Tutorial #3 Modelado de topicos
En este capítulo nos introduciremos a una técnica de aprendizaje no supervisado en el campo del procesamiento del lenguaje natural: el modelado de tópicos (topic modeling). Esta técnica busca construir tópicos o temas en base a las distribuciones de palabras en un conjunto de documentos.
A lo largo de este ejercicio veremos:
- cómo pre-procesar texto para su posterior análisis;
- cómo construir vectores de documentos por términos;
- cómo modelar tópicos;
- cómo interpretar los tópicos, leyendo los resultados junto con nuestro propio análisis cualitativo, entre otras indagaciones.
Vamos a utilizar esta técnica para intentar explorar ¿Cuál es la tematización del big data en la prensa?, utilizando un corpus de noticias que incluyen la palabra “big data”, tomadas de periódicos digitales argentinos. Nos interesa particularmente indagar de qué manera el big data es contextualizado, de modo tal que el modelado de tópicos pueden asistir al análisis de “frames” discursivos. Este tipo de análisis son útiles para investigar acerca de la construcción social de un fenómeno por parte de un sistema de comunicación, como es la prensa (Jacobi, Atteveldt, and Welbers 2016).
A lo largo de este tutorial trabajaremos con varias librerías, que podemos instalar con el siguiente código:
install.packages(c("readr", "tidyverse", "tidytext", "udpipe")) # las hemos instalado en capítulos anteriores
install.packages(c("topicmodels", "stopwords")) # las usaremos por primera vez3.1 Pre-procesamiento de texto
Como en toda tarea de procesamiento del lenguaje natural, comenzaremos por cargar el corpus y preprocesar el texto.
library(tidyverse) # para manipular en general
library(tidytext) # para convertir los objetos a formatos requeridos / devueltos por LDA
noticias <- readr::read_csv("https://raw.githubusercontent.com/gastonbecerra/curso-intro-r/main/data/noticias_tm.csv") %>%
mutate(id=1:n())
glimpse(noticias) # miramos la estructura de la base## Rows: 100
## Columns: 5
## $ id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, …
## $ fecha <date> 2018-03-25, 2017-07-30, 2017-09-30, 2012-06-05, 2016-10-25, 20…
## $ titulo <chr> "El escándalo Facebook: la periodista que reveló la filtración …
## $ txt <chr> "Durante un año investigaron a Cambridge Analytica . Una empres…
## $ fuente <chr> "www.clarin.com", "www.clarin.com", "www.clarin.com", "www.clar…Para poder completar nuestros análisis primeros realizaremos varias tareas de preprocesamiento:
- Haremos un análisis morfosintático para determinar los distintos componentes de la oración;
- Reduciremos las palabras a sus lemmas, formas básicas de las palabras, sin género ni conjugación;
- Descartaremos algunas palabras comunes, quedándonos sólo con las más significativas.
Para estas tareas trabajaremos con la librería UdPipe, desarrollada por el Instituto de linguistica formal y aplicada de la Universidad de la República Checa, que tiene un modelo para procesar texto en castellano, y que usamos en el capítulo anterior.
#install.packages("udpipe") # instalamos la libreria
library(udpipe) # la cargamos
modelo_sp <- udpipe::udpipe_download_model('spanish') # descarga el modelo y guarda la referencia
modelo_sp$file_model # refrencia al modelo descargado
modelo_sp <- udpipe_load_model(file = modelo_sp$file_model) # cargamos el modelo en memorianoticias_anotadas <- udpipe_annotate(
object = modelo_sp, # el modelo de idioma
x = noticias$txt, # el texto a anotar,
doc_id = noticias$id, # el id de cada oracion (el resultado tendrá 1 palabra x fila)
trace = 20
) %>% as.data.frame(.) # convertimos el resultado en data frameAl igual que en el capítulo anterior, usaremos la información de upos para filtrar las palabras que podrían ser más signficativas: adjetivos, verbos, y sustantivos.
Aquí omitimos los adverbios, ya que no nos interesan las posibles modificaciones del sentido entre palabras cercanas, como negaciones o amplificaciones.
Además introduciremos otro filtro: eliminaremos palabras muy comunes en el lenguaje, que dificilmente puedan ayudarnos a identificar un campo semántico. Para eso recurrimos a un diccionario de palabras comunes, del pack stopwords, y eliminaremos esos registros con filter. Además, incluimos un conjunto de verbos ad-hoc para ser eliminados.
library(stopwords)
noticias_anotadas2 <- noticias_anotadas %>%
filter(upos=="ADJ"| upos=="VERB"| upos=="NOUN") %>% # filtramos por tipo de palabra
select( doc_id, lemma ) %>% # seleccionamos solo las columnas que nos interesan, esto no es necesario
filter(!lemma %in% stopwords::stopwords(language = "es")) %>% # filtrar las que no están en la tabla de stopwords
filter(!lemma %in% c("ser", "decir", "tener", "haber", "estar", "hacer", "ver", "leer","comentar","ir")) %>% # filtramos verbos muy comunes
filter(!lemma %in% c("año","dia","vez")) # filtramos palabras típicas del género de los documentos
glimpse(noticias_anotadas2)## Rows: 37,084
## Columns: 2
## $ doc_id <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
## $ lemma <chr> "investigar", "empresa", "británico", "construir", "millón", "p…3.2 Vectorizado del texto
Comúnmente, los modelos de machine learning son entrenados con datos estructurados en forma de tablas. Cuando trabajamos con texto debemos construir estas tablas a partir de las palabras del documento con el que estemos trabajando. Esto lo hacemos con el vectorizado.
Supongamos que tenemos dos documentos con una oración cada uno: El big data es el conjunto de técnicas que las grandes corporaciones analizan para manipular nuestro pensamiento en función de sus intereses privados y Google analiza big data para inferir el ritmo de contagio de la gripe H1N1, que en su forma lemmatizada y filtrada serían bigdata ser conjunto tecnica grande corporacion analizar manipular pensamiento funcion interes privado y google analizar bigdata inferir ritmo contagio gripe h1n1.
Veamos cómo se vería estas oraciones vectorizadas (las primeras palabras):
## Index bigdata ser conjunto tecnica grande corporacion analizar manipular
## 1 1 1 1 1 1 1 1 1 1
## 2 2 1 0 0 0 0 0 1 0Aquí hemos reducido cada oración a una “bolsa de palabras”, que ha resignado el contexto de formulación de las expresiones verbales, perdiendo el orden. Nos quedamos entonces sólo con un vocabulario general que, para cada oración, anota la frecuencia de aparición con 1 y 0, es decir, con datos que son interpretables por una computadora y que nos pueden servir para entrenar un modelo de machine learning.
con la función count() es muy fácil armar un vector, si usamos como inputs el id del documento y las palabras. Luego, podemos convertir nuestra tabla de distribución de palabras en este tipo de objeto utilizando la función cast_dtm de la librería tidytext.
noticias_dtm <- noticias_anotadas2 %>%
count(doc_id, lemma, sort = TRUE) %>% # contamos palabras x documento
cast_dtm(doc_id, lemma, n) # convertimos a vector
noticias_dtm## <<DocumentTermMatrix (documents: 100, terms: 6848)>>
## Non-/sparse entries: 25326/659474
## Sparsity : 96%
## Maximal term length: 25
## Weighting : term frequency (tf)El objeto tipo DocumentTermMatrix nos informa la cantidad de documentos y la cantidad de palabras distintas, y nos indica un % de palabras que aparecen 0 veces en un documento (Sparsity).
3.3 Modelado de tópicos con LDA
Topic models draw on the notion of distributional semantics (Turney & Pantel, 2010) and particularly make use of the so-called bag of words assumption, i.e., the ordering of words within each document is ignored. To grasp the thematic structure of a document, it is sufficient to describe its distribution of words (Grimmer & Stewart, 2013). Maier et al. (2018).
Seemingly unsupervised model becomes extremely supervised due to classification work such as setting number of topics, cleaning data in a particular way with an apriori understanding of “meaningful” clusters and interpreting clusters with parent classes manually Bechmann and Bowker (2019)
3.3.1 Sobre el modelo LDA
Para construir los tópicos usaremos el modelo Latent Dirichlet Allocation, a través del pack topicmodels. Este modelo genera tópicos proponiendo una cierta distribución de todas las palabras del corpus, y calcula la distribución de estos tópicos en cada documentos.
En términos gráficos (Blei (2012)):
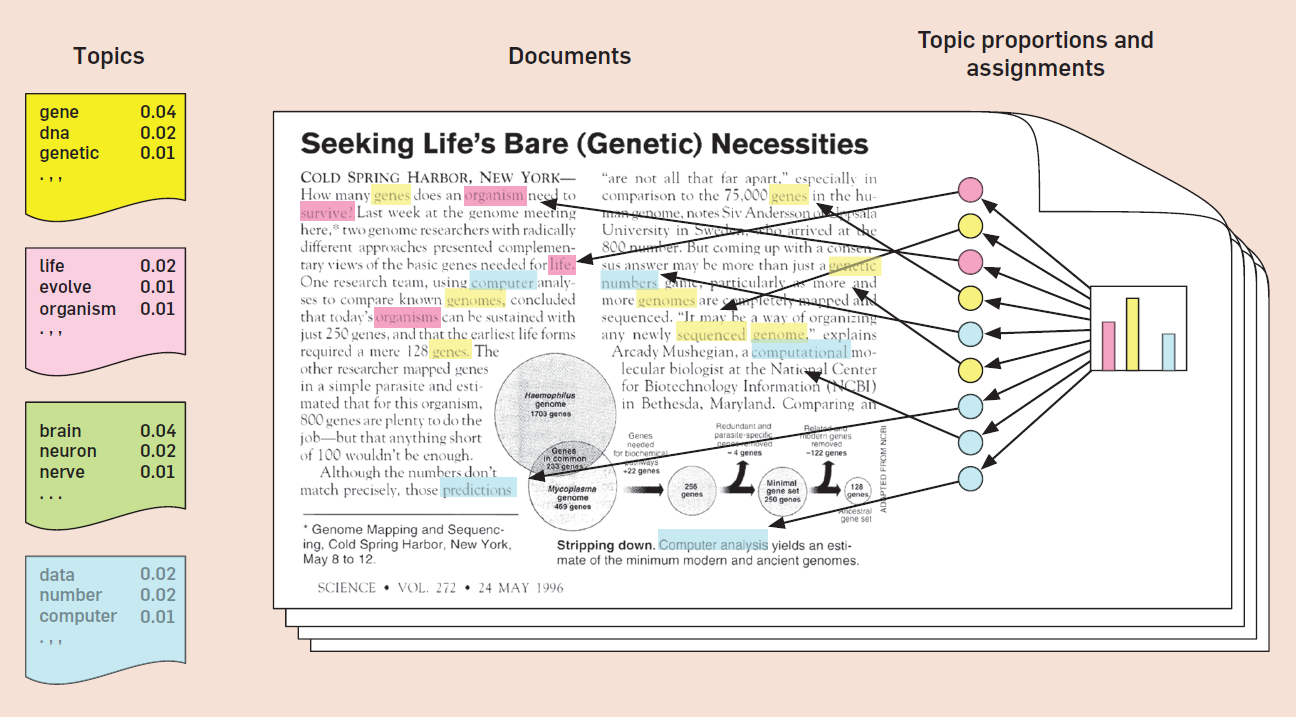
Lo interesante de esta manera de operativizar los temas, es que cada tópico puede ser entendido como un campo semántico, un conjunto de palabras que suelen correlacionar en distintos documentos. Luego, en el momento del análisis de estos resultados, buscaremos inferir un tema a partir de las palabras que más contribuyen a cada tópico. E.g., podríamos inferir de un tópico en el que contribuyen fuertemente los términos “venta”, “producto” y “comprador” al tema “comercio”. Según uno de los autores del modelo, la interpretabilidad de la mayoría de los temas es el resultado de “la estructura estadística del lenguaje y cómo interactúa con los supuestos probabilísticos específicos de LDA” (D. Blei, 2012, p. 79).
A la vez, las palabras no son exclusivas de un tópico sino que cruzan todos los tópicos con una “contribución” relativa. Esto es justamente lo que nos interesa ya queremos comparar distintas maneras de “contextualizar” al mismo término (“big data”) a través de distintos tópicos, caracterizados por el uso de ciertas otras palabras.
3.3.2 Aplicar LDA
Vamos a construir el modelo con la función LDA. Una decisión importante, que debe ser introducida como un parámetro para realizar los análisis, es el número de tópicos a generar. Empecemos por un número criterioso, rápido para testear, y fácil de examinar, y volvamos sobre este problema.
library(topicmodels)
k_topics <- 6 # numero de topicos
noticias_tm <- topicmodels::LDA(
noticias_dtm, # vector de terminos por documentos
k = k_topics, # cantidad de topicos
method = "Gibbs", # metodo de sampleo de los documentos
control = list(seed = 1:5, nstart=5, verbose=1000))## Loading required package: topicmodels## Warning: package 'topicmodels' was built under R version 4.2.3## A LDA_Gibbs topic model with 6 topics.Ahora vamos a exportar los resultados en los 2 formatos que nos interesa explorar, utilizando la función tidy, y especificando la qué probabilidades que nos interesan:
- beta: probabilidad topico x palabra;
- gamma: probabilidad topico x documento;
noticias_tm_beta <- tidy(noticias_tm, matrix = "beta")
noticias_tm_gamma <- tidy(noticias_tm, matrix = "gamma")
glimpse(noticias_tm_beta)## Rows: 41,088
## Columns: 3
## $ topic <int> 1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5, 6, 1, 2, 3, 4…
## $ term <chr> "dato", "dato", "dato", "dato", "dato", "dato", "información", "…
## $ beta <dbl> 5.635662e-02, 1.852607e-05, 1.618699e-05, 3.894570e-04, 1.625805…## Rows: 600
## Columns: 3
## $ document <chr> "41", "51", "6", "23", "65", "77", "57", "99", "60", "95", "3…
## $ topic <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
## $ gamma <dbl> 0.61111111, 0.43291667, 0.55637773, 0.36412316, 0.45619492, 0…3.4 Interpretar el modelo
Los resultados arrojados por el modelo pueden ser útiles para inferir tópicos. No obstante, esto implica un proceso iterativo de interpretación por parte del investigador, que incluye varios momentos:
- etiquetado manual y organización de los tópicos;
- análisis de contenido;
- validación;
Al igual que en los diseños cualitativos debemos tener en consideración 2 cuestiones: (1) que las distintas tareas y momentos del análisis no son secuenciales sino más bien iterativos, y que constantemente iremos tomando decisiones que afectan (hacia adelante) y que informan (hacia atras) a otros momentos; (2) que todas estas decisiones serán mas claras y robustas si son producto del consenso entre distintos analistas que trabajan en forma autónoma y que documentan e intercambian la razones de sus decisiones (Auerbach and Silverstein 2003). No obstante, para todos los momentos que siguen vamos a asumir una escala pequeña de investigación, es decir, donde las tareas puedan ser llevadas por 1 solo investigador. Cuando la investigación cuenta con recursos (humanos) suficientes se pueden plantear estrategias mucho más complejas para cada momento1, generando así resultados más confiables y robustos.
3.4.1 Etiquetado manual y organización de los tópicos
El etiquetado no es un proceso distinto al de la codificación cualitativa, es decir, a la interpretación interativa de ideas y expresiones repetidas y la imputación de un código o etiqueta que lo identifica.
En términos de codeo, preparar los datos para esta tarea es muy fácil: simplemente listamos los términos que más contribuyen a cada tópico.
noticias_tm_beta %>% # principales términos en cada tópico
group_by(topic) %>%
top_n(15) %>%
ungroup() %>%
arrange(topic, -beta) %>% # vamos a mostrarlo como grafico
ggplot(aes(x=reorder(term, (beta)),y=beta)) +
geom_col() +
facet_wrap(~topic, scales = "free_y") +
coord_flip() +
theme_minimal()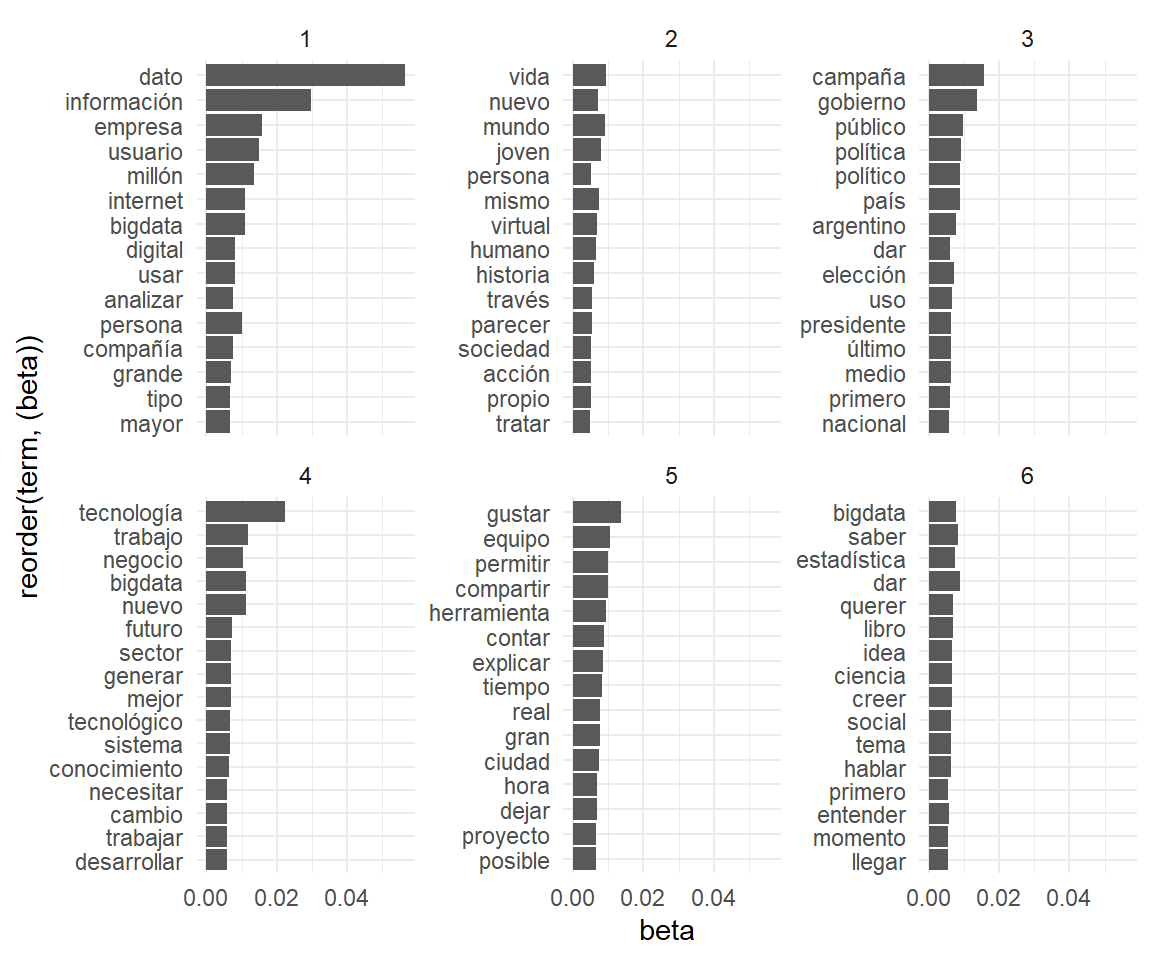
El objetivo del análisis que haremos (manualmente) sobre estos datos es el de evaluar si hay un campo coherente de palabras en cada tópico, para luego asignarle una etiqueta que lo describa. En tanto estas son todas inferencias nuestras, en el mejor de los casos, guidados por nuestro conocimiento teórico del fenómeno, nos ubicamos en el plano de las hipótesis.
Veamos esto con nuestros datos, tendiendo en mente el criterio de construcción del corpus (noticias que incluyen “big data”):
- Tópico 1: dato, información, empresa, usuario, millón, personas e internet son nociones que nos remiten a redes sociales y plataformas. Esta es una interpretación (hipotética) de las palabras en relación a los conceptos de la datificación y el big data social (Dijck 2014);
- Tópico 2: vida, mismo, nuevo, humano son expresiones esperables en artículos críticos de los avances tecnológicos;
- Tópico 3: campañana, político, gobierno, elección nos permiten inferir el campo de las elecciones políticas;
- Tópico 4: negocio, tecnología, trabajo, innovación son términos que podrían corresponder a noticias sobre el mercado laboral y las empresas;
- Tópico 5: equipo, tiempo, sensor, ciudad no parece permitirnos inferir un campo semántico muy coherente sino más bien un conjunto de artículos de áreas diversas en las que ha impactado la datificación.
- Tópico 6: bigdata, saber, entender, tiempo, estadística y conocimiento nos permiten suponer que se trata de la “promesa epistémica” del big data, es decir, de su vinculación con la generación de conocimiento novedoso (Becerra 2018);
Vamos a escribir estas etiquetas en un array de nombres de tópicos, por si necesitamos incluirlos en futuros gráficos como etiquetas:
topicos_nombres <- rbind(
c(topic = 1 , nombre = "1. Redes sociales"),
c(topic = 2 , nombre = "2. Críticas"),
c(topic = 3 , nombre = "3. Elecciones"),
c(topic = 4 , nombre = "4. Negocios y trabajo"),
c(topic = 5 , nombre = "5. Conocimiento"),
c(topic = 6 , nombre = "6. Datificación")
) %>% as_tibble() %>% mutate(topic=as.integer(topic))Es importante tener en cuenta que no siempre todos los tópicos presentarán un campo semántico coherente: en muchos casos pueden referir a regularidades propias del tipo de comunicación que estamos analizando (e.g., palabras que remiten a una interacción por parte del usuario, si es que estamos trabajando con contenido tomado de páginas interactivas), o una mixtura de palabras tal que en lugar de permitirnos inferir un campo unívoco, nos resulte incoherente.
Luego, debemos organizar nuestros tópicos:
¿Descartamos tópicos irrelevantes?: Más allá de los tópicos incoherentes o para los que un campo semántico no es tan evidente, podemos decidir filtrar otros tópicos en vistas de su (ir)relevancia para nuestra pregunta teórica. En nuestro caso, todos los tópicos parecen incluir aspectos sociales en los que el big data interviene
¿Agrupar tópicos?: Generalmente, en una codificación cualitativa, el proceso se repite iterativamente, haciendo inferencias cada vez más generales (mayor abstracción) y coordinadas (mayor coherencia), lo que nos permite pasar de los códigos a los temas y argumentos. El modelo LDA no tiene esa estructura jerárquica, pero nosotros podemos agrupar o colapsar tópicos en temáticas más generales. Esto es casi siempre necesario cuando trabajamos con un K elevado.
3.4.2 Análisis de contenido (muestreo cualitativo)
Dados los objetivos de nuestra investigación -indagar las distintas maneras en que se tematiza al big data en la prensa-, no podemos quedarnos con estos resultados que, en el mejor de los casos, son una de tantas clasificación probables. Más bien, nos interesa hacer un análisis de contenido de los documentos en relación a cada tópico (Krippendorff 2004), no sólo para aclarar las etiquetas dadas, sino también para responder a nuestras preguntas de investigación. Este tipo de análisis, en este momento de la exploración, nos permitirá comprender los contextos semánticos en los que se definen las palabras de nuestros tópicos. Para ello, conviene tener preguntas teóricamente guiadas, como por ejemplo: ¿con qué fines se asocia al big data? ¿se lo define explicitamente o se lo da por supuesto? ¿qué actores sociales están involucrados?
En este momento sólo usaremos R para seleccionar documentos de cada tópico (construir una muestra) para su posterior análisis. Trabajaremos estas muestras manualmente en otro entorno o software destinado al análisis cualitativo o CAQDAS. (Aunque existe una implementación básica de una interfaz como la de otros CAQDAS en R: RDQA (R package for Qualitative Data Analysis), https://rqda.r-forge.r-project.org/).
Una forma muy básica de construir esta muestra puede ser simplemente identificar aquellos documentos que tienen mayor probabilidad en cada tópico, a partir de noticias_tm_gamma. Asumamos que con 10 documentos podemos empezar nuestros análisis, aunque recordemos que en muestreos teóricos (cualitativos), este número no es fijo sino que se llega por un proceso de exploración:
El muestreo teórico se realiza para descubrir categorías y sus propiedades, y para sugerir las interrelaciones dentro de una teoría. El muestreo estadístico se realiza para obtener evidencia precisa sobre distribuciones de una población entre categorías, que pueden ser utilizadas en descripciones o verificaciones (Glaser y Strauss, 1967: 62). Por el muestreo teórico el investigador selecciona casos a estudiar según su potencial para ayudar a refinar o expandir los conceptos o teorías ya desarrollados. La «saturación teórica» significa que agregar nuevos casos no representará hallar información adicional por medio de la cual el investigador pueda desarrollar nuevas propiedades de las categorías. Gialdino (2006)2
Sin embargo, esto supondría un riesgo. Consideremos la manera en que se distribuye la probabilidad de cada tópico por documento, observando los primeros documentos de nuestro corpus:
noticias_tm_gamma %>% filter(document %in% c(1:20)) %>%
ggplot(aes(x=document,y=gamma,label=topic,color=as.factor(topic))) +
geom_text(size=5, show.legend = FALSE) +
coord_flip()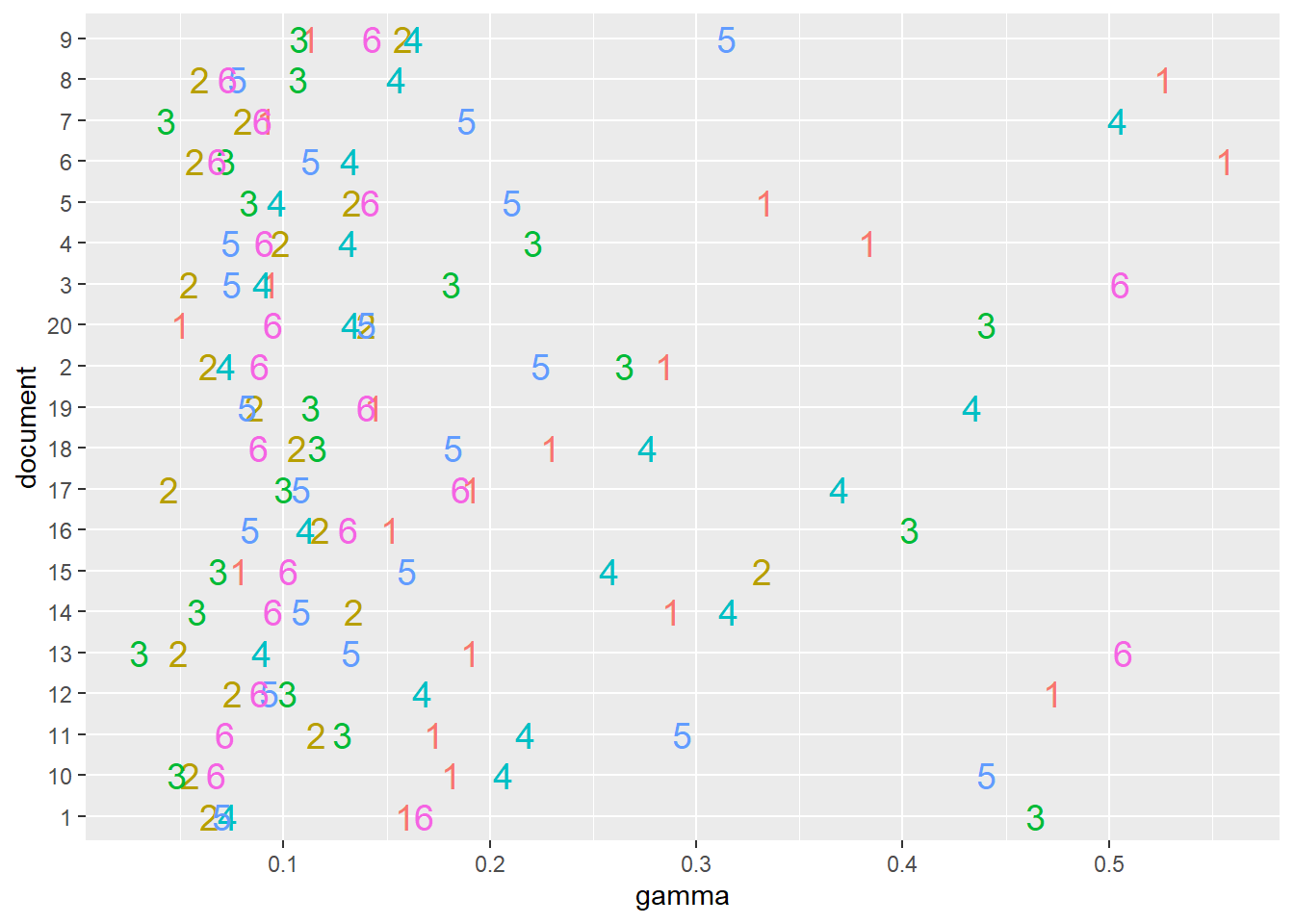
En algunos documentos se observa una clara preminencia de un tópico, mientras que en otros esta distribución es más pareja (e.g., documentos #10 y #12). Si nos quedásemos sólo con el tópico que más alto puntúa en cada documento para asignarlos a una muestra, podríamos perder la chance de observar de qué manera algún tópico menos predominante se contextualiza. Para ello conviene construir nuestra muestra para que incluya tanto documentos con los valores más altos de afinidad, y otros seleccionados al azar que incluyan al tópico en un cierto umbral de relevancia. Esta es una decisión que deberemos considerar para otros momentos en los que querramos referir al conjunto de documentos que creemos relevante para un tópico.
muestra_mixta_1 <- noticias_tm_gamma %>%
group_by(topic) %>%
slice_max(gamma, n=5)
muestra_mixta_2 <- noticias_tm_gamma %>%
filter(gamma > 0.2) %>% # definimos el umbral
filter(!document %in% muestra_mixta_1$document) %>%
group_by(topic) %>%
slice_sample(n = 5)
muestra_mixta <- rbind(muestra_mixta_1, muestra_mixta_2)3.4.3 Validación
En el momento de la validación se busca indagar cuán sólida es nuestra interpretación de los datos.
Hay diversas formas de validación pero podemos agruparlas en 2:
- validación de hipótesis con contenidos y metadatos;
- validación estadística;
La validación de hipótesis con contenido y metadatos (también llamada validación semántica intratópico y externa, respectivamente) consiste en hipotetizar cierta información presente en nuestros datos o metadatos, generalmente no analizados por nuestro modelo, para explorarla con los resultados del modelo.
Por ejemplo, en nuestra base de noticias tenemos algunos meta-datos con información que nuestro modelo no analizó (como la fecha de publicación de los artículos o sus títulos), de modo que podríamos usarlos para evaluar su coherencia. Naturalmente, esto deja muchas definiciones de criterios en manos del investigador y lo compromete a justificar sus decisiones.
noticias_tm_gamma %>%
filter(
gamma > 0.2 # vamos a incluir a todas las noticias con este % de relevancia
) %>%
mutate(
id=as.integer(document), # modificamos los nombres de columnas para dp hacer join
topic=as.integer(topic)
) %>%
left_join(x = ., y = noticias, by="id") %>% # agregamos los metadatos de noticias
left_join(topicos_nombres, by="topic") %>% # agregamos los nombres de los topicos
group_by(nombre, month = lubridate::floor_date(fecha, unit = "month")) %>% # agrupamos las noticias por meses
summarize(n=n()) %>%
ggplot( aes(x = month, y = n, color=nombre)) +
geom_line()+
scale_x_date(date_breaks = "3 months", date_labels = "%m/%y") +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust=1))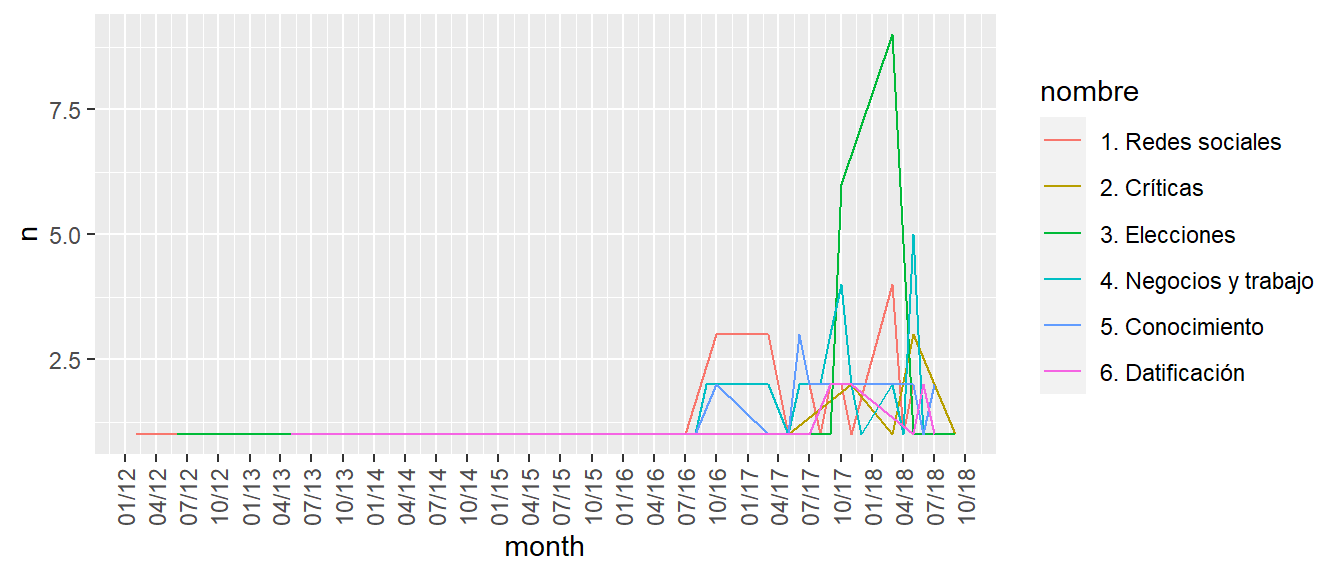
Por caso, en relación al tópico de las elecciones políticas, vemos un pico de noticias en los últimos meses de 2017 y principios del 2018, en el que se desarrollaron las elecciones legislativas argentinas y se conoció la explotación de datos de Facebook por parte de Cambridge Analytica. Se debe notar que aquí introducimos un nuevo supuesto: que la manera en que hemos construído nuestra muestra habilita a un análisis de frecuencia.
A la vez, este momento de validación puede dar inicio a exploraciones heurísticas muy interesantes. Por ejemplo, en nuestra investigación sobre el tratamiento del big data por parte de la prensa digital, buscamos comparar el tratamiento del big data a través de estos tópicos en 3 niveles: artículos, oraciones que incluían los términos “big data”, y las fotos que acompañaban el artículo.
Por su parte, la validación estadística busca medir cuán confiable es el modelo, aunque solamente en términos de cuán consistentes son sus resultados.
Perplexity es la medida más usada en este tipo de pruebas. Esta es una métrica que resulta de una prueba tipo held-out likelihood en los que, una vez entrenado el modelo con ciertos parámetros, se utiliza para predecir los tópicos de documentos “nuevos” para el modelo, es decir, documentos que no eran parte del corpus con el que se entrenó. Volveremos sobre este diseño en el próximo capítulo con más detalle.
Por ahora, nos interesa observar que este tipo de pruebas es mayormente útil para estimar distintos modelos con diferentes parámetros. En este tutorial hemos utilizado sólo 2 inputs: el número de tópicos (K) y nuestro corpus. En lo que sigue vamos a separar algunos documentos de nuestro corpus para tener documentos “nuevos” (subseteamos los primeros 10); luego, vamos a vamos a entrenar varios TM con distintos valores de K; y finalmente vamos a graficar los resultados de las pruebas de perplexity.
# atención: aquí vamos a entrenar 5 veces el modelo LDA.
# este código puede ser computacionalmente pesado y lento.
posibles_k <- c(5, 10, 20, 50, 100)
comparar_posibles_k <- posibles_k %>%
map(LDA,
x = noticias_dtm[-c(1:10),], # subseteamos todos los documentos menos los primeros 10
method = "Gibbs",
control = list(seed = 1:5, nstart=5, verbose=1000))tibble(k = posibles_k,
perplex = map_dbl(comparar_posibles_k, perplexity,
newdata=noticias_dtm[c(1:10),],
estimate_theta=FALSE)) %>%
ggplot(aes(k, perplex)) +
geom_point() +
geom_line()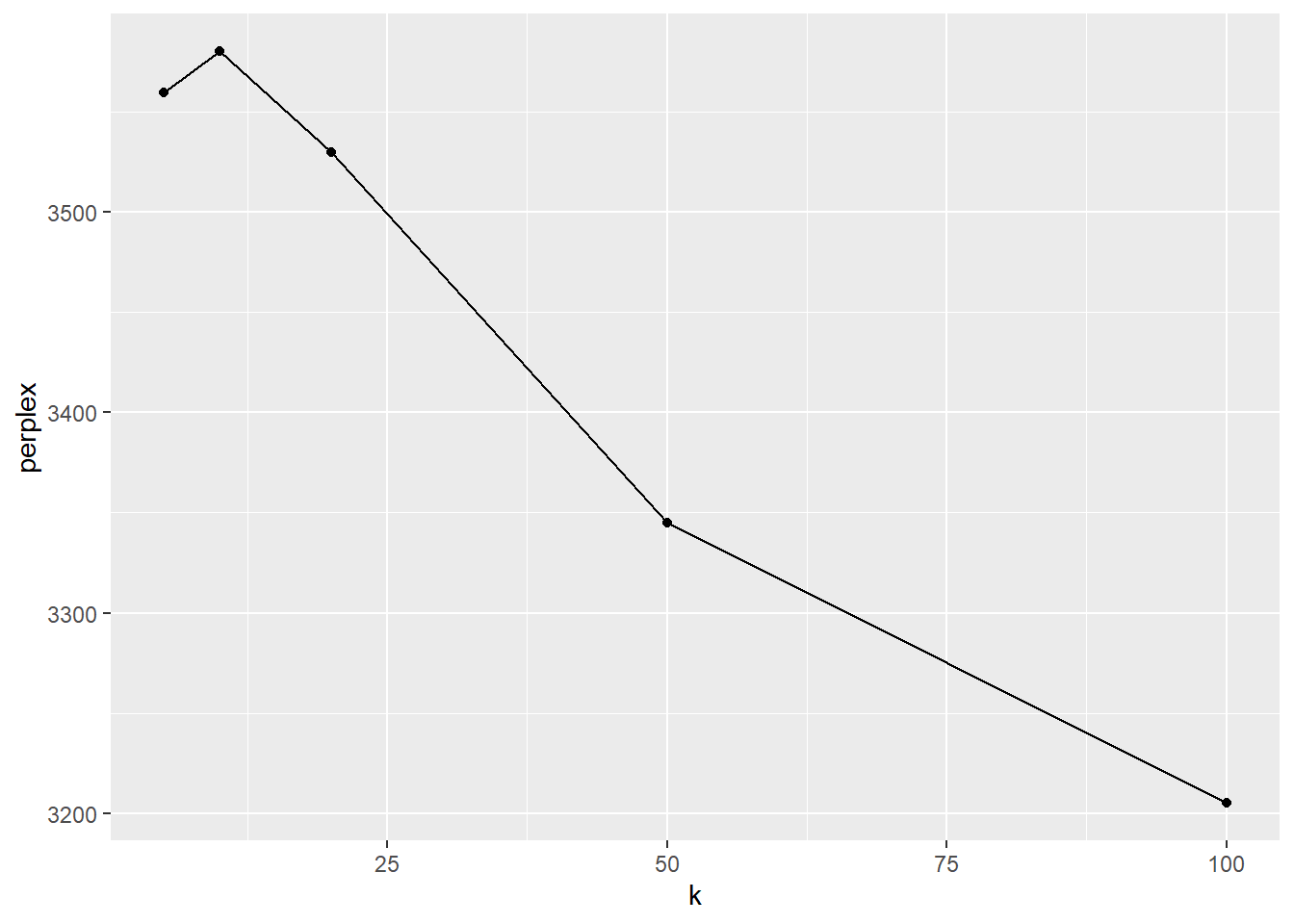
Dado que perplexity es una medida de inconsistencia, conviene un valor más bajo. Generalmente estos valores se consiguen a un K mayor. En este ejemplo vemos un caso extremo e improbable, en el que suponemos más tópicos (K=100) que documentos en el corpus de entrenamiento (90). Veamos cómo se ven algunos tópicos de este último modelo, en términos de distribuciones probables de palabras (beta):
## A LDA_Gibbs topic model with 50 topics.tidy(comparar_posibles_k[[4]], matrix = "beta") %>%
filter(topic %in% c(1:15)) %>%
group_by(topic) %>%
top_n(10) %>%
group_by(topic) %>%
summarize(terminos = paste(term, collapse = " , ") %>% stringr::str_sub(string = ., start = 1, end = 80))## Selecting by beta## # A tibble: 15 × 2
## topic terminos
## <int> <chr>
## 1 1 "lector , cultural , patrón , gusto , recomendación , mapa , historial…
## 2 2 "industria , marca , pasarela , web , buscador , moda , sitio , foto ,…
## 3 3 "paciente , salud , médico , sensor , dispositivo , calidad , monitore…
## 4 4 "riego , producción , proyecto , productor , climático , eficiente , m…
## 5 5 "vida , cuestión , condición , peso , crédito , útil , abierto , proce…
## 6 6 "dato , información , empresa , mundo , persona , bigdata , digital , …
## 7 7 "caballo , universidad , plataforma , necesidad , docente , nube , com…
## 8 8 "seguridad , humano , negocio , tecnología , trabajo , tecnológico , r…
## 9 9 "virtual , forma , ejercicio , realidad , inteligente , llevar , infor…
## 10 10 "dólar , búsqueda , pregunta , celular , tarjeta , pago , precio , ven…
## 11 11 "página , realidad , serie , llamar , centro , escala , comprador , pr…
## 12 12 "saber , peso , móvil , asistente , desempleo , presentar , fuga , deb…
## 13 13 "fuente , provincia , explicar , vigilancia , representativo , proyect…
## 14 14 "último , película , cine , suscripción , entrada , siglo , probar , v…
## 15 15 "vivir , inmigrante , inteligencia , detectar , periodista , relaciona…## A LDA_Gibbs topic model with 100 topics.tidy(comparar_posibles_k[[5]], matrix = "beta") %>%
filter(topic %in% c(1:15)) %>%
group_by(topic) %>%
top_n(10) %>%
group_by(topic) %>%
summarize(terminos = paste(term, collapse = " , ") %>% stringr::str_sub(string = ., start = 1, end = 80)) ## Selecting by beta## # A tibble: 15 × 2
## topic terminos
## <int> <chr>
## 1 1 conocimiento , palabra , ciencia , historia , investigación , análisis…
## 2 2 saber , puesto , carrera , docente , calidad , siglo , consultor , cas…
## 3 3 paciente , salud , médico , dispositivo , clínico , diagnóstico , reso…
## 4 4 niño , estadística , lucha , posible , recomendación , estudio , calid…
## 5 5 dato , día , buscar , quedar , nube , conjunto , felicidad , momento ,…
## 6 6 tema , fuente , conversación , real , grande , personal , conjunto , i…
## 7 7 usar , vender , producción , beneficio , técnica , medio , aprendizaje…
## 8 8 campaña , ciudad , sector , acción , sistema , aplicación , falta , tr…
## 9 9 fuente , explicar , sociedad , posible , semana , comisión , matrimoni…
## 10 10 ciudad , marca , punto , cultural , inteligente , término , creer , ca…
## 11 11 equipo , béisbol , deporte , partido , historia , alemán , jugador , c…
## 12 12 habilidad , institución , grupo , comunicación , consulta , analizar ,…
## 13 13 campaña , gobierno , ley , argentino , presidente , política , comunic…
## 14 14 mujer , trabajo , salario , habilidad , puesto , gerente , carrera , d…
## 15 15 riego , producción , productor , climático , chico , eficiente , facil…¿Te resultan tópicos más claros? Diferentes estudios (Hagen (2018), Maier et al. (2018), Boyd-Graber, Mimno, and Newman (2014), Chang et al. (2009)) muestran que números elevandos de K, si bien son más útiles para una clasificación efectiva de documentos nuevos, no suelen dar tópicos más interpretables, es decir, más claros en términos de distinguir los sentidos que se incluyen. De hecho, parece más bien haber una correlación negativa entre la interpretabilidad de los tópicos y medidas predictivas como perplexity! Incluso, algunos de estos estudios afirman que un K > 50 no es humanamente interpretable, dada la dificultad de leer los resultados sin confundir u olvidar los tópicos posibles.
¿Entonces, cómo determinar K, y con ello la validez de nuestro modelo? Bueno, por el momento parece haber sólo algunos lineamientos generales:
- se procede por prueba y error, buscando agregar y desagregar tópicos, maximizando el número de tópicos coherentes;
- asumiendo que K debe ser lo suficiente pequeño como para que sean recordados e interpretables;
- y lo suficiente grande como para evitarnos asignar documentos muy dispares al mismo grupo;
- usar pruebas estadísticas entre K de ordenes muy distintos, para tener una idea de los límites del overfitting;
Finalmente, el criterio no parece ser muy distinto que el que podemos aplicar en investigación cualitativa: realizar muestreos teóricos a conciencia, transparentar nuestros criterios a la hora de inferir y tomar decisiones, explicitar el marco de sentido de nuestras interpretaciones (nuestro marco teórico y epistemológico), discutir nuestras conclusiones y buscar acuerdos, sabiendo que el sentido del análisis no es tener la última palabra sino ofrecer una interpretación razonable empíricamente fundada.
¿Es esta dependencia en el análisis cualitativo algo negativo? Sólo si nuestro objetivo es automatizar un análisis fiable sin intervención (y costos) del trabajo humano… pero esto también es una limitación en los objetivos del análisis, no pudiendo avanzar sobre un ejercicio clasificatorio. Más promisorio es tomar al modelado de tópicos como un primer paso, una herramienta heurística, en nuestra exploración de los datos.
Topic models must find what we know is there. Ultimately, a topic model’s trustworthiness must be determined by informed human judgments. In particular, the model must find the broad trends and facts known to be true by the practitioner of the domain. Without such support in finding the known, topic models have limited value in discovering the unknown — i.e. quantifying known trends or discovering unexpected ones. (Ramage et al. 2009)
Referencias
Por ejemplo, Chang et al. (2009) diseñaron una serie de pruebas (humanas) rápidas para evaluar la coherencia de los tópicos, como por ejemplo, incluir términos extraños en un tópico para ver si un interprete podía identificarlo. Si te interesa esto, no te pierdas la presentación de los autores.↩︎