5 Scraping the Web – Extracting Data
In the prior chapter you were shown how to make calls to web pages and get responses. Moreover, you were introduced to making calls to APIs which (usually) give you content in a nice and structured manner. In this chapter, the guiding topic will be how you can extract content from web pages in a structured way. The (in our opinion) easiest way to achieve that is by harnessing the way the web is written.
Before we start to extract data from the web, we will briefly touch upon how the web is written. This is since we will harness this structure to extract content in an automated manner. Basic commands will be shown thereafter.
#install.packages("needs")
needs::needs(janitor, polite, rvest, tidyverse)5.1 HTML 101
Web content is usually written in HTML (Hyper Text Markup Language). An HTML document is comprised of elements that are letting its content appear in a certain way.
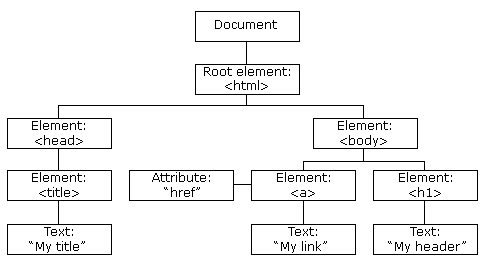
The way these elements look is defined by so-called tags.

The opening tag is the name of the element (p in this case) in angle brackets, and the closing tag is the same with a forward slash before the name. p stands for a paragraph element and would look like this (since RMarkdown can handle HTML tags, the second line will showcase how it would appear on a web page):
<p> My cat is very grumpy. <p/>
My cat is very grumpy.
The <p> tag makes sure that the text is standing by itself and that a line break is included thereafter:
<p>My cat is very grumpy</p>. And so is my dog. would look like this:
My cat is very grumpy
. And so is my dog.
There do exist many types of tags indicating different kinds of elements (about 100). Every page’s content must be in an <html> element with two children <head> and <body>. The former contains the page title and some metadata, the latter the contents you are seeing in your browser. So-called block tags, e.g., <h1> (heading 1), <p> (paragraph), or <ol> (ordered list), structure the page. Inline tags (<b> – bold, <a> – link) format text inside block tags.
You can nest elements, e.g., if you want to make certain things bold, you can wrap text in <b>:
<p>My cat is <b> very </b> grumpy</p>
My cat is very grumpy
Then, the <b> element is considered the child of the <p> element.
Elements can also bear attributes:

Those attributes will not appear in the actual content. Moreover, they are super-handy for us as scrapers. Here, class is the attribute name and "editor-note" the value. Another important attribute is id. Combined with CSS, they control the appearance of the element on the actual page. A class can be used by multiple HTML elements whereas an id is unique.
5.2 Extracting content in rvest
To scrape the web, the first step is to simply read in the web page. rvest then stores it in the XML format – just another format to store information. For this, we use rvest’s read_html() function.
To demonstrate the usage of CSS selectors, I create my own, basic web page using the rvest function minimal_html():
basic_html <- minimal_html('
<html>
<head>
<title>Page title</title>
</head>
<body>
<h1 id="first">A heading</h1>
<p class="paragraph">Some text & <b>some bold text.</b></p>
<a> Some more <i> italicized text which is not in a paragraph. </i> </a>
<a class="paragraph">even more text & <i>some italicized text.</i></p>
<a id="link" href="www.nyt.com"> The New York Times </a>
</body>
')
basic_html{html_document}
<html>
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
[2] <body>\n <h1 id="first">A heading</h1>\n <p class="paragraph">Some ...#https://htmledit.squarefree.comCSS is the abbreviation for cascading style sheets and is used to define the visual styling of HTML documents. CSS selectors map elements in the HTML code to the relevant styles in the CSS. Hence, they define patterns that allow us to easily select certain elements on the page. CSS selectors can be used in conjunction with the rvest function html_elements() which takes as arguments the read-in page and a CSS selector. Alternatively, you can also provide an XPath which is usually a bit more complicated and will not be covered in this tutorial.
pselects all<p>elements.
basic_html |> html_elements(css = "p"){xml_nodeset (1)}
[1] <p class="paragraph">Some text & <b>some bold text.</b></p>.titleselects all elements that are ofclass“title”
basic_html |> html_elements(css = ".title"){xml_nodeset (0)}There are no elements of class “title”. But some of class “paragraph”.
basic_html |> html_elements(css = ".paragraph"){xml_nodeset (2)}
[1] <p class="paragraph">Some text & <b>some bold text.</b></p>
[2] <a class="paragraph">even more text & <i>some italicized text.</i>\n ...p.paragraphanalogously takes every<p>element which is ofclass“paragraph”.
basic_html |> html_elements(css = "p.paragraph"){xml_nodeset (1)}
[1] <p class="paragraph">Some text & <b>some bold text.</b></p>#linkscrapes elements that are ofid“link”
basic_html |> html_elements(css = "#link"){xml_nodeset (1)}
[1] <a id="link" href="www.nyt.com"> The New York Times </a>You can also connect children with their parents by using the combinator. For instance, to extract the italicized text from “a.paragraph,” I can do “a.paragraph i”.
basic_html |> html_elements(css = "a.paragraph i"){xml_nodeset (1)}
[1] <i>some italicized text.</i>You can also look at the children by using html_children():
basic_html |> html_elements(css = "a.paragraph") |> html_children(){xml_nodeset (1)}
[1] <i>some italicized text.</i>read_html("https://rvest.tidyverse.org") |>
html_elements("#installation , p"){xml_nodeset (8)}
[1] <p>rvest helps you scrape (or harvest) data from web pages. It is designe ...
[2] <p>If you’re scraping multiple pages, I highly recommend using rvest in c ...
[3] <h2 id="installation">Installation<a class="anchor" aria-label="anchor" h ...
[4] <p>If the page contains tabular data you can convert it directly to a dat ...
[5] <p></p>
[6] <p>Developed by <a href="http://hadley.nz" class="external-link">Hadley W ...
[7] <p></p>
[8] <p>Site built with <a href="https://pkgdown.r-lib.org/" class="external-l ...Unfortunately, web pages in the wild are usually not as easily readable as the small example one I came up with. Hence, I would recommend you to use the SelectorGadget – just drag it into your bookmarks list.
Its usage could hardly be simpler:
- Activate it – i.e., click on the bookmark.
- Click on the content you want to scrape – the things the CSS selector selects will appear green.
- Click on the green things that you don’t want – they will turn red; click on what’s not green yet but what you want – it will turn green.
- copy the CSS selector the gadget provides you with and paste it into the
html_elements()function.
read_html("https://en.wikipedia.org/wiki/Hadley_Wickham") |>
html_elements(css = "p:nth-child(4)") |>
html_text()[1] "Hadley Alexander Wickham (born 14 October 1979) is a New Zealand statistician known for his work on open-source software for the R statistical programming environment. He is the chief scientist at Posit, PBC and an adjunct professor of statistics at the University of Auckland, Stanford University, and Rice University. His work includes the data visualisation system ggplot2 and the tidyverse, a collection of R packages for data science based on the concept of tidy data.\n"5.3 Scraping HTML pages with rvest
So far, I have shown you how HTML is written and how to select elements. However, what we want to achieve is extracting the data the elements contained in a proper format and storing it in some sort of tibble. Therefore, we need functions that allow us to grab the data.
The following overview taken from the web scraping cheatsheet shows you the basic “flow” of scraping web pages plus the corresponding functions. In this tutorial, I will limit myself to rvest functions. Those are of course perfectly compatible with things, for instance, RSelenium, as long as you feed the content in XML format (i.e., by using read_html()).
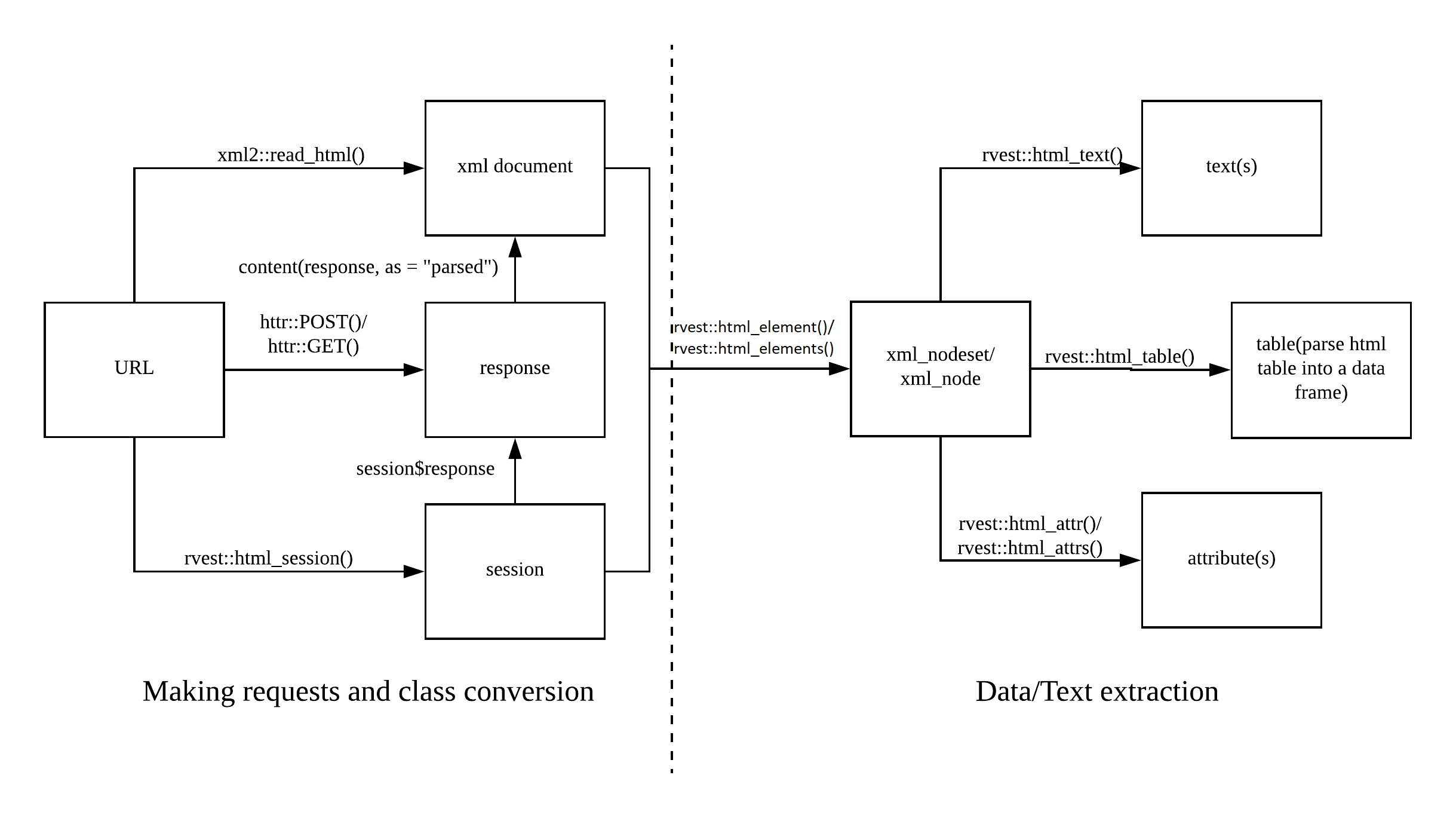
In the prior chapter, I have introduced you to acquiring the contents of singular pages. Given that you now know how to choose the content you want, all that you are lacking for successful scraping is the tools to extract these contents in a proper format.
5.3.1 html_text() and html_text2()
Extracting text from HTML is easy. You use html_text() or html_text2(). The former is faster but will give you not-so-nice results. The latter will give you the text like it would be returned in a web browser.
The following example is taken from the documentation
# To understand the difference between html_text() and html_text2()
# take the following html:
html <- minimal_html(
"<p>This is a paragraph.
This is another sentence.<br>This should start on a new line<p/>"
)# html_text() returns the raw underlying text, which includes white space
# that would be ignored by a browser, and ignores the <br>
html |> html_element("p") |> html_text() |> writeLines()This is a paragraph.
This is another sentence.This should start on a new line# html_text2() simulates what a browser would display. Non-significant
# white space is collapsed, and <br> is turned into a line break
html |> html_element("p") |> html_text2() |> writeLines()This is a paragraph. This is another sentence.
This should start on a new lineA “real example” would then look like this:
us_senators <- read_html("https://en.wikipedia.org/wiki/List_of_current_United_States_senators")
text <- us_senators |>
html_elements(css = "p:nth-child(6)") |>
html_text2()5.3.2 Extracting tables
The general output format we strive for is a tibble. Oftentimes, data is already stored online in a table format, basically ready for us to analyze them. In the next example, I want to get a table from the Wikipedia page that contains the senators of different States in the United States I have used before. For this first, basic example, I do not use selectors for extracting the right table. You can use rvest::html_table(). It will give you a list containing all tables on this particular page. We can inspect it using str() which returns an overview of the list and the tibbles it contains.
Here, the table I want is the sixth one. We can grab it by either using double square brackets – [[6]] – or purrr’s pluck(6).
senators <- tables |>
pluck(6)
glimpse(senators)Rows: 100
Columns: 12
$ State <chr> "Alabama", "Alabama", "Alaska", "Alaska",…
$ Portrait <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ Senator <chr> "Tommy Tuberville", "Katie Britt", "Lisa …
$ Party <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ Party <chr> "Republican", "Republican", "Republican",…
$ Born <chr> "(1954-09-18) September 18, 1954 (age 69)…
$ `Occupation(s)` <chr> "College football coachInvestment managem…
$ `Previous electiveoffice(s)` <chr> "None", "None", "Alaska House of Represen…
$ Education <chr> "Southern Arkansas University (BS)", "Uni…
$ `Assumed office` <chr> "January 3, 2021", "January 3, 2023", "De…
$ Class <chr> "2026Class 2", "2028Class 3", "2028Class …
$ `Residence[5]` <chr> "Auburn[6]", "Montgomery", "Girdwood", "A…## alternative approach using css
senators <- us_senators |>
html_elements(css = "#senators") |>
html_table() |>
pluck(1) |>
janitor::clean_names()You can see that the tibble contains “dirty” names and that the party column appears twice – which will make it impossible to work with the tibble later on. Hence, I use clean_names() from the janitor package to fix that.
5.3.3 Extracting attributes
You can also extract attributes such as links using html_attrs(). An example would be to extract the headlines and their corresponding links from r-bloggers.com.
rbloggers <- read_html("https://www.r-bloggers.com")A quick check with the SelectorGadget told me that the element I am looking for is of class “.loop-title” and the child of it is “a”, standing for normal text. With html_attrs() I can extract the attributes. This gives me a list of named vectors containing the name of the attribute and the value:
Links are stored as attribute “href” – hyperlink reference. html_attr() allows me to extract the attribute’s value. Hence, building a tibble with the article’s title and its corresponding hyperlink is straight-forward now:
tibble(
title = r_blogger_postings |> html_text2(),
link = r_blogger_postings |> html_attr(name = "href")
)# A tibble: 20 × 2
title link
<chr> <chr>
1 Explain that tidymodels blackbox! http…
2 Optimizing the parameters of the spatial kinetic Ising model to simula… http…
3 Factor Analysis in R workshop http…
4 How to Execute the Code on My Blog by Downloading the Quarto File http…
5 Unveiling the Smooth Operator: Rolling Averages in R http…
6 Probability intervals with GAMs http…
7 Harness the Power of R for Survival Analysis: Join Our {ggsurvfit} Web… http…
8 Learnings from the First R-Based Submission to FDA by Novo Nordisk http…
9 Your Data’s Untold Secrets: An Introduction to Descriptive Stats with R http…
10 Reflecting on the Past Year: A LinkedIn Year in Review (2023) http…
11 Icons in a Shiny dropdown input http…
12 Cryptocurrency Market Data in R http…
13 .I in data.table http…
14 .I in data.table http…
15 Using great circle distance to determine Twin Cities http…
16 PowerQuery Puzzle solved with R http…
17 How Inclusivity, Women in STEM, and Trips to the Pub Together Enrich t… http…
18 R Solution for Excel Puzzles http…
19 Automating updates to dashboards on Shiny Server workshop http…
20 Most popular posts – 2023 http…Another approach for this would be using the polite package and its function html_attrs_dfr() which binds together all the different attributes column-wise and the different elements row-wise.
rbloggers |>
html_elements(css = ".loop-title a") |>
html_attrs_dfr() |>
select(title = 3,
link = 1) |>
glimpse()Rows: 20
Columns: 2
$ title <chr> "Explain that tidymodels blackbox!", "Optimizing the parameters …
$ link <chr> "https://www.r-bloggers.com/2024/01/explain-that-tidymodels-blac…5.4 Exercise
- Download the links and names of the top 250 IMDb movies. Put them in a tibble with the columns
rank– in numeric format (you know regexes already),title,urlto IMDb entry,rating– in numeric format,number_votes– the number of votes a movie has received, in numeric format.
imdb_top250 <- read_html("https://www.imdb.com/chart/top/?ref_=nv_mv_250")
movies <- tibble(
rank = imdb_top250 |>
html_elements(".cli-title .ipc-title__text") |>
html_text2() |>
str_extract("^[0-9]+(?=\\.)") |>
parse_integer(),
title = imdb_top250 |>
html_elements(".cli-title .ipc-title__text") |>
html_text2() |>
str_remove("^[0-9]+\\. "),
url = imdb_top250 |>
html_elements(".cli-title a") |>
html_attr("href") |>
str_c("https://www.imdb.com", x = _),
rating = imdb_top250 |>
html_elements(".ratingGroup--imdb-rating") |>
html_text() |>
str_extract("[0-9]\\.[0-9]") |>
parse_double(),
no_votes = imdb_top250 |>
html_elements(".ratingGroup--imdb-rating") |>
html_text() |>
str_remove("^[0-9]\\.[0-9]") |>
str_remove_all("[() ]")
)5.5 Automating scraping
Well, grabbing singular points of data from websites is nice. However, if you want to do things such as collecting large amounts of data or multiple pages, you will not be able to do this without some automation.
An example here would again be the R-bloggers page. It provides you with plenty of R-related content. If you were now eager to scrape all the articles, you would first need to acquire all the different links leading to the blog postings. Hence, you would need to navigate through the site’s pages first to acquire the links.
In general, there are two ways to go about this. The first is to manually create a list of URLs the scraper will visit and take the content you need, therefore not needing to identify where it needs to go next. The other one would be automatically acquiring its next destination from the page (i.e., identifying the “go on” button). Both strategies can also be nicely combined with some sort of session().
5.5.1 Looping over pages
For the first approach, we need to check the URLs first. How do they change as we navigate through the pages?
url_1 <- "https://www.r-bloggers.com/page/2/"
url_2 <- "https://www.r-bloggers.com/page/3/"
initial_dist <- adist(url_1, url_2, counts = TRUE) |>
attr("trafos") |>
diag() |>
str_locate_all("[^M]")
str_sub(url_1, start = initial_dist[[1]][1]-5, end = initial_dist[[1]][1]+5) # makes sense for longer urls[1] "page/2/"str_sub(url_2, start = initial_dist[[1]][1]-5, end = initial_dist[[1]][1]+5)[1] "page/3/"There is some sort of underlying pattern and we can harness that. url_1 refers to the second page, url_2 to the third. Hence, if we just combine the basic URL and, say, the numbers from 1 to 10, we could then visit all the pages (exercise 3a) and extract the content we want.
urls <- str_c("https://www.r-bloggers.com/page/", 1:10, "/") # this is the stringr equivalent of paste()
urls [1] "https://www.r-bloggers.com/page/1/" "https://www.r-bloggers.com/page/2/"
[3] "https://www.r-bloggers.com/page/3/" "https://www.r-bloggers.com/page/4/"
[5] "https://www.r-bloggers.com/page/5/" "https://www.r-bloggers.com/page/6/"
[7] "https://www.r-bloggers.com/page/7/" "https://www.r-bloggers.com/page/8/"
[9] "https://www.r-bloggers.com/page/9/" "https://www.r-bloggers.com/page/10/"You can run this in a for-loop, here’s a quick revision. For the loop to run efficiently, space for every object should be pre-allocated (i.e., you create a list beforehand, and its length can be determined by an educated guess).
## THIS IS PSEUDO CODE!!!
result_list <- vector(mode = "list", length = length(urls)) # pre-allocate space!!!
starting_link <- "https://www.r-bloggers.com/page/1/"
####PSEUDO CODE!!!
for (i in seq_along(urls)){
read in urls[[i]] --> page <- read_html(url)
store content of page in result_list result_list[[i]] <- extract_content(page)
}5.6 Conclusion
To sum it up: when you have a good research idea that relies on Digital Trace Data that you need to collect, ask yourself the following questions:
- Is there an R package for the web service?
- If 1. == FALSE: Is there an API where I can get the data (if TRUE, use it)
- If 1. == FALSE & 2. == FALSE: Is screen scraping an option and any structure in the data that you can harness?
If you have to rely on screen scraping, also ask yourself the question how you can minimize the number of requests you make to the server. Going back and forth on web pages or navigating through them might not be the best option since it requires multiple requests. The most efficient way is usually to try to get a list of URLs of some sort which you can then just loop over.
5.6.1 Exercise
- Scrape 5 pages of the latest UN press releases in an automated fashion. Make sure to take breaks between requests by including
Sys.sleep(2). For each iteration, store the articles and links in a tibble containing the columnstitle,link, anddate(bonus: store it in date format). (Tip: wrap the code that extracts and stores content in a tibble in a function.)
- Do so using running numbers in the urls.
- Do so by using
session()in a loop. (Note: make sure to specifycss =)
scrape_press_releases <- function(page){
tibble(
title = page |>
html_elements(".field__item a") |>
html_text2(),
link = page |>
html_elements(".field__item a") |>
html_attr("href"),
date = page |>
html_elements(".field--type-datetime") |>
html_text2() |>
as.Date(format = "%d %B %Y")
)
}
#a
urls <- str_c("https://press.un.org/en/content/secretary-general/press-release?page=", 0:4)
pages <- map(urls,
\(x){
Sys.sleep(2)
read_html(x) |>
scrape_press_releases()
}
)
#b
un_session <- session("https://press.un.org/en/content/secretary-general/press-release")
i <- 1
page_list <- vector(mode = "list", length = 5L)
while (i < 6) {
page_list[[i]] <- read_html(un_session) |>
scrape_press_releases()
un_session <- un_session |>
session_follow_link(css = ".pager__item--next .page-link")
i <- i + 1
Sys.sleep(2)
}5.7 Further links
- APIs for social scientists: A collaborative review
- More on HTML
- More on CSS selectors
- The
rvestvignette - A “laymen’s guide” on web scraping (blog post)