3 Практична частина. Робота з даними
3.1 Про дані в цій книзі
У цій книзі ми будемо використовувати дані моніторингу забруднення атмосферного повітря в місті Кривий Ріг Дніпропетровської області (Україна). У Кривому Розі працює декілька незалежних мереж моніторингу. Ми будемо використовувати дані з двох мереж: мережа спостережних постів Гідрометеоцентру України та мережа автоматизованих спостережних постів ПАТ «АрселорМіттал Кривий Ріг». Від Гідрометеоцентру України в Кривому Розі працює 5 постів. Мережа «АрселорМіттал Кривий Ріг» представлена трьома автоматизованими постами. Розташування постів на місцевості показано на схемі. Фоновим рисунком для схеми є знімок космічного апарату Sentinel-2A від 5 квітня 2016 року. На знімку добре видно як дим від криворізьких заводів поширюється над житловими районами Кривого Рогу.
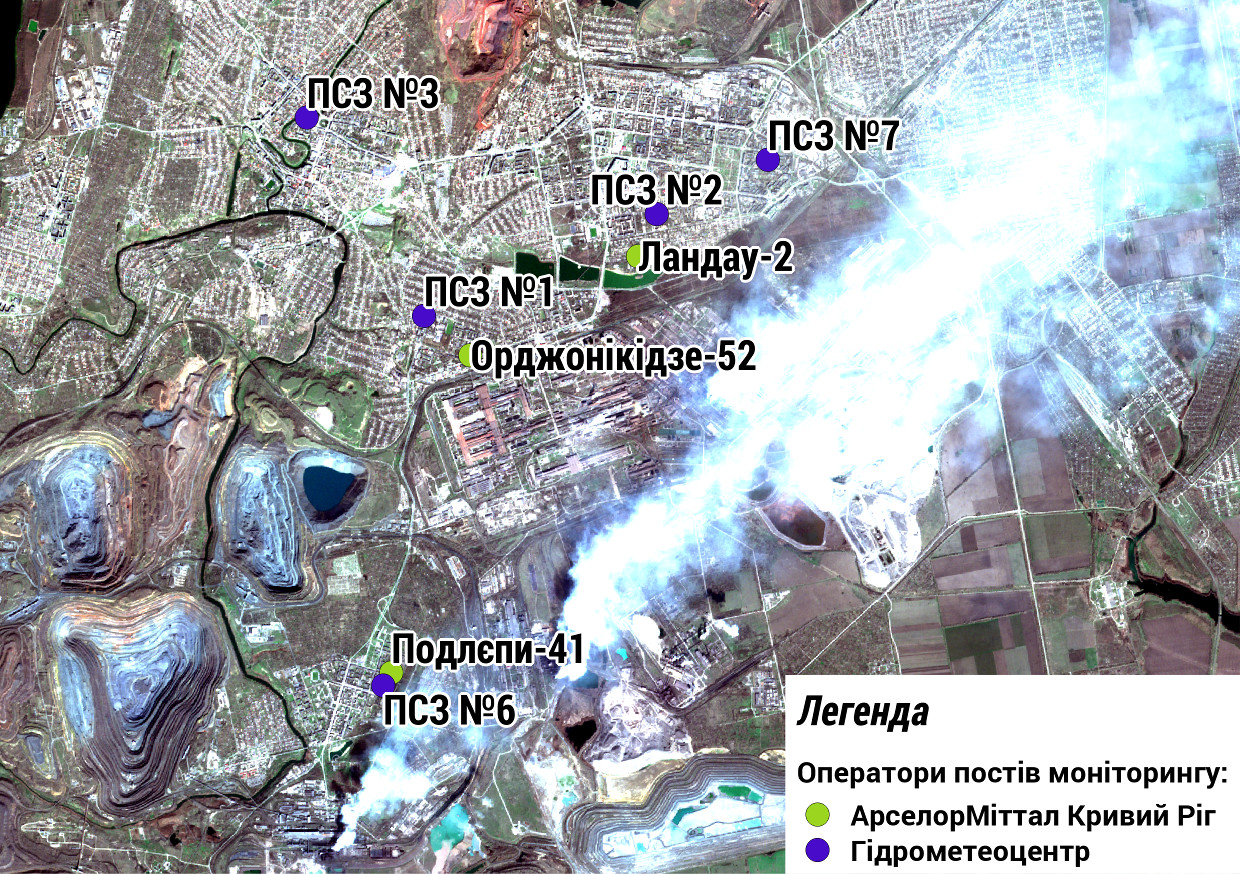
Figure 3.1: Схема розташування постів моніторингу забруднення повітря в Кривому Розі
Спостережні пости Гідрометеоцентру являють собою напівавтоматизовані агрегати. Вимірювання концентрацій забруднюючих речовин здійснюється 2-4 рази на добу. Відібране повітря аналізується в лабораторії. Первинні дані раз на місяць передаються до центрального обчислювального центру (м.Київ) у закодованому вигляді. Файл з даними, які ми будемо використовувати, називається air_pollution.csv і містить результати спостережень упродовж січня — серпня 2016 року.

Figure 3.2: Загальний вигляд спостережного посту Гідрометеоцентру
Кожна проба повітря відбирається протягом 20 хвилин. Тобто проба, відібрана о 7:00 буде характеризувати концентрації забрудників о 6:40-7:00. В подальшому ми будемо оперувати тільки часом закінчення відбору проби, передбачаючи що протягом 20 хвилин суттєвих змін у складі повітря не відбувалось. Таке спрощення дозволить нам поєднувати дані моніторингу з метеорологічними даними «напряму», уникаючи при цьому перетворення первинних даних.
Таблиця із даними Гідрометеоцентру містить наступні поля:
date.proba — дата відбору проби повітря
time.proba — час відбору проби повітря
name — назва спостережного посту
TSP — концентрація пилу (суспендовані тверді частки), мг/м³ (вимірюється на постах «ПСЗ-2», «ПСЗ-6», «ПСЗ-7»)
SO2 — концентрація діоксиду сірки, мг/м³
CO — концентрація монооксиду вуглецю, мг/м³
NO2 — концентрація діоксиду азоту, мг/м³
NO — концентрація монооксиду азоту (вимірюється тільки на пості «ПСЗ-3»), мг/м³
H2S — концентрація сірководню, мг/м³
C6H6O — концентрація фенолу, мг/м³
NH3 — концентрація аміаку, мг/м³
CH2O — концентрація формальдегіду, мг/м³
Для завантаження файлу з даними Гідрометеоцентру в робоче середовище мови R слід використати команду:
#Завантажуємо файл air_poolution.csv:
air_pollution <- read.csv("air_pollution.csv", header = TRUE, sep = ";", dec = ",")Таблиця з даними Гідрометеоцентру містить 12 полів та 3609 записів.
#Виводимо на екран структуру таблиці air_pollution.
#Примусово викликаємо функцію glimpse із пакету dplyr
dplyr::glimpse(air_pollution)## Observations: 3,609
## Variables: 12
## $ date.proba <fct> 2016-01-02, 2016-01-02, 2016-01-02, 2016-01-04, 2016-…
## $ time.proba <fct> 07:00, 13:00, 19:00, 07:00, 13:00, 19:00, 01:00, 07:0…
## $ name <fct> ПСЗ-1, ПСЗ-1, ПСЗ-1, ПСЗ-1, ПСЗ-1, ПСЗ-1, ПСЗ-1, ПСЗ-…
## $ TSP <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ SO2 <dbl> 0.023, NA, 0.031, 0.025, NA, 0.029, NA, 0.028, NA, 0.…
## $ CO <int> 1, NA, 1, 4, NA, 3, NA, 2, NA, 2, NA, 1, 1, NA, 2, NA…
## $ NO2 <dbl> 0.03, NA, 0.03, 0.03, NA, 0.09, NA, 0.07, NA, 0.05, N…
## $ NO <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ H2S <dbl> 0.000, 0.001, 0.001, 0.001, 0.002, 0.002, 0.000, 0.00…
## $ C6H6O <dbl> 0.000, 0.000, 0.001, 0.001, 0.001, 0.001, 0.000, 0.00…
## $ NH3 <dbl> 0.00, 0.01, 0.01, 0.02, 0.02, 0.02, 0.01, 0.02, 0.02,…
## $ CH2O <dbl> 0.002, NA, 0.003, 0.005, NA, 0.008, NA, 0.003, NA, 0.…Як бачимо з виводу таблиці на екран — поля date.proba, time.proba та name належать до класу «фактор» (<fctr> — factor). Поле CO належить до класу цілих чисел (<int> — integer). Воно так розпізналось через те, що концентрації монооксиду вуглецю вказани тільки цілими числами. Всі інші поля належать до класу числових (<dbl> — double).
Дані автоматизованого моніторингу забруднення повітря представлено даними, отриманими на трьох спостережних постах ПАТ «АрселорМіттал Кривий Ріг». Ці дані містяться в трьох окремих файлах. Це файли під назвами Ordzh52.csv, Landau2a.csv та Podlepy41.csv. У цих файлах міститься інформація про концентрації забруднюючих речовин упродовж 1 січня 2015 року — 22 вересня 2015 року.

Figure 3.3: Загальний вигляд автоматизованого спостережного посту
За нормального режиму роботи вимірювання виконуються кожні 20 хвилин. Проте, іноді трапляються збої в роботі обладнання або в мережі передачі даних. Через це дані автоматизованого моніторингу містять пропущені значення. Складності до структури даних додає методика запису в базу даних. Справа у тому, що кожен із трьох автоматизованих постів складається з двох окремих систем. Це система вимірювання концентрацій газоподібних речовин та система вимірювання метеорологічних параметрів та концентрацій пилу. При цьому вимірювання метеорологічних параметрів здійснюється кожні 10 хвилин. Кожна з цих двох систем надсилає дані окремо. Як результат — вимірювання, які виконано в однакові проміжки часу записуються до бази даних окремими рядками. Але існує ще одна проблема! Справа у тому, що через збої обладнання зміщуються часові інтервали вимірювань. Як наслідок — вимірювання «кожні 20 хвилин» будуть не обов’язково у 00-20-40 хвилин кожної години. Вони можуть виконуватись, наприклад, у 13-33-53 хвилини або у 07-27-47 хвилин. Це призводить до того, що у нас зміщуються всі вимірювання і в такому великому масиві даних ми втрачаємо можливість адекватного поєднання та порівняння даних. Щоб уникнути цієї проблеми можна фактичні інтервали вимірювань «округляти» до найближчого інтервалу 00, 20 або 40 хвилин. При цьому ми приймаємо тезу, що в ці хвилини, на які ми зміщуємо фактичний час вимірювання, у довкіллі суттєвих змін не відбувалось.
Таблиці з даними ПАТ «АрселорМіттал Кривий Ріг» містять наступні поля:
name — назва спостережного посту
date.time — дата та час вимірювання
NO2 — концентрація діоксиду азоту, мг/м³
NO — концентрація монооксиду азоту, мг/м³
SO2 — концентрація діоксиду сірки, мг/м³
CO — концентрація монооксиду вуглецю, мг/м³
NH3 — концентрація аміаку, мг/м³ (вимірюється лише на посту «Ландау-2»)
H2S — концентрація сірководню, мг/м³ (вимірюється лише на посту «Ландау-2»)
ws.post — швидкість вітру в місці розташування посту, м/с
wd.post — напрям вітру в місці розташування посту (звідки дме), градуси
temp.post — температура в місці розташування посту, °C
rh.post — відносна вологість повітря в місці розташування посту, %
press.post — атмосферний тиск у місці розташування посту, мм.рт.ст.
TSP — концентрація пилу (суспендовані тверді частки), мг/м³
Для того, щоб завантажити файли з даними ПАТ «АрселорМіттал Кривий Ріг», слід виконати команди:
#Завантажуємо файл Ordzh52.csv:
Ordzh52 <- read.csv("Ordzh52.csv", header = TRUE, sep = ";", dec = ",")
#Завантажуємо файл Landau2a.csv
Landau2a <- read.csv("Landau2a.csv", header = TRUE, sep = ";", dec = ",")
#Завантажуємо файл
Podlepy41 <- read.csv("Podlepy41.csv", header = TRUE, sep = ";", dec = ",")Розміри таблиць з даними автоматизованого моніторингу наступні:
Ordzh52 - 14 полів та 57481 записів
Landau2a - 14 полів та 61653 записів
Podlepy41 - 14 полів та 47686 записів
Структура всіх трьох таблиць однакова. Єдине, що треба зауважити — для таблиць Ordzh52 та Podlepy41 в полях «аміак» (NH3) та «сірководень» (H2S) будуть лише порожні значення (NA), оскільки на цих двох постах ці речовини не вимірюються.
#Виводимо на екран структуру таблиці Landau2a.
#Примусово викликаємо функцію glimpse із пакету dplyr
dplyr::glimpse(Landau2a)## Observations: 61,653
## Variables: 14
## $ name <fct> Ландау-2, Ландау-2, Ландау-2, Ландау-2, Ландау-2, Лан…
## $ date.time <fct> 01/01/2015 00:00:00, 01/01/2015 00:00:00, 01/01/2015 …
## $ NO2 <dbl> 0, NA, NA, 0, NA, 0, NA, NA, NA, NA, 0, NA, NA, 0, NA…
## $ NO <int> 0, NA, NA, 0, NA, 0, NA, NA, NA, NA, 0, NA, NA, 0, NA…
## $ SO2 <dbl> 0.07, NA, NA, 0.07, NA, 0.07, NA, NA, NA, NA, 0.07, N…
## $ CO <dbl> 0, NA, NA, 0, NA, 0, NA, NA, NA, NA, 0, NA, NA, 0, NA…
## $ NH3 <dbl> 0, NA, NA, 0, NA, 0, NA, NA, NA, NA, 0, NA, NA, 0, NA…
## $ H2S <dbl> 0, NA, NA, 0, NA, 0, NA, NA, NA, NA, 0, NA, NA, 0, NA…
## $ ws.post <dbl> NA, 0.5, 0.7, 0.5, 0.5, NA, 0.5, 0.6, 0.8, 0.6, NA, 0…
## $ wd.post <int> NA, 227, 243, 225, 223, NA, 224, 249, 260, 252, NA, 2…
## $ temp.post <dbl> NA, -16.5, -16.4, -16.3, -16.5, NA, -16.5, -16.6, -16…
## $ rh.post <int> NA, 74, 73, 74, 73, NA, 72, 72, 73, 75, NA, 75, 73, N…
## $ press.post <dbl> NA, 764.9, 764.9, 764.8, 764.7, NA, 764.6, 764.5, 764…
## $ TSP <dbl> 0.459, NA, NA, 0.409, NA, 0.463, NA, NA, NA, NA, 0.45…В таблицях Ordzh52, Landau2a та Podlepy41 поля name та date.time належать до класу «фактор» (<fctr> — factor). Всі інші поля є числовими і належать до класів цілих чисел (<int> — integer) та десяткових дробів (<dbl> — double). Зверніть увагу на те, що в записах таблиці дублюється час вимірювань: два записи за 01/01/2015 00:00:00, два записи за 01/01/2015 00:40:00. Це пов’язано із тим, що кожен із автоматизованих постів має дві подсистеми вимірювань: окремо вимірюються концентрації газоподібних забруднюючих речовин, окремо — меторологічні параметри та концентрації пилу. Тим більше — в той час як концентрації газоподібних забруднюючих речовин та пилу вимірюються кожні 20 хвилин, метеорологічні параметри вимірюються кожні 10 хвилин. Як привести такі вимірювання до єдиної позначки часу ми розглянемо в розділі 3.5.3.
3.2 Звіримо годинники!
Все програмне забезпечення, яке розглядається у цій книзі, є вільним кросплатформним програмним забезпеченням. Усі ці програми будуть працювати й в середовищі операційної системи Linux, й в середовищі Windows, й у FreeBSD і в інших системах… Проте, правилами гарного тону вважається наведення відомостей — в якій конкретно системі працює автор та яку версію програмного забезпечення він використовує. Щоб подивитись параметри власного комп’ютера та версію мови програмування R слід використати функцію sessionInfo.
## R version 3.6.1 (2019-07-05)
## Platform: x86_64-pc-linux-gnu (64-bit)
## Running under: Debian GNU/Linux 10 (buster)
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/atlas/libblas.so.3.10.3
## LAPACK: /usr/lib/x86_64-linux-gnu/atlas/liblapack.so.3.10.3
##
## Random number generation:
## RNG: Mersenne-Twister
## Normal: Inversion
## Sample: Rounding
##
## locale:
## [1] LC_CTYPE=uk_UA.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=uk_UA.UTF-8 LC_COLLATE=uk_UA.UTF-8
## [5] LC_MONETARY=uk_UA.UTF-8 LC_MESSAGES=uk_UA.UTF-8
## [7] LC_PAPER=uk_UA.UTF-8 LC_NAME=C
## [9] LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=uk_UA.UTF-8 LC_IDENTIFICATION=C
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] dplyr_0.8.3 stationaRy_0.4.1
##
## loaded via a namespace (and not attached):
## [1] progress_1.2.2 tidyselect_0.2.5 xfun_0.8
## [4] purrr_0.3.2 colorspace_1.4-1 vctrs_0.2.0
## [7] htmltools_0.3.6 yaml_2.2.0 utf8_1.1.4
## [10] rlang_0.4.0 pillar_1.4.2 later_0.8.0
## [13] glue_1.3.1 ggcorrplot_0.1.3 plyr_1.8.4
## [16] stringr_1.4.0 munsell_0.5.0 gtable_0.3.0
## [19] htmlwidgets_1.3 evaluate_0.14 knitr_1.23
## [22] httpuv_1.5.1 crosstalk_1.0.0 fansi_0.4.0
## [25] highr_0.8 Rcpp_1.0.2 xtable_1.8-4
## [28] readr_1.3.1 scales_1.0.0 backports_1.1.4
## [31] promises_1.0.1 leaflet_2.0.2 mime_0.7
## [34] ggplot2_3.2.0 hms_0.5.0 png_0.1-7
## [37] digest_0.6.20 stringi_1.4.3 bookdown_0.12
## [40] shiny_1.3.2 grid_3.6.1 cli_1.1.0
## [43] tools_3.6.1 magrittr_1.5 lazyeval_0.2.2
## [46] tibble_2.1.3 crayon_1.3.4 tidyr_0.8.3
## [49] pkgconfig_2.0.2 zeallot_0.1.0 downloader_0.4
## [52] prettyunits_1.0.2 lubridate_1.7.4 assertthat_0.2.1
## [55] rmarkdown_1.14 rstudioapi_0.10 R6_2.4.0
## [58] compiler_3.6.1Як зрозуміло з відповіді функції sessionInfo — автор працює на комп’ютері зі встановленою операційною системою Debian GNU/Linux 10 (buster) та використовує мову програмування R версії 3: R version 3.6.1 (2019-07-05).
Функція sessionInfo також виводить інформацію про локалізацію операційної системи: uk_UA.UTF-8 і про завантажені в поточній сесії додаткові пакети.
Стосовно інтегрованого середовища розробки RStudio — використовується RStudio версії 1.2.1335.
Іще перевіремо — які гарнітури у мене встановлено в системній директорії мови R. Для цього використаємо команду fonts пакету extrafont. Щоб не занімати багато місця, подивимось тільки перші 10 встановлених гарнітур.
## [1] "Amiri" "Amiri Quran"
## [3] "Amiri Quran Colored" "Arimo"
## [5] "Baekmuk Batang" "Baekmuk Dotum"
## [7] "Baekmuk Gulim" "Baekmuk Headline"
## [9] "Bitstream Vera Sans" "Bitstream Vera Sans Mono"Загалом, у мене для роботи R встановлено 290 гарнітур, які можна використовувати при створенні графічних матеріалів беспосередньо засобами мови R.
3.3 Підготовка даних моніторингу
3.4 Отримання метеорологічних даних
У розділах 1.2.1 та 2.2 було коротко розглянуто пакет stationaRy та можливості отримання даних метеорологічних спостережень. Зараз ми, нарешті, приступаємо до практичної частини — отримання метеорологічних даних з бази даних Агенції атмосферних та океанічних досліджень США NOAA. Сподіваюсь — ви не забули встановити та запустити пакет stationaRy?
Також нам знадобиться пакет dplyr. Ми будемо використовувати функцію filter із цього пакету і так званий «тунельний інтерфейс» (pipeline). Що це за інтерфейс ми розглядали в розділі 1.2.2.
У таблиці @ref(ukrstations.table) розділу 2.2 ми перелічили всі доступні в базі даних NOAA українські метеостанції. Свій вибір ми зупинили на метеостанції (точніше — на масиві даних) під назвою «LOZUVATKA INTL». Це метеорологічні спостереження для цивільної авіації. Якщо вам треба ознайомитись з усіма доступними в базі NOAA масивами даних, ви можете використати наступну команду, яка отримає з сервера перелік всіх доступних масивів даних та збереже його у вигляді таблиці met_stations безпосередньо в R:
Ми можемо зберігти таблицю met_stations в окремий файл, наприклад формату CSV:
Якщо ви хочете одразу вибрати лише українські метеостанції, то вам треба відфільтрувати загальний перелік за полем country_name:
У випадку коли ви не знаєте як може називатись найближча до вас метеостанція — можна відфільтрувати метеостанції в межах конкретних географічних координат. Для цього слід задати фільтрування в географічних координатах
## # A tibble: 11 x 16
## usaf wban name country state lat lon elev begin end
## <dbl> <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 330003 99999 LOZU… UP "" 48.0 33.2 124. 2004 2015
## 2 330004 99999 DNIP… UP "" 48.4 35.1 147. 2004 2015
## 3 335980 99999 NOVO… UP "" 48.8 31.6 179 1959 2015
## 4 336090 99999 ZNAM… UP "" 48.7 32.7 181 1959 2015
## 5 337110 99999 KIRO… UP "" 48.5 32.2 171 1936 2015
## 6 337170 99999 BOBR… UP "" 48.1 32.2 143 1959 2015
## 7 337230 99999 KOMI… UP "" 48.4 33.9 118 1959 2015
## 8 337910 99999 KRYV… UP "" 48.0 33.2 124 1948 2015
## 9 344070 99999 HUBY… UP "" 48.8 35.2 127 1959 2015
## 10 345000 99999 P0DG… UP "" 48.6 35.0 61 1957 1963
## 11 345040 99999 DNIP… UP "" 48.6 35.0 143 1932 2015
## # … with 6 more variables: gmt_offset <dbl>, time_zone_id <chr>,
## # country_name <chr>, country_code <chr>, iso3166_2_subd <chr>,
## # fips10_4_subd <chr>У заданих координатах знаходяться 11 метеорологічних станцій, дані з яких доступні в базі даних NOAA. Із цих станцій працюють всі окрім метеостанції в місті Підгородне Дніпропетровської області (P0DGORODNOYE). Для цієї метеостанції доступні дані лише за 1957-1963 рр.
Тепер можна приступати безпосередньо до отримання даних. В цьому процесі є невеличка незручність. Справа у тому, що дані формату METAR передаються із позначкою часу UTC (всесвітній координований час). Але різниця часу між UTC та місцевим часом в Україні становить 2 години взимку і 3 години влітку. І коли ми будемо вибирати дані, наприклад, за 2016 рік, то фактично ми отримаємо таблицю в якій будуть відсутні 4 спостереження за 1 січня, натомість будуть зайві (для місцевого часу) спостереження 31 грудня. Щоб уникнути цього — доведеться вказати діапазон із запасом «на рік назад» і завантажувати дані за два роки: 2015 та 2016.
Отримання метеорологічних даних з бази даних NOAA і збереження в окрему таблицю здійснюється за допомогою набору команд:
#отримуємо повний перелік метеостанцій:
get_isd_stations() %>%
#вибираємо метеостанцію «LOZUVATKA INTL»:
select_isd_station(name = "LOZUVATKA INTL") %>%
#записуємо отримані дані в таблицю KrR_meteo:
get_isd_station_data(startyear = 2015, endyear = 2016) -> KrR_meteoМи отримали таблицю KrR_meteo, в якій містяться всі повідомлення формату METAR від метеостанції «Кривий Ріг» за 2015 та 2016 роки. Ну, точніше, не зовсім всі: за місцевим часом відсутні повідомлення за перші 2 години 2015 року проте присутні зайві повідомлення за перші дві години 2017 року… Таблиця містить 18 полів та 36460 записів!
Давайте розглянемо — які метеорологічні дані ми отримали:
## Observations: 36,460
## Variables: 18
## $ usaf <chr> "330003", "330003", "330003", "330003", "330003", "33…
## $ wban <chr> "99999", "99999", "99999", "99999", "99999", "99999",…
## $ year <dbl> 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015,…
## $ month <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
## $ day <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
## $ hour <dbl> 0, 0, 1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8,…
## $ minute <dbl> 0, 30, 0, 30, 0, 30, 0, 30, 0, 30, 0, 30, 0, 30, 0, 3…
## $ lat <dbl> 48.043, 48.043, 48.043, 48.043, 48.043, 48.043, 48.04…
## $ lon <dbl> 33.21, 33.21, 33.21, 33.21, 33.21, 33.21, 33.21, 33.2…
## $ elev <dbl> 124, 124, 124, 124, 124, 124, 124, 124, 124, 124, 124…
## $ wd <dbl> NA, NA, 270, 250, 250, 220, 220, 220, 220, 230, 240, …
## $ ws <dbl> 0, 0, 2, 2, 2, 2, 2, 3, 3, 2, 2, 2, 2, 2, 2, 3, 2, 2,…
## $ ceil_hgt <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ temp <dbl> -18, -18, -18, -18, -18, -18, -20, -20, -20, -20, -20…
## $ dew_point <dbl> -20, -20, -20, -20, -20, -20, -22, -22, -22, -22, -21…
## $ atmos_pres <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ rh <dbl> 84.3, 84.3, 84.3, 84.3, 84.3, 84.3, 84.0, 84.0, 84.0,…
## $ time <dttm> 2015-01-01 00:00:00, 2015-01-01 00:30:00, 2015-01-01…Ми примусово викликали функцію glimpse пакету dplyr і таблиця KrR_meteo розпізнається як об’єкт tibble. Без завантаженого dplyr вона буде розпізнаватись як звичайний data.frame. Таблиця складається переважно з числових полів (<dbl> — double). Лише два перші поля — символьні (<chr> — character) і останнє поле дата-час у форматі POSIXct (<dttm> — date-time).
Бажано перевірити отриману таблицю на наповненість даними, щоб мати загальну уяву про показники в таблиці. Найпростіший варіант — використати функцію summary:
## usaf wban year month
## Length:36460 Length:36460 Min. :2015 Min. : 1.000
## Class :character Class :character 1st Qu.:2015 1st Qu.: 4.000
## Mode :character Mode :character Median :2015 Median : 7.000
## Mean :2015 Mean : 6.524
## 3rd Qu.:2016 3rd Qu.:10.000
## Max. :2016 Max. :12.000
##
## day hour minute lat
## Min. : 1.00 Min. : 0.00 Min. : 0.00 Min. :48.04
## 1st Qu.: 8.00 1st Qu.: 6.00 1st Qu.: 0.00 1st Qu.:48.04
## Median :16.00 Median :12.00 Median :26.00 Median :48.04
## Mean :15.76 Mean :11.51 Mean :15.59 Mean :48.04
## 3rd Qu.:23.00 3rd Qu.:17.00 3rd Qu.:30.00 3rd Qu.:48.04
## Max. :31.00 Max. :23.00 Max. :58.00 Max. :48.04
##
## lon elev wd ws
## Min. :33.21 Min. :124 Min. : 10.0 Min. : 0.000
## 1st Qu.:33.21 1st Qu.:124 1st Qu.: 70.0 1st Qu.: 2.000
## Median :33.21 Median :124 Median :190.0 Median : 4.000
## Mean :33.21 Mean :124 Mean :181.2 Mean : 3.837
## 3rd Qu.:33.21 3rd Qu.:124 3rd Qu.:290.0 3rd Qu.: 5.000
## Max. :33.21 Max. :124 Max. :360.0 Max. :16.000
## NA's :4970 NA's :7
## ceil_hgt temp dew_point atmos_pres
## Min. : 30 Min. :-24.00 Min. :-25.00 Min. : NA
## 1st Qu.: 244 1st Qu.: 2.00 1st Qu.: -1.00 1st Qu.: NA
## Median : 610 Median : 9.00 Median : 4.00 Median : NA
## Mean : 1908 Mean : 10.19 Mean : 4.09 Mean :NaN
## 3rd Qu.: 3048 3rd Qu.: 19.00 3rd Qu.: 10.00 3rd Qu.: NA
## Max. :22000 Max. : 37.00 Max. : 22.00 Max. : NA
## NA's :20465 NA's :5 NA's :5 NA's :36460
## rh time
## Min. : 16.4 Min. :2015-01-01 00:00:00
## 1st Qu.: 54.6 1st Qu.:2015-06-25 20:22:30
## Median : 74.8 Median :2015-12-29 03:15:00
## Mean : 70.3 Mean :2015-12-31 01:31:16
## 3rd Qu.: 86.8 3rd Qu.:2016-07-06 00:37:30
## Max. :100.0 Max. :2016-12-31 23:30:00
## NA's :5Тепер розглянемо що власне означають поля таблиці. Перші два поля usaf та wban — це індексація масиву даних «LOZUVATKA INTL» в загальній базі даних NOAA. Ці два поля нас зовсім не цікавлять. Стосовно дати та часу — не забувайте, що в повідомленнях METAR позначка часу ставиться у форматі UTC! Із усіх полів таблиці для нас важливі поля метеорологічних параметрів та останнє поле дати-часу. Метеорологічні параметри в таблиці наступні:
wd — напрям вітру, градуси (звідки дме!)
ws — швидкість вітру, м/с
ceil_hgt — висота нижньої границі хмарності, м
temp — температура повітря, °C
dew_point — точка роси, °C
atmos_pres — атмосферний тиск приведений до рівня моря, гПа
rh — відносна вологість повітря, %
В отриманій таблиці не вистачає дуже важливого параметру — атмосферного тиску. Поле «атмосферний тиск» в таблиці є (atmos_pres), але воно порожнє. Справа в тому, що окрім основного масиву даних існують також додаткові. В цих додаткових масивах міститься ще дуже багато інформації, зокрема — типи метеорологічних ситуацій під час спостережень. Ознайомитись зі структурою даних, які зберігаються на ресурсах NOAA можна за документом Національного центру кліматичних даних США (Fleet Numerical Meteorology and Oceanography Detachment 2015). Більш стистено інформація про додаткові масиви даних міститься на сторінці GitHub автора пакету stationaRy. Загалом у переліку фігурують 86 масивів даних, із яких можна завантажити 489 додаткових параметрів, включаючи параметри якості самих даних. Різні метеорологічні станції надають різні додаткові масиви даних. Все залежіть від спеціалізації метеостанції: гірська, прибережна, розташована на рівніні та інше.
Дізнатись які саме додаткові масиви даних ще додаються до даних конкретної метеорологічної станції можна із використанням параметру add_data_report функції get_isd_station_data.
#отримуємо повний перелік метеостанцій:
get_isd_stations() %>%
#вибираємо метеостанцію «LOZUVATKA INTL»:
select_isd_station(name = "LOZUVATKA INTL") %>%
#вибираємо часовий проміжок метеорологічних даних:
get_isd_station_data(startyear = 2018, endyear = 2018,
#активуємо параметр add_data_report:
add_data_report = TRUE) -> KrR_meteo_dataДивимось наповнення таблиці KrR_meteo_data:
## category total_count
## 1 CT1 163
## 2 ED1 1212
## 3 GA1 17466
## 4 GF1 18421
## 5 MA1 37382
## 6 MW1 8366
## 7 OC1 551Як ми можемо бачити з таблиці KrR_meteo_data, до даних метеорологічної станції в Міжнародному аеропорту “Кривий Ріг” додаються 7 масивів метеорологічних даних. В полі total_count міститься інформація про кількість непорожніх значень для кожного з додаткових масивів даних.
Дані про атмосферний тиск містяться в додатковому масиві даних MA1. Щоб отримати таблицю зі значеннями атмосферного тиску — треба «замовити доставку» даних із цього додаткового масиву:
#отримуємо повний перелік метеостанцій:
get_isd_stations() %>%
#вибираємо метеостанцію «LOZUVATKA INTL»:
select_isd_station(name = "LOZUVATKA INTL") %>%
#вибираємо часовий проміжок метеорологічних даних:
get_isd_station_data(startyear = 2015, endyear = 2016,
#вказуємо додатковий масив, який треба приєднати:
select_additional_data = c("MA1")) -> KrR_meteo2Тепер у нас є таблиця KrR_meteo2. У порівнянні з попередньою таблицею, в цій додалось ще чотири поля: ma1_1, ma1_2, ma1_3 та ma1_4. Значення атмосферного тиску містяться у полі ma1_1.
Ми просто перепишем дані атмосферного тиску в поле atmos_pres і викинемо з таблиці непотрібні поля:
#заганяємо таблицю KrR_meteo2 в тунель
KrR_meteo2 %>%
#переписуємо дані з поля ma1_1 в поле atmos_pres
mutate(atmos_pres = ma1_1) %>%
#викидаємо непотрібні поля та записуємо результат
select(-c(usaf, wban, ceil_hgt, ma1_1,
ma1_2, ma1_3, ma1_4)) -> KrR_meteo2Але наші маніпуляції з метеорологічними даними ще не закінчились! Нам треба перевести час із часового поясу UTC у час за Києвом. А ще треба напрямок вітру із градусів перевести в румби.
Перевести час доволі просто:
#примусово задаємо даним часовий пояс UTC в новому полі
KrR_meteo2$time.UTC <- as.POSIXct(format(KrR_meteo2$time), tz = "UTC")
#створюємо нове поле та переводимо час
KrR_meteo2$time.Kiev <- as.POSIXct(format(KrR_meteo2$time.UTC,
tz = "Europe/Kiev", usetz = TRUE))Із напрямками вітру ситуація дещо складніша. Справа у тому, що окрім стійкого вітру певного напрямку можливі ще два типи «вітру» — слабкий вітер змінного напрямку та повний штиль. Щоб врахувати ці два типи нам необхідно оперувати не тільки показником «напрямок вітру», а й показником «швидкість вітру». Поєднання двох цих полів дає нам три варіанти метеорологічних умов:
стійкий вітер певного напрямку — швидкість вітру більше нуля і непорожнє значення напрямку вітру
вітер змінного напрямку — швидкість вітру більше нуля і порожнє значення напрямку вітру
повний штиль — швидкість вітру дорівнює нулю і порожнє значення напрямку вітру
Для напрямків вітру ми використаємо 16-рубмову схему. В результаті виконання нижченаведеного скрипту ми отримаємо в таблиці KrR_meteo2 поле DD.meteo.from. У цьому полі будуть міститись ранжовані за зростанням 16 румбів (за годинниковою стрілкою) та два додаткових параметри: вітер змінного напрямку (VRB) і повний штиль (CALM). Навіщо ми ранжували значення? — В подальшому при побудові графіків напрямки вітру будуть відображатись в порядку румбів, а не в алфавітному порядку.
tbl_df(KrR_meteo2) %>%
#присвоюємо "-1" порожнім значенням напрямку вітру:
mutate(wd = ifelse(is.na(wd), -1, wd)) %>%
#створюємо та обчислюємо поле DD.meteo.from
mutate(DD.meteo.from = ordered(
ifelse((wd >= 168.75 & wd < 191.25 & ws > 0),"S",
ifelse((wd >= 191.25 & wd < 213.75 & ws > 0),"SSW",
ifelse((wd >= 213.75 & wd < 236.25 & ws > 0),"SW",
ifelse((wd >= 236.25 & wd < 258.75 & ws > 0),"WSW",
ifelse((wd >= 258.75 & wd < 281.25 & ws > 0),"W",
ifelse((wd >= 281.25 & wd < 303.75 & ws > 0),"WNW",
ifelse((wd >= 303.75 & wd < 326.25 & ws > 0),"NW",
ifelse((wd >= 326.25 & wd < 348.75 & ws > 0),"NNW",
ifelse((wd >= 348.75 & wd <= 360 & ws > 0),"N",
ifelse((wd >= 0 & wd < 11.25 & ws > 0),"N",
ifelse((wd >= 11.25 & wd < 33.75 & ws > 0),"NNE",
ifelse((wd >= 33.75 & wd < 56.25 & ws > 0),"NE",
ifelse((wd >= 56.25 & wd < 78.75 & ws > 0),"ENE",
ifelse((wd >= 78.75 & wd < 101.25 & ws > 0),"E",
ifelse((wd >= 101.25 & wd < 123.75 & ws > 0),"ESE",
ifelse((wd >= 123.75 & wd < 146.25 & ws > 0),"SE",
ifelse((wd >= 146.25 & wd < 168.75 & ws > 0),"SSE",
ifelse((wd < 0 & ws > 0), "VRB", "CALM"
)))))))))))))))))), levels = c("N","NNE","NE",
"ENE","E","ESE","SE","SSE","S","SSW", "SW","WSW",
"W","WNW","NW","NNW", "VRB", "CALM"))) %>%
#повертаємо на місце порожні значення
mutate(wd = ifelse(wd == -1, NA, wd)) -> KrR_meteo2В принципі — все! Тепер у нас є готова для використання таблиця метеорологічних спостережень. В наступних розділах ми приєднаємо дані з цієї таблиці до даних моніторингу якості атмосферного повітря. Це надасть нам можливість аналізувати зв’язок погодних умов із показниками забруднення атмосферного повітря. Єдине, що слід додати — це те, що отримані метеорологічні дані не завадить перевірити. У мене було декілька випадків, коли через проблеми з інтернет-з’єднанням дані надходили не в повному обсязі: були пробіли від декількох днів до декількох тижнів. Одним із способів перевірки такого великого обсягу даних є побудова так званих «календарних діаграм», коли в якості відображуваного параметру використовується кількість записів для кожного дня. За умов стабільної роботи метеостанція «Кривий Ріг» повинна передавати не менше 48 METAR-повідомлень щодоби. Якщо в отриманій вами таблиці деякі дні містять лише 2-3 записи, а деякі дні — взагалі відсутні, скоріше за все це проблема передачі-отримання даних. Створення «календарних діаграм» ми розглянемо в розділі 4.5.
3.5 Об’єднання метеорологічних та екологічних даних
У розділі 3.4 ми отримали дані метеорологічних спостережень на метеостанції «Кривий Ріг». Тепер нам треба об’єднати дані моніторингу якості атмосферного повітря із результатами метеорологічних спостережень. Як і будь-які інші задачі в R, цю можна виконати декількома шляхами. Можна застовувати базову функцію merge, яка об’єднує таблиці даних за ключовим полем. Але оскільки ми майже постійно використовуєм пакет dplyr, ми будемо для об’єднання таблиць даних використовувати функцію left_join пакету dplyr. Ця функція дозволяє об’єднувати датасети одразу за декількома ключовими полями. Проте, для об’єднання наших даних нам потрібен найпростіший варіант - об’єднання таблиць даних за одним ключовим полем. В якості ключового поля ми будемо використовувати поле, в якому міститься дата та час проведення спостережень.
Окремо хочу зазначити, що пакет dplyr містить декілька варіантів оператора join. Ці варіанти викликаються окремими функціями: inner_join, left_join, right_join, full_join, semi_join, anti_join. Подивитись чим розрізняються ці функції можна командою довідки help(join), або її коротким варіантом ?join.
При використанні команди left_join виникає принципове питання: що до чого ми повінні під’єднати? Чи нам треба дані моніторингу забруднення приєднати до таблиці метеорологічних спостережень, чи навпаки. Відповідь проста - оскільки в рамках даної книги об’єктом дослідження є забруднення повітря, ми будемо використовувати таблиці з даними про забруднення в якості головних. До таблиць з результатами моніторингу забруднення повітря ми будемо приєднувати дані метеорологічних спостережень. Не навпаки!
3.5.1 Спостереження співпадають за часом
Коли спостереження співпадають за часом - це найпростіший варіант. Нам просто треба поєднати синхронні за часом вимірювання з різних таблиць: дані моніторингу забруднення повітря та дані метеорологічних спостережень.
Співпадіння за часом (умовне) у нас спостерігається між даними Гідрометецентру та даними метеорологічних спостережень. Нам просто треба приєднати одну таблицю до іншої. Ми приєднаємо дані метеорологічних спостережень до таблиці з результатами моніторингу забруднення повітря. Але перед цим нам треба поля date.proba та time.proba об’єднати та перевести у формат дата-час. При цьому ми створимо нову таблицю, щоб не чіпати первинних даних.
air_pollution.time <- air_pollution
air_pollution.time$time.Kiev <- as.POSIXct(as.character(paste(air_pollution$date.proba,
air_pollution$time.proba, sep = " ")), format = "%Y-%m-%d %H:%M", tz = "Europe/Kiev")Тепер ми можемо безперешкодно приєднати дані метеорологічних спостережень до таблиці із результатами моніторингу забруднення повітря. Тільки треба визначитись — які поля з таблиці метеорологічних спостережень нам потрібні. Приєднувати всю таблицю повністю немає сенсу. Ми виберемо наступні поля: напрям вітру (wd), швидкість вітру (ws), температура повітря (temp), точка роси (dew_point), атмосферний тиск (atmos_pres), відносна вологість повітря (rh) та перерахований на румби напрямок вітру (DD.meteo.from). В таблиці метеорологічних спостережень KrR_meteo2 це поля знаходяться під номерами 9, 10, 11, 12, 13, 14 та 18. Іще з цієї таблиці нам знадобиться поле 17 у якому знаходяться дані про дату-час вимірювань переведені у час за Києвом. Що стосується таблиці з даними моніторингу забруднення — то тепер нам не потрібні первинні поля date.proba та time.proba, оскільки у нас є більш універсальне поле time.Kiev. Ці два поля ми при об’єднанні вилучемо.
За допомогою функції left_join пакету dplyr ми об’єднуємо таблиці, вибираючі при цьому потрібні нам поля. Функція left_join автоматично розпізнає поля з однаковими назвами (time.Kiev) і використає їх у якості ключових полів.
air_pollution.join <- dplyr::left_join(air_pollution.time[, -c(1:2)],
KrR_meteo2[, c(9, 10, 11, 12, 13, 14, 18, 17)])## Joining, by = "time.Kiev"Можемо пересвідчитись, що тепер ми маємо в таблиці air_pollution.join поєднання даних про забруднення повітря із результатами метеорологічних спостережень
#Виводимо на екран структуру таблиці air_pollution.join.
#Примусово викликаємо функцію glimpse із пакету dplyr
dplyr::glimpse(air_pollution.join)## Observations: 3,609
## Variables: 18
## $ name <fct> ПСЗ-1, ПСЗ-1, ПСЗ-1, ПСЗ-1, ПСЗ-1, ПСЗ-1, ПСЗ-1, П…
## $ TSP <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ SO2 <dbl> 0.023, NA, 0.031, 0.025, NA, 0.029, NA, 0.028, NA,…
## $ CO <int> 1, NA, 1, 4, NA, 3, NA, 2, NA, 2, NA, 1, 1, NA, 2,…
## $ NO2 <dbl> 0.03, NA, 0.03, 0.03, NA, 0.09, NA, 0.07, NA, 0.05…
## $ NO <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ H2S <dbl> 0.000, 0.001, 0.001, 0.001, 0.002, 0.002, 0.000, 0…
## $ C6H6O <dbl> 0.000, 0.000, 0.001, 0.001, 0.001, 0.001, 0.000, 0…
## $ NH3 <dbl> 0.00, 0.01, 0.01, 0.02, 0.02, 0.02, 0.01, 0.02, 0.…
## $ CH2O <dbl> 0.002, NA, 0.003, 0.005, NA, 0.008, NA, 0.003, NA,…
## $ time.Kiev <dttm> 2016-01-02 05:00:00, 2016-01-02 11:00:00, 2016-01…
## $ wd <dbl> 20, 30, 20, 330, NA, 60, 60, 90, 90, 60, 60, NA, 7…
## $ ws <dbl> 2, 3, 4, 2, 1, 3, 3, 3, 3, 3, 3, 0, 3, 0, 7, 7, 7,…
## $ temp <dbl> -18, -15, -15, -23, -16, -17, -18, -14, -11, -8, -…
## $ dew_point <dbl> -19, -17, -17, -25, -19, -20, -20, -16, -15, -12, …
## $ atmos_pres <dbl> 1029, 1029, 1029, 1020, 1017, 1014, 1012, 1009, 10…
## $ rh <dbl> 91.9, 84.7, 84.7, 83.6, 77.7, 77.5, 84.3, 84.8, 72…
## $ DD.meteo.from <ord> NNE, NNE, NNE, NNW, VRB, ENE, ENE, E, E, ENE, ENE,…3.5.2 Спостереження не співпадають за часом
У випадку, коли спостереження не співпадають за часом, я пропоную використовувати інтерполяцію значень. Як це працює? - Ми просто «розтягуємо» значення одного із масивів: або даних моніторингу повітря, або даних метеорологічних спостережень. Приймаючи до уваги те, що у нашому випадку базовим об’єктом досліджень є дані моніторингу повітря, доцільніше робити інтерполяцію даних метеоспостережень. Ми обчислемо проміжні значення щоб у нас були «вимірювання» метеопараметрів не кожні 30, а кожні 10 хвилин. І допоможе нам це зробити пакет zoo, який ми з вами розглядали в розділі 1.2.4.
Пакет zoo працює з об’єктами власного формату. Формат (клас) цих об’єктів так і називається: zoo. Після інтерполяції нам треба буде переформатувати результат у таблицю даних (data frame). Перед початком роботи слід завантажити пакет zoo.
Для інтерполяції даних метеорологічних спостережень ми використаємо таблицю KrR_meteo2, яку отримали в розділі 3.4. Тільки нам доведеться викинути з цієї таблиці всі зайві поля, інтерполяція яких не матимиме сенсу: рік, година, хвилина, широта-довгота, висотна позначка, два непотрібні нам поля дата-час та поле румбів. Румби ми потом визначимо наново, використавши для цього вже інтерпольовані значення з поля «напрям вітру» (wd).
Наша інтерполяція базується на апріорній тезі, що метеорологічні умови змінюються між двома граничними точками інтерполяції поступово і з однаковою швидкістю. Тобто — від 00 хвилин до 30 хвилин кожної години якщо ми будемо інтерполювати значення на відрізки по 10 хвилин — то змінення значень всередині цих трьох відрізків буде однаковим. Тобто ми застосовуємо просту лінійну інтерполяцію. Що стосується поля «напрям вітру», яке представлено в градусах, ми також приймаємо тезу, що змінення напрямку вітру між граничними точками відбувається на рівнозначні величини. Але в полі «напрям вітру» є ще порожні значення. Якщо граничні точки інтерполяції містять порожні значення, то порожніми будуть всі значення між ними і також всі значення до наступного непорожнього значення.
Із напрямком вітру це ще не всі проблеми з якими ми зустрілись. Справа у тому, що напрям вітру — циклічна величина. Вона вимірюється у градусах і в неї немає початку відліку. Нуль одночасно є і закінченням. Щоб інтерполювати значення між двома точками ми не можемо напряму використати лінійну інтерполяцію. Ми не зможемо проінтерполювати значення між 340° та 10° — у нас вийдуть значення в діапазоні від 10 до 340… Для вирішення цієї проблеми я зробив перетворення за допомогою тригонометричних функцій і в самому кінці «зібрав» синуси та косинуси в єдине значення. І замість порожніх значень нам потрібні великі від’ємні числа. Це робиться для того, щоб потім в процесі інтерполяції відрізнити первинні порожні значення від порожніх значень у новостворених часових інтервалах. В самому кінці розрахунку всім великим від’ємним числам ми повернемо значення NA.
#створюємо робочу таблицю первинних значень для інтерполяції:
met.approx <- KrR_meteo2[, c(9:14, 17)]
#обчислюємо сінуси та косінуси напрямків вітру:
met.approx$wd.sin <- sin(pi * met.approx$wd/180)
met.approx$wd.cos <- cos(pi * met.approx$wd/180)
#присвоюємо значення -1000000 порожнім записам:
met.approx$wd.sin[is.na(met.approx$wd.sin)] <- -1e+6
met.approx$wd.cos[is.na(met.approx$wd.cos)] <- -1e+6
#створюємо часовий вектор із кроком 600 секунд
#на основі цього вектору будемо здійснювати інтерполяцію:
seq.time <- zoo(order.by = (as.POSIXct(seq(min(met.approx$time.Kiev),
max(met.approx$time.Kiev), by = 600))))
#об’єднуємо таблицю первинних значень із часовим вектором:
mer.meteo <- merge(zoo(x = met.approx[c(2:6, 8, 9)], order.by = unique(met.approx$time.Kiev)), seq.time)
#здійснюємо інтерполяцію значень метеорологічних параметрів:
approx.meteo <- na.approx(mer.meteo)Щоб перетворити об’єкт zoo у звичайну таблицю даних можна створити власну функцію zooToDf. Написання цієї функції я підгледів на Stack Overflow. Ми власноруч створюємо цю функцію. При цьому її буде збережено в нашому робочому середовищі.
zooToDf <- function(z) {
df <- base::as.data.frame(z)
df$Date <- stats::time(z) #create a Date column
rownames(df) <- NULL #so row names not filled with dates
df <- df[,c(ncol(df), 1:(ncol(df)-1))] #reorder columns so Date first
return(df)
}Нам слід застосувати функцію zooToDf до нашого об’єкту з результатами інтерполяції approx.meteo. Після перетворення його на таблицю даних ми перейменуємо перше поле таблиці на time.Kiev та перетворимо це поле на текстове.
#перетворюємо об’єкт approx.meteo на таблицю даних:
approx.meteo.df <- zooToDf(approx.meteo)
#перейменовуємо перше поле таблиці:
colnames(approx.meteo.df)[1] <- "time.Kiev"
#перетворюємо перше поле таблиці на текстове:
approx.meteo.df$time.Kiev <- as.character(approx.meteo.df$time.Kiev)Тепер нам треба зі значень синусів-косинусів повернути нормальне значення напряму вітру. Спочатку ми об’єднаємо все в єдине поле і перерахуємо в градуси. Потім округлимо ці значення до десятків градусів. Далі нам треба додати 360 до від’ємних значень, щоб перевести їх в систему координат «0-360 градусів».
У самому кінці нам треба винайти всі значення напряму вітру, які в первинній таблиці даних були порожніми і всі значення, які є результатом інтерполяції цих порожніх значень. Ви пам’ятаєте — на самому початку інтерполяції ми присвоїли значення -1000000 всім порожнім полям синусів та косинусів. Тепер ми використаємо всі нереальні значення синусів та косинусів, щоб присвоїти значення NA в полі напрямку вітру. Для цього нам просто треба знайти сінуси та косінуси, які менші за -1.
#об’єднуємо значення сінусів та косинусів в поле «напрям вітру»:
approx.meteo.df$wd <- as.vector(atan2(approx.meteo.df$wd.sin, approx.meteo.df$wd.cos) * 360/2/pi)
#округляємо поле «напрям вітру» до десятків градусів:
approx.meteo.df$wd <- round(approx.meteo.df$wd, -1)
#додаємо 360 градусів всім від’ємним значенням напряму вітру:
approx.meteo.df$wd2 <- ifelse(approx.meteo.df$wd < 0, approx.meteo.df$wd + 360, approx.meteo.df$wd)
#присвоюємо порожнє значення в поле напрям вітру тим
#записам, для яких сінуси та косінуси мають
#нереальні значення:
approx.meteo.df$wd <- ifelse(approx.meteo.df$wd.sin < -1 | approx.meteo.df$wd.cos < -1, NA, approx.meteo.df$wd2)В первинній таблиці KrR_meteo2 було 4970 порожніх значень напрямку вітру. Після інтерполяції ми маємо 17967 порожніх значень.
## [1] 4970## [1] 17967Все! Тепер у нас є часовий ряд щільних метеорологічних даних із частотою кожні 10 хвилин. Нам залишилось лише видалити всі зайві поля із кінцевої таблиці.
Для того, щоб остаточно привести таблицю до первинного стану нам треба округлити значення: швидкості вітру, температури, точки роси й атмосферного тиску — до цілих значень, відносної вологості повітря — до десятих часток.
meteo.interpolation$ws <- round(meteo.interpolation$ws, 0)
meteo.interpolation$temp <- round(meteo.interpolation$temp, 0)
meteo.interpolation$dew_point <- round(meteo.interpolation$dew_point, 0)
meteo.interpolation$atmos_pres <- round(meteo.interpolation$atmos_pres, 0)
meteo.interpolation$rh <- round(meteo.interpolation$rh, 1)Щоб пересвідчитись у тому, що ми все зробили правильно — продивимось перші 10 рядків нашої кінцевої таблиці meteo.interpolation.
## time.Kiev ws temp dew_point atmos_pres rh wd
## 1 2015-01-01 02:00:00 0 -18 -20 1030 84.3 NA
## 2 2015-01-01 02:10:00 0 -18 -20 1030 84.3 NA
## 3 2015-01-01 02:20:00 0 -18 -20 1030 84.3 NA
## 4 2015-01-01 02:30:00 0 -18 -20 1030 84.3 NA
## 5 2015-01-01 02:40:00 1 -18 -20 1030 84.3 NA
## 6 2015-01-01 02:50:00 1 -18 -20 1029 84.3 NA
## 7 2015-01-01 03:00:00 2 -18 -20 1029 84.3 270
## 8 2015-01-01 03:10:00 2 -18 -20 1029 84.3 260
## 9 2015-01-01 03:20:00 2 -18 -20 1029 84.3 260
## 10 2015-01-01 03:30:00 2 -18 -20 1029 84.3 250У нашій таблиці meteo.interpolation міститься 106690 записів. В первинній таблиці метеорологічних даних KrR_meteo2 було 36460 записів. Тепер у нас майже в 3 рази більше даних. Якщо у нас були вимірювання тільки два рази на годину — в 0 та 30 хвилин, то тепер у нас є шість значень — кожні 10 хвилин. При цьому не слід забувати, що вимірювання о 0 та 30 хвилин кожної години нікуди не поділись і вони є базовими для всіх інших часових інтервалів.
Остання операція з даними отриманої таблиці meteo.interpolation — переформатування поля time.Kiev у формат POSIXct.
meteo.interpolation$time.Kiev <- as.POSIXct(meteo.interpolation$time.Kiev,
format = "%Y-%m-%d %H:%M:%S", tz = "Europe/Kiev")І тепер ми можемо об’єднати дані моніторингу забруднення повітря разом із даними метеорологічних спостережень. Ми використаємо таблицю Landau2a і приєднаємо до неї поля з метеорологічними даними з таблиці meteo.interpolation. Але перед цим нам треба поле date.time в таблиці Landau2a переробити на таким чином, щоб записи в цьому полі виглядали однаково із записами в полі time.Kiev таблиці meteo.interpolation. Для цього ми просто переформатуємо поле date.time таблиці Landau2a у формат POSIXct. Після переформатування збережемо дані в нову таблицю Landau2a.new.
tbl_df(Landau2a) %>%
mutate(date.time.pos = as.POSIXct(as.character(date.time), format = "%d/%m/%Y %H:%M:%S", tz = "Europe/Kiev")) -> Landau2a.newІ, нарешті, об’єднуємо дві таблиці!
Landau2a.new.join <- dplyr::left_join(Landau2a.new,
meteo.interpolation, by = c("date.time.pos" = "time.Kiev"))Щоб пересвідчитись у тому, що ми маємо в таблиці Landau2a.new.join поєднання даних про забруднення повітря із результатами метеорологічних спостережень, переглянемо опис структури нашої новоствореної таблиці.
#Виводимо на екран структуру таблиці Landau2a.new.join.
#Примусово викликаємо функцію glimpse із пакету dplyr
dplyr::glimpse(Landau2a.new.join)## Observations: 61,653
## Variables: 21
## $ name <fct> Ландау-2, Ландау-2, Ландау-2, Ландау-2, Ландау-2, …
## $ date.time <fct> 01/01/2015 00:00:00, 01/01/2015 00:00:00, 01/01/20…
## $ NO2 <dbl> 0, NA, NA, 0, NA, 0, NA, NA, NA, NA, 0, NA, NA, 0,…
## $ NO <int> 0, NA, NA, 0, NA, 0, NA, NA, NA, NA, 0, NA, NA, 0,…
## $ SO2 <dbl> 0.07, NA, NA, 0.07, NA, 0.07, NA, NA, NA, NA, 0.07…
## $ CO <dbl> 0, NA, NA, 0, NA, 0, NA, NA, NA, NA, 0, NA, NA, 0,…
## $ NH3 <dbl> 0, NA, NA, 0, NA, 0, NA, NA, NA, NA, 0, NA, NA, 0,…
## $ H2S <dbl> 0, NA, NA, 0, NA, 0, NA, NA, NA, NA, 0, NA, NA, 0,…
## $ ws.post <dbl> NA, 0.5, 0.7, 0.5, 0.5, NA, 0.5, 0.6, 0.8, 0.6, NA…
## $ wd.post <int> NA, 227, 243, 225, 223, NA, 224, 249, 260, 252, NA…
## $ temp.post <dbl> NA, -16.5, -16.4, -16.3, -16.5, NA, -16.5, -16.6, …
## $ rh.post <int> NA, 74, 73, 74, 73, NA, 72, 72, 73, 75, NA, 75, 73…
## $ press.post <dbl> NA, 764.9, 764.9, 764.8, 764.7, NA, 764.6, 764.5, …
## $ TSP <dbl> 0.459, NA, NA, 0.409, NA, 0.463, NA, NA, NA, NA, 0…
## $ date.time.pos <dttm> 2015-01-01 00:00:00, 2015-01-01 00:00:00, 2015-01…
## $ ws <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ temp <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ dew_point <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ atmos_pres <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ rh <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ wd <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…Також дуже важливо продивитись описову статистику для новоствореної таблиці Landau2a.new.join.
## name date.time NO2
## Ландау-2:61653 01/05/2015 00:00:00: 4 Min. : 0.00
## 01/05/2015 00:20:00: 4 1st Qu.: 0.00
## 01/05/2015 00:40:00: 4 Median : 0.00
## 01/05/2015 01:00:00: 4 Mean : 1.03
## 01/05/2015 01:20:00: 4 3rd Qu.: 0.00
## 01/05/2015 01:40:00: 4 Max. :10.00
## (Other) :61629 NA's :43006
## NO SO2 CO NH3
## Min. :0 Min. :0.00 Min. : 0.00 Min. :0.00
## 1st Qu.:0 1st Qu.:0.00 1st Qu.: 0.10 1st Qu.:0.00
## Median :0 Median :0.00 Median : 0.20 Median :0.00
## Mean :0 Mean :0.01 Mean : 0.49 Mean :0.00
## 3rd Qu.:0 3rd Qu.:0.01 3rd Qu.: 0.60 3rd Qu.:0.00
## Max. :0 Max. :0.15 Max. :16.90 Max. :0.33
## NA's :43006 NA's :43006 NA's :43006 NA's :43006
## H2S ws.post wd.post temp.post
## Min. :0 Min. :0.000 Min. : 0.0 Min. :-19.60
## 1st Qu.:0 1st Qu.:0.800 1st Qu.: 63.0 1st Qu.: 3.70
## Median :0 Median :1.300 Median :130.0 Median : 15.00
## Mean :0 Mean :1.443 Mean :162.1 Mean : 13.46
## 3rd Qu.:0 3rd Qu.:1.900 3rd Qu.:261.0 3rd Qu.: 22.00
## Max. :0 Max. :6.500 Max. :359.0 Max. : 36.30
## NA's :43006 NA's :23987 NA's :23987 NA's :23987
## rh.post press.post TSP
## Min. :12.00 Min. :730.4 Min. :0.00
## 1st Qu.:43.00 1st Qu.:750.2 1st Qu.:0.04
## Median :62.00 Median :753.6 Median :0.08
## Mean :60.47 Mean :753.6 Mean :0.12
## 3rd Qu.:79.00 3rd Qu.:757.1 3rd Qu.:0.15
## Max. :93.00 Max. :771.1 Max. :2.38
## NA's :23987 NA's :23987 NA's :42716
## date.time.pos ws temp
## Min. :2015-01-01 00:00:00 Min. : 0.000 Min. :-23.00
## 1st Qu.:2015-03-11 19:39:00 1st Qu.: 2.000 1st Qu.: 3.00
## Median :2015-05-12 19:40:00 Median : 4.000 Median : 14.00
## Mean :2015-05-12 18:23:02 Mean : 3.881 Mean : 12.64
## 3rd Qu.:2015-07-13 18:20:00 3rd Qu.: 5.000 3rd Qu.: 21.00
## Max. :2015-09-22 12:50:00 Max. :16.000 Max. : 36.00
## NA's :5465 NA's :5465
## dew_point atmos_pres rh wd
## Min. :-25.000 Min. : 984 Min. : 16.40 Min. : 0.0
## 1st Qu.: -1.000 1st Qu.:1011 1st Qu.: 46.30 1st Qu.: 40.0
## Median : 6.000 Median :1015 Median : 66.50 Median :130.0
## Mean : 5.098 Mean :1015 Mean : 65.01 Mean :152.6
## 3rd Qu.: 11.000 3rd Qu.:1020 3rd Qu.: 84.60 3rd Qu.:260.0
## Max. : 21.000 Max. :1039 Max. :100.00 Max. :350.0
## NA's :5465 NA's :5465 NA's :5465 NA's :15000У розділі 3.1 ми розглядали що система автоматизованого моніторингу повітря ПАТ «АрселорМіттал Кривий Ріг» витримує 20-хвилинні інтервали часу між відбором проб повітря. Але ці інтервали не завжди припадають на значення 00-20-40 хвилин кожної години. Це можуть бути 17-37-57 хвилин, або 03-23-43 хвилини кожної години. Це пов’язано із періодичними вимкненнями електроенергії та іншими позаштатними ситуаціями. Також система моніторингу ПАТ «АрселорМіттал Кривий Ріг» виконує два незалежних ряди спостережень: окремо вимірюються концентрації газоподібних забруднюючих речовин, окремо — меторологічні параметри та концентрації пилу. Це призводить до дублювання та втрати синхронізації позначок часу. Наприклад, давайте подивимось на декілька рядків стовпців date.time.pos, ws та temp з таблиці Landau2a.new.join:
## # A tibble: 10 x 3
## date.time.pos ws temp
## <dttm> <dbl> <dbl>
## 1 2015-06-01 14:30:00 2 23
## 2 2015-06-01 14:40:00 2 23
## 3 2015-06-01 14:40:00 2 23
## 4 2015-06-01 14:42:00 NA NA
## 5 2015-06-01 14:50:00 3 23
## 6 2015-06-01 15:00:00 3 23
## 7 2015-06-01 15:00:00 3 23
## 8 2015-06-01 15:02:00 NA NA
## 9 2015-06-01 15:10:00 3 23
## 10 2015-06-01 15:20:00 3 24Як ми бачимо — дані метеорологічних спостережень не приєднались до записів, які мають позначки часу 2015-06-01 14:42:00 та 2015-06-01 15:02:00. Так і повинно бути! Функція left_join, яку ми використали для об’єднання двох таблиць даних, шукає тільки повні відповідності. Але порушення кратності в інтервалах моніторингу повітря руйнує нам кратність і унеможливлює приєднання даних до таблиці.
В результаті ми не можемо напряму приєднати дані метеорологічних спостережень. Єдиний вихід — робити інтерполяцію для інтервалів не 10 хвилин, а 1 хвилина, або навіть 30 секунд. Проте — отримана таблиця матиме занадто величезний розмір. Натомість я пропоную інший варіант. Ми зробимо «округлення» позначок часу в даних моніторингу якості повітря. Всі часові позначки ми приведемо до форми 00-20-40 хвилин. Тобто значення 2015-06-01 14:42:00 перетвориться на 2015-06-01 14:40:00, а значення 2015-06-02 14:55:00 на 2015-06-02 15:00:00. І займемося ми цим в розділі 3.5.3.
3.5.3 Невитримані інтервали спостережень
Отже, у розділі 3.5.2 ми спробували зробити інтерполяцію даних метеорологічних спостережень та приєднати їх до таблиці з даними моніторингу якості повітря. Але не так сталося, як гадалося! Як виявилось — в таблиці з даними моніторингу повітря не витримується кратність інтервалів часу. Періодично відбувається зміщення в той чи інший бік від значень 00-20-40 хвилин. Як результат — ми не можемо напряму приєднати дані з таблиці метеорологічних спостережень. Хіба що зробити інтерполяцію метеорологічних даних з інтервалом в 1 хвилину або, навіть, 30 секунд.
Але в таблицях із даними автоматизованого моніторингу якості атмосферного повітря, який здійснюється ПАТ «АрселорМіттал Кривий Ріг», є ще одна незручність. Справа у тому — що система моніторингу виконує два незалежних ряди спостережень і об’єднує їх дані в одну таблицю. Окремо здійснюється моніторинг концентрацій газоподібних забруднюючих речовин, окремо — меторологічних параметрів та концентрацій пилу. Як наслідок ми маємо дублювання часових інтервалів та об’ємну напівпорожню таблицю даних:
## name date.time NO2 NO SO2 CO NH3 H2S ws.post wd.post
## 1 Ландау-2 01/01/2015 00:00:00 0 0 0.07 0 0 0 NA NA
## 2 Ландау-2 01/01/2015 00:00:00 NA NA NA NA NA NA 0.5 227
## 3 Ландау-2 01/01/2015 00:10:00 NA NA NA NA NA NA 0.7 243
## 4 Ландау-2 01/01/2015 00:20:00 0 0 0.07 0 0 0 0.5 225
## 5 Ландау-2 01/01/2015 00:30:00 NA NA NA NA NA NA 0.5 223
## 6 Ландау-2 01/01/2015 00:40:00 0 0 0.07 0 0 0 NA NA
## temp.post rh.post press.post TSP
## 1 NA NA NA 0.459
## 2 -16.5 74 764.9 NA
## 3 -16.4 73 764.9 NA
## 4 -16.3 74 764.8 0.409
## 5 -16.5 73 764.7 NA
## 6 NA NA NA 0.463Ми можемо поцілити одразу двох зайців! По-перше — привети всі позначки часу до вигляду 00-20-40 хвилин. По-друге — ми можемо «стиснути» таблицю і залишити тільки унікальні позначки часу, позбувшись дублювання та зайвого «розтягування» таблиці.
Для роботи в цьому розділі ми візьмемо первинну таблицю Landau2a. Спочатку виконаємо «округлення» позначок часу до вигляду 00-20-40 хвилин, а потім — позбавимось дублювання рядків з однаковими позначками часу.
#Запускаємо таблицю Landau2a в тунель:
tbl_df(Landau2a) %>%
#Переводимо значення дати-часу в формат POSIXct:
mutate(date.time.pos = as.POSIXct(as.character(date.time), format = "%d/%m/%Y %H:%M:%S", tz = "Europe/Kiev")) %>%
#Приводимо всі позначки часу до інтервалів 00-20-40 хвилин
#і записуємо результат в таблицю Landau2a.uni:
mutate(date.time.pos.uni = as.POSIXct(round(as.double(date.time.pos)/(20*60))*(20*60), origin = '1970-01-01', tz = "Europe/Kiev")) -> Landau2a.uniТепер продивимось чотири останні стовпці отриманої таблиці Landau2a.uni приблизно посередині таблиці. Як ми пам’ятаємо з розділу 3.5.2 — там були позначки часу 2015-06-01 14:42:00 та 2015-06-01 15:02:00.
## # A tibble: 10 x 5
## rh.post press.post TSP date.time.pos date.time.pos.uni
## <int> <dbl> <dbl> <dttm> <dttm>
## 1 36 756. NA 2015-06-01 14:30:00 2015-06-01 14:20:00
## 2 NA NA 0.034 2015-06-01 14:40:00 2015-06-01 14:40:00
## 3 33 756. NA 2015-06-01 14:40:00 2015-06-01 14:40:00
## 4 NA NA NA 2015-06-01 14:42:00 2015-06-01 14:40:00
## 5 34 756. NA 2015-06-01 14:50:00 2015-06-01 15:00:00
## 6 NA NA 0.031 2015-06-01 15:00:00 2015-06-01 15:00:00
## 7 34 756. NA 2015-06-01 15:00:00 2015-06-01 15:00:00
## 8 NA NA NA 2015-06-01 15:02:00 2015-06-01 15:00:00
## 9 33 756. NA 2015-06-01 15:10:00 2015-06-01 15:00:00
## 10 NA NA 0.026 2015-06-01 15:20:00 2015-06-01 15:20:00Ми можемо побачити, що значення 2015-06-01 14:50:00, 2015-06-01 15:02:00 та 2015-06-01 15:10:00 перетворились на 2015-06-01 15:00:00. В останньому стовпці date.time.pos.uni у нас міститься аж 5 позначок часу 2015-06-01 15:00:00. Як ми можемо викинути з таблиці дубльовані позначки часу і не втратити при цьому значення інших стовпців таблиці? Найпростіший варіант — усереднення. Згрупувати таблицю за позначками часу та обчислити середні значення для всіх числових стовпців.
#Запускаємо таблицю Landau2a.uni в тунель:
tbl_df(Landau2a.uni) %>%
#Групуємо дані за значеннями поля date.time.pos.uni:
group_by(date.time.pos.uni) %>%
#Обчислюємо середні значення для всіх числових стовпців:
summarise(NO2 = mean(NO2, na.rm = TRUE),
NO = mean(NO, na.rm = TRUE),
SO2 = mean(SO2, na.rm = TRUE),
CO = mean(CO, na.rm = TRUE),
NH3 = mean(NH3, na.rm = TRUE),
H2S = mean(H2S, na.rm = TRUE),
ws.post = mean(ws.post, na.rm = TRUE),
wd.post = mean(wd.post, na.rm = TRUE),
temp.post = mean(temp.post, na.rm = TRUE),
rh.post = mean(rh.post, na.rm = TRUE),
press.post = mean(press.post, na.rm = TRUE),
TSP = mean(TSP, na.rm = TRUE)) %>%
#Додаємо поле з назвою поста спостереження
#та записуємо результат в таблицю Landau2a.uni.mean
mutate(name = "Ландау-2")-> Landau2a.uni.meanУ таблиці Landau2a містилось 61653 записів. Нова таблиця Landau2a.uni.mean містить лише 18925. Також можна порівняти наповненість таблиці порожніми значеннями. Наприклад, в первинній таблиці Landau2a поле TSP (концентрації пилу) містило 42716 порожніх значень. У кінцевій таблиці Landau2a.uni.mean поле TSP містить лише 60 порожніх значень.
Тепер ми приєднаємо до таблиці Landau2a.uni.mean таблицю meteo.interpolation, яку створили в розділі 3.5.2.
Landau2a.uni.mean.join <- dplyr::left_join(Landau2a.uni.mean,
meteo.interpolation, by = c("date.time.pos.uni" = "time.Kiev"))І все! Тепер у нас є об’єднана таблиця, в якій метеорологічні дані без пропусків приєднані до результатів моніторингу якості повітря. Порожніх значень в таблиці Landau2a.uni.mean.join небагато і вони пов’язані з відсутністю деяких значень в первинних результатах спостережень. Не забуваємо обов’язково продивитись описову статистику таблиці. Не забуваємо про самоперевірку!
## date.time.pos.uni NO2 NO
## Min. :2015-01-01 00:00:00 Min. : 0.000 Min. :0
## 1st Qu.:2015-03-07 17:40:00 1st Qu.: 0.000 1st Qu.:0
## Median :2015-05-13 06:40:00 Median : 0.000 Median :0
## Mean :2015-05-13 02:54:34 Mean : 1.013 Mean :0
## 3rd Qu.:2015-07-18 07:20:00 3rd Qu.: 0.000 3rd Qu.:0
## Max. :2015-09-22 13:00:00 Max. :10.000 Max. :0
## NA's :368 NA's :368
## SO2 CO NH3 H2S
## Min. :0.0000 Min. : 0.0000 Min. :0.0000 Min. :0.000
## 1st Qu.:0.0000 1st Qu.: 0.1000 1st Qu.:0.0000 1st Qu.:0.000
## Median :0.0000 Median : 0.2000 Median :0.0000 Median :0.000
## Mean :0.0093 Mean : 0.4936 Mean :0.0001 Mean :0.000
## 3rd Qu.:0.0100 3rd Qu.: 0.6000 3rd Qu.:0.0000 3rd Qu.:0.000
## Max. :0.1500 Max. :16.9000 Max. :0.3300 Max. :0.001
## NA's :368 NA's :368 NA's :368 NA's :368
## ws.post wd.post temp.post rh.post
## Min. :0.000 Min. : 0.0 Min. :-19.50 Min. :12.00
## 1st Qu.:0.800 1st Qu.: 65.0 1st Qu.: 3.70 1st Qu.:42.67
## Median :1.300 Median :136.0 Median : 15.07 Median :62.00
## Mean :1.446 Mean :161.7 Mean : 13.46 Mean :60.44
## 3rd Qu.:1.900 3rd Qu.:257.0 3rd Qu.: 22.04 3rd Qu.:79.00
## Max. :6.100 Max. :359.0 Max. : 36.10 Max. :93.00
## NA's :134 NA's :134 NA's :134 NA's :134
## press.post TSP name ws
## Min. :730.5 Min. :0.0000 Length:18925 Min. : 0.000
## 1st Qu.:750.2 1st Qu.:0.0450 Class :character 1st Qu.: 2.000
## Median :753.6 Median :0.0770 Mode :character Median : 4.000
## Mean :753.7 Mean :0.1214 Mean : 3.897
## 3rd Qu.:757.1 3rd Qu.:0.1500 3rd Qu.: 5.000
## Max. :771.1 Max. :2.3760 Max. :15.000
## NA's :134 NA's :60 NA's :6
## temp dew_point atmos_pres rh
## Min. :-23.00 Min. :-25.00 Min. : 984 Min. : 16.40
## 1st Qu.: 3.00 1st Qu.: -1.00 1st Qu.:1011 1st Qu.: 46.50
## Median : 14.00 Median : 6.00 Median :1015 Median : 66.90
## Mean : 12.47 Mean : 4.99 Mean :1015 Mean : 65.26
## 3rd Qu.: 21.00 3rd Qu.: 11.00 3rd Qu.:1020 3rd Qu.: 85.60
## Max. : 36.00 Max. : 21.00 Max. :1039 Max. :100.00
## NA's :6 NA's :6 NA's :6 NA's :6
## wd
## Min. : 0.0
## 1st Qu.: 40.0
## Median :130.0
## Mean :153.2
## 3rd Qu.:260.0
## Max. :350.0
## NA's :3180Посилання
Fleet Numerical Meteorology and Oceanography Detachment. 2015. Federal Climate Complex Data Documentation for Integrated Surface Data. Asheville, USA: National Climatic Data Center. https://www1.ncdc.noaa.gov/pub/data/ish/ish-format-document.pdf.