Introducción a la inferencia
1 Introducción
En este apartado se expondrán la teoría y los métodos de la inferencia estadística que servirán como base para los modelos estadísticos. Un problema de inferencia estadística es un problema en el cual se han de analizar datos que han sido generados de acuerdo con una distribución de probabilidad desconocida y en la que se debe realizar algún tipo de inferencia (“conocer su comportamiento”) acerca de tal distribución. En la mayoría de situaciones reales, existe un número infinito de distribuciones posibles distintas que podrían haber generado los datos. En la práctica, dado el tipo de variable aleatoria considerada, se suele asumir un modelo de distribución de probabilidad que es completamente conocida salvo excepto por los valores de los parámetros que la especifican completamente. Utilizamos los datos de la muestra para obtener información sobre dichos parámetros desconocidos y poder asumir de esta forma una distribución de probabilidad completa para todos los datos de la población.
Por ejemplo, se podría saber que la duración de cierto tipo de marcapasos tiene una distribución exponencial con parámetro \(\lambda\) pero desconocer el valor exacto de dicho parámetro. Si se puede observar la duración de varios marcapasos de este tipo, entonces, a partir de estos valores observados y de cualquier otra información relevante de la que se pudiera disponer, es posible producir una inferencia acerca de ese valor desconocido \(\lambda\). Podría interesar producir la mejor estimación del valor de dicho parámetro o especificar un intervalo en el cual se piensa que pueda estar incluido el verdadero valor de \(\lambda\), o decidir si dicho parámetro es menor que un valor específico, ya que en ningún caso es posible obtener el verdadero valor de \(\lambda\) ya que sería necesario obtener la información de todos los sujetos de la población y no sólo los de la muestra.
En un problema de inferencia estadística, cualquier característica de la distribución que genera los datos experimentales que tenga un valor desconocido, como \(\lambda\) en el ejemplo anterior, se llama parámetro de la distribución. El conjunto \(\Omega\) de todos los valores posibles de dicho parámetro se llama espacio parámetrico. Cuando nuestra distribución de probabilidad tiene dos parámetros (por ejemplo la distribución Normal) el espacio paramétrico vendrá dado por todo el conjunto de parejas de valores de \(\mu\) y \(\sigma^2\).
2 Estimador y estimación
Si tenemos una variable aleatoria \(X\) cuya función de distribución viene caracterizada por un parámetro o conjunto de parámetros \(\delta\), y una muestra aleatoria de tamaño \(n\), \(X_1,...,X_n\), a partir de la cual se observan el conjunto de datos muestrales \(x_1,...,x_n\) vamos a definir dos conceptos relevantes en todo proceso de inferencia: estimador y estimación.
Un estimador del parámetro \(\delta\), basado en las variables aleatorias \(X_1,...,X_n\), es una función \(\delta(X_1,...,X_n)\) que especifica una valor para \(\delta\). Se trata de una función matemática que tiene la misma forma independientemente de la muestra utilizada. Por ejemplo, los estimadores para la media, varianza (y cuasivarainza), y proporción poblacionales vienen dados por: Media muestral
\[\delta_1 (X_1,...,X_n)=\bar{X}=\frac{(X_1+X_2+...+X_n}{n}\]
Varianza muestral
\[\delta_2 (X_1,...,X_n)=S^2=\frac{\sum_{1=1}^n (X_i-\bar{X})}{n}\]
Cuasi-Varianza muestral
\[\delta_3 (X_1,...,X_n)=S_q^2 = \frac{n}{n-1} S^2\]
Para una variable de tipo discreto se aplican las mismas definiciones si consideramos cada \(X_i\) como una realización de dicha variable. Para una variable que mide “éxito” o “fracaso” los valores de \(X_i\) serán 1 o 0 respectivamente, de forma que la media muestral coincide con la proporción muestral ya que tendríamos la suma de 1 en el numerador dividido por el tamaño de muestra en el denominador.
Una estimación es el valor numérico del estimador para unos datos dados \((x_1,...,x_n)\), es decir, sustituimos en \(\delta(X_1,...,X_n)\) por sus valores observados y obtendríamos la estimación del parámetro. De forma habitual se identifica con el “gorro” encima del parámetro indica la estimación de un parámetro:
\[\hat{\mu} = \bar{x}\]
\[\hat{\sigma}^2 = s^2\]
3 Información contenida en la muestra
Antes de comenzar a describir los procesos de inferencia estadística es necesario conocer como podemos relacionar la información contenida en una muestra con la distribución de probabilidad de la variable aleatoria de interés. Para ello una vez fijada la población del estudio y el objetivo principal es necesario:
Establecer la variable de interés, \(X\) (y su tipo), en función del objetivo principal.
Establecer una distribución de probabilidad para la variable aleatoria, \(f(X|\theta)\), acorde con el tipo de dicha variable y lo más sencilla posible, donde θ representa el parámetro o parámetros que especifican dicha distribución.
Muestra aleatoria de tamaño n de la variable de interés, \(X_1,X_2,...,X_n\) de forma que cada observación tiene probabilidad \(f(X_1 |\theta)\), \(f(X_2 |\theta)\),…,\(f(X_n |\theta)\) respectivamente y sus valores observados vienen dados por \(x_1,...,x_n\).
Obtener los descriptivos muestrales habituales: media, varianza, desviación típica, o proporción.
Se define entonces la función de verosimilitud L(X|θ) como:
\[L(X|\theta)=\prod_{i=1}^n f(X_i |\theta)\]
La función de verosimilitud contiene toda la información sobre la muestra y la relaciona con el parámetro o parámetros de interés a través de la distribución de probabilidad establecida. Se convierte por tanto en la herramienta más importante, desde el punto de vista de la estadística frecuentista, para los procesos de inferencia estadística que estudiaremos a continuación. Además, se utiliza como base para la caracterización de la distribución en el muestreo de los diferentes estimadores, aproximaciones numéricas del verdadero valor del parámetro o parámetros de la distribución de probabilidad asumida, que se utilizan en los procesos inferenciales.
Para evitar la complejidad matemática que supone trabajar con productos se suele definir el logaritmo de la función de verosimilitud, log-verosimilitud, \(LL(X|θ)\) como:
\[LL(X|\theta)=log\left(\prod_{i=1}^n f(X_i |\theta)\right) = \sum_{i=1}^n log(f(X_i |\theta))\]
3.1 Verosimilitud para una población Bernouilli
Consideramos una variable de tipo discreto, \(X,\) que sólo puede tomar valores 1 (“éxito”) con probabilidad \(\theta\) y valor 0 (fracaso) con probabilidad \(1-\theta\). La distribución de probabilidad asociada con esta variable se conoce como distribución Bernouilli (Binomial de tamaño n = 1) y su función de densidad viene dada por:
\[f(X=1|\theta)=\theta; f(X=0|\theta)=1-\theta\]
Si obtenemos una muestra de tamaño \(n\), \(X_1,X_2,...X_n\), y denotamos por \(s\) a la suma de todos los valores \(X_i\) iguales a 1 la función de verosimilitud y log-verosimilitud vienen dadas por:
\[L(X|\theta)=f(X_1 |\theta)f(X_2 |\theta)⋯f(X_n |\theta)=\theta^s (1-\theta)^{n-s}\]
\[LL(X|\theta)=s*log(\theta)+(n-s)*log(1-\theta)\]
3.2 Verosimilitud para una población Normal
Consideramos una variable de tipo continuo, \(X\), cuya distribución de probabilidad es \(N(\mu,\sigma^2)\) de forma que su función de densidad viene dada por:
\[f(X|\mu,\sigma^2)=\sqrt{\frac{1}{2\pi\sigma^2}} exp\left(\frac{(X-\mu)^2}{2\sigma^2}\right)\]
Si obtenemos una muestra de tamaño \(n\), \(X_1,X_2,...X_n,\) y denotamos por \(bar{X}\) a la media muestral y \(S^2\) a la varianza muestral, la función de verosimilitud y log-verosimilitud vienen dadas por:
\[L(X|\mu,\sigma^2)=\left(\frac{1}{2\pi\sigma^2}\right)^{n/2} exp\left(\frac{nS^2+n(\mu-\bar{X})^2}{2\sigma^2}\right)\]
\[LL(X|\mu,\sigma^2)=-\frac{n}{2}*log(2\pi\sigma^2)+\left(\frac{nS^2+n(\mu-\bar{X})^2}{2\sigma^2}\right)\]
En este caso la representación gráfica es más compleja ya que debemos hacerlo en un gráfico bidimensional, pero utilizando las expresiones la forma de la verosimilitud, resulta posible descomponerla de la siguiente forma:
\[L(X|\mu,\sigma^2)=\left(\frac{1}{2\pi\sigma^2}\right)^{n/2} exp\left(\frac{nS^2}{2σ^2}\right)exp\left(\frac{n(\mu-\bar{X})^2}{2\sigma^2}\right)\]
donde el radical y la primera exponencial dependen únicamente de las varianzas, mientras que la segunda exponencial depende de las medias dado el valor de la varianza poblacional.
4 Procedimientos de inferencia estadística
Estudiamos en este punto los distintos procedimientos de inferencia que tratamos en esta unidad. Realizamos una pequeña introducción de cada uno de ellos y ejemplificaremos su uso en el análisis de una población.
4.1 Estimación puntual
Es el procedimiento de inferencia estadística más sencillo y consiste en obtener un único valor aproximado del parámetro de interés a partir de un estimador de dicho parámetro y de los datos observados de una muestra. Aunque en las situaciones más sencillas (media, varianza y proporción) tanto el estimador como la estimación son fáciles de obtener, hay que establecer un procedimiento general para obtener dichas estimaciones.
Dicho procedimiento consiste en encontrar el máximo de la función de verosimilitud (o más concretamente de la log-verosimilitud) para el parámetro o parámetros involucrados en dicha función, es decir, el valor o valores que se obtienen al igualar a cero la derivada de la función de log-verosimilitud:
\[\frac{d}{d\theta} LL(X|θ)=0\]
4.1.1 Estiamdor de una proporción
La estimación de proporciones surge de forma natural en poblaciones Bernouilli cuya función de log-verosimilitud viene dada por:
\[LL(X|\theta)=s*log(\theta)+(n-s)*log(1-\theta)\]
Derivando e igualando a cero:
\[\frac{d}{d\theta} LL(X|\theta)=\frac{s}{\theta}- \frac{n-s}{1-\theta}=0\]
Despejando obtenemos:
\[\hat{\theta}=\frac{s}{n}\]
que es el estimador habitual para obtener la proporción muestral.
4.1.2 Estiamdor de la media
Si asumimos que la variable aleatoria es \(N(\mu,\sigma^2)\) la función de log verosimilitud viene dada por:
\[LL(X|\mu,\sigma^2)=-\frac{n}{2}*log(2\pi\sigma^2)+\left(\frac{nS^2+n(\mu-\bar{X})^2}{2\sigma^2}\right)\]
Si derivamos respecto de μ e igualamos a cero:
\[\frac{d}{d\mu} LL(X|\mu,\sigma^2)=-\frac{2n(\mu-\bar{X})}{2\sigma^2} = 0\]
Despejando obtenemos el estimador para la media:
\[\hat{\mu}=\bar{X}\]
4.1.3 Estiamdor de la varianza
De forma similar, derivando respecto de σ^2 e igualando a cero la función de log-verosimilitud tenemos que el estimador para la varianza viene dado por:
\[\hat{\sigma}^2=S^2\]
Podemos ver que en las situaciones habituales los estimadores de los parámetros poblacionales coinciden con las funciones que nos permiten obtener las medidas de localización y dispersión muestrales.
El problema con la estimación puntual es que únicamente nos da un valor posible para el parámetro poblacional pero sin ninguna medida del posible error que estamos cometiendo, dado que la estimación obtenida depende de la muestra seleccionada. Dos muestras distintas podrían dar dos estimaciones distintas y por tanto dos valores para el parámetro poblacional. Para introducir una medida del error cometido con la muestra seleccionada se utiliza los procedimiento de inferencia basados en intervalos de confianza, pero antes de pasar con ellos es necesario describir un poco más el comportamiento aleatorio de los estimadores que acabamos de obtener.
4.2 Distribución en el muestreo
Dado que todos los estimadores se construyen a partir de una colección de realizaciones aleatorias \(X_1,...X_n\) de la variable aleatoria \(X\), resulta que dicho estimador es una nueva variable aleatoria (que toma valores según los datos observados de la muestra) y por tanto su distribución puede ser deducida a partir de las distribuciones de cada una de las \(X_i\), utilizando la función de verosimilitud. En algunos casos (variables discretas) será necesario utilizar el Teorema Central del Límite para determinar una forma aproximada de dicha distribución de probabilidad que nos permita realizar los procesos inferenciales sin demasiada complejidad matemática. La distribución de los estimadores se conoce con el nombre de distribución en el muestreo
En los puntos siguiente se muestran las distribuciones en el muestro para los estimadores obtenidos en este apartado. Se eliminan todos los desarrollos matemáticos y simplemente se muestran las distribuciones obtenidas.
4.2.1 Distribución en el muestreo de una media poblacional con varianza poblacional conocida
Tenemos una población de N sujetos sobre la que se desea estudiar una variable aleatoria de tipo continuo (\(X\)) que sigue una distribución \(N(\mu,\sigma^2)\) y cuyo parámetro de interés es la media (\(\mu\)) pero donde conocemos el valor de \(\sigma^2\). Por la aplicación directa del Teorema Central del Límite la distribución en el muestreo de \(\bar{X}\) viene dada por:
\[\bar{X} \sim N\left(\mu, \frac{\sigma^2}{n}\right)\]
y por tanto la variable tipificada tiene distribución Normal estándar, es decir:
\[\frac{\bar{X}-\mu}{\sigma/√n}∼N(0,1)\]
4.3 Distribución en el muestreo de una media poblacional con varianza poblacional desconocida
Cuando la varianza es desconocida también se puede obtener la distribución en el muestreo de la media muestral sin más que sustituir la varianza poblacional por un estimador. Tipificando tenemos que:
\[T = \frac{\bar{X} - \mu}{S/√(n-1)} = \frac{\bar{X} - \mu}{S_q/√n}\]
se distribuye según una distribución t de Student con n-1 grados de libertad,
\[T \sim t_{n-1}\]
4.4 Distribución en el muestreo de una varianza poblacional
En la situación poblacional anterior la distribución en el muestreo de la varianza si consideramos la variable aleatoria:
\[\chi^2 = \frac{nS^2}{\sigma^2} = \frac{(n-1)S_q^2}{\sigma^2}\]
que se distribuye según una distribución Chi cuadrado con n-1 grados de libertad,
\[\chi^2 \sim \chi_{n-1}^2\]
La obtención de esta distribución se hace a partir de la forma de la función de verosimilitud para una población Normal con ambos parámetros desconocidos.
4.5 Distribución en el muestreo para una proporción poblacional
Tenemos una población de N sujetos sobre la que se desea estudiar una variable aleatoria de tipo discreto (\(X\)) cuyo parámetro de interés es la proporción de sujetos (\(\theta\)) que cumplen con cierta condición. En esta situación si obtenemos una muestra de tamaño \(n\) de dicha variable \(X_1,...,X_n\) (donde cada uno de ellos toma el valor 1 si cumple con la condición y 0 si no cumple), la proporción de éxito muestral (\(\hat{\theta}\)) viene dada por:
\[\hat{\theta}=\frac{\sum_{i=1}^n X_i}{n}\]
En esta situación la distribución en el muestreo para \(\hat{\theta}\), cuando \(n\) es grande (\(n \geq 30\)), viene dada por:
\[\hat{\theta} \sim N\left(θ,\frac{θ(1-θ)}{n}\right)\]
de forma que la variable aleatoria tipificada \(Z\) cumple que:
\[Z=\frac{\hat{\theta}-\theta}{\sqrt{\frac{θ(1-θ)}{n}}} \sim N(0,1)\]
La obtención de estas distribuciones en el muestreo nos permite realizar cálculos de probabilidades sobre dichas cantidades aleatorias, con lo que resulta posible conocer cuál es la probabilidad de que la media muestral supere cierto valor, y por tanto, podamos tener una mayor certeza del verdadero valor del parámetro poblacional.
4.6 Error estándar
Para cuantificar la bondad de la estimación obtenida se define el error estándar (es()) como la desviación típica de la distribución en el muestreo del estimador. De esta forma:
- Error estándar de la media en una población Normal con varianza conocida
\[es(\bar{X})=\frac{\sigma}{\sqrt{n}}\]
- Error estándar de la media en una población Normal con varianza desconocida
\[es(\bar{X})=\frac{S{\sqrt{n}}\]
- Error estándar de una proporción en una población Bernouilli
\[es(\bar{X})=\sqrt{\frac{\hat{θ}(1-\hat{θ})}{n}}\]
5 Estimación por intervalos de confianza
Un intervalo de confianza al nivel \(100*(1-\alpha)%\) representa la confianza que tenemos en que el verdadero valor del parámetro de la población se encuentre contenido entre los limites de dicho intervalo, que se construye a partir de la información muestral y la distribución en el muestreo del estimador. Si tenemos un intervalo de confianza al 95%, es decir \(\alpha = 0.05\), lo que estamos indicando es que si obtuviéramos 100 muestras y calculáramos los 100 intervalos asociados, solo en 95 de ellos contendrían al verdadero valor del parámetro poblacional. Dado que habitualmente tomamos una única muestra debemos confiar en que el intervalo producido sea uno de los 95 que contiene al verdadero valor del parámetro poblacional. El valor de \(\alpha\) se conoce como significatividad.
Supongamos que tenemos una población sobre la deseamos estudiar una variable aleatoria \(X\) cuya función de distribución es conocida y viene caracterizada por el parámetro \(\theta\), \(f(X|\theta)\). Vamos a obtener una muestra de tamaño \(n\), \(X_1,...,X_n\) y consideramos el estimador \(\hat{\theta}\) de \(\theta\) del que conocemos su distribución en el muestreo, \(f_n\),y podemos especificar su error estándar, \(es(\hat{\theta})\). Si fijamos el valor de \(\alpha\) el intervalo de confianza para el parámetro poblacional viene dado por la expresión:
\[IC_{1-\alpha} (\theta)=(\hat{\theta}-q_{\alpha/2}*es(\hat{\theta}),\hat{\theta}+q_{1-\alpha/2}*es(\hat{\theta}))\]
donde \(q_{\alpha/2}\) y \(q_{1-\alpha/2}\) son los cuantiles \(\alpha/2\) y \(1-\alpha/2\) de la distribución en el muestreo, es decir,
\[P(\hat{\theta} \leq q_{\alpha/2})=\alpha/2\]$
\[P(\hat{\theta} \leq q_{1-\alpha/2})=1-\alpha/2\]
Si la distribución en el muestreo es simétrica \(q_{1-\alpha/2}= - q_{\alpha/2}\)
Antes de estudiar la forma explicita de los intervalos de confianza para una proporción, una media, y una varianza vamos a ver una herramienta de simulación que nos permite comprobar el funcionamiento de dichos intervalos. El funcionamiento de la aplicación es:
- Fijar valor del parámetro poblacional
- Fijar el tamaño de la muestra
- Establecer el límite de confianza
- Establecer el número de muestras de trabajo y simularlas representando los intervalos de confianza obtenidos.
- Podemos ver entonces cuantos de esos intervalos contienen al verdadero valor del parámetro.
5.1 Intervalo de confianza para una proporción
El intervalo de confianza al nivel \(100*(1-\alpha)%\) para una proporción poblacional viene dado por:
\[IC_{1-\alpha} (\theta)=\left(\hat{\theta}-q_{1-\alpha/2}*\sqrt{\frac{\hat{θ}(1-\hat{θ})}{n}},\hat{\theta}+q_{1-\alpha/2}*\sqrt{\frac{\hat{θ}(1-\hat{θ})}{n}})\right)\] donde \(q_{1-\alpha/2}\) es el cuantil \(1-\alpha/2\) de una distribución Normal estándar, \(\hat{\theta}\) es la proporción muestral y \(n\) es el tamaño muestral.
Ejemplo. Como parte de un estudio sobre la salud alimenticia de las jóvenes entre 12 y 15 se midieron los niveles de hierro de 786 chicas y se detecto que 71 de ellas tenían deficiencia de hierro. Veamos como obtener un intervalo de confianza al 95% para la proporción de mujeres entre 12 y 15 años con deficiencia de hierro.
# Para realizar el proceso de estimación utilizamos la función
# prop.test()
deficiencia <- 71
muestra <- 786
# Estimador puntual
analisis <- prop.test(deficiencia, muestra, conf.level = 0.95)
analisis$estimate## p
## 0.09033079## [1] 0.07166294 0.11310912
## attr(,"conf.level")
## [1] 0.95La conclusión que podemos extraer es: “Con una confianza del 95% la proporción de mujeres entre 12 y 15 años con deficiencia de hierro se sitúa entre el 7.61% y el 11.3%. La estimación de la proporción de mujeres con deficiencia de hierro se sitúa en el 9.03%”
Veamos gráficamente la representación del intervalo de confianza. Se puede ver la distribución en el muestreo, la estimación obtenida (línea azul), los límites del intervalo de confianza para el parámetro (líneas rojas), y el intervalo de confianza obtenido (zona amarilla).
# Distribución en el muestreo
# Rango de valores (Tomamos solo valores entre 0 y 2 dada la esimacion puntual obtenida)
probabilidades <- seq(0,0.2,0.0001)
# media y desviación tipica de la distribución en el muestreo
media <- analisis$estimate
dtip <- sqrt(media*(1-media)/muestra)
densidad <- dnorm(probabilidades,media,dtip)
# Función para representar el IC
dnorm_IC <- function(x,m,sd,ic){
norm_ic <- dnorm(x,m,sd)
# Valores NA fuera del rango del intervalo de confianza:
norm_ic[x <= ic[1] | x >= ic[2]] <- NA
return(norm_ic)
}
# Plot:
df <- data.frame(x = probabilidades, y = densidad)
# Gráfico
base <- ggplot(df,aes(x,y)) +
geom_line() +
scale_x_continuous(breaks = seq(0, 0.2, 0.02)) +
labs(x = "Probabilidad de éxito") +
geom_vline(xintercept = c(analisis$conf.int[1], analisis$conf.int[2]), colour = "red") +
geom_vline(xintercept = c(analisis$estimate), colour = "blue") +
stat_function(fun = dnorm_IC, args = list(m=media, sd = dtip, ic = analisis$conf.int), geom = "area", fill = "yellow", alpha = 0.3)
base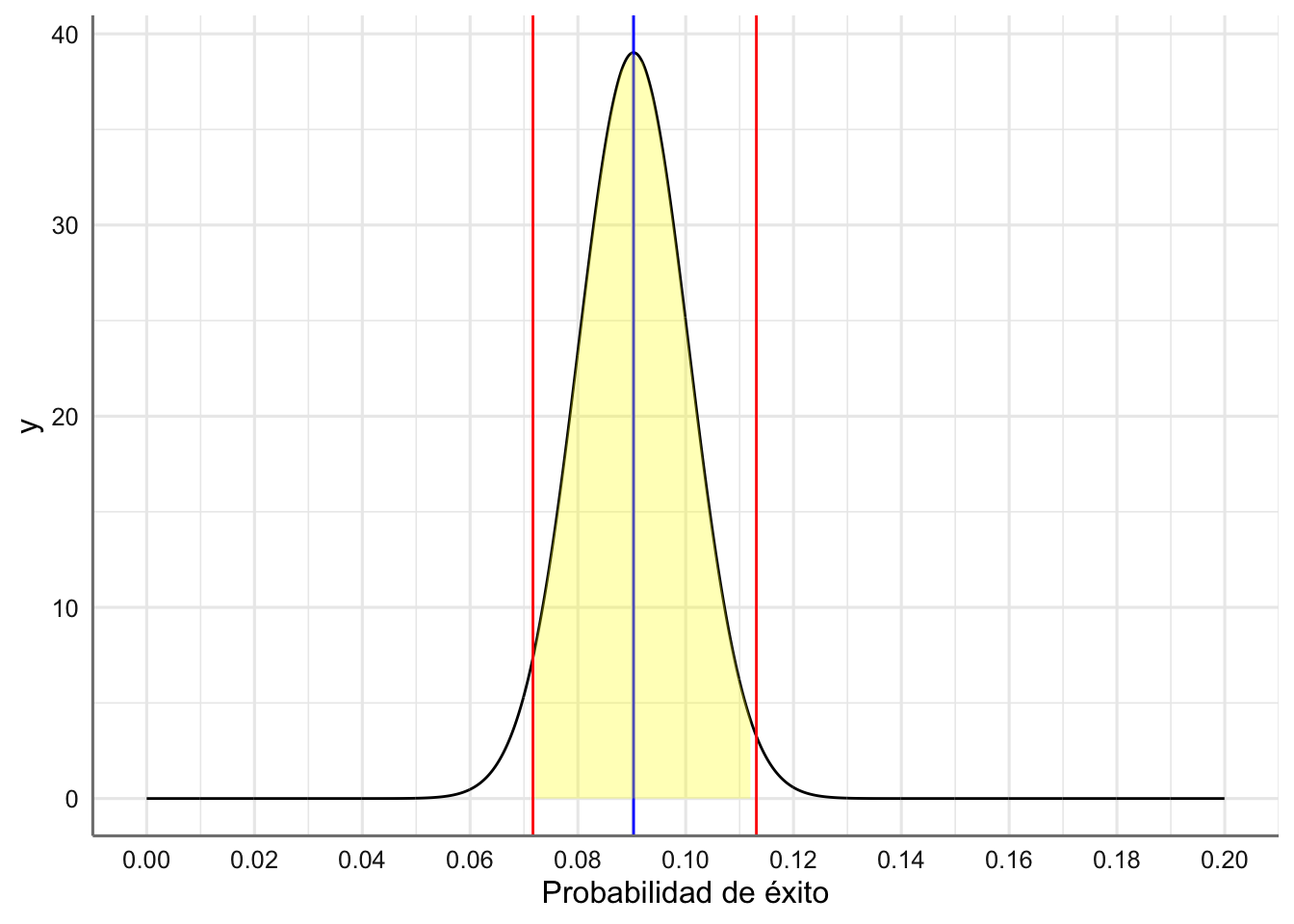
5.2 Intervalo de confianza para la media
El intervalo de confianza al nivel \(100*(1 - \alpha)\%\) para la media de una población Normal con varianza desconocida viene dado por:
\[IC_{1-\alpha}(\mu) = \left(\bar{x} - q_{1-\alpha/2}*\frac{s}{\sqrt{n-1}},\bar{x} + q_{1-\alpha/2}*\frac{s}{\sqrt{n-1}}\right)\] donde \(q_{1-\alpha/2}\) es el cuantil \(1-\alpha/2\) de una distribución \(t\) se Student con \(n-1\) grados de libertad, \(\bar x\) es la media muestral, \(s\) es la desviación típica muestral, y \(n\) es el tamaño de muestra.
Ejemplo. Human beta-endorphin (HBE) es una endorfina secretada pro la galdula pituitaria bajo condiciones de stres. Un investigador lleva a cabo una investigación para conocer si un programa de ejercico regular puede reducir el nivel de stres. Para ello se toman 10 sujetos y se mide su nivel de HBE (en pg/ml) antes de comenzar el porhgrama y seis meses después de manterner el prohgrama de ejercicio físico. La diferencia (medida antes - medida después) en los niveles de HBE de los diez sujetos vienen dados a continuación: 20, 18, 28, 0, 7, 34, 16, -5, 8, 4. Veamos como obtener un intervalo de confianza al 95% para la reducción media del nivel de HBE después del programa de ejercicio.
# Para realizar el proceso de estimación utilizamos la función t.test()
datos <- c(20, 18, 28, 0, 7, 34, 16, -5, 8, 4)
# Estimador puntual
analisis <- t.test(datos,conf.level = 0.95)
analisis$estimate## mean of x
## 13## [1] 4.129062 21.870938
## attr(,"conf.level")
## [1] 0.95La reducción media del nivel de HBE tras el programa de ejercicio se ha situado en 13 pg/ml. Con una confianza del 95% la reducción media del nivel de HBE se sitúa entre 4.13 pg/ml y 21.87 pg/ml.
5.3 Intervalo de confianza para la varianza
El intervalo de confianza al nivel \(100*(1 - \alpha)\%\) para la varianza de una población Normal viene dado por:
\[IC_{1-\alpha}(\sigma^2) = \left(\frac{(n-1)s^2}{q_{1-\alpha/2}}, \frac{(n-1)s^2}{q_{\alpha/2}}\right)\] donde \(q_{1-\alpha/2}\) y \(q_{\alpha/2}\) son los cuantiles \(1-\alpha/2\) y \(\alpha/2\) de una distribución \(Chi^2\) con \(n-1\) grados de libertad, \(s^2\) es la varianza muestral, y \(n\) es el tamaño de muestra.
Ejemplo. Para los datos del ejemplo anterior obtén un intervalo de confianza al 95% de la varianza poblacional de la reducción de HBE tras el programa de ejercicios.
# Para realizar el proceso de estimación debemos crear una función para la otención del IC
# Función para el IC
var.IC <-function(x, conf.level)
{
n <- length(x)
varianza <- var(x)
alfa <- 1 - conf.level
l1 <- (n - 1) * varianza / qchisq(1 - alfa / 2,n - 1)
l2 <- (n - 1) * varianza / qchisq(alfa / 2,n - 1)
ic <- c(l1,l2)
return(ic)
}
## Obtención del IC
datos <- c(20, 18, 28, 0, 7, 34, 16, -5, 8, 4)
# Estimador puntual
var(datos)## [1] 153.7778## [1] 72.75492 512.51866La variabilidad de la reducción del nivel de HBE tras el programa de ejercicio se ha situado en 153.78. Con una confianza del 95% la variabilidad de la reducción del nivel de HBE se sitúa entre 72.75 y 512.52.
6 Contraste de hipótesis
Un procedimiento de contraste de hipótesis tiene por objetivo valorar la evidencia proporcionada por los datos a favor de alguna hipótesis planteada sobre el parámetro o parámetros que identifican a la población bajo estudio. En el caso más sencillo, imaginemos que tenemos un parámetro poblacional \(\theta\) que puede tomar valores en el conjunto \(\Theta\)
Ejemplo: Estamos interesados en conocer si la proporción de alumnos que superan la asignatura de Estadística en la convocatoria de junio es mayor o igual al 50%. El parámetro de interés, \(\theta\), es entonces la proporción de aprobados en la convocatoria de junio, y el conjunto de posibles valores de dicho parámetro puede tomar valores entre 0 y 100. El contraste de interés viene dado por:
\[\theta \geq 0.5\]
Para resolver cualquier procedimiento de contraste debemos establecer dos subconjuntos disjuntos del espacio paramétrico, \(\Theta_0\) y \(\Theta_1\) cumpliendo que \(\Theta = \Theta_0 \cup \Theta_1\), con los posibles valores del parámetro de interés que denominamos hipótesis:
- Hipótesis nula, que se denota por \(H_0\), y que generalmente expresa el valor o conjunto de valores del parámetro,\(\Theta_0\), que corresponde con la idea que deseamos verificar.
- Hipótesis alternativa, que se denota por \(H_a\), y que generalmente expresa el valor o conjunto de valores complementarios, \(\Theta_1\), a los dados en la hipótesis nula. Formalmente, el problema de contraste de hipótesis se plantea como: \[\left\{\begin{array}{ll} H_0: & \theta \in \Theta_0\\ H_a: & \theta \in \Theta_1\end{array}\right.\]
Estas hipótesis se deben establecer antes de obtener la información muestral ya que deben reflejar conocimiento previo sobre el parámetro poblacional de interés. La muestra recogida aportará las evidencias suficientes para rechazar o no rechazar la hipótesis nula planteada.
En nuestro ejemplo
\[\left\{\begin{array}{ll} H_0: & \theta \geq 0.5\\ H_a: & \theta < 0.5\end{array}\right.\]
6.1 Posibles contrastes
Dada la estructura del procedimiento de contraste se plantean únicamente dos tipos de posibilidades:
Contraste bilateral: El conjunto de posibles valores del parámetro de interés establecidos en la hipótesis nula se concentra en un único valor, \(\theta_0\), es decir, \[\left\{\begin{array}{ll} H_0: & \theta = \theta_0\\ H_a: & \text{ no } \theta_0 \end{array}\right.\]
Contraste unilateral: El conjunto de posibles valores del parámetro de interés establecidos en la hipótesis nula se concentra en un conjunto de valores dado por una desigualdad con respecto a \(\theta_0\), es decir,
\[\left\{\begin{array}{ll} H_0: & \theta \geq \theta_0\\ H_a: & \text{ no } \theta_0 \end{array}\right.\] \[\left\{\begin{array}{ll} H_0: & \theta \leq \theta_0\\ H_a: & \text{ no } \theta_0 \end{array}\right.\]
6.2 Resolución de contraste
Para establecer evidencias a favor de una hipótesis u otra se debe:
- Elegir un nivel de significación, \(\alpha\), que refleja el riesgo que tomamos cuando rechazamos la hipótesis nula o probabilidad de rechazar la hipótesis nula cuando es cierta, es decir: \[\alpha = P(\text{ Rechazar } H_0 | H_0 \text{ cierta})\]
Normalmente se eligen valores pequeños, \(\alpha=0,1, 0.05, y 0.01\) que resultan los equivalentes del 90%, 95%, y 99% al nivel de confianza en el proceso de estimación.
Ejemplo. Si tomamos una significación del 5%, tendremos una probabilidad de 0.05 de rechazar la hipótesis nula cuando en realidad es cierta.
- Establecer estadístico de contraste (\(EC\)) que nos permita, utilizando la información muestral, estudiar la compatibilidad de dicha información con la hipótesis nula planteada. La forma habitual suele ser:
\[EC = \frac{\theta - \hat{\theta}}{es(\hat{\theta})}\]
donde \(\hat{\theta}\) es un estimador puntual del parámetro poblacional y \(es(\hat{\theta})\) es una medida del error estándar que cometemos con el estimador utilizado.
- Para decidir sobre el contraste planteado utilizaremos el \(p-valor\), que representa la probabilidad de que el valor del EC sea superior al valor de dicho estadístico evaluado en los datos muestrales, \(EC_{obs}\),atendiendo a la distribución en el muestreo, es decir,
\[p-valor = P(EC \geq EC_{obs})\]
Para tomar una decisión sobre el contraste miramos si el p-valor obtenido y concluimos que:
- Si \(p-valor < \alpha\), tenemos evidencias estadísticas suficientes para rechazar la hipótesis nula a favor de la hipótesis alternativa.
- Si \(p-valor > \alpha\), no tenemos evidencias estadísticas suficientes para rechazar la hipótesis nula.
A continuación vemos como ampliar el procedimiento de contraste para una proporción y una media. El proceso de contraste sobre una varianza no suele tener interés práctico ya que resulta más habitual obtener un intervalo de confianza. Como veremos en el tema siguiente, si que resulta relevante el proceso de contraste cuando se involucran dos poblaciones y estamos interesados en comparar la variabilidad de ambas.
6.3 Una proporción
Tenemos una población de tipo Bernouilli que viene especificada a partir de la proporción de sujetos que alcanzan el “éxito”, \(\theta\), y una estimación de dicho parámetro dada por \(\hat{\theta}\). Anteriormente ya hemos visto que para una muestra de tamaño \(n\) el error estándar viene dado por:
\[es(\hat{\theta}) = \sqrt{\frac{\hat{\theta} (1-\hat{\theta}))}{n}}.\]
Tanto para el contraste unilateral como el bilateral el estadístico de contraste viene dado por: \[EC = \frac{\theta - \hat{\theta}}{\sqrt{\frac{\hat{\theta} (1-\hat{\theta}))}{n}}}\] cuya distribución en el muestreo es \(N(0,1)\). Dicho estadístico valora lo cerca que queda el estimador respecto del valor poblacional teniendo en cuenta el error cometido en el proceso de estimación.
Ejemplo. Se está estudiando el efecto de los rayos X sobre la viabilidad huevo-larva en Tribolium casteneum. Se plantean tres situaciones: a) la proporción de viabilidad es del 50%, b) la proporción de viabilidad es superior al 60%, c) la proporción de viabilidad es inferior al 55%. Los contrastes asociados con cada situación son: \[\left\{\begin{array}{ll} H_0: & \theta = 0.5\\ H_a: & \theta \neq 0,5 \end{array}\right.\] \[\left\{\begin{array}{ll} H_0: & \theta \geq 0.6\\ H_a: & \theta < 0.6 \end{array}\right.\] \[\left\{\begin{array}{ll} H_0: & \theta \leq 0.55\\ H_a: & \theta > 0.55 \end{array}\right.\]
Para verificar dichios contarstes se irradiaron 1000 huevos de los que resultaron 572 larvas.
Para resolver contrastes en estas situaciones utiliamos la función
prop.test()
# Situación 1
n <- 1000
larvas <- 572
# Debemos fijar el valor del contraste, el tipo (two.sided), y el nivel de significación o su análogo como el nivel de confianza
prop.test(larvas, n, p = 0.5, alternative = "two.sided", conf.level = 0.95)##
## 1-sample proportions test with continuity correction
##
## data: larvas out of n
## X-squared = 20.449, df = 1, p-value = 6.124e-06
## alternative hypothesis: true p is not equal to 0.5
## 95 percent confidence interval:
## 0.5406126 0.6028273
## sample estimates:
## p
## 0.572El p-valor resultante es 6.124e-06 que resulta inferior al nivel de significación prefijado de 0.05. Por lo tanto hay evidencias para rechazar la hipótesis nula y concluir que la proporción de viabilidad una vez irradiamos los huevos con rayos X es distinta del 50%.
# Situación 2
n <- 1000
larvas <- 572
# Debemos fijar el valor del contraste, el tipo (two.sided), y el nivel de significación o su análogo como el nivel de confianza
prop.test(larvas, n, p = 0.6, alternative = "less", conf.level = 0.95)##
## 1-sample proportions test with continuity correction
##
## data: larvas out of n
## X-squared = 3.151, df = 1, p-value = 0.03794
## alternative hypothesis: true p is less than 0.6
## 95 percent confidence interval:
## 0.0000000 0.5980029
## sample estimates:
## p
## 0.572El p-valor resultante es 0.03794 que resulta inferior al nivel de significación prefijado de 0.05. Por lo tanto hay evidencias para rechazar la hipótesis nula y concluir que la proporción de viabilidad una vez irradiamos los huevos es mayor o igual al 60%.
# Situación 2
n <- 1000
larvas <- 572
# Debemos fijar el valor del contraste, el tipo (two.sided), y el nivel de significación o su análogo como el nivel de confianza
prop.test(larvas, n, p = 0.55, alternative = "greater", conf.level = 0.95)##
## 1-sample proportions test with continuity correction
##
## data: larvas out of n
## X-squared = 1.8677, df = 1, p-value = 0.08587
## alternative hypothesis: true p is greater than 0.55
## 95 percent confidence interval:
## 0.545601 1.000000
## sample estimates:
## p
## 0.572El p-valor resultante es 0.08587 que resulta superior al nivel de significación prefijado de 0.05. Por lo tanto hay evidencias para no rechazar la hipótesis nula y concluir que la proporción de viabilidad una vez irradiamos los huevos puede ser menor o igual al 55%.
6.4 Una media
Tenemos una población Normal que viene especificada a partir de la media (\(\mu\)) y varianza (\(\sigma^2\)). Por el momento estamos interesados en los procedimientos de contraste sobre la media cuando desconocemos el valor de la varianza poblacional. Tomamos los estimadores habituales \(\bar X\), \(S^2\), y consideramos el error estándar: \[es(\bar X) = \frac{s}{\sqrt{n-1}}.\] Tanto para el contraste unilateral como el bilateral el estadístico de contraste viene dado por: \[EC = \frac{\mu - \bar X}{\frac{s}{\sqrt{n-1}}}\] cuya distribución en el muestreo es una \(t\) de Student con n-1 grados de libertad.
Ejemplo. La concentración media de dióxido de carbono en el aire en una cierta zona no es habitualmente mayor que 335 ppmv (partes por millon en volumen). Se sospecha que esta concentración es mayor en la capa de aire más próxima a la superficie. Los investigadores quieren comprobar si la concentración en la superficie es mayor o igual a dicho valor con una significación de 0.05. Se plantea el contraste:
\[\left\{\begin{array}{ll} H_0: & \mu \geq 335\\ H_a: & \mu < 335 \end{array}\right.\] Para tratar de ratificar su hipótesis Se ha analizado el aire en 20 puntos elegidos aleatoriamente a una misma altura cerca del suelo, resultando los siguientes datos: 332, 320, 312, 270, 330, 354, 356, 310, 341, 313, 223, 224, 305, 321, 325, 333, 332, 345, 312, 331.
Para resolver este contraste utilizamos la función
t.test()
datos <- c(332, 320, 312, 270, 330, 354, 356, 310, 341, 313, 223, 224, 305, 321, 325, 333, 332, 345, 312, 331)
# Debemos fijar el valor del contraste, el tipo (two.sided), y el nivel de significación o su análogo como el nivel de confianza
t.test(datos, mu = 335, alternative = "less", conf.level = 0.95)##
## One Sample t-test
##
## data: datos
## t = -2.5219, df = 19, p-value = 0.01038
## alternative hypothesis: true mean is less than 335
## 95 percent confidence interval:
## -Inf 328.5403
## sample estimates:
## mean of x
## 314.45El p-valor resultante es 0.01038 que resulta inferior al nivel de significación prefijado de 0.05. Por lo tanto hay evidencias para rechazar la hipótesis nula y concluir que la media del nivel de dióxido de carbono en la capa de aire más cercana a la superficie es menor a 335 ppmv.
7 Inferencia para dos poblaciones
En este tema completamos el estudio inferencial visto en el tema anterior. Más concretamente se muestra el análisis inferencial para la comparación de dos proporciones o dos medias. En la situación de la comparación de dos medias veremos también la influencia que tiene el estudio de las varianzas de ambas poblaciones. No se presentan todas las formulaciones y distribuciones asociadas con estos análisis sino que se presenta directamente la forma de resolverlos. se pueden consultar los desarrollos estadísticos en cualquier libro de estadística básica.
7.1 Poblaciones Bernouilli
Sean dos poblaciones sobre las que se desea estudiar una misma característica de interés de tipo discreto (1 = éxito; 0 = fracaso), que identificamos por \(X_{P1}\) y \(X_{P2}\) respectivamente. El parámetro de interés en cada población es la proporción de éxito, \(\theta_1\) y \(\theta_2\) respectivamente, pero el interés inferencial principal es la comparación de \(\theta_1\) y \(\theta_2\), es decir, comprobar si la proporción de éxito en la población 1 es comparable con la proporción de éxito en la población 2. Para realizar dicha comparación se utiliza el parámetro que viene dado por la diferencia de proporciones de éxito: \[\theta_1 - \theta_2\]
Si las proporciones son iguales la diferencia debería estar próximo a cero, mientras que si son distintas la diferencia sería estadísticamente diferente a cero.
7.2 Poblaciones Normales
Sean dos poblaciones normales sobre las que se desea estudiar una misma característica de interés de tipo continuo que identificamos por \(X_{P1}\) y \(X_{P2}\) respectivamente. Cada población viene caracterizada por su media y varianza, es decir, \[X_{P1} \sim N(\mu_1,\sigma^2_1) \text{ ; } X_{P2} \sim N(\mu_2,\sigma^2_2)\] En este caso el proceso inferencial se centras en todos los parámetros, medias y varianzas, pero habitualmente el objetivo inferencial principal se centra en comprobar si las medias de ambas poblaciones pueden considerarse iguales o diferentes. Por tanto, el parámetro de interés es la diferencia de medias poblacionales: \[\mu_1 - \mu_2\] Como ocurre con las proporciones, se considera que las medias son iguales cuando la diferencia de las medias es estadísticamente cero. Sin embargo, para poder realizar dicho estudio es necesario conocer en primer lugar si las varianzas de ambas poblaciones pueden considerarse iguales o distintas. En función del resultado de dicha comparación se deberá utilizar un proceso inferencial diferente para la comparación de medias. Dado que las varianzas siempre son positivas el parámetro de interés para la comparación de varianzas viene dado por su cociente: \[\frac{\sigma^2_1}{\sigma^2_1}\]
7.3 Inferencia para dos proporciones
Dada una muestra aleatoria en cada una de las poblaciones de interés de tamaños \(n_1\) y \(n_2\), utilizamos los estimadores habituales de la proporción poblacional dados por las proporciones muestrales \(\hat{\theta}_1\) y \(\hat{\theta}_2\). Como ya hemos dicho el parámetro objetivo en esta situación es la diferencia de proporciones poblacionales.
Ejemplo: La angina de pecho es una afección cardíaca en la que el paciente sufre ataque períodicos de dolor. En un estudio para analizar la efectividad de una nueva droga para prevenir dichos ataques se han seleccionado dos grupos de sujetos. Al primero de ellos se les dará la nueva droga mientras que al otro se les dará el tratamiento estándar. Los resultados obtenidos después de un periodo de 28 semanas viene dados en la tabla siguiente:
| Estado / Tratamiento | Droga nueva | Droga antigua |
|---|---|---|
| Sin angina | 44 | 19 |
| Con angina | 116 | 128 |
| Total | 160 | 147 |
Se está interesado en conocer con una confianza del 90% (significación de 0.1) si la porporción de pacientes mejorados con la nueva droga es diferente con respecto a la droga antigua.
library(tidyverse)
# carga de datos
muestra <- c(160,147)
mejoras <- c(44,19)
# Tabla
res <- data.frame(mejoras, muestra)
colnames(res) <- c("mejoras","muestra")
res## mejoras muestra
## 1 44 160
## 2 19 1477.4 Estimador puntual
El estimador puntual de la diferencia de proporciones poblacionales se consigue partir de los estimadores puntuales de cada una de las proporciones de éxito muestrales.
Para los datos de nuestro ejemplo, si la población 1 identifica a los usjetos que toman la nueva droga y la pobalción 2 a los que toman la droga antigua, tendríamos: \(\widehat{\theta_1 - \theta_2} = \widehat{\theta_1} - \widehat{\theta_2} = \frac{44}{160} - \frac{19}{147} = 0.1457\)
Se observa una diferencia en la mejora de los sujetos del 14.57% de los que toman la droga nueva frente a los que toman la droga estándar.
7.5 Estimador por intervalos de confianza
Para obtener el intervalo de confianza para la diferencia de proporciones utilizamos la función prop.test(). Esta función también nos permite realizar el correspondiente contarte pero por le momento solo pediremos los resultados referidos al intervalo de confianza.
## [1] 0.0654468 0.2260498
## attr(,"conf.level")
## [1] 0.9Para los datos de nuestro ejemplo el intervalo de confianza al 90% indica que la diferencia de proporciones de mejora entre los que usan la droga nueva frente a os que usan la droga estándar se sitúa entre el 6.5% y el 22.6%
7.6 Contraste de hipótesis
EL contraste habitual en esta situación viene dado por:
\[\left\{\begin{array}{ll} H_0: & \theta_1 = \theta_2\\ H_a: & \theta_1 \neq \theta_2 \end{array}\right.\] donde estamos interesados en verificar si las proporciones de éxito poblacionales pueden considerarse iguales o distintas.
Para los datos de nuestro ejemplo tenemos:
##
## 2-sample test for equality of proportions with continuity correction
##
## data: mejoras out of muestra
## X-squared = 9.1046, df = 1, p-value = 0.00255
## alternative hypothesis: two.sided
## 90 percent confidence interval:
## 0.0654468 0.2260498
## sample estimates:
## prop 1 prop 2
## 0.2750000 0.1292517Dado que el pvalor obtenido (0.00255) es inferior al nivel de siginificación prefijado (0.1) hay eviedencias estadísticas para rechazar la hipótesis nula, es decir, hay evidendaicas para concluir que las proporciones de mejora con mabsa drogas son distintas. Además el intervalo de confianza ya nos indicaba qye dicha mejoría era a favor de la droga nueva con los valores obtenidos en el aprtado anterior
Podríamos plantearnos contrastes unilaterales pero siempre antes de ver los resultados muestrales. Si estamos tratando de probar un nuevo tratamiento lo más lógico hubiera sido plantear el contraste: \[\left\{\begin{array}{ll} H_0: & \theta_1 = \theta_2\\ H_a: & \theta_1 > \theta_2 \end{array}\right.\]
En nuestro ejemplo:
analisis <- prop.test(mejoras,muestra,alternative = "greater", conf.level = 0.90)
# Resultados completos
analisis##
## 2-sample test for equality of proportions with continuity correction
##
## data: mejoras out of muestra
## X-squared = 9.1046, df = 1, p-value = 0.001275
## alternative hypothesis: greater
## 90 percent confidence interval:
## 0.08174166 1.00000000
## sample estimates:
## prop 1 prop 2
## 0.2750000 0.1292517La conclusión es que rechazamos que las proporciones de mejora sean iguales frente a que la proporción de de mejora en la población 1 sea mayor al de la población 2.
7.7 Inferencia para dos medias
Los problemas de inferencia asociados con la comparación de dos medias poblacionales para variables Normales presentan diferentes situaciones:
- Estudio de dos poblaciones independientes con variabilidades iguales
- Estudio de dos poblaciones independientes con variabilidades distintas
- Estudio de la evolución de una población (medidas antes - después)
A continuación se detalla como realizar el análisis de cada uno de ellos, pero antes de pasar con ellos debemos estudiar el problema de como comparar las variabilidades en dos poblaciones independientes. Presentamos en primer lugar los diferentes ejemplos de trabajo.
Ejemplo 1. Para realizar un estudio de la concentración de una hormona en una solución vamos a utilizar dos métodos. Disponemos de 10 dosis preparadas en el laboratorio y medimos la concentración de cada una con los dos métodos. Se obtienen los siguientes resultados:
| Dosis | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Método A | 10.7 | 11.2 | 15.3 | 14.9 | 13.9 | 15 | 15.6 | 15.7 | 14.3 | 10.8 |
| Método B | 11.1 | 11.4 | 15 | 15.1 | 14.3 | 15.4 | 15.4 | 16 | 14.3 | 11.2 |
Se desea realizar el estudio inferencial con una confianza del 95%
Ejemplo 2. Una compañía contrata 10 tubos con filamentos del tipo A y 12 tubos con filamentos del tipo B. Las duraciones medias observadas se muestran en la siguiente tabla:
| Tipo/Duración | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | 1614 | 1094 | 1293 | 1643 | 1466 | 1270 | 1340 | 1380 | 1081 | 1497 | ||
| B | 1383 | 1138 | 920 | 1143 | 1017 | 961 | 1627 | 821 | 1711 | 865 | 1662 | 1698 |
Se desea realizar el estudio inferencial con una confianza del 90%
Ejemplo 3. En una unidad del sueño se está probando con un nuevo somnífero. Para comprobar su eficacia se toman 10 individuos al azar. Un día no se les suministra el somnífero y se les anota el número de horas de sueño, al día siguiente se les suministra y se vuelve a comprobar las horas de sueño. Los resultados entes y después del tratamiento han sido los siguientes:
| Instante/Sujeto | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Antes | 7.3 | 8.2 | 6.3 | 5.2 | 6.9 | 5.8 | 5.3 | 7.1 | 6.9 | 8.1 |
| Después | 8.2 | 7.9 | 6.4 | 5.1 | 7.1 | 6.3 | 5.9 | 8.2 | 7.1 | 7.7 |
Se desea realizar el estudio inferencial con una confianza del 90%
7.8 Análisis de dos varianzas poblacionales
Supongamos que tenemos dos poblaciones Normales y que deseamos comprobar si la variabilidad en ambas poblaciones pueden considerarse estadísticamente iguales o distintas. Como ya vimos en la introducción este problema se reduce a la comparación de ambas varianzas a través del cociente de ambas. Para resolver este problema utilizamos la función var.test(). El contraste utilizado es:
\[\left\{\begin{array}{ll} H_0: & \frac{\sigma^2_1}{\sigma^2_2} = 1\\ H_a: & \frac{\sigma^2_1}{\sigma^2_2} \neq 1 \end{array}\right.\]
Para los datos del ejemplo 1
# Cargamos los datos
MetodoA <- c(10.7, 11.2, 15.3, 14.9, 13.9, 15, 15.6, 15.7, 14.3, 10.8)
MetodoB <- c(11.1, 11.4, 15, 15.1, 14.3, 15.4, 15.4, 16, 14.3, 11.2)
var.test(MetodoA, MetodoB, conf.level = 0.95)##
## F test to compare two variances
##
## data: MetodoA and MetodoB
## F = 1.1229, num df = 9, denom df = 9, p-value = 0.8657
## alternative hypothesis: true ratio of variances is not equal to 1
## 95 percent confidence interval:
## 0.2789187 4.5208902
## sample estimates:
## ratio of variances
## 1.122925Dado que el pvalor resultante es superior a la significatividad prefijada, tenemos evidencias estadísticas para no rechazar la hipótesis nula, y por tanto concluir que ambas varianzas no pueden considerarse distintas.
Para los datos del ejemplo 2
# Cargamos los datos
TipoA <- c(1614,1094,1293,1643,1466,1270,1340,1380,1081,1497)
TipoB <- c(1383,1138,920,1143,1017,961,1627,821,1711,865,1662,1698)
var.test(TipoA, TipoB, conf.level = 0.9)##
## F test to compare two variances
##
## data: TipoA and TipoB
## F = 0.3052, num df = 9, denom df = 11, p-value = 0.08543
## alternative hypothesis: true ratio of variances is not equal to 1
## 90 percent confidence interval:
## 0.1053789 0.9468807
## sample estimates:
## ratio of variances
## 0.3052007Puesto que el pvalor es inferior a la significatividad prefijada podemos concluir que hya evidencias estad´sitivas apra concluir que las varaibilidades en ambas poblaciones pueden considerarse distintas.
En todos los análisis inferenciales asociados con la comparación de dos medias utilizamos la función t.test(), aunque con difrentes opciones en función de que las varianzas sean iguales o no, o de que las muestras sean independientes o no.*
7.9 Dos medias para poblaciones independientes con varianzas iguales
El contraste de hipótesis para esta situación viene dado por:
\[\left\{\begin{array}{ll} H_0: & \mu_1 = \mu_2\\ H_a: & \mu_1 \neq \mu_2 \end{array}\right.\]
Utilizamos los datos del ejemplo 1, ya que como hemos visto anteriormente las varianzas de ambas pobalciones puden considerarse iguales
# Cargamos los datos
MetodoA <- c(10.7, 11.2, 15.3, 14.9, 13.9, 15, 15.6, 15.7, 14.3, 10.8)
MetodoB <- c(11.1, 11.4, 15, 15.1, 14.3, 15.4, 15.4, 16, 14.3, 11.2)
t.test(MetodoA, MetodoB, alternative = "two.sided", var.equal = TRUE, conf.level = 0.95)##
## Two Sample t-test
##
## data: MetodoA and MetodoB
## t = -0.20323, df = 18, p-value = 0.8412
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -2.040763 1.680763
## sample estimates:
## mean of x mean of y
## 13.74 13.92Dado que el pavalor es superior a la significatividad prefijada, hay evidencias estadísticas para concluir que las medias de concentración con ambos métodos pueden considerarse iguales
7.10 Dos medias para poblaciones independientes con varianzas distintas
El constaste de hipótesis en esta situación es el mismo que en el punto anterior.
Utilizamos los datos del ejemplo 2, ya que como hemos visto anteriormente las varianzas de ambas pobalciones puden considerarse distintas
# Cargamos los datos
TipoA <- c(1614,1094,1293,1643,1466,1270,1340,1380,1081,1497)
TipoB <- c(1383,1138,920,1143,1017,961,1627,821,1711,865,1662,1698)
t.test(TipoA, TipoB, alternative = "two.sided", var.equal = TRUE, conf.level = 0.9)##
## Two Sample t-test
##
## data: TipoA and TipoB
## t = 0.98508, df = 20, p-value = 0.3364
## alternative hypothesis: true difference in means is not equal to 0
## 90 percent confidence interval:
## -91.82747 336.42747
## sample estimates:
## mean of x mean of y
## 1367.8 1245.5Dado que el pvalor es superior a la significatividad prefijada, hay evidencias estadísticas para concluir que las medias de duración de los filamentos en ambos tipos pueden considerarse iguales
7.11 Dos medias para poblaciones emparejadas
Es muy habitual que en ciertas situaciones experimentales nos encontramos que queremos estudiar la evolución (medidas antes -después) de un grupo de sujetos después de ser sometidos a cierta prueba experimental. En esta caso no tenemos dos poblaciones independientes sino sólo una que medimos en dos ocasiones. Por tanto, los procedimientos anteriores tienen que ser modificados para tener en cuenta esta situación. El constaste de hipótesis para esta situación viene dado por:
\[\left\{\begin{array}{ll} H_0: & \mu_{antes} = \mu_{despues}\\ H_a: & \mu_{antes} \neq \mu_{despues} \end{array}\right.\]
De nuevo podemos utilizar la función t.test() con el parámetro paired.
Utilizamos los datos del ejemplo 3, donde tenemos una única muestra se sujetos
# Cargamos los datos
antes <- c(7.3,8.2,6.3,5.2,6.9,5.8,5.3,7.1,6.9,8.1)
despues <- c(8.2,7.9,6.4,5.1,7.1,6.3,5.9,8.2,7.1,7.7)
t.test(antes, despues, alternative = "two.sided", paired = TRUE, var.equal = TRUE, conf.level = 0.9)##
## Paired t-test
##
## data: antes and despues
## t = -1.7925, df = 9, p-value = 0.1066
## alternative hypothesis: true difference in means is not equal to 0
## 90 percent confidence interval:
## -0.566341394 0.006341394
## sample estimates:
## mean of the differences
## -0.28Dado que el pvalor es superior a la significatividad prefijada, hay evidencias estadísticas para concluir que las horas medias de sueño antes y después de tomar el somnifero no pueden considerarse estadísticamente distintas
8 Tests no paramétricos
Todos los procedimientos de inferencia sobre dos medias se basan en la suposición de que las variables sobre las que estamos trabajando se puede considerar que se distribuyen normalmente. Sin embargo, cuando tenemos tamaños muestrales pequeños o simplemente por el tipo de variable que estamos midiendo, dicha suposición no resulta creible y es necesario comporbarla antes de poder aplicar estos procedimientos. SI la distribución no resulta Normal podemos utilizar los procedimientos denominados no parámetricos para la comparación de dos medias. A continuación presentamso el test de normalidad y los contrastes no paramétricos.
8.1 Normalidad
Este requisito implica que la variable objetivo tiene que distribuirse según una normal para cualquiera de las pobalciones donde se pueda medir. El test utilizado para resolver este problema es el de Shapiro-Wilks. En R utilizamos la función shapiro.test() para concluir estadísticamente sobre este contraste. Siempre utilizamos significatividad de 0.05 en estas situaciones.
Para los datos del ejemplo 1 comprobamos si los datos muestrales en cada población pueden considerarse que se distribuyen según una normal.
# Cargamos los datos
MetodoA <- c(10.7, 11.2, 15.3, 14.9, 13.9, 15, 15.6, 15.7, 14.3, 10.8)
MetodoB <- c(11.1, 11.4, 15, 15.1, 14.3, 15.4, 15.4, 16, 14.3, 11.2)
shapiro.test(MetodoA)##
## Shapiro-Wilk normality test
##
## data: MetodoA
## W = 0.8058, p-value = 0.01705##
## Shapiro-Wilk normality test
##
## data: MetodoB
## W = 0.80577, p-value = 0.01704En ambos casos las conclusión es que rechazamos que los datos se distribuyan según una normal, ya que el pvalor es inferior a la significatividad prefijada
Para los datos del ejemplo 2:
# Cargamos los datos
TipoA <- c(1614,1094,1293,1643,1466,1270,1340,1380,1081,1497)
TipoB <- c(1383,1138,920,1143,1017,961,1627,821,1711,865,1662,1698)
shapiro.test(TipoA)##
## Shapiro-Wilk normality test
##
## data: TipoA
## W = 0.95009, p-value = 0.6696##
## Shapiro-Wilk normality test
##
## data: TipoB
## W = 0.86377, p-value = 0.05451En ambos casos no podemos rechzar que los datos sean normales, ya que el pvalor es superior a la significatividad.
8.2 Dos medianas en poblaciones independientes
El test no paramétrico no se centra en la comparación de medias sino en la comparación de las medianas. Esto es así porque uno de los incumplimientos más habituales de la normalidad es porque los datos no son simétricos, es decir, la media coincide con la mediana. Para resolver este contraste utilizamos el test de Wilcoxon y su función en R wilcox.test().
Dado que los datos del ejmplo 1 no pueden considerarse normales, utilizamos el test no paramétrico apra concluir si las medianas de ambas poblaciones pueden considerarse iguales o distintas. Fijamos la significatividad en 0.05.
# Cargamos los datos
MetodoA <- c(10.7, 11.2, 15.3, 14.9, 13.9, 15, 15.6, 15.7, 14.3, 10.8)
MetodoB <- c(11.1, 11.4, 15, 15.1, 14.3, 15.4, 15.4, 16, 14.3, 11.2)
wilcox.test(MetodoA,MetodoB)##
## Wilcoxon rank sum test with continuity correction
##
## data: MetodoA and MetodoB
## W = 44, p-value = 0.6768
## alternative hypothesis: true location shift is not equal to 0Dado que el pvalor es superior a la significatividad, tenemos evidencias para concluir que no podemos considerar que las medianas de ambas poblaciones sean distintas.
8.3 Dos medianas en poblaciones dependientes
También existe una versión del test de wilcoxon para la comparación en poblaciones dependientes. Este es muy habitual ya que en este tipo de situaciones lo nomral es tener pocos sujetos, y por tanto la hipótesis de normalidad es muy difícil de verificar.
Para los datos del ejmplo 3 tenemos:
# Cargamos los datos
antes <- c(7.3,8.2,6.3,5.2,6.9,5.8,5.3,7.1,6.9,8.1)
despues <- c(8.2,7.9,6.4,5.1,7.1,6.3,5.9,8.2,7.1,7.7)
wilcox.test(antes, despues,paired = TRUE)##
## Wilcoxon signed rank test with continuity correction
##
## data: antes and despues
## V = 12.5, p-value = 0.1389
## alternative hypothesis: true location shift is not equal to 0Dado que el pvalor es superior a la significatividad, podemos conluir que la mediana antes y después no pueden considerarse distintas.
9 Ejercicios
Ejercicio 1. Una cadena de supermercados vende pan recién horneado. Los cálculos realizados conforme a la teoría de inventarios indican que para balancear los costos del pan no vendido (por estar duro) y la satisfacción de los clientes, la cadena debería agotar sus existencias de pan el 20% de los días. Se elige una muestra aleatoria de 50 tiendas y se comprobó que 14 de ellas quedaron desabastecidas. Realiza un análisis inferencial con una confianza del 95% para esta situación.
Ejercicio 2. El anterior director (por muchos años) de servicios municipales de la ciudad obtuvo del gobierno federal la subvención solicitada el 50% de las veces que pidió ayuda. Se nombró un nuevo director de servicios municipales de la ciudad quién presento 18 solicitudes de ayuda al gobierno federal durante su primer año. Si 7 de las 18 solicitudes fueron subvencionadas, el concejo municipal quieres saber si hay un cambio en la tasa de resultados positivos bajo la nueva dirección. Realiza un análisis inferencial con una confianza del 95% para esta situación.
Ejercicio 3. El gerente de investigación y desarrollo de una compañía de alimentos comprobó que sólo el 40% de los nuevos productos potenciales que se han sometido a prueba con los clientes son comercializados. Para determinar qué productos han de someterse a prueba por los clientes, el gerente toma 20 nuevos productos potenciales de los cuales 8 fueron comercializados. Realiza un análisis inferencial con una confianza del 90% para esta situación.
Ejercicio 4. Un distribuidor minorista de computadoras está tratando de decidir entre dos métodos para dar servicio a los equipos de los clientes. El primer método enfatiza el mantenimiento preventivo; el segundo una respuesta rápida a los problemas. Se atienden dos muestras de clientes, cada una con uno de esos métodos. Después de seis meses, se encuentra que 171 de los 200 clientes atendidos con el primer método están muy satisfechos con el servicio, comparados con los 153 de los 200 clientes atendidos con el segundo método. Realiza un análisis inferencial con una confianza del 90% para esta situación.
Ejercicio 5. Se realizan pruebas de fiabilidad muy severas con dos muestras de 30 motores eléctricos para impresoras. De los motores del proveedor 1, pasaron la prueba 22; de los motores del proveedor 2, sólo 16 se aprobaron. Realiza un análisis inferencial con una confianza del 95% para esta situación.
Por el momento, en todos los ejercicios que siguen asumiremos que todas las distribuciones son normales. NO hace falta comporbar la hipótesis de normalidad.
Ejercicio 6. El gerente de una organización para la conservación de la salud ha fijado como objetivo que aquellos pacientes que no acudan por alguna emergencia esperen menos de 30 minutos en ser atendidos. En un control por sondeo se recogen los tiempos de espera de 22 pacientes obteniendo los resultados siguientes:
tiempos <- c(28.0,47.9, 38.8, 45.7, 47.3, 34.3, 41.1, 26.9, 26.4,
21.8,39.3, 31.5, 37.5, 25.4, 24.1, 30.8, 22.3, 44.5,
43.1, 45.8, 42.0, 57.2)Realiza un análisis inferencial con una confianza del 95% para esta situación.
Ejercicio 7. Un distribuidor de papel reciclado coloca contenedores vacíos en varios lugares, éstos se llenan gradualmente con los periódicos viejos y materiales similares que traen varios individuos. Los contenedores se recogen (y se reemplazan por otros vacíos) siguiendo distintos itinerarios. En uno de tales trayectos se hace la recolección cada dos semanas. Este plan es aconsejable si la cantidad media de papel reciclado en cada período de dos semanas es mayor que 1600 píes cúbicos. Distintos registros correspondientes a 18 períodos de dos semanas muestran los siguientes volúmenes (en píes cúbicos) para un lugar particular:
volumen <- c(1660,1820,1590,1440,1730,1680,1750,1720,1900,1570,1700,
1900,1800,1770,2010,1580,1620,1690)Realiza un análisis inferencial con una confianza del 95% para esta situación.
Ejercicio 8. Un organismo de control estatal está investigando una afirmación publicitaria de que cierto dispositivo reduce el consumo de gasolina en los automóviles. Se han comprado e instalado siete dispositivos en autos que pertenecen a la institución. Se espera que la distancia recorrida por cada 10 litros sea de 100 km. Para comparar los rendimientos en condiciones estándar, se miden los kilómetros que cada automóvil recorre con 10 litros de gasolina en las dos situaciones. Los datos recogidos son:
Realiza un análisis inferencial con una confianza del 95% para esta situación.
Ejercicio 9. Un fabricante de ropa compra tela en rollos y la corta. En el proceso, cierta cantidad de tela se desperdicia. Con los métodos estándar, el desperdicio es del 9.26%. Un productor de máquinas controladas por computadora le permitió probar una de sus máquinas con una muestra de 26 cortes distintos. Los datos se presentan a continuación:
desperdicio <- c(8.7, 7.3, 9.5, 7.9, 9.1, 11.1, 10.0, 8.6, 8.4,
8.8, 9.3, 11.1, 8.0, 8.7, 8.4, 9.6, 8.4, 7.8,
8.5, 7.7, 8.1, 11.1, 9.2, 10.2, 8.8, 8.5)Realiza un análisis inferencial con una confianza del 95% para esta situación.
Ejercicio 10. Un industrial que produce cereal inflado ensaya dos procedimientos de mantenimiento preventivo con dos de las pistolas utilizadas en el procesamiento. Se registra el número de horas de operación entre los periodos de paro total:
pistola1 <- c(40.6, 121.5, 54.5, 78.7, 153.8, 22.4, -0.5, -53.9, 162.1, 93.1,
59.1, 135.1, 2.2, 74.5, 79.1, 128.7, 71.9, 98.8, -50.3, 80.2,
100.9, 97.8, 86.3, 127.4, 21.8, 119.9, 127.7, 18.7, 66.6, 84.2,
44.2, 43.8, 92.1, 78.1, 81, 161.7, 57.5, 46, 61.6, 127.2, 77.8,
97.4, 56.6, 87.3, 94.9, 98.5, 69.7, 80.4, 55.9, 64.2, 28.5, 28.6,
8, 66.6, 62.6, 70.7, 54.5, 69.8, 133.4, 11.6, 73.6, 137.2, -47.6,
45.2, 106.9, 50.6, 137.3, 32, 53.3, 98.9, 19.5, 82.1, 14, 92.2,
91.5, 8.3, 8.3, 19.4, 70.5, 126.2, 89.1, 86.7, 85.3, 134.8, 47.2,
4.5, 28.3, 22.8, 150.6, 95.7, 91.2, 62.9, 58.4, 13.8, 15.1, 59.5,
40.3, 96.9, 134.2, 88.2, -8.1, 62.1, 63.7, 2.1, 91.6, 27, 78.3,
-0.7, 43.9, 63.8, 121, 50.2, 79.9, 81.5, 105.7, 12.8, 59.5, 84.8,
9.5, 92.3, 40.9, 35.9, 5, 72.4, 49.8, 47)
pistola2 <- c(6.2, 143, 1.2, -28.3, 40, 63.1, 65.2, 15.1, 137.6, 64.9, 101,
24.1, 53.3, 84.4, 107.9, -8.4, 72.1, 82.2, 43.3, 112.2, 92.7,
26.3, 33, 56.3, 23.7, 31.1, 79.6, 18.1, 46.8, 24.1, 50.7, 48.2,
39, 96.3, 58.4, 36, 40.2, 114, 63.1, 75.8, 71.6, 72.6, 72.3,
80.8, 158.5, 12.4, 81.2, 42.8, -6.8, 44, 34.6, 106.5, 74.8, 100,
23.9, 51.8, 86.7, -6.9, 13.2, 50.6, 90, 42, 79.5, 95.7, 71, 78.3,
80.8, 69.7, 1.6, 71.4, 115.5, 109.7, 36.6, 75.8, 64.7, 31.9,
43.4, 110.9, 137.2, 112, 42.6, 105, 51.8, 60.9, -11.9, 79.9,
83.4, 82.8, 14.5, 70.6, 103.6, 14, 50.9, 70, 91.6, 42.9, 43.6,
92.2, 97.6, 83, 109.1, -3.6, 51.2, 85.1, 59.5, 51.1, 35.9, 72.7,
41, 69.5, 1.4, 77.9, -47.2, 35.6, 98.1, 40.8, 105.9, -16, 44.4,
19.9, 67.7, 50.1, 41.3, 70.6, 122.1, 135.4, 113.3, 3.1, 48.4,
101.2, -14.3, 42.7, 19.1, 82.9, 109.5, 46.7, -10.7, 60.1, 132.1,
21.3, 35.1, 88.4, 64.4, -15.3, 75.4, 30.1, 95.5, 46.8, 3.4, 32.1,
-30.8, 43.5, 38.2, 59.2, 32.3)Realiza un análisis inferencial con una confianza del 95% para esta situación.
Ejercicio 11. Un mayorista especializado en productos farmacéuticos incurre en gastos considerablemente elevados para “documentar” cada pedido. En un esfuerzo por reducir el tiempo requerido, se ha programado una minicomputadora para enumerar los artículos de manera eficiente. Se prueban dos programas basados en diferentes principios de eficiencia. Se corre un centenar de pedidos con cada uno de ellos y se registra el tiempo total de trabajo por orden. Los datos obtenidos son:
programa1 <- c(0.1, 2.3, 1.9, 0.6, 1.3, 1.6, 0.7, 2.3, 0.5, 4.1, 2.7, 1.2,
2.2, 1.4, 3.4, 2.6, 1, 0.8, -0.4, 0, 0.6, 0.1, 2.1, 0.9, 2, 0.9,
1.2, 2.2, 1.8, 0.5, 2.6, 2.2, 0.5, 2.1, 2.1, 1.4, 1.5, 3.5, 1.1,
2.5, 0.9, 1.3, 1.4, 1.5, 1.1, -0.2, 2.3, 1.6, 2.5, 1.4, 1.4,
2.3, 1.6, 1.2, 2.3, 0.8, 2.3, 2.8, 2.4, 2.2, 1.4, 2.2, -0.6,
3.1, 0.6, 2.2, -0.9, 1.1, 0.9, 2.4, 0.3, 1.5, 1.6, -0.2, 0.1,
1.3, 1, 0.1, 3.4, 1.1, 2.7, 2.3, 2.9, 2.8, 2.8, 0.3, 0.9, 2.4,
1.7, 2.1, 1.9, 0.7, 0.8, 1.3, 1.1, 3.2, 0.8, 1.9, 1.9, 2.8)
programa2 <- c(0.8, 2.1, 1.1, 3, 1.1, 0.9, 1.9, 0.2, 2, 0.4, 2.3, -0.2, 0.6,
1.1, 0.2, 1.3, 0.6, 1.7, -0.2, 2.4, 1.7, 1, 1.7, 1.5, 0.6, -0.6,
0.6, 2.3, -0.5, 0, 0.5, 0.8, 2.5, 0.7, 0.6, 0.6, 2.5, 1, 0.2,
0.8, 0.4, 1.4, -0.1, 1.2, 1.4, 1.4, 0.2, -0.2, 1.9, -0.3, -0.3,
3.2, -0.1, -1.6, 2.2, 2, 1.1, 0.1, 1.4, -0.4, 0.1, 0.5, -0.3,
1.9, 0.3, 1.5, -0.8, 1.3, -2.3, -0.2, 1.1, 0.4, 0.4, 2.3, 1.6,
0.5, 2, 0.7, 1, 0.6, 0, 1.9, 2.7, 0.2, 1.2, 0.8, -1.4, 1.3, 1,
1.7, 1.2, 0.6, 1.2, 1.6, 1, 1.7, 0, 1.3, 1.1, 0.6)Realiza un análisis inferencial con una confianza del 95% para esta situación.
Ejercicio 12. Una compañía tiene una política generosa, pero bastante complicada, relativa a los bonos de fin de año para el personal gerencial de bajo rango. El factor clave de la política es el juicio subjetivo de contribución a las metas de la empresa. El director de personal toma una muestra de 24 mujeres y 36 hombres que desempeñan cargos gerenciales para ver si hay diferencias en los bonos, expresadas como porcentaje de salario anual. Los datos son los siguientes:
hombres <- c(10.4,8.9,11.7,12.0,8.7,9.4,9.8,9.0,9.2,9.7,9.1,8.8,7.9,9.9,
10.0,10.1,9.0,11.4,8.7,9.6,9.2,9.7,8.9,9.2,9.4,9.7,8.9,9.3,
10.4,11.9,9.0,12.0,9.6,9.2,9.9,9.0)
mujeres <- c(9.2,7.7,11.9,6.2,9.0,8.4,6.9,7.6,7.4,8.0,9.9,6.7,8.4,9.3,
9.1,8.7,9.2,9.1,8.4,9.6,7.7,9.0,9.0,8.4)Realiza un análisis inferencial con una confianza del 95% para esta situación.
Ejercicio 13. Un fabricante que elabora botes de aluminio reciclado está preocupado por los niveles de impurezas (principalmente otros metales) en lotes que tienen distintos orígenes. Los análisis del laboratorio de una muestra de lotes arrojan los siguientes datos (kilogramos de impurezas por cada 100 kilogramos del producto):
origen1 <- c(3.8,3.5,4.1,2.5,3.6,4.3,2.1,2.9,3.2,3.7,2.8,2.7)
origen2 <- c(1.8,2.2,1.3,5.1,4.0,4.7,3.3,4.3,4.2,2.5,5.4,4.6)Realiza un análisis inferencial con una confianza del 90% para esta situación.
Ejercicio 14. Los ejecutivos de una compañía están preocupados por el tiempo que un medicamento particular conserva su potencia. Una muestra aleatoria de 10 frascos del producto se extrae de la producción cotidiana y se analiza su potencia. Se toma una segunda muestra, se almacena por un año y después se analiza. Las lecturas obtenidas son:
inicio <- c(10.2,10.5,10.3,9.8,10.6,10.7,10.2,10.0,10.8,10.6)
final <- c(9.8,9.6,10.1,10.2,10.1,9.7,9.5,9.6,9.8,9.8)Realiza un análisis inferencial con una confianza del 95% para esta situación.
Ejercicio 15. Un fabricante de compresores de aire y bombas para neumáticos quiere probar dos modos de exhibir sus mercancías en los puntos de venta. Sus productos se venden a través de tiendas independientes, que varían enormemente en sus volúmenes de venta. Un total de 15 tiendas están de acuerdo en participar por un mes en la exposición. Las tiendas utilizarán ambos periodos de exposición (modo A y B) por un periodo de un mes. Tras cada mes se registran las ventas realizadas. En la tabla siguiente aparecen las ventas realizadas por cada modo:
modoA <- c(46,39,40,37,32,26,21,23,20,17,13,15,11,8)
modoB <- c(37,42,37,38,27,19,20,17,20,12,12,9,7,2)Realiza un análisis inferencial con una confianza del 90% para esta situación.
Ejercicio 16. Un fabricante tiene la alternativa de utilizar el servicio postal público o un transportista privado para enviar sus productos. Para facilitar la elección, el fabricante selecciona 10 destinos y envía parte de sus embarques por cada medio. Los tiempos de entrega (en días) son:
Realiza un análisis inferencial con una confianza del 95% para esta situación.
Ejercicio 18. Una compañía de ventas por correo prueba dos versiones distintas de un catálogo de ofertas especiales. Se selecciona una muestra de códigos postales de la lista de correos de la compañía, y para cada código postal se envía cada versión del catálogo a una mitad de las personas que viven en dicha zona postal. Para cada código, se registran las respuestas por millar de catálogos enviados. Los datos son los siguientes:
catalogoA <- c(10.8,13.4,8.9,10.6,17.0,14.1,11.2,13.4,9.9,10.7)
catalogoB <- c(11.3,15.0,9.9,10.0,17.7,12.6,11.8,13.7,10.4,9.9)Realiza un análisis inferencial con una confianza del 95% para esta situación.
Ejercicio 19. Verifica la normalidad para los datos de los ejercicios 10,11, 12 y 13. Si detectas falta de normalidad realiza el análisis inferencial basado en el correspondientes test no paramétrico.
Ejercicio 20. Utiliza el test no paramétrico adecuado para resolver los problemas inferenciales planteados en los ejercicios 14 a 18.
10 Ejercicios de aplicación
Estos ejercicios sirven para pensar en diferentes posibilidades de análisis inferencial (intervalo de confianza y contraste de hipótesis) sin haber analizado los datos muestrales. En los contrastes de hipótesis es necesario establece ambas hipótesis y describir las posibles conclusiones de ese contraste.
Antes de comenzar es necesario tener en cuenta ciertos aspecto técnicos a la hora de resolver las situaciones inferenciales. Si tenemos un banco de datos donde en una columna, X, tenemos la variable de interés y en otra columna, Y, tenemos almacenado el tratamiento al que se ha sometido cada sujeto (dos posibles tratamientos), el t.test de comparación de dos poblaciones se puede escribir como: t.test(X~Y), para indicar que la varaible X se debe dividir y comparar según los dos grupos definidos por Y.
Ejercicio 1. Para el banco de datos Airquality descrito en la Unidad 1, define tres situaciones que requieran un procedimiento inferencial y obtén los resultados de dichos análisis.
10.1 Airquality [@ChamCleKleTuk83].
Los datos para este ejemplo se obtuvieron del Departamento de Conservación del Estado de Nueva York (datos sobre el ozono) y del Servicio Meteorológico Nacional (datos meteorológicos). Los datos recogidos son las lecturas diarias de los siguientes valores de calidad del aire desde el 1 de mayo de 1973 y el 30 de septiembre de 1973 (153 días en total):
- Ozone: ozono medio en partes por billón de 13:00 a 15:00 horas en la Isla Roosevelt.
- Solar.R: Radiación solar en Langleys en la banda de frecuencia 4000-7700 Angstroms de 08:00 a 12:00 horas en Central Park.
- Wind: Velocidad media del viento en millas por hora a las 07:00 y las 10:00 horas en el Aeropuerto La Guardia.
- Temp: Temperatura máxima diaria en grados Fahrenheit en el Aeropuerto La Guardia.
- Month: Mes del año en código numérico.
- Temp: Día de la semana en código numérico.
## Ozone Solar.R Wind Temp Month Day
## 1 41 190 7.4 67 5 1
## 2 36 118 8.0 72 5 2
## 3 12 149 12.6 74 5 3
## 4 18 313 11.5 62 5 4
## 5 NA NA 14.3 56 5 5
## 6 28 NA 14.9 66 5 6
## 7 23 299 8.6 65 5 7
## 8 19 99 13.8 59 5 8
## 9 8 19 20.1 61 5 9
## 10 NA 194 8.6 69 5 10
## 11 7 NA 6.9 74 5 11
## 12 16 256 9.7 69 5 12
## 13 11 290 9.2 66 5 13
## 14 14 274 10.9 68 5 14
## 15 18 65 13.2 58 5 15
## 16 14 334 11.5 64 5 16
## 17 34 307 12.0 66 5 17
## 18 6 78 18.4 57 5 18
## 19 30 322 11.5 68 5 19
## 20 11 44 9.7 62 5 20
## 21 1 8 9.7 59 5 21
## 22 11 320 16.6 73 5 22
## 23 4 25 9.7 61 5 23
## 24 32 92 12.0 61 5 24
## 25 NA 66 16.6 57 5 25
## 26 NA 266 14.9 58 5 26
## 27 NA NA 8.0 57 5 27
## 28 23 13 12.0 67 5 28
## 29 45 252 14.9 81 5 29
## 30 115 223 5.7 79 5 30
## 31 37 279 7.4 76 5 31
## 32 NA 286 8.6 78 6 1
## 33 NA 287 9.7 74 6 2
## 34 NA 242 16.1 67 6 3
## 35 NA 186 9.2 84 6 4
## 36 NA 220 8.6 85 6 5
## 37 NA 264 14.3 79 6 6
## 38 29 127 9.7 82 6 7
## 39 NA 273 6.9 87 6 8
## 40 71 291 13.8 90 6 9
## 41 39 323 11.5 87 6 10
## 42 NA 259 10.9 93 6 11
## 43 NA 250 9.2 92 6 12
## 44 23 148 8.0 82 6 13
## 45 NA 332 13.8 80 6 14
## 46 NA 322 11.5 79 6 15
## 47 21 191 14.9 77 6 16
## 48 37 284 20.7 72 6 17
## 49 20 37 9.2 65 6 18
## 50 12 120 11.5 73 6 19
## 51 13 137 10.3 76 6 20
## 52 NA 150 6.3 77 6 21
## 53 NA 59 1.7 76 6 22
## 54 NA 91 4.6 76 6 23
## 55 NA 250 6.3 76 6 24
## 56 NA 135 8.0 75 6 25
## 57 NA 127 8.0 78 6 26
## 58 NA 47 10.3 73 6 27
## 59 NA 98 11.5 80 6 28
## 60 NA 31 14.9 77 6 29
## 61 NA 138 8.0 83 6 30
## 62 135 269 4.1 84 7 1
## 63 49 248 9.2 85 7 2
## 64 32 236 9.2 81 7 3
## 65 NA 101 10.9 84 7 4
## 66 64 175 4.6 83 7 5
## 67 40 314 10.9 83 7 6
## 68 77 276 5.1 88 7 7
## 69 97 267 6.3 92 7 8
## 70 97 272 5.7 92 7 9
## 71 85 175 7.4 89 7 10
## 72 NA 139 8.6 82 7 11
## 73 10 264 14.3 73 7 12
## 74 27 175 14.9 81 7 13
## 75 NA 291 14.9 91 7 14
## 76 7 48 14.3 80 7 15
## 77 48 260 6.9 81 7 16
## 78 35 274 10.3 82 7 17
## 79 61 285 6.3 84 7 18
## 80 79 187 5.1 87 7 19
## 81 63 220 11.5 85 7 20
## 82 16 7 6.9 74 7 21
## 83 NA 258 9.7 81 7 22
## 84 NA 295 11.5 82 7 23
## 85 80 294 8.6 86 7 24
## 86 108 223 8.0 85 7 25
## 87 20 81 8.6 82 7 26
## 88 52 82 12.0 86 7 27
## 89 82 213 7.4 88 7 28
## 90 50 275 7.4 86 7 29
## 91 64 253 7.4 83 7 30
## 92 59 254 9.2 81 7 31
## 93 39 83 6.9 81 8 1
## 94 9 24 13.8 81 8 2
## 95 16 77 7.4 82 8 3
## 96 78 NA 6.9 86 8 4
## 97 35 NA 7.4 85 8 5
## 98 66 NA 4.6 87 8 6
## 99 122 255 4.0 89 8 7
## 100 89 229 10.3 90 8 8
## 101 110 207 8.0 90 8 9
## 102 NA 222 8.6 92 8 10
## 103 NA 137 11.5 86 8 11
## 104 44 192 11.5 86 8 12
## 105 28 273 11.5 82 8 13
## 106 65 157 9.7 80 8 14
## 107 NA 64 11.5 79 8 15
## 108 22 71 10.3 77 8 16
## 109 59 51 6.3 79 8 17
## 110 23 115 7.4 76 8 18
## 111 31 244 10.9 78 8 19
## 112 44 190 10.3 78 8 20
## 113 21 259 15.5 77 8 21
## 114 9 36 14.3 72 8 22
## 115 NA 255 12.6 75 8 23
## 116 45 212 9.7 79 8 24
## 117 168 238 3.4 81 8 25
## 118 73 215 8.0 86 8 26
## 119 NA 153 5.7 88 8 27
## 120 76 203 9.7 97 8 28
## 121 118 225 2.3 94 8 29
## 122 84 237 6.3 96 8 30
## 123 85 188 6.3 94 8 31
## 124 96 167 6.9 91 9 1
## 125 78 197 5.1 92 9 2
## 126 73 183 2.8 93 9 3
## 127 91 189 4.6 93 9 4
## 128 47 95 7.4 87 9 5
## 129 32 92 15.5 84 9 6
## 130 20 252 10.9 80 9 7
## 131 23 220 10.3 78 9 8
## 132 21 230 10.9 75 9 9
## 133 24 259 9.7 73 9 10
## 134 44 236 14.9 81 9 11
## 135 21 259 15.5 76 9 12
## 136 28 238 6.3 77 9 13
## 137 9 24 10.9 71 9 14
## 138 13 112 11.5 71 9 15
## 139 46 237 6.9 78 9 16
## 140 18 224 13.8 67 9 17
## 141 13 27 10.3 76 9 18
## 142 24 238 10.3 68 9 19
## 143 16 201 8.0 82 9 20
## 144 13 238 12.6 64 9 21
## 145 23 14 9.2 71 9 22
## 146 36 139 10.3 81 9 23
## 147 7 49 10.3 69 9 24
## 148 14 20 16.6 63 9 25
## 149 30 193 6.9 70 9 26
## 150 NA 145 13.2 77 9 27
## 151 14 191 14.3 75 9 28
## 152 18 131 8.0 76 9 29
## 153 20 223 11.5 68 9 30## Ozone Solar.R Wind Temp
## Min. : 1.00 Min. : 7.0 Min. : 1.700 Min. :56.00
## 1st Qu.: 18.00 1st Qu.:115.8 1st Qu.: 7.400 1st Qu.:72.00
## Median : 31.50 Median :205.0 Median : 9.700 Median :79.00
## Mean : 42.13 Mean :185.9 Mean : 9.958 Mean :77.88
## 3rd Qu.: 63.25 3rd Qu.:258.8 3rd Qu.:11.500 3rd Qu.:85.00
## Max. :168.00 Max. :334.0 Max. :20.700 Max. :97.00
## NA's :37 NA's :7
## Month Day
## Min. :5.000 Min. : 1.0
## 1st Qu.:6.000 1st Qu.: 8.0
## Median :7.000 Median :16.0
## Mean :6.993 Mean :15.8
## 3rd Qu.:8.000 3rd Qu.:23.0
## Max. :9.000 Max. :31.0
## Ejercicio 2. Para el banco de datos Puromycin descrito en la Unidad 1, define tres situaciones que requieran un procedimiento inferencial y obtén los resultados de dichos análisis.
El banco de datos de Puromycin contiene 23 mediciones sobre la velocidad de reacción enzimática frente a la concentración de sustrato para células tratadas o no tratadas con Puromicina. Las variables registradas son:
- conc: Concentración de sustrato en partes por millón (ppm).
- rate: Velocidad instántanea de reacción (recuentos/min/min).
- state: Estado (Tratatado o no tratado con Puromicina.
## conc rate state
## 1 0.02 76 treated
## 2 0.02 47 treated
## 3 0.06 97 treated
## 4 0.06 107 treated
## 5 0.11 123 treated
## 6 0.11 139 treated
## 7 0.22 159 treated
## 8 0.22 152 treated
## 9 0.56 191 treated
## 10 0.56 201 treated
## 11 1.10 207 treated
## 12 1.10 200 treated
## 13 0.02 67 untreated
## 14 0.02 51 untreated
## 15 0.06 84 untreated
## 16 0.06 86 untreated
## 17 0.11 98 untreated
## 18 0.11 115 untreated
## 19 0.22 131 untreated
## 20 0.22 124 untreated
## 21 0.56 144 untreated
## 22 0.56 158 untreated
## 23 1.10 160 untreated## conc rate state
## Min. :0.0200 Min. : 47.0 treated :12
## 1st Qu.:0.0600 1st Qu.: 91.5 untreated:11
## Median :0.1100 Median :124.0
## Mean :0.3122 Mean :126.8
## 3rd Qu.:0.5600 3rd Qu.:158.5
## Max. :1.1000 Max. :207.0Ejercicio 3. Para el banco de datos NCBIRTH800 descrito en la Unidad 1, define tres situaciones que requieran un procedimiento inferencial y obtén los resultados de dichos análisis.
El banco de datos presenta la información referida al nacimiento y mortalidad infantil de 800 niños nacidos en el estado de Carolina del Norte. Las variables consideradas en el estudio son:
- plural: Número de hijos nacidos del embarazo.
- sex: Sexo del bebe.
- mage: Edad de la madre.
- weeks: Semanas completas de gestación.
- marital: Estado matrimonial (“married”=1; “not married”=2).
- racemom: Raza de la madre (“other non white”=0,“White”=1,“Black”=2,“America indian”=3,“Chinese”=4,“Hawaiian”=5,“Filipino”=6,“Other asian”=7).
- hispmom: Madre de origen hispánico (“Cuban”=C,“Mexican”=M,“Non-Hispanic”=N,“Other”=O,“Puerto Rican”=P,“Central/South american”=S,“Not classificable”=U).
- gained: Peso ganado durante el embarazo (en libras).
- smoke: Madre fumadora (“Yes”=1,“No”=0).
- drink: Madre bebedora (“Yes”=1,“No”=0).
- tounces: Peso del bebe (en onzas).
- tgrams: Peso del bebe (en gramos).
- low: Bebe de poco peso (“Yes”=1,“No”=0).
- premie: Bebe prematuro (“Yes”=1,“No”=0).
## plural sex mage weeks marital
## Min. :1.000 male :418 Min. :15.00 Min. :22.00 married :537
## 1st Qu.:1.000 female:382 1st Qu.:22.00 1st Qu.:38.00 not married:263
## Median :1.000 Median :26.00 Median :39.00
## Mean :1.032 Mean :26.91 Mean :38.61
## 3rd Qu.:1.000 3rd Qu.:32.00 3rd Qu.:40.00
## Max. :2.000 Max. :42.00 Max. :45.00
## NA's :1
## racemom hispmom gained smoke
## White :604 Cuban : 2 Min. : 0.00 No :684
## Black :169 Mexican : 55 1st Qu.:20.00 Yes :114
## America indian: 12 Non-Hispanic :718 Median :30.00 NA's: 2
## Chinese : 2 Other : 2 Mean :30.58
## Other asian : 1 Puerto Rican : 7 3rd Qu.:40.00
## Other : 12 Central/South american: 16 Max. :95.00
## NA's :23
## drink tounces tgrams low premie
## No :794 Min. : 12.0 Min. : 340.2 No :730 No :707
## Yes : 4 1st Qu.:106.0 1st Qu.:3005.1 Yes: 70 Yes: 93
## NA's: 2 Median :118.0 Median :3345.3
## Mean :116.4 Mean :3299.3
## 3rd Qu.:130.0 3rd Qu.:3685.5
## Max. :169.0 Max. :4791.1
## Ejercicio 4. Para el banco de datos PCKDATA descrito en la Unidad 1, define tres situaciones que requieran un procedimiento inferencial y obtén los resultados de dichos análisis.
Los datos corresponden a las mediciones de las niveles de la creatina fosfoquinasa para dos grupos de sujetos. En total hay 2010 sujetos y las variables consideradas en el estudio son:
- SUBJ: Sujeto.
- Grupo: Grupo al que se encuentra asignado cada sujeto del estudio (“A” o “B”).
- cretine: Nivel de creatinina para cada sujeto.
## SUBJ Grupo creatine
## Min. : 1 Length:2010 Min. : 13.0
## 1st Qu.: 252 Class :character 1st Qu.:114.0
## Median : 503 Mode :character Median :143.0
## Mean : 503 Mean :143.8
## 3rd Qu.: 754 3rd Qu.:175.0
## Max. :1005 Max. :334.0Javier Morales, email: j.morales@.umh.es.
Mª Asunción Martínez, email: am.mayoral@umh.es.