Tutorial #2 Procesamiento del lenguaje natural y Analisis de sentimiento
En este capítulo nos introduciremos al procesamiento del lenguaje natural, y a una tarea particular de dicho campo: el análisis de sentimiento o polaridad.
Particularmente, vamos a aprender a:
- pre-procesar texto para su posterior análisis;
- cruzar tablas (en nuestro caso, oraciones y diccionarios);
- realizar un análisis de sentimiento, incluyendo la preparación de los datos para el uso de librerías específicas.
Trabajaremos con un corpus de oraciones, extraídas de noticias argentinas que incluyen la palabra “big data”. El objetivo de nuestro análisis será determinar si el big data es valorado como un fenómeno positivo o negativo, de acuerdo a la carga valorativa de las palabras que le dan contexto. Esta tarea puede ser útil para comenzar a explorar el fenómeno de la polaridad del big data. Al respecto, luego de analizar noticias acerca de big data en diarios de Estados Unidos, Reino Unido y Australia, Paganoni (2019) sugiere:
Big data appears to be framed between two poles—data and information as opposed to rights and privacy—whose gap has of late been emphasised by a number of data scandals affecting business, health and politics, and culminating in the major unforeseen event of Cambridge Analytica and Facebook.
A lo largo de este tutorial trabajaremos con varias librerías, que podemos instalar con el siguiente código:
install.packages(c("readr", "tidyverse", "tidytext")) # las hemos instalado en capítulos anteriores
install.packages(c("udpipe")) # las usaremos por primera vez2.1 Pre-procesamiento de texto
Naturalmente, antes de todo proyecto de análisis de datos, necesitamos datos. El dataset con el que trabajaremos en este capítulo fue construido a través de la técnica de scrapping, que consiste en capturar datos a partir de la exploración de los elementos y anotaciones HTML de sitios webs. Ahora bien, si quisiéramos inmediatamente “procesar” estos datos, nos encontraríamos con varios problemas. Para empezar, ¿Cómo podríamos hacer para que el montón de textos que tenemos sea interpretable por una máquina que no habla ni entiende nuestro idioma?
Pues bien, con cualquier dataset, digamos, mayormente numérico, el problema del procesamiento consta de realizar ciertas tareas casi estandarizadas: eliminar outliers, normalizar los datos, completar o desechar valores faltantes, etc. Así, si quisiéramos analizar datos relativos a departamentos en alquiler, por ejemplo, donde nos interesaría predecir el precio de nuevas unidades en función de características como la ubicación, superficie y antigüedad, deberíamos realizar esta serie de operaciones que describimos recientemente para asegurarnos de tener los mejores resultados posibles. Esto no aplica directamente en el terreno del lenguaje natural, donde las tareas de preprocesamiento serán distintas.
El preprocesamiento de datos extraídos del lenguaje natural apunta a la construcción de una representación matemática de los mismos que, como tal, sea entendible y computable por nuestras funciones y modelos. En particular, la representación “matemática” de la que aquí hablaremos será la de un vector, pero hablaremos de esto un poco más adelante. Por lo pronto, es importante entender que lo que se busca es “estructurar” los datos “no-estructurados” para volverlos computables.
Para llegar a esta instancia de “estructuración” del lenguaje natural, el preprocesamiento deberá encargarse de una serie de operaciones sobre nuestro corpus de texto tendientes a su normalización. En este capítulo haremos 2 tareas específicas: (1) tokenización y análisis morfosintáctico, (2) reducción de las palabras del vocabulario.
Para ello empecemos por cargar los datos
library(readr) # para leer csv
library(tidyverse) # para manipular tablas
oraciones <- readr::read_csv(file = "https://raw.githubusercontent.com/gastonbecerra/curso-intro-r/main/data/oraciones_entrenamiento.csv") # importamos datos
glimpse(oraciones) # miramos la estructura de la base## Rows: 400
## Columns: 3
## $ doc_id <dbl> 3578, 2300, 405, 2540, 2016, 2713, 1503, 534, 1101, 3043, 1458…
## $ oracion <chr> "vale aclarar que bigdata es el nombre que se utiliza para des…
## $ estado <chr> "positivo", "positivo", "positivo", "positivo", "positivo", "p…Para el análisis morfosintáctico trabajaremos con la librería UdPipe, desarrollada por el Instituto de linguistica formal y aplicada de la Universidad de la República Checa, que tiene un modelo para procesar texto en castellano.
Lo primero que debemos hacer es instalar la librería. Luego, deberemos descargar el modelo del idioma que nos interesa.
install.packages("udpipe") # instalamos la libreria
library(udpipe) # la cargamos
modelo_sp <- udpipe::udpipe_download_model('spanish') # descarga el modelo y guarda la referencia
modelo_sp$file_model # refrencia al modelo descargado
modelo_sp <- udpipe_load_model(file = modelo_sp$file_model) # cargamos el modelo en memoria## Warning: package 'udpipe' was built under R version 4.2.3Con el modelo ya estamos en condiciones de empezar a parsear nuestro corpus de oraciones, y anotar qué tipo de componente es cada palabra.
oraciones_anotadas <- udpipe_annotate(
object = modelo_sp, # el modelo de idioma
x = oraciones$oracion, # el texto a anotar,
doc_id = oraciones$doc_id, # el id de cada oracion (el resultado tendrá 1 palabra x fila)
trace = 100
) %>% as.data.frame(.) # convertimos el resultado en data frameVamos a examinar la tabla con las oraciones parseadas:
## Rows: 12,153
## Columns: 14
## $ doc_id <dbl> 3578, 3578, 3578, 3578, 3578, 3578, 3578, 3578, 3578, 35…
## $ paragraph_id <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
## $ sentence_id <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
## $ sentence <chr> "vale aclarar que bigdata es el nombre que se utiliza pa…
## $ token_id <chr> "1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11",…
## $ token <chr> "vale", "aclarar", "que", "bigdata", "es", "el", "nombre…
## $ lemma <chr> "valer", "aclarar", "que", "bigdata", "ser", "el", "nomb…
## $ upos <chr> "VERB", "VERB", "SCONJ", "PROPN", "AUX", "DET", "NOUN", …
## $ xpos <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
## $ feats <chr> "Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",…
## $ head_token_id <dbl> 0, 1, 7, 7, 7, 7, 2, 10, 10, 7, 12, 10, 16, 16, 16, 12, …
## $ dep_rel <chr> "root", "xcomp", "mark", "nsubj", "cop", "det", "ccomp",…
## $ deps <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
## $ misc <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …Esta anotación se ha encargado de muchas tareas típicas del pre-procesamiento de texto:
- tokenización: la unidad mínima del análisis es ahora cada palabra (notá que por eso hay muchas mas filas que antes). El
doc_idnos permitirá volver a unir las piezas cuando hagamos tareas por oraciones; - para cada palabra se ha anotado el tipo en
upos; - se ha convertido la palabra a su raíz en
lemma.
Podemos usar upos para filtrar palabras. Este paso es una alternativa a la eliminación de stopwords y palabras que no aportan contenido semántico de manera directa (por ejemplo, las preposiciones).
La lemmatización es un procedimiento que busca reducir las palabras a su forma no flexionada o conjugada. Es una alternativa a la stemmization, que intenta reducir heurística e iterativamente la extensión de las palabras, removiendo caracteres, hasta reducirlas a su raíz. Así, la expresión “Google analiza big data para inferir el ritmo de contagio de la gripe H1N1”, queda lemmatizada como “google analizar bigdata inferir ritmo contagio gripe h1n1”.
oraciones_anotadas2 <- oraciones_anotadas %>%
filter(upos=="ADJ"| upos=="VERB"| upos=="NOUN" | upos=="ADV") # filtramos por tipo de palabra
glimpse(oraciones_anotadas2)## Rows: 5,445
## Columns: 14
## $ doc_id <dbl> 3578, 3578, 3578, 3578, 3578, 3578, 3578, 3578, 3578, 35…
## $ paragraph_id <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
## $ sentence_id <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
## $ sentence <chr> "vale aclarar que bigdata es el nombre que se utiliza pa…
## $ token_id <chr> "1", "2", "7", "10", "12", "15", "16", "18", "21", "23",…
## $ token <chr> "vale", "aclarar", "nombre", "utiliza", "describir", "gr…
## $ lemma <chr> "valer", "aclarar", "nombre", "utilizar", "describir", "…
## $ upos <chr> "VERB", "VERB", "NOUN", "VERB", "VERB", "ADJ", "NOUN", "…
## $ xpos <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
## $ feats <chr> "Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin",…
## $ head_token_id <dbl> 0, 1, 2, 7, 10, 16, 12, 16, 16, 21, 21, 21, 21, 30, 30, …
## $ dep_rel <chr> "root", "xcomp", "ccomp", "acl:relcl", "advcl", "amod", …
## $ deps <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
## $ misc <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …Es interesante señalar que pasamos de 12153 palabras parseadas y anotadas, a solo 5445, que son con las que trabajaremos.
2.2 Análisis de sentimiento
Generalmente se acepta que hay 2 métodos para este tipo de análisis:
- un enfoque basado en “lexicos” o “lexicones” (diccionarios que incluyen para cada palabra una valoración en alguna dimensión afectiva, como el agrado), y que consiste en calcular la valoración media del texto que nos interesa, a partir de pesar aquellas palabras que están en los lexicones;
- un enfoque basado en clasificación / aprendizaje automático, que busca inferir reglas para establecer la polaridad de una oración a partir de estudiar un dataset de oraciones previamente clasificadas (por un humano).
En este capítulos nos centraremos en el primer enfoque (lexicones), dejando el aprendizaje para un capítulo posterior. Buscaremos implementar esto de dos maneras:
- en primer lugar, cruzando la tabla de oraciones con el lexicon, y haciendo nosotros alguna evaluación;
- en segundo lugar, con una librería que contemple las falencias de nuestro primer enfoque.
2.2.1 Cruce con lexicones
Ahora podemos cruzar los lemmas de nuestras oraciones con los lexicones, para calcular la orientación de cada oración que incluye big data.
Vamos a trabajar con 1 lexicón construido a partir de otros dos: 1. Spanish Dictionary Affect Language (sdal), desarrollado por Gravano and Dell’Amerlina Ríos (2014), que replica el modelo de Whissell (2009). Este es un lexicon formado por 2700+ términos, clasificados manualmente en tres dimensiones afectivas, de las cuales aquí utilizamos el agrado; 2. Lexicon de evocaciones a big data (evoc), desarrollado por Becerra and López-alurralde (2020) en el marco de una investigación sobre las representaciones sociales del big data con la técnica de la evocación libre de palabras, a la que se añadió la posibilidad de aclarar la valoración del término incluído. Este es un lexicon formado por 1500+ términos. Para unir estos lexicones tuvimos que lemmatizar los términos, escalar las valoraciones dentro del rango -1 y 1, eliminamos ambigüedades calculando la media.
lexicones <- readr::read_csv('https://raw.githubusercontent.com/gastonbecerra/curso-intro-r/main/data/lexicones.csv')## Rows: 4005 Columns: 2
## ── Column specification ──────
## Delimiter: ","
## chr (1): lemma
## dbl (1): v
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## lemma v
## Length:4005 Min. :-1.0000
## Class :character 1st Qu.: 0.2000
## Mode :character Median : 0.4667
## Mean : 0.3796
## 3rd Qu.: 0.7333
## Max. : 1.0000Ahora sí: vamos a cruzar tablas! Particularmente, nos interesa ver si los lemmas que extrajimos de nuestras oraciones coinciden con los lemmas en los lexicones. En cuyo caso, vamos a anotar la media de las valoraciones de estos lexicones, junto con la cantidad de lemmas que tomamos de cada oracion (para saber cuantos lemmas con valoraciones hay en la oracion), entre otros indicadores que podamos usar para evaluar y filtrar resultados.
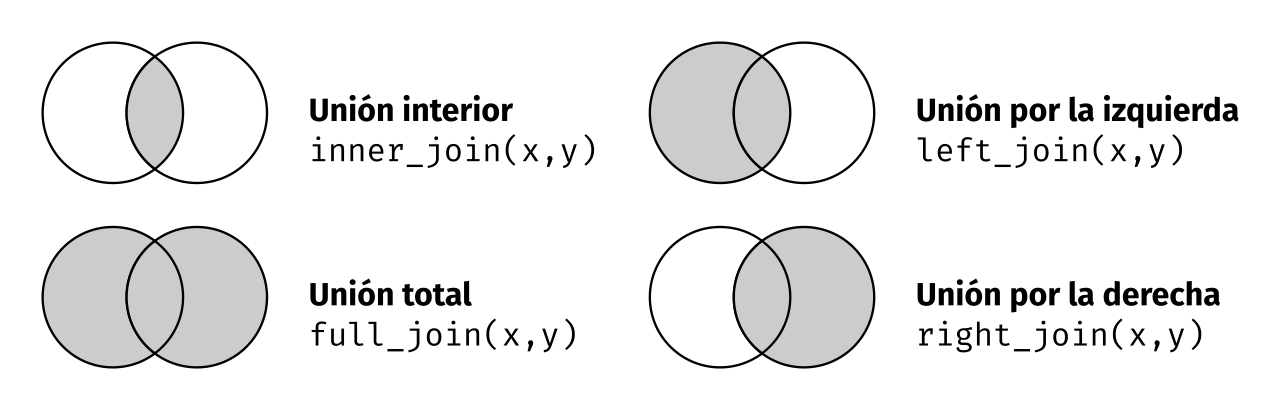
Para cruzar tablas usaremos los verbos _join, o más específicamente, left_join que mantiene todas las filas de nuestra tabla, agregandole las columnas con los valores de otra. Para hacer el cruce de tablas, _join utiliza las columnas de nombre coincidente (aunque podés especificar los pares con by = c("x"="y")). Esta es una opción de unión entre otras: left_join, inner_join, anti_join.
oraciones_lexicones <- oraciones_anotadas2 %>%
select(doc_id, lemma) %>%
mutate(doc_id=as.integer(doc_id)) %>%
left_join(lexicones, by="lemma") %>% # cruzamos con el lexicon sobre los registros de nuestra tabla
group_by(doc_id) %>% # ahora vamos a calcular valores por oración
summarise(
valor=mean(v, na.rm = TRUE), # valoración media
cruzadas_n=length(v[!is.na(v)]), # cantidad de palabras con valoracion
cruzadas_lemmas=paste(lemma[!is.na(v)], collapse = " ") # palabras con valoracion
)
glimpse(oraciones_lexicones)## Rows: 400
## Columns: 4
## $ doc_id <int> 10, 12, 27, 30, 32, 39, 41, 47, 52, 54, 72, 73, 74, 81…
## $ valor <dbl> 0.55729783, 0.48465926, 0.58677755, 0.42708333, 0.5487…
## $ cruzadas_n <int> 13, 9, 14, 8, 11, 7, 10, 7, 2, 8, 6, 15, 7, 6, 7, 4, 4…
## $ cruzadas_lemmas <chr> "información ser utilidad estudio mercado tendencia bú…## doc_id valor cruzadas_n cruzadas_lemmas
## Min. : 10 Min. :-0.08889 Min. : 1.000 Length:400
## 1st Qu.:1051 1st Qu.: 0.44121 1st Qu.: 7.000 Class :character
## Median :1827 Median : 0.50713 Median :10.000 Mode :character
## Mean :1869 Mean : 0.49712 Mean : 9.518
## 3rd Qu.:2778 3rd Qu.: 0.56774 3rd Qu.:12.000
## Max. :3688 Max. : 0.86667 Max. :21.000Exploremos un poco estos resultados. Busquemos oraciones con las valoraciones más altas y más bajas. Para poder comprender mejor lo que estamos evaluando, volvamos a incluir las oraciones, previas a nuestro preprocesamiento.
oraciones_lexicones %>%
slice_max(order_by = valor, n = 10) %>%
inner_join(oraciones, by="doc_id") %>% # indicamos el par de columnas a usar para el cruce
head(8)## # A tibble: 8 × 6
## doc_id valor cruzadas_n cruzadas_lemmas oracion estado
## <dbl> <dbl> <int> <chr> <chr> <chr>
## 1 324 0.867 4 ganador carrera caballo gracia ¿ pode… posit…
## 2 2712 0.85 2 salvar vida mirá t… posit…
## 3 1164 0.810 6 deporte objetivo mejorar rendimiento g… el dep… posit…
## 4 2605 0.773 2 intentar ciencia los pr… negat…
## 5 2938 0.767 2 más pequeño pero a… negat…
## 6 1114 0.757 7 nombre novedoso transformar dato relac… el big… posit…
## 7 116 0.753 4 aplicación beneficio potencial amplio ' evid… posit…
## 8 1742 0.733 3 conocer bien social es lo … posit…oraciones_lexicones %>%
slice_min(order_by = valor, n = 10) %>%
inner_join(oraciones, by="doc_id") %>% # indicamos el par de columnas a usar para el cruce
head(8)## # A tibble: 8 × 6
## doc_id valor cruzadas_n cruzadas_lemmas oracion estado
## <dbl> <dbl> <int> <chr> <chr> <chr>
## 1 985 -0.0889 3 decir industria obligar dijo q… negat…
## 2 129 -0.0192 4 haber gran amenaza intimidad ' hay … negat…
## 3 1064 0.0622 11 gobierno estado valley analizar dime… el ase… negat…
## 4 3367 0.0667 2 vez temer tal ve… negat…
## 5 380 0.151 9 diferencia encuesta encuesta polític… a dife… negat…
## 6 3412 0.170 7 empresa quedar robar información mil… tanto … negat…
## 7 2183 0.180 9 combinación estrategia miedo mucho p… la com… negat…
## 8 2184 0.180 9 combinación estrategia miedo mucho p… la com… negat…Evaluemos los resultados y tomemos decisiones: ¿Nos resultan satisfactorios, considerando nuestros objetivos y el uso que daremos a estos datos posteriormente? ¿Queremos introducir reglas ad-hoc para mejorar estos resultados? ¿Cuántos casos se pierden por introducir reglas? ¿Cuán arbitrario se vuelve nuestro modelo?
Estamos otra vez en el momento iterativo de la exploración. Volvamos a probar introduciendo un mínimo de palabras con valoración por oración…
oraciones_lexicones %>%
filter(cruzadas_n>2) %>%
slice_max(order_by = valor, n = 10) %>%
inner_join(oraciones, by="doc_id") %>% # indicamos el par de columnas a usar para el cruce
head(8)## # A tibble: 8 × 6
## doc_id valor cruzadas_n cruzadas_lemmas oracion estado
## <dbl> <dbl> <int> <chr> <chr> <chr>
## 1 324 0.867 4 ganador carrera caballo gracia ¿ pode… posit…
## 2 1164 0.810 6 deporte objetivo mejorar rendimiento g… el dep… posit…
## 3 1114 0.757 7 nombre novedoso transformar dato relac… el big… posit…
## 4 116 0.753 4 aplicación beneficio potencial amplio ' evid… posit…
## 5 1742 0.733 3 conocer bien social es lo … posit…
## 6 1133 0.722 3 herramienta transformar ciudad el big… posit…
## 7 2016 0.718 4 entender herramienta mucho bien hay qu… posit…
## 8 1740 0.709 6 magia considerar clase herramienta cap… es la … posit…oraciones_lexicones %>%
filter(cruzadas_n>2) %>%
slice_min(order_by = valor, n = 10) %>%
inner_join(oraciones, by="doc_id") %>% # indicamos el par de columnas a usar para el cruce
head(8)## # A tibble: 8 × 6
## doc_id valor cruzadas_n cruzadas_lemmas oracion estado
## <dbl> <dbl> <int> <chr> <chr> <chr>
## 1 985 -0.0889 3 decir industria obligar dijo q… negat…
## 2 129 -0.0192 4 haber gran amenaza intimidad ' hay … negat…
## 3 1064 0.0622 11 gobierno estado valley analizar dime… el ase… negat…
## 4 380 0.151 9 diferencia encuesta encuesta polític… a dife… negat…
## 5 3412 0.170 7 empresa quedar robar información mil… tanto … negat…
## 6 2183 0.180 9 combinación estrategia miedo mucho p… la com… negat…
## 7 2184 0.180 9 combinación estrategia miedo mucho p… la com… negat…
## 8 1376 0.184 3 privacidad dato usuario el tal… negat…Estos resultados parecen ser un poco mejores, aunque esta evaluación dependerá mucho del uso que querramos darle luego. Recordemos que el dato es un momento en un proceso…
Ahora que podemos intuir los límites y potenciales de este tipo de procesamiento del lenguaje, vamos a volver a realizar estos análisis, con un procedimiento mucho más robusto, utilizando funciones de librerías o packages.
2.2.2 Uso de packages
En lo que sigue vamos a realizar sentiment analysis utilizando packages, particularmente con txt_sentiment del package Udpipe que ya usamos para anotar las oraciones.
Los pasos generales cuando quieras trabajar con funciones de packages son:
- consultar la documentación;
- preprocesar los datos y transformar los objetos;
- usar la función y evaluar los resultados;
Primero, vamos a consultar la documentación del package para conocer qué funciones podemos ejecturar. Un buen punto de entrada es consultar la vignette, generalmente una suerte de introducción rápida del pack.
Otra opción es ir directamente a la documentación de la función, en la que encontraremos una descripción de los parámetros y ejemplos:
Veamos qué debemos especificar en esta función:
xes el dataframe que devuelve el preprocesamiento con udpipe;termes el nombre de la columna (dentro dex) que contiene las oraciones a analizar;polarity_termses un dataframe que contiene 2 columnas: términos (terms) y polaridad (polarity), que puede ser de 1 o -1.polarity_negators,polarity_amplifiers,polarity_deamplifiersson vectores de palabras que niegan, aumentan o reducen la orientación de las palabras (por ejemplo, si tenemos “bueno” en el lexicon con una valoración de 1, y “muy” dentro de los amplifiers, “muy bueno” podría suponer una valoración más alta que la dada por el lexicon, con un factor que se explicita enamplifier_weight). La ventana de palabras en las que se buscan estas palabras se configura conn_beforeyn_after.
Vamos a preparar los datos para cumplir estos parámetros:
# preparamos el lexicon para que los términos tengan 2 valores: 1 positivas y -1 negativas
polarity_terms <- lexicones %>%
mutate(polarity = if_else(v>0,1,-1)) %>%
select(term=lemma, polarity)
# preparamos los términos que modifican pesos
polarity_negators <- c("no","nunca","nadie")
polarity_amplifiers <- c("muy", "mucho", "mas")
polarity_deamplifiers <- c("poco", "casi", "alguno", "menos")Recordemos que tenemos las oraciones ya preprocesadas con udpipe en oraciones_anotadas2.
Todo listo! Corremos la función y vemos el objeto resultante.
oraciones_txt_sentiment <- txt_sentiment(
x = oraciones_anotadas2,
term = "lemma",
polarity_terms = polarity_terms,
polarity_negators = polarity_negators,
polarity_amplifiers = polarity_amplifiers,
polarity_deamplifiers = polarity_deamplifiers)
glimpse(oraciones_txt_sentiment)## List of 2
## $ data :'data.frame': 5445 obs. of 16 variables:
## ..$ doc_id : num [1:5445] 3578 3578 3578 3578 3578 ...
## ..$ paragraph_id : num [1:5445] 1 1 1 1 1 1 1 1 1 1 ...
## ..$ sentence_id : num [1:5445] 1 1 1 1 1 1 1 1 1 1 ...
## ..$ sentence : chr [1:5445] "vale aclarar que bigdata es el nombre que se utiliza para describir a los grandes volúmenes de información , su"| __truncated__ "vale aclarar que bigdata es el nombre que se utiliza para describir a los grandes volúmenes de información , su"| __truncated__ "vale aclarar que bigdata es el nombre que se utiliza para describir a los grandes volúmenes de información , su"| __truncated__ "vale aclarar que bigdata es el nombre que se utiliza para describir a los grandes volúmenes de información , su"| __truncated__ ...
## ..$ token_id : chr [1:5445] "1" "2" "7" "10" ...
## ..$ token : chr [1:5445] "vale" "aclarar" "nombre" "utiliza" ...
## ..$ lemma : chr [1:5445] "valer" "aclarar" "nombre" "utilizar" ...
## ..$ upos : chr [1:5445] "VERB" "VERB" "NOUN" "VERB" ...
## ..$ xpos : logi [1:5445] NA NA NA NA NA NA ...
## ..$ feats : chr [1:5445] "Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin" "VerbForm=Inf" "Gender=Masc|Number=Sing" "Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin" ...
## ..$ head_token_id : num [1:5445] 0 1 2 7 10 16 12 16 16 21 ...
## ..$ dep_rel : chr [1:5445] "root" "xcomp" "ccomp" "acl:relcl" ...
## ..$ deps : logi [1:5445] NA NA NA NA NA NA ...
## ..$ misc : chr [1:5445] NA NA NA NA ...
## ..$ polarity : num [1:5445] 1 NA 1 1 1 1 1 1 1 1 ...
## ..$ sentiment_polarity: num [1:5445] 1 NA 1 1 1 1 1 1 1 1 ...
## ..- attr(*, "spec")=
## .. .. cols(
## .. .. doc_id = col_double(),
## .. .. paragraph_id = col_double(),
## .. .. sentence_id = col_double(),
## .. .. sentence = col_character(),
## .. .. token_id = col_character(),
## .. .. token = col_character(),
## .. .. lemma = col_character(),
## .. .. upos = col_character(),
## .. .. xpos = col_logical(),
## .. .. feats = col_character(),
## .. .. head_token_id = col_double(),
## .. .. dep_rel = col_character(),
## .. .. deps = col_logical(),
## .. .. misc = col_character()
## .. .. )
## ..- attr(*, "problems")=<externalptr>
## $ overall:Classes 'data.table' and 'data.frame': 400 obs. of 8 variables:
## ..$ doc_id : num [1:400] 3578 2300 405 2540 2016 ...
## ..$ sentiment_polarity : num [1:400] 12 15 10 7 4 9 7 10 6 13 ...
## ..$ sentences : int [1:400] 1 1 1 1 1 1 1 1 1 1 ...
## ..$ terms : int [1:400] 18 18 12 9 6 17 9 14 8 15 ...
## ..$ terms_positive : chr [1:400] "almacenamiento, análisis, clasificación, describir, grande, información, múltiple, nombre, surgir, través, util"| __truncated__ "ayudar, cosa, decisión, empresa, escala, generar, gran, información, internet, mejor, pensar, permitir, proyect"| __truncated__ "categoría, crear, disponer, empresa, entorno, grande, hacer, partir, tecnología, virtual" "beneficio, conseguir, fútbol, mucho, real, realmente, ventaja" ...
## ..$ terms_negative : chr [1:400] "dispositivo" "" "" "" ...
## ..$ terms_negation : chr [1:400] "" "" "" "" ...
## ..$ terms_amplification: chr [1:400] "" "" "" "" ...
## ..- attr(*, ".internal.selfref")=<externalptr>Este tipo de objetos son muy comunes en los objetos que devuelven las funciones y modelos. Se trata de una lista: un objeto que aloja otros objetos, como por ejemplo, un dataframe y un vector. Accedemos a estos elementos con el operador $.
En el caso del objeto devuelto por txt_sentiment, hay 2 objetos que podemos consultar
oraciones_txt_sentiment$dataque tiene la tabla resultante del cruce de las oraciones anotadas (recordemos: 1 fila x lemma) con los diccionarios y modificadores, dando un valor finaloraciones_txt_sentiment$data$sentiment_polarity;oraciones_txt_sentiment$overallque tiene la tabla con los valores a nivel oración, incluyendo la polaridad enoraciones_txt_sentiment$overall$sentiment_polarity;
Veamos este último objeto, para evaluar los resultados:
oraciones_txt_sentiment$overall %>%
slice_max(order_by = sentiment_polarity, n=10) %>%
left_join(oraciones, by="doc_id")## doc_id sentiment_polarity sentences terms
## 1: 3644 21 1 21
## 2: 3643 21 1 22
## 3: 3521 17 1 20
## 4: 3567 17 1 21
## 5: 1380 16 1 21
## 6: 2772 16 1 19
## 7: 866 16 1 21
## 8: 2300 15 1 18
## 9: 2774 15 1 21
## 10: 3439 15 1 19
## 11: 1395 15 1 21
## 12: 817 15 1 17
## 13: 2022 15 1 21
## 14: 73 15 1 20
## 15: 3157 15 1 17
## 16: 2499 15 1 18
## 17: 1038 15 1 21
## 18: 3166 15 1 21
## 19: 492 15 1 21
## 20: 172 15 1 22
## terms_positive
## 1: algoritmo, alimentar, cerebro, conformar, constituir, controlar, dato, digital, diverso, economía, especie, inteligencia_artificial, más, masa, materia, nuevo, permitir, primo, sector, ser, social
## 2: algoritmo, alimentar, cerebro, conformar, constituir, controlar, dato, digital, diverso, economía, especie, inteligencia_artificial, más, masa, materia, nuevo, permitir, primo, sector, ser, social
## 3: caso, combinación, dar, demostrar, diferente, estudio, hardware, mejor, mercado, reciente, requerir, resultado, servicio, software, tecnología, uso
## 4: adquirir, alto, cliente, conservar, desarrollar, fuente, identificar, impacto, ingreso, más, nuevo, opción, principalmente, producto, servicio, utilizar, vez
## 5: almacenamiento, análisis, comportamiento, dato, diverso, fin, grande, información, masivo, referir, registro, sistema, social, tendencia, término, volumen
## 6: decisión, día, estar, libre, más, mercado, millón, país, permitir, procesar, publicación, tecnología, tomar, utilizar, vender
## 7: análisis, ayudar, conocimiento, convertir, cotidiano, datar, dato, encontrar, flujo, futuro, grande, herramienta, información, partir, solución, tecnología
## 8: ayudar, cosa, decisión, empresa, escala, generar, gran, información, internet, mejor, pensar, permitir, proyecto, tendencia, tomar
## 9: adquirir, análisis, área, científico, concepto, dato, decisión, enorme, estrategia, importancia, nota, potencial, técnico, tener
## 10: acuerdo, anunciar, aplicación, caso, cliente, dato, desarrollar, desear, empresa, interno, lanzar, paquete, producto, uso, vender
## 11: asistencia, atención, científico, conocimiento, dato, experiencia, grande, mejor, objetivo, paciente, profesional, proporcionar, salud, tener, uso, volumen
## 12: alcanzar, analizar, crear, dato, establecer, fenómeno, leer, millón, patrón, poder, posibilidad, real, solución, tiempo, valioso
## 13: análisis, analizar, cantidad, complejo, comprar, factor, haber, información, inmenso, llegar, patrón, persona, producto, simple, subir
## 14: acceso, adaptar, aprovechar, dato, decisión, empresa, forma, más, proceso, producir, rápido, saber, tema, tomar, uso
## 15: analizar, cantidad, capacidad, capturar, dato, decisión, enorme, generación, herramienta, llamar, real, tener, tiempo, tomar, último
## 16: calidad, eficacia, establecimiento, hacer, herramienta, impacto, incorporar, información, lograr, mayor, modelo, modo, posible, tener
## 17: aplicación, cantidad, dato, enorme, grande, información, interminable, procesamiento, real, tendencia, tiempo, traer, transmitir, útil, volumen
## 18: capturar, considerar, definición, gestionar, habilidad, hacer, herramienta, información, período, procesar, referencia, siguiente, tamaño, tiempo
## 19: analizar, concepto, costumbre, crecer, diseñar, fuerte, gente, información, mejor, mucho, obtener, sector, señalar, sistema, transportar, viajar
## 20: analizar, celular, costo, dato, decir, desarrollar, desarrollo, director, encargado, fuente, herramienta, llevar, lograr, mucho, tecnología, usar
## terms_negative terms_negation terms_amplification
## 1:
## 2:
## 3:
## 4: negocio
## 5:
## 6:
## 7: problema
## 8:
## 9:
## 10:
## 11: personal
## 12:
## 13:
## 14:
## 15:
## 16:
## 17:
## 18:
## 19: transporte
## 20: negocio
## oracion
## 1: y es que los datos en masa ( o ' bigdata\u0094 ) constituyen la materia prima de la nueva economía digital : alimentan los algoritmos y la inteligencia_artificial , conformando una especie de ' cerebro social ' que permite controlar los más diversos sectores .
## 2: y es que los datos en masa ( ' bigdata ' ) constituyen la materia prima de la nueva economía digital : alimentan los algoritmos y la inteligencia_artificial , conformando una especie de ' cerebro social ' que permite controlar los más diversos sectores .
## 3: un reciente estudio de idc ( international data corporation ) sobre usos y mercados para la tecnología y servicios de bigdata demuestra que cada caso requiere combinaciones diferentes de software , hardware y servicios para dar los mejores resultados .
## 4: utilizado principalmente para identificar nuevas fuentes de ingresos ( 94% ) , conservar y adquirir clientes ( 90% ) y desarrollar nuevos productos y servicios ( 89% ) , el bigdata se posiciona cada vez más como una opción de alto impacto para los negocios .
## 5: el término ' bigdata ' - o datos masivos - , refiere al registro , almacenamiento y análisis de grandes volúmenes de información recolectados por sistemas informáticos para diversos fines , desde publicitarios a detección de comportamientos o tendencias sociales .
## 6: nosotros le proveemos y utilizamos tecnología de bigdata y todos los días procesamos más de 40 millones de publicaciones de mercado libre en los 17 países donde está , para tomar decisiones que les permita vender más .
## 7: convertir datos en conocimiento bigdata , data mining e internet_cosas son las herramientas y tecnologías que ayudarán –en un futuro cercano– a encontrar soluciones a problemas cotidianos a partir del análisis de grandes flujos de datos e información .
## 8: la internet de las cosas es una tendencia que se complementa con bigdata y puede ayudar a generar información que permita a las empresas tomar mejores decisiones : ' vamos a poder pensar en proyectos de gran escala ' , subrayó .
## 9: nota relacionada : ' bigdata es un concepto que tiene un potencial enorme ' estas técnicas han adquirido enorme importancia en áreas tales como estrategias de mercadeo , soporte de decisiones , planeamiento financiero y el análisis de datos científicos , entre otras .
## 10: telefónica y huawei anunciaron un acuerdo para lanzar un paquete de productos de bigdata orientados a empresas que desean desarrollar tanto casos de uso internos como vender aplicaciones de datos a sus clientes .
## 11: el uso de grandes volúmenes de datos o bigdata en la asistencia sanitaria ' tiene como objetivo proporcionar a cada paciente una atención personalizada , que combine los mejores conocimientos científicos con la experiencia personal de los profesionales de la salud ' .
## 12: con el fenómeno de bigdata se crearon soluciones tecnológicas que alcanzan su poder : la posibilidad de leer millones de datos en tiempo real , analizar y establecer patrones valiosos .
## 13: hay simples ( subir varios escalones para llegar a la terraza ) y complejos ( los factores que una persona analiza para comprar un producto ) bigdata : análisis y cruzamiento de una inmensa cantidad de información para detectar patrones determinados .
## 14: ' el uso de bigdata produce un acceso más rápido y certero ; el tema es saber cómo las empresas van a aprovechar esos datos para tomar decisiones en forma ágil y adaptar sus procesos velozmente .
## 15: se llama ' bigdata ' , y es una herramienta tecnológica de última generación , que tiene la capacidad de capturar y analizar una enorme cantidad de datos en tiempo real para tomar decisiones .
## 16: lo hacen mediante herramientas de bigdata , modelos scoring e incorporando información de calidad para tener mayor eficacia en la detección cuando van a un establecimiento , de modo de lograr el mayor impacto posible .
## 17: el abanico de aplicaciones es interminable ; toda información que pueda ser útil en tiempo real puede ser transmitida y procesada , aún en enormes volúmenes , lo que trae aparejada otra tendencia llamada bigdata para procesamiento de grandes cantidades de datos .
## 18: se puede considerar la siguiente definición : bigdata hace referencia a la información cuyo tamaño excede la habilidad de las herramientas utilizadas actualmente para capturar , gestionar y procesar la información , dentro de un período de tiempo aceptable .
## 19: agosta señaló que ' está creciendo en el sector transporte muy fuerte el concepto de bigdata : analizar cómo viaja la gente , obtener esa información , sus costumbres y preferencias , para poder diseñar un mejor sistema de transporte .
## 20: ' logramos desarrollar una tecnología asertiva usando como fuente bigdata y herramientas de muy bajo costo para analizar los datos y llevar al celular de cada encargado ' , dice rafael sánchez , director de desarrollo de negocios de bsg .
## estado
## 1: positivo
## 2: positivo
## 3: positivo
## 4: positivo
## 5: positivo
## 6: positivo
## 7: positivo
## 8: positivo
## 9: positivo
## 10: positivo
## 11: positivo
## 12: positivo
## 13: positivo
## 14: positivo
## 15: positivo
## 16: positivo
## 17: positivo
## 18: positivo
## 19: positivo
## 20: positivooraciones_txt_sentiment$overall %>%
slice_min(order_by = sentiment_polarity, n=10) %>%
left_join(oraciones, by="doc_id")## doc_id sentiment_polarity sentences terms
## 1: 1717 -5 1 16
## 2: 3566 -2 1 9
## 3: 2206 -2 1 10
## 4: 348 -2 1 15
## 5: 3680 -2 1 7
## 6: 12 -1 1 12
## 7: 2770 -1 1 14
## 8: 1952 -1 1 13
## 9: 123 -1 1 10
## 10: 985 -1 1 5
## 11: 1412 -1 1 15
## terms_positive
## 1: área, común, dato, dirección, disponible, empresa, organización, percibir, sistema
## 2: dar, nube, rápido, solución, usar
## 3: democracia, institución, preparar
## 4: dar, decir, marco, peña, querer, tiempo, último
## 5: mucho, necesitar
## 6: acostumbrar, conocer, generación, hacer, información, joven, querer, último
## 7: aparecer, profesión, programador
## 8: altura, ciudad, comunicación, demanda, estar, generar, principal, procesamiento, territorio
## 9: almacenamiento, analizar, apuntar, ejecutivo, hacer, información, solo
## 10: decir
## 11: claramente, confesar, defensa, encontrar, fila, lado, mismo, oscuro, sistema, virtud
## terms_negative terms_negation terms_amplification
## 1: no
## 2: caro no
## 3: destruir no
## 4: dispositivo no
## 5: no
## 6: no
## 7: no
## 8: no
## 9: no
## 10: industria, obligar
## 11: víctima no
## oracion
## 1: es común detectar ' silos ' de datos , en sistemas erp o crm no disponibles a toda la organización ; o empresas cuyas direcciones aún no perciben a bigdata como un área estratégica .
## 2: usar bigdata ' no es caro , porque la nube te da soluciones rápidas y baratas .
## 3: la democracia representativa no está preparada para el bigdata y está siendo destruida ¿ y la democracia es una de esas instituciones que está siendo destruida por el bigdata ?
## 4: \u0096 ¿ quieren decir que no fueron seducidos por la sobredimensión que se le dio en el último tiempo al dispositivo comunicacional durán barba - marcos peña - bigdata ?
## 5: ya es así y no necesitamos el bigdata porque estamos muy acostumbrados a eso .
## 6: ' ahora todo lo que se hace se conoce , todo es ' bigdata ' y uno no quiere que esa información se conozca ; pero los jóvenes , la última generación , se está acostumbrando a eso .
## 7: nos rayan los ' cerebritos ' no busques nada a lo black mirror en el ranking , pues no aparecen profesiones relacionadas con el bigdata ni tampoco programadores informáticos .
## 8: fuera de las cuatro o cinco ciudades principales , las comunicaciones en el ochenta por ciento del territorio son pésimas y no están a la altura de la demanda que genera el procesamiento de la bigdata .
## 9: ' hasta que no se pueda analizar la información , lo que se estará haciendo no es bigdata , es solo almacenamiento ' , apuntó el ejecutivo .
## 10: dijo que la industria bigdata obliga a la modernización .
## 11: ella misma confiesa que no se encuentra entre las filas de los predicadores de las virtudes del bigdata y se alinea claramente en la defensa de las víctimas del lado oscuro del sistema .
## estado
## 1: negativo
## 2: positivo
## 3: negativo
## 4: negativo
## 5: negativo
## 6: negativo
## 7: negativo
## 8: negativo
## 9: negativo
## 10: negativo
## 11: negativotxt_sentiment suma los scores de las palabras por oración, lo que hace esperable que las oraciones más largas muestren una polaridad más extrema. Por ello tal vez convenga normalizar este score por la cantidad de palabras en cada oración:
oraciones_txt_sentiment$overall %>%
mutate(sentiment_polarity2=sentiment_polarity/terms) %>%
slice_max(order_by = sentiment_polarity2, n=10) %>%
left_join(oraciones, by="doc_id") %>%
select(sentiment_polarity2,oracion)## sentiment_polarity2
## 1: 1.0000000
## 2: 0.9545455
## 3: 0.9333333
## 4: 0.9285714
## 5: 0.9166667
## 6: 0.9166667
## 7: 0.9090909
## 8: 0.9000000
## 9: 0.8888889
## 10: 0.8888889
## oracion
## 1: y es que los datos en masa ( o ' bigdata\u0094 ) constituyen la materia prima de la nueva economía digital : alimentan los algoritmos y la inteligencia_artificial , conformando una especie de ' cerebro social ' que permite controlar los más diversos sectores .
## 2: y es que los datos en masa ( ' bigdata ' ) constituyen la materia prima de la nueva economía digital : alimentan los algoritmos y la inteligencia_artificial , conformando una especie de ' cerebro social ' que permite controlar los más diversos sectores .
## 3: con los nuevos cambios la empresa quiere poner al usuario en el centro de la compañía a través seis elementos claves entre los que destacan el ' bigdata ' y la ' internet de las cosas ' .
## 4: como resultado de este trabajo y mediante el uso de herramientas de análisis de bigdata , se lograron desarrollar algoritmos que nos permiten proyectar rendimientos para la futura campaña .
## 5: rojas planteó que este año , el crecimiento del mercado de bigdata será de entre 26 y 30% , lo que representa un nivel de crecimiento mucho mayor que el de otras tecnologías .
## 6: ' cuando hablamos de bigdata , el principal uso que hacemos es construir productos que la gente quiere para generar comunidad ' , aseguró .
## 7: el bigdata aporta mucho al deporte más popular del mundo a la hora de generar , enviar y recibir información .
## 8: el análisis de bigdata ayuda a las organizaciones a aprovechar sus datos y utilizar para identificar nuevas oportunidades .
## 9: para las empresas con gran cantidad de procesos operativos , bigdata puede ofrecer frutos inmediatos o quick - wins .
## 10: ' la bigdata que genera un sitio como vorterix ayuda en parte a ver cuáles son los comportamientos de los usuarios de ese sitio .oraciones_txt_sentiment$overall %>%
mutate(sentiment_polarity2=sentiment_polarity/terms) %>%
slice_min(order_by = sentiment_polarity2, n=10) %>%
left_join(oraciones, by="doc_id") %>%
select(sentiment_polarity2,oracion)## sentiment_polarity2
## 1: -0.31250000
## 2: -0.28571429
## 3: -0.22222222
## 4: -0.20000000
## 5: -0.20000000
## 6: -0.13333333
## 7: -0.10000000
## 8: -0.08333333
## 9: -0.07692308
## 10: -0.07142857
## oracion
## 1: es común detectar ' silos ' de datos , en sistemas erp o crm no disponibles a toda la organización ; o empresas cuyas direcciones aún no perciben a bigdata como un área estratégica .
## 2: ya es así y no necesitamos el bigdata porque estamos muy acostumbrados a eso .
## 3: usar bigdata ' no es caro , porque la nube te da soluciones rápidas y baratas .
## 4: la democracia representativa no está preparada para el bigdata y está siendo destruida ¿ y la democracia es una de esas instituciones que está siendo destruida por el bigdata ?
## 5: dijo que la industria bigdata obliga a la modernización .
## 6: \u0096 ¿ quieren decir que no fueron seducidos por la sobredimensión que se le dio en el último tiempo al dispositivo comunicacional durán barba - marcos peña - bigdata ?
## 7: ' hasta que no se pueda analizar la información , lo que se estará haciendo no es bigdata , es solo almacenamiento ' , apuntó el ejecutivo .
## 8: ' ahora todo lo que se hace se conoce , todo es ' bigdata ' y uno no quiere que esa información se conozca ; pero los jóvenes , la última generación , se está acostumbrando a eso .
## 9: fuera de las cuatro o cinco ciudades principales , las comunicaciones en el ochenta por ciento del territorio son pésimas y no están a la altura de la demanda que genera el procesamiento de la bigdata .
## 10: nos rayan los ' cerebritos ' no busques nada a lo black mirror en el ranking , pues no aparecen profesiones relacionadas con el bigdata ni tampoco programadores informáticos .Tiene bastante sentido, no?