7 Demoskops paket
Under tiden jag jobbat med R på Demoskop har jag utvecklat en del egna funktioner som är anpassade efter arbetet här. Jag började med att ta fram en enkel funktion för att slumpa bort äldre repsondenter från ett för stort urval. Sen utvecklade jag en funktion för att kunna räkna och väga ord i öppna svar. I början sparade jag funktionerna i separata R-script på olika platser. Men det är ett ganska ineffektivt sätt att spara funktioner så nu finns de alla samlade i paketet demoskop. Här redovisas vilka funktioner som finns i paketet.
7.1 Installera demoskop
Eftersom paketet är internt och inte finns på CRAN så behöver man installera paketet från platsen där det finns sparat.
install.packages("S:\\R-project\\Interna paket\\demoskop_0.4.0.tar.gz",
repos = NULL, type = "source")Sedan laddar du paketet i vanlig ordning.
7.2 Skapa ålderskategorier
alder_k är en funktion för att på ett snabbt och enkelt sätt kunna skapa de åldersintervall vi vanligtvis använder. Den skapar en ny variabel i data som heter alder_k när den används i en mutate-sats.
library(demoskop)
library(dplyr)
library(haven)
data <- read_sas("P:\\_Kund\\INPL\\0001\\Data\\inpl0001raw.sas7bdat")
data %>%
mutate(alder_k = alder_k(alder)) %>%
group_by(alder_k) %>%
summarise(n = n(),
procent = sum(vikt, na.rm = T) / nrow(data))## # A tibble: 5 x 3
## alder_k n procent
## <chr> <int> <dbl>
## 1 16-39 år 345 0.3187218
## 2 40-49 år 189 0.1410829
## 3 50-64 år 272 0.1977714
## 4 65- år 234 0.2076485
## 5 <NA> 162 0.1347754case_when() är funktionen som används för att skapa kategorierna. Du kan använda den funktionen för att skapa egna kategorier.
7.3 Slumpa bort äldre när du har för många svar
demo_sample() är en funktion som jag skapade när jag fick ett för stort antal respondenter som svarade på en undersökning och ville slumpa bort de äldsta i undersöknikngen men ha kvar de yngre. Just slumpmässigheten är otroligt viktig här.
Funktionen är enkel att använda, den har fyra argument: data, n = den önskade storleken, hsid_limit = gräns för hsid, alder_limit = ålder efter vilken en repsondent ska betraktas som gammal.
Vi använder den så här:
data <- data %>% filter(!is.na(alder))
data_sample <- demo_sample(data, n = 950, hsid_limit = 10, alder_limit = 60)
data_sample %>%
mutate(alder_k = alder_k(alder)) %>%
group_by(alder_k) %>%
summarise(n = n(),
procent = sum(vikt, na.rm = T) / nrow(data))## # A tibble: 4 x 3
## alder_k n procent
## <chr> <int> <dbl>
## 1 16-39 år 345 0.3683689
## 2 40-49 år 189 0.1630592
## 3 50-64 år 245 0.2060295
## 4 65- år 171 0.1752376Data kan nu exporteras till en tabellkörning.
NOTIS: demo_sample kräver att variabelnamnet för Högst besvarade sida är hsid (inte MaxPagePos eller liknande) och att åldersvariabeln heter alder. Du döper om variabler enkelt såhär (notera att det är omvänd ordning på rename jämfört med SAS-kod):
data <- data %>%
rename(hsid = MaxPagePos,
alder = Age)7.4 Automatkodning
I våra undersökningar har vi oftast flera frågor med öppna svar. De öppna svaren hanteras i regel på två sätt: Antigen kodas de manuellt av en leverantör (i sällsynta fall av oss själva) eller så redovisas de i ett ordmoln. Ordmoln är visuellt tilltalande och ger en bild av vilka ord som används mest i de öppna svaren men de har sina baksidor:
- Ordmoln är inte konsekventa i sin storlek. Om orden “bra” och “dåligt” används lika mycket kommer “dåligt” att bli större i ordmolnet för att ordet är längre.
- Den hemsida vi använder för ordmoln, wordle.net, kan inte ta hänsyn till vikt vilket gör att vi redovisar oviktade resultat.
I demoskop finns funktioner för att få ut viktade frekvenstabeller över de ord som används mest i ett öppet svar.
7.4.1 Ordfrekvenser
ord_frek() används för att få ut en frekvenstabell över de mest använda orden.
library(tm)
ord_frek(data, data$ktillT, vikt = vikt, n = 11, ord = c("idag"))## ord n_tot procent
## 1 Inga 172.84166 16.619391
## 2 Compricer 127.44195 12.254034
## 3 Pricerunner 106.48101 10.238558
## 4 Vet 69.97441 6.728308
## 5 Insplanet 47.58101 4.575097
## 6 Prisjakt 41.88325 4.027236
## 7 Compriser 14.76357 1.419574En komplement-funktion till ord_frek() är ord_frek_token() som gör samma sak men räknar två ord i taget, du får alltså en lista över de vanligaste ordkombinationerna. Funktionen är nyttig om du exempelvis vill räkna hur många gånger en partiledares för och efternamn nämns.
7.4.2 Viktade ordmoln
7.4.2.1 Wordcloud
Jag har redan skrivit lite om bristerna i att använda ordmoln för analys, men ibland behövs dom ändå. Det finns några olika sätt att göra ordmoln på i R. Vi kan använda paketet wordcloud. Eftersom vi vill ha med många ord i ordmolnet (typ 100) sätter vi n = 1.
ord_frek <- ord_frek(data, data$ktillT, vikt = vikt, n = 1,
ord = c("idag", "inga", "vet"))Vi kan nu skapa ordmolnet.
library(wordcloud)
wordcloud(ord_frek$ord, ord_frek$n_tot, max.words = 100,
color = brewer.pal(6, "Dark2"))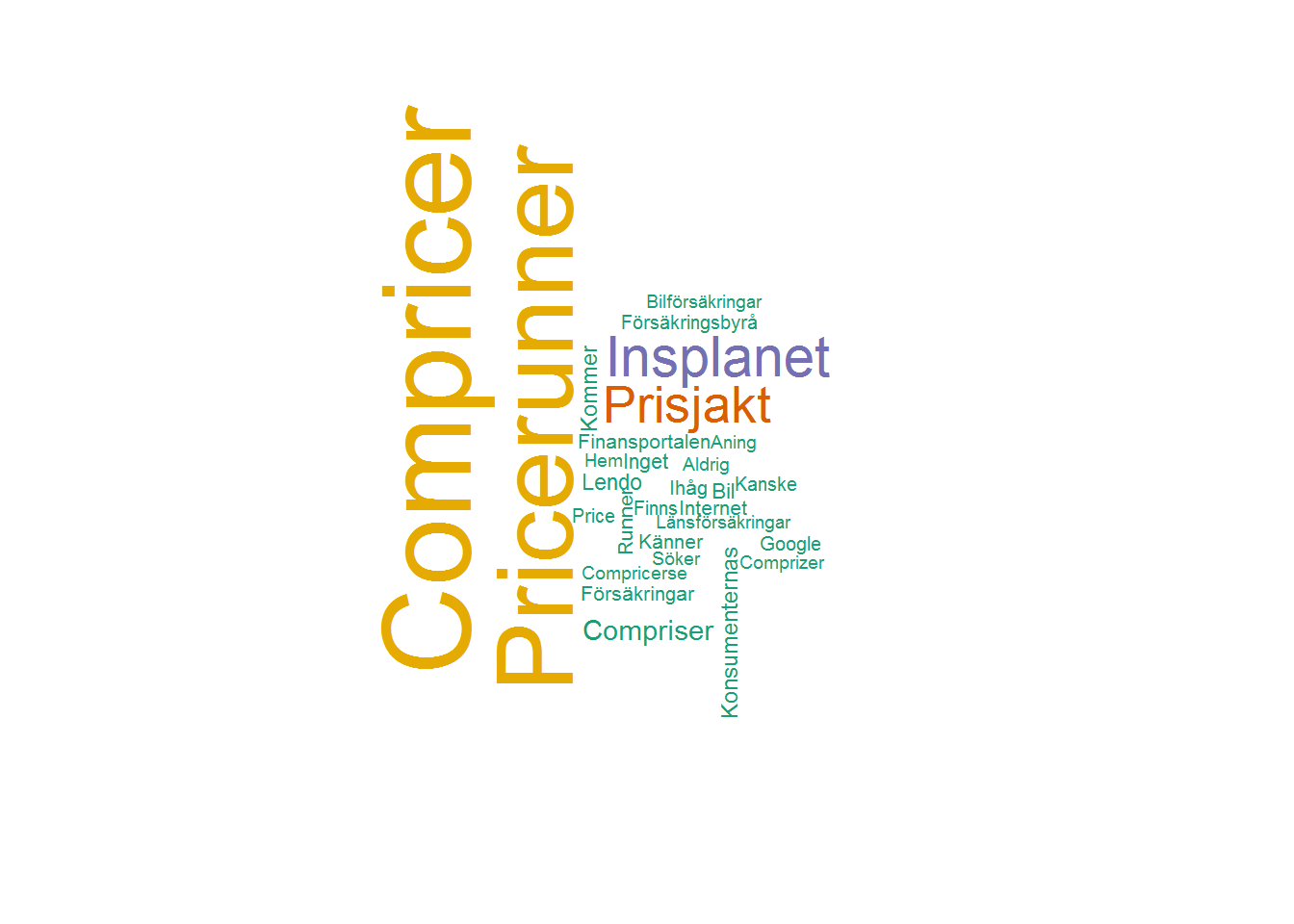 Det här ser bra ut men är (i min mening) inte riktigt lika snyggt som
Det här ser bra ut men är (i min mening) inte riktigt lika snyggt som wordle.
7.4.2.2 wordcloud2
Vi testar ett relativt nytt paket för ordmoln wordcloud2 för att få lite mer estetiskt tilltalande ordmoln.
library(wordcloud2)
ord_frek %>%
wordcloud2(color = sample(brewer.pal(6, "Dark2"), 1000, replace = TRUE),
fontFamily = 'Gill Sans MT', minRotation = 0, maxRotation = 0,
size = 0.6)wordcloud2 blir defintivt snyggare och är dessutom interaktivt, d.v.s. vi kan markera ett ord och se hur många som nämnt det ordet.
Problemet är att den typen av interaktiva grafer inte går att redovisa i PowerPoint. Vi behöver därför spara det här som bild. Det kan man göra genom att exportera bilden i R:s Viewer. Alternativt kan man spara ordmolnet som en HTML-widget och ta en webshot av den. På så sätt kan man också specificera storleken på bilden. Det är viktigt att sätta delay = en siffra, i det här fallet 10. Delay styr när webshot ska tas. Eftersom ordmolnet animeras fram vill vi ta webshot när molnet är komplett, vilket oftast är efter några sekunder.
ordmoln <- ord_frek %>%
wordcloud2(color = sample(brewer.pal(6, "Dark2"), 1000, replace = TRUE),
fontFamily = 'Gill Sans MT', minRotation = 0, maxRotation = 0,
size = 0.8)
saveWidget(ordmoln, "tmp.html", selfcontained = F)
# and in pdf
webshot("tmp.html", "ordmoln.png"), delay = 10, vwidth = 900, vheight = 480)7.4.3 Skapade automatkodade variabler
Ibland räcker det inte med frekvenslista utan du vill få ut resultatet i dina SAS-tabeller. Med funktionen ord() kan du enkelt skapa en kodad variabel för ett visst ord.
data_ord <- ord(data, data$ktillT, c("compricer", "pricerunner"), ipnr = ipnr)
data_ord %>%
select(alder, ktillT, compricer, pricerunner) %>%
head()## # A tibble: 6 x 4
## alder ktillT compricer pricerunner
## <dbl> <chr> <dbl> <dbl>
## 1 47 Inga 0 0
## 2 52 Compricer 1 0
## 3 66 Inga 0 0
## 4 63 Compricer, prisrunner 1 0
## 5 63 0 0
## 6 67 pricerunner compricer 1 1Den här datafilen kan nu exporteras och användas i en SAS-körning för att få med resultatet i en vanlig lst-tabell. Som du ser är data formatterat som om det vore manuellt kodat.
7.4.4 Felstavningar
Inte sällan dyker det upp felstavningar i öppna svar, senast i tabellen ovan(prisrunner). Hur hanterar vi dessa? Enklast är med paketet stringr som är ett paket för olika bearbetningar av strings(text). Läs mer om stringr här.
I fallet ovan gör vi en såkallad string replacement med str_replace():
library(stringr)
data_ord <- data %>%
mutate(ktillT = str_replace(ktillT, "prisrunner", "pricerunner"))
data_ord <- ord(data_ord, data_ord$ktillT, c("compricer", "pricerunner"), ipnr = ipnr)
data_ord %>%
select(alder, ktillT, compricer, pricerunner) %>%
head()## # A tibble: 6 x 4
## alder ktillT compricer pricerunner
## <dbl> <chr> <dbl> <dbl>
## 1 47 Inga 0 0
## 2 52 Compricer 1 0
## 3 66 Inga 0 0
## 4 63 Compricer, pricerunner 1 1
## 5 63 0 0
## 6 67 pricerunner compricer 1 17.5 Från personnummer till ålder
age_calc är en funktion för att beräkna ålder från ett datum. R är bra på att reda ut datum. Ibland kan vi få externa urval med knepigt formaterade datum-variabler.
För att få bra förståelse för datum i R kan jag rekommendera den här kursen.
Här är ett exempel från en undersökning vi gjorde för Försvarsmakten där vi fick datum som skulle bli ålder.
library(readxl)
library(demoskop)
data <- read_excel("P:/_Kund/FORS/0159/Data/Fors0159_r.xlsx")
data$alder <- age_calc(as.Date(data$foddat), unit = "years")
data %>%
group_by(alder) %>%
summarise(n()) %>%
head(10)## # A tibble: 10 x 2
## alder `n()`
## <dbl> <int>
## 1 20 17
## 2 21 13
## 3 22 19
## 4 23 23
## 5 24 22
## 6 25 22
## 7 26 17
## 8 27 31
## 9 28 31
## 10 29 33