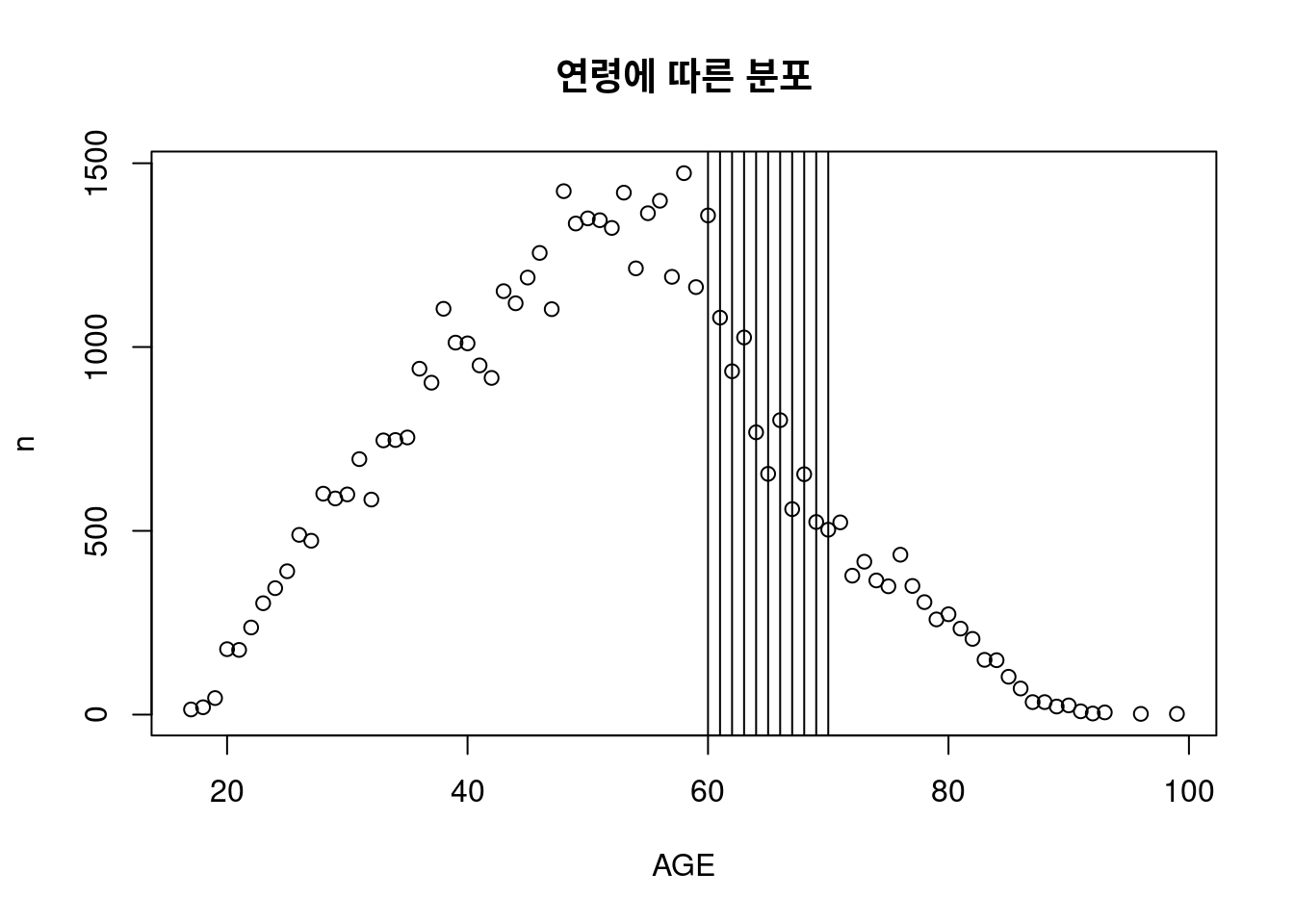 65세 미만을 제외해서
65세 미만을 제외해서 a1을 만들죠. 이때는 행(row)를 선택하는 것으로 filter를 사용하겠습니다.
15세 미만인 경우도 제외한다면 filter(AGE>15) 이렇게 하면되지만, 다음과 같이 논리연산을 이용할 수 있습니다.
위에서 book을 살펴보았을 때 근무시간에 결측값이 많았죠. 이후 filter 명령을 하게되면 TRUE만 남게 되므로 이요하겠습니다.
##
## FALSE TRUE
## 41695 112##
## FALSE TRUE
## 112 41695이처럼 filter안에 논리값을 사용할 수 있는데, 두번째 교과서 https://r4ds.had.co.nz 에서 잘정리 해놓은 것을 잘 읽어 보시기 바랍니다. 이외에도 %in%도 자주 쓰입니다.
아래는 어떤 의미일까요?
## # A tibble: 5 x 2
## # Groups: TEF1 [5]
## TEF1 n
## <dbl> <int>
## 1 1 5205
## 2 2 4546
## 3 3 19156
## 4 4 21246
## 5 9 52## # A tibble: 5 x 2
## # Groups: Q69 [5]
## Q69 n
## <dbl> <int>
## 1 1 1923
## 2 2 35965
## 3 3 10791
## 4 4 1472
## 5 9 54아래처럼 데이터를 변환시키면 어떻게 될까요?
a0 %>%
filter(AGE <65) %>% #50205 --> 41807 : 8401명 제외
filter(!is.na(Q22_1)) %>%
filter(TEF1==1|TEF1==2|TEF1==3|TEF1==4) %>%
filter(Q69 %in% c(1,2,3,4)) %>%
filter(!Q62_1_8 == 9) %>% # 41807 --> 41589 :218 명 제외
nrow()## [1] 41589위에 변환과 같나요?
a0 %>%
filter(AGE <65 ) %>% #50205 --> 41807 : 8401명 제외
filter(!is.na(Q22_1)) %>%
filter(!TEF1 == 9) %>%
filter(!Q69 == 9) %>%
filter(!Q62_1_8 == 9) %>%# 41807 --> 41589 :218 명 제외
nrow()## [1] 41589아래는 같은가요? 같네요. 이중 가장 편한 것을 사용하면되는데, 두번째 것이 결국 논문작성에는 가장 많은 도움이 됩니다.
a0 %>%
filter(AGE <65 ) %>% #50205 --> 41807 : 8401명 제외
filter(!is.na(Q22_1),!TEF1 == 9,!Q69 == 9, !Q62_1_8 == 9 ) %>%
nrow()## [1] 415895.3 변수 생성 (mutate)
이번에는 변수를 생성해 보겠습니다. 변수생성은 mutate를 주로 사용하게 됩니다. mutate뒤에 논리 값이나 연산을 하여 생성하게되는 것입니다.
첫번째 Q35변수를 기억하기 쉽게 oncall 이란 변수로 만들겠습니다.
a1 <-a0 %>%
filter(AGE <65 ) %>% #50205 --> 41807 : 8401명 제외
filter(!is.na(Q22_1)) %>%
filter(!TEF1 == 9) %>%
filter(!Q69 == 9) %>%
filter(!Q62_1_8 == 9) %>% # 41807 --> 41589 :218 명 제외
mutate(oncall = Q35)
head(a1[, c(1,12)])## # A tibble: 6 x 2
## Q35 oncall
## <dbl> <dbl>
## 1 5 5
## 2 4 4
## 3 4 4
## 4 4 4
## 5 4 4
## 6 5 5전에 공부했던 ifelse를 이용하여 변수를 새로 생성해 보겠습니다.
a1 <-a0 %>%
filter(AGE <65 ) %>% #50205 --> 41807 : 8401명 제외
filter(!is.na(Q22_1)) %>%
filter(!TEF1 == 9) %>%
filter(!Q69 == 9) %>%
filter(!Q62_1_8 == 9) %>% # 41807 --> 41589 :218 명 제외
mutate(oncall = Q35) %>%
mutate(oncallgp = ifelse(oncall %in% c(1, 2, 3), "on call", "non-on call")) %>%
mutate(oncallgp3 = ifelse(oncall %in% c(1,2,3), "several times a month",
ifelse(oncall %in% c(4), "rarely", "none"))) %>%
mutate(oncallgp3 = factor(oncallgp3,
levels=c("none", "rarely", "several times a month")))%>%
mutate(agegp = ifelse(AGE <30, '<30',
ifelse(AGE <40, '30-49',
ifelse(AGE <50, '40-49',
ifelse(AGE < 60, '50-59', '≥60')))))매우 많은 논리 값이 필요한 경우 ifelse는 코딩을 하는데 매우 높은 집중력을 필요합니다. 이에 case_when이나 cut, breaks를 사용하고는 합니다.
age <- 1:10
agegp <- cut(age, breaks = c(-Inf, 4, 8, Inf))
agegp2 <- cut(age, breaks = c(-Inf, 4, 8, Inf),
labels = c('<5', '5-8', '>8'))
data.frame(age, agegp, agegp2)## age agegp agegp2
## 1 1 (-Inf,4] <5
## 2 2 (-Inf,4] <5
## 3 3 (-Inf,4] <5
## 4 4 (-Inf,4] <5
## 5 5 (4,8] 5-8
## 6 6 (4,8] 5-8
## 7 7 (4,8] 5-8
## 8 8 (4,8] 5-8
## 9 9 (8, Inf] >8
## 10 10 (8, Inf] >8여기에 factor변환 부분도 고민해야 합니다. 예를 들어 dep라는 변수가 있고 dep가 1이면 우울증, 2 이면 우울증이 아니다라고 한다면 다음과 같이 변수를 만들수 있습니다.
dat <- data.frame(sui = c(1, 2, 1, 2, 1, 2, 2, 2, 2 ))
dat1 <-dat %>%
mutate(suicide = case_when(sui ==1 ~ 'suicidal thought',
TRUE ~'non-suicidal thought'))
dat1 %>%
group_by(suicide) %>%
count()## # A tibble: 2 x 2
## # Groups: suicide [2]
## suicide n
## <chr> <int>
## 1 non-suicidal thought 6
## 2 suicidal thought 3그런데 여기서 non-suicidal thought가 먼저 출력되고 이후 suicidal thought가 뒤이어 출력됩니다. 알파벳 순서 때문인데요, 이 순서를 바꿀 수 있을까요? 논문을 쓸때만다 수작업으로 바꿔주는 것은 고된 일인되요;; factor로 바꾸어 순서를 주는 것입니다. 아래와 같습니다.
dat1 <-dat %>%
mutate(suicide = structure(
factor(sui, levels = c(1, 2),
labels =c("suicidal thought", "non-suicidal thgouht"))))
dat1 %>%
group_by(suicide) %>%
count()## # A tibble: 2 x 2
## # Groups: suicide [2]
## suicide n
## <fct> <int>
## 1 suicidal thought 3
## 2 non-suicidal thgouht 6이모든거을 종합해서 아래와 같이 데이터를 만들어 볼 수 있습니다.
#근로 시간을 나누어 봅시다. Q22_1
Wh_breaks <- c(-Inf, 35, 45, 55, 65, Inf)
Wh_labels <- c('<35','35-44','45-54','55-64','>=65');Wh_labels## [1] "<35" "35-44" "45-54" "55-64" ">=65"## [1] -Inf 100 200 300 400 Infinc_label <- c('<100', '100-199', '200-299', '300-399', '>400')
a1 <-a0 %>%
filter(AGE <65 ) %>% #50205 --> 41807 : 8401명 제외
filter(!is.na(Q22_1)) %>%
filter(!TEF1 == 9) %>%
filter(!Q69 == 9) %>%
filter(!Q62_1_8 == 9) %>% # 41807 --> 41589 :218 명 제외
mutate(oncall = Q35) %>%
mutate(oncallgp = ifelse(oncall %in% c(1, 2, 3), "on call", "non-on call")) %>%
mutate(oncallgp3 = ifelse(oncall %in% c(1,2,3), "several times a month",
ifelse(oncall %in% c(4), "rarely", "none"))) %>%
mutate(oncallgp3 = factor(oncallgp3,
levels=c("none", "rarely", "several times a month")))%>%
mutate(agegp = ifelse(AGE <30, '<30',
ifelse(AGE <40, '30-49',
ifelse(AGE <50, '40-49',
ifelse(AGE < 60, '50-59', '≥60'))))) %>%
mutate(Wh=cut(Q22_1, breaks=Wh_breaks, include.lowest=TRUE, right=FALSE,
labels=Wh_labels)) %>%
mutate(Wh=structure(Wh, label='Working hours')) %>%
mutate(Gender=factor(TSEX, levels=c(1,2), labels=c('Men', 'Women') )) %>%
mutate(Education=factor(TEF1, levels=c(1,2,3,4),
labels=(c('Primary', 'Middle', 'High', 'University')))) %>%
mutate(Statusw=ifelse(Q05 %in% c(1,2), 'Self employer',
ifelse(Q05 %in% c(3), 'Paid worker',
'Family workers and others'))) %>%
mutate(inc1=ifelse(EF11 <10000, EF11, ifelse(EF12<10, EF12*100-50, NA) )) %>%
mutate(inc=cut(inc1, breaks=inc_break, labels=inc_label)) %>%
mutate(job_st = factor(Q69, levels = c(1:4),
labels = c("Very satisfied", "Satisfied", "Unsatisfied", "Very unsatisfied"))) %>%
mutate(job_st = structure(job_st, label = 'Job Satisfaction')) %>%
mutate(depression = Q62_1_8)%>%
mutate(depression = structure(factor(depression, levels=c(1, 2),
labels=c("Depression", "Non depression"))))5.4 실습 과제
- 본인이 생각하는 변수를 2가지 생성해 주세요. 그리고 생성된 변수를 어떻게 정의하였는지 기술하세요
조작적 정의.
| 실습과제 | 내용 |
|---|---|
| 종속변수 생성 | 우울과 같은 종속변수 생성 |
| 독립변수 생성 | 온콜과 비슷한 독립변수(위험요인) |
| 결측값 처리 | 원 변수 (생성전 변수)의 NA 값 갯수를 보여주세요 |
| 생성변수 분포 | group_by 와 count를 이용해 분포를 보여주세요 |
- Table 1만들기: 아래 표에서 on.call 이 먼저 나오게 만드시오 (structure, factor 를 사용하세요)
tb2<-make.table(dat = a1,
strat = c("oncallgp"),
cat.varlist = c("agegp", "Gender", "Education", "Wh",
'inc'),
#"job_st",
cat.rmstat = list(c("count", "col", "miss")),
cat.ptype = c("chisq"),
cont.varlist = c("AGE"),
cont.rmstat = list(c("count","miss", "minmax", "q1q3", "mediqr")),
cont.ptype = c( "ttest"))## Variable non.on.call on.call Overall p.value
## AGE 0.639
## Mean (SD) 46.28 (11.10) 46.41 (10.97) 46.29 (11.09) t-test
##
## agegp 0.616
## (Row %) Chi-square
## <30 3682 (95.99%) 154 ( 4.01%) 3836 (100.00%)
## ≥60 4928 (96.02%) 204 ( 3.98%) 5132 (100.00%)
## 30-49 7698 (95.71%) 345 ( 4.29%) 8043 (100.00%)
## 40-49 10918 (95.76%) 483 ( 4.24%) 11401 (100.00%)
## 50-59 12592 (95.56%) 585 ( 4.44%) 13177 (100.00%)
##
## Wh <0.001
## (Row %) Chi-square
## <35 3853 (94.39%) 229 ( 5.61%) 4082 (100.00%)
## 35-44 15557 (96.20%) 614 ( 3.80%) 16171 (100.00%)
## 45-54 11327 (95.03%) 592 ( 4.97%) 11919 (100.00%)
## 55-64 6100 (96.58%) 216 ( 3.42%) 6316 (100.00%)
## >=65 2981 (96.13%) 120 ( 3.87%) 3101 (100.00%)
##
## Gender <0.001
## (Row %) Chi-square
## Men 18840 (95.37%) 914 ( 4.63%) 19754 (100.00%)
## Women 20978 (96.08%) 857 ( 3.92%) 21835 (100.00%)
##
## Education 0.021
## (Row %) Chi-square
## Primary 834 (97.54%) 21 ( 2.46%) 855 (100.00%)
## Middle 2483 (96.17%) 99 ( 3.83%) 2582 (100.00%)
## High 16604 (95.81%) 727 ( 4.19%) 17331 (100.00%)
## University 19897 (95.56%) 924 ( 4.44%) 20821 (100.00%)
##
## inc 0.002
## (Row %) Chi-square
## <100 3279 (96.53%) 118 ( 3.47%) 3397 (100.00%)
## 100-199 13534 (96.00%) 564 ( 4.00%) 14098 (100.00%)
## 200-299 11795 (95.18%) 597 ( 4.82%) 12392 (100.00%)
## 300-399 6010 (95.58%) 278 ( 4.42%) 6288 (100.00%)
## >400 4328 (95.69%) 195 ( 4.31%) 4523 (100.00%)
## | Variable | non.on.call | on.call | Overall | p.value | |
|---|---|---|---|---|---|
| 1 | AGE | 0.639 | |||
| 2 | Mean (SD) | 46.28 (11.10) | 46.41 (10.97) | 46.29 (11.09) | t-test |
| 3 | |||||
| 4 | agegp | 0.616 | |||
| 5 | (Row %) | Chi-square | |||
| 6 | <30 | 3682 (95.99%) | 154 ( 4.01%) | 3836 (100.00%) | |
| 7 | ≥60 | 4928 (96.02%) | 204 ( 3.98%) | 5132 (100.00%) | |
| 8 | 30-49 | 7698 (95.71%) | 345 ( 4.29%) | 8043 (100.00%) | |
| 9 | 40-49 | 10918 (95.76%) | 483 ( 4.24%) | 11401 (100.00%) | |
| 10 | 50-59 | 12592 (95.56%) | 585 ( 4.44%) | 13177 (100.00%) | |
| 11 | |||||
| 12 | Wh | <0.001 | |||
| 13 | (Row %) | Chi-square | |||
| 14 | <35 | 3853 (94.39%) | 229 ( 5.61%) | 4082 (100.00%) | |
| 15 | 35-44 | 15557 (96.20%) | 614 ( 3.80%) | 16171 (100.00%) | |
| 16 | 45-54 | 11327 (95.03%) | 592 ( 4.97%) | 11919 (100.00%) | |
| 17 | 55-64 | 6100 (96.58%) | 216 ( 3.42%) | 6316 (100.00%) | |
| 18 |
=65 |
2981 (96.13%) | 120 ( 3.87%) | 3101 (100.00%) | |
| 19 | |||||
| 20 | Gender | <0.001 | |||
| 21 | (Row %) | Chi-square | |||
| 22 | Men | 18840 (95.37%) | 914 ( 4.63%) | 19754 (100.00%) | |
| 23 | Women | 20978 (96.08%) | 857 ( 3.92%) | 21835 (100.00%) | |
| 24 | |||||
| 25 | Education | 0.021 | |||
| 26 | (Row %) | Chi-square | |||
| 27 | Primary | 834 (97.54%) | 21 ( 2.46%) | 855 (100.00%) | |
| 28 | Middle | 2483 (96.17%) | 99 ( 3.83%) | 2582 (100.00%) | |
| 29 | High | 16604 (95.81%) | 727 ( 4.19%) | 17331 (100.00%) | |
| 30 | University | 19897 (95.56%) | 924 ( 4.44%) | 20821 (100.00%) | |
| 31 | |||||
| 32 | inc | 0.002 | |||
| 33 | (Row %) | Chi-square | |||
| 34 | <100 | 3279 (96.53%) | 118 ( 3.47%) | 3397 (100.00%) | |
| 35 | 100-199 | 13534 (96.00%) | 564 ( 4.00%) | 14098 (100.00%) | |
| 36 | 200-299 | 11795 (95.18%) | 597 ( 4.82%) | 12392 (100.00%) | |
| 37 | 300-399 | 6010 (95.58%) | 278 ( 4.42%) | 6288 (100.00%) | |
| 38 |
400 |
4328 (95.69%) | 195 ( 4.31%) | 4523 (100.00%) | |
| 39 |
- 자신만의 Table 1만들기: oncallgp 대신에 자신이 만든 종속변수를 넣고, 맨 첫줄에 자신이 만든 독립변수를 넣어서 표1을 만드시오.
1)2)3)의 과제를 구글클래스에 업로드 해주세요.